
1. Introdução
Sempre fui fascinado pela intensidade do tribunal, imaginando-me navegando habilmente pelas complexidades e apresentando argumentos finais convincentes. Embora minha carreira tenha me levado a outro lugar, tenho o prazer de compartilhar que, com a ajuda da IA, podemos estar mais perto de realizar esse sonho de tribunal.

Hoje, vamos mergulhar em como usar as ferramentas de IA avançadas do Google, como a Vertex AI, o Firestore e as Cloud Run Functions, para processar e entender dados jurídicos, fazer pesquisas rápidas e, quem sabe, ajudar seu cliente imaginário (ou você mesmo) a sair de uma situação difícil.
Você não vai fazer um contrainterrogatório de uma testemunha, mas com nosso sistema, poderá analisar montanhas de informações, gerar resumos claros e apresentar os dados mais relevantes em segundos.
2. Arquitetura
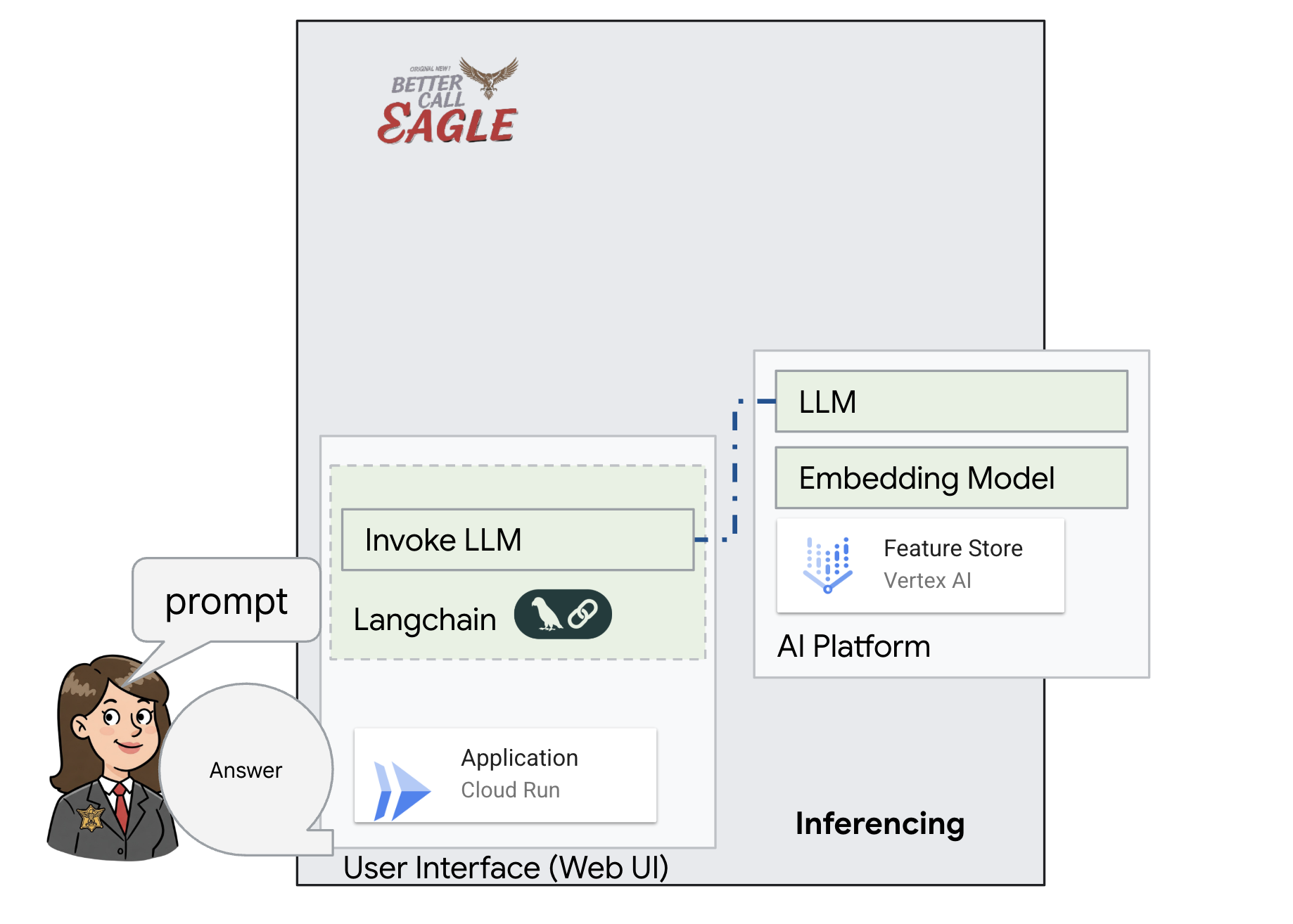
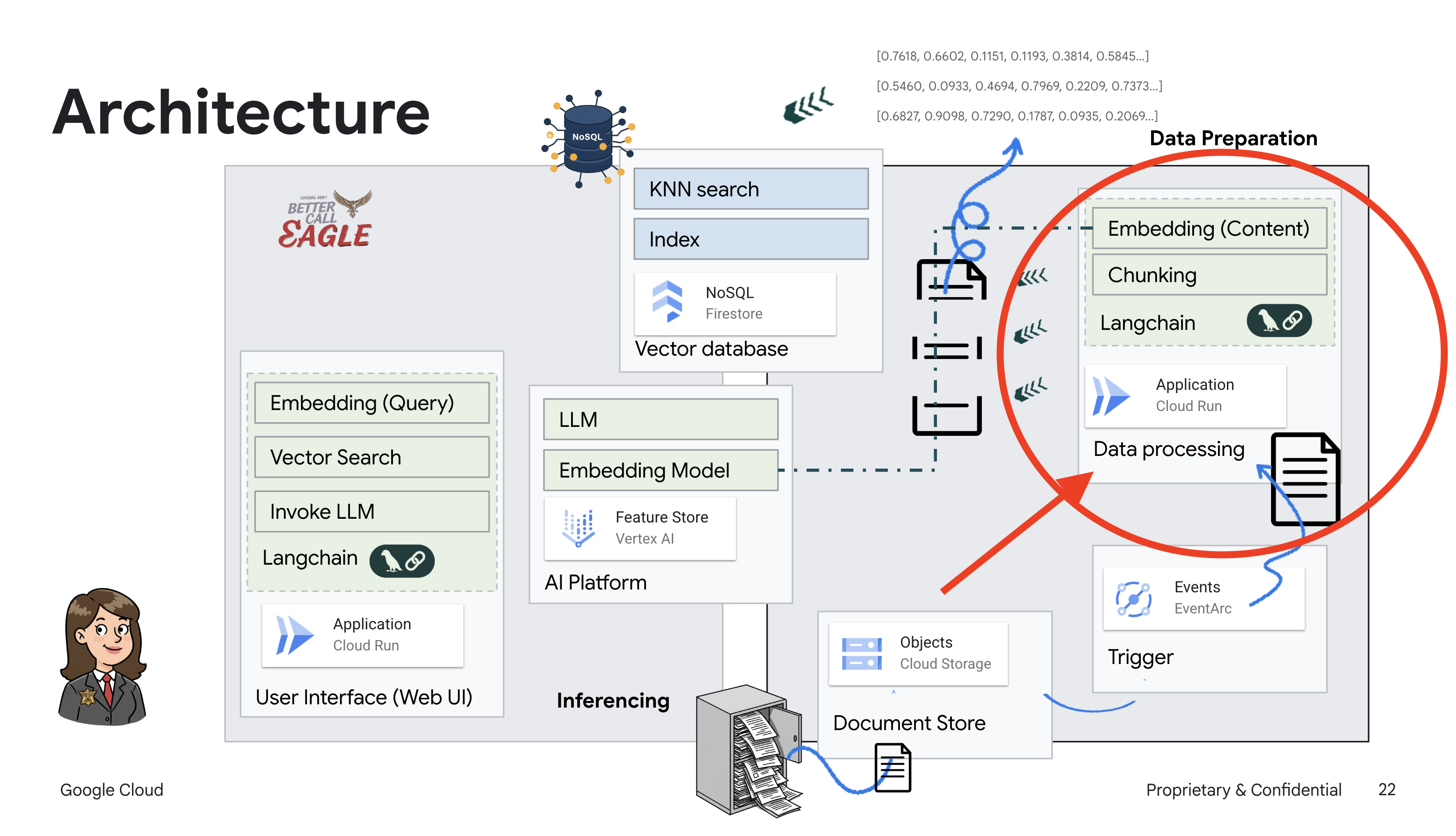
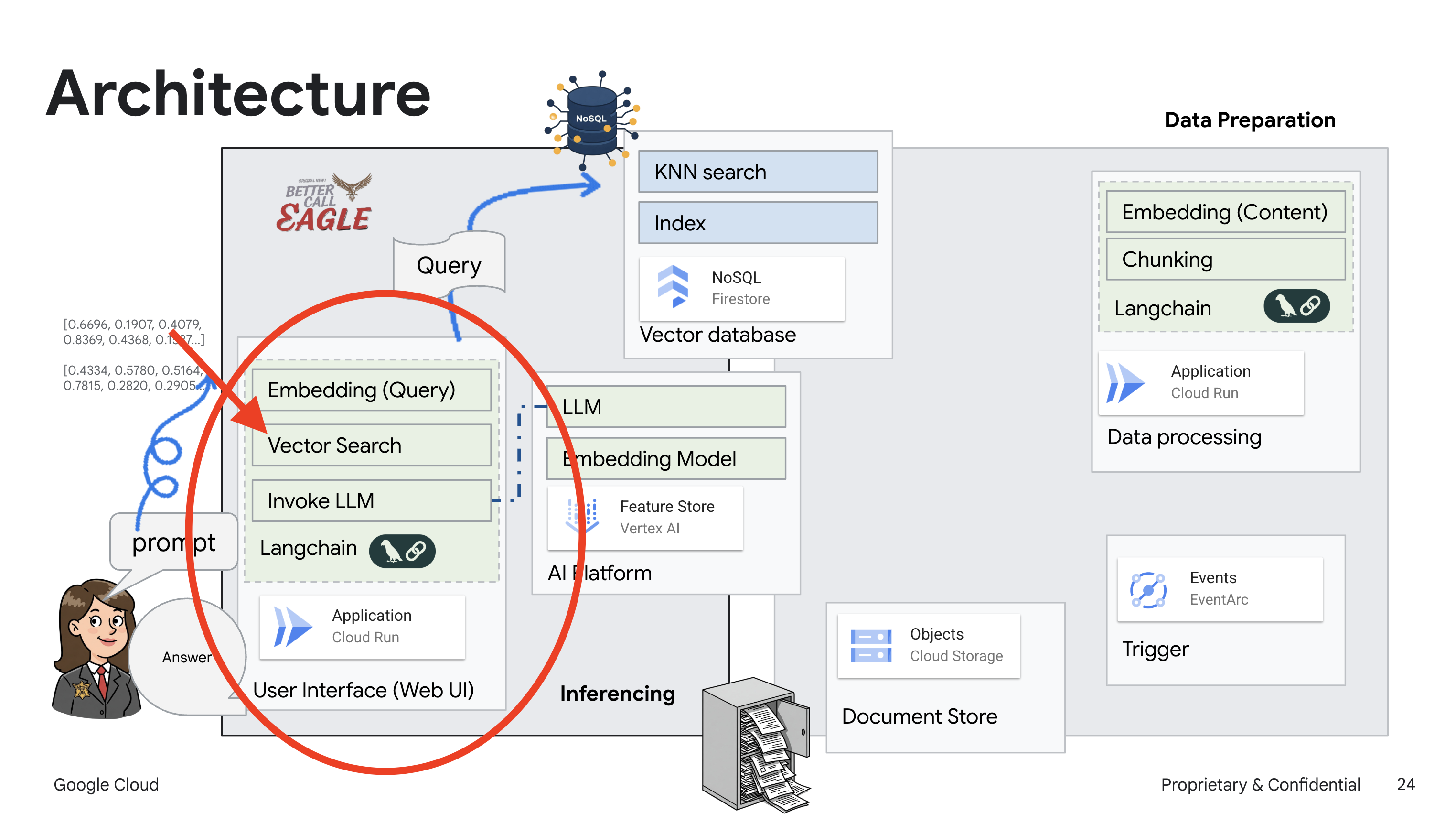
Este projeto se concentra na criação de um assistente jurídico usando ferramentas de IA do Google Cloud, enfatizando como processar, entender e pesquisar dados jurídicos. O sistema foi projetado para analisar grandes quantidades de informações, gerar resumos e apresentar dados relevantes com rapidez. A arquitetura do assistente jurídico envolve vários componentes principais:
Criação de uma base de conhecimento com dados não estruturados: o Google Cloud Storage (GCS) é usado para armazenar documentos jurídicos. O Firestore, um banco de dados NoSQL, funciona como um repositório de vetores, armazenando partes de documentos e os incorporações correspondentes. A pesquisa vetorial está ativada no Firestore para permitir pesquisas de similaridade. Quando um novo documento jurídico é enviado para o GCS, o Eventarc aciona uma função do Cloud Run. Essa função processa o documento dividindo-o em partes e gerando embeddings para cada parte usando o modelo de embedding de texto da Vertex AI. Esses embeddings são armazenados no Firestore junto com os trechos de texto. 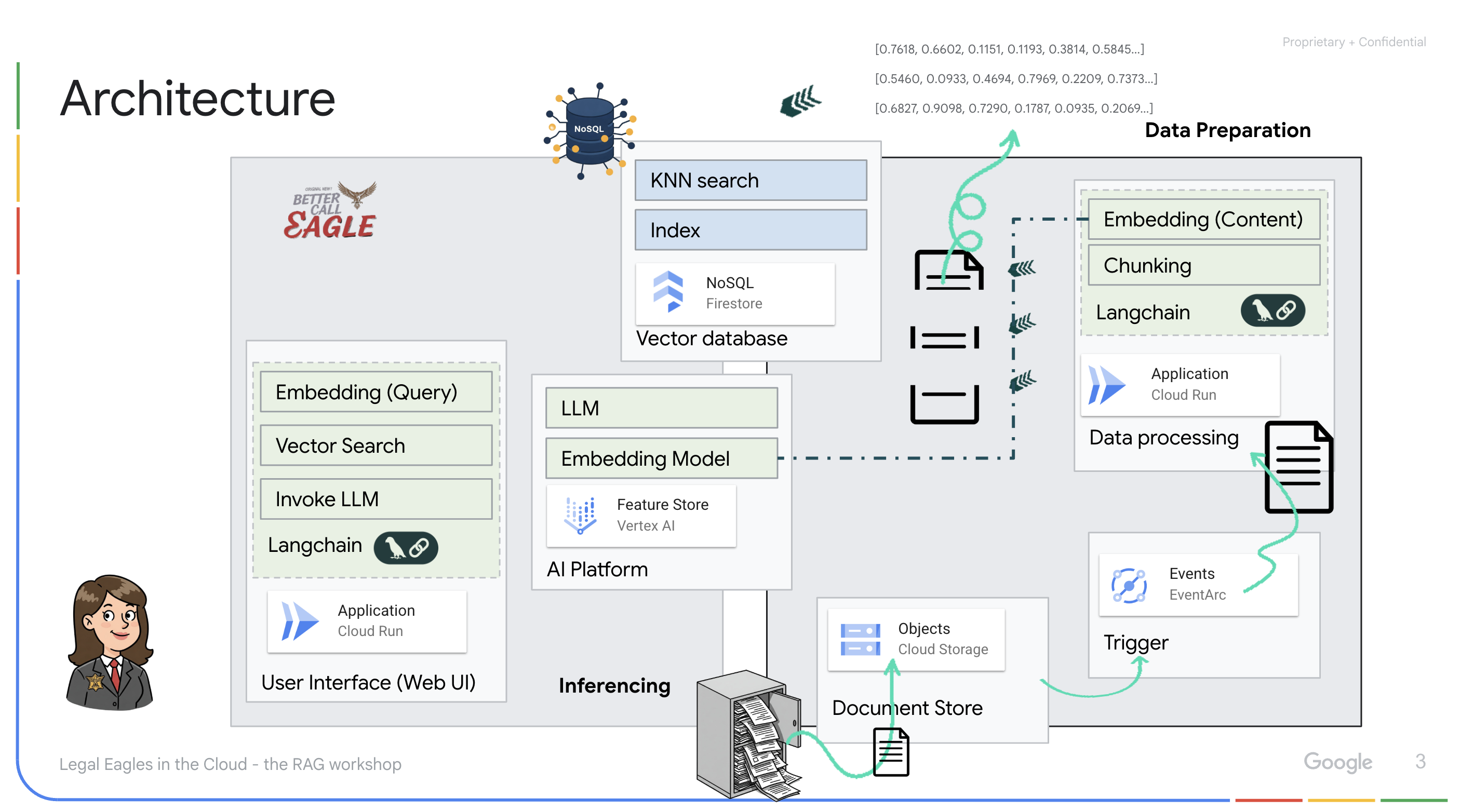
Aplicativo com tecnologia de LLM e RAG : o núcleo do sistema de perguntas e respostas é a função ask_llm, que usa a biblioteca langchain para interagir com um modelo de linguagem grande do Gemini da Vertex AI. Ele cria uma HumanMessage com base na consulta do usuário e inclui uma SystemMessage que instrui o LLM a agir como um assistente jurídico útil. O sistema usa uma abordagem de geração aumentada por recuperação (RAG), em que, antes de responder a uma consulta, ele usa a função search_resource para recuperar o contexto relevante do repositório de vetores do Firestore. Esse contexto é incluído no SystemMessage para embasar a resposta do LLM nas informações legais fornecidas. 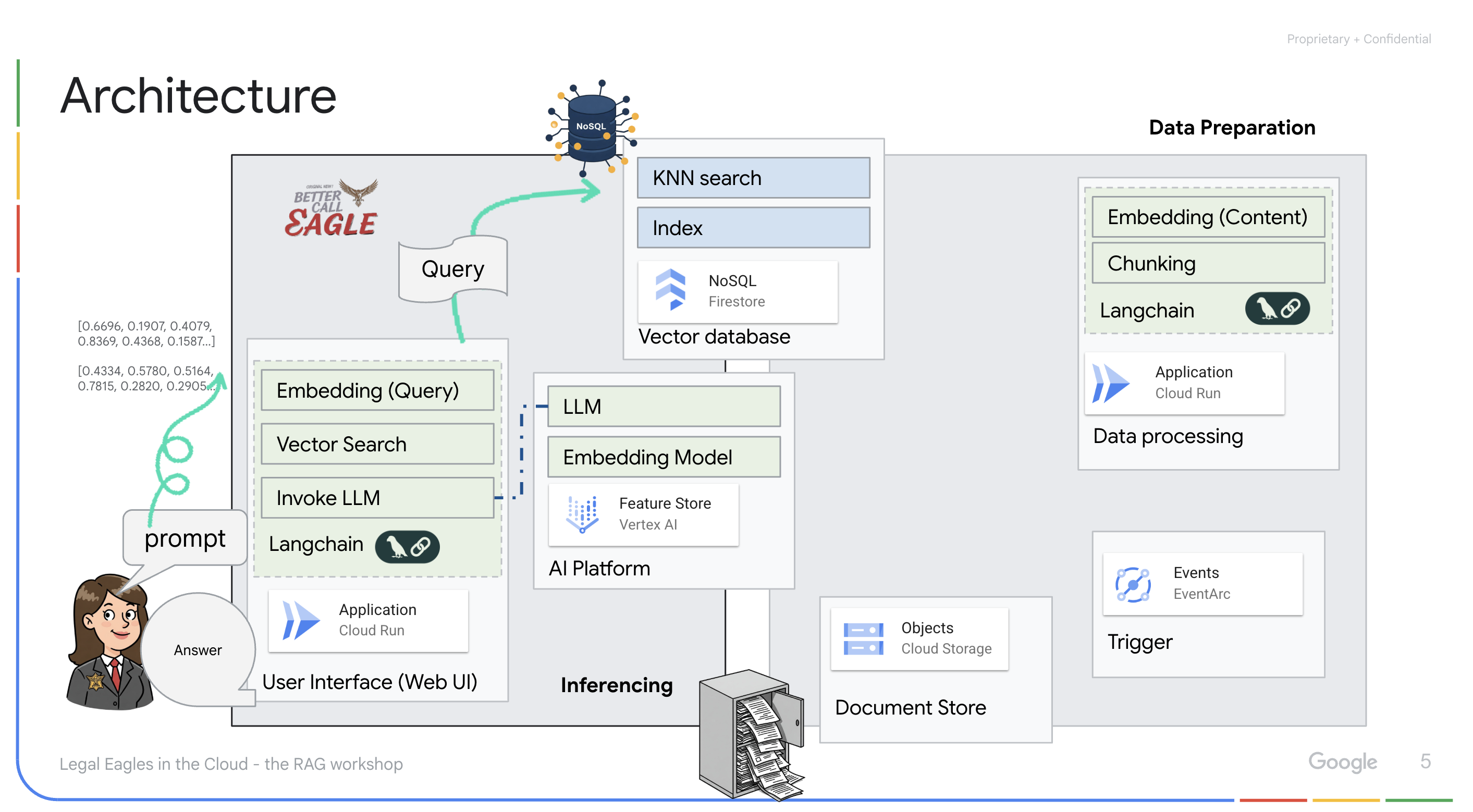
O projeto visa evitar as "interpretações criativas" dos LLMs usando a RAG, que primeiro recupera informações relevantes de uma fonte jurídica confiável antes de gerar uma resposta. Isso resulta em respostas mais precisas e informadas com base em informações legais reais. O sistema é criado usando vários serviços do Google Cloud, como Google Cloud Shell, Vertex AI, Firestore, Cloud Run e Eventarc.
3. Antes de começar
No console do Google Cloud, na página do seletor de projetos, selecione ou crie um projeto do Google Cloud. Verifique se o faturamento está ativado para seu projeto do Cloud. Saiba como verificar se o faturamento está ativado em um projeto.
Ativar o Gemini Code Assist no Cloud Shell IDE
👉 No console do Google Cloud, acesse as Ferramentas do Gemini Code Assist e ative o Gemini Code Assist sem custos financeiros concordando com os Termos e Condições.
Ignore a configuração de permissão e saia desta página.
Trabalhar no editor do Cloud Shell
👉 Clique em "Ativar o Cloud Shell" na parte de cima do console do Google Cloud. É o ícone em forma de terminal na parte de cima do painel do Cloud Shell.
👉 Clique no botão "Abrir editor" (parece uma pasta aberta com um lápis). Isso vai abrir o editor do Cloud Shell na janela. Um explorador de arquivos vai aparecer no lado esquerdo.

👉 Clique no botão Fazer login no Cloud Code na barra de status inferior, conforme mostrado. Autorize o plug-in conforme instruído. Se a barra de status mostrar Cloud Code – sem projeto, clique na opção e escolha o projeto do Google Cloud com que você quer trabalhar no menu suspenso "Selecionar um projeto do Google Cloud".
👉 Abra o terminal no IDE na nuvem, 
👉 No novo terminal, verifique se você já está autenticado e se o projeto está definido como seu ID do projeto usando o seguinte comando:
gcloud auth list
👉 Clique em Ativar o Cloud Shell na parte de cima do console do Google Cloud.
gcloud config set project <YOUR_PROJECT_ID>
👉 Execute o comando a seguir para ativar as APIs do Cloud necessárias:
gcloud services enable storage.googleapis.com \
run.googleapis.com \
artifactregistry.googleapis.com \
aiplatform.googleapis.com \
eventarc.googleapis.com \
cloudresourcemanager.googleapis.com \
firestore.googleapis.com \
cloudaicompanion.googleapis.com
Na barra de ferramentas do Cloud Shell (na parte de cima do painel do Cloud Shell), clique no botão "Abrir editor" (parece uma pasta aberta com um lápis). Isso vai abrir o editor de código do Cloud Shell na janela. Um explorador de arquivos vai aparecer no lado esquerdo.
👉 No terminal, faça o download do projeto Bootstrap Skeleton:
git clone https://github.com/weimeilin79/legal-eagle.git
OPCIONAL: VERSÃO EM ESPANHOL
👉 Existe una versión alternativa en español. Por favor, utilice la siguiente instrucción para clonar la versión correcta.
git clone -b spanish https://github.com/weimeilin79/legal-eagle.git
Depois de executar esse comando no terminal do Cloud Shell, uma nova pasta com o nome do repositório legal-eagle será criada no ambiente shell do Cloud Shell.
4. Como escrever o aplicativo de inferência com o Gemini Code Assist
Nesta seção, vamos nos concentrar na criação do núcleo do nosso assistente jurídico: o aplicativo da Web que recebe perguntas dos usuários e interage com o modelo de IA para gerar respostas. Vamos usar o Gemini Code Assist para escrever o código Python dessa parte de inferência.
Inicialmente, vamos criar um aplicativo Flask que usa a biblioteca LangChain para se comunicar diretamente com o modelo Gemini da Vertex AI. Essa primeira versão vai funcionar como um assistente jurídico útil com base no conhecimento geral do modelo, mas ainda não terá acesso aos documentos específicos do nosso caso judicial. Isso vai permitir que vejamos o desempenho de base do LLM antes de melhorá-lo com a RAG.
No painel Explorer do editor do Cloud Code (geralmente à esquerda), você vai encontrar a pasta criada quando clonou o repositório Git legal-eagle. Abra a pasta raiz do projeto no Explorer. Você vai encontrar uma subpasta webapp. Abra também. 
👉 Edite o arquivo legal.py no editor do Cloud Code. Você pode usar diferentes métodos para solicitar o Gemini Code Assist.
👉 Copie o seguinte comando para a parte de baixo de legal.py, descrevendo claramente o que você quer que o Gemini Code Assist gere. Clique no ícone de lâmpada 💡 e selecione Gemini: Gerar código. O item de menu exato pode variar um pouco dependendo da versão do Cloud Code.
"""
Write a Python function called `ask_llm` that takes a user `query` as input. This function should use the `langchain` library to interact with a Vertex AI Gemini Large Language Model. Specifically, it should:
1. Create a `HumanMessage` object from the user's `query`.
2. Create a `ChatPromptTemplate` that includes a `SystemMessage` and the `HumanMessage`. The system message should instruct the LLM to act as a helpful assistant in a courtroom setting, aiding an attorney by providing necessary information. It should also specify that the LLM should respond in a high-energy tone, using no more than 100 words, and offer a humorous apology if it doesn't know the answer.
3. Format the `ChatPromptTemplate` with the provided messages.
4. Invoke the Vertex AI LLM with the formatted prompt using the `VertexAI` class (assuming it's already initialized elsewhere as `llm`).
5. Print the LLM's `response`.
6. Return the `response`.
7. Include error handling that prints an error message to the console and returns a user-friendly error message if any issues occur during the process. The Vertex AI model should be "gemini-2.0-flash".
"""
Revise cuidadosamente o código gerado
- Ela segue aproximadamente as etapas que você descreveu no comentário?
- Ele cria um
ChatPromptTemplatecomSystemMessageeHumanMessage? - Ele inclui tratamento de erros básico (
try...except)?
Se o código gerado for bom e estiver quase todo correto, aceite-o. Pressione Tab ou Enter para sugestões inline ou clique em "Aceitar" para blocos de código maiores.
Se o código gerado não for exatamente o que você quer ou tiver erros, não se preocupe! O Gemini Code Assist é uma ferramenta para ajudar você, não para escrever um código perfeito na primeira tentativa.
Edite e modifique o código gerado para refinar, corrigir erros e atender melhor aos seus requisitos. Você pode dar mais comandos ao Gemini Code Assist adicionando mais comentários ou fazendo perguntas específicas no painel de chat do Code Assist.
Se você ainda não conhece o SDK, confira um exemplo funcional.
👉 Copie, cole e SUBSTITUA o código a seguir no seu legal.py:
import os
import signal
import sys
import vertexai
import random
from langchain_google_vertexai import VertexAI
from langchain_core.prompts import PromptTemplate, ChatPromptTemplate
from langchain_core.messages import HumanMessage, SystemMessage
# Connect to resourse needed from Google Cloud
llm = VertexAI(model_name="gemini-2.0-flash")
def ask_llm(query):
try:
query_message = {
"type": "text",
"text": query,
}
input_msg = HumanMessage(content=[query_message])
prompt_template = ChatPromptTemplate.from_messages(
[
SystemMessage(
content=(
"You are a helpful assistant, and you are with the attorney in a courtroom, you are helping him to win the case by providing the information he needs "
"Don't answer if you don't know the answer, just say sorry in a funny way possible"
"Use high engergy tone, don't use more than 100 words to answer"
# f"Here is some past conversation history between you and the user {relevant_history}"
# f"Here is some context that is relevant to the question {relevant_resource} that you might use"
)
),
input_msg,
]
)
prompt = prompt_template.format()
response = llm.invoke(prompt)
print(f"response: {response}")
return response
except Exception as e:
print(f"Error sending message to chatbot: {e}") # Log this error too!
return f"Unable to process your request at this time. Due to the following reason: {str(e)}"
👉 OPCIONAL: VERSÃO EM ESPANHOL
Sustituye el siguiente texto como se indica: You are a helpful assistant, to You are a helpful assistant that speaks Spanish,
Em seguida, crie uma função para processar uma rota que responda às perguntas do usuário.
Abra main.py no editor do Cloud Shell. Assim como você gerou ask_llm em legal.py, use o Gemini Code Assist para gerar a rota do Flask e a função ask_question. Digite o seguinte COMANDO como um comentário em main.py: (verifique se ele foi adicionado antes de iniciar o app Flask em if __name__ == "__main__":)
.....
@app.route('/',methods=['GET'])
def index():
return render_template('index.html')
"""
PROMPT:
Create a Flask endpoint that accepts POST requests at the '/ask' route.
The request should contain a JSON payload with a 'question' field. Extract the question from the JSON payload.
Call a function named ask_llm (located in a file named legal.py) with the extracted question as an argument.
Return the result of the ask_llm function as the response with a 200 status code.
If any error occurs during the process, return a 500 status code with the error message.
"""
# Add this block to start the Flask app when running locally
if __name__ == "__main__":
.....
Aceite SOMENTE se o código gerado for bom e estiver quase todo correto. Se você não conhece Python, copie e cole este exemplo funcional em main.py abaixo do código que já está lá.
👉 Cole o seguinte ANTES do início do aplicativo da Web (se name == "main":)
@app.route('/ask', methods=['POST'])
def ask_question():
data = request.get_json()
question = data.get('question')
try:
# call the ask_llm in legal.py
answer_markdown = legal.ask_llm(question)
print(f"answer_markdown: {answer_markdown}")
# Return the Markdown as the response
return answer_markdown, 200
except Exception as e:
return f"Error: {str(e)}", 500 # Handle errors appropriately
Seguindo estas etapas, você poderá ativar o Gemini Code Assist, configurar seu projeto e usá-lo para gerar a função ask no arquivo main.py.
5. Teste local no editor do Cloud
👉 No terminal do editor,instale as bibliotecas dependentes e inicie a interface da Web localmente.
cd ~/legal-eagle/webapp
python -m venv env
source env/bin/activate
export PROJECT_ID=$(gcloud config get project)
pip install -r requirements.txt
python main.py
Procure mensagens de inicialização na saída do terminal do Cloud Shell. O Flask geralmente imprime mensagens indicando que está em execução e em qual porta.
- Running on http://127.0.0.1:8080
O aplicativo precisa continuar em execução para atender às solicitações.
👉 No menu "Visualização na Web", escolha Visualizar na porta 8080. O Cloud Shell vai abrir uma nova guia ou janela do navegador com a visualização da Web do seu aplicativo. 
👉 Na interface do aplicativo, digite algumas perguntas relacionadas especificamente a referências de casos judiciais e veja como o LLM responde. Por exemplo, tente:
- A quantos anos de prisão Michael Brown foi condenado?
- Quanto dinheiro em cobranças indevidas foi gerado como resultado das ações de Jane Smith?
- Qual foi o papel dos depoimentos dos vizinhos na investigação do caso de Emily White?
👉 OPCIONAL: VERSÃO EM ESPANHOL
- ¿A cuántos años de prisión fue sentenciado Michael Brown?
- ¿Cuánto dinero en cargos no autorizados se generó como resultado de las acciones de Jane Smith?
- ¿Qué papel jugaron los testimonios de los vecinos en la investigación del caso de Emily White?
Se você analisar as respostas com atenção, vai perceber que o modelo pode alucinar, ser vago ou genérico e, às vezes, interpretar mal suas perguntas, principalmente porque ainda não tem acesso a documentos jurídicos específicos.
👉 Pressione Ctrl+C para interromper o script.
👉 Saia do ambiente virtual. No terminal, execute:
deactivate
6. Configurar o repositório de vetores
É hora de acabar com essas "interpretações criativas" da lei pelos LLMs. É aí que a geração aumentada por recuperação (RAG) entra em ação. É como dar ao LLM acesso a uma biblioteca jurídica superpoderosa antes de ele responder às suas perguntas. Em vez de depender apenas do conhecimento geral (que pode ser impreciso ou desatualizado, dependendo do modelo), a RAG primeiro busca informações relevantes de uma fonte confiável (no nosso caso, documentos legais) e usa esse contexto para gerar uma resposta muito mais informada e precisa. É como se o LLM fizesse o dever de casa antes de entrar no tribunal.
Para criar nosso sistema RAG, precisamos de um lugar para armazenar todos esses documentos legais e, principalmente, permitir que eles sejam pesquisados por significado. É aí que entra o Firestore. O Firestore é o banco de dados de documentos NoSQL flexível e escalonável do Google Cloud.
Vamos usar o Firestore como nosso repositório de vetores. Vamos armazenar partes dos nossos documentos jurídicos no Firestore e, para cada parte, também vamos armazenar o embedding, que é a representação numérica do significado dela.
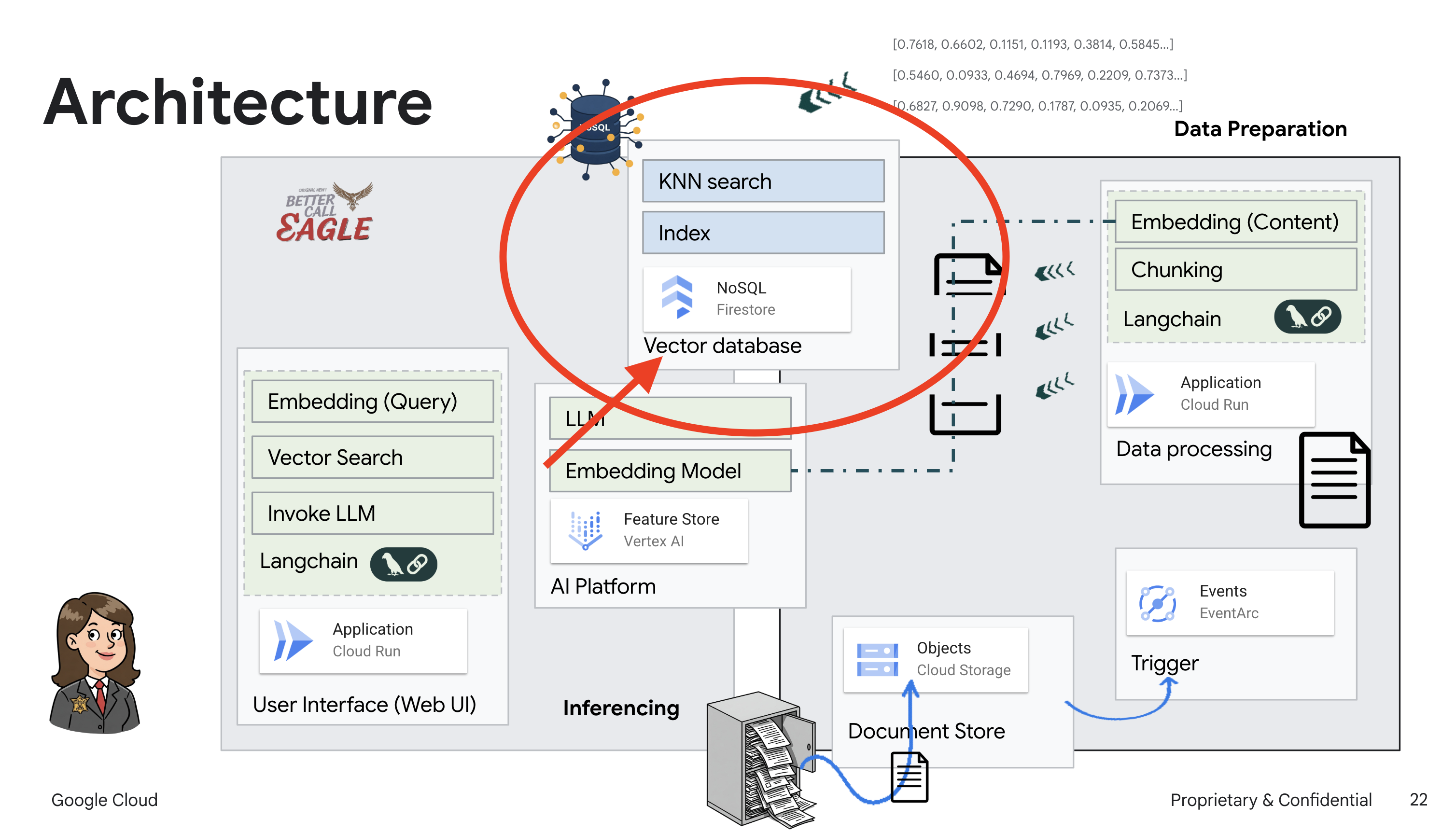
Depois, quando você fizer uma pergunta ao Legal Eagle, vamos usar a pesquisa vetorial do Firestore para encontrar os trechos de texto jurídico mais relevantes para sua consulta. Esse contexto recuperado é o que a RAG usa para dar respostas baseadas em informações jurídicas reais, não apenas na imaginação do LLM.
👉 Em uma nova guia/janela, acesse o Firestore no console do Google Cloud.
👉 Clique em Criar banco de dados.
👉 Escolha Native mode e o nome do banco de dados como (default).
👉 Selecione region único: us-central1 e clique em Criar banco de dados. O Firestore vai provisionar seu banco de dados, o que pode levar alguns instantes.
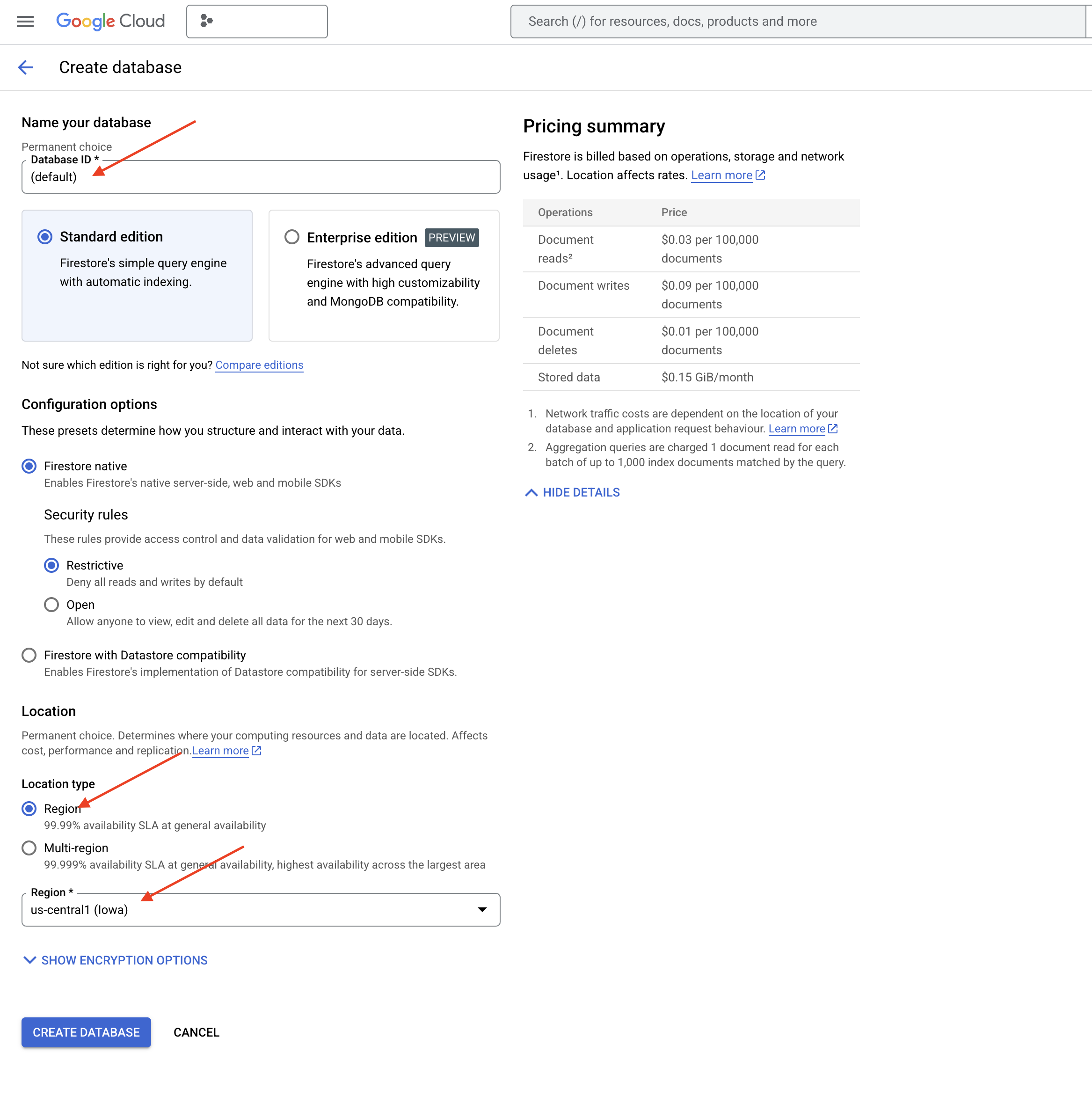
👉 De volta ao terminal do Cloud IDE, crie um índice de vetor no campo "embedding_vector" para ativar a pesquisa vetorial na sua coleção "legal_documents".
export PROJECT_ID=$(gcloud config get project)
gcloud firestore indexes composite create \
--collection-group=legal_documents \
--query-scope=COLLECTION \
--field-config field-path=embedding,vector-config='{"dimension":"768", "flat": "{}"}' \
--project=${PROJECT_ID}
O Firestore vai começar a criar o índice vetorial. A criação do índice pode levar algum tempo, principalmente para conjuntos de dados maiores. O índice vai aparecer no estado "Criando" e vai mudar para "Pronto" quando for criado. 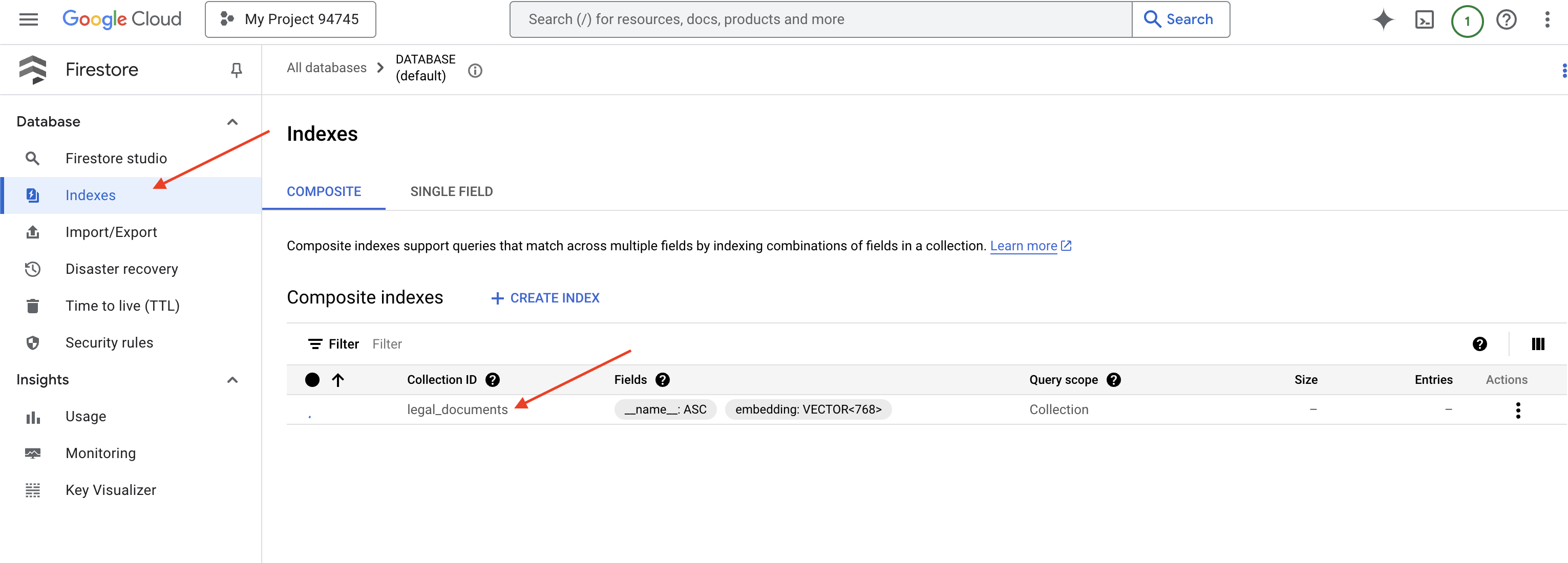
7. Como carregar dados no repositório de vetores
Agora que entendemos o RAG e o repositório de vetores, é hora de criar o mecanismo que preenche nossa biblioteca jurídica. Então, como podemos fazer com que documentos legais sejam "pesquisáveis por significado"? A magia está nos embeddings! Pense nos embeddings como a conversão de palavras, frases ou até mesmo documentos inteiros em vetores numéricos, ou seja, listas de números que capturam o significado semântico. Conceitos semelhantes recebem vetores que estão "próximos" uns dos outros no espaço vetorial. Usamos modelos avançados, como os da Vertex AI, para realizar essa conversão.
Para automatizar o carregamento de documentos, vamos usar as funções do Cloud Run e o Eventarc. As funções do Cloud Run são um contêiner leve e sem servidor que executa seu código apenas quando necessário. Vamos empacotar nosso script Python de processamento de documentos em um contêiner e implantá-lo como uma função do Cloud Run.
👉 Em uma nova guia/janela, acesse o Cloud Storage.
👉 Clique em "Buckets" no menu à esquerda.
👉 Clique no botão "+ CRIAR" na parte de cima.
👉 Configure seu bucket (configurações importantes):
- Nome do bucket: yourprojectID-doc-bucket. É obrigatório ter o sufixo -doc-bucket no final.
- região: selecione a região
us-central1. - Classe de armazenamento: "Padrão". A classe Standard é adequada para dados acessados com frequência.
- Controle de acesso: deixe selecionado o padrão "Controle de acesso uniforme". Isso fornece controle de acesso consistente no nível do bucket.
- Opções avançadas: para este tutorial, as configurações padrão geralmente são suficientes.
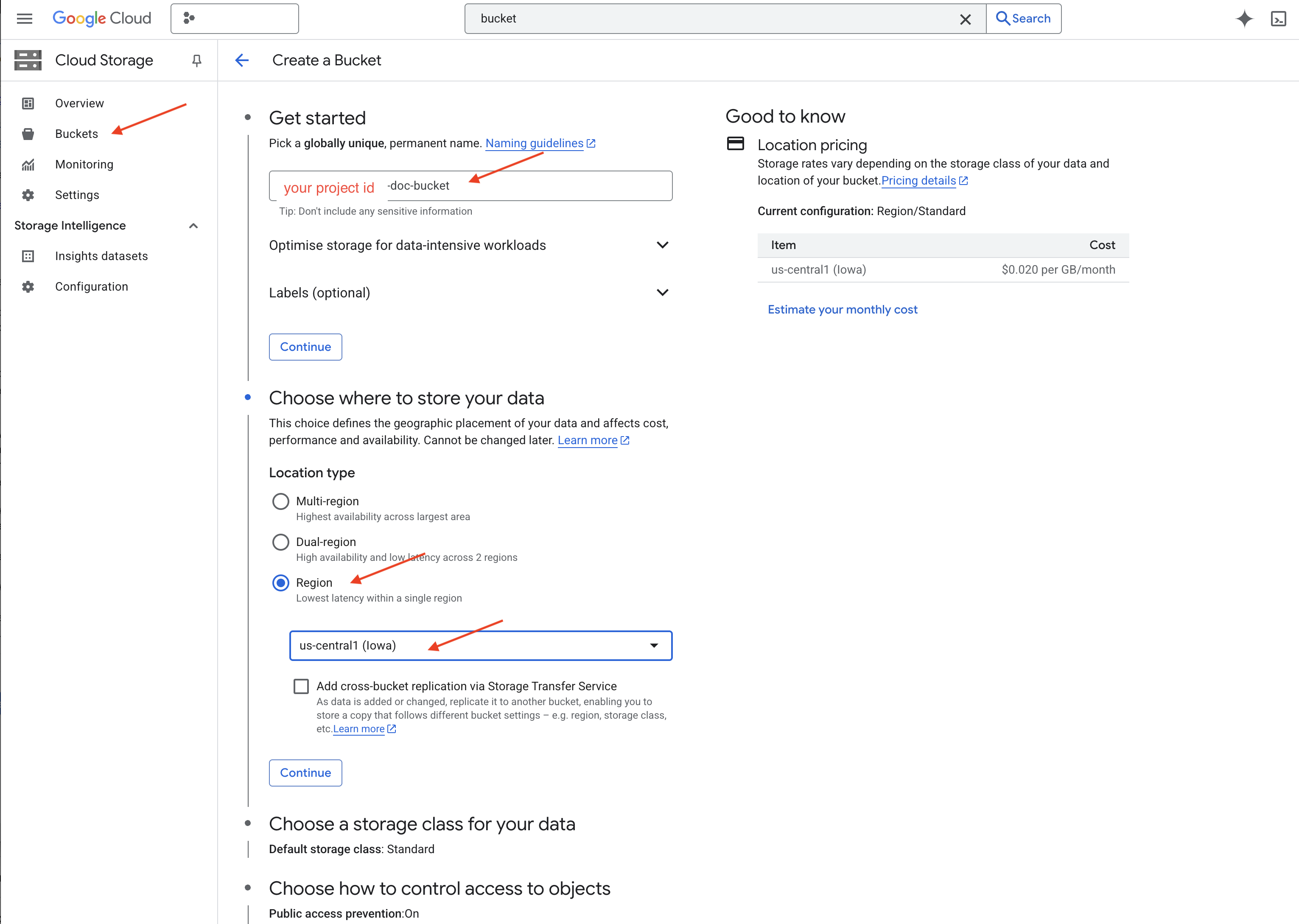
👉 Clique no botão CRIAR para criar o bucket.
👉 Talvez apareça um pop-up sobre a prevenção do acesso público. Deixe a caixa marcada e clique em "Confirmar".
O bucket recém-criado vai aparecer na lista "Buckets". Lembre-se do nome do bucket, porque você vai precisar dele depois.
8. Configurar uma função do Cloud Run
👉 No editor de código do Cloud Shell, navegue até o diretório de trabalho legal-eagle: use o comando cd no terminal do editor do Cloud para criar a pasta.
cd ~/legal-eagle
mkdir loader
cd loader
👉 Crie arquivos main.py, requirements.txt e Dockerfile. No terminal do Cloud Shell, use o comando touch para criar os arquivos:
touch main.py requirements.txt Dockerfile
Você vai encontrar a pasta recém-criada chamada *loader e os três arquivos.
👉 Edite main.py na pasta loader. No explorador de arquivos à esquerda, navegue até o diretório em que você criou os arquivos e clique duas vezes em main.py para abrir no editor.
Cole o seguinte código Python em main.py:
Esse aplicativo processa novos arquivos enviados para o bucket do GCS, divide o texto em partes, gera embeddings para cada parte e armazena as partes e os embeddings no Firestore.
import os
import json
from google.cloud import storage
import functions_framework
from langchain_google_vertexai import VertexAI, VertexAIEmbeddings
from langchain_google_firestore import FirestoreVectorStore
from langchain.text_splitter import RecursiveCharacterTextSplitter
import vertexai
PROJECT_ID = os.environ.get("GOOGLE_CLOUD_PROJECT") # Get project ID from env
embedding_model = VertexAIEmbeddings(
model_name="text-embedding-004" ,
project=PROJECT_ID,)
COLLECTION_NAME = "legal_documents"
# Create a vector store
vector_store = FirestoreVectorStore(
collection="legal_documents",
embedding_service=embedding_model,
content_field="original_text",
embedding_field="embedding",
)
@functions_framework.cloud_event
def process_file(cloud_event):
print(f"CloudEvent received: {cloud_event.data}") # Print the parsed event data
"""Triggered by a Cloud Storage event.
Args:
cloud_event (functions_framework.CloudEvent): The CloudEvent
containing the Cloud Storage event data.
"""
try:
event_data = cloud_event.data
bucket_name = event_data['bucket']
file_name = event_data['name']
except (json.JSONDecodeError, AttributeError, KeyError) as e: # Catch JSON errors
print(f"Error decoding CloudEvent data: {e} - Data: {cloud_event.data}")
return "Error processing event", 500 # Return an error response
print(f"New file detected in bucket: {bucket_name}, file: {file_name}")
storage_client = storage.Client()
bucket = storage_client.bucket(bucket_name)
blob = bucket.blob(file_name)
try:
# Download the file content as string (assuming UTF-8 encoded text file)
file_content_string = blob.download_as_string().decode("utf-8")
print(f"File content downloaded. Processing...")
# Split text into chunks using RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=100,
length_function=len,
)
text_chunks = text_splitter.split_text(file_content_string)
print(f"Text split into {len(text_chunks)} chunks.")
# Add the docs to the vector store
vector_store.add_texts(text_chunks)
print(f"File processing and Firestore upsert complete for file: {file_name}")
return "File processed successfully", 200 # Return success response
except Exception as e:
print(f"Error processing file {file_name}: {e}")
Edite requirements.txt.Cole as seguintes linhas no arquivo:
Flask==2.3.3
requests==2.31.0
google-generativeai>=0.2.0
langchain
langchain_google_vertexai
langchain-community
langchain-google-firestore
google-cloud-storage
functions-framework
9. Testar e criar a função do Cloud Run
👉 Vamos executar isso em um ambiente virtual e instalar as bibliotecas Python necessárias para a função do Cloud Run.
cd ~/legal-eagle/loader
python -m venv env
source env/bin/activate
pip install -r requirements.txt
👉 Inicie um emulador local para a função do Cloud Run
functions-framework --target process_file --signature-type=cloudevent --source main.py
👉 Mantenha o último terminal em execução, abra um novo terminal e execute o comando para fazer upload de um arquivo para o bucket.
export DOC_BUCKET_NAME=$(gcloud storage buckets list --format="value(name)" | grep doc-bucket)
gsutil cp ~/legal-eagle/court_cases/case-01.txt gs://$DOC_BUCKET_NAME/

👉 Enquanto o emulador estiver em execução, você poderá enviar CloudEvents de teste para ele. Você vai precisar de um terminal separado no ambiente de desenvolvimento integrado para isso.
curl -X POST -H "Content-Type: application/json" \
-d "{
\"specversion\": \"1.0\",
\"type\": \"google.cloud.storage.object.v1.finalized\",
\"source\": \"//storage.googleapis.com/$DOC_BUCKET_NAME\",
\"subject\": \"objects/case-01.txt\",
\"id\": \"my-event-id\",
\"time\": \"2024-01-01T12:00:00Z\",
\"data\": {
\"bucket\": \"$DOC_BUCKET_NAME\",
\"name\": \"case-01.txt\"
}
}" http://localhost:8080/
Ele vai retornar "OK".
👉 Verifique os dados no Firestore. Acesse o console do Google Cloud, navegue até "Bancos de dados" e "Firestore", selecione a guia "Dados" e a coleção legal_documents. Você vai notar que novos documentos foram criados na sua coleção, cada um representando um trecho do texto do arquivo enviado. 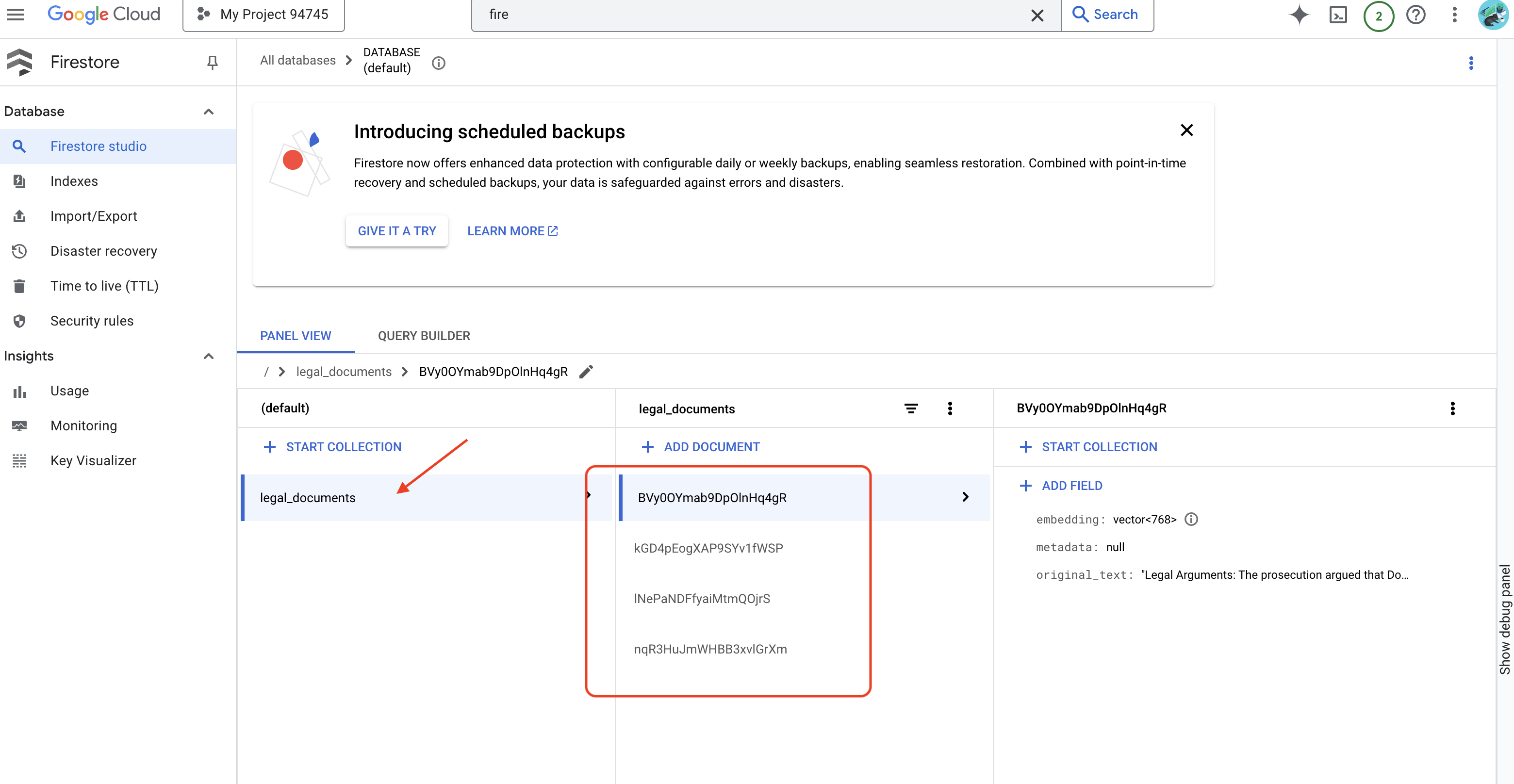
👉 No terminal que executa o emulador, digite Ctrl+C para sair. e feche o segundo terminal.
Execute "deactivate" para sair do ambiente virtual.
deactivate
10. Criar imagem do contêiner e enviar para repositórios de artefatos
👉 É hora de implantar isso na nuvem. No explorador de arquivos, clique duas vezes em Dockerfile. Peça ao Gemini para gerar o Dockerfile, abra o Gemini Code Assist e use o seguinte comando para gerar o arquivo.
In the loader folder,
Generate a Dockerfile for a Python 3.12 Cloud Run service that uses functions-framework. It needs to:
1. Use a Python 3.12 slim base image.
2. Set the working directory to /app.
3. Copy requirements.txt and install Python dependencies.
4. Copy main.py.
5. Set the command to run functions-framework, targeting the 'process_file' function on port 8080
Como prática recomendada, clique em Comparar com o arquivo aberto(duas setas em direções opostas) e aceite as mudanças. 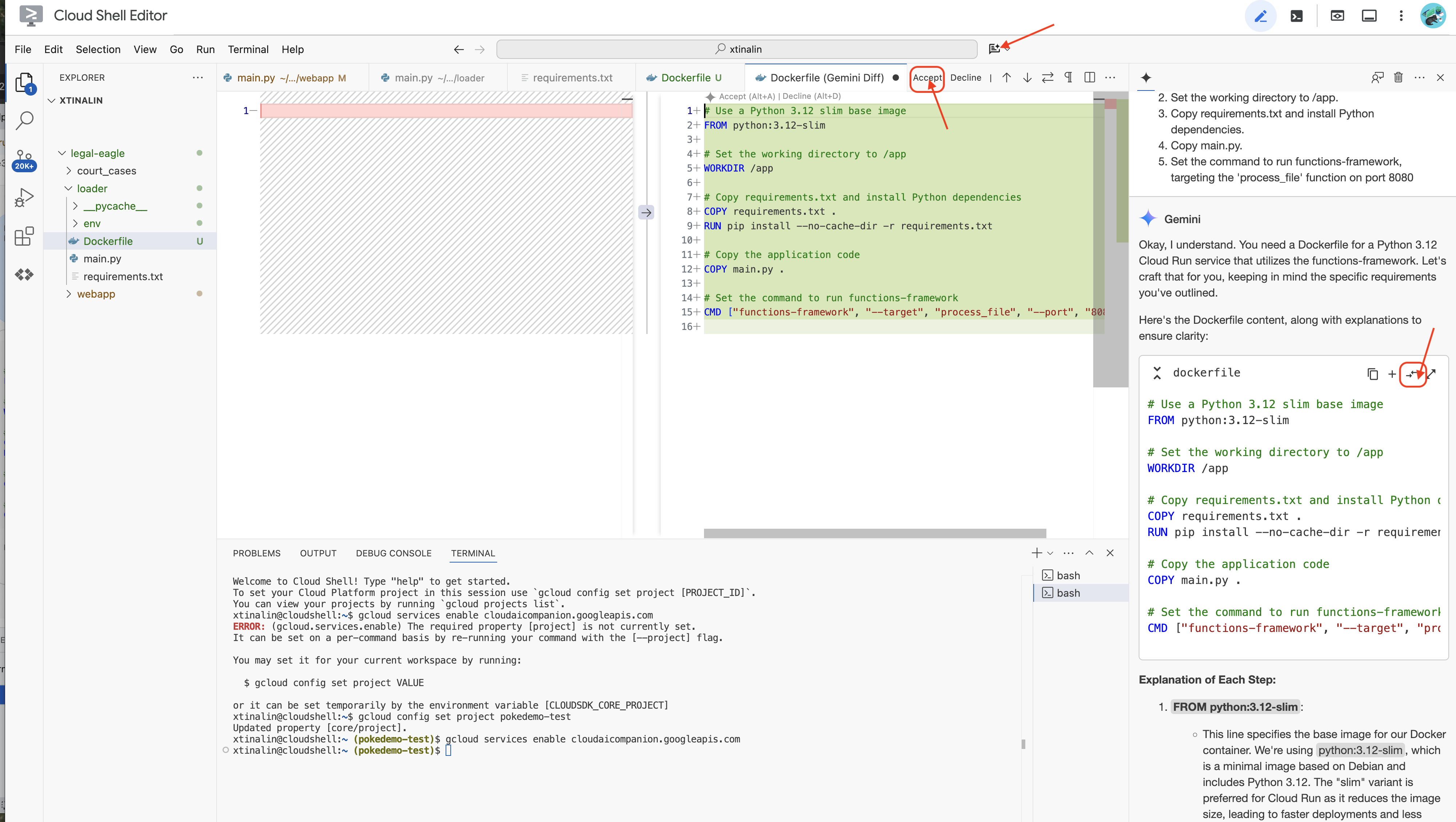
👉 Se você não tem experiência com contêineres, confira um exemplo prático:
# Use a Python 3.12 slim base image
FROM python:3.12-slim
# Set the working directory to /app
WORKDIR /app
# Copy requirements.txt and install Python dependencies
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
# Copy main.py
COPY main.py .
# Set the command to run functions-framework
CMD ["functions-framework", "--target", "process_file", "--port", "8080"]
👉 No terminal, crie um repositório de artefatos para armazenar a imagem do Docker que vamos criar.
gcloud artifacts repositories create my-repository \
--repository-format=docker \
--location=us-central1 \
--description="My repository"
Você vai ver Created repository [my-repository].
👉 Execute o comando a seguir para criar a imagem Docker.
cd ~/legal-eagle/loader
export PROJECT_ID=$(gcloud config get project)
docker build -t gcr.io/${PROJECT_ID}/legal-eagle-loader .
👉 Agora você vai enviar isso para o registro
export PROJECT_ID=$(gcloud config get project)
docker tag gcr.io/${PROJECT_ID}/legal-eagle-loader us-central1-docker.pkg.dev/${PROJECT_ID}/my-repository/legal-eagle-loader
docker push us-central1-docker.pkg.dev/${PROJECT_ID}/my-repository/legal-eagle-loader
A imagem Docker agora está disponível no my-repository repositório de artefatos.
11. Criar a função do Cloud Run e configurar o gatilho do Eventarc
Antes de entrar nos detalhes da implantação do nosso carregador de documentos jurídicos, vamos entender brevemente os componentes envolvidos: o Cloud Run é uma plataforma sem servidor totalmente gerenciada que permite implantar aplicativos conteinerizados com rapidez e facilidade. Ele abstrai o gerenciamento da infraestrutura, permitindo que você se concentre na criação e implantação do código.
Vamos implantar nosso carregador de documentos como um serviço do Cloud Run. Agora, vamos configurar a função do Cloud Run:
👉 No console do Google Cloud, acesse o Cloud Run.
👉 Acesse Implantar contêiner e, no menu suspenso, clique em SERVIÇO.
👉 Configure o serviço do Cloud Run:
- Imagem do contêiner: clique em "Selecionar" no campo de URL. Encontre o URL da imagem que você enviou para o Artifact Registry (por exemplo, us-central1-docker.pkg.dev/your-project-id/my-repository/legal-eagle-loader/yourimage).
- Nome do serviço:
legal-eagle-loader - Região: selecione a região
us-central1. - Autenticação: para fins deste workshop, você pode permitir "Permitir invocações não autenticadas". Para produção, é recomendável restringir o acesso.
- Contêiner, rede, segurança : padrão.
👉 Clique em CRIAR. O Cloud Run vai implantar seu serviço. 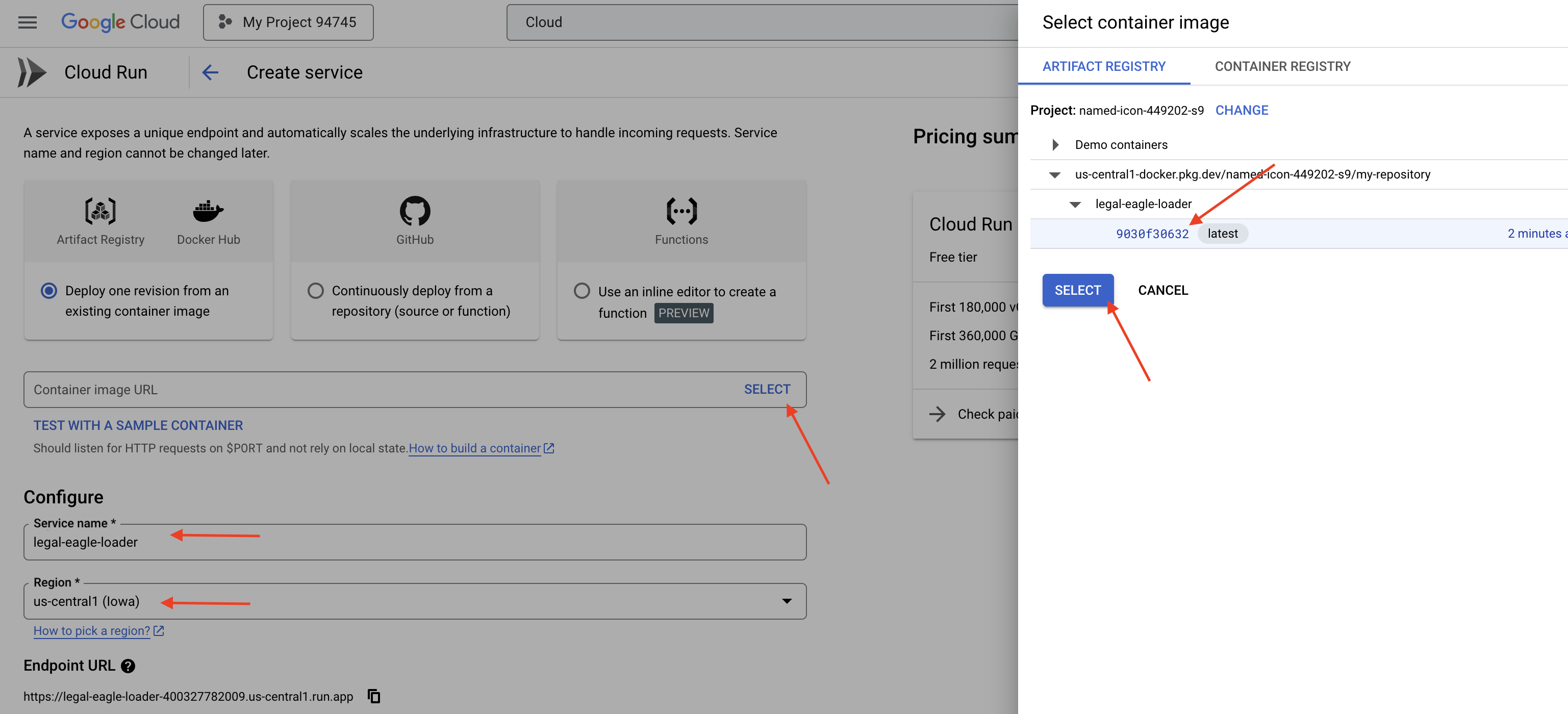
Para acionar esse serviço automaticamente quando novos arquivos forem adicionados ao nosso bucket de armazenamento, vamos usar o Eventarc. O Eventarc permite criar arquiteturas orientadas a eventos roteando eventos de várias fontes para seus serviços.
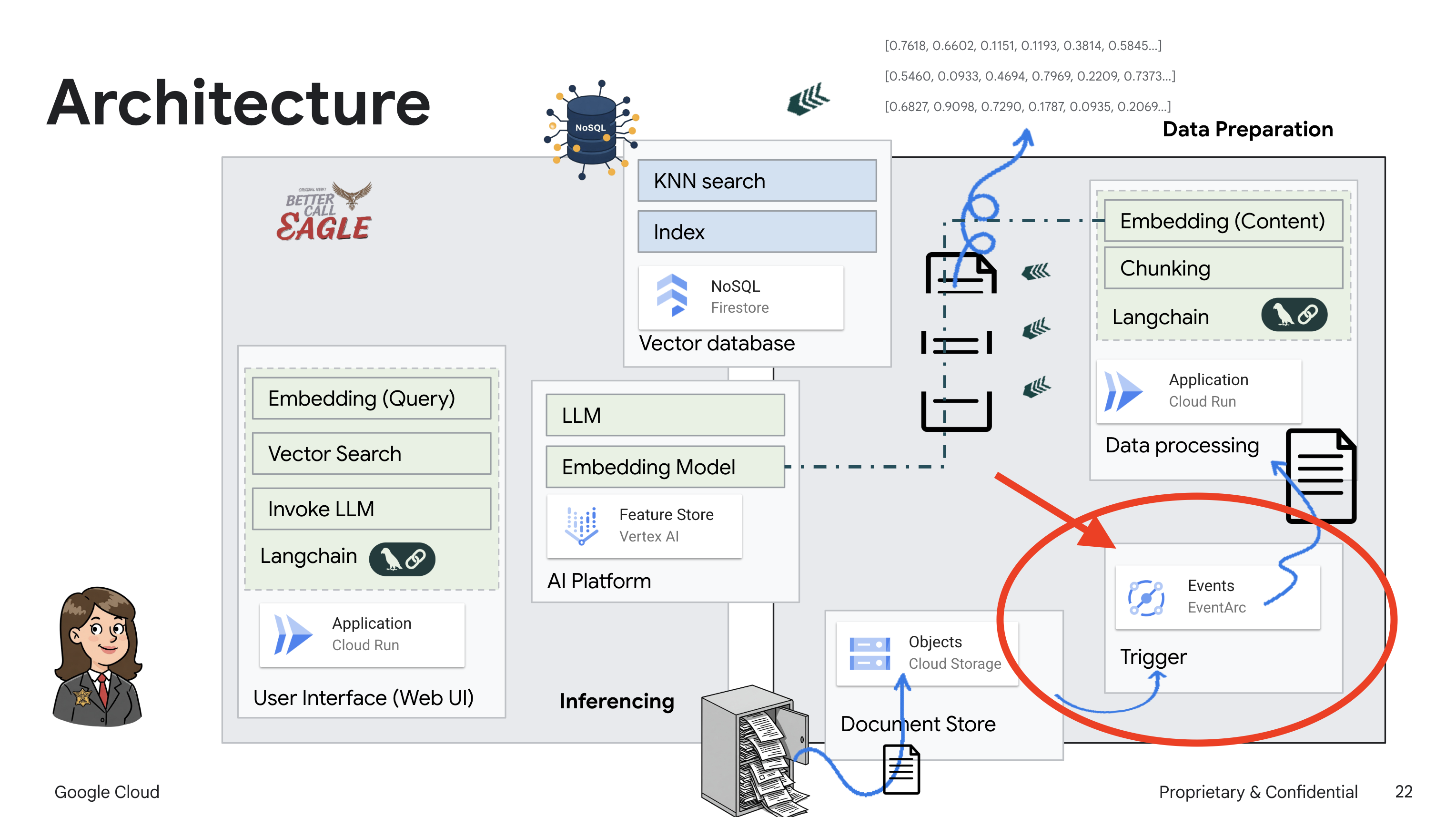
Ao configurar o Eventarc, nosso serviço do Cloud Run carrega automaticamente os documentos recém-adicionados no Firestore assim que eles são enviados, permitindo atualizações de dados em tempo real para nosso aplicativo RAG.
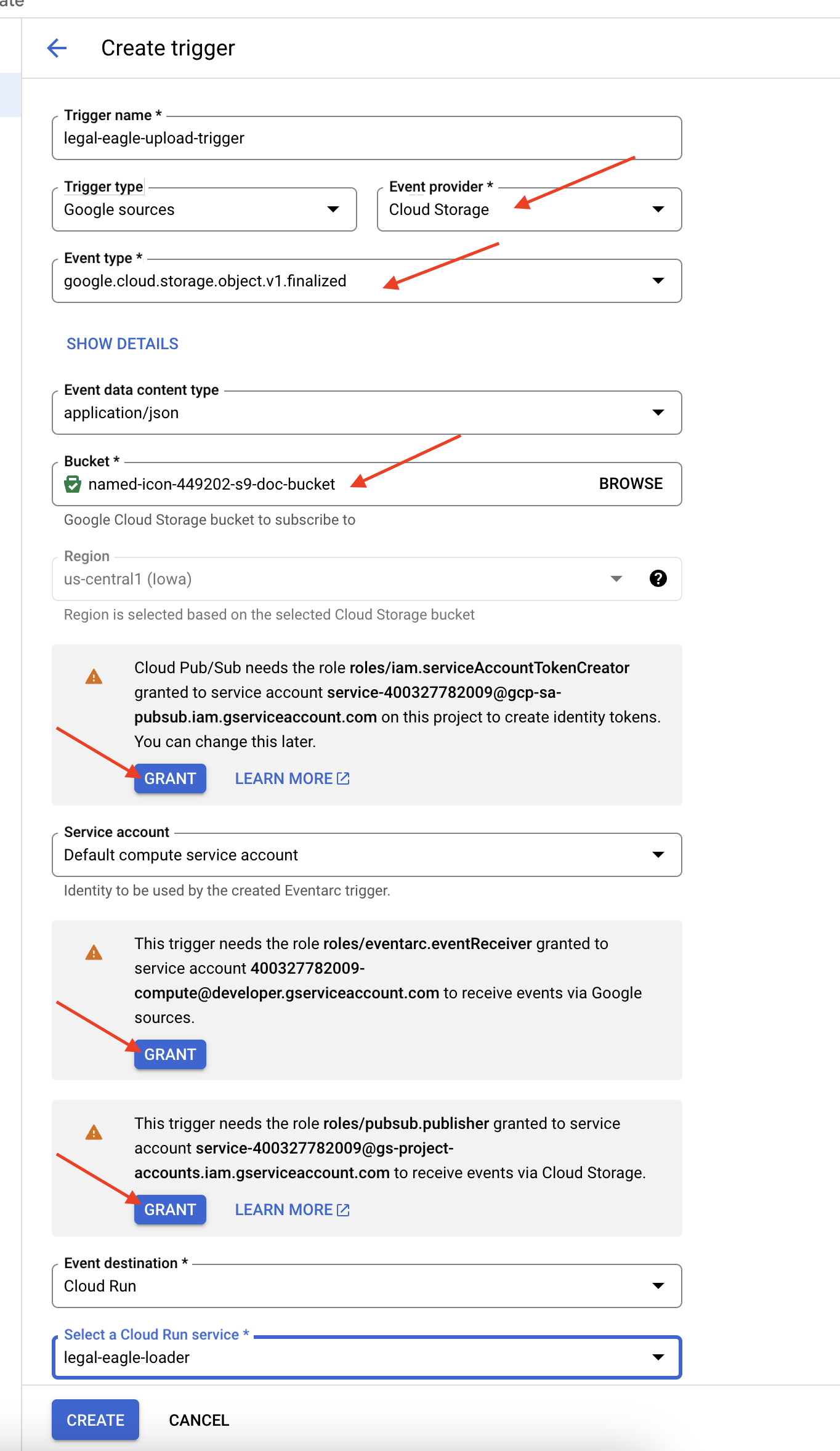
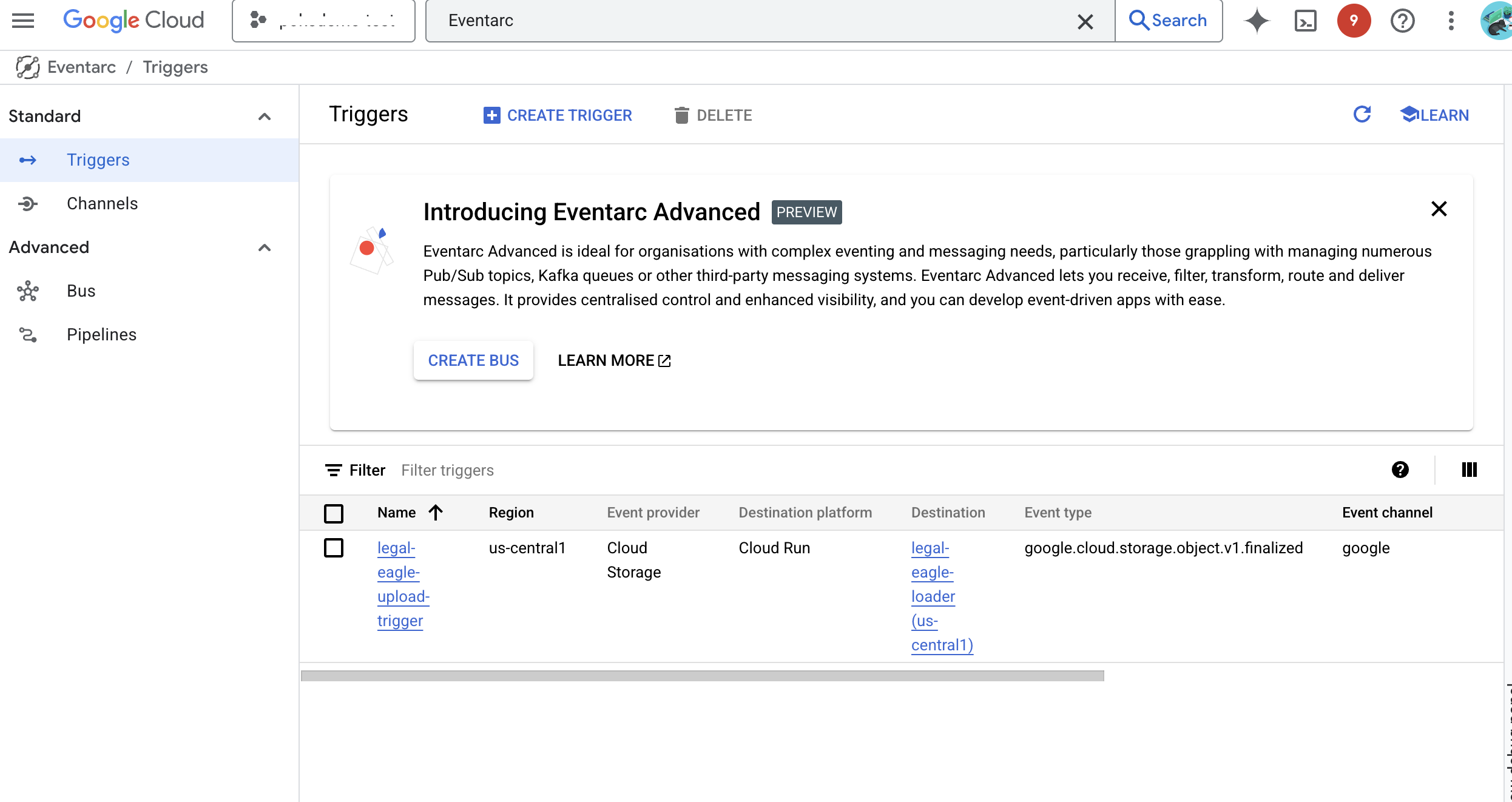
👉 No console do Google Cloud, acesse Gatilhos em EventArc. Clique em "+ CRIAR GATILHO". 👉 Configure o gatilho do Eventarc:
- Nome do gatilho:
legal-eagle-upload-trigger. - TriggerType: fontes do Google
- Provedor de eventos: selecione Cloud Storage.
- Tipo de evento: escolha
google.cloud.storage.object.v1.finalized - Bucket do Cloud Storage: selecione seu bucket do GCS no menu suspenso.
- Tipo de destino: "Serviço do Cloud Run".
- Serviço: selecione
legal-eagle-loader. - Região:
us-central1 - Caminho: deixe em branco por enquanto .
- Conceda todas as permissões solicitadas na página.
👉 Clique em CRIAR. O Eventarc vai configurar o gatilho.
O serviço do Cloud Run precisa de permissão para ler arquivos de vários componentes. Precisamos conceder à conta de serviço do serviço a permissão necessária.
12. Fazer upload de documentos legais para o bucket do GCS
👉 Faça upload do arquivo do caso judicial para o bucket do GCS. Substitua o nome do bucket.
export DOC_BUCKET_NAME=$(gcloud storage buckets list --format="value(name)" | grep doc-bucket)
gsutil cp ~/legal-eagle/court_cases/case-02.txt gs://$DOC_BUCKET_NAME/
gsutil cp ~/legal-eagle/court_cases/case-03.txt gs://$DOC_BUCKET_NAME/
gsutil cp ~/legal-eagle/court_cases/case-06.txt gs://$DOC_BUCKET_NAME/
Monitore os registros do serviço do Cloud Run. Acesse Cloud Run -> seu serviço legal-eagle-loader -> "Registros". Verifique os registros de mensagens de processamento bem-sucedido, incluindo:
xxx
POST200130 B8.3 sAPIs-Google; (+https://developers.google.com/webmasters/APIs-Google.html) https://legal-eagle-loader-bmngrueyta-uc.a.run.app/?__GCP_CloudEventsMode=GCS_NOTIFICATION
xxx
POST200130 B520 msAPIs-Google; (+https://developers.google.com/webmasters/APIs-Google.html) https://legal-eagle-loader-bmngrueyta-uc.a.run.app/?__GCP_CloudEventsMode=GCS_NOTIFICATION
xxx
POST200130 B514 msAPIs-Google; (+https://developers.google.com/webmasters/APIs-Google.html) https://legal-eagle-loader-bmngrueyta-uc.a.run.app/?__GCP_CloudEventsMode=GCS_NOTIFICATION
E, dependendo da velocidade com que o registro foi configurado, você também verá registros mais detalhados aqui.
"CloudEvent received:"
"New file detected in bucket:"
"File content downloaded. Processing..."
"Text split into ... chunks."
"File processing and Firestore upsert complete..."
Procure mensagens de erro nos registros e resolva os problemas, se necessário. 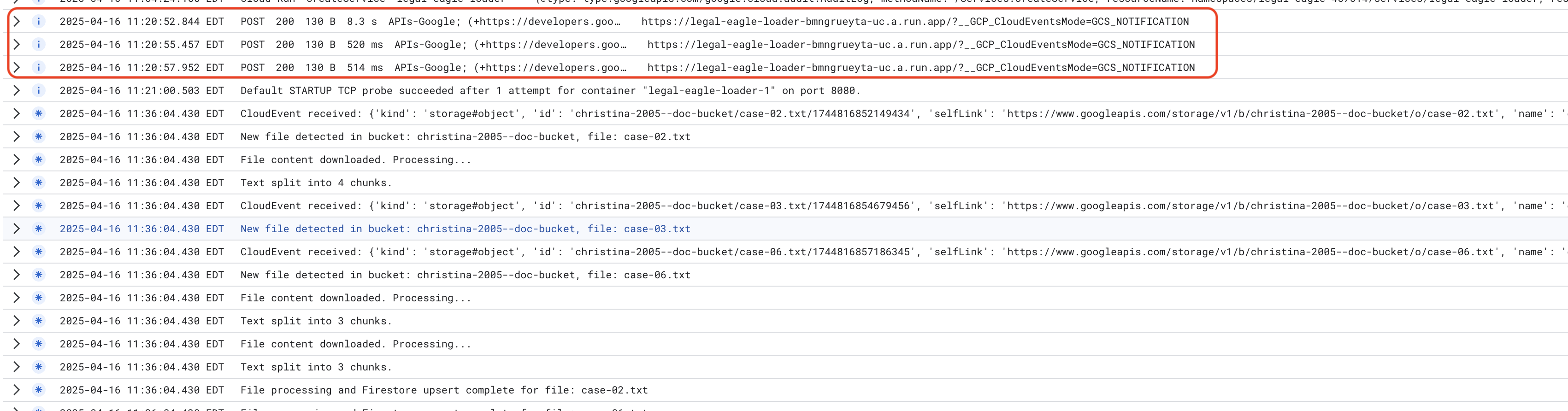
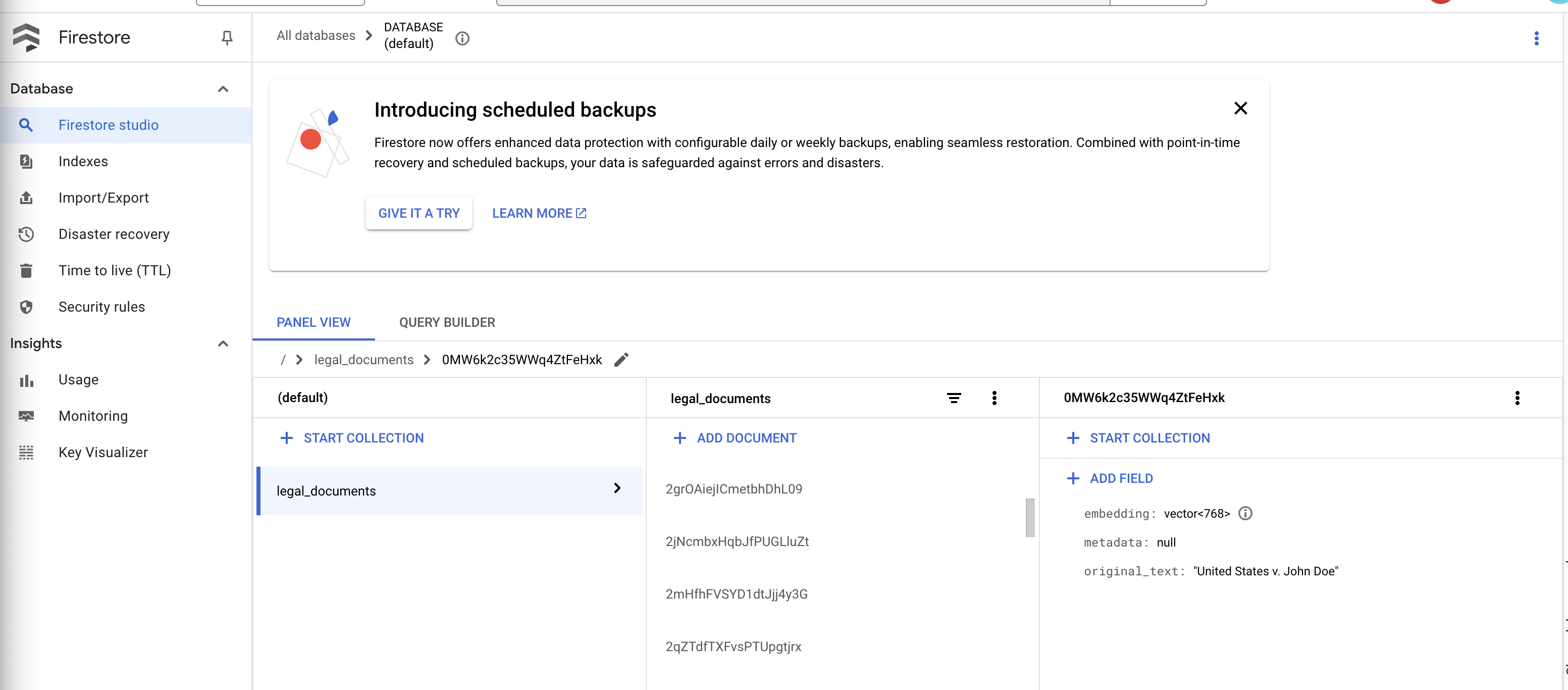
👉 Verifique os dados no Firestore. Abra a coleção legal_documents.
👉 Você vai ver novos documentos criados na sua coleção. Cada documento vai representar um trecho do texto do arquivo enviado e vai conter:
metadata: currently empty
original_text_chunk: The text chunk content.
embedding_: A list of floating-point numbers (the Vertex AI embedding).
13. Implementação do RAG
O LangChain é um framework avançado criado para simplificar o desenvolvimento de aplicativos com tecnologia de modelos de linguagem grandes (LLMs). Em vez de lidar diretamente com as complexidades das APIs de LLM, da engenharia de comandos e do processamento de dados, o LangChain oferece uma camada de abstração de alto nível. Ele oferece componentes e ferramentas pré-criados para tarefas como conexão com vários LLMs (como os da OpenAI, do Google ou de outros), criação de cadeias complexas de operações (por exemplo, recuperação de dados seguida de resumo) e gerenciamento da memória de conversação.
Para a RAG, os repositórios de vetores no LangChain são essenciais para ativar o aspecto de recuperação da RAG. São bancos de dados especializados projetados para armazenar e consultar embeddings de vetores com eficiência, em que trechos de texto semanticamente semelhantes são mapeados para pontos próximos no espaço vetorial. O LangChain cuida da parte de baixo nível, permitindo que os desenvolvedores se concentrem na lógica e na funcionalidade principais do aplicativo RAG. Isso reduz significativamente o tempo e a complexidade do desenvolvimento, permitindo que você crie protótipos e implante rapidamente aplicativos baseados em RAG, aproveitando a robustez e a escalabilidade da infraestrutura em nuvem do Google Cloud.
Agora que você já conhece o LangChain, precisa atualizar o arquivo legal.py na pasta webapp para a implementação do RAG. Isso permite que o LLM pesquise documentos relevantes no Firestore antes de fornecer uma resposta.
👉 Importe FirestoreVectorStore e outros módulos necessários de langchain e vertexai. Adicione o seguinte ao legal.py atual
from langchain_google_vertexai import VertexAIEmbeddings
from langchain_google_firestore import FirestoreVectorStore
👉 Inicialize a Vertex AI e o modelo de embedding.Você vai usar text-embedding-004. Adicione o seguinte código logo após importar os módulos.
PROJECT_ID = os.environ.get("GOOGLE_CLOUD_PROJECT") # Get project ID from env
embedding_model = VertexAIEmbeddings(
model_name="text-embedding-004" ,
project=PROJECT_ID,)
👉 Crie um FirestoreVectorStore apontando para a coleção legal_documents, usando o modelo de embedding inicializado e especificando os campos de conteúdo e embedding. Adicione isso logo após o código do modelo de incorporação anterior.
COLLECTION_NAME = "legal_documents"
# Create a vector store
vector_store = FirestoreVectorStore(
collection="legal_documents",
embedding_service=embedding_model,
content_field="original_text",
embedding_field="embedding",
)
👉 Defina uma função chamada search_resource que recebe uma consulta, realiza uma pesquisa de similaridade usando vector_store.similarity_search e retorna os resultados combinados.
def search_resource(query):
results = []
results = vector_store.similarity_search(query, k=5)
combined_results = "\n".join([result.page_content for result in results])
print(f"==>{combined_results}")
return combined_results
👉 SUBSTITUA a função ask_llm e use a função search_resource para recuperar o contexto relevante com base na consulta do usuário.
def ask_llm(query):
try:
query_message = {
"type": "text",
"text": query,
}
relevant_resource = search_resource(query)
input_msg = HumanMessage(content=[query_message])
prompt_template = ChatPromptTemplate.from_messages(
[
SystemMessage(
content=(
"You are a helpful assistant, and you are with the attorney in a courtroom, you are helping him to win the case by providing the information he needs "
"Don't answer if you don't know the answer, just say sorry in a funny way possible"
"Use high engergy tone, don't use more than 100 words to answer"
f"Here is some context that is relevant to the question {relevant_resource} that you might use"
)
),
input_msg,
]
)
prompt = prompt_template.format()
response = llm.invoke(prompt)
print(f"response: {response}")
return response
except Exception as e:
print(f"Error sending message to chatbot: {e}") # Log this error too!
return f"Unable to process your request at this time. Due to the following reason: {str(e)}"
👉 OPCIONAL: VERSÃO EM ESPANHOL
Sustituye el siguiente texto como se indica: You are a helpful assistant, to You are a helpful assistant that speaks Spanish,
👉 Depois de implementar o RAG em legal.py, teste localmente antes de implantar. Execute o aplicativo com o comando:
cd ~/legal-eagle/webapp
source env/bin/activate
python main.py
👉 Use o webpreview para acessar o aplicativo, converse com o assistente e digite ctrl+c para sair do processo executado localmente. Execute "deactivate" para sair do ambiente virtual.
deactivate
👉 Para implantar o aplicativo da Web no Cloud Run, o processo é semelhante à função de carregador. Você vai criar, atribuir uma tag e enviar a imagem Docker para o Artifact Registry:
export PROJECT_ID=$(gcloud config get project)
docker build -t gcr.io/${PROJECT_ID}/legal-eagle-webapp .
docker tag gcr.io/${PROJECT_ID}/legal-eagle-webapp us-central1-docker.pkg.dev/${PROJECT_ID}/my-repository/legal-eagle-webapp
docker push us-central1-docker.pkg.dev/${PROJECT_ID}/my-repository/legal-eagle-webapp
👉 Agora é hora de implantar o web app no Google Cloud. No terminal, execute estes comandos:
export PROJECT_ID=$(gcloud config get project)
gcloud run deploy legal-eagle-webapp \
--image us-central1-docker.pkg.dev/$PROJECT_ID/my-repository/legal-eagle-webapp \
--region us-central1 \
--set-env-vars=GOOGLE_CLOUD_PROJECT=${PROJECT_ID} \
--allow-unauthenticated
Para verificar a implantação, acesse Cloud Run no console do Google Cloud.Um novo serviço chamado legal-eagle-webapp vai aparecer na lista.
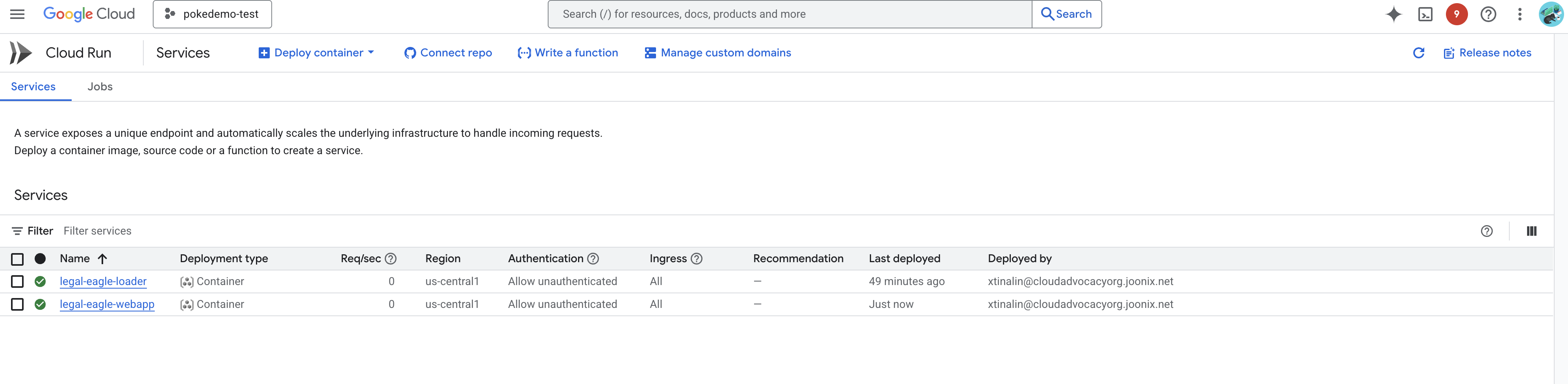
Clique no serviço para acessar a página de detalhes. O URL implantado está disponível na parte de cima. 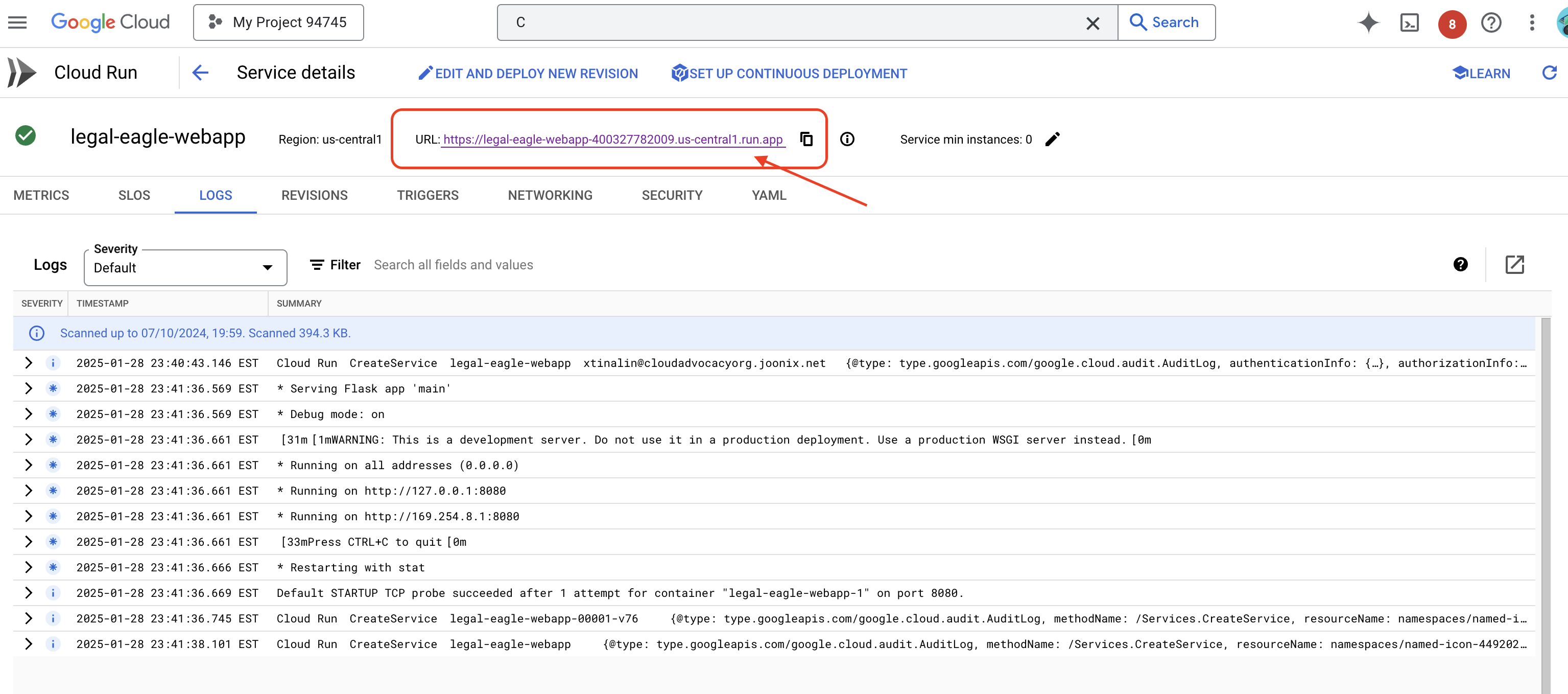
👉 Agora, abra o URL implantado em uma nova guia do navegador. Você pode interagir com o assistente jurídico e fazer perguntas relacionadas aos casos judiciais que carregou(na pasta "court_cases"):
- A quantos anos de prisão Michael Brown foi condenado?
- Quanto dinheiro em cobranças indevidas foi gerado como resultado das ações de Jane Smith?
- Qual foi o papel dos depoimentos dos vizinhos na investigação do caso de Emily White?
👉 OPCIONAL: VERSÃO EM ESPANHOL
- ¿A cuántos años de prisión fue sentenciado Michael Brown?
- ¿Cuánto dinero en cargos no autorizados se generó como resultado de las acciones de Jane Smith?
- ¿Qué papel jugaron los testimonios de los vecinos en la investigación del caso de Emily White?
Você vai notar que as respostas agora são mais precisas e baseadas no conteúdo dos documentos jurídicos que você enviou, mostrando o poder da RAG.
Parabéns por concluir o workshop! Você criou e implantou um aplicativo de análise de documentos jurídicos usando LLMs, LangChain e Google Cloud. Você aprendeu a ingerir e processar documentos jurídicos, aumentar as respostas do LLM com informações relevantes usando o RAG e implantar seu aplicativo como um serviço sem servidor. Esse conhecimento e o aplicativo criado vão ajudar você a explorar ainda mais o poder dos LLMs para tarefas jurídicas. Muito bem!"
14. Desafio
Tipos de mídia diversos:
Como ingerir e processar diversos tipos de mídia, como vídeos e gravações de áudio de tribunais, e extrair texto relevante.
Recursos on-line:
Como processar recursos on-line, como páginas da Web, ao vivo.