
1. 소개
법정의 긴장감에 항상 매료되어 복잡한 상황을 능숙하게 헤쳐나가고 강력한 최종 변론을 하는 내 모습을 상상해 왔습니다. 제 경력은 다른 방향으로 나아갔지만, AI의 도움으로 우리 모두가 법정의 꿈을 실현하는 데 더 가까워질 수 있다는 소식을 전해드리게 되어 기쁩니다.

오늘은 Vertex AI, Firestore, Cloud Run Functions와 같은 Google의 강력한 AI 도구를 사용하여 법률 데이터를 처리하고 이해하며, 번개처럼 빠른 검색을 수행하고, 가상의 고객 (또는 자신)이 난처한 상황에서 벗어날 수 있도록 돕는 방법을 살펴보겠습니다.
증인을 반대 심문하지는 않지만 Google 시스템을 사용하면 방대한 정보를 선별하고, 명확한 요약을 생성하고, 가장 관련성 높은 데이터를 몇 초 만에 제시할 수 있습니다.
2. 아키텍처
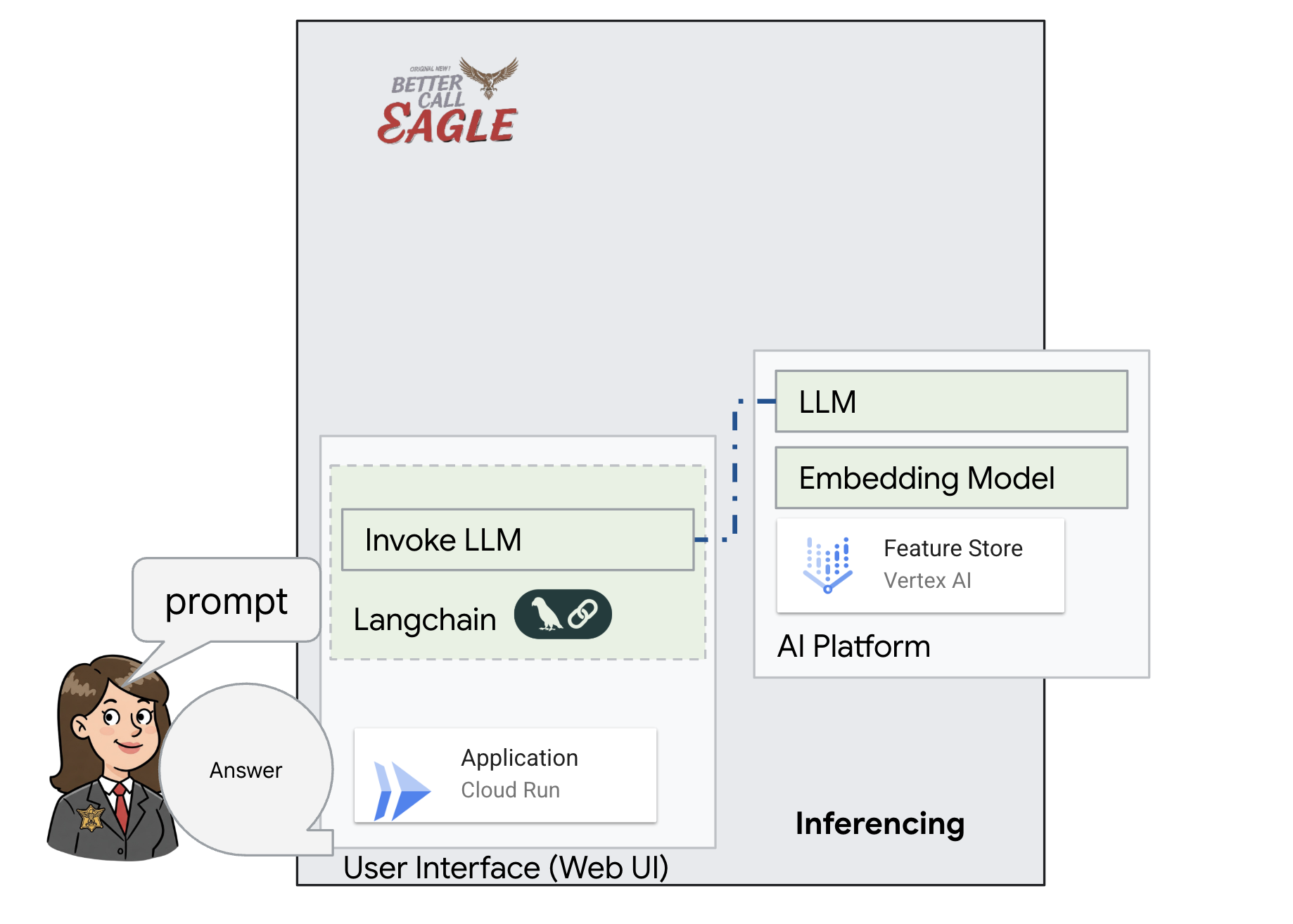
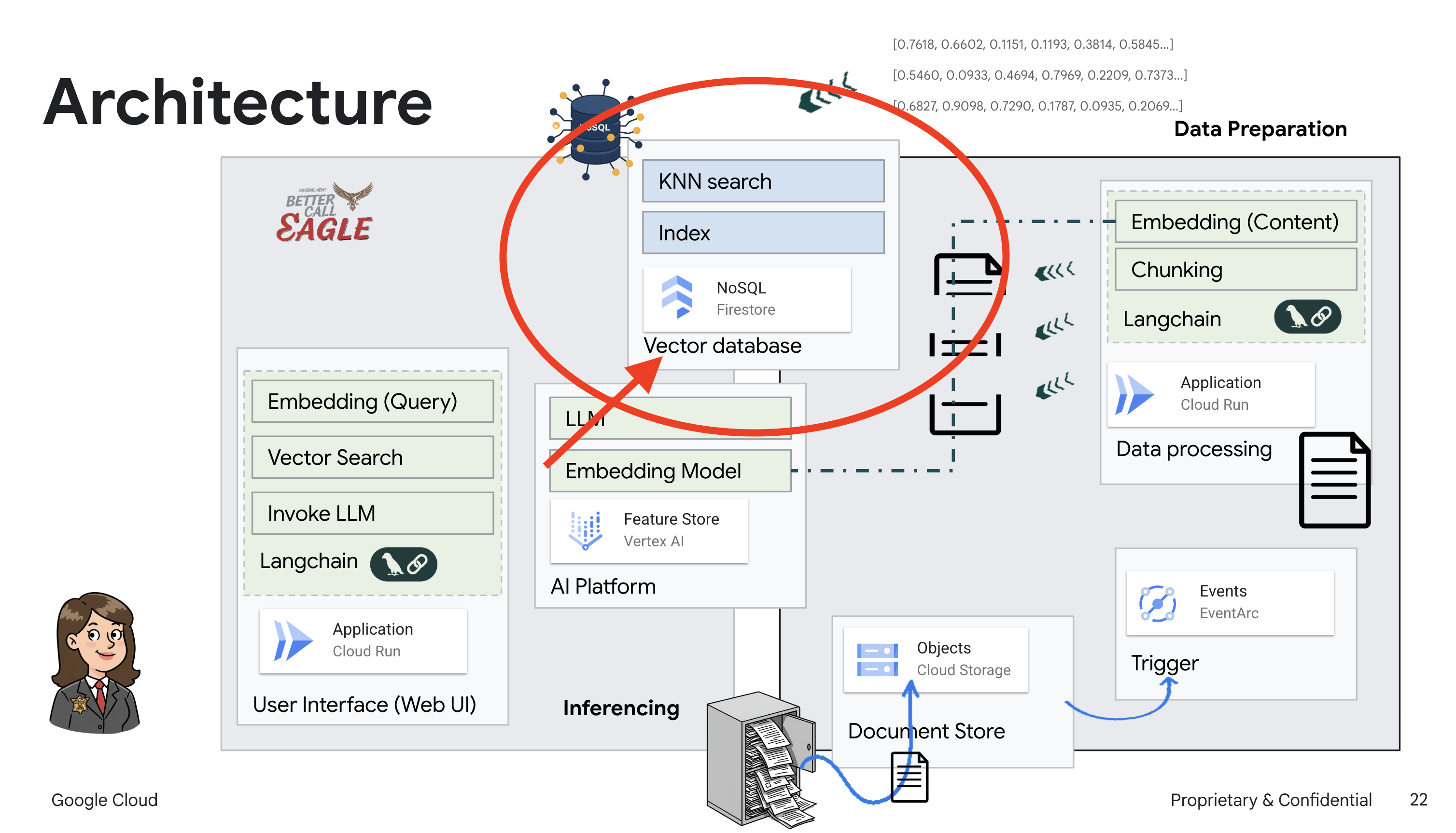
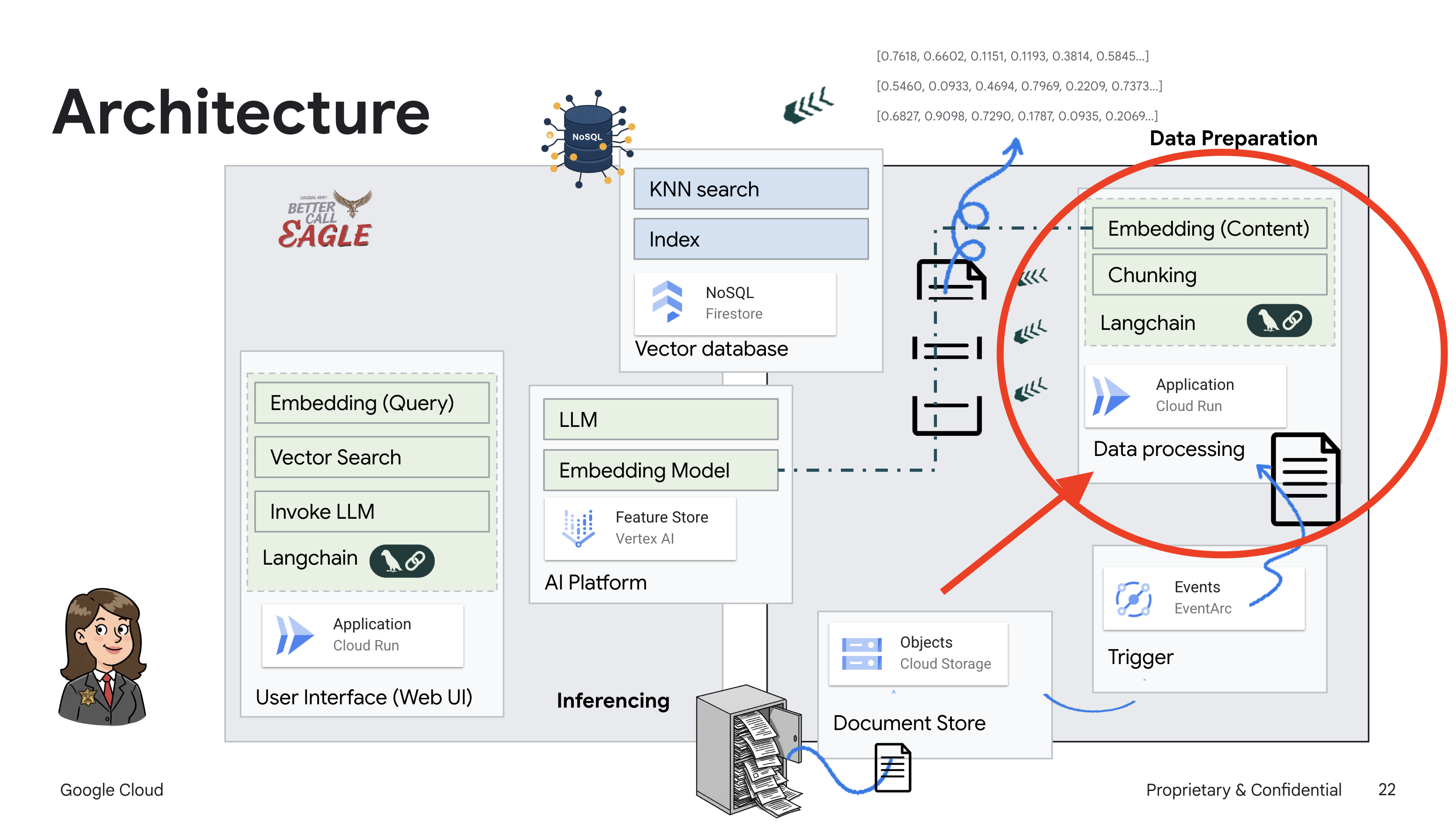
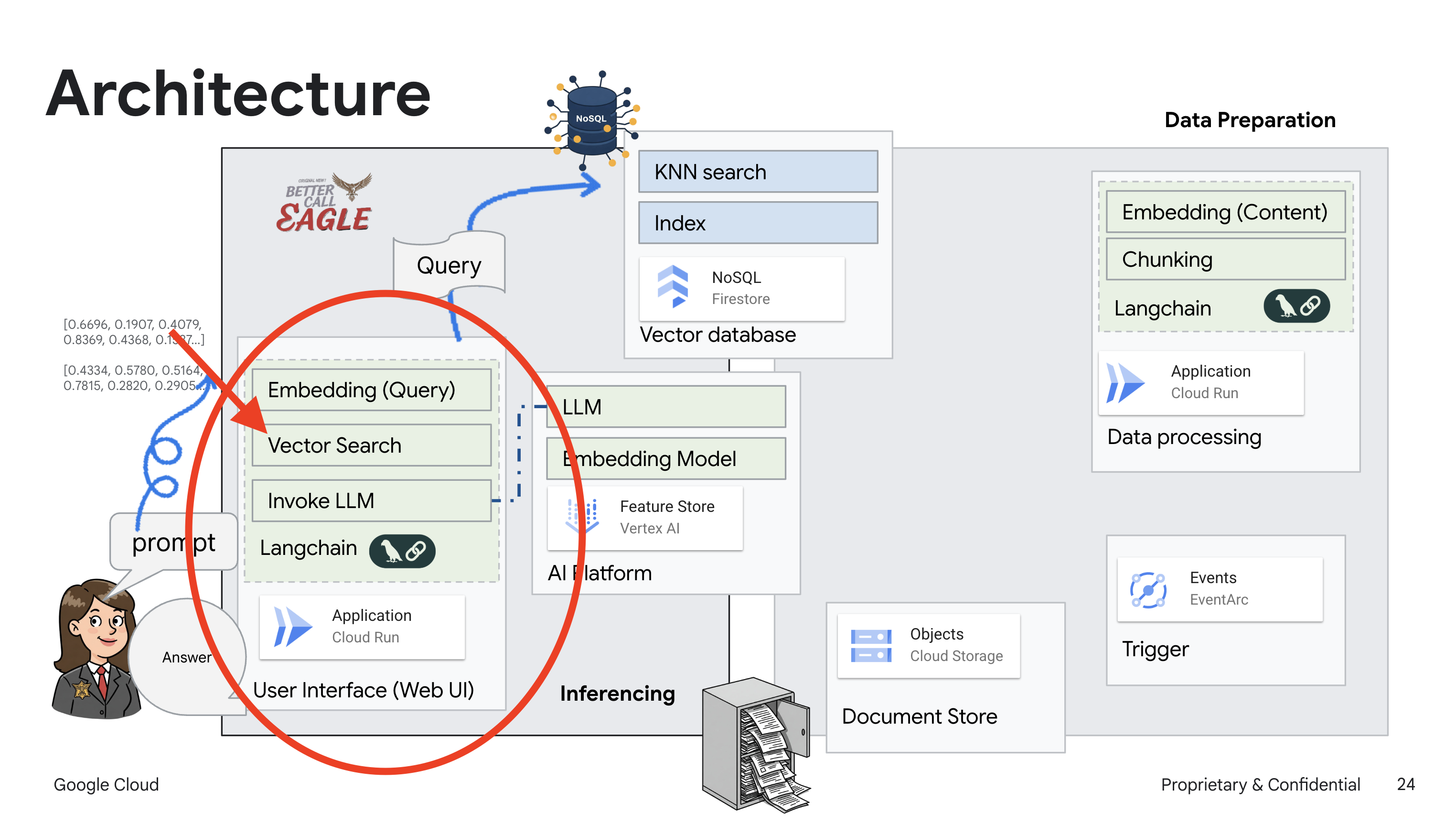
이 프로젝트는 Google Cloud AI 도구를 사용하여 법률 도우미를 빌드하는 데 중점을 두며, 법률 데이터를 처리, 이해, 검색하는 방법을 강조합니다. 이 시스템은 대량의 정보를 선별하고, 요약을 생성하고, 관련 데이터를 빠르게 표시하도록 설계되었습니다. 법률 도우미의 아키텍처에는 다음과 같은 여러 주요 구성요소가 포함됩니다.
비정형 데이터에서 지식 베이스 빌드: Google Cloud Storage (GCS)는 법률 문서를 저장하는 데 사용됩니다. NoSQL 데이터베이스인 Firestore는 문서 청크와 해당 임베딩을 보유하는 벡터 저장소로 작동합니다. 유사성 검색을 지원하기 위해 Firestore에서 벡터 검색이 사용 설정됩니다. 새 법적 문서가 GCS에 업로드되면 Eventarc가 Cloud Run 함수를 트리거합니다. 이 함수는 문서를 청크로 분할하고 Vertex AI의 텍스트 임베딩 모델을 사용하여 각 청크의 임베딩을 생성하여 문서를 처리합니다. 그런 다음 이러한 임베딩은 텍스트 청크와 함께 Firestore에 저장됩니다. 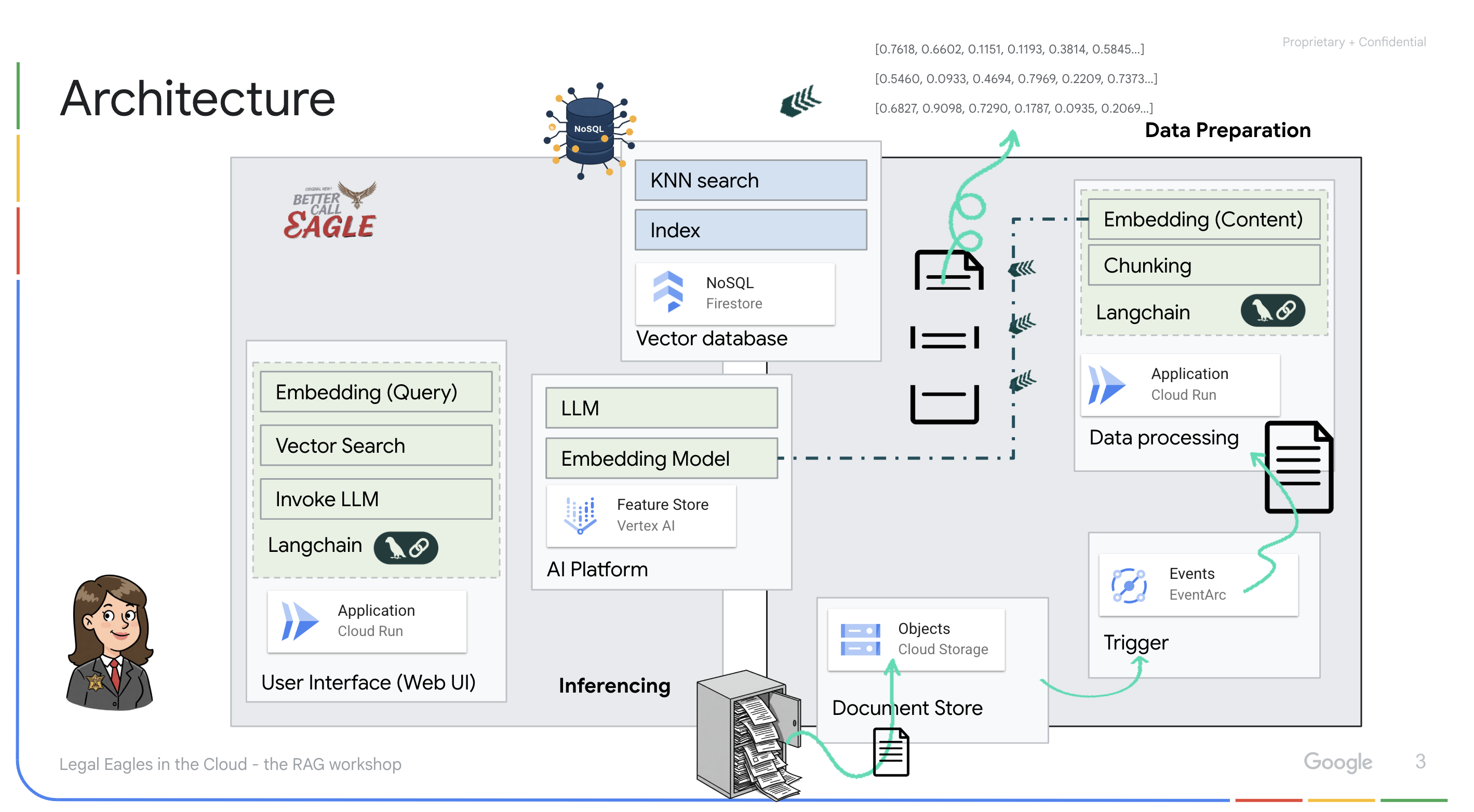
LLM 및 RAG 기반 애플리케이션 : 질문 및 답변 시스템의 핵심은 langchain 라이브러리를 사용하여 Vertex AI Gemini 대규모 언어 모델과 상호작용하는 ask_llm 함수입니다. 사용자의 질문에서 HumanMessage를 생성하고 LLM이 유용한 법률 도우미 역할을 하도록 지시하는 SystemMessage를 포함합니다. 시스템은 검색 증강 생성 (RAG) 접근 방식을 사용합니다. 질문에 답변하기 전에 시스템은 search_resource 함수를 사용하여 Firestore 벡터 저장소에서 관련 컨텍스트를 가져옵니다. 이 컨텍스트는 SystemMessage에 포함되어 LLM의 대답이 제공된 법률 정보를 기반으로 합니다. 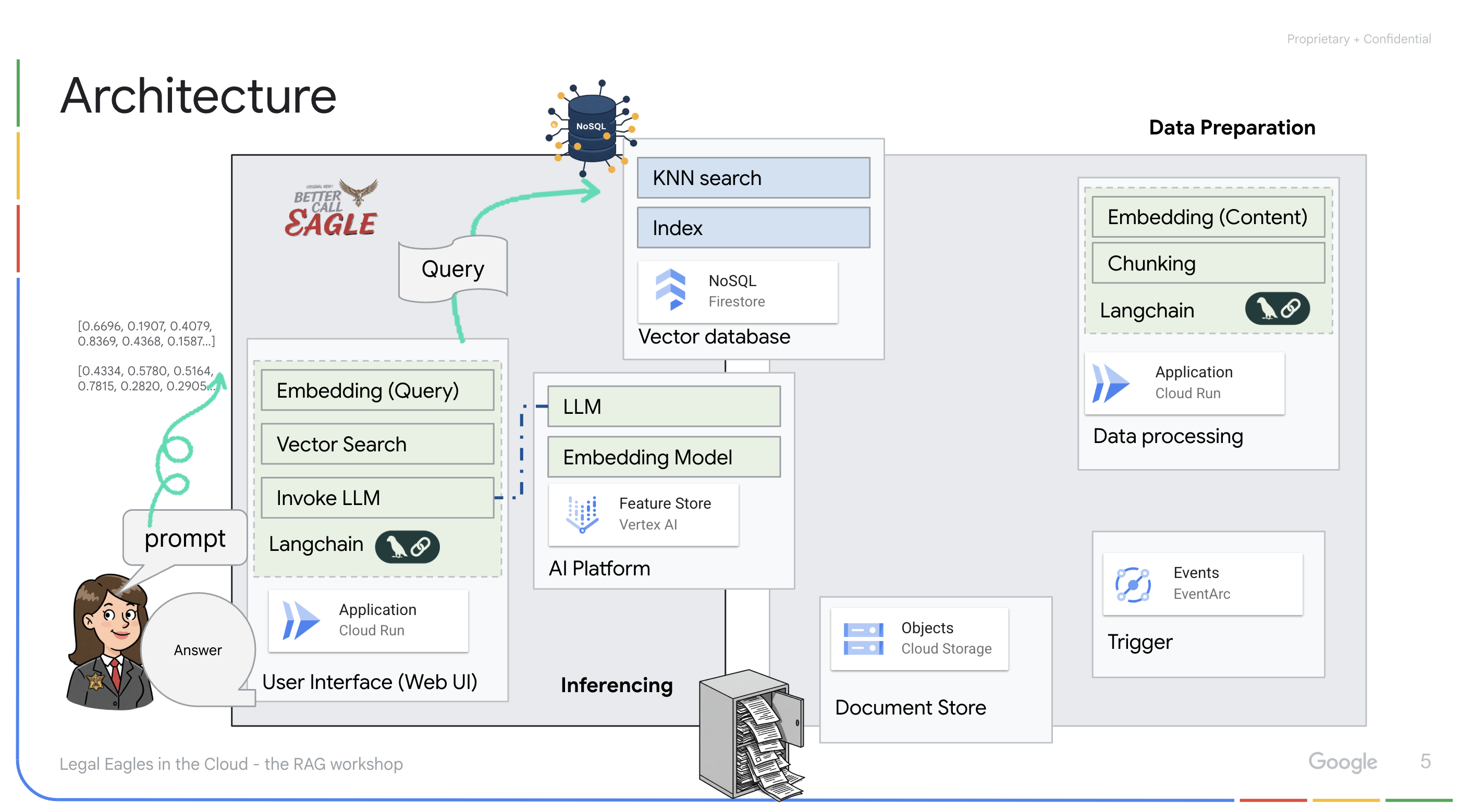
이 프로젝트는 대답을 생성하기 전에 먼저 신뢰할 수 있는 법률 소스에서 관련 정보를 검색하는 RAG를 사용하여 LLM의 '창의적인 해석'을 피하는 것을 목표로 합니다. 따라서 실제 법률 정보를 기반으로 더 정확하고 정보에 입각한 대답을 제공할 수 있습니다. 이 시스템은 Google Cloud Shell, Vertex AI, Firestore, Cloud Run, Eventarc와 같은 다양한 Google Cloud 서비스를 사용하여 빌드됩니다.
3. 시작하기 전에
Google Cloud 콘솔의 프로젝트 선택기 페이지에서 Google Cloud 프로젝트를 선택하거나 만듭니다. Cloud 프로젝트에 결제가 사용 설정되어 있는지 확인합니다. 프로젝트에 결제가 사용 설정되어 있는지 확인하는 방법을 알아보세요.
Cloud Shell IDE에서 Gemini Code Assist 사용 설정
👉 Google Cloud 콘솔에서 Gemini Code Assist 도구로 이동하여 약관에 동의하여 Gemini Code Assist를 무료로 사용 설정합니다.
권한 설정을 무시하고 이 페이지를 나갑니다.
Cloud Shell 편집기에서 작업하기
👉 Google Cloud 콘솔 상단에서 Cloud Shell 활성화를 클릭합니다 (Cloud Shell 창 상단의 터미널 모양 아이콘).
👉 '편집기 열기' 버튼 (연필이 있는 열린 폴더 모양)을 클릭합니다. 그러면 창에 Cloud Shell 편집기가 열립니다. 왼쪽에 파일 탐색기가 표시됩니다.

👉 그림과 같이 하단 상태 표시줄에서 Cloud Code 로그인 버튼을 클릭합니다. 안내에 따라 플러그인을 승인합니다. 상태 표시줄에 Cloud Code - 프로젝트 없음이 표시되면 이를 선택한 다음 드롭다운에서 'Google Cloud 프로젝트 선택'을 선택하고 작업하려는 프로젝트 목록에서 특정 Google Cloud 프로젝트를 선택합니다.
👉 클라우드 IDE에서 터미널을 엽니다. 
👉 새 터미널에서 다음 명령어를 사용하여 이미 인증되었는지, 프로젝트가 프로젝트 ID로 설정되었는지 확인합니다.
gcloud auth list
👉 Google Cloud 콘솔 상단에서 Cloud Shell 활성화를 클릭합니다.
gcloud config set project <YOUR_PROJECT_ID>
👉 다음 명령어를 실행하여 필요한 Google Cloud API를 사용 설정합니다.
gcloud services enable storage.googleapis.com \
run.googleapis.com \
artifactregistry.googleapis.com \
aiplatform.googleapis.com \
eventarc.googleapis.com \
cloudresourcemanager.googleapis.com \
firestore.googleapis.com \
cloudaicompanion.googleapis.com
Cloud Shell 툴바 (Cloud Shell 창 상단)에서 '편집기 열기' 버튼 (연필이 있는 열린 폴더 모양)을 클릭합니다. 그러면 창에 Cloud Shell 코드 편집기가 열립니다. 왼쪽에 파일 탐색기가 표시됩니다.
👉 터미널에서 부트스트랩 스켈레톤 프로젝트를 다운로드합니다.
git clone https://github.com/weimeilin79/legal-eagle.git
선택사항: 스페인어 버전
👉 Existe una versión alternativa en español. Por favor, utilice la siguiente instrucción para clonar la versión correcta.
git clone -b spanish https://github.com/weimeilin79/legal-eagle.git
Cloud Shell 터미널에서 이 명령어를 실행하면 Cloud Shell 환경에 저장소 이름이 legal-eagle인 새 폴더가 생성됩니다.
4. Gemini Code Assist로 추론 애플리케이션 작성
이 섹션에서는 법률 도우미의 핵심인 사용자 질문을 수신하고 AI 모델과 상호작용하여 답변을 생성하는 웹 애플리케이션을 빌드하는 데 중점을 둡니다. Gemini Code Assist를 활용하여 이 추론 부분의 Python 코드를 작성합니다.
먼저 LangChain 라이브러리를 사용하여 Vertex AI Gemini 모델과 직접 통신하는 Flask 애플리케이션을 만듭니다. 이 첫 번째 버전은 모델의 일반적인 지식을 기반으로 유용한 법률 도우미 역할을 하지만 아직 Google의 특정 법원 사건 문서에 액세스할 수는 없습니다. 이렇게 하면 나중에 RAG로 개선하기 전에 LLM의 기준 실적을 확인할 수 있습니다.
이제 Cloud Code 편집기의 탐색기 창 (일반적으로 왼쪽)에 Git 저장소를 복제할 때 생성된 폴더가 표시됩니다. 탐색기에서 프로젝트의 루트 폴더를 엽니다.legal-eagle webapp 하위 폴더가 표시되면 이 폴더도 엽니다. 
👉 Cloud Code 편집기에서 legal.py 파일을 수정할 때 다양한 방법으로 Gemini Code Assist에 프롬프트를 표시할 수 있습니다.
👉 Gemini Code Assist가 생성할 내용을 명확하게 설명하는 다음 프롬프트를 legal.py 하단에 복사하고, 표시된 전구 💡 아이콘을 클릭한 다음 Gemini: Generate Code를 선택합니다 (정확한 메뉴 항목은 Cloud Code 버전에 따라 약간 다를 수 있음).
"""
Write a Python function called `ask_llm` that takes a user `query` as input. This function should use the `langchain` library to interact with a Vertex AI Gemini Large Language Model. Specifically, it should:
1. Create a `HumanMessage` object from the user's `query`.
2. Create a `ChatPromptTemplate` that includes a `SystemMessage` and the `HumanMessage`. The system message should instruct the LLM to act as a helpful assistant in a courtroom setting, aiding an attorney by providing necessary information. It should also specify that the LLM should respond in a high-energy tone, using no more than 100 words, and offer a humorous apology if it doesn't know the answer.
3. Format the `ChatPromptTemplate` with the provided messages.
4. Invoke the Vertex AI LLM with the formatted prompt using the `VertexAI` class (assuming it's already initialized elsewhere as `llm`).
5. Print the LLM's `response`.
6. Return the `response`.
7. Include error handling that prints an error message to the console and returns a user-friendly error message if any issues occur during the process. The Vertex AI model should be "gemini-2.0-flash".
"""
생성된 코드를 신중하게 검토하세요.
- 대략적으로 댓글에 설명한 단계를 따르나요?
SystemMessage및HumanMessage로ChatPromptTemplate를 만드나요?- 기본 오류 처리 (
try...except)가 포함되어 있나요?
생성된 코드가 양호하고 대부분 올바른 경우 이를 수락할 수 있습니다 (인라인 제안의 경우 Tab 또는 Enter 키를 누르거나 더 큰 코드 블록의 경우 '수락'을 클릭).
생성된 코드가 원하는 것과 정확히 일치하지 않거나 오류가 있어도 걱정하지 마세요. Gemini Code Assist는 완벽한 코드를 처음부터 작성하는 도구가 아니라 사용자를 지원하는 도구입니다.
생성된 코드를 수정하여 다듬고, 오류를 수정하고, 요구사항에 더 잘 맞도록 합니다. Code Assist 채팅 패널에 주석을 추가하거나 구체적인 질문을 하여 Gemini Code Assist에 추가 프롬프트를 제공할 수 있습니다.
SDK를 처음 사용하는 경우 다음은 작동하는 예입니다.
👉 다음 코드를 legal.py에 복사하여 붙여넣고 대체합니다.
import os
import signal
import sys
import vertexai
import random
from langchain_google_vertexai import VertexAI
from langchain_core.prompts import PromptTemplate, ChatPromptTemplate
from langchain_core.messages import HumanMessage, SystemMessage
# Connect to resourse needed from Google Cloud
llm = VertexAI(model_name="gemini-2.0-flash")
def ask_llm(query):
try:
query_message = {
"type": "text",
"text": query,
}
input_msg = HumanMessage(content=[query_message])
prompt_template = ChatPromptTemplate.from_messages(
[
SystemMessage(
content=(
"You are a helpful assistant, and you are with the attorney in a courtroom, you are helping him to win the case by providing the information he needs "
"Don't answer if you don't know the answer, just say sorry in a funny way possible"
"Use high engergy tone, don't use more than 100 words to answer"
# f"Here is some past conversation history between you and the user {relevant_history}"
# f"Here is some context that is relevant to the question {relevant_resource} that you might use"
)
),
input_msg,
]
)
prompt = prompt_template.format()
response = llm.invoke(prompt)
print(f"response: {response}")
return response
except Exception as e:
print(f"Error sending message to chatbot: {e}") # Log this error too!
return f"Unable to process your request at this time. Due to the following reason: {str(e)}"
👉 선택사항: 스페인어 버전
Sustituye el siguiente texto como se indica: You are a helpful assistant, to You are a helpful assistant that speaks Spanish,
다음으로 사용자의 질문에 응답하는 경로를 처리하는 함수를 만듭니다.
Cloud Shell 편집기에서 main.py를 엽니다. legal.py에서 ask_llm을 생성한 것과 마찬가지로 Gemini Code Assist를 사용하여 Flask 경로와 ask_question 함수를 생성합니다. main.py에 다음 프롬프트를 주석으로 입력합니다. (if __name__ == "__main__":에서 Flask 앱을 시작하기 전에 추가해야 합니다.)
.....
@app.route('/',methods=['GET'])
def index():
return render_template('index.html')
"""
PROMPT:
Create a Flask endpoint that accepts POST requests at the '/ask' route.
The request should contain a JSON payload with a 'question' field. Extract the question from the JSON payload.
Call a function named ask_llm (located in a file named legal.py) with the extracted question as an argument.
Return the result of the ask_llm function as the response with a 200 status code.
If any error occurs during the process, return a 500 status code with the error message.
"""
# Add this block to start the Flask app when running locally
if __name__ == "__main__":
.....
생성된 코드가 양호하고 대체로 올바른 경우에만 수락합니다. Python에 익숙하지 않은 경우 다음은 작동하는 예입니다.이를 복사하여 붙여넣기하여 이미 있는 코드 아래의 main.py에 붙여넣으세요.
👉 웹 애플리케이션 시작 전에 다음을 붙여넣어야 합니다 (if name == 'main':)
@app.route('/ask', methods=['POST'])
def ask_question():
data = request.get_json()
question = data.get('question')
try:
# call the ask_llm in legal.py
answer_markdown = legal.ask_llm(question)
print(f"answer_markdown: {answer_markdown}")
# Return the Markdown as the response
return answer_markdown, 200
except Exception as e:
return f"Error: {str(e)}", 500 # Handle errors appropriately
이 단계를 따르면 Gemini Code Assist를 사용 설정하고, 프로젝트를 설정하고, 이를 사용하여 main.py 파일에서 ask 함수를 생성할 수 있습니다.
5. Cloud 편집기에서 로컬 테스트
👉 편집기의 터미널에서 종속 라이브러리를 설치하고 웹 UI를 로컬로 시작합니다.
cd ~/legal-eagle/webapp
python -m venv env
source env/bin/activate
export PROJECT_ID=$(gcloud config get project)
pip install -r requirements.txt
python main.py
Cloud Shell 터미널 출력에서 시작 메시지를 찾습니다. Flask는 일반적으로 실행 중이며 어떤 포트에서 실행 중인지 나타내는 메시지를 출력합니다.
- Running on http://127.0.0.1:8080
요청을 처리하려면 애플리케이션이 계속 실행되어야 합니다.
👉 '웹 미리보기' 메뉴에서 포트 8080에서 미리보기를 선택합니다. Cloud Shell에서 애플리케이션의 웹 미리보기가 표시된 새 브라우저 탭 또는 창이 열립니다. 
👉 애플리케이션 인터페이스에서 법적 사례 참조와 관련된 질문을 몇 개 입력하고 LLM이 어떻게 대답하는지 확인합니다. 예를 들어 다음과 같이 시도해 볼 수 있습니다.
- 마이클 브라운은 몇 년의 징역형을 선고받았나요?
- 김영희의 행위로 인해 발생한 승인되지 않은 청구 금액은 얼마인가요?
- 에밀리 화이트 사건 조사에서 이웃의 증언은 어떤 역할을 했나요?
👉 선택사항: 스페인어 버전
- ¿A cuántos años de prisión fue sentenciado Michael Brown?
- ¿Cuánto dinero en cargos no autorizados se generó como resultado de las acciones de Jane Smith?
- ¿Qué papel jugaron los testimonios de los vecinos en la investigación del caso de Emily White?
대답을 자세히 살펴보면 모델이 할루시네이션을 일으키거나, 모호하거나 일반적이며, 때로는 질문을 잘못 해석할 수 있다는 것을 알 수 있습니다. 아직 특정 법률 문서에 액세스할 수 없기 때문입니다.
👉 Ctrl+C를 눌러 스크립트를 중지합니다.
👉 가상 환경을 종료하려면 터미널에서 다음을 실행하세요.
deactivate
6. 벡터 스토어 설정
법에 대한 LLM의'창의적인 해석'을 끝낼 때가 왔습니다. 이때 검색 증강 생성 (RAG)이 도움이 됩니다. 질문에 답변하기 직전에 LLM에 강력한 법률 라이브러리에 대한 액세스 권한을 부여하는 것과 같습니다. RAG는 모델에 따라 모호하거나 오래된 일반 지식에만 의존하는 대신 먼저 신뢰할 수 있는 소스 (이 경우 법적 문서)에서 관련 정보를 가져온 다음 해당 컨텍스트를 사용하여 훨씬 더 풍부한 정보를 바탕으로 정확한 답변을 생성합니다. LLM이 법정에 들어가기 전에 숙제를 하는 것과 같습니다.
RAG 시스템을 빌드하려면 모든 법률 문서를 저장하고 의미별로 검색할 수 있는 공간이 필요합니다. 이때 Firestore가 유용합니다. Firestore는 Google Cloud의 유연하고 확장 가능한 NoSQL 문서 데이터베이스입니다.
Firestore를 벡터 스토어로 사용합니다. 법률 문서의 청크를 Firestore에 저장하고 각 청크의 의미를 나타내는 숫자 표현인 임베딩도 저장합니다.
그런 다음 Legal Eagle에게 질문하면 Firestore의 벡터 검색을 사용하여 질문과 가장 관련성이 높은 법률 텍스트 청크를 찾습니다. 이 검색된 컨텍스트는 RAG가 LLM의 상상력이 아닌 실제 법률 정보에 기반한 답변을 제공하는 데 사용하는 것입니다.
👉 새 탭/창에서 Google Cloud 콘솔의 Firestore로 이동합니다.
👉 데이터베이스 만들기를 클릭합니다.
👉 Native mode를 선택하고 데이터베이스 이름을 (default)로 지정합니다.
👉 단일 region 선택: us-central1를 선택하고 데이터베이스 만들기를 클릭합니다. Firestore에서 데이터베이스를 프로비저닝하며, 이 작업은 잠시 걸릴 수 있습니다.
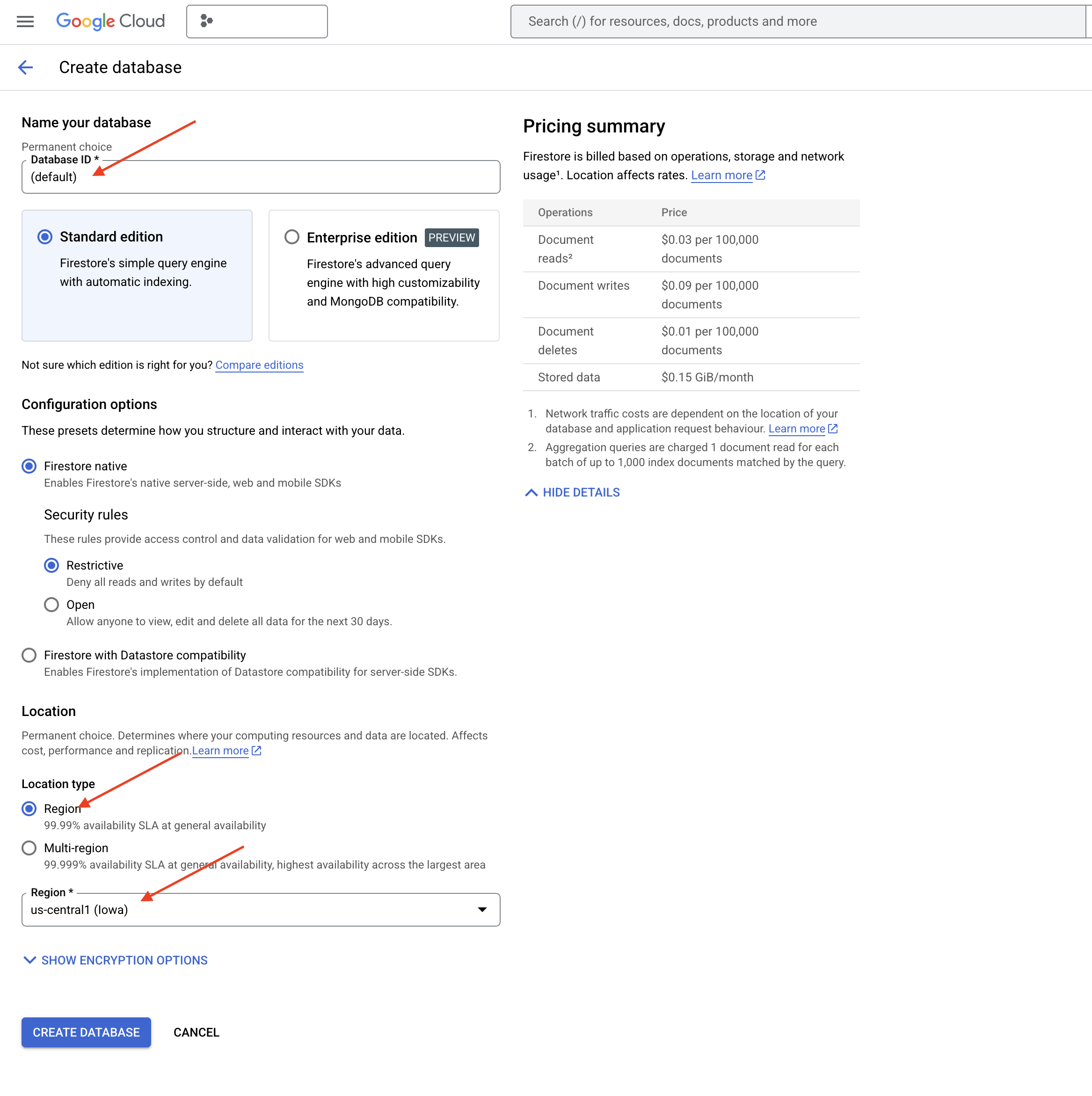
👉 Cloud IDE의 터미널로 돌아가서 embedding_vector 필드에 벡터 색인을 만들어 legal_documents 컬렉션에서 벡터 검색을 사용 설정합니다.
export PROJECT_ID=$(gcloud config get project)
gcloud firestore indexes composite create \
--collection-group=legal_documents \
--query-scope=COLLECTION \
--field-config field-path=embedding,vector-config='{"dimension":"768", "flat": "{}"}' \
--project=${PROJECT_ID}
Firestore에서 벡터 색인 생성을 시작합니다. 특히 대규모 데이터 세트의 경우 색인을 만드는 데 시간이 걸릴 수 있습니다. 색인이 '생성 중' 상태로 표시되며, 빌드되면 '준비됨'으로 전환됩니다. 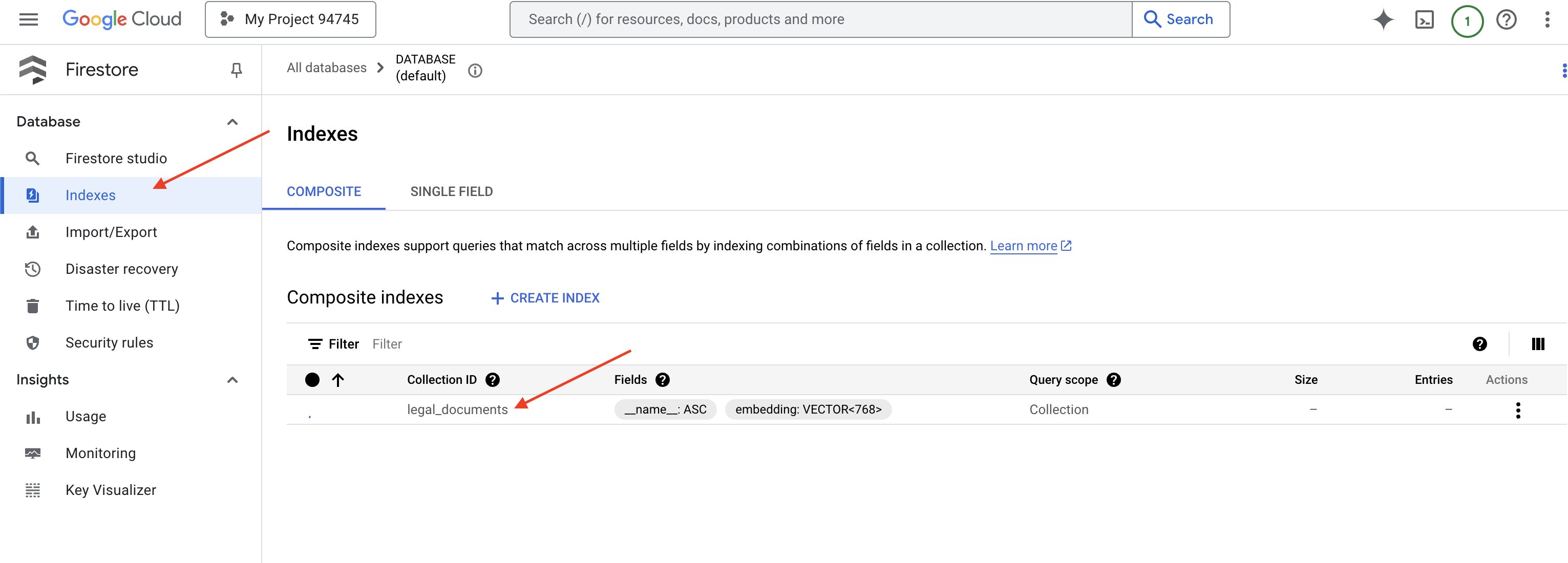
7. 벡터 스토어에 데이터 로드
이제 RAG와 벡터 스토어를 이해했으니 법률 라이브러리를 채우는 엔진을 빌드할 차례입니다. 그렇다면 법률 문서를 '의미로 검색'할 수 있도록 만들려면 어떻게 해야 할까요? 마법은 임베딩에 있습니다. 임베딩은 단어, 문장 또는 전체 문서를 시맨틱 의미를 포착하는 숫자 목록인 숫자 벡터로 변환하는 것으로 생각할 수 있습니다. 유사한 개념은 벡터 공간에서 서로 '가까운' 벡터를 갖습니다. Google에서는 강력한 모델 (예: Vertex AI의 모델)을 사용하여 이 변환을 실행합니다.
문서 로딩을 자동화하기 위해 Cloud Run Functions와 Eventarc를 사용합니다. Cloud Run Functions는 필요할 때만 코드를 실행하는 경량 서버리스 컨테이너입니다. 문서 처리 Python 스크립트를 컨테이너로 패키징하고 Cloud Run 함수로 배포합니다.
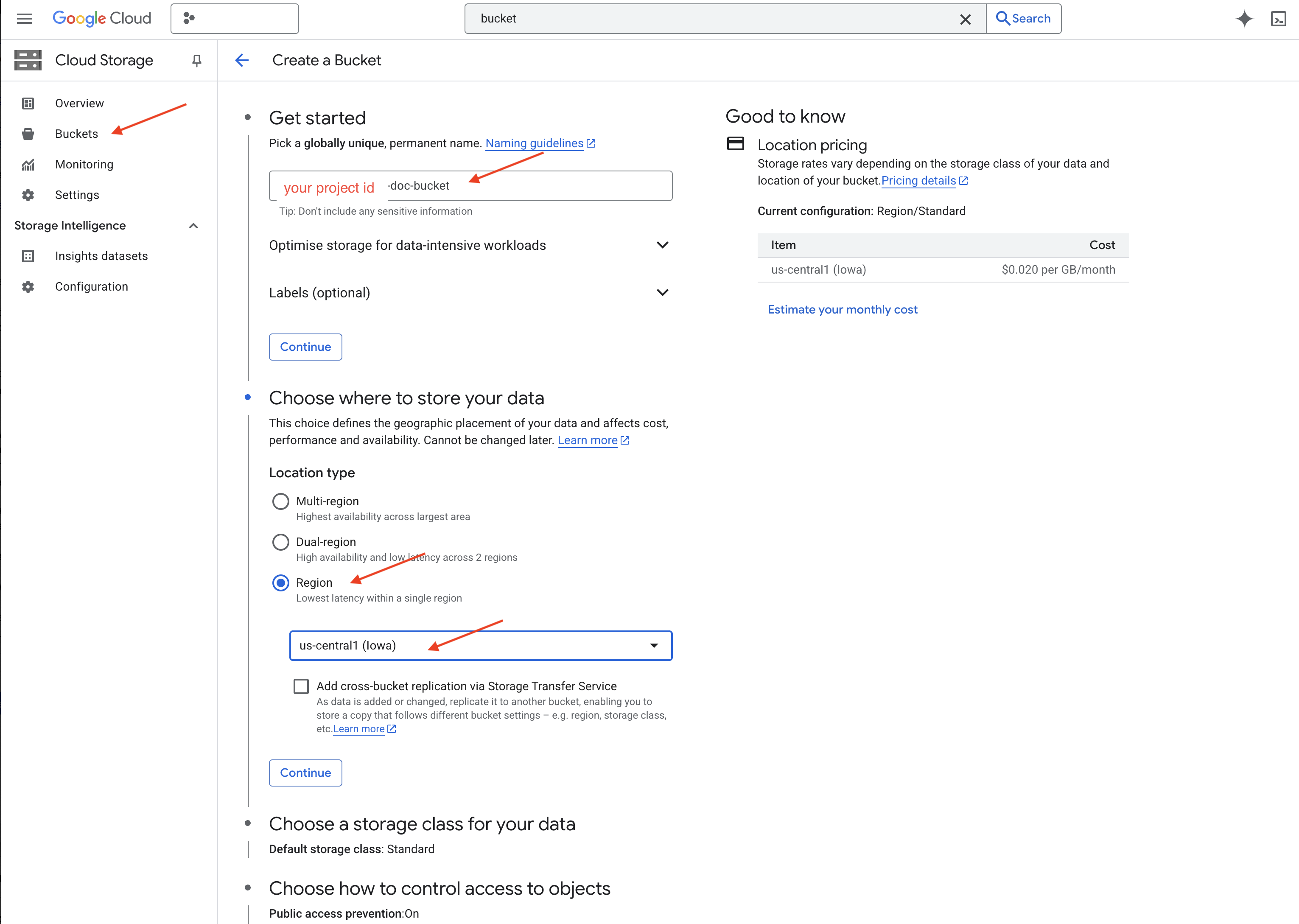
👉 새 탭/창에서 Cloud Storage로 이동합니다.
👉 왼쪽 메뉴에서 '버킷'을 클릭합니다.
👉 상단의 '+ 만들기' 버튼을 클릭합니다.
👉 버킷 구성 (중요 설정):
- 버킷 이름: 'yourprojectID'-doc-bucket (끝에 -doc-bucket 접미사가 있어야 함)
- region:
us-central1리전을 선택합니다. - 스토리지 클래스: 'Standard' Standard는 자주 액세스하는 데이터에 적합합니다.
- 액세스 제어: 기본값인 '균일한 액세스 제어'를 선택된 상태로 둡니다. 이렇게 하면 일관된 버킷 수준 액세스 제어가 제공됩니다.
- 고급 옵션: 이 튜토리얼에서는 기본 설정으로 충분합니다.
👉 만들기 버튼을 클릭하여 버킷을 만듭니다.
👉 공개 액세스 방지에 관한 팝업이 표시될 수 있습니다. 체크박스를 선택한 상태로 '확인'을 클릭합니다.
이제 버킷 목록에 새로 만든 버킷이 표시됩니다. 나중에 필요하므로 버킷 이름을 기억해 둡니다.
8. Cloud Run 함수 설정
👉 Cloud Shell 코드 편집기에서 작업 디렉터리 legal-eagle로 이동합니다. Cloud 편집기 터미널에서 cd 명령어를 사용하여 폴더를 만듭니다.
cd ~/legal-eagle
mkdir loader
cd loader
👉 main.py,requirements.txt, Dockerfile 파일을 만듭니다. Cloud Shell 터미널에서 touch 명령어를 사용하여 파일을 만듭니다.
touch main.py requirements.txt Dockerfile
*loader라는 새로 생성된 폴더와 세 개의 파일이 표시됩니다.
👉 loader 폴더에서 main.py을 수정합니다. 왼쪽의 파일 탐색기에서 파일을 만든 디렉터리로 이동한 후 main.py를 더블클릭하여 편집기에서 엽니다.
다음 Python 코드를 main.py에 붙여넣습니다.
이 애플리케이션은 GCS 버킷에 업로드된 새 파일을 처리하고, 텍스트를 청크로 분할하고, 각 청크의 임베딩을 생성하고, 청크와 임베딩을 Firestore에 저장합니다.
import os
import json
from google.cloud import storage
import functions_framework
from langchain_google_vertexai import VertexAI, VertexAIEmbeddings
from langchain_google_firestore import FirestoreVectorStore
from langchain.text_splitter import RecursiveCharacterTextSplitter
import vertexai
PROJECT_ID = os.environ.get("GOOGLE_CLOUD_PROJECT") # Get project ID from env
embedding_model = VertexAIEmbeddings(
model_name="text-embedding-004" ,
project=PROJECT_ID,)
COLLECTION_NAME = "legal_documents"
# Create a vector store
vector_store = FirestoreVectorStore(
collection="legal_documents",
embedding_service=embedding_model,
content_field="original_text",
embedding_field="embedding",
)
@functions_framework.cloud_event
def process_file(cloud_event):
print(f"CloudEvent received: {cloud_event.data}") # Print the parsed event data
"""Triggered by a Cloud Storage event.
Args:
cloud_event (functions_framework.CloudEvent): The CloudEvent
containing the Cloud Storage event data.
"""
try:
event_data = cloud_event.data
bucket_name = event_data['bucket']
file_name = event_data['name']
except (json.JSONDecodeError, AttributeError, KeyError) as e: # Catch JSON errors
print(f"Error decoding CloudEvent data: {e} - Data: {cloud_event.data}")
return "Error processing event", 500 # Return an error response
print(f"New file detected in bucket: {bucket_name}, file: {file_name}")
storage_client = storage.Client()
bucket = storage_client.bucket(bucket_name)
blob = bucket.blob(file_name)
try:
# Download the file content as string (assuming UTF-8 encoded text file)
file_content_string = blob.download_as_string().decode("utf-8")
print(f"File content downloaded. Processing...")
# Split text into chunks using RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=100,
length_function=len,
)
text_chunks = text_splitter.split_text(file_content_string)
print(f"Text split into {len(text_chunks)} chunks.")
# Add the docs to the vector store
vector_store.add_texts(text_chunks)
print(f"File processing and Firestore upsert complete for file: {file_name}")
return "File processed successfully", 200 # Return success response
except Exception as e:
print(f"Error processing file {file_name}: {e}")
requirements.txt를 수정합니다. 다음 줄을 파일에 붙여넣습니다.
Flask==2.3.3
requests==2.31.0
google-generativeai>=0.2.0
langchain
langchain_google_vertexai
langchain-community
langchain-google-firestore
google-cloud-storage
functions-framework
9. Cloud Run 함수 테스트 및 빌드
👉 가상 환경에서 이를 실행하고 Cloud Run 함수에 필요한 Python 라이브러리를 설치합니다.
cd ~/legal-eagle/loader
python -m venv env
source env/bin/activate
pip install -r requirements.txt
👉 Cloud Run 함수의 로컬 에뮬레이터 시작
functions-framework --target process_file --signature-type=cloudevent --source main.py
👉 마지막 터미널을 실행 상태로 유지하고 새 터미널을 열어 버킷에 파일을 업로드하는 명령어를 실행합니다.
export DOC_BUCKET_NAME=$(gcloud storage buckets list --format="value(name)" | grep doc-bucket)
gsutil cp ~/legal-eagle/court_cases/case-01.txt gs://$DOC_BUCKET_NAME/

👉 에뮬레이터가 실행되는 동안 테스트 CloudEvent를 에뮬레이터로 보낼 수 있습니다. 이를 위해서는 IDE에 별도의 터미널이 필요합니다.
curl -X POST -H "Content-Type: application/json" \
-d "{
\"specversion\": \"1.0\",
\"type\": \"google.cloud.storage.object.v1.finalized\",
\"source\": \"//storage.googleapis.com/$DOC_BUCKET_NAME\",
\"subject\": \"objects/case-01.txt\",
\"id\": \"my-event-id\",
\"time\": \"2024-01-01T12:00:00Z\",
\"data\": {
\"bucket\": \"$DOC_BUCKET_NAME\",
\"name\": \"case-01.txt\"
}
}" http://localhost:8080/
OK를 반환해야 합니다.
👉 Firestore에서 데이터를 확인합니다. Google Cloud 콘솔로 이동하여 '데이터베이스'와 'Firestore'를 차례로 선택하고 '데이터' 탭과 legal_documents 컬렉션을 선택합니다. 컬렉션에 새 문서가 생성된 것을 확인할 수 있습니다. 각 문서는 업로드된 파일의 텍스트 청크를 나타냅니다. 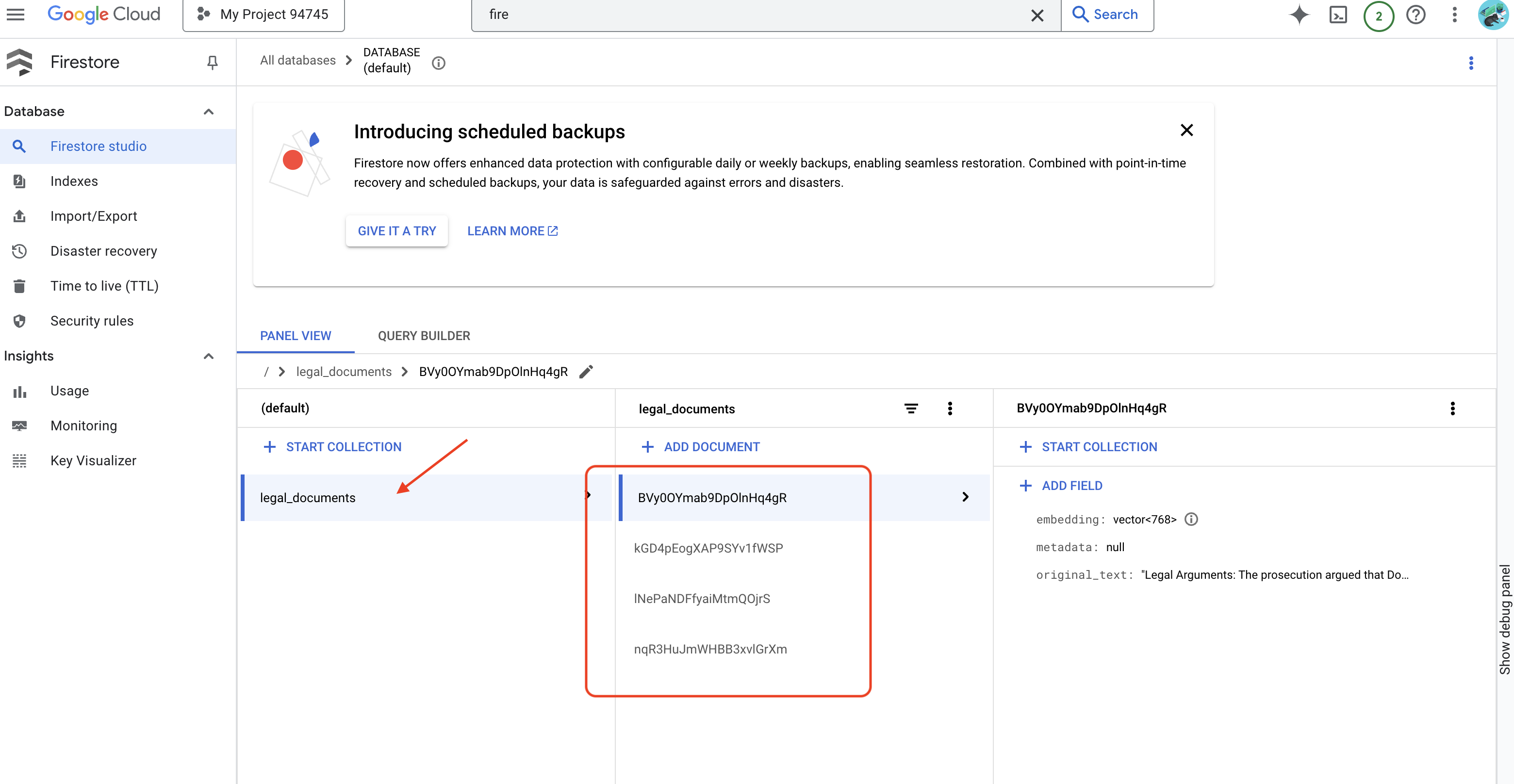
👉 에뮬레이터를 실행하는 터미널에서 Ctrl+C를 입력하여 종료합니다. 두 번째 터미널을 닫습니다.
👉 deactivate를 실행하여 가상 환경을 종료합니다.
deactivate
10. 컨테이너 이미지를 빌드하고 아티팩트 저장소에 푸시
👉 이제 클라우드에 배포할 시간입니다. 파일 탐색기에서 Dockerfile을 더블클릭합니다. Gemini에 Dockerfile을 생성해 달라고 요청하고 Gemini Code Assist를 열고 다음 프롬프트를 사용하여 파일을 생성합니다.
In the loader folder,
Generate a Dockerfile for a Python 3.12 Cloud Run service that uses functions-framework. It needs to:
1. Use a Python 3.12 slim base image.
2. Set the working directory to /app.
3. Copy requirements.txt and install Python dependencies.
4. Copy main.py.
5. Set the command to run functions-framework, targeting the 'process_file' function on port 8080
권장사항에 따라 열린 파일과 비교(방향이 반대인 화살표 2개)를 클릭하고 변경사항을 수락하는 것이 좋습니다. 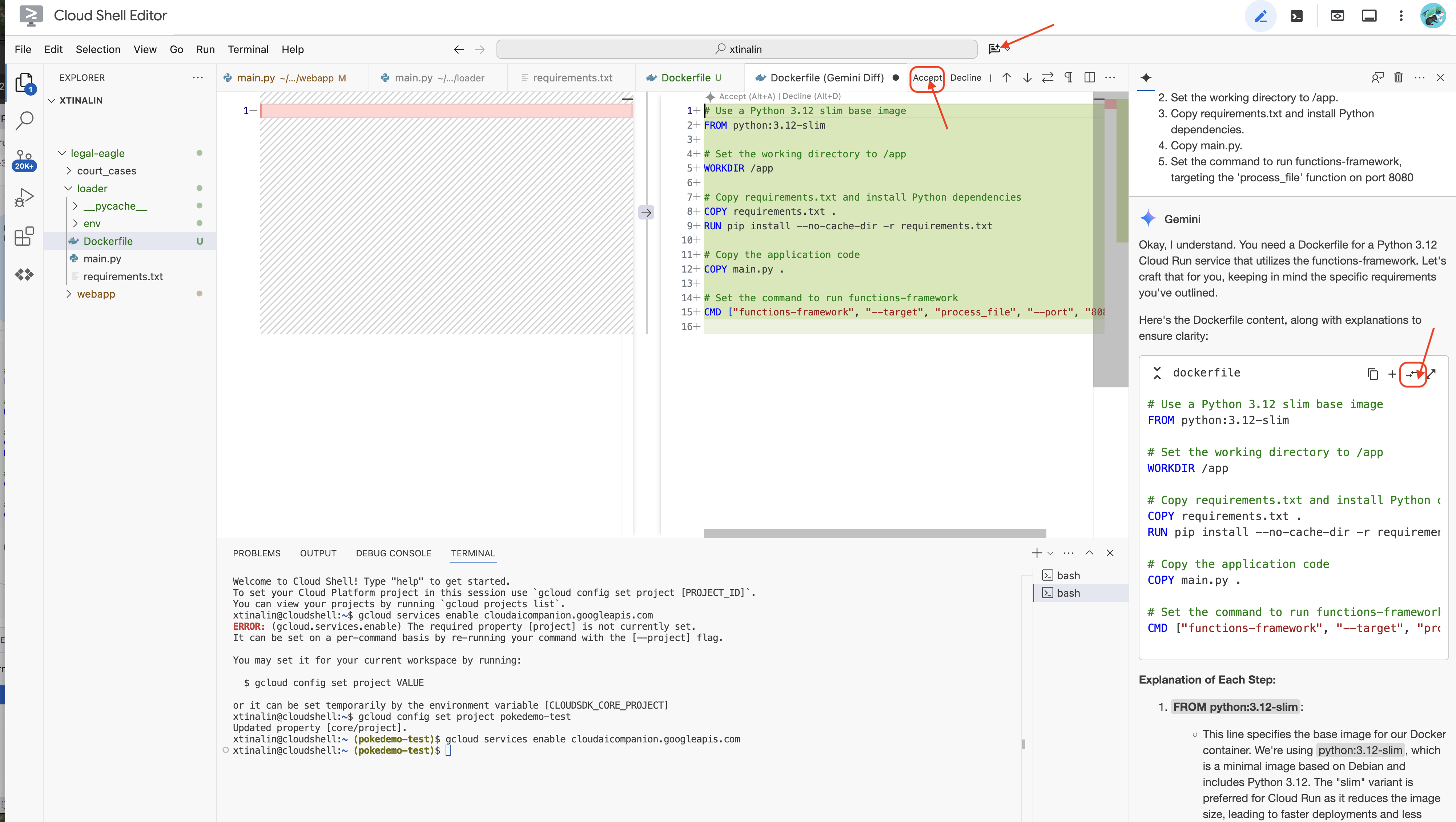
👉 컨테이너를 처음 사용하는 경우 다음은 작동 예시입니다.
# Use a Python 3.12 slim base image
FROM python:3.12-slim
# Set the working directory to /app
WORKDIR /app
# Copy requirements.txt and install Python dependencies
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
# Copy main.py
COPY main.py .
# Set the command to run functions-framework
CMD ["functions-framework", "--target", "process_file", "--port", "8080"]
👉 터미널에서 빌드할 Docker 이미지를 저장할 아티팩트 저장소를 만듭니다.
gcloud artifacts repositories create my-repository \
--repository-format=docker \
--location=us-central1 \
--description="My repository"
Created repository [my-repository].가 표시됩니다.
👉 다음 명령어를 실행하여 Docker 이미지를 빌드합니다.
cd ~/legal-eagle/loader
export PROJECT_ID=$(gcloud config get project)
docker build -t gcr.io/${PROJECT_ID}/legal-eagle-loader .
👉 이제 레지스트리에 푸시합니다.
export PROJECT_ID=$(gcloud config get project)
docker tag gcr.io/${PROJECT_ID}/legal-eagle-loader us-central1-docker.pkg.dev/${PROJECT_ID}/my-repository/legal-eagle-loader
docker push us-central1-docker.pkg.dev/${PROJECT_ID}/my-repository/legal-eagle-loader
이제 Docker 이미지를 my-repository Artifacts Repository에서 사용할 수 있습니다.
11. Cloud Run 함수를 만들고 Eventarc 트리거 설정
법률 문서 로더 배포의 세부사항을 살펴보기 전에 관련 구성요소를 간략하게 이해해 보겠습니다. Cloud Run은 컨테이너화된 애플리케이션을 빠르고 쉽게 배포할 수 있는 완전 관리형 서버리스 플랫폼입니다. 인프라 관리를 추상화하여 코드 작성 및 배포에 집중할 수 있습니다.
문서 로더를 Cloud Run 서비스로 배포합니다. 이제 Cloud Run 함수를 설정해 보겠습니다.
👉 Google Cloud 콘솔에서 Cloud Run으로 이동합니다.
👉 컨테이너 배포로 이동하여 드롭다운에서 서비스를 클릭합니다.
👉 Cloud Run 서비스를 구성합니다.
- 컨테이너 이미지: URL 필드에서 '선택'을 클릭합니다. Artifact Registry에 푸시한 이미지 URL을 찾습니다 (예: us-central1-docker.pkg.dev/your-project-id/my-repository/legal-eagle-loader/yourimage).
- 서비스 이름:
legal-eagle-loader - 리전:
us-central1리전을 선택합니다. - 인증: 이 워크숍에서는 '인증되지 않은 호출 허용'을 허용해도 됩니다. 프로덕션의 경우 액세스를 제한하는 것이 좋습니다.
- 컨테이너, 네트워킹, 보안 : 기본값입니다.
👉 만들기를 클릭합니다. Cloud Run에서 서비스를 배포합니다. 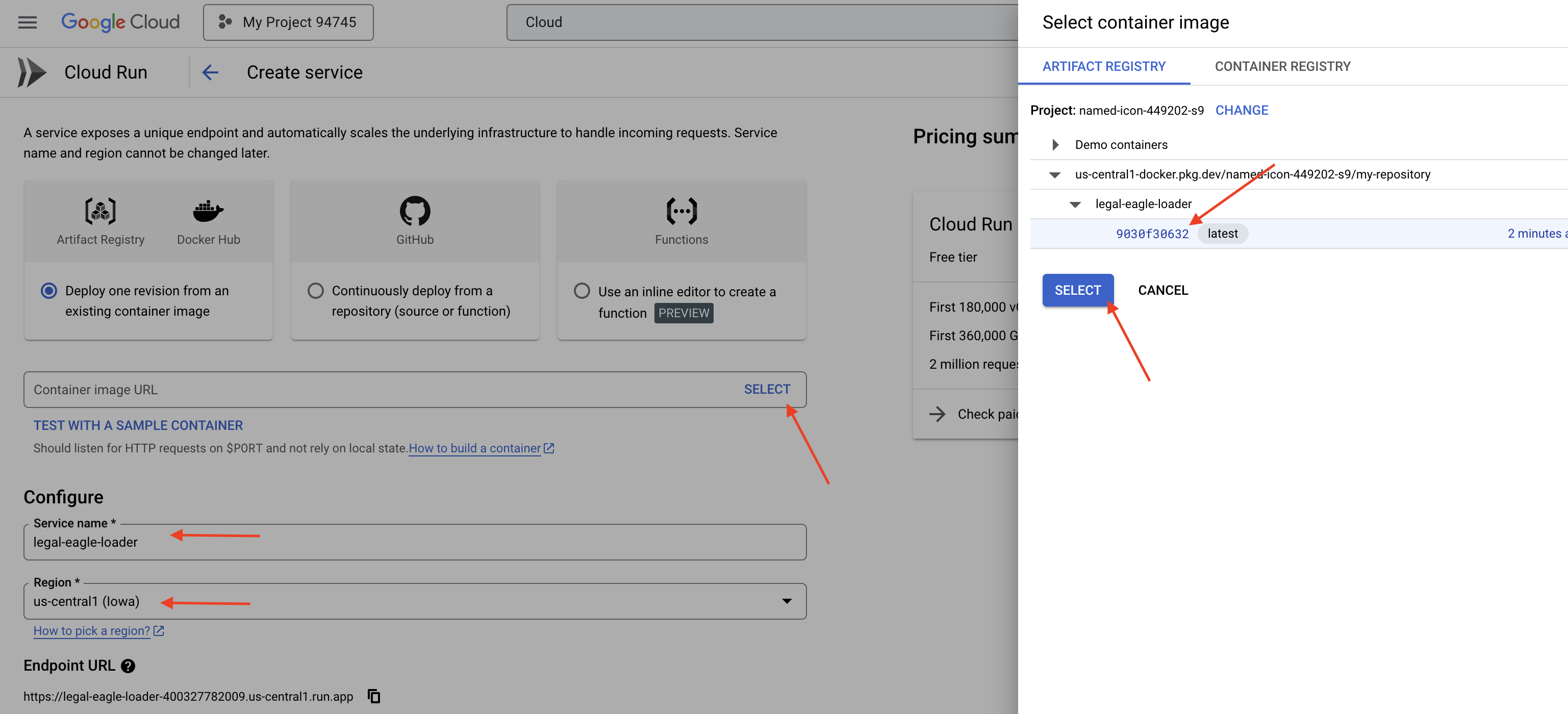
새 파일이 스토리지 버킷에 추가될 때 이 서비스를 자동으로 트리거하기 위해 Eventarc를 사용합니다. Eventarc를 사용하면 다양한 소스의 이벤트를 서비스로 라우팅하여 이벤트 기반 아키텍처를 만들 수 있습니다.
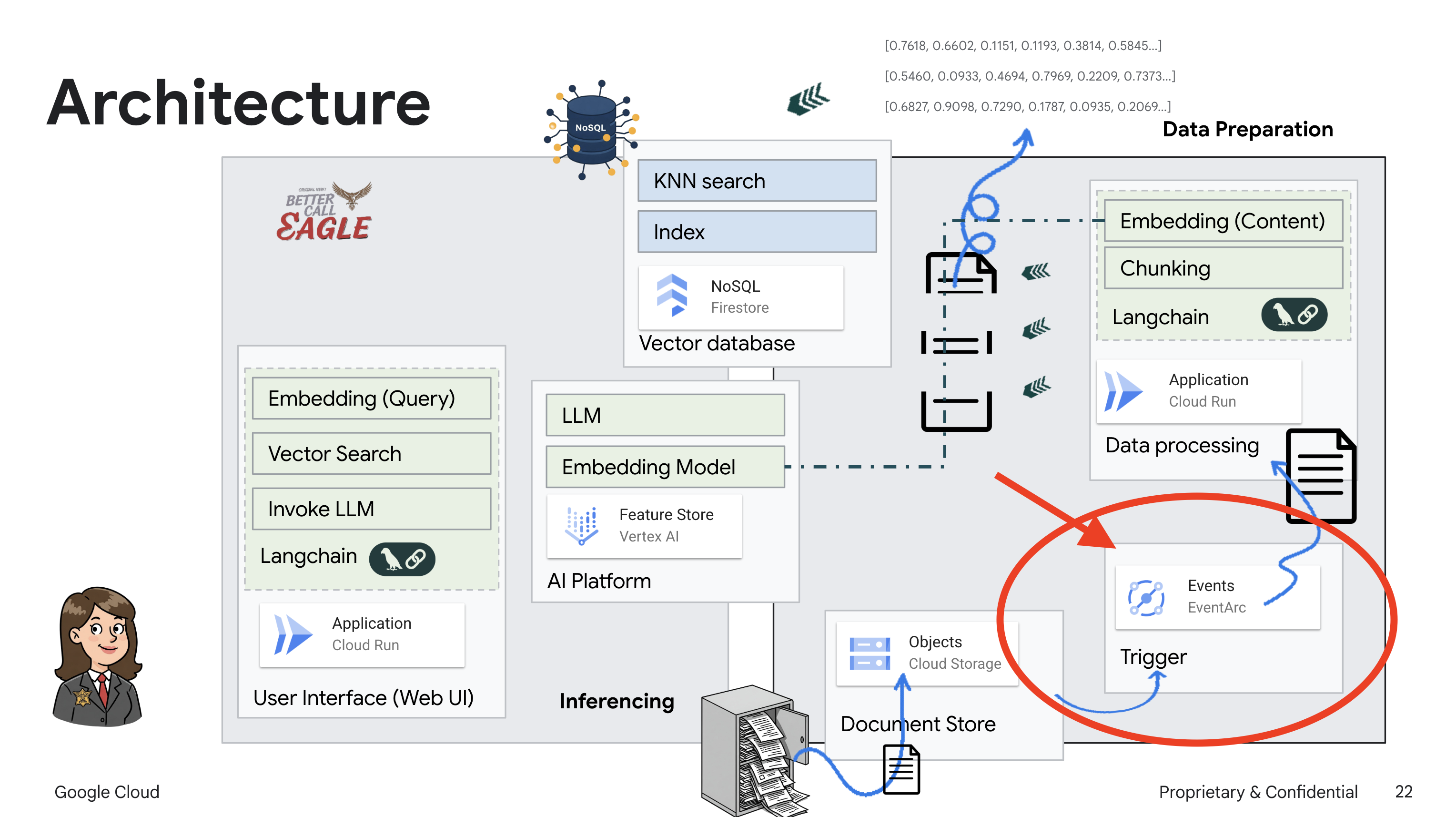
Eventarc를 설정하면 새로 추가된 문서가 업로드되는 즉시 Cloud Run 서비스가 Firestore에 자동으로 로드되어 RAG 애플리케이션의 실시간 데이터 업데이트가 가능해집니다.
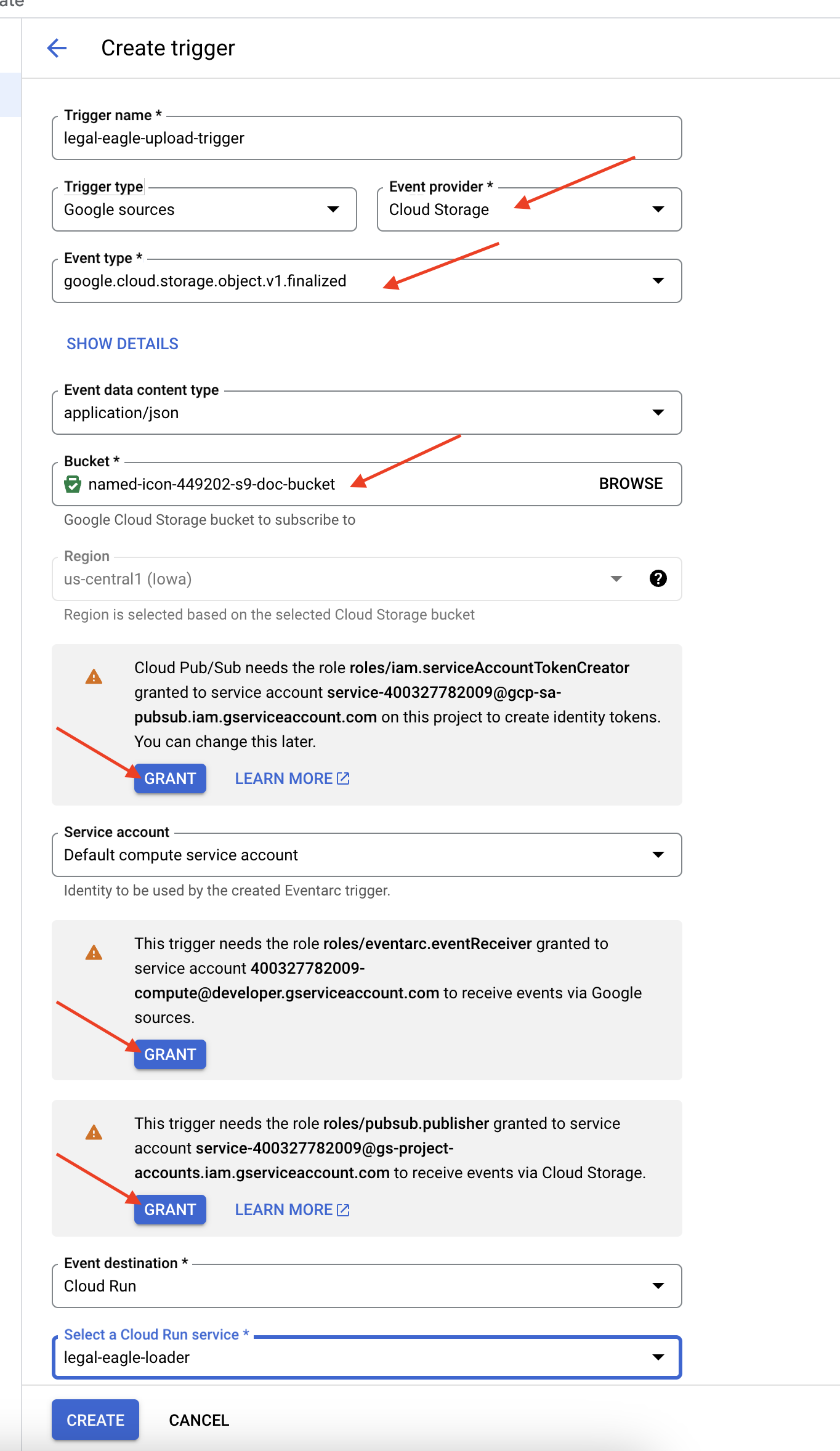
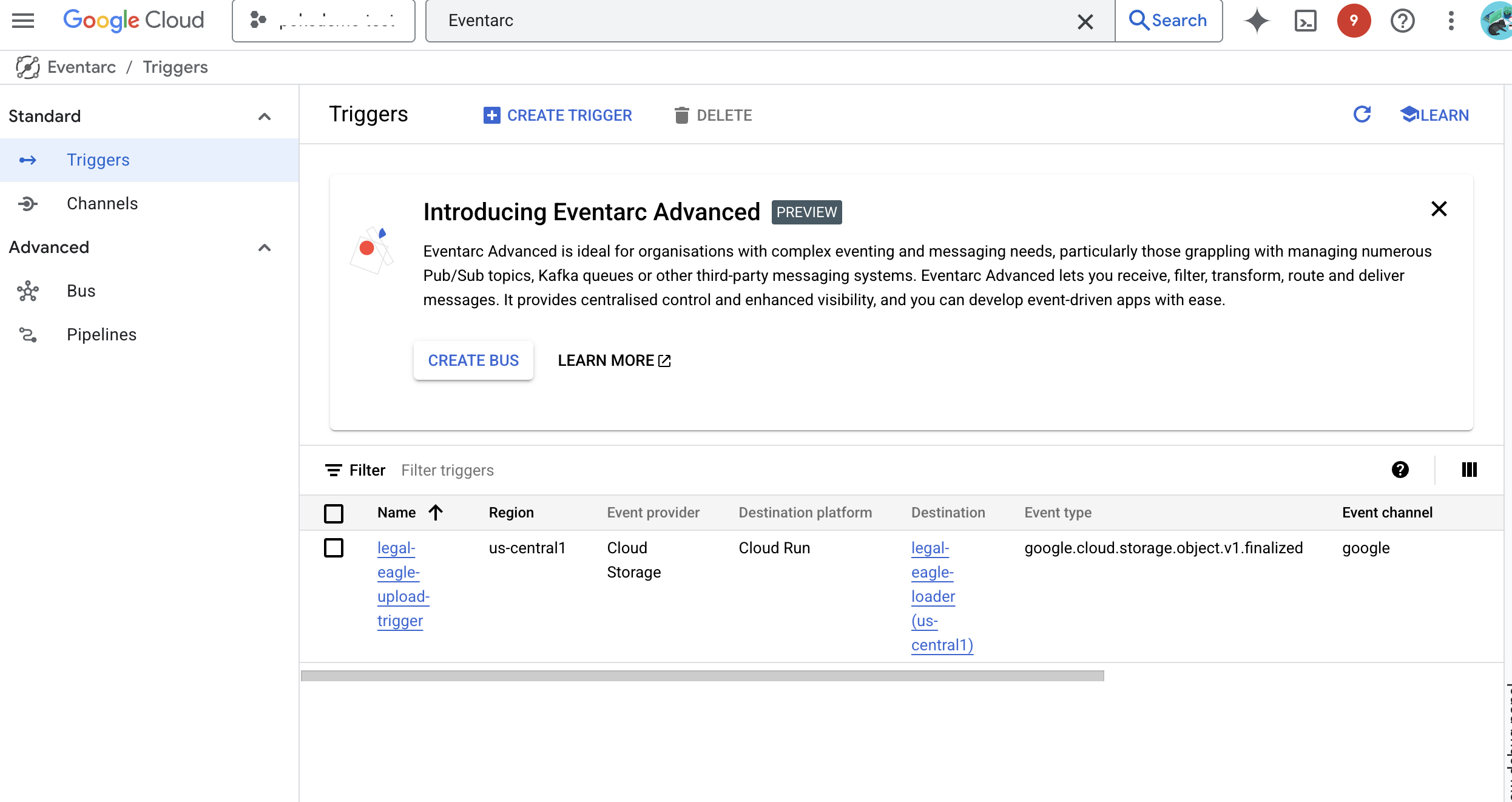
👉 Google Cloud 콘솔의 EventArc에서 트리거로 이동합니다. '+ 트리거 만들기'를 클릭합니다. 👉 Eventarc 트리거 구성:
- 트리거 이름:
legal-eagle-upload-trigger - TriggerType: Google 소스
- 이벤트 제공자: Cloud Storage를 선택합니다.
- 이벤트 유형:
google.cloud.storage.object.v1.finalized선택 - Cloud Storage 버킷: 드롭다운에서 GCS 버킷을 선택합니다.
- 대상 유형: 'Cloud Run 서비스'
- 서비스:
legal-eagle-loader를 선택합니다. - 리전:
us-central1 - 경로: 지금은 비워 둡니다 .
- 페이지에 표시된 모든 권한을 부여합니다.
👉 만들기를 클릭합니다. 이제 Eventarc에서 트리거를 설정합니다.
Cloud Run 서비스에는 다양한 구성요소에서 파일을 읽을 수 있는 권한이 필요합니다. 서비스의 서비스 계정에 필요한 권한을 부여해야 합니다.
12. GCS 버킷에 법적 문서 업로드
👉 법원 소송 파일을 GCS 버킷에 업로드합니다. 버킷 이름을 바꿔야 합니다.
export DOC_BUCKET_NAME=$(gcloud storage buckets list --format="value(name)" | grep doc-bucket)
gsutil cp ~/legal-eagle/court_cases/case-02.txt gs://$DOC_BUCKET_NAME/
gsutil cp ~/legal-eagle/court_cases/case-03.txt gs://$DOC_BUCKET_NAME/
gsutil cp ~/legal-eagle/court_cases/case-06.txt gs://$DOC_BUCKET_NAME/
Cloud Run 서비스 로그를 모니터링하려면 Cloud Run -> 서비스 legal-eagle-loader -> '로그'로 이동합니다. 다음을 비롯한 성공적인 처리 메시지의 로그를 확인합니다.
xxx
POST200130 B8.3 sAPIs-Google; (+https://developers.google.com/webmasters/APIs-Google.html) https://legal-eagle-loader-bmngrueyta-uc.a.run.app/?__GCP_CloudEventsMode=GCS_NOTIFICATION
xxx
POST200130 B520 msAPIs-Google; (+https://developers.google.com/webmasters/APIs-Google.html) https://legal-eagle-loader-bmngrueyta-uc.a.run.app/?__GCP_CloudEventsMode=GCS_NOTIFICATION
xxx
POST200130 B514 msAPIs-Google; (+https://developers.google.com/webmasters/APIs-Google.html) https://legal-eagle-loader-bmngrueyta-uc.a.run.app/?__GCP_CloudEventsMode=GCS_NOTIFICATION
로깅이 얼마나 빠르게 설정되었는지에 따라 여기에 더 자세한 로그도 표시됩니다.
"CloudEvent received:"
"New file detected in bucket:"
"File content downloaded. Processing..."
"Text split into ... chunks."
"File processing and Firestore upsert complete..."
로그에서 오류 메시지를 찾아 필요한 경우 문제를 해결합니다. 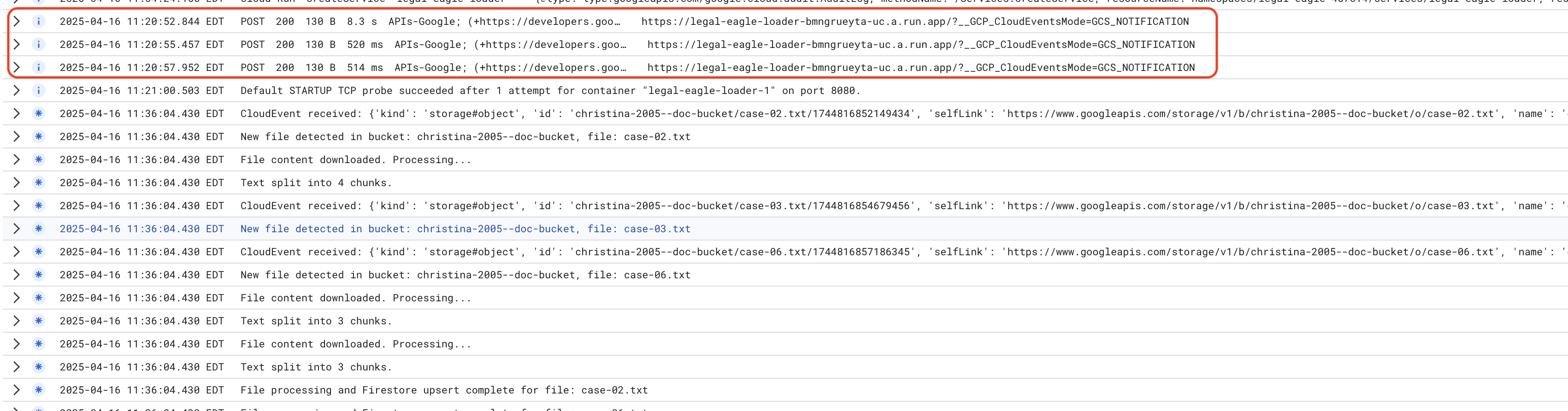
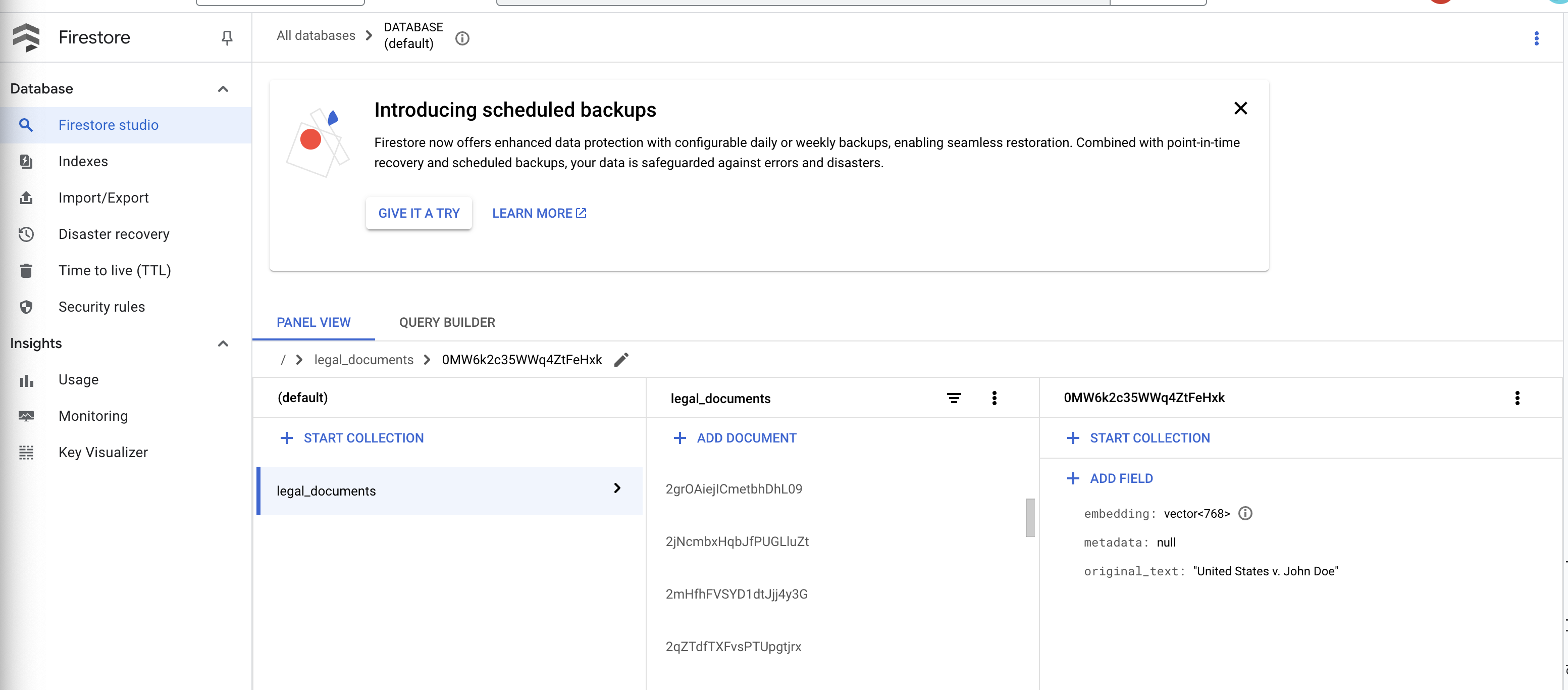
👉 Firestore에서 데이터를 확인합니다. legal_documents 컬렉션을 엽니다.
👉 컬렉션에 새로 생성된 문서가 표시됩니다. 각 문서는 업로드한 파일의 텍스트 청크를 나타내며 다음을 포함합니다.
metadata: currently empty
original_text_chunk: The text chunk content.
embedding_: A list of floating-point numbers (the Vertex AI embedding).
13. RAG 구현
LangChain은 대규모 언어 모델 (LLM)로 구동되는 애플리케이션의 개발을 간소화하도록 설계된 강력한 프레임워크입니다. LLM API, 프롬프트 엔지니어링, 데이터 처리의 복잡성을 직접 다루는 대신 LangChain은 상위 수준 추상화 레이어를 제공합니다. 다양한 LLM (예: OpenAI, Google 등의 LLM)에 연결하고, 복잡한 작업 체인 (예: 데이터 검색 후 요약)을 빌드하고, 대화형 메모리를 관리하는 등의 작업을 위한 사전 빌드된 구성요소와 도구를 제공합니다.
특히 RAG의 경우 LangChain의 벡터 스토어는 RAG의 검색 측면을 지원하는 데 필수적입니다. 의미적으로 유사한 텍스트 조각이 벡터 공간에서 서로 가까운 점에 매핑되는 벡터 임베딩을 효율적으로 저장하고 쿼리하도록 설계된 특수 데이터베이스입니다. LangChain은 하위 수준 배관을 처리하므로 개발자는 RAG 애플리케이션의 핵심 로직과 기능에 집중할 수 있습니다. 이를 통해 개발 시간과 복잡성이 크게 줄어들어 Google Cloud 인프라의 견고성과 확장성을 활용하면서 RAG 기반 애플리케이션을 신속하게 프로토타입 제작하고 배포할 수 있습니다.
LangChain을 설명했으므로 이제 RAG 구현을 위해 webapp 폴더 아래의 legal.py 파일을 업데이트해야 합니다. 이렇게 하면 LLM이 답변을 제공하기 전에 Firestore에서 관련 문서를 검색할 수 있습니다.
👉 langchain 및 vertexai에서 FirestoreVectorStore 및 기타 필수 모듈을 가져옵니다. 현재 legal.py에 다음을 추가합니다.
from langchain_google_vertexai import VertexAIEmbeddings
from langchain_google_firestore import FirestoreVectorStore
👉 Vertex AI와 임베딩 모델을 초기화합니다.text-embedding-004를 사용합니다. 모듈을 가져온 직후 다음 코드를 추가합니다.
PROJECT_ID = os.environ.get("GOOGLE_CLOUD_PROJECT") # Get project ID from env
embedding_model = VertexAIEmbeddings(
model_name="text-embedding-004" ,
project=PROJECT_ID,)
👉 초기화된 임베딩 모델을 사용하고 콘텐츠 및 임베딩 필드를 지정하여 legal_documents 컬렉션을 가리키는 FirestoreVectorStore를 만듭니다. 이 코드를 이전 삽입 모델 코드 바로 뒤에 추가합니다.
COLLECTION_NAME = "legal_documents"
# Create a vector store
vector_store = FirestoreVectorStore(
collection="legal_documents",
embedding_service=embedding_model,
content_field="original_text",
embedding_field="embedding",
)
👉 쿼리를 가져와 vector_store.similarity_search를 사용하여 유사성 검색을 실행하고 결합된 결과를 반환하는 search_resource라는 함수를 정의합니다.
def search_resource(query):
results = []
results = vector_store.similarity_search(query, k=5)
combined_results = "\n".join([result.page_content for result in results])
print(f"==>{combined_results}")
return combined_results
👉 ask_llm 함수를 대체하고 search_resource 함수를 사용하여 사용자의 질문에 따라 관련 맥락을 가져옵니다.
def ask_llm(query):
try:
query_message = {
"type": "text",
"text": query,
}
relevant_resource = search_resource(query)
input_msg = HumanMessage(content=[query_message])
prompt_template = ChatPromptTemplate.from_messages(
[
SystemMessage(
content=(
"You are a helpful assistant, and you are with the attorney in a courtroom, you are helping him to win the case by providing the information he needs "
"Don't answer if you don't know the answer, just say sorry in a funny way possible"
"Use high engergy tone, don't use more than 100 words to answer"
f"Here is some context that is relevant to the question {relevant_resource} that you might use"
)
),
input_msg,
]
)
prompt = prompt_template.format()
response = llm.invoke(prompt)
print(f"response: {response}")
return response
except Exception as e:
print(f"Error sending message to chatbot: {e}") # Log this error too!
return f"Unable to process your request at this time. Due to the following reason: {str(e)}"
👉 선택사항: 스페인어 버전
Sustituye el siguiente texto como se indica: You are a helpful assistant, to You are a helpful assistant that speaks Spanish,
👉 legal.py에 RAG를 구현한 후 배포하기 전에 로컬에서 테스트해야 합니다. 다음 명령어로 애플리케이션을 실행하세요.
cd ~/legal-eagle/webapp
source env/bin/activate
python main.py
👉 webpreview를 사용하여 애플리케이션에 액세스하고, 어시스턴트와 대화하고, ctrl+c를 입력하여 로컬에서 실행되는 프로세스를 종료합니다. deactivate를 실행하여 가상 환경을 종료합니다.
deactivate
👉 웹 애플리케이션을 Cloud Run에 배포하는 것은 로더 함수와 유사합니다. Docker 이미지를 빌드하고 태그를 지정한 후 Artifact Registry에 푸시합니다.
export PROJECT_ID=$(gcloud config get project)
docker build -t gcr.io/${PROJECT_ID}/legal-eagle-webapp .
docker tag gcr.io/${PROJECT_ID}/legal-eagle-webapp us-central1-docker.pkg.dev/${PROJECT_ID}/my-repository/legal-eagle-webapp
docker push us-central1-docker.pkg.dev/${PROJECT_ID}/my-repository/legal-eagle-webapp
👉 이제 웹 애플리케이션을 Google Cloud에 배포할 시간입니다. 터미널에서 다음 명령어를 실행합니다.
export PROJECT_ID=$(gcloud config get project)
gcloud run deploy legal-eagle-webapp \
--image us-central1-docker.pkg.dev/$PROJECT_ID/my-repository/legal-eagle-webapp \
--region us-central1 \
--set-env-vars=GOOGLE_CLOUD_PROJECT=${PROJECT_ID} \
--allow-unauthenticated
Google Cloud 콘솔에서 Cloud Run으로 이동하여 배포를 확인합니다.legal-eagle-webapp라는 새 서비스가 표시됩니다.
서비스를 클릭하여 세부정보 페이지로 이동하면 상단에 배포된 URL이 표시됩니다. 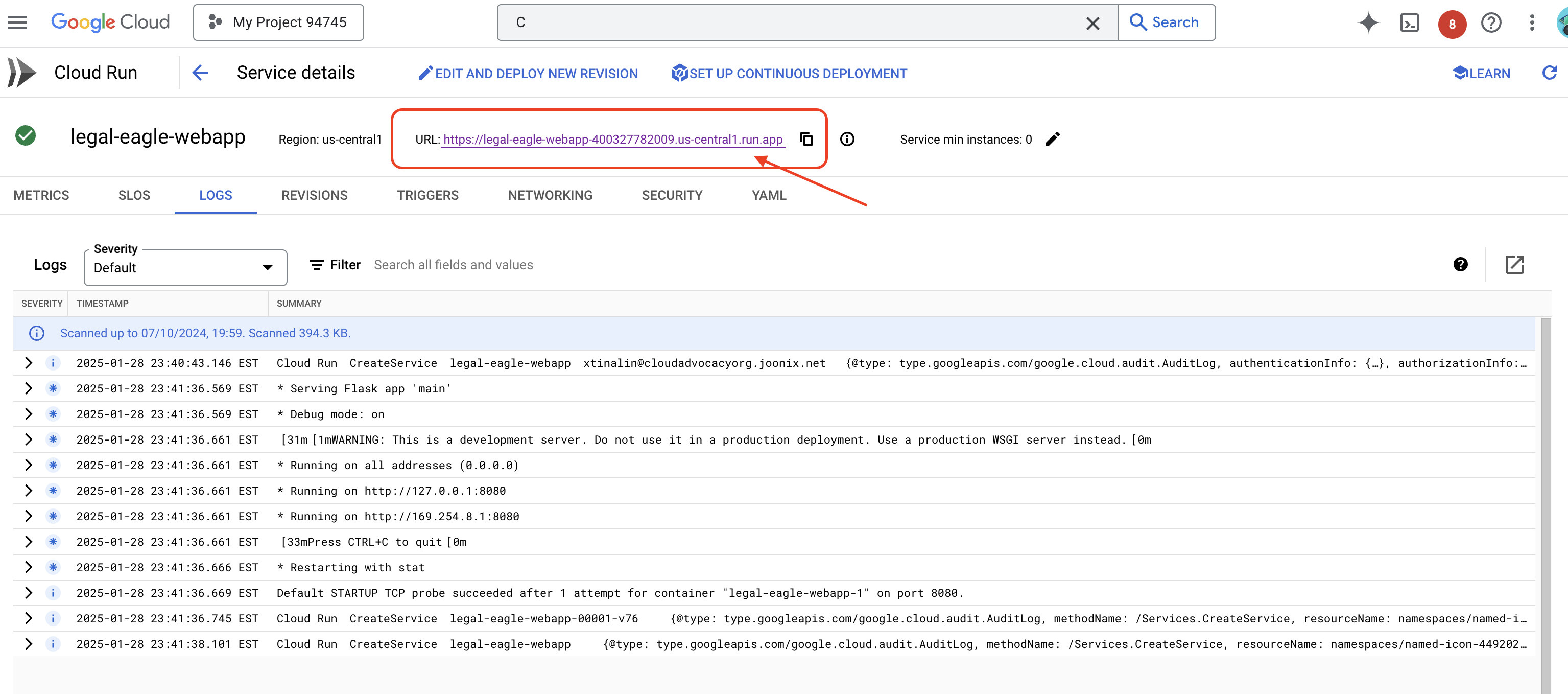
👉 이제 배포된 URL을 새 브라우저 탭에서 엽니다. 법률 어시스턴트와 상호작용하고 로드한 법원 사건(court_cases 폴더 아래)과 관련된 질문을 할 수 있습니다.
- 마이클 브라운은 몇 년의 징역형을 선고받았나요?
- 김영희의 행위로 인해 발생한 승인되지 않은 청구 금액은 얼마인가요?
- 에밀리 화이트 사건 조사에서 이웃의 증언은 어떤 역할을 했나요?
👉 선택사항: 스페인어 버전
- ¿A cuántos años de prisión fue sentenciado Michael Brown?
- ¿Cuánto dinero en cargos no autorizados se generó como resultado de las acciones de Jane Smith?
- ¿Qué papel jugaron los testimonios de los vecinos en la investigación del caso de Emily White?
이제 대답이 더 정확해지고 업로드한 법적 문서의 내용을 기반으로 그라운딩되어 RAG의 강력한 기능을 보여줍니다.
워크숍을 완료하신 것을 축하드립니다. LLM, LangChain, Google Cloud를 사용하여 법률 문서 분석 애플리케이션을 성공적으로 빌드하고 배포했습니다. 법률 문서를 수집하고 처리하는 방법, RAG를 사용하여 관련 정보로 LLM 응답을 보강하는 방법, 애플리케이션을 서버리스 서비스로 배포하는 방법을 배웠습니다. 이 지식과 빌드된 애플리케이션은 법률 작업에 LLM을 활용하는 방법을 더 자세히 알아보는 데 도움이 됩니다. 잘하셨습니다!'
14. 도전과제
다양한 미디어 유형:
법정 동영상, 오디오 녹음 파일과 같은 다양한 미디어 유형을 수집하고 처리하여 관련 텍스트를 추출하는 방법
온라인 애셋:
웹페이지와 같은 온라인 애셋을 실시간으로 처리하는 방법