
1. Introduction
Dans cet atelier de programmation, j'ai listé les étapes à suivre pour résumer le code source des dépôts GitHub et identifier le langage de programmation utilisé dans le dépôt, à l'aide du grand modèle de langage Vertex AI pour la génération de texte ( text-bison) en tant que fonction distante hébergée dans BigQuery. Grâce au projet d'archivage de GitHub, nous disposons désormais d'un instantané complet de plus de 2,8 millions de dépôts GitHub Open Source dans les ensembles de données publics Google BigQuery. Voici la liste des services utilisés :
- BigQuery ML
- API Vertex AI PaLM
Ce que vous allez faire
Vous allez créer
- un ensemble de données BigQuery qui contiendra le modèle ;
- Modèle BigQuery qui héberge l'API PaLM Vertex AI en tant que fonction distante
- Une connexion externe pour établir la connexion entre BigQuery et Vertex AI
2. Conditions requises
3. Avant de commencer
- Dans la console Google Cloud, sur la page du sélecteur de projet, sélectionnez ou créez un projet Google Cloud.
- Assurez-vous que la facturation est activée pour votre projet Cloud. Découvrez comment vérifier si la facturation est activée sur un projet.
- Assurez-vous que toutes les API nécessaires (API BigQuery, API Vertex AI, API BigQuery Connection) sont activées.
- Vous allez utiliser Cloud Shell, un environnement de ligne de commande exécuté dans Google Cloud et fourni avec bq. Consultez la documentation pour connaître les commandes gcloud ainsi que leur utilisation.
Dans la console Cloud, cliquez sur "Activer Cloud Shell" en haut à droite :
Si votre projet n'est pas défini, utilisez la commande suivante pour le définir :
gcloud config set project <YOUR_PROJECT_ID>
- Accédez directement à la console BigQuery en saisissant l'URL suivante dans votre navigateur : https://console.cloud.google.com/bigquery.
4. Préparation des données…
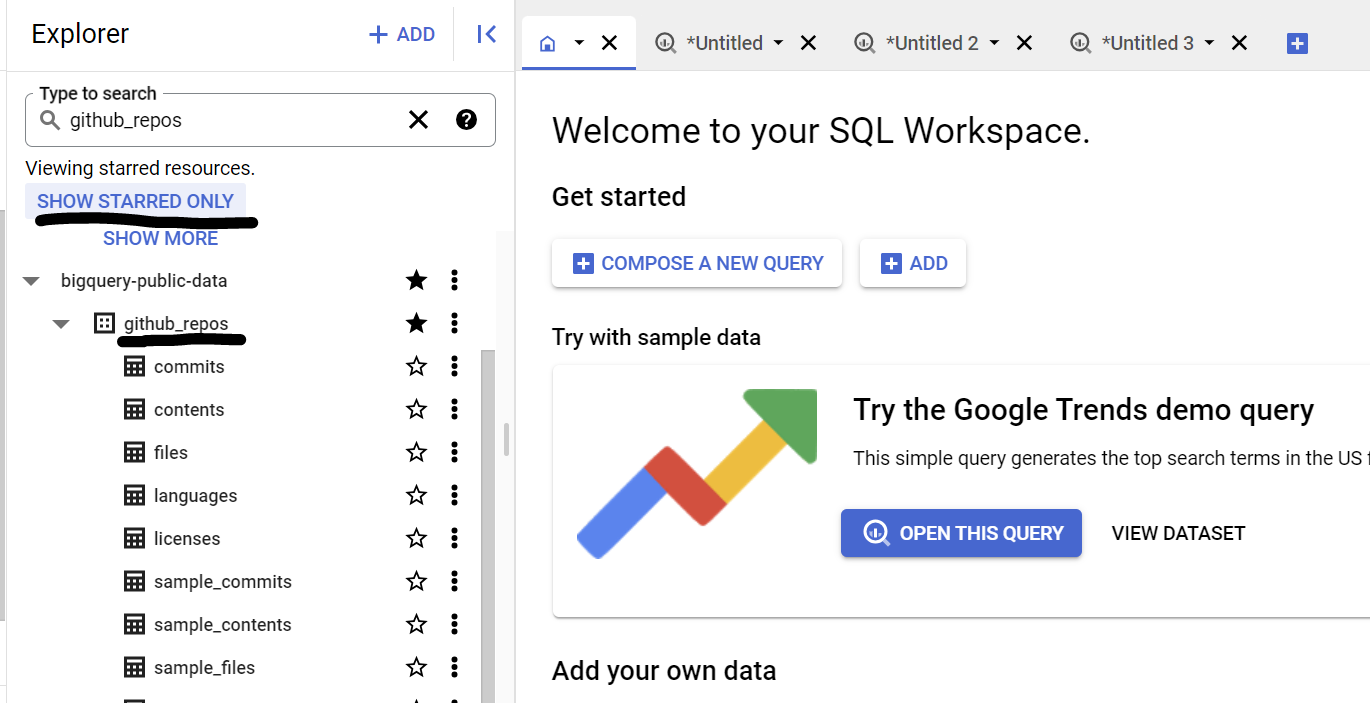
Dans ce cas d'utilisation, nous utilisons le contenu du code source de l'ensemble de données github_repos dans les ensembles de données publics Google BigQuery. Pour ce faire, dans la console BigQuery, recherchez "github_repos", puis appuyez sur Entrée. Cliquez sur l'étoile à côté de l'ensemble de données qui apparaît dans les résultats de recherche. Cliquez ensuite sur l'option "AFFICHER UNIQUEMENT LES FAVORIS" pour n'afficher que cet ensemble de données parmi les ensembles de données publics.
Développez les tables de l'ensemble de données pour afficher le schéma et un aperçu des données. Nous allons utiliser sample_contents, qui ne contient qu'un échantillon (10 %) des données complètes du tableau "contents". Voici un aperçu des données :

5. Créer un ensemble de données BigQuery
Un ensemble de données BigQuery est une collection de tables. Toutes les tables d'un ensemble de données sont stockées au même emplacement. Vous pouvez également associer des contrôles d'accès personnalisés pour limiter l'accès à un ensemble de données et à ses tables.
Créez un ensemble de données dans la région "US" (ou dans la région de votre choix) nommé bq_llm.

Cet ensemble de données hébergera le modèle de ML que nous allons créer dans les prochaines étapes. En règle générale, nous stockons également les données que nous utilisons dans l'application de ML dans un tableau de cet ensemble de données. Toutefois, dans notre cas d'utilisation, les données se trouvent déjà dans un ensemble de données public BigQuery. Nous allons donc y faire directement référence à partir de l'ensemble de données que nous venons de créer, selon les besoins. Si vous souhaitez réaliser ce projet sur votre propre ensemble de données stocké dans un fichier CSV (ou tout autre fichier), vous pouvez charger vos données dans un ensemble de données BigQuery en exécutant la commande ci-dessous à partir du terminal Cloud Shell :
bq load --source_format=CSV --skip_leading_rows=1 bq_llm.table_to_hold_your_data \
./your_file.csv \ text:string,label:string
6. Créer une connexion externe
Créez une connexion externe (activez l'API BQ Connection si ce n'est pas déjà fait) et notez l'ID du compte de service à partir des informations de configuration de la connexion :
- Cliquez sur le bouton + AJOUTER dans le volet de l'explorateur BigQuery (à gauche de la console BigQuery), puis sur "Connexion à des sources de données externes" dans la liste des sources populaires.
- Sélectionnez "BigLake et fonctions distantes" comme type de connexion, puis indiquez "llm-conn" comme ID de connexion.

- Une fois la connexion créée, notez le compte de service généré à partir des informations de configuration de la connexion.
7. Accorder des autorisations
Dans cette étape, nous allons accorder des autorisations au compte de service pour accéder au service Vertex AI :
Ouvrez IAM, puis ajoutez le compte de service que vous avez copié après avoir créé la connexion externe en tant que compte principal et sélectionnez le rôle "Utilisateur Vertex AI".

8. Créer un modèle de ML distant
Créez le modèle distant représentant un grand modèle de langage Vertex AI hébergé :
CREATE OR REPLACE MODEL bq_llm.llm_model
REMOTE WITH CONNECTION `us.llm-conn`
OPTIONS (remote_service_type = 'CLOUD_AI_LARGE_LANGUAGE_MODEL_V1');
Il crée un modèle nommé llm_model dans l'ensemble de données bq_llm qui utilise l'API CLOUD_AI_LARGE_LANGUAGE_MODEL_V1 de Vertex AI comme fonction distante. Cette opération prend quelques secondes.
9. Générer du texte à l'aide du modèle de ML
Une fois le modèle créé, utilisez-le pour générer, résumer ou catégoriser du texte.
SELECT
ml_generate_text_result['predictions'][0]['content'] AS generated_text,
ml_generate_text_result['predictions'][0]['safetyAttributes']
AS safety_attributes,
* EXCEPT (ml_generate_text_result)
FROM
ML.GENERATE_TEXT(
MODEL `bq_llm.llm_model`,
(
SELECT
CONCAT('Can you read the code in the following text and generate a summary for what the code is doing and what language it is written in:', content)
AS prompt from `bigquery-public-data.github_repos.sample_contents`
limit 5
),
STRUCT(
0.2 AS temperature,
100 AS max_output_tokens));
**Explication :
**ml_generate_text_result** est la réponse du modèle de génération de texte au format JSON, qui contient à la fois des attributs de contenu et de sécurité : a. Le contenu représente le résultat du texte généré b. Les attributs de sécurité représentent le filtre de contenu intégré avec un seuil ajustable qui est activé dans l'API Vertex AI Palm pour éviter toute réponse involontaire ou imprévue du grand modèle de langage. La réponse est bloquée si elle ne respecte pas le seuil de sécurité.
ML.GENERATE_TEXT est la construction que vous utilisez dans BigQuery pour accéder au LLM Vertex AI et effectuer des tâches de génération de texte.
CONCAT ajoute votre instruction PROMPT et l'enregistrement de la base de données.
github_repos est le nom de l'ensemble de données et sample_contents est le nom de la table contenant les données que nous utiliserons dans la conception de la requête.
La température est le paramètre de requête qui permet de contrôler le degré de hasard de la réponse. Plus elle est basse, plus la réponse est pertinente.
Max_output_tokens correspond au nombre de mots que vous souhaitez dans la réponse.
La réponse à la requête se présente comme suit :

10. Aplatir le résultat de la requête
Aplatissons le résultat pour ne pas avoir à décoder explicitement le JSON dans la requête :
SELECT *
FROM
ML.GENERATE_TEXT(
MODEL `bq_llm.llm_model`,
(
SELECT
CONCAT('Can you read the code in the following text and generate a summary for what the code is doing and what language it is written in:', content)
AS prompt from `bigquery-public-data.github_repos.sample_contents`
limit 5
),
STRUCT(
0.2 AS temperature,
100 AS max_output_tokens,
TRUE AS flatten_json_output));
**Explication :
** Flatten_json_output ** représente la valeur booléenne. Si elle est définie sur "true", elle renvoie un texte clair extrait de la réponse JSON.
La réponse à la requête se présente comme suit :

11. Effectuer un nettoyage
Pour éviter que les ressources utilisées dans cet article soient facturées sur votre compte Google Cloud, procédez comme suit :
- Dans la console Google Cloud, accédez à la page Gérer les ressources.
- Dans la liste des projets, sélectionnez le projet que vous souhaitez supprimer, puis cliquez sur "Supprimer".
- Dans la boîte de dialogue, saisissez l'ID du projet, puis cliquez sur "Arrêter" pour supprimer le projet.
12. Félicitations
Félicitations ! Vous avez réussi à utiliser un LLM de génération de texte Vertex AI de manière programmatique pour effectuer des analyses de texte sur vos données en utilisant uniquement des requêtes SQL. Consultez la documentation du produit LLM Vertex AI pour en savoir plus sur les modèles disponibles.