
۱. مقدمه
در این آزمایشگاه کد، مراحل خلاصهسازی کد منبع از مخازن گیتهاب و شناسایی زبان برنامهنویسی در مخزن را با استفاده از مدل زبان بزرگ Vertex AI برای تولید متن ( text-bison ) به عنوان یک تابع از راه دور میزبانی شده در BigQuery فهرست کردهام. به لطف پروژه بایگانی گیتهاب، اکنون یک تصویر کلی از بیش از ۲.۸ میلیون مخزن متنباز گیتهاب در مجموعه دادههای عمومی گوگل بیگکوئری داریم. فهرست سرویسهای مورد استفاده عبارتند از:
- بیگکوئری امال
- رابط برنامهنویسی کاربردی Vertex AI و PaLM
آنچه خواهید ساخت
تو خلق خواهی کرد
- یک مجموعه داده BigQuery برای شامل کردن مدل
- یک مدل BigQuery که میزبان API Vertex AI PaLM به عنوان یک تابع از راه دور است
- یک اتصال خارجی برای ایجاد ارتباط بین BigQuery و Vertex AI
۲. الزامات
۳. قبل از شروع
- در کنسول گوگل کلود ، در صفحه انتخاب پروژه، یک پروژه گوگل کلود را انتخاب یا ایجاد کنید
- مطمئن شوید که صورتحساب برای پروژه ابری شما فعال است. یاد بگیرید که چگونه بررسی کنید که آیا صورتحساب در یک پروژه فعال است یا خیر.
- مطمئن شوید که تمام APIهای لازم (BigQuery API، Vertex AI API، BigQuery Connection API) فعال هستند.
- شما از Cloud Shell ، یک محیط خط فرمان که در Google Cloud اجرا میشود و bq از قبل روی آن بارگذاری شده است، استفاده خواهید کرد. برای دستورات و نحوه استفاده از gcloud به مستندات مراجعه کنید.
از کنسول ابری، روی فعال کردن پوسته ابری در گوشه بالا سمت راست کلیک کنید:

اگر پروژه شما تنظیم نشده است، از دستور زیر برای تنظیم آن استفاده کنید:
gcloud config set project <YOUR_PROJECT_ID>
- با وارد کردن آدرس اینترنتی زیر در مرورگر خود، مستقیماً به کنسول BigQuery بروید: https://console.cloud.google.com/bigquery
۴. آمادهسازی دادهها
در این مورد استفاده، ما از محتوای کد منبع مجموعه داده github_repos در مجموعه دادههای عمومی Google BigQuery استفاده میکنیم. برای استفاده از این، در کنسول BigQuery، عبارت "github_repos" را جستجو کرده و Enter را فشار دهید. روی ستاره کنار مجموعه دادهای که به عنوان نتیجه جستجو فهرست شده است کلیک کنید. سپس روی گزینه "فقط نمایش ستارهدار" کلیک کنید تا آن مجموعه داده را فقط از مجموعه دادههای عمومی مشاهده کنید.

برای مشاهده طرح و پیشنمایش دادهها، جداول موجود در مجموعه دادهها را باز کنید. ما قصد داریم از sample_contents استفاده کنیم که فقط شامل یک نمونه (10٪) از کل دادههای جدول محتوا است. در اینجا پیشنمایشی از دادهها آمده است:
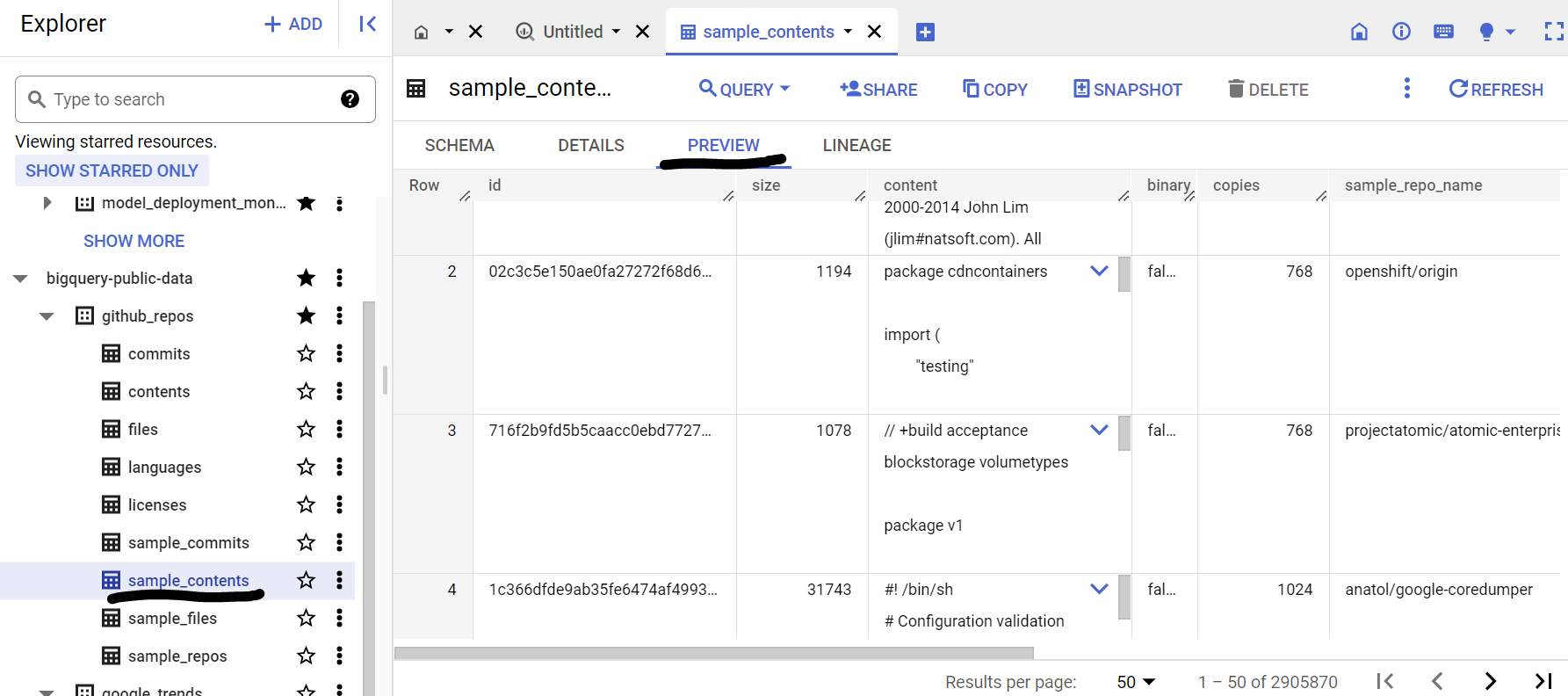
۵. ایجاد مجموعه داده BigQuery
یک مجموعه داده BigQuery مجموعهای از جداول است. تمام جداول موجود در یک مجموعه داده در یک مکان داده ذخیره میشوند. همچنین میتوانید کنترلهای دسترسی سفارشی را برای محدود کردن دسترسی به یک مجموعه داده و جداول آن پیوست کنید.
یک مجموعه داده در منطقه "US" (یا هر منطقه دلخواه ما) با نام bq_llm ایجاد کنید.
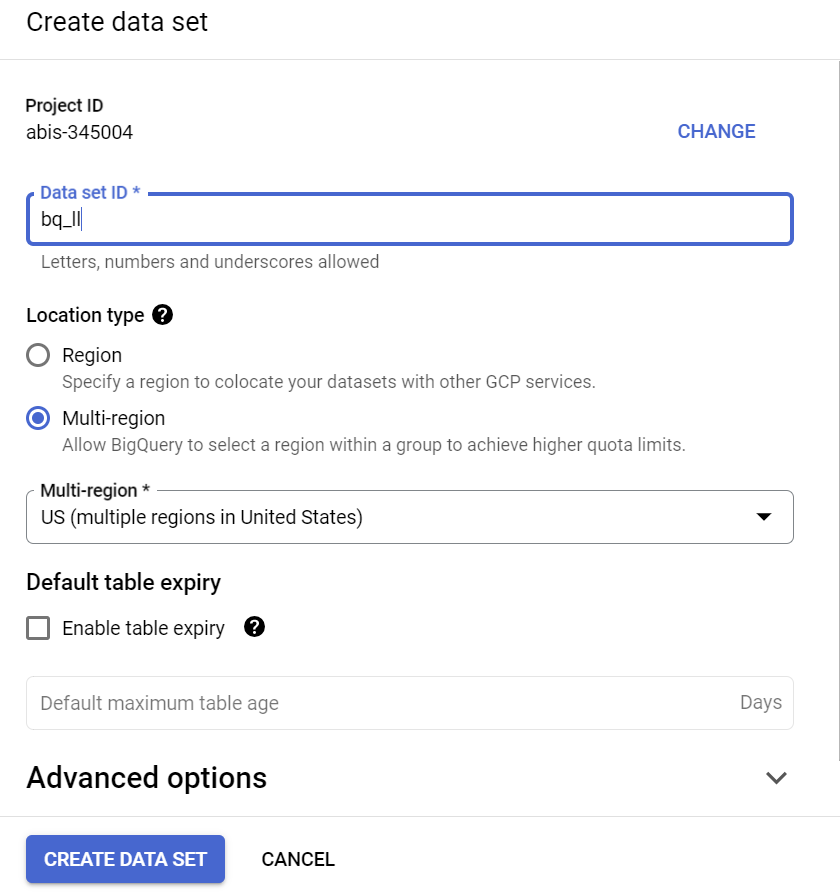
این مجموعه داده، مدل یادگیری ماشینی را که در مراحل بعدی ایجاد خواهیم کرد، در خود جای میدهد. معمولاً دادههایی را که در برنامه یادگیری ماشینی استفاده میکنیم، در جدولی در این مجموعه داده نیز ذخیره میکنیم، اما در مورد استفاده ما، دادهها از قبل در یک مجموعه داده عمومی BigQuery وجود دارند و در صورت نیاز، مستقیماً از مجموعه داده جدید ایجاد شده خود به آنها ارجاع خواهیم داد. اگر میخواهید این پروژه را روی مجموعه داده خودتان که در یک CSV (یا هر فایل دیگری) قرار دارد، انجام دهید، میتوانید دادههای خود را با اجرای دستور زیر از ترمینال Cloud Shell در یک مجموعه داده BigQuery در جدول بارگذاری کنید:
bq load --source_format=CSV --skip_leading_rows=1 bq_llm.table_to_hold_your_data \
./your_file.csv \ text:string,label:string
۶. ایجاد ارتباط خارجی
یک اتصال خارجی ایجاد کنید (اگر قبلاً این کار را نکردهاید، BQ Connection API را فعال کنید) و شناسه حساب سرویس را از جزئیات پیکربندی اتصال یادداشت کنید:
- روی دکمه +ADD در پنل BigQuery Explorer (در سمت چپ کنسول BigQuery) کلیک کنید و در منابع محبوب فهرست شده، روی «اتصال به منابع داده خارجی» کلیک کنید.
- نوع اتصال را «BigLake and remote functions» انتخاب کنید و «llm-conn» را به عنوان شناسه اتصال وارد کنید.
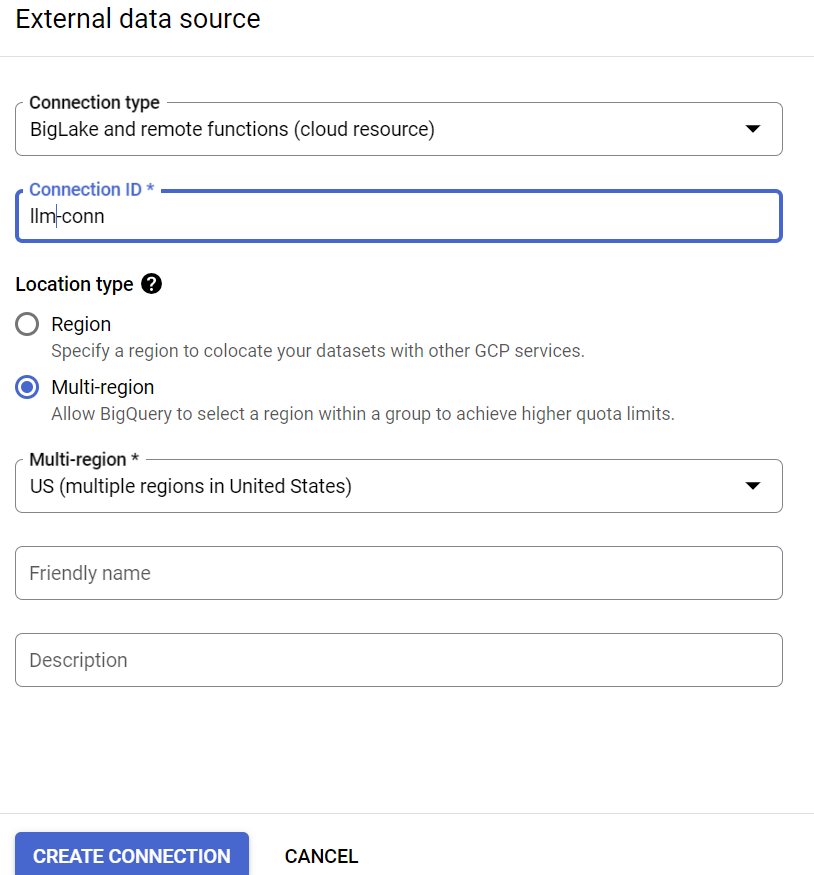
- پس از ایجاد اتصال، حساب کاربری سرویس ایجاد شده از جزئیات پیکربندی اتصال را یادداشت کنید.
۷. اعطای مجوزها
در این مرحله، مجوزهایی را به حساب سرویس (Service Account) برای دسترسی به سرویس Vertex AI اعطا خواهیم کرد:
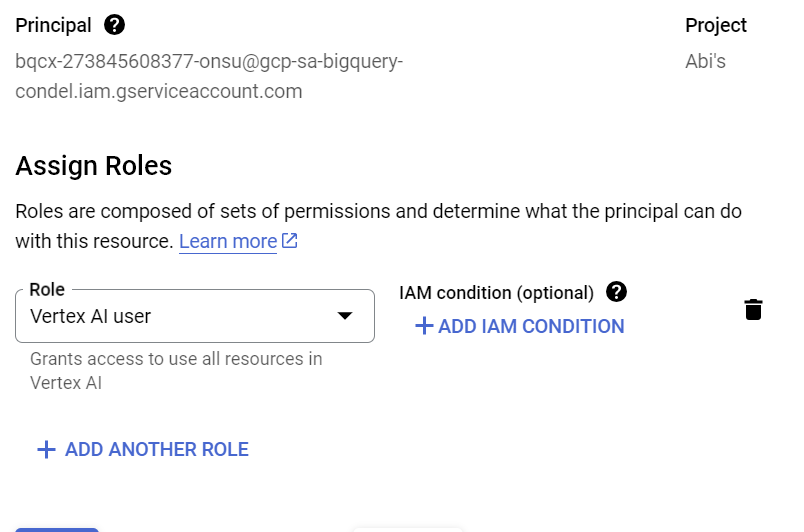
IAM را باز کنید و حساب کاربری سرویسی که پس از ایجاد اتصال خارجی به عنوان Principal کپی کردهاید را اضافه کنید و نقش "Vertex AI User" را انتخاب کنید.
۸. یک مدل یادگیری ماشین از راه دور ایجاد کنید
یک مدل از راه دور ایجاد کنید که نشان دهنده یک مدل زبان بزرگ هوش مصنوعی Vertex میزبان باشد:
CREATE OR REPLACE MODEL bq_llm.llm_model
REMOTE WITH CONNECTION `us.llm-conn`
OPTIONS (remote_service_type = 'CLOUD_AI_LARGE_LANGUAGE_MODEL_V1');
این مدلی به نام llm_model در مجموعه داده bq_llm ایجاد میکند که از API CLOUD_AI_LARGE_LANGUAGE_MODEL_V1 مربوط به Vertex AI به عنوان یک تابع از راه دور استفاده میکند. تکمیل این کار چند ثانیه طول میکشد.
۹. تولید متن با استفاده از مدل یادگیری ماشین
پس از ایجاد مدل، از آن برای تولید، خلاصهسازی یا دستهبندی متن استفاده کنید.
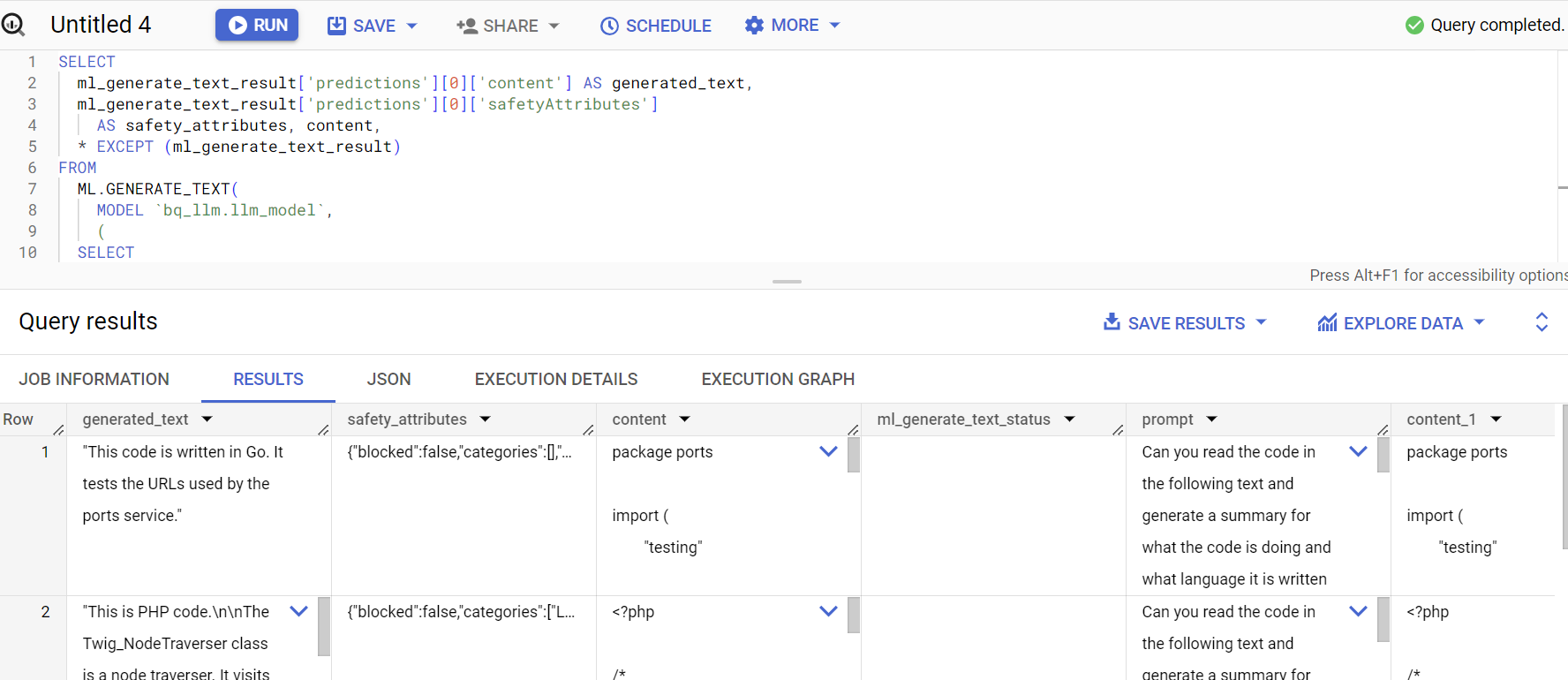
SELECT
ml_generate_text_result['predictions'][0]['content'] AS generated_text,
ml_generate_text_result['predictions'][0]['safetyAttributes']
AS safety_attributes,
* EXCEPT (ml_generate_text_result)
FROM
ML.GENERATE_TEXT(
MODEL `bq_llm.llm_model`,
(
SELECT
CONCAT('Can you read the code in the following text and generate a summary for what the code is doing and what language it is written in:', content)
AS prompt from `bigquery-public-data.github_repos.sample_contents`
limit 5
),
STRUCT(
0.2 AS temperature,
100 AS max_output_tokens));
**توضیح:
ml_generate_text_result** پاسخی از مدل تولید متن در قالب JSON است که شامل هر دو ویژگی محتوا و ایمنی است: الف. محتوا نشان دهنده نتیجه متن تولید شده است. ب. ویژگیهای ایمنی نشان دهنده فیلتر محتوای داخلی با آستانه قابل تنظیم است که در Vertex AI Palm API فعال شده است تا از هرگونه پاسخ ناخواسته یا پیشبینی نشده از مدل زبان بزرگ جلوگیری شود - اگر پاسخ آستانه ایمنی را نقض کند، مسدود میشود.
ML.GENERATE_TEXT ساختاری است که شما در BigQuery برای دسترسی به Vertex AI LLM جهت انجام وظایف تولید متن از آن استفاده میکنید.
CONCAT دستور PROMPT و رکورد پایگاه داده شما را به هم متصل میکند.
github_repos نام مجموعه داده و sample_contents نام جدولی است که دادههایی را که در طراحی اعلان استفاده خواهیم کرد، در خود جای داده است.
دما پارامتر سریعی برای کنترل تصادفی بودن پاسخ است - هرچه کمتر باشد، از نظر مرتبط بودن بهتر است
Max_output_tokens تعداد کلماتی است که میخواهید در پاسخ نمایش داده شوند.
پاسخ پرس و جو به این شکل است:
۱۰. نتیجه پرس و جو را مسطح کنید
بیایید نتیجه را مسطح کنیم تا مجبور نباشیم JSON را به طور صریح در پرس و جو رمزگشایی کنیم:
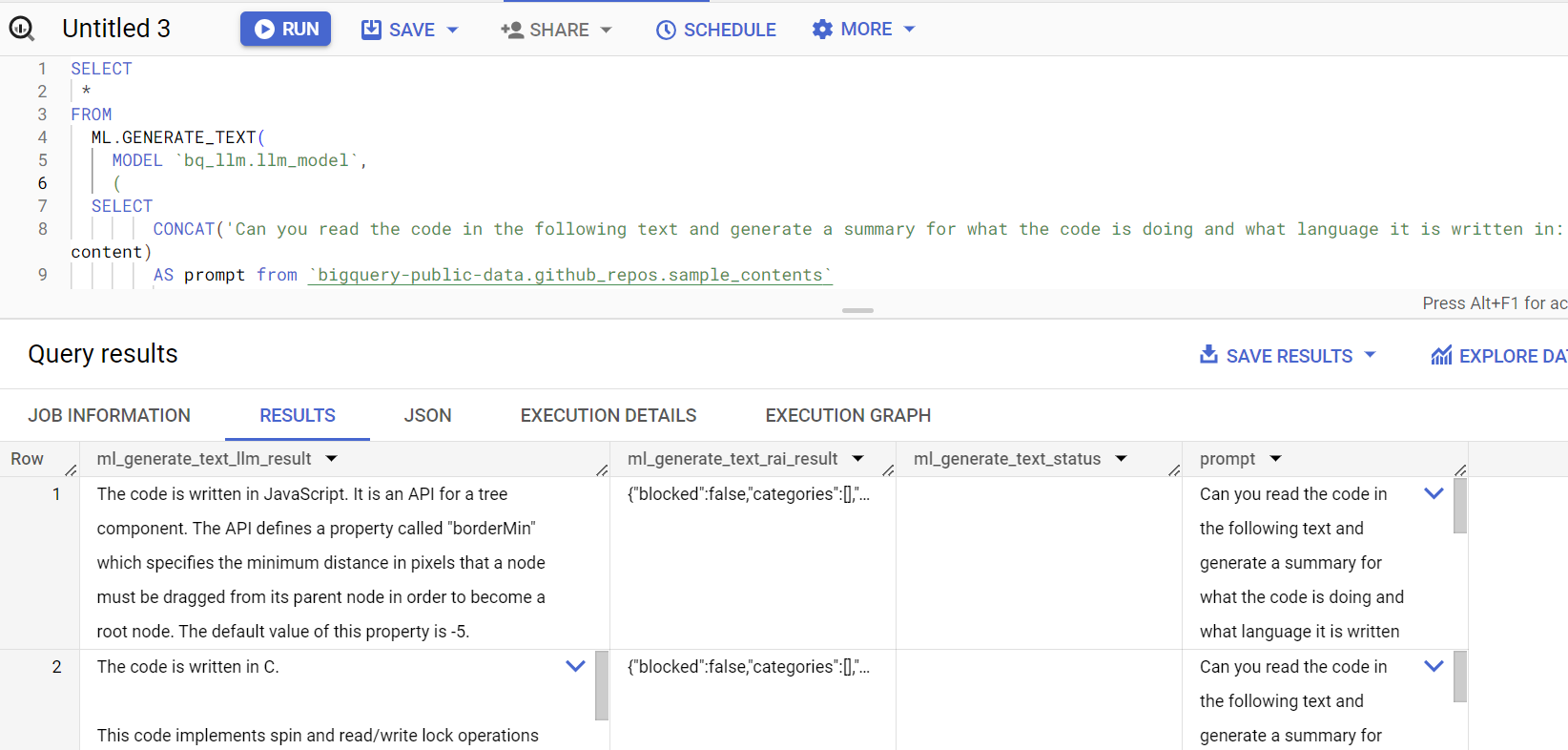
SELECT *
FROM
ML.GENERATE_TEXT(
MODEL `bq_llm.llm_model`,
(
SELECT
CONCAT('Can you read the code in the following text and generate a summary for what the code is doing and what language it is written in:', content)
AS prompt from `bigquery-public-data.github_repos.sample_contents`
limit 5
),
STRUCT(
0.2 AS temperature,
100 AS max_output_tokens,
TRUE AS flatten_json_output));
**توضیح:
Flatten_json_output** نشان دهنده مقدار بولی است که اگر روی true تنظیم شود، یک متن مسطح و قابل فهم را که از پاسخ JSON استخراج شده است، برمیگرداند.
پاسخ پرس و جو به این شکل است:
۱۱. تمیز کردن
برای جلوگیری از تحمیل هزینه به حساب Google Cloud خود برای منابع استفاده شده در این پست، این مراحل را دنبال کنید:
- در کنسول گوگل کلود، به صفحه مدیریت منابع بروید
- در لیست پروژهها، پروژهای را که میخواهید حذف کنید انتخاب کنید و سپس روی «حذف» کلیک کنید.
- در کادر محاورهای، شناسه پروژه را تایپ کنید و سپس برای حذف پروژه، روی خاموش کردن کلیک کنید.
۱۲. تبریک
تبریک! شما با موفقیت از یک Vertex AI Text Generation LLM به صورت برنامهنویسی شده برای انجام تجزیه و تحلیل متن روی دادههای خود فقط با استفاده از پرسوجوهای SQL استفاده کردید. برای کسب اطلاعات بیشتر در مورد مدلهای موجود، مستندات محصول Vertex AI LLM را بررسی کنید.