
1. Introduzione
Sono sempre stato affascinato dall'intensità dell'aula del tribunale, immaginando di destreggiarmi abilmente tra le sue complessità e di pronunciare arringhe conclusive efficaci. Anche se la mia carriera mi ha portato altrove, sono felice di condividere che, con l'aiuto dell'AI, potremmo essere tutti più vicini a realizzare quel sogno di lavorare in tribunale.

Oggi vedremo come utilizzare i potenti strumenti AI di Google, come Vertex AI, Firestore e Cloud Run Functions, per elaborare e comprendere i dati legali, eseguire ricerche velocissime e, forse, aiutare il tuo cliente immaginario (o te stesso) a uscire da una situazione difficile.
Non dovrai controinterrogare un testimone, ma con il nostro sistema potrai esaminare montagne di informazioni, generare riepiloghi chiari e presentare i dati più pertinenti in pochi secondi.
2. Architettura
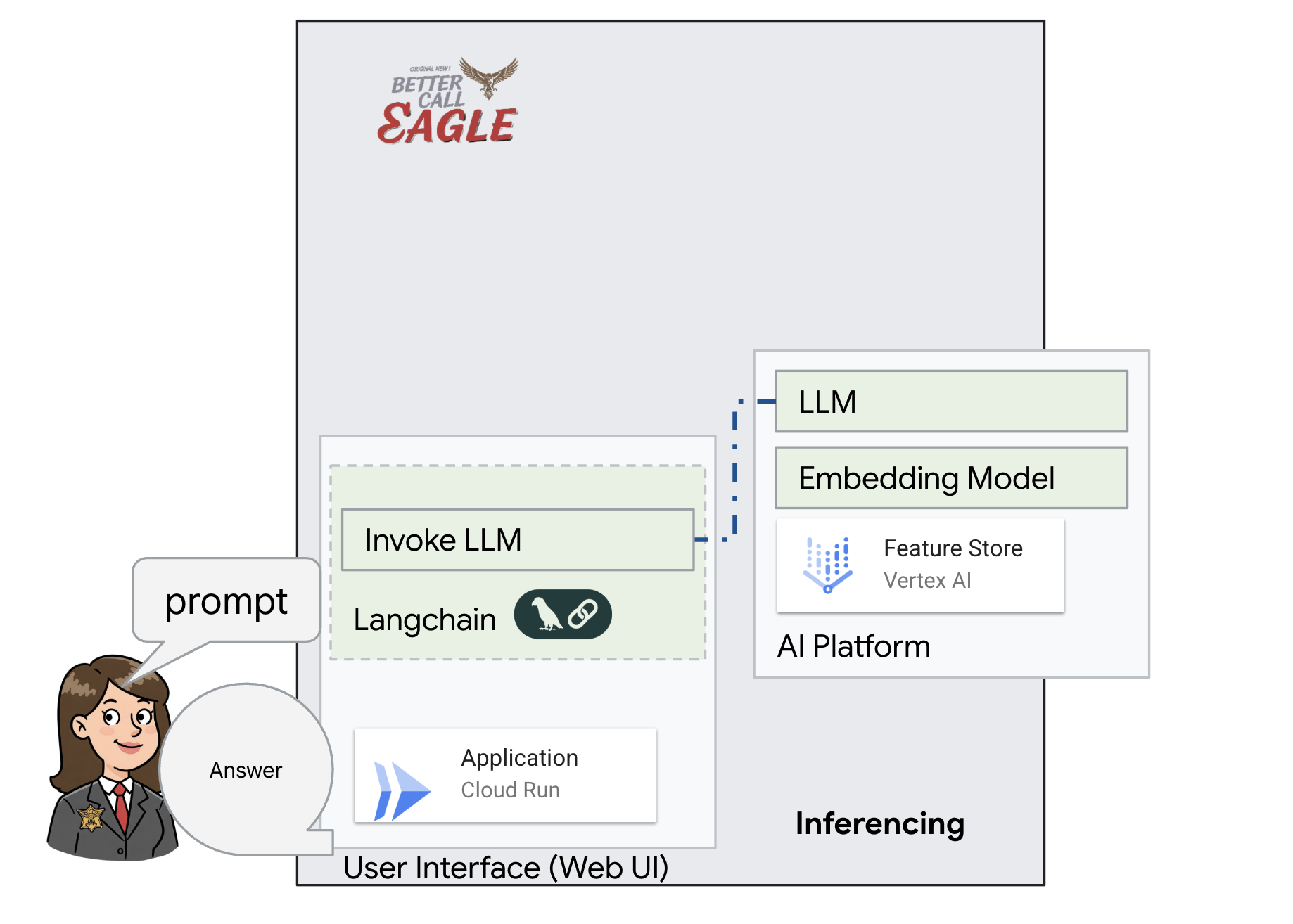
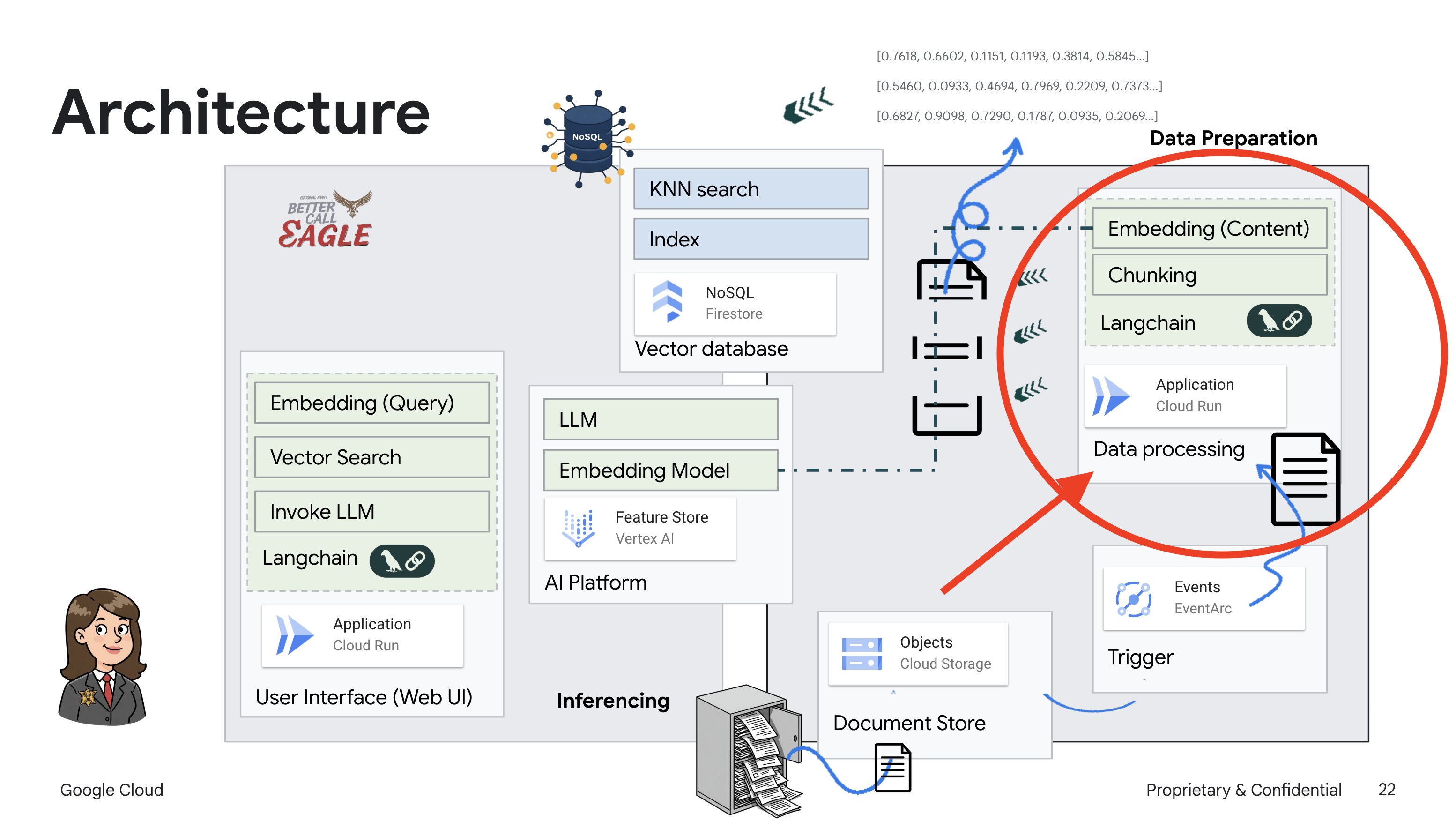
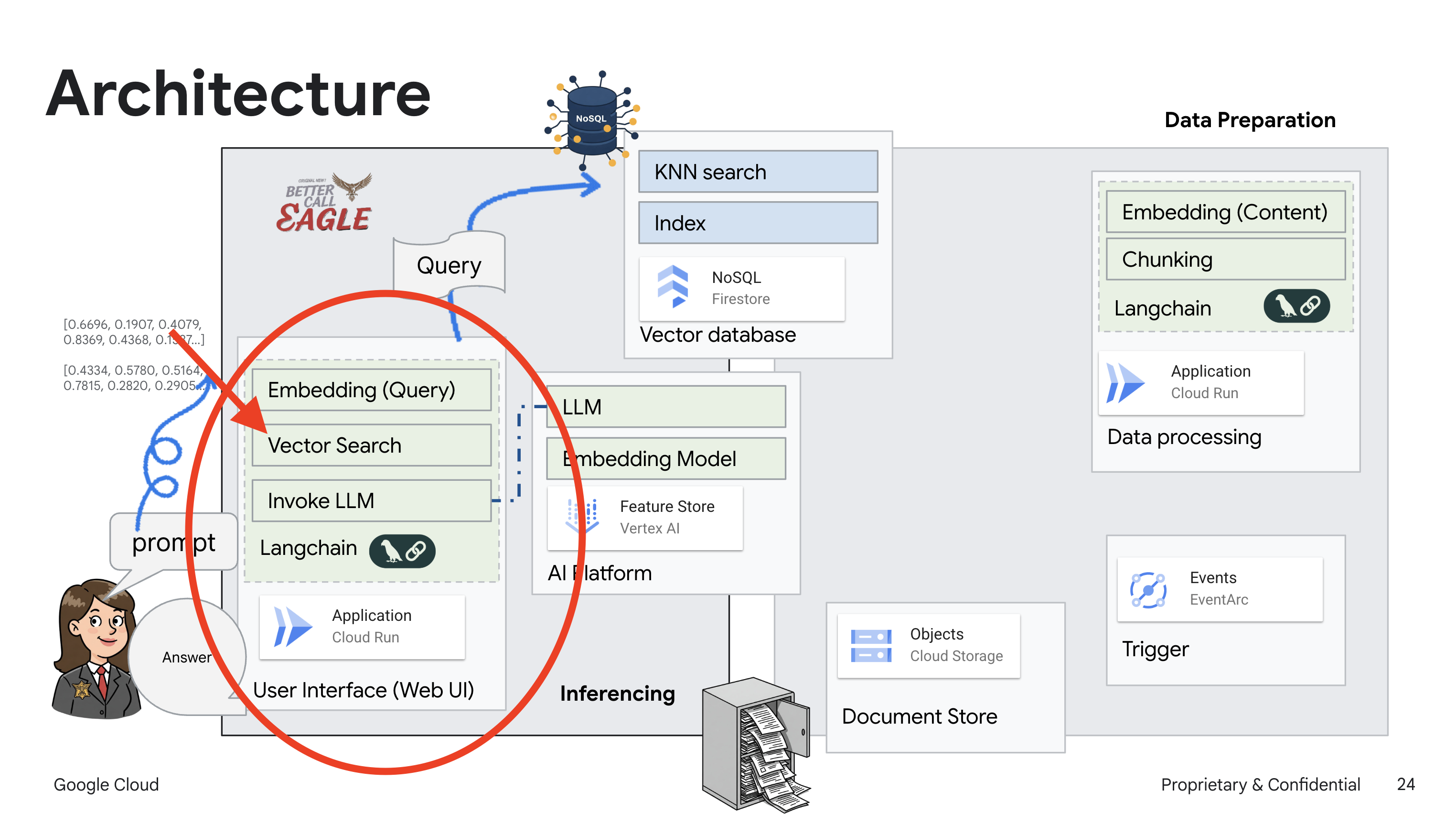
Questo progetto si concentra sulla creazione di un assistente legale utilizzando gli strumenti di AI Google Cloud, sottolineando come elaborare, comprendere e cercare dati legali. Il sistema è progettato per analizzare grandi quantità di informazioni, generare riepiloghi e presentare rapidamente i dati pertinenti. L'architettura dell'assistente legale coinvolge diversi componenti chiave:
Creazione di una knowledge base da dati non strutturati: Google Cloud Storage (GCS) viene utilizzato per archiviare i documenti legali. Firestore, un database NoSQL, funge da archivio vettoriale, contenente blocchi di documenti e i relativi embedding. La ricerca vettoriale è abilitata in Firestore per consentire le ricerche di somiglianza. Quando un nuovo documento legale viene caricato in GCS, Eventarc attiva una funzione Cloud Run. Questa funzione elabora il documento dividendolo in blocchi e generando embedding per ogni blocco utilizzando il modello di text embedding di Vertex AI. Questi incorporamenti vengono quindi archiviati in Firestore insieme ai blocchi di testo. 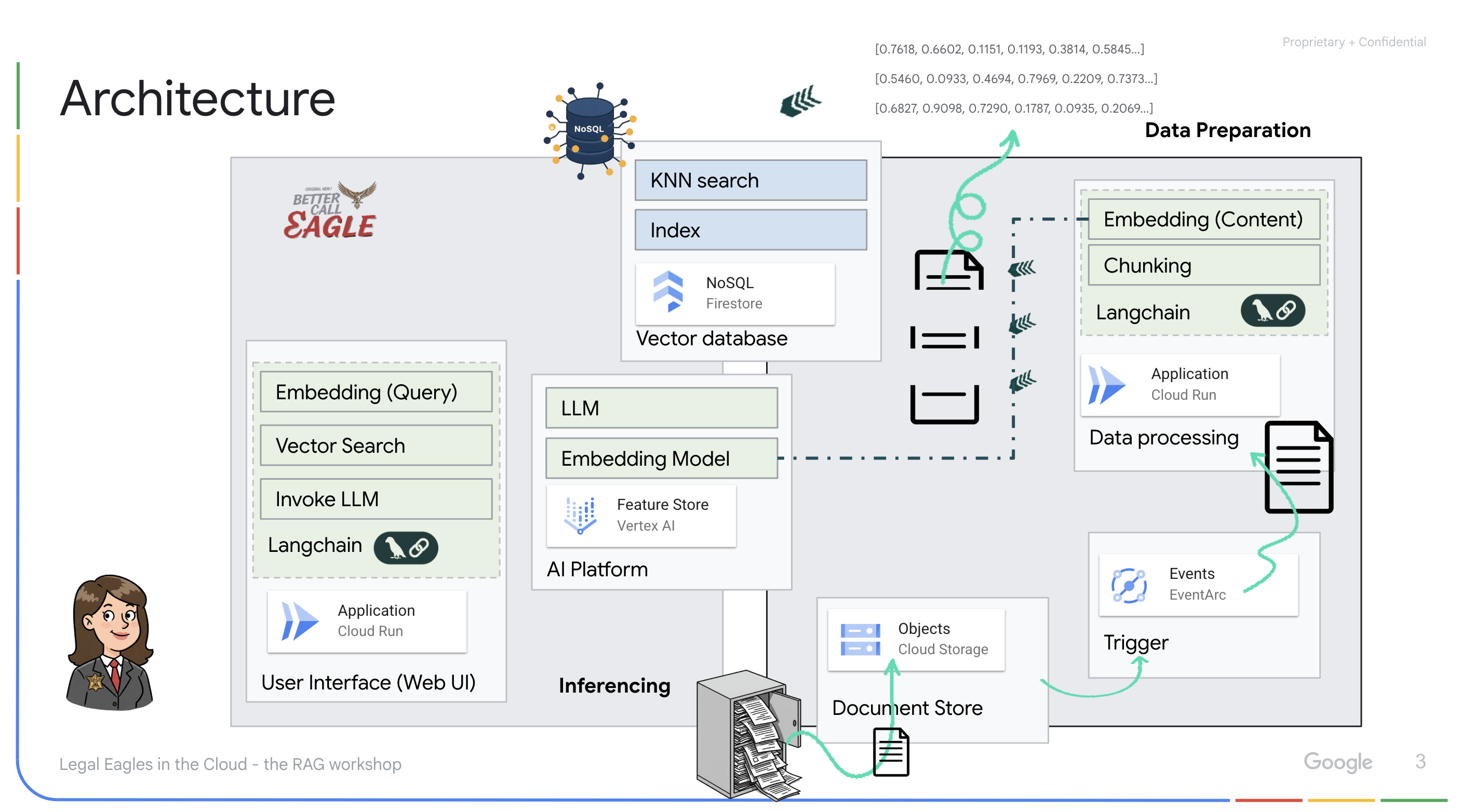
Applicazione basata su LLM e RAG : il fulcro del sistema di domande e risposte è la funzione ask_llm, che utilizza la libreria langchain per interagire con un modello linguistico di grandi dimensioni Gemini di Vertex AI. Crea un HumanMessage dalla query dell'utente e include un SystemMessage che indica all'LLM di agire come un assistente legale utile. Il sistema utilizza un approccio di Retrieval-Augmented Generation (RAG), in cui, prima di rispondere a una query, utilizza la funzione search_resource per recuperare il contesto pertinente dallo spazio di archiviazione vettoriale Firestore. Questo contesto viene quindi incluso in SystemMessage per basare la risposta dell'LLM sulle informazioni legali fornite. 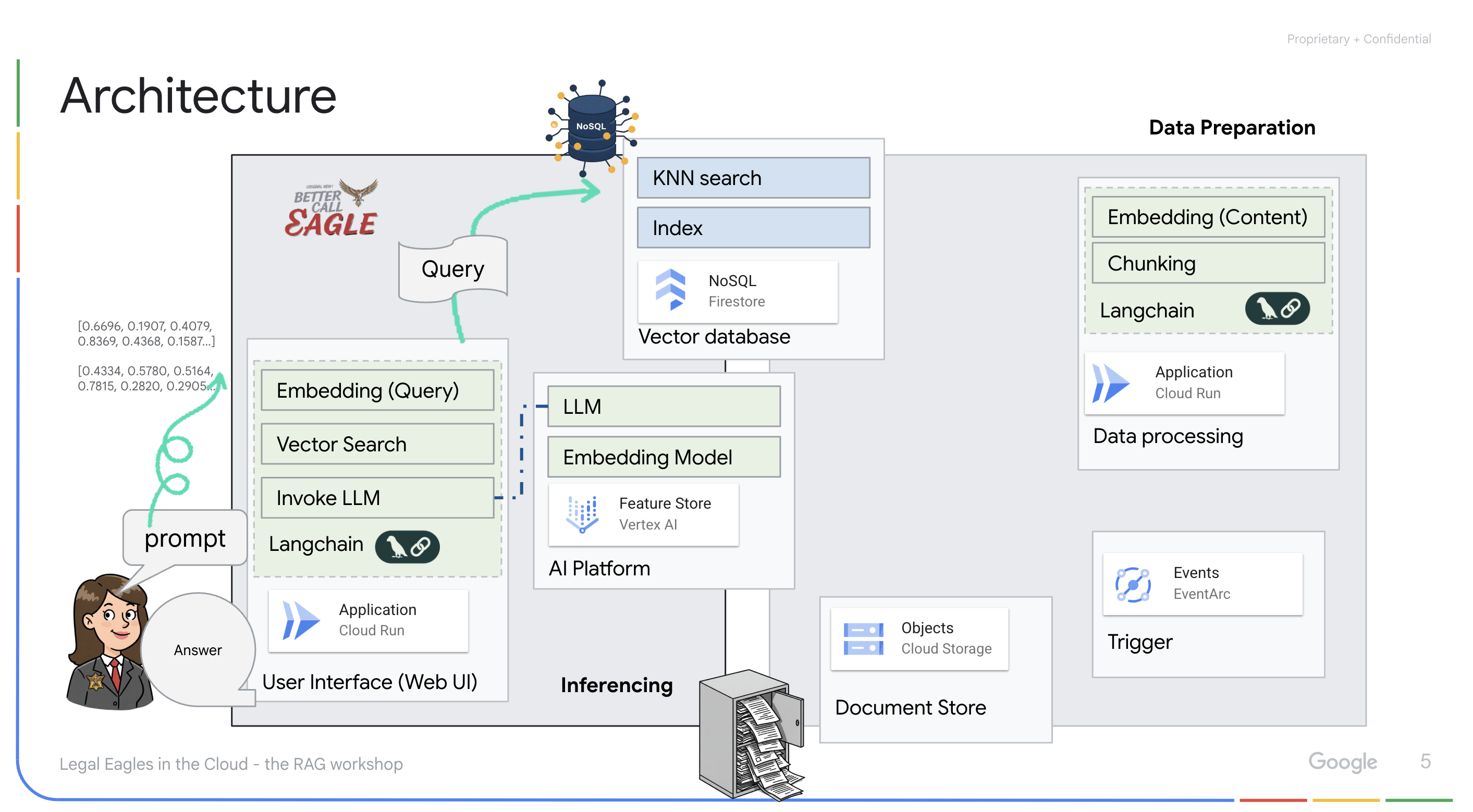
Il progetto mira a superare le "interpretazioni creative" degli LLM utilizzando la RAG, che recupera prima le informazioni pertinenti da una fonte giuridica attendibile prima di generare una risposta. In questo modo, le risposte sono più accurate e informate, in quanto basate su informazioni legali effettive. Il sistema è creato utilizzando vari servizi Google Cloud, come Google Cloud Shell, Vertex AI, Firestore, Cloud Run ed Eventarc.
3. Prima di iniziare
Nella console Google Cloud, nella pagina di selezione del progetto, seleziona o crea un progetto Google Cloud. Verifica che la fatturazione sia attivata per il tuo progetto Cloud. Scopri come verificare se la fatturazione è abilitata per un progetto.
Abilitare Gemini Code Assist nell'IDE di Cloud Shell
👉 Nella console Google Cloud, vai a Strumenti di Gemini Code Assist, abilita Gemini Code Assist senza costi accettando i termini e le condizioni.
Ignora la configurazione delle autorizzazioni e abbandona questa pagina.
Utilizzare l'editor di Cloud Shell
👉 Fai clic su Attiva Cloud Shell nella parte superiore della console Google Cloud (l'icona a forma di terminale nella parte superiore del riquadro Cloud Shell).
👉 Fai clic sul pulsante "Apri editor" (ha l'aspetto di una cartella aperta con una matita). Verrà aperto l'editor di Cloud Shell nella finestra. Vedrai un esploratore di file sul lato sinistro.

👉 Fai clic sul pulsante Accedi a Cloud Code nella barra di stato in basso, come mostrato. Autorizza il plug-in come indicato. Se nella barra di stato vedi Cloud Code - no project, selezionalo, poi seleziona "Select a Google Cloud Project" (Seleziona un progetto Google Cloud) nel menu a discesa e infine seleziona il progetto Google Cloud specifico dall'elenco dei progetti con cui prevedi di lavorare.
👉 Apri il terminale nell'IDE cloud, 
👉 Nel nuovo terminale, verifica di essere già autenticato e che il progetto sia impostato sul tuo ID progetto utilizzando il seguente comando:
gcloud auth list
👉 Fai clic su Attiva Cloud Shell nella parte superiore della console Google Cloud.
gcloud config set project <YOUR_PROJECT_ID>
👉 Esegui il seguente comando per abilitare le API Cloud necessarie:
gcloud services enable storage.googleapis.com \
run.googleapis.com \
artifactregistry.googleapis.com \
aiplatform.googleapis.com \
eventarc.googleapis.com \
cloudresourcemanager.googleapis.com \
firestore.googleapis.com \
cloudaicompanion.googleapis.com
Nella barra degli strumenti di Cloud Shell (nella parte superiore del riquadro di Cloud Shell), fai clic sul pulsante "Apri editor" (a forma di cartella aperta con una matita). Si aprirà l'editor di codice di Cloud Shell nella finestra. Vedrai un esploratore di file sul lato sinistro.
👉 Nel terminale, scarica il progetto Bootstrap Skeleton:
git clone https://github.com/weimeilin79/legal-eagle.git
FACOLTATIVO: VERSIONE IN SPAGNOLO
👉 Existe una versión alternativa en español. Utiliza la siguiente instrucción para clonar la versión correcta.
git clone -b spanish https://github.com/weimeilin79/legal-eagle.git
Dopo aver eseguito questo comando nel terminale Cloud Shell, nel tuo ambiente Cloud Shell verrà creata una nuova cartella con il nome del repository legal-eagle.
4. Scrivere l'applicazione di inferenza con Gemini Code Assist
In questa sezione ci concentreremo sulla creazione del nucleo del nostro assistente legale: l'applicazione web che riceve le domande degli utenti e interagisce con il modello di AI per generare risposte. Sfrutteremo Gemini Code Assist per scrivere il codice Python per questa parte di inferenza.
Inizialmente, creeremo un'applicazione Flask che utilizza la libreria LangChain per comunicare direttamente con il modello Gemini di Vertex AI. Questa prima versione fungerà da assistente legale utile basato sulle conoscenze generali del modello, ma non avrà ancora accesso ai nostri documenti specifici relativi alle cause giudiziarie. In questo modo potremo vedere il rendimento di base del LLM prima di migliorarlo con RAG in un secondo momento.
Nel riquadro Explorer dell'editor di Cloud Code (di solito sul lato sinistro), ora dovresti vedere la cartella creata quando hai clonato il repository Git legal-eagle. Apri la cartella principale del progetto in Explorer. Al suo interno troverai una sottocartella webapp, aprila. 
👉 Modifica il file legal.py nell'editor di Cloud Code. Puoi utilizzare diversi metodi per richiedere a Gemini Code Assist.
👉 Copia il seguente prompt in fondo a legal.py che descrive chiaramente ciò che vuoi che Gemini Code Assist generi, fai clic sull'icona a forma di lampadina 💡 visualizzata e seleziona Gemini: Generate Code (la voce di menu esatta potrebbe variare leggermente a seconda della versione di Cloud Code).
"""
Write a Python function called `ask_llm` that takes a user `query` as input. This function should use the `langchain` library to interact with a Vertex AI Gemini Large Language Model. Specifically, it should:
1. Create a `HumanMessage` object from the user's `query`.
2. Create a `ChatPromptTemplate` that includes a `SystemMessage` and the `HumanMessage`. The system message should instruct the LLM to act as a helpful assistant in a courtroom setting, aiding an attorney by providing necessary information. It should also specify that the LLM should respond in a high-energy tone, using no more than 100 words, and offer a humorous apology if it doesn't know the answer.
3. Format the `ChatPromptTemplate` with the provided messages.
4. Invoke the Vertex AI LLM with the formatted prompt using the `VertexAI` class (assuming it's already initialized elsewhere as `llm`).
5. Print the LLM's `response`.
6. Return the `response`.
7. Include error handling that prints an error message to the console and returns a user-friendly error message if any issues occur during the process. The Vertex AI model should be "gemini-2.0-flash".
"""
Esamina attentamente il codice generato
- Seguono più o meno i passaggi che hai descritto nel commento?
- Crea un
ChatPromptTemplateconSystemMessageeHumanMessage? - Include la gestione degli errori di base (
try...except)?
Se il codice generato è buono e per lo più corretto, puoi accettarlo (premi Tab o Invio per i suggerimenti in linea oppure fai clic su "Accetta" per i blocchi di codice più grandi).
Se il codice generato non è esattamente quello che vuoi o presenta errori, non preoccuparti. Gemini Code Assist è uno strumento per aiutarti, non per scrivere codice perfetto al primo tentativo.
Modifica il codice generato per perfezionarlo, correggere gli errori e soddisfare meglio i tuoi requisiti. Puoi chiedere ulteriori informazioni a Gemini Code Assist aggiungendo altri commenti o ponendo domande specifiche nel riquadro della chat di Code Assist.
Se non hai ancora familiarità con l'SDK, ecco un esempio funzionante.
👉 Copia e incolla e SOSTITUISCI il seguente codice in legal.py:
import os
import signal
import sys
import vertexai
import random
from langchain_google_vertexai import VertexAI
from langchain_core.prompts import PromptTemplate, ChatPromptTemplate
from langchain_core.messages import HumanMessage, SystemMessage
# Connect to resourse needed from Google Cloud
llm = VertexAI(model_name="gemini-2.0-flash")
def ask_llm(query):
try:
query_message = {
"type": "text",
"text": query,
}
input_msg = HumanMessage(content=[query_message])
prompt_template = ChatPromptTemplate.from_messages(
[
SystemMessage(
content=(
"You are a helpful assistant, and you are with the attorney in a courtroom, you are helping him to win the case by providing the information he needs "
"Don't answer if you don't know the answer, just say sorry in a funny way possible"
"Use high engergy tone, don't use more than 100 words to answer"
# f"Here is some past conversation history between you and the user {relevant_history}"
# f"Here is some context that is relevant to the question {relevant_resource} that you might use"
)
),
input_msg,
]
)
prompt = prompt_template.format()
response = llm.invoke(prompt)
print(f"response: {response}")
return response
except Exception as e:
print(f"Error sending message to chatbot: {e}") # Log this error too!
return f"Unable to process your request at this time. Due to the following reason: {str(e)}"
👉 FACOLTATIVO: VERSIONE IN SPAGNOLO
Sostituisci il seguente testo come indicato: You are a helpful assistant, con You are a helpful assistant that speaks Spanish,
Poi, crea una funzione per gestire una route che risponda alle domande dell'utente.
Apri main.py nell'editor di Cloud Shell. In modo simile a come hai generato ask_llm in legal.py, utilizza Gemini Code Assist per generare la route Flask e la funzione ask_question. Digita il seguente PROMPT come commento in main.py: (assicurati che venga aggiunto prima di avviare l'app Flask all'indirizzo if __name__ == "__main__":)
.....
@app.route('/',methods=['GET'])
def index():
return render_template('index.html')
"""
PROMPT:
Create a Flask endpoint that accepts POST requests at the '/ask' route.
The request should contain a JSON payload with a 'question' field. Extract the question from the JSON payload.
Call a function named ask_llm (located in a file named legal.py) with the extracted question as an argument.
Return the result of the ask_llm function as the response with a 200 status code.
If any error occurs during the process, return a 500 status code with the error message.
"""
# Add this block to start the Flask app when running locally
if __name__ == "__main__":
.....
Accetta SOLO se il codice generato è valido e per lo più corretto. Se non hai familiarità con Python, ecco un esempio funzionante.Copia e incolla questo codice in main.py sotto il codice già presente.
👉 Assicurati di incollare quanto segue PRIMA dell'inizio dell'applicazione web (if name == "main":)
@app.route('/ask', methods=['POST'])
def ask_question():
data = request.get_json()
question = data.get('question')
try:
# call the ask_llm in legal.py
answer_markdown = legal.ask_llm(question)
print(f"answer_markdown: {answer_markdown}")
# Return the Markdown as the response
return answer_markdown, 200
except Exception as e:
return f"Error: {str(e)}", 500 # Handle errors appropriately
Se segui questi passaggi, dovresti riuscire ad attivare Gemini Code Assist, configurare il progetto e utilizzarlo per generare la funzione ask nel file main.py.
5. Test locale in Cloud Editor
👉 Nel terminale dell'editor,installa le librerie dipendenti e avvia l'interfaccia utente web localmente.
cd ~/legal-eagle/webapp
python -m venv env
source env/bin/activate
export PROJECT_ID=$(gcloud config get project)
pip install -r requirements.txt
python main.py
Cerca i messaggi di avvio nell'output del terminale Cloud Shell. Flask di solito stampa messaggi che indicano che è in esecuzione e su quale porta.
- Running on http://127.0.0.1:8080
L'applicazione deve continuare a essere eseguita per gestire le richieste.
👉 Nel menu "Anteprima web", scegli Anteprima sulla porta 8080. Cloud Shell aprirà una nuova scheda o finestra del browser con l'anteprima web della tua applicazione. 
👉 Nell'interfaccia dell'applicazione, digita alcune domande relative in modo specifico ai riferimenti di casi legali e vedi come risponde l'LLM. Ad esempio, potresti provare:
- A quanti anni di reclusione è stato condannato Michael Brown?
- Qual è l'importo degli addebiti non autorizzati generati a seguito delle azioni di Maria Rossi?
- Quale ruolo hanno svolto le testimonianze dei vicini nell'indagine sul caso di Emily White?
👉 FACOLTATIVO: VERSIONE IN SPAGNOLO
- ¿A cuántos años de prisión fue sentenciado Michael Brown?
- ¿Cuánto dinero en cargos no autorizados se generó como resultado de las acciones de Jane Smith?
- ¿Qué papel jugaron los testimonios de los vecinos en la investigación del caso de Emily White?
Se esamini attentamente le risposte, probabilmente noterai che il modello può avere allucinazioni, essere vago o generico e a volte interpretare male le tue domande, soprattutto perché non ha ancora accesso a documenti legali specifici.
👉 Interrompi lo script premendo Ctrl+C.
👉 Esci dall'ambiente virtuale eseguendo questo comando nel terminale:
deactivate
6. Configurazione del datastore vettoriale
È ora di porre fine a queste "interpretazioni creative" della legge da parte degli LLM. È qui che entra in gioco la Retrieval-Augmented Generation (RAG). È come dare al nostro LLM l'accesso a una biblioteca legale super potente prima che risponda alle tue domande. Anziché basarsi esclusivamente sulle sue conoscenze generali (che possono essere vaghe o obsolete a seconda del modello), la RAG recupera innanzitutto informazioni pertinenti da una fonte attendibile, nel nostro caso documenti legali, e poi utilizza questo contesto per generare una risposta molto più informata e accurata. È come se l'LLM facesse i compiti prima di entrare in tribunale.
Per creare il nostro sistema RAG, abbiamo bisogno di un posto dove archiviare tutti questi documenti legali e, soprattutto, renderli ricercabili per significato. È qui che entra in gioco Firestore. Firestore è il database di documenti NoSQL flessibile e scalabile di Google Cloud.
Utilizzeremo Firestore come datastore vettoriale. Memorizzeremo blocchi dei nostri documenti legali in Firestore e, per ogni blocco, memorizzeremo anche il relativo embedding, ovvero la rappresentazione numerica del suo significato.
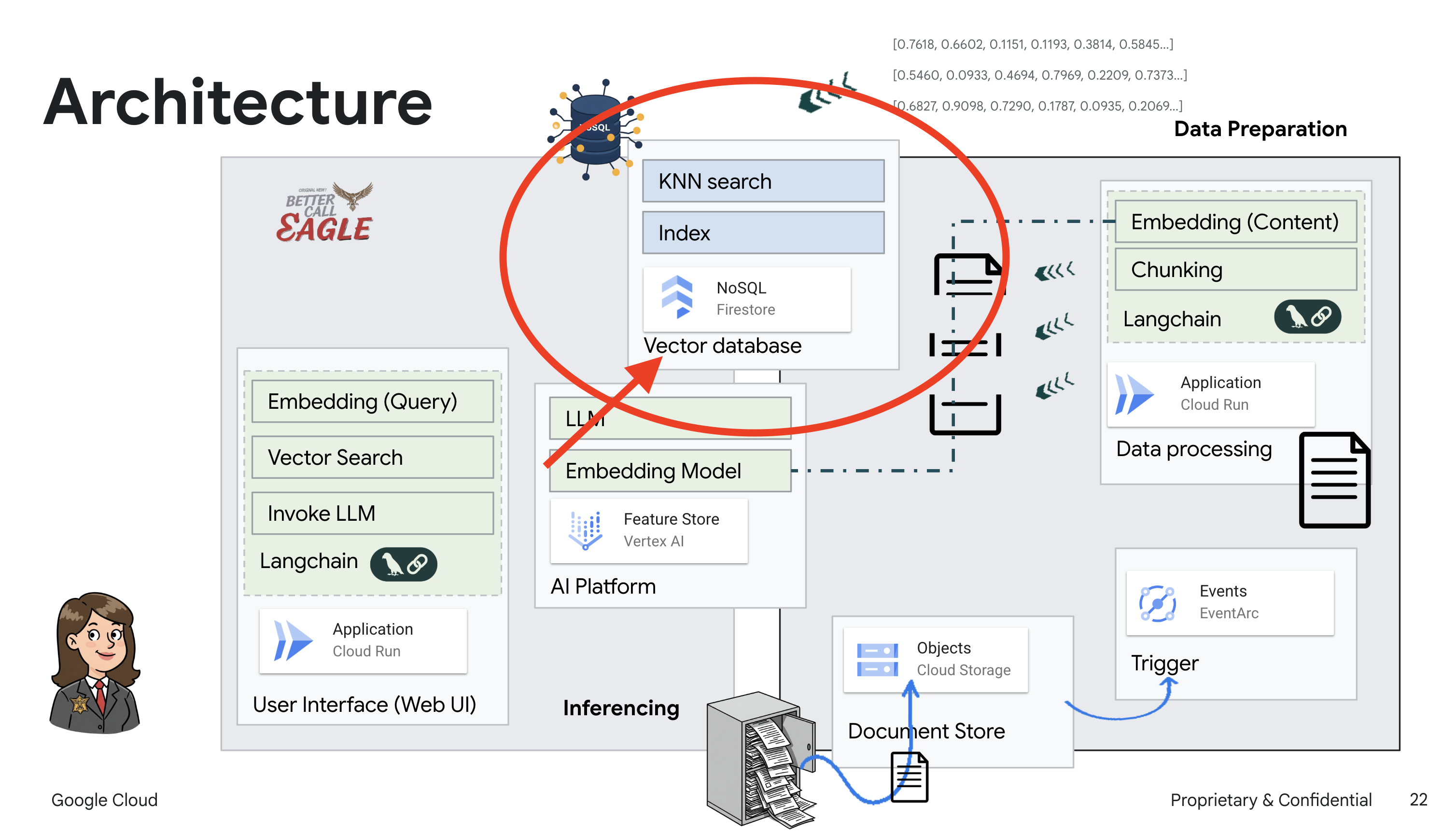
Poi, quando poni una domanda al nostro Legal Eagle, utilizzeremo la ricerca vettoriale di Firestore per trovare i blocchi di testo legale più pertinenti per la tua query. Questo contesto recuperato è ciò che la RAG utilizza per fornirti risposte basate su informazioni legali reali, non solo sull'immaginazione dell'LLM.
👉 In una nuova scheda/finestra, vai a Firestore nella console Google Cloud.
👉 Fai clic su Crea database.
👉 Scegli Native mode e il nome del database come (default).
👉 Seleziona un singolo region: us-central1 e fai clic su Crea database. Firestore eseguirà il provisioning del database, il che potrebbe richiedere alcuni istanti.
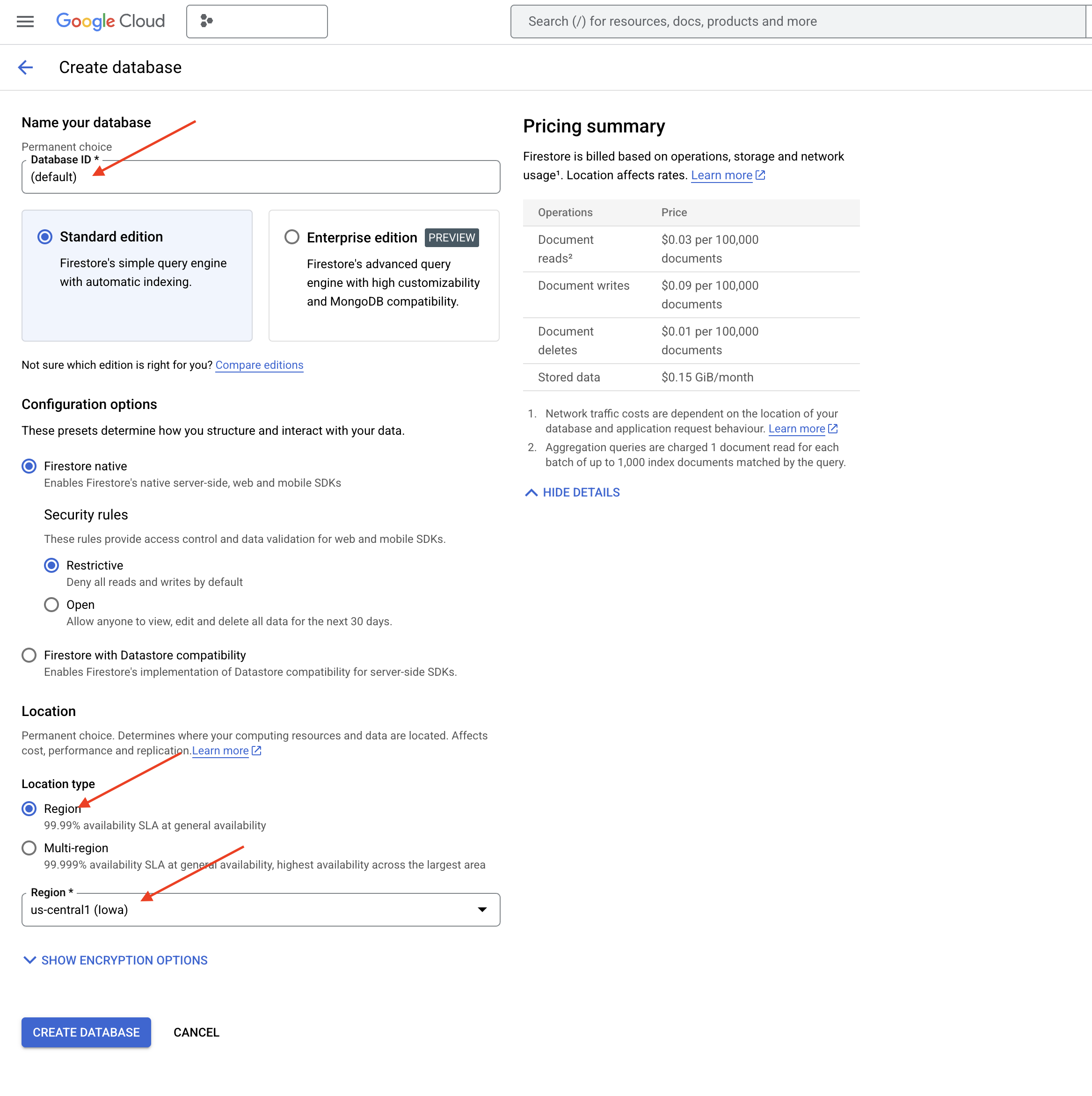
👉 Nel terminale di Cloud IDE, crea un indice vettoriale sul campo embedding_vector per abilitare la ricerca vettoriale nella raccolta legal_documents.
export PROJECT_ID=$(gcloud config get project)
gcloud firestore indexes composite create \
--collection-group=legal_documents \
--query-scope=COLLECTION \
--field-config field-path=embedding,vector-config='{"dimension":"768", "flat": "{}"}' \
--project=${PROJECT_ID}
Firestore inizierà a creare l'indice vettoriale. La creazione dell'indice può richiedere del tempo, soprattutto per set di dati più grandi. Vedrai l'indice nello stato "Creazione", che passerà a "Pronto" una volta creato. 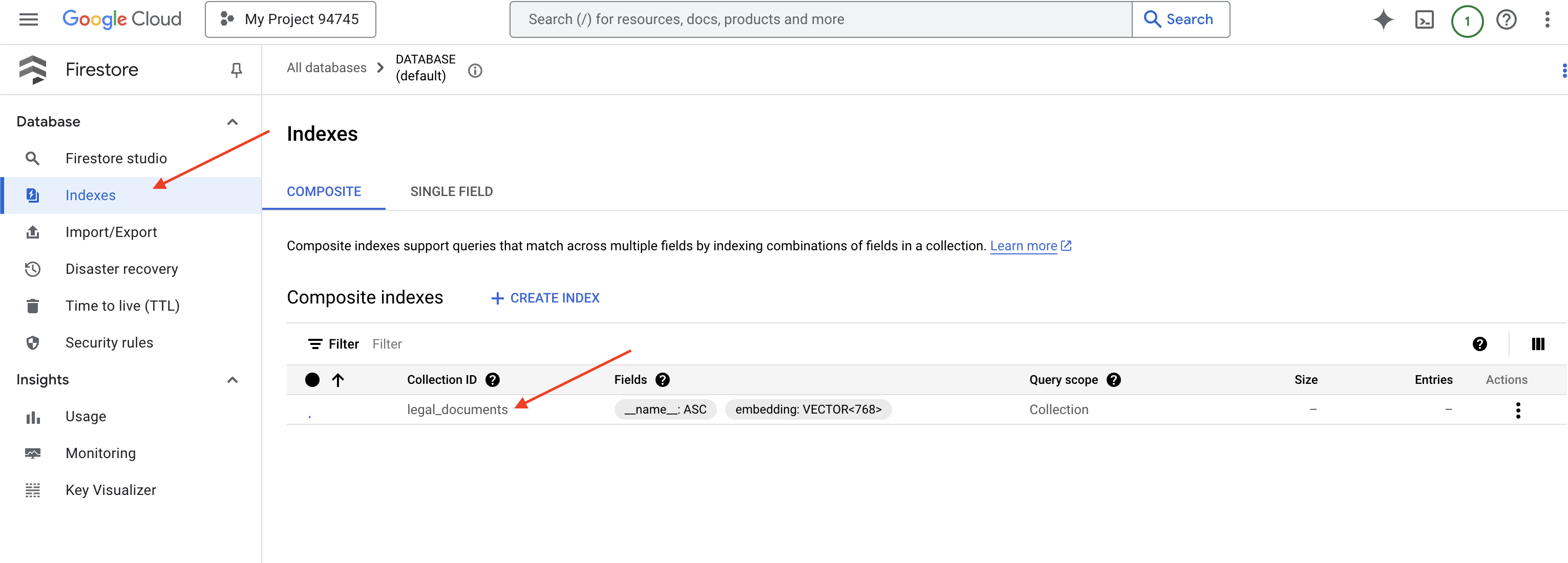
7. Caricamento dei dati nel Vector Store
Ora che abbiamo compreso RAG e il nostro vector store, è il momento di creare il motore che popola la nostra biblioteca legale. Quindi, come facciamo a rendere i documenti legali "ricercabili per significato"? La magia sta negli incorporamenti. Pensa agli embedding come alla conversione di parole, frasi o persino interi documenti in vettori numerici, ovvero elenchi di numeri che ne acquisiscono il significato semantico. I concetti simili hanno vettori "vicini" tra loro nello spazio vettoriale. Utilizziamo modelli potenti (come quelli di Vertex AI) per eseguire questa conversione.
Per automatizzare il caricamento dei documenti, utilizzeremo Cloud Run Functions ed Eventarc. Cloud Run Functions è un container serverless leggero che esegue il codice solo quando necessario. Pacchettizzeremo il nostro script Python di elaborazione dei documenti in un container e lo implementeremo come funzione Cloud Run.
👉 In una nuova scheda/finestra, vai a Cloud Storage.
👉 Fai clic su "Bucket" nel menu a sinistra.
👉 Fai clic sul pulsante "+ CREA" in alto.
👉 Configura il bucket (impostazioni importanti):
- Nome del bucket: 'yourprojectID'-doc-bucket (DEVI avere il suffisso -doc-bucket alla fine)
- region: seleziona la regione
us-central1. - Classe di archiviazione: "Standard". Standard è adatta ai dati a cui si accede di frequente.
- Controllo dell'accesso: lascia selezionata l'opzione predefinita "Controllo dell'accesso uniforme". In questo modo, il controllo degli accessi a livello di bucket è coerente.
- Opzioni avanzate: per questo tutorial, in genere le impostazioni predefinite sono sufficienti.
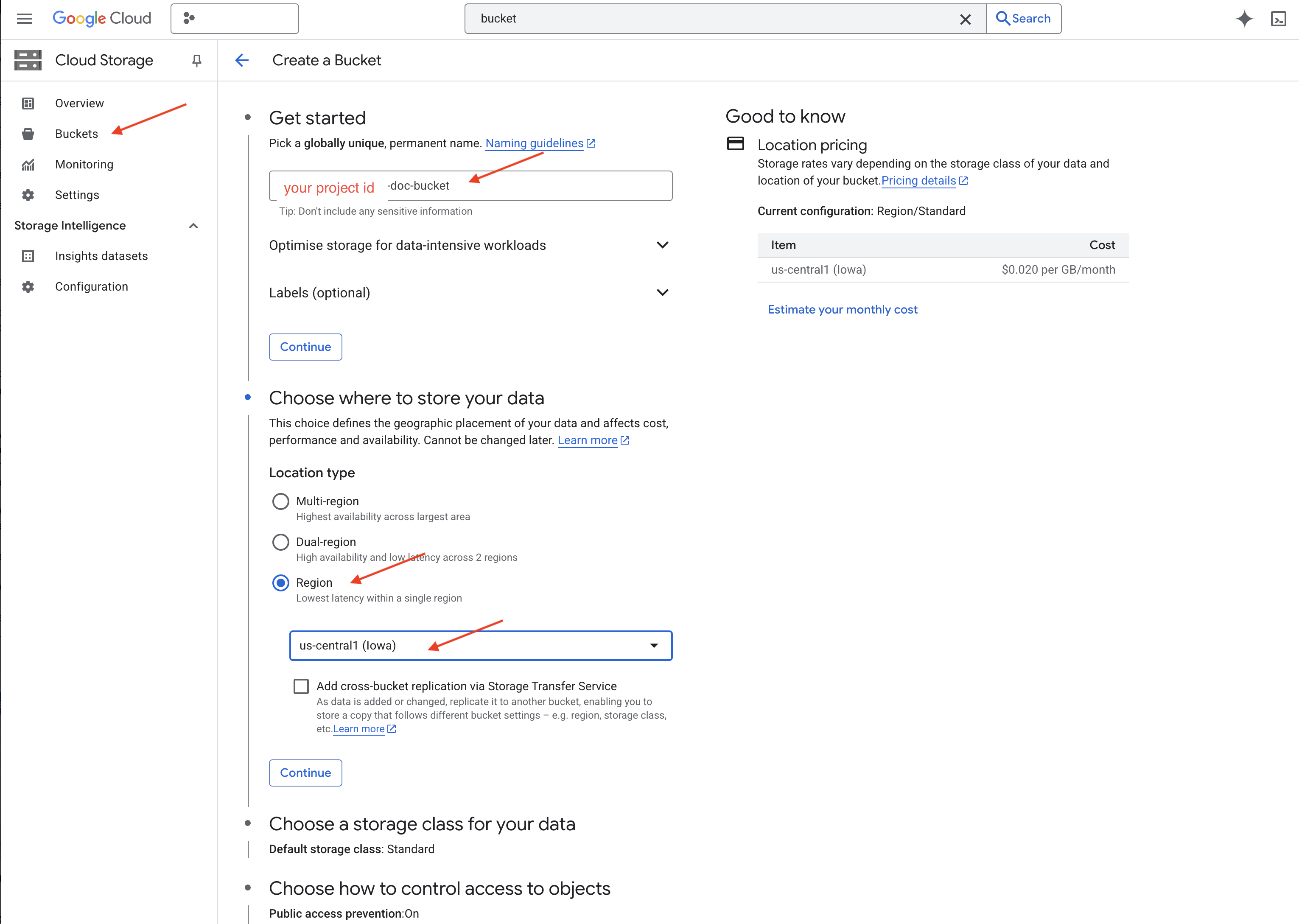
👉 Fai clic sul pulsante CREA per creare il bucket.
👉 Potresti visualizzare un popup relativo alla prevenzione dell'accesso pubblico. Lascia la casella selezionata e fai clic su "Conferma".
Ora vedrai il bucket appena creato nell'elenco Bucket. Ricorda il nome del bucket, ti servirà in seguito.
8. Configura una funzione Cloud Run
👉 Nell'editor di codice Cloud Shell, vai alla directory di lavoro legal-eagle: utilizza il comando cd nel terminale dell'editor di codice per creare la cartella.
cd ~/legal-eagle
mkdir loader
cd loader
👉 Crea file main.py,requirements.txt e Dockerfile. Nel terminale Cloud Shell, utilizza il comando touch per creare i file:
touch main.py requirements.txt Dockerfile
Vedrai la cartella appena creata denominata *loader e i tre file.
👉 Modifica main.py nella cartella loader. In Esplora file a sinistra, vai alla directory in cui hai creato i file e fai doppio clic su main.py per aprirlo nell'editor.
Incolla il seguente codice Python in main.py:
Questa applicazione elabora i nuovi file caricati nel bucket GCS, divide il testo in blocchi, genera embedding per ogni blocco e memorizza i blocchi e i relativi embedding in Firestore.
import os
import json
from google.cloud import storage
import functions_framework
from langchain_google_vertexai import VertexAI, VertexAIEmbeddings
from langchain_google_firestore import FirestoreVectorStore
from langchain.text_splitter import RecursiveCharacterTextSplitter
import vertexai
PROJECT_ID = os.environ.get("GOOGLE_CLOUD_PROJECT") # Get project ID from env
embedding_model = VertexAIEmbeddings(
model_name="text-embedding-004" ,
project=PROJECT_ID,)
COLLECTION_NAME = "legal_documents"
# Create a vector store
vector_store = FirestoreVectorStore(
collection="legal_documents",
embedding_service=embedding_model,
content_field="original_text",
embedding_field="embedding",
)
@functions_framework.cloud_event
def process_file(cloud_event):
print(f"CloudEvent received: {cloud_event.data}") # Print the parsed event data
"""Triggered by a Cloud Storage event.
Args:
cloud_event (functions_framework.CloudEvent): The CloudEvent
containing the Cloud Storage event data.
"""
try:
event_data = cloud_event.data
bucket_name = event_data['bucket']
file_name = event_data['name']
except (json.JSONDecodeError, AttributeError, KeyError) as e: # Catch JSON errors
print(f"Error decoding CloudEvent data: {e} - Data: {cloud_event.data}")
return "Error processing event", 500 # Return an error response
print(f"New file detected in bucket: {bucket_name}, file: {file_name}")
storage_client = storage.Client()
bucket = storage_client.bucket(bucket_name)
blob = bucket.blob(file_name)
try:
# Download the file content as string (assuming UTF-8 encoded text file)
file_content_string = blob.download_as_string().decode("utf-8")
print(f"File content downloaded. Processing...")
# Split text into chunks using RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=100,
length_function=len,
)
text_chunks = text_splitter.split_text(file_content_string)
print(f"Text split into {len(text_chunks)} chunks.")
# Add the docs to the vector store
vector_store.add_texts(text_chunks)
print(f"File processing and Firestore upsert complete for file: {file_name}")
return "File processed successfully", 200 # Return success response
except Exception as e:
print(f"Error processing file {file_name}: {e}")
Modifica requirements.txt.Incolla le seguenti righe nel file:
Flask==2.3.3
requests==2.31.0
google-generativeai>=0.2.0
langchain
langchain_google_vertexai
langchain-community
langchain-google-firestore
google-cloud-storage
functions-framework
9. Testare e creare la funzione Cloud Run
👉 Eseguiremo questa operazione in un ambiente virtuale e installeremo le librerie Python necessarie per la funzione Cloud Run.
cd ~/legal-eagle/loader
python -m venv env
source env/bin/activate
pip install -r requirements.txt
👉 Avvia un emulatore locale per la funzione Cloud Run
functions-framework --target process_file --signature-type=cloudevent --source main.py
👉 Mantieni in esecuzione l'ultimo terminale, apri un nuovo terminale ed esegui il comando per caricare un file nel bucket.
export DOC_BUCKET_NAME=$(gcloud storage buckets list --format="value(name)" | grep doc-bucket)
gsutil cp ~/legal-eagle/court_cases/case-01.txt gs://$DOC_BUCKET_NAME/

👉 Mentre l'emulatore è in esecuzione, puoi inviargli CloudEvent di test. Per questa operazione è necessario un terminale separato nell'IDE.
curl -X POST -H "Content-Type: application/json" \
-d "{
\"specversion\": \"1.0\",
\"type\": \"google.cloud.storage.object.v1.finalized\",
\"source\": \"//storage.googleapis.com/$DOC_BUCKET_NAME\",
\"subject\": \"objects/case-01.txt\",
\"id\": \"my-event-id\",
\"time\": \"2024-01-01T12:00:00Z\",
\"data\": {
\"bucket\": \"$DOC_BUCKET_NAME\",
\"name\": \"case-01.txt\"
}
}" http://localhost:8080/
Dovrebbe restituire OK.
👉 Per verificare i dati in Firestore, vai alla console Google Cloud, seleziona "Database", poi "Firestore", seleziona la scheda "Dati" e infine la raccolta legal_documents. Vedrai che nella raccolta sono stati creati nuovi documenti, ognuno dei quali rappresenta una parte del testo del file caricato. 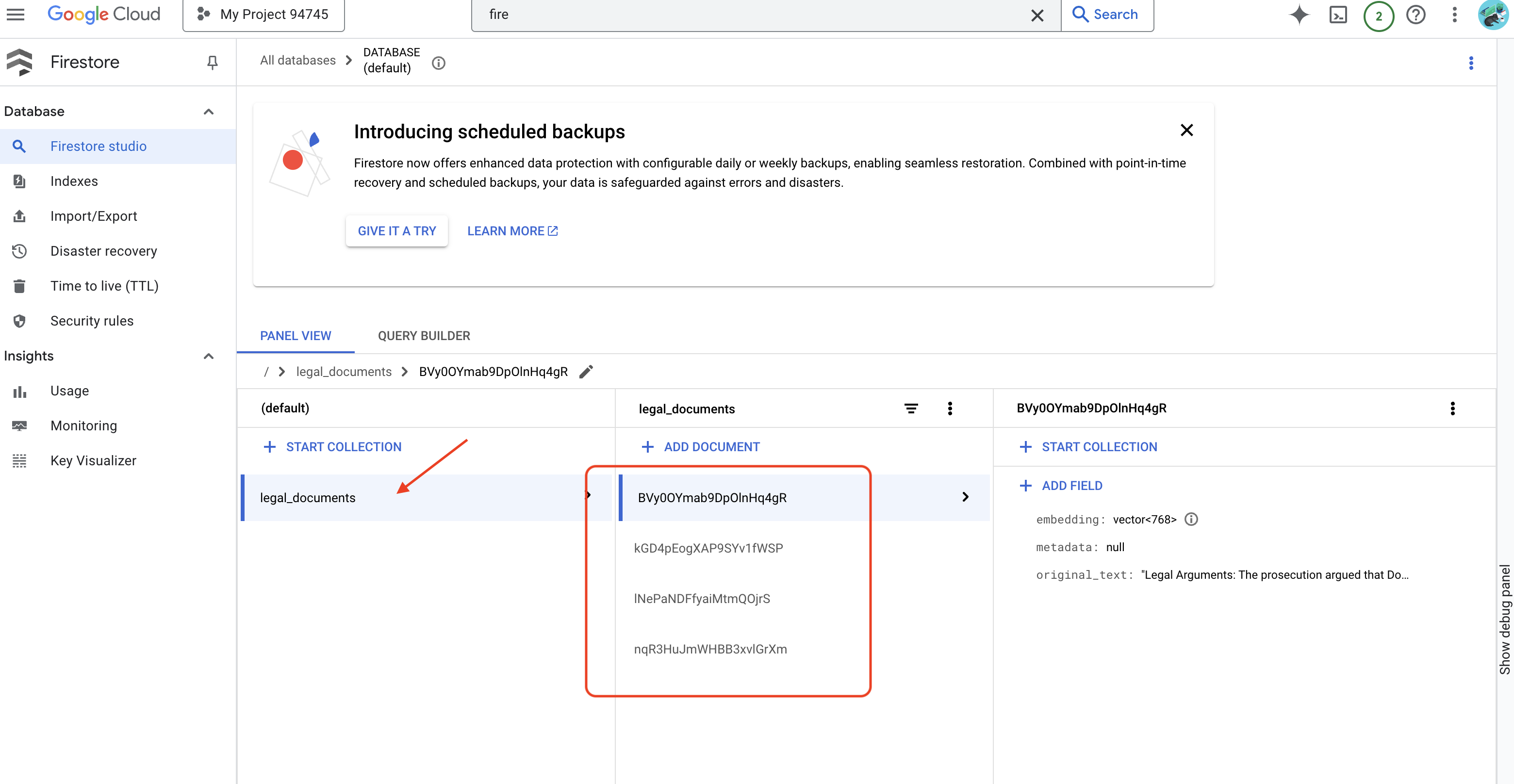
👉 Nel terminale in cui è in esecuzione l'emulatore, digita Ctrl+C per uscire. e chiudi il secondo terminale.
👉 Esegui deactivate per uscire dall'ambiente virtuale.
deactivate
10. Crea l'immagine container ed eseguine il push nei repository Artifacts
👉 È ora di eseguire il deployment nel cloud. In Esplora file, fai doppio clic su Dockerfile. Chiedi a Gemini di generare il Dockerfile per te, apri Gemini Code Assist e usa il seguente prompt per generare il file.
In the loader folder,
Generate a Dockerfile for a Python 3.12 Cloud Run service that uses functions-framework. It needs to:
1. Use a Python 3.12 slim base image.
2. Set the working directory to /app.
3. Copy requirements.txt and install Python dependencies.
4. Copy main.py.
5. Set the command to run functions-framework, targeting the 'process_file' function on port 8080
Per una best practice, ti consigliamo di fare clic su Diff with Open File(due frecce in direzioni opposte) e accettare le modifiche. 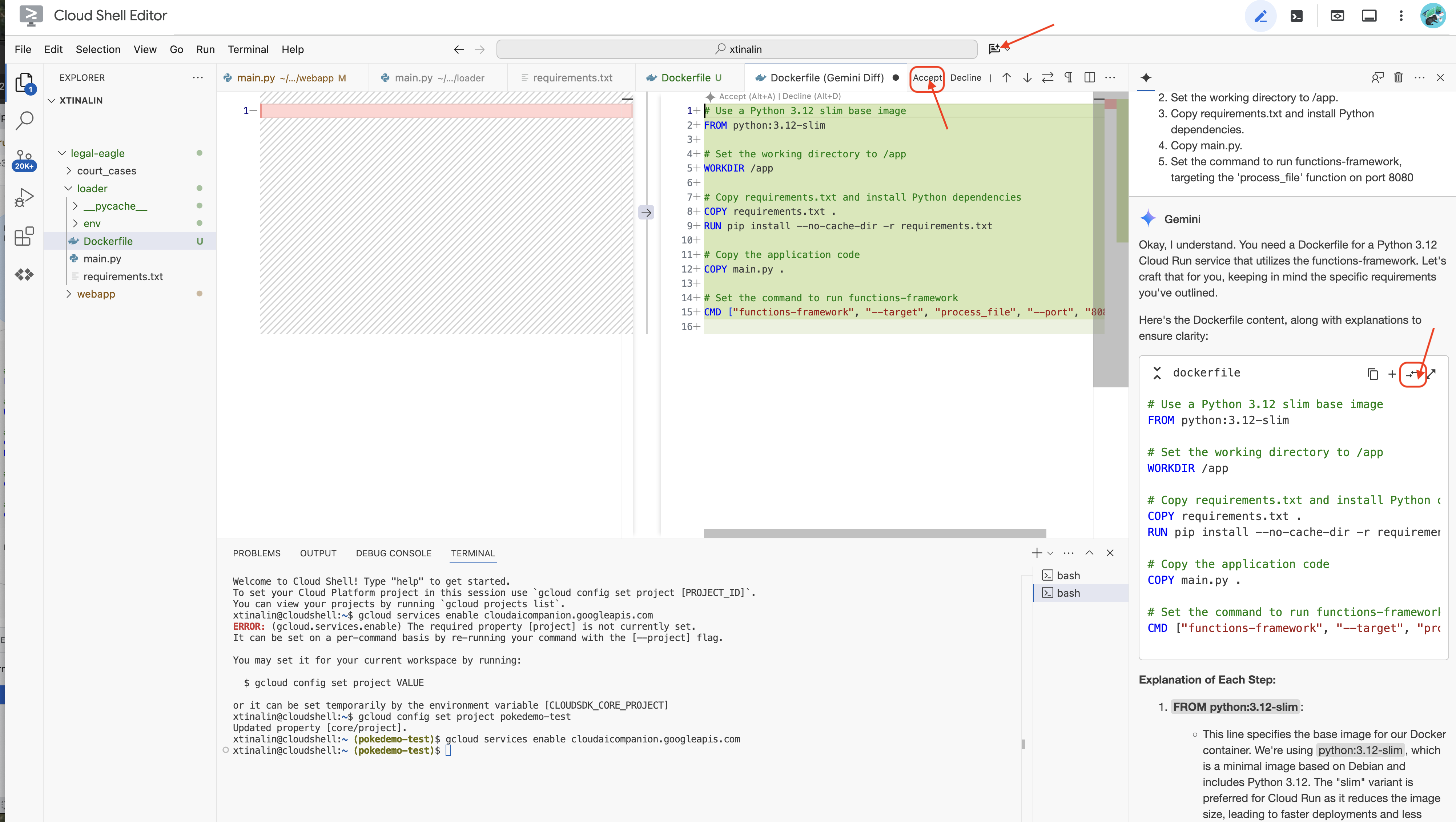
👉 Se non hai mai utilizzato i container, ecco un esempio pratico:
# Use a Python 3.12 slim base image
FROM python:3.12-slim
# Set the working directory to /app
WORKDIR /app
# Copy requirements.txt and install Python dependencies
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
# Copy main.py
COPY main.py .
# Set the command to run functions-framework
CMD ["functions-framework", "--target", "process_file", "--port", "8080"]
Nel terminale, crea un repository di artefatti per archiviare l'immagine Docker che creeremo.
gcloud artifacts repositories create my-repository \
--repository-format=docker \
--location=us-central1 \
--description="My repository"
Dovresti visualizzare il messaggio Repository [my-repository] creato.
👉 Esegui questo comando per creare l'immagine Docker.
cd ~/legal-eagle/loader
export PROJECT_ID=$(gcloud config get project)
docker build -t gcr.io/${PROJECT_ID}/legal-eagle-loader .
👉 Ora lo invierai al registry
export PROJECT_ID=$(gcloud config get project)
docker tag gcr.io/${PROJECT_ID}/legal-eagle-loader us-central1-docker.pkg.dev/${PROJECT_ID}/my-repository/legal-eagle-loader
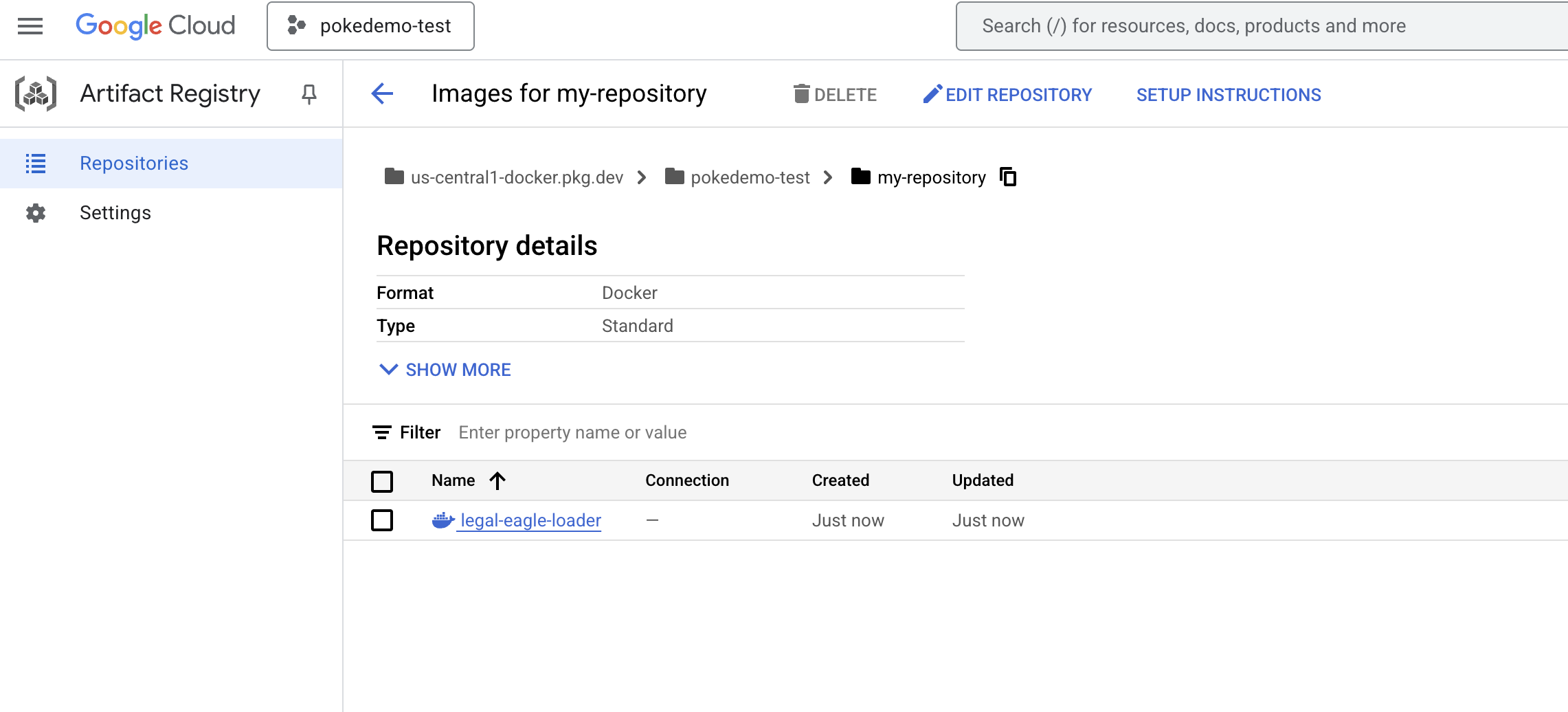
docker push us-central1-docker.pkg.dev/${PROJECT_ID}/my-repository/legal-eagle-loader
L'immagine Docker è ora disponibile nel repository Artifacts my-repository .
11. Crea la funzione Cloud Run e configura il trigger Eventarc
Prima di entrare nei dettagli del deployment del nostro loader di documenti legali, vediamo brevemente i componenti coinvolti: Cloud Run è una piattaforma serverless completamente gestita che consente di eseguire il deployment di applicazioni containerizzate in modo rapido e semplice. Astrae la gestione dell'infrastruttura, consentendoti di concentrarti sulla scrittura e sul deployment del codice.
Eseguiremo il deployment del nostro caricatore di documenti come servizio Cloud Run. Ora procediamo con la configurazione della nostra funzione Cloud Run:
👉 Nella console Google Cloud, vai a Cloud Run.
👉 Vai a Esegui il deployment del container e fai clic su SERVIZIO nel menu a discesa.
👉 Configura il servizio Cloud Run:
- Immagine container: fai clic su "Seleziona" nel campo URL. Trova l'URL dell'immagine di cui hai eseguito il push in Artifact Registry (ad es. us-central1-docker.pkg.dev/your-project-id/my-repository/legal-eagle-loader/yourimage).
- Nome del servizio:
legal-eagle-loader - Regione: seleziona la regione
us-central1. - Autenticazione: ai fini di questo workshop, puoi consentire "Consenti chiamate non autenticate". Per la produzione, probabilmente vorrai limitare l'accesso.
- Container, networking, sicurezza : predefinito.
👉 Fai clic su CREA. Cloud Run eseguirà il deployment del tuo servizio. 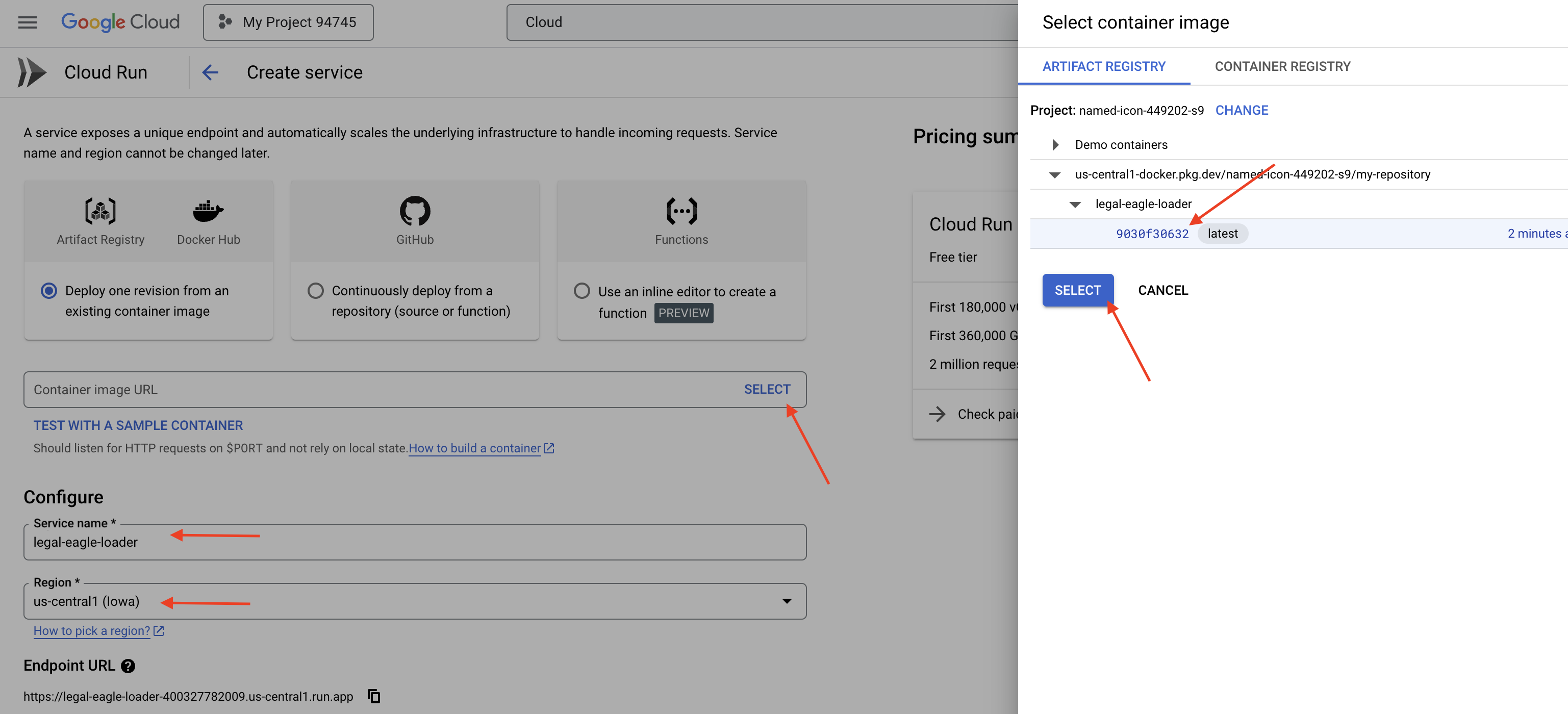
Per attivare automaticamente questo servizio quando vengono aggiunti nuovi file al nostro bucket di archiviazione, utilizzeremo Eventarc. Eventarc ti consente di creare architetture basate su eventi indirizzando gli eventi da varie origini ai tuoi servizi.
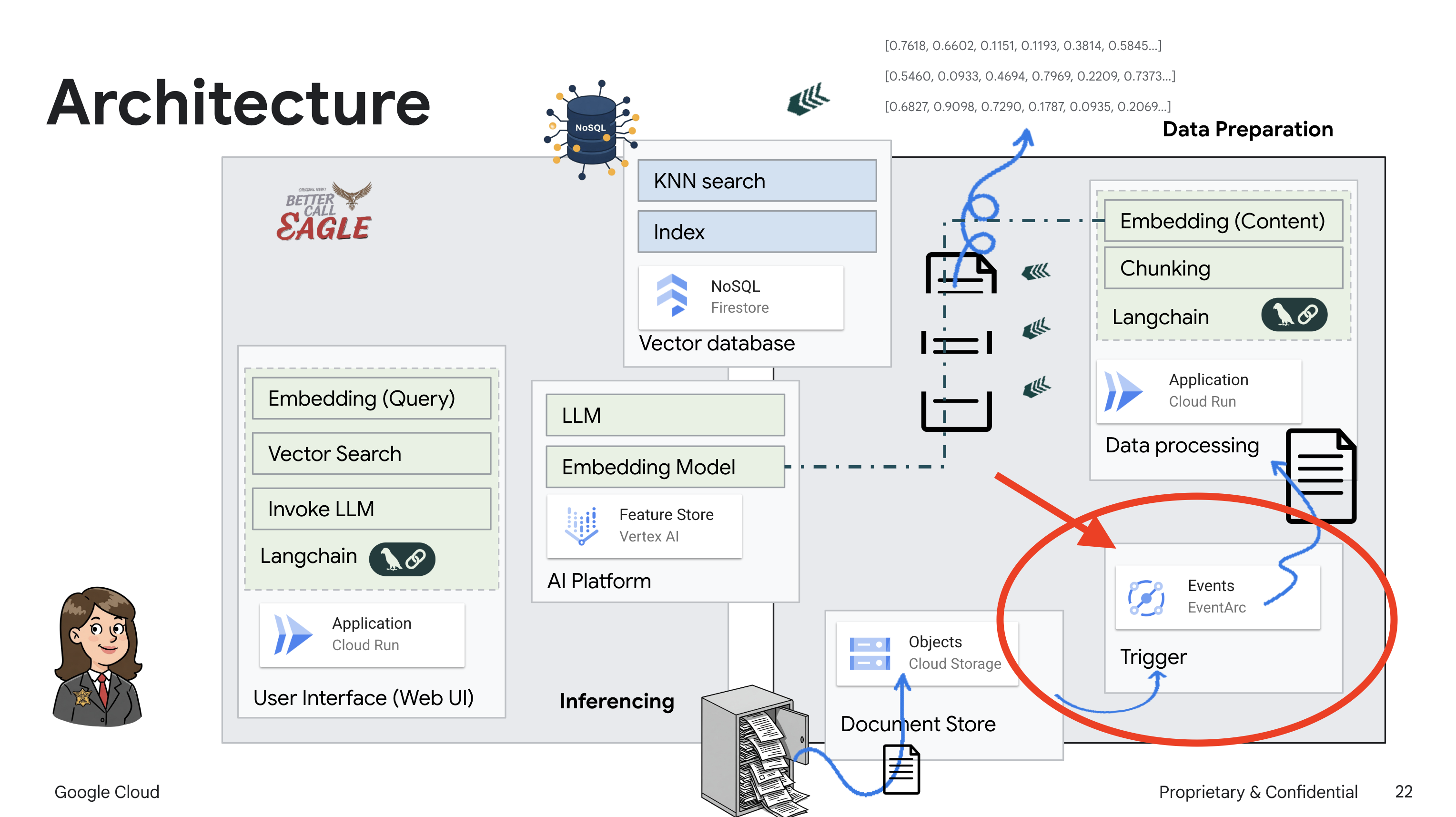
Configurando Eventarc, il nostro servizio Cloud Run caricherà automaticamente i documenti appena aggiunti in Firestore non appena vengono caricati, consentendo aggiornamenti dei dati in tempo reale per la nostra applicazione RAG.
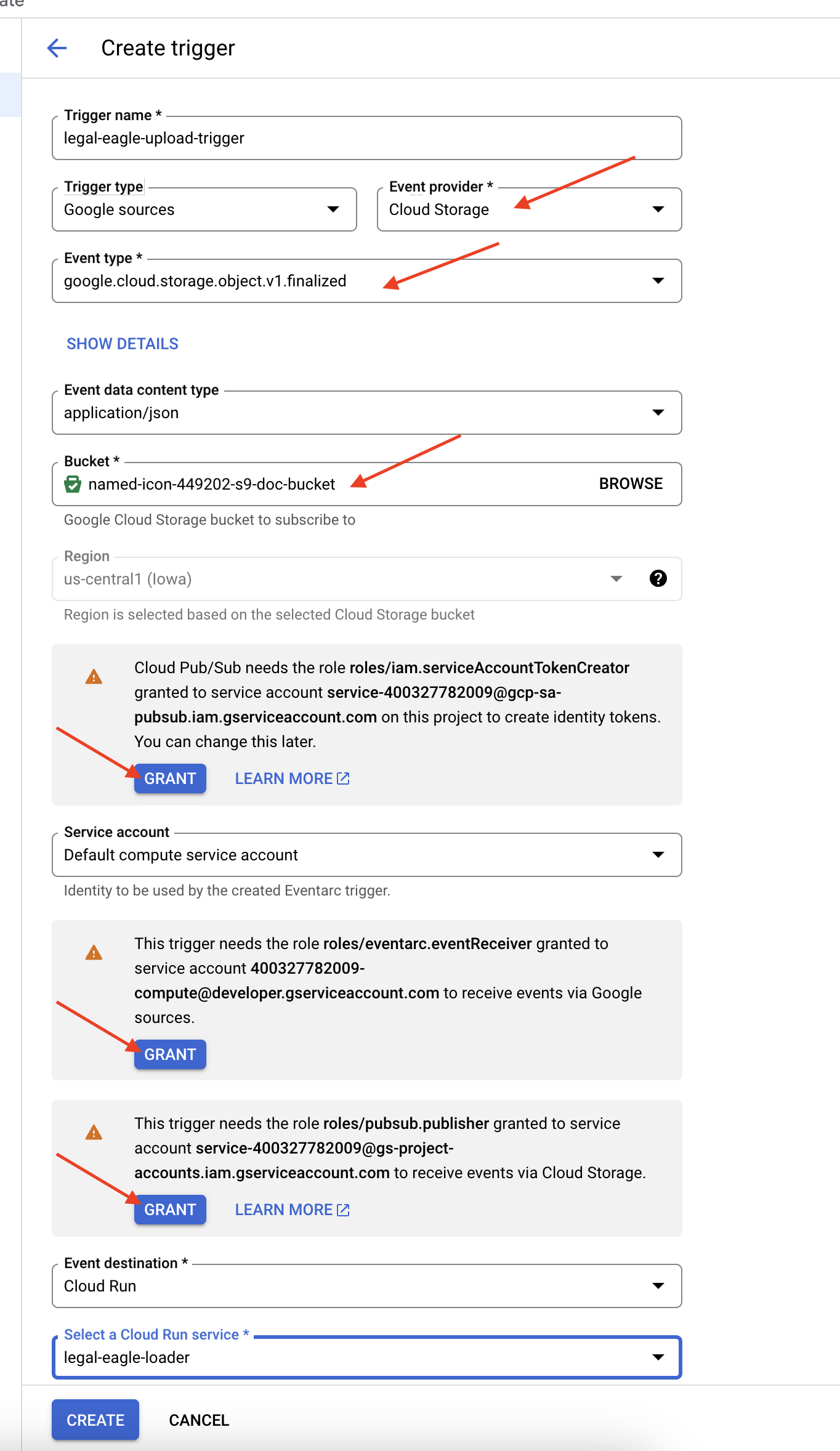
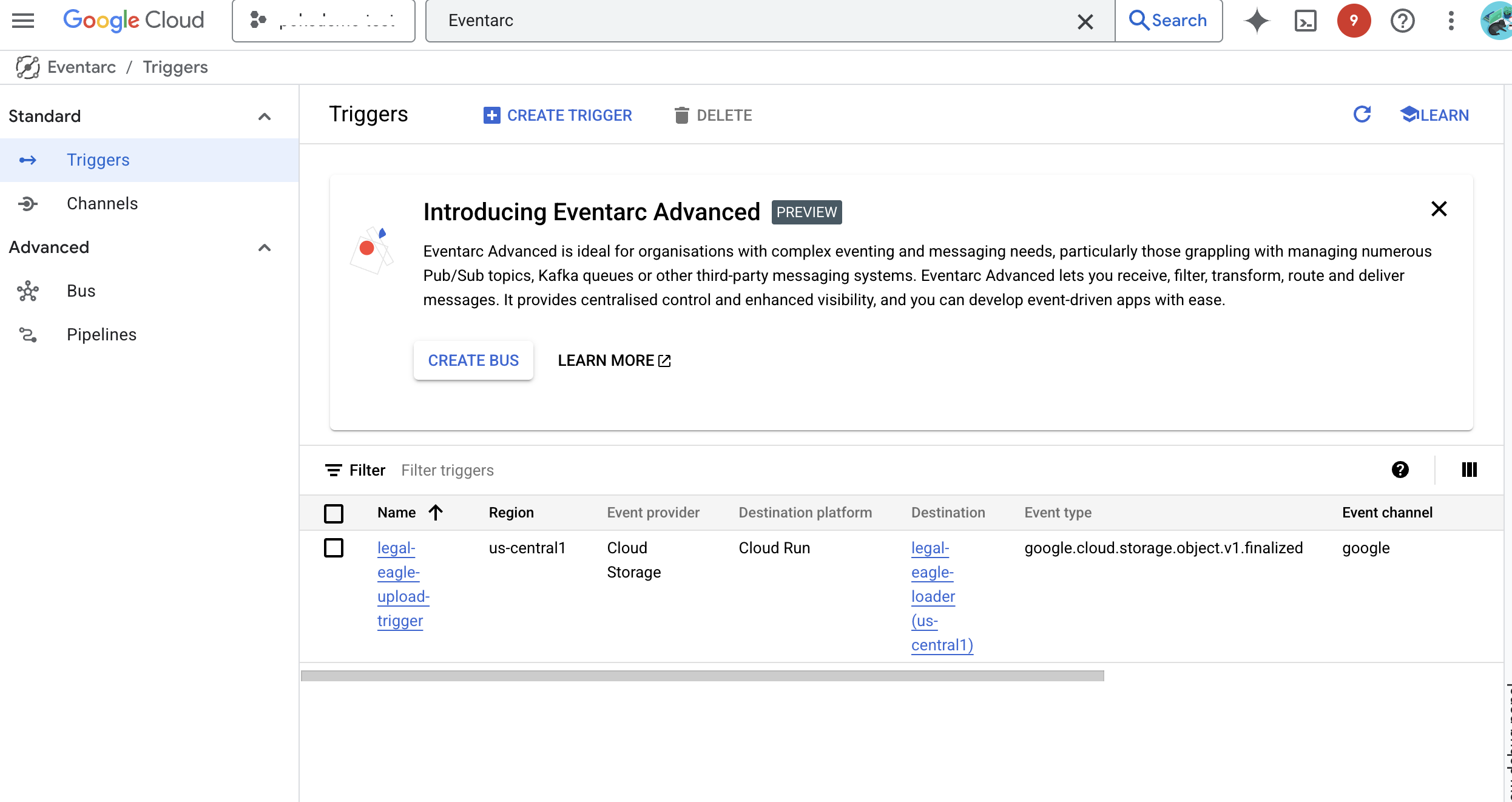
👉 Nella console Google Cloud, vai a Trigger in Eventarc. Fai clic su "+ CREA TRIGGER". 👉 Configura il trigger Eventarc:
- Nome trigger:
legal-eagle-upload-trigger. - TriggerType: Origini Google
- Provider di eventi: seleziona Cloud Storage.
- Tipo di evento: scegli
google.cloud.storage.object.v1.finalized - Bucket Cloud Storage: seleziona il bucket GCS dal menu a discesa.
- Tipo di destinazione: "Servizio Cloud Run".
- Servizio: seleziona
legal-eagle-loader. - Regione:
us-central1 - Percorso: per ora lascia vuoto questo campo .
- Concedi tutte le autorizzazioni richieste nella pagina.
👉 Fai clic su CREA. Eventarc configurerà il trigger.
Il servizio Cloud Run ha bisogno dell'autorizzazione per leggere i file da vari componenti. Dobbiamo concedere all'account di servizio del servizio l'autorizzazione necessaria.
12. Carica i documenti legali nel bucket GCS
👉 Carica il file della causa giudiziaria nel bucket GCS. Ricordati di sostituire il nome del bucket.
export DOC_BUCKET_NAME=$(gcloud storage buckets list --format="value(name)" | grep doc-bucket)
gsutil cp ~/legal-eagle/court_cases/case-02.txt gs://$DOC_BUCKET_NAME/
gsutil cp ~/legal-eagle/court_cases/case-03.txt gs://$DOC_BUCKET_NAME/
gsutil cp ~/legal-eagle/court_cases/case-06.txt gs://$DOC_BUCKET_NAME/
Per monitorare i log del servizio Cloud Run, vai a Cloud Run -> il tuo servizio legal-eagle-loader -> "Log". Controlla i log per i messaggi di elaborazione riuscita, tra cui:
xxx
POST200130 B8.3 sAPIs-Google; (+https://developers.google.com/webmasters/APIs-Google.html) https://legal-eagle-loader-bmngrueyta-uc.a.run.app/?__GCP_CloudEventsMode=GCS_NOTIFICATION
xxx
POST200130 B520 msAPIs-Google; (+https://developers.google.com/webmasters/APIs-Google.html) https://legal-eagle-loader-bmngrueyta-uc.a.run.app/?__GCP_CloudEventsMode=GCS_NOTIFICATION
xxx
POST200130 B514 msAPIs-Google; (+https://developers.google.com/webmasters/APIs-Google.html) https://legal-eagle-loader-bmngrueyta-uc.a.run.app/?__GCP_CloudEventsMode=GCS_NOTIFICATION
A seconda della velocità di configurazione della registrazione, qui vedrai anche log più dettagliati.
"CloudEvent received:"
"New file detected in bucket:"
"File content downloaded. Processing..."
"Text split into ... chunks."
"File processing and Firestore upsert complete..."
Cerca eventuali messaggi di errore nei log e risolvi i problemi, se necessario. 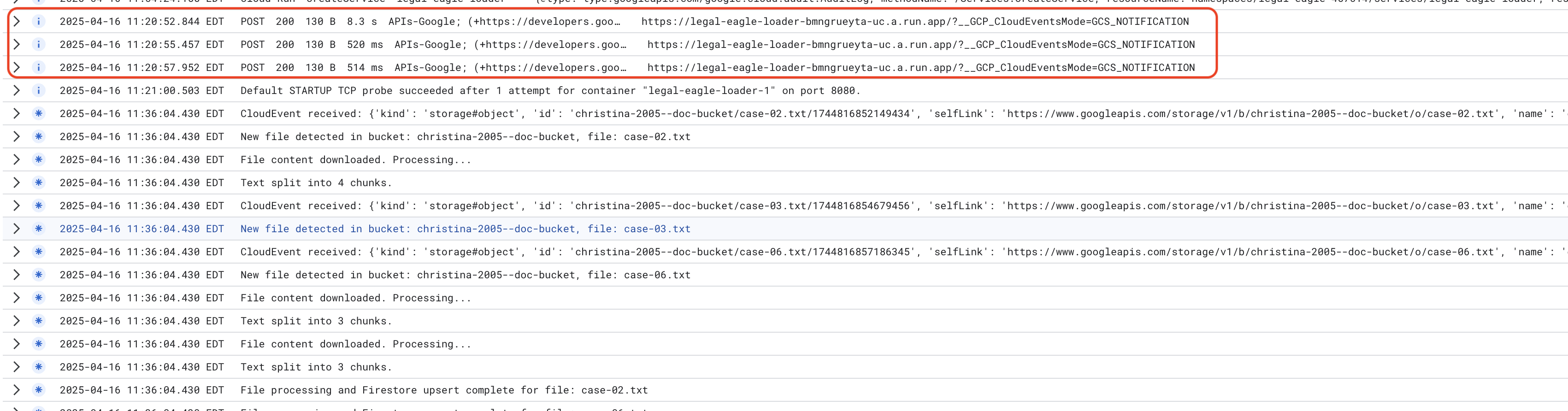
👉 Verifica i dati in Firestore. e apri la raccolta legal_documents.
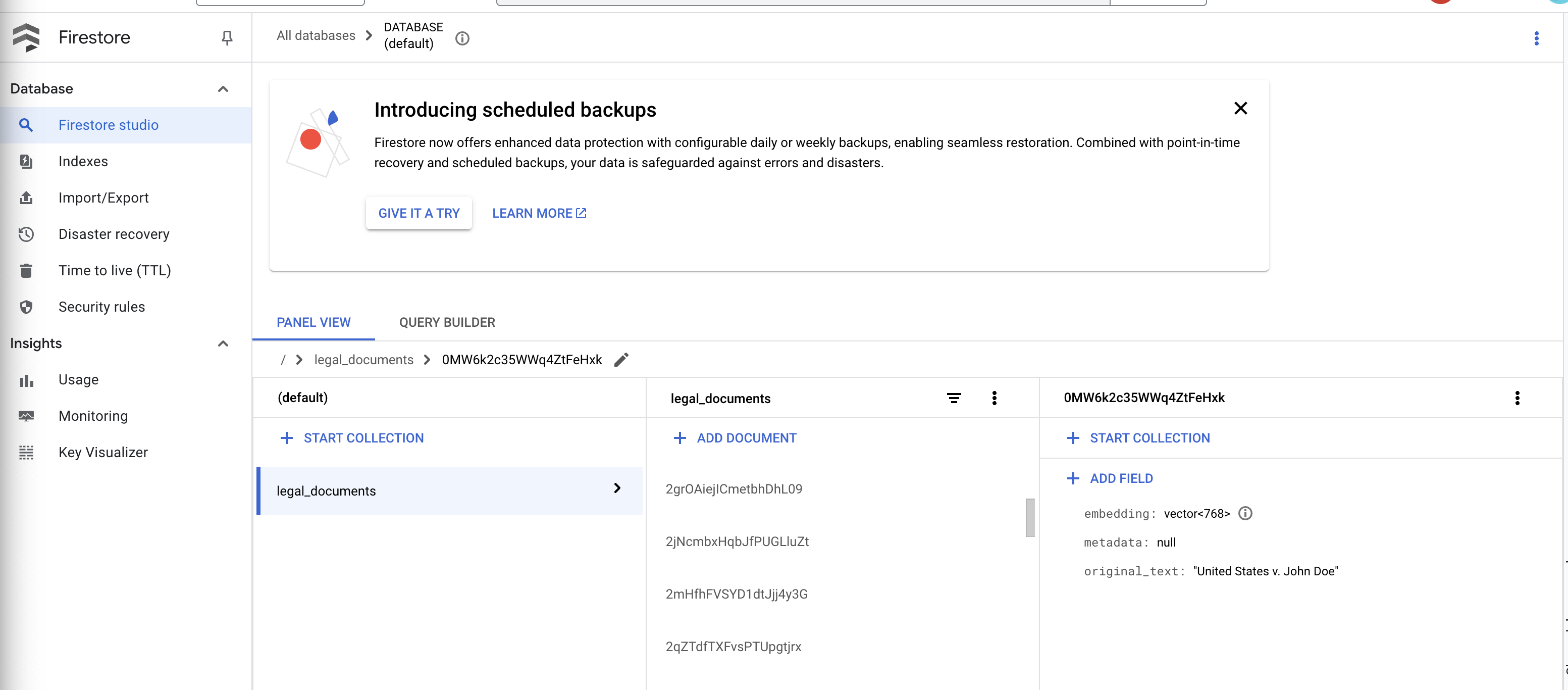
👉 Dovresti vedere i nuovi documenti creati nella raccolta. Ogni documento rappresenterà una parte del testo del file che hai caricato e conterrà:
metadata: currently empty
original_text_chunk: The text chunk content.
embedding_: A list of floating-point numbers (the Vertex AI embedding).
13. Implementazione di RAG
LangChain è un framework potente progettato per semplificare lo sviluppo di applicazioni basate su modelli linguistici di grandi dimensioni (LLM). Anziché affrontare direttamente le complessità delle API LLM, dell'ingegneria dei prompt e della gestione dei dati, LangChain fornisce un livello di astrazione di alto livello. Offre componenti e strumenti predefiniti per attività come la connessione a vari LLM (come quelli di OpenAI, Google o altri), la creazione di catene complesse di operazioni (ad es. recupero dei dati seguito dal riepilogo) e la gestione della memoria conversazionale.
Per RAG in particolare, gli archivi vettoriali in LangChain sono essenziali per abilitare l'aspetto del recupero di RAG. Si tratta di database specializzati progettati per archiviare ed eseguire query in modo efficiente sugli incorporamenti vettoriali, in cui i brani di testo semanticamente simili vengono mappati a punti vicini nello spazio vettoriale. LangChain si occupa delle operazioni di basso livello, consentendo agli sviluppatori di concentrarsi sulla logica e sulla funzionalità di base della loro applicazione RAG. Ciò riduce significativamente i tempi e la complessità di sviluppo, consentendoti di prototipare ed eseguire il deployment rapidamente di applicazioni basate su RAG sfruttando la robustezza e la scalabilità dell'infrastruttura Google Cloud.
Ora che hai compreso il funzionamento di LangChain, devi aggiornare il file legal.py nella cartella webapp per l'implementazione di RAG. In questo modo, l'LLM potrà cercare documenti pertinenti in Firestore prima di fornire una risposta.
👉 Importa FirestoreVectorStore e altri moduli richiesti da langchain e vertexai. Aggiungi i seguenti membri a legal.py
from langchain_google_vertexai import VertexAIEmbeddings
from langchain_google_firestore import FirestoreVectorStore
👉 Inizializza Vertex AI e il modello di incorporamento.Utilizzerai text-embedding-004. Aggiungi il seguente codice subito dopo aver importato i moduli.
PROJECT_ID = os.environ.get("GOOGLE_CLOUD_PROJECT") # Get project ID from env
embedding_model = VertexAIEmbeddings(
model_name="text-embedding-004" ,
project=PROJECT_ID,)
👉 Crea un FirestoreVectorStore che punta alla raccolta legal_documents, utilizzando il modello di incorporamento inizializzato e specificando i campi content ed embedding. Aggiungi questo codice subito dopo il codice del modello di incorporamento precedente.
COLLECTION_NAME = "legal_documents"
# Create a vector store
vector_store = FirestoreVectorStore(
collection="legal_documents",
embedding_service=embedding_model,
content_field="original_text",
embedding_field="embedding",
)
👉 Definisci una funzione chiamata search_resource che accetta una query, esegue una ricerca di similarità utilizzando vector_store.similarity_search e restituisce i risultati combinati.
def search_resource(query):
results = []
results = vector_store.similarity_search(query, k=5)
combined_results = "\n".join([result.page_content for result in results])
print(f"==>{combined_results}")
return combined_results
👉 SOSTITUISCI la funzione ask_llm e utilizza la funzione search_resource per recuperare il contesto pertinente in base alla query dell'utente.
def ask_llm(query):
try:
query_message = {
"type": "text",
"text": query,
}
relevant_resource = search_resource(query)
input_msg = HumanMessage(content=[query_message])
prompt_template = ChatPromptTemplate.from_messages(
[
SystemMessage(
content=(
"You are a helpful assistant, and you are with the attorney in a courtroom, you are helping him to win the case by providing the information he needs "
"Don't answer if you don't know the answer, just say sorry in a funny way possible"
"Use high engergy tone, don't use more than 100 words to answer"
f"Here is some context that is relevant to the question {relevant_resource} that you might use"
)
),
input_msg,
]
)
prompt = prompt_template.format()
response = llm.invoke(prompt)
print(f"response: {response}")
return response
except Exception as e:
print(f"Error sending message to chatbot: {e}") # Log this error too!
return f"Unable to process your request at this time. Due to the following reason: {str(e)}"
👉 FACOLTATIVO: VERSIONE IN SPAGNOLO
Sostituisci il seguente testo come indicato: You are a helpful assistant, con You are a helpful assistant that speaks Spanish,
👉 Dopo aver implementato RAG in legal.py, devi testarlo localmente prima del deployment. Esegui l'applicazione con il comando:
cd ~/legal-eagle/webapp
source env/bin/activate
python main.py
👉 Utilizza webpreview per accedere all'applicazione, parlare con l'assistente e digitare ctrl+c per uscire dal processo eseguito localmente ed esegui deactivate per uscire dall'ambiente virtuale.
deactivate
👉 Per eseguire il deployment dell'applicazione web su Cloud Run, la procedura è simile a quella della funzione di caricamento. Creerai, taggherai ed eseguirai il push dell'immagine Docker in Artifact Registry:
export PROJECT_ID=$(gcloud config get project)
docker build -t gcr.io/${PROJECT_ID}/legal-eagle-webapp .
docker tag gcr.io/${PROJECT_ID}/legal-eagle-webapp us-central1-docker.pkg.dev/${PROJECT_ID}/my-repository/legal-eagle-webapp
docker push us-central1-docker.pkg.dev/${PROJECT_ID}/my-repository/legal-eagle-webapp
👉 È il momento di eseguire il deployment dell'applicazione web su Google Cloud. Nel terminale, esegui questi comandi:
export PROJECT_ID=$(gcloud config get project)
gcloud run deploy legal-eagle-webapp \
--image us-central1-docker.pkg.dev/$PROJECT_ID/my-repository/legal-eagle-webapp \
--region us-central1 \
--set-env-vars=GOOGLE_CLOUD_PROJECT=${PROJECT_ID} \
--allow-unauthenticated
Verifica il deployment andando su Cloud Run nella console Google Cloud.Dovresti visualizzare un nuovo servizio denominato legal-eagle-webapp.
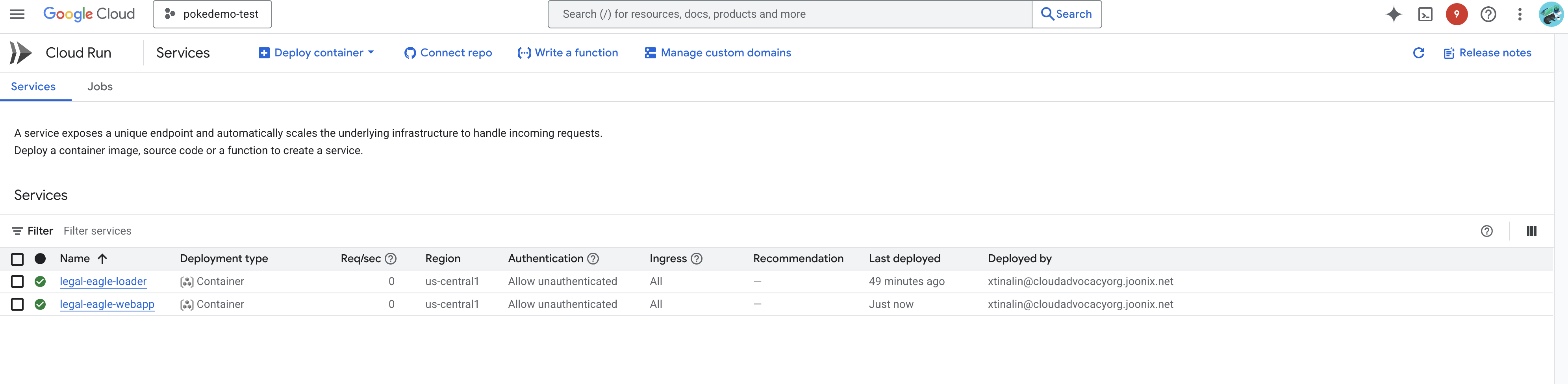
Fai clic sul servizio per accedere alla pagina dei dettagli. L'URL di deployment è disponibile nella parte superiore della pagina. 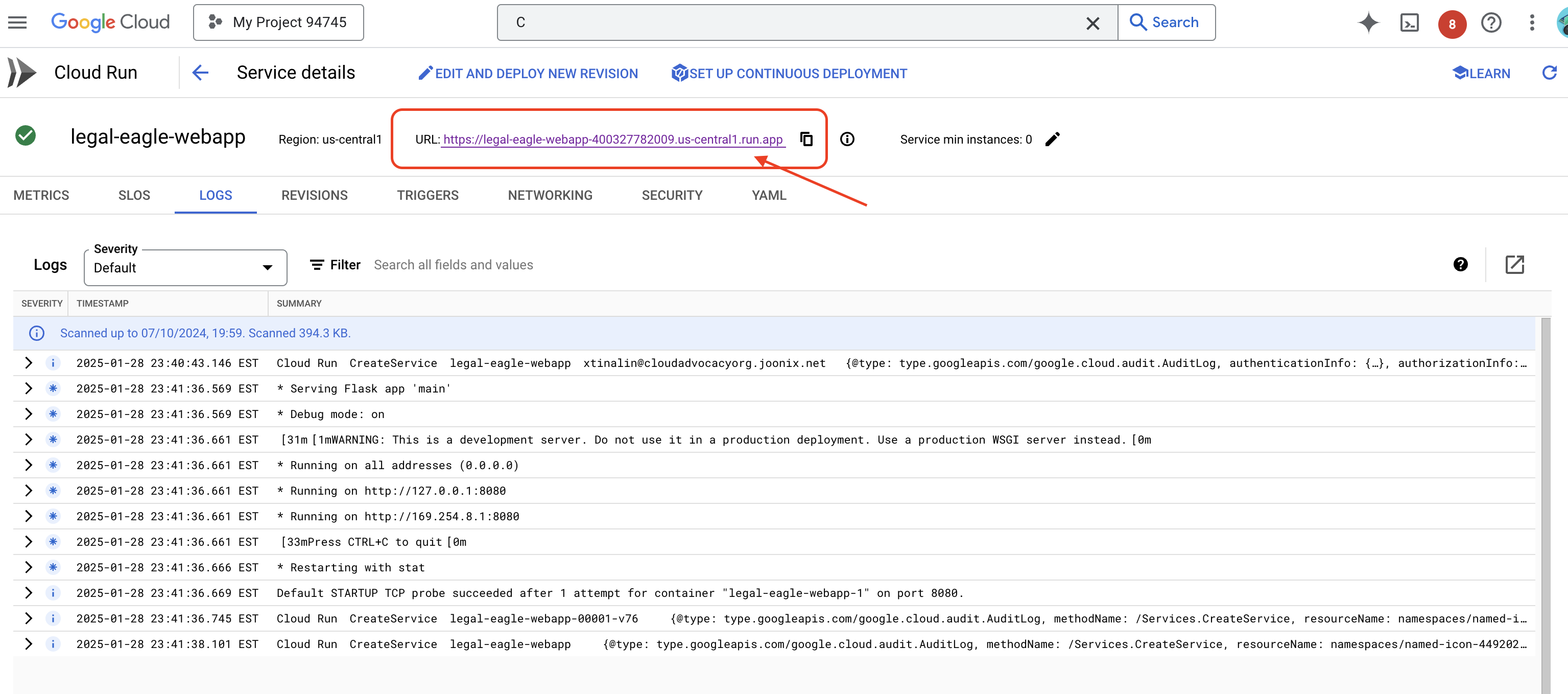
👉 Ora apri l'URL di cui è stato eseguito il deployment in una nuova scheda del browser. Puoi interagire con l'assistente legale e porre domande relative alle cause giudiziarie che hai caricato(nella cartella court_cases):
- A quanti anni di reclusione è stato condannato Michael Brown?
- Qual è l'importo degli addebiti non autorizzati generati a seguito delle azioni di Maria Rossi?
- Quale ruolo hanno svolto le testimonianze dei vicini nell'indagine sul caso di Emily White?
👉 FACOLTATIVO: VERSIONE IN SPAGNOLO
- ¿A cuántos años de prisión fue sentenciado Michael Brown?
- ¿Cuánto dinero en cargos no autorizados se generó como resultado de las acciones de Jane Smith?
- ¿Qué papel jugaron los testimonios de los vecinos en la investigación del caso de Emily White?
Noterai che le risposte sono ora più accurate e basate sui contenuti dei documenti legali che hai caricato, il che dimostra la potenza di RAG.
Congratulazioni per aver completato il workshop. Hai creato e implementato correttamente un'applicazione di analisi di documenti legali utilizzando LLM, LangChain e Google Cloud. Hai imparato a importare ed elaborare documenti legali, ad arricchire le risposte LLM con informazioni pertinenti utilizzando RAG e a eseguire il deployment dell'applicazione come servizio serverless. Queste conoscenze e l'applicazione creata ti aiuteranno a esplorare ulteriormente il potenziale degli LLM per le attività legali. Ben fatto!"
14. La sfida
Diversi tipi di media:
Come importare ed elaborare diversi tipi di contenuti multimediali, come video e registrazioni audio di tribunali, ed estrarre il testo pertinente.
Asset online:
Come elaborare in tempo reale gli asset online come le pagine web.