
1. Giới thiệu
Tôi luôn bị cuốn hút bởi sự căng thẳng trong phòng xử án, tưởng tượng mình khéo léo vượt qua những phức tạp của nó và đưa ra những lập luận kết thúc mạnh mẽ. Mặc dù con đường sự nghiệp đã đưa tôi đến một nơi khác, nhưng tôi rất vui khi chia sẻ rằng với sự trợ giúp của AI (trí tuệ nhân tạo), tất cả chúng ta có thể sẽ sớm thực hiện được ước mơ làm việc tại toà án.

Hôm nay, chúng ta sẽ tìm hiểu cách sử dụng các công cụ AI mạnh mẽ của Google (chẳng hạn như Vertex AI, Firestore và Cloud Run Functions) để xử lý và hiểu dữ liệu pháp lý, thực hiện các tìm kiếm cực nhanh và có thể giúp khách hàng (hoặc chính bạn) thoát khỏi tình huống khó khăn.
Bạn có thể không cần phải chất vấn nhân chứng, nhưng với hệ thống của chúng tôi, bạn sẽ có thể sàng lọc hàng núi thông tin, tạo ra bản tóm tắt rõ ràng và trình bày dữ liệu phù hợp nhất trong vài giây.
2. Kiến trúc
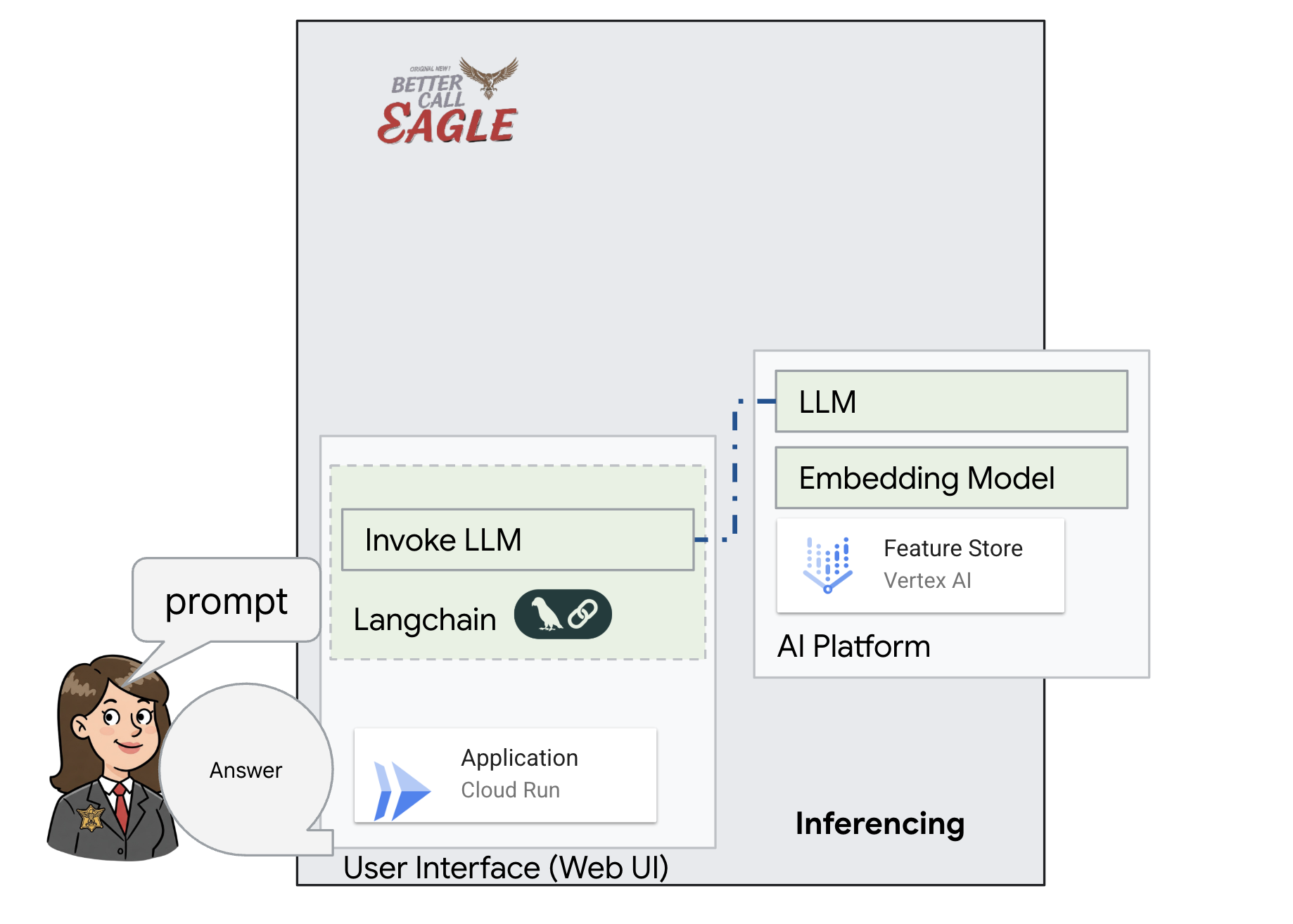
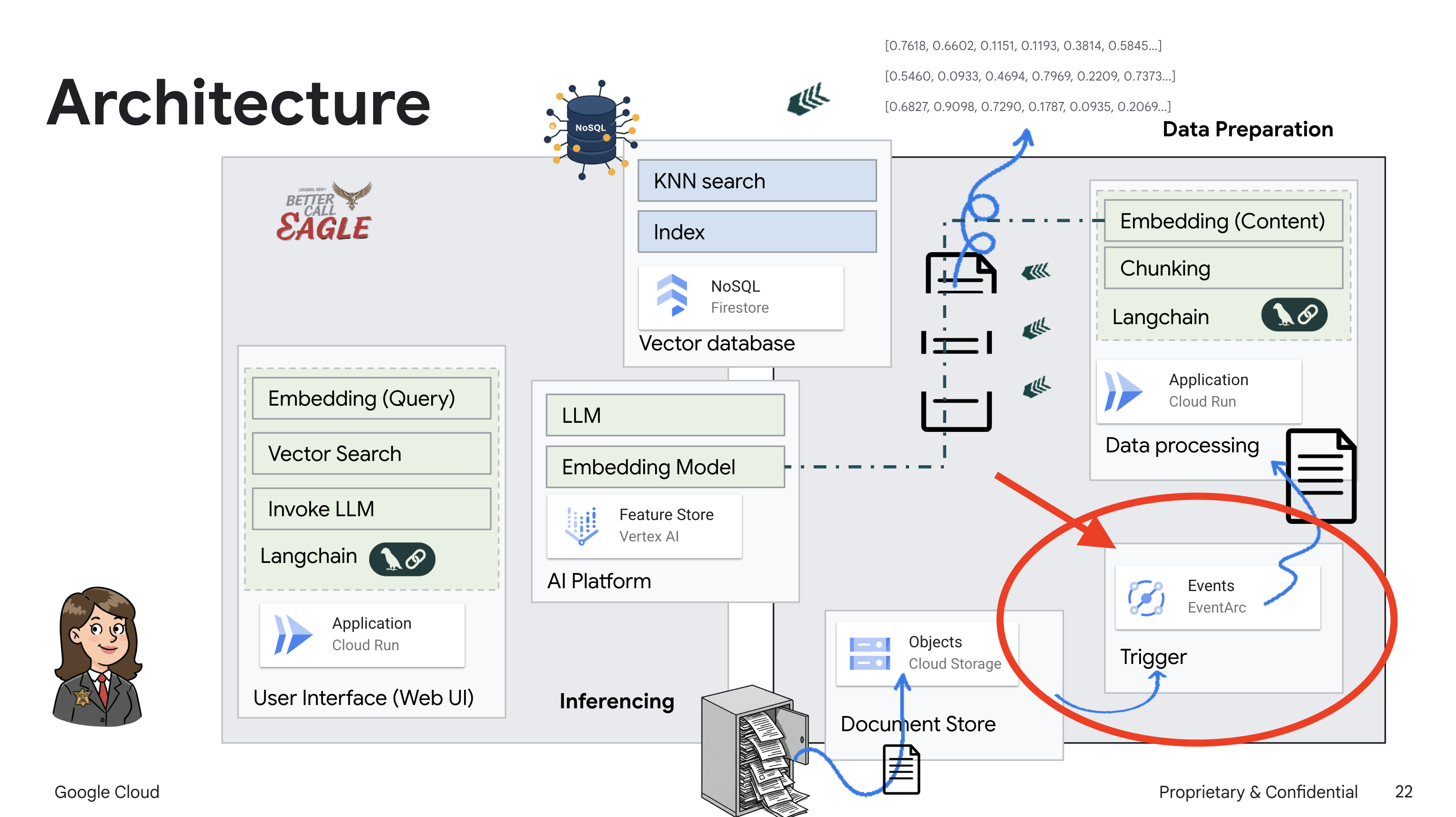
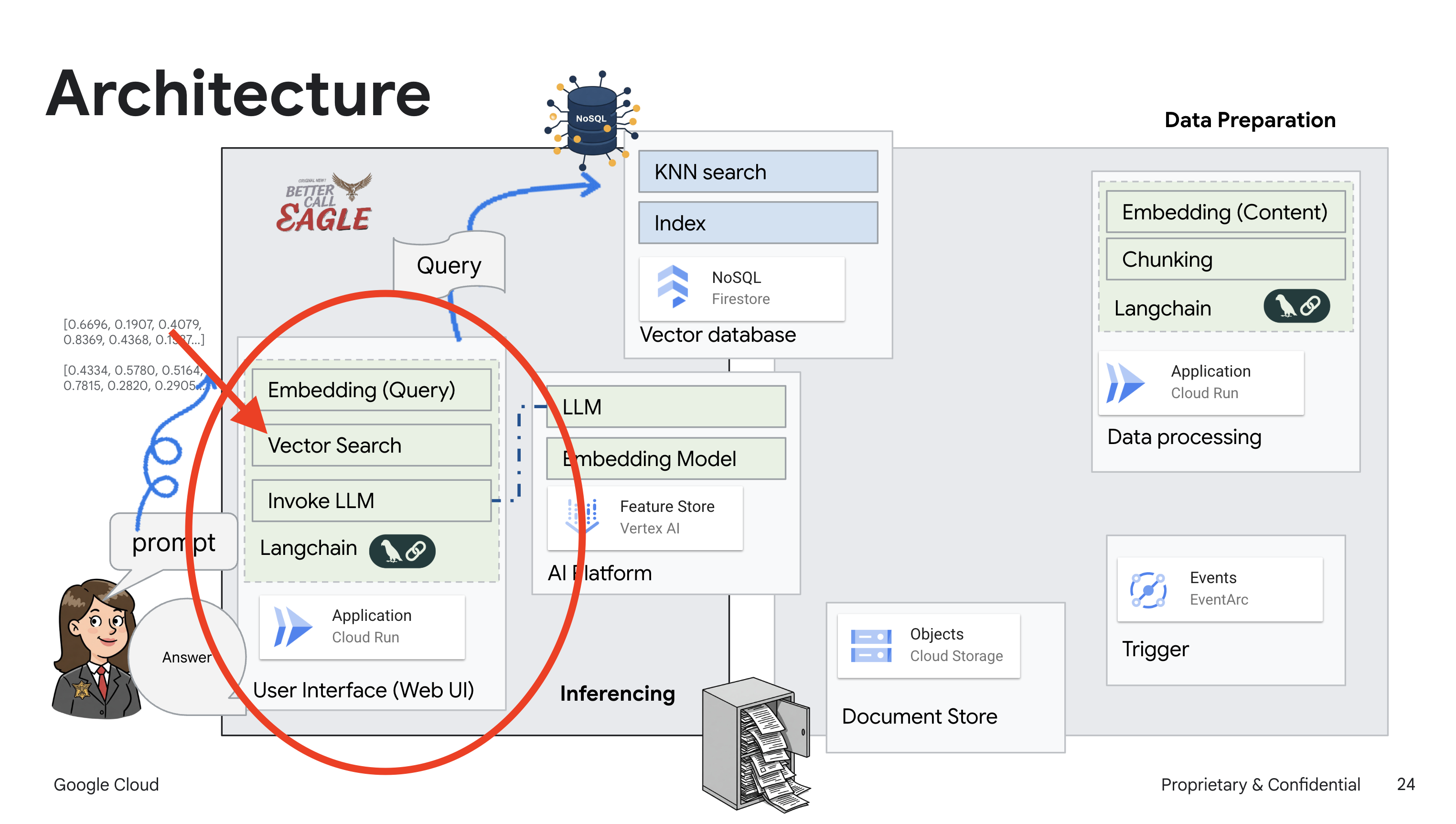
Dự án này tập trung vào việc xây dựng một trợ lý pháp lý bằng các công cụ AI của Google Cloud, đồng thời nhấn mạnh cách xử lý, hiểu và tìm kiếm dữ liệu pháp lý. Hệ thống này được thiết kế để sàng lọc lượng lớn thông tin, tạo bản tóm tắt và trình bày dữ liệu liên quan một cách nhanh chóng. Cấu trúc của trợ lý pháp lý bao gồm một số thành phần chính:
Xây dựng cơ sở kiến thức từ dữ liệu không có cấu trúc: Google Cloud Storage (GCS) được dùng để lưu trữ các tài liệu pháp lý. Firestore, một cơ sở dữ liệu NoSQL, hoạt động như một kho lưu trữ vectơ, lưu giữ các khối tài liệu và các mục nhúng tương ứng. Tính năng Tìm kiếm vectơ được bật trong Firestore để cho phép tìm kiếm sự tương đồng. Khi một tài liệu pháp lý mới được tải lên GCS, Eventarc sẽ kích hoạt một hàm Cloud Run. Hàm này xử lý tài liệu bằng cách chia tài liệu thành các đoạn và tạo vectơ nhúng cho từng đoạn bằng mô hình vectơ nhúng văn bản của Vertex AI. Sau đó, các mục nhúng này được lưu trữ trong Firestore cùng với các đoạn văn bản. 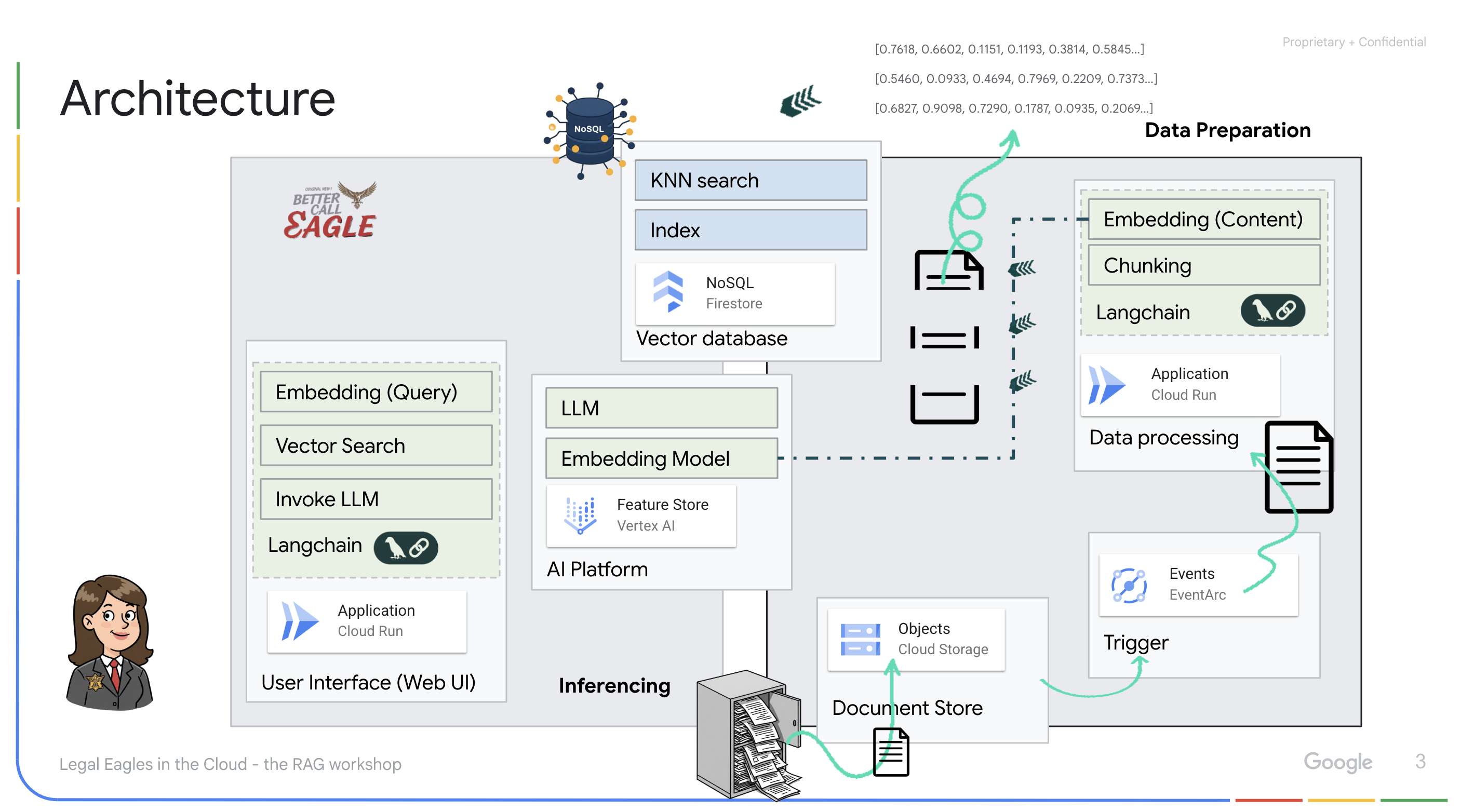
Ứng dụng dựa trên LLM và RAG : Cốt lõi của hệ thống hỏi đáp là hàm ask_llm, sử dụng thư viện langchain để tương tác với Mô hình ngôn ngữ lớn Gemini của Vertex AI. Thao tác này sẽ tạo một HumanMessage từ truy vấn của người dùng và bao gồm một SystemMessage hướng dẫn LLM đóng vai trò là một trợ lý pháp lý hữu ích. Hệ thống sử dụng phương pháp Tạo tăng cường khả năng truy xuất (RAG), trong đó, trước khi trả lời một truy vấn, hệ thống sẽ sử dụng hàm search_resource để truy xuất ngữ cảnh có liên quan từ kho lưu trữ vectơ Firestore. Sau đó, ngữ cảnh này sẽ được đưa vào SystemMessage để câu trả lời của LLM dựa trên thông tin pháp lý được cung cấp. 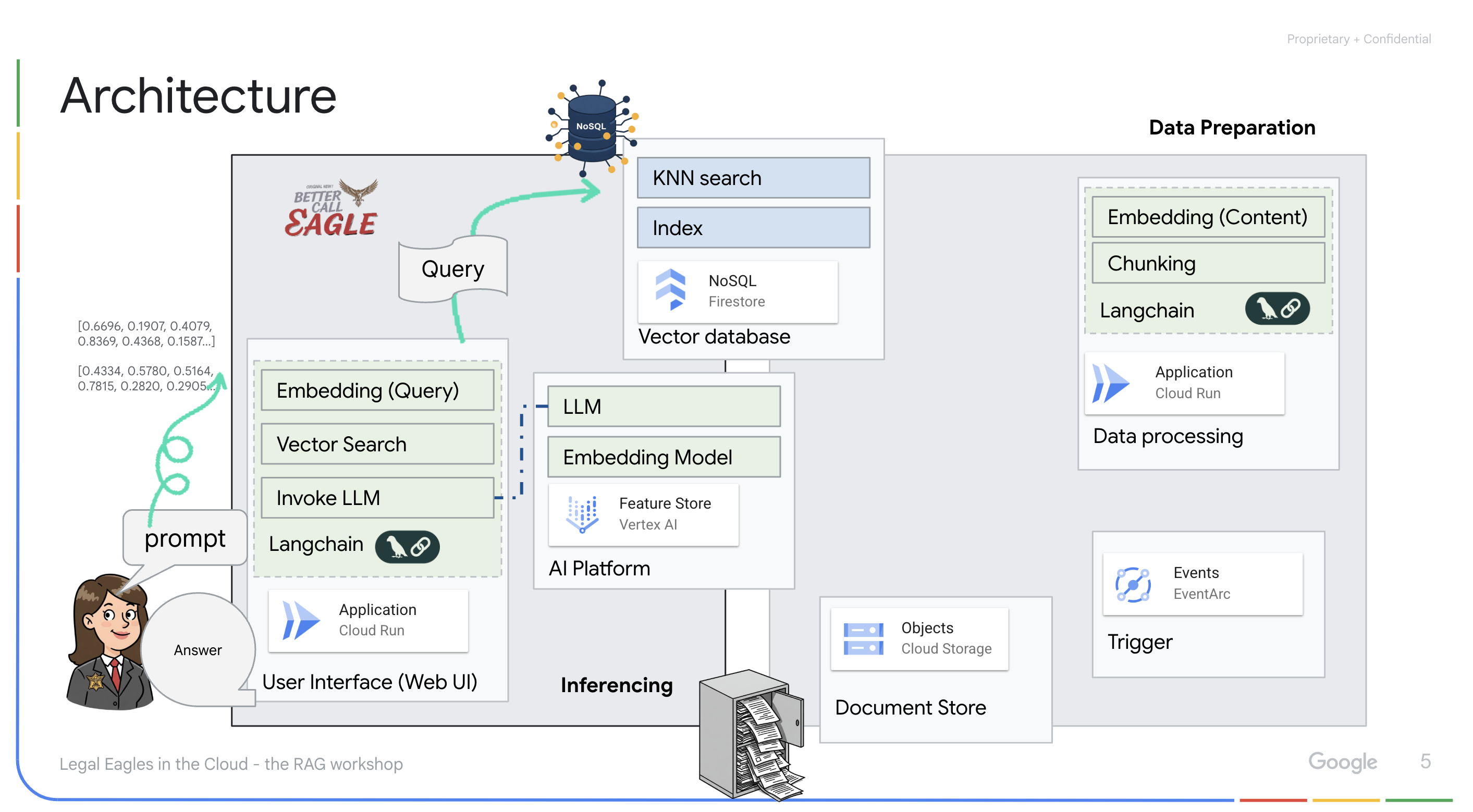
Dự án này hướng đến việc loại bỏ "cách diễn giải sáng tạo" của LLM bằng cách sử dụng RAG. RAG sẽ truy xuất thông tin liên quan từ một nguồn pháp lý đáng tin cậy trước khi tạo câu trả lời. Điều này giúp bạn nhận được câu trả lời chính xác và đầy đủ hơn dựa trên thông tin pháp lý thực tế. Hệ thống này được xây dựng bằng nhiều dịch vụ của Google Cloud, chẳng hạn như Google Cloud Shell, Vertex AI, Firestore, Cloud Run và Eventarc.
3. Trước khi bắt đầu
Trong Google Cloud Console, trên trang chọn dự án, hãy chọn hoặc tạo một dự án trên Google Cloud. Đảm bảo rằng bạn đã bật tính năng thanh toán cho dự án trên Cloud. Tìm hiểu cách kiểm tra xem tính năng thanh toán có được bật trên một dự án hay không.
Bật Gemini Code Assist trong Cloud Shell IDE
👉 Trong bảng điều khiển Cloud, hãy chuyển đến Gemini Code Assist Tools (Các công cụ Gemini Code Assist), bật Gemini Code Assist mà không mất phí bằng cách đồng ý với các Điều khoản và điều kiện.
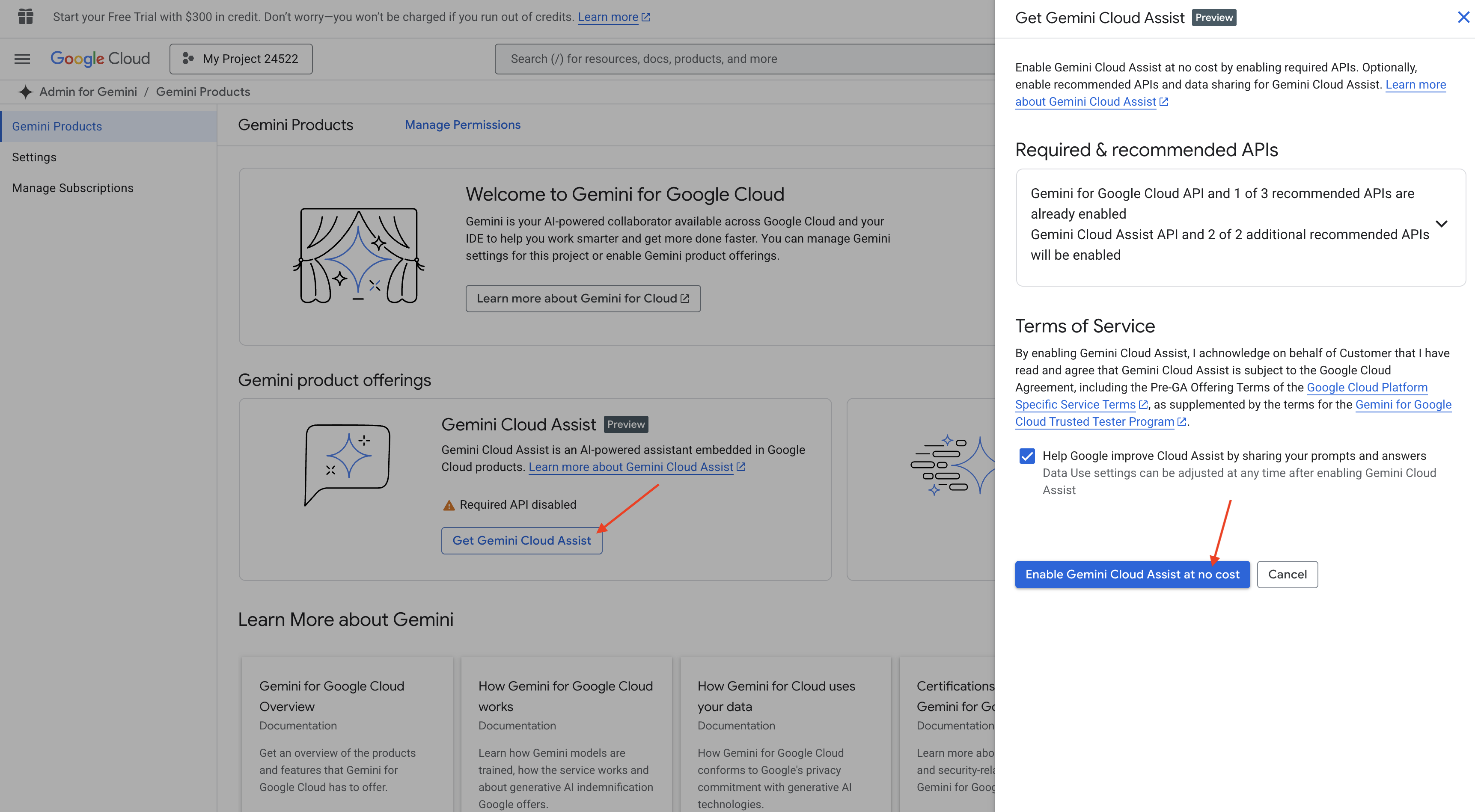
Bỏ qua chế độ thiết lập quyền, rời khỏi trang này.
Làm việc trên Cloud Shell Editor
👉 Nhấp vào Kích hoạt Cloud Shell ở đầu bảng điều khiển Google Cloud (Đây là biểu tượng có hình dạng thiết bị đầu cuối ở đầu ngăn Cloud Shell)
👉 Nhấp vào nút "Mở trình chỉnh sửa" (nút này trông giống như một thư mục đang mở có bút chì). Thao tác này sẽ mở Cloud Shell Editor trong cửa sổ. Bạn sẽ thấy một trình khám phá tệp ở bên trái.

👉 Nhấp vào nút Đăng nhập bằng mã trên đám mây trong thanh trạng thái ở dưới cùng như minh hoạ. Uỷ quyền cho trình bổ trợ theo hướng dẫn. Nếu bạn thấy Cloud Code – no project (Cloud Code – không có dự án) trong thanh trạng thái, hãy chọn mục đó rồi chọn "Select a Google Cloud Project" (Chọn một dự án trên Google Cloud) trong trình đơn thả xuống, sau đó chọn dự án cụ thể trên Google Cloud trong danh sách các dự án mà bạn dự định làm việc.
👉 Mở cửa sổ dòng lệnh trong IDE trên đám mây, 
👉 Trong thiết bị đầu cuối mới, hãy xác minh rằng bạn đã được xác thực và dự án được đặt thành mã dự án của bạn bằng lệnh sau:
gcloud auth list
👉 Nhấp vào Kích hoạt Cloud Shell ở đầu bảng điều khiển Cloud.
gcloud config set project <YOUR_PROJECT_ID>
👉 Chạy lệnh sau để bật các Cloud APIs cần thiết của Google Cloud:
gcloud services enable storage.googleapis.com \
run.googleapis.com \
artifactregistry.googleapis.com \
aiplatform.googleapis.com \
eventarc.googleapis.com \
cloudresourcemanager.googleapis.com \
firestore.googleapis.com \
cloudaicompanion.googleapis.com
Trong thanh công cụ Cloud Shell (ở đầu ngăn Cloud Shell), hãy nhấp vào nút "Mở trình chỉnh sửa" (nút này trông giống như một thư mục đang mở có bút chì). Thao tác này sẽ mở Trình chỉnh sửa mã Cloud Shell trong cửa sổ. Bạn sẽ thấy một trình khám phá tệp ở bên trái.
👉 Trong cửa sổ dòng lệnh, hãy tải Dự án Bootstrap Skeleton xuống:
git clone https://github.com/weimeilin79/legal-eagle.git
KHÔNG BẮT BUỘC: PHIÊN BẢN TIẾNG TÂY BAN NHA
👉 Existe una versión alternativa en español. Por favor, utilice la siguiente instrucción para clonar la versión correcta.
git clone -b spanish https://github.com/weimeilin79/legal-eagle.git
Sau khi bạn chạy lệnh này trong thiết bị đầu cuối Cloud Shell, một thư mục mới có tên kho lưu trữ legal-eagle sẽ được tạo trong môi trường Cloud Shell.
4. Viết ứng dụng suy luận bằng Gemini Code Assist
Trong phần này, chúng ta sẽ tập trung vào việc xây dựng cốt lõi của trợ lý pháp lý – ứng dụng web nhận câu hỏi của người dùng và tương tác với mô hình AI để tạo câu trả lời. Chúng ta sẽ tận dụng Gemini Code Assist để giúp viết mã Python cho phần suy luận này.
Ban đầu, chúng ta sẽ tạo một ứng dụng Flask sử dụng thư viện LangChain để giao tiếp trực tiếp với mô hình Vertex AI Gemini. Phiên bản đầu tiên này sẽ đóng vai trò là một trợ lý pháp lý hữu ích dựa trên kiến thức chung của mô hình, nhưng chưa có quyền truy cập vào các tài liệu cụ thể về vụ kiện của chúng tôi. Điều này sẽ giúp chúng ta biết được hiệu suất cơ bản của LLM trước khi cải thiện bằng RAG sau này.
Trong ngăn Explorer (Trình khám phá) của Cloud Code Editor (Trình chỉnh sửa Cloud Code) (thường ở bên trái), giờ đây, bạn sẽ thấy thư mục được tạo khi bạn sao chép kho lưu trữ Git legal-eagle, Mở thư mục gốc của dự án trong Trình khám phá. Bạn sẽ thấy một thư mục con webapp trong thư mục đó, hãy mở thư mục con này. 
👉 Chỉnh sửa tệp legal.py trong Cloud Code Editor, bạn có thể sử dụng nhiều phương thức để ra lệnh cho Gemini Code Assist.
👉 Sao chép câu lệnh sau vào cuối legal.py để mô tả rõ ràng nội dung bạn muốn Gemini Code Assist tạo, nhấp vào biểu tượng bóng đèn 💡 xuất hiện và chọn Gemini: Tạo mã (mục trình đơn chính xác có thể thay đổi một chút tuỳ thuộc vào phiên bản Cloud Code).
"""
Write a Python function called `ask_llm` that takes a user `query` as input. This function should use the `langchain` library to interact with a Vertex AI Gemini Large Language Model. Specifically, it should:
1. Create a `HumanMessage` object from the user's `query`.
2. Create a `ChatPromptTemplate` that includes a `SystemMessage` and the `HumanMessage`. The system message should instruct the LLM to act as a helpful assistant in a courtroom setting, aiding an attorney by providing necessary information. It should also specify that the LLM should respond in a high-energy tone, using no more than 100 words, and offer a humorous apology if it doesn't know the answer.
3. Format the `ChatPromptTemplate` with the provided messages.
4. Invoke the Vertex AI LLM with the formatted prompt using the `VertexAI` class (assuming it's already initialized elsewhere as `llm`).
5. Print the LLM's `response`.
6. Return the `response`.
7. Include error handling that prints an error message to the console and returns a user-friendly error message if any issues occur during the process. The Vertex AI model should be "gemini-2.0-flash".
"""
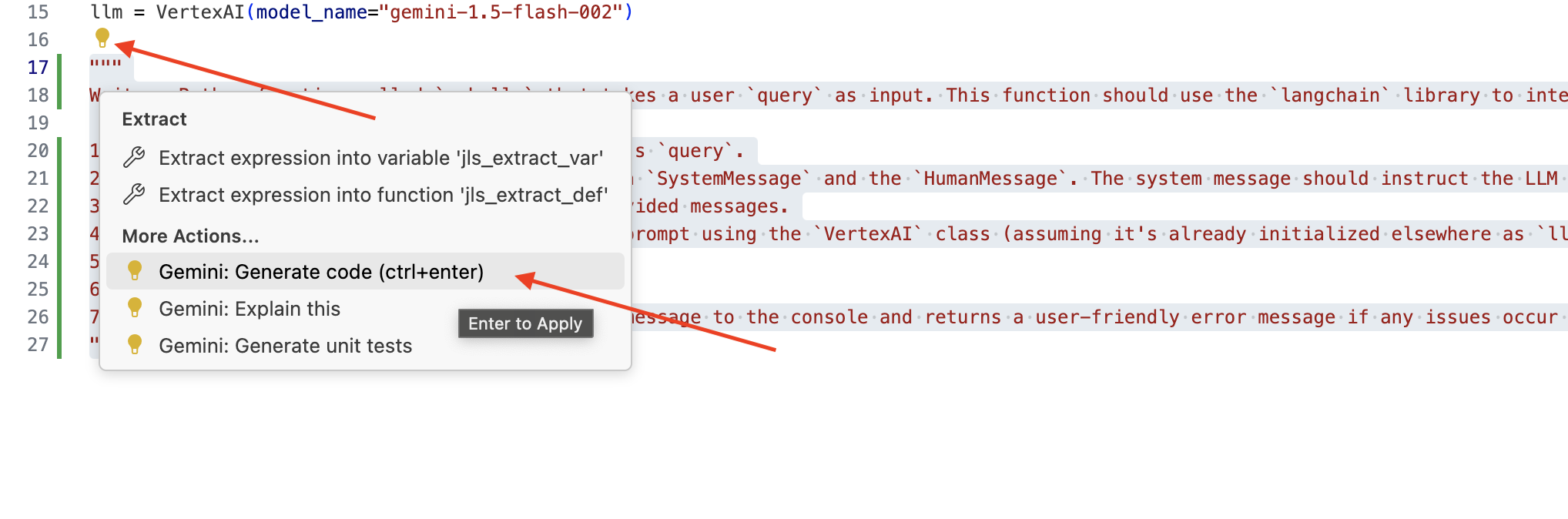
Xem xét kỹ mã được tạo
- Liệu câu trả lời đó có đi theo các bước mà bạn đã nêu trong phần bình luận không?
- Thao tác này có tạo
ChatPromptTemplatebằngSystemMessagevàHumanMessagekhông? - Có bao gồm tính năng xử lý lỗi cơ bản (
try...except) không?
Nếu mã được tạo là mã tốt và hầu hết là chính xác, bạn có thể chấp nhận mã đó (Nhấn phím Tab hoặc Enter để xem các đề xuất cùng dòng, hoặc nhấp vào "Chấp nhận" đối với các khối mã lớn hơn).
Nếu mã được tạo không chính xác như bạn muốn hoặc có lỗi, đừng lo lắng! Gemini Code Assist là một công cụ hỗ trợ bạn, chứ không phải để viết mã hoàn hảo ngay từ lần đầu tiên.
Chỉnh sửa và sửa đổi mã được tạo để tinh chỉnh, sửa lỗi và đáp ứng tốt hơn các yêu cầu của bạn. Bạn có thể tiếp tục đưa ra câu lệnh cho Gemini Code Assist bằng cách thêm bình luận hoặc đặt câu hỏi cụ thể trong bảng điều khiển trò chuyện của Code Assist.
Và nếu bạn vẫn chưa quen với SDK này, thì đây là một ví dụ minh hoạ.
👉 Sao chép và dán, sau đó THAY THẾ mã sau vào legal.py:
import os
import signal
import sys
import vertexai
import random
from langchain_google_vertexai import VertexAI
from langchain_core.prompts import PromptTemplate, ChatPromptTemplate
from langchain_core.messages import HumanMessage, SystemMessage
# Connect to resourse needed from Google Cloud
llm = VertexAI(model_name="gemini-2.0-flash")
def ask_llm(query):
try:
query_message = {
"type": "text",
"text": query,
}
input_msg = HumanMessage(content=[query_message])
prompt_template = ChatPromptTemplate.from_messages(
[
SystemMessage(
content=(
"You are a helpful assistant, and you are with the attorney in a courtroom, you are helping him to win the case by providing the information he needs "
"Don't answer if you don't know the answer, just say sorry in a funny way possible"
"Use high engergy tone, don't use more than 100 words to answer"
# f"Here is some past conversation history between you and the user {relevant_history}"
# f"Here is some context that is relevant to the question {relevant_resource} that you might use"
)
),
input_msg,
]
)
prompt = prompt_template.format()
response = llm.invoke(prompt)
print(f"response: {response}")
return response
except Exception as e:
print(f"Error sending message to chatbot: {e}") # Log this error too!
return f"Unable to process your request at this time. Due to the following reason: {str(e)}"
👉 KHÔNG BẮT BUỘC: BẢN TIẾNG TÂY BAN NHA
Thay thế văn bản sau như se indica: You are a helpful assistant, thành You are a helpful assistant that speaks Spanish,
Tiếp theo, hãy tạo một hàm để xử lý một tuyến đường sẽ phản hồi các câu hỏi của người dùng.
Mở main.py trong Trình chỉnh sửa Cloud Shell. Tương tự như cách bạn tạo ask_llm trong legal.py, hãy sử dụng Gemini Code Assist để tạo Flask Route và hàm ask_question. Nhập CÂU LỆNH sau đây dưới dạng nhận xét trong main.py: (Đảm bảo bạn thêm câu lệnh này trước khi bắt đầu ứng dụng Flask tại if __name__ == "__main__":)
.....
@app.route('/',methods=['GET'])
def index():
return render_template('index.html')
"""
PROMPT:
Create a Flask endpoint that accepts POST requests at the '/ask' route.
The request should contain a JSON payload with a 'question' field. Extract the question from the JSON payload.
Call a function named ask_llm (located in a file named legal.py) with the extracted question as an argument.
Return the result of the ask_llm function as the response with a 200 status code.
If any error occurs during the process, return a 500 status code with the error message.
"""
# Add this block to start the Flask app when running locally
if __name__ == "__main__":
.....
Chỉ chấp nhận nếu mã được tạo là mã tốt và hầu hết là chính xác. Nếu bạn chưa quen với Python, thì đây là một ví dụ minh hoạ cách hoạt động.Hãy sao chép và dán ví dụ này vào main.py trong mã đã có.
👉 Đảm bảo bạn dán nội dung sau TRƯỚC khi bắt đầu ứng dụng web (if name == "main":)
@app.route('/ask', methods=['POST'])
def ask_question():
data = request.get_json()
question = data.get('question')
try:
# call the ask_llm in legal.py
answer_markdown = legal.ask_llm(question)
print(f"answer_markdown: {answer_markdown}")
# Return the Markdown as the response
return answer_markdown, 200
except Exception as e:
return f"Error: {str(e)}", 500 # Handle errors appropriately
Bằng cách làm theo các bước này, bạn có thể bật thành công Gemini Code Assist, thiết lập dự án và sử dụng công cụ này để tạo hàm ask trong tệp main.py.
5. Kiểm thử cục bộ trong Cloud Editor
👉 Trong thiết bị đầu cuối của trình chỉnh sửa,hãy cài đặt các thư viện phụ thuộc và khởi động Giao diện người dùng web cục bộ.
cd ~/legal-eagle/webapp
python -m venv env
source env/bin/activate
export PROJECT_ID=$(gcloud config get project)
pip install -r requirements.txt
python main.py
Tìm thông báo khởi động trong đầu ra của cửa sổ dòng lệnh Cloud Shell. Flask thường in các thông báo cho biết rằng ứng dụng đang chạy và chạy trên cổng nào.
- Chạy trên http://127.0.0.1:8080
Ứng dụng cần tiếp tục chạy để xử lý các yêu cầu.
👉 Trong trình đơn "Xem trước trên web", hãy chọn Xem trước trên cổng 8080. Cloud Shell sẽ mở một thẻ trình duyệt hoặc cửa sổ mới có bản xem trước trên web của ứng dụng. 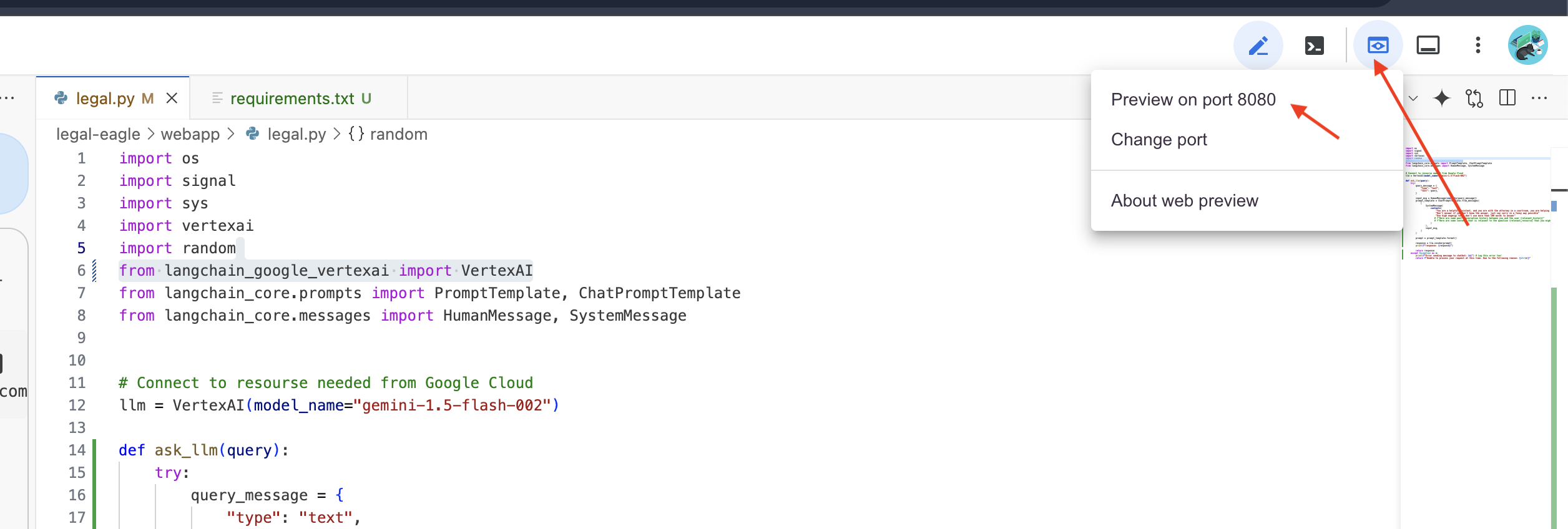
👉 Trong giao diện ứng dụng, hãy nhập một vài câu hỏi liên quan cụ thể đến thông tin tham khảo về vụ kiện pháp lý và xem LLM phản hồi như thế nào. Ví dụ: bạn có thể thử:
- Michael Brown bị kết án bao nhiêu năm tù?
- Hành động của Jane Smith đã tạo ra bao nhiêu tiền từ các khoản phí trái phép?
- Lời khai của những người hàng xóm đóng vai trò gì trong cuộc điều tra vụ án của Emily White?
👉 KHÔNG BẮT BUỘC: BẢN TIẾNG TÂY BAN NHA
- ¿A cuántos años de prisión fue sentenciado Michael Brown?
- ¿Cuánto dinero en cargos no autorizados se generó como resultado de las acciones de Jane Smith?
- ¿Qué papel jugaron los testimonios de los vecinos en la investigación del caso de Emily White?
Nếu xem xét kỹ các câu trả lời, bạn có thể nhận thấy rằng mô hình có thể đưa ra thông tin sai lệch, mơ hồ hoặc chung chung, đồng thời đôi khi hiểu sai câu hỏi của bạn, đặc biệt là vì mô hình này chưa có quyền truy cập vào các tài liệu pháp lý cụ thể.
👉 Tiếp tục và dừng tập lệnh bằng cách nhấn tổ hợp phím Ctrl+C.
👉 Thoát khỏi môi trường ảo, trong dòng lệnh, hãy chạy:
deactivate
6. Thiết lập Vector Store
Đã đến lúc chấm dứt những "cách diễn giải sáng tạo" này của LLM về luật.Đó là lúc tính năng Tạo sinh tăng cường truy xuất (RAG) phát huy tác dụng! Bạn có thể hình dung việc này giống như việc cấp cho LLM của chúng tôi quyền truy cập vào một thư viện pháp lý siêu mạnh ngay trước khi LLM trả lời câu hỏi của bạn. Thay vì chỉ dựa vào kiến thức chung (có thể không rõ ràng hoặc lỗi thời tuỳ thuộc vào mô hình), RAG trước tiên sẽ tìm nạp thông tin liên quan từ một nguồn đáng tin cậy (trong trường hợp của chúng tôi là các tài liệu pháp lý), sau đó sử dụng ngữ cảnh đó để tạo ra câu trả lời chính xác và có nhiều thông tin hơn. Giống như LLM làm bài tập về nhà trước khi bước vào phòng xử án!
Để xây dựng hệ thống RAG, chúng ta cần một nơi để lưu trữ tất cả các tài liệu pháp lý đó và điều quan trọng là phải giúp người dùng tìm kiếm được theo ý nghĩa. Đó là lúc Firestore xuất hiện! Firestore là cơ sở dữ liệu dạng tài liệu NoSQL linh hoạt và có thể mở rộng của Google Cloud.
Chúng ta sẽ sử dụng Firestore làm kho lưu trữ vectơ. Chúng ta sẽ lưu trữ các đoạn tài liệu pháp lý trong Firestore và đối với mỗi đoạn, chúng ta cũng sẽ lưu trữ thông tin nhúng của đoạn đó – tức là biểu diễn bằng số về ý nghĩa của đoạn.
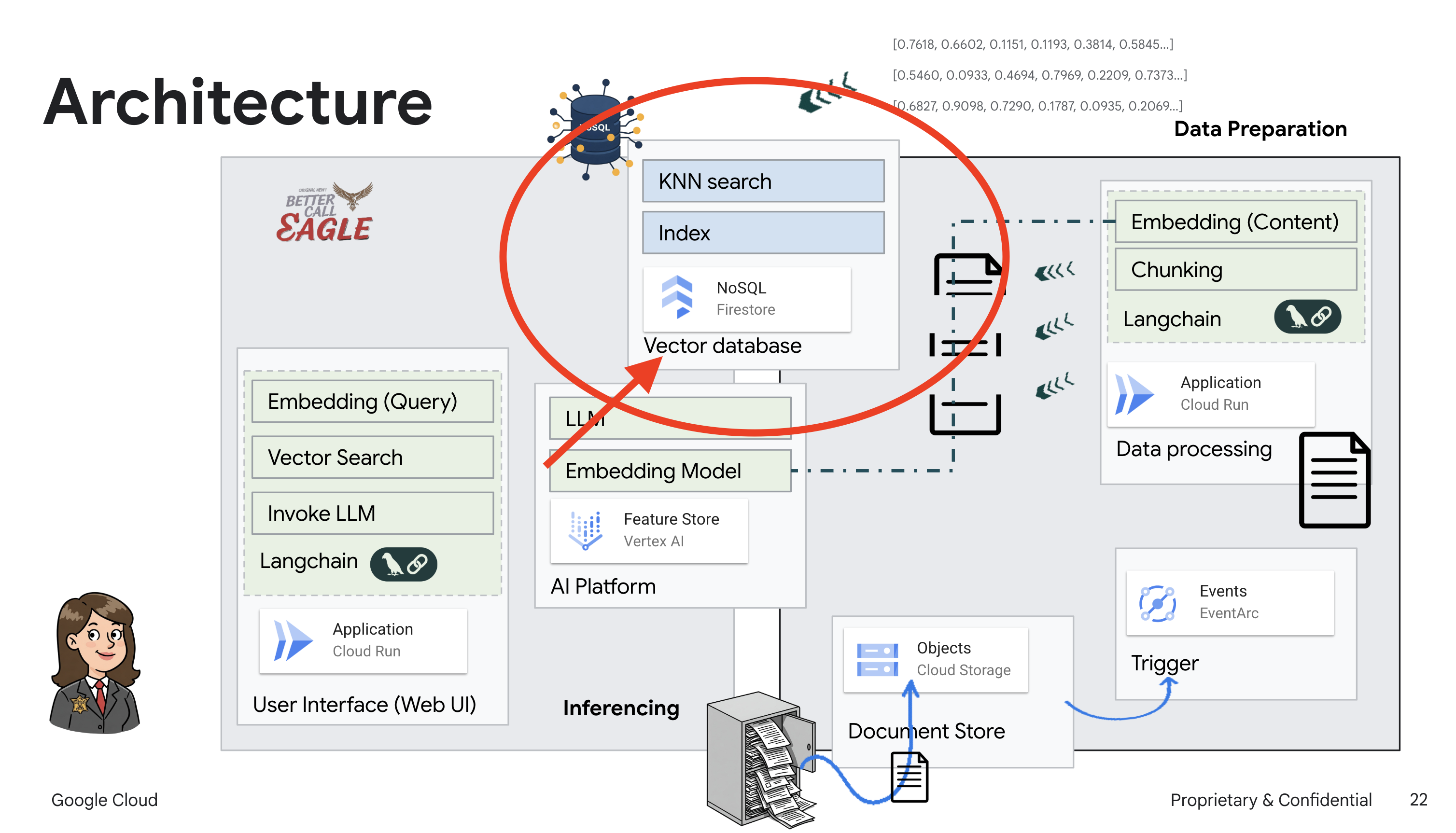
Sau đó, khi bạn đặt câu hỏi cho Legal Eagle, chúng tôi sẽ sử dụng tính năng tìm kiếm vectơ của Firestore để tìm những đoạn văn bản pháp lý phù hợp nhất với câu hỏi của bạn. Bối cảnh được truy xuất này là những gì RAG sử dụng để cung cấp cho bạn câu trả lời dựa trên thông tin pháp lý thực tế, chứ không chỉ là trí tưởng tượng của LLM!
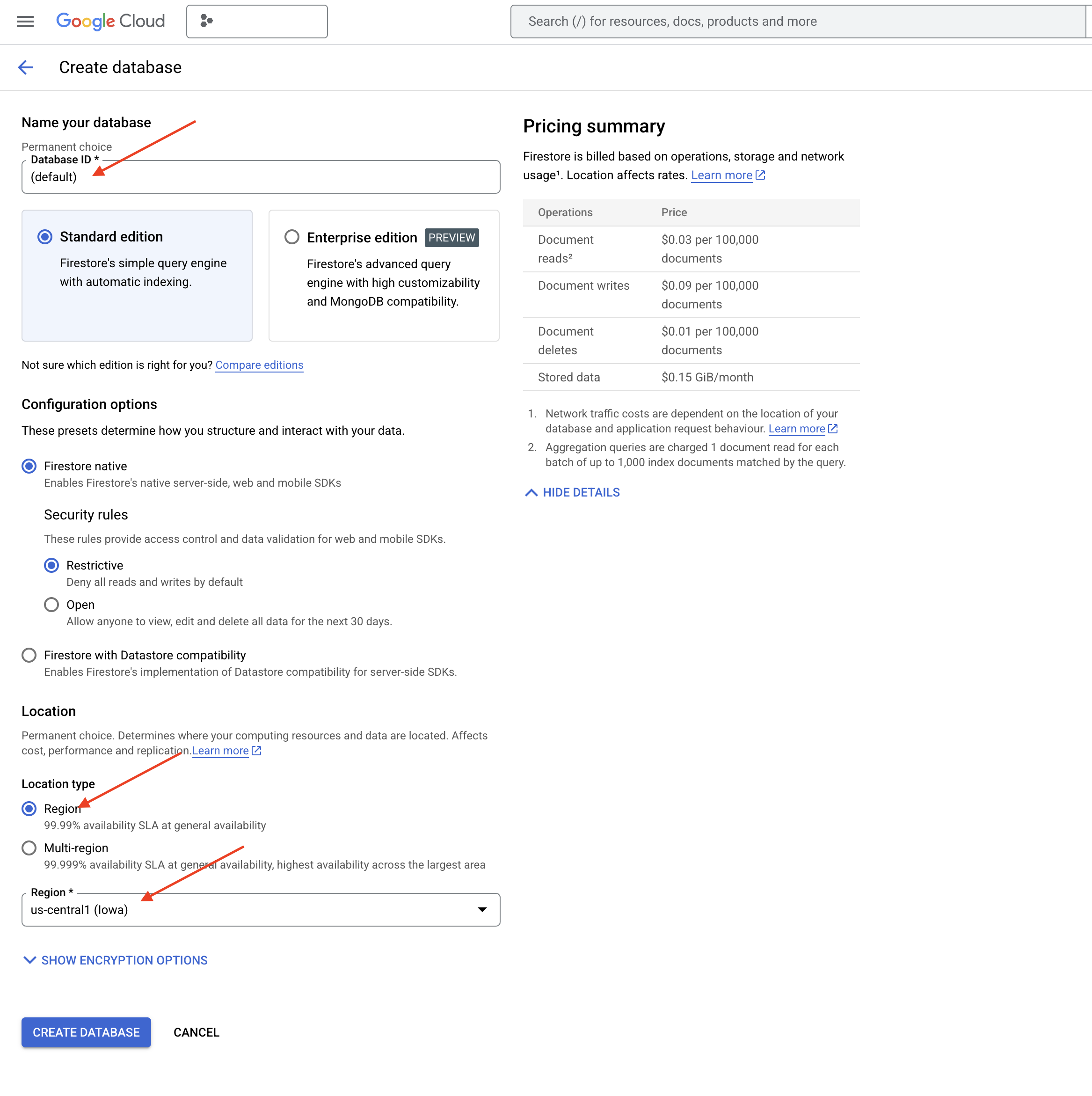
👉 Trong một thẻ/cửa sổ mới, hãy chuyển đến Firestore trong bảng điều khiển Cloud.
👉 Nhấp vào Tạo cơ sở dữ liệu
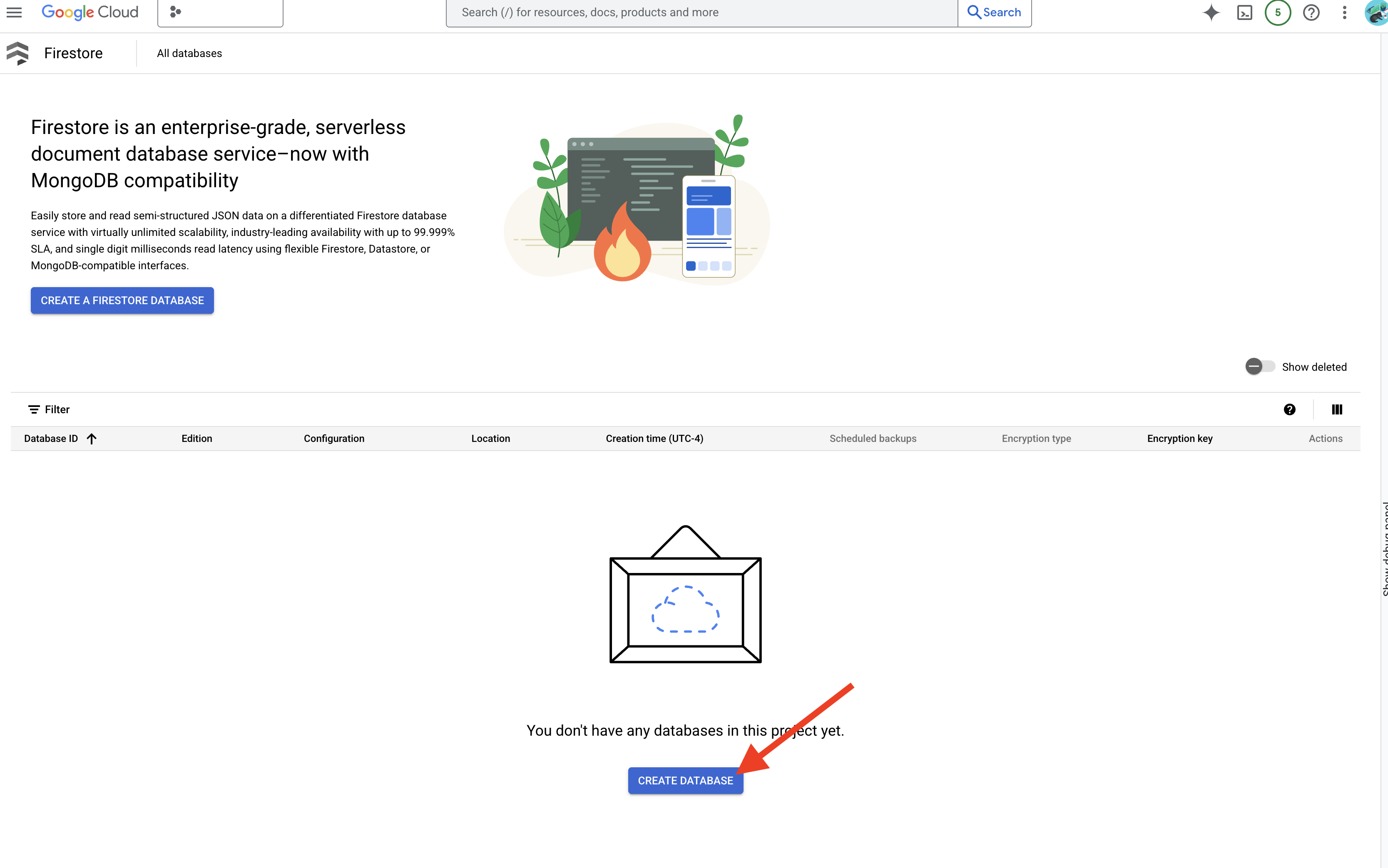
👉 Chọn Native mode và tên cơ sở dữ liệu là (default).
👉 Chọn một region: us-central1 , rồi nhấp vào Tạo cơ sở dữ liệu. Firestore sẽ cung cấp cơ sở dữ liệu của bạn. Quá trình này có thể mất vài phút.
👉 Quay lại thiết bị đầu cuối của Cloud IDE – tạo Chỉ mục vectơ trên trường embedding_vector để bật tính năng tìm kiếm vectơ trong bộ sưu tập legal_documents.
export PROJECT_ID=$(gcloud config get project)
gcloud firestore indexes composite create \
--collection-group=legal_documents \
--query-scope=COLLECTION \
--field-config field-path=embedding,vector-config='{"dimension":"768", "flat": "{}"}' \
--project=${PROJECT_ID}
Firestore sẽ bắt đầu tạo chỉ mục vectơ. Quá trình tạo chỉ mục có thể mất một chút thời gian, đặc biệt là đối với các tập dữ liệu lớn hơn. Bạn sẽ thấy chỉ mục ở trạng thái "Đang tạo" và chỉ mục sẽ chuyển sang trạng thái "Sẵn sàng" khi được tạo. 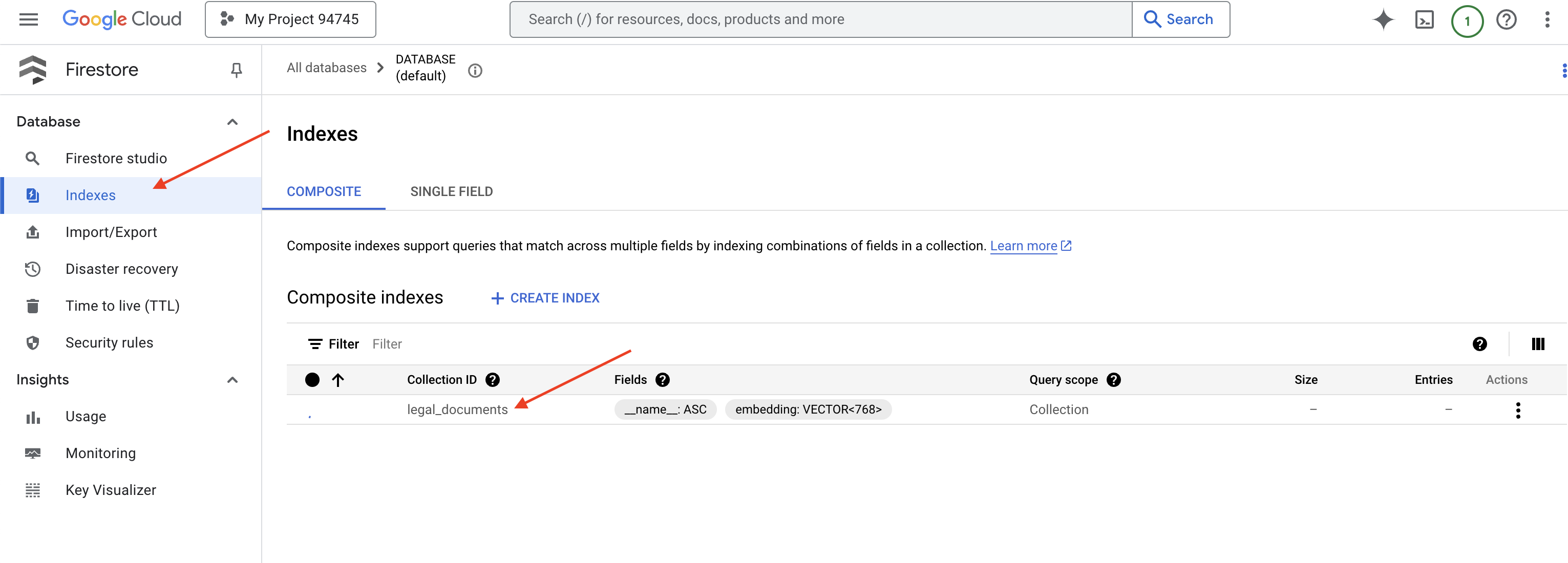
7. Tải dữ liệu vào Kho lưu trữ vectơ
Giờ đây, khi đã hiểu về RAG và kho lưu trữ vectơ, đã đến lúc chúng ta xây dựng công cụ điền sẵn thư viện pháp lý! Vậy làm cách nào để các văn bản pháp lý có thể "tìm kiếm theo ý nghĩa"? Phép màu nằm ở các vectơ nhúng! Hãy coi việc nhúng là chuyển đổi các từ, câu hoặc thậm chí toàn bộ tài liệu thành vectơ số – danh sách các số nắm bắt ý nghĩa ngữ nghĩa của chúng. Các khái niệm tương tự sẽ có các vectơ "gần" nhau trong không gian vectơ. Chúng tôi sử dụng các mô hình mạnh mẽ (chẳng hạn như các mô hình từ Vertex AI) để thực hiện quá trình chuyển đổi này.
Để tự động hoá quá trình tải tài liệu, chúng ta sẽ sử dụng các hàm Cloud Run và Eventarc. Cloud Run Functions là một vùng chứa không máy chủ, có dung lượng nhẹ và chỉ chạy mã của bạn khi cần. Chúng ta sẽ đóng gói tập lệnh Python xử lý tài liệu vào một vùng chứa và triển khai tập lệnh đó dưới dạng một Hàm Cloud Run.
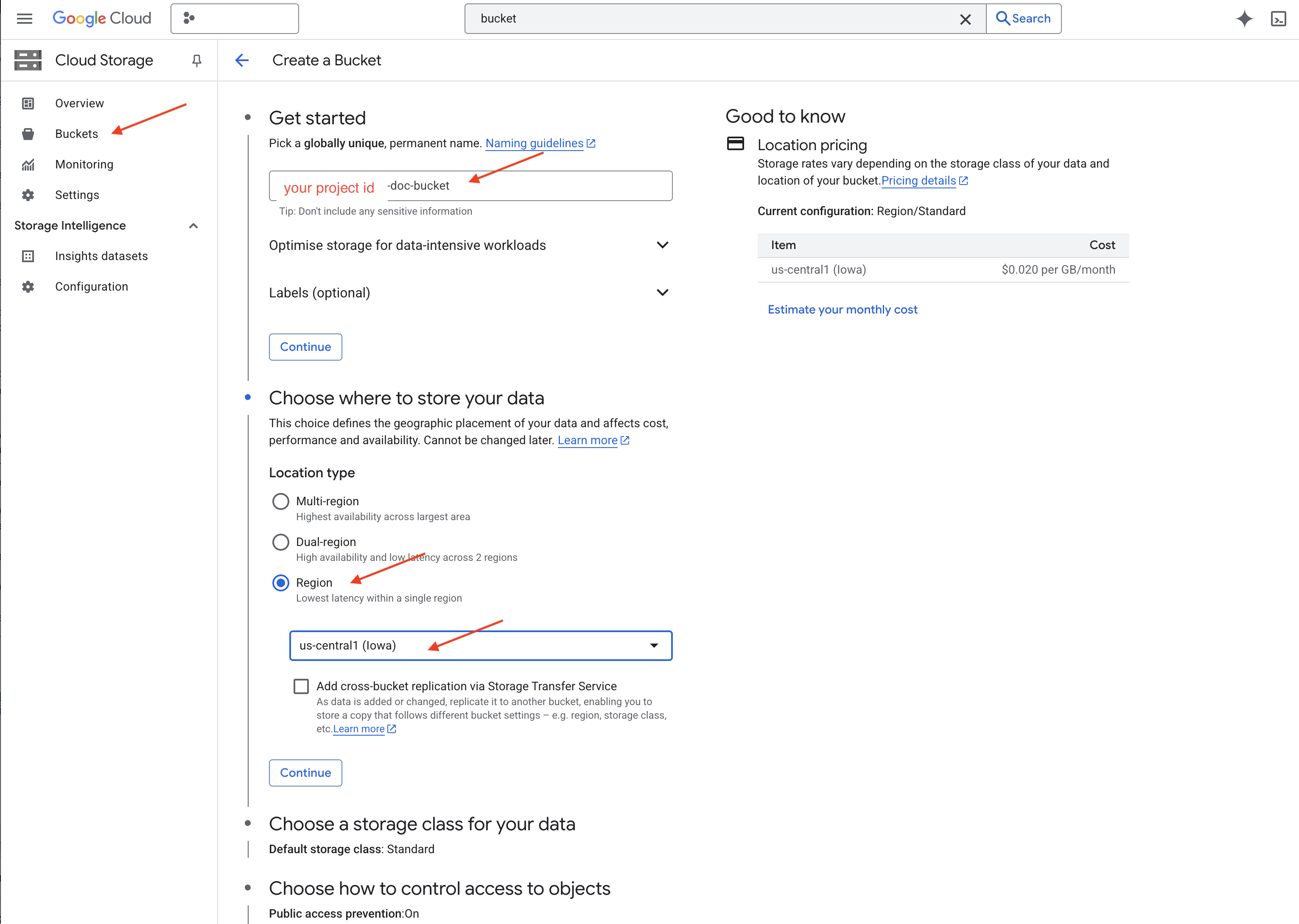
👉 Trong một thẻ/cửa sổ mới, hãy chuyển đến Cloud Storage.
👉 Nhấp vào "Nhóm" trong trình đơn bên trái.
👉 Nhấp vào nút "+ TẠO" ở trên cùng.
👉 Định cấu hình vùng chứa (Chế độ cài đặt quan trọng):
- tên bộ chứa: "yourprojectID"-doc-bucket (BẠN PHẢI có hậu tố -doc-bucket ở cuối)
- khu vực: Chọn khu vực
us-central1. - Lớp lưu trữ: "Tiêu chuẩn". Lớp chuẩn phù hợp với dữ liệu thường xuyên được truy cập.
- Kiểm soát quyền truy cập: Giữ nguyên chế độ "Kiểm soát quyền truy cập đồng nhất" mặc định. Điều này giúp kiểm soát quyền truy cập nhất quán ở cấp bộ chứa.
- Lựa chọn nâng cao: Đối với hướng dẫn này, các chế độ cài đặt mặc định thường là đủ.
👉 Nhấp vào nút TẠO để tạo vùng chứa.
👉 Bạn có thể thấy một cửa sổ bật lên về biện pháp phòng tránh truy cập công khai. Đánh dấu vào hộp rồi nhấp vào "Xác nhận".
Bây giờ, bạn sẽ thấy nhóm mới tạo trong danh sách Nhóm. Hãy nhớ tên nhóm của bạn, bạn sẽ cần tên này sau.
8. Thiết lập một hàm Cloud Run
👉 Trong Cloud Shell Code Editor, hãy chuyển đến thư mục đang hoạt động legal-eagle: Sử dụng lệnh cd trong cửa sổ dòng lệnh của Cloud Editor để tạo thư mục.
cd ~/legal-eagle
mkdir loader
cd loader
👉 Tạo các tệp main.py, requirements.txt và Dockerfile. Trong cửa sổ dòng lệnh Cloud Shell, hãy dùng lệnh touch để tạo các tệp:
touch main.py requirements.txt Dockerfile
Bạn sẽ thấy thư mục mới tạo có tên là *loader và 3 tệp.
👉 Chỉnh sửa main.py trong thư mục loader. Trong trình khám phá tệp ở bên trái, hãy chuyển đến thư mục nơi bạn tạo các tệp rồi nhấp đúp vào main.py để mở thư mục đó trong trình chỉnh sửa.
Dán mã Python sau vào main.py:
Ứng dụng này xử lý các tệp mới được tải lên bộ chứa GCS, chia văn bản thành các đoạn, tạo các mục nhúng cho từng đoạn và lưu trữ các đoạn cũng như mục nhúng của chúng trong Firestore.
import os
import json
from google.cloud import storage
import functions_framework
from langchain_google_vertexai import VertexAI, VertexAIEmbeddings
from langchain_google_firestore import FirestoreVectorStore
from langchain.text_splitter import RecursiveCharacterTextSplitter
import vertexai
PROJECT_ID = os.environ.get("GOOGLE_CLOUD_PROJECT") # Get project ID from env
embedding_model = VertexAIEmbeddings(
model_name="text-embedding-004" ,
project=PROJECT_ID,)
COLLECTION_NAME = "legal_documents"
# Create a vector store
vector_store = FirestoreVectorStore(
collection="legal_documents",
embedding_service=embedding_model,
content_field="original_text",
embedding_field="embedding",
)
@functions_framework.cloud_event
def process_file(cloud_event):
print(f"CloudEvent received: {cloud_event.data}") # Print the parsed event data
"""Triggered by a Cloud Storage event.
Args:
cloud_event (functions_framework.CloudEvent): The CloudEvent
containing the Cloud Storage event data.
"""
try:
event_data = cloud_event.data
bucket_name = event_data['bucket']
file_name = event_data['name']
except (json.JSONDecodeError, AttributeError, KeyError) as e: # Catch JSON errors
print(f"Error decoding CloudEvent data: {e} - Data: {cloud_event.data}")
return "Error processing event", 500 # Return an error response
print(f"New file detected in bucket: {bucket_name}, file: {file_name}")
storage_client = storage.Client()
bucket = storage_client.bucket(bucket_name)
blob = bucket.blob(file_name)
try:
# Download the file content as string (assuming UTF-8 encoded text file)
file_content_string = blob.download_as_string().decode("utf-8")
print(f"File content downloaded. Processing...")
# Split text into chunks using RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=100,
length_function=len,
)
text_chunks = text_splitter.split_text(file_content_string)
print(f"Text split into {len(text_chunks)} chunks.")
# Add the docs to the vector store
vector_store.add_texts(text_chunks)
print(f"File processing and Firestore upsert complete for file: {file_name}")
return "File processed successfully", 200 # Return success response
except Exception as e:
print(f"Error processing file {file_name}: {e}")
Chỉnh sửa requirements.txt.Dán các dòng sau vào tệp:
Flask==2.3.3
requests==2.31.0
google-generativeai>=0.2.0
langchain
langchain_google_vertexai
langchain-community
langchain-google-firestore
google-cloud-storage
functions-framework
9. Kiểm thử và tạo hàm Cloud Run
👉 Chúng ta sẽ chạy lệnh này trong một môi trường ảo và cài đặt các thư viện Python cần thiết cho hàm Cloud Run.
cd ~/legal-eagle/loader
python -m venv env
source env/bin/activate
pip install -r requirements.txt
👉 Khởi động trình mô phỏng cục bộ cho hàm Cloud Run
functions-framework --target process_file --signature-type=cloudevent --source main.py
👉 Giữ cho thiết bị đầu cuối cuối cùng đang chạy, mở một thiết bị đầu cuối mới và chạy lệnh để tải một tệp lên bộ chứa.
export DOC_BUCKET_NAME=$(gcloud storage buckets list --format="value(name)" | grep doc-bucket)
gsutil cp ~/legal-eagle/court_cases/case-01.txt gs://$DOC_BUCKET_NAME/

👉 Trong khi trình mô phỏng đang chạy, bạn có thể gửi CloudEvents thử nghiệm đến trình mô phỏng. Bạn sẽ cần một thiết bị đầu cuối riêng trong IDE cho việc này.
curl -X POST -H "Content-Type: application/json" \
-d "{
\"specversion\": \"1.0\",
\"type\": \"google.cloud.storage.object.v1.finalized\",
\"source\": \"//storage.googleapis.com/$DOC_BUCKET_NAME\",
\"subject\": \"objects/case-01.txt\",
\"id\": \"my-event-id\",
\"time\": \"2024-01-01T12:00:00Z\",
\"data\": {
\"bucket\": \"$DOC_BUCKET_NAME\",
\"name\": \"case-01.txt\"
}
}" http://localhost:8080/
Thao tác này sẽ trả về OK.
👉 Bạn sẽ xác minh Dữ liệu trong Firestore, chuyển đến Bảng điều khiển Google Cloud rồi chuyển đến "Cơ sở dữ liệu", sau đó chọn "Firestore", rồi chọn thẻ "Dữ liệu" và sau đó chọn tập hợp legal_documents. Bạn sẽ thấy các tài liệu mới đã được tạo trong bộ sưu tập của mình, mỗi tài liệu đại diện cho một đoạn văn bản trong tệp đã tải lên. 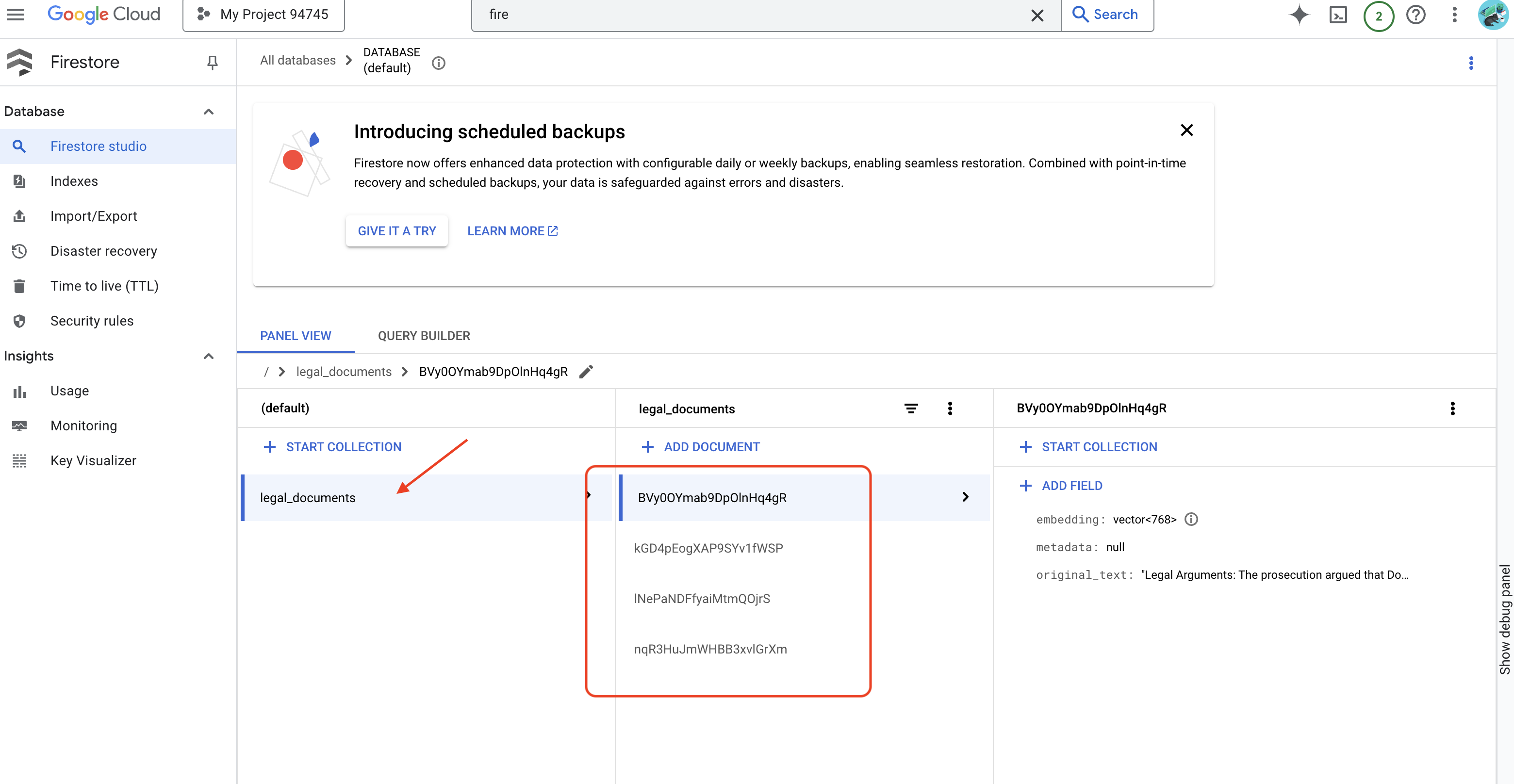
👉 Trong cửa sổ dòng lệnh đang chạy trình mô phỏng, hãy nhập Ctrl+C để thoát. Đóng cửa sổ dòng lệnh thứ hai.
👉 Chạy lệnh deactivate để thoát khỏi môi trường ảo.
deactivate
10. Tạo hình ảnh vùng chứa và đẩy vào kho lưu trữ Artifacts
👉 Đã đến lúc triển khai việc này lên đám mây. Trong trình khám phá tệp, hãy nhấp đúp vào Dockerfile. Yêu cầu Gemini tạo tệp Docker cho bạn, mở Gemini Code Assist và dùng câu lệnh sau để tạo tệp.
In the loader folder,
Generate a Dockerfile for a Python 3.12 Cloud Run service that uses functions-framework. It needs to:
1. Use a Python 3.12 slim base image.
2. Set the working directory to /app.
3. Copy requirements.txt and install Python dependencies.
4. Copy main.py.
5. Set the command to run functions-framework, targeting the 'process_file' function on port 8080
Theo phương pháp hay nhất, bạn nên nhấp vào Diff with Open File (So sánh với tệp đang mở) (hai mũi tên ngược chiều nhau và chấp nhận các thay đổi). 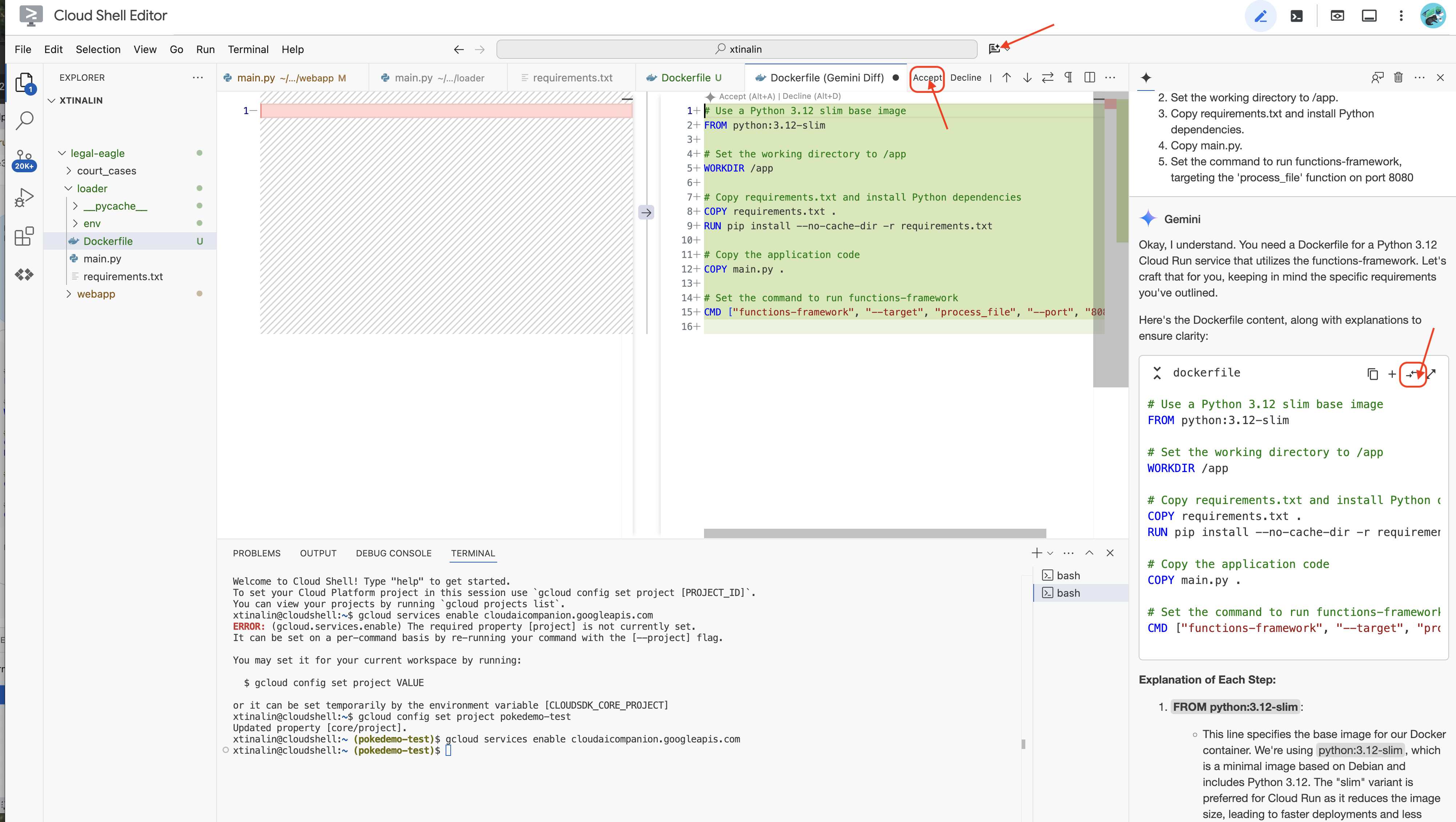
👉 Nếu bạn mới làm quen với Vùng chứa, thì đây là một ví dụ minh hoạ:
# Use a Python 3.12 slim base image
FROM python:3.12-slim
# Set the working directory to /app
WORKDIR /app
# Copy requirements.txt and install Python dependencies
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
# Copy main.py
COPY main.py .
# Set the command to run functions-framework
CMD ["functions-framework", "--target", "process_file", "--port", "8080"]
Trong Terminal, hãy tạo một kho lưu trữ cấu phần phần mềm để lưu trữ hình ảnh docker mà chúng ta sẽ tạo.
gcloud artifacts repositories create my-repository \
--repository-format=docker \
--location=us-central1 \
--description="My repository"
Bạn sẽ thấy thông báo Created repository [my-repository]. (Đã tạo kho lưu trữ [my-repository]).
👉 Chạy lệnh sau để tạo hình ảnh Docker.
cd ~/legal-eagle/loader
export PROJECT_ID=$(gcloud config get project)
docker build -t gcr.io/${PROJECT_ID}/legal-eagle-loader .
👉 Giờ đây, bạn sẽ đẩy nội dung đó vào sổ đăng ký
export PROJECT_ID=$(gcloud config get project)
docker tag gcr.io/${PROJECT_ID}/legal-eagle-loader us-central1-docker.pkg.dev/${PROJECT_ID}/my-repository/legal-eagle-loader
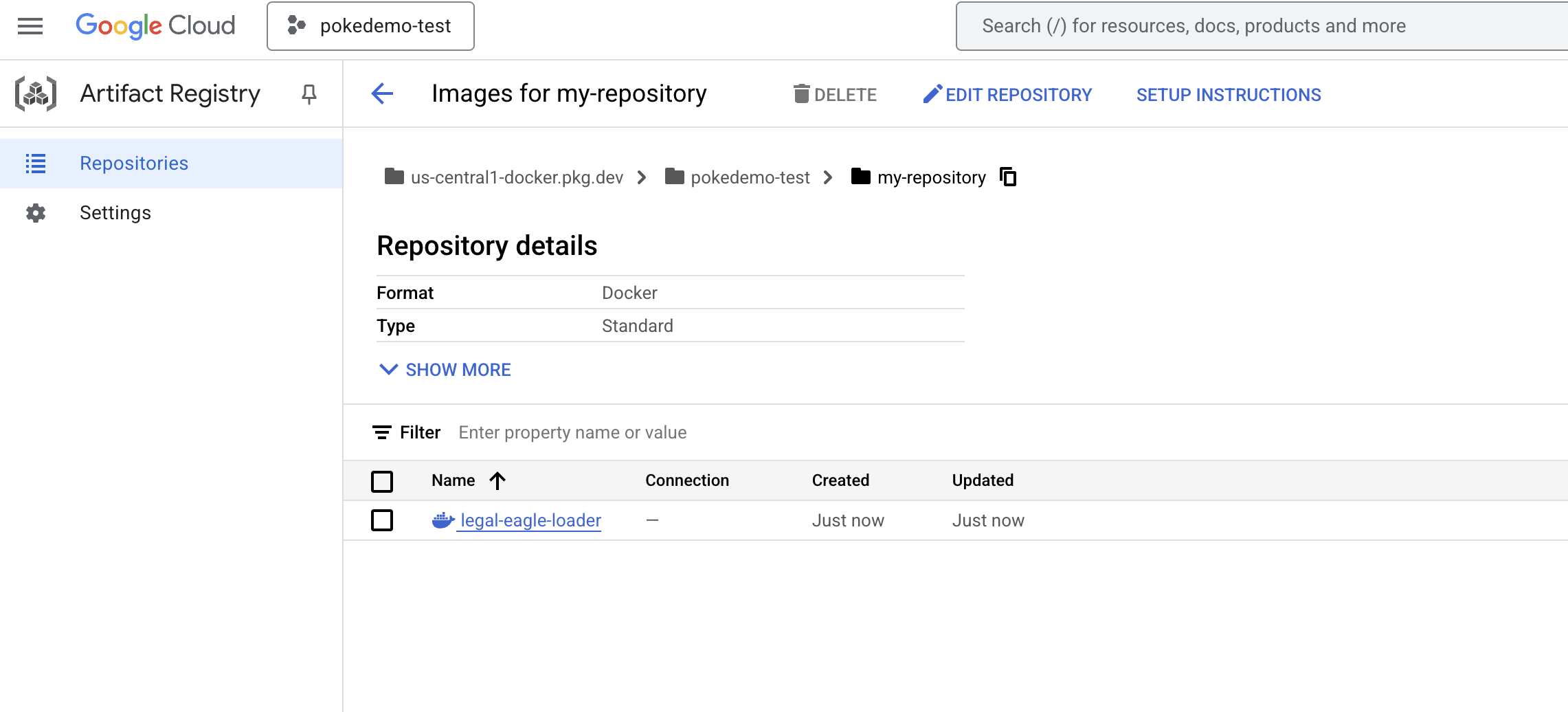
docker push us-central1-docker.pkg.dev/${PROJECT_ID}/my-repository/legal-eagle-loader
Giờ đây, hình ảnh Docker có trong my-repository Artifacts Repository (Kho lưu trữ hiện vật).
11. Tạo hàm Cloud Run và thiết lập trình kích hoạt Eventarc
Trước khi đi sâu vào các thông số kỹ thuật của việc triển khai trình tải tài liệu pháp lý, hãy cùng tìm hiểu sơ bộ về các thành phần liên quan: Cloud Run là một nền tảng phi máy chủ được quản lý toàn diện, cho phép bạn triển khai các ứng dụng vùng chứa riêng một cách nhanh chóng và dễ dàng. Nền tảng này tách biệt việc quản lý cơ sở hạ tầng, giúp bạn tập trung vào việc viết và triển khai mã.
Chúng ta sẽ triển khai trình tải tài liệu dưới dạng một dịch vụ Cloud Run. Bây giờ, hãy tiếp tục thiết lập hàm Cloud Run:
👉 Trong Google Cloud Console, hãy chuyển đến Cloud Run.
👉 Chuyển đến Deploy Container (Triển khai vùng chứa) rồi nhấp vào SERVICE (DỊCH VỤ) trong trình đơn thả xuống.
👉 Định cấu hình dịch vụ Cloud Run:
- Hình ảnh vùng chứa: Nhấp vào "Chọn" trong trường URL. Tìm URL hình ảnh mà bạn đã chuyển đến Artifact Registry (ví dụ: us-central1-docker.pkg.dev/your-project-id/my-repository/legal-eagle-loader/yourimage).
- Tên dịch vụ:
legal-eagle-loader - Khu vực: Chọn khu vực
us-central1. - Xác thực: Trong phạm vi hội thảo này, bạn có thể chọn "Cho phép lệnh gọi chưa xác thực". Đối với bản phát hành công khai, bạn nên hạn chế quyền truy cập.
- Vùng chứa, Mạng, Bảo mật : mặc định.
👉 Nhấp vào TẠO. Cloud Run sẽ triển khai dịch vụ của bạn. 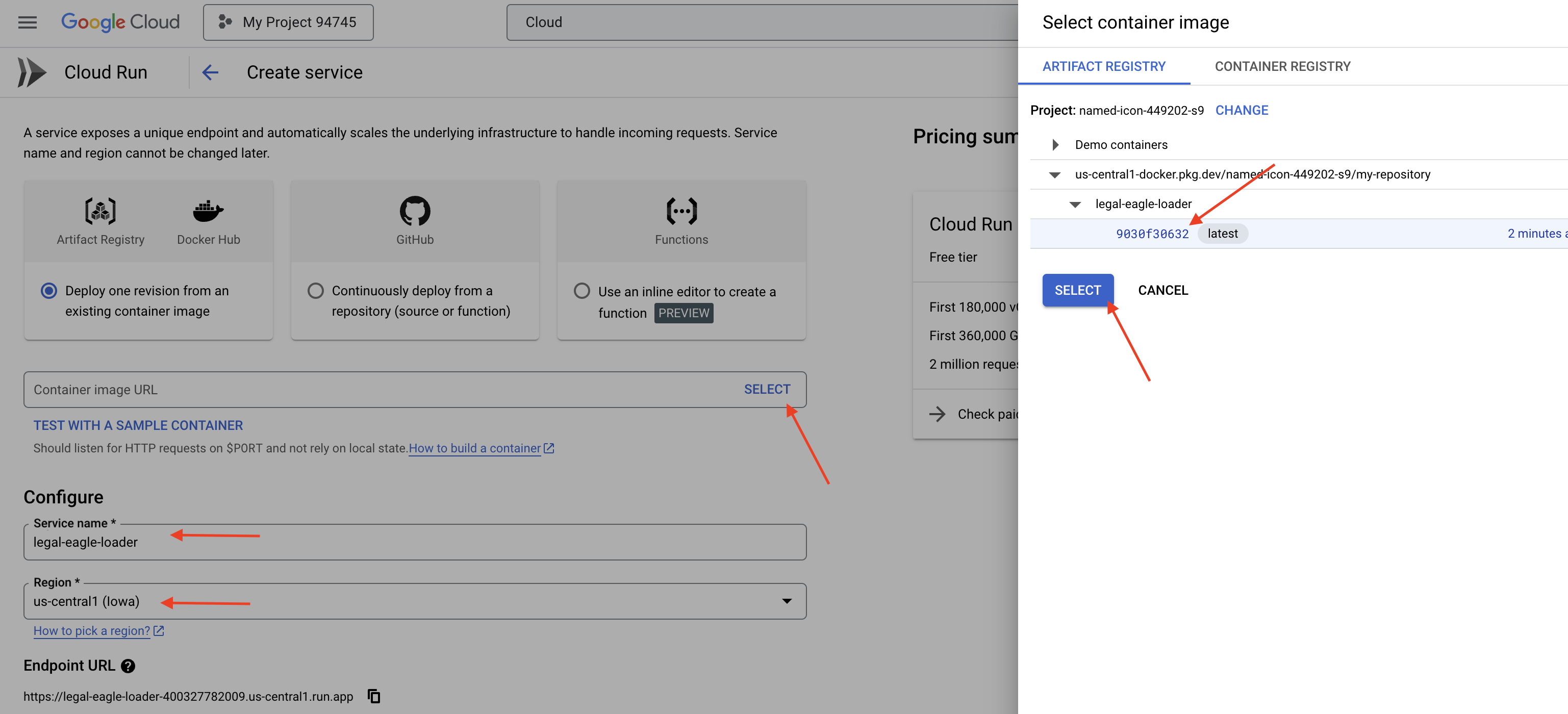
Để tự động kích hoạt dịch vụ này khi có tệp mới được thêm vào bộ chứa lưu trữ của chúng tôi, chúng ta sẽ sử dụng Eventarc. Eventarc cho phép bạn tạo cấu trúc hướng sự kiện bằng cách định tuyến các sự kiện từ nhiều nguồn đến các dịch vụ của bạn.
Bằng cách thiết lập Eventarc, dịch vụ Cloud Run của chúng tôi sẽ tự động tải các tài liệu mới được thêm vào Firestore ngay khi chúng được tải lên, cho phép cập nhật dữ liệu theo thời gian thực cho ứng dụng RAG.
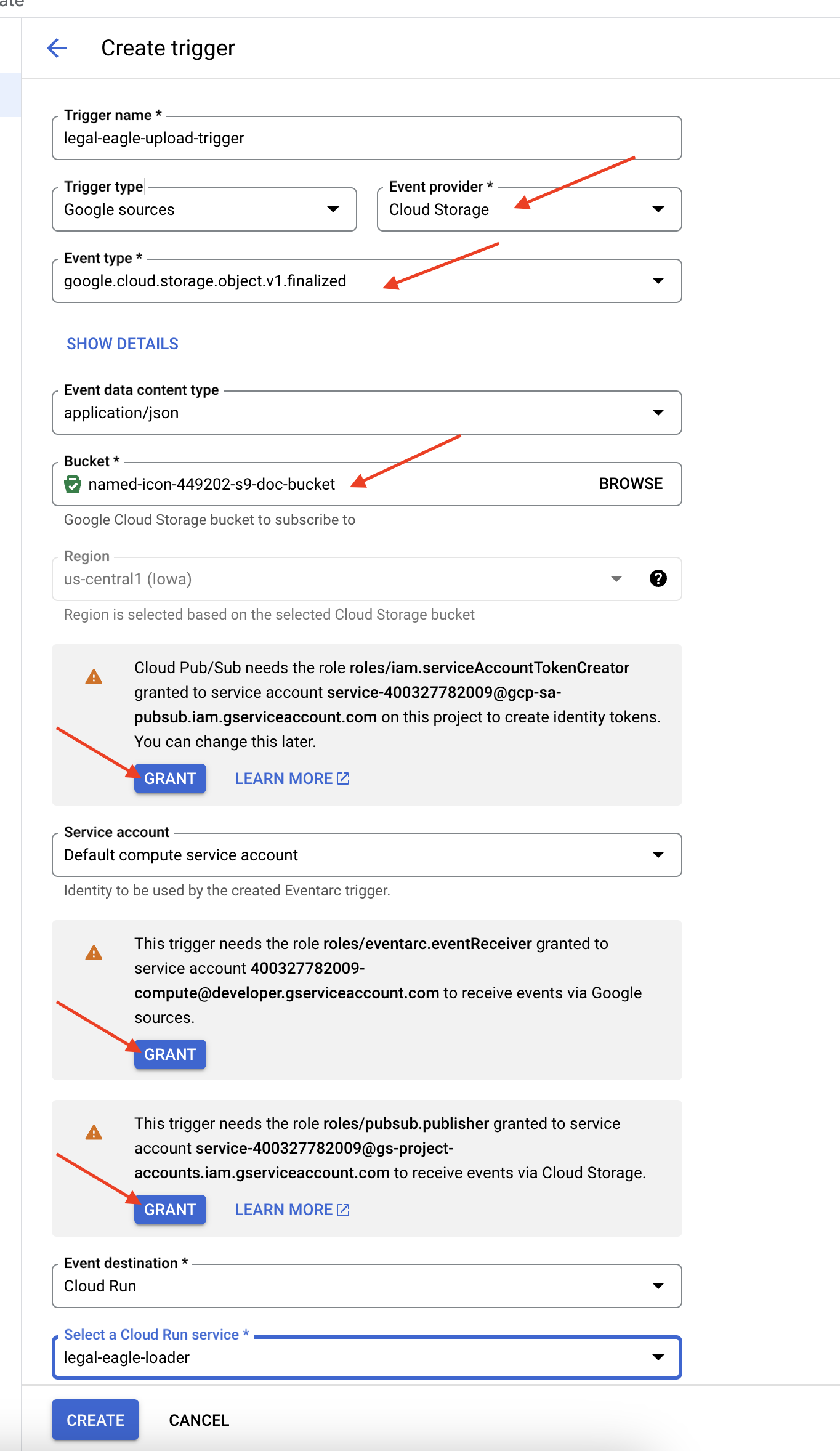
👉 Trong Google Cloud Console, hãy chuyển đến Triggers (Điều kiện kích hoạt) trong EventArc. Nhấp vào "+ TẠO ĐIỀU KIỆN KÍCH HOẠT". 👉 Định cấu hình điều kiện kích hoạt Eventarc:
- Tên điều kiện kích hoạt:
legal-eagle-upload-trigger. - TriggerType: Nguồn Google
- Nhà cung cấp sự kiện: Chọn Cloud Storage.
- Loại sự kiện: Chọn
google.cloud.storage.object.v1.finalized - Bộ chứa Cloud Storage: Chọn bộ chứa GCS trong trình đơn thả xuống.
- Loại đích đến: "Dịch vụ Cloud Run".
- Dịch vụ: Chọn
legal-eagle-loader. - Vùng:
us-central1 - Đường dẫn: Hiện tại, hãy để trống trường này .
- Cấp tất cả các quyền mà ứng dụng nhắc trên trang
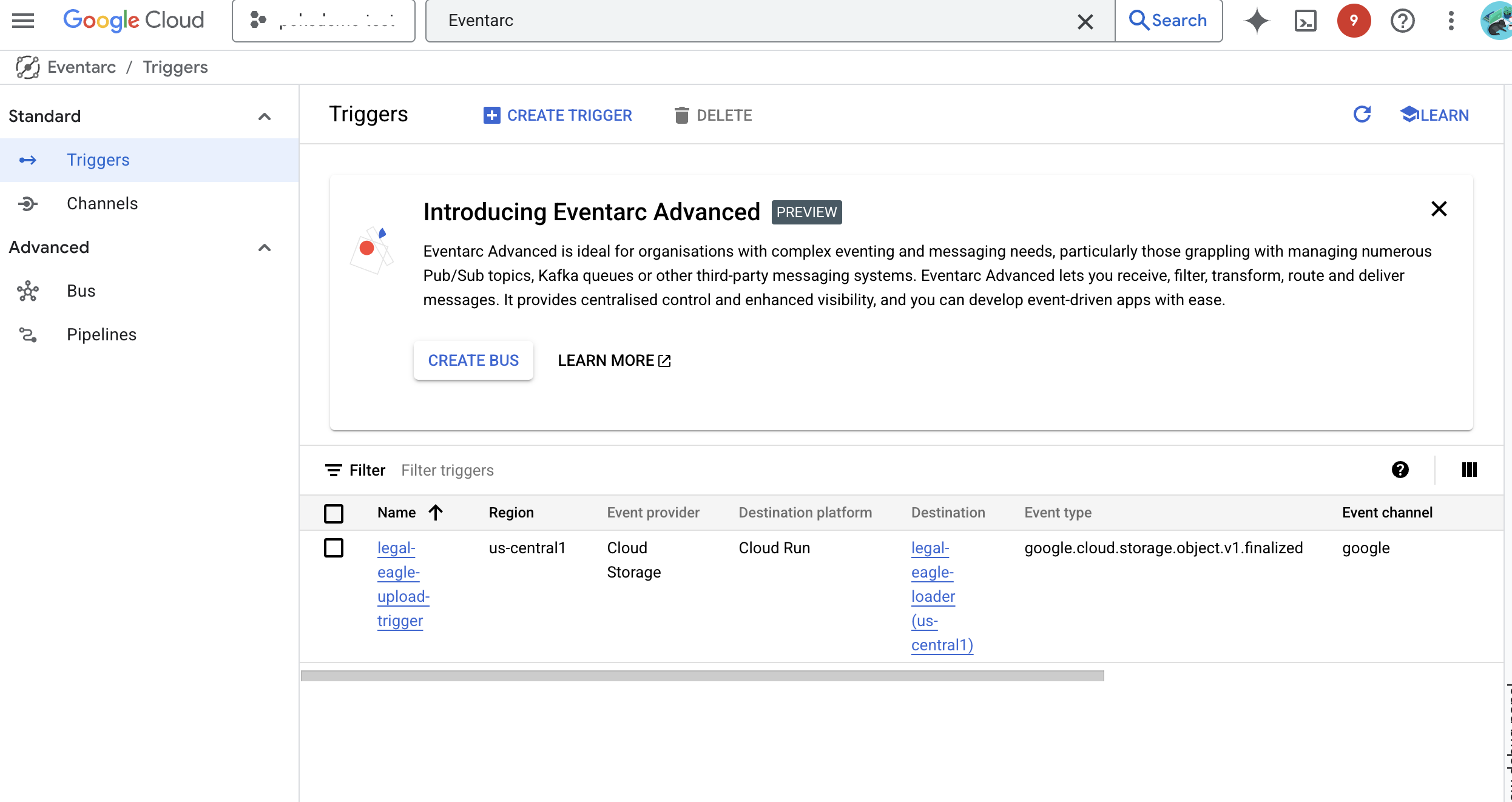
👉 Nhấp vào TẠO. Eventarc sẽ thiết lập điều kiện kích hoạt.
Dịch vụ Cloud Run cần có quyền đọc tệp từ nhiều thành phần. Chúng ta cần cấp cho tài khoản dịch vụ của dịch vụ quyền cần thiết.
12. Tải giấy tờ pháp lý lên bộ chứa GCS
👉 Tải tệp hồ sơ vụ kiện lên bộ chứa GCS. Hãy nhớ thay thế tên nhóm.
export DOC_BUCKET_NAME=$(gcloud storage buckets list --format="value(name)" | grep doc-bucket)
gsutil cp ~/legal-eagle/court_cases/case-02.txt gs://$DOC_BUCKET_NAME/
gsutil cp ~/legal-eagle/court_cases/case-03.txt gs://$DOC_BUCKET_NAME/
gsutil cp ~/legal-eagle/court_cases/case-06.txt gs://$DOC_BUCKET_NAME/
Để theo dõi Nhật ký dịch vụ Cloud Run, hãy chuyển đến Cloud Run -> dịch vụ của bạn legal-eagle-loader -> "Nhật ký". Kiểm tra nhật ký để biết các thông báo xử lý thành công, bao gồm:
xxx
POST200130 B8.3 sAPIs-Google; (+https://developers.google.com/webmasters/APIs-Google.html) https://legal-eagle-loader-bmngrueyta-uc.a.run.app/?__GCP_CloudEventsMode=GCS_NOTIFICATION
xxx
POST200130 B520 msAPIs-Google; (+https://developers.google.com/webmasters/APIs-Google.html) https://legal-eagle-loader-bmngrueyta-uc.a.run.app/?__GCP_CloudEventsMode=GCS_NOTIFICATION
xxx
POST200130 B514 msAPIs-Google; (+https://developers.google.com/webmasters/APIs-Google.html) https://legal-eagle-loader-bmngrueyta-uc.a.run.app/?__GCP_CloudEventsMode=GCS_NOTIFICATION
Tuỳ thuộc vào tốc độ thiết lập tính năng ghi nhật ký, bạn cũng sẽ thấy nhiều nhật ký chi tiết hơn tại đây
"CloudEvent received:"
"New file detected in bucket:"
"File content downloaded. Processing..."
"Text split into ... chunks."
"File processing and Firestore upsert complete..."
Tìm mọi thông báo lỗi trong nhật ký và khắc phục sự cố nếu cần. 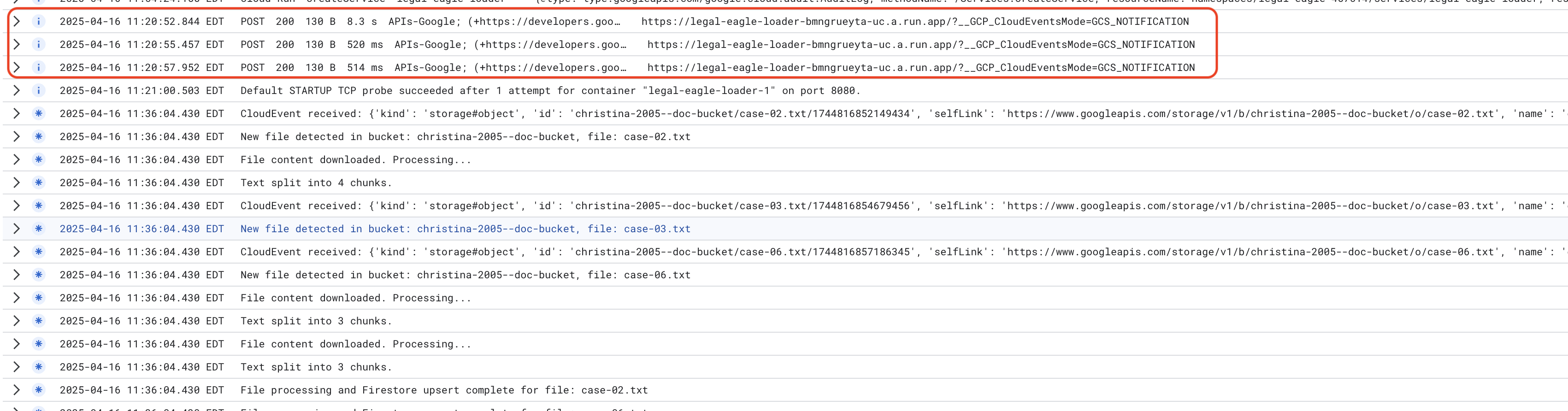
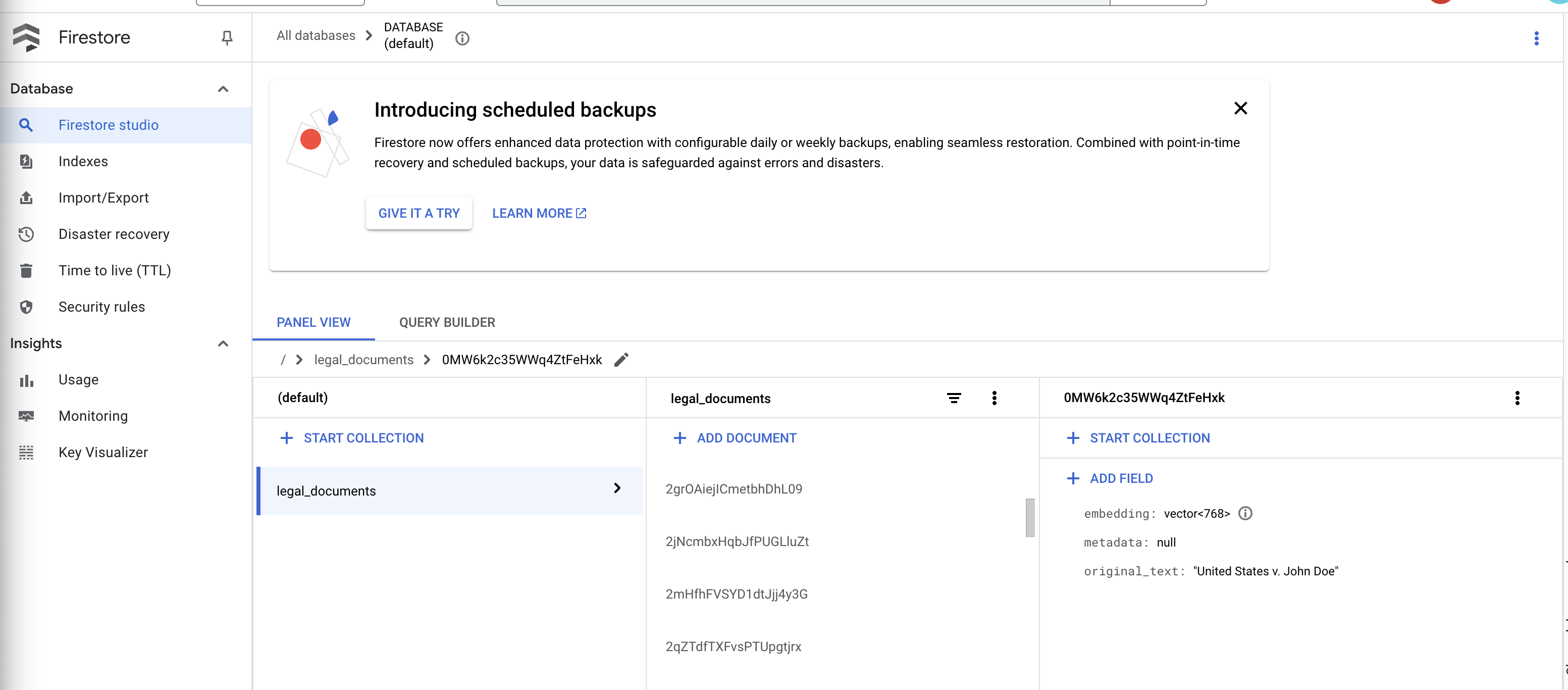
👉 Xác minh dữ liệu trong Firestore. Mở bộ sưu tập legal_documents.
👉 Bạn sẽ thấy các tài liệu mới được tạo trong bộ sưu tập của mình. Mỗi tài liệu sẽ đại diện cho một đoạn văn bản trong tệp bạn đã tải lên và sẽ chứa:
metadata: currently empty
original_text_chunk: The text chunk content.
embedding_: A list of floating-point numbers (the Vertex AI embedding).
13. Triển khai RAG
LangChain là một khung mạnh mẽ được thiết kế để đơn giản hoá quá trình phát triển các ứng dụng dựa trên mô hình ngôn ngữ lớn (LLM). Thay vì trực tiếp xử lý những điểm phức tạp của API LLM, thiết kế câu lệnh và xử lý dữ liệu, LangChain cung cấp một lớp trừu tượng cấp cao. LangChain cung cấp các thành phần và công cụ được tạo sẵn cho các tác vụ như kết nối với nhiều LLM (chẳng hạn như LLM của OpenAI, Google hoặc các LLM khác), xây dựng các chuỗi hoạt động phức tạp (ví dụ: truy xuất dữ liệu rồi tóm tắt) và quản lý bộ nhớ đàm thoại.
Cụ thể đối với RAG, các kho lưu trữ vectơ trong LangChain là yếu tố cần thiết để cho phép khía cạnh truy xuất của RAG. Đây là những cơ sở dữ liệu chuyên biệt được thiết kế để lưu trữ và truy vấn hiệu quả các vectơ nhúng, trong đó các đoạn văn bản tương tự về mặt ngữ nghĩa được ánh xạ đến các điểm gần nhau trong không gian vectơ. LangChain đảm nhận việc thiết lập cơ sở hạ tầng cấp thấp, cho phép nhà phát triển tập trung vào logic và chức năng cốt lõi của ứng dụng RAG. Điều này giúp giảm đáng kể thời gian và độ phức tạp của quá trình phát triển, cho phép bạn tạo mẫu và triển khai nhanh các ứng dụng dựa trên RAG trong khi tận dụng tính mạnh mẽ và khả năng mở rộng của cơ sở hạ tầng Google Cloud.
Sau khi tìm hiểu về LangChain, bạn sẽ cần cập nhật tệp legal.py trong thư mục webapp để triển khai RAG. Điều này sẽ cho phép LLM tìm kiếm các tài liệu có liên quan trong Firestore trước khi đưa ra câu trả lời.
👉 Nhập FirestoreVectorStore và các mô-đun bắt buộc khác từ langchain và vertexai. Thêm nội dung sau vào legal.py hiện tại
from langchain_google_vertexai import VertexAIEmbeddings
from langchain_google_firestore import FirestoreVectorStore
👉 Khởi động Vertex AI và mô hình nhúng.Bạn sẽ sử dụng text-embedding-004. Thêm mã sau ngay sau khi nhập các mô-đun.
PROJECT_ID = os.environ.get("GOOGLE_CLOUD_PROJECT") # Get project ID from env
embedding_model = VertexAIEmbeddings(
model_name="text-embedding-004" ,
project=PROJECT_ID,)
👉 Tạo một FirestoreVectorStore trỏ đến tập hợp legal_documents, sử dụng mô hình nhúng đã khởi tạo và chỉ định các trường nội dung và nhúng. Thêm mã này ngay sau mã mô hình nhúng trước đó.
COLLECTION_NAME = "legal_documents"
# Create a vector store
vector_store = FirestoreVectorStore(
collection="legal_documents",
embedding_service=embedding_model,
content_field="original_text",
embedding_field="embedding",
)
👉 Xác định một hàm có tên là search_resource. Hàm này sẽ lấy một truy vấn, thực hiện tìm kiếm tương tự bằng vector_store.similarity_search và trả về kết quả kết hợp.
def search_resource(query):
results = []
results = vector_store.similarity_search(query, k=5)
combined_results = "\n".join([result.page_content for result in results])
print(f"==>{combined_results}")
return combined_results
👉 THAY THẾ hàm ask_llm và sử dụng hàm search_resource để truy xuất ngữ cảnh phù hợp dựa trên truy vấn của người dùng.
def ask_llm(query):
try:
query_message = {
"type": "text",
"text": query,
}
relevant_resource = search_resource(query)
input_msg = HumanMessage(content=[query_message])
prompt_template = ChatPromptTemplate.from_messages(
[
SystemMessage(
content=(
"You are a helpful assistant, and you are with the attorney in a courtroom, you are helping him to win the case by providing the information he needs "
"Don't answer if you don't know the answer, just say sorry in a funny way possible"
"Use high engergy tone, don't use more than 100 words to answer"
f"Here is some context that is relevant to the question {relevant_resource} that you might use"
)
),
input_msg,
]
)
prompt = prompt_template.format()
response = llm.invoke(prompt)
print(f"response: {response}")
return response
except Exception as e:
print(f"Error sending message to chatbot: {e}") # Log this error too!
return f"Unable to process your request at this time. Due to the following reason: {str(e)}"
👉 KHÔNG BẮT BUỘC: BẢN TIẾNG TÂY BAN NHA
Thay thế văn bản sau như se indica: You are a helpful assistant, thành You are a helpful assistant that speaks Spanish,
👉 Sau khi triển khai RAG trong legal.py, bạn nên kiểm thử cục bộ trước khi triển khai, chạy ứng dụng bằng lệnh:
cd ~/legal-eagle/webapp
source env/bin/activate
python main.py
👉 Sử dụng webpreview để truy cập vào ứng dụng, trò chuyện với trợ lý và nhập ctrl+c để thoát khỏi quy trình chạy cục bộ, đồng thời chạy lệnh deactivate để thoát khỏi môi trường ảo.
deactivate
👉 Để triển khai ứng dụng web vào Cloud Run, bạn có thể dùng hàm trình tải. Bạn sẽ tạo, gắn thẻ và đẩy hình ảnh Docker vào Artifact Registry:
export PROJECT_ID=$(gcloud config get project)
docker build -t gcr.io/${PROJECT_ID}/legal-eagle-webapp .
docker tag gcr.io/${PROJECT_ID}/legal-eagle-webapp us-central1-docker.pkg.dev/${PROJECT_ID}/my-repository/legal-eagle-webapp
docker push us-central1-docker.pkg.dev/${PROJECT_ID}/my-repository/legal-eagle-webapp
👉 Đã đến lúc triển khai ứng dụng web lên Google Cloud. Trong cửa sổ dòng lệnh, hãy chạy các lệnh sau:
export PROJECT_ID=$(gcloud config get project)
gcloud run deploy legal-eagle-webapp \
--image us-central1-docker.pkg.dev/$PROJECT_ID/my-repository/legal-eagle-webapp \
--region us-central1 \
--set-env-vars=GOOGLE_CLOUD_PROJECT=${PROJECT_ID} \
--allow-unauthenticated
Xác minh việc triển khai bằng cách chuyển đến Cloud Run trong Google Cloud Console.Bạn sẽ thấy một dịch vụ mới có tên là legal-eagle-webapp trong danh sách.
Nhấp vào dịch vụ để chuyển đến trang chi tiết. Bạn có thể tìm thấy URL đã triển khai ở trên cùng. 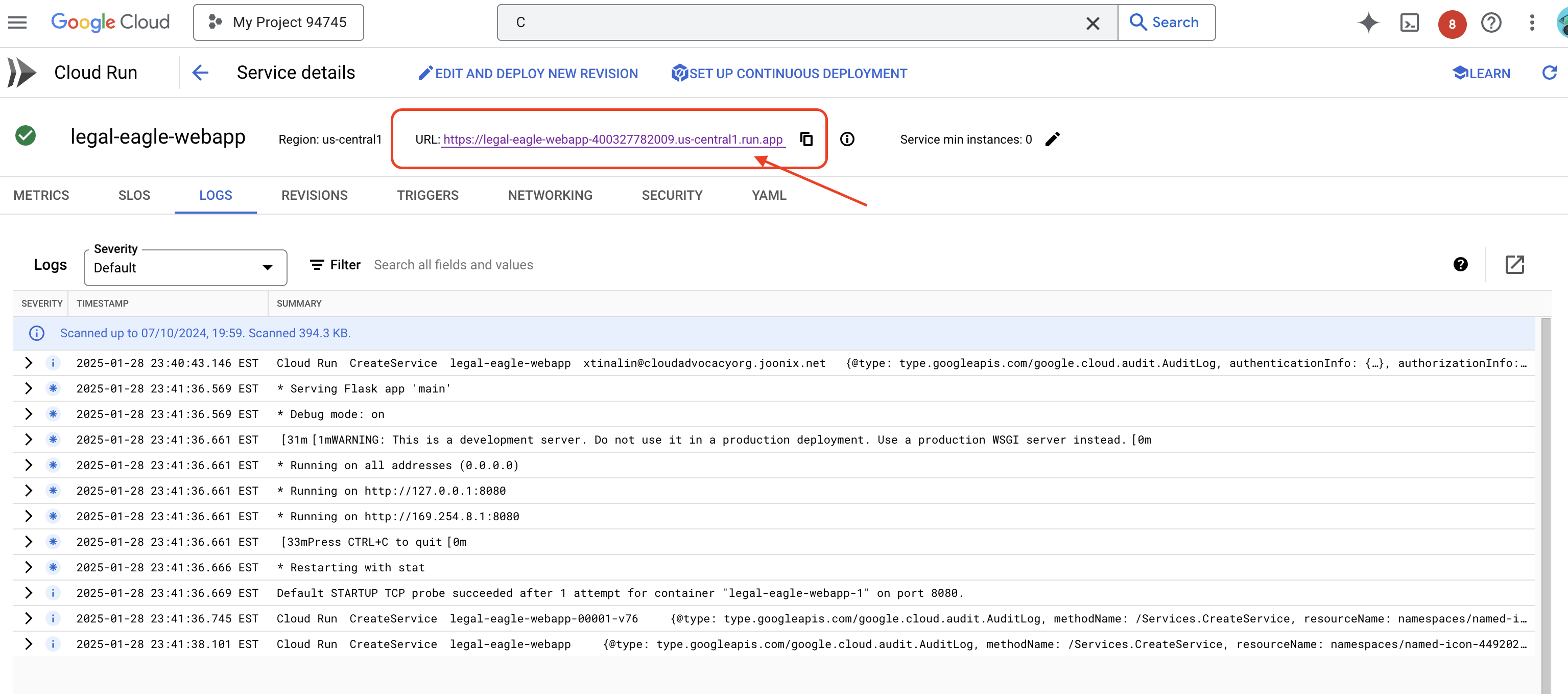
👉 Bây giờ, hãy mở URL đã triển khai trong một thẻ trình duyệt mới. Bạn có thể tương tác với trợ lý pháp lý và đặt câu hỏi liên quan đến các vụ kiện mà bạn đã tải(trong thư mục court_cases):
- Michael Brown bị kết án bao nhiêu năm tù?
- Hành động của Jane Smith đã tạo ra bao nhiêu tiền từ các khoản phí trái phép?
- Lời khai của những người hàng xóm đóng vai trò gì trong cuộc điều tra vụ án của Emily White?
👉 KHÔNG BẮT BUỘC: BẢN TIẾNG TÂY BAN NHA
- ¿A cuántos años de prisión fue sentenciado Michael Brown?
- ¿Cuánto dinero en cargos no autorizados se generó como resultado de las acciones de Jane Smith?
- ¿Qué papel jugaron los testimonios de los vecinos en la investigación del caso de Emily White?
Bạn sẽ nhận thấy rằng các câu trả lời hiện chính xác hơn và dựa trên nội dung của các tài liệu pháp lý mà bạn đã tải lên, cho thấy sức mạnh của RAG!
Chúc mừng bạn đã hoàn thành buổi hội thảo này!! Bạn đã tạo và triển khai thành công một ứng dụng phân tích tài liệu pháp lý bằng LLM, LangChain và Google Cloud. Bạn đã tìm hiểu cách nhập và xử lý các tài liệu pháp lý, tăng cường phản hồi của LLM bằng thông tin liên quan bằng cách sử dụng RAG và triển khai ứng dụng của bạn dưới dạng một dịch vụ phi máy chủ. Kiến thức này và ứng dụng bạn xây dựng sẽ giúp bạn khám phá thêm sức mạnh của LLM cho các công việc pháp lý. Tốt lắm!"
14. Thách thức
Nhiều loại nội dung nghe nhìn::
Cách nhập và xử lý nhiều loại nội dung nghe nhìn, chẳng hạn như video và bản ghi âm tại toà án, cũng như trích xuất văn bản liên quan.
Tài sản trực tuyến:
Cách xử lý các tài sản trực tuyến như trang web trực tiếp.