
1. Descripción general
Un agente es un programa autónomo que habla con un modelo de IA para realizar una operación basada en objetivos con las herramientas y el contexto que tiene, y es capaz de tomar decisiones autónomas basadas en la verdad.
Cuando tu aplicación tiene varios agentes que trabajan juntos de forma autónoma y según sea necesario para cumplir con su propósito más amplio, y cada uno de sus agentes tiene conocimientos de forma independiente y es responsable de un área de enfoque específica, tu aplicación se convierte en un sistema multiagente.
El Kit de desarrollo de agentes (ADK)
El Kit de desarrollo de agentes (ADK) es un framework flexible y modular para desarrollar y, luego, implementar agentes de IA. El ADK admite la creación de aplicaciones sofisticadas a través de la composición de varias instancias de agentes distintos en un sistema multiagente (MAS).
En el ADK, un sistema multiagente es una aplicación en la que diferentes agentes, que a menudo forman una jerarquía, colaboran o se coordinan para lograr un objetivo mayor. Estructurar tu aplicación de esta manera ofrece ventajas significativas, como mayor modularidad, especialización, reutilización, capacidad de mantenimiento y la posibilidad de definir flujos de control estructurados con agentes de flujo de trabajo dedicados.
Aspectos que debes tener en cuenta para un sistema multiagente
Primero, es importante comprender y razonar correctamente la especialización de cada agente. "¿Sabes por qué necesitas un subagente específico para algo?", primero averigua eso.
Segundo, cómo reunirlos con un agente raíz para enrutar y comprender cada una de las respuestas.
Tercero, existen varios tipos de enrutamiento de agentes que puedes encontrar aquí en esta documentación. Asegúrate de elegir el que mejor se adapte al flujo de tu aplicación. También debes definir los diversos contextos y estados que necesitas para el control de flujo de tu sistema multiagente.
Qué compilarás
Creemos un sistema multiagente para encargarnos de las renovaciones de la cocina. Eso es lo que haremos. Compilaremos un sistema con 3 agentes.
- Agente de propuestas de renovación
- Agente de verificación de permisos y cumplimiento
- Agente de verificación del estado del pedido
Agente de propuestas de renovación, para generar el documento de propuesta de renovación de la cocina.
Agente de Permisos y Cumplimiento, para ocuparse de las tareas relacionadas con los permisos y el cumplimiento
Agente de verificación del estado del pedido, para verificar el estado del pedido de materiales trabajando en la base de datos de administración de pedidos que configuramos en AlloyDB.
Tendremos un agente raíz que coordinará estos agentes según el requisito.
Requisitos
2. Antes de comenzar
Crea un proyecto
- En la página del selector de proyectos de la consola de Google Cloud, selecciona o crea un proyecto de Google Cloud.
- Asegúrate de que la facturación esté habilitada para tu proyecto de Cloud. Obtén información para verificar si la facturación está habilitada en un proyecto .
- Haz clic en este vínculo para activar Cloud Shell. Para alternar entre la terminal de Cloud Shell (para ejecutar comandos de Cloud) y el editor (para compilar proyectos), haz clic en el botón correspondiente de Cloud Shell.
- Una vez que te conectes a Cloud Shell, verifica que ya te autenticaste y que el proyecto se configuró con tu ID del proyecto con el siguiente comando:
gcloud auth list
- En Cloud Shell, ejecuta el siguiente comando para confirmar que el comando gcloud conoce tu proyecto.
gcloud config list project
- Si tu proyecto no está configurado, usa el siguiente comando para hacerlo:
gcloud config set project <YOUR_PROJECT_ID>
- Asegúrate de tener Python 3.9 o una versión posterior.
- Ejecuta los siguientes comandos para habilitar las APIs:
gcloud services enable artifactregistry.googleapis.com \cloudbuild.googleapis.com \run.googleapis.com \aiplatform.googleapis.com
- Consulta la documentación para ver los comandos y el uso de gcloud.
3. Prototipo
Puedes omitir este paso si decides usar el modelo "Gemini 2.5 Pro" para el proyecto.
Ve a Google AI Studio. Comienza a escribir la instrucción. Esta es mi instrucción:
I want to renovate my kitchen, basically just remodel it. I don't know where to start. So I want to use Gemini to generate a plan. For that I need a good prompt. Give me a short yet detailed prompt that I can use.
Ajusta y configura los parámetros del lado derecho para obtener una respuesta óptima.
Según esta simple descripción, Gemini me creó una instrucción increíblemente detallada para comenzar mi renovación. En efecto, usamos Gemini para obtener respuestas aún mejores de AI Studio y nuestros modelos. También puedes seleccionar diferentes modelos para usar, según tu caso de uso.
Elegimos Gemini 2.5 Pro. Este es un modelo de razonamiento, lo que significa que obtenemos aún más tokens de salida, en este caso hasta 65,000 tokens, para análisis de formato largo y documentación detallada. La caja de pensamiento de Gemini aparece cuando habilitas Gemini 2.5 Pro, que tiene capacidades de razonamiento nativas y puede procesar solicitudes de contexto largo.
A continuación, se muestra un fragmento de la respuesta:
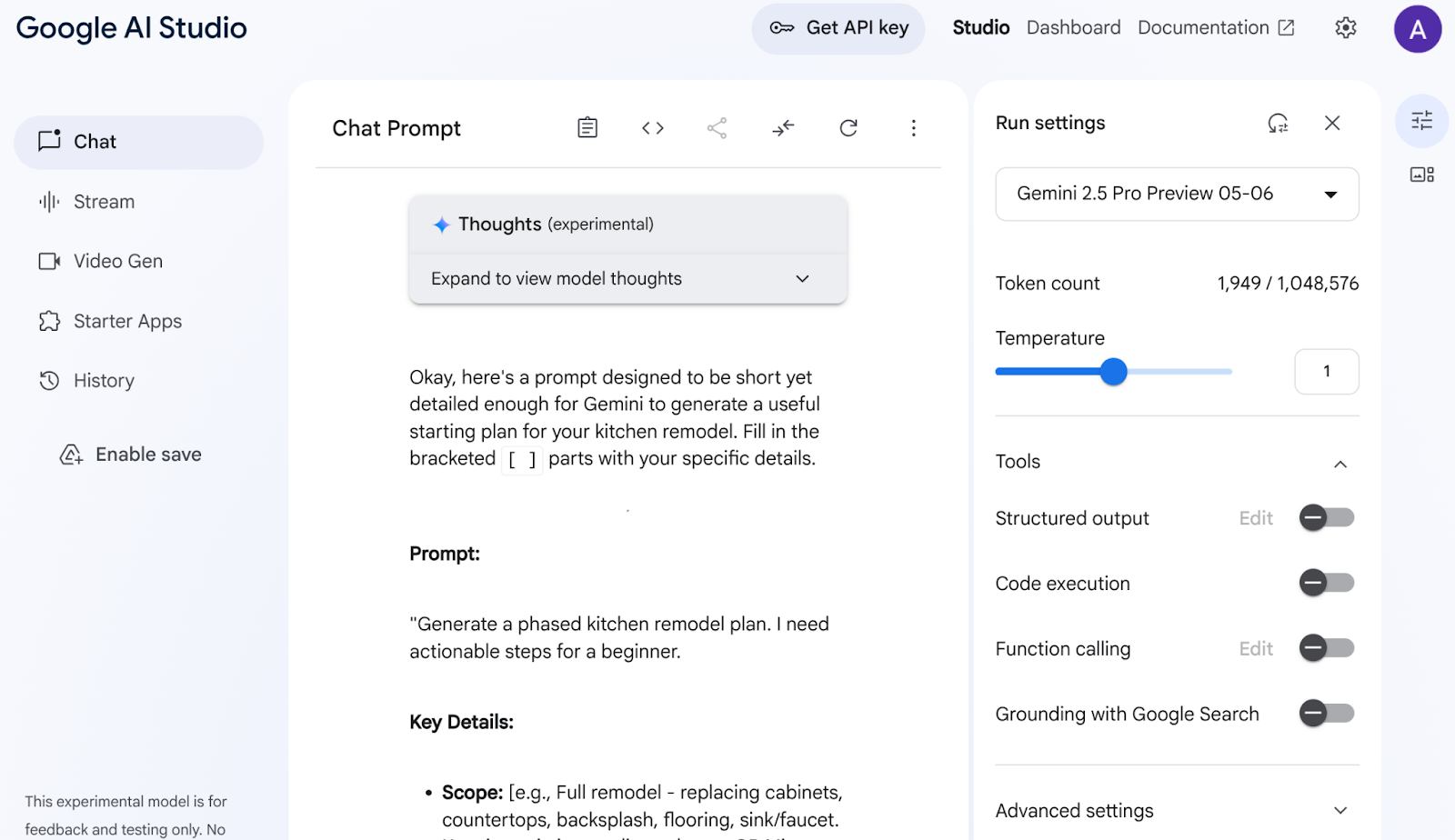
AI Studio analizó mis datos y produjo todos estos elementos, como gabinetes, encimeras, salpicaduras, pisos, fregaderos, cohesión, paleta de colores y selección de materiales. Gemini incluso cita fuentes.
Repite el proceso con diferentes opciones de modelos hasta que estés conforme con el resultado. Pero diría que no vale la pena hacer todo eso cuando tienes Gemini 2.5 :)
De todos modos, ahora intenta ver cómo la idea cobra vida con otra instrucción:
Add flat and circular light accessories above the island area for my current kitchen in the attached image.
Adjunta un vínculo a la imagen de tu cocina actual (o cualquier imagen de cocina de muestra). Cambia el modelo a "Gemini 2.0 Flash Preview Image Generation" para poder generar imágenes.
Obtuve este resultado:

Ese es el poder de Gemini.
Desde comprender videos hasta generar imágenes de forma nativa y fundamentar información real con la Búsqueda de Google, hay cosas que solo se pueden crear con la tecnología de Gemini.
En AI Studio, puedes tomar este prototipo, obtener la clave de API y escalarlo a una aplicación basada en agentes completa con la potencia del ADK de Vertex AI.
4. Configuración del ADK
- Crea y activa el entorno virtual (recomendado)
En la terminal de Cloud Shell, crea un entorno virtual:
python -m venv .venv
Activa el entorno virtual:
source .venv/bin/activate
- Instala el ADK.
pip install google-adk
5. Estructura del proyecto
- Desde la terminal de Cloud Shell, crea un directorio en la ubicación del proyecto que desees.
mkdir agentic-apps
cd agentic-apps
mkdir renovation-agent
- Ve al Editor de Cloud Shell y crea la siguiente estructura de proyecto creando los archivos (vacíos al principio):
renovation-agent/
__init__.py
agent.py
.env
requirements.txt
6. Código fuente
- Ve a "init.py" y actualízalo con el siguiente contenido:
from . import agent
- Ve a agent.py y actualiza el archivo con el siguiente contenido de la siguiente ruta:
https://github.com/AbiramiSukumaran/adk-renovation-agent/blob/main/agent.py
En agent.py, importamos las dependencias necesarias, recuperamos los parámetros de configuración del archivo .env y definimos el root_agent que coordina los 3 subagentes que nos propusimos crear en esta aplicación. Existen varias herramientas que ayudan con las funciones principales y de asistencia de estos subagentes.
- Asegúrate de tener el bucket de Cloud Storage
Es para almacenar el documento de propuesta que genera el agente. Crea el archivo y proporciona acceso para que el sistema multiagente creado con Vertex AI pueda acceder a él. Sigue estos pasos:
https://cloud.google.com/storage/docs/creating-buckets#console
Asigna el nombre "next-demo-store" a tu bucket. Si le asignas otro nombre, recuerda actualizar el valor de STORAGE_BUCKET en el archivo .env (en el paso de configuración de las variables de entorno).
- Para configurar el acceso al bucket, ve a la consola de Cloud Storage y a tu bucket de almacenamiento (en nuestro caso, el nombre del bucket es "next-demo-storage": https://console.cloud.google.com/storage/browser/next-demo-storage.
Navega a Permisos -> Ver entidades -> Otorgar acceso. Selecciona Principals como "allUsers" y Role como "Storage Object User".
Make sure to not enable "prevent public access". Since this is a demo/study application we are going with a public bucket. Remember to configure permission settings appropriately when you are building your application.
- Crea una lista de dependencias
Enumera todas las dependencias en requirements.txt. Puedes copiarlo desde repo.
Explicación del código fuente del sistema multiagente
El archivo agent.py define la estructura y el comportamiento de nuestro sistema multiagente de renovación de cocina con el Kit de desarrollo de agentes (ADK). Desglosemos los componentes clave:
Definiciones de agentes
RenovationProposalAgent
Este agente es responsable de crear el documento de propuesta de renovación de la cocina. De manera opcional, toma parámetros de entrada, como el tamaño de la cocina, el estilo deseado, el presupuesto y las preferencias del cliente. Según esta información, usa un modelo de lenguaje grande (LLM) Gemini 2.5 para generar una propuesta detallada. Luego, la propuesta generada se almacena en un bucket de Cloud Storage.
PermitsAndComplianceCheckAgent
Este agente se enfoca en garantizar que el proyecto de renovación cumpla con los códigos y reglamentaciones de construcción locales. Recibe información sobre la renovación propuesta (p.ej., cambios estructurales, trabajos eléctricos, modificaciones de plomería) y usa el LLM para verificar los requisitos de permisos y las reglas de cumplimiento. El agente usa información de una base de conocimiento (que puedes personalizar para acceder a APIs externas y recopilar reglamentaciones pertinentes).
OrderingAgent
Este agente (puedes comentarlo si no quieres implementarlo ahora) se encarga de verificar el estado del pedido de los materiales y el equipo necesarios para la renovación. Para habilitarlo, deberás crear una función de Cloud Run como se describe en los pasos de configuración. Luego, el agente llamará a esta función de Cloud Run, que interactúa con una base de datos de AlloyDB que contiene información de pedidos. Esto demuestra la integración con un sistema de base de datos para hacer un seguimiento de los datos en tiempo real.
Agente raíz (organizador)
El root_agent actúa como el organizador central del sistema multiagente. Recibe la solicitud de renovación inicial y determina qué subagentes invocar según las necesidades de la solicitud. Por ejemplo, si la solicitud requiere verificar los requisitos de permisos, llamará a PermitsAndComplianceCheckAgent. Si el usuario quiere verificar el estado del pedido, se llamará a OrderingAgent (si está habilitado).
Luego, el agente raíz recopila las respuestas de los subagentes y las combina para proporcionar una respuesta integral al usuario. Esto podría implicar resumir la propuesta, enumerar los permisos necesarios y proporcionar actualizaciones del estado del pedido.
Flujo de datos y conceptos clave
El usuario inicia una solicitud a través de la interfaz del ADK (ya sea la terminal o la IU web).
- El agente raíz recibe la solicitud.
- El agente raíz analiza la solicitud y la enruta a los agentes secundarios adecuados.
- Los subagentes usan LLMs, bases de conocimiento, APIs y bases de datos para procesar la solicitud y generar respuestas.
- Los subagentes devuelven sus respuestas al root_agent.
- El agente raíz combina las respuestas y proporciona un resultado final al usuario.
LLM (modelos de lenguaje grandes)
Los agentes dependen en gran medida de los LLMs para generar texto, responder preguntas y realizar tareas de razonamiento. Los LLM son el "cerebro" detrás de la capacidad de los agentes para comprender y responder a las solicitudes de los usuarios. En esta aplicación, usamos Gemini 2.5.
Google Cloud Storage
Se usa para almacenar los documentos de la propuesta de renovación generada. Debes crear un bucket y otorgar los permisos necesarios para que los agentes accedan a él.
Cloud Run (opcional)
OrderingAgent usa una función de Cloud Run para interactuar con AlloyDB. Cloud Run proporciona un entorno sin servidores para ejecutar código en respuesta a solicitudes HTTP.
AlloyDB
Si usas OrderingAgent, deberás configurar una base de datos de AlloyDB para almacenar la información de los pedidos. Veremos los detalles en la siguiente sección, "Configuración de la base de datos".
Archivo.env
El archivo .env almacena información sensible, como claves de API, credenciales de bases de datos y nombres de buckets. Es fundamental mantener este archivo seguro y no confirmarlo en tu repositorio. También almacena la configuración de los agentes y tu proyecto de Google Cloud. Por lo general, las funciones de root_agent o de asistencia leerán valores de este archivo. Asegúrate de que todas las variables obligatorias estén configuradas correctamente en el archivo .env. Esto incluye el nombre del bucket de Cloud Storage.
7. Configuración de la base de datos
En una de las herramientas que usa ordering_agent, llamada "check_status", accedemos a la base de datos de pedidos de AlloyDB para obtener el estado de los pedidos. En esta sección, configuraremos un clúster y una instancia de la base de datos de AlloyDB.
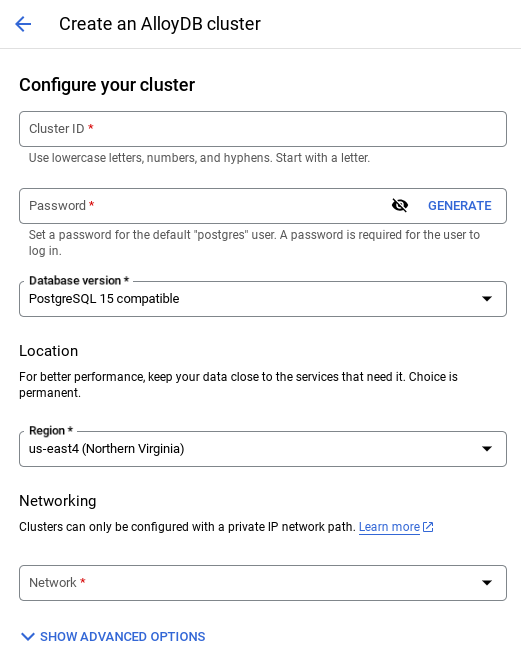
Crea un clúster y una instancia
- Navega por la página de AlloyDB en Cloud Console. Una forma sencilla de encontrar la mayoría de las páginas en la consola de Cloud es buscarlas con la barra de búsqueda de la consola.
- Selecciona CREATE CLUSTER en esa página:

- Verás una pantalla como la que se muestra a continuación. Crea un clúster y una instancia con los siguientes valores (asegúrate de que los valores coincidan si clonas el código de la aplicación desde el repo):
- ID del clúster: "
vector-cluster" - contraseña: "
alloydb" - PostgreSQL 15 o la versión recomendada más reciente
- Región: "
us-central1" - Networking: "
default"
- Cuando selecciones la red predeterminada, verás una pantalla como la que se muestra a continuación.
Selecciona CONFIGURAR CONEXIÓN.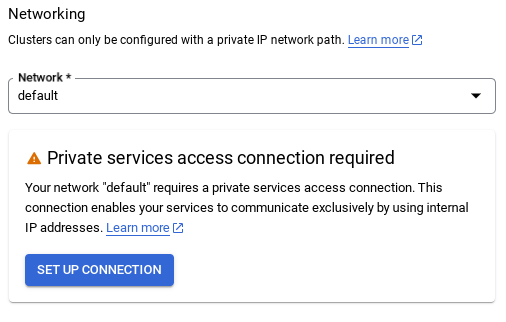
- Allí, selecciona "Usar un rango de IP asignado automáticamente" y haz clic en Continuar. Después de revisar la información, selecciona CREAR CONEXIÓN.
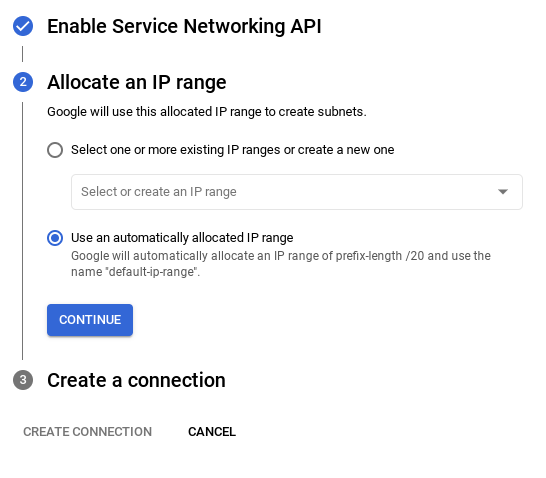
- Una vez que configures tu red, podrás continuar con la creación del clúster. Haz clic en CREATE CLUSTER para completar la configuración del clúster, como se muestra a continuación:
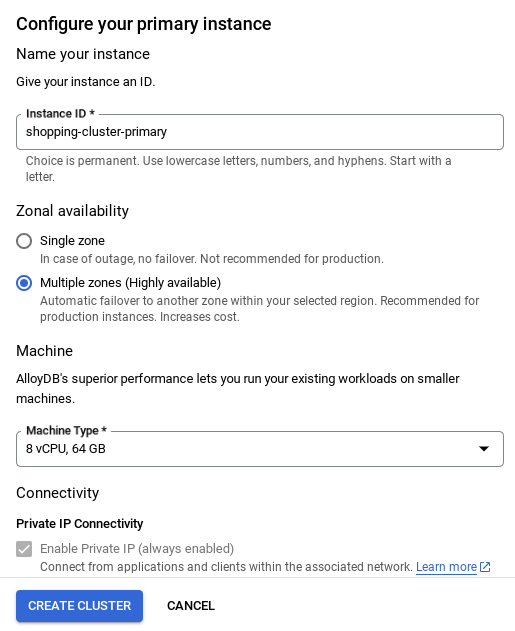
Asegúrate de cambiar el ID de la instancia (que puedes encontrar en el momento de configurar el clúster o la instancia) a
vector-instance. Si no puedes cambiarlo, recuerda usar el ID de tu instancia en todas las referencias futuras.
Ten en cuenta que la creación del clúster tardará alrededor de 10 minutos. Una vez que se complete correctamente, deberías ver una pantalla que muestre el resumen del clúster que acabas de crear.
Transferencia de datos
Ahora es el momento de agregar una tabla con los datos de la tienda. Navega a AlloyDB, selecciona el clúster principal y, luego, AlloyDB Studio:
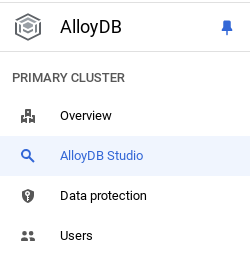
Es posible que debas esperar a que termine de crearse la instancia. Una vez que lo hagas, accede a AlloyDB con las credenciales que creaste cuando creaste el clúster. Usa los siguientes datos para autenticarte en PostgreSQL:
- Nombre de usuario : "
postgres" - Base de datos : "
postgres" - Contraseña : "
alloydb"
Una vez que te autentiques correctamente en AlloyDB Studio, ingresa los comandos SQL en el editor. Puedes agregar varias ventanas del editor con el signo más que se encuentra a la derecha de la última ventana.
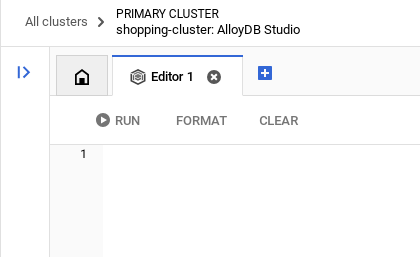
Ingresarás comandos para AlloyDB en ventanas del editor, y usarás las opciones Ejecutar, Formatear y Borrar según sea necesario.
Crea una tabla
Puedes crear una tabla con la siguiente instrucción DDL en AlloyDB Studio:
-- Table DDL for Procurement Material Order Status
CREATE TABLE material_order_status (
order_id VARCHAR(50) PRIMARY KEY,
material_name VARCHAR(100) NOT NULL,
supplier_name VARCHAR(100) NOT NULL,
order_date DATE NOT NULL,
estimated_delivery_date DATE,
actual_delivery_date DATE,
quantity_ordered INT NOT NULL,
quantity_received INT,
unit_price DECIMAL(10, 2) NOT NULL,
total_amount DECIMAL(12, 2),
order_status VARCHAR(50) NOT NULL, -- e.g., "Ordered", "Shipped", "Delivered", "Cancelled"
delivery_address VARCHAR(255),
contact_person VARCHAR(100),
contact_phone VARCHAR(20),
tracking_number VARCHAR(100),
notes TEXT,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
quality_check_passed BOOLEAN, -- Indicates if the material passed quality control
quality_check_notes TEXT, -- Notes from the quality control check
priority VARCHAR(20), -- e.g., "High", "Medium", "Low"
project_id VARCHAR(50), -- Link to a specific project
receiver_name VARCHAR(100), -- Name of the person who received the delivery
return_reason TEXT, -- Reason for returning material if applicable
po_number VARCHAR(50) -- Purchase order number
);
Insertar registros
Copia la instrucción de consulta insert de la secuencia de comandos database_script.sql mencionada anteriormente en el editor.
Haz clic en Ejecutar.
Ahora que el conjunto de datos está listo, creemos una aplicación de Cloud Run Functions en Java para extraer el estado.
Crea una función de Cloud Run en Java para extraer información sobre el estado del pedido
- Crea una Cloud Run Function desde aquí: https://console.cloud.google.com/run/create?deploymentType=function
- Establece el nombre de la función como "check-status" y elige "Java 17" como el tiempo de ejecución.
- Puedes configurar la autenticación como "Permitir invocaciones no autenticadas", ya que se trata de una aplicación de demostración.
- Elige Java 17 como entorno de ejecución y Editor directo para el código fuente.
- En este punto, se cargará el código de marcador de posición en el editor.
Reemplaza el código del marcador de posición
- Cambia el nombre del archivo Java a "ProposalOrdersTool.java" y el nombre de la clase a "ProposalOrdersTool".
- Reemplaza el código de marcador de posición en ProposalOrdersTool.java y pom.xml por el código de los archivos respectivos en la carpeta "Cloud Run Function" en este repo.
- En ProposalOrdersTool.java, busca la siguiente línea de código y reemplaza los valores de marcador de posición por los valores de tu configuración:
String ALLOYDB_INSTANCE_NAME = "projects/<<YOUR_PROJECT_ID>>/locations/us-central1/clusters/<<YOUR_CLUSTER>>/instances/<<YOUR_INSTANCE>>";
- Haz clic en Crear.
- Se creará y se implementará la Cloud Run Function.
PASO IMPORTANTE:
Una vez implementada, crearemos el conector de VPC para permitir que la Cloud Function acceda a nuestra instancia de base de datos de AlloyDB.
Una vez que te dispongas a realizar la implementación, deberías poder ver las funciones en la consola de Google Cloud Run Functions. Busca la función recién creada (check-status), haz clic en ella y, luego, en EDITAR Y, LUEGO, IMPLEMENTAR REVISIONES NUEVAS (identificado por el ícono de edición (lápiz) en la parte superior de la consola de Cloud Run Functions) y cambia lo siguiente:
- Ve a la pestaña Networking:
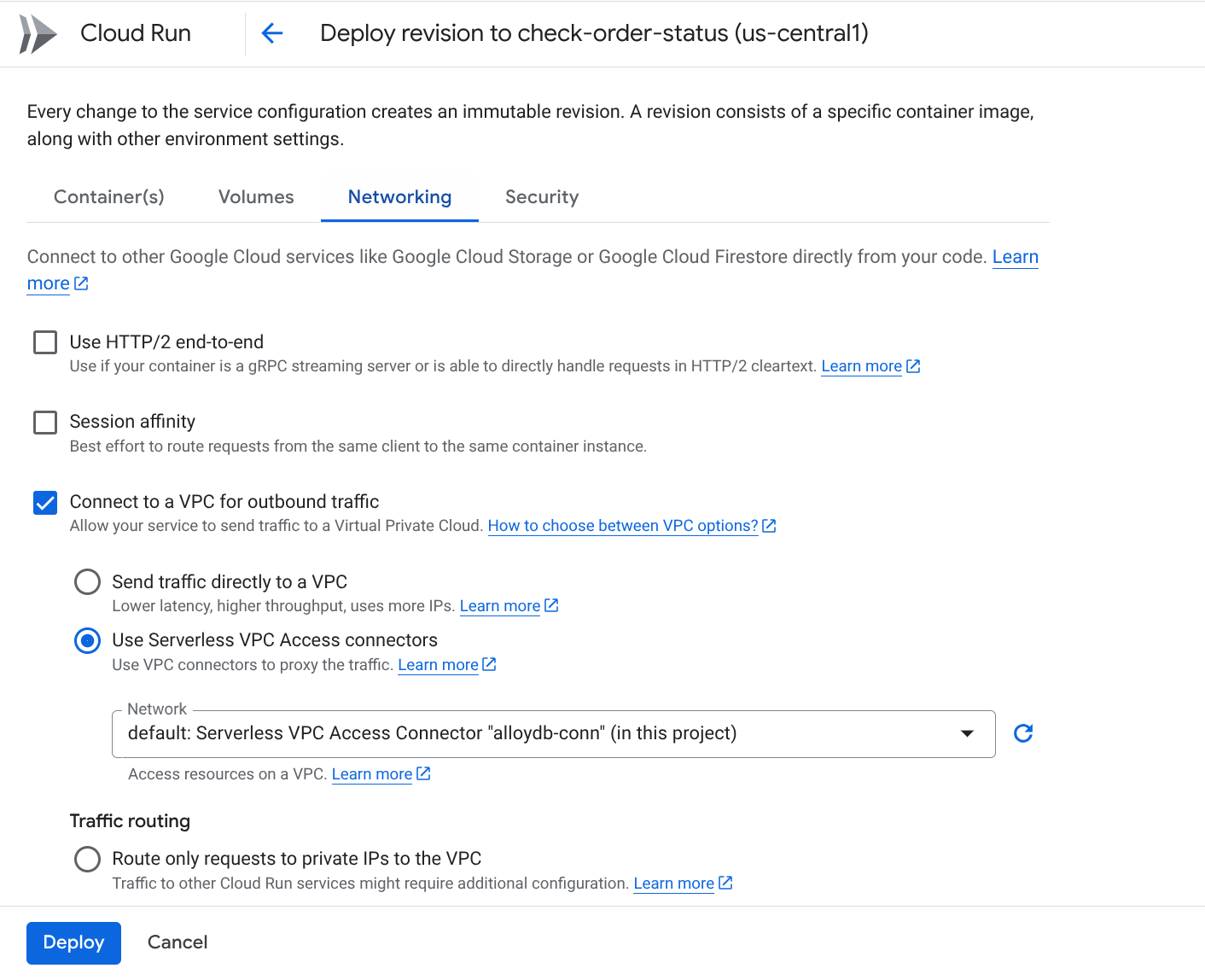
- Selecciona "Conéctate a una VPC para el tráfico saliente" y, luego, "Usa conectores de acceso a VPC sin servidores".
- En el menú desplegable Red, haz clic en el menú desplegable Red y selecciona la opción "Agregar un conector de VPC nuevo" (si aún no configuraste el conector predeterminado) y sigue las instrucciones que aparecen en el cuadro de diálogo emergente:
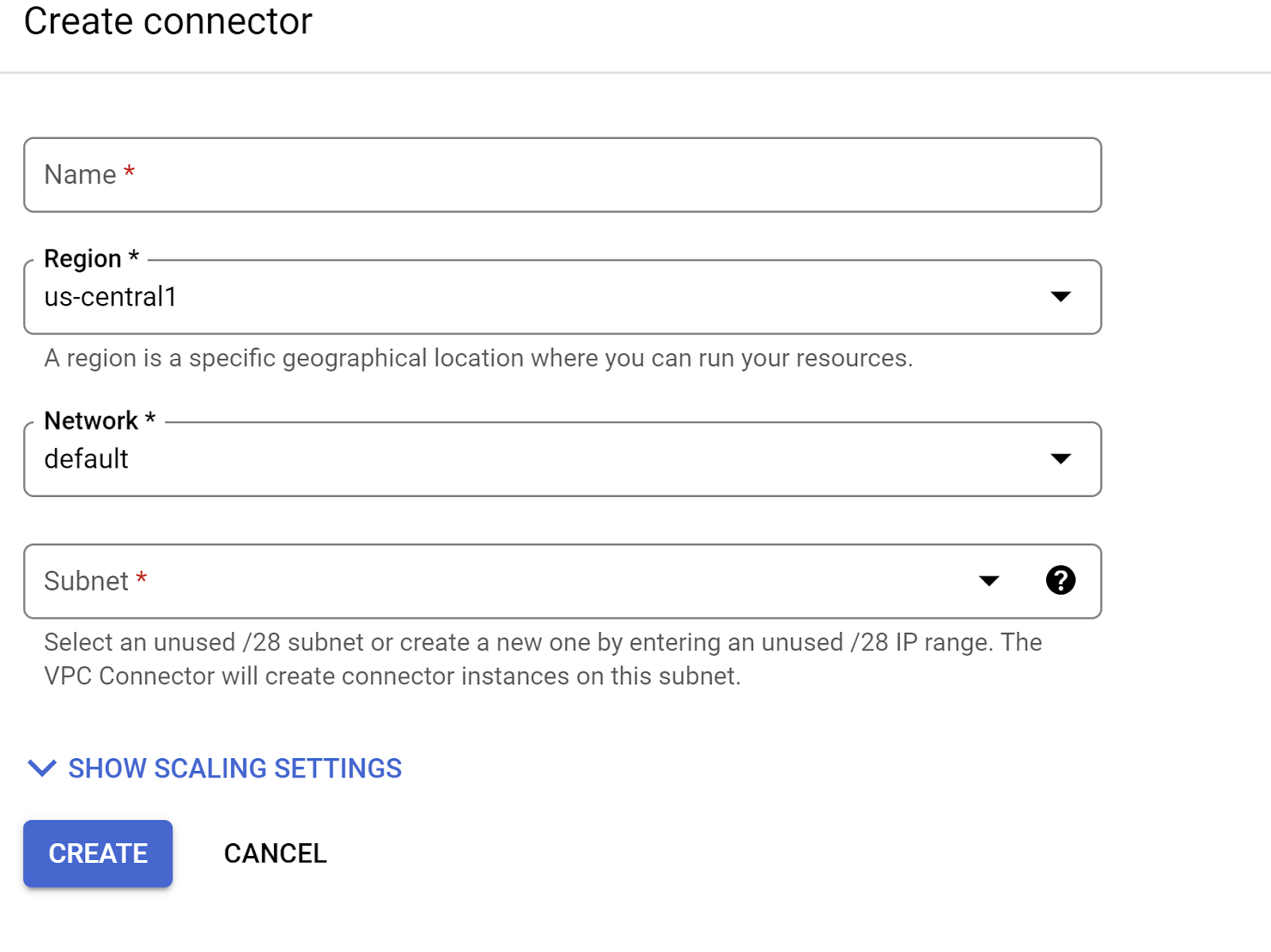
- Proporciona un nombre para el conector de VPC y asegúrate de que la región sea la misma que la de tu instancia. Deja el valor de la red como predeterminado y establece la subred como rango de IP personalizado con el rango de IP 10.8.0.0 o uno similar que esté disponible.
- Expande SHOW SCALING SETTINGS y asegúrate de que la configuración sea exactamente la siguiente:
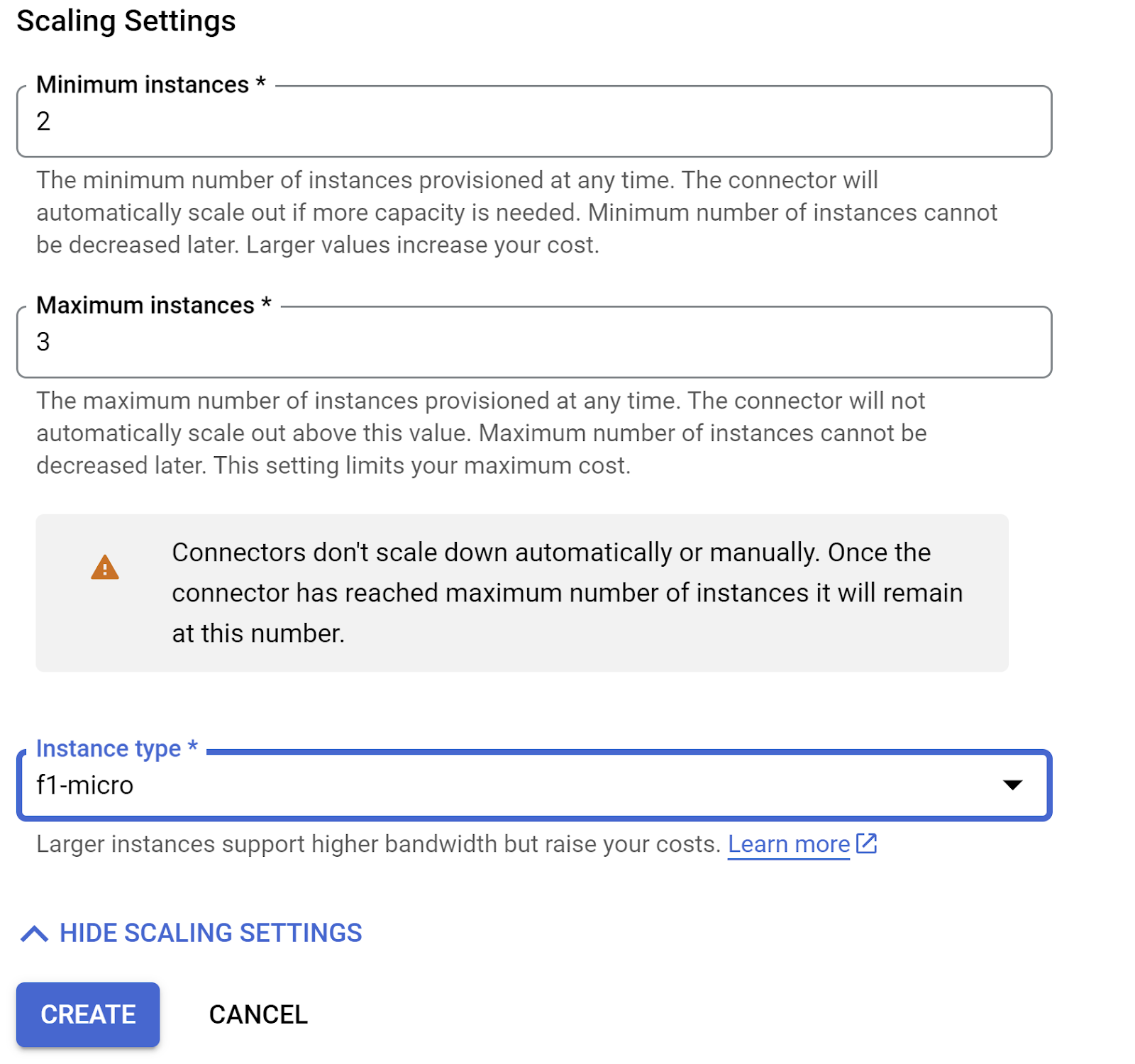
- Haz clic en CREATE y este conector debería aparecer en la configuración de salida.
- Selecciona el conector recién creado.
- Opta por que todo el tráfico se enrute a través de este conector de VPC.
- Haz clic en SIGUIENTE y, luego, en IMPLEMENTAR.
- Una vez que se implemente la Cloud Function actualizada, deberías ver el extremo generado.
- Para probarla, haz clic en el botón PROBAR en la parte superior de la consola de Cloud Run Functions y ejecuta el comando resultante en la terminal de Cloud Shell.
- El extremo implementado es la URL que debes actualizar en la variable
CHECK_ORDER_STATUS_ENDPOINTde .env.
8. Configuración del modelo
La capacidad de tu agente para comprender las solicitudes de los usuarios y generar respuestas se basa en un modelo de lenguaje grande (LLM). Tu agente debe realizar llamadas seguras a este servicio externo de LLM, lo que requiere credenciales de autenticación. Sin una autenticación válida, el servicio de LLM rechazará las solicitudes del agente y este no podrá funcionar.
- Obtén una clave de API de Google AI Studio.
- En el siguiente paso, en el que configurarás el archivo .env, reemplaza
<<your API KEY>>por el valor real de tu clave de API.
9. Configuración de variables de entorno
- Configura tus valores para los parámetros en el archivo .env de la plantilla en este repo. En mi caso, el archivo .env tiene estas variables:
GOOGLE_GENAI_USE_VERTEXAI=FALSE
GOOGLE_API_KEY=<<your API KEY>>
GOOGLE_CLOUD_LOCATION=us-central1 <<or your region>>
GOOGLE_CLOUD_PROJECT=<<your project id>>
PROJECT_ID=<<your project id>>
GOOGLE_CLOUD_REGION=us-central1 <<or your region>>
STORAGE_BUCKET=next-demo-store <<or your storage bucket name>>
CHECK_ORDER_STATUS_ENDPOINT=<<YOUR_ENDPOINT_TO_CLOUD FUNCTION_TO_READ_ORDER_DATA_FROM_ALLOYDB>>
Reemplaza los marcadores de posición por tus valores.
10. Ejecuta tu agente
- Con la terminal, navega al directorio principal de tu proyecto del agente:
cd renovation-agent
- Instala todas las dependencias
pip install -r requirements.txt
- Puedes ejecutar el siguiente comando en tu terminal de Cloud Shell para ejecutar el agente:
adk run .
- Puedes ejecutar lo siguiente para ejecutarlo en una IU web aprovisionada por el ADK:
adk web
- Haz la prueba con las siguientes instrucciones:
user>>
Hello. Generate Proposal Document for the kitchen remodel requirement. I have no other specification.
11. Resultado
@ Sistema multiagente para tareas de renovación de cocina
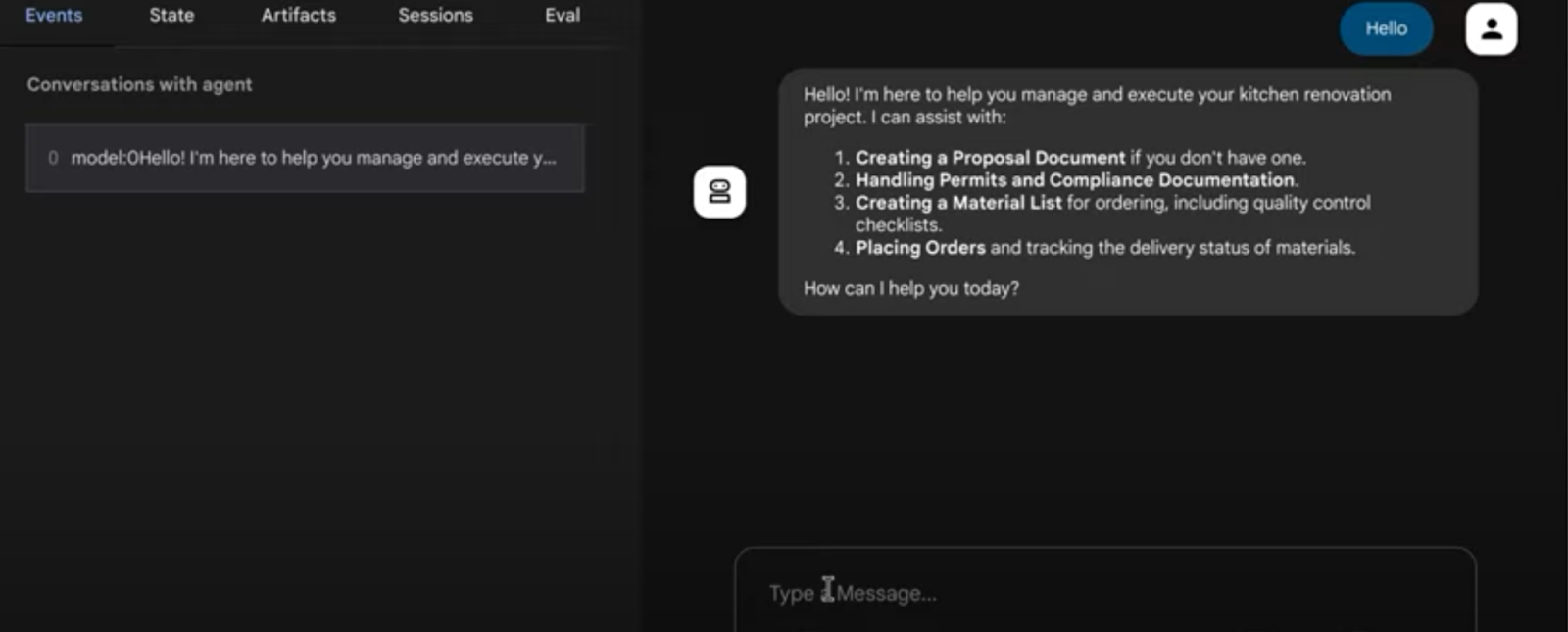
12. Implementación en Agent Engine
Ahora que probaste que el sistema multiagente funciona correctamente, hagámoslo sin servidores y disponible en la nube para que cualquier persona o aplicación lo pueda usar. Quita las marcas de comentario del siguiente fragmento de código en agent.py del repo y podrás implementar tu sistema de varios agentes:
# Agent Engine Deployment:
# Create a remote app for our multiagent with agent Engine.
# This may take 1-2 minutes to finish.
# Uncomment the below segment when you're ready to deploy.
app = AdkApp(
agent=root_agent,
enable_tracing=True,
)
vertexai.init(
project=PROJECT_ID,
location=GOOGLE_CLOUD_LOCATION,
staging_bucket=STAGING_BUCKET,
)
remote_app = agent_engines.create(
app,
requirements=[
"google-cloud-aiplatform[agent_engines,adk]>=1.88",
"google-adk",
"pysqlite3-binary",
"toolbox-langchain==0.1.0",
"pdfplumber",
"google-cloud-aiplatform",
"cloudpickle==3.1.1",
"pydantic==2.10.6",
"pytest",
"overrides",
"scikit-learn",
"reportlab",
"google-auth",
"google-cloud-storage",
],
)
# Deployment to Agent Engine related code ends
Vuelve a ejecutar este agent.py desde la carpeta del proyecto con el siguiente comando:
>> cd adk-renovation-agent
>> python agent.py
Este proceso tardará unos minutos en completarse. Cuando termine, recibirás un extremo similar al siguiente:
'projects/123456789/locations/us-central1/reasoningEngines/123456'
Puedes probar tu agente implementado con el siguiente código agregando un nuevo archivo "test.py".
import vertexai
from vertexai.preview import reasoning_engines
from vertexai import agent_engines
import os
import warnings
from dotenv import load_dotenv
load_dotenv()
GOOGLE_CLOUD_PROJECT = os.environ["GOOGLE_CLOUD_PROJECT"]
GOOGLE_CLOUD_LOCATION = os.environ["GOOGLE_CLOUD_LOCATION"]
GOOGLE_API_KEY = os.environ["GOOGLE_API_KEY"]
GOOGLE_GENAI_USE_VERTEXAI=os.environ["GOOGLE_GENAI_USE_VERTEXAI"]
AGENT_NAME = "adk_renovation_agent"
MODEL_NAME = "gemini-2.5-pro-preview-03-25"
warnings.filterwarnings("ignore")
PROJECT_ID = GOOGLE_CLOUD_PROJECT
reasoning_engine_id = "<<YOUR_DEPLOYED_ENGINE_ID>>"
vertexai.init(project=PROJECT_ID, location="us-central1")
agent = agent_engines.get(reasoning_engine_id)
print("**********************")
print(agent)
print("**********************")
for event in agent.stream_query(
user_id="test_user",
message="I want you to check order status.",
):
print(event)
En el código anterior, reemplaza el valor del marcador de posición "<<YOUR_DEPLOYED_ENGINE_ID>>", ejecuta el comando "python test.py" y todo estará listo para interactuar con un sistema de varios agentes que implementó Agent Engine y para renovar tu cocina.
13. Opciones de implementación de una sola línea
Ahora que probaste el sistema multiagente implementado, veamos métodos más sencillos que abstraen el paso de implementación que realizamos en el paso anterior: OPCIONES DE IMPLEMENTACIÓN CON UNA SOLA LÍNEA:
- En Cloud Run, haz lo siguiente:
Sintaxis:
adk deploy cloud_run \
--project=<<YOUR_PROJECT_ID>> \
--region=us-central1 \
--service_name=<<YOUR_SERVICE_NAME>> \
--app_name=<<YOUR_APP_NAME>> \
--with_ui \
./<<YOUR_AGENT_PROJECT_NAME>>
En este caso, ocurre lo siguiente:
adk deploy cloud_run \
--project=<<YOUR_PROJECT_ID>> \
--region=us-central1 \
--service_name=renovation-agent \
--app_name=renovation-app \
--with_ui \
./renovation-agent
Puedes usar el extremo implementado para las integraciones posteriores.
- Para Agent Engine:
Sintaxis:
adk deploy agent_engine \
--project <your-project-id> \
--region us-central1 \
--staging_bucket gs://<your-google-cloud-storage-bucket> \
--trace_to_cloud \
path/to/agent/folder
En este caso, ocurre lo siguiente:
adk deploy agent_engine --project <<YOUR_PROJECT_ID>> --region us-central1 --staging_bucket gs://<<YOUR_BUCKET_NAME>> --trace_to_cloud renovation-agent
Deberías ver un agente nuevo en la IU de Agent Engine en la consola de Google Cloud. Consulta este blog para obtener más detalles.
14. Limpia
Sigue estos pasos para evitar que se apliquen cargos a tu cuenta de Google Cloud por los recursos que usaste en esta publicación:
- En la consola de Google Cloud, ve a la página Administrar recursos.
- En la lista de proyectos, elige el proyecto que deseas borrar y haz clic en Borrar.
- En el diálogo, escribe el ID del proyecto y, luego, haz clic en Cerrar para borrarlo.
15. Felicitaciones
¡Felicitaciones! Creaste tu primer agente con el ADK y pudiste interactuar con él.