
1. Présentation
Un agent est un programme autonome qui communique avec un modèle d'IA pour effectuer une opération basée sur un objectif à l'aide des outils et du contexte dont il dispose. Il est capable de prendre des décisions autonomes basées sur la vérité.
Lorsque votre application comporte plusieurs agents qui travaillent ensemble de manière autonome et collaborative pour atteindre un objectif plus vaste, chacun étant responsable d'un domaine d'expertise spécifique, elle devient un système multi-agents.
Agent Development Kit (ADK)
Agent Development Kit (ADK) est un framework flexible et modulaire permettant de développer et de déployer des agents IA. ADK permet de créer des applications sophistiquées en composant plusieurs instances d'agent distinctes dans un système multi-agents (MAS).
Dans ADK, un système multi-agents est une application dans laquelle différents agents, formant souvent une hiérarchie, collaborent ou se coordonnent pour atteindre un objectif plus vaste. Cette structure offre des avantages considérables, y compris une modularité, une spécialisation, une réutilisabilité et une facilité de maintenance améliorées, ainsi que la possibilité de définir des flux de contrôle structurés à l'aide d'agents de workflow dédiés.
Points à retenir pour un système multi-agents
Tout d'abord, il est important de bien comprendre et de justifier la spécialisation de chaque agent. — "sais-tu pourquoi tu as besoin d'un sous-agent spécifique pour quelque chose ?", commence par trouver la réponse.
Deuxièmement, comment les rassembler avec un agent racine pour les distribuer et les interpréter.
Troisièmement, il existe plusieurs types de routage d'agent que vous pouvez trouver dans cette documentation. Choisissez celui qui convient le mieux au flux de votre application. Quels sont les différents contextes et états dont vous avez besoin pour le contrôle du flux de votre système multi-agents ?
Ce que vous allez faire
Créons un système multi-agent pour gérer les rénovations de cuisine. C'est ce que nous allons faire. Nous allons créer un système avec trois agents.
- Agent de proposition de rénovation
- Agent de vérification des autorisations et de la conformité
- Agent de vérification de l'état des commandes
Agent de proposition de rénovation, pour générer le document de proposition de rénovation de la cuisine.
un agent chargé des autorisations et de la conformité, pour gérer les tâches liées aux autorisations et à la conformité.
Agent de vérification de l'état des commandes, pour vérifier l'état des commandes de matériel en travaillant sur la base de données de gestion des commandes que nous avons configurée dans AlloyDB.
Nous aurons un agent racine qui orchestrera ces agents en fonction des besoins.
Conditions requises
2. Avant de commencer
Créer un projet
- Dans la console Google Cloud, sur la page du sélecteur de projet, sélectionnez ou créez un projet Google Cloud.
- Assurez-vous que la facturation est activée pour votre projet Cloud. Découvrez comment vérifier si la facturation est activée sur un projet .
- Cliquez sur ce lien pour activer Cloud Shell. Vous pouvez basculer entre le terminal Cloud Shell (pour exécuter des commandes cloud) et l'éditeur (pour créer des projets) en cliquant sur le bouton correspondant dans Cloud Shell.
- Une fois connecté à Cloud Shell, vérifiez que vous êtes déjà authentifié et que le projet est défini sur votre ID de projet à l'aide de la commande suivante :
gcloud auth list
- Exécutez la commande suivante dans Cloud Shell pour vérifier que la commande gcloud connaît votre projet.
gcloud config list project
- Si votre projet n'est pas défini, utilisez la commande suivante pour le définir :
gcloud config set project <YOUR_PROJECT_ID>
- Assurez-vous d'avoir Python 3.9 ou version ultérieure.
- Activez les API suivantes en exécutant les commandes suivantes :
gcloud services enable artifactregistry.googleapis.com \cloudbuild.googleapis.com \run.googleapis.com \aiplatform.googleapis.com
- Consultez la documentation pour connaître les commandes gcloud ainsi que leur utilisation.
3. Prototype
Vous pouvez ignorer cette étape si vous décidez d'utiliser le modèle Gemini 2.5 Pro pour le projet.
Accédez à Google AI Studio. Commencez à saisir votre requête. Voici ma requête :
I want to renovate my kitchen, basically just remodel it. I don't know where to start. So I want to use Gemini to generate a plan. For that I need a good prompt. Give me a short yet detailed prompt that I can use.
Ajustez et configurez les paramètres sur la droite pour obtenir une réponse optimale.
À partir de cette simple description, Gemini m'a fourni une requête incroyablement détaillée pour lancer mes travaux de rénovation ! En effet, nous utilisons Gemini pour obtenir des réponses encore plus pertinentes d'AI Studio et de nos modèles. Vous pouvez également sélectionner différents modèles à utiliser, en fonction de votre cas d'utilisation.
Nous avons choisi Gemini 2.5 Pro. Il s'agit d'un modèle de réflexion, ce qui signifie que nous obtenons encore plus de jetons de sortie, dans ce cas jusqu'à 65 000 jetons, pour les analyses longues et les documents détaillés. La boîte de réflexion Gemini s'affiche lorsque vous activez Gemini 2.5 Pro, qui dispose de capacités de raisonnement natives et peut traiter les requêtes de contexte long.
Consultez l'extrait de la réponse ci-dessous :
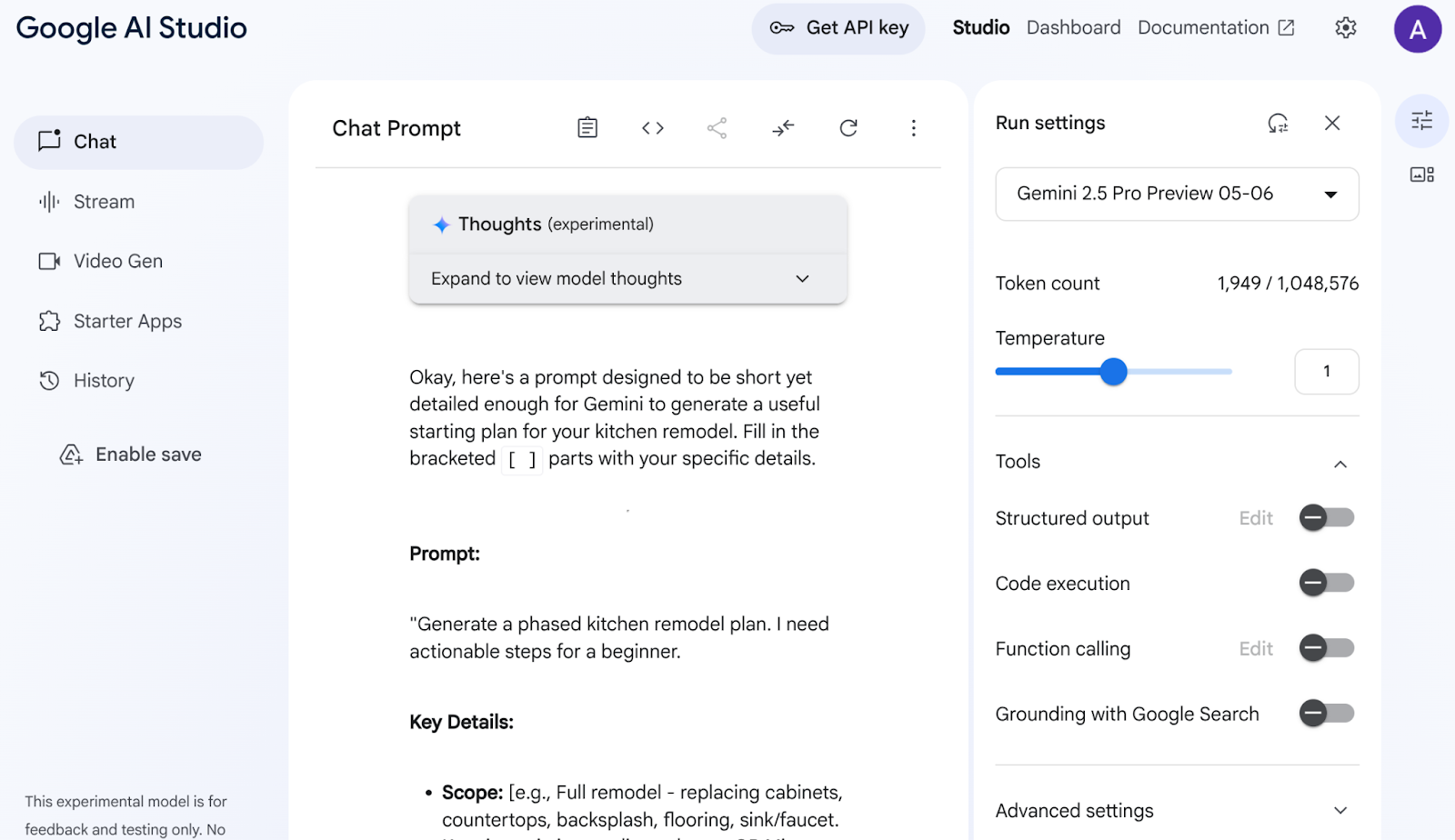
AI Studio a analysé mes données et a produit tous ces éléments : meubles, plans de travail, crédence, revêtement de sol, évier, cohésion, palette de couleurs et sélection de matériaux. Gemini cite même ses sources !
Répétez le processus avec différents choix de modèles jusqu'à ce que vous soyez satisfait du résultat. Mais je me demande pourquoi passer par tout ça quand vous avez Gemini 2.5 :)
Essayez maintenant de voir l'idée prendre vie avec un autre prompt :
Add flat and circular light accessories above the island area for my current kitchen in the attached image.
Joignez un lien vers l'image de votre cuisine actuelle (ou une image de cuisine type). Définissez le modèle sur "Génération d'images Gemini 2.0 Flash (preview)" pour pouvoir générer des images.
J'ai obtenu le résultat suivant :

C'est tout le potentiel de Gemini !
Qu'il s'agisse de comprendre des vidéos, de générer des images de manière native ou d'ancrer des informations réelles avec la recherche Google, certaines choses ne peuvent être créées qu'avec Gemini.
Dans AI Studio, vous pouvez prendre ce prototype, récupérer la clé API et le faire évoluer vers une application agentique complète grâce à la puissance du kit ADK Vertex AI.
4. Configuration d'ADK
- Créer et activer un environnement virtuel (recommandé)
À partir de votre terminal Cloud Shell, créez un environnement virtuel :
python -m venv .venv
Activez l'environnement virtuel :
source .venv/bin/activate
- Installer ADK
pip install google-adk
5. Structure du projet
- Dans le terminal Cloud Shell, créez un répertoire à l'emplacement de votre choix dans le projet.
mkdir agentic-apps
cd agentic-apps
mkdir renovation-agent
- Accédez à l'éditeur Cloud Shell et créez la structure de projet suivante en créant les fichiers (vides au début) :
renovation-agent/
__init__.py
agent.py
.env
requirements.txt
6. Code source
- Accédez à "init.py" et mettez à jour le contenu comme suit :
from . import agent
- Accédez à agent.py et mettez à jour le fichier avec le contenu suivant à partir du chemin d'accès suivant :
https://github.com/AbiramiSukumaran/adk-renovation-agent/blob/main/agent.py
Dans agent.py, nous importons les dépendances nécessaires, récupérons les paramètres de configuration du fichier .env et définissons le root_agent qui orchestre les trois sous-agents que nous avons décidé de créer dans cette application. Plusieurs outils permettent d'effectuer les fonctions principales et auxiliaires de ces sous-agents.
- Assurez-vous d'avoir le bucket Cloud Storage
Cela permet de stocker le document de proposition généré par l'agent. Créez-le et accordez-y l'accès afin que le système multi-agents créé avec Vertex AI puisse y accéder. Voici comment procéder :
https://cloud.google.com/storage/docs/creating-buckets#console
Nommez votre bucket "next-demo-store". Si vous lui donnez un autre nom, n'oubliez pas de mettre à jour la valeur de STORAGE_BUCKET dans le fichier .env (à l'étape de configuration des variables d'environnement).
- Pour configurer l'accès au bucket, accédez à la console Cloud Storage et à votre bucket Storage (dans notre cas, le nom du bucket est "next-demo-storage") : https://console.cloud.google.com/storage/browser/next-demo-storage.
Accédez à Autorisations > Afficher les comptes principaux > Accorder l'accès. Sélectionnez "allUsers" pour les principaux et "Utilisateur des objets Storage" pour le rôle.
Make sure to not enable "prevent public access". Since this is a demo/study application we are going with a public bucket. Remember to configure permission settings appropriately when you are building your application.
- Créer une liste de dépendances
Listez toutes les dépendances dans requirements.txt. Vous pouvez le copier depuis le dépôt.
Explication du code source du système multi-agents
Le fichier agent.py définit la structure et le comportement de notre système multi-agents de rénovation de cuisine à l'aide de l'Agent Development Kit (ADK). Découvrons les principaux composants :
Définitions des agents
RenovationProposalAgent
Cet agent est responsable de la création du document de proposition de rénovation de la cuisine. Il accepte éventuellement des paramètres d'entrée tels que la taille de la cuisine, le style souhaité, le budget et les préférences du client. Sur la base de ces informations, il utilise un grand modèle de langage (LLM) Gemini 2.5 pour générer une proposition détaillée. La proposition générée est ensuite stockée dans un bucket Google Cloud Storage.
PermitsAndComplianceCheckAgent
Cet agent se concentre sur la conformité du projet de rénovation aux codes et réglementations du bâtiment locaux. Il reçoit des informations sur la rénovation proposée (par exemple, les modifications structurelles, les travaux d'électricité ou de plomberie) et utilise le LLM pour vérifier les exigences en matière de permis et les règles de conformité. L'agent utilise les informations d'une base de connaissances (que vous pouvez personnaliser pour accéder à des API externes et collecter les réglementations pertinentes).
OrderingAgent
Cet agent (que vous pouvez commenter si vous ne souhaitez pas l'implémenter maintenant) gère la vérification de l'état de la commande des matériaux et équipements nécessaires à la rénovation. Pour l'activer, vous devez créer une fonction Cloud Run, comme décrit dans les étapes de configuration. L'agent appellera ensuite cette fonction Cloud Run, qui interagit avec une base de données AlloyDB contenant des informations sur les commandes. Cela montre l'intégration à un système de base de données pour suivre les données en temps réel.
Agent racine (Orchestrator)
L'agent racine sert d'orchestrateur central du système multi-agent. Il reçoit la demande de rénovation initiale et détermine les sous-agents à invoquer en fonction des besoins de la demande. Par exemple, si la demande nécessite de vérifier les exigences en matière de permis, elle appellera l'agent PermitsAndComplianceCheckAgent. Si l'utilisateur souhaite vérifier l'état d'une commande, il appellera l'OrderingAgent (si activé).
L'agent racine collecte ensuite les réponses des sous-agents et les combine pour fournir une réponse complète à l'utilisateur. Il peut s'agir de résumer la proposition, de lister les autorisations requises et de fournir des informations sur l'état de la commande.
Flux de données et concepts clés
L'utilisateur lance une requête via l'interface ADK (terminal ou interface utilisateur Web).
- La demande est reçue par l'agent racine.
- L'agent racine analyse la requête et l'achemine vers les sous-agents appropriés.
- Les sous-agents utilisent des LLM, des bases de connaissances, des API et des bases de données pour traiter la demande et générer des réponses.
- Les sous-agents renvoient leurs réponses à l'agent racine.
- L'agent racine combine les réponses et fournit un résultat final à l'utilisateur.
LLM (grands modèles de langage)
Les agents s'appuient fortement sur les LLM pour générer du texte, répondre à des questions et effectuer des tâches de raisonnement. Les LLM sont le "cerveau" qui permet aux agents de comprendre les requêtes des utilisateurs et d'y répondre. Nous utilisons Gemini 2.5 dans cette application.
Google Cloud Storage
Permet de stocker les documents de proposition de rénovation générés. Vous devez créer un bucket et accorder les autorisations nécessaires aux agents pour y accéder.
Cloud Run (facultatif)
OrderingAgent utilise une fonction Cloud Run pour l'interface avec AlloyDB. Cloud Run fournit un environnement sans serveur pour exécuter du code en réponse aux requêtes HTTP.
AlloyDB
Si vous utilisez OrderingAgent, vous devez configurer une base de données AlloyDB pour stocker les informations sur les commandes. Nous aborderons les détails de cette configuration dans la section suivante, "Configuration de la base de données".
Fichier.env
Le fichier .env stocke des informations sensibles telles que les clés API, les identifiants de base de données et les noms de buckets. Il est essentiel de conserver ce fichier de manière sécurisée et de ne pas l'inclure dans votre dépôt. Il stocke également les paramètres de configuration des agents et de votre projet Google Cloud. Les fonctions root_agent ou d'assistance lisent généralement les valeurs de ce fichier. Assurez-vous que toutes les variables requises sont correctement définies dans le fichier .env. (y compris le nom du bucket Cloud Storage)
7. Configuration de la base de données
Dans l'un des outils utilisés par l'ordering_agent, appelé "check_status", nous accédons à la base de données des commandes AlloyDB pour obtenir l'état des commandes. Dans cette section, nous allons configurer un cluster et une instance de base de données AlloyDB.
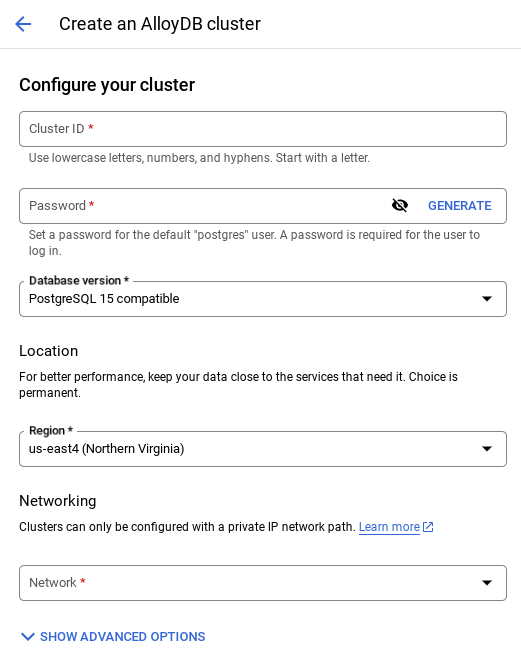
Créer un cluster et une instance
- Accédez à la page AlloyDB de la console Cloud. Pour trouver la plupart des pages de la console Cloud, le plus simple est de les rechercher à l'aide de la barre de recherche de la console.
- Sélectionnez CRÉER UN CLUSTER sur cette page :

- Un écran semblable à celui ci-dessous s'affiche. Créez un cluster et une instance avec les valeurs suivantes (assurez-vous que les valeurs correspondent si vous clonez le code de l'application à partir du dépôt) :
- ID du cluster : "
vector-cluster" - password : "
alloydb" - PostgreSQL 15 / dernière version recommandée
- Région : "
us-central1" - Networking : "
default"
- Lorsque vous sélectionnez le réseau par défaut, un écran semblable à celui ci-dessous s'affiche.
Sélectionnez CONFIGURER LA CONNEXION.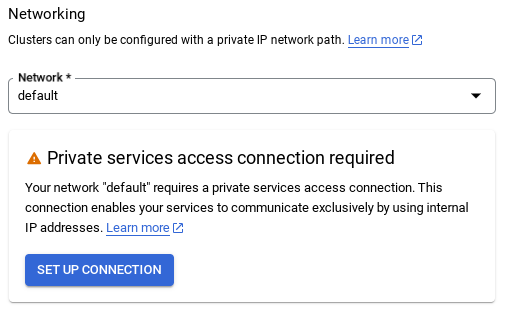
- Sélectionnez ensuite Utiliser une plage d'adresses IP automatiquement allouée, puis cliquez sur "Continuer". Après avoir vérifié les informations, sélectionnez CRÉER UNE CONNEXION.
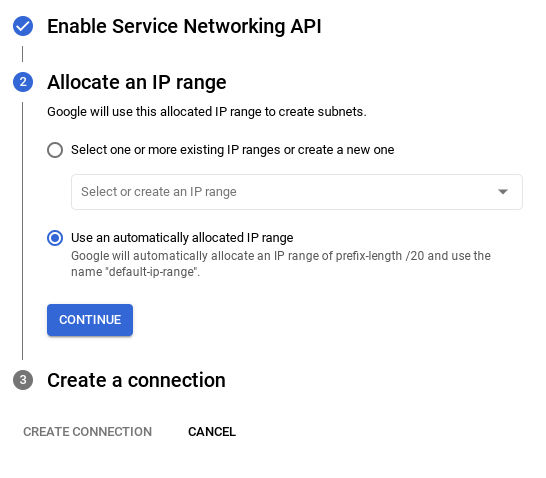
- Une fois votre réseau configuré, vous pouvez continuer à créer votre cluster. Cliquez sur CRÉER UN CLUSTER pour terminer la configuration du cluster, comme indiqué ci-dessous :
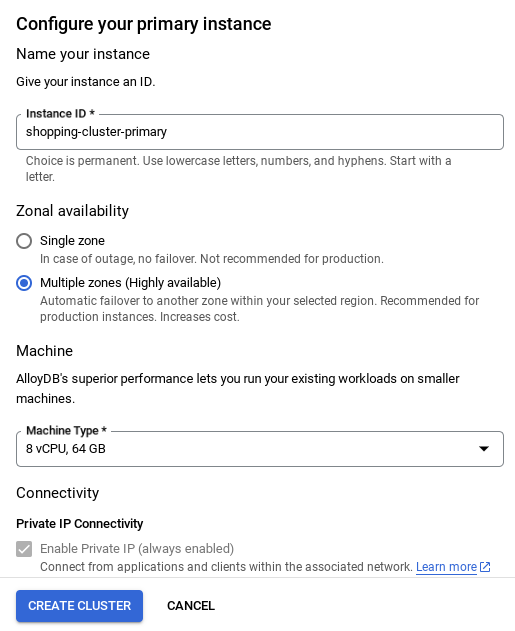
Veillez à modifier l'ID de l'instance (que vous trouverez lors de la configuration du cluster / de l'instance) en
vector-instance. Si vous ne pouvez pas le modifier, n'oubliez pas d'utiliser l'ID de votre instance dans toutes les références à venir.
Notez que la création du cluster prendra environ 10 minutes. Une fois l'opération terminée, un écran présentant le cluster que vous venez de créer devrait s'afficher.
Ingestion de données
Il est maintenant temps d'ajouter un tableau contenant les données sur le magasin. Accédez à AlloyDB, sélectionnez le cluster principal, puis AlloyDB Studio :
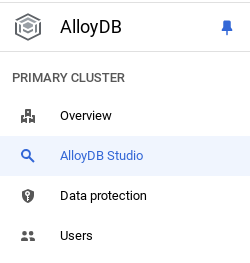
Vous devrez peut-être attendre que votre instance soit créée. Une fois le cluster créé, connectez-vous à AlloyDB à l'aide des identifiants que vous avez créés. Utilisez les données suivantes pour vous authentifier auprès de PostgreSQL :
- Nom d'utilisateur : "
postgres" - Base de données : "
postgres" - Mot de passe : "
alloydb"
Une fois l'authentification réussie dans AlloyDB Studio, les commandes SQL sont saisies dans l'éditeur. Vous pouvez ajouter plusieurs fenêtres de l'éditeur en cliquant sur le signe plus à droite de la dernière fenêtre.
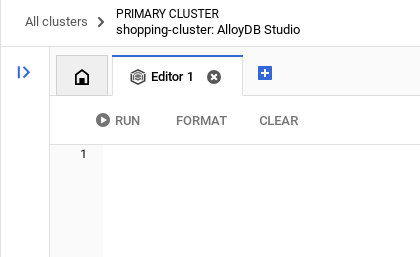
Vous saisirez les commandes pour AlloyDB dans les fenêtres de l'éditeur, en utilisant les options "Exécuter", "Mettre en forme" et "Effacer" selon les besoins.
Créer une table
Vous pouvez créer une table à l'aide de l'instruction LDD ci-dessous dans AlloyDB Studio :
-- Table DDL for Procurement Material Order Status
CREATE TABLE material_order_status (
order_id VARCHAR(50) PRIMARY KEY,
material_name VARCHAR(100) NOT NULL,
supplier_name VARCHAR(100) NOT NULL,
order_date DATE NOT NULL,
estimated_delivery_date DATE,
actual_delivery_date DATE,
quantity_ordered INT NOT NULL,
quantity_received INT,
unit_price DECIMAL(10, 2) NOT NULL,
total_amount DECIMAL(12, 2),
order_status VARCHAR(50) NOT NULL, -- e.g., "Ordered", "Shipped", "Delivered", "Cancelled"
delivery_address VARCHAR(255),
contact_person VARCHAR(100),
contact_phone VARCHAR(20),
tracking_number VARCHAR(100),
notes TEXT,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
quality_check_passed BOOLEAN, -- Indicates if the material passed quality control
quality_check_notes TEXT, -- Notes from the quality control check
priority VARCHAR(20), -- e.g., "High", "Medium", "Low"
project_id VARCHAR(50), -- Link to a specific project
receiver_name VARCHAR(100), -- Name of the person who received the delivery
return_reason TEXT, -- Reason for returning material if applicable
po_number VARCHAR(50) -- Purchase order number
);
Insérer des enregistrements
Copiez l'instruction de requête insert du script database_script.sql mentionné ci-dessus dans l'éditeur.
Cliquez sur Exécuter.
Maintenant que l'ensemble de données est prêt, créons une application Java Cloud Run Functions pour extraire l'état.
Créer une fonction Cloud Run en Java pour extraire les informations sur l'état des commandes
- Créez une fonction Cloud Run à partir de cette page : https://console.cloud.google.com/run/create?deploymentType=function.
- Définissez le nom de la fonction sur check-status et choisissez Java 17 comme environnement d'exécution.
- Vous pouvez définir l'authentification sur Autoriser les appels non authentifiés, car il s'agit d'une application de démonstration.
- Choisissez Java 17 comme environnement d'exécution et l'éditeur intégré pour le code source.
- À ce stade, le code de l'espace réservé sera chargé dans l'éditeur.
Remplacer le code de l'espace réservé
- Remplacez le nom du fichier Java par ProposalOrdersTool.java et le nom de la classe par ProposalOrdersTool.
- Remplacez le code de l'espace réservé dans ProposalOrdersTool.java et pom.xml par le code des fichiers correspondants dans le dossier "Cloud Run Function" de ce dépôt.
- Dans ProposalOrdersTool.java, recherchez la ligne de code suivante et remplacez les valeurs d'espace réservé par les valeurs de votre configuration :
String ALLOYDB_INSTANCE_NAME = "projects/<<YOUR_PROJECT_ID>>/locations/us-central1/clusters/<<YOUR_CLUSTER>>/instances/<<YOUR_INSTANCE>>";
- Cliquez sur Créer.
- La fonction Cloud Run est créée et déployée.
ÉTAPE IMPORTANTE :
Une fois déployée, nous allons créer le connecteur VPC pour permettre à Cloud Functions d'accéder à notre instance de base de données AlloyDB.
Une fois le déploiement lancé, vous devriez pouvoir voir les fonctions dans la console Google Cloud Run Functions. Recherchez la fonction que vous venez de créer (check-status), cliquez dessus, puis sur MODIFIER ET DÉPLOYER LA NOUVELLE RÉVISION (identifié par l'icône de modification (stylo) en haut de la console Cloud Run Functions) et modifiez les éléments suivants :
- Accédez à l'onglet "Réseau" :
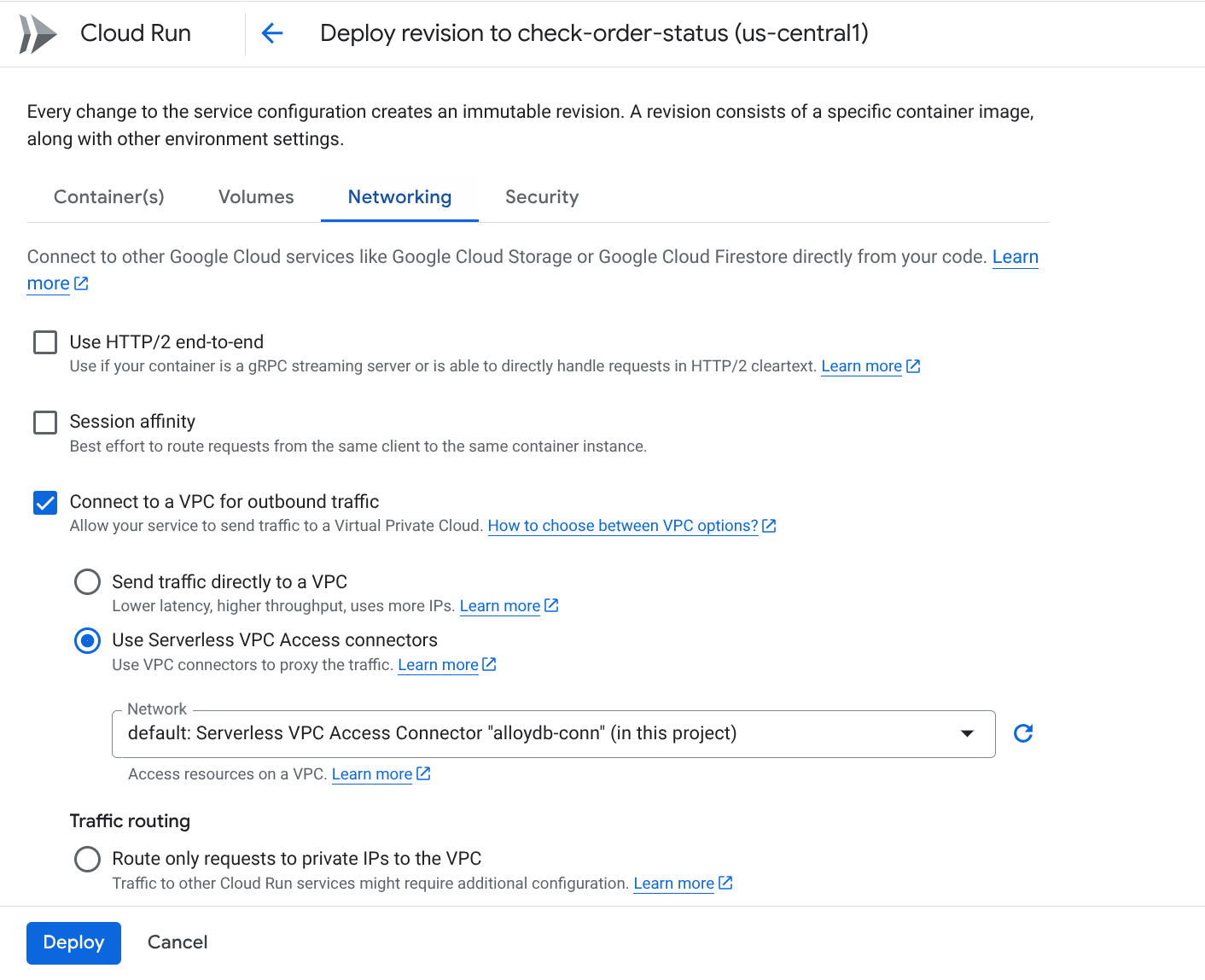
- Sélectionnez Se connecter à un VPC pour le trafic sortant, puis Utiliser les connecteurs d'accès au VPC sans serveur.
- Dans le menu déroulant "Réseau", cliquez sur l'option Ajouter un connecteur VPC (si vous n'avez pas encore configuré le connecteur par défaut), puis suivez les instructions qui s'affichent dans la boîte de dialogue :
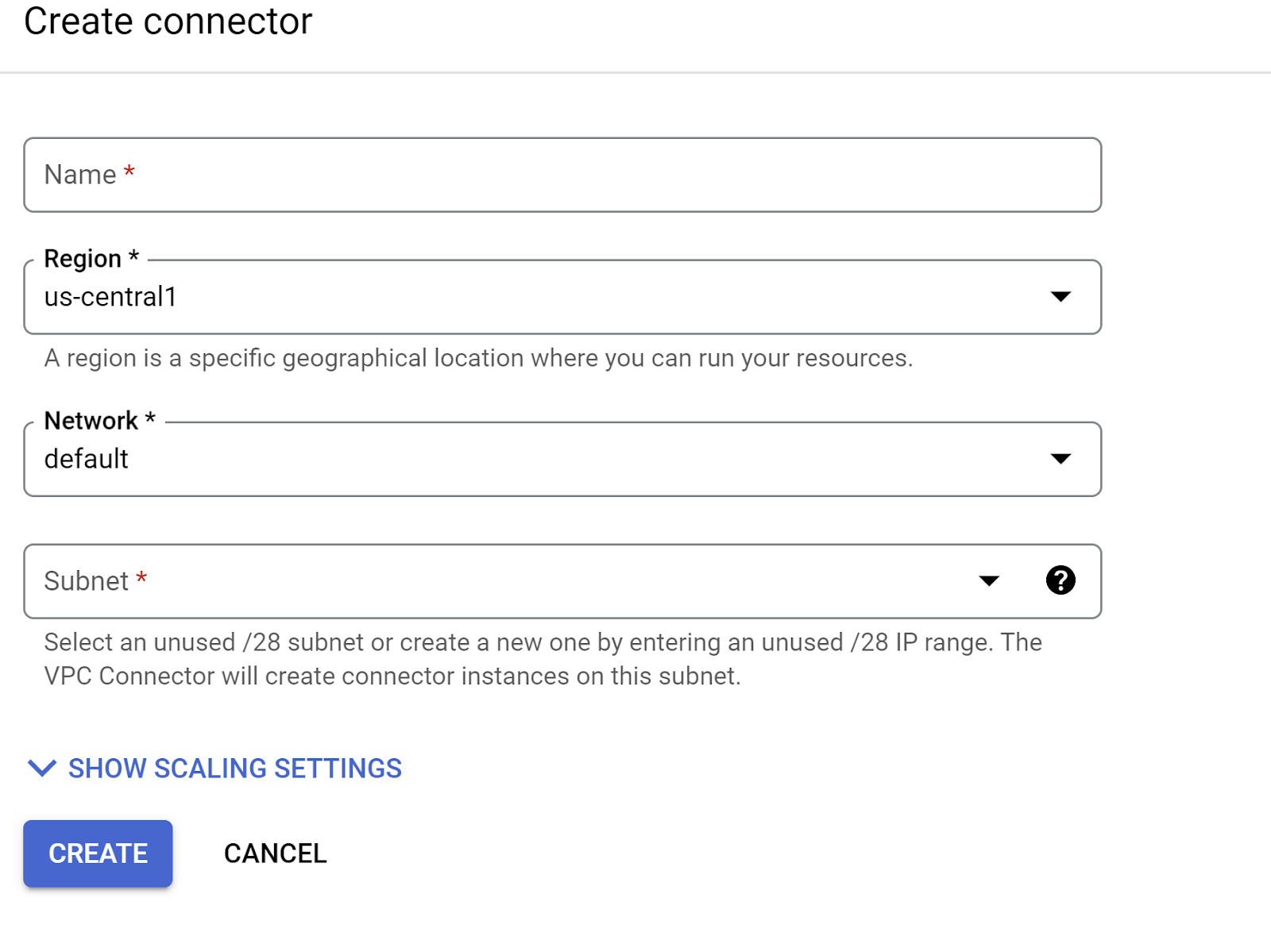
- Donnez un nom au connecteur VPC et assurez-vous que la région est la même que celle de votre instance. Laissez la valeur du réseau par défaut et définissez le sous-réseau sur "Plage d'adresses IP personnalisée" avec la plage d'adresses IP 10.8.0.0 ou une plage similaire disponible.
- Développez AFFICHER LES PARAMÈTRES DE SCALING et assurez-vous que la configuration est exactement la suivante :
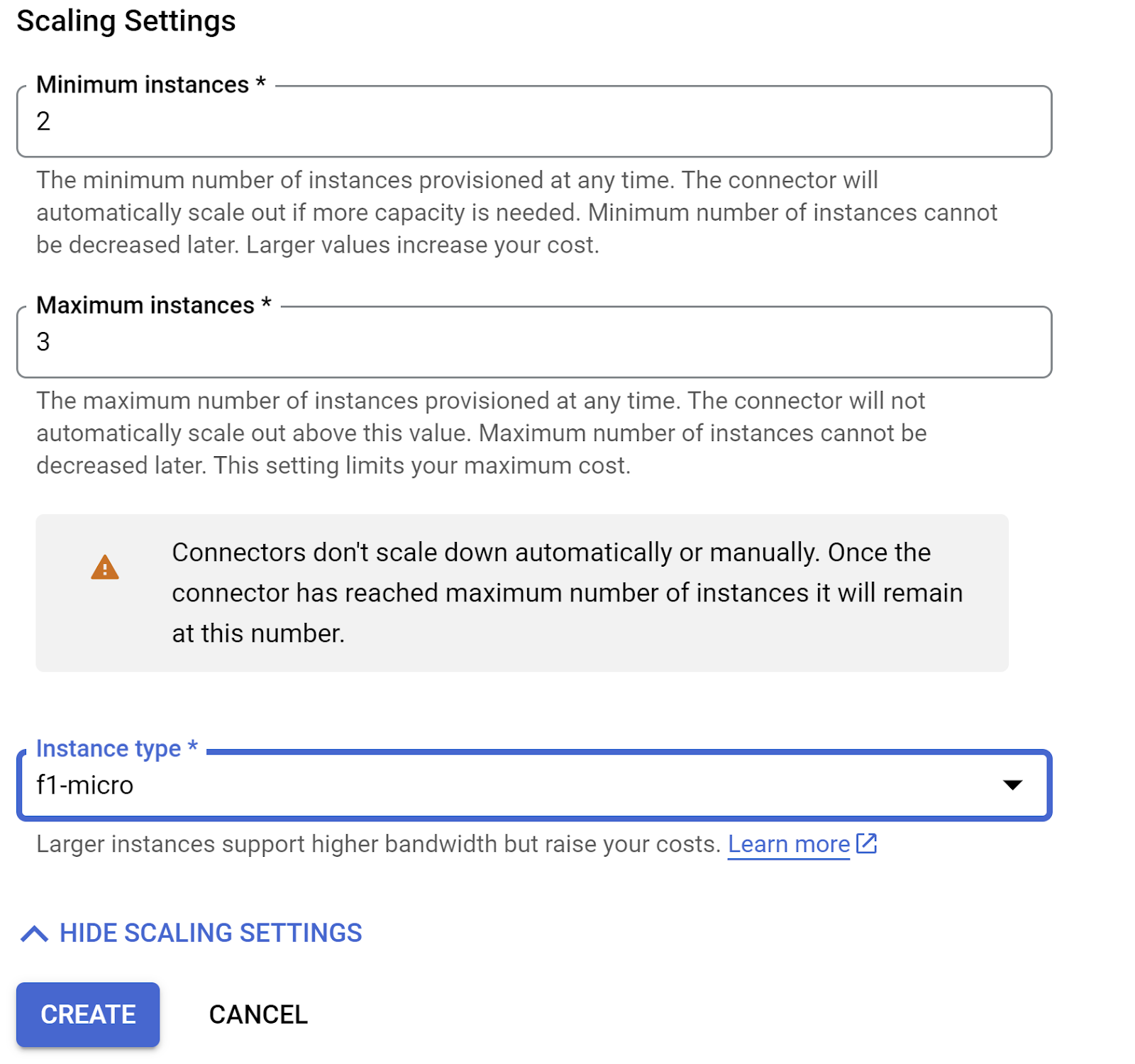
- Cliquez sur CRÉER. Ce connecteur devrait maintenant figurer dans les paramètres de sortie.
- Sélectionnez le connecteur que vous venez de créer.
- Choisissez d'acheminer tout le trafic via ce connecteur VPC.
- Cliquez sur SUIVANT, puis sur DÉPLOYER.
- Une fois la fonction Cloud mise à jour déployée, le point de terminaison généré devrait s'afficher.
- Vous devriez pouvoir la tester en cliquant sur le bouton TEST en haut de la console Cloud Run Functions et en exécutant la commande résultante dans le terminal Cloud Shell.
- Le point de terminaison déployé est l'URL que vous devez mettre à jour dans la variable .env
CHECK_ORDER_STATUS_ENDPOINT.
8. Configuration du modèle
La capacité de votre agent à comprendre les requêtes des utilisateurs et à générer des réponses repose sur un grand modèle de langage (LLM). Votre agent doit effectuer des appels sécurisés à ce service LLM externe, ce qui nécessite des identifiants d'authentification. Sans authentification valide, le service LLM refusera les requêtes de l'agent, qui ne pourra pas fonctionner.
- Obtenez une clé API depuis Google AI Studio.
- À l'étape suivante, lorsque vous configurez le fichier .env, remplacez
<<your API KEY>>par la valeur de votre clé API.
9. Configurer les variables d'environnement
- Configurez les valeurs des paramètres dans le fichier .env du modèle dans ce dépôt. Dans mon cas, le fichier .env contient les variables suivantes :
GOOGLE_GENAI_USE_VERTEXAI=FALSE
GOOGLE_API_KEY=<<your API KEY>>
GOOGLE_CLOUD_LOCATION=us-central1 <<or your region>>
GOOGLE_CLOUD_PROJECT=<<your project id>>
PROJECT_ID=<<your project id>>
GOOGLE_CLOUD_REGION=us-central1 <<or your region>>
STORAGE_BUCKET=next-demo-store <<or your storage bucket name>>
CHECK_ORDER_STATUS_ENDPOINT=<<YOUR_ENDPOINT_TO_CLOUD FUNCTION_TO_READ_ORDER_DATA_FROM_ALLOYDB>>
Remplacez les espaces réservés par vos valeurs.
10. Exécuter votre agent
- Dans le terminal, accédez au répertoire parent de votre projet d'agent :
cd renovation-agent
- Installer toutes les dépendances
pip install -r requirements.txt
- Vous pouvez exécuter la commande suivante dans votre terminal Cloud Shell pour exécuter l'agent :
adk run .
- Pour l'exécuter dans une interface utilisateur Web provisionnée par ADK, exécutez la commande suivante :
adk web
- Effectuez un test avec les requêtes suivantes :
user>>
Hello. Generate Proposal Document for the kitchen remodel requirement. I have no other specification.
11. Résultat
@ Système multi-agents pour les tâches de rénovation de cuisine
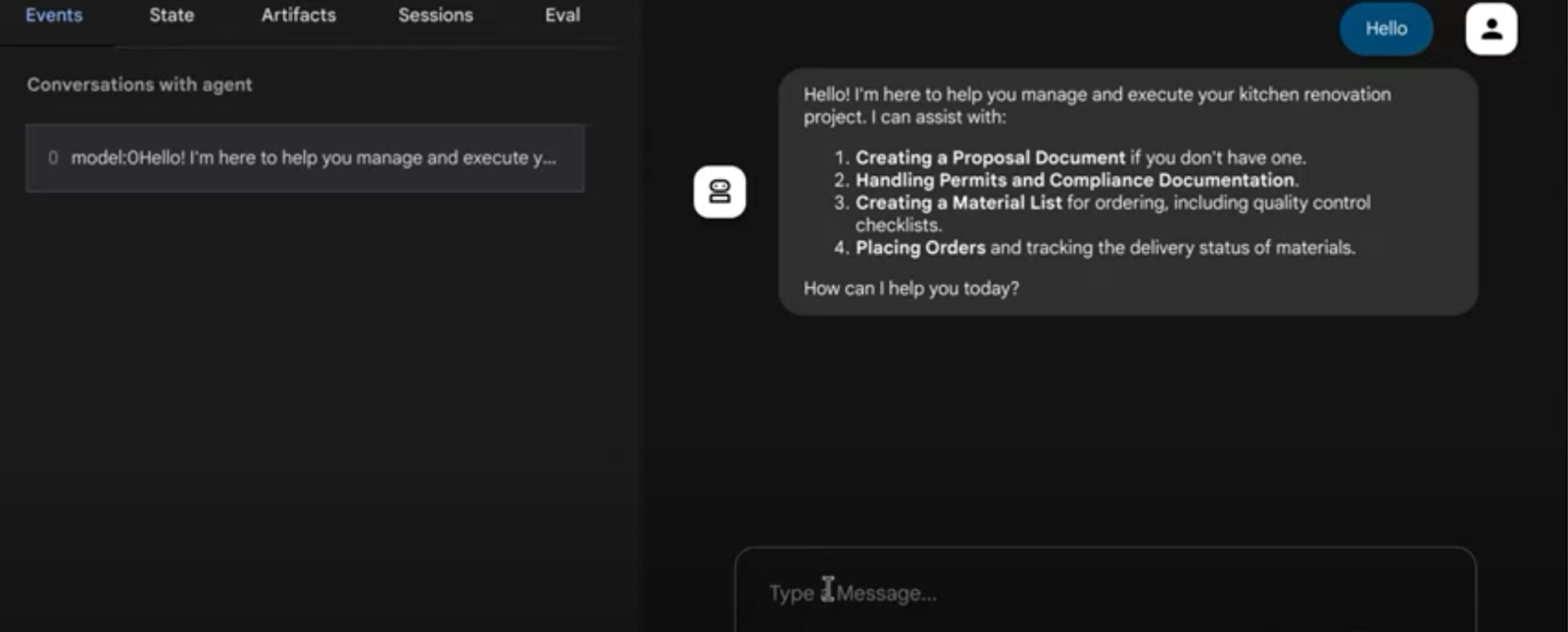
12. Déploiement sur Agent Engine
Maintenant que vous avez testé le système multi-agents et qu'il fonctionne correctement, rendons-le sans serveur et disponible dans le cloud pour que n'importe qui ou n'importe quelle application puisse l'utiliser. Décommentez l'extrait de code ci-dessous dans agent.py à partir du dépôt. Vous pouvez ensuite déployer votre système multi-agent :
# Agent Engine Deployment:
# Create a remote app for our multiagent with agent Engine.
# This may take 1-2 minutes to finish.
# Uncomment the below segment when you're ready to deploy.
app = AdkApp(
agent=root_agent,
enable_tracing=True,
)
vertexai.init(
project=PROJECT_ID,
location=GOOGLE_CLOUD_LOCATION,
staging_bucket=STAGING_BUCKET,
)
remote_app = agent_engines.create(
app,
requirements=[
"google-cloud-aiplatform[agent_engines,adk]>=1.88",
"google-adk",
"pysqlite3-binary",
"toolbox-langchain==0.1.0",
"pdfplumber",
"google-cloud-aiplatform",
"cloudpickle==3.1.1",
"pydantic==2.10.6",
"pytest",
"overrides",
"scikit-learn",
"reportlab",
"google-auth",
"google-cloud-storage",
],
)
# Deployment to Agent Engine related code ends
Exécutez à nouveau agent.py à partir du dossier du projet à l'aide de la commande suivante :
>> cd adk-renovation-agent
>> python agent.py
L'exécution de ce code prendra quelques minutes. Une fois l'opération terminée, vous recevrez un point de terminaison qui se présentera comme suit :
'projects/123456789/locations/us-central1/reasoningEngines/123456'
Vous pouvez tester votre agent déployé avec le code suivant en ajoutant un fichier " test.py"
import vertexai
from vertexai.preview import reasoning_engines
from vertexai import agent_engines
import os
import warnings
from dotenv import load_dotenv
load_dotenv()
GOOGLE_CLOUD_PROJECT = os.environ["GOOGLE_CLOUD_PROJECT"]
GOOGLE_CLOUD_LOCATION = os.environ["GOOGLE_CLOUD_LOCATION"]
GOOGLE_API_KEY = os.environ["GOOGLE_API_KEY"]
GOOGLE_GENAI_USE_VERTEXAI=os.environ["GOOGLE_GENAI_USE_VERTEXAI"]
AGENT_NAME = "adk_renovation_agent"
MODEL_NAME = "gemini-2.5-pro-preview-03-25"
warnings.filterwarnings("ignore")
PROJECT_ID = GOOGLE_CLOUD_PROJECT
reasoning_engine_id = "<<YOUR_DEPLOYED_ENGINE_ID>>"
vertexai.init(project=PROJECT_ID, location="us-central1")
agent = agent_engines.get(reasoning_engine_id)
print("**********************")
print(agent)
print("**********************")
for event in agent.stream_query(
user_id="test_user",
message="I want you to check order status.",
):
print(event)
Dans le code ci-dessus, remplacez la valeur de l'espace réservé <<YOUR_DEPLOYED_ENGINE_ID>> et exécutez la commande python test.py. Vous êtes prêt à interagir avec un système multi-agents déployé dans Agent Engine et à rénover votre cuisine !
13. Options de déploiement sur une seule ligne
Maintenant que vous avez testé le système multi-agents déployé, découvrons des méthodes plus simples qui font abstraction de l'étape de déploiement que nous avons effectuée à l'étape précédente : OPTIONS DE DÉPLOIEMENT SUR UNE SEULE LIGNE :
- Vers Cloud Run :
Syntaxe :
adk deploy cloud_run \
--project=<<YOUR_PROJECT_ID>> \
--region=us-central1 \
--service_name=<<YOUR_SERVICE_NAME>> \
--app_name=<<YOUR_APP_NAME>> \
--with_ui \
./<<YOUR_AGENT_PROJECT_NAME>>
Dans ce cas :
adk deploy cloud_run \
--project=<<YOUR_PROJECT_ID>> \
--region=us-central1 \
--service_name=renovation-agent \
--app_name=renovation-app \
--with_ui \
./renovation-agent
Vous pouvez utiliser le point de terminaison déployé pour les intégrations en aval.
- Vers Agent Engine :
Syntaxe :
adk deploy agent_engine \
--project <your-project-id> \
--region us-central1 \
--staging_bucket gs://<your-google-cloud-storage-bucket> \
--trace_to_cloud \
path/to/agent/folder
Dans ce cas :
adk deploy agent_engine --project <<YOUR_PROJECT_ID>> --region us-central1 --staging_bucket gs://<<YOUR_BUCKET_NAME>> --trace_to_cloud renovation-agent
Un nouvel agent doit s'afficher dans l'interface utilisateur Agent Engine de la console Google Cloud. Pour en savoir plus, consultez cet article de blog.
14. Effectuer un nettoyage
Pour éviter que les ressources utilisées dans cet article soient facturées sur votre compte Google Cloud, procédez comme suit :
- Dans la console Google Cloud, accédez à la page Gérer les ressources.
- Dans la liste des projets, sélectionnez le projet que vous souhaitez supprimer, puis cliquez sur Supprimer.
- Dans la boîte de dialogue, saisissez l'ID du projet, puis cliquez sur Arrêter pour supprimer le projet.
15. Félicitations
Félicitations ! Vous avez créé votre premier agent et interagi avec lui à l'aide de l'ADK.