
1. Wprowadzenie
W tym ćwiczeniu znajdziesz instrukcje podsumowywania kodu źródłowego z repozytoriów GitHub i identyfikowania języka programowania w repozytorium za pomocą dużego modelu językowego Vertex AI do generowania tekstu ( text-bison) jako hostowanej funkcji zdalnej w BigQuery. Dzięki projektowi archiwizacji GitHub mamy teraz pełną migawkę ponad 2, 8 mln repozytoriów open source GitHub w publicznych zbiorach danych Google BigQuery. Lista używanych usług:
- BigQuery ML
- Vertex AI PaLM API
Co utworzysz
Utworzysz
- Zbiór danych BigQuery, który będzie zawierać model.
- Model BigQuery, który hostuje interfejs Vertex AI PaLM API jako funkcję zdalną
- połączenie zewnętrzne, które umożliwia połączenie BigQuery z Vertex AI;
2. Wymagania
3. Zanim zaczniesz
- W konsoli Google Cloud na stronie selektora projektu wybierz lub utwórz projekt Google Cloud.
- Sprawdź, czy w projekcie Cloud włączone są płatności. Dowiedz się, jak sprawdzić, czy w projekcie włączone są płatności
- Upewnij się, że wszystkie niezbędne interfejsy API (BigQuery API, Vertex AI API, BigQuery Connection API) są włączone.
- Będziesz używać Cloud Shell, czyli środowiska wiersza poleceń działającego w Google Cloud, które jest wstępnie załadowane narzędziem bq. Informacje o poleceniach gcloud i sposobie ich używania znajdziesz w dokumentacji.
W konsoli Cloud kliknij Aktywuj Cloud Shell w prawym górnym rogu:

Jeśli projekt nie jest ustawiony, użyj tego polecenia, aby go ustawić:
gcloud config set project <YOUR_PROJECT_ID>
- Otwórz konsolę BigQuery, wpisując w przeglądarce ten adres URL: https://console.cloud.google.com/bigquery
4. Przygotowywanie danych
W tym przypadku używamy treści kodu źródłowego ze zbioru danych github_repos w publicznych zbiorach danych Google BigQuery. Aby z niej skorzystać, w konsoli BigQuery wyszukaj „github_repos” i naciśnij Enter. Kliknij gwiazdkę obok zbioru danych, który jest wyświetlany jako wynik wyszukiwania. Następnie kliknij opcję „POKAŻ TYLKO OZNAKOWANE GWIAZDKĄ”, aby wyświetlić tylko ten zbiór danych z publicznych zbiorów danych.
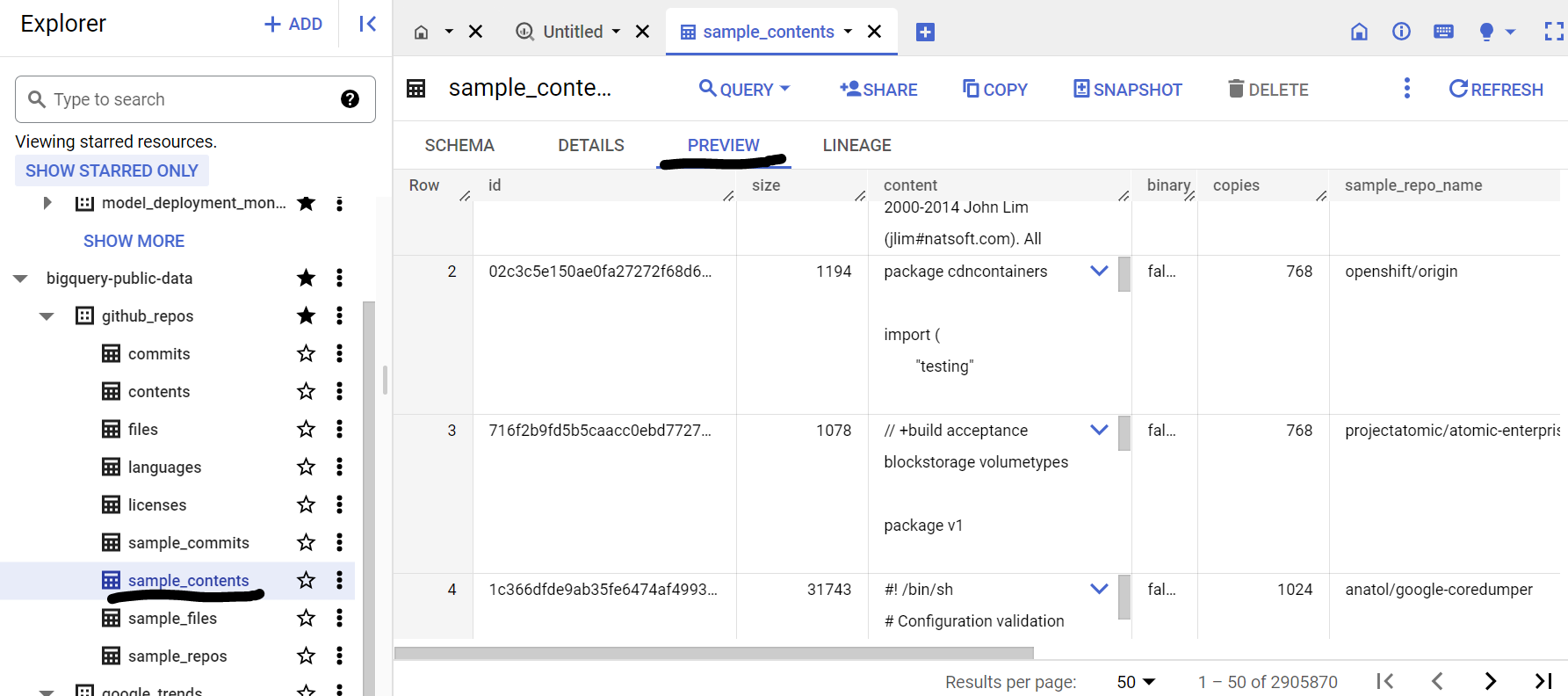
Rozwiń tabele w zbiorze danych, aby wyświetlić schemat i podgląd danych. Użyjemy tabeli sample_contents, która zawiera tylko próbkę (10%) pełnych danych z tabeli contents. Oto podgląd danych:
5. Tworzenie zbioru danych BigQuery
Zbiór danych BigQuery to zbiór tabel. Wszystkie tabele w zbiorze danych są przechowywane w tej samej lokalizacji danych. Możesz też dołączyć niestandardowe ustawienia kontroli dostępu, aby ograniczyć dostęp do zbioru danych i jego tabel.
Utwórz zbiór danych w regionie „US” (lub w dowolnym innym regionie) o nazwie bq_llm.
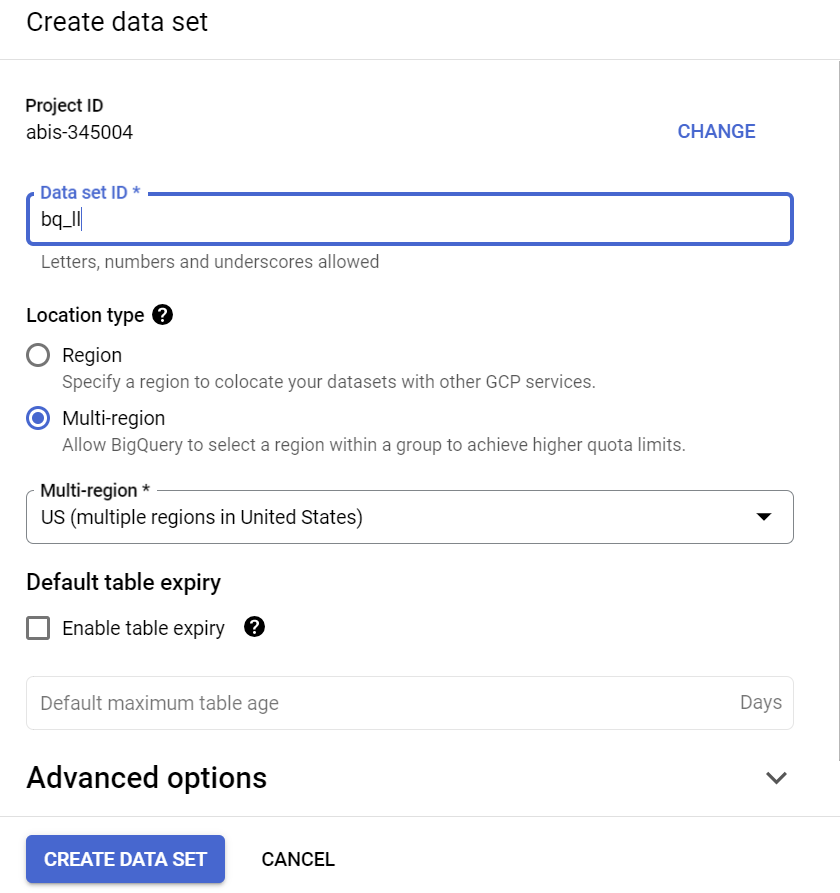
Ten zbiór danych będzie zawierać model ML, który utworzymy w kolejnych krokach. Zazwyczaj dane używane w aplikacji ML przechowujemy w tabeli w tym zbiorze danych, ale w naszym przypadku dane znajdują się już w publicznym zbiorze danych BigQuery, więc będziemy się do nich odwoływać bezpośrednio z nowo utworzonego zbioru danych. Jeśli chcesz wykonać ten projekt na własnym zbiorze danych znajdującym się w pliku CSV (lub innym), możesz wczytać dane do zbioru danych BigQuery w tabeli, uruchamiając poniższe polecenie w terminalu Cloud Shell:
bq load --source_format=CSV --skip_leading_rows=1 bq_llm.table_to_hold_your_data \
./your_file.csv \ text:string,label:string
6. Tworzenie połączenia zewnętrznego
Utwórz połączenie zewnętrzne (jeśli nie zostało jeszcze utworzone, włącz interfejs BQ Connection API) i zanotuj identyfikator konta usługi ze szczegółów konfiguracji połączenia:
- W panelu eksploratora BigQuery (po lewej stronie konsoli BigQuery) kliknij przycisk +DODAJ i w sekcji popularnych źródeł kliknij „Połączenie ze źródłami danych zewnętrznych”.
- Jako typ połączenia wybierz „BigLake i funkcje zdalne”, a jako identyfikator połączenia podaj „llm-conn”.
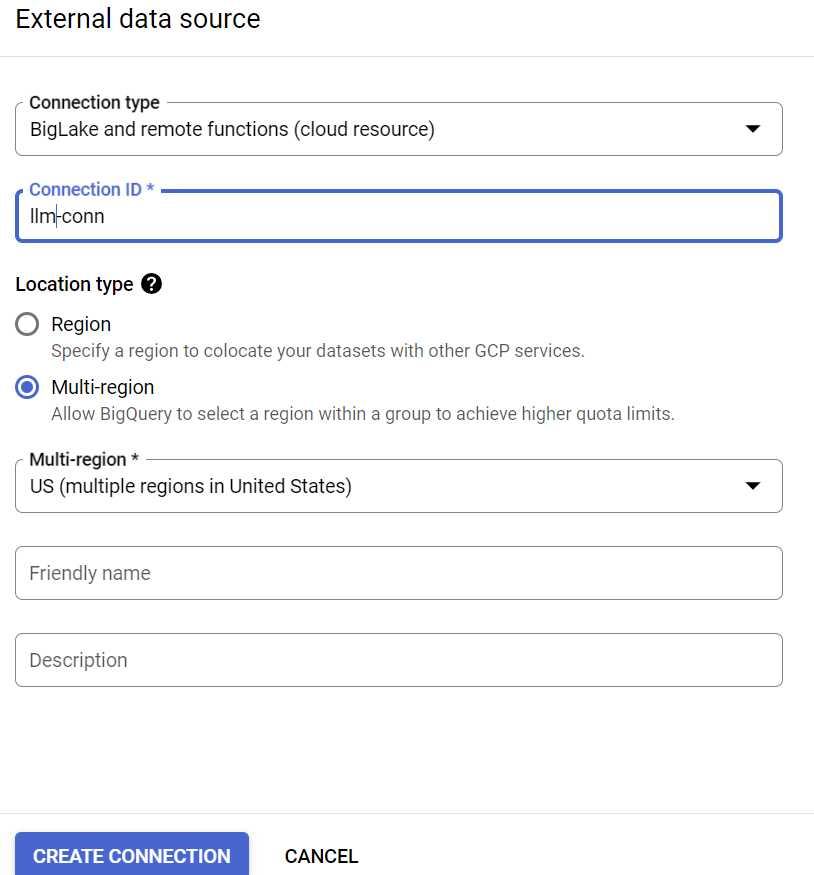
- Po utworzeniu połączenia zanotuj konto usługi wygenerowane na podstawie szczegółów konfiguracji połączenia.
7. Przyznaj uprawnienia
W tym kroku przyznamy kontu usługi uprawnienia dostępu do usługi Vertex AI:
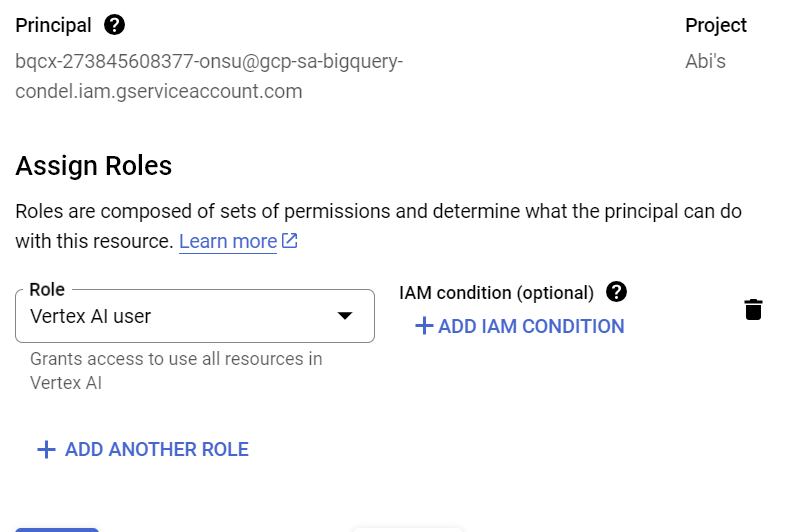
Otwórz IAM i dodaj skopiowane po utworzeniu połączenia zewnętrznego konto usługi jako podmiot zabezpieczeń, a następnie wybierz rolę „Użytkownik Vertex AI”.
8. Tworzenie zdalnego modelu ML
Utwórz model zdalny, który reprezentuje hostowany duży model językowy Vertex AI:
CREATE OR REPLACE MODEL bq_llm.llm_model
REMOTE WITH CONNECTION `us.llm-conn`
OPTIONS (remote_service_type = 'CLOUD_AI_LARGE_LANGUAGE_MODEL_V1');
Tworzy w zbiorze danych bq_llm model o nazwie llm_model, który wykorzystuje interfejs CLOUD_AI_LARGE_LANGUAGE_MODEL_V1 API Vertex AI jako funkcję zdalną. Wykonanie polecenia może potrwać kilka sekund.
9. Generowanie tekstu za pomocą modelu ML
Po utworzeniu modelu możesz go używać do generowania, podsumowywania lub kategoryzowania tekstu.
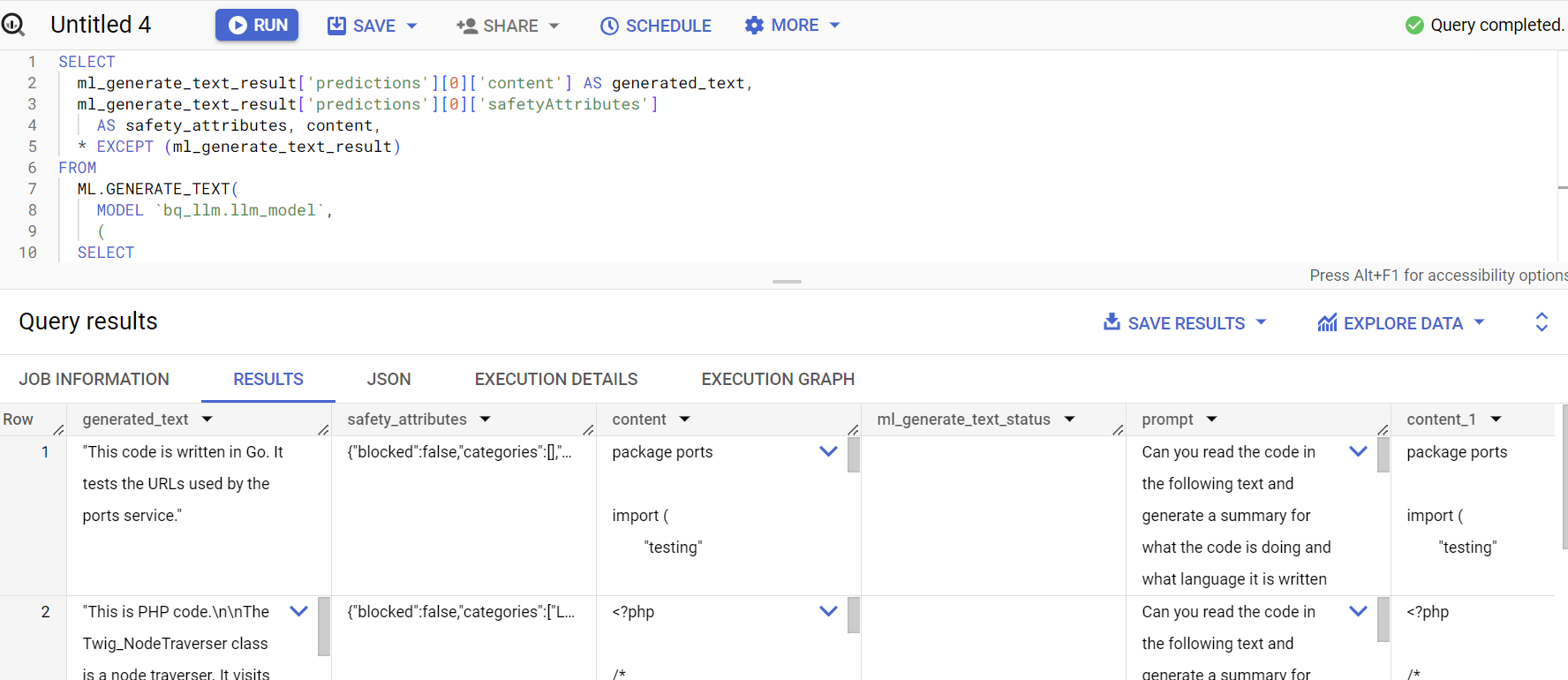
SELECT
ml_generate_text_result['predictions'][0]['content'] AS generated_text,
ml_generate_text_result['predictions'][0]['safetyAttributes']
AS safety_attributes,
* EXCEPT (ml_generate_text_result)
FROM
ML.GENERATE_TEXT(
MODEL `bq_llm.llm_model`,
(
SELECT
CONCAT('Can you read the code in the following text and generate a summary for what the code is doing and what language it is written in:', content)
AS prompt from `bigquery-public-data.github_repos.sample_contents`
limit 5
),
STRUCT(
0.2 AS temperature,
100 AS max_output_tokens));
**Wyjaśnienie:
ml_generate_text_result** to odpowiedź modelu generowania tekstu w formacie JSON, która zawiera zarówno treść, jak i atrybuty bezpieczeństwa: a. Treść reprezentuje wygenerowany tekst b. Atrybuty bezpieczeństwa to wbudowany filtr treści z regulowanym progiem, który jest włączony w interfejsie Vertex AI PaLM API, aby uniknąć niezamierzonych lub nieprzewidzianych odpowiedzi z dużego modelu językowego. Jeśli odpowiedź narusza próg bezpieczeństwa, jest blokowana.
ML.GENERATE_TEXT to konstrukcja, której używasz w BigQuery, aby uzyskać dostęp do modelu LLM Vertex AI i wykonywać zadania generowania tekstu.
Funkcja CONCAT dołącza instrukcję PROMPT i rekord bazy danych.
github_repos to nazwa zbioru danych, a sample_contents to nazwa tabeli zawierającej dane, których użyjemy w projektowaniu prompta.
Temperatura to parametr promptu, który kontroluje losowość odpowiedzi. Im niższa wartość, tym lepsza trafność.
Max_output_tokens to liczba słów, które mają się znaleźć w odpowiedzi.
Odpowiedź na zapytanie wygląda tak:
10. Spłaszczanie wyniku zapytania
Spłaszczmy wynik, aby nie trzeba było jawnie dekodować kodu JSON w zapytaniu:
SELECT *
FROM
ML.GENERATE_TEXT(
MODEL `bq_llm.llm_model`,
(
SELECT
CONCAT('Can you read the code in the following text and generate a summary for what the code is doing and what language it is written in:', content)
AS prompt from `bigquery-public-data.github_repos.sample_contents`
limit 5
),
STRUCT(
0.2 AS temperature,
100 AS max_output_tokens,
TRUE AS flatten_json_output));
**Wyjaśnienie:
Flatten_json_output** to wartość logiczna, która po ustawieniu na „true” zwraca płaski, zrozumiały tekst wyodrębniony z odpowiedzi JSON.
Odpowiedź na zapytanie wygląda tak:

11. Czyszczenie danych
Aby uniknąć obciążenia konta Google Cloud opłatami za zasoby użyte w tym poście, wykonaj te czynności:
- W konsoli Google Cloud otwórz stronę Zarządzanie zasobami.
- Z listy projektów wybierz projekt do usunięcia, a potem kliknij Usuń.
- W oknie wpisz identyfikator projektu i kliknij Wyłącz, aby usunąć projekt.
12. Gratulacje
Gratulacje! Udało Ci się użyć modelu LLM do generowania tekstu w Vertex AI w sposób zautomatyzowany, aby przeprowadzić analitykę tekstu na podstawie danych przy użyciu tylko zapytań SQL. Więcej informacji o dostępnych modelach znajdziesz w dokumentacji produktu Vertex AI LLM.