
1. Введение
В этом практическом занятии я описал шаги по суммированию исходного кода из репозиториев GitHub и определению языка программирования в репозитории с использованием Vertex AI Large Language Model for text generation ( text-bison ) в качестве удаленной функции в BigQuery. Благодаря проекту GitHub Archive Project у нас теперь есть полный снимок более 2,8 миллионов репозиториев с открытым исходным кодом GitHub в общедоступных наборах данных Google BigQuery . Список используемых сервисов:
- BigQuery ML
- Vertex AI PaLM API
Что вы построите
Вы создадите
- Набор данных BigQuery для хранения модели.
- Модель BigQuery, которая предоставляет API Vertex AI PaLM в качестве удаленной функции.
- Внешнее соединение для установления связи между BigQuery и Vertex AI.
2. Требования
3. Прежде чем начать
- В консоли Google Cloud на странице выбора проекта выберите или создайте проект Google Cloud.
- Убедитесь, что для вашего облачного проекта включена функция выставления счетов. Узнайте, как проверить, включена ли функция выставления счетов для проекта.
- Убедитесь, что все необходимые API (BigQuery API, Vertex AI API, BigQuery Connection API) включены .
- Вы будете использовать Cloud Shell — среду командной строки, работающую в Google Cloud и поставляемую с предустановленным пакетом bq . Для получения информации о командах и использовании gcloud обратитесь к документации.
В консоли Cloud Console нажмите кнопку «Активировать Cloud Shell» в правом верхнем углу:
Если ваш проект не задан, используйте следующую команду для его установки:
gcloud config set project <YOUR_PROJECT_ID>
- Перейдите непосредственно в консоль BigQuery , введя в браузере следующий URL-адрес: https://console.cloud.google.com/bigquery
4. Подготовка данных
В данном примере мы используем исходный код из набора данных github_repos в общедоступных наборах данных Google BigQuery . Для этого в консоли BigQuery найдите "github_repos" и нажмите Enter. Щелкните звездочку рядом с набором данных, который отображается в результатах поиска. Затем щелкните параметр "ПОКАЗАТЬ ТОЛЬКО ПОЗВЕЗДОЧНЫЕ", чтобы увидеть только этот набор данных из общедоступных наборов данных.

Разверните таблицы в наборе данных, чтобы просмотреть схему и предварительный просмотр данных. Мы будем использовать таблицу sample_contents, которая содержит только выборку (10%) от полных данных таблицы contents. Вот предварительный просмотр данных:

5. Создание набора данных BigQuery
Набор данных BigQuery представляет собой коллекцию таблиц. Все таблицы в наборе данных хранятся в одном и том же месте . Вы также можете добавить пользовательские элементы управления доступом, чтобы ограничить доступ к набору данных и его таблицам.
Создайте набор данных в регионе "США" (или любом другом регионе по вашему выбору) с именем bq_llm.

В этом наборе данных будет размещена модель машинного обучения, которую мы создадим на следующих этапах. Обычно данные, используемые в приложении машинного обучения, также хранятся в таблице в этом же наборе данных, однако в нашем случае данные уже находятся в общедоступном наборе данных BigQuery, и мы будем ссылаться на него напрямую из нашего нового набора данных по мере необходимости. Если вы хотите выполнить этот проект со своим собственным набором данных, хранящимся в CSV-файле (или любом другом файле), вы можете загрузить свои данные в набор данных BigQuery в таблицу, выполнив команду ниже в терминале Cloud Shell:
bq load --source_format=CSV --skip_leading_rows=1 bq_llm.table_to_hold_your_data \
./your_file.csv \ text:string,label:string
6. Создание внешнего соединения
Создайте внешнее подключение (включите API подключения BQ, если это еще не сделано) и запишите идентификатор учетной записи службы из сведений о конфигурации подключения:
- Нажмите кнопку +ДОБАВИТЬ на панели «Обозреватель BigQuery» (в левой части консоли BigQuery) и выберите «Подключение к внешним источникам данных» в списке популярных источников.
- Выберите тип подключения «BigLake и удаленные функции» и укажите «llm-conn» в качестве идентификатора подключения.

- После установления соединения запишите учетную запись службы, сгенерированную в параметрах конфигурации соединения.
7. Предоставить разрешения
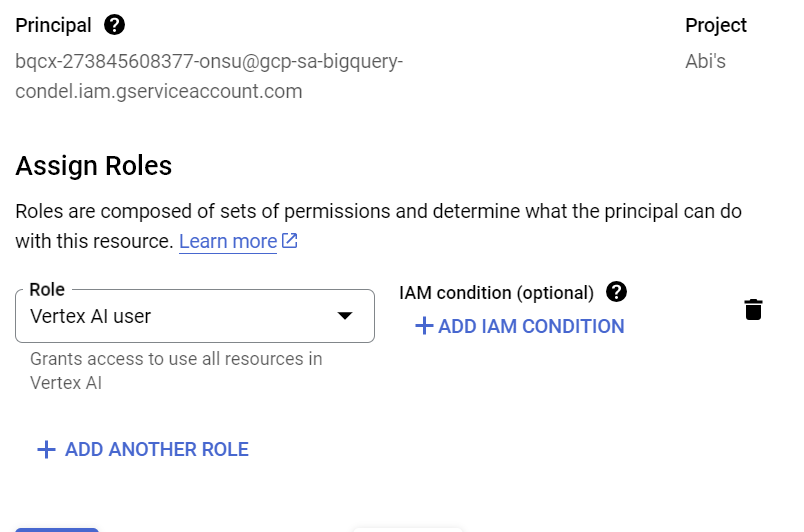
На этом этапе мы предоставим учетной записи службы права доступа к сервису Vertex AI:
Откройте IAM и добавьте учетную запись службы, скопированную после создания внешнего подключения, в качестве основного пользователя, затем выберите роль «Пользователь Vertex AI».
8. Создайте удалённую модель машинного обучения.
Создайте удалённую модель, представляющую собой размещённую большую языковую модель Vertex AI:
CREATE OR REPLACE MODEL bq_llm.llm_model
REMOTE WITH CONNECTION `us.llm-conn`
OPTIONS (remote_service_type = 'CLOUD_AI_LARGE_LANGUAGE_MODEL_V1');
Эта функция создает модель с именем llm_model в наборе данных bq_llm, которая использует API CLOUD_AI_LARGE_LANGUAGE_MODEL_V1 от Vertex AI в качестве удаленной функции. Выполнение этой операции займет несколько секунд.
9. Сгенерируйте текст, используя модель машинного обучения.
После создания модели используйте её для генерации, обобщения или классификации текста.
SELECT
ml_generate_text_result['predictions'][0]['content'] AS generated_text,
ml_generate_text_result['predictions'][0]['safetyAttributes']
AS safety_attributes,
* EXCEPT (ml_generate_text_result)
FROM
ML.GENERATE_TEXT(
MODEL `bq_llm.llm_model`,
(
SELECT
CONCAT('Can you read the code in the following text and generate a summary for what the code is doing and what language it is written in:', content)
AS prompt from `bigquery-public-data.github_repos.sample_contents`
limit 5
),
STRUCT(
0.2 AS temperature,
100 AS max_output_tokens));
**Объяснение:
ml_generate_text_result** — это ответ от модели генерации текста в формате JSON, содержащий атрибуты содержимого и безопасности: a. Содержимое представляет собой сгенерированный текстовый результат; b. Атрибуты безопасности представляют собой встроенный фильтр содержимого с регулируемым порогом, который включен в API Vertex AI Palm для предотвращения любых непредвиденных или неожиданных ответов от большой языковой модели — ответ блокируется, если он нарушает порог безопасности.
ML.GENERATE_TEXT — это конструкция, используемая в BigQuery для доступа к Vertex AI LLM для выполнения задач генерации текста.
CONCAT добавляет ваш оператор PROMPT и запись в базу данных.
github_repos — это имя набора данных, а sample_contents — имя таблицы, содержащей данные, которые мы будем использовать в дизайне задания.
Температура — это параметр, позволяющий контролировать случайность реакции: чем ниже температура, тем лучше с точки зрения релевантности.
Max_output_tokens — это количество слов, которое вы хотите получить в ответе.
Ответ на запрос выглядит следующим образом:

10. Сгладьте результат запроса.
Давайте преобразуем результат в однородный формат, чтобы нам не приходилось явно декодировать JSON в запросе:
SELECT *
FROM
ML.GENERATE_TEXT(
MODEL `bq_llm.llm_model`,
(
SELECT
CONCAT('Can you read the code in the following text and generate a summary for what the code is doing and what language it is written in:', content)
AS prompt from `bigquery-public-data.github_repos.sample_contents`
limit 5
),
STRUCT(
0.2 AS temperature,
100 AS max_output_tokens,
TRUE AS flatten_json_output));
**Объяснение:
Параметр Flatten_json_output** представляет собой логическое значение, которое, если установлено в true, возвращает плоский, понятный текст, извлеченный из JSON-ответа.
Ответ на запрос выглядит следующим образом:

11. Уборка
Чтобы избежать списания средств с вашего аккаунта Google Cloud за ресурсы, использованные в этой статье, выполните следующие действия:
- В консоли Google Cloud перейдите на страницу «Управление ресурсами» .
- В списке проектов выберите проект, который хотите удалить, и нажмите «Удалить».
- В диалоговом окне введите идентификатор проекта, а затем нажмите «Завершить», чтобы удалить проект.
12. Поздравляем!
Поздравляем! Вы успешно использовали Vertex AI Text Generation LLM программным способом для проведения текстового анализа ваших данных с помощью SQL-запросов. Для получения дополнительной информации о доступных моделях ознакомьтесь с документацией по продукту Vertex AI LLM .