
1. Wprowadzenie
Zawsze fascynowała mnie intensywność sali sądowej. Wyobrażałem sobie, jak sprawnie poruszam się po jej zawiłościach i wygłaszam przekonujące mowy końcowe. Moja ścieżka kariery potoczyła się inaczej, ale cieszę się, że dzięki AI możemy być bliżej realizacji tego marzenia.

Dziś przyjrzymy się, jak korzystać z zaawansowanych narzędzi AI od Google, takich jak Vertex AI, Firestore i funkcje Cloud Run, aby przetwarzać i analizować dane prawne, przeprowadzać błyskawiczne wyszukiwania i być może pomóc wyimaginowanemu klientowi (lub sobie) wyjść z trudnej sytuacji.
Nie będziesz przesłuchiwać świadka, ale dzięki naszemu systemowi możesz przeglądać ogromne ilości informacji, generować jasne podsumowania i w kilka sekund prezentować najbardziej istotne dane.
2. Architektura
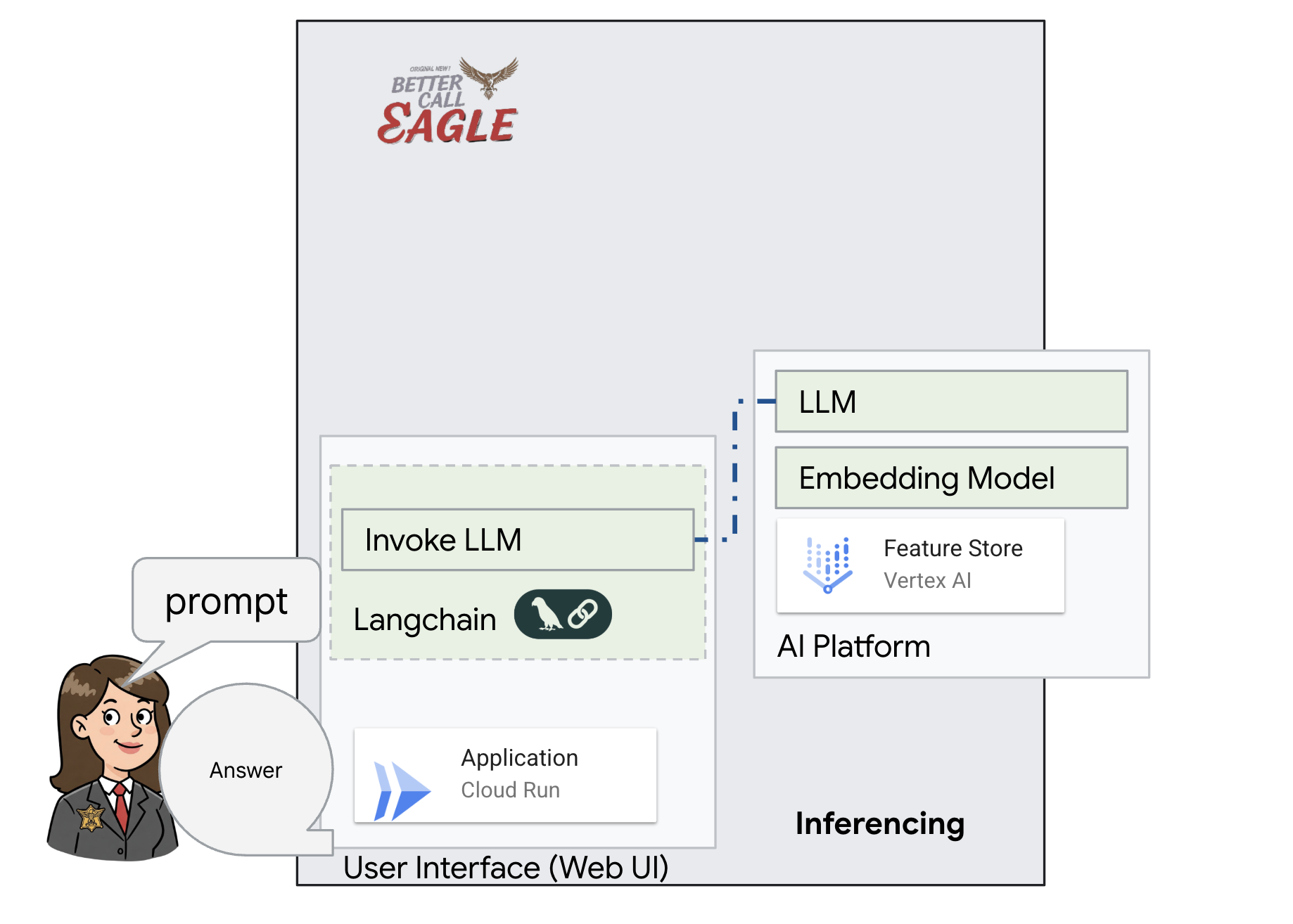
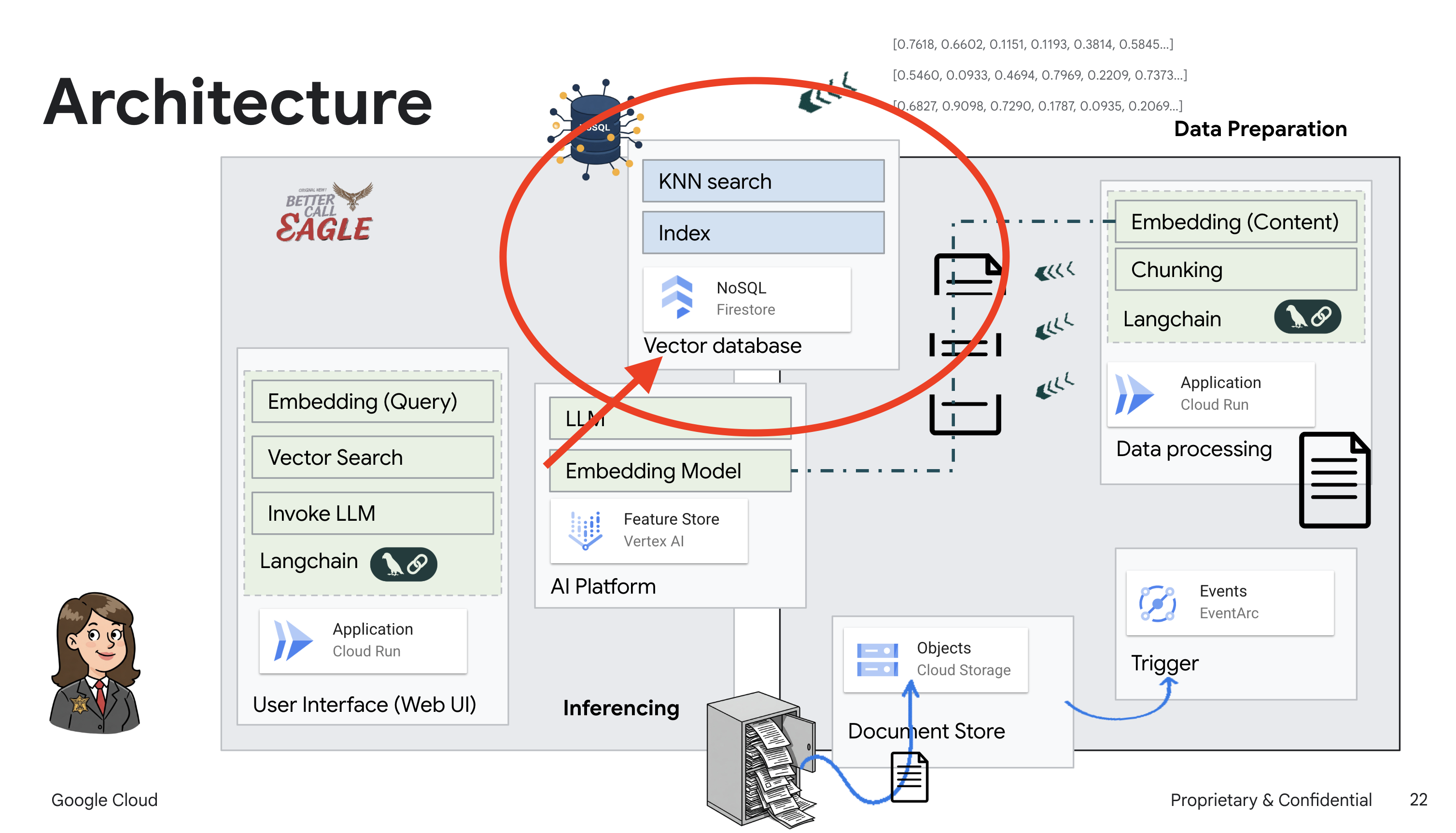
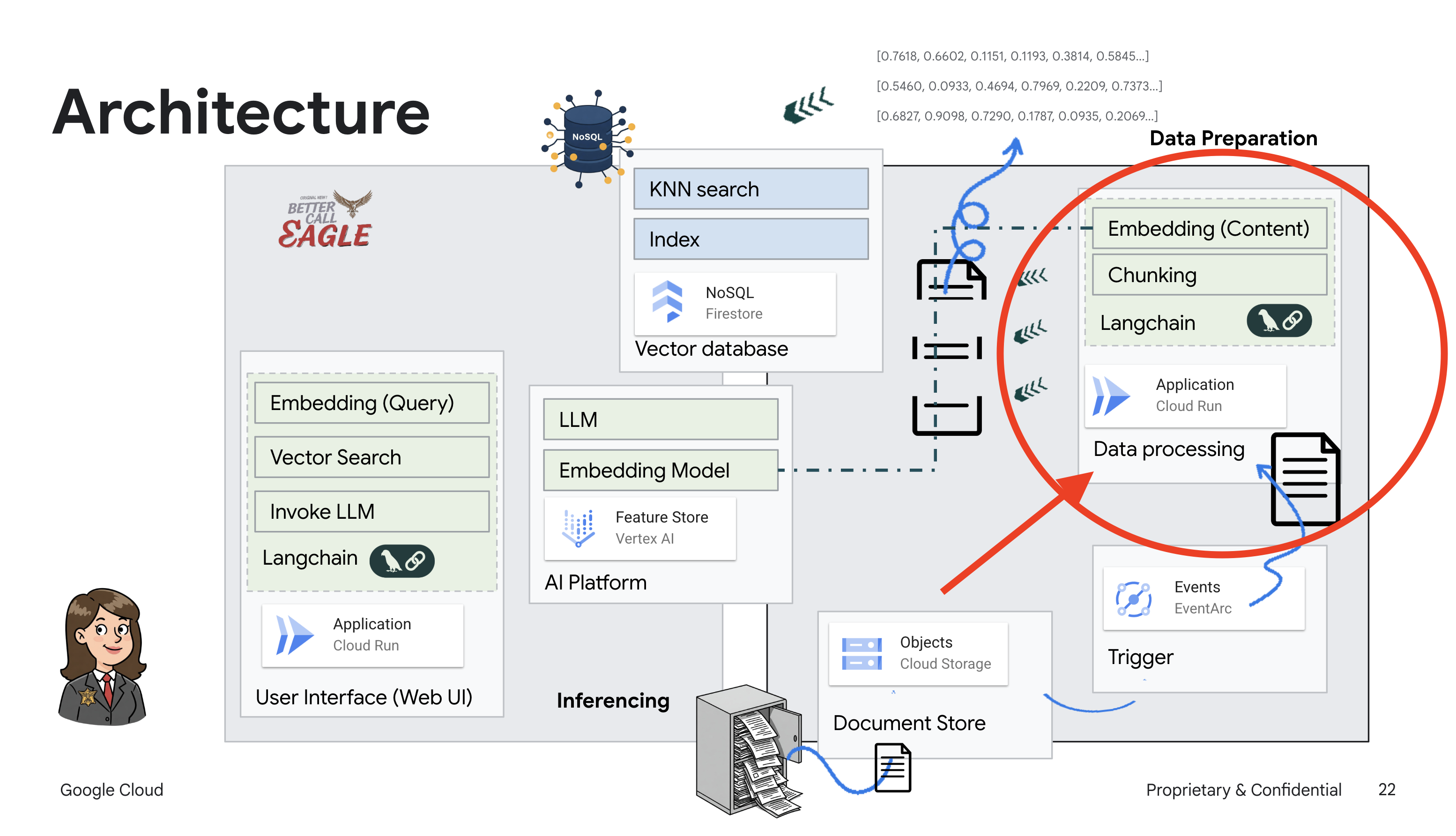
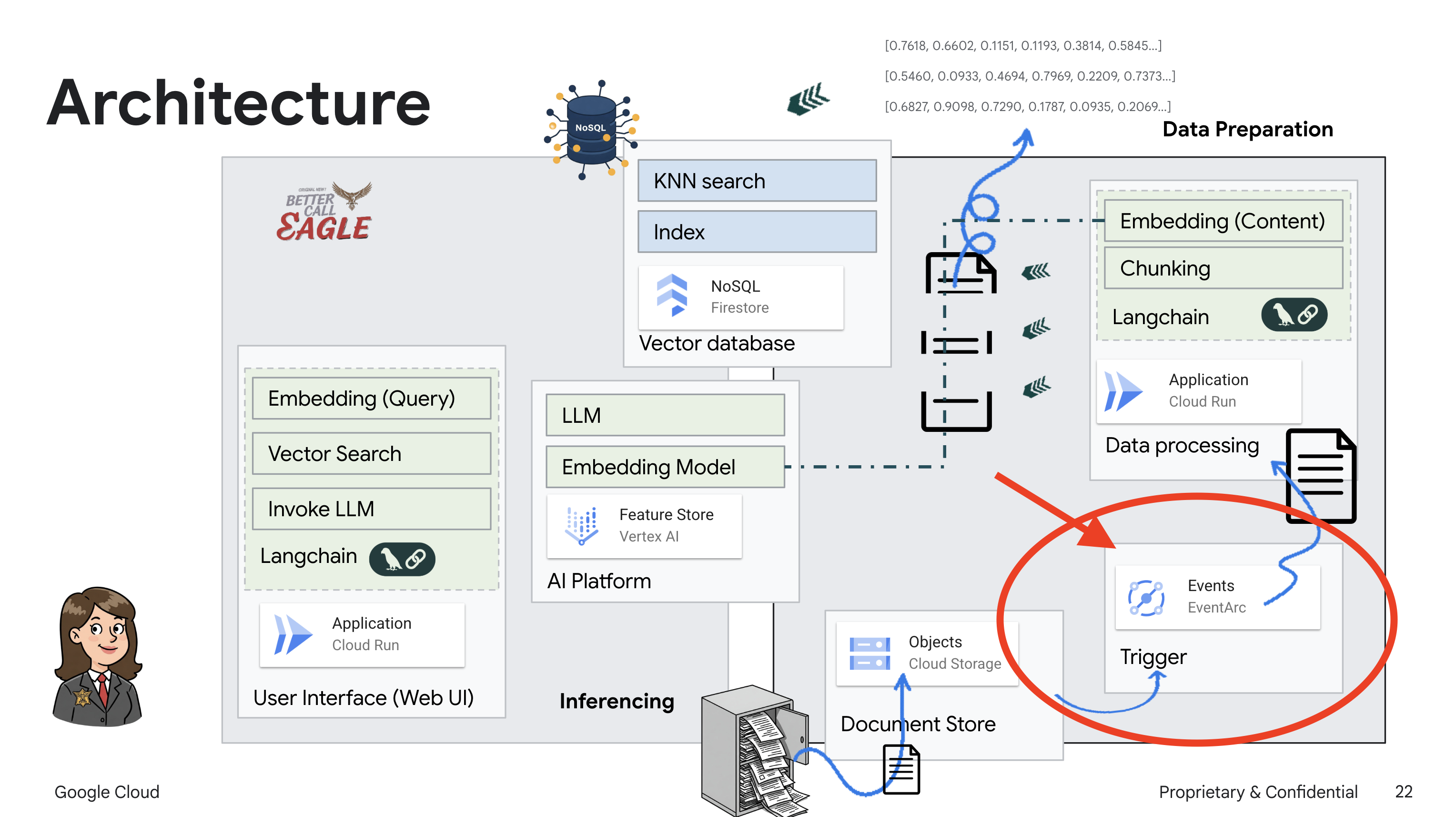
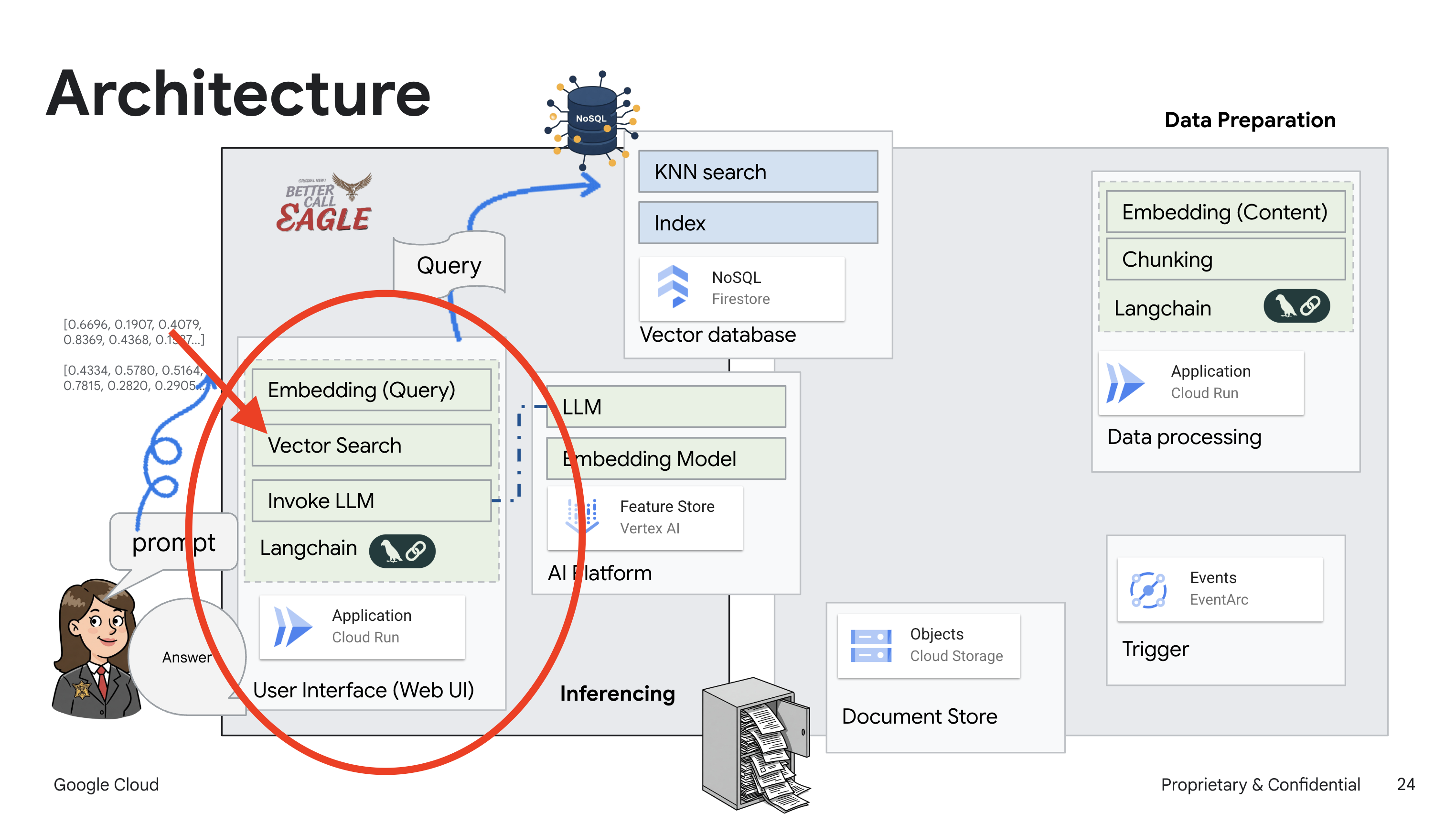
Ten projekt skupia się na tworzeniu asystenta prawnego przy użyciu narzędzi AI w Google Cloud, ze szczególnym uwzględnieniem przetwarzania, rozumienia i wyszukiwania danych prawnych. System został zaprojektowany tak, aby przeglądać duże ilości informacji, generować podsumowania i szybko prezentować odpowiednie dane. Architektura asystenta prawnego obejmuje kilka kluczowych komponentów:
Tworzenie bazy wiedzy na podstawie danych nieustrukturyzowanych: Google Cloud Storage (GCS) służy do przechowywania dokumentów prawnych. Firestore, baza danych NoSQL, działa jako magazyn wektorów, w którym przechowywane są fragmenty dokumentów i odpowiadające im wektory dystrybucyjne. Wyszukiwanie wektorowe jest włączone w Firestore, aby umożliwić wyszukiwanie podobieństw. Gdy nowy dokument prawny zostanie przesłany do GCS, Eventarc uruchomi funkcję Cloud Run. Ta funkcja przetwarza dokument, dzieląc go na części i generując wektory dystrybucyjne dla każdej części za pomocą modelu wektorów dystrybucyjnych tekstu w Vertex AI. Te wektory są następnie przechowywane w Firestore obok fragmentów tekstu. 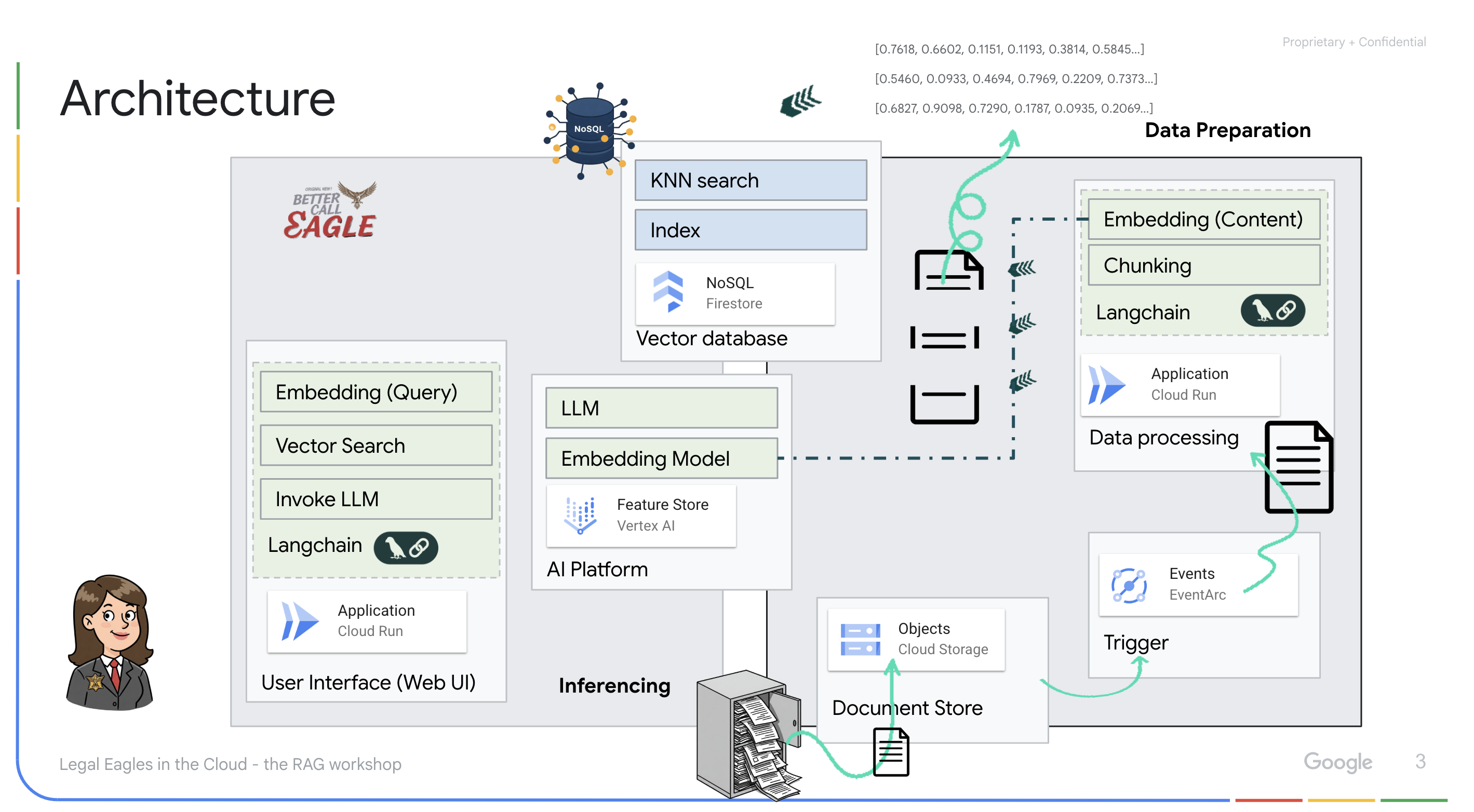
Aplikacja oparta na LLM i RAG : podstawą systemu odpowiadania na pytania jest funkcja ask_llm, która używa biblioteki langchain do interakcji z dużym modelem językowym Gemini w Vertex AI. Tworzy on obiekt HumanMessage na podstawie zapytania użytkownika i zawiera obiekt SystemMessage, który instruuje LLM, aby działał jako pomocny asystent prawny. System korzysta z podejścia generowania wspomaganego wyszukiwaniem (RAG), w którym przed udzieleniem odpowiedzi na zapytanie używa funkcji search_resource do pobrania odpowiedniego kontekstu z magazynu wektorów Firestore. Ten kontekst jest następnie uwzględniany w wiadomości systemowej, aby odpowiedź LLM była oparta na podanych informacjach prawnych. 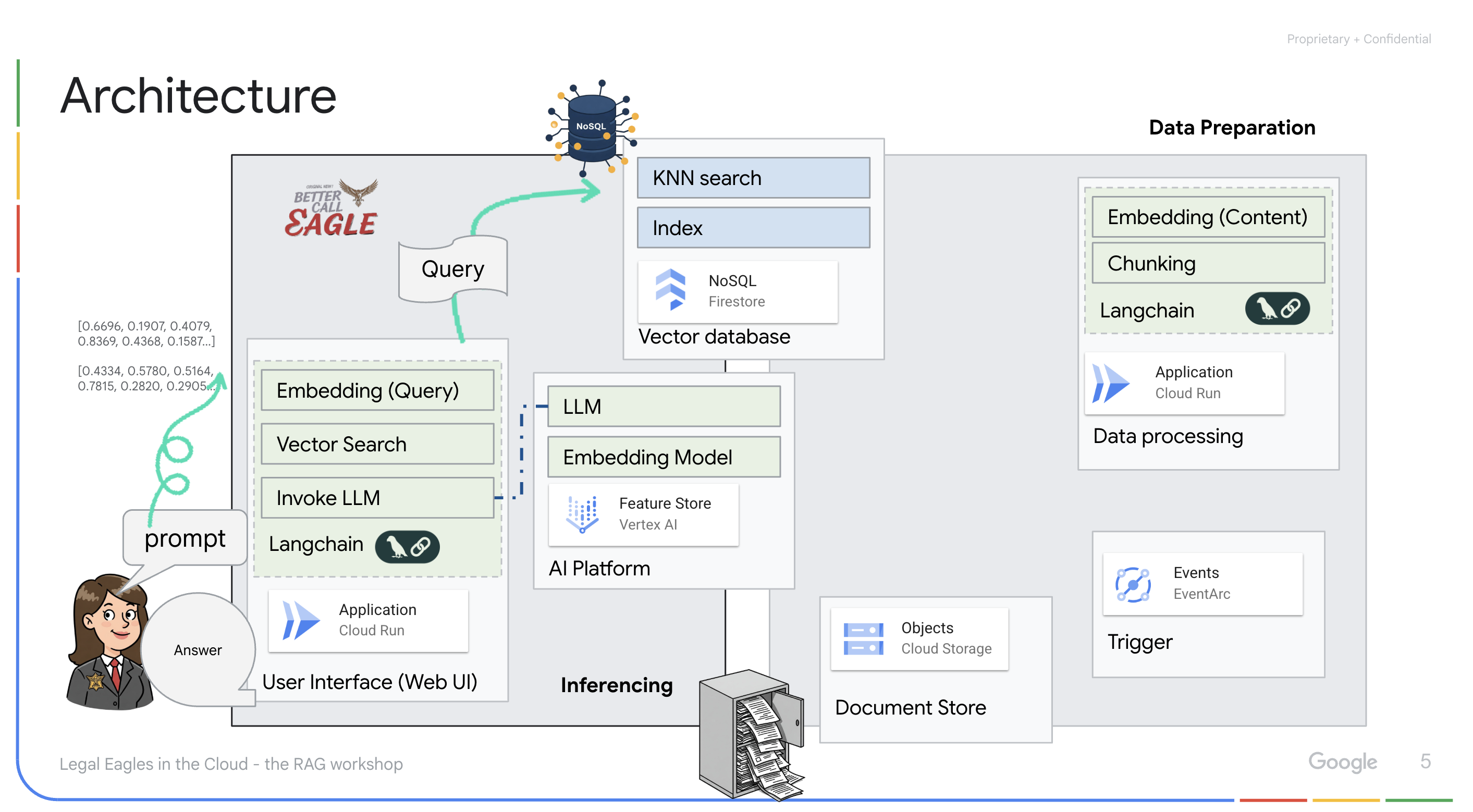
Celem projektu jest odejście od „kreatywnych interpretacji” modeli LLM poprzez wykorzystanie techniki RAG, która najpierw pobiera odpowiednie informacje z zaufanego źródła prawnego, a następnie generuje odpowiedź. Dzięki temu odpowiedzi są dokładniejsze i bardziej świadome, ponieważ bazują na rzeczywistych informacjach prawnych. System jest zbudowany z użyciem różnych usług Google Cloud, takich jak Google Cloud Shell, Vertex AI, Firestore, Cloud Run i Eventarc.
3. Zanim zaczniesz
W konsoli Google Cloud na stronie selektora projektów wybierz lub utwórz projekt Google Cloud. Sprawdź, czy w projekcie Cloud włączone są płatności. Dowiedz się, jak sprawdzić, czy w projekcie są włączone płatności
Włączanie Gemini Code Assist w środowisku IDE Cloud Shell
👉 W konsoli Google Cloud otwórz Narzędzia Gemini Code Assist i włącz Gemini Code Assist bezpłatnie, akceptując warunki.
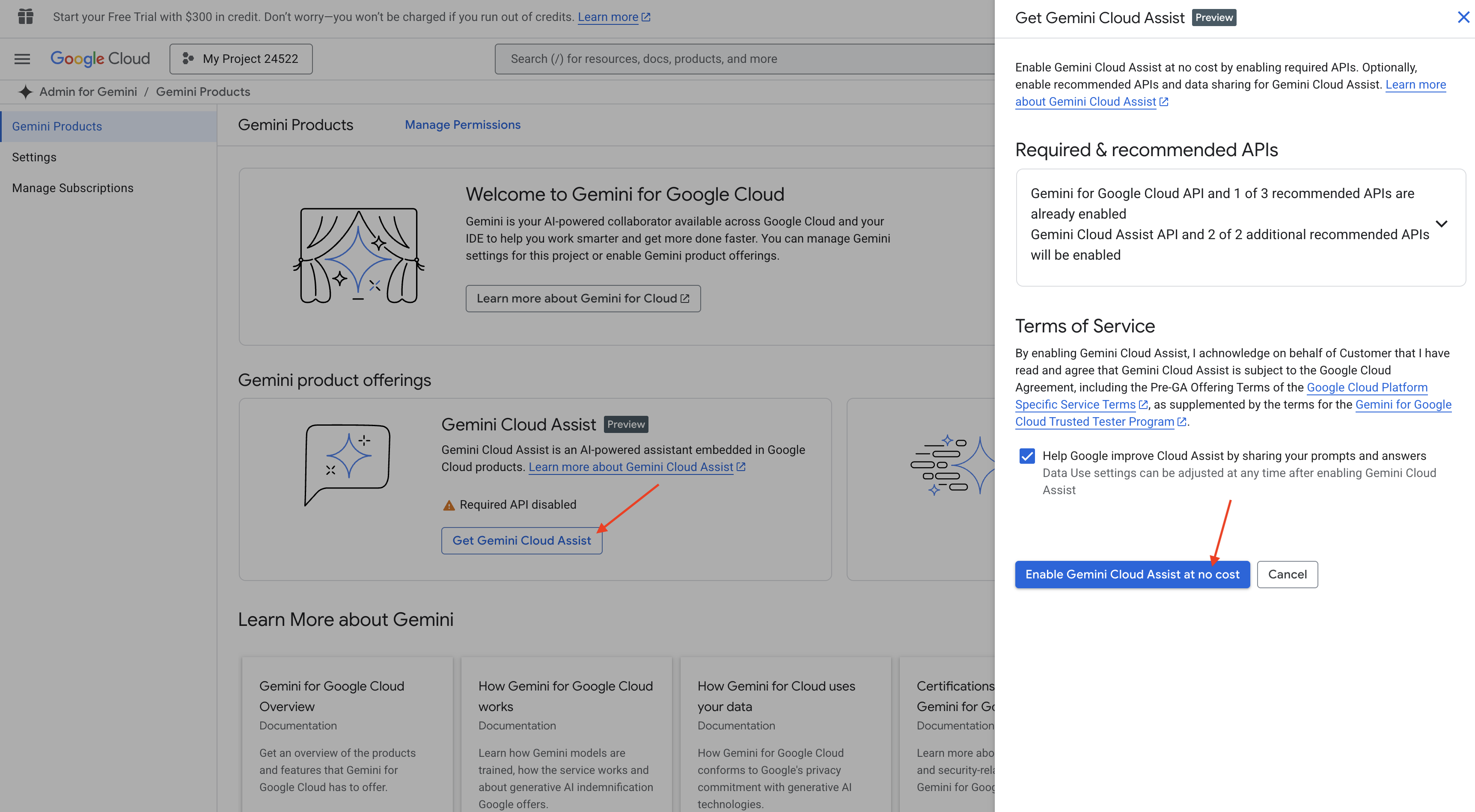
Zignoruj konfigurację uprawnień i opuść tę stronę.
Praca w edytorze Cloud Shell
👉 U góry konsoli Google Cloud kliknij Aktywuj Cloud Shell (jest to ikona w kształcie terminala u góry panelu Cloud Shell).
👉 Kliknij przycisk „Otwórz edytor” (wygląda jak otwarty folder z ołówkiem). W oknie otworzy się edytor Cloud Shell. Po lewej stronie zobaczysz eksplorator plików.

👉 Na pasku stanu u dołu kliknij przycisk Zaloguj się w Cloud Code, jak pokazano na ilustracji. Autoryzuj wtyczkę zgodnie z instrukcjami. Jeśli na pasku stanu widzisz Cloud Code – brak projektu, kliknij to pole, a następnie w menu „Wybierz projekt Google Cloud” wybierz konkretny projekt Google Cloud z listy projektów, z którymi chcesz pracować.
👉 Otwórz terminal w chmurowym IDE 
👉 W nowym terminalu sprawdź, czy uwierzytelnianie zostało już przeprowadzone, a projekt jest już ustawiony na Twój identyfikator projektu. Użyj tego polecenia:
gcloud auth list
👉 U góry konsoli Google Cloud kliknij Aktywuj Cloud Shell.
gcloud config set project <YOUR_PROJECT_ID>
👉 Aby włączyć niezbędne interfejsy Google Cloud API, uruchom to polecenie:
gcloud services enable storage.googleapis.com \
run.googleapis.com \
artifactregistry.googleapis.com \
aiplatform.googleapis.com \
eventarc.googleapis.com \
cloudresourcemanager.googleapis.com \
firestore.googleapis.com \
cloudaicompanion.googleapis.com
Na pasku narzędzi Cloud Shell (u góry panelu Cloud Shell) kliknij przycisk „Otwórz edytor” (wygląda jak otwarty folder z ołówkiem). W oknie otworzy się edytor kodu Cloud Shell. Po lewej stronie zobaczysz eksplorator plików.
👉 W terminalu pobierz projekt szkieletowy Bootstrap:
git clone https://github.com/weimeilin79/legal-eagle.git
OPCJONALNIE: WERSJA W JĘZYKU HISZPAŃSKIM
👉 Existe una versión alternativa en español. Por favor, utilice la siguiente instrucción para clonar la versión correcta.
git clone -b spanish https://github.com/weimeilin79/legal-eagle.git
Po uruchomieniu tego polecenia w terminalu Cloud Shell w środowisku powłoki Cloud Shell zostanie utworzony nowy folder o nazwie repozytorium legal-eagle.
4. Pisanie aplikacji do wnioskowania za pomocą Gemini Code Assist
W tej sekcji skupimy się na stworzeniu podstaw naszego asystenta prawnego – aplikacji internetowej, która będzie otrzymywać pytania od użytkowników i wchodzić w interakcję z modelem AI, aby generować odpowiedzi. Wykorzystamy Gemini Code Assist, aby pomóc sobie w napisaniu kodu w Pythonie dla tej części wnioskowania.
Na początek utworzymy aplikację Flask, która korzysta z biblioteki LangChain do bezpośredniej komunikacji z modelem Vertex AI Gemini. Pierwsza wersja będzie pełnić funkcję pomocnego asystenta prawnego, który będzie korzystać z ogólnej wiedzy modelu, ale nie będzie jeszcze mieć dostępu do naszych konkretnych dokumentów dotyczących spraw sądowych. Dzięki temu będziemy mogli zobaczyć podstawową skuteczność LLM, zanim później zwiększymy ją za pomocą RAG.
W panelu Eksplorator edytora Cloud Code (zwykle po lewej stronie) powinien być widoczny folder utworzony podczas klonowania repozytorium Git. legal-eagle Otwórz folder główny projektu w Eksploratorze. Znajdziesz w nim podfolder webapp, który też otwórz. 
👉 Edytuj plik legal.py w edytorze Cloud Code. Możesz użyć różnych metod, aby poprosić Gemini Code Assist o pomoc.
👉 Skopiuj poniższy prompt na dół legal.py, który jasno opisuje, co ma wygenerować Gemini Code Assist. Kliknij ikonę żarówki 💡, która się pojawi, i wybierz Gemini: Generate Code (dokładna nazwa pozycji menu może się nieznacznie różnić w zależności od wersji Cloud Code).
"""
Write a Python function called `ask_llm` that takes a user `query` as input. This function should use the `langchain` library to interact with a Vertex AI Gemini Large Language Model. Specifically, it should:
1. Create a `HumanMessage` object from the user's `query`.
2. Create a `ChatPromptTemplate` that includes a `SystemMessage` and the `HumanMessage`. The system message should instruct the LLM to act as a helpful assistant in a courtroom setting, aiding an attorney by providing necessary information. It should also specify that the LLM should respond in a high-energy tone, using no more than 100 words, and offer a humorous apology if it doesn't know the answer.
3. Format the `ChatPromptTemplate` with the provided messages.
4. Invoke the Vertex AI LLM with the formatted prompt using the `VertexAI` class (assuming it's already initialized elsewhere as `llm`).
5. Print the LLM's `response`.
6. Return the `response`.
7. Include error handling that prints an error message to the console and returns a user-friendly error message if any issues occur during the process. The Vertex AI model should be "gemini-2.0-flash".
"""
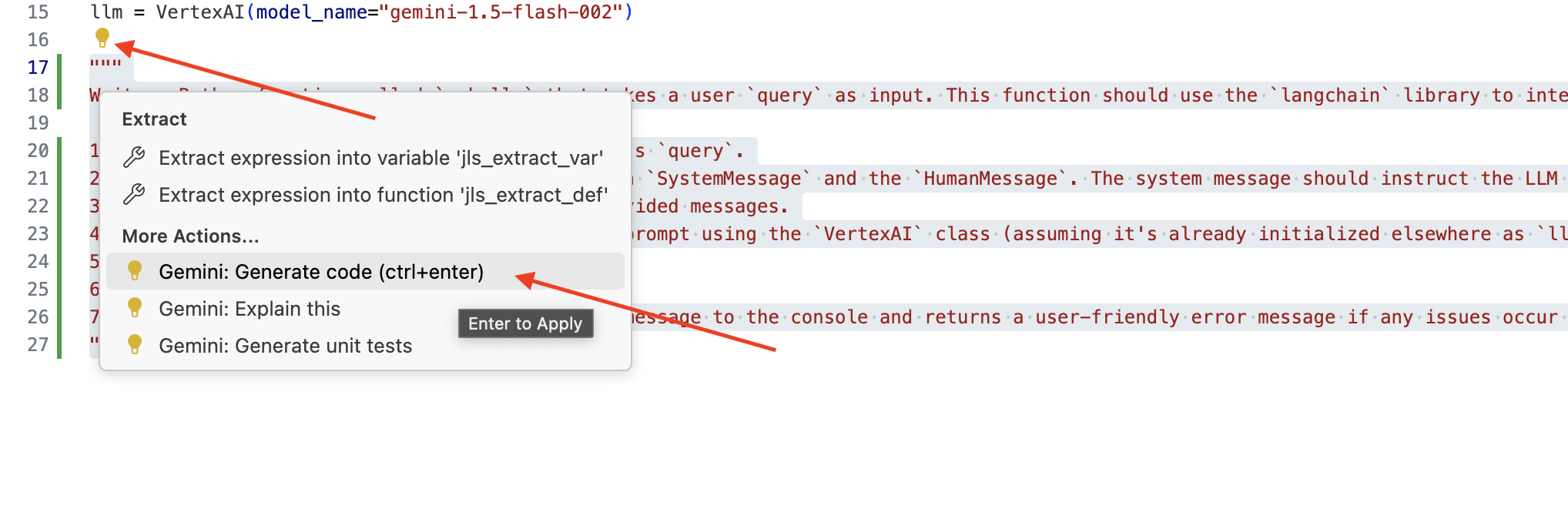
Dokładnie sprawdź wygenerowany kod.
- Czy mniej więcej odpowiada to czynnościom opisanym w komentarzu?
- Czy tworzy
ChatPromptTemplatez użytkownikamiSystemMessageiHumanMessage? - Czy obejmuje podstawową obsługę błędów (
try...except)?
Jeśli wygenerowany kod jest dobry i w większości poprawny, możesz go zaakceptować (naciśnij Tab lub Enter w przypadku sugestii wbudowanych albo kliknij „Zaakceptuj” w przypadku większych bloków kodu).
Jeśli wygenerowany kod nie jest dokładnie taki, jakiego oczekujesz, lub zawiera błędy, nie martw się. Gemini Code Assist to narzędzie, które ma Ci pomagać, a nie pisać idealny kod za pierwszym razem.
Edytuj i modyfikuj wygenerowany kod, aby go dopracować, poprawić błędy i lepiej dopasować do swoich wymagań. Możesz dodatkowo poprosić Gemini Code Assist, dodając więcej komentarzy lub zadając konkretne pytania w panelu czatu Code Assist.
Jeśli dopiero zaczynasz korzystać z pakietu SDK, tutaj znajdziesz działający przykład.
👉 Skopiuj i wklej poniższy kod, a następnie ZASTĄP nim zawartość pliku legal.py:
import os
import signal
import sys
import vertexai
import random
from langchain_google_vertexai import VertexAI
from langchain_core.prompts import PromptTemplate, ChatPromptTemplate
from langchain_core.messages import HumanMessage, SystemMessage
# Connect to resourse needed from Google Cloud
llm = VertexAI(model_name="gemini-2.0-flash")
def ask_llm(query):
try:
query_message = {
"type": "text",
"text": query,
}
input_msg = HumanMessage(content=[query_message])
prompt_template = ChatPromptTemplate.from_messages(
[
SystemMessage(
content=(
"You are a helpful assistant, and you are with the attorney in a courtroom, you are helping him to win the case by providing the information he needs "
"Don't answer if you don't know the answer, just say sorry in a funny way possible"
"Use high engergy tone, don't use more than 100 words to answer"
# f"Here is some past conversation history between you and the user {relevant_history}"
# f"Here is some context that is relevant to the question {relevant_resource} that you might use"
)
),
input_msg,
]
)
prompt = prompt_template.format()
response = llm.invoke(prompt)
print(f"response: {response}")
return response
except Exception as e:
print(f"Error sending message to chatbot: {e}") # Log this error too!
return f"Unable to process your request at this time. Due to the following reason: {str(e)}"
👉 OPCJONALNIE: WERSJA W JĘZYKU HISZPAŃSKIM
Sustituye el siguiente texto como se indica: You are a helpful assistant, to You are a helpful assistant that speaks Spanish,
Następnie utwórz funkcję obsługującą ścieżkę, która będzie odpowiadać na pytania użytkowników.
Otwórz plik main.py w edytorze Cloud Shell. Podobnie jak w przypadku generowania funkcji ask_llm w legal.py, użyj Gemini Code Assist, aby wygenerować ścieżkę Flask i funkcję ask_question. Wpisz w main.py ten PROMPT jako komentarz: (pamiętaj, aby dodać go przed uruchomieniem aplikacji Flask w if __name__ == "__main__":)
.....
@app.route('/',methods=['GET'])
def index():
return render_template('index.html')
"""
PROMPT:
Create a Flask endpoint that accepts POST requests at the '/ask' route.
The request should contain a JSON payload with a 'question' field. Extract the question from the JSON payload.
Call a function named ask_llm (located in a file named legal.py) with the extracted question as an argument.
Return the result of the ask_llm function as the response with a 200 status code.
If any error occurs during the process, return a 500 status code with the error message.
"""
# Add this block to start the Flask app when running locally
if __name__ == "__main__":
.....
Zaakceptuj TYLKO wtedy, gdy wygenerowany kod jest dobry i w większości prawidłowy. Jeśli nie znasz Pythona, możesz skopiować i wkleić ten przykład do pliku main.py pod istniejącym już kodem.
👉 Przed uruchomieniem aplikacji internetowej wklej poniższy kod (if name == "main":)
@app.route('/ask', methods=['POST'])
def ask_question():
data = request.get_json()
question = data.get('question')
try:
# call the ask_llm in legal.py
answer_markdown = legal.ask_llm(question)
print(f"answer_markdown: {answer_markdown}")
# Return the Markdown as the response
return answer_markdown, 200
except Exception as e:
return f"Error: {str(e)}", 500 # Handle errors appropriately
Wykonując te czynności, możesz włączyć Gemini Code Assist, skonfigurować projekt i używać go do generowania funkcji ask w pliku main.py.
5. Testowanie lokalne w edytorze Cloud
👉 W terminalu edytora zainstaluj biblioteki zależne i uruchom lokalnie interfejs internetowy.
cd ~/legal-eagle/webapp
python -m venv env
source env/bin/activate
export PROJECT_ID=$(gcloud config get project)
pip install -r requirements.txt
python main.py
Poszukaj komunikatów startowych w danych wyjściowych terminala Cloud Shell. Flask zwykle wyświetla komunikaty informujące o tym, że działa i na jakim porcie.
- Running on http://127.0.0.1:8080
Aby obsługiwać żądania, aplikacja musi działać.
👉 W menu „Podgląd w przeglądarce” wybierz Podejrzyj na porcie 8080. Cloud Shell otworzy nową kartę lub nowe okno przeglądarki z podglądem internetowym aplikacji. 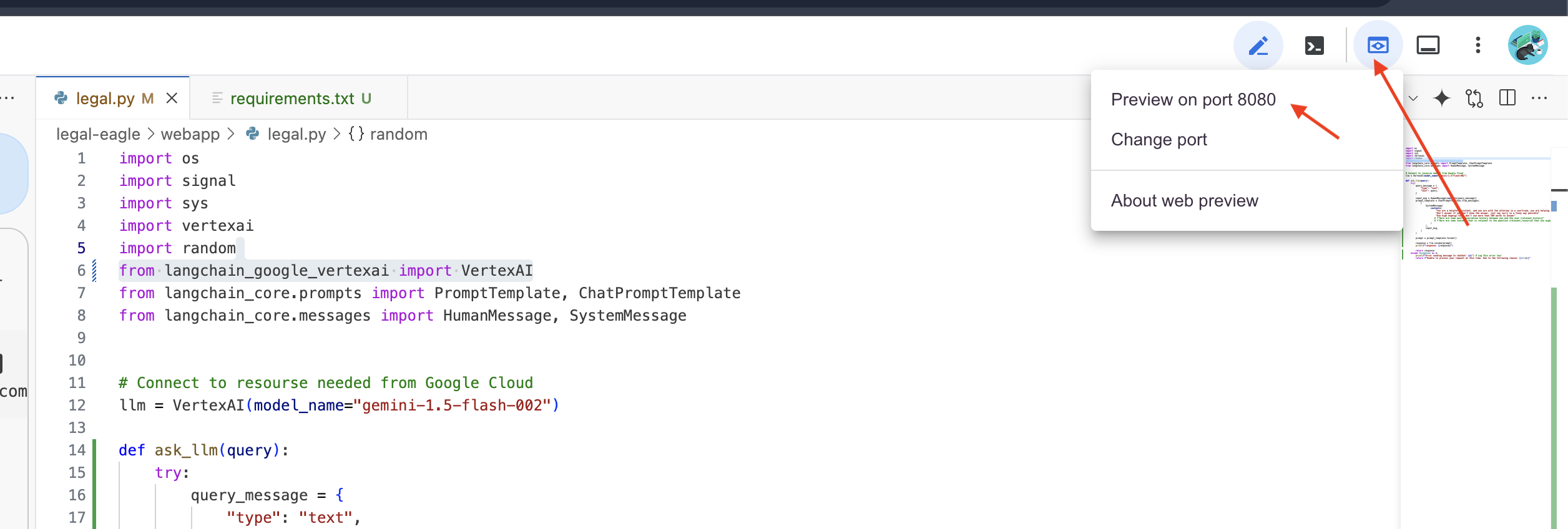
👉 W interfejsie aplikacji wpisz kilka pytań dotyczących konkretnych odniesień do spraw sądowych i sprawdź, jak odpowie na nie model LLM. Możesz na przykład spróbować:
- Na ile lat więzienia skazano Michaela Browna?
- Ile nieautoryzowanych obciążeń wygenerowano w wyniku działań Janiny Nowak?
- Jaką rolę w śledztwie w sprawie Emily White odegrały zeznania sąsiadów?
👉 OPCJONALNIE: WERSJA W JĘZYKU HISZPAŃSKIM
- ¿A cuántos años de prisión fue sentenciado Michael Brown?
- ¿Cuánto dinero en cargos no autorizados se generó como resultado de las acciones de Jane Smith?
- ¿Qué papel jugaron los testimonios de los vecinos en la investigación del caso de Emily White?
Jeśli przyjrzysz się uważnie odpowiedziom, prawdopodobnie zauważysz, że model może halucynować, być niejasny lub ogólny, a czasami błędnie interpretować Twoje pytania, zwłaszcza że nie ma jeszcze dostępu do konkretnych dokumentów prawnych.
👉 Zatrzymaj skrypt, naciskając Ctrl+C.
👉 Aby zamknąć środowisko wirtualne, w terminalu uruchom polecenie:
deactivate
6. Konfigurowanie magazynu wektorów
Czas położyć kres tym „kreatywnym interpretacjom” prawa przez LLM. W tym celu warto skorzystać z technologii generowania wspomaganego wyszukiwaniem (RAG). To tak, jakby przed udzieleniem odpowiedzi na Twoje pytania nasz LLM miał dostęp do superzaawansowanej biblioteki prawnej. Zamiast polegać wyłącznie na swojej ogólnej wiedzy (która może być niejasna lub nieaktualna w zależności od modelu), RAG najpierw pobiera odpowiednie informacje z zaufanego źródła – w naszym przypadku z dokumentów prawnych – a następnie wykorzystuje ten kontekst do wygenerowania znacznie bardziej szczegółowej i dokładnej odpowiedzi. To tak, jakby LLM odrabiał pracę domową przed wejściem na salę sądową.
Aby zbudować system RAG, potrzebujemy miejsca do przechowywania wszystkich dokumentów prawnych i co ważne, umożliwiającego wyszukiwanie ich według znaczenia. Właśnie dlatego powstała usługa Firestore. Firestore to elastyczna i skalowalna baza danych dokumentów NoSQL w Google Cloud.
Jako magazyn wektorowy wykorzystamy Firestore. Będziemy przechowywać fragmenty naszych dokumentów prawnych w Firestore, a w przypadku każdego fragmentu będziemy też przechowywać jego wektor osadzania, czyli numeryczną reprezentację jego znaczenia.
Gdy zadasz pytanie naszemu Legal Eagle, użyjemy wyszukiwania wektorowego w Firestore, aby znaleźć fragmenty tekstu prawnego, które są najbardziej trafne w odniesieniu do Twojego zapytania. Ten pobrany kontekst jest wykorzystywany przez RAG do udzielania odpowiedzi opartych na rzeczywistych informacjach prawnych, a nie tylko na wyobraźni LLM.
👉 Na nowej karcie lub w nowym oknie otwórz Firestore w konsoli Google Cloud.
👉 Kliknij Utwórz bazę danych.
👉 Wybierz Native mode i nazwę bazy danych (default).
👉 Wybierz pojedynczy znak region: us-central1 i kliknij Utwórz bazę danych. Firestore utworzy bazę danych, co może potrwać kilka chwil.
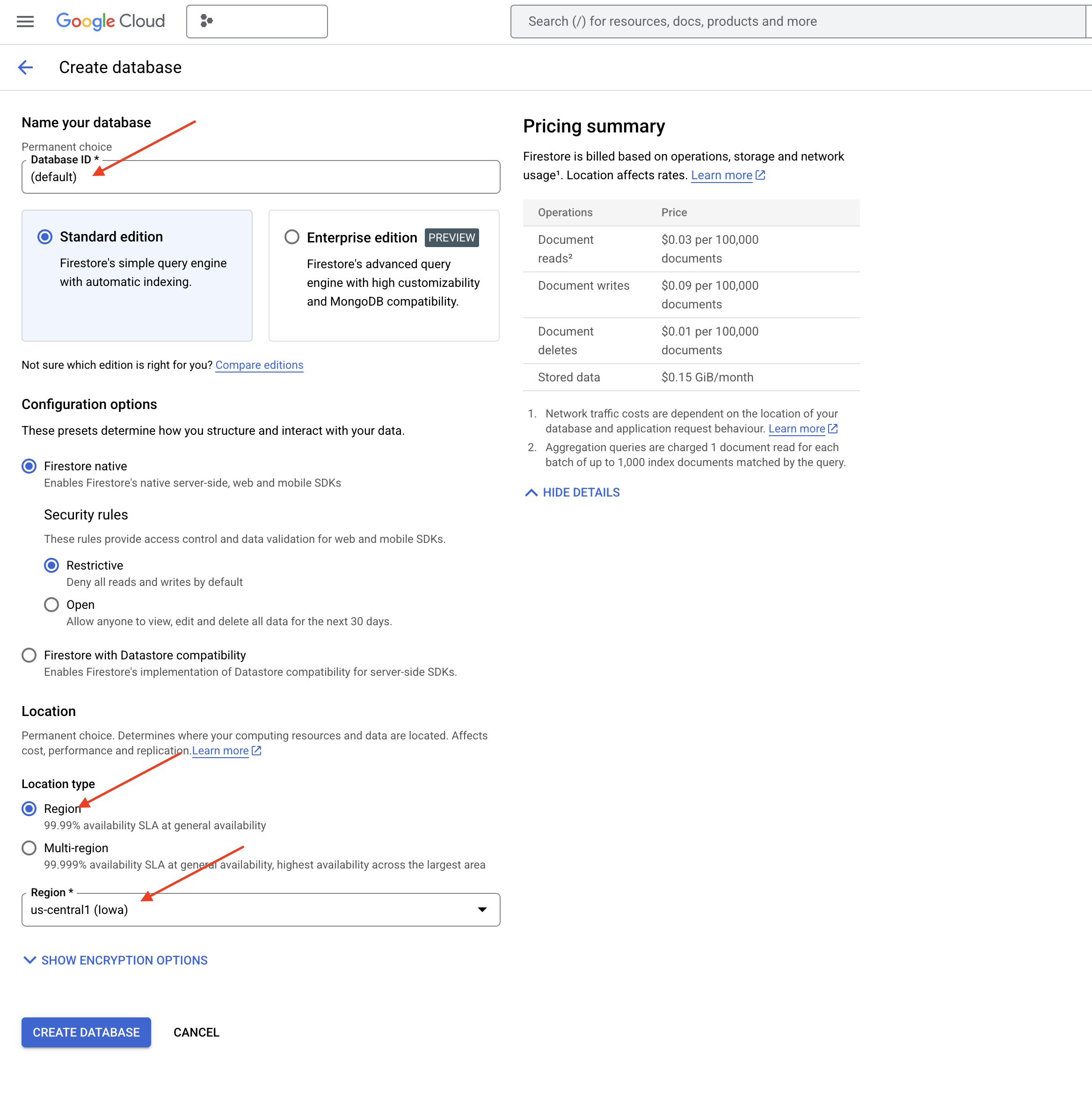
👉 Wróć do terminala Cloud IDE i utwórz indeks wektorowy w polu embedding_vector, aby włączyć wyszukiwanie wektorowe w kolekcji legal_documents.
export PROJECT_ID=$(gcloud config get project)
gcloud firestore indexes composite create \
--collection-group=legal_documents \
--query-scope=COLLECTION \
--field-config field-path=embedding,vector-config='{"dimension":"768", "flat": "{}"}' \
--project=${PROJECT_ID}
Firestore rozpocznie tworzenie indeksu wektorowego. Tworzenie indeksu może zająć trochę czasu, zwłaszcza w przypadku większych zbiorów danych. Indeks będzie miał stan „Tworzenie”, a po utworzeniu zmieni się na „Gotowy”. 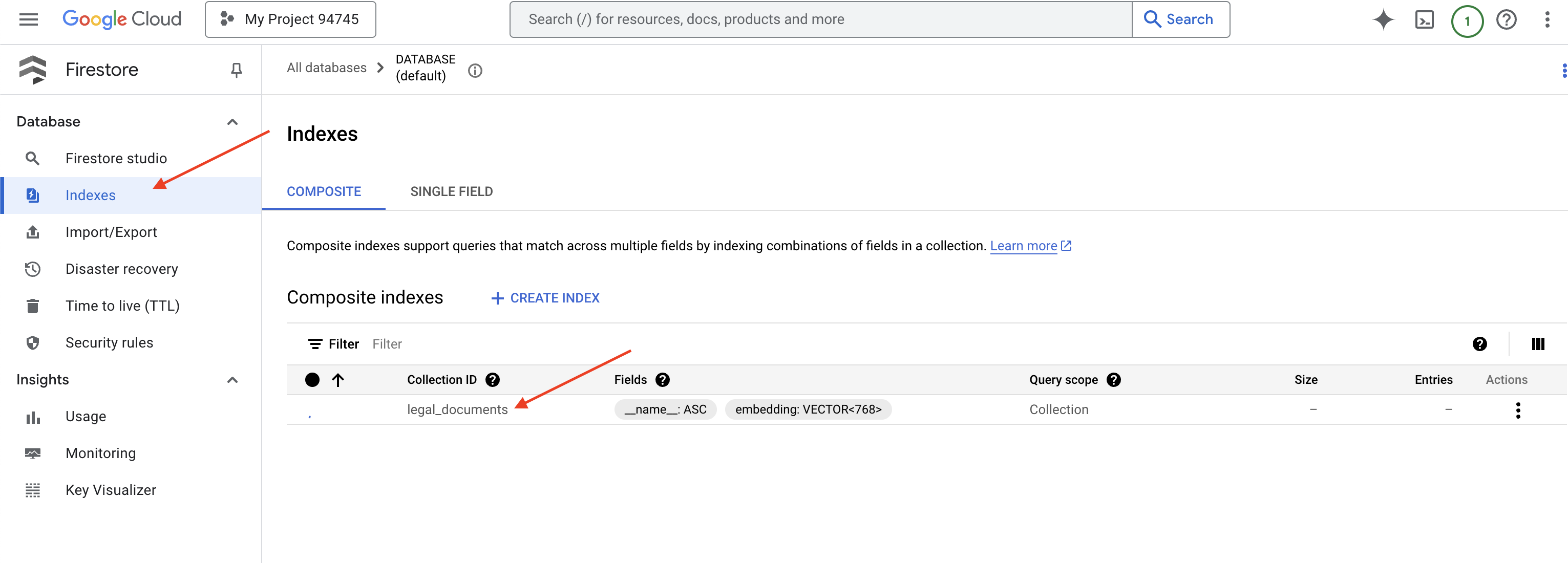
7. Wczytywanie danych do magazynu wektorów
Teraz, gdy już wiemy, czym jest RAG i nasz magazyn wektorów, możemy zbudować silnik, który wypełni naszą bibliotekę prawną. Jak sprawić, aby dokumenty prawne można było wyszukiwać według znaczenia? Magia tkwi w wektorach dystrybucyjnych. Wektory dystrybucyjne to przekształcanie słów, zdań, a nawet całych dokumentów w wektory liczbowe, czyli listy liczb, które odzwierciedlają ich znaczenie semantyczne. Podobne pojęcia otrzymują wektory, które są „blisko” siebie w przestrzeni wektorowej. Do przeprowadzenia tej konwersji używamy zaawansowanych modeli (takich jak modele z Vertex AI).
Aby zautomatyzować wczytywanie dokumentów, użyjemy funkcji Cloud Run i Eventarc. Cloud Run Functions to lekki, bezserwerowy kontener, który uruchamia Twój kod tylko wtedy, gdy jest to potrzebne. Spakujemy skrypt Pythona do przetwarzania dokumentów w kontenerze i wdrożymy go jako funkcję Cloud Run.
👉 W nowej karcie lub nowym oknie otwórz Cloud Storage.
👉 W menu po lewej stronie kliknij „Buckets” (Kosz).
👉 U góry kliknij przycisk „+ UTWÓRZ”.
👉 Skonfiguruj zasobnik (ważne ustawienia):
- nazwa zasobnika: ‘yourprojectID'-doc-bucket (na końcu MUSI być przyrostek -doc-bucket)
- region: wybierz region
us-central1. - Klasa pamięci masowej: „Standardowa”. Standardowa klasa pamięci jest odpowiednia w przypadku danych, do których często sięga się użytkownik.
- Kontrola dostępu: pozostaw domyślnie wybraną opcję „Jednolita kontrola dostępu”. Zapewnia to spójną kontrolę dostępu na poziomie zasobnika.
- Opcje zaawansowane: na potrzeby tego samouczka zwykle wystarczą ustawienia domyślne.
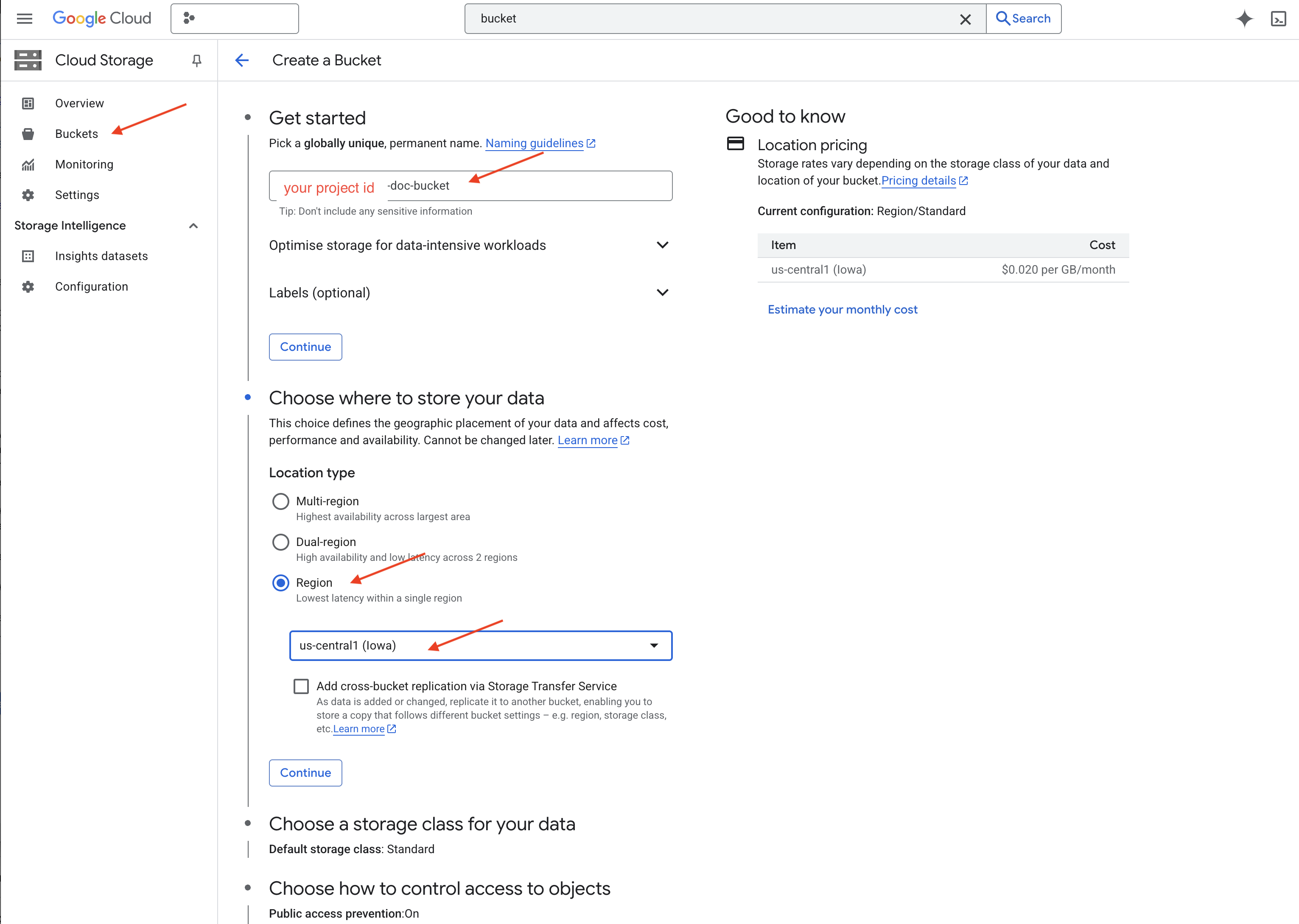
👉 Aby utworzyć zasobnik, kliknij przycisk UTWÓRZ.
👉 Może pojawić się wyskakujące okienko dotyczące blokady dostępu publicznego. Pozostaw zaznaczone pole i kliknij „Potwierdź”.
Nowo utworzony zasobnik pojawi się na liście Zasobniki. Zapamiętaj nazwę zasobnika, będzie Ci później potrzebna.
8. Konfigurowanie funkcji Cloud Run
👉 W edytorze kodu Cloud Shell przejdź do katalogu roboczego legal-eagle: użyj polecenia cd w terminalu edytora Cloud, aby utworzyć folder.
cd ~/legal-eagle
mkdir loader
cd loader
👉 Utwórz pliki main.py, requirements.txt i Dockerfile. W terminalu Cloud Shell utwórz pliki za pomocą polecenia touch:
touch main.py requirements.txt Dockerfile
Zobaczysz nowo utworzony folder o nazwie *loader i 3 pliki.
👉 Kliknij Edytuj main.py w folderze loader. W eksploratorze plików po lewej stronie przejdź do katalogu, w którym utworzono pliki, i kliknij dwukrotnie main.py, aby otworzyć go w edytorze.
Wklej do pliku main.py ten kod w Pythonie:
Ta aplikacja przetwarza nowe pliki przesłane do zasobnika GCS, dzieli tekst na fragmenty, generuje wektory dystrybucyjne dla każdego fragmentu i zapisuje fragmenty oraz ich wektory dystrybucyjne w Firestore.
import os
import json
from google.cloud import storage
import functions_framework
from langchain_google_vertexai import VertexAI, VertexAIEmbeddings
from langchain_google_firestore import FirestoreVectorStore
from langchain.text_splitter import RecursiveCharacterTextSplitter
import vertexai
PROJECT_ID = os.environ.get("GOOGLE_CLOUD_PROJECT") # Get project ID from env
embedding_model = VertexAIEmbeddings(
model_name="text-embedding-004" ,
project=PROJECT_ID,)
COLLECTION_NAME = "legal_documents"
# Create a vector store
vector_store = FirestoreVectorStore(
collection="legal_documents",
embedding_service=embedding_model,
content_field="original_text",
embedding_field="embedding",
)
@functions_framework.cloud_event
def process_file(cloud_event):
print(f"CloudEvent received: {cloud_event.data}") # Print the parsed event data
"""Triggered by a Cloud Storage event.
Args:
cloud_event (functions_framework.CloudEvent): The CloudEvent
containing the Cloud Storage event data.
"""
try:
event_data = cloud_event.data
bucket_name = event_data['bucket']
file_name = event_data['name']
except (json.JSONDecodeError, AttributeError, KeyError) as e: # Catch JSON errors
print(f"Error decoding CloudEvent data: {e} - Data: {cloud_event.data}")
return "Error processing event", 500 # Return an error response
print(f"New file detected in bucket: {bucket_name}, file: {file_name}")
storage_client = storage.Client()
bucket = storage_client.bucket(bucket_name)
blob = bucket.blob(file_name)
try:
# Download the file content as string (assuming UTF-8 encoded text file)
file_content_string = blob.download_as_string().decode("utf-8")
print(f"File content downloaded. Processing...")
# Split text into chunks using RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=100,
length_function=len,
)
text_chunks = text_splitter.split_text(file_content_string)
print(f"Text split into {len(text_chunks)} chunks.")
# Add the docs to the vector store
vector_store.add_texts(text_chunks)
print(f"File processing and Firestore upsert complete for file: {file_name}")
return "File processed successfully", 200 # Return success response
except Exception as e:
print(f"Error processing file {file_name}: {e}")
Edytuj requirements.txt.Wklej do pliku te wiersze:
Flask==2.3.3
requests==2.31.0
google-generativeai>=0.2.0
langchain
langchain_google_vertexai
langchain-community
langchain-google-firestore
google-cloud-storage
functions-framework
9. Testowanie i kompilowanie funkcji Cloud Run
👉 Uruchomimy to w środowisku wirtualnym i zainstalujemy niezbędne biblioteki Pythona dla funkcji Cloud Run.
cd ~/legal-eagle/loader
python -m venv env
source env/bin/activate
pip install -r requirements.txt
👉 Uruchom lokalny emulator funkcji Cloud Run
functions-framework --target process_file --signature-type=cloudevent --source main.py
👉 Pozostaw ostatni terminal uruchomiony, otwórz nowy terminal i uruchom polecenie, aby przesłać plik do zasobnika.
export DOC_BUCKET_NAME=$(gcloud storage buckets list --format="value(name)" | grep doc-bucket)
gsutil cp ~/legal-eagle/court_cases/case-01.txt gs://$DOC_BUCKET_NAME/

👉 Gdy emulator jest uruchomiony, możesz wysyłać do niego testowe zdarzenia CloudEvents. W tym celu musisz mieć osobny terminal w IDE.
curl -X POST -H "Content-Type: application/json" \
-d "{
\"specversion\": \"1.0\",
\"type\": \"google.cloud.storage.object.v1.finalized\",
\"source\": \"//storage.googleapis.com/$DOC_BUCKET_NAME\",
\"subject\": \"objects/case-01.txt\",
\"id\": \"my-event-id\",
\"time\": \"2024-01-01T12:00:00Z\",
\"data\": {
\"bucket\": \"$DOC_BUCKET_NAME\",
\"name\": \"case-01.txt\"
}
}" http://localhost:8080/
Powinien zwrócić OK.
👉 Dane możesz sprawdzić w Firestore. W tym celu otwórz konsolę Google Cloud, kliknij kolejno „Bazy danych” i „Firestore”, wybierz kartę „Dane”, a następnie kolekcję legal_documents. W kolekcji pojawią się nowe dokumenty, z których każdy będzie zawierać fragment tekstu z przesłanego pliku. 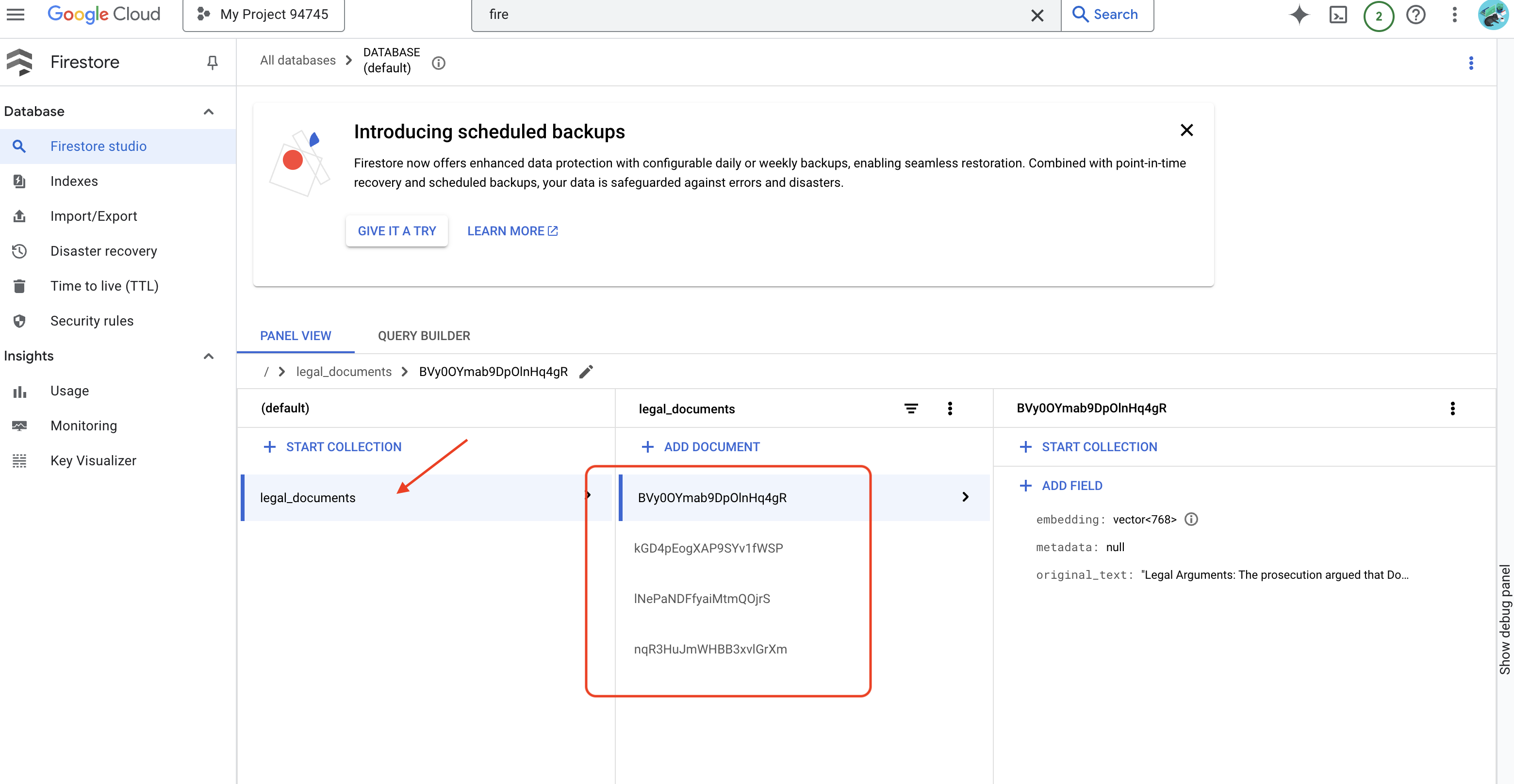
👉 W terminalu, w którym działa emulator, wpisz Ctrl+C, aby zamknąć emulator. Zamknij drugi terminal.
👉 Aby zamknąć środowisko wirtualne, uruchom polecenie deactivate.
deactivate
10. Tworzenie obrazu kontenera i przesyłanie go do repozytoriów artefaktów
👉 Czas wdrożyć to w chmurze. W eksploratorze plików kliknij dwukrotnie plik Dockerfile. Zapytaj Gemini o wygenerowanie pliku Dockerfile, otwórz Gemini Code Assist i użyj tego prompta, aby wygenerować plik.
In the loader folder,
Generate a Dockerfile for a Python 3.12 Cloud Run service that uses functions-framework. It needs to:
1. Use a Python 3.12 slim base image.
2. Set the working directory to /app.
3. Copy requirements.txt and install Python dependencies.
4. Copy main.py.
5. Set the command to run functions-framework, targeting the 'process_file' function on port 8080
Zalecamy kliknięcie Porównaj z otwartym plikiem(dwie strzałki w przeciwnych kierunkach) i zaakceptowanie zmian. 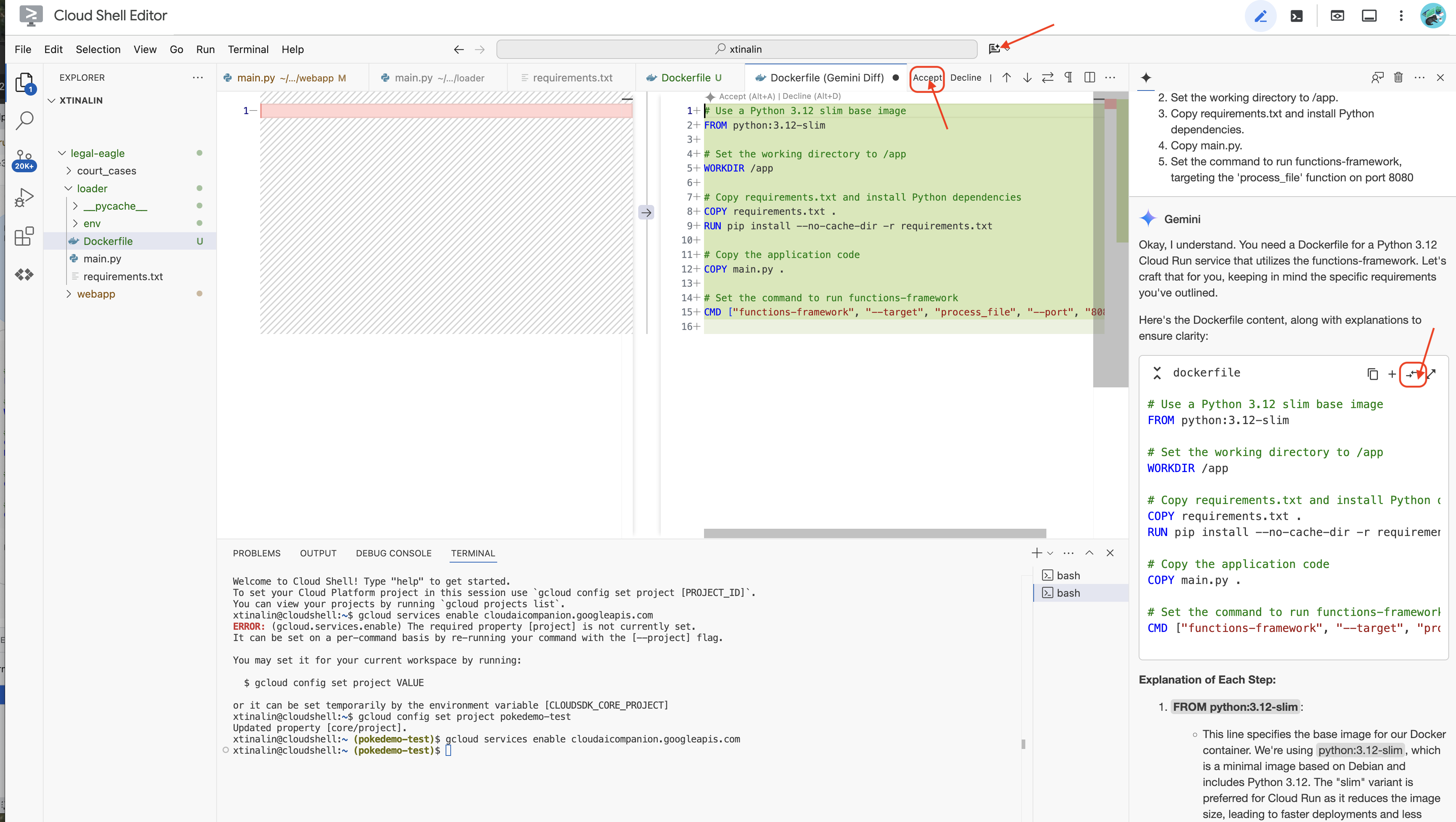
👉 Jeśli dopiero zaczynasz korzystać z kontenerów, oto działający przykład:
# Use a Python 3.12 slim base image
FROM python:3.12-slim
# Set the working directory to /app
WORKDIR /app
# Copy requirements.txt and install Python dependencies
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
# Copy main.py
COPY main.py .
# Set the command to run functions-framework
CMD ["functions-framework", "--target", "process_file", "--port", "8080"]
👉 W terminalu utwórz repozytorium artefaktów, w którym zapiszesz obraz Dockera, który zamierzamy utworzyć.
gcloud artifacts repositories create my-repository \
--repository-format=docker \
--location=us-central1 \
--description="My repository"
Powinien wyświetlić się komunikat Utworzono repozytorium [my-repository].
👉 Aby utworzyć obraz Dockera, uruchom to polecenie.
cd ~/legal-eagle/loader
export PROJECT_ID=$(gcloud config get project)
docker build -t gcr.io/${PROJECT_ID}/legal-eagle-loader .
👉 Teraz prześlesz go do rejestru
export PROJECT_ID=$(gcloud config get project)
docker tag gcr.io/${PROJECT_ID}/legal-eagle-loader us-central1-docker.pkg.dev/${PROJECT_ID}/my-repository/legal-eagle-loader
docker push us-central1-docker.pkg.dev/${PROJECT_ID}/my-repository/legal-eagle-loader
Obraz Dockera jest teraz dostępny w repozytorium artefaktów my-repository .
11. Tworzenie funkcji Cloud Run i konfigurowanie aktywatora Eventarc
Zanim przejdziemy do szczegółów wdrażania naszego narzędzia do wczytywania dokumentów prawnych, przyjrzyjmy się krótko komponentom, których będziemy używać: Cloud Run to w pełni zarządzana platforma bezserwerowa, która umożliwia szybkie i łatwe wdrażanie aplikacji w kontenerach. Usługa nie wymaga zarządzania infrastrukturą, dzięki czemu możesz skupić się na pisaniu i wdrażaniu kodu.
Nasz moduł wczytywania dokumentów wdrożymy jako usługę Cloud Run. Teraz skonfigurujmy funkcję Cloud Run:
👉 W konsoli Google Cloud otwórz Cloud Run.
👉 Kliknij Wdróż kontener i w menu kliknij USŁUGA.
👉 Skonfiguruj usługę Cloud Run:
- Obraz kontenera: w polu adresu URL kliknij „Wybierz”. Znajdź adres URL obrazu przesłanego do Artifact Registry (np. us-central1-docker.pkg.dev/your-project-id/my-repository/legal-eagle-loader/yourimage).
- Nazwa usługi:
legal-eagle-loader - Region: wybierz region
us-central1. - Uwierzytelnianie: na potrzeby tych warsztatów możesz zezwolić na „Zezwalaj na nieuwierzytelnione wywołania”. W przypadku wersji produkcyjnej prawdopodobnie zechcesz ograniczyć dostęp.
- Kontener, sieć, zabezpieczenia : domyślne.
👉 Kliknij UTWÓRZ. Cloud Run wdroży Twoją usługę. 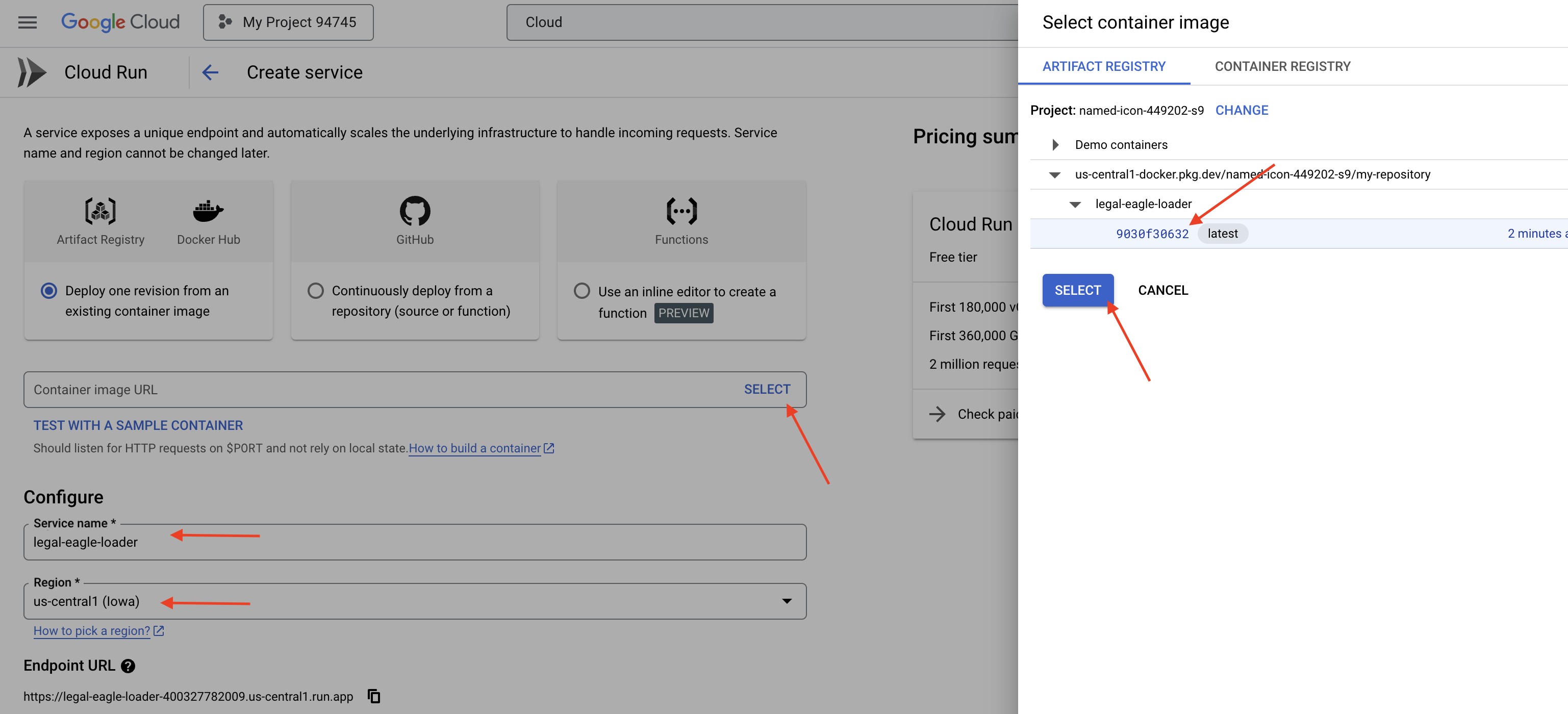
Aby automatycznie uruchamiać tę usługę, gdy do zasobnika pamięci dodawane są nowe pliki, użyjemy Eventarc. Eventarc umożliwia tworzenie architektur opartych na zdarzeniach przez kierowanie zdarzeń z różnych źródeł do Twoich usług.
Dzięki skonfigurowaniu Eventarc nasza usługa Cloud Run będzie automatycznie wczytywać nowo dodane dokumenty do Firestore natychmiast po ich przesłaniu, co umożliwi aktualizowanie danych w czasie rzeczywistym w naszej aplikacji RAG.
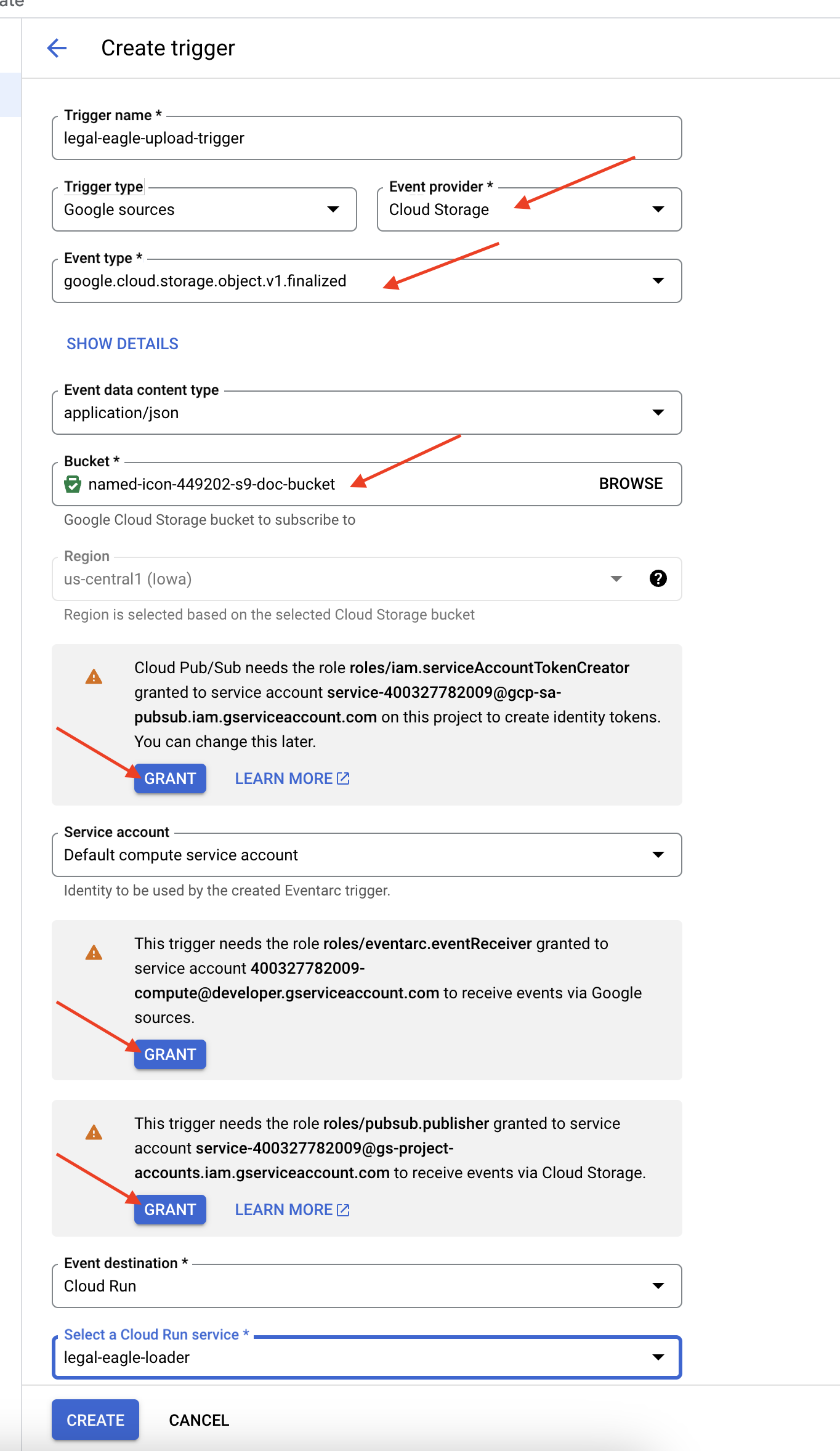
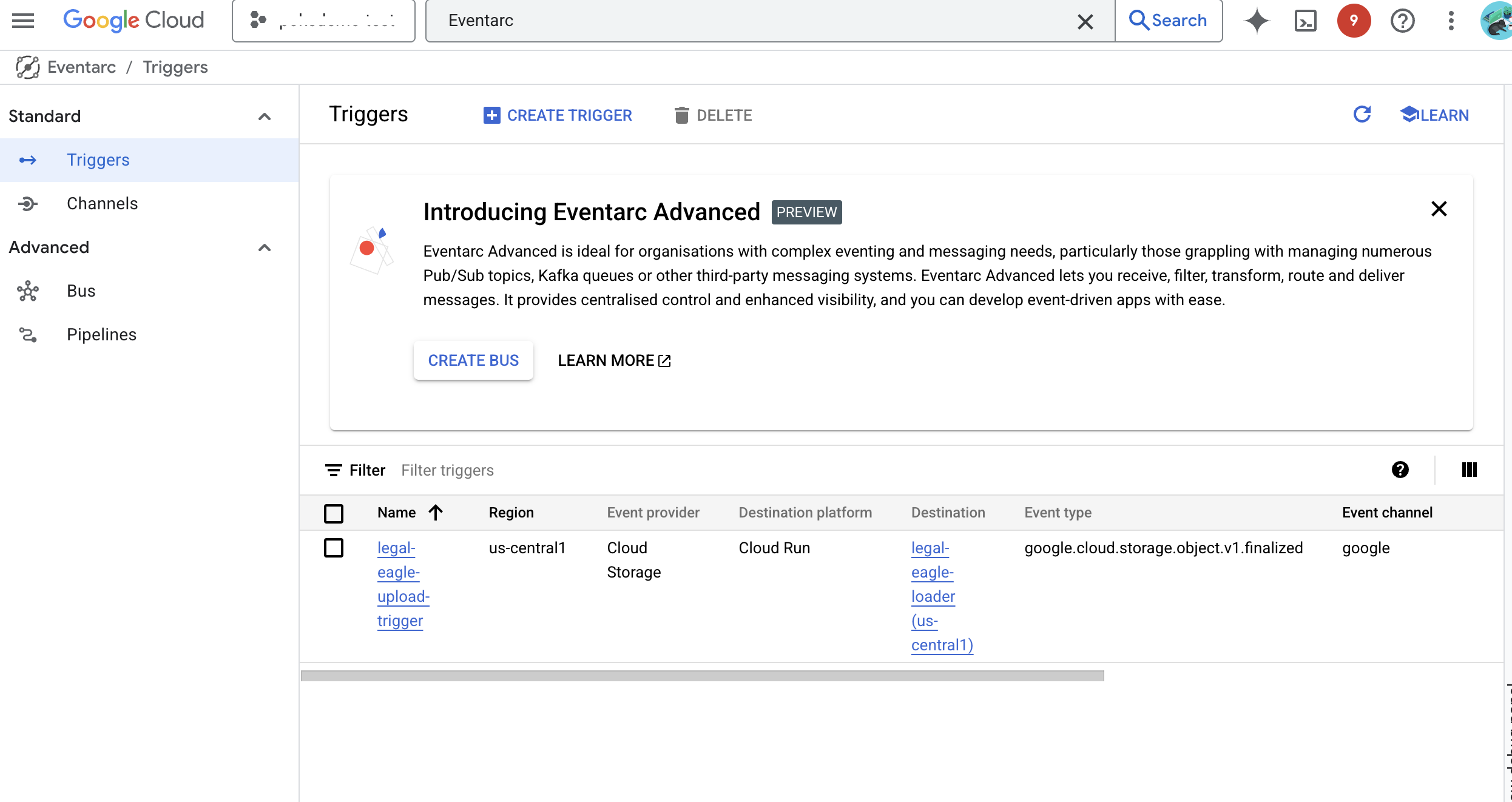
👉 W konsoli Google Cloud otwórz Aktywatory w Eventarc. Kliknij „+ UTWÓRZ AKTYWATOR”. 👉 Skonfiguruj aktywator Eventarc:
- Nazwa aktywatora:
legal-eagle-upload-trigger. - TriggerType: Google Sources
- Dostawca zdarzeń: wybierz Cloud Storage.
- Typ wydarzenia: wybierz
google.cloud.storage.object.v1.finalized - Zasobnik Cloud Storage: z menu wybierz zasobnik GCS.
- Typ miejsca docelowego: „Usługa Cloud Run”.
- Usługa: kliknij
legal-eagle-loader. - Region:
us-central1 - Ścieżka: na razie pozostaw to pole puste .
- Przyznaj wszystkie uprawnienia, o które poproszono na stronie.
👉 Kliknij UTWÓRZ. Eventarc skonfiguruje teraz aktywator.
Usługa Cloud Run potrzebuje uprawnień do odczytywania plików z różnych komponentów. Musimy przyznać kontu usługi usługi uprawnienia, których potrzebuje.
12. Przesyłanie dokumentów prawnych do zasobnika GCS
👉 Prześlij plik sprawy sądowej do zasobnika GCS. Pamiętaj, aby zastąpić nazwę zasobnika.
export DOC_BUCKET_NAME=$(gcloud storage buckets list --format="value(name)" | grep doc-bucket)
gsutil cp ~/legal-eagle/court_cases/case-02.txt gs://$DOC_BUCKET_NAME/
gsutil cp ~/legal-eagle/court_cases/case-03.txt gs://$DOC_BUCKET_NAME/
gsutil cp ~/legal-eagle/court_cases/case-06.txt gs://$DOC_BUCKET_NAME/
Aby monitorować logi usługi Cloud Run, otwórz Cloud Run –> Twoja usługa legal-eagle-loader –> „Logi”. Sprawdź logi pod kątem komunikatów o pomyślnym przetwarzaniu, w tym:
xxx
POST200130 B8.3 sAPIs-Google; (+https://developers.google.com/webmasters/APIs-Google.html) https://legal-eagle-loader-bmngrueyta-uc.a.run.app/?__GCP_CloudEventsMode=GCS_NOTIFICATION
xxx
POST200130 B520 msAPIs-Google; (+https://developers.google.com/webmasters/APIs-Google.html) https://legal-eagle-loader-bmngrueyta-uc.a.run.app/?__GCP_CloudEventsMode=GCS_NOTIFICATION
xxx
POST200130 B514 msAPIs-Google; (+https://developers.google.com/webmasters/APIs-Google.html) https://legal-eagle-loader-bmngrueyta-uc.a.run.app/?__GCP_CloudEventsMode=GCS_NOTIFICATION
W zależności od tego, jak szybko skonfigurowano rejestrowanie, zobaczysz tu też bardziej szczegółowe logi.
"CloudEvent received:"
"New file detected in bucket:"
"File content downloaded. Processing..."
"Text split into ... chunks."
"File processing and Firestore upsert complete..."
Sprawdź, czy w dziennikach nie ma komunikatów o błędach, i w razie potrzeby rozwiąż problemy. 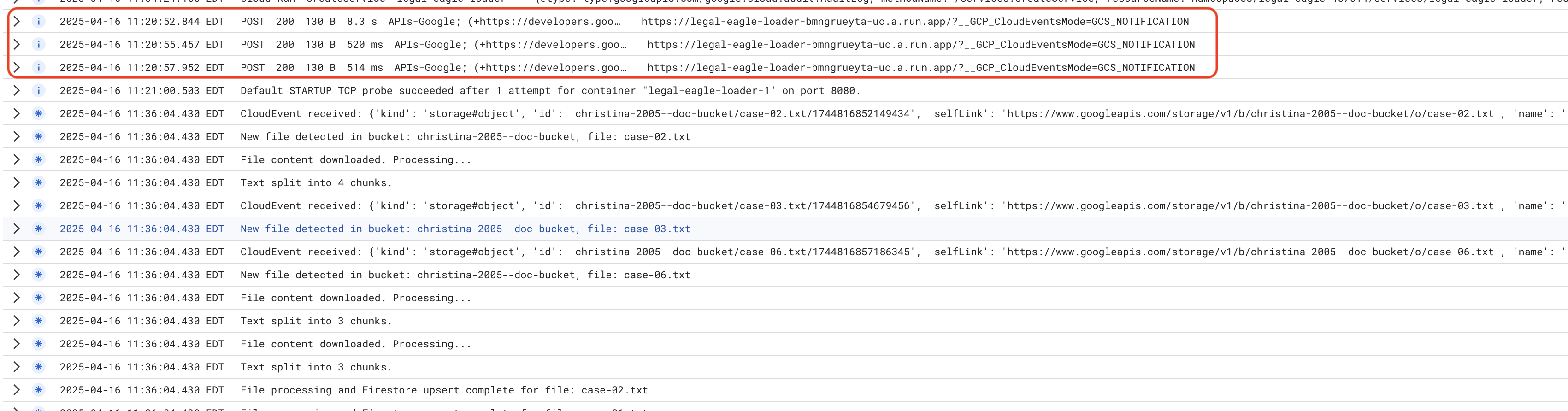
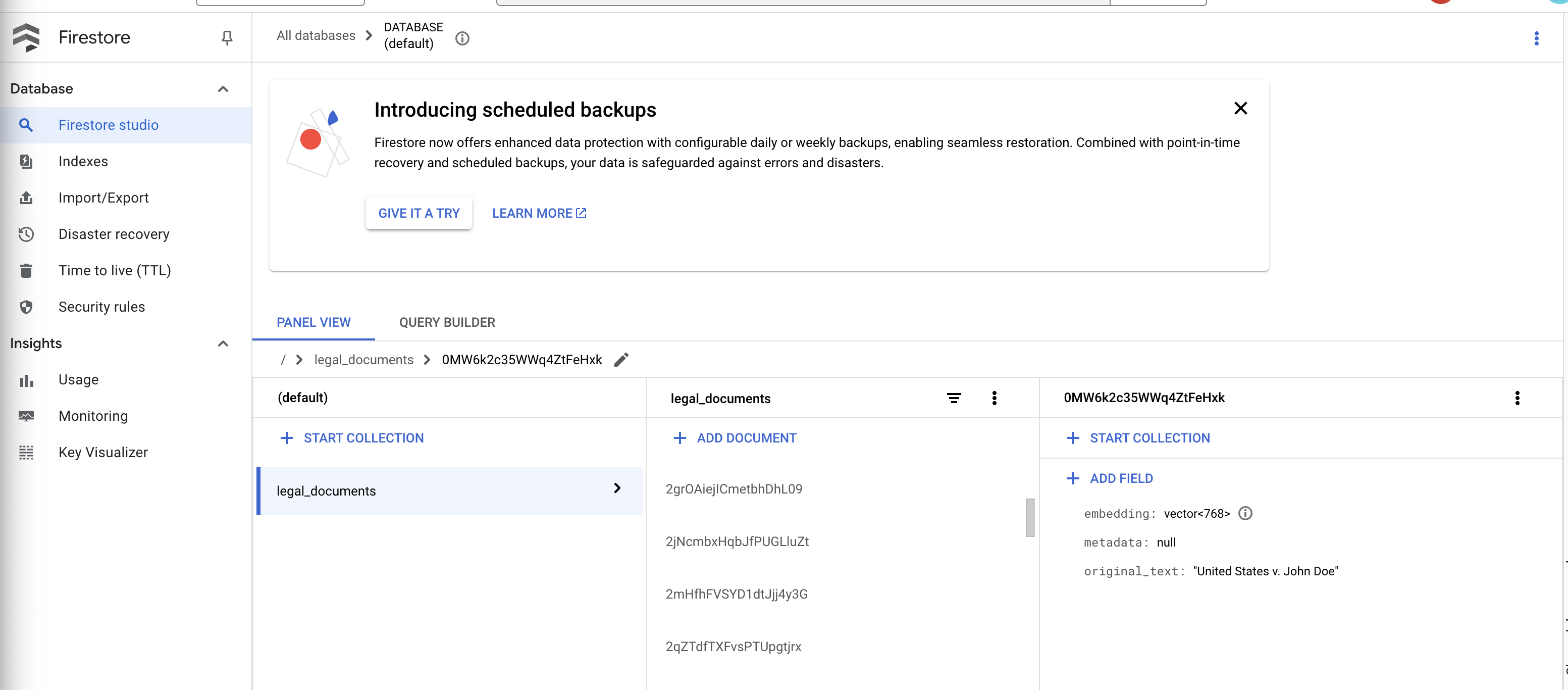
👉 Sprawdź dane w Firestore. Otwórz kolekcję legal_documents.
👉 W kolekcji powinny pojawić się nowe dokumenty. Każdy dokument będzie zawierać fragment tekstu z przesłanego pliku i będzie zawierać:
metadata: currently empty
original_text_chunk: The text chunk content.
embedding_: A list of floating-point numbers (the Vertex AI embedding).
13. Wdrażanie RAG
LangChain to zaawansowana platforma zaprojektowana w celu usprawnienia tworzenia aplikacji opartych na dużych modelach językowych (LLM). Zamiast bezpośrednio zmagać się ze złożonością interfejsów LLM API, inżynierii promptów i obsługi danych, LangChain zapewnia warstwę abstrakcji wysokiego poziomu. Zawiera gotowe komponenty i narzędzia do wykonywania zadań takich jak łączenie się z różnymi modelami LLM (np.OpenAI, Google i innymi), tworzenie złożonych łańcuchów operacji (np. pobieranie danych, a następnie podsumowywanie) i zarządzanie pamięcią konwersacyjną.
W przypadku RAG kluczowe znaczenie mają bazy danych wektorów w LangChain, które umożliwiają pobieranie informacji. Są to specjalistyczne bazy danych zaprojektowane do wydajnego przechowywania wektorów dystrybucyjnych i wysyłania zapytań o nie. W przestrzeni wektorowej semantycznie podobne fragmenty tekstu są mapowane na punkty znajdujące się blisko siebie. LangChain zajmuje się niskopoziomowymi szczegółami technicznymi, dzięki czemu deweloperzy mogą skupić się na podstawowej logice i funkcjonalności aplikacji RAG. Znacznie skraca to czas programowania i zmniejsza jego złożoność, umożliwiając szybkie tworzenie prototypów i wdrażanie aplikacji opartych na RAG przy jednoczesnym wykorzystaniu niezawodności i skalowalności infrastruktury w chmurze Google Cloud.
Po wyjaśnieniu działania LangChain musisz teraz zaktualizować plik legal.py w folderze webapp na potrzeby implementacji RAG. Umożliwi to modelowi LLM wyszukiwanie odpowiednich dokumentów w Firestore przed udzieleniem odpowiedzi.
👉 Zaimportuj FirestoreVectorStore i inne wymagane moduły z langchain i vertexai. Dodać tych użytkowników do pokoju „legal.py”?
from langchain_google_vertexai import VertexAIEmbeddings
from langchain_google_firestore import FirestoreVectorStore
👉 Zainicjuj Vertex AI i model osadzania.Będziesz używać text-embedding-004. Dodaj ten kod zaraz po zaimportowaniu modułów.
PROJECT_ID = os.environ.get("GOOGLE_CLOUD_PROJECT") # Get project ID from env
embedding_model = VertexAIEmbeddings(
model_name="text-embedding-004" ,
project=PROJECT_ID,)
👉 Utwórz obiekt FirestoreVectorStore wskazujący kolekcję legal_documents, używając zainicjowanego modelu osadzania i określając pola treści i osadzania. Dodaj ten kod bezpośrednio po poprzednim kodzie modelu do osadzania.
COLLECTION_NAME = "legal_documents"
# Create a vector store
vector_store = FirestoreVectorStore(
collection="legal_documents",
embedding_service=embedding_model,
content_field="original_text",
embedding_field="embedding",
)
👉 Zdefiniuj funkcję o nazwie search_resource, która przyjmuje zapytanie, przeprowadza wyszukiwanie podobieństwa za pomocą funkcji vector_store.similarity_search i zwraca połączone wyniki.
def search_resource(query):
results = []
results = vector_store.similarity_search(query, k=5)
combined_results = "\n".join([result.page_content for result in results])
print(f"==>{combined_results}")
return combined_results
👉 Zastąp funkcję ask_llm funkcją search_resource, aby pobrać odpowiedni kontekst na podstawie zapytania użytkownika.
def ask_llm(query):
try:
query_message = {
"type": "text",
"text": query,
}
relevant_resource = search_resource(query)
input_msg = HumanMessage(content=[query_message])
prompt_template = ChatPromptTemplate.from_messages(
[
SystemMessage(
content=(
"You are a helpful assistant, and you are with the attorney in a courtroom, you are helping him to win the case by providing the information he needs "
"Don't answer if you don't know the answer, just say sorry in a funny way possible"
"Use high engergy tone, don't use more than 100 words to answer"
f"Here is some context that is relevant to the question {relevant_resource} that you might use"
)
),
input_msg,
]
)
prompt = prompt_template.format()
response = llm.invoke(prompt)
print(f"response: {response}")
return response
except Exception as e:
print(f"Error sending message to chatbot: {e}") # Log this error too!
return f"Unable to process your request at this time. Due to the following reason: {str(e)}"
👉 OPCJONALNIE: WERSJA W JĘZYKU HISZPAŃSKIM
Sustituye el siguiente texto como se indica: You are a helpful assistant, to You are a helpful assistant that speaks Spanish,
👉 Po wdrożeniu RAG w pliku legal.py przetestuj go lokalnie przed wdrożeniem. Uruchom aplikację za pomocą polecenia:
cd ~/legal-eagle/webapp
source env/bin/activate
python main.py
👉 Użyj podglądu internetowego, aby uzyskać dostęp do aplikacji, porozmawiać z asystentem i wpisać ctrl+c, aby zakończyć proces uruchomiony lokalnie. Następnie uruchom polecenie deactivate, aby zamknąć środowisko wirtualne.
deactivate
👉 Aby wdrożyć aplikację internetową w Cloud Run, wykonaj podobne czynności jak w przypadku funkcji wczytywania. Utworzysz obraz Dockera, dodasz do niego tag i przeniesiesz go do Artifact Registry:
export PROJECT_ID=$(gcloud config get project)
docker build -t gcr.io/${PROJECT_ID}/legal-eagle-webapp .
docker tag gcr.io/${PROJECT_ID}/legal-eagle-webapp us-central1-docker.pkg.dev/${PROJECT_ID}/my-repository/legal-eagle-webapp
docker push us-central1-docker.pkg.dev/${PROJECT_ID}/my-repository/legal-eagle-webapp
👉 Czas wdrożyć aplikację internetową w Google Cloud. W terminalu uruchom te polecenia:
export PROJECT_ID=$(gcloud config get project)
gcloud run deploy legal-eagle-webapp \
--image us-central1-docker.pkg.dev/$PROJECT_ID/my-repository/legal-eagle-webapp \
--region us-central1 \
--set-env-vars=GOOGLE_CLOUD_PROJECT=${PROJECT_ID} \
--allow-unauthenticated
Sprawdź wdrożenie, otwierając Cloud Run w konsoli Google Cloud.Powinna się tam pojawić nowa usługa o nazwie legal-eagle-webapp.
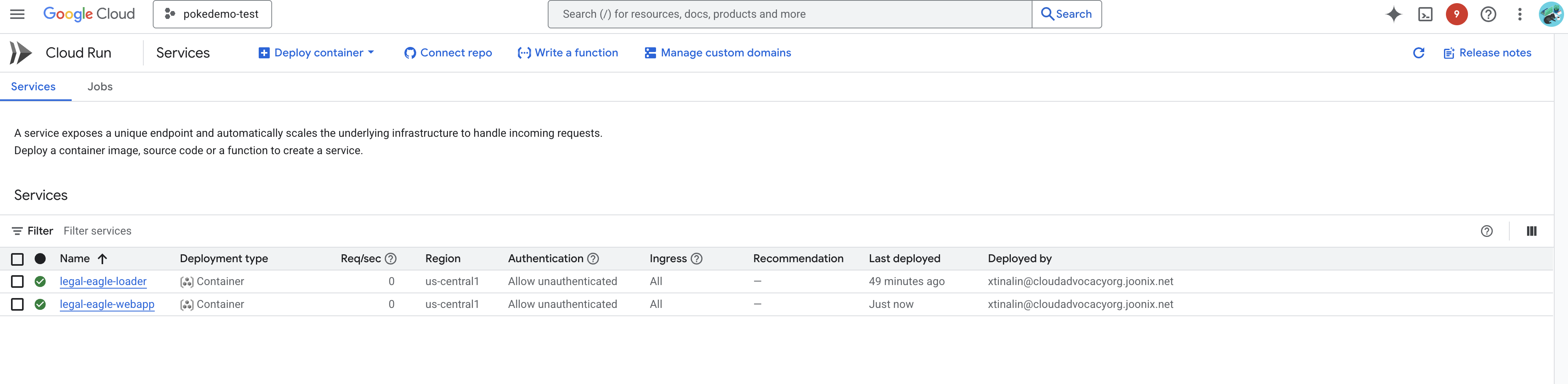
Kliknij usługę, aby przejść do strony z jej szczegółami. U góry znajdziesz wdrożony adres URL. 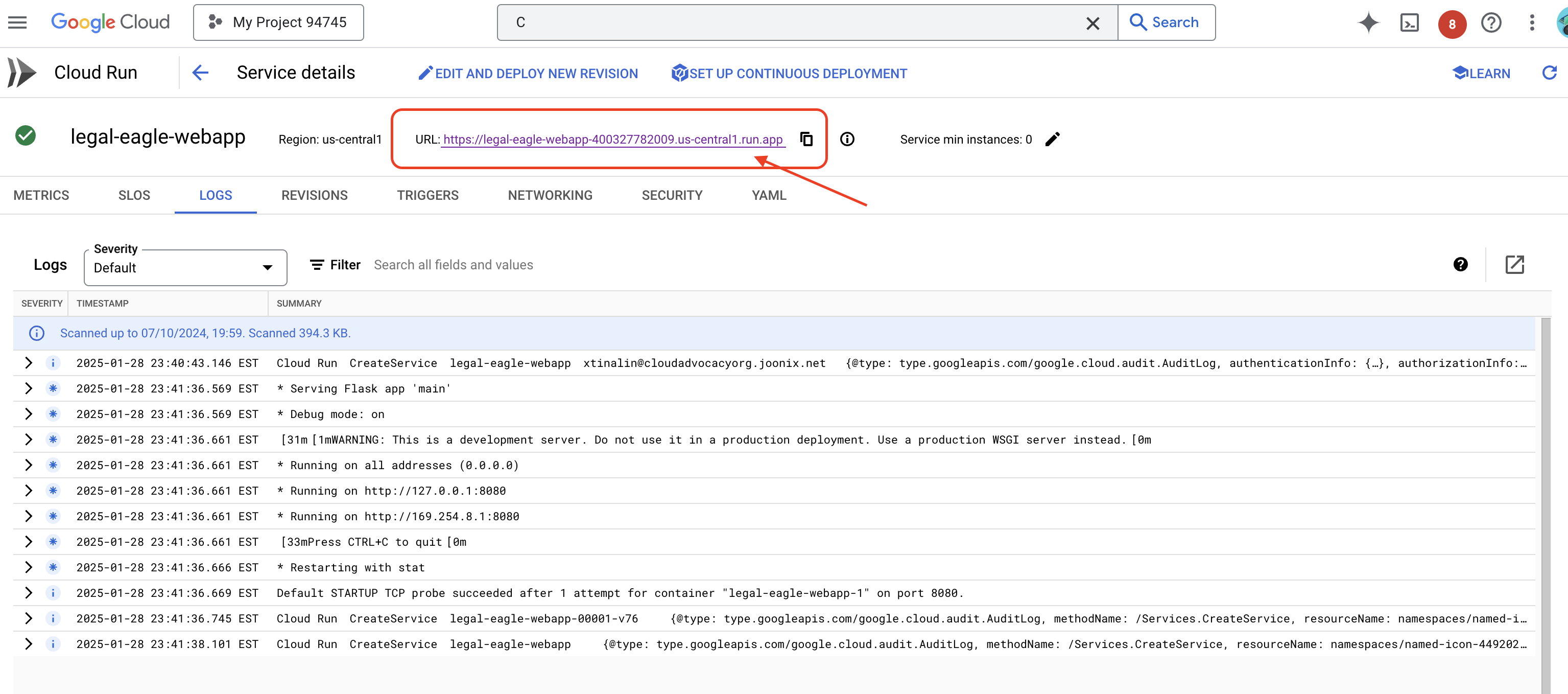
👉 Teraz otwórz wdrożony adres URL w nowej karcie przeglądarki. Możesz korzystać z pomocy prawnej i zadawać pytania dotyczące spraw sądowych, które zostały przez Ciebie wczytane(w folderze court_cases):
- Na ile lat więzienia został skazany Michael Brown?
- Ile nieautoryzowanych obciążeń wygenerowano w wyniku działań Janiny Nowak?
- Jaką rolę w śledztwie w sprawie Emily White odegrały zeznania sąsiadów?
👉 OPCJONALNIE: WERSJA W JĘZYKU HISZPAŃSKIM
- ¿A cuántos años de prisión fue sentenciado Michael Brown?
- ¿Cuánto dinero en cargos no autorizados se generó como resultado de las acciones de Jane Smith?
- ¿Qué papel jugaron los testimonios de los vecinos en la investigación del caso de Emily White?
Zauważysz, że odpowiedzi są teraz dokładniejsze i bardziej oparte na treści przesłanych dokumentów prawnych, co pokazuje możliwości RAG.
Gratulujemy ukończenia warsztatów! Udało Ci się utworzyć i wdrożyć aplikację do analizy dokumentów prawnych za pomocą LLM, LangChain i Google Cloud. Dowiedzieliśmy się, jak wczytywać i przetwarzać dokumenty prawne, wzbogacać odpowiedzi LLM o trafne informacje za pomocą RAG oraz wdrażać aplikację jako usługę bezserwerową. Ta wiedza i zbudowana aplikacja pomogą Ci lepiej poznać możliwości modeli LLM w zakresie zadań prawnych. Brawo!”.
14. Wyzwanie
Różne typy multimediów:
Jak przetwarzać różne typy multimediów, takie jak nagrania wideo i audio z sali sądowej, oraz wyodrębniać z nich odpowiedni tekst.
Komponenty online:
Jak przetwarzać zasoby online, takie jak strony internetowe, na żywo.