
1. 簡介
在本程式碼研究室中,我列出了使用 Vertex AI 大型語言模型 (用於文字生成) (text-bison) 做為 BigQuery 中代管的遠端函式,從 GitHub 存放區摘要原始碼,並識別存放區中程式設計語言的步驟。感謝 GitHub 封存專案,我們現在已在 Google BigQuery 公開資料集中,完整擷取超過 280 萬個開放原始碼 GitHub 存放區的快照。使用的服務包括:
- BigQuery ML
- Vertex AI PaLM API
建構項目
您將建立
- 包含模型的 BigQuery 資料集
- BigQuery 模型,將 Vertex AI PaLM API 做為遠端函式
- 外部連線,用於建立 BigQuery 和 Vertex AI 之間的連線
2. 需求條件
3. 事前準備
- 在 Google Cloud 控制台的專案選取器頁面中,選取或建立 Google Cloud 專案
- 確認 Cloud 專案已啟用計費功能。瞭解如何檢查專案是否已啟用計費功能
- 確認所有必要 API (BigQuery API、Vertex AI API、BigQuery Connection API) 均已啟用
- 您將使用 Cloud Shell,這是 Google Cloud 中執行的指令列環境,已預先載入 bq。如需 gcloud 指令和用法,請參閱說明文件
在 Cloud 控制台,按一下右上角的「啟用 Cloud Shell」:
如果未設定專案,請使用下列指令來設定:
gcloud config set project <YOUR_PROJECT_ID>
- 在瀏覽器中輸入下列網址,直接前往 BigQuery 控制台:https://console.cloud.google.com/bigquery
4. 準備資料
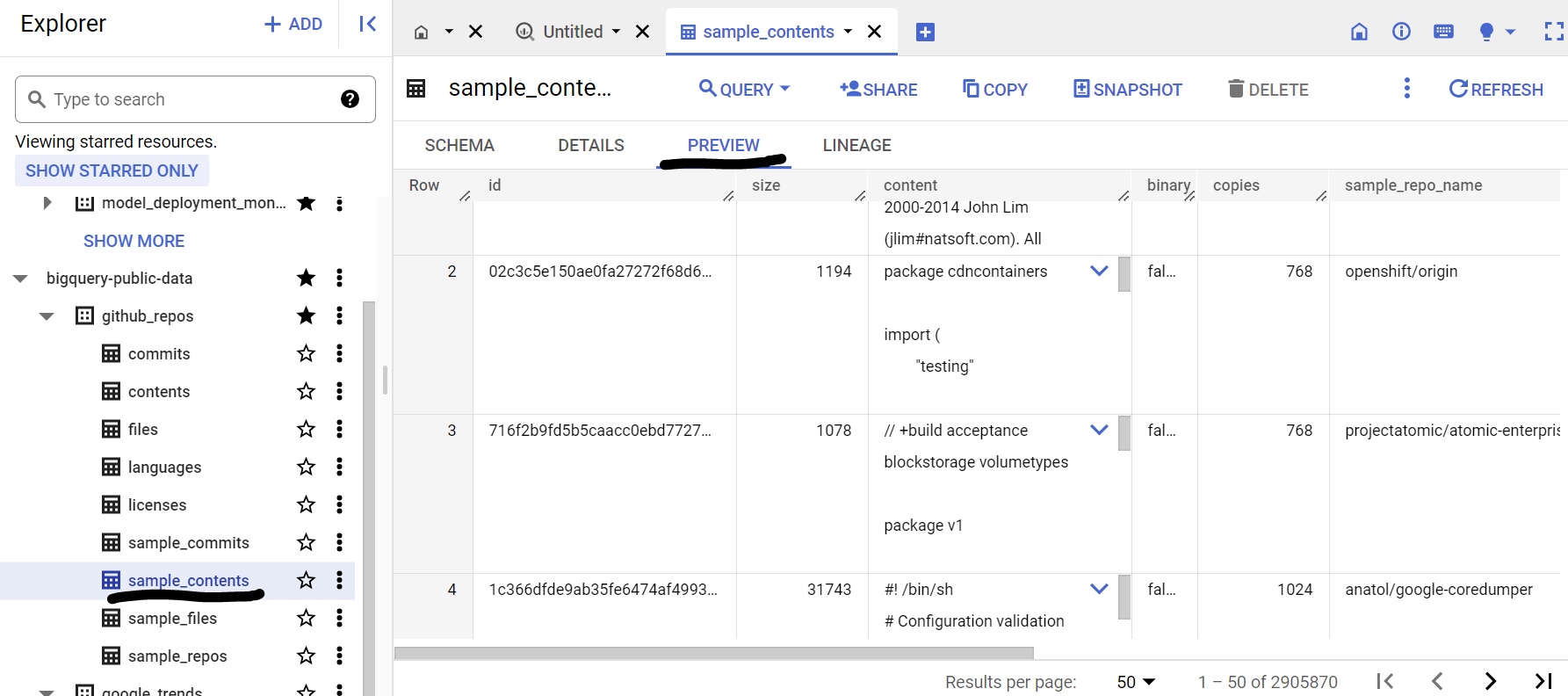
在本應用情境中,我們使用 Google BigQuery 公開資料集中的 github_repos 資料集來源程式碼內容。如要使用這項功能,請在 BigQuery 控制台中搜尋「github_repos」,然後按下 Enter 鍵。按一下搜尋結果中資料集旁的星號,然後點選「只顯示已加星號的項目」選項,即可只查看公開資料集中的該資料集。

展開資料集中的資料表,即可查看結構定義和資料預覽畫面。我們將使用 sample_contents,其中只包含內容資料表完整資料的樣本 (10%)。以下是資料預覽畫面:
5. 建立 BigQuery 資料集
BigQuery 資料集是資料表的集合,資料集中的所有資料表都儲存在同一個資料位置。您也可以附加自訂存取權控管,限制資料集及其資料表的存取權。
在「美國」區域 (或任何偏好區域) 建立名為 bq_llm 的資料集

這個資料集會存放我們在後續步驟中建立的機器學習模型。一般來說,我們也會將 ML 應用程式中使用的資料儲存在這個資料集本身的資料表中,但我們的用途是資料已存在 BigQuery 公開資料集中,因此我們會視需要直接從新建立的資料集參照該資料。如要使用 CSV (或其他檔案) 中的資料集進行這個專案,請從 Cloud Shell 終端機執行下列指令,將資料載入 BigQuery 資料集中的資料表:
bq load --source_format=CSV --skip_leading_rows=1 bq_llm.table_to_hold_your_data \
./your_file.csv \ text:string,label:string
6. 建立外部連線
建立外部連線 (如果尚未啟用 BQ Connection API,請先啟用),並記下連線設定詳細資料中的服務帳戶 ID:
- 在 BigQuery Explorer 窗格 (位於 BigQuery 控制台左側) 中,按一下「+新增」按鈕,然後在列出的熱門來源中,按一下「連線至外部資料來源」
- 選取「BigLake 和遠端函式」做為連線類型,並提供「llm-conn」做為連線 ID

- 連線建立完畢後,請記下連線設定詳細資料中產生的服務帳戶
7. 授予權限
在這個步驟中,我們會將存取 Vertex AI 服務的權限授予服務帳戶:
開啟 IAM,將您在建立外部連線後複製的服務帳戶新增為主體,然後選取「Vertex AI 使用者」角色

8. 建立遠端機器學習模型
建立遠端模型,代表代管的 Vertex AI 大型語言模型:
CREATE OR REPLACE MODEL bq_llm.llm_model
REMOTE WITH CONNECTION `us.llm-conn`
OPTIONS (remote_service_type = 'CLOUD_AI_LARGE_LANGUAGE_MODEL_V1');
這會在 bq_llm 資料集中建立名為 llm_model 的模型,並將 Vertex AI 的 CLOUD_AI_LARGE_LANGUAGE_MODEL_V1 API 做為遠端函式。這項作業需要幾秒鐘才能完成。
9. 使用機器學習模型生成文字
模型建立完成後,即可用來生成、摘要或分類文字。
SELECT
ml_generate_text_result['predictions'][0]['content'] AS generated_text,
ml_generate_text_result['predictions'][0]['safetyAttributes']
AS safety_attributes,
* EXCEPT (ml_generate_text_result)
FROM
ML.GENERATE_TEXT(
MODEL `bq_llm.llm_model`,
(
SELECT
CONCAT('Can you read the code in the following text and generate a summary for what the code is doing and what language it is written in:', content)
AS prompt from `bigquery-public-data.github_repos.sample_contents`
limit 5
),
STRUCT(
0.2 AS temperature,
100 AS max_output_tokens));
**說明:
**ml_generate_text_result** 是文字生成模型的回應,採用 JSON 格式,包含內容和安全性屬性:a. Content 代表產生的文字結果 b。安全屬性代表內建內容篩選器,可調整門檻,並在 Vertex AI Palm API 中啟用,避免大型語言模型產生任何非預期或無法預測的回覆。如果回覆違反安全門檻,系統就會封鎖該回覆。
ML.GENERATE_TEXT 是您在 BigQuery 中使用的建構函式,可存取 Vertex AI LLM 來執行文字生成工作
CONCAT 會附加 PROMPT 陳述式和資料庫記錄
github_repos 是資料集名稱,sample_contents 則是保存資料的資料表名稱,我們會在提示設計中使用這些資料
溫度參數是提示詞參數,可控制回覆的隨機程度,越低越能確保回覆內容與提示詞相關
Max_output_tokens 是指回覆中的字數
查詢回應如下所示:

10. 將查詢結果扁平化
讓我們將結果攤平,這樣就不必在查詢中明確解碼 JSON:
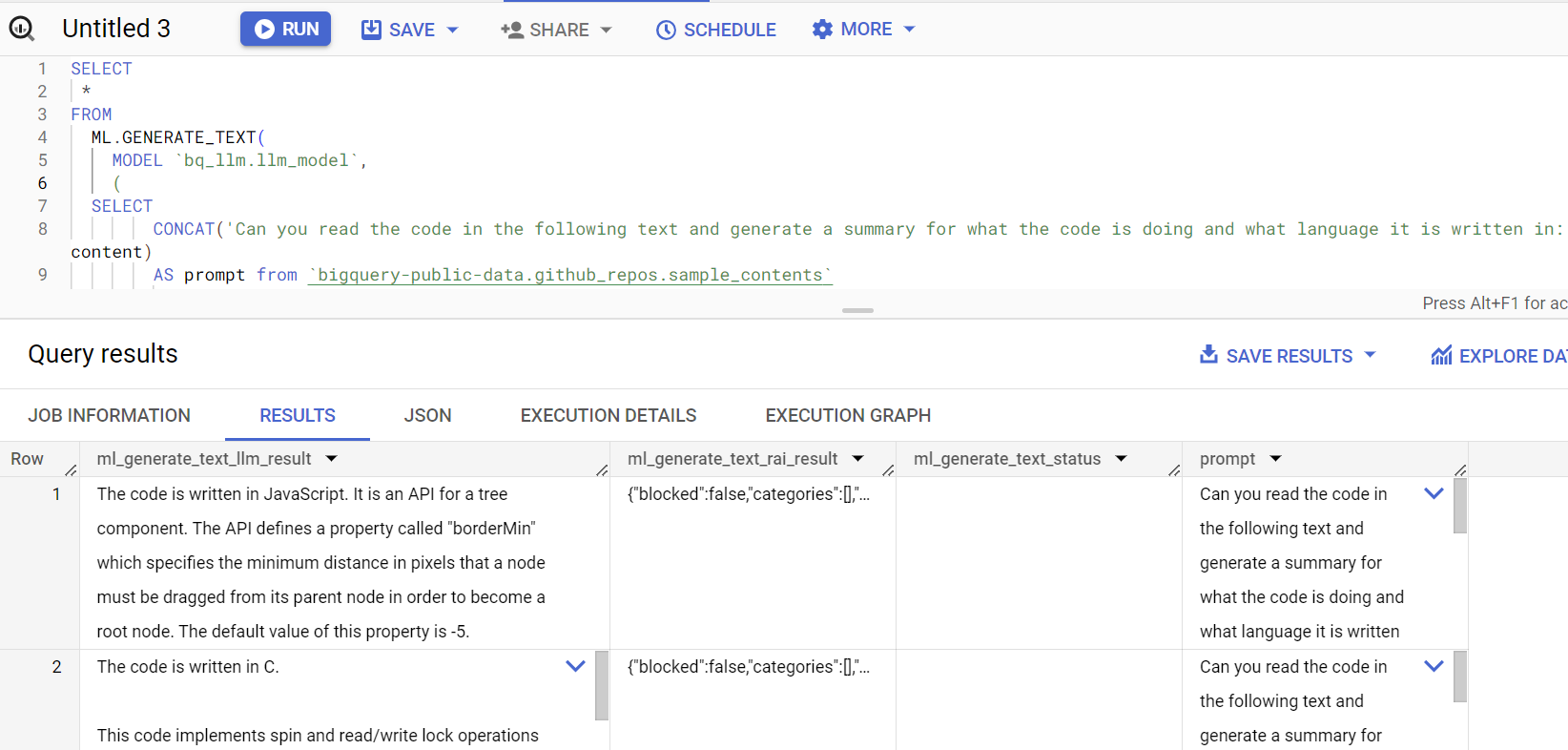
SELECT *
FROM
ML.GENERATE_TEXT(
MODEL `bq_llm.llm_model`,
(
SELECT
CONCAT('Can you read the code in the following text and generate a summary for what the code is doing and what language it is written in:', content)
AS prompt from `bigquery-public-data.github_repos.sample_contents`
limit 5
),
STRUCT(
0.2 AS temperature,
100 AS max_output_tokens,
TRUE AS flatten_json_output));
**說明:
Flatten_json_output** 代表布林值,如果設為 true,系統會傳回從 JSON 回應中擷取的扁平易懂文字。
查詢回應如下所示:
11. 清理
如要避免系統向您的 Google Cloud 帳戶收取本文章所用資源的費用,請按照下列步驟操作:
12. 恭喜
恭喜!您已成功使用 Vertex AI Text Generation LLM,以程式輔助方式對資料執行文字分析,且僅使用 SQL 查詢。如要進一步瞭解可用模型,請參閱 Vertex AI LLM 產品說明文件。