
1. Wprowadzenie
W tym ćwiczeniu użyjesz narzędzi MCP dla baz danych, aby udostępnić zbiory danych BigQuery.
W ramach ćwiczeń z programowania będziesz wykonywać kolejne czynności:
- Wskaż konkretny zbiór danych BigQuery („Google Cloud Release Notes”) z programu publicznych zbiorów danych BigQuery.
- Skonfiguruj Narzędzia MCP dla baz danych, które łączą się ze zbiorem danych BigQuery.
- Tworzenie agenta za pomocą pakietu Agent Development Kit (ADK), który będzie korzystać z zestawu narzędzi MCP, aby odpowiadać na zapytania użytkownika dotyczące informacji o wersjach Google Cloud
Co musisz zrobić
- Skonfiguruj narzędzia MCP dla baz danych, aby udostępniać informacje o wersjach Google Cloud, publiczny zbiór danych BigQuery, jako interfejs MCP dla innych klientów MCP (IDE, narzędzia itp.).
Czego się nauczysz
- Przeglądaj publiczne zbiory danych BigQuery i wybierz konkretny zbiór danych.
- Skonfiguruj narzędzia MCP dla baz danych w przypadku publicznego zbioru danych BigQuery, który chcesz udostępnić klientom MCP.
- Projektowanie i tworzenie agenta za pomocą pakietu Agent Development Kit (ADK) w celu odpowiadania na zapytania użytkowników.
- Przetestuj agenta i zestaw narzędzi MCP dla baz danych w środowisku lokalnym.
Czego potrzebujesz
- przeglądarki Chrome;
- lokalne środowisko programistyczne Pythona,
2. Zanim zaczniesz
Utwórz projekt
- W konsoli Google Cloud na stronie wyboru projektu wybierz lub utwórz projekt Google Cloud.
- Sprawdź, czy w projekcie Cloud włączone są płatności. Dowiedz się, jak sprawdzić, czy w projekcie są włączone płatności .
- Będziesz używać Cloud Shell, czyli środowiska wiersza poleceń działającego w Google Cloud, które jest wstępnie załadowane narzędziem bq. U góry konsoli Google Cloud kliknij Aktywuj Cloud Shell.

- Po połączeniu z Cloud Shell sprawdź, czy uwierzytelnianie zostało już przeprowadzone, a projekt jest już ustawiony na Twój identyfikator projektu, używając tego polecenia:
gcloud auth list
- Aby potwierdzić, że polecenie gcloud zna Twój projekt, uruchom w Cloud Shell to polecenie:
gcloud config list project
- Jeśli projekt nie jest ustawiony, użyj tego polecenia, aby go ustawić:
gcloud config set project <YOUR_PROJECT_ID>
- Włącz wymagane interfejsy API za pomocą polecenia pokazanego poniżej. Może to potrwać kilka minut, więc zachowaj cierpliwość.
gcloud services enable cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
cloudfunctions.googleapis.com \
aiplatform.googleapis.com \
sqladmin.googleapis.com \
compute.googleapis.com
Po pomyślnym wykonaniu polecenia powinien wyświetlić się komunikat podobny do tego poniżej:
Operation "operations/..." finished successfully.
Alternatywą dla polecenia gcloud jest wyszukanie poszczególnych usług w konsoli lub skorzystanie z tego linku.
Jeśli pominiesz jakiś interfejs API, możesz go włączyć w trakcie wdrażania.
Informacje o poleceniach gcloud i ich użyciu znajdziesz w dokumentacji.
3. Zbiór danych z informacjami o wersjach Google i klienci MCP
Najpierw zapoznajmy się z informacjami o wersjach Google Cloud, które są regularnie aktualizowane na oficjalnej stronie z informacjami o wersjach Google Cloud. Zrzut ekranu tej strony znajdziesz poniżej:
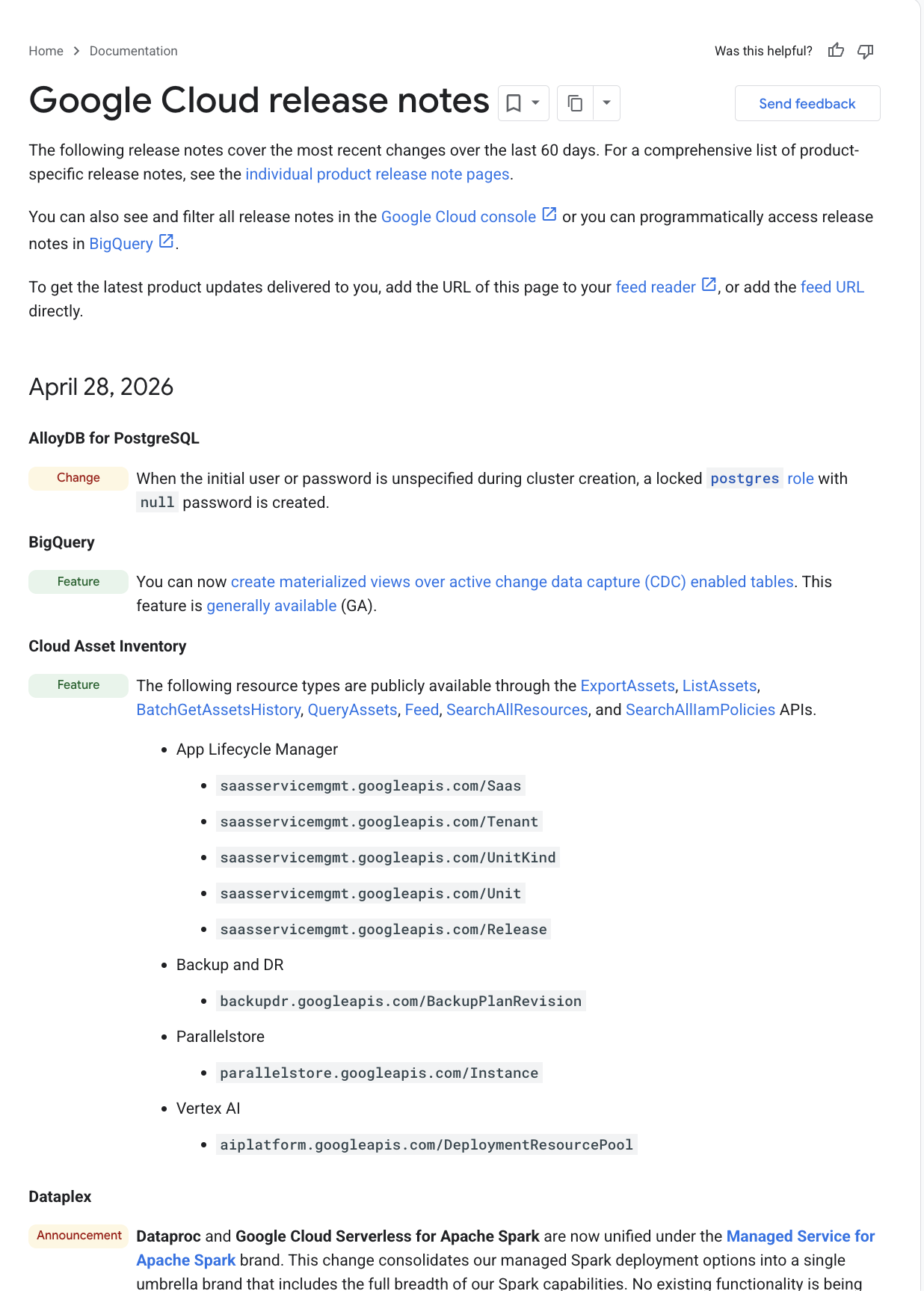
Możesz subskrybować adres URL kanału, ale co by było, gdybyśmy mogli po prostu zapytać na czacie agenta o te informacje o wersji. Może to być proste zapytanie, np. „Powiadom mnie o informacjach o wersji Google Cloud”.
4. Narzędzia MCP dla baz danych
MCP Toolbox for Databases to serwer MCP typu open source dla baz danych. Został zaprojektowany z myślą o zastosowaniach w przedsiębiorstwach i jakości produkcyjnej. Umożliwia łatwiejsze, szybsze i bezpieczniejsze tworzenie narzędzi dzięki obsłudze złożonych procesów, takich jak pula połączeń, uwierzytelnianie i inne.
Zestaw narzędzi pomaga tworzyć narzędzia generatywnej AI, które umożliwiają agentom dostęp do danych w bazie danych. Zestaw narzędzi zapewnia:
- Uproszczone tworzenie: zintegruj narzędzia z agentem za pomocą mniej niż 10 wierszy kodu, ponownie wykorzystuj narzędzia w wielu agentach lub platformach i łatwiej wdrażaj nowe wersje narzędzi.
- Lepsza wydajność: sprawdzone metody, takie jak pula połączeń, uwierzytelnianie i inne.
- Ulepszone zabezpieczenia: zintegrowane uwierzytelnianie zapewniające bezpieczniejszy dostęp do danych
- Kompleksowa widoczność: gotowe wskaźniki i śledzenie z wbudowaną obsługą OpenTelemetry.
- Narzędzia ułatwiają łączenie baz danych z dowolnymi asystentami AI obsługującymi MCP, nawet tymi w IDE.
Toolbox znajduje się między platformą orkiestracji aplikacji a bazą danych, zapewniając platformę sterującą, która służy do modyfikowania, rozpowszechniania i wywoływania narzędzi. Upraszcza zarządzanie narzędziami, ponieważ zapewnia centralną lokalizację do przechowywania i aktualizowania narzędzi. Umożliwia też udostępnianie narzędzi agentom i aplikacjom oraz aktualizowanie ich bez konieczności ponownego wdrażania aplikacji.
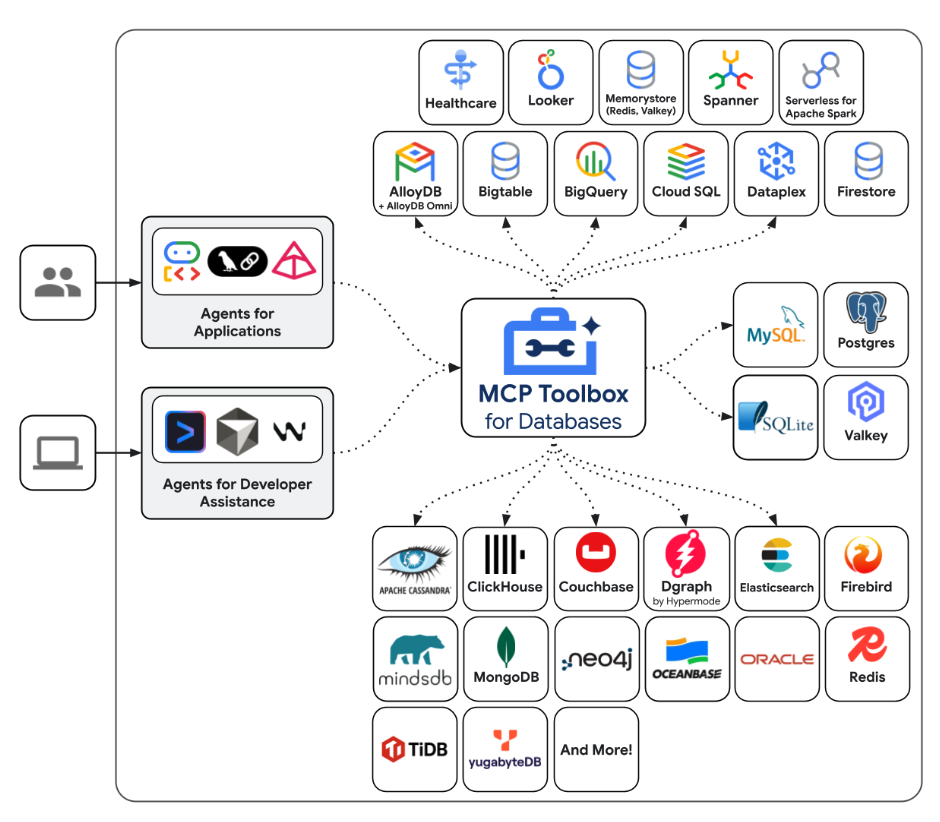
Podsumowując w prostych słowach:
- MCP Toolbox jest dostępny jako plik binarny, obraz kontenera lub można go utworzyć z kodu źródłowego.
- Udostępnia zestaw narzędzi, które konfigurujesz za pomocą pliku tools.yaml. Narzędzia te można traktować jako połączenia ze źródłami danych. Możesz zobaczyć różne źródła danych, które obsługuje : AlloyDB, BigQuery itp.
- Ponieważ ten zestaw narzędzi obsługuje teraz MCP, automatycznie masz punkt końcowy serwera MCP, który może być używany przez agentów (IDE) lub podczas tworzenia aplikacji agentów przy użyciu różnych platform, takich jak pakiet Agent Development Kit (ADK).
W tym poście na blogu skupimy się na obszarach wyróżnionych poniżej:
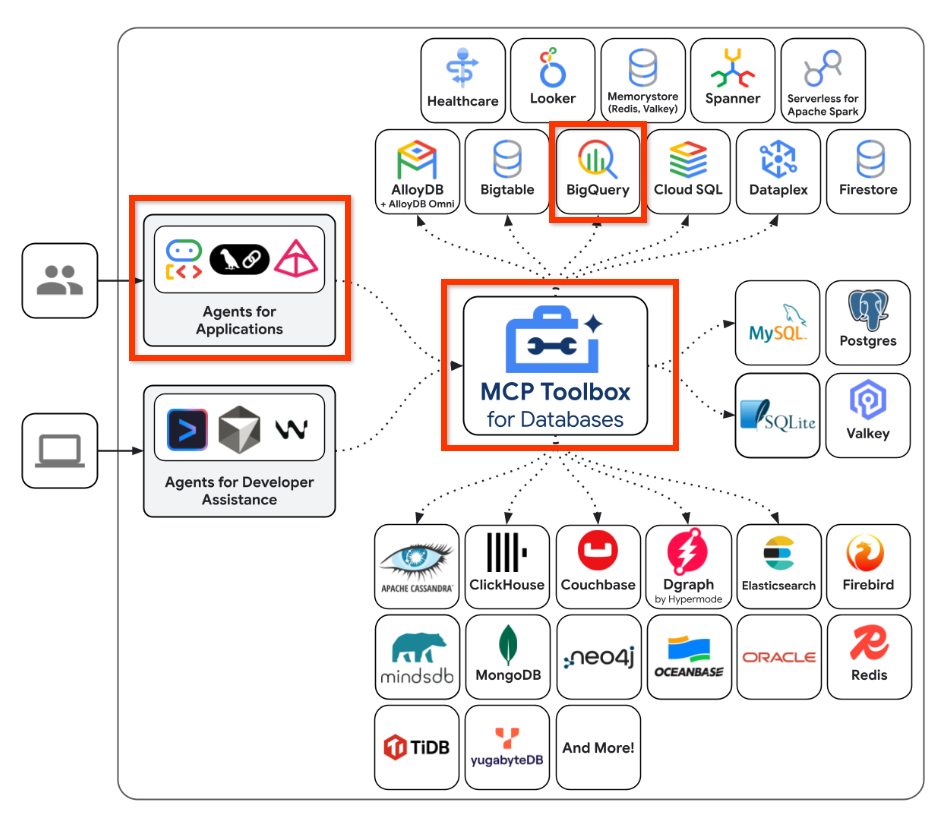
Podsumowując, utworzymy konfigurację w narzędziach MCP dla baz danych, która będzie wiedzieć, jak połączyć się ze zbiorem danych BigQuery. Następnie za pomocą pakietu Agent Development Kit (ADK) utworzymy agenta, który będzie zintegrowany z punktem końcowym zestawu narzędzi MCP i umożliwi nam wysyłanie zapytań w języku naturalnym dotyczących naszego zbioru danych. Możesz ją traktować jako aplikację opartą na agentach, którą tworzysz i która wie, jak komunikować się ze zbiorem danych BigQuery i uruchamiać zapytania.
5. Informacje o wersji zbioru danych BigQuery dla Google Cloud
Program publicznych zbiorów danych Google Cloud udostępnia szereg zbiorów danych dla Twoich aplikacji. Jednym z takich zbiorów danych jest baza danych informacji o wersjach Google Cloud. Ten zbiór danych zawiera te same informacje co oficjalna strona z informacjami o wersjach Google Cloud i jest dostępny jako publiczny zbiór danych, w którym można wykonywać zapytania.
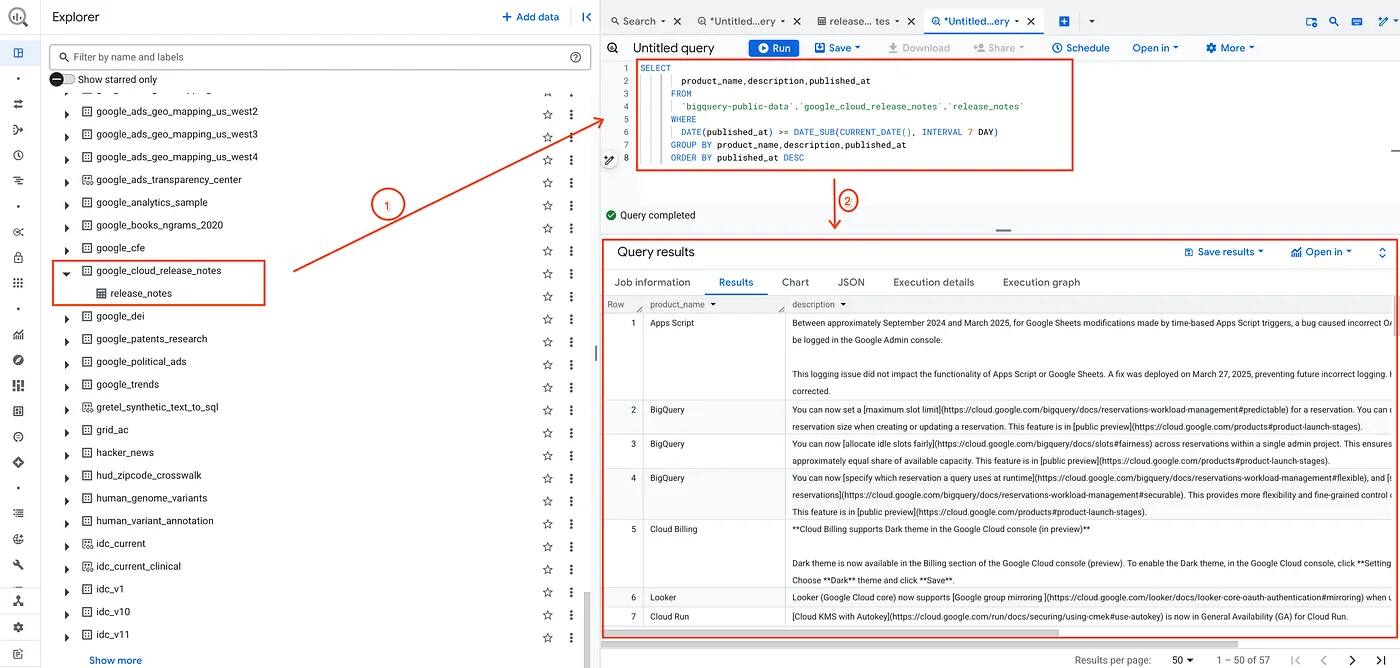
W ramach testu po prostu weryfikuję zbiór danych, uruchamiając proste zapytanie pokazane poniżej:
SELECT
product_name,description,published_at
FROM
`bigquery-public-data`.`google_cloud_release_notes`.`release_notes`
WHERE
DATE(published_at) >= DATE_SUB(CURRENT_DATE(), INTERVAL 7 DAY)
GROUP BY product_name,description,published_at
ORDER BY published_at DESC
W ten sposób otrzymam listę rekordów z zestawu danych Release Notes, które zostały opublikowane w ciągu ostatnich 7 dni.
Zastąp go dowolnym innym zbiorem danych oraz odpowiednimi zapytaniami i parametrami. Teraz musimy tylko skonfigurować to jako źródło danych i narzędzie w MCP Toolbox for Databases. Zobaczmy, jak to zrobić.
6. Instalowanie zestawu narzędzi MCP dla baz danych
Otwórz terminal na komputerze lokalnym i utwórz folder o nazwie mcp-toolbox.
mkdir mcp-toolbox
Otwórz folder mcp-toolbox za pomocą tego polecenia:
cd mcp-toolbox
Zainstaluj binarną wersję zestawu narzędzi MCP dla baz danych za pomocą skryptu podanego poniżej. Poniższe polecenie jest przeznaczone dla systemu Linux, ale jeśli używasz komputera Mac lub Windows, pobierz odpowiedni plik binarny. Odwiedź stronę wydań dla swojego systemu operacyjnego i architektury i pobierz odpowiedni plik binarny.
export VERSION=1.1.0
curl -L -o toolbox https://storage.googleapis.com/mcp-toolbox-for-databases/v$VERSION/linux/amd64/toolbox
chmod +x toolbox
Mamy teraz gotową do użycia wersję binarną zestawu narzędzi. Następnym krokiem jest skonfigurowanie skrzynki narzędziowej za pomocą naszych źródeł danych i innych ustawień.
7. Konfigurowanie zestawu narzędzi MCP dla baz danych
Teraz musimy zdefiniować zbiór danych i narzędzia BigQuery w pliku tools.yaml, który jest potrzebny w narzędziach MCP dla baz danych. Plik tools.yaml to podstawowy sposób konfigurowania Toolboxa.
W tym samym folderze, czyli mcp-toolbox, utwórz plik o nazwie tools.yaml, którego zawartość jest pokazana poniżej.
Możesz użyć edytora nano dostępnego w Cloud Shell. Polecenie nano ma postać: „nano tools.yaml”.
Pamiętaj, aby zastąpić wartość YOUR_PROJECT_ID identyfikatorem projektu Google Cloud.
kind: source
name: my-bq-source
type: bigquery
project: gcp-experiments-349209
---
kind: tool
name: search_release_notes_bq
type: bigquery-sql
source: my-bq-source
description: Use this tool to get information on Google Cloud Release Notes.
statement: |
SELECT
product_name,description,published_at
FROM
`bigquery-public-data`.`google_cloud_release_notes`.`release_notes`
WHERE
DATE(published_at) >= DATE_SUB(CURRENT_DATE(), INTERVAL 7 DAY)
GROUP BY product_name,description,published_at
ORDER BY published_at DESC;
---
kind: toolset
name: my_bq_toolset
tools:
- search_release_notes_bq
Krótko opisz plik:
- Źródła to różne źródła danych, z którymi narzędzie może wchodzić w interakcje. Źródło to źródło danych, z którym narzędzie może wchodzić w interakcje. Źródła możesz zdefiniować jako mapę w sekcji źródeł pliku tools.yaml. Zwykle konfiguracja źródła zawiera wszystkie informacje potrzebne do połączenia z bazą danych i korzystania z niej. W naszym przypadku zdefiniowaliśmy źródło BigQuery
my-bq-sourcei musisz podać identyfikator projektu Google Cloud. Więcej informacji znajdziesz w sekcji Źródła. - Narzędzia określają działania, które może wykonać agent, np. odczytywanie i zapisywanie w źródle. Narzędzie reprezentuje działanie, które może wykonać Twój agent, np. uruchomienie instrukcji SQL. Narzędzia możesz zdefiniować jako mapę w sekcji narzędzi w pliku tools.yaml. Zwykle narzędzie wymaga źródła, na którym ma działać. W naszym przypadku definiujemy jedno narzędzie
search_release_notes_bq. Odwołuje się to do źródła BigQuerymy-bq-source, które zostało zdefiniowane w pierwszym kroku. Zawiera też oświadczenie i instrukcję, które będą używane przez klientów agenta AI. Więcej informacji znajdziesz w dokumentacji. - Na koniec mamy Zestaw narzędzi, który umożliwia definiowanie grup narzędzi, które chcesz wczytywać razem. Może to być przydatne do definiowania różnych grup na podstawie agenta lub aplikacji. W naszym przypadku mamy definicję zestawu narzędzi, w której zdefiniowaliśmy tylko 1 istniejące narzędzie
search_release_notes_bq. Możesz mieć więcej niż 1 zestaw narzędzi, który zawiera kombinację różnych narzędzi.
Obecnie mamy zdefiniowane tylko jedno narzędzie, które pobiera informacje o wersji z ostatnich 7 dni zgodnie z zapytaniem. Możesz jednak tworzyć różne kombinacje z parametrami.
Więcej szczegółów konfiguracji znajdziesz w konfiguracji źródła danych BigQuery w narzędziach MCP dla baz danych.
8. Testowanie narzędzi MCP dla baz danych
Pobraliśmy i skonfigurowaliśmy Toolbox za pomocą pliku tools.yaml w folderze mcp-toolbox. Najpierw uruchommy go lokalnie.
Uruchom to polecenie:
./toolbox --config "tools.yaml"
Po pomyślnym wykonaniu powinny pojawić się dane wyjściowe podobne do tych poniżej:
2026-04-29T10:26:15.435384+05:30 INFO "Initialized 1 sources: my-bq-source"
2026-04-29T10:26:15.435424+05:30 INFO "Initialized 0 authServices: "
2026-04-29T10:26:15.435428+05:30 INFO "Initialized 0 embeddingModels: "
2026-04-29T10:26:15.435446+05:30 INFO "Initialized 1 tools: search_release_notes_bq"
2026-04-29T10:26:15.435456+05:30 INFO "Initialized 2 toolsets: my_bq_toolset, default"
2026-04-29T10:26:15.435461+05:30 INFO "Initialized 0 prompts: "
2026-04-29T10:26:15.435467+05:30 INFO "Initialized 1 promptsets: default"
2026-04-29T10:26:15.435487+05:30 WARN "wildcard (`*`) allows all origin to access the resource and is not secure. Use it with cautious for public, non-sensitive data, or during local development. Recommended to use `--allowed-origins` flag"
2026-04-29T10:26:15.435508+05:30 WARN "wildcard (`*`) allows all hosts to access the resource and is not secure. Use it with cautious for public, non-sensitive data, or during local development. Recommended to use `--allowed-hosts` flag to prevent DNS rebinding attacks"
2026-04-29T10:26:15.435728+05:30 INFO "Server ready to serve!"
Serwer MCP Toolbox działa domyślnie na porcie 5000. Jeśli port 5000 jest już używany, możesz użyć innego portu (np. 7000), jak pokazano w poniższym poleceniu. W kolejnych poleceniach używaj portu 7000 zamiast portu 5000.
./toolbox --config "tools.yaml" --port 7000
Aby to przetestować, użyjemy Cloud Shell.
W Cloud Shell kliknij Podgląd w przeglądarce, jak pokazano poniżej:
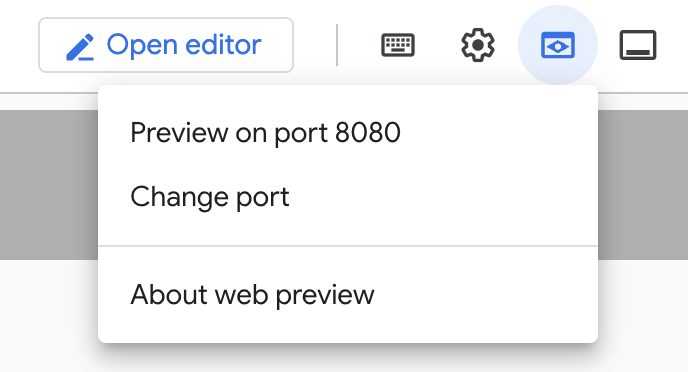
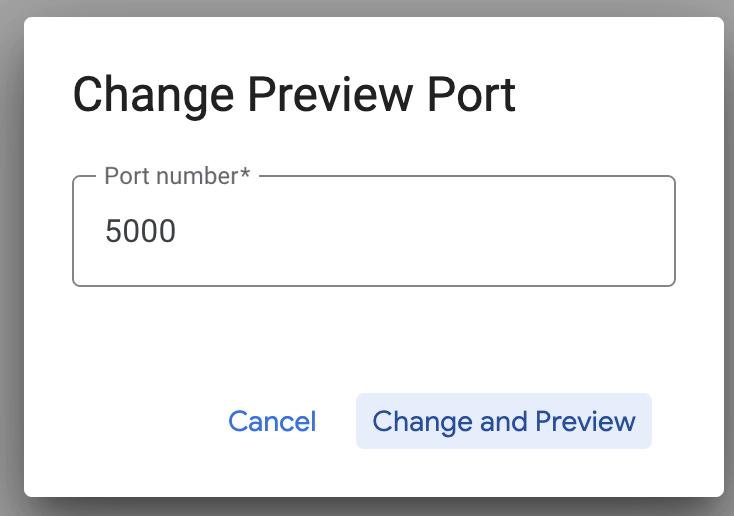
Kliknij Zmień port i ustaw port na 5000, jak pokazano poniżej. Następnie kliknij Zmień i wyświetl podgląd.
Powinny się wyświetlić te dane wyjściowe:
Testowanie narzędzi w interfejsie MCP Toolbox for Databases
Zestaw narzędzi udostępnia interfejs wizualny (interfejs zestawu narzędzi), który umożliwia bezpośrednie korzystanie z narzędzi przez modyfikowanie parametrów, zarządzanie nagłówkami i wykonywanie wywołań w prostym interfejsie internetowym.
Jeśli chcesz to przetestować, możesz uruchomić poprzednie polecenie, którego użyliśmy do uruchomienia serwera Toolbox, z opcją --ui.
Aby to zrobić, zamknij poprzednią instancję serwera MCP Toolbox for Databases, która może być uruchomiona, i wpisz to polecenie:
./toolbox --tools-file "tools.yaml" --ui
Powinien pojawić się komunikat informujący, że serwer połączył się z naszymi źródłami danych oraz załadował zestaw narzędzi i narzędzia. Poniżej znajdziesz przykładowe dane wyjściowe. Zauważysz, że zawierają one informację o tym, że interfejs Toolbox działa.
2026-04-29T10:29:44.750446+05:30 INFO "Initialized 1 sources: my-bq-source"
2026-04-29T10:29:44.750463+05:30 INFO "Initialized 0 authServices: "
2026-04-29T10:29:44.750467+05:30 INFO "Initialized 0 embeddingModels: "
2026-04-29T10:29:44.750474+05:30 INFO "Initialized 1 tools: search_release_notes_bq"
2026-04-29T10:29:44.750482+05:30 INFO "Initialized 2 toolsets: my_bq_toolset, default"
2026-04-29T10:29:44.750487+05:30 INFO "Initialized 0 prompts: "
2026-04-29T10:29:44.750493+05:30 INFO "Initialized 1 promptsets: default"
2026-04-29T10:29:44.7505+05:30 WARN "wildcard (`*`) allows all origin to access the resource and is not secure. Use it with cautious for public, non-sensitive data, or during local development. Recommended to use `--allowed-origins` flag"
2026-04-29T10:29:44.750512+05:30 WARN "wildcard (`*`) allows all hosts to access the resource and is not secure. Use it with cautious for public, non-sensitive data, or during local development. Recommended to use `--allowed-hosts` flag to prevent DNS rebinding attacks"
2026-04-29T10:29:44.750601+05:30 INFO "Server ready to serve!"
2026-04-29T10:29:44.750605+05:30 INFO "Toolbox UI is up and running at: http://127.0.0.1:5000/ui"
Kliknij adres URL interfejsu i upewnij się, że na końcu adresu URL znajduje się znak /ui. Wyświetli się interfejs podobny do tego poniżej:
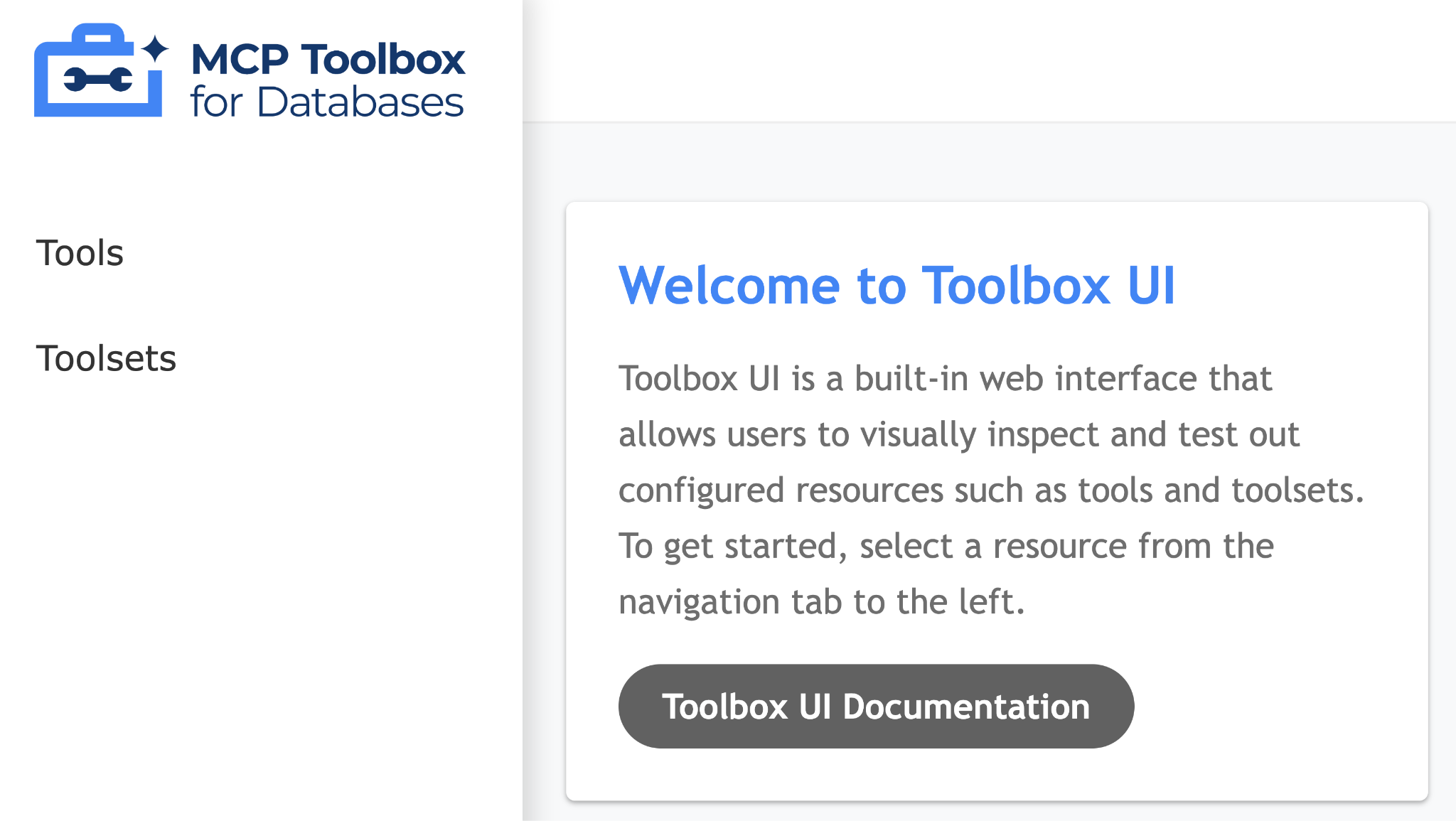
Po lewej stronie kliknij opcję Narzędzia, aby wyświetlić skonfigurowane narzędzia. W naszym przypadku powinno być tylko jedno, czyli search_release_notes_bq, jak pokazano poniżej:
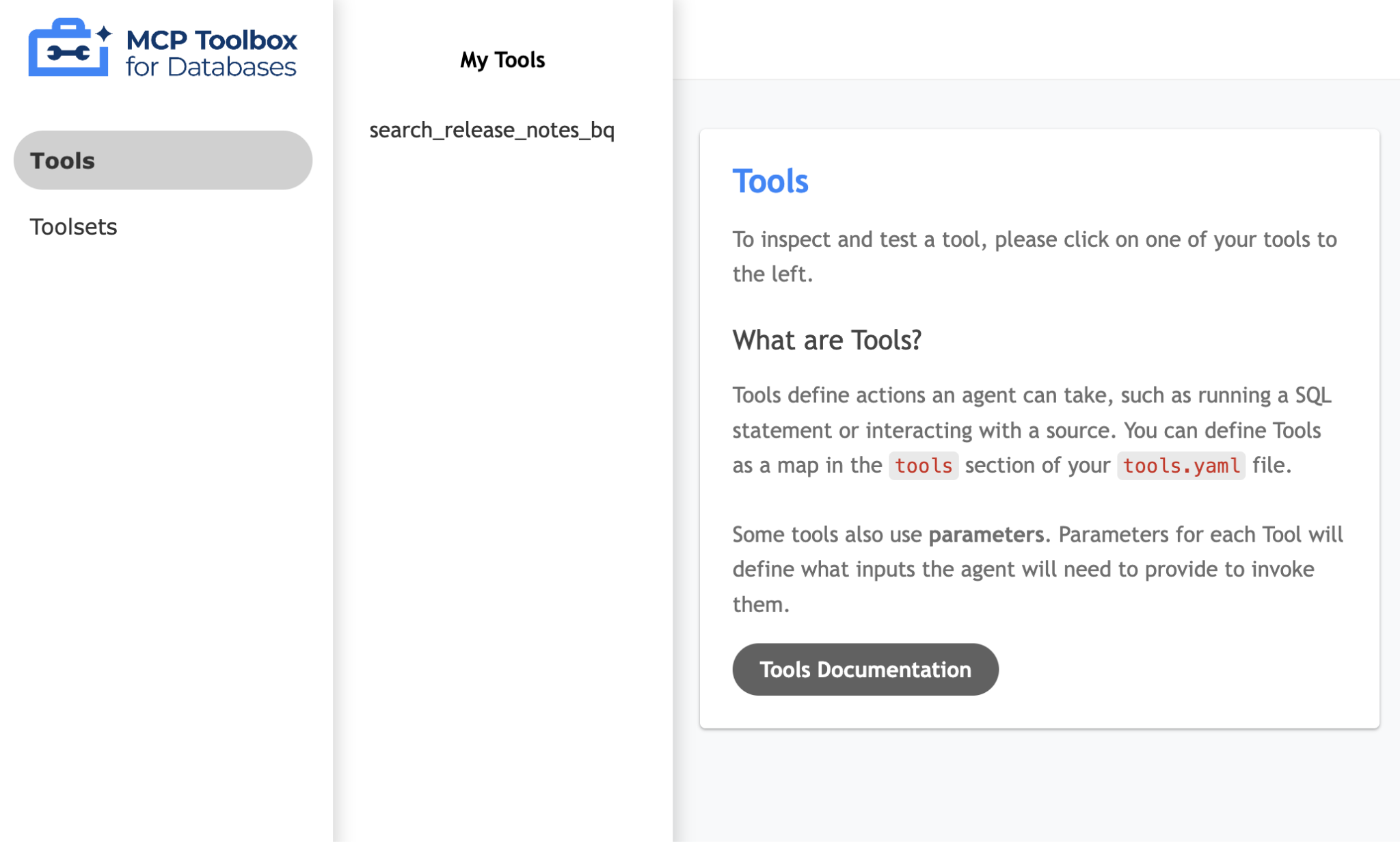
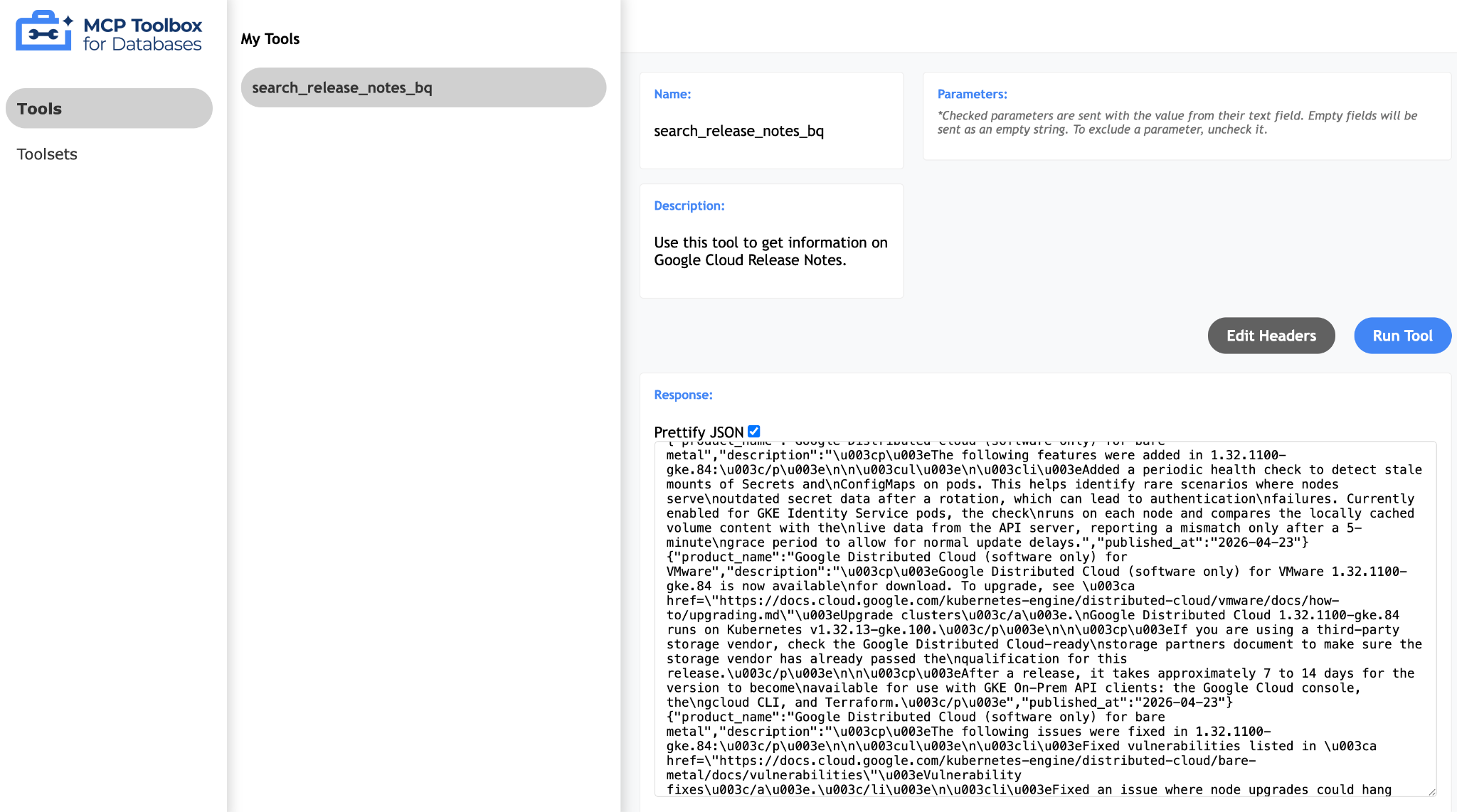
Wystarczy kliknąć narzędzia search_release_notes_bq, aby otworzyć stronę, na której możesz je przetestować. Nie musisz podawać żadnych parametrów. Aby zobaczyć wynik, wystarczy kliknąć Uruchom narzędzie. Przykładowe uruchomienie pokazano poniżej:
9. Tworzenie agenta za pomocą pakietu Agent Development Kit (ADK)
Instalowanie pakietu Agent Development Kit (ADK)
Otwórz nową kartę terminala w Cloud Shell i utwórz folder o nazwie my-agents w ten sposób: Przejdź też do folderu my-agents.
mkdir my-agents
cd my-agents
Teraz utwórzmy wirtualne środowisko Pythona za pomocą narzędzia venv:
python -m venv .venv
Aktywuj środowisko wirtualne w ten sposób:
source .venv/bin/activate
Zainstaluj pakiety ADK i MCP Toolbox for Databases wraz z zależnością langchain w ten sposób:
pip install google-adk toolbox-core
Narzędzie adk możesz teraz wywołać w ten sposób.
adk
Wyświetli się lista poleceń.
$ adk
Usage: adk [OPTIONS] COMMAND [ARGS]...
Agent Development Kit CLI tools.
Options:
--help Show this message and exit.
Commands:
api_server Starts a FastAPI server for agents.
create Creates a new app in the current folder with prepopulated agent template.
deploy Deploys agent to hosted environments.
eval Evaluates an agent given the eval sets.
run Runs an interactive CLI for a certain agent.
web Starts a FastAPI server with Web UI for agents.
Tworzenie pierwszej aplikacji agenta
Teraz użyjemy adk, aby utworzyć szkielet aplikacji Google Cloud Release Notes Agent za pomocą polecenia adk create z nazwą aplikacji **(gcp_releasenotes_agent_app)**podaną poniżej.
adk create gcp_releasenotes_agent_app
Wykonaj te czynności:
- Model Gemini do wybierania modelu dla agenta głównego.
- Wybierz Vertex AI jako backend.
- Wyświetli się domyślny identyfikator projektu Google i region. Wybierz domyślne ustawienie.
Choose a model for the root agent:
1. gemini-2.5-flash
2. Other models (fill later)
Choose model (1, 2): 1
1. Google AI
2. Vertex AI
Choose a backend (1, 2): 2
You need an existing Google Cloud account and project, check out this link for details:
https://google.github.io/adk-docs/get-started/quickstart/#gemini---google-cloud-vertex-ai
Enter Google Cloud project ID [YOUR_GOOGLE_PROJECT_ID]:
Enter Google Cloud region [us-central1]:
Agent created in ../my-agents/gcp_releasenotes_agent_app:
- .env
- __init__.py
- agent.py
Sprawdź folder, w którym utworzono szablon domyślny i wymagane pliki dla agenta.
Pierwszy z nich to plik .env. Ich zawartość jest widoczna poniżej:
GOOGLE_GENAI_USE_VERTEXAI=1
GOOGLE_CLOUD_PROJECT=YOUR_GOOGLE_PROJECT_ID
GOOGLE_CLOUD_LOCATION=YOUR_GOOGLE_PROJECT_REGION
Wartości te wskazują, że będziemy korzystać z Gemini przez Vertex AI wraz z odpowiednimi wartościami identyfikatora projektu Google Cloud i lokalizacji.
Następnie mamy plik __init__.py, który oznacza folder jako moduł i zawiera pojedynczą instrukcję importowania agenta z pliku agent.py.
from . import agent
Na koniec przyjrzyjmy się plikowi agent.py. Treści są widoczne poniżej:
from google.adk.agents import Agent
root_agent = Agent(
model='gemini-2.5-flash',
name='root_agent',
description='A helpful assistant for user questions.',
instruction='Answer user questions to the best of your knowledge',
)
Jest to najprostszy agent, jakiego możesz napisać za pomocą pakietu ADK. Z dokumentacji pakietu ADK wynika, że agent to samodzielna jednostka wykonawcza zaprojektowana do autonomicznego działania w celu osiągnięcia określonych celów. Agenci mogą wykonywać zadania, wchodzić w interakcje z użytkownikami, korzystać z narzędzi zewnętrznych i współpracować z innymi agentami.
W szczególności LLMAgent, zwykle nazywany Agentem, wykorzystuje duże modele językowe (LLM) jako główny silnik do rozumienia języka naturalnego, wnioskowania, planowania, generowania odpowiedzi i dynamicznego decydowania, jak postępować lub których narzędzi używać. Dzięki temu idealnie nadaje się do elastycznych zadań związanych z językiem. Więcej informacji o agentach LLM znajdziesz tutaj.
To już koniec tworzenia szkieletu do wygenerowania podstawowego agenta za pomocą pakietu Agent Development Kit (ADK). Teraz połączymy agenta z MCP Toolbox, aby mógł używać tego narzędzia do odpowiadania na zapytania użytkownika (w tym przypadku będą to informacje o wersjach Google Cloud).
10. Łączenie agenta z narzędziami
Połączymy teraz tego agenta z narzędziami. W kontekście pakietu ADK narzędzie to konkretna zdolność udostępniana agentowi AI, która umożliwia mu wykonywanie działań i interakcje ze światem wykraczające poza podstawowe możliwości generowania tekstu i rozumowania.
W tym przypadku wyposażymy teraz naszego agenta w narzędzia, które skonfigurowaliśmy w zestawie narzędzi MCP dla baz danych.
Zmodyfikuj plik agent.py, dodając do niego ten kod. Zwróć uwagę, że w kodzie używamy domyślnego portu 5000, ale jeśli używasz innego numeru portu, wpisz go.
from google.adk.agents import Agent
from toolbox_core import ToolboxSyncClient
toolbox = ToolboxSyncClient("http://127.0.0.1:5000")
# Load all the tools
tools = toolbox.load_toolset('my_bq_toolset')
root_agent = Agent(
name="gcp_releasenotes_agent",
model="gemini-2.5-flash",
description=(
"Agent to answer questions about Google Cloud Release notes."
),
instruction=(
"You are a helpful agent who can answer user questions about the Google Cloud Release notes. Use the tools to answer the question"
),
tools=tools,
)
Możemy teraz przetestować agenta, który będzie pobierać rzeczywiste dane z naszego zbioru danych BigQuery skonfigurowanego za pomocą MCP Toolbox for Databases.
Aby to zrobić, wykonaj te czynności:
W jednym z terminali Cloud Shell uruchom narzędzia MCP Toolbox for Databases. Może być już uruchomiony lokalnie na porcie 5000, ponieważ testowaliśmy go wcześniej. Jeśli nie, uruchom to polecenie (z folderu mcp-toolbox), aby uruchomić serwer:
./toolbox --config "tools.yaml"
Powinien pojawić się komunikat informujący, że serwer połączył się z naszymi źródłami danych oraz załadował zestaw narzędzi i narzędzia.
Gdy serwer MCP zostanie uruchomiony, w innym terminalu uruchom agenta za pomocą polecenia adk run (z folderu my-agents) pokazanego poniżej. Możesz też użyć polecenia adk web.
$ adk run gcp_releasenotes_agent_app/
Running agent gcp_releasenotes_agent, type exit to exit.
[user]: Hello
[gcp_releasenotes_agent]: Hello! I'm here to help you with Google Cloud Release Notes. What would you like to know today?
[user]: get me the google cloud release notes
[gcp_releasenotes_agent]: Here are the Google Cloud Release Notes:
* **Cloud Asset Inventory** (Published: 2026-04-28)
The following resource types are publicly available through the ExportAssets, ListAssets, BatchGetAssetsHistory, QueryAssets, Feed, SearchAllResources, and SearchAllIamPolicies APIs.
* App Lifecycle Manager
* `saasservicemgmt.googleapis.com/Saas`
* `saasservicemgmt.googleapis.com/Tenant`
* `saasservicemgmt.googleapis.com/UnitKind`
* `saasservicemgmt.googleapis.com/Unit`
* `saasservicemgmt.googleapis.com/Release`
* Backup and DR
* `backupdr.googleapis.com/BackupPlanRevision`
* Parallelstore
* `parallelstore.googleapis.com/Instance`
* Vertex AI
* `aiplatform.googleapis.com/DeploymentResourcePool`
* **Google Cloud Contact Center as a Service** (Published: 2026-04-27)
**Call scheduling improvements**
We've made the following improvements to call scheduling for web SDK v3 and the headless web SDK:
* **Configurable time slots**. You can configure the length of call-scheduling time slots.
* **Day-based time slot selection**. End-users can browse available time slots organized by day.
* **Rescheduling**. If an end-user reopens the web SDK and has an existing scheduled call, they're prompted to manage that appointment (reschedule or cancel) before starting a new flow.
* **Cancellation**. End-users can cancel a previously scheduled call.
* **Queue-level configuration**. You can configure call scheduling at the queue level.
**Note:** Headless web SDK users must specify `useAdvancedCallScheduling: true` with calls to the `getTimeSlots` method to access these call scheduling improvements.
Administrators:
* There's a new **Scheduled Calls** pane on the **Settings > Calls** page.
* There's a new **Scheduled Calls** section in the **Settings > Queue > Web > SELECT_QUEUE** pane.
* We moved **Scheduled Call Countdown** and **Scheduled Call Expiration** from **Settings > Calls > Call Details** to **Settings > Calls > Scheduled Calls**.
* We've added the following settings to the **Settings > Calls > Scheduled Calls** pane:
* **Consumers can schedule calls up to SELECT_INTEGER day(s) in the future**
* **Static > Maximum calls per time slot**
User experience changes:
* For **Scheduled Calls**, if you select **Consumers can schedule calls up to SELECT_INTEGER day(s) in the future**, a new **Select a day** screen appears to end-users who reschedule a call.
* **Compute Engine** (Published: 2026-04-27)
**Generally available**: Compute Engine now offers support for AI zones. To learn more, see AI zones.
* **Cloud Storage** (Published: 2026-04-27)
Cloud Storage now offers support for AI zones. To learn more, see AI zones.
* **Apigee hybrid** (Published: 2026-04-27)
**Sidecar authentication for Workload Identity Federation on non-GKE platforms**
Starting in version v1.14.4, you can now use a sidecar along with Workload Identity Federation on non-GKE platforms to mount security tokens from your preferred identity provider (IDP) for service account authentication. See Use sidecar authentication for Workload Identity Federation on non-GKE platforms.
* **Cloud Workstations** (Published: 2026-04-27)
The preconfigured base images include a notification when the `running_timeout` for the workstation is close to being reached.
* **Cloud Trace** (Published: 2026-04-27)
Cloud Trace is a service covered by the Cloud Obse
......
......
Zwróć uwagę, że agent korzysta z narzędzia skonfigurowanego w MCP Toolbox for Databases (search_release_notes_bq), pobiera dane ze zbioru danych BigQuery i odpowiednio formatuje odpowiedź.
11. Gratulacje
Gratulacje. Udało Ci się skonfigurować Narzędzia MCP dla baz danych i zbiór danych BigQuery na potrzeby dostępu w klientach MCP.