
1. Giriş
Mahkeme salonunun yoğunluğu her zaman ilgimi çekmiştir. Kendimi, karmaşıklıklarını ustaca yönetip güçlü kapanış argümanları sunarken hayal ederim. Kariyer yolum beni başka bir yere götürmüş olsa da yapay zekanın yardımıyla hepimizin o mahkeme salonu hayaline ulaşmaya daha yakın olabileceğini paylaşmaktan heyecan duyuyorum.

Bugün, yasal verileri işlemek ve anlamak, ışık hızında aramalar yapmak ve belki de hayali müşterinizin (veya kendinizin) zor bir durumdan kurtulmasına yardımcı olmak için Vertex AI, Firestore ve Cloud Run Functions gibi Google'ın güçlü yapay zeka araçlarını nasıl kullanacağımızı ele alacağız.
Tanığı çapraz sorgulamıyor olabilirsiniz ancak sistemimizle birlikte dağlar kadar bilgiyi eleyebilir, net özetler oluşturabilir ve en alakalı verileri saniyeler içinde sunabilirsiniz.
2. Mimari
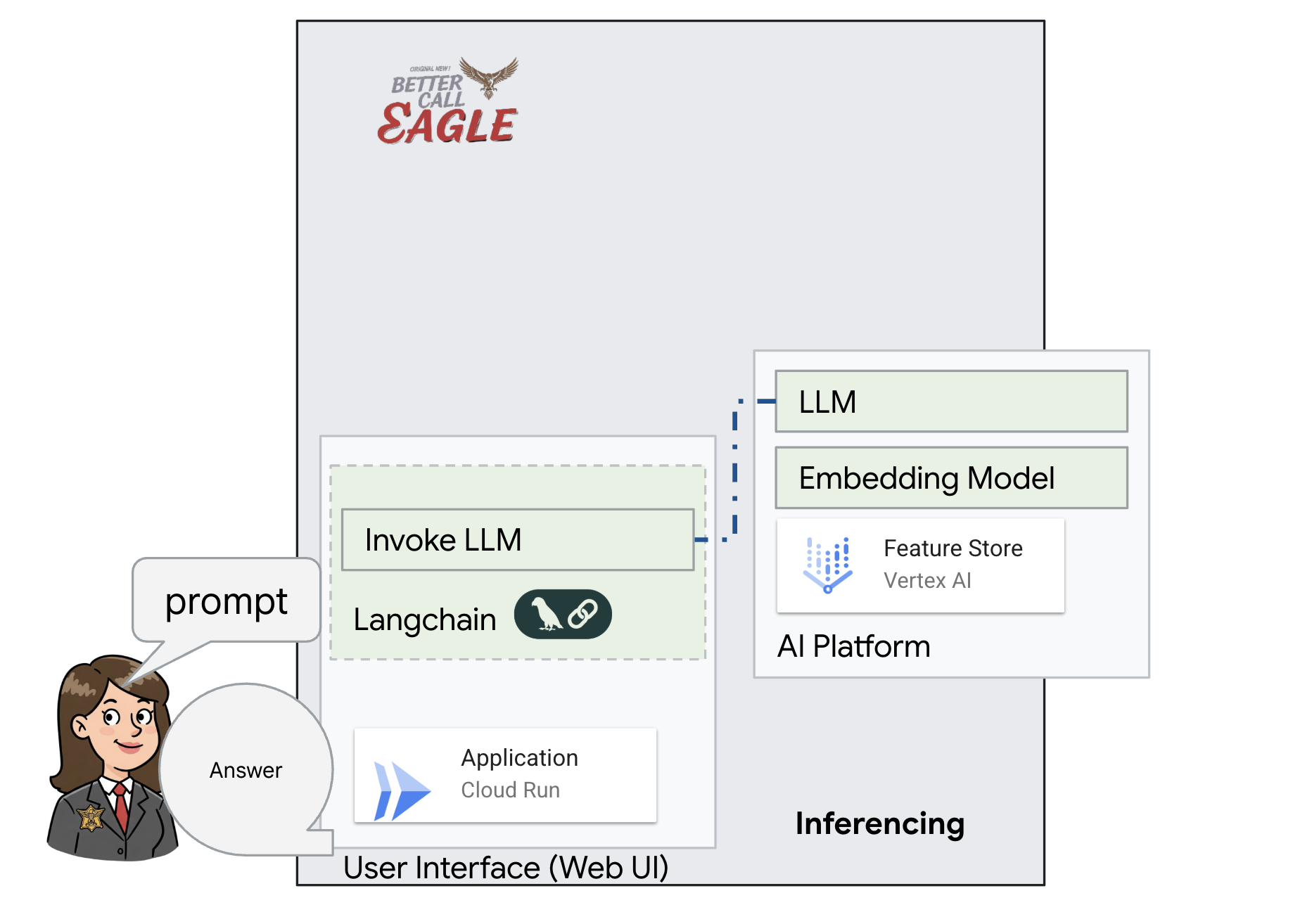
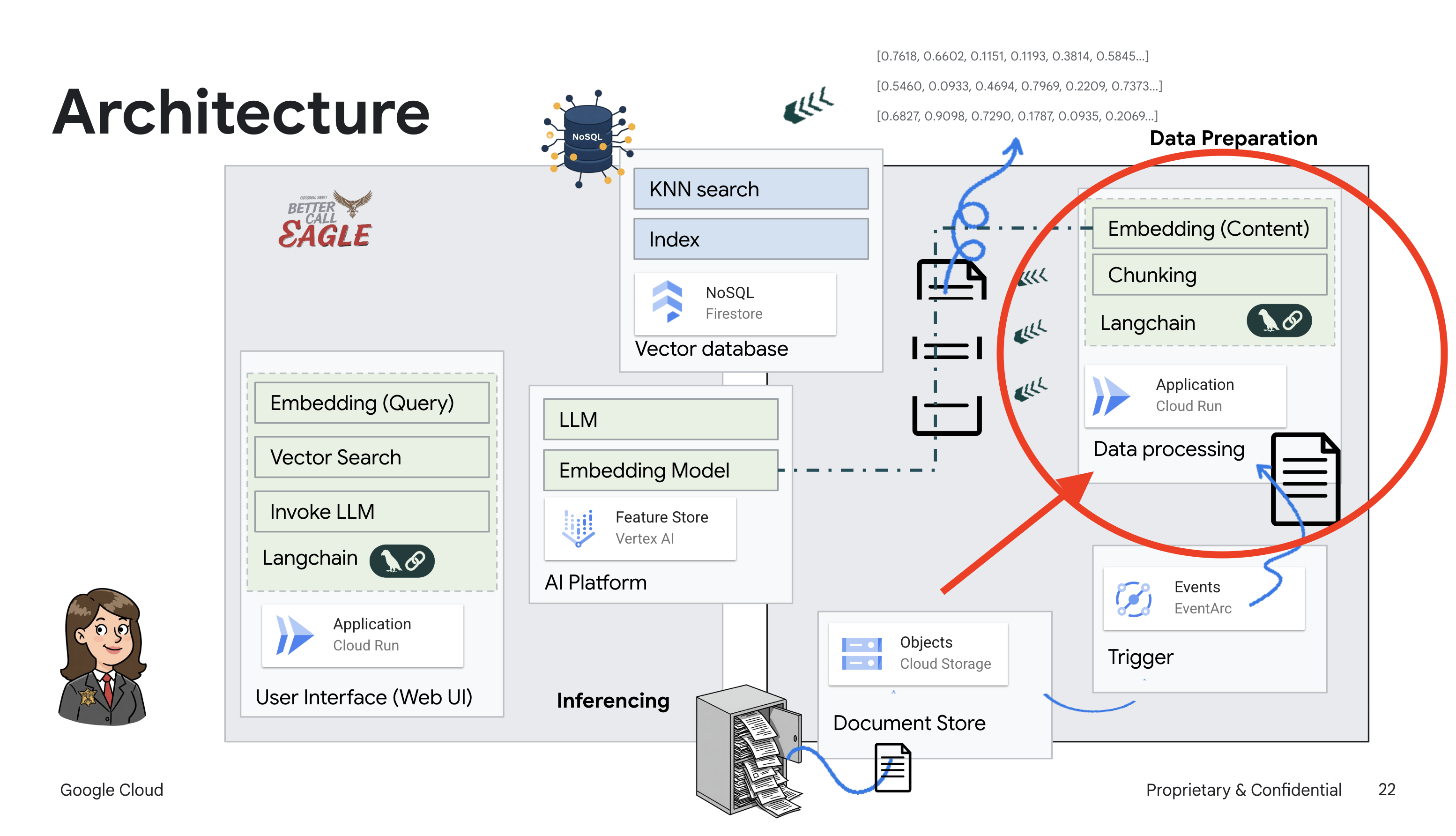
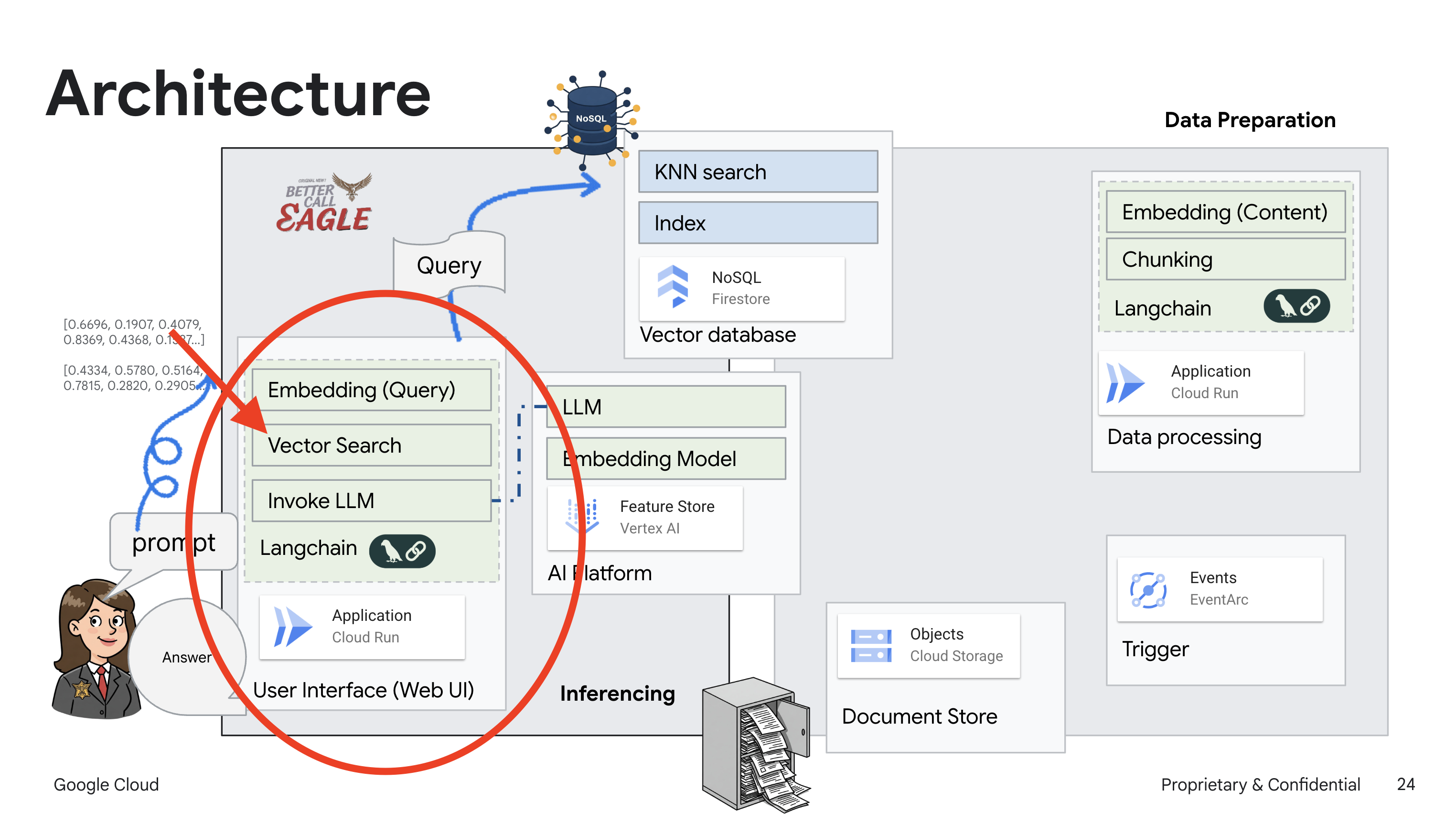
Bu proje, Google Cloud Yapay Zeka araçlarını kullanarak bir hukuk asistanı oluşturmaya odaklanıyor ve yasal verilerin nasıl işleneceğini, anlaşılacağını ve aranacağını vurguluyor. Sistem, büyük miktarda bilgiyi elemek, özetler oluşturmak ve alakalı verileri hızlı bir şekilde sunmak için tasarlanmıştır. Hukuk asistanının mimarisi çeşitli temel bileşenlerden oluşur:
Yapılandırılmamış verilerden bilgi bankası oluşturma: Yasal belgeleri depolamak için Google Cloud Storage (GCS) kullanılır. NoSQL veritabanı olan Firestore, belge parçalarını ve bunlara karşılık gelen gömmeleri tutarak bir vektör deposu olarak işlev görür. Benzerlik aramalarına olanak tanımak için Firestore'da Vector Search etkinleştirilir. GCS'ye yeni bir yasal belge yüklendiğinde Eventarc, Cloud Run işlevini tetikler. Bu işlev, belgeyi parçalara ayırarak ve Vertex AI'ın metin yerleştirme modelini kullanarak her parça için yerleştirmeler oluşturarak işler. Bu yerleştirmeler daha sonra metin parçalarıyla birlikte Firestore'da depolanır. 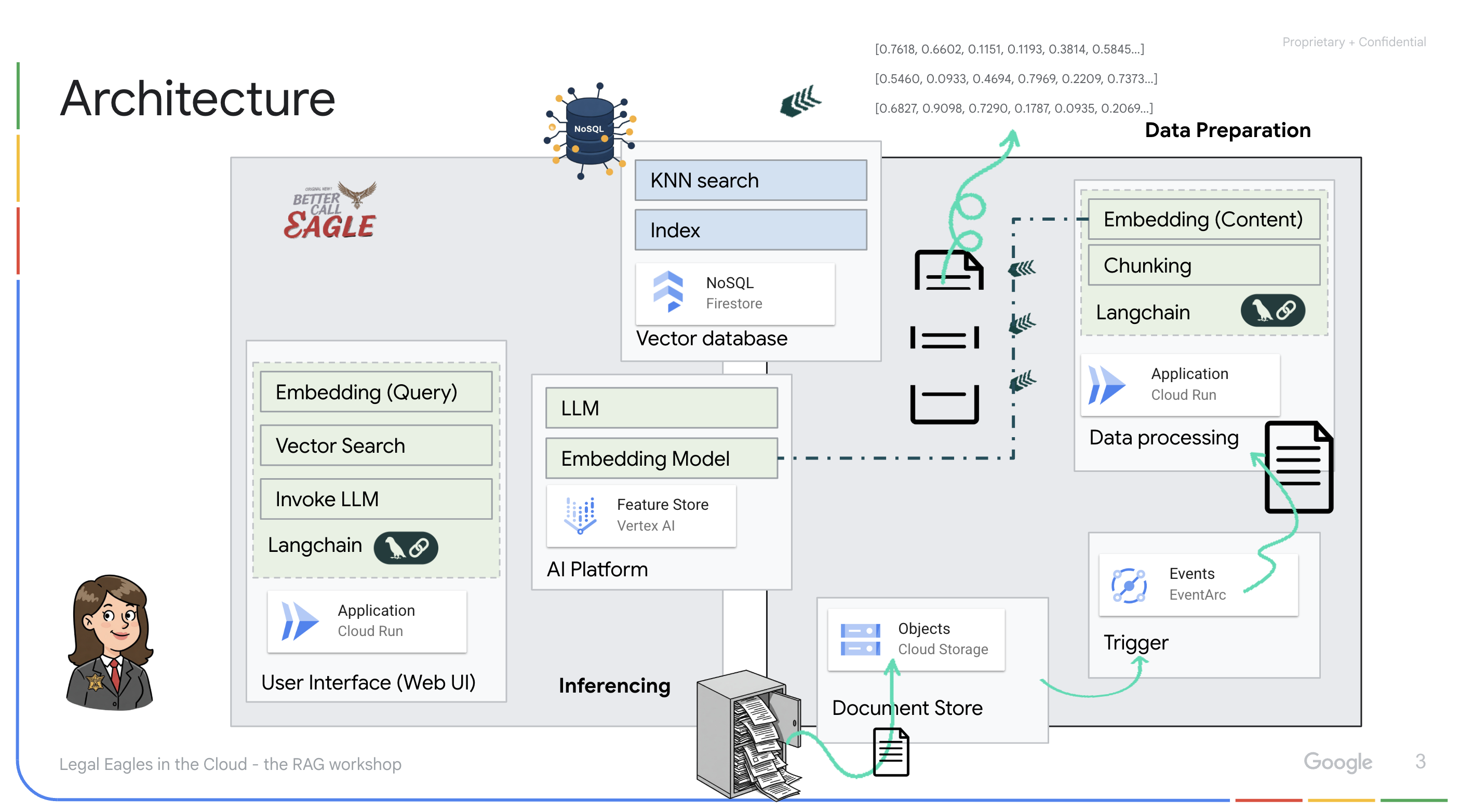
LLM ve RAG destekli uygulama : Soru-cevap sisteminin temelini, Vertex AI Gemini büyük dil modeliyle etkileşim kurmak için langchain kitaplığını kullanan ask_llm işlevi oluşturur. Kullanıcının sorgusundan HumanMessage oluşturur ve LLM'ye faydalı bir hukuk asistanı gibi davranmasını söyleyen bir SystemMessage içerir. Sistem, veriyle artırılmış üretim (RAG) yaklaşımını kullanır. Bu yaklaşımda sistem, bir sorguyu yanıtlamadan önce Firestore vektör deposundan alakalı bağlamı almak için search_resource işlevini kullanır. Bu bağlam daha sonra, LLM'nin yanıtını sağlanan yasal bilgilerle temellendirmek için SystemMessage'a dahil edilir. 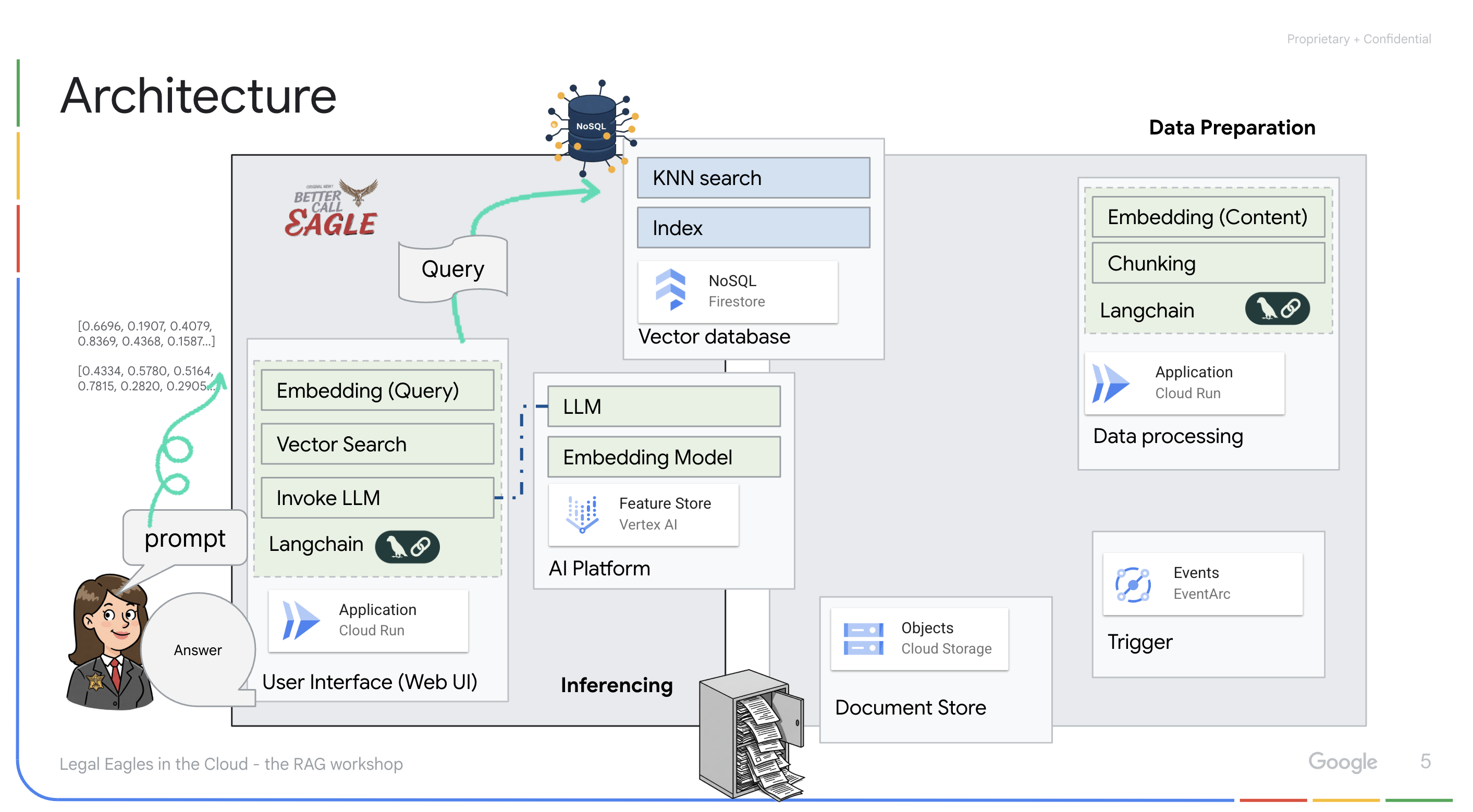
Proje, önce güvenilir bir yasal kaynaktan ilgili bilgileri alıp ardından yanıt üreten RAG'yi kullanarak LLM'lerin "yaratıcı yorumlarından" uzaklaşmayı amaçlıyor. Bu sayede, gerçek yasal bilgilere dayalı daha doğru ve bilinçli yanıtlar elde edilir. Sistem, Google Cloud Shell, Vertex AI, Firestore, Cloud Run ve Eventarc gibi çeşitli Google Cloud hizmetleri kullanılarak oluşturulmuştur.
3. Başlamadan önce
Google Cloud Console'daki proje seçici sayfasında bir Google Cloud projesi seçin veya oluşturun. Cloud projeniz için faturalandırmanın etkinleştirildiğinden emin olun. Faturalandırmanın bir projede etkin olup olmadığını nasıl kontrol edeceğinizi öğrenin.
Cloud Shell IDE'de Gemini Code Assist'i etkinleştirme
👉 Google Cloud Console'da Gemini Code Assist Araçları'na gidin, hüküm ve koşulları kabul ederek Gemini Code Assist'i ücretsiz etkinleştirin.
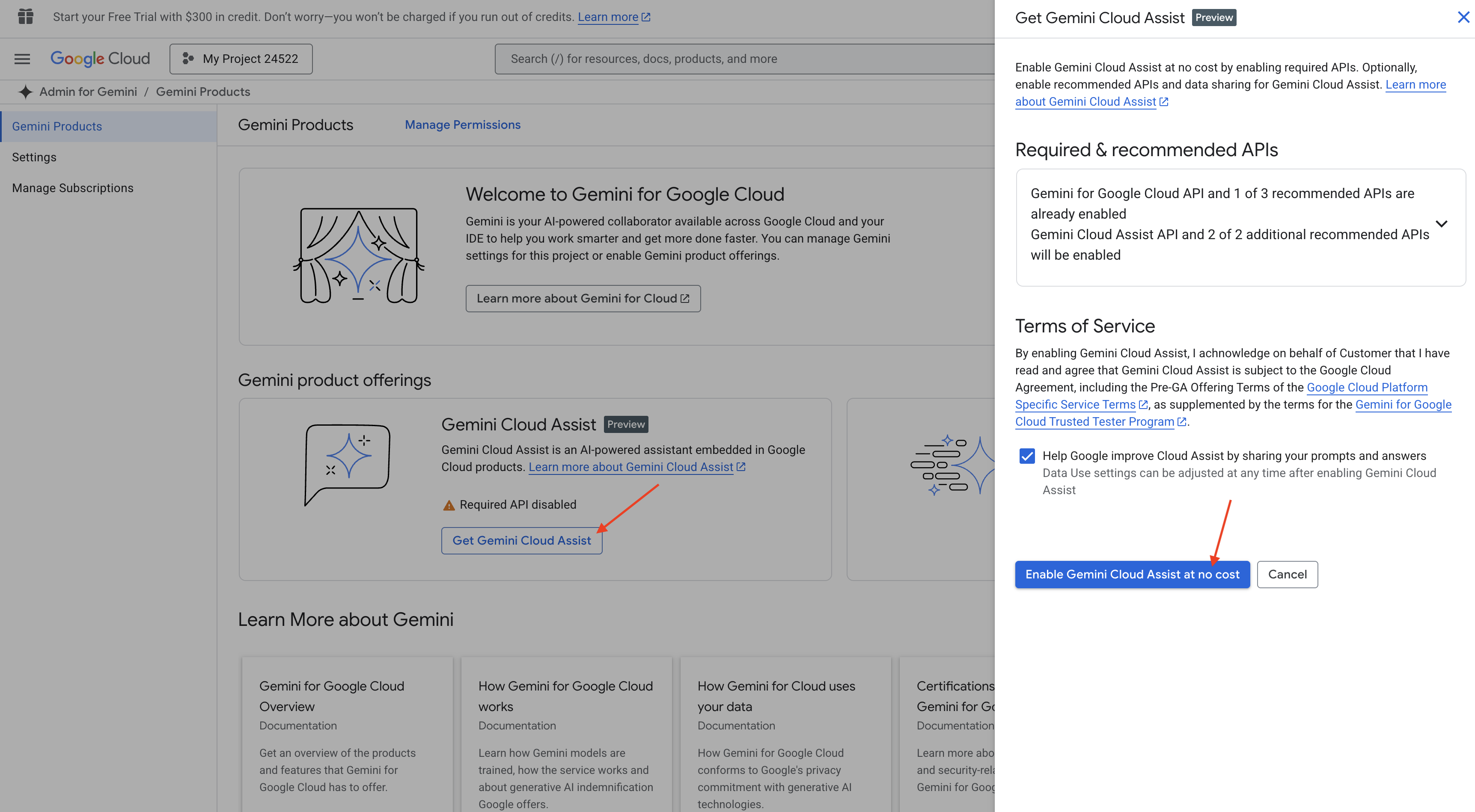
İzin kurulumunu yoksayın ve bu sayfadan ayrılın.
Cloud Shell Düzenleyici'de çalışma
👉 Google Cloud Console'un üst kısmında Cloud Shell'i etkinleştir'i tıklayın (Cloud Shell bölmesinin üst kısmındaki terminal şeklindeki simge).
👉 "Open Editor" (Düzenleyiciyi aç) düğmesini tıklayın (kalemli açık bir klasöre benzer). Bu işlem, pencerede Cloud Shell Düzenleyici'yi açar. Sol tarafta bir dosya gezgini görürsünüz.

👉 Gösterildiği gibi, alt durum çubuğundaki Cloud Code ile Oturum Açma düğmesini tıklayın. Eklentiyi talimatlara uygun şekilde yetkilendirin. Durum çubuğunda Cloud Code - no project (Cloud Code - proje yok) ifadesini görüyorsanız bunu seçin, ardından açılır listede "Google Cloud projesi seçin"i ve çalışmayı planladığınız projeler listesinden belirli bir Google Cloud projesini seçin.
👉 Bulut IDE'sinde terminali açın. 
👉 Yeni terminalde, aşağıdaki komutu kullanarak kimliğinizin doğrulandığını ve projenin proje kimliğinize ayarlandığını doğrulayın:
gcloud auth list
👉 Google Cloud Console'un üst kısmından Cloud Shell'i etkinleştir'i tıklayın.
gcloud config set project <YOUR_PROJECT_ID>
👉 Gerekli Google Cloud API'lerini etkinleştirmek için aşağıdaki komutu çalıştırın:
gcloud services enable storage.googleapis.com \
run.googleapis.com \
artifactregistry.googleapis.com \
aiplatform.googleapis.com \
eventarc.googleapis.com \
cloudresourcemanager.googleapis.com \
firestore.googleapis.com \
cloudaicompanion.googleapis.com
Cloud Shell araç çubuğunda (Cloud Shell bölmesinin üst kısmında) "Open Editor" (Düzenleyiciyi aç) düğmesini (kalemli açık klasör gibi görünür) tıklayın. Bu işlem, pencerede Cloud Shell kod düzenleyiciyi açar. Sol tarafta bir dosya gezgini görürsünüz.
👉 Terminalde Bootstrap Skeleton Project'i indirin:
git clone https://github.com/weimeilin79/legal-eagle.git
İSTEĞE BAĞLI: İSPANYOLCA VERSİYON
👉 Existe una versión alternativa en español. Por favor, utilice la siguiente instrucción para clonar la versión correcta.
git clone -b spanish https://github.com/weimeilin79/legal-eagle.git
Bu komutu Cloud Shell terminalinde çalıştırdıktan sonra Cloud Shell kabuk ortamınızda legal-eagle adlı yeni bir klasör oluşturulur.
4. Gemini Code Assist ile çıkarım uygulaması yazma
Bu bölümde, hukuk asistanımızın temelini oluşturmaya odaklanacağız. Bu temel, kullanıcı sorularını alan ve yanıt oluşturmak için yapay zeka modeliyle etkileşim kuran web uygulamasıdır. Bu çıkarım bölümünün Python kodunu yazmamıza yardımcı olması için Gemini Code Assist'ten yararlanacağız.
İlk olarak, Vertex AI Gemini modeliyle doğrudan iletişim kurmak için LangChain kitaplığını kullanan bir Flask uygulaması oluşturacağız. Bu ilk sürüm, modelin genel bilgisine dayalı olarak faydalı bir hukuki asistan görevi görecek ancak henüz belirli mahkeme davası belgelerimize erişemeyecek. Bu sayede, LLM'yi daha sonra RAG ile geliştirmeden önce temel performansını görebiliriz.
Cloud Code Editor'ın Gezgin bölmesinde (genellikle sol tarafta) Git deposunu klonladığınızda oluşturulan klasörü görmeniz gerekir. legal-eagle Projenizin kök klasörünü Gezgin'de açın. Bu klasörde webapp alt klasörünü bulup açın. 
👉 Cloud Code Düzenleyici'de legal.py dosyasını düzenlerken Gemini Code Assist'e istem göndermek için farklı yöntemler kullanabilirsiniz.
👉 Aşağıdaki istemi, legal.py'nın en altına kopyalayın. Bu istemde, Gemini Code Assist'in ne oluşturmasını istediğinizi net bir şekilde açıklayın. Ardından, görünen ampul 💡 simgesini tıklayın ve Gemini: Kod Oluştur'u seçin (Cloud Code sürümüne bağlı olarak menü öğesi biraz farklılık gösterebilir).
"""
Write a Python function called `ask_llm` that takes a user `query` as input. This function should use the `langchain` library to interact with a Vertex AI Gemini Large Language Model. Specifically, it should:
1. Create a `HumanMessage` object from the user's `query`.
2. Create a `ChatPromptTemplate` that includes a `SystemMessage` and the `HumanMessage`. The system message should instruct the LLM to act as a helpful assistant in a courtroom setting, aiding an attorney by providing necessary information. It should also specify that the LLM should respond in a high-energy tone, using no more than 100 words, and offer a humorous apology if it doesn't know the answer.
3. Format the `ChatPromptTemplate` with the provided messages.
4. Invoke the Vertex AI LLM with the formatted prompt using the `VertexAI` class (assuming it's already initialized elsewhere as `llm`).
5. Print the LLM's `response`.
6. Return the `response`.
7. Include error handling that prints an error message to the console and returns a user-friendly error message if any issues occur during the process. The Vertex AI model should be "gemini-2.0-flash".
"""
Oluşturulan kodu dikkatlice inceleyin.
- Yorumda belirttiğiniz adımları kabaca uyguluyor mu?
SystemMessageveHumanMessageileChatPromptTemplateoluşturuyor mu?- Temel hata işleme (
try...except) içeriyor mu?
Oluşturulan kod iyi ve çoğunlukla doğruysa kodu kabul edebilirsiniz (satır içi öneriler için Tab veya Enter tuşuna basın ya da daha büyük kod blokları için "Kabul et"i tıklayın).
Oluşturulan kod tam olarak istediğiniz gibi değilse veya hatalar içeriyorsa endişelenmeyin. Gemini Code Assist, ilk denemede mükemmel kod yazmak için değil, size yardımcı olmak için tasarlanmış bir araçtır.
Oluşturulan kodu düzenleyip değiştirerek iyileştirin, hataları düzeltin ve gereksinimlerinize daha iyi uyacak şekilde ayarlayın. Code Assist sohbet paneline daha fazla yorum ekleyerek veya belirli sorular sorarak Gemini Code Assist'i daha fazla istemde bulunabilirsiniz.
SDK'yı yeni kullanmaya başladıysanız çalışan bir örneği burada bulabilirsiniz.
👉 Aşağıdaki kodu legal.py dosyanıza kopyalayıp yapıştırın ve DEĞİŞTİRİN:
import os
import signal
import sys
import vertexai
import random
from langchain_google_vertexai import VertexAI
from langchain_core.prompts import PromptTemplate, ChatPromptTemplate
from langchain_core.messages import HumanMessage, SystemMessage
# Connect to resourse needed from Google Cloud
llm = VertexAI(model_name="gemini-2.0-flash")
def ask_llm(query):
try:
query_message = {
"type": "text",
"text": query,
}
input_msg = HumanMessage(content=[query_message])
prompt_template = ChatPromptTemplate.from_messages(
[
SystemMessage(
content=(
"You are a helpful assistant, and you are with the attorney in a courtroom, you are helping him to win the case by providing the information he needs "
"Don't answer if you don't know the answer, just say sorry in a funny way possible"
"Use high engergy tone, don't use more than 100 words to answer"
# f"Here is some past conversation history between you and the user {relevant_history}"
# f"Here is some context that is relevant to the question {relevant_resource} that you might use"
)
),
input_msg,
]
)
prompt = prompt_template.format()
response = llm.invoke(prompt)
print(f"response: {response}")
return response
except Exception as e:
print(f"Error sending message to chatbot: {e}") # Log this error too!
return f"Unable to process your request at this time. Due to the following reason: {str(e)}"
👉 İSTEĞE BAĞLI: İSPANYOLCA VERSİYON
Sustituye el siguiente texto como se indica: You are a helpful assistant, to You are a helpful assistant that speaks Spanish,
Ardından, kullanıcının sorularını yanıtlayacak bir rotayı işleyecek bir işlev oluşturun.
Cloud Shell Düzenleyici'de main.py dosyasını açın. legal.py bölümünde ask_llm'yi oluşturma şeklinize benzer şekilde, Gemini Code Assist'i kullanarak Flask Route ve ask_question işlevini oluşturun. main.py bölümüne yorum olarak aşağıdaki İSTEM'i yazın: (Flask uygulamasını if __name__ == "__main__": adresinde başlatmadan önce eklendiğinden emin olun)
.....
@app.route('/',methods=['GET'])
def index():
return render_template('index.html')
"""
PROMPT:
Create a Flask endpoint that accepts POST requests at the '/ask' route.
The request should contain a JSON payload with a 'question' field. Extract the question from the JSON payload.
Call a function named ask_llm (located in a file named legal.py) with the extracted question as an argument.
Return the result of the ask_llm function as the response with a 200 status code.
If any error occurs during the process, return a 500 status code with the error message.
"""
# Add this block to start the Flask app when running locally
if __name__ == "__main__":
.....
YALNIZCA oluşturulan kod iyi ve çoğunlukla doğruysa kabul edin. Python'a aşina değilseniz. Çalışan bir örnek için bunu kopyalayıp yapıştırın. main.py bölümünde, mevcut kodun altına yapıştırın.
👉 Web uygulamasının başlangıcından ÖNCE (if name == "main":) aşağıdakileri yapıştırdığınızdan emin olun.
@app.route('/ask', methods=['POST'])
def ask_question():
data = request.get_json()
question = data.get('question')
try:
# call the ask_llm in legal.py
answer_markdown = legal.ask_llm(question)
print(f"answer_markdown: {answer_markdown}")
# Return the Markdown as the response
return answer_markdown, 200
except Exception as e:
return f"Error: {str(e)}", 500 # Handle errors appropriately
Bu adımları uygulayarak Gemini Code Assist'i başarıyla etkinleştirebilir, projenizi ayarlayabilir ve main.py dosyanızda ask işlevini oluşturmak için kullanabilirsiniz.
5. Cloud Düzenleyici'de Yerel Test
👉 Düzenleyicinin terminalinde,bağımlı kitaplıkları yükleyin ve web kullanıcı arayüzünü yerel olarak başlatın.
cd ~/legal-eagle/webapp
python -m venv env
source env/bin/activate
export PROJECT_ID=$(gcloud config get project)
pip install -r requirements.txt
python main.py
Cloud Shell terminal çıkışında başlangıç mesajlarını bulun. Flask genellikle çalıştığını ve hangi bağlantı noktasında çalıştığını belirten mesajlar yazdırır.
- Running on http://127.0.0.1:8080
İsteklerin karşılanması için uygulamanın çalışmaya devam etmesi gerekir.
👉 "Web önizlemesi" menüsünde 8080 bağlantı noktasında önizle'yi seçin. Cloud Shell, uygulamanızın web önizlemesini içeren yeni bir tarayıcı sekmesi veya penceresi açar. 
👉 Uygulama arayüzünde, özellikle yasal dava referanslarıyla ilgili birkaç soru yazın ve LLM'nin nasıl yanıt verdiğini görün. Örneğin, şunları deneyebilirsiniz:
- Michael Brown kaç yıl hapis cezasına çarptırıldı?
- Ayşe Yılmaz'ın işlemleri sonucunda ne kadar yetkisiz ödeme yapıldı?
- Komşuların ifadeleri, Emily White ile ilgili davanın soruşturulmasında nasıl bir rol oynadı?
👉 İSTEĞE BAĞLI: İSPANYOLCA VERSİYON
- ¿A cuántos años de prisión fue sentenciado Michael Brown?
- ¿Cuánto dinero en cargos no autorizados se generó como resultado de las acciones de Jane Smith?
- ¿Qué papel jugaron los testimonios de los vecinos en la investigación del caso de Emily White?
Yanıtları dikkatlice incelerseniz modelin halüsinasyon gördüğünü, belirsiz veya genel yanıtlar verdiğini ve bazen sorularınızı yanlış yorumladığını fark edebilirsiniz. Bunun nedeni, modelin henüz belirli yasal belgelere erişememesidir.
👉 Ctrl+C tuşlarına basarak komut dosyasını durdurun.
👉 Sanal ortamdan çıkmak için terminalde şu komutu çalıştırın:
deactivate
6. Vector Store'u ayarlama
Artık LLM'lerin yasaları "yaratıcı bir şekilde yorumlamasına" son verme zamanı. İşte bu noktada, Almayla Artırılmış Üretim (RAG) devreye giriyor. Bunu, LLM'mize sorularınızı yanıtlamadan hemen önce süper güçlü bir hukuk kütüphanesine erişim izni vermek gibi düşünebilirsiniz. RAG, yalnızca genel bilgilerine (modele bağlı olarak belirsiz veya eski olabilir) güvenmek yerine önce güvenilir bir kaynaktan (bizim durumumuzda yasal belgeler) alakalı bilgileri alır ve ardından bu bağlamı kullanarak çok daha bilinçli ve doğru bir yanıt oluşturur. Bu, LLM'nin mahkeme salonuna girmeden önce ödevini yapmasına benzer.
RAG sistemimizi oluşturmak için tüm bu yasal belgeleri depolayabileceğimiz ve en önemlisi, anlamlarına göre aranabilir hale getirebileceğimiz bir yer gerekiyor. İşte bu noktada Firestore devreye girer. Firestore, Google Cloud'un esnek ve ölçeklenebilir NoSQL belge veritabanıdır.
Firestore'u vektör mağazamız olarak kullanacağız. Yasal belgelerimizin parçalarını Firestore'da saklayacağız ve her parça için anlamının sayısal gösterimi olan yerleştirmesini de saklayacağız.
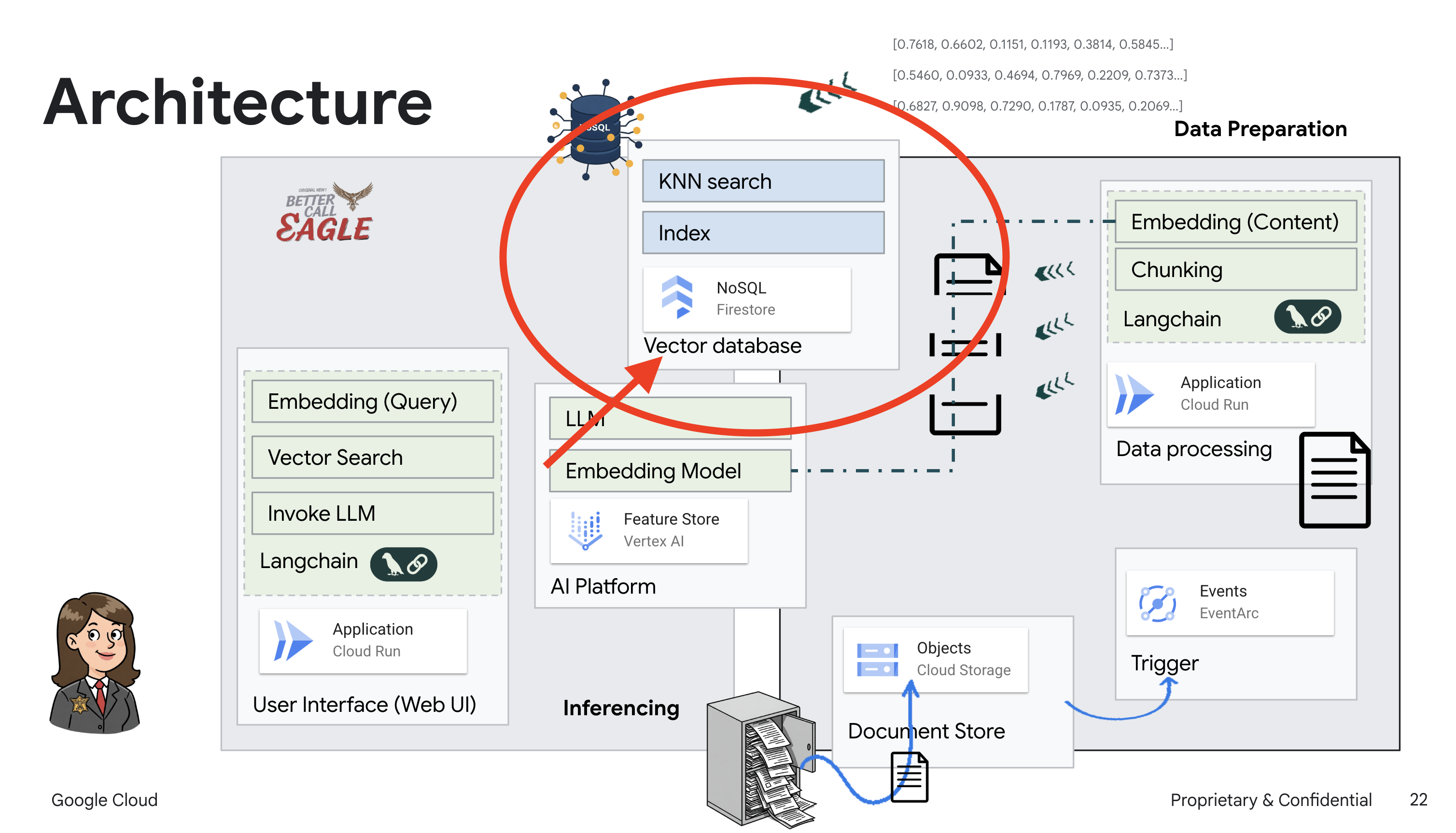
Ardından, Legal Eagle'a bir soru sorduğunuzda, sorgunuzla en alakalı olan yasal metin parçalarını bulmak için Firestore'un vektör arama özelliğini kullanırız. RAG, bu alınan bağlamı kullanarak size yalnızca LLM'nin hayal gücüne dayalı değil, gerçek yasal bilgilere dayalı yanıtlar verir.
👉 Yeni bir sekmede/pencerede Google Cloud Console'da Firestore'a gidin.
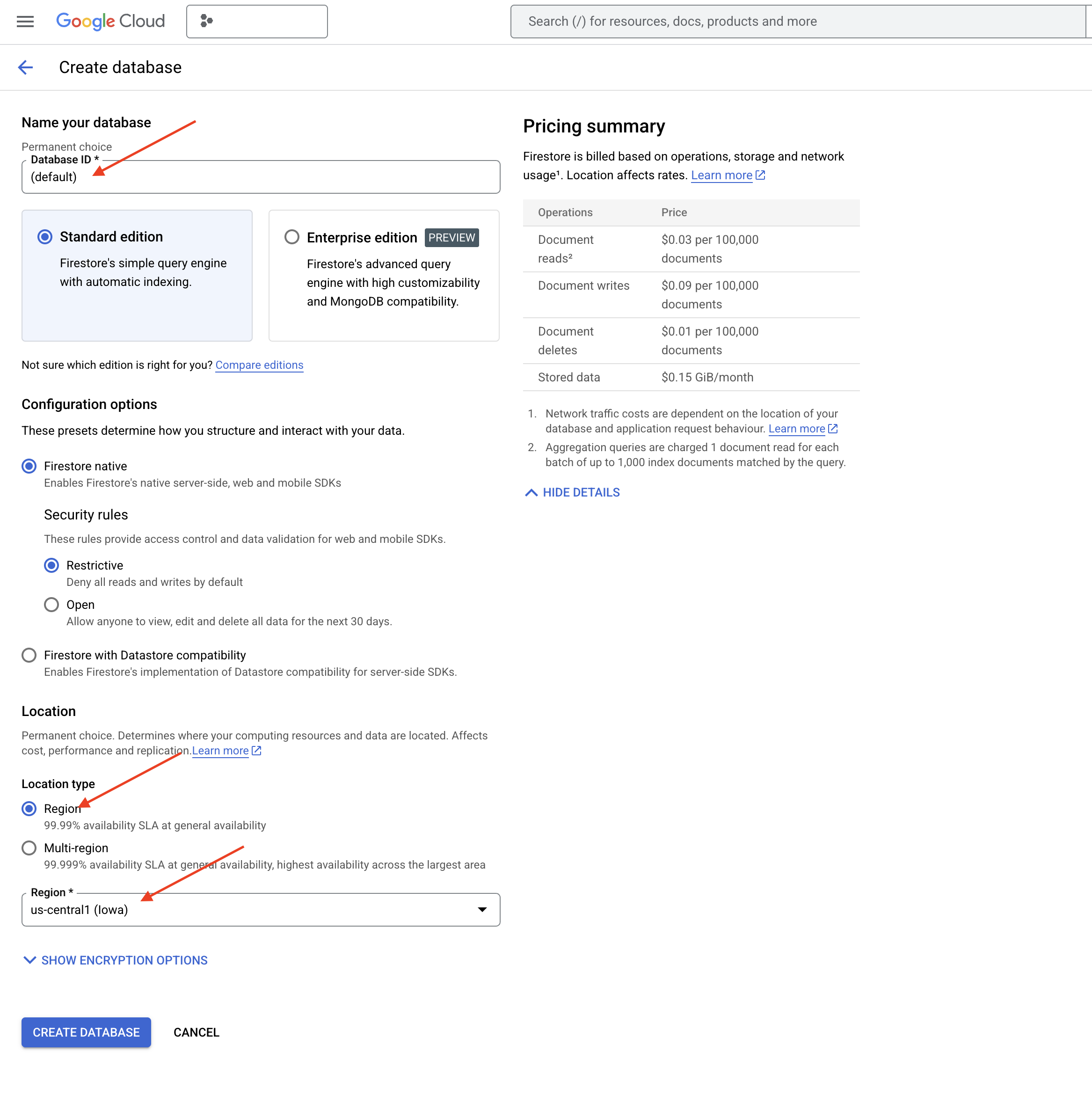
👉 Veritabanı oluştur'u tıklayın.
👉 Native mode ve veritabanı adını (default) olarak seçin.
👉 Tek bir region seçin: us-central1 ve Veritabanı Oluştur'u tıklayın. Firestore, veritabanınızı sağlar. Bu işlem birkaç dakika sürebilir.
👉 Cloud IDE'nin terminaline geri dönün. legal_documents koleksiyonunuzda vektör aramayı etkinleştirmek için embedding_vector alanında bir vektör dizini oluşturun.
export PROJECT_ID=$(gcloud config get project)
gcloud firestore indexes composite create \
--collection-group=legal_documents \
--query-scope=COLLECTION \
--field-config field-path=embedding,vector-config='{"dimension":"768", "flat": "{}"}' \
--project=${PROJECT_ID}
Firestore, vektör dizinini oluşturmaya başlar. Dizin oluşturma işlemi, özellikle daha büyük veri kümeleri için biraz zaman alabilir. Dizini "Oluşturuluyor" durumunda görürsünüz. Dizin oluşturulduğunda "Hazır" durumuna geçer. 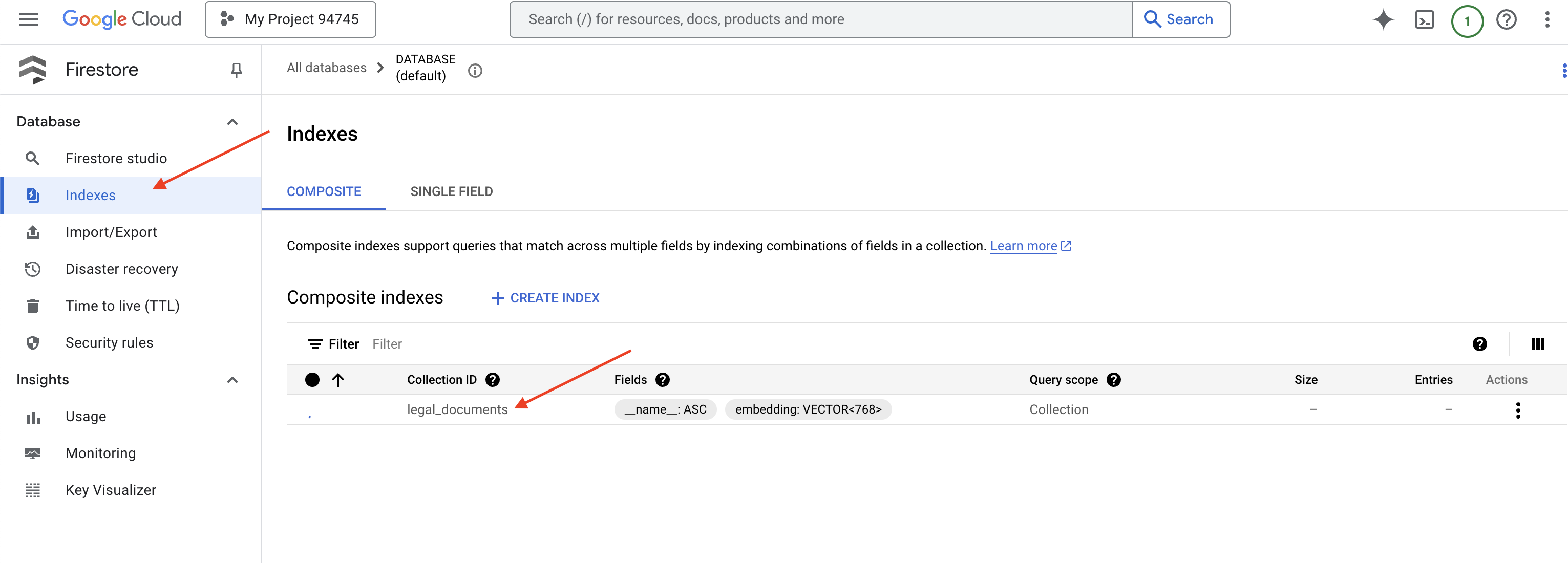
7. Vektör deposuna veri yükleme
RAG'yi ve vektör depomuzu anladığımıza göre artık yasal kitaplığımızı dolduracak motoru oluşturma zamanı geldi. Peki, yasal belgeleri nasıl "anlama göre aranabilir" hâle getiririz? İşin sırrı yerleştirmelerde! Yerleştirmeleri, kelimeleri, cümleleri veya hatta tüm belgeleri sayısal vektörlere (anlamsal anlamlarını yakalayan sayı listeleri) dönüştürme olarak düşünebilirsiniz. Benzer kavramlar, vektör uzayında birbirine "yakın" vektörler alır. Bu dönüşümü gerçekleştirmek için güçlü modeller (ör. Vertex AI'daki modeller) kullanırız.
Belge yükleme işlemimizi otomatikleştirmek için Cloud Run işlevlerini ve Eventarc'ı kullanacağız. Cloud Run Functions, kodunuzu yalnızca gerektiğinde çalıştıran hafif ve sunucusuz bir kapsayıcıdır. Doküman işleme Python komut dosyamızı bir container'a paketleyip Cloud Run işlevi olarak dağıtacağız.
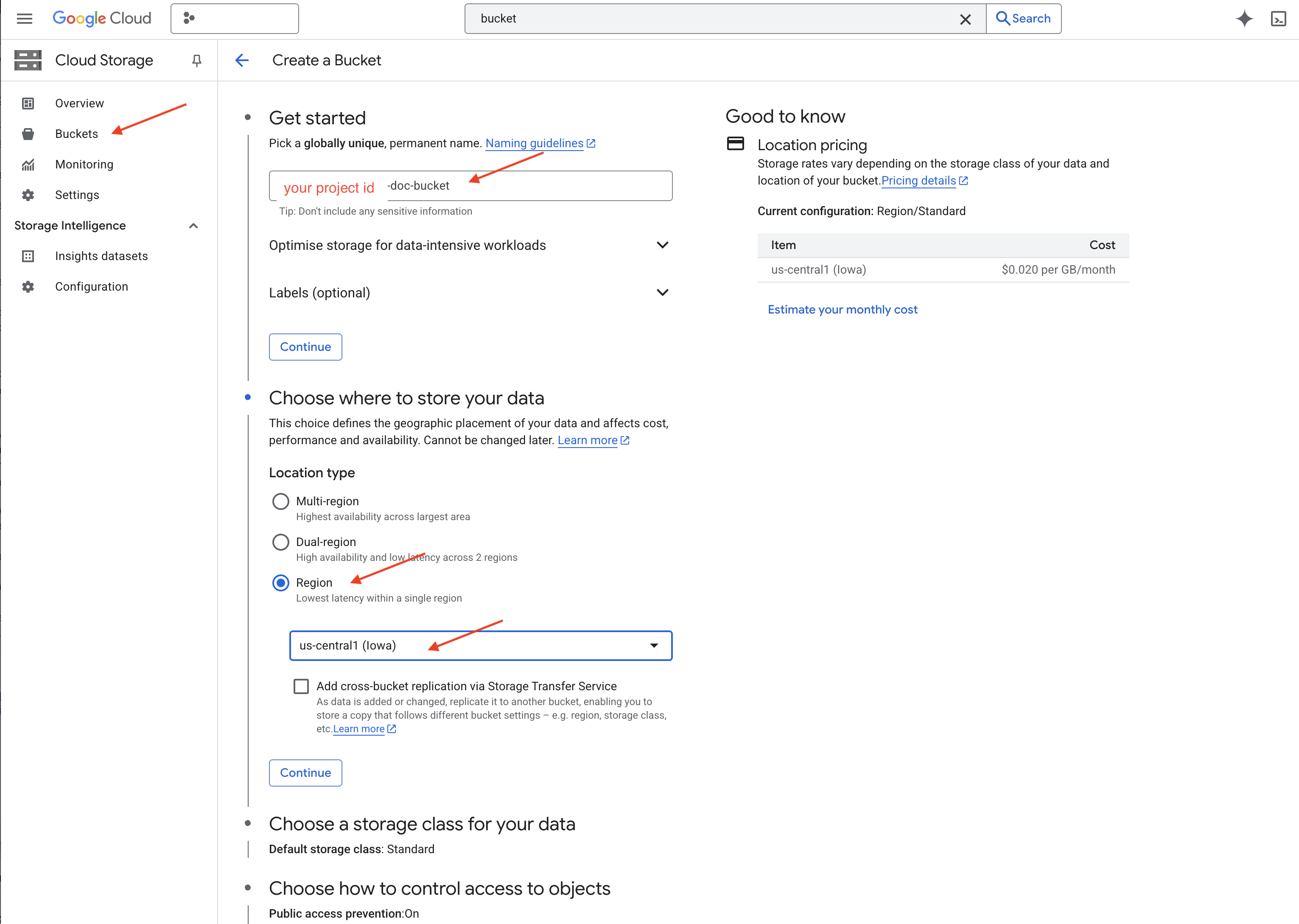
👉 Yeni bir sekmede/pencerede Cloud Storage'a gidin.
👉 Soldaki menüde "Gruplar"ı tıklayın.
👉 En üstteki "+ OLUŞTUR" düğmesini tıklayın.
👉 Paketinizin ayarlarını yapılandırın (Önemli ayarlar):
- Paket adı: yourprojectID-doc-bucket (Sonda -doc-bucket soneki OLMALIDIR)
- region:
us-central1bölgesini seçin. - Depolama sınıfı: "Standart". Standart, sık erişilen veriler için uygundur.
- Erişim denetimi: Varsayılan "Tek tip erişim denetimi" seçeneğini işaretli bırakın. Bu, tutarlı ve paket düzeyinde erişim denetimi sağlar.
- Gelişmiş seçenekler: Bu eğitim için genellikle varsayılan ayarlar yeterlidir.
👉 Paketinizi oluşturmak için OLUŞTUR düğmesini tıklayın.
👉 Herkese açık erişimi önleme hakkında bir pop-up görebilirsiniz. Kutuyu işaretli bırakın ve "Onayla"yı tıklayın.
Yeni oluşturduğunuz paketi artık Paketler listesinde görebilirsiniz. Paketinizin adını unutmayın, daha sonra bu bilgiye ihtiyacınız olacak.
8. Cloud Run işlevi oluşturma
👉 Cloud Shell kod düzenleyicide legal-eagle çalışma dizinine gidin: Klasörü oluşturmak için Cloud Editor terminalinde cd komutunu kullanın.
cd ~/legal-eagle
mkdir loader
cd loader
👉 main.py,requirements.txt ve Dockerfile dosyaları oluşturun. Cloud Shell terminalinde, touch komutunu kullanarak dosyaları oluşturun:
touch main.py requirements.txt Dockerfile
*loader adlı yeni oluşturulan klasörü ve üç dosyayı görürsünüz.
👉 loader klasöründe main.py öğesini düzenleyin. Soldaki dosya gezgininde, dosyaları oluşturduğunuz dizine gidin ve main.py simgesini çift tıklayarak düzenleyicide açın.
Aşağıdaki Python kodunu main.py içine yapıştırın:
Bu uygulama, GCS paketine yüklenen yeni dosyaları işler, metni parçalara ayırır, her parça için yerleştirmeler oluşturur ve parçaları ile yerleştirmelerini Firestore'da depolar.
import os
import json
from google.cloud import storage
import functions_framework
from langchain_google_vertexai import VertexAI, VertexAIEmbeddings
from langchain_google_firestore import FirestoreVectorStore
from langchain.text_splitter import RecursiveCharacterTextSplitter
import vertexai
PROJECT_ID = os.environ.get("GOOGLE_CLOUD_PROJECT") # Get project ID from env
embedding_model = VertexAIEmbeddings(
model_name="text-embedding-004" ,
project=PROJECT_ID,)
COLLECTION_NAME = "legal_documents"
# Create a vector store
vector_store = FirestoreVectorStore(
collection="legal_documents",
embedding_service=embedding_model,
content_field="original_text",
embedding_field="embedding",
)
@functions_framework.cloud_event
def process_file(cloud_event):
print(f"CloudEvent received: {cloud_event.data}") # Print the parsed event data
"""Triggered by a Cloud Storage event.
Args:
cloud_event (functions_framework.CloudEvent): The CloudEvent
containing the Cloud Storage event data.
"""
try:
event_data = cloud_event.data
bucket_name = event_data['bucket']
file_name = event_data['name']
except (json.JSONDecodeError, AttributeError, KeyError) as e: # Catch JSON errors
print(f"Error decoding CloudEvent data: {e} - Data: {cloud_event.data}")
return "Error processing event", 500 # Return an error response
print(f"New file detected in bucket: {bucket_name}, file: {file_name}")
storage_client = storage.Client()
bucket = storage_client.bucket(bucket_name)
blob = bucket.blob(file_name)
try:
# Download the file content as string (assuming UTF-8 encoded text file)
file_content_string = blob.download_as_string().decode("utf-8")
print(f"File content downloaded. Processing...")
# Split text into chunks using RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=100,
length_function=len,
)
text_chunks = text_splitter.split_text(file_content_string)
print(f"Text split into {len(text_chunks)} chunks.")
# Add the docs to the vector store
vector_store.add_texts(text_chunks)
print(f"File processing and Firestore upsert complete for file: {file_name}")
return "File processed successfully", 200 # Return success response
except Exception as e:
print(f"Error processing file {file_name}: {e}")
requirements.txt dosyasını düzenleyin.Aşağıdaki satırları dosyaya yapıştırın:
Flask==2.3.3
requests==2.31.0
google-generativeai>=0.2.0
langchain
langchain_google_vertexai
langchain-community
langchain-google-firestore
google-cloud-storage
functions-framework
9. Cloud Run işlevini test etme ve oluşturma
Bu kodu sanal bir ortamda çalıştırıp Cloud Run işlevi için gerekli Python kitaplıklarını yükleyeceğiz.
cd ~/legal-eagle/loader
python -m venv env
source env/bin/activate
pip install -r requirements.txt
👉 Cloud Run işlevi için yerel bir emülatör başlatın
functions-framework --target process_file --signature-type=cloudevent --source main.py
👉 Son terminali çalışır durumda bırakın, yeni bir terminal açın ve dosyayı pakete yükleme komutunu çalıştırın.
export DOC_BUCKET_NAME=$(gcloud storage buckets list --format="value(name)" | grep doc-bucket)
gsutil cp ~/legal-eagle/court_cases/case-01.txt gs://$DOC_BUCKET_NAME/

👉 Emülatör çalışırken test CloudEvent'leri gönderebilirsiniz. Bu işlem için IDE'de ayrı bir terminale ihtiyacınız vardır.
curl -X POST -H "Content-Type: application/json" \
-d "{
\"specversion\": \"1.0\",
\"type\": \"google.cloud.storage.object.v1.finalized\",
\"source\": \"//storage.googleapis.com/$DOC_BUCKET_NAME\",
\"subject\": \"objects/case-01.txt\",
\"id\": \"my-event-id\",
\"time\": \"2024-01-01T12:00:00Z\",
\"data\": {
\"bucket\": \"$DOC_BUCKET_NAME\",
\"name\": \"case-01.txt\"
}
}" http://localhost:8080/
OK döndürmelidir.
👉 Verileri Firestore'da doğrulayacaksınız. Google Cloud Console'a gidip "Veritabanları" ve ardından "Firestore"a gidin. "Veri" sekmesini ve legal_documents koleksiyonunu seçin. Koleksiyonunuzda, yüklenen dosyadaki metnin bir bölümünü temsil eden yeni dokümanlar oluşturulduğunu görürsünüz. 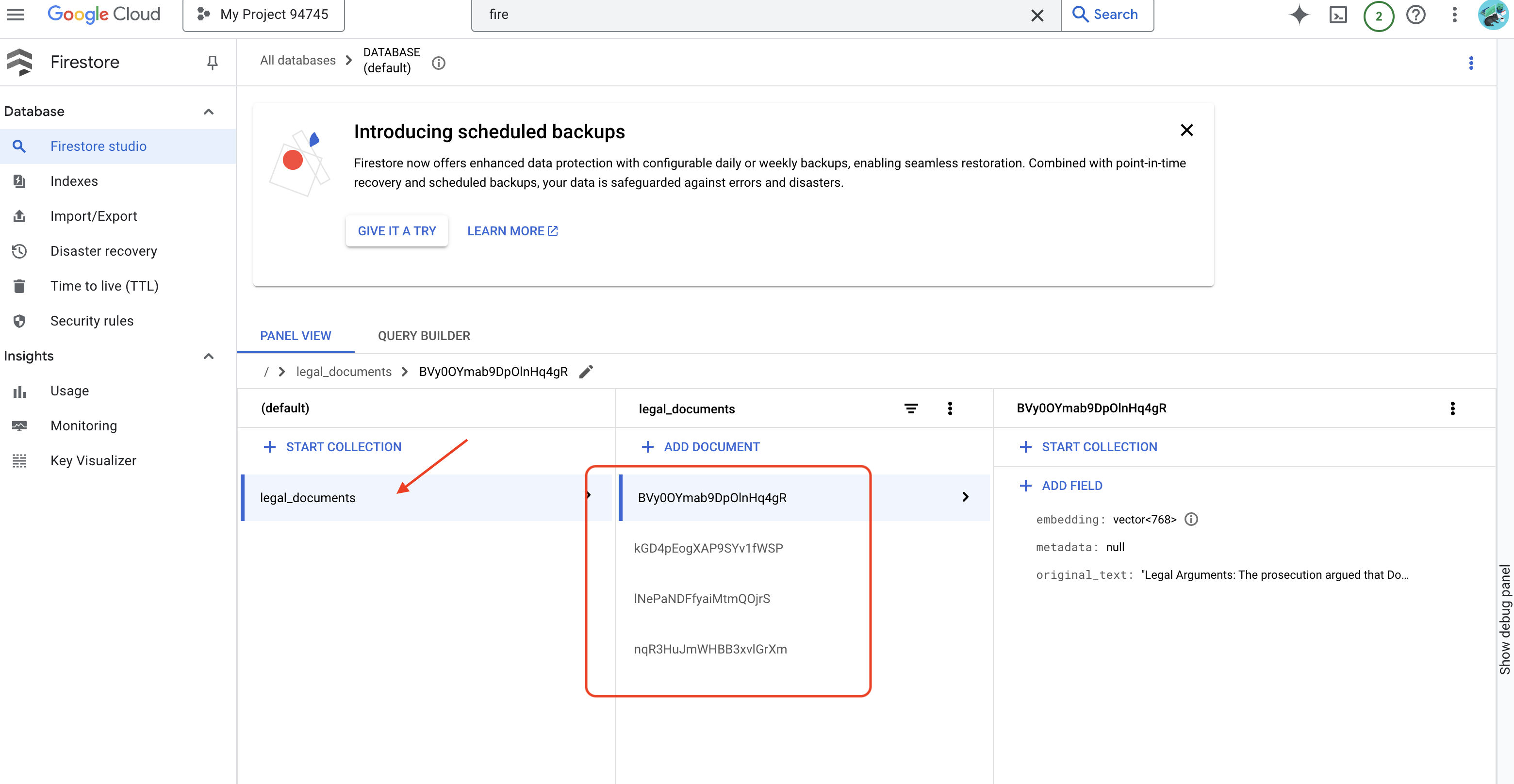
👉 Emülatörün çalıştığı terminalde çıkmak için Ctrl+C yazın. İkinci terminali kapatın.
👉 Sanal ortamdan çıkmak için deactivate komutunu çalıştırın.
deactivate
10. Container görüntüsü oluşturma ve Artifacts depolarına aktarma
👉 Bunu buluta dağıtma zamanı. Dosya Gezgini'nde Dockerfile'ı çift tıklayın. Gemini'dan dockerfile oluşturmasını isteyin, Gemini Code Assist'i açın ve dosyayı oluşturmak için aşağıdaki istemi kullanın.
In the loader folder,
Generate a Dockerfile for a Python 3.12 Cloud Run service that uses functions-framework. It needs to:
1. Use a Python 3.12 slim base image.
2. Set the working directory to /app.
3. Copy requirements.txt and install Python dependencies.
4. Copy main.py.
5. Set the command to run functions-framework, targeting the 'process_file' function on port 8080
En iyi uygulama için Açık Dosyayla Karşılaştır'ı(zıt yönlerde iki ok) tıklamanız ve değişiklikleri kabul etmeniz önerilir. 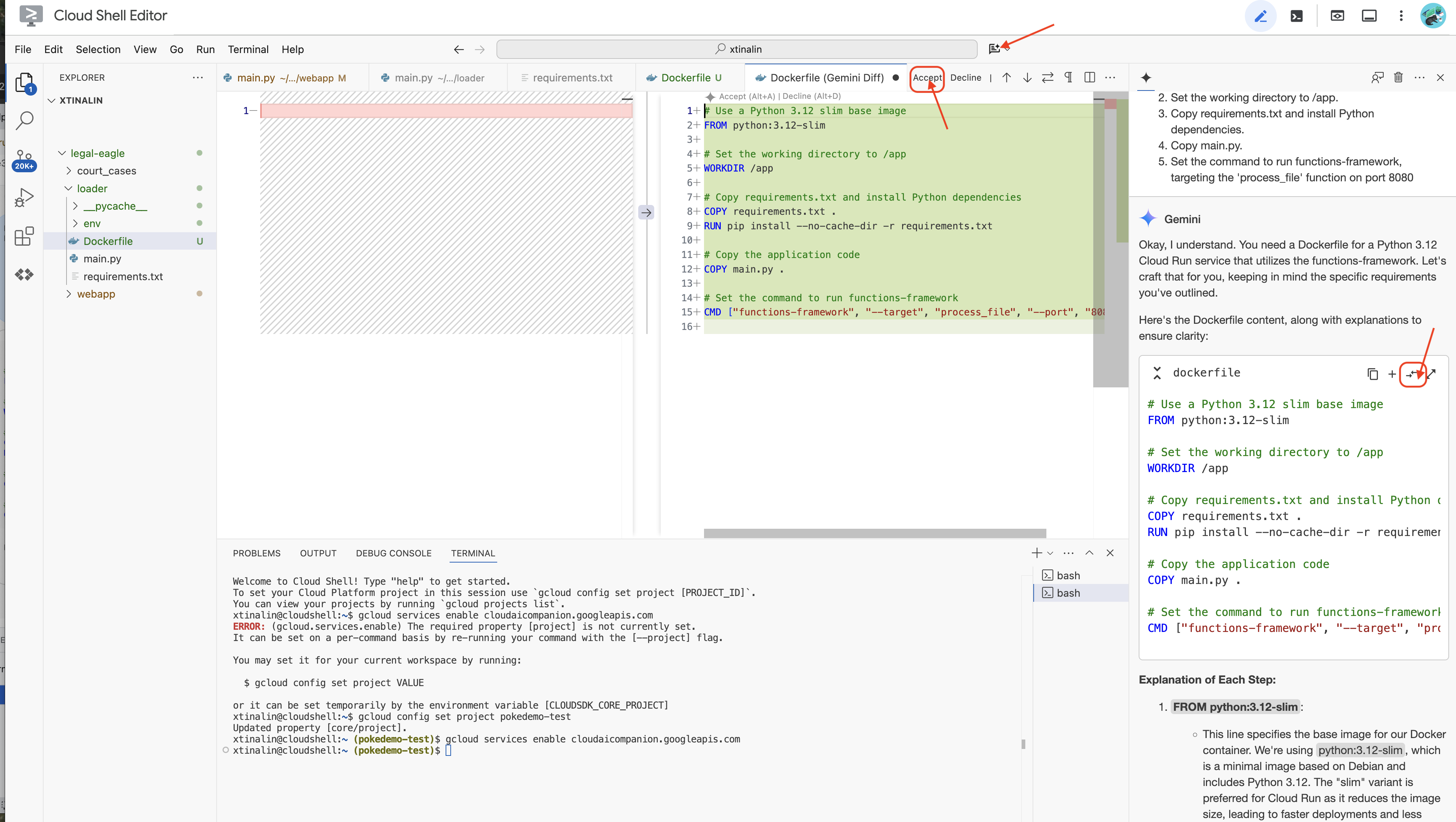
👉 Container'ları kullanmaya yeni başladıysanız çalışan bir örneği aşağıda bulabilirsiniz:
# Use a Python 3.12 slim base image
FROM python:3.12-slim
# Set the working directory to /app
WORKDIR /app
# Copy requirements.txt and install Python dependencies
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
# Copy main.py
COPY main.py .
# Set the command to run functions-framework
CMD ["functions-framework", "--target", "process_file", "--port", "8080"]
👉 Terminalde, oluşturacağımız Docker görüntüsünü depolamak için bir yapılar deposu oluşturun.
gcloud artifacts repositories create my-repository \
--repository-format=docker \
--location=us-central1 \
--description="My repository"
Created repository [my-repository]. (Kod deposu [my-repository] oluşturuldu.) mesajını görürsünüz.
👉 Docker görüntüsünü oluşturmak için aşağıdaki komutu çalıştırın.
cd ~/legal-eagle/loader
export PROJECT_ID=$(gcloud config get project)
docker build -t gcr.io/${PROJECT_ID}/legal-eagle-loader .
Bunu şimdi kayıt defterine göndereceksiniz
export PROJECT_ID=$(gcloud config get project)
docker tag gcr.io/${PROJECT_ID}/legal-eagle-loader us-central1-docker.pkg.dev/${PROJECT_ID}/my-repository/legal-eagle-loader
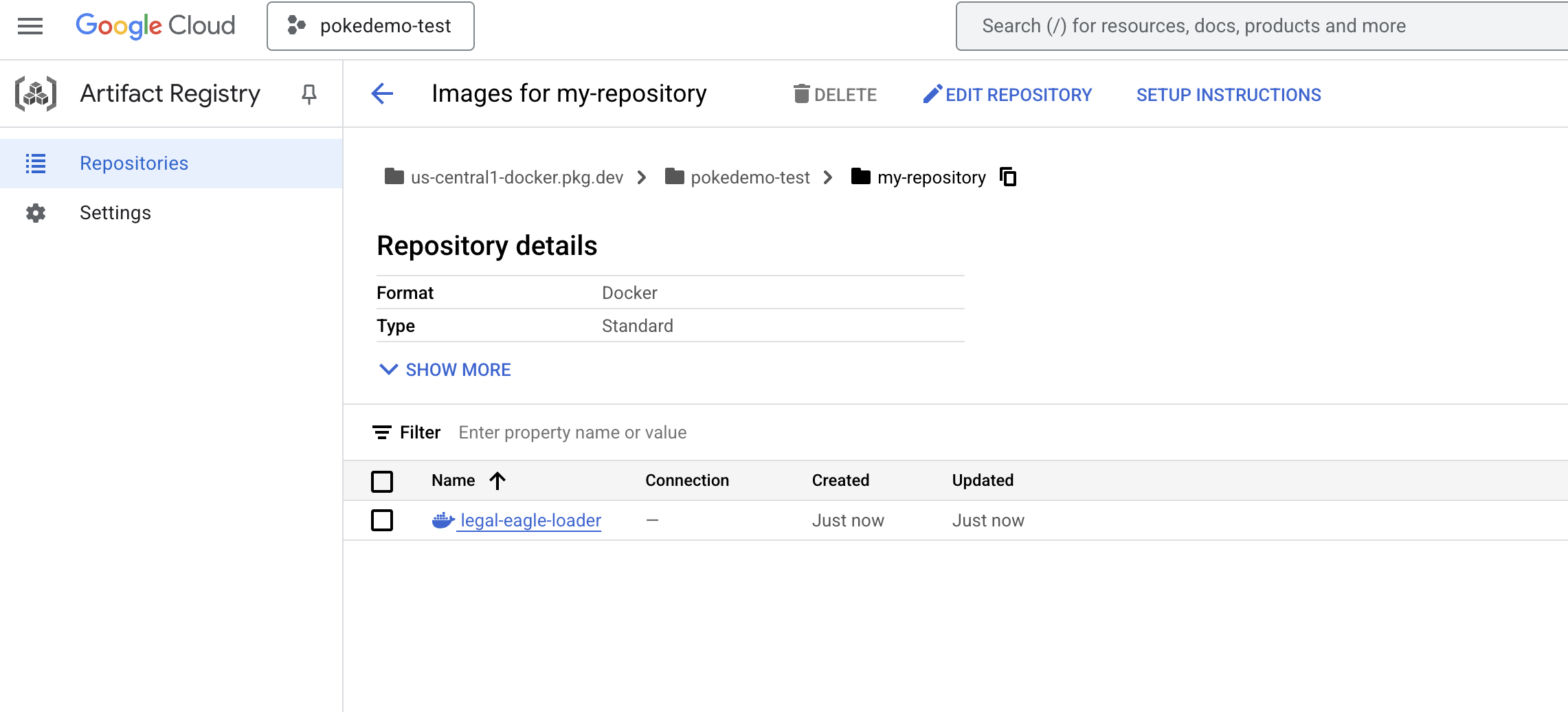
docker push us-central1-docker.pkg.dev/${PROJECT_ID}/my-repository/legal-eagle-loader
Docker görüntüsü artık my-repository Artifacts Repository'de kullanılabilir.
11. Cloud Run işlevini oluşturma ve Eventarc tetikleyicisini ayarlama
Yasal belge yükleyicimizi dağıtmanın ayrıntılarına girmeden önce, ilgili bileşenleri kısaca anlayalım: Cloud Run, container mimarisine alınmış uygulamaları hızlı ve kolay bir şekilde dağıtmanıza olanak tanıyan, tümüyle yönetilen sunucusuz bir platformdur. Altyapı yönetimini soyutlayarak kodunuzu yazmaya ve dağıtmaya odaklanmanızı sağlar.
Doküman yükleyicimizi Cloud Run hizmeti olarak dağıtacağız. Şimdi Cloud Run işlevimizi ayarlamaya devam edelim:
👉 Google Cloud Console'da Cloud Run'a gidin.
👉 Kapsayıcıyı Dağıt'a gidin ve açılır listede HİZMET'i tıklayın.
👉 Cloud Run hizmetinizi yapılandırın:
- Container resmi: URL alanında "Seç"i tıklayın. Artifact Registry'ye aktardığınız resim URL'sini bulun (ör. us-central1-docker.pkg.dev/your-project-id/my-repository/legal-eagle-loader/yourimage).
- Hizmet adı:
legal-eagle-loader - Bölge:
us-central1bölgesini seçin. - Kimlik doğrulama: Bu atölye çalışması kapsamında "Kimliği doğrulanmamış çağrılara izin ver" seçeneğini etkinleştirebilirsiniz. Üretim için erişimi kısıtlamak isteyebilirsiniz.
- Container, Networking, Security (Kapsayıcı, Ağ, Güvenlik): varsayılan.
👉 OLUŞTUR'u tıklayın. Cloud Run, hizmetinizi dağıtır. 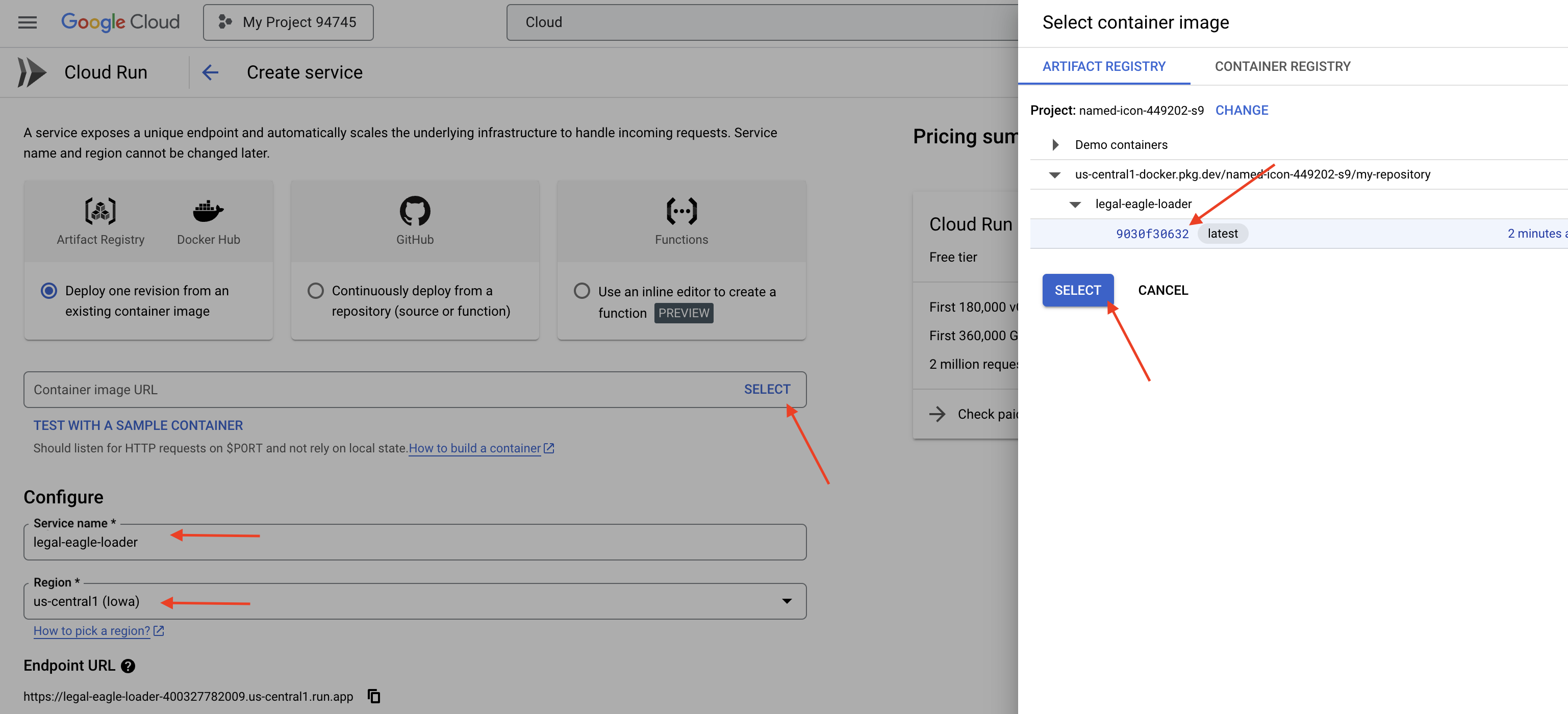
Depolama paketimize yeni dosyalar eklendiğinde bu hizmetin otomatik olarak tetiklenmesi için Eventarc'ı kullanacağız. Eventarc, çeşitli kaynaklardan gelen etkinlikleri hizmetlerinize yönlendirerek etkinliğe dayalı mimariler oluşturmanıza olanak tanır.
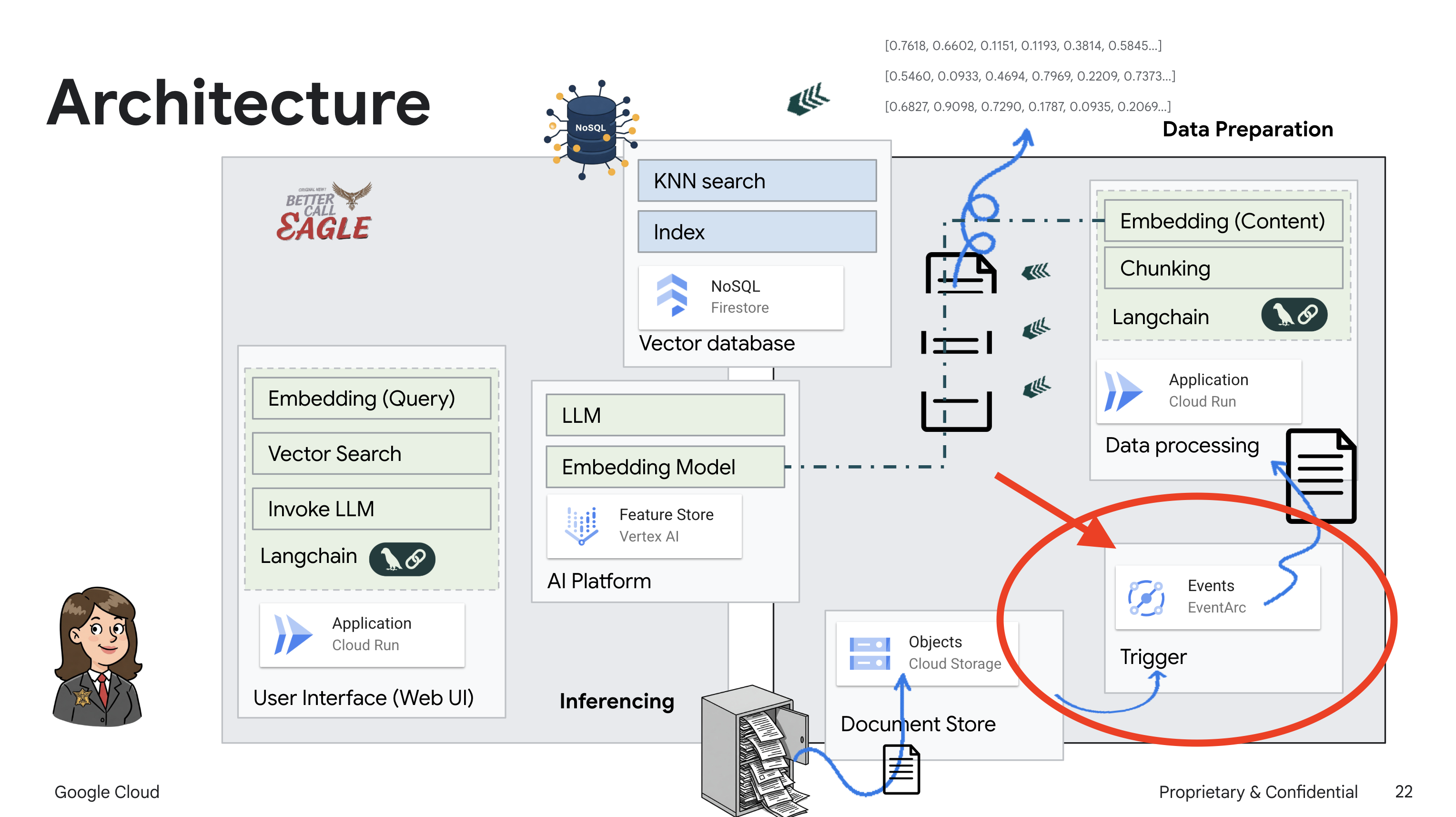
Eventarc'ı ayarlayarak Cloud Run hizmetimizin, yeni eklenen dokümanları yüklenir yüklenmez Firestore'a otomatik olarak yüklemesini sağlayacağız. Böylece RAG uygulamamız için gerçek zamanlı veri güncellemeleri mümkün olacak.
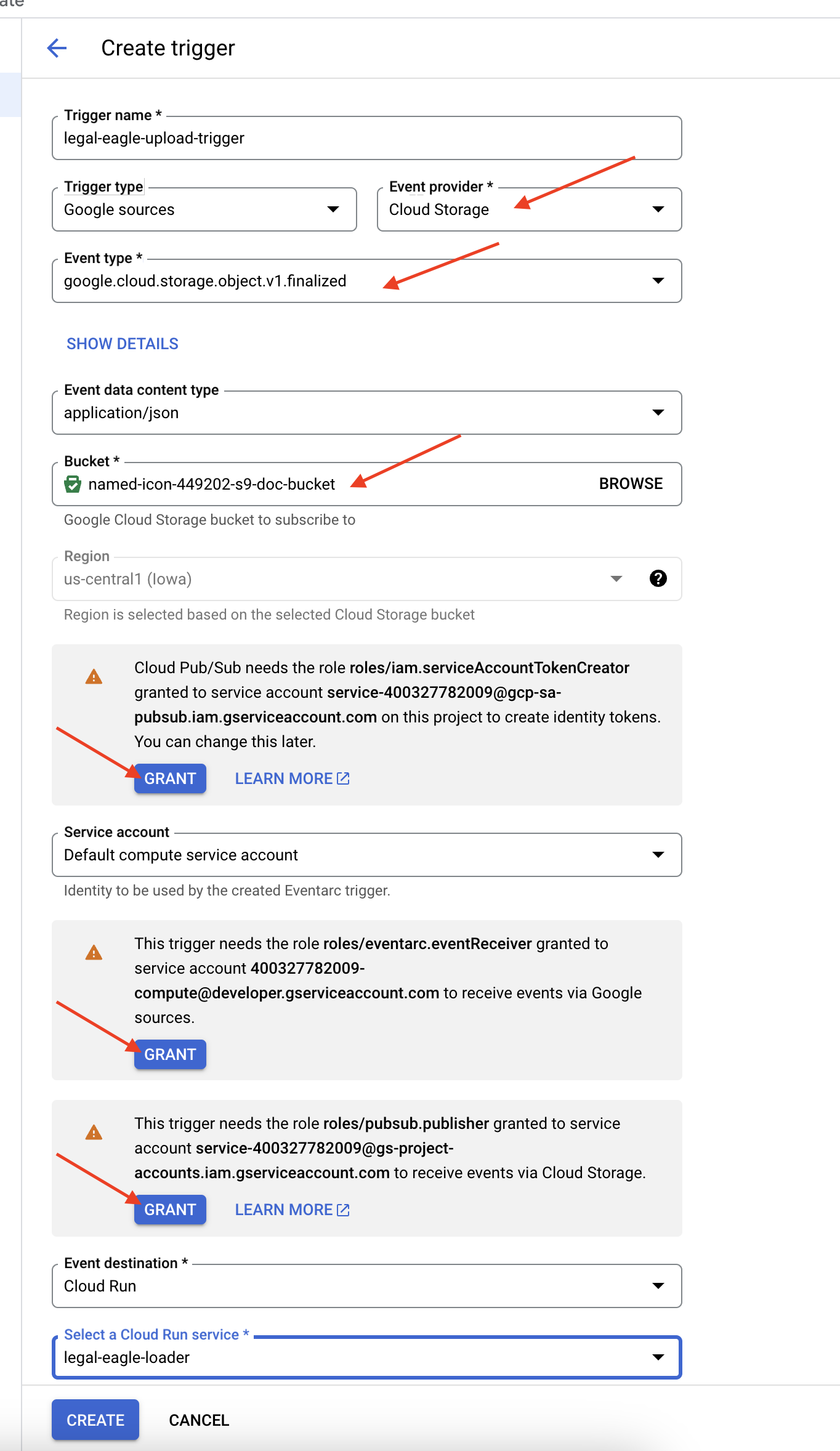
👉 Google Cloud Console'da EventArc'ın altındaki Tetikleyiciler'e gidin. "+ TETİKLEYİCİ OLUŞTUR"u tıklayın. 👉 Eventarc tetikleyicisini yapılandırın:
- Tetikleyici adı:
legal-eagle-upload-trigger. - TriggerType: Google Kaynakları
- Etkinlik sağlayıcı: Cloud Storage'ı seçin.
- Etkinlik türü:
google.cloud.storage.object.v1.finalizedseçeneğini belirleyin. - Cloud Storage paketi: Açılır listeden GCS paketinizi seçin.
- Hedef türü: "Cloud Run hizmeti".
- Hizmet:
legal-eagle-loadersimgesini seçin. - Bölge:
us-central1 - Yol: Şimdilik bu alanı boş bırakın .
- Sayfada istenen tüm izinleri verin.
👉 OLUŞTUR'u tıklayın. Eventarc artık tetikleyiciyi ayarlayacak.
Cloud Run hizmetinin, çeşitli bileşenlerdeki dosyaları okuma izni olması gerekir. Hizmetin hizmet hesabına ihtiyacı olan izni vermemiz gerekir.
12. Yasal belgeleri GCS paketine yükleme
👉 Mahkeme davası dosyasını GCS paketinize yükleyin. Paket adınızı değiştirmeyi unutmayın.
export DOC_BUCKET_NAME=$(gcloud storage buckets list --format="value(name)" | grep doc-bucket)
gsutil cp ~/legal-eagle/court_cases/case-02.txt gs://$DOC_BUCKET_NAME/
gsutil cp ~/legal-eagle/court_cases/case-03.txt gs://$DOC_BUCKET_NAME/
gsutil cp ~/legal-eagle/court_cases/case-06.txt gs://$DOC_BUCKET_NAME/
Cloud Run hizmet günlüklerini izlemek için Cloud Run -> hizmetiniz legal-eagle-loader -> "Günlükler"e gidin. Aşağıdakiler de dahil olmak üzere iletilerin başarılı bir şekilde işlenmesiyle ilgili günlükleri kontrol edin:
xxx
POST200130 B8.3 sAPIs-Google; (+https://developers.google.com/webmasters/APIs-Google.html) https://legal-eagle-loader-bmngrueyta-uc.a.run.app/?__GCP_CloudEventsMode=GCS_NOTIFICATION
xxx
POST200130 B520 msAPIs-Google; (+https://developers.google.com/webmasters/APIs-Google.html) https://legal-eagle-loader-bmngrueyta-uc.a.run.app/?__GCP_CloudEventsMode=GCS_NOTIFICATION
xxx
POST200130 B514 msAPIs-Google; (+https://developers.google.com/webmasters/APIs-Google.html) https://legal-eagle-loader-bmngrueyta-uc.a.run.app/?__GCP_CloudEventsMode=GCS_NOTIFICATION
Günlüğün ne kadar hızlı ayarlandığına bağlı olarak, burada daha ayrıntılı günlükler de görürsünüz.
"CloudEvent received:"
"New file detected in bucket:"
"File content downloaded. Processing..."
"Text split into ... chunks."
"File processing and Firestore upsert complete..."
Günlüklerde hata mesajı olup olmadığına bakın ve gerekirse sorun giderin. 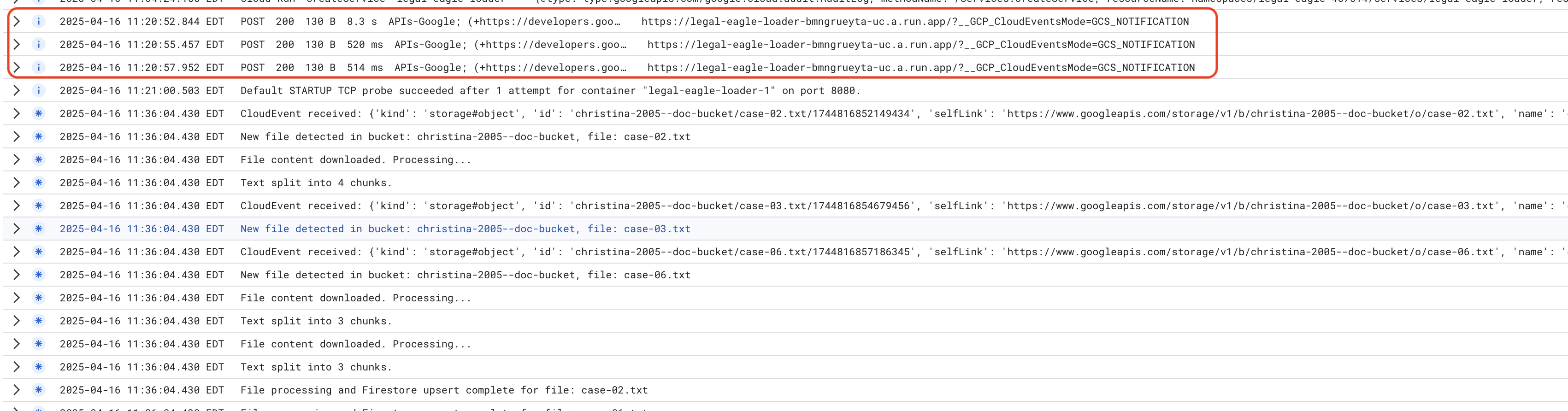
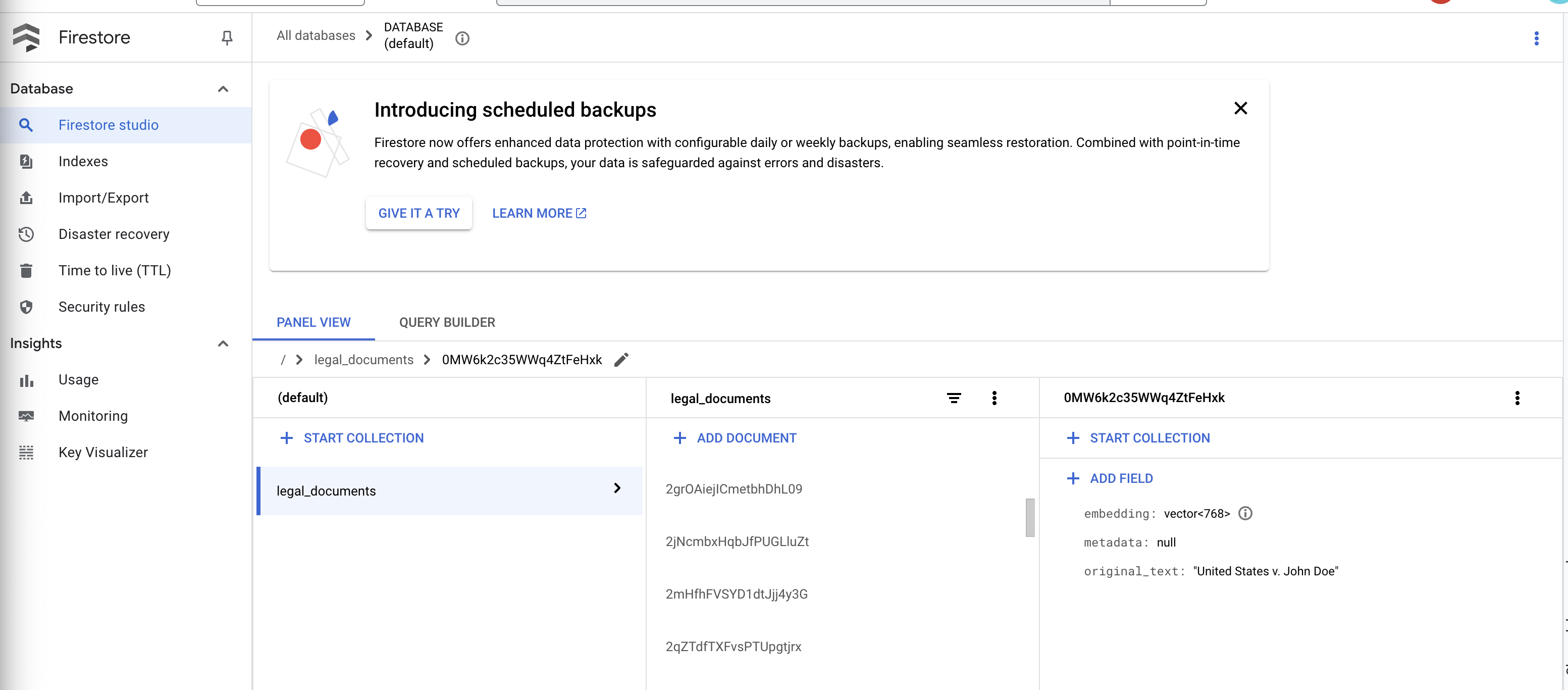
👉 Firestore'daki verileri doğrulayın. legal_documents koleksiyonunuzu açın.
👉 Koleksiyonunuzda yeni oluşturulan dokümanları görmeniz gerekir. Her doküman, yüklediğiniz dosyadaki metnin bir bölümünü temsil eder ve şunları içerir:
metadata: currently empty
original_text_chunk: The text chunk content.
embedding_: A list of floating-point numbers (the Vertex AI embedding).
13. RAG'yi uygulama
LangChain, büyük dil modelleri (LLM'ler) tarafından desteklenen uygulamaların geliştirilmesini kolaylaştırmak için tasarlanmış güçlü bir çerçevedir. LangChain, LLM API'lerinin, istem mühendisliğinin ve veri işlemenin karmaşıklıklarıyla doğrudan uğraşmak yerine üst düzey bir soyutlama katmanı sağlar. Çeşitli LLM'lere (OpenAI, Google vb.) bağlanma, karmaşık işlem zincirleri oluşturma (ör. veri alma ve ardından özetleme) ve sohbet belleğini yönetme gibi görevler için önceden oluşturulmuş bileşenler ve araçlar sunar.
Özellikle RAG için LangChain'deki Vector depoları, RAG'in getirme yönünü etkinleştirmek açısından önemlidir. Bunlar, semantik olarak benzer metin parçalarının vektör uzayında birbirine yakın noktalara eşlendiği, vektör yerleştirmelerini verimli bir şekilde depolamak ve sorgulamak için tasarlanmış özel veritabanlarıdır. LangChain, alt düzey tesisat işlerini halleder ve geliştiricilerin RAG uygulamalarının temel mantığına ve işlevselliğine odaklanmasına olanak tanır. Bu sayede geliştirme süresi ve karmaşıklığı önemli ölçüde azalır. Google Cloud altyapısının sağlamlığından ve ölçeklenebilirliğinden yararlanırken RAG tabanlı uygulamaları hızlı bir şekilde prototipleyip dağıtabilirsiniz.
LangChain'i açıkladıktan sonra, RAG uygulaması için webapp klasöründeki legal.py dosyanızı güncellemeniz gerekir. Bu sayede LLM, yanıt vermeden önce Firestore'da ilgili dokümanları arayabilir.
👉 FirestoreVectorStore ve diğer gerekli modülleri langchain ve vertexai'den içe aktarın. Aşağıdakileri mevcut legal.py alanına ekleyin.
from langchain_google_vertexai import VertexAIEmbeddings
from langchain_google_firestore import FirestoreVectorStore
👉 Vertex AI'ı ve yerleştirme modelini başlatın.text-embedding-004 kullanacaksınız. Modülleri içe aktardıktan hemen sonra aşağıdaki kodu ekleyin.
PROJECT_ID = os.environ.get("GOOGLE_CLOUD_PROJECT") # Get project ID from env
embedding_model = VertexAIEmbeddings(
model_name="text-embedding-004" ,
project=PROJECT_ID,)
👉 Başlatılan yerleştirme modelini kullanarak ve içerik ile yerleştirme alanlarını belirterek legal_documents koleksiyonunu işaret eden bir FirestoreVectorStore oluşturun. Bu kodu, önceki yerleştirme modeli kodunun hemen sonrasına ekleyin.
COLLECTION_NAME = "legal_documents"
# Create a vector store
vector_store = FirestoreVectorStore(
collection="legal_documents",
embedding_service=embedding_model,
content_field="original_text",
embedding_field="embedding",
)
👉 Bir sorgu alan, vector_store.similarity_search kullanarak benzerlik araması yapan ve birleştirilmiş sonuçları döndüren search_resource adlı bir işlev tanımlayın.
def search_resource(query):
results = []
results = vector_store.similarity_search(query, k=5)
combined_results = "\n".join([result.page_content for result in results])
print(f"==>{combined_results}")
return combined_results
👉 ask_llm işlevini DEĞİŞTİRİN ve kullanıcının sorgusuna göre alakalı bağlamı almak için search_resource işlevini kullanın.
def ask_llm(query):
try:
query_message = {
"type": "text",
"text": query,
}
relevant_resource = search_resource(query)
input_msg = HumanMessage(content=[query_message])
prompt_template = ChatPromptTemplate.from_messages(
[
SystemMessage(
content=(
"You are a helpful assistant, and you are with the attorney in a courtroom, you are helping him to win the case by providing the information he needs "
"Don't answer if you don't know the answer, just say sorry in a funny way possible"
"Use high engergy tone, don't use more than 100 words to answer"
f"Here is some context that is relevant to the question {relevant_resource} that you might use"
)
),
input_msg,
]
)
prompt = prompt_template.format()
response = llm.invoke(prompt)
print(f"response: {response}")
return response
except Exception as e:
print(f"Error sending message to chatbot: {e}") # Log this error too!
return f"Unable to process your request at this time. Due to the following reason: {str(e)}"
👉 İSTEĞE BAĞLI: İSPANYOLCA VERSİYON
Sustituye el siguiente texto como se indica: You are a helpful assistant, to You are a helpful assistant that speaks Spanish,
👉 RAG'yi legal.py'ye uyguladıktan sonra dağıtmadan önce yerel olarak test etmeniz gerekir. Uygulamayı şu komutla çalıştırın:
cd ~/legal-eagle/webapp
source env/bin/activate
python main.py
👉 Uygulamaya erişmek, asistanla konuşmak ve yerel olarak çalıştırılan işlemden çıkmak için ctrl+c yazmak üzere webpreview'u kullanın. Sanal ortamdan çıkmak için devre dışı bırakma işlemini çalıştırın.
deactivate
Web uygulamasını Cloud Run'a dağıtmak için yükleyici işlevine benzer bir işlem yapmanız gerekir. Docker görüntüsünü oluşturup etiketleyerek Artifact Registry'ye aktaracaksınız:
export PROJECT_ID=$(gcloud config get project)
docker build -t gcr.io/${PROJECT_ID}/legal-eagle-webapp .
docker tag gcr.io/${PROJECT_ID}/legal-eagle-webapp us-central1-docker.pkg.dev/${PROJECT_ID}/my-repository/legal-eagle-webapp
docker push us-central1-docker.pkg.dev/${PROJECT_ID}/my-repository/legal-eagle-webapp
👉 Web uygulamasını Google Cloud'a dağıtma zamanı geldi. Terminalde şu komutları çalıştırın:
export PROJECT_ID=$(gcloud config get project)
gcloud run deploy legal-eagle-webapp \
--image us-central1-docker.pkg.dev/$PROJECT_ID/my-repository/legal-eagle-webapp \
--region us-central1 \
--set-env-vars=GOOGLE_CLOUD_PROJECT=${PROJECT_ID} \
--allow-unauthenticated
Google Cloud Console'da Cloud Run'a giderek dağıtımı doğrulayın.legal-eagle-webapp adlı yeni bir hizmet görmeniz gerekir.
Hizmeti tıklayarak ayrıntılar sayfasına gidin. Dağıtılan URL'yi en üstte bulabilirsiniz. 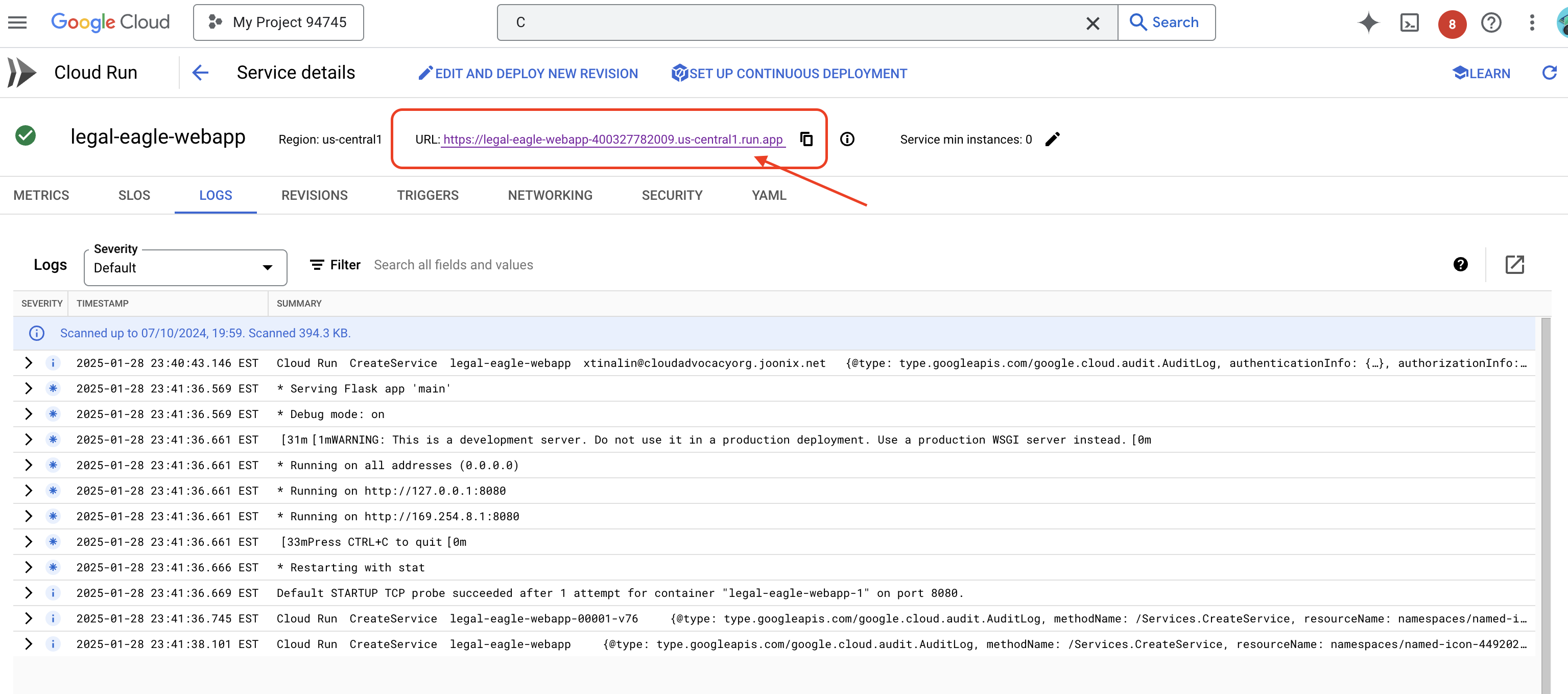
👉 Şimdi dağıtılan URL'yi yeni bir tarayıcı sekmesinde açın. Yasal asistanla etkileşim kurabilir ve yüklediğiniz mahkeme davalarıyla(court_cases klasöründe) ilgili sorular sorabilirsiniz:
- Michael Brown kaç yıl hapis cezasına çarptırıldı?
- Ayşe Yılmaz'ın işlemleri sonucunda ne kadar yetkisiz ödeme yapıldı?
- Komşuların ifadeleri, Emily White ile ilgili davanın soruşturulmasında nasıl bir rol oynadı?
👉 İSTEĞE BAĞLI: İSPANYOLCA VERSİYON
- ¿A cuántos años de prisión fue sentenciado Michael Brown?
- ¿Cuánto dinero en cargos no autorizados se generó como resultado de las acciones de Jane Smith?
- ¿Qué papel jugaron los testimonios de los vecinos en la investigación del caso de Emily White?
Yanıtların artık daha doğru olduğunu ve yüklediğiniz yasal belgelerin içeriğine dayandığını fark edeceksiniz. Bu, RAG'nin gücünü gösteriyor.
Atölyeyi tamamladığınız için tebrikler. LLM'leri, LangChain'i ve Google Cloud'u kullanarak yasal belge analizi uygulaması oluşturup dağıtma işlemini başarıyla tamamladınız. Yasal belgeleri nasıl alıp işleyeceğinizi, RAG kullanarak LLM yanıtlarını alakalı bilgilerle nasıl artıracağınızı ve uygulamanızı sunucusuz hizmet olarak nasıl dağıtacağınızı öğrendiniz. Bu bilgiler ve oluşturulan uygulama, büyük dil modellerinin hukuk görevlerindeki gücünü daha ayrıntılı bir şekilde keşfetmenize yardımcı olacaktır. Tebrikler!"
14. Zorluk
Çeşitli medya türleri::
Mahkeme videoları ve ses kayıtları gibi çeşitli medya türlerinin nasıl alınacağı ve işleneceği, ayrıca ilgili metinlerin nasıl ayıklanacağı
Online Varlıklar:
Web sayfaları gibi online öğeleri canlı olarak işleme