
1. บทนำ
ฉันหลงใหลในความเข้มข้นของห้องพิจารณาคดีมาโดยตลอด และจินตนาการว่าตัวเองกำลังจัดการกับความซับซ้อนของคดีอย่างชำนาญและนำเสนอข้อโต้แย้งปิดคดีที่ทรงพลัง แม้ว่าเส้นทางอาชีพจะนำพาฉันไปที่อื่น แต่ฉันก็ตื่นเต้นที่จะบอกว่าด้วยความช่วยเหลือจาก AI เราทุกคนอาจเข้าใกล้ความฝันที่จะได้ขึ้นศาลมากขึ้น

วันนี้เราจะมาเจาะลึกวิธีใช้เครื่องมือ AI ที่มีประสิทธิภาพของ Google เช่น Vertex AI, Firestore และฟังก์ชัน Cloud Run เพื่อประมวลผลและทำความเข้าใจข้อมูลทางกฎหมาย ทำการค้นหาที่รวดเร็ว และอาจช่วยลูกค้าในจินตนาการ (หรือตัวคุณเอง) ให้พ้นจากสถานการณ์ที่ยากลำบาก
คุณอาจไม่ได้ซักถามพยาน แต่ระบบของเราจะช่วยให้คุณสามารถกลั่นกรองข้อมูลจำนวนมาก สร้างข้อมูลสรุปที่ชัดเจน และนำเสนอข้อมูลที่เกี่ยวข้องที่สุดได้ในไม่กี่วินาที
2. สถาปัตยกรรม
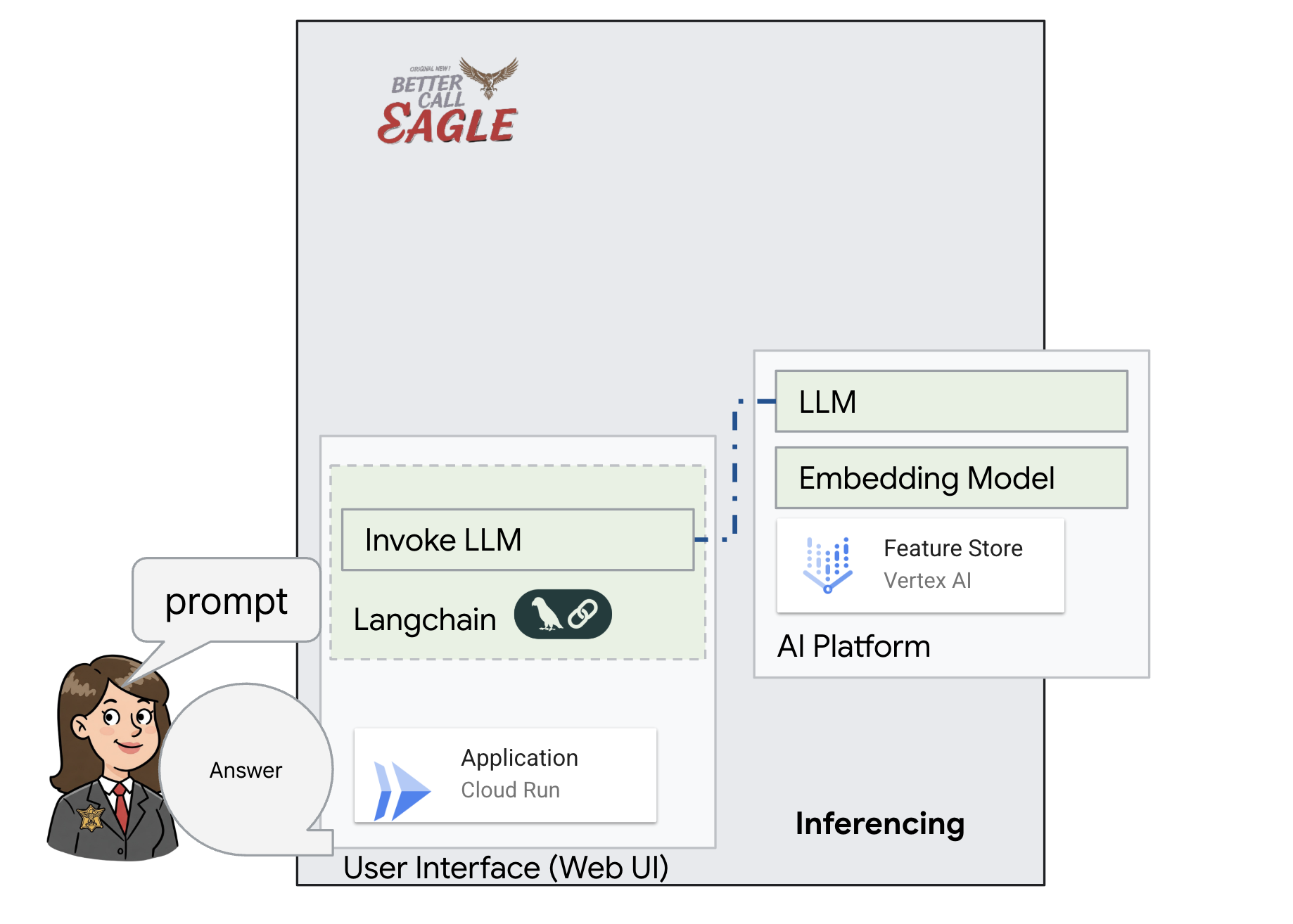
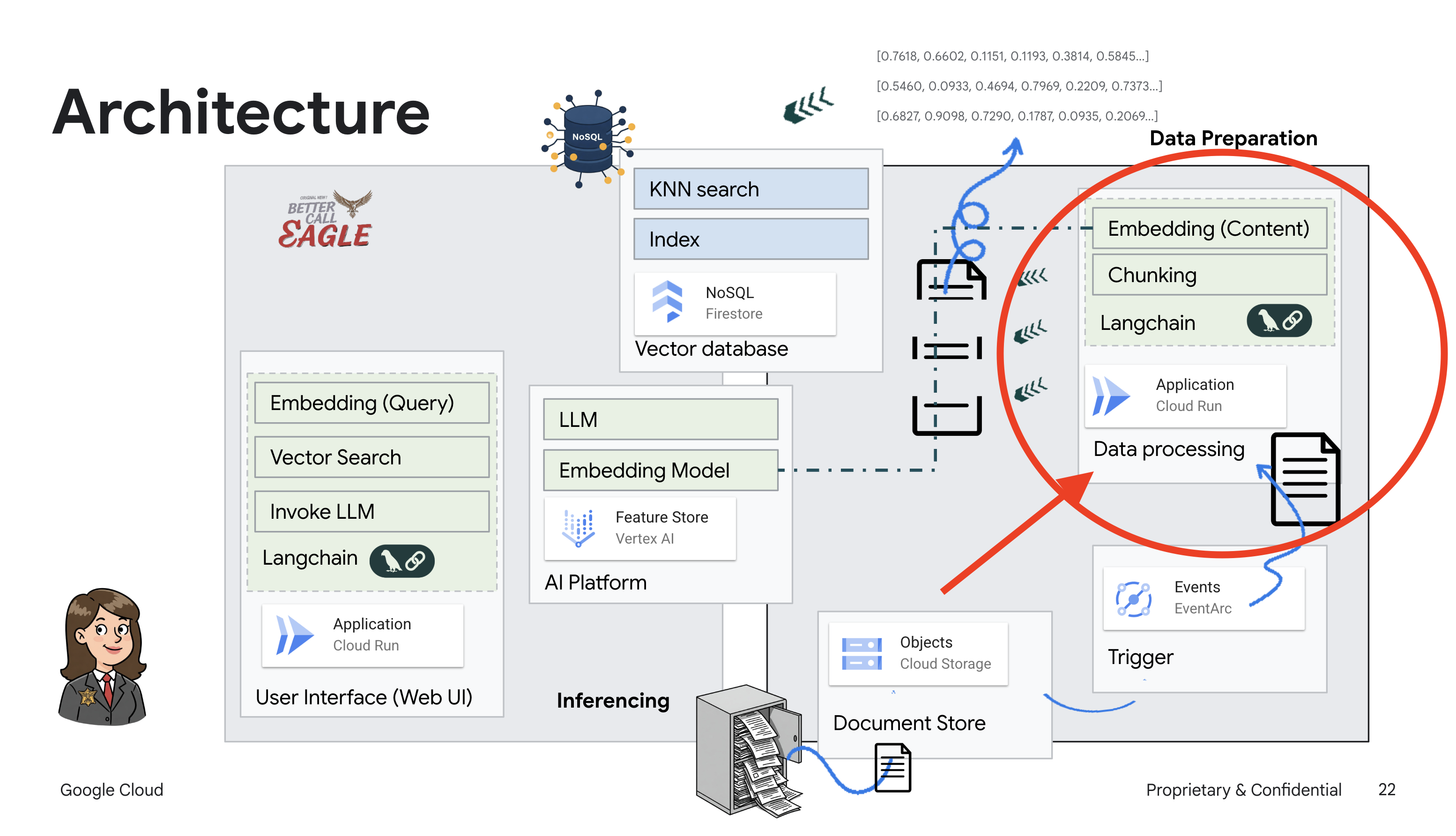
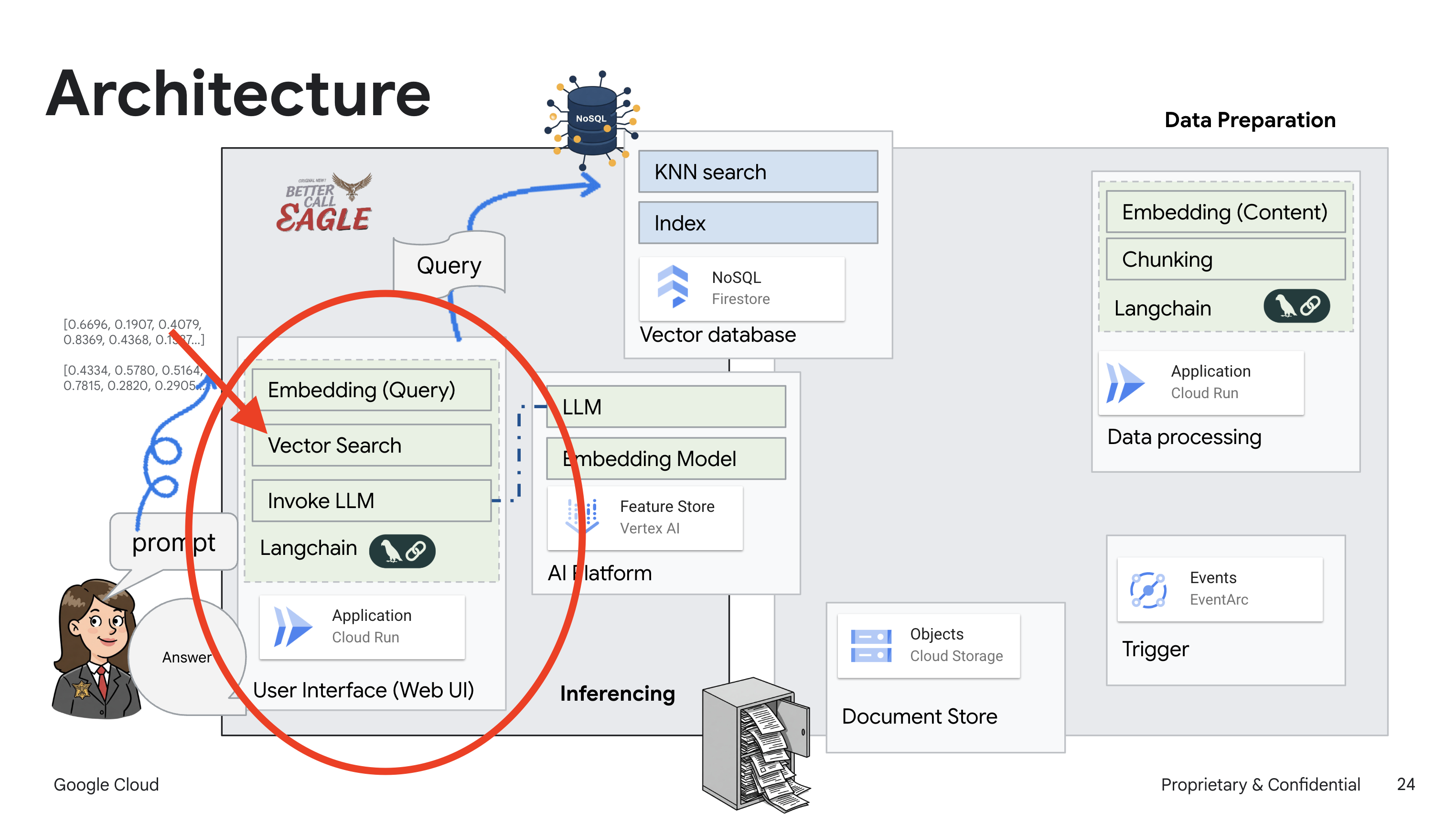
โปรเจ็กต์นี้มุ่งเน้นการสร้างผู้ช่วยด้านกฎหมายโดยใช้เครื่องมือ AI ของ Google Cloud โดยเน้นวิธีประมวลผล ทำความเข้าใจ และค้นหาข้อมูลทางกฎหมาย ระบบได้รับการออกแบบมาเพื่อกรองข้อมูลจำนวนมาก สร้างข้อมูลสรุป และนำเสนอข้อมูลที่เกี่ยวข้องอย่างรวดเร็ว สถาปัตยกรรมของผู้ช่วยด้านกฎหมายมีองค์ประกอบสำคัญหลายอย่าง ดังนี้
การสร้างฐานความรู้จากข้อมูลที่ไม่มีโครงสร้าง: ใช้ Google Cloud Storage (GCS) เพื่อจัดเก็บเอกสารทางกฎหมาย Firestore ซึ่งเป็นฐานข้อมูล NoSQL จะทําหน้าที่เป็นที่เก็บเวกเตอร์ โดยจะจัดเก็บกลุ่มเอกสารและการฝังที่เกี่ยวข้อง ระบบเปิดใช้การค้นหาเวกเตอร์ใน Firestore เพื่ออนุญาตการค้นหาความคล้ายคลึงกัน เมื่อมีการอัปโหลดเอกสารทางกฎหมายใหม่ไปยัง GCS แล้ว Eventarc จะทริกเกอร์ฟังก์ชัน Cloud Run ฟังก์ชันนี้จะประมวลผลเอกสารโดยการแยกเอกสารออกเป็นส่วนๆ และสร้างการฝังสำหรับแต่ละส่วนโดยใช้โมเดลการฝังข้อความของ Vertex AI จากนั้นระบบจะจัดเก็บการฝังเหล่านี้ไว้ใน Firestore พร้อมกับส่วนของข้อความ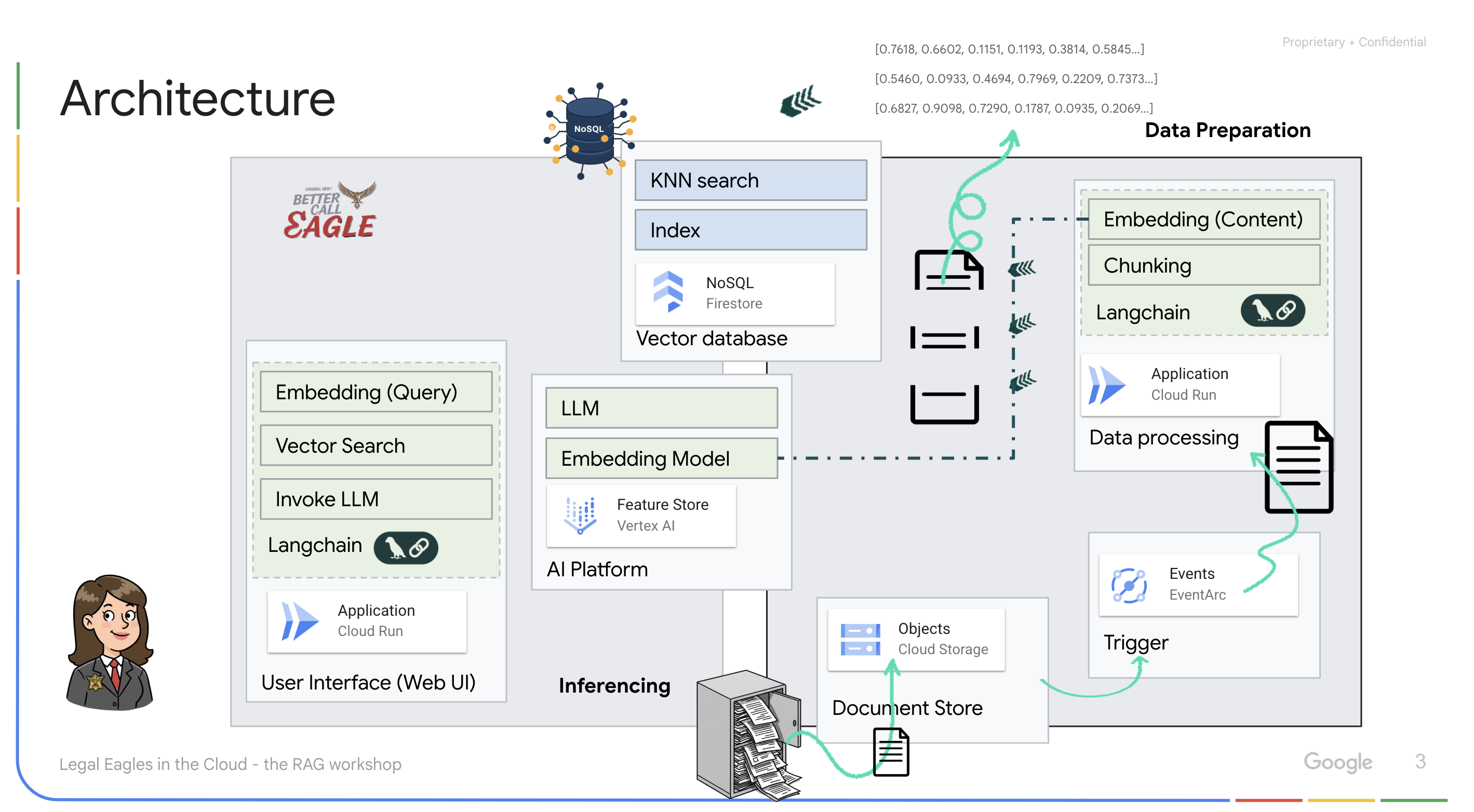
แอปพลิเคชันที่ขับเคลื่อนโดย LLM และ RAG : หัวใจสำคัญของระบบถามและตอบคือask_llmฟังก์ชัน ซึ่งใช้ไลบรารี Langchain เพื่อโต้ตอบกับโมเดลภาษาขนาดใหญ่ Gemini ของ Vertex AI โดยจะสร้าง HumanMessage จากคำค้นหาของผู้ใช้ และรวม SystemMessage ที่สั่งให้ LLM ทำหน้าที่เป็นผู้ช่วยด้านกฎหมายที่มีประโยชน์ ระบบใช้แนวทางการสร้างการดึงข้อมูล (RAG) ซึ่งก่อนที่จะตอบคำค้นหา ระบบจะใช้ฟังก์ชัน search_resource เพื่อดึงบริบทที่เกี่ยวข้องจากที่เก็บเวกเตอร์ Firestore จากนั้นบริบทนี้จะรวมอยู่ใน SystemMessage เพื่อให้คำตอบของ LLM อิงตามข้อมูลทางกฎหมายที่ให้ไว้ 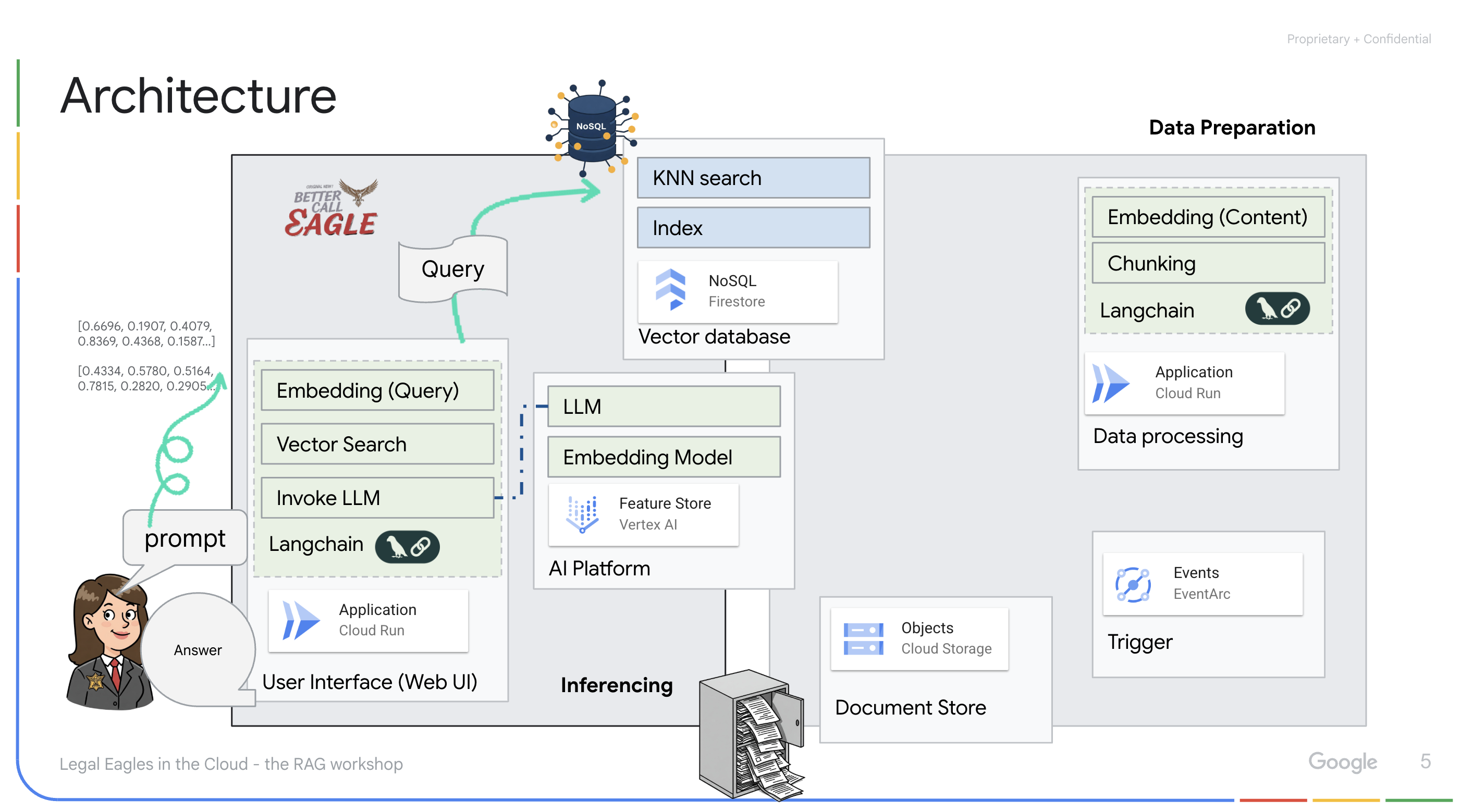
โปรเจ็กต์นี้มีเป้าหมายที่จะหลีกเลี่ยง "การตีความอย่างสร้างสรรค์" ของ LLM โดยใช้ RAG ซึ่งจะดึงข้อมูลที่เกี่ยวข้องจากแหล่งข้อมูลทางกฎหมายที่เชื่อถือได้ก่อนที่จะสร้างคำตอบ ซึ่งจะช่วยให้ได้คำตอบที่แม่นยำและมีข้อมูลมากขึ้นโดยอิงตามข้อมูลทางกฎหมายจริง ระบบนี้สร้างขึ้นโดยใช้บริการต่างๆ ของ Google Cloud เช่น Google Cloud Shell, Vertex AI, Firestore, Cloud Run และ Eventarc
3. ก่อนเริ่มต้น
ใน คอนโซล Google Cloud ในหน้าตัวเลือกโปรเจ็กต์ ให้เลือกหรือสร้างโปรเจ็กต์ Google Cloud ตรวจสอบว่าได้เปิดใช้การเรียกเก็บเงินสำหรับโปรเจ็กต์ Cloud แล้ว ดูวิธีตรวจสอบว่าได้เปิดใช้การเรียกเก็บเงินในโปรเจ็กต์แล้วหรือไม่
เปิดใช้ Gemini Code Assist ใน Cloud Shell IDE
👉 ในคอนโซล Google Cloud ให้ไปที่เครื่องมือ Gemini Code Assist แล้วเปิดใช้ Gemini Code Assist โดยไม่มีค่าใช้จ่ายด้วยการยอมรับข้อกำหนดและเงื่อนไข
ไม่ต้องตั้งค่าสิทธิ์และออกจากหน้านี้
ทำงานใน Cloud Shell Editor
👉 คลิกเปิดใช้งาน Cloud Shell ที่ด้านบนของคอนโซล Google Cloud (เป็นไอคอนรูปเทอร์มินัลที่ด้านบนของแผง Cloud Shell)
👉 คลิกปุ่ม "เปิดโปรแกรมแก้ไข" (ปุ่มนี้มีลักษณะเป็นโฟลเดอร์ที่เปิดอยู่พร้อมดินสอ) ซึ่งจะเปิด Cloud Shell Editor ในหน้าต่าง คุณจะเห็น File Explorer ทางด้านซ้าย

👉 คลิกปุ่มลงชื่อเข้าใช้ Cloud Code ในแถบสถานะด้านล่างตามที่แสดง ให้สิทธิ์ปลั๊กอินตามวิธีการ หากเห็น Cloud Code - ไม่มีโปรเจ็กต์ในแถบสถานะ ให้เลือกโปรเจ็กต์นั้น แล้วเลือก "เลือกโปรเจ็กต์ Google Cloud" ในเมนูแบบเลื่อนลง จากนั้นเลือกโปรเจ็กต์ Google Cloud ที่ต้องการจากรายการโปรเจ็กต์ที่คุณวางแผนจะใช้
👉 เปิดเทอร์มินัลใน Cloud IDE 
👉 ในเทอร์มินัลใหม่ ให้ตรวจสอบว่าคุณได้รับการตรวจสอบสิทธิ์แล้วและตั้งค่าโปรเจ็กต์เป็นรหัสโปรเจ็กต์ของคุณโดยใช้คำสั่งต่อไปนี้
gcloud auth list
👉 คลิกเปิดใช้งาน Cloud Shell ที่ด้านบนของคอนโซล Google Cloud
gcloud config set project <YOUR_PROJECT_ID>
👉 เรียกใช้คำสั่งต่อไปนี้เพื่อเปิดใช้ Google Cloud APIs ที่จำเป็น
gcloud services enable storage.googleapis.com \
run.googleapis.com \
artifactregistry.googleapis.com \
aiplatform.googleapis.com \
eventarc.googleapis.com \
cloudresourcemanager.googleapis.com \
firestore.googleapis.com \
cloudaicompanion.googleapis.com
ในแถบเครื่องมือ Cloud Shell (ที่ด้านบนของแผง Cloud Shell) ให้คลิกปุ่ม "เปิดตัวแก้ไข" (มีลักษณะเป็นโฟลเดอร์ที่เปิดอยู่พร้อมดินสอ) ซึ่งจะเปิดตัวแก้ไขโค้ด Cloud Shell ในหน้าต่าง คุณจะเห็น File Explorer ทางด้านซ้าย
👉 ในเทอร์มินัล ให้ดาวน์โหลดโปรเจ็กต์โครงสร้าง Bootstrap โดยทำดังนี้
git clone https://github.com/weimeilin79/legal-eagle.git
ไม่บังคับ: เวอร์ชันภาษาสเปน
👉 Existe una versión alternativa en español. Por favor, utilice la siguiente instrucción para clonar la versión correcta.
git clone -b spanish https://github.com/weimeilin79/legal-eagle.git
หลังจากเรียกใช้คำสั่งนี้ในเทอร์มินัล Cloud Shell แล้ว ระบบจะสร้างโฟลเดอร์ใหม่ที่มีชื่อที่เก็บ legal-eagle ในสภาพแวดล้อมของ Shell ใน Cloud Shell
4. การเขียนแอปพลิเคชันการอนุมานด้วย Gemini Code Assist
ในส่วนนี้ เราจะมุ่งเน้นที่การสร้างแกนหลักของผู้ช่วยด้านกฎหมาย ซึ่งก็คือเว็บแอปพลิเคชันที่รับคำถามจากผู้ใช้และโต้ตอบกับโมเดล AI เพื่อสร้างคำตอบ เราจะใช้ประโยชน์จาก Gemini Code Assist เพื่อช่วยเขียนโค้ด Python สำหรับส่วนการอนุมานนี้
ในตอนแรก เราจะสร้างแอปพลิเคชัน Flask ที่ใช้ไลบรารี LangChain เพื่อสื่อสารกับโมเดล Gemini ของ Vertex AI โดยตรง เวอร์ชันแรกนี้จะทำหน้าที่เป็นผู้ช่วยด้านกฎหมายที่มีประโยชน์โดยอิงตามความรู้ทั่วไปของโมเดล แต่จะยังไม่มีสิทธิ์เข้าถึงเอกสารคดีในศาลที่เฉพาะเจาะจงของเรา ซึ่งจะช่วยให้เราเห็นประสิทธิภาพพื้นฐานของ LLM ก่อนที่จะปรับปรุงด้วย RAG ในภายหลัง
ในแผง Explorer ของโปรแกรมแก้ไข Cloud Code (โดยปกติจะอยู่ทางด้านซ้าย) คุณควรเห็นโฟลเดอร์ที่สร้างขึ้นเมื่อโคลนที่เก็บ Git legal-eagle เปิดโฟลเดอร์รูทของโปรเจ็กต์ใน Explorer คุณจะเห็นwebappโฟลเดอร์ย่อยภายในโฟลเดอร์นั้น ให้เปิดโฟลเดอร์ย่อยด้วย 
👉 แก้ไขlegal.pyไฟล์ใน Cloud Code Editor คุณสามารถใช้หลายวิธีเพื่อเขียนพรอมต์ Gemini Code Assist
👉 คัดลอกพรอมต์ต่อไปนี้ไปวางที่ด้านล่างของ legal.py ซึ่งอธิบายสิ่งที่คุณต้องการให้ Gemini Code Assist สร้างอย่างชัดเจน จากนั้นคลิกไอคอนหลอดไฟ 💡 ที่ปรากฏขึ้น แล้วเลือก Gemini: สร้างโค้ด (รายการเมนูที่แน่นอนอาจแตกต่างกันเล็กน้อยขึ้นอยู่กับเวอร์ชันของ Cloud Code)
"""
Write a Python function called `ask_llm` that takes a user `query` as input. This function should use the `langchain` library to interact with a Vertex AI Gemini Large Language Model. Specifically, it should:
1. Create a `HumanMessage` object from the user's `query`.
2. Create a `ChatPromptTemplate` that includes a `SystemMessage` and the `HumanMessage`. The system message should instruct the LLM to act as a helpful assistant in a courtroom setting, aiding an attorney by providing necessary information. It should also specify that the LLM should respond in a high-energy tone, using no more than 100 words, and offer a humorous apology if it doesn't know the answer.
3. Format the `ChatPromptTemplate` with the provided messages.
4. Invoke the Vertex AI LLM with the formatted prompt using the `VertexAI` class (assuming it's already initialized elsewhere as `llm`).
5. Print the LLM's `response`.
6. Return the `response`.
7. Include error handling that prints an error message to the console and returns a user-friendly error message if any issues occur during the process. The Vertex AI model should be "gemini-2.0-flash".
"""
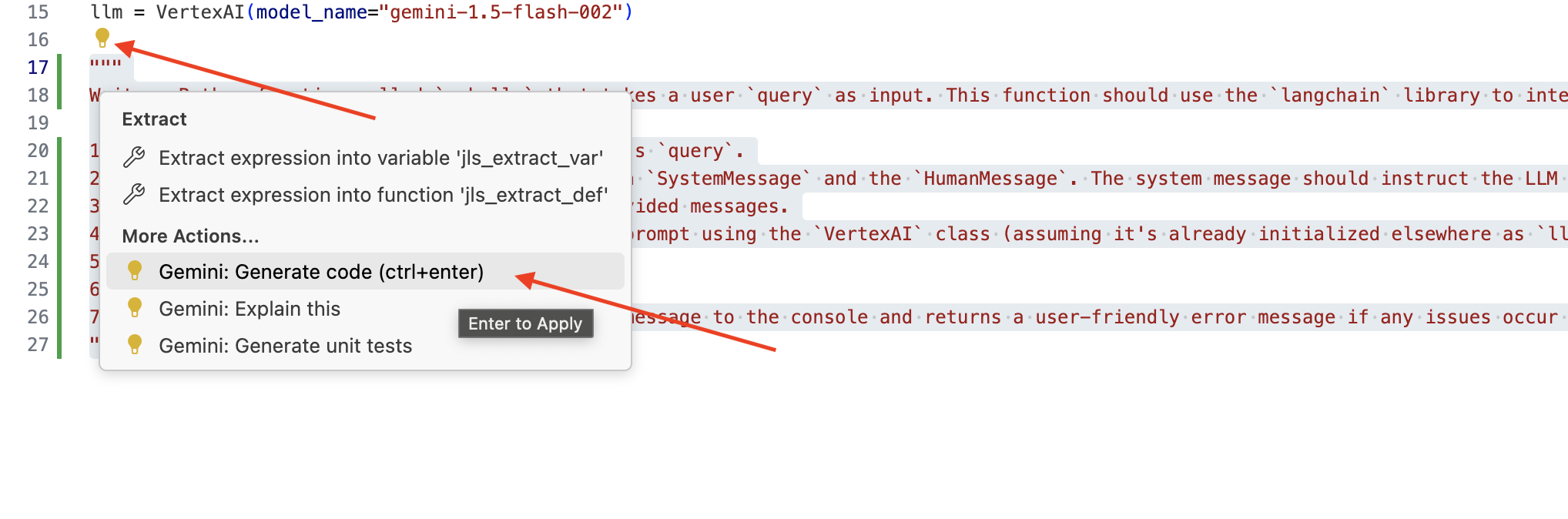
ตรวจสอบโค้ดที่สร้างขึ้นอย่างละเอียด
- โดยประมาณแล้วขั้นตอนตรงกับที่คุณระบุไว้ในความคิดเห็นไหม
- ระบบจะสร้าง
ChatPromptTemplateที่มีSystemMessageและHumanMessageไหม - มีฟีเจอร์การจัดการข้อผิดพลาดขั้นพื้นฐาน (
try...except) ไหม
หากโค้ดที่สร้างขึ้นดีและถูกต้องเป็นส่วนใหญ่ คุณก็ยอมรับโค้ดนั้นได้ (กด Tab หรือ Enter สำหรับคำแนะนำในบรรทัด หรือคลิก "ยอมรับ" สำหรับบล็อกโค้ดขนาดใหญ่)
หากโค้ดที่สร้างขึ้นไม่ตรงกับที่คุณต้องการหรือมีข้อผิดพลาด ก็ไม่ต้องกังวล Gemini Code Assist เป็นเครื่องมือที่ช่วยคุณ ไม่ใช่เขียนโค้ดที่สมบูรณ์แบบตั้งแต่ครั้งแรก
แก้ไขและปรับเปลี่ยนโค้ดที่สร้างขึ้นเพื่อปรับแต่ง แก้ไขข้อผิดพลาด และให้ตรงกับข้อกำหนดของคุณมากขึ้น คุณสามารถเขียนพรอมต์ Gemini Code Assist เพิ่มเติมได้โดยการเพิ่มความคิดเห็นหรือถามคำถามที่เฉพาะเจาะจงในแผงแชทของ Code Assist
และหากคุณยังใหม่กับ SDK โปรดดูตัวอย่างการทำงานที่นี่
👉 คัดลอกและวางและแทนที่โค้ดต่อไปนี้ลงใน legal.py
import os
import signal
import sys
import vertexai
import random
from langchain_google_vertexai import VertexAI
from langchain_core.prompts import PromptTemplate, ChatPromptTemplate
from langchain_core.messages import HumanMessage, SystemMessage
# Connect to resourse needed from Google Cloud
llm = VertexAI(model_name="gemini-2.0-flash")
def ask_llm(query):
try:
query_message = {
"type": "text",
"text": query,
}
input_msg = HumanMessage(content=[query_message])
prompt_template = ChatPromptTemplate.from_messages(
[
SystemMessage(
content=(
"You are a helpful assistant, and you are with the attorney in a courtroom, you are helping him to win the case by providing the information he needs "
"Don't answer if you don't know the answer, just say sorry in a funny way possible"
"Use high engergy tone, don't use more than 100 words to answer"
# f"Here is some past conversation history between you and the user {relevant_history}"
# f"Here is some context that is relevant to the question {relevant_resource} that you might use"
)
),
input_msg,
]
)
prompt = prompt_template.format()
response = llm.invoke(prompt)
print(f"response: {response}")
return response
except Exception as e:
print(f"Error sending message to chatbot: {e}") # Log this error too!
return f"Unable to process your request at this time. Due to the following reason: {str(e)}"
👉 ไม่บังคับ: เวอร์ชันภาษาสเปน
Sustituye el siguiente texto como se indica: You are a helpful assistant, to You are a helpful assistant that speaks Spanish,
จากนั้นสร้างฟังก์ชันเพื่อจัดการเส้นทางที่จะตอบคำถามของผู้ใช้
เปิด main.py ใน Cloud Shell Editor เช่นเดียวกับวิธีสร้าง ask_llm ใน legal.py ให้ใช้ Gemini Code Assist เพื่อสร้างฟังก์ชัน Flask Route และ ask_question พิมพ์ PROMPT ต่อไปนี้เป็นความคิดเห็นใน main.py (ตรวจสอบว่าได้เพิ่ม ก่อนเริ่มแอป Flask ที่ if __name__ == "__main__":)
.....
@app.route('/',methods=['GET'])
def index():
return render_template('index.html')
"""
PROMPT:
Create a Flask endpoint that accepts POST requests at the '/ask' route.
The request should contain a JSON payload with a 'question' field. Extract the question from the JSON payload.
Call a function named ask_llm (located in a file named legal.py) with the extracted question as an argument.
Return the result of the ask_llm function as the response with a 200 status code.
If any error occurs during the process, return a 500 status code with the error message.
"""
# Add this block to start the Flask app when running locally
if __name__ == "__main__":
.....
ยอมรับเฉพาะในกรณีที่โค้ดที่สร้างขึ้นดีและถูกต้องเป็นส่วนใหญ่เท่านั้น หากไม่คุ้นเคยกับ Python นี่คือตัวอย่างที่ใช้งานได้ ให้คัดลอกและวางลงใน main.py ใต้โค้ดที่มีอยู่แล้ว
👉 ตรวจสอบว่าคุณวางข้อความต่อไปนี้ก่อนเริ่มเว็บแอปพลิเคชัน (if name == "main":)
@app.route('/ask', methods=['POST'])
def ask_question():
data = request.get_json()
question = data.get('question')
try:
# call the ask_llm in legal.py
answer_markdown = legal.ask_llm(question)
print(f"answer_markdown: {answer_markdown}")
# Return the Markdown as the response
return answer_markdown, 200
except Exception as e:
return f"Error: {str(e)}", 500 # Handle errors appropriately
เมื่อทำตามขั้นตอนเหล่านี้ คุณจะเปิดใช้ Gemini Code Assist ตั้งค่าโปรเจ็กต์ และใช้เพื่อสร้างฟังก์ชัน ask ในไฟล์ main.py ได้สำเร็จ
5. การทดสอบในเครื่องใน Cloud Editor
👉 ในเทอร์มินัลของเอดิเตอร์ ให้ติดตั้งไลบรารีที่ขึ้นต่อกันและเริ่ม UI ของเว็บในเครื่อง
cd ~/legal-eagle/webapp
python -m venv env
source env/bin/activate
export PROJECT_ID=$(gcloud config get project)
pip install -r requirements.txt
python main.py
มองหาข้อความเริ่มต้นในเอาต์พุตเทอร์มินัลของ Cloud Shell โดยปกติแล้ว Flask จะพิมพ์ข้อความที่ระบุว่ากำลังทำงานและทำงานบนพอร์ตใด
- ทำงานบน http://127.0.0.1:8080
แอปพลิเคชันต้องทำงานต่อไปเพื่อให้บริการคำขอ
👉 จากเมนู "ตัวอย่างเว็บ" ให้เลือกแสดงตัวอย่างบนพอร์ต 8080 Cloud Shell จะเปิดแท็บเบราว์เซอร์หรือหน้าต่างใหม่พร้อมแสดงตัวอย่างเว็บของแอปพลิเคชัน 
👉 ในอินเทอร์เฟซแอปพลิเคชัน ให้พิมพ์คำถาม 2-3 ข้อที่เกี่ยวข้องกับการอ้างอิงคดีทางกฎหมายโดยเฉพาะ แล้วดูว่า LLM ตอบสนองอย่างไร เช่น คุณอาจลองทำสิ่งต่อไปนี้
- Michael Brown ถูกตัดสินจำคุกกี่ปี
- การกระทำของเจน สมิธทำให้เกิดการเรียกเก็บเงินที่ไม่ได้รับอนุญาตเป็นจำนวนเท่าใด
- คำให้การของเพื่อนบ้านมีบทบาทอย่างไรในการสืบสวนคดีของเอมิลี ไวท์
👉 ไม่บังคับ: เวอร์ชันภาษาสเปน
- ¿A cuántos años de prisión fue sentenciado Michael Brown?
- ¿Cuánto dinero en cargos no autorizados se generó como resultado de las acciones de Jane Smith?
- ¿Qué papel jugaron los testimonios de los vecinos en la investigación del caso de Emily White?
หากพิจารณาคำตอบอย่างละเอียด คุณอาจสังเกตเห็นว่าโมเดลอาจเกิดอาการหลอนของ AI คลุมเครือ หรือทั่วไป และบางครั้งอาจตีความคำถามของคุณผิด โดยเฉพาะอย่างยิ่งเนื่องจากโมเดลยังไม่มีสิทธิ์เข้าถึงเอกสารทางกฎหมายที่เฉพาะเจาะจง
👉 หยุดสคริปต์โดยกด Ctrl+C
👉 ออกจากสภาพแวดล้อมเสมือนจริงโดยเรียกใช้คำสั่งต่อไปนี้ในเทอร์มินัล
deactivate
6. การตั้งค่าที่เก็บเวกเตอร์
ถึงเวลาหยุด "การตีความอย่างสร้างสรรค์" ของกฎหมายโดย LLM เหล่านี้แล้ว และนี่คือจุดที่การสร้างแบบดึงข้อมูลมาเสริม (RAG) เข้ามาช่วย ซึ่งก็เหมือนกับการให้สิทธิ์ LLM ของเราเข้าถึงคลังกฎหมายที่มีประสิทธิภาพสูงก่อนที่จะตอบคำถามของคุณ แทนที่จะอาศัยความรู้ทั่วไปเพียงอย่างเดียว (ซึ่งอาจไม่ชัดเจนหรือล้าสมัยขึ้นอยู่กับโมเดล) RAG จะดึงข้อมูลที่เกี่ยวข้องจากแหล่งที่มาที่เชื่อถือได้ก่อน ซึ่งในกรณีนี้คือเอกสารทางกฎหมาย จากนั้นจึงใช้บริบทดังกล่าวเพื่อสร้างคำตอบที่แม่นยำและมีข้อมูลมากขึ้น เหมือนกับ LLM ทำการบ้านก่อนเข้าห้องพิจารณาคดี
หากต้องการสร้างระบบ RAG เราต้องมีที่จัดเก็บเอกสารทางกฎหมายทั้งหมด และที่สำคัญคือต้องทำให้ค้นหาได้ตามความหมาย Firestore จึงเข้ามามีบทบาทในจุดนี้ Firestore คือฐานข้อมูลเอกสาร NoSQL ที่ยืดหยุ่นและปรับขนาดได้ของ Google Cloud
เราจะใช้ Firestore เป็นที่เก็บเวกเตอร์ เราจะจัดเก็บกลุ่มเอกสารทางกฎหมายไว้ใน Firestore และสำหรับแต่ละกลุ่ม เราจะจัดเก็บการฝังของกลุ่มนั้นด้วย ซึ่งเป็นการแสดงความหมายของกลุ่มในรูปแบบตัวเลข
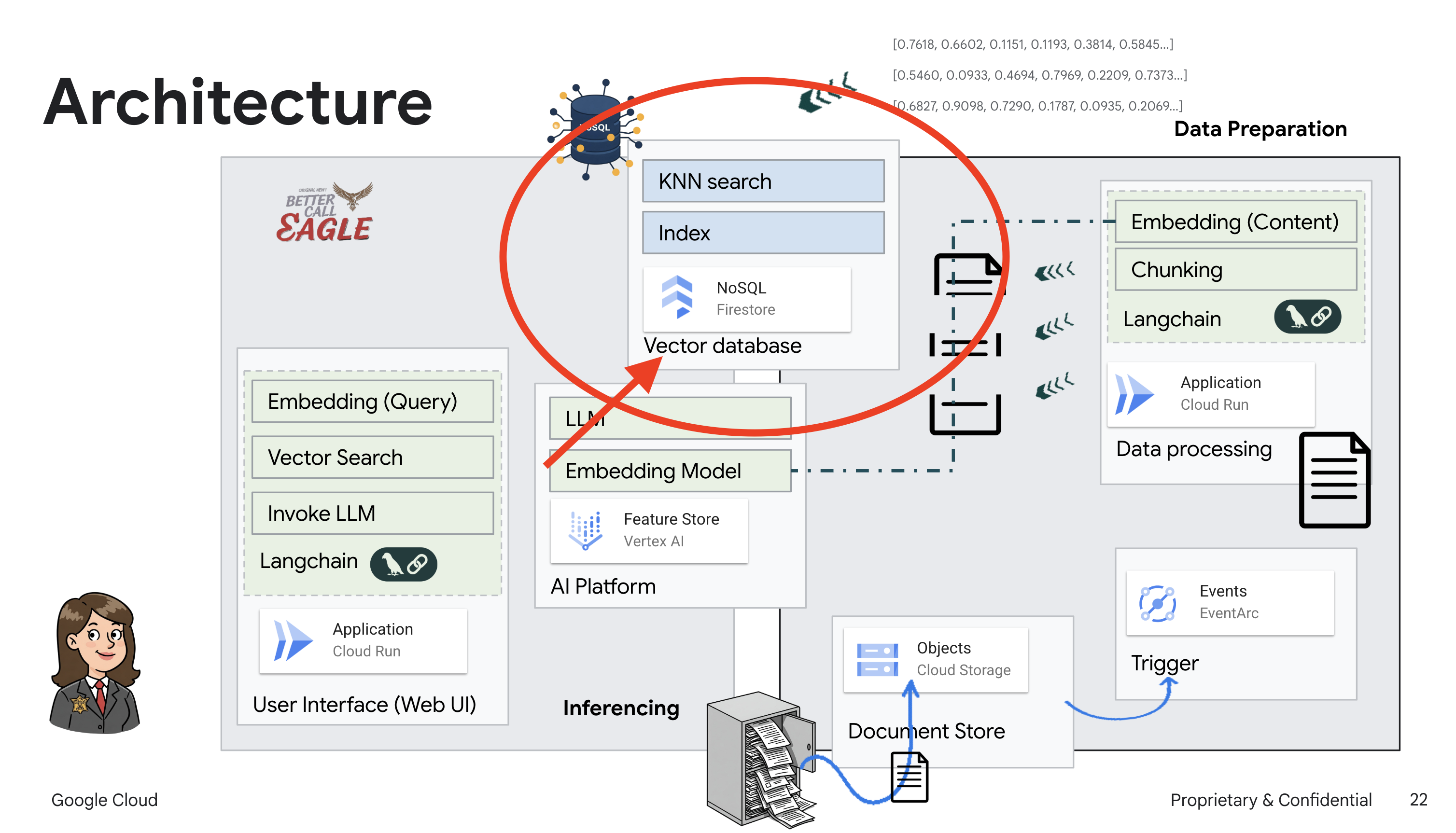
จากนั้นเมื่อคุณถามคำถามกับ Legal Eagle เราจะใช้การค้นหาเวกเตอร์ของ Firestore เพื่อค้นหาข้อความทางกฎหมายที่เกี่ยวข้องกับคำถามของคุณมากที่สุด บริบทที่ดึงมานี้คือสิ่งที่ RAG ใช้เพื่อให้คำตอบที่อิงตามข้อมูลทางกฎหมายจริง ไม่ใช่แค่จินตนาการของ LLM
👉 ในแท็บ/หน้าต่างใหม่ ให้ไปที่ Firestore ในคอนโซล Google Cloud
👉 คลิกสร้างฐานข้อมูล
👉 เลือก Native mode และชื่อฐานข้อมูลเป็น (default)
👉 เลือกรายการเดียว region: us-central1 แล้วคลิกสร้างฐานข้อมูล Firestore จะจัดสรรฐานข้อมูล ซึ่งอาจใช้เวลาสักครู่
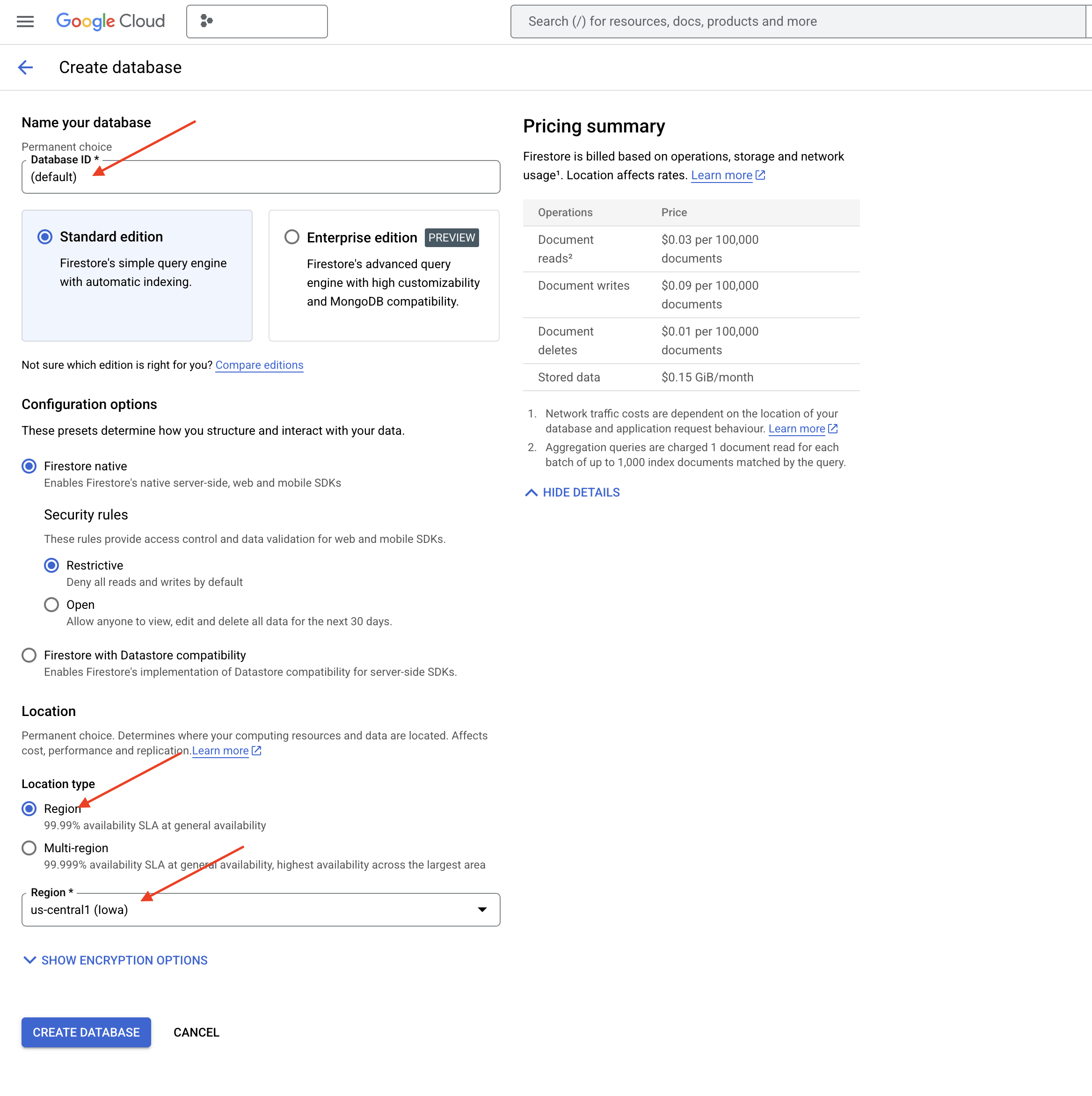
👉 กลับไปที่เทอร์มินัลของ Cloud IDE ให้สร้างดัชนีเวกเตอร์ในช่อง embedding_vector เพื่อเปิดใช้การค้นหาเวกเตอร์ในคอลเล็กชัน legal_documents
export PROJECT_ID=$(gcloud config get project)
gcloud firestore indexes composite create \
--collection-group=legal_documents \
--query-scope=COLLECTION \
--field-config field-path=embedding,vector-config='{"dimension":"768", "flat": "{}"}' \
--project=${PROJECT_ID}
Firestore จะเริ่มสร้างดัชนีเวกเตอร์ การสร้างดัชนีอาจใช้เวลาสักครู่ โดยเฉพาะสำหรับชุดข้อมูลขนาดใหญ่ คุณจะเห็นดัชนีในสถานะ "กำลังสร้าง" และจะเปลี่ยนเป็น "พร้อม" เมื่อสร้างเสร็จแล้ว 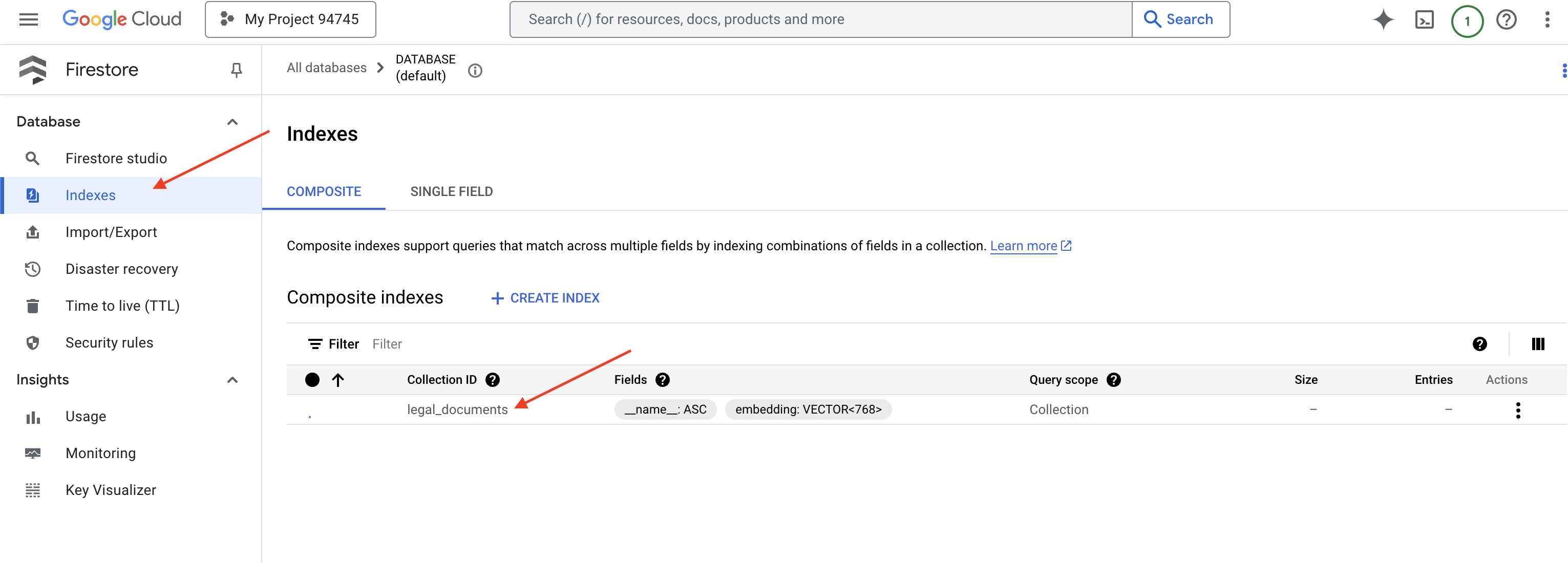
7. การโหลดข้อมูลลงใน Vector Store
ตอนนี้เราเข้าใจ RAG และที่เก็บเวกเตอร์แล้ว ก็ถึงเวลาสร้างเครื่องมือที่จะป้อนข้อมูลในคลังกฎหมายของเรา แล้วเราจะทำให้เอกสารทางกฎหมาย "ค้นหาตามความหมาย" ได้อย่างไร การฝังคือเคล็ดลับสำคัญ การฝังคือการแปลงคำ ประโยค หรือแม้แต่ทั้งเอกสารเป็นเวกเตอร์เชิงตัวเลข ซึ่งก็คือรายการตัวเลขที่บันทึกความหมายเชิงความหมายของคำ ประโยค หรือเอกสารนั้นๆ แนวคิดที่คล้ายกันจะมีเวกเตอร์ที่ "ใกล้" กันในพื้นที่เวกเตอร์ เราใช้โมเดลที่มีประสิทธิภาพ (เช่น โมเดลจาก Vertex AI) เพื่อทำการแปลงนี้
และเราจะใช้ฟังก์ชัน Cloud Run และ Eventarc เพื่อทำให้การโหลดเอกสารเป็นแบบอัตโนมัติ ฟังก์ชัน Cloud Run เป็นคอนเทนเนอร์แบบ Serverless ที่ใช้งานง่ายซึ่งเรียกใช้โค้ดเมื่อจำเป็นเท่านั้น เราจะแพ็กเกจสคริปต์ Python สำหรับการประมวลผลเอกสารลงในคอนเทนเนอร์และทำให้ใช้งานได้เป็นฟังก์ชัน Cloud Run
👉 ในแท็บ/หน้าต่างใหม่ ให้ไปที่ Cloud Storage
👉 คลิก "Buckets" ในเมนูด้านซ้าย
👉 คลิกปุ่ม "+ สร้าง" ที่ด้านบน
👉 กำหนดค่าที่เก็บข้อมูล (การตั้งค่าที่สำคัญ)
- ชื่อที่เก็บข้อมูล: ‘yourprojectID'-doc-bucket (คุณต้องมีคำต่อท้าย -doc-bucket ที่ส่วนท้าย)
- region: เลือก
us-central1 - คลาสพื้นที่เก็บข้อมูล: "มาตรฐาน" มาตรฐานเหมาะสำหรับข้อมูลที่มีการเข้าถึงบ่อย
- การควบคุมการเข้าถึง: เลือก "การควบคุมการเข้าถึงแบบเดียวกัน" ที่เป็นค่าเริ่มต้นไว้ ซึ่งจะช่วยให้การควบคุมการเข้าถึงระดับ Bucket สอดคล้องกัน
- ตัวเลือกขั้นสูง: สำหรับบทแนะนำนี้ โดยปกติแล้วการตั้งค่าเริ่มต้นก็เพียงพอแล้ว
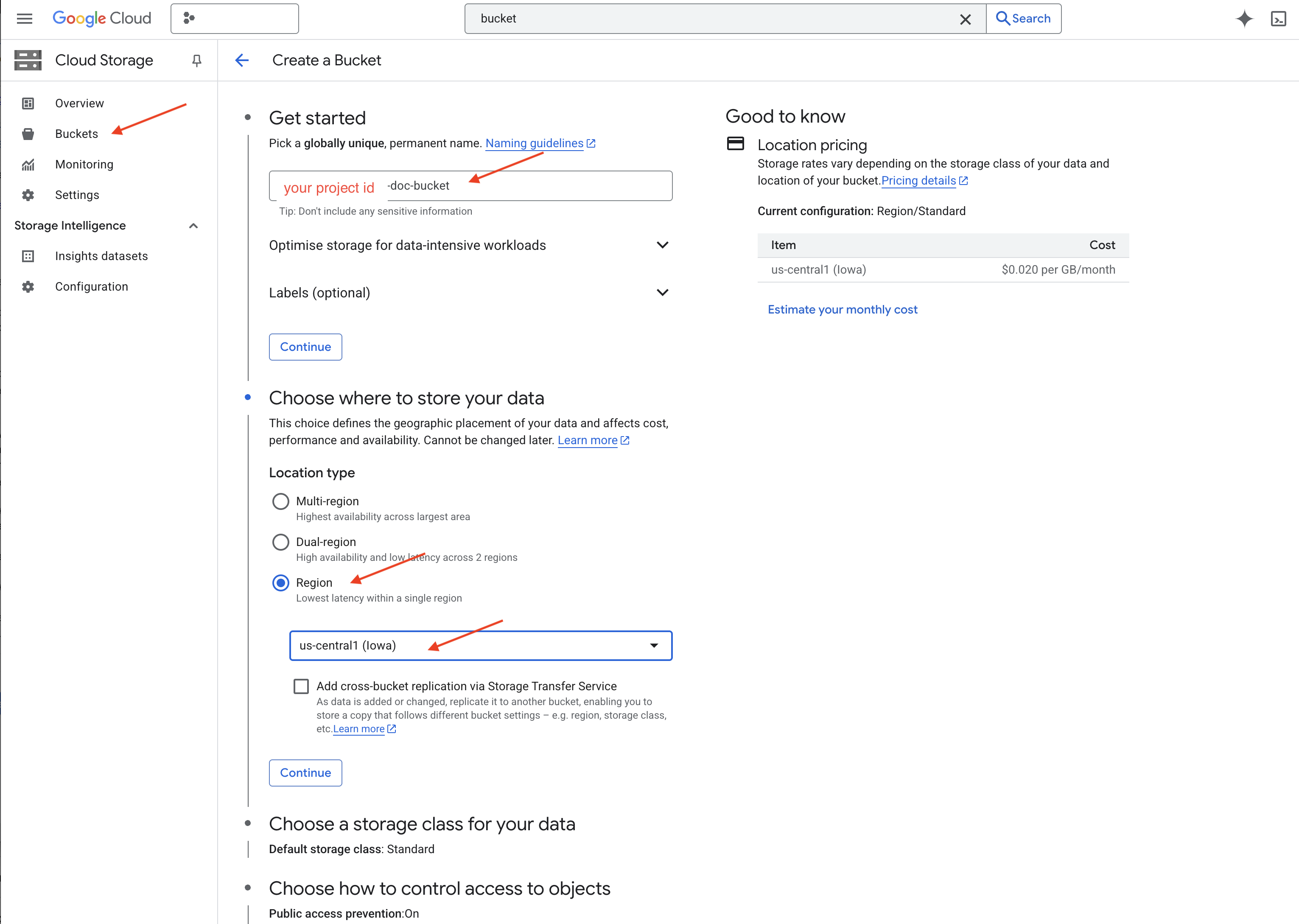
👉 คลิกปุ่มสร้างเพื่อสร้าง Bucket
👉 คุณอาจเห็นป๊อปอัปเกี่ยวกับการป้องกันการเข้าถึงแบบสาธารณะ เลือกช่องไว้แล้วคลิก "ยืนยัน"
ตอนนี้คุณจะเห็นที่เก็บข้อมูลที่สร้างใหม่ในรายการที่เก็บข้อมูล โปรดจำชื่อที่เก็บข้อมูลไว้เพื่อใช้งานในภายหลัง
8. ตั้งค่าฟังก์ชัน Cloud Run
👉 ในโปรแกรมแก้ไขโค้ดของ Cloud Shell ให้ไปที่ไดเรกทอรีการทำงาน legal-eagle: ใช้คำสั่ง cd ในเทอร์มินัลของ Cloud Editor เพื่อสร้างโฟลเดอร์
cd ~/legal-eagle
mkdir loader
cd loader
👉 สร้างไฟล์ main.py,requirements.txt และ Dockerfile ในเทอร์มินัล Cloud Shell ให้ใช้คำสั่ง touch เพื่อสร้างไฟล์
touch main.py requirements.txt Dockerfile
คุณจะเห็นโฟลเดอร์ที่สร้างใหม่ชื่อ *loader และไฟล์ทั้ง 3 ไฟล์
👉 แก้ไข main.py ในโฟลเดอร์ loader ใน File Explorer ทางด้านซ้าย ให้ไปที่ไดเรกทอรีที่คุณสร้างไฟล์ แล้วดับเบิลคลิก main.py เพื่อเปิดในโปรแกรมแก้ไข
วางโค้ด Python ต่อไปนี้ลงใน main.py
แอปพลิเคชันนี้จะประมวลผลไฟล์ใหม่ที่อัปโหลดไปยัง Bucket ของ GCS, แยกข้อความเป็นก้อน, สร้างการฝังสำหรับแต่ละก้อน และจัดเก็บก้อนและการฝังของก้อนเหล่านั้นใน Firestore
import os
import json
from google.cloud import storage
import functions_framework
from langchain_google_vertexai import VertexAI, VertexAIEmbeddings
from langchain_google_firestore import FirestoreVectorStore
from langchain.text_splitter import RecursiveCharacterTextSplitter
import vertexai
PROJECT_ID = os.environ.get("GOOGLE_CLOUD_PROJECT") # Get project ID from env
embedding_model = VertexAIEmbeddings(
model_name="text-embedding-004" ,
project=PROJECT_ID,)
COLLECTION_NAME = "legal_documents"
# Create a vector store
vector_store = FirestoreVectorStore(
collection="legal_documents",
embedding_service=embedding_model,
content_field="original_text",
embedding_field="embedding",
)
@functions_framework.cloud_event
def process_file(cloud_event):
print(f"CloudEvent received: {cloud_event.data}") # Print the parsed event data
"""Triggered by a Cloud Storage event.
Args:
cloud_event (functions_framework.CloudEvent): The CloudEvent
containing the Cloud Storage event data.
"""
try:
event_data = cloud_event.data
bucket_name = event_data['bucket']
file_name = event_data['name']
except (json.JSONDecodeError, AttributeError, KeyError) as e: # Catch JSON errors
print(f"Error decoding CloudEvent data: {e} - Data: {cloud_event.data}")
return "Error processing event", 500 # Return an error response
print(f"New file detected in bucket: {bucket_name}, file: {file_name}")
storage_client = storage.Client()
bucket = storage_client.bucket(bucket_name)
blob = bucket.blob(file_name)
try:
# Download the file content as string (assuming UTF-8 encoded text file)
file_content_string = blob.download_as_string().decode("utf-8")
print(f"File content downloaded. Processing...")
# Split text into chunks using RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=100,
length_function=len,
)
text_chunks = text_splitter.split_text(file_content_string)
print(f"Text split into {len(text_chunks)} chunks.")
# Add the docs to the vector store
vector_store.add_texts(text_chunks)
print(f"File processing and Firestore upsert complete for file: {file_name}")
return "File processed successfully", 200 # Return success response
except Exception as e:
print(f"Error processing file {file_name}: {e}")
แก้ไข requirements.txt วางบรรทัดต่อไปนี้ลงในไฟล์
Flask==2.3.3
requests==2.31.0
google-generativeai>=0.2.0
langchain
langchain_google_vertexai
langchain-community
langchain-google-firestore
google-cloud-storage
functions-framework
9. ทดสอบและสร้างฟังก์ชัน Cloud Run
👉 เราจะเรียกใช้คำสั่งนี้ในสภาพแวดล้อมเสมือนและติดตั้งไลบรารี Python ที่จำเป็นสำหรับฟังก์ชัน Cloud Run
cd ~/legal-eagle/loader
python -m venv env
source env/bin/activate
pip install -r requirements.txt
👉 เริ่มโปรแกรมจำลองในเครื่องสำหรับฟังก์ชัน Cloud Run
functions-framework --target process_file --signature-type=cloudevent --source main.py
👉 เปิดเทอร์มินัลล่าสุดไว้ เปิดเทอร์มินัลใหม่ แล้วเรียกใช้คำสั่งเพื่ออัปโหลดไฟล์ไปยังที่เก็บข้อมูล
export DOC_BUCKET_NAME=$(gcloud storage buckets list --format="value(name)" | grep doc-bucket)
gsutil cp ~/legal-eagle/court_cases/case-01.txt gs://$DOC_BUCKET_NAME/

👉 ขณะที่โปรแกรมจำลองทำงานอยู่ คุณสามารถส่ง CloudEvents ทดสอบไปยังโปรแกรมจำลองได้ คุณจะต้องมีเทอร์มินัลแยกต่างหากใน IDE สำหรับการดำเนินการนี้
curl -X POST -H "Content-Type: application/json" \
-d "{
\"specversion\": \"1.0\",
\"type\": \"google.cloud.storage.object.v1.finalized\",
\"source\": \"//storage.googleapis.com/$DOC_BUCKET_NAME\",
\"subject\": \"objects/case-01.txt\",
\"id\": \"my-event-id\",
\"time\": \"2024-01-01T12:00:00Z\",
\"data\": {
\"bucket\": \"$DOC_BUCKET_NAME\",
\"name\": \"case-01.txt\"
}
}" http://localhost:8080/
ซึ่งควรแสดงผลเป็น OK
👉 คุณจะยืนยันข้อมูลใน Firestore ได้โดยไปที่ คอนโซล Google Cloud แล้วไปที่ "ฐานข้อมูล" จากนั้นไปที่ "Firestore" แล้วเลือกแท็บ "ข้อมูล" จากนั้นเลือกคอลเล็กชัน legal_documents คุณจะเห็นว่าระบบได้สร้างเอกสารใหม่ในคอลเล็กชันของคุณ โดยแต่ละเอกสารจะแสดงข้อความส่วนหนึ่งจากไฟล์ที่อัปโหลด 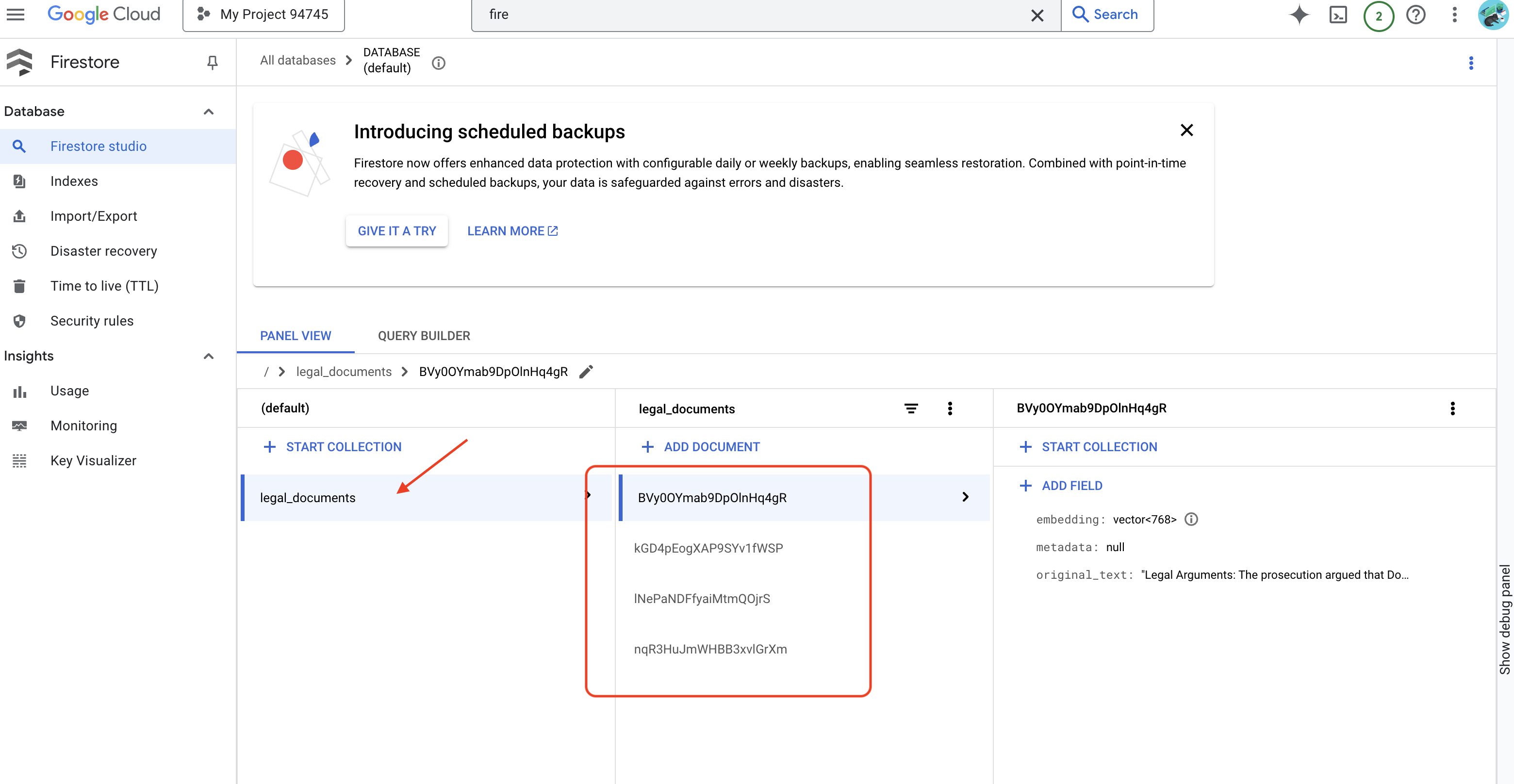
👉 ในเทอร์มินัลที่เรียกใช้โปรแกรมจำลอง ให้พิมพ์ Ctrl+C เพื่อออก แล้วปิดเทอร์มินัลที่ 2
เรียกใช้ deactivate เพื่อออกจากสภาพแวดล้อมเสมือน
deactivate
10. สร้างอิมเมจคอนเทนเนอร์และพุชไปยังที่เก็บ Artifact
ได้เวลาทำให้ใช้งานได้ในระบบคลาวด์แล้ว ใน File Explorer ให้ดับเบิลคลิก Dockerfile ขอความช่วยเหลือจาก Gemini เพื่อสร้าง Dockerfile ให้คุณ เปิด Gemini Code Assist แล้วใช้พรอมต์ต่อไปนี้เพื่อสร้างไฟล์
In the loader folder,
Generate a Dockerfile for a Python 3.12 Cloud Run service that uses functions-framework. It needs to:
1. Use a Python 3.12 slim base image.
2. Set the working directory to /app.
3. Copy requirements.txt and install Python dependencies.
4. Copy main.py.
5. Set the command to run functions-framework, targeting the 'process_file' function on port 8080
แนวทางปฏิบัติแนะนำคือคลิก Diff with Open File(ลูกศร 2 อันชี้ไปในทิศทางตรงกันข้าม และยอมรับการเปลี่ยนแปลง) 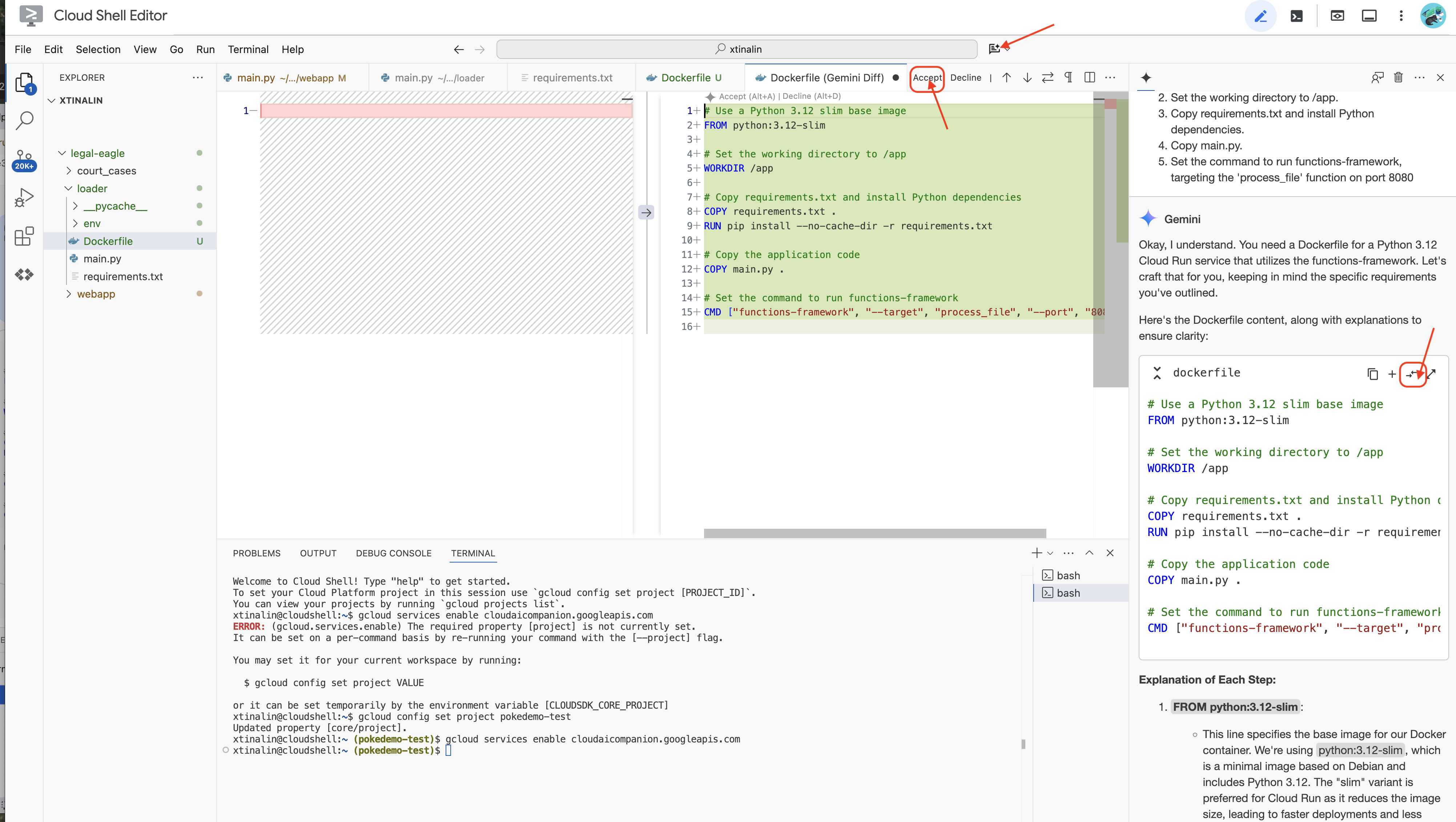
👉 หากคุณเพิ่งเริ่มใช้คอนเทนเนอร์ โปรดดูตัวอย่างที่ใช้งานได้ต่อไปนี้
# Use a Python 3.12 slim base image
FROM python:3.12-slim
# Set the working directory to /app
WORKDIR /app
# Copy requirements.txt and install Python dependencies
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
# Copy main.py
COPY main.py .
# Set the command to run functions-framework
CMD ["functions-framework", "--target", "process_file", "--port", "8080"]
สร้างที่เก็บที่เก็บอาร์ติแฟกต์ในเทอร์มินัลเพื่อจัดเก็บอิมเมจ Docker ที่เราจะสร้าง
gcloud artifacts repositories create my-repository \
--repository-format=docker \
--location=us-central1 \
--description="My repository"
คุณควรเห็นข้อความสร้างที่เก็บ [my-repository] แล้ว
👉 เรียกใช้คำสั่งต่อไปนี้เพื่อสร้างอิมเมจ Docker
cd ~/legal-eagle/loader
export PROJECT_ID=$(gcloud config get project)
docker build -t gcr.io/${PROJECT_ID}/legal-eagle-loader .
👉 ตอนนี้คุณจะพุชไปยังรีจิสทรี
export PROJECT_ID=$(gcloud config get project)
docker tag gcr.io/${PROJECT_ID}/legal-eagle-loader us-central1-docker.pkg.dev/${PROJECT_ID}/my-repository/legal-eagle-loader
docker push us-central1-docker.pkg.dev/${PROJECT_ID}/my-repository/legal-eagle-loader
ตอนนี้อิมเมจ Docker พร้อมใช้งานในที่เก็บ my-repository ที่เก็บ Artifact แล้ว
11. สร้างฟังก์ชัน Cloud Run และตั้งค่าทริกเกอร์ Eventarc
ก่อนที่จะเจาะลึกรายละเอียดของการทำให้ใช้งานได้โปรแกรมโหลดเอกสารทางกฎหมาย เรามาทำความเข้าใจคร่าวๆ เกี่ยวกับคอมโพเนนต์ที่เกี่ยวข้องกันก่อน Cloud Run เป็นแพลตฟอร์มแบบ Serverless ที่มีการจัดการครบวงจร ซึ่งช่วยให้คุณทำให้ใช้งานได้แอปพลิเคชันที่สร้างโดยใช้คอนเทนเนอร์ได้อย่างรวดเร็วและง่ายดาย ซึ่งตัดการจัดการโครงสร้างพื้นฐานออก เพื่อให้คุณมุ่งเน้นเฉพาะการเขียนและการติดตั้งใช้งานโค้ดเท่านั้น
เราจะทำให้โปรแกรมโหลดเอกสารใช้งานได้เป็นบริการ Cloud Run ตอนนี้มาตั้งค่าฟังก์ชัน Cloud Run กัน
ใน คอนโซล Google Cloud ให้ไปที่ Cloud Run
👉 ไปที่ติดตั้งใช้งานคอนเทนเนอร์ แล้วคลิก SERVICE ในเมนูแบบเลื่อนลง
👉 กำหนดค่าบริการ Cloud Run
- อิมเมจคอนเทนเนอร์: คลิก "เลือก" ในช่อง URL ค้นหา URL ของรูปภาพที่คุณพุชไปยัง Artifact Registry (เช่น us-central1-docker.pkg.dev/your-project-id/my-repository/legal-eagle-loader/yourimage)
- ชื่อบริการ:
legal-eagle-loader - ภูมิภาค: เลือกภูมิภาค
us-central1 - การตรวจสอบสิทธิ์: สำหรับเวิร์กช็อปนี้ คุณสามารถเลือก "อนุญาตการเรียกใช้ที่ไม่ผ่านการตรวจสอบสิทธิ์" สำหรับเวอร์ชันที่ใช้งานจริง คุณอาจต้องจำกัดการเข้าถึง
- คอนเทนเนอร์ เครือข่าย ความปลอดภัย : ค่าเริ่มต้น
👉 คลิกสร้าง Cloud Run จะทำให้บริการใช้งานได้ 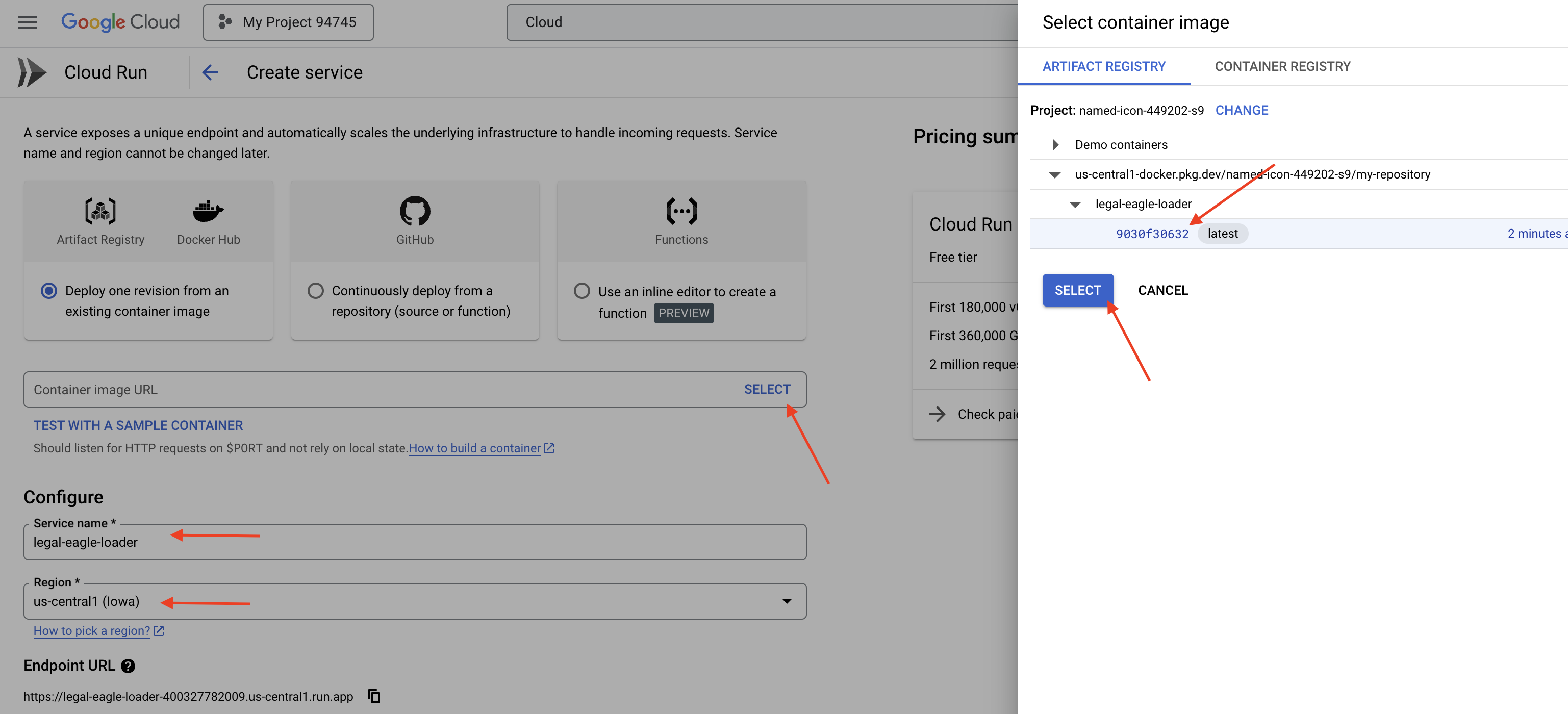
เราจะใช้ Eventarc เพื่อทริกเกอร์บริการนี้โดยอัตโนมัติเมื่อมีการเพิ่มไฟล์ใหม่ลงในที่เก็บข้อมูล Eventarc ช่วยให้คุณสร้างสถาปัตยกรรมที่ขับเคลื่อนด้วยเหตุการณ์ได้โดยการกำหนดเส้นทางเหตุการณ์จากแหล่งที่มาต่างๆ ไปยังบริการของคุณ
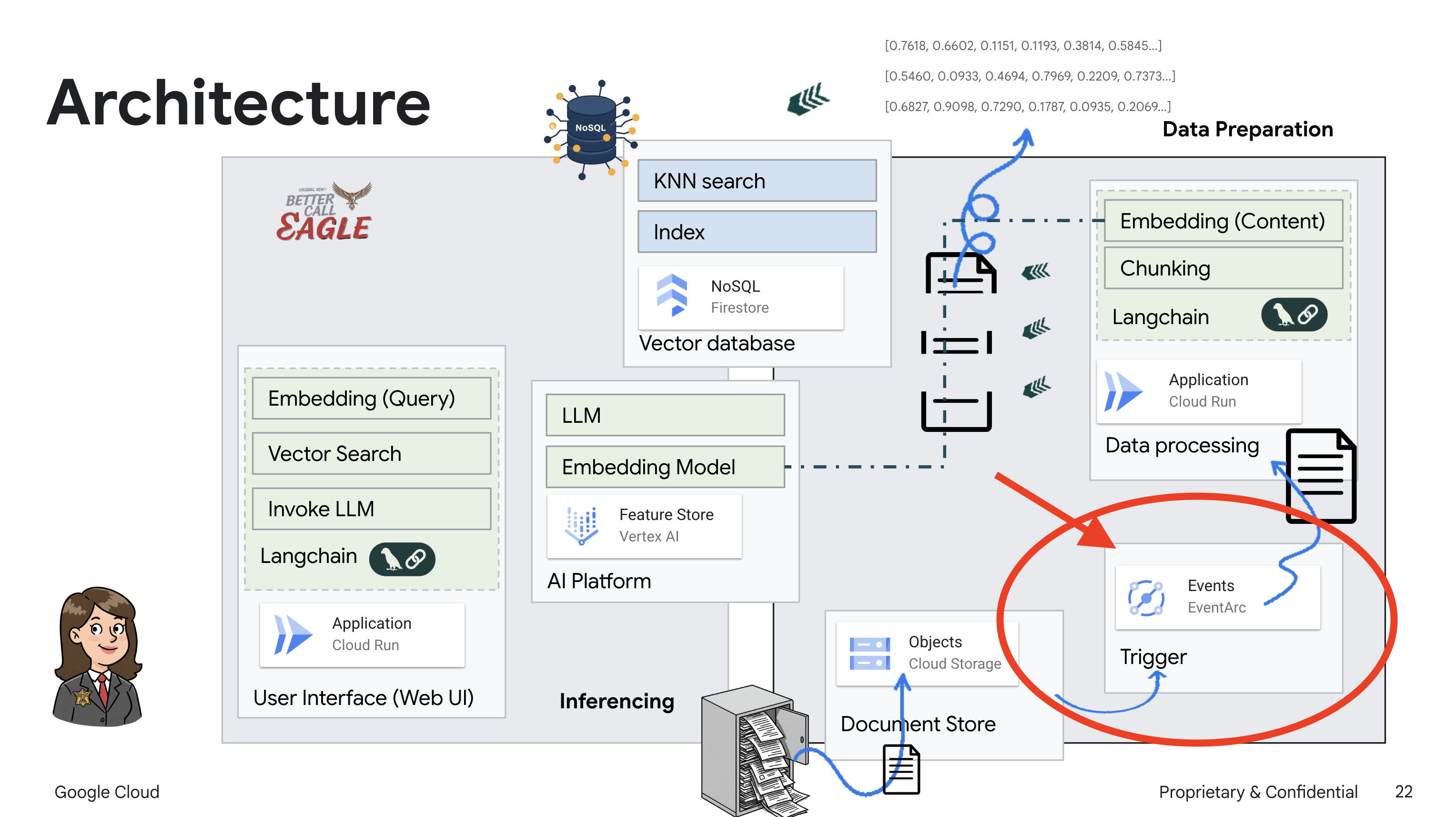
การตั้งค่า Eventarc จะช่วยให้บริการ Cloud Run โหลดเอกสารที่เพิ่มใหม่ลงใน Firestore โดยอัตโนมัติทันทีที่มีการอัปโหลด ซึ่งจะช่วยให้แอปพลิเคชัน RAG ของเราอัปเดตข้อมูลแบบเรียลไทม์ได้
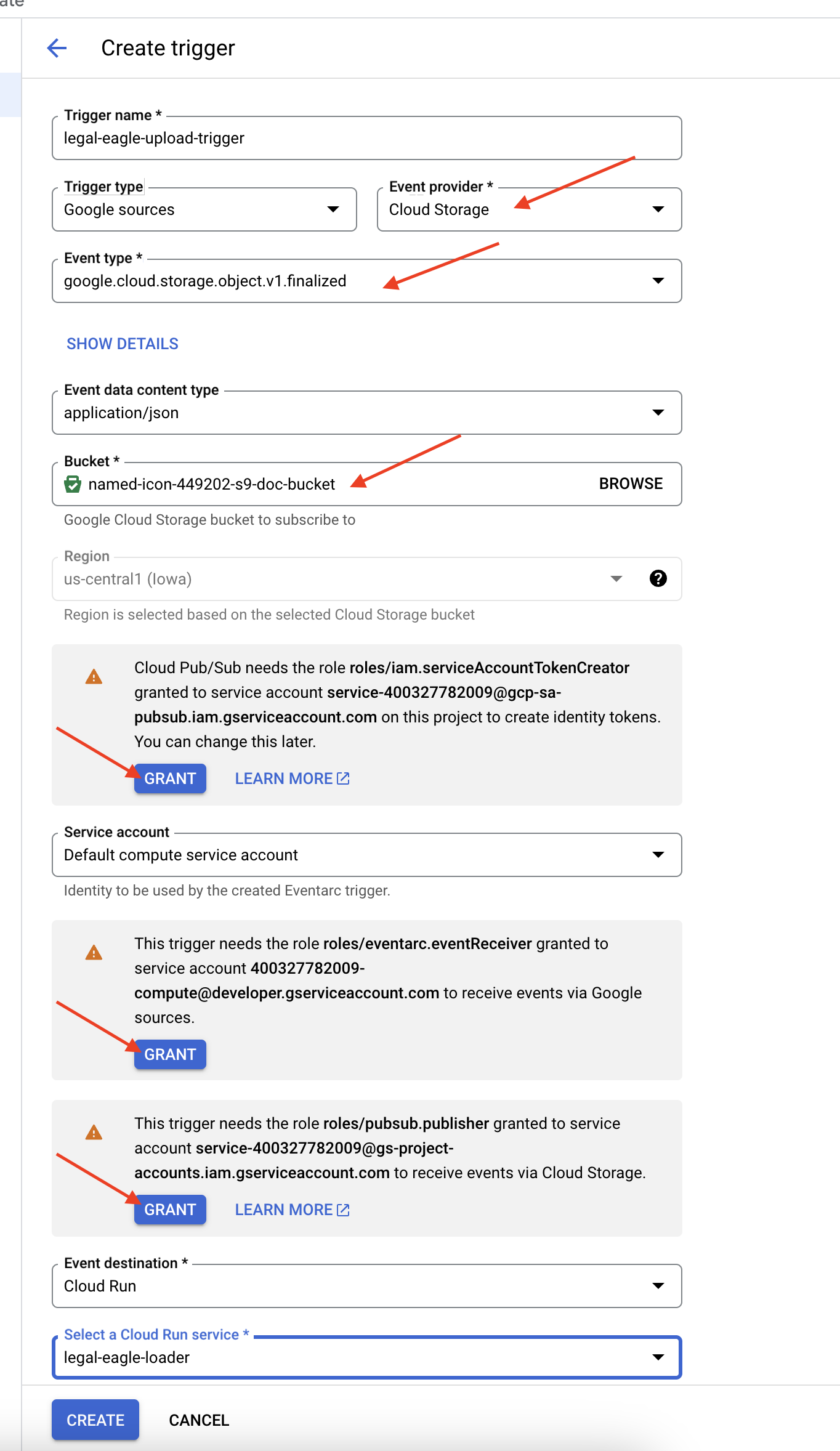
👉 ในคอนโซล Google Cloud ให้ไปที่ทริกเกอร์ใน EventArc คลิก "+ สร้างทริกเกอร์" 👉 กำหนดค่าทริกเกอร์ Eventarc:
- ชื่อทริกเกอร์:
legal-eagle-upload-trigger - TriggerType: แหล่งที่มาของ Google
- ผู้ให้บริการเหตุการณ์: เลือก Cloud Storage
- ประเภทกิจกรรม: เลือก
google.cloud.storage.object.v1.finalized - Bucket ของ Cloud Storage: เลือก Bucket ของ GCS จากเมนูแบบเลื่อนลง
- ประเภทปลายทาง: "บริการ Cloud Run"
- บริการ: เลือก
legal-eagle-loader - ภูมิภาค:
us-central1 - เส้นทาง: เว้นว่างไว้ก่อน
- ให้สิทธิ์ทั้งหมดที่ระบบแจ้งในหน้าเว็บ
👉 คลิกสร้าง ตอนนี้ Eventarc จะตั้งค่าทริกเกอร์
บริการ Cloud Run ต้องมีสิทธิ์อ่านไฟล์จากคอมโพเนนต์ต่างๆ เราต้องให้สิทธิ์บัญชีบริการของบริการตามที่จำเป็น
12. อัปโหลดเอกสารทางกฎหมายไปยังที่เก็บข้อมูล GCS
👉 อัปโหลดไฟล์คดีในศาลไปยังที่เก็บข้อมูล GCS อย่าลืมแทนที่ชื่อที่เก็บข้อมูล
export DOC_BUCKET_NAME=$(gcloud storage buckets list --format="value(name)" | grep doc-bucket)
gsutil cp ~/legal-eagle/court_cases/case-02.txt gs://$DOC_BUCKET_NAME/
gsutil cp ~/legal-eagle/court_cases/case-03.txt gs://$DOC_BUCKET_NAME/
gsutil cp ~/legal-eagle/court_cases/case-06.txt gs://$DOC_BUCKET_NAME/
ตรวจสอบบันทึกบริการ Cloud Run โดยไปที่ Cloud Run -> บริการ legal-eagle-loader -> "บันทึก" ตรวจสอบบันทึกเพื่อดูข้อความการประมวลผลที่สําเร็จ ซึ่งรวมถึง
xxx
POST200130 B8.3 sAPIs-Google; (+https://developers.google.com/webmasters/APIs-Google.html) https://legal-eagle-loader-bmngrueyta-uc.a.run.app/?__GCP_CloudEventsMode=GCS_NOTIFICATION
xxx
POST200130 B520 msAPIs-Google; (+https://developers.google.com/webmasters/APIs-Google.html) https://legal-eagle-loader-bmngrueyta-uc.a.run.app/?__GCP_CloudEventsMode=GCS_NOTIFICATION
xxx
POST200130 B514 msAPIs-Google; (+https://developers.google.com/webmasters/APIs-Google.html) https://legal-eagle-loader-bmngrueyta-uc.a.run.app/?__GCP_CloudEventsMode=GCS_NOTIFICATION
และคุณจะเห็นบันทึกโดยละเอียดเพิ่มเติมที่นี่ด้วย โดยขึ้นอยู่กับความเร็วในการตั้งค่าการบันทึก
"CloudEvent received:"
"New file detected in bucket:"
"File content downloaded. Processing..."
"Text split into ... chunks."
"File processing and Firestore upsert complete..."
มองหาข้อความแสดงข้อผิดพลาดในบันทึกและแก้ปัญหาหากจำเป็น 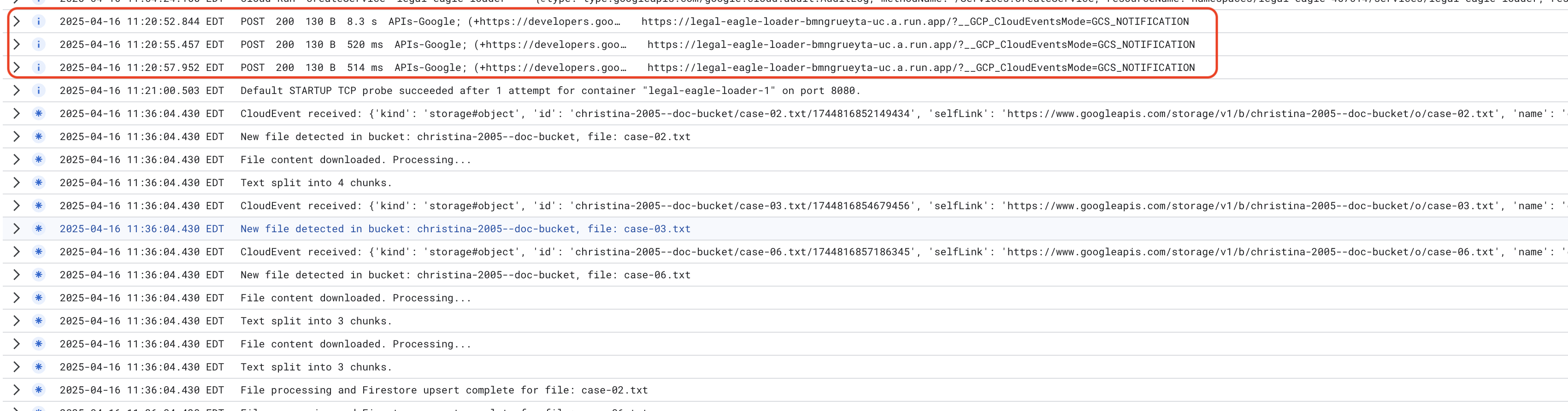
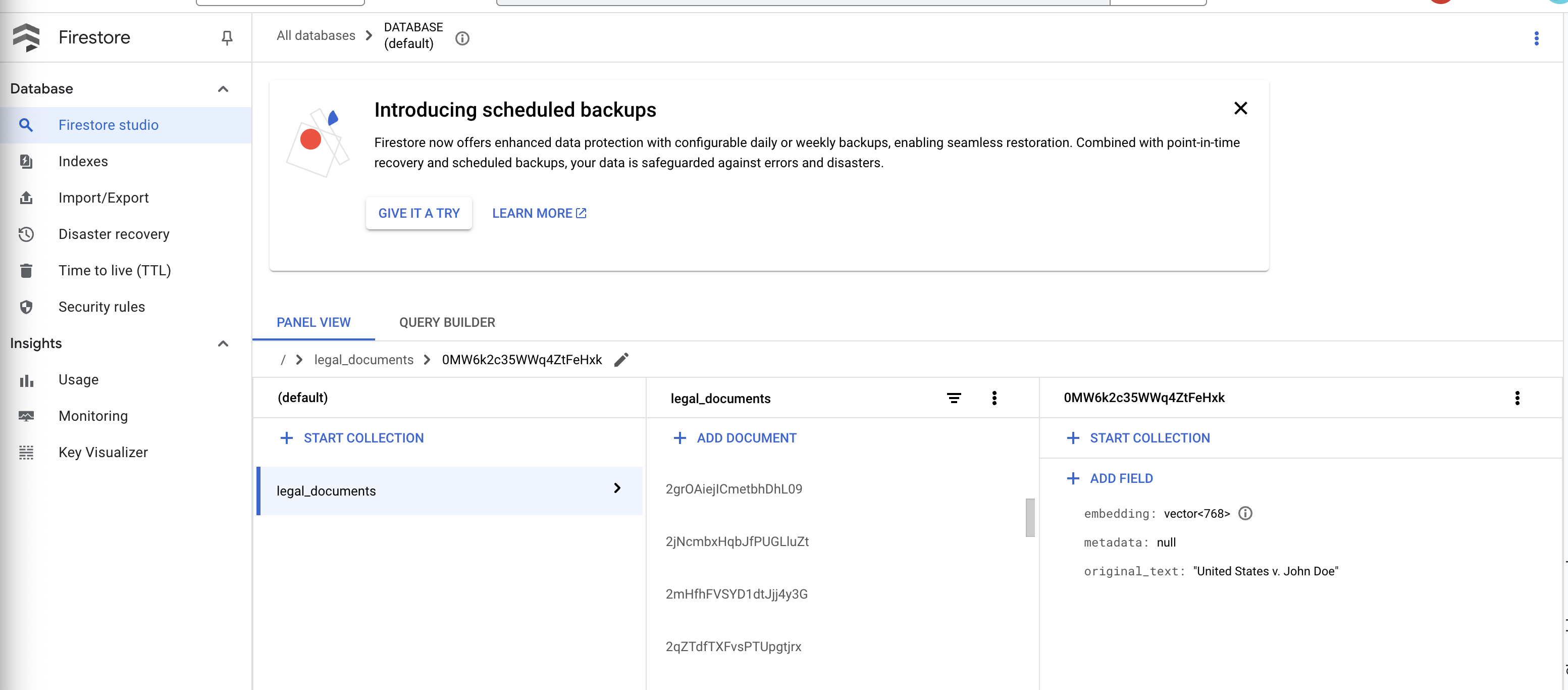
👉 ตรวจสอบข้อมูลใน Firestore แล้วเปิดคอลเล็กชัน legal_documents
👉 คุณควรเห็นเอกสารใหม่ที่สร้างขึ้นในคอลเล็กชัน เอกสารแต่ละฉบับจะแสดงข้อความส่วนหนึ่งจากไฟล์ที่คุณอัปโหลด และจะมีข้อมูลต่อไปนี้
metadata: currently empty
original_text_chunk: The text chunk content.
embedding_: A list of floating-point numbers (the Vertex AI embedding).
13. การใช้ RAG
LangChain เป็นเฟรมเวิร์กที่มีประสิทธิภาพซึ่งออกแบบมาเพื่อเพิ่มประสิทธิภาพการพัฒนาแอปพลิเคชันที่ขับเคลื่อนโดยโมเดลภาษาขนาดใหญ่ (LLM) LangChain มีเลเยอร์การแยกข้อมูลระดับสูงแทนที่จะต้องจัดการกับความซับซ้อนของ API ของ LLM, วิศวกรรมพรอมต์ (Prompt Engineering) และการจัดการข้อมูลโดยตรง โดยมีคอมโพเนนต์และเครื่องมือที่สร้างไว้ล่วงหน้าสำหรับงานต่างๆ เช่น การเชื่อมต่อกับ LLM ต่างๆ (เช่น LLM จาก OpenAI, Google หรืออื่นๆ) การสร้างเชนการดำเนินการที่ซับซ้อน (เช่น การดึงข้อมูลตามด้วยการสรุป) และการจัดการหน่วยความจำในการสนทนา
สำหรับ RAG โดยเฉพาะนั้น Vector Store ใน LangChain เป็นสิ่งจำเป็นในการเปิดใช้การดึงข้อมูลของ RAG ซึ่งเป็นฐานข้อมูลเฉพาะที่ออกแบบมาเพื่อจัดเก็บและค้นหาการฝังเวกเตอร์อย่างมีประสิทธิภาพ โดยจะแมปข้อความที่มีความคล้ายกันทางความหมายกับจุดที่อยู่ใกล้กันในพื้นที่เวกเตอร์ LangChain จะจัดการการเชื่อมต่อระดับล่าง เพื่อให้นักพัฒนาซอฟต์แวร์มุ่งเน้นที่ตรรกะและฟังก์ชันหลักของแอปพลิเคชัน RAG ได้ ซึ่งช่วยลดเวลาในการพัฒนาและความซับซ้อนได้อย่างมาก ทำให้คุณสามารถสร้างต้นแบบและทำให้แอปพลิเคชันที่ใช้ RAG ใช้งานได้อย่างรวดเร็ว พร้อมทั้งใช้ประโยชน์จากความแข็งแกร่งและความสามารถในการปรับขนาดของโครงสร้างพื้นฐานของระบบคลาวด์ Google Cloud
เมื่อทราบเกี่ยวกับ LangChain แล้ว ตอนนี้คุณจะต้องอัปเดตไฟล์ legal.py ในโฟลเดอร์ webapp เพื่อใช้การติดตั้งใช้งาน RAG ซึ่งจะช่วยให้ LLM ค้นหาเอกสารที่เกี่ยวข้องใน Firestore ก่อนที่จะให้คำตอบได้
👉 นำเข้า FirestoreVectorStore และโมดูลอื่นๆ ที่จำเป็นจาก Langchain และ Vertex AI เพิ่มรายการต่อไปนี้ลงใน legal.py ปัจจุบัน
from langchain_google_vertexai import VertexAIEmbeddings
from langchain_google_firestore import FirestoreVectorStore
👉 เริ่มต้น Vertex AI และโมเดลการฝัง คุณจะใช้ text-embedding-004 เพิ่มโค้ดต่อไปนี้หลังจากนำเข้าโมดูล
PROJECT_ID = os.environ.get("GOOGLE_CLOUD_PROJECT") # Get project ID from env
embedding_model = VertexAIEmbeddings(
model_name="text-embedding-004" ,
project=PROJECT_ID,)
👉 สร้าง FirestoreVectorStore ที่ชี้ไปยังคอลเล็กชัน legal_documents โดยใช้โมเดลการฝังที่เริ่มต้นแล้ว และระบุช่องเนื้อหาและการฝัง เพิ่มโค้ดนี้ต่อจากโค้ดโมเดลการฝังก่อนหน้า
COLLECTION_NAME = "legal_documents"
# Create a vector store
vector_store = FirestoreVectorStore(
collection="legal_documents",
embedding_service=embedding_model,
content_field="original_text",
embedding_field="embedding",
)
👉 กำหนดฟังก์ชันชื่อ search_resource ที่รับการค้นหา ดำเนินการค้นหาความคล้ายคลึงโดยใช้ vector_store.similarity_search และแสดงผลลัพธ์ที่รวมกัน
def search_resource(query):
results = []
results = vector_store.similarity_search(query, k=5)
combined_results = "\n".join([result.page_content for result in results])
print(f"==>{combined_results}")
return combined_results
👉 แทนที่ฟังก์ชัน ask_llm แล้วใช้ฟังก์ชัน search_resource เพื่อดึงบริบทที่เกี่ยวข้องตามคำค้นหาของผู้ใช้
def ask_llm(query):
try:
query_message = {
"type": "text",
"text": query,
}
relevant_resource = search_resource(query)
input_msg = HumanMessage(content=[query_message])
prompt_template = ChatPromptTemplate.from_messages(
[
SystemMessage(
content=(
"You are a helpful assistant, and you are with the attorney in a courtroom, you are helping him to win the case by providing the information he needs "
"Don't answer if you don't know the answer, just say sorry in a funny way possible"
"Use high engergy tone, don't use more than 100 words to answer"
f"Here is some context that is relevant to the question {relevant_resource} that you might use"
)
),
input_msg,
]
)
prompt = prompt_template.format()
response = llm.invoke(prompt)
print(f"response: {response}")
return response
except Exception as e:
print(f"Error sending message to chatbot: {e}") # Log this error too!
return f"Unable to process your request at this time. Due to the following reason: {str(e)}"
👉 ไม่บังคับ: เวอร์ชันภาษาสเปน
Sustituye el siguiente texto como se indica: You are a helpful assistant, to You are a helpful assistant that speaks Spanish,
👉 หลังจากติดตั้งใช้งาน RAG ใน legal.py แล้ว คุณควรทดสอบในเครื่องก่อนที่จะนำไปใช้งาน โดยเรียกใช้แอปพลิเคชันด้วยคำสั่งต่อไปนี้
cd ~/legal-eagle/webapp
source env/bin/activate
python main.py
👉 ใช้ webpreview เพื่อเข้าถึงแอปพลิเคชัน พูดคุยกับผู้ช่วย และพิมพ์ ctrl+c เพื่อออกจากกระบวนการที่ทำงานในเครื่อง และเรียกใช้ deactivate เพื่อออกจากสภาพแวดล้อมเสมือน
deactivate
หากต้องการทำให้เว็บแอปพลิเคชันใช้งานได้ใน Cloud Run ก็จะคล้ายกับฟังก์ชันตัวโหลด คุณจะสร้าง ติดแท็ก และพุชอิมเมจ Docker ไปยัง Artifact Registry โดยทำดังนี้
export PROJECT_ID=$(gcloud config get project)
docker build -t gcr.io/${PROJECT_ID}/legal-eagle-webapp .
docker tag gcr.io/${PROJECT_ID}/legal-eagle-webapp us-central1-docker.pkg.dev/${PROJECT_ID}/my-repository/legal-eagle-webapp
docker push us-central1-docker.pkg.dev/${PROJECT_ID}/my-repository/legal-eagle-webapp
ได้เวลาติดตั้งใช้งานเว็บแอปพลิเคชันใน Google Cloud แล้ว เรียกใช้คำสั่งต่อไปนี้ในเทอร์มินัล
export PROJECT_ID=$(gcloud config get project)
gcloud run deploy legal-eagle-webapp \
--image us-central1-docker.pkg.dev/$PROJECT_ID/my-repository/legal-eagle-webapp \
--region us-central1 \
--set-env-vars=GOOGLE_CLOUD_PROJECT=${PROJECT_ID} \
--allow-unauthenticated
ยืนยันการติดตั้งใช้งานโดยไปที่ Cloud Run ใน Google Cloud Console คุณควรเห็นบริการใหม่ชื่อ legal-eagle-webapp แสดงอยู่
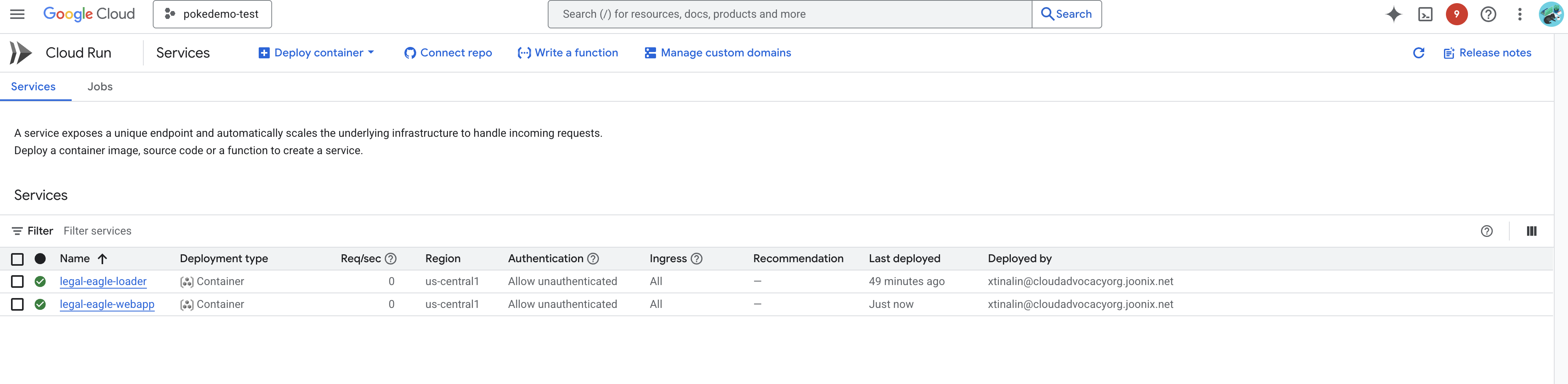
คลิกบริการเพื่อไปยังหน้ารายละเอียด คุณจะเห็น URL ที่ใช้งานได้ที่ด้านบน 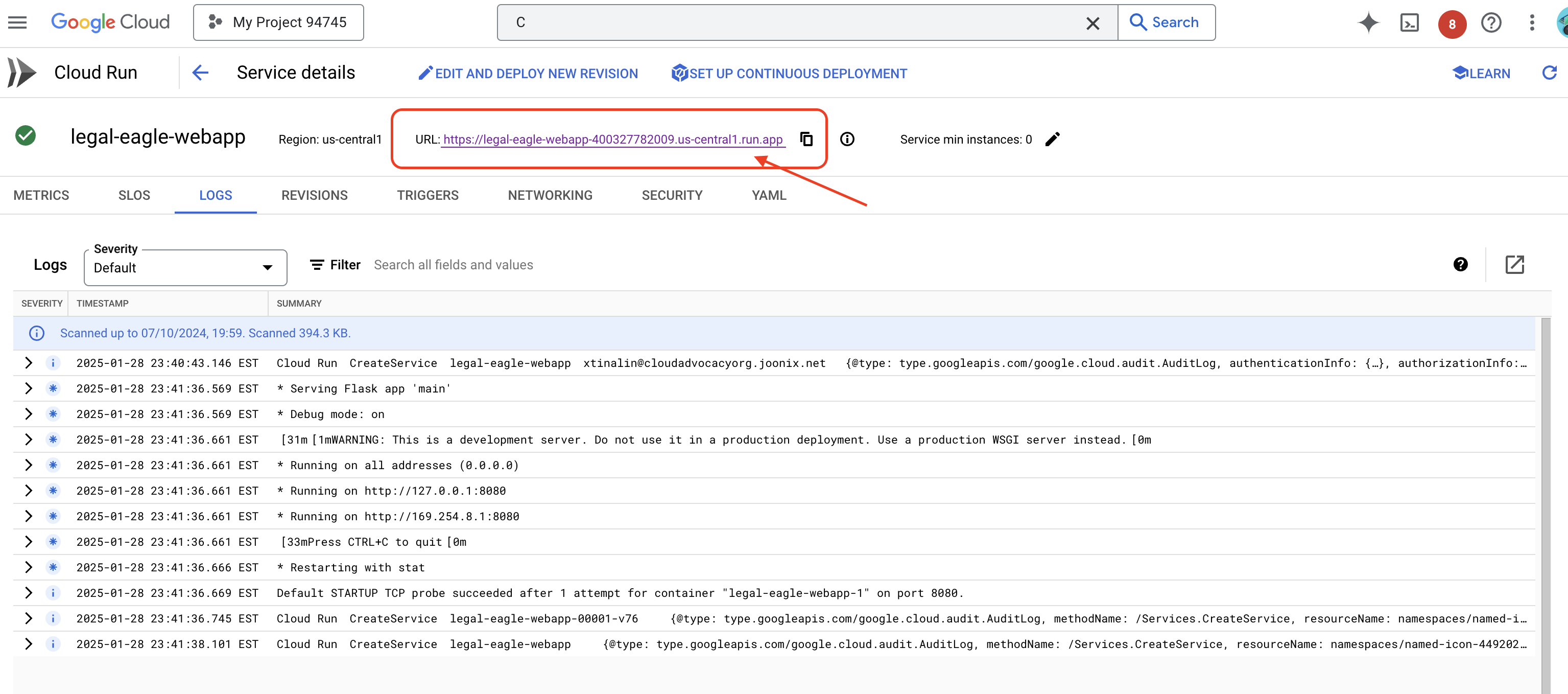
👉 ตอนนี้ให้เปิด URL ที่ติดตั้งใช้งานในแท็บเบราว์เซอร์ใหม่ คุณสามารถโต้ตอบกับผู้ช่วยด้านกฎหมายและถามคำถามที่เกี่ยวข้องกับคดีในศาลที่คุณโหลดไว้(ในโฟลเดอร์ court_cases) ได้โดยทำดังนี้
- Michael Brown ถูกตัดสินจำคุกกี่ปี
- การกระทำของเจน สมิธทำให้เกิดการเรียกเก็บเงินที่ไม่ได้รับอนุญาตเป็นจำนวนเท่าใด
- คำให้การของเพื่อนบ้านมีบทบาทอย่างไรในการสืบสวนคดีของเอมิลี ไวท์
👉 ไม่บังคับ: เวอร์ชันภาษาสเปน
- ¿A cuántos años de prisión fue sentenciado Michael Brown?
- ¿Cuánto dinero en cargos no autorizados se generó como resultado de las acciones de Jane Smith?
- ¿Qué papel jugaron los testimonios de los vecinos en la investigación del caso de Emily White?
คุณจะเห็นว่าตอนนี้คำตอบมีความแม่นยำมากขึ้นและอิงตามเนื้อหาของเอกสารทางกฎหมายที่คุณอัปโหลด ซึ่งแสดงให้เห็นถึงประสิทธิภาพของ RAG
ขอแสดงความยินดีที่จบเวิร์กช็อป คุณสร้างและใช้งานแอปพลิเคชันวิเคราะห์เอกสารทางกฎหมายโดยใช้ LLM, LangChain และ Google Cloud เรียบร้อยแล้ว คุณได้เรียนรู้วิธีการนำเข้าและประมวลผลเอกสารทางกฎหมาย เพิ่มคำตอบของ LLM ด้วยข้อมูลที่เกี่ยวข้องโดยใช้ RAG และทำให้ใช้งานได้แอปพลิเคชันเป็นบริการแบบ Serverless ความรู้และแอปพลิเคชันที่สร้างขึ้นนี้จะช่วยให้คุณสำรวจศักยภาพของ LLM สำหรับงานด้านกฎหมายได้มากยิ่งขึ้น ทำได้ดีมาก"
14. ความท้าทาย
ประเภทสื่อที่หลากหลาย:
วิธีนำเข้าและประมวลผลสื่อประเภทต่างๆ เช่น วิดีโอในศาลและไฟล์บันทึกเสียง รวมถึงวิธีแยกข้อความที่เกี่ยวข้อง
ชิ้นงานออนไลน์:
วิธีประมวลผลชิ้นงานออนไลน์ เช่น หน้าเว็บแบบสด