
1. Введение
Меня всегда завораживала напряженность судебного процесса, я представляла себя искусно справляющейся со всеми его сложностями и произносящей убедительные заключительные речи. Хотя моя карьера привела меня в другое русло, я рада поделиться тем, что с помощью искусственного интеллекта мы все можем приблизиться к осуществлению этой мечты о работе в суде.

Сегодня мы углубимся в то, как использовать мощные инструменты искусственного интеллекта Google — такие как Vertex AI, Firestore и Cloud Run Functions — для обработки и понимания юридических данных, выполнения молниеносных поисков и, возможно, чтобы помочь вашему воображаемому клиенту (или себе) выбраться из сложной ситуации.
Возможно, вы и не будете допрашивать свидетеля, но с помощью нашей системы вы сможете за считанные секунды просеять огромные массивы информации, составить четкие резюме и представить наиболее важные данные.
2. Архитектура
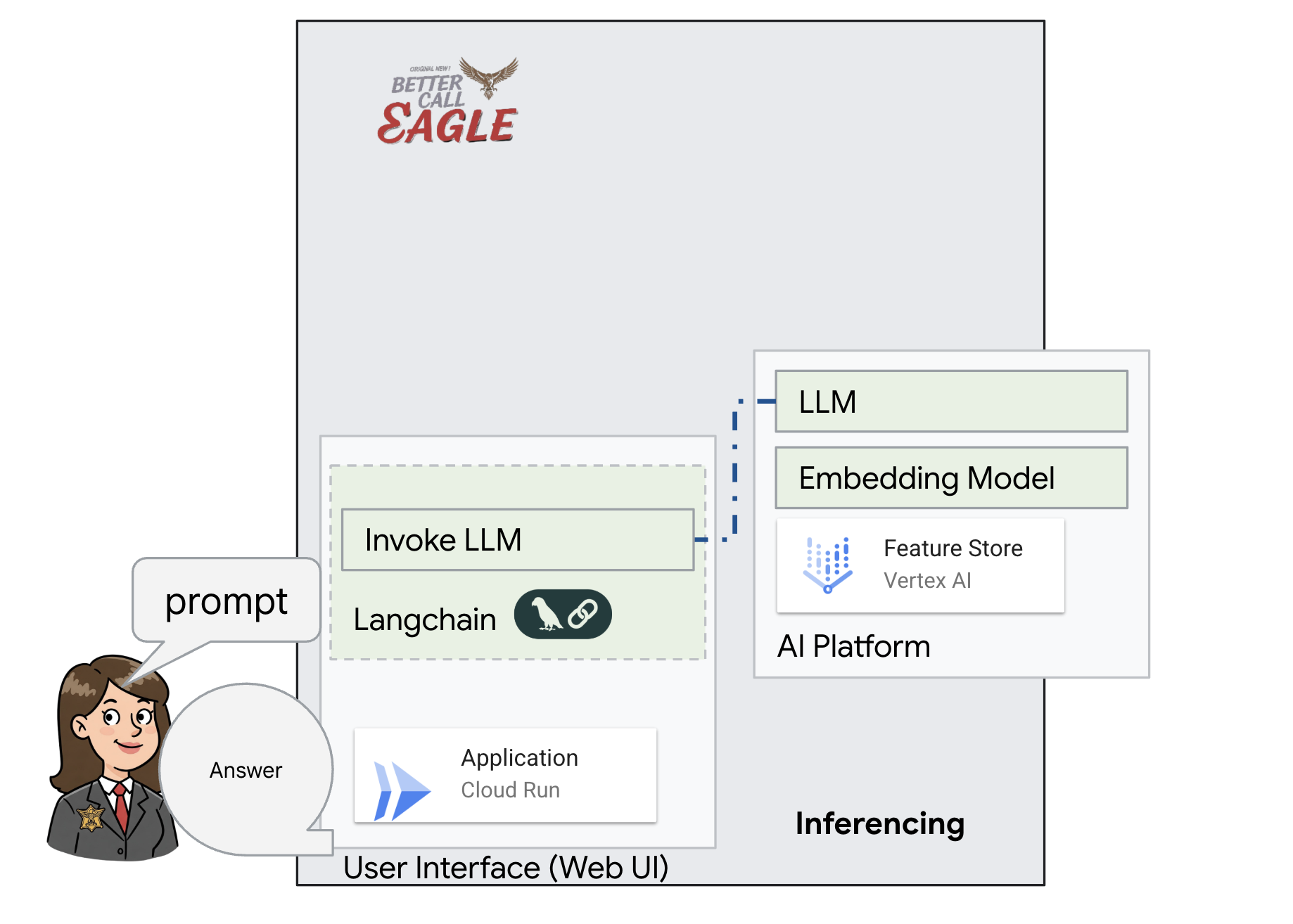
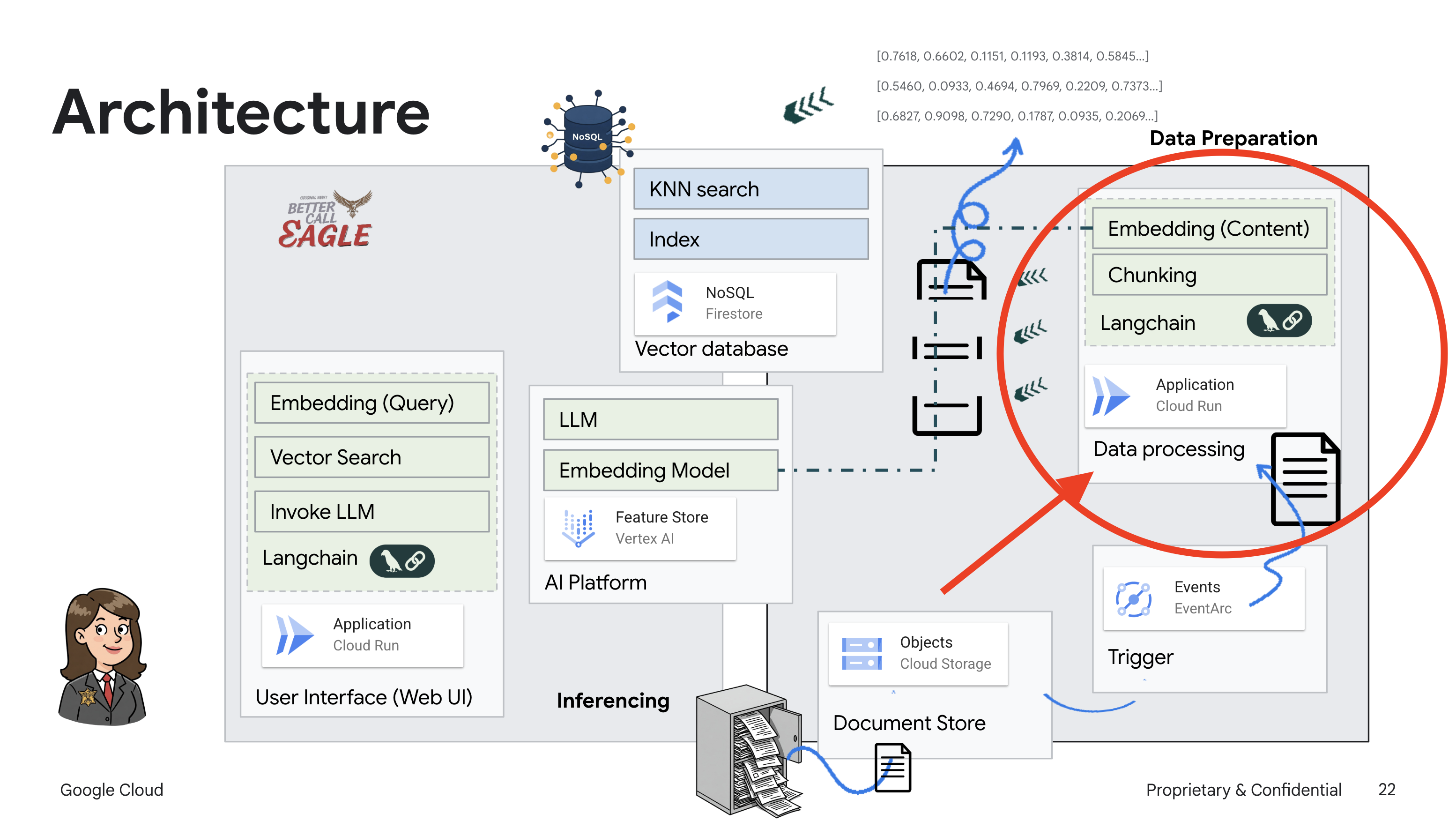
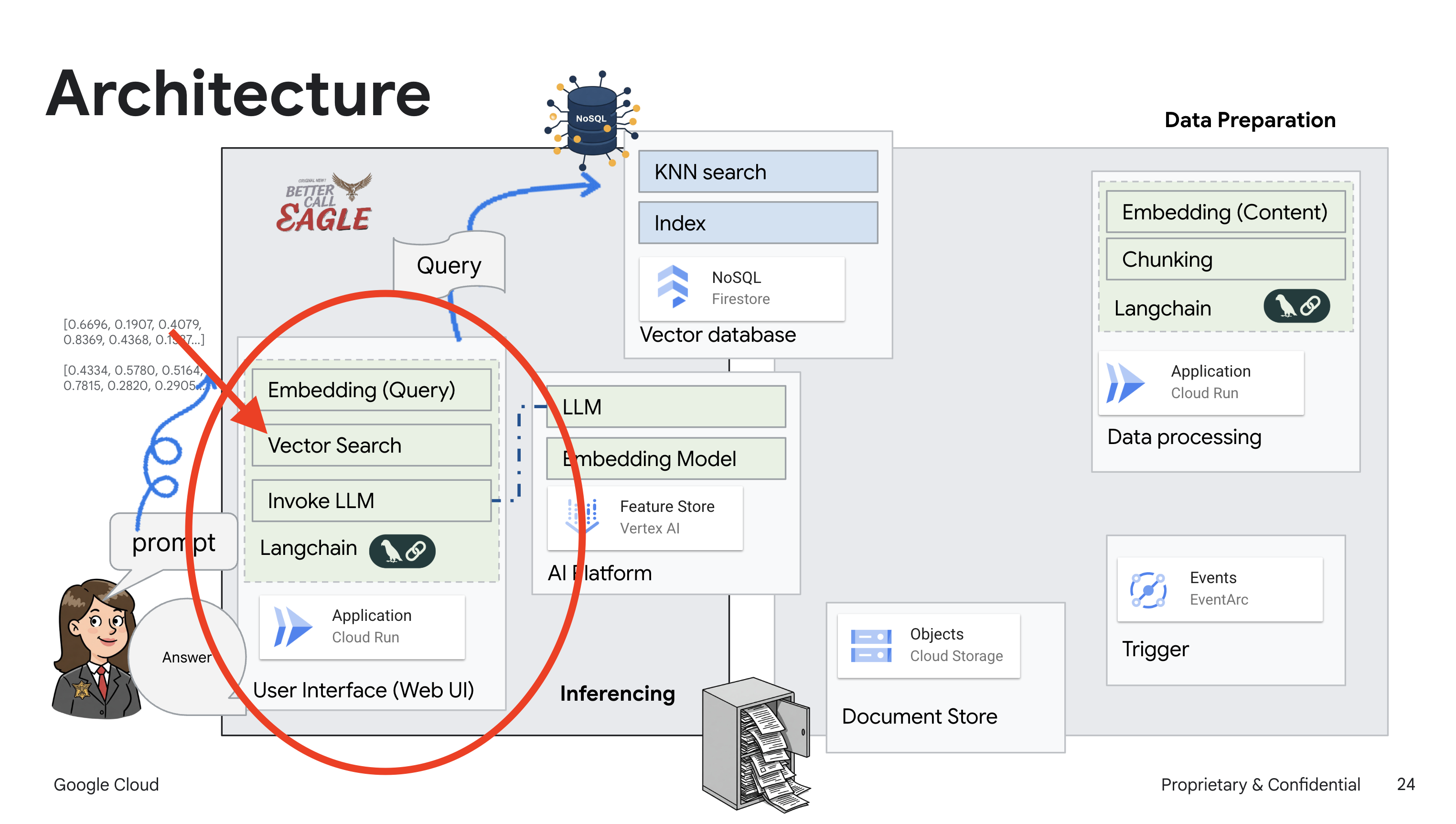
Данный проект посвящен созданию юридического помощника с использованием инструментов Google Cloud AI, с акцентом на обработку, понимание и поиск юридических данных. Система предназначена для анализа больших объемов информации, генерации сводок и быстрого представления релевантных данных. Архитектура юридического помощника включает в себя несколько ключевых компонентов:
Создание базы знаний из неструктурированных данных : Google Cloud Storage (GCS) используется для хранения юридических документов. Firestore, база данных NoSQL, функционирует как векторное хранилище, хранящее фрагменты документов и соответствующие им векторные представления. В Firestore включен векторный поиск для поиска по сходству. Когда новый юридический документ загружается в GCS, Eventarc запускает функцию Cloud Run. Эта функция обрабатывает документ, разбивая его на фрагменты и генерируя векторные представления для каждого фрагмента с помощью модели векторного представления текста Vertex AI. Затем эти векторные представления сохраняются в Firestore вместе с фрагментами текста. 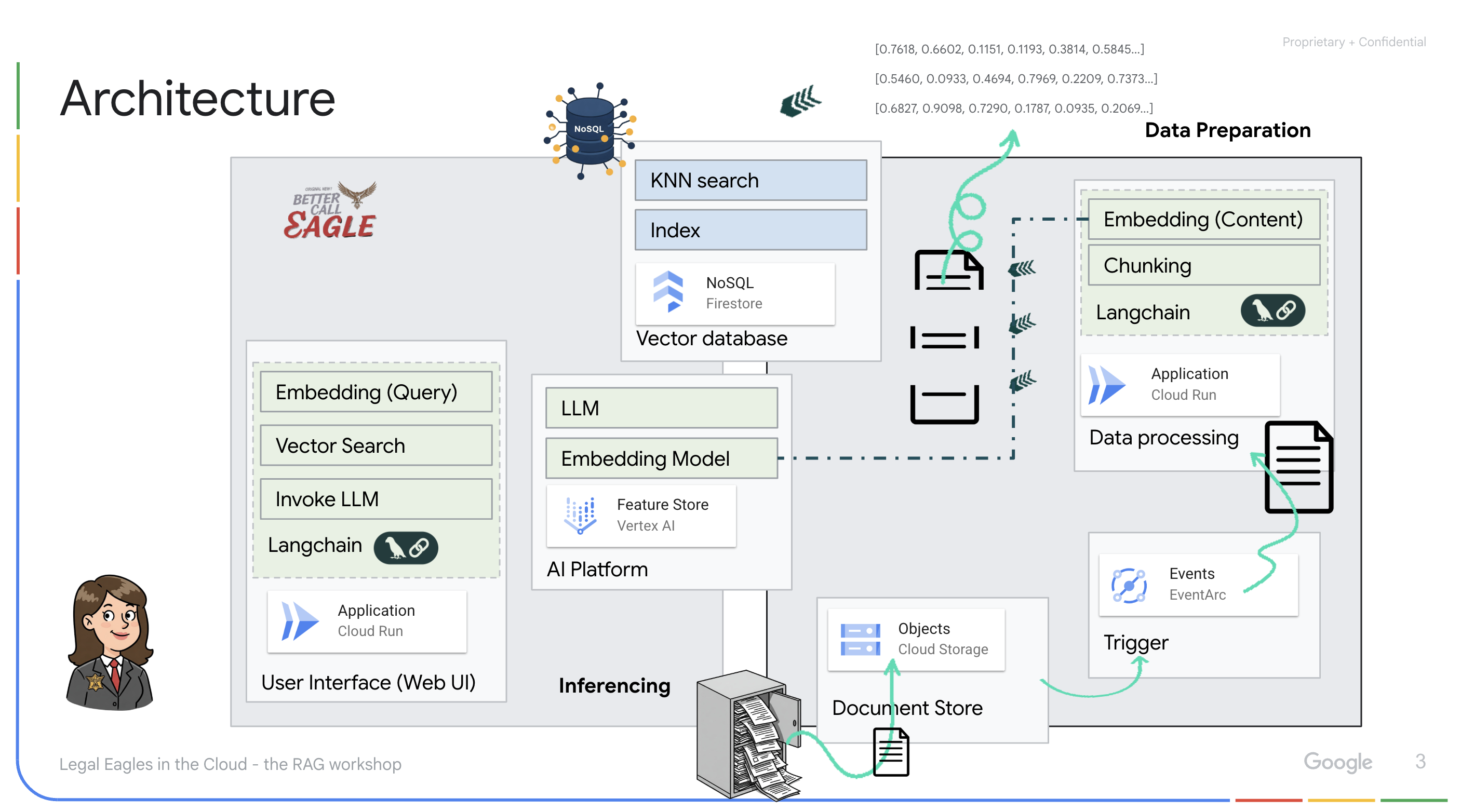
Приложение на базе LLM и RAG : ядром системы ответов на вопросы является функция ask_llm , которая использует библиотеку langchain для взаимодействия с большой языковой моделью Vertex AI Gemini. Она создает HumanMessage на основе запроса пользователя и включает SystemMessage, который инструктирует LLM действовать в качестве полезного юридического помощника. Система использует подход Retrieval-Augmented Generation (RAG), при котором перед ответом на запрос система использует функцию search_resource для извлечения соответствующего контекста из векторного хранилища Firestore. Затем этот контекст включается в SystemMessage, чтобы обосновать ответ LLM на предоставленной юридической информации. 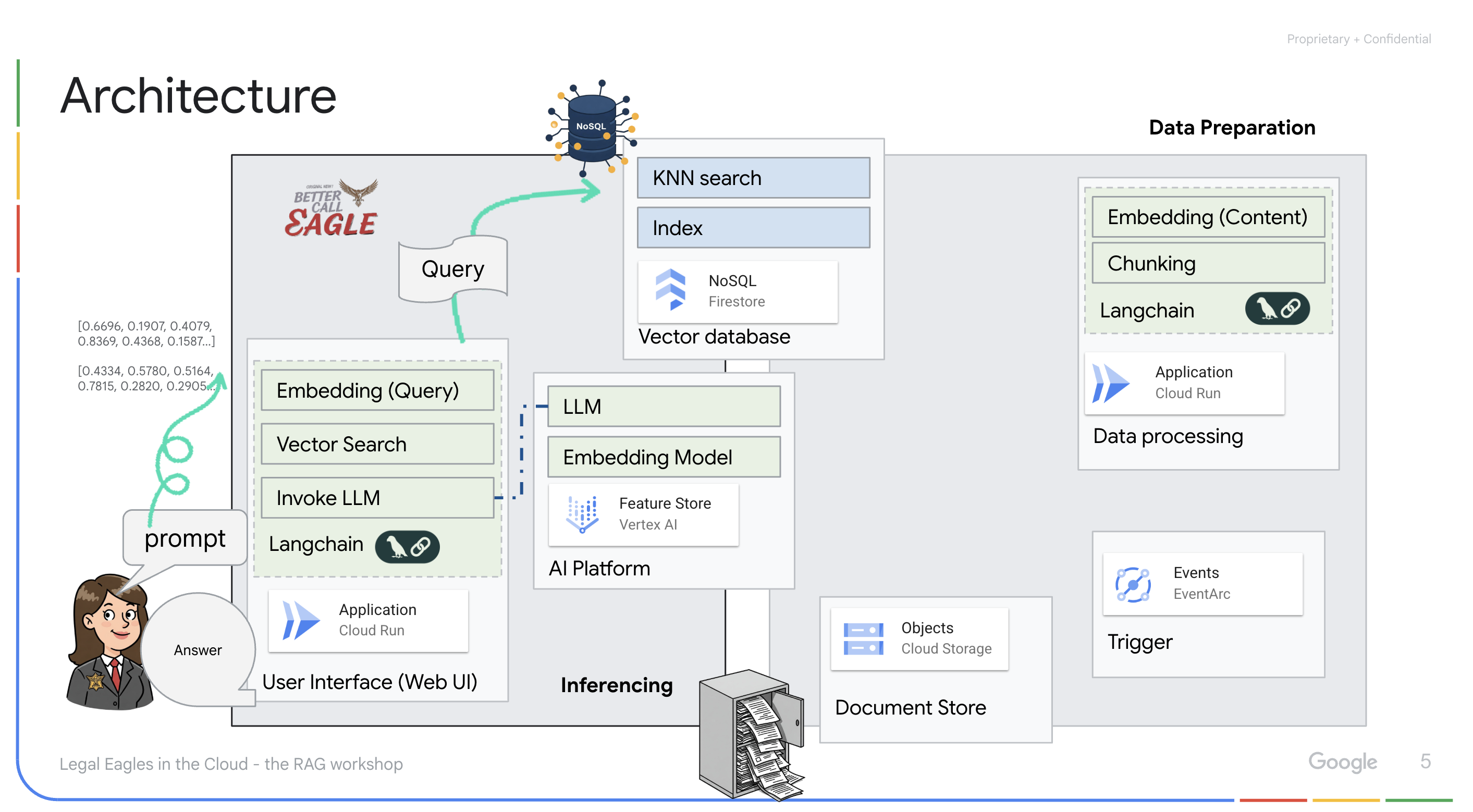
Цель проекта — отойти от «творческих интерпретаций» юридических факультетов, используя алгоритм RAG, который сначала извлекает необходимую информацию из надежного юридического источника, а затем генерирует ответ. Это приводит к более точным и обоснованным ответам, основанным на реальной юридической информации. Система построена с использованием различных сервисов Google Cloud, таких как Google Cloud Shell, Vertex AI, Firestore, Cloud Run и Eventarc.
3. Прежде чем начать
В консоли Google Cloud на странице выбора проекта выберите или создайте проект Google Cloud. Убедитесь, что для вашего проекта Cloud включена оплата. Узнайте, как проверить, включена ли оплата для проекта .
Включите функцию Gemini Code Assist в IDE Cloud Shell.
👉 В консоли Google Cloud перейдите в раздел «Инструменты Gemini Code Assist » и бесплатно активируйте Gemini Code Assist, согласившись с условиями использования.
Проигнорируйте настройку прав доступа и покиньте эту страницу.
Работа над редактором Cloud Shell
👉 Нажмите «Активировать Cloud Shell» в верхней части консоли Google Cloud (это значок терминала в верхней части панели Cloud Shell).
👉 Нажмите на кнопку «Открыть редактор» (она выглядит как открытая папка с карандашом). Это откроет редактор Cloud Shell в окне. Слева вы увидите файловый менеджер.

👉 Нажмите на кнопку « Вход в Cloud Code» в нижней строке состояния, как показано на рисунке. Авторизуйте плагин в соответствии с инструкциями. Если в строке состояния отображается «Cloud Code — нет проекта» , выберите его, затем в раскрывающемся списке «Выберите проект Google Cloud» выберите конкретный проект Google Cloud из списка проектов, с которыми вы планируете работать.
👉 Откройте терминал в облачной IDE, 
👉 В новом терминале убедитесь, что вы уже авторизованы и что проект настроен на ваш идентификатор проекта, используя следующую команду:
gcloud auth list
👉 Нажмите «Активировать Cloud Shell» в верхней части консоли Google Cloud.
gcloud config set project <YOUR_PROJECT_ID>
👉 Выполните следующую команду, чтобы включить необходимые API Google Cloud:
gcloud services enable storage.googleapis.com \
run.googleapis.com \
artifactregistry.googleapis.com \
aiplatform.googleapis.com \
eventarc.googleapis.com \
cloudresourcemanager.googleapis.com \
firestore.googleapis.com \
cloudaicompanion.googleapis.com
На панели инструментов Cloud Shell (в верхней части окна Cloud Shell) нажмите кнопку «Открыть редактор» (она выглядит как открытая папка с карандашом). Это откроет редактор кода Cloud Shell в окне. Слева вы увидите файловый менеджер.
👉 В терминале скачайте шаблон проекта Bootstrap:
git clone https://github.com/weimeilin79/legal-eagle.git
ДОПОЛНИТЕЛЬНО: ИСПАНСКАЯ ВЕРСИЯ
👉 Существует альтернативная версия на испанском языке. Пожалуйста, воспользуйтесь следующей инструкцией, чтобы клонировать правильную версию.
git clone -b spanish https://github.com/weimeilin79/legal-eagle.git
После выполнения этой команды в терминале Cloud Shell в вашей среде Cloud Shell будет создана новая папка с именем репозитория legal-eagle .
4. Разработка приложения для вывода результатов с помощью Gemini Code Assist.
В этом разделе мы сосредоточимся на создании ядра нашего юридического помощника — веб-приложения, которое получает вопросы пользователей и взаимодействует с моделью ИИ для генерации ответов. Мы будем использовать Gemini Code Assist для написания кода на Python для этой части, отвечающей за вывод информации.
Для начала мы создадим приложение Flask, использующее библиотеку LangChain для прямой связи с моделью Vertex AI Gemini. Эта первая версия будет выступать в роли полезного юридического помощника, основанного на общих знаниях модели, но пока не будет иметь доступа к нашим конкретным судебным документам. Это позволит нам оценить базовую производительность LLM, прежде чем мы улучшим её с помощью RAG.
В панели проводника редактора кода Cloud Code Editor (обычно слева) вы должны увидеть папку, созданную при клонировании репозитория Git legal-eagle . Откройте корневую папку вашего проекта в проводнике. Внутри неё вы найдёте подпапку webapp , откройте и её. 
👉 Отредактируйте файл legal.py в облачном редакторе кода. Вы можете использовать различные методы для вызова функции Gemini Code Assist.
👉 Скопируйте следующий текст в конец файла legal.py , который четко описывает, что вы хотите, чтобы Gemini Code Assist сгенерировал, нажмите на появившийся значок лампочки 💡 и выберите Gemini: Generate Code (точный пункт меню может немного отличаться в зависимости от версии Cloud Code).
"""
Write a Python function called `ask_llm` that takes a user `query` as input. This function should use the `langchain` library to interact with a Vertex AI Gemini Large Language Model. Specifically, it should:
1. Create a `HumanMessage` object from the user's `query`.
2. Create a `ChatPromptTemplate` that includes a `SystemMessage` and the `HumanMessage`. The system message should instruct the LLM to act as a helpful assistant in a courtroom setting, aiding an attorney by providing necessary information. It should also specify that the LLM should respond in a high-energy tone, using no more than 100 words, and offer a humorous apology if it doesn't know the answer.
3. Format the `ChatPromptTemplate` with the provided messages.
4. Invoke the Vertex AI LLM with the formatted prompt using the `VertexAI` class (assuming it's already initialized elsewhere as `llm`).
5. Print the LLM's `response`.
6. Return the `response`.
7. Include error handling that prints an error message to the console and returns a user-friendly error message if any issues occur during the process. The Vertex AI model should be "gemini-2.0-flash".
"""
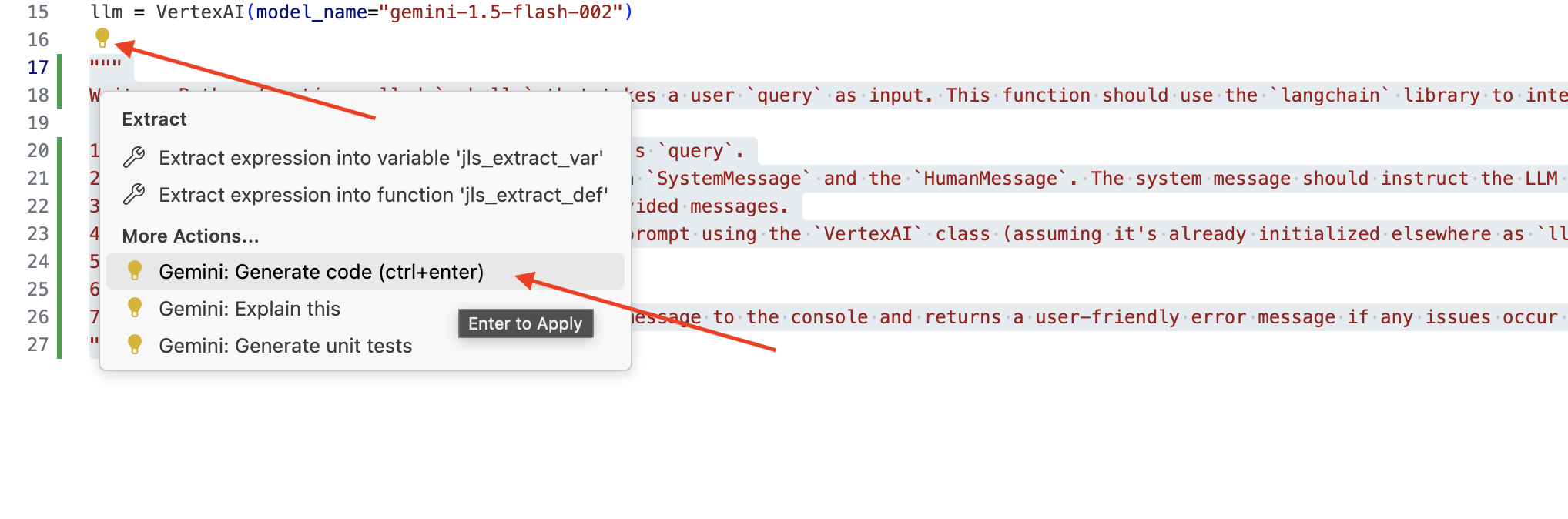
Внимательно проверьте сгенерированный код.
- Соответствует ли это примерно тем шагам, которые вы описали в комментарии?
- Создаёт ли это шаблон
ChatPromptTemplateсSystemMessageиHumanMessage? - Включает ли он базовую обработку ошибок (
try...except)?
Если сгенерированный код корректен и в основном правилен, вы можете его принять (нажмите Tab или Enter для получения встроенных подсказок или кнопку «Принять» для больших блоков кода).
Если сгенерированный код не совсем соответствует вашим ожиданиям или содержит ошибки, не волнуйтесь! Gemini Code Assist — это инструмент, призванный помочь вам, а не обеспечить написание идеального кода с первой попытки.
Редактируйте и изменяйте сгенерированный код, чтобы улучшить его, исправить ошибки и лучше соответствовать вашим требованиям. Вы можете дополнительно активировать Gemini Code Assist , добавив комментарии или задав конкретные вопросы в чате Code Assist.
А если вы ещё не знакомы с SDK, вот рабочий пример.
👉 Скопируйте, вставьте и замените следующий код в файл legal.py :
import os
import signal
import sys
import vertexai
import random
from langchain_google_vertexai import VertexAI
from langchain_core.prompts import PromptTemplate, ChatPromptTemplate
from langchain_core.messages import HumanMessage, SystemMessage
# Connect to resourse needed from Google Cloud
llm = VertexAI(model_name="gemini-2.0-flash")
def ask_llm(query):
try:
query_message = {
"type": "text",
"text": query,
}
input_msg = HumanMessage(content=[query_message])
prompt_template = ChatPromptTemplate.from_messages(
[
SystemMessage(
content=(
"You are a helpful assistant, and you are with the attorney in a courtroom, you are helping him to win the case by providing the information he needs "
"Don't answer if you don't know the answer, just say sorry in a funny way possible"
"Use high engergy tone, don't use more than 100 words to answer"
# f"Here is some past conversation history between you and the user {relevant_history}"
# f"Here is some context that is relevant to the question {relevant_resource} that you might use"
)
),
input_msg,
]
)
prompt = prompt_template.format()
response = llm.invoke(prompt)
print(f"response: {response}")
return response
except Exception as e:
print(f"Error sending message to chatbot: {e}") # Log this error too!
return f"Unable to process your request at this time. Due to the following reason: {str(e)}"
👉 ДОПОЛНИТЕЛЬНО: ВЕРСИЯ НА ИСПАНСКОМ ЯЗЫКЕ
Sustituye el siguiente texto como se indica: You are a helpful assistant, « You are a helpful assistant that speaks Spanish,
Далее создайте функцию для обработки маршрута, который будет отвечать на вопросы пользователя.
Откройте main.py в редакторе Cloud Shell. Аналогично тому, как вы создавали функцию ask_llm в legal.py , используйте Gemini Code Assist для генерации маршрута Flask и функции ask_question . Введите следующий PROMPT в качестве комментария в main.py : (Убедитесь, что он добавлен перед запуском приложения Flask в строке if __name__ == "__main__": )
.....
@app.route('/',methods=['GET'])
def index():
return render_template('index.html')
"""
PROMPT:
Create a Flask endpoint that accepts POST requests at the '/ask' route.
The request should contain a JSON payload with a 'question' field. Extract the question from the JSON payload.
Call a function named ask_llm (located in a file named legal.py) with the extracted question as an argument.
Return the result of the ask_llm function as the response with a 200 status code.
If any error occurs during the process, return a 500 status code with the error message.
"""
# Add this block to start the Flask app when running locally
if __name__ == "__main__":
.....
Принимайте только в том случае, если сгенерированный код хороший и в основном корректный. Если вы не знакомы с Python, вот рабочий пример, скопируйте и вставьте его в ваш main.py под уже существующий код.
👉 Убедитесь, что вы вставили следующее ПЕРЕД запуском веб-приложения (если имя == "main":)
@app.route('/ask', methods=['POST'])
def ask_question():
data = request.get_json()
question = data.get('question')
try:
# call the ask_llm in legal.py
answer_markdown = legal.ask_llm(question)
print(f"answer_markdown: {answer_markdown}")
# Return the Markdown as the response
return answer_markdown, 200
except Exception as e:
return f"Error: {str(e)}", 500 # Handle errors appropriately
Выполнив эти шаги, вы сможете успешно включить Gemini Code Assist , настроить свой проект и использовать его для генерации функции ask в файле main.py
5. Локальное тестирование в облачном редакторе
👉 В терминале редактора установите зависимые библиотеки и запустите веб-интерфейс локально.
cd ~/legal-eagle/webapp
python -m venv env
source env/bin/activate
export PROJECT_ID=$(gcloud config get project)
pip install -r requirements.txt
python main.py
Обратите внимание на сообщения о запуске в выводе терминала Cloud Shell. Flask обычно выводит сообщения, указывающие на то, что он запущен и на каком порту.
- Работает по адресу http://127.0.0.1:8080
Для обработки запросов приложению необходимо постоянное выполнение.
👉 В меню «Предварительный просмотр веб-страницы» выберите «Предварительный просмотр на порту 8080 ». Cloud Shell откроет новую вкладку или окно браузера с предварительным просмотром вашего приложения. 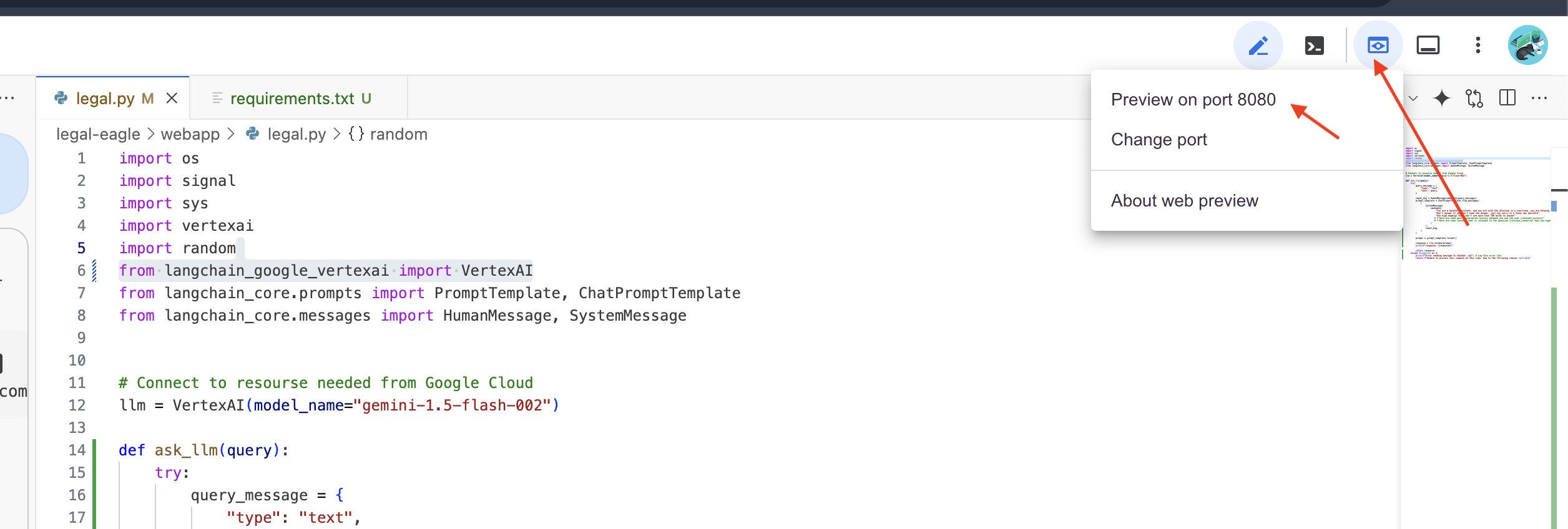
👉 В интерфейсе приложения введите несколько вопросов, касающихся конкретных примеров из юридической практики, и посмотрите, как ответит программа LLM. Например, вы можете попробовать:
- К какому сроку тюремного заключения был приговорен Майкл Браун?
- Какова сумма денег, списанная в результате действий Джейн Смит в результате несанкционированных платежей?
- Какую роль сыграли показания соседей в расследовании дела Эмили Уайт?
👉 ДОПОЛНИТЕЛЬНО: ВЕРСИЯ НА ИСПАНСКОМ ЯЗЫКЕ
- Сколько времени прошло с приговором Майклу Брауну?
- ¿Какие деньги и грузы не авторизованы, если они получены в результате действий Джейн Смит?
- ¿Qué papel jugaron los vecinos de los vecinos в расследовании дела Эмили Уайт?
Если внимательно присмотреться к ответам, вы, вероятно, заметите, что модель может давать галлюцинации, быть расплывчатой или общей, а иногда и неправильно истолковывать ваши вопросы, особенно учитывая, что у нее пока нет доступа к конкретным юридическим документам.
👉 Вы можете остановить выполнение скрипта, нажав Ctrl+C .
👉 Чтобы выйти из виртуальной среды, в терминале выполните:
deactivate
6. Настройка хранилища векторных изображений
Пора положить конец этим «творческим интерпретациям» закона, предлагаемым магистрами права. Вот тут-то и приходит на помощь метод генерации с расширенным поиском информации (Retrieval-Augmented Generation, RAG)! Представьте, что вы предоставляете нашему магистру права доступ к сверхмощной юридической библиотеке прямо перед тем, как он ответит на ваши вопросы. Вместо того чтобы полагаться исключительно на свои общие знания (которые могут быть неточными или устаревшими в зависимости от модели), RAG сначала извлекает соответствующую информацию из надежного источника — в нашем случае, из юридических документов — а затем использует этот контекст для генерации гораздо более обоснованного и точного ответа. Это как если бы магистр права делал домашнее задание перед тем, как войти в зал суда!
Для создания нашей системы RAG нам необходимо место для хранения всех этих юридических документов и, что немаловажно, для обеспечения возможности поиска по смыслу. Вот тут-то и пригодится Firestore! Firestore — это гибкая и масштабируемая документоориентированная база данных NoSQL от Google Cloud.
В качестве векторного хранилища мы будем использовать Firestore . Мы будем хранить фрагменты наших юридических документов в Firestore , и для каждого фрагмента мы также будем хранить его векторное представление — числовое отображение его смысла.
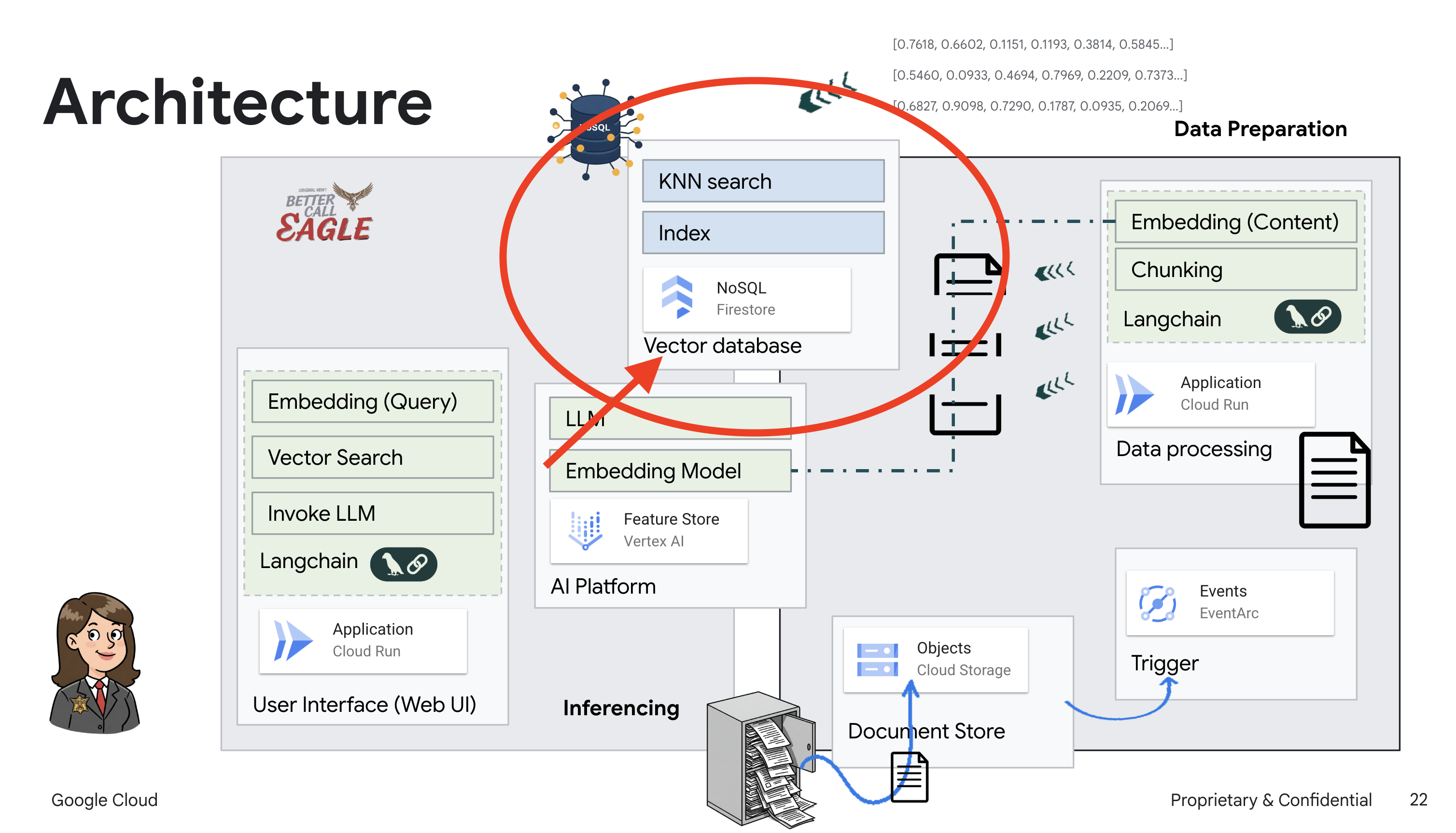
Затем, когда вы зададите вопрос нашему специалисту по правовым вопросам, мы воспользуемся векторным поиском Firestore, чтобы найти фрагменты юридического текста, наиболее релевантные вашему запросу. Именно этот полученный контекст RAG использует для предоставления вам ответов, основанных на реальной юридической информации, а не просто на воображении выпускников магистратуры!
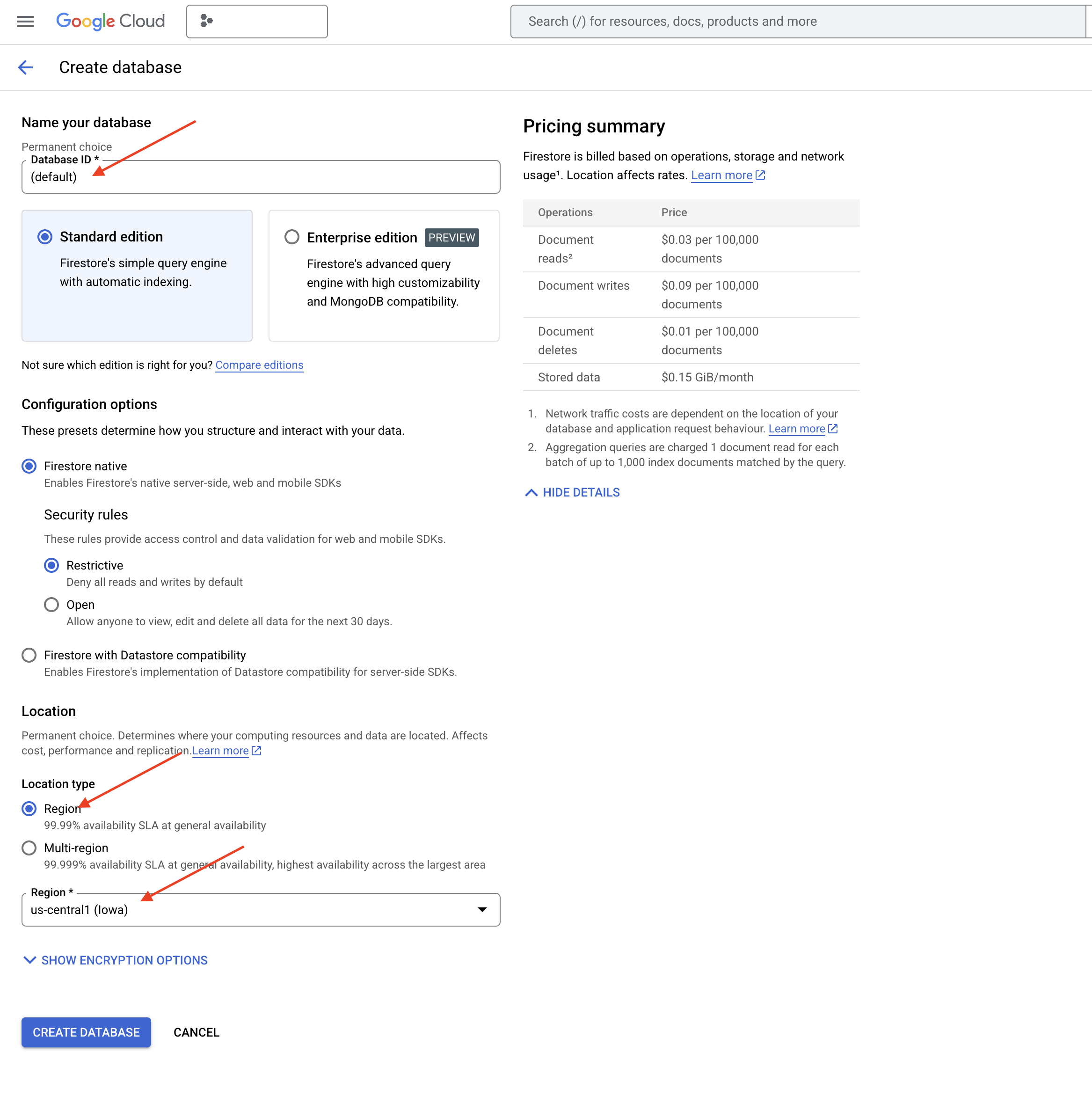
👉 В новой вкладке/окне перейдите в консоль Google Cloud в раздел Firestore.
👉 Нажмите «Создать базу данных»
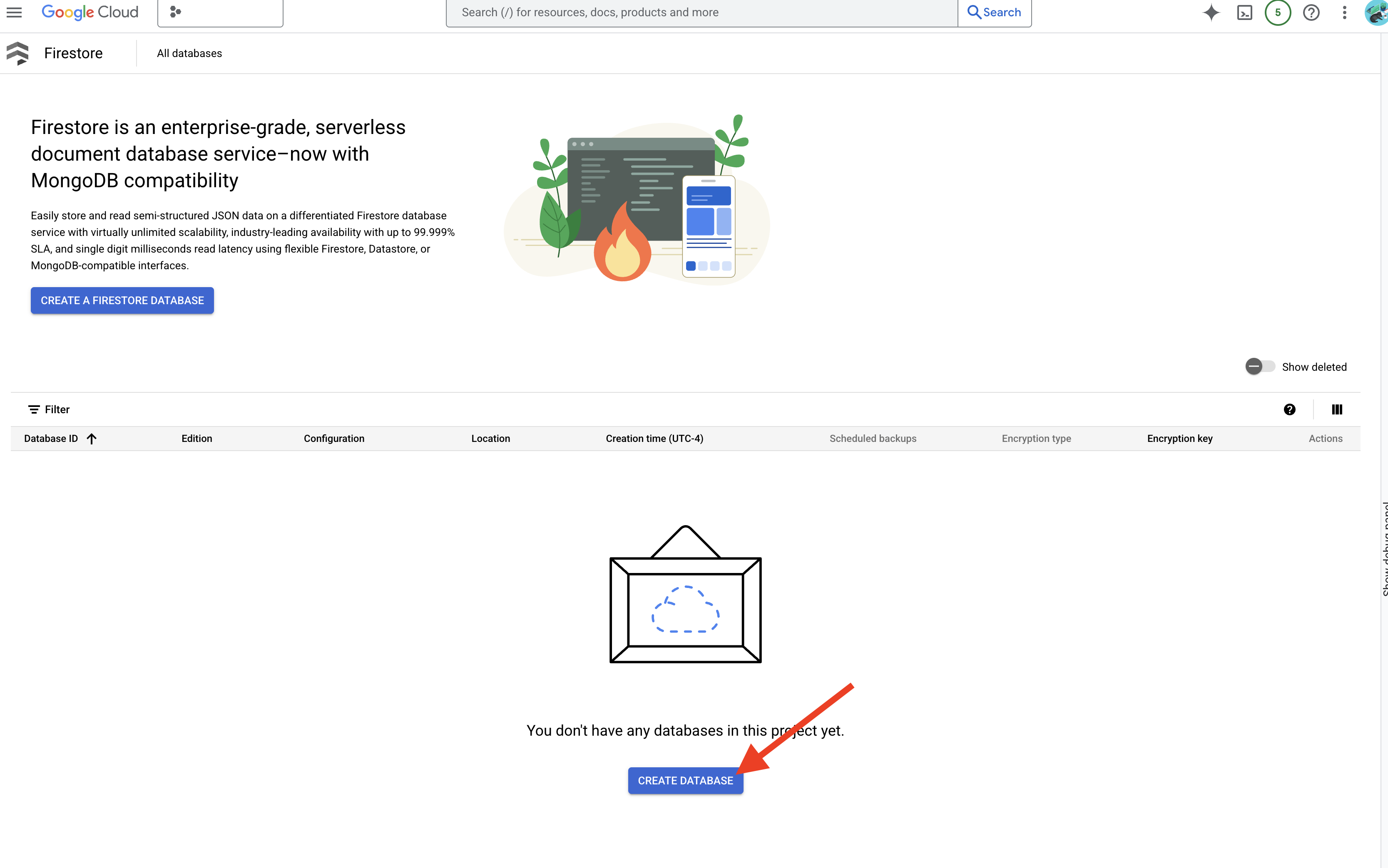
👉 Выберите Native mode и имя базы данных (default) .
👉 Выберите один region : us-central1 и нажмите «Создать базу данных» . Firestore создаст вашу базу данных, что может занять несколько минут.
👉 Вернитесь в терминал Cloud IDE и создайте векторный индекс для поля embedding_vector, чтобы включить векторный поиск в вашей коллекции legal_documents.
export PROJECT_ID=$(gcloud config get project)
gcloud firestore indexes composite create \
--collection-group=legal_documents \
--query-scope=COLLECTION \
--field-config field-path=embedding,vector-config='{"dimension":"768", "flat": "{}"}' \
--project=${PROJECT_ID}
Firestore начнет создание векторного индекса. Создание индекса может занять некоторое время, особенно для больших наборов данных. Вы увидите, что индекс находится в состоянии «Создается», и он перейдет в состояние «Готов», когда будет создан. 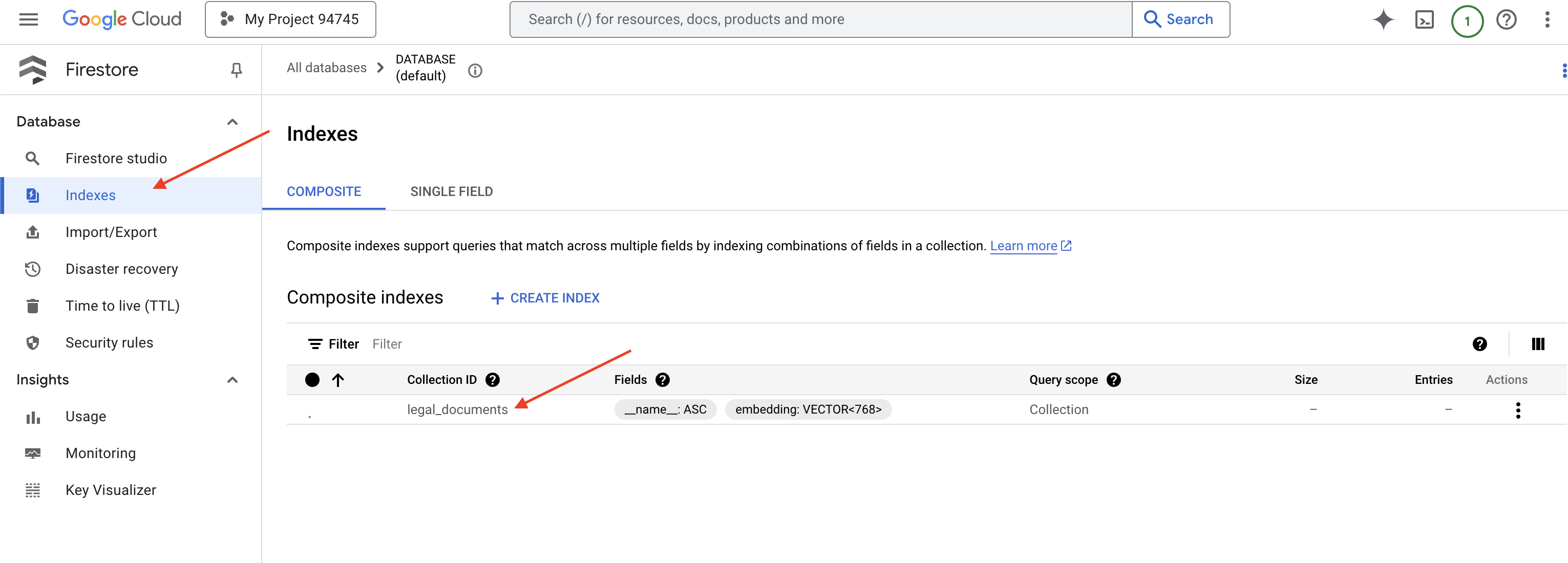
7. Загрузка данных в векторное хранилище
Теперь, когда мы разобрались с RAG и нашим хранилищем векторов, пришло время создать механизм, который будет наполнять нашу юридическую библиотеку! Итак, как же сделать юридические документы «доступными для поиска по смыслу»? Магия кроется в эмбеддингах! Представьте себе эмбеддинги как преобразование слов, предложений или даже целых документов в числовые векторы — списки чисел, которые отражают их семантическое значение. Аналогичные концепции позволяют получить векторы, которые «близки» друг к другу в векторном пространстве. Для выполнения этого преобразования мы используем мощные модели (например, от Vertex AI).
Для автоматизации загрузки документов мы будем использовать Cloud Run Functions и Eventarc . Cloud Run Functions — это легковесный бессерверный контейнер, который запускает ваш код только тогда, когда это необходимо. Мы упакуем наш скрипт обработки документов на Python в контейнер и развернем его как функцию Cloud Run.
👉 В новой вкладке/окне перейдите в раздел «Облачное хранилище» .
👉 Нажмите на «Корзины» в меню слева.
👉 Нажмите на кнопку "+ СОЗДАТЬ" вверху.
👉 Настройте свой бакет (важные параметры):
- Имя корзины : 'yourprojectID' -doc-bucket (Вам обязательно нужно добавить суффикс -doc-bucket в конце)
- регион : Выберите регион
us-central1. - Класс хранения : «Стандартный». Стандартный класс подходит для часто используемых данных.
- Контроль доступа : Оставьте выбранным параметр «Единый контроль доступа» по умолчанию. Это обеспечивает согласованный контроль доступа на уровне сегментов.
- Расширенные параметры : Для данного руководства обычно достаточно настроек по умолчанию.
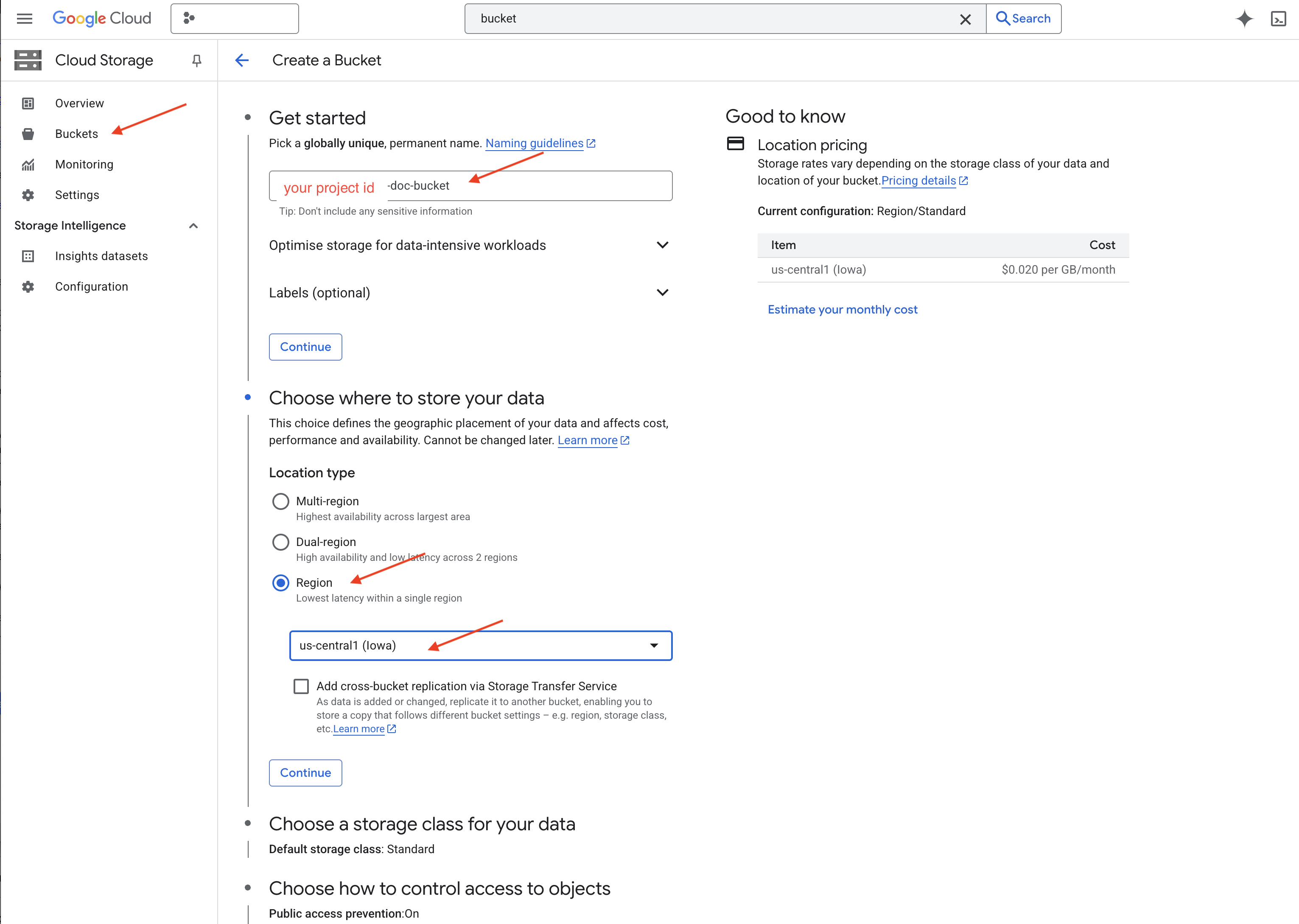
👉 Нажмите кнопку СОЗДАТЬ , чтобы создать свой бакет.
👉 Возможно, появится всплывающее окно о запрете публичного доступа. Оставьте флажок отмеченным и нажмите «Подтвердить».
Теперь вы увидите созданный вами контейнер в списке контейнеров. Запомните название контейнера, оно понадобится вам позже.
8. Настройка функции запуска в облаке
👉 В редакторе кода Cloud Shell перейдите в рабочую директорию legal-eagle : используйте команду cd в терминале Cloud Editor, чтобы создать папку.
cd ~/legal-eagle
mkdir loader
cd loader
👉 Создайте файлы main.py , requirements.txt и Dockerfile . В терминале Cloud Shell используйте команду touch для создания этих файлов:
touch main.py requirements.txt Dockerfile
Вы увидите недавно созданную папку под названием *loader и три файла.
👉 Отредактируйте main.py в папке loader . В файловом менеджере слева перейдите в каталог, где вы создали файлы, и дважды щелкните main.py , чтобы открыть его в редакторе.
Вставьте следующий код Python в main.py :
Это приложение обрабатывает новые файлы, загруженные в хранилище GCS, разбивает текст на фрагменты, генерирует векторные представления для каждого фрагмента и сохраняет фрагменты и их векторные представления в Firestore.
import os
import json
from google.cloud import storage
import functions_framework
from langchain_google_vertexai import VertexAI, VertexAIEmbeddings
from langchain_google_firestore import FirestoreVectorStore
from langchain.text_splitter import RecursiveCharacterTextSplitter
import vertexai
PROJECT_ID = os.environ.get("GOOGLE_CLOUD_PROJECT") # Get project ID from env
embedding_model = VertexAIEmbeddings(
model_name="text-embedding-004" ,
project=PROJECT_ID,)
COLLECTION_NAME = "legal_documents"
# Create a vector store
vector_store = FirestoreVectorStore(
collection="legal_documents",
embedding_service=embedding_model,
content_field="original_text",
embedding_field="embedding",
)
@functions_framework.cloud_event
def process_file(cloud_event):
print(f"CloudEvent received: {cloud_event.data}") # Print the parsed event data
"""Triggered by a Cloud Storage event.
Args:
cloud_event (functions_framework.CloudEvent): The CloudEvent
containing the Cloud Storage event data.
"""
try:
event_data = cloud_event.data
bucket_name = event_data['bucket']
file_name = event_data['name']
except (json.JSONDecodeError, AttributeError, KeyError) as e: # Catch JSON errors
print(f"Error decoding CloudEvent data: {e} - Data: {cloud_event.data}")
return "Error processing event", 500 # Return an error response
print(f"New file detected in bucket: {bucket_name}, file: {file_name}")
storage_client = storage.Client()
bucket = storage_client.bucket(bucket_name)
blob = bucket.blob(file_name)
try:
# Download the file content as string (assuming UTF-8 encoded text file)
file_content_string = blob.download_as_string().decode("utf-8")
print(f"File content downloaded. Processing...")
# Split text into chunks using RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=100,
length_function=len,
)
text_chunks = text_splitter.split_text(file_content_string)
print(f"Text split into {len(text_chunks)} chunks.")
# Add the docs to the vector store
vector_store.add_texts(text_chunks)
print(f"File processing and Firestore upsert complete for file: {file_name}")
return "File processed successfully", 200 # Return success response
except Exception as e:
print(f"Error processing file {file_name}: {e}")
Отредактируйте файл requirements.txt и вставьте в него следующие строки:
Flask==2.3.3
requests==2.31.0
google-generativeai>=0.2.0
langchain
langchain_google_vertexai
langchain-community
langchain-google-firestore
google-cloud-storage
functions-framework
9. Протестируйте и создайте функцию запуска облачных приложений.
👉 Мы запустим это в виртуальной среде и установим необходимые библиотеки Python для функции Cloud Run.
cd ~/legal-eagle/loader
python -m venv env
source env/bin/activate
pip install -r requirements.txt
👉 Запустите локальный эмулятор для функции Cloud Run
functions-framework --target process_file --signature-type=cloudevent --source main.py
👉 Оставьте запущенным последний терминал, откройте новый терминал и выполните команду для загрузки файла в хранилище.
export DOC_BUCKET_NAME=$(gcloud storage buckets list --format="value(name)" | grep doc-bucket)
gsutil cp ~/legal-eagle/court_cases/case-01.txt gs://$DOC_BUCKET_NAME/

👉 Пока эмулятор запущен, вы можете отправлять на него тестовые события CloudEvent. Для этого вам понадобится отдельный терминал в IDE.
curl -X POST -H "Content-Type: application/json" \
-d "{
\"specversion\": \"1.0\",
\"type\": \"google.cloud.storage.object.v1.finalized\",
\"source\": \"//storage.googleapis.com/$DOC_BUCKET_NAME\",
\"subject\": \"objects/case-01.txt\",
\"id\": \"my-event-id\",
\"time\": \"2024-01-01T12:00:00Z\",
\"data\": {
\"bucket\": \"$DOC_BUCKET_NAME\",
\"name\": \"case-01.txt\"
}
}" http://localhost:8080/
Должен отобразиться "ОК".
👉 Чтобы проверить данные в Firestore , перейдите в консоль Google Cloud, затем в раздел «Базы данных», далее в «Firestore», выберите вкладку «Данные» и коллекцию legal_documents . Вы увидите, что в вашей коллекции созданы новые документы, каждый из которых представляет собой фрагмент текста из загруженного файла. 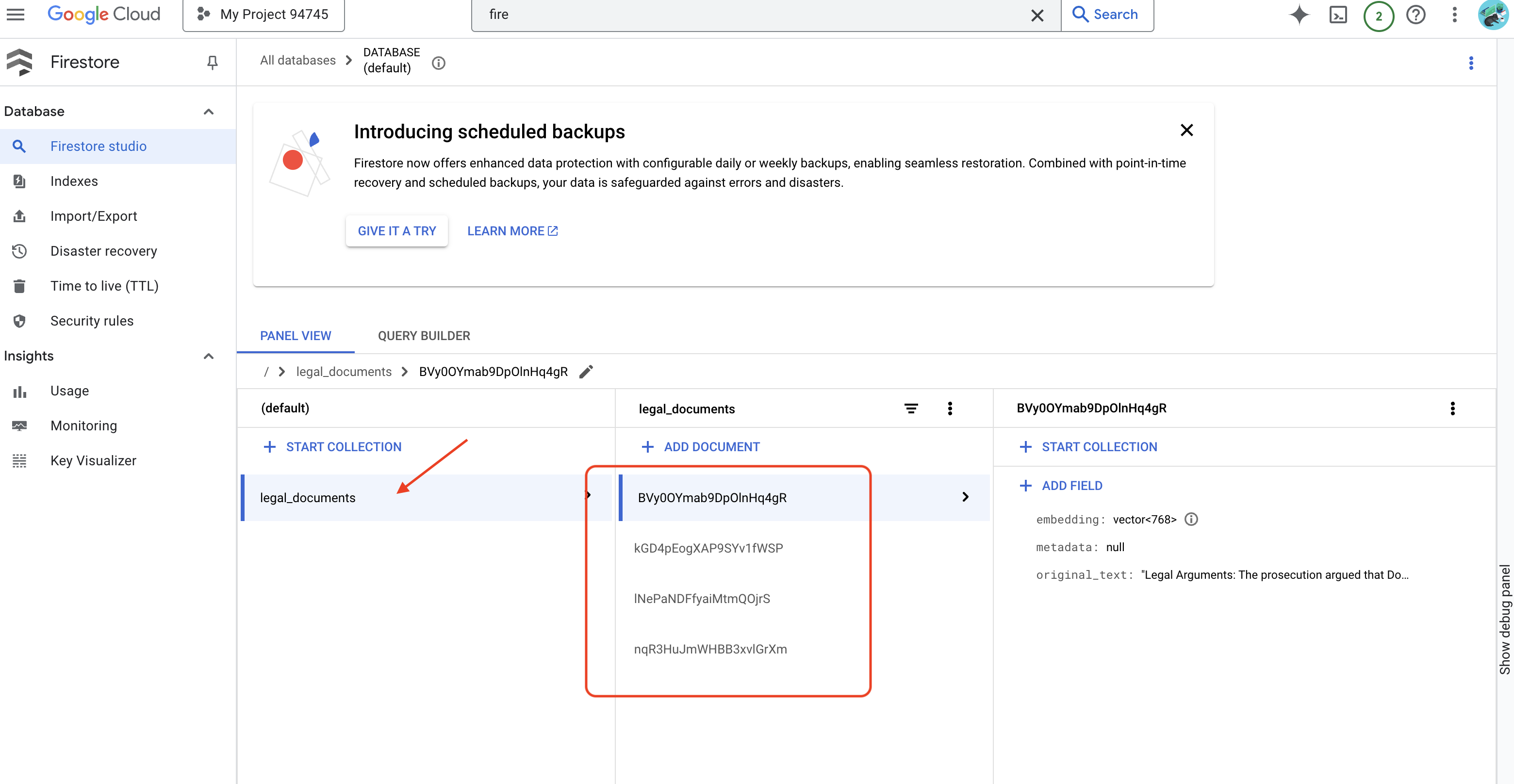
👉 В терминале, где запущен эмулятор, нажмите Ctrl+C для выхода. Затем закройте второй терминал.
👉 Для выхода из виртуальной среды выполните команду deactivate.
deactivate
10. Создайте образ контейнера и загрузите его в репозитории Artifacts.
👉 Пришло время развернуть это в облаке. В файловом менеджере дважды щелкните по Dockerfile. Попросите Gemini сгенерировать для вас Dockerfile, откройте Gemini Code Assist и используйте следующую подсказку для генерации файла.
In the loader folder,
Generate a Dockerfile for a Python 3.12 Cloud Run service that uses functions-framework. It needs to:
1. Use a Python 3.12 slim base image.
2. Set the working directory to /app.
3. Copy requirements.txt and install Python dependencies.
4. Copy main.py.
5. Set the command to run functions-framework, targeting the 'process_file' function on port 8080
Для оптимальной работы рекомендуется нажать кнопку «Различия с открытым файлом» (две стрелки в противоположных направлениях) и принять изменения. 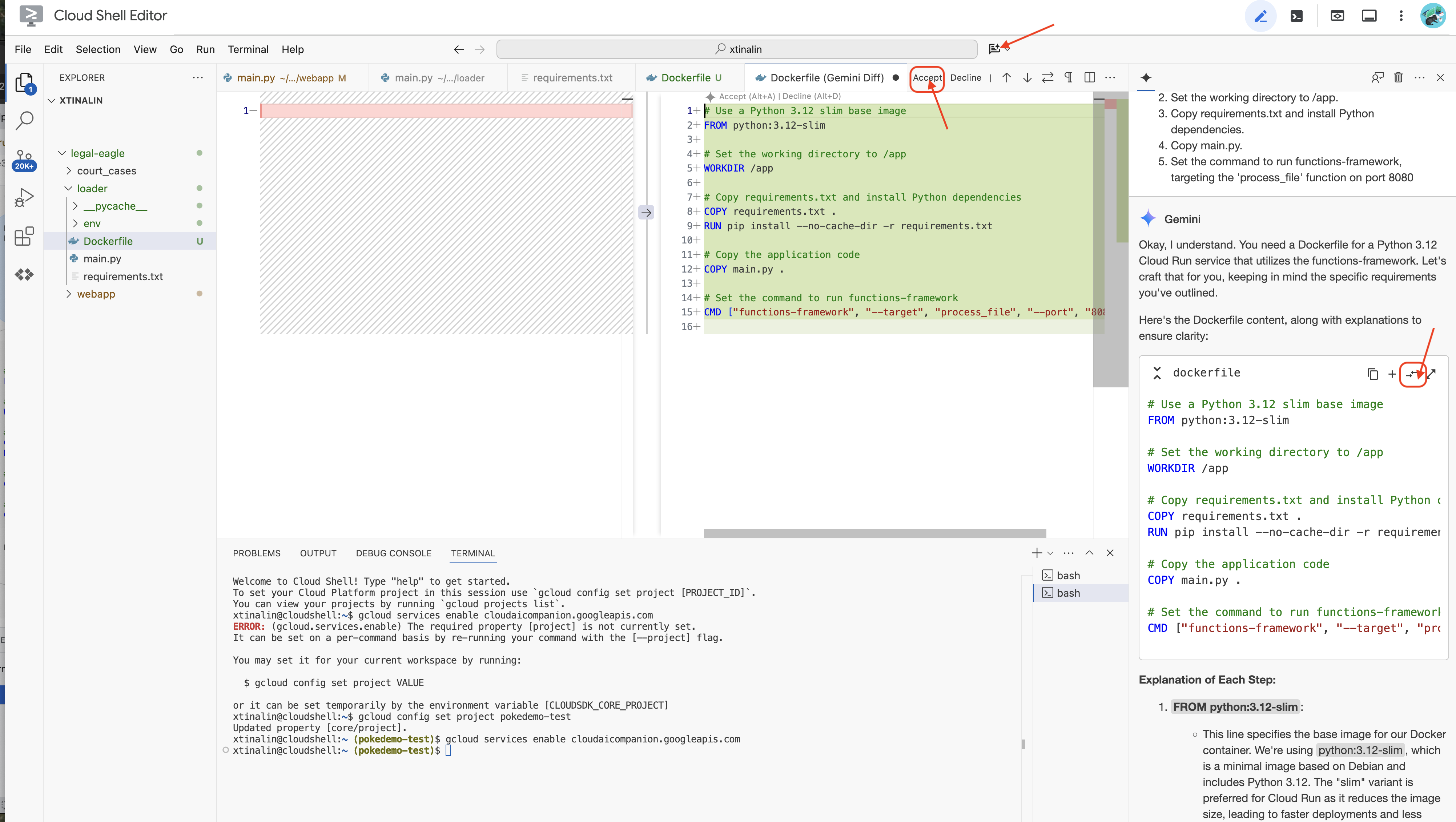
👉 Если вы новичок в контейнерах, вот рабочий пример:
# Use a Python 3.12 slim base image
FROM python:3.12-slim
# Set the working directory to /app
WORKDIR /app
# Copy requirements.txt and install Python dependencies
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
# Copy main.py
COPY main.py .
# Set the command to run functions-framework
CMD ["functions-framework", "--target", "process_file", "--port", "8080"]
👉 В терминале создайте репозиторий артефактов для хранения образа Docker, который мы собираемся собрать.
gcloud artifacts repositories create my-repository \
--repository-format=docker \
--location=us-central1 \
--description="My repository"
Вы должны увидеть сообщение «Создан репозиторий [мой-репозиторий]».
👉 Выполните следующую команду для сборки образа Docker.
cd ~/legal-eagle/loader
export PROJECT_ID=$(gcloud config get project)
docker build -t gcr.io/${PROJECT_ID}/legal-eagle-loader .
👉 Теперь вы отправите это в реестр.
export PROJECT_ID=$(gcloud config get project)
docker tag gcr.io/${PROJECT_ID}/legal-eagle-loader us-central1-docker.pkg.dev/${PROJECT_ID}/my-repository/legal-eagle-loader
docker push us-central1-docker.pkg.dev/${PROJECT_ID}/my-repository/legal-eagle-loader
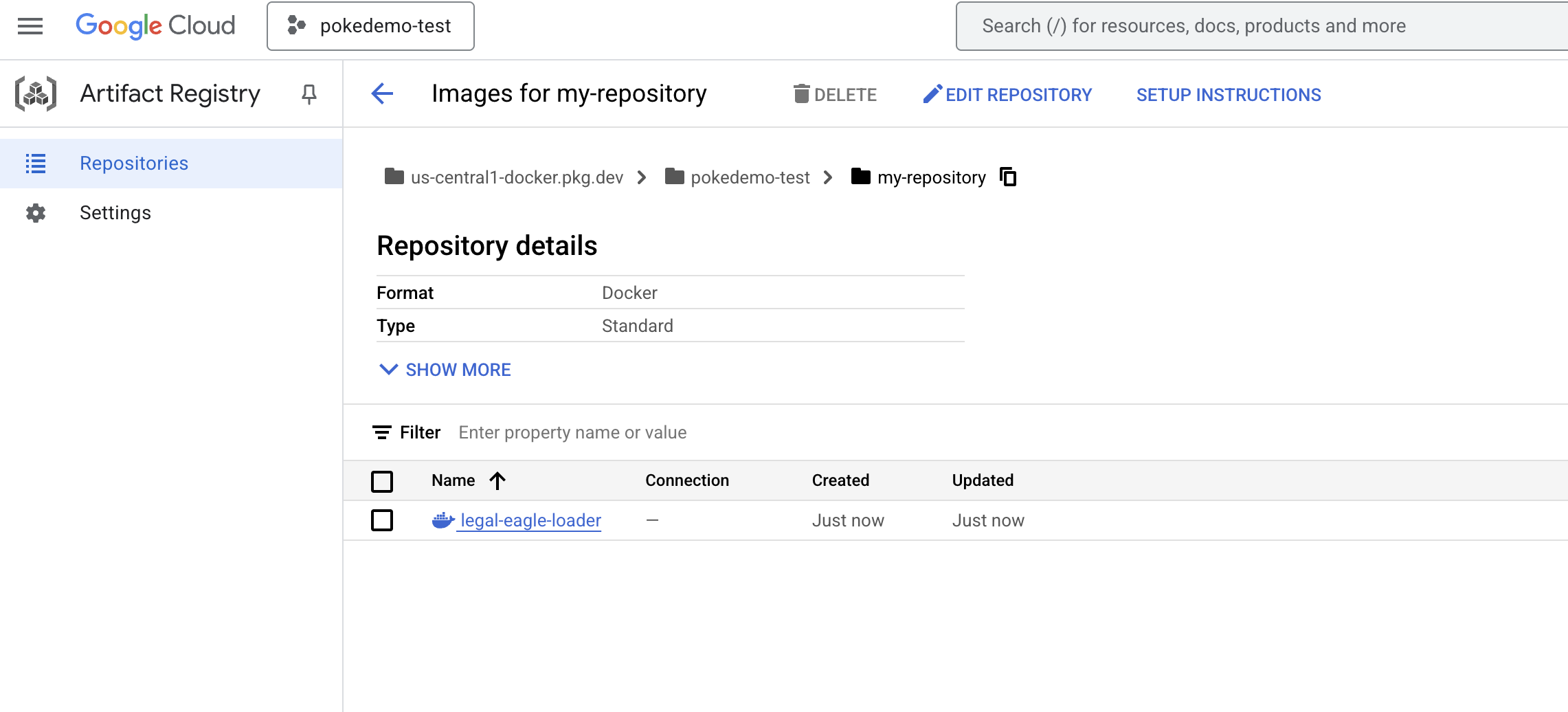
Образ Docker теперь доступен в репозитории артефактов my-repository .
11. Создайте функцию Cloud Run и настройте триггер Eventarc.
Прежде чем углубляться в детали развертывания нашего загрузчика юридических документов, давайте кратко рассмотрим задействованные компоненты: Cloud Run — это полностью управляемая бессерверная платформа, которая позволяет быстро и легко развертывать контейнеризированные приложения. Она абстрагирует управление инфраструктурой, позволяя вам сосредоточиться на написании и развертывании кода.
Мы развернем наш загрузчик документов как сервис Cloud Run. Теперь перейдем к настройке нашей функции Cloud Run:
👉 В консоли Google Cloud перейдите в раздел Cloud Run .
👉 Перейдите в раздел «Развертывание контейнера» и в выпадающем списке выберите «СЕРВИС» .
👉 Настройте службу Cloud Run:
- Образ контейнера : нажмите «Выбрать» в поле URL. Найдите URL-адрес образа, который вы загрузили в реестр артефактов (например, us-central1-docker.pkg.dev/your-project-id/my-repository/legal-eagle-loader/yourimage).
- Название сервиса :
legal-eagle-loader - Регион : Выберите регион
us-central1. - Аутентификация : Для целей этого семинара вы можете разрешить «Разрешить вызовы без аутентификации». В производственной среде, скорее всего, вам потребуется ограничить доступ.
- Контейнеры, сети, безопасность : по умолчанию.
👉 Нажмите СОЗДАТЬ . Cloud Run развернет вашу службу. 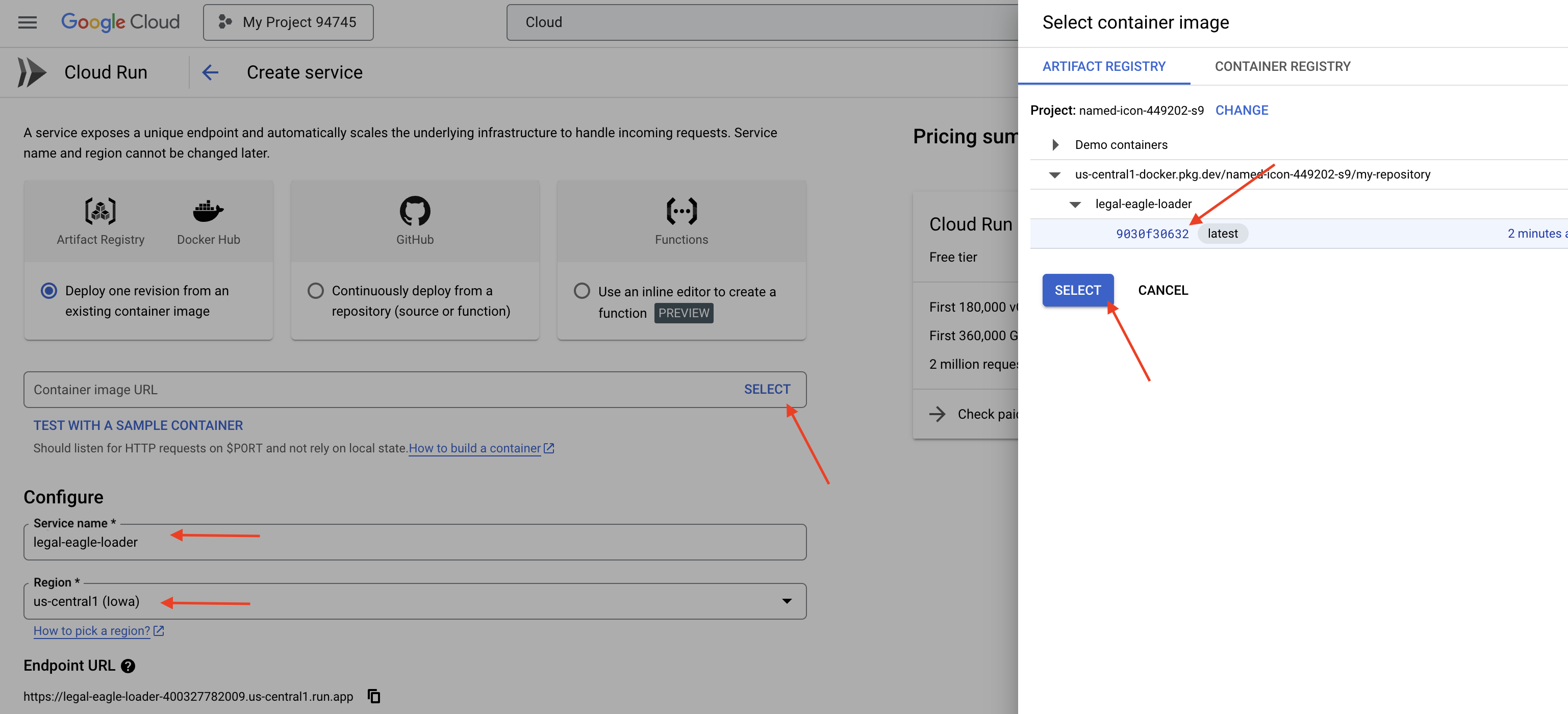
Для автоматического запуска этой службы при добавлении новых файлов в наше хранилище мы будем использовать Eventarc . Eventarc позволяет создавать архитектуры, управляемые событиями, путем маршрутизации событий из различных источников к вашим службам.
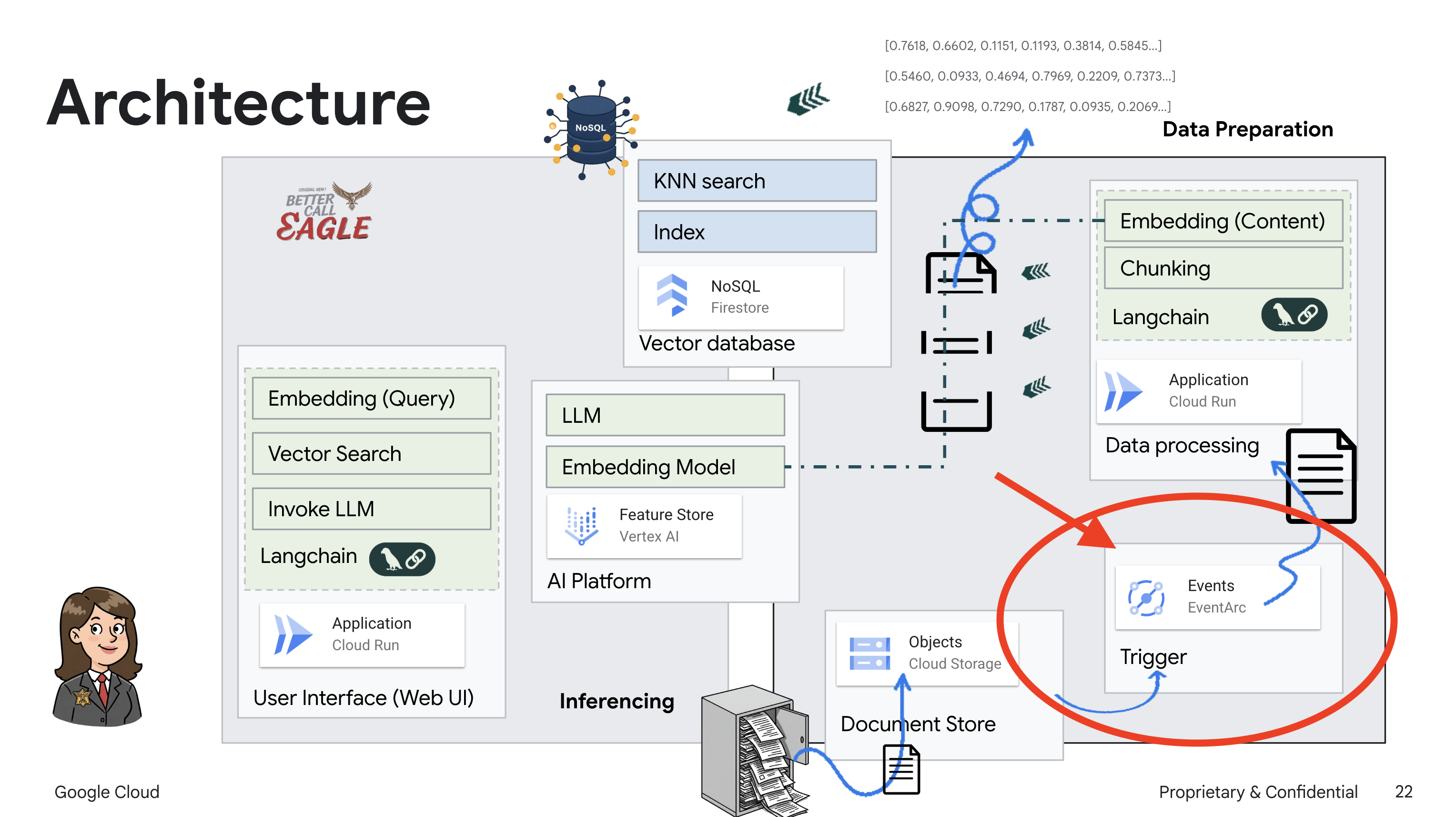
Настроив Eventarc, наша служба Cloud Run будет автоматически загружать вновь добавленные документы в Firestore сразу после их загрузки, обеспечивая обновление данных в режиме реального времени для нашего приложения RAG.
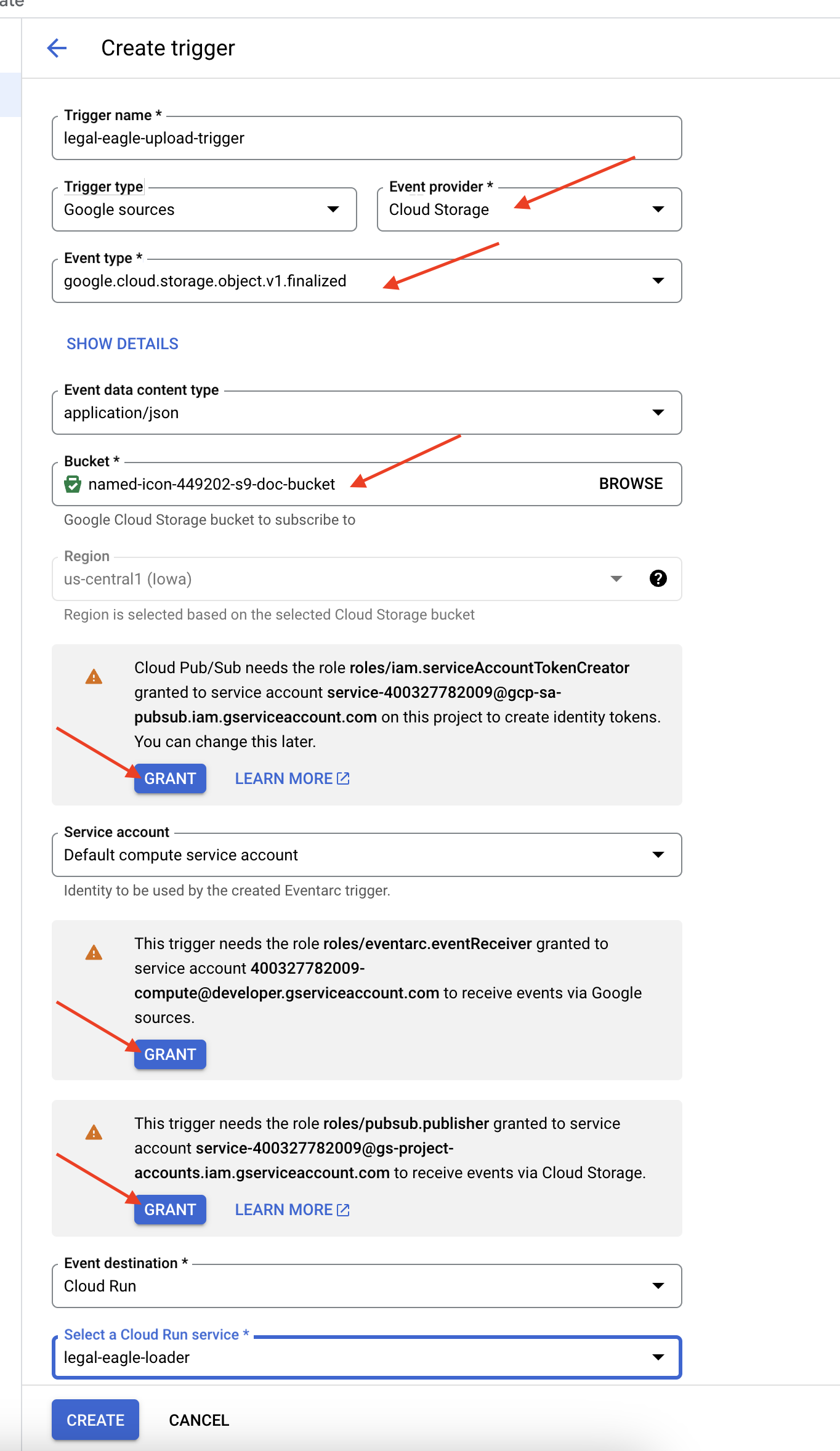
👉 В консоли Google Cloud перейдите в раздел «Триггеры» в EventArc. Нажмите «+ СОЗДАТЬ ТРИГГЕР». 👉 Настройте триггер Eventarc :
- Название триггера:
legal-eagle-upload-trigger. - TriggerType: Google Sources
- Поставщик событий: выберите «Облачное хранилище» .
- Тип события: Выберите
google.cloud.storage.object.v1.finalized - Корзина облачного хранилища: выберите свою корзину GCS из выпадающего списка.
- Тип назначения: "Сервис Cloud Run".
- Услуга: Выберите
legal-eagle-loader. - Регион:
us-central1 - Путь: Пока оставьте это поле пустым.
- Предоставьте все запрошенные разрешения на странице.
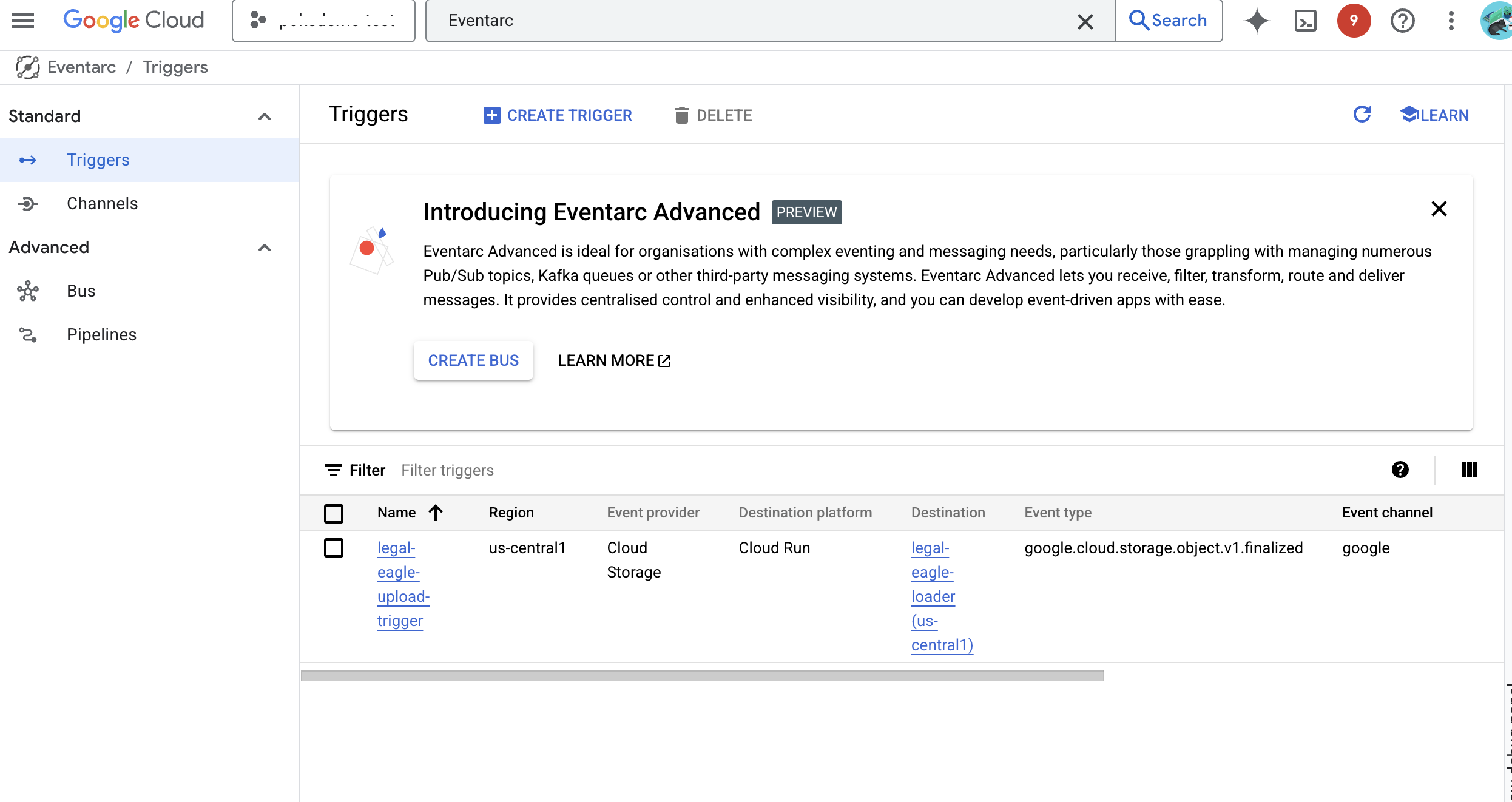
👉 Нажмите СОЗДАТЬ . Eventarc настроит триггер.
Сервису Cloud Run требуется разрешение на чтение файлов из различных компонентов. Нам необходимо предоставить учетной записи сервиса необходимые для этого разрешения.
12. Загрузите юридические документы в хранилище GCS.
👉 Загрузите файл судебного дела в свой бакет GCS. Не забудьте заменить название бакета.
export DOC_BUCKET_NAME=$(gcloud storage buckets list --format="value(name)" | grep doc-bucket)
gsutil cp ~/legal-eagle/court_cases/case-02.txt gs://$DOC_BUCKET_NAME/
gsutil cp ~/legal-eagle/court_cases/case-03.txt gs://$DOC_BUCKET_NAME/
gsutil cp ~/legal-eagle/court_cases/case-06.txt gs://$DOC_BUCKET_NAME/
Для мониторинга журналов службы Cloud Run перейдите в Cloud Run -> ваша служба legal-eagle-loader -> "Журналы". Проверьте журналы на наличие сообщений об успешной обработке, в том числе:
xxx
POST200130 B8.3 sAPIs-Google; (+https://developers.google.com/webmasters/APIs-Google.html) https://legal-eagle-loader-bmngrueyta-uc.a.run.app/?__GCP_CloudEventsMode=GCS_NOTIFICATION
xxx
POST200130 B520 msAPIs-Google; (+https://developers.google.com/webmasters/APIs-Google.html) https://legal-eagle-loader-bmngrueyta-uc.a.run.app/?__GCP_CloudEventsMode=GCS_NOTIFICATION
xxx
POST200130 B514 msAPIs-Google; (+https://developers.google.com/webmasters/APIs-Google.html) https://legal-eagle-loader-bmngrueyta-uc.a.run.app/?__GCP_CloudEventsMode=GCS_NOTIFICATION
А также в зависимости от того, насколько быстро была настроена система логирования; здесь вы также увидите более подробные логи.
"CloudEvent received:"
"New file detected in bucket:"
"File content downloaded. Processing..."
"Text split into ... chunks."
"File processing and Firestore upsert complete..."
Найдите в журналах сообщения об ошибках и при необходимости устраните неполадки. 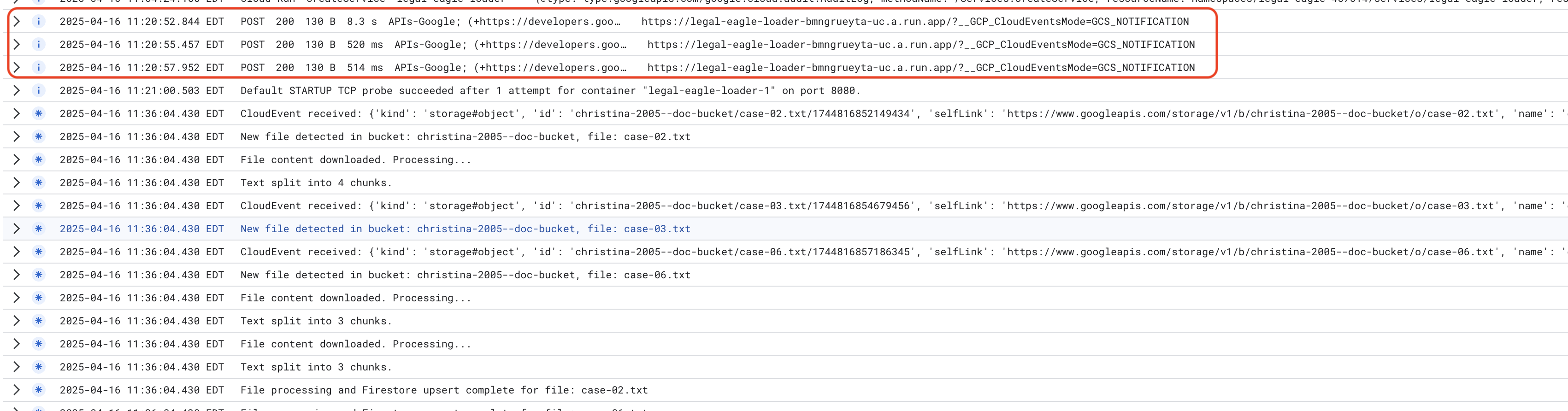
👉 Проверьте данные в Firestore . И откройте свою коллекцию legal_documents .
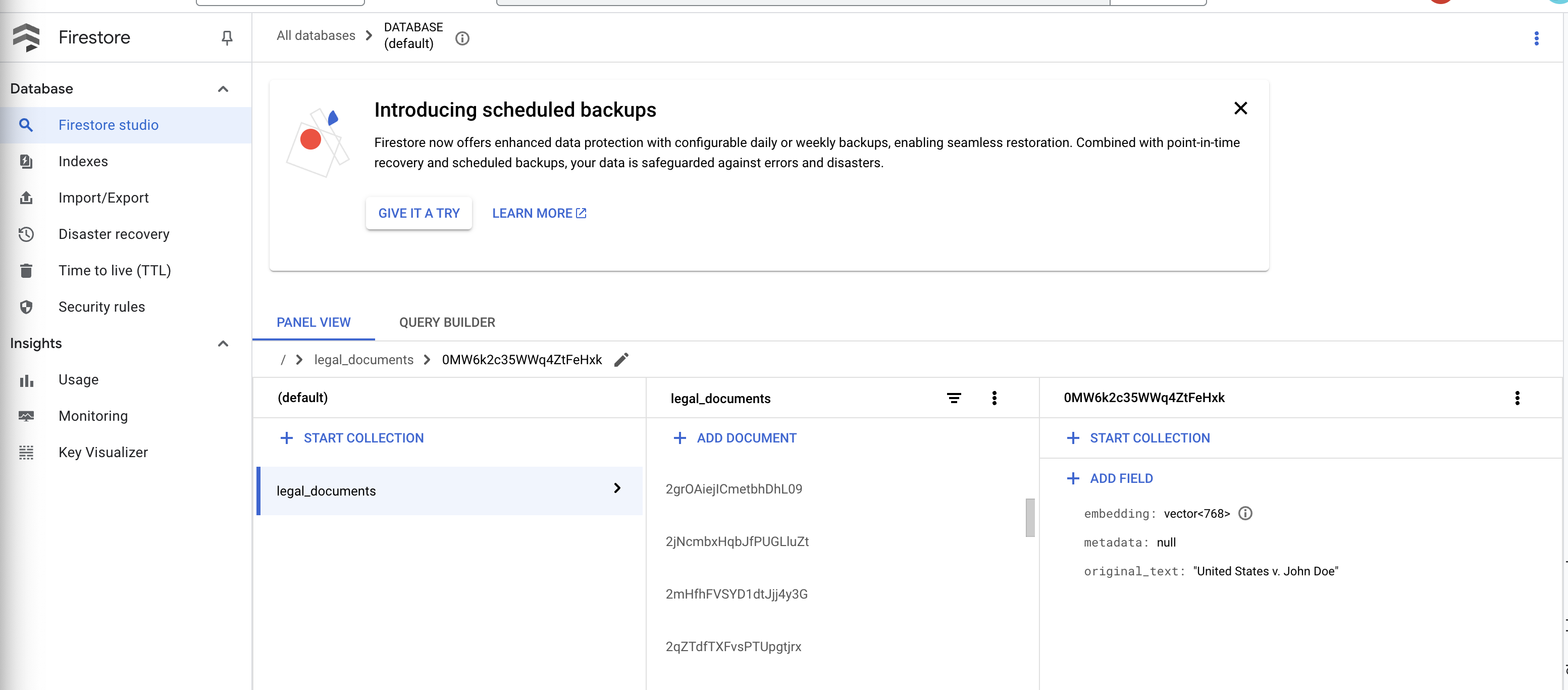
👉 В вашей коллекции должны появиться новые документы. Каждый документ будет представлять собой фрагмент текста из загруженного вами файла и будет содержать:
metadata: currently empty
original_text_chunk: The text chunk content.
embedding_: A list of floating-point numbers (the Vertex AI embedding).
13. Внедрение RAG
LangChain — это мощный фреймворк, разработанный для упрощения разработки приложений, использующих большие языковые модели (LLM). Вместо того чтобы напрямую разбираться в тонкостях API LLM, разработке подсказок и обработке данных, LangChain предоставляет высокоуровневый уровень абстракции. Он предлагает готовые компоненты и инструменты для таких задач, как подключение к различным LLM (например, от OpenAI, Google и других), построение сложных цепочек операций (например, извлечение данных с последующим их суммированием) и управление памятью диалогов.
В частности, для RAG хранилища векторов в LangChain имеют решающее значение для обеспечения возможности поиска в RAG. Это специализированные базы данных, предназначенные для эффективного хранения и запроса векторных вложений, где семантически похожие фрагменты текста сопоставляются с точками, расположенными близко друг к другу в векторном пространстве. LangChain берет на себя низкоуровневую инфраструктуру, позволяя разработчикам сосредоточиться на основной логике и функциональности своего RAG-приложения. Это значительно сокращает время и сложность разработки, позволяя быстро создавать прототипы и развертывать приложения на основе RAG, используя при этом надежность и масштабируемость инфраструктуры Google Cloud.
После объяснения принципа работы LangChain вам необходимо обновить файл legal.py в папке webapp для реализации RAG. Это позволит LLM искать соответствующие документы в Firestore перед предоставлением ответа.
👉 Импортируйте FirestoreVectorStore и другие необходимые модули из langchain и vertexai. Добавьте следующее в текущий legal.py
from langchain_google_vertexai import VertexAIEmbeddings
from langchain_google_firestore import FirestoreVectorStore
👉 Инициализируйте Vertex AI и модель встраивания. Вы будете использовать text-embedding-004 . Добавьте следующий код сразу после импорта модулей.
PROJECT_ID = os.environ.get("GOOGLE_CLOUD_PROJECT") # Get project ID from env
embedding_model = VertexAIEmbeddings(
model_name="text-embedding-004" ,
project=PROJECT_ID,)
👉 Создайте объект FirestoreVectorStore, указывающий на коллекцию legal_documents, используя инициализированную модель встраивания и указав поля content и embedding. Добавьте это сразу после предыдущего кода модели встраивания.
COLLECTION_NAME = "legal_documents"
# Create a vector store
vector_store = FirestoreVectorStore(
collection="legal_documents",
embedding_service=embedding_model,
content_field="original_text",
embedding_field="embedding",
)
👉 Определите функцию с именем search_resource , которая принимает запрос, выполняет поиск сходства с помощью vector_store.similarity_search и возвращает объединенные результаты.
def search_resource(query):
results = []
results = vector_store.similarity_search(query, k=5)
combined_results = "\n".join([result.page_content for result in results])
print(f"==>{combined_results}")
return combined_results
👉 ЗАМЕНИТЕ функцию ask_llm и используйте функцию search_resource для получения релевантного контекста на основе запроса пользователя.
def ask_llm(query):
try:
query_message = {
"type": "text",
"text": query,
}
relevant_resource = search_resource(query)
input_msg = HumanMessage(content=[query_message])
prompt_template = ChatPromptTemplate.from_messages(
[
SystemMessage(
content=(
"You are a helpful assistant, and you are with the attorney in a courtroom, you are helping him to win the case by providing the information he needs "
"Don't answer if you don't know the answer, just say sorry in a funny way possible"
"Use high engergy tone, don't use more than 100 words to answer"
f"Here is some context that is relevant to the question {relevant_resource} that you might use"
)
),
input_msg,
]
)
prompt = prompt_template.format()
response = llm.invoke(prompt)
print(f"response: {response}")
return response
except Exception as e:
print(f"Error sending message to chatbot: {e}") # Log this error too!
return f"Unable to process your request at this time. Due to the following reason: {str(e)}"
👉 ДОПОЛНИТЕЛЬНО: ВЕРСИЯ НА ИСПАНСКОМ ЯЗЫКЕ
Sustituye el siguiente texto como se indica: You are a helpful assistant, « You are a helpful assistant that speaks Spanish,
👉 После внедрения RAG в файл legal.py, перед развертыванием необходимо протестировать его локально, запустив приложение с помощью команды:
cd ~/legal-eagle/webapp
source env/bin/activate
python main.py
👉 Используйте webpreview для доступа к приложению, обратитесь в службу поддержки и нажмите ctrl+c для завершения локально запущенного процесса. Затем запустите команду deactivate для выхода из виртуальной среды.
deactivate
👉 Для развертывания веб-приложения в Cloud Run используется аналогичная функция загрузчика. Вы создадите, пометите и отправите образ Docker в реестр артефактов:
export PROJECT_ID=$(gcloud config get project)
docker build -t gcr.io/${PROJECT_ID}/legal-eagle-webapp .
docker tag gcr.io/${PROJECT_ID}/legal-eagle-webapp us-central1-docker.pkg.dev/${PROJECT_ID}/my-repository/legal-eagle-webapp
docker push us-central1-docker.pkg.dev/${PROJECT_ID}/my-repository/legal-eagle-webapp
👉 Пришло время развернуть веб-приложение в Google Cloud. В терминале выполните следующие команды:
export PROJECT_ID=$(gcloud config get project)
gcloud run deploy legal-eagle-webapp \
--image us-central1-docker.pkg.dev/$PROJECT_ID/my-repository/legal-eagle-webapp \
--region us-central1 \
--set-env-vars=GOOGLE_CLOUD_PROJECT=${PROJECT_ID} \
--allow-unauthenticated
Проверьте развертывание, перейдя в раздел Cloud Run в консоли Google Cloud. Вы должны увидеть новый сервис с именем legal-eagle-webapp .
Перейдите по ссылке на страницу с подробной информацией о сервисе; URL-адрес развернутого сервиса находится вверху страницы. 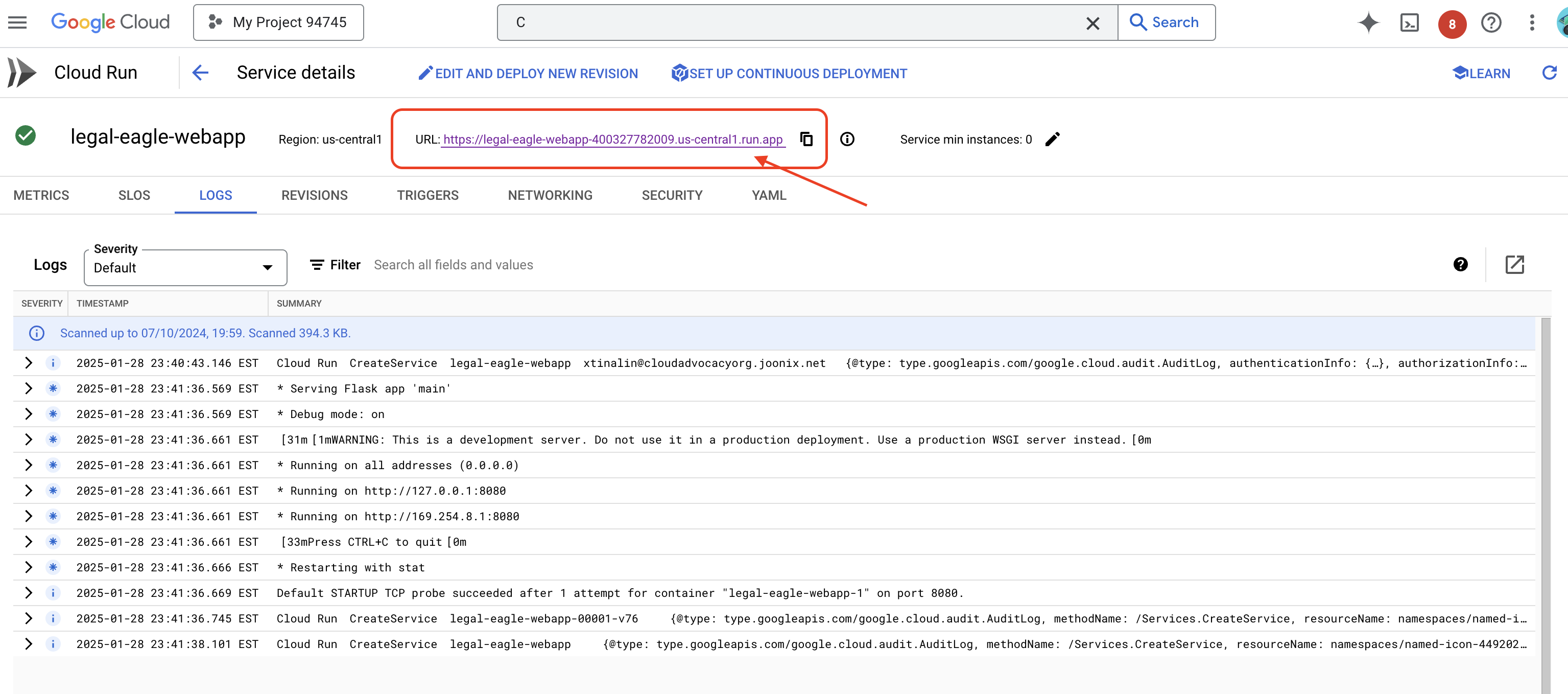
👉 Теперь откройте развернутый URL-адрес в новой вкладке браузера. Вы сможете взаимодействовать с юридическим помощником и задавать вопросы, касающиеся загруженных вами судебных дел (в папке court_cases):
- К какому сроку тюремного заключения был приговорен Майкл Браун?
- Какова сумма денег, списанная в результате действий Джейн Смит в результате несанкционированных платежей?
- Какую роль сыграли показания соседей в расследовании дела Эмили Уайт?
👉 ДОПОЛНИТЕЛЬНО: ВЕРСИЯ НА ИСПАНСКОМ ЯЗЫКЕ
- Сколько времени прошло с приговором Майклу Брауну?
- ¿Какие деньги и грузы не авторизованы, если они получены в результате действий Джейн Смит?
- ¿Qué papel jugaron los vecinos de los vecinos в расследовании дела Эмили Уайт?
Обратите внимание, что ответы теперь более точные и соответствуют содержанию загруженных вами юридических документов, что демонстрирует возможности RAG!
Поздравляем с завершением мастер-класса! Вы успешно разработали и развернули приложение для анализа юридических документов с использованием LLM, LangChain и Google Cloud. Вы научились загружать и обрабатывать юридические документы, дополнять ответы LLM соответствующей информацией с помощью RAG и развертывать приложение в качестве бессерверного сервиса. Эти знания и созданное приложение помогут вам в дальнейшем изучении возможностей LLM для решения юридических задач. Отлично!
14. Вызов
Разнообразные типы медиа:
Как обрабатывать различные типы медиафайлов, такие как видеозаписи судебных заседаний и аудиозаписи, и извлекать из них соответствующий текст.
Онлайн-активы :
Как обрабатывать онлайн-ресурсы, такие как веб-страницы, в режиме реального времени.