
1. 简介
在此 Codelab 中,我列出了以下步骤:使用 Vertex AI 大语言模型 ( text-bison)(作为 BigQuery 中的托管远程函数)对 GitHub 代码库中的源代码进行总结,并识别代码库中的编程语言。借助 GitHub Archive Project,我们现在可以在 Google BigQuery 公共数据集中获得超过 280 万个开源 GitHub 代码库的完整快照。使用的服务列表如下:
- BigQuery ML
- Vertex AI PaLM API
构建内容
您将创建
- 包含模型的 BigQuery 数据集
- 将 Vertex AI PaLM API 作为远程函数托管的 BigQuery 模型
- 用于在 BigQuery 和 Vertex AI 之间建立连接的外部连接
2. 要求
3. 准备工作
- 在 Google Cloud 控制台的项目选择器页面上,选择或创建一个 Google Cloud 项目
- 确保您的 Cloud 项目已启用结算功能。了解如何检查项目是否已启用结算功能
- 确保所有必需的 API(BigQuery API、Vertex AI API、BigQuery Connection API)均已启用
- 您将使用 Cloud Shell,这是一个在 Google Cloud 中运行的命令行环境,它预加载了 bq。如需了解 gcloud 命令和用法,请参阅文档
在 Cloud 控制台中,点击右上角的“激活 Cloud Shell”:

如果项目未设置,请使用以下命令进行设置:
gcloud config set project <YOUR_PROJECT_ID>
- 在浏览器中输入以下网址,直接前往 BigQuery 控制台:https://console.cloud.google.com/bigquery
4. 准备数据
在此使用情形中,我们使用的是 Google BigQuery 公共数据集中 github_repos 数据集的源代码内容。如需使用此功能,请在 BigQuery 控制台中搜索“github_repos”,然后按 Enter 键。点击搜索结果中列出的数据集旁边的星标。然后,点击“仅显示已加星标的项”选项,即可仅从公共数据集中看到该数据集。

展开数据集中的表,以查看架构和数据预览。我们将使用 sample_contents,其中仅包含 contents 表中完整数据的样本 (10%)。以下是数据预览:

5. 创建 BigQuery 数据集
BigQuery 数据集是表的集合。数据集中的所有表都存储在同一数据位置。您还可以附加自定义访问权限控制,以限制对数据集及其表的访问权限。
在“美国”区域(或我们偏好的任何区域)中创建一个名为 bq_llm 的数据集

此数据集将包含我们在后续步骤中创建的机器学习模型。通常,我们还会将机器学习应用中使用的数据存储在此数据集本身的表中,但在我们的使用情形中,数据已存在于 BigQuery 公开数据集中,我们将根据需要直接从新创建的数据集中引用该数据。如果您想使用自己的数据集(以 CSV 或任何其他文件格式存储)完成此项目,可以运行以下命令,将数据加载到 BigQuery 数据集中的表中:
bq load --source_format=CSV --skip_leading_rows=1 bq_llm.table_to_hold_your_data \
./your_file.csv \ text:string,label:string
6. 创建外部连接
创建外部连接(如果尚未完成,请启用 BQ Connection API),并记下连接配置详情中的服务账号 ID:
- 点击 BigQuery 探索器窗格(位于 BigQuery 控制台左侧)中的“+ 添加”按钮,然后点击列出的热门来源中的“与外部数据源的连接”
- 选择“BigLake 和远程函数”作为连接类型,并提供“llm-conn”作为连接 ID

- 连接创建完毕后,请记下从连接配置详细信息中生成的服务账号
7. 授予权限
在此步骤中,我们将向服务账号授予访问 Vertex AI 服务的权限:
打开 IAM,将您在创建外部连接后复制的服务账号添加为主账号,然后选择“Vertex AI User”角色

8. 创建远程机器学习模型
创建表示托管式 Vertex AI 大语言模型的远程模型:
CREATE OR REPLACE MODEL bq_llm.llm_model
REMOTE WITH CONNECTION `us.llm-conn`
OPTIONS (remote_service_type = 'CLOUD_AI_LARGE_LANGUAGE_MODEL_V1');
它会在数据集 bq_llm 中创建一个名为 llm_model 的模型,该模型利用 Vertex AI 的 CLOUD_AI_LARGE_LANGUAGE_MODEL_V1 API 作为远程函数。完成此操作需要几秒钟时间。
9. 使用机器学习模型生成文本
模型创建完毕后,您可以使用该模型生成、总结或分类文本。
SELECT
ml_generate_text_result['predictions'][0]['content'] AS generated_text,
ml_generate_text_result['predictions'][0]['safetyAttributes']
AS safety_attributes,
* EXCEPT (ml_generate_text_result)
FROM
ML.GENERATE_TEXT(
MODEL `bq_llm.llm_model`,
(
SELECT
CONCAT('Can you read the code in the following text and generate a summary for what the code is doing and what language it is written in:', content)
AS prompt from `bigquery-public-data.github_repos.sample_contents`
limit 5
),
STRUCT(
0.2 AS temperature,
100 AS max_output_tokens));
**说明:
ml_generate_text_result** 是文本生成模型以 JSON 格式返回的响应,其中包含内容和安全属性:a. Content 表示生成的文本结果 b。安全属性表示 Vertex AI PaLM API 中启用的内置内容过滤器,该过滤器具有可调节的阈值,可避免大语言模型生成任何意外或不可预见的回答 - 如果回答违反安全阈值,则会被屏蔽
ML.GENERATE_TEXT 是您在 BigQuery 中使用的结构,用于访问 Vertex AI 大语言模型以执行文本生成任务
CONCAT 会附加您的 PROMPT 语句和数据库记录
github_repos 是数据集名称,sample_contents 是包含我们将在提示设计中使用的数据的表的名称
温度是用于控制回答随机性的提示参数 - 就相关性而言,温度越低越好
Max_output_tokens 是您希望回答中包含的字数
查询响应如下所示:

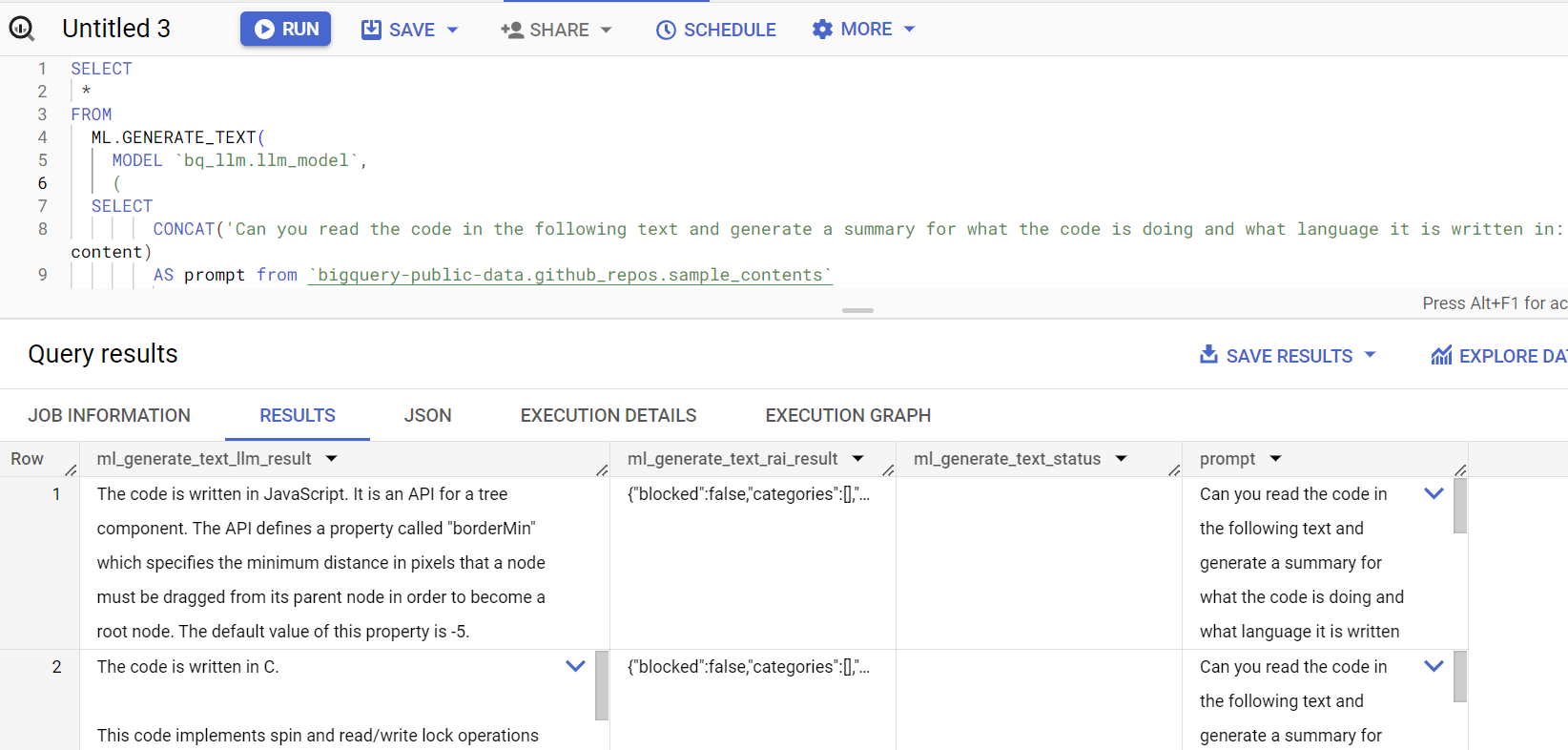
10. 展平查询结果
我们来展平结果,这样就不必在查询中显式解码 JSON:
SELECT *
FROM
ML.GENERATE_TEXT(
MODEL `bq_llm.llm_model`,
(
SELECT
CONCAT('Can you read the code in the following text and generate a summary for what the code is doing and what language it is written in:', content)
AS prompt from `bigquery-public-data.github_repos.sample_contents`
limit 5
),
STRUCT(
0.2 AS temperature,
100 AS max_output_tokens,
TRUE AS flatten_json_output));
**说明:
Flatten_json_output** 表示布尔值,如果设置为 true,则返回从 JSON 响应中提取的易于理解的展平文本。
查询响应如下所示:
11. 清理
为避免系统因本博文中使用的资源向您的 Google Cloud 账号收取费用,请按照以下步骤操作:
- 在 Google Cloud 控制台中,进入管理资源页面
- 在项目列表中,选择要删除的项目,然后点击“删除”
- 在对话框中输入项目 ID,然后点击“关停”以删除项目
12. 恭喜
恭喜!您已成功以编程方式使用 Vertex AI 文本生成 LLM,仅使用 SQL 查询对数据执行文本分析。如需详细了解可用模型,请参阅 Vertex AI LLM 产品文档。