
1. Przegląd
Agent to autonomiczny program, który komunikuje się z modelem AI, aby wykonywać operacje oparte na celach przy użyciu dostępnych narzędzi i kontekstu. Potrafi podejmować autonomiczne decyzje oparte na faktach.
Jeśli aplikacja ma wielu agentów, którzy działają autonomicznie i współpracują ze sobą w razie potrzeby, aby realizować jej szerszy cel, a każdy z nich ma niezależną wiedzę i odpowiada za określony obszar, aplikacja staje się systemem wieloagentowym.
Pakiet Agent Development Kit (ADK)
Pakiet Agent Development Kit (ADK) to elastyczna i modułowa platforma do tworzenia oraz wdrażania agentów AI. Pakiet ADK umożliwia tworzenie zaawansowanych aplikacji przez łączenie wielu różnych instancji agentów w system wieloagentowy (MAS).
W pakiecie ADK system wieloagentowy to aplikacja, w której różne agenty, często tworzące hierarchię, współpracują lub koordynują działania, aby osiągnąć większy cel. Taka struktura aplikacji zapewnia wiele korzyści, w tym większą modułowość, specjalizację, możliwość ponownego użycia, łatwość konserwacji i możliwość definiowania strukturalnych przepływów sterowania za pomocą dedykowanych agentów przepływu pracy.
O czym warto pamiętać w przypadku systemu z wieloma agentami
Po pierwsze, ważne jest, aby mieć odpowiednie rozumowanie i zrozumienie specjalizacji każdego agenta. – „czy wiesz, dlaczego do czegoś potrzebujesz konkretnego subagenta” – najpierw to ustal.
Po drugie, jak połączyć je z agentem głównym, aby kierować odpowiedzi i je interpretować.
Po trzecie, w tej dokumentacji znajdziesz różne typy routingu do agentów. Sprawdź, który z nich pasuje do działania Twojej aplikacji. Określ też różne konteksty i stany, które są potrzebne do sterowania przepływem w systemie z wieloma agentami.
Co utworzysz
Zbudujmy system z wieloma agentami, który będzie obsługiwać remonty kuchni. Zrobimy to. Stworzymy system z 3 agentami.
- Agent ds. propozycji remontów
- Agent ds. zezwoleń i zgodności
- Agent sprawdzania stanu zamówienia
Renovation Proposal Agent, aby wygenerować dokument z propozycją remontu kuchni.
Agent ds. zezwoleń i zgodności, który zajmuje się zadaniami związanymi z zezwoleniami i zgodnością.
Agent sprawdzający stan zamówienia, który sprawdza stan zamówienia materiałów, korzystając z bazy danych zarządzania zamówieniami skonfigurowanej w AlloyDB.
Będziemy mieć agenta głównego, który będzie koordynować pracę tych agentów na podstawie wymagań.
Wymagania
2. Zanim zaczniesz
Utwórz projekt
- W konsoli Google Cloud na stronie selektora projektów wybierz lub utwórz projekt Google Cloud.
- Sprawdź, czy w projekcie Cloud włączone są płatności. Dowiedz się, jak sprawdzić, czy w projekcie są włączone płatności .
- Aktywuj Cloud Shell, klikając ten link. Możesz przełączać się między terminalem Cloud Shell (do uruchamiania poleceń w chmurze) a edytorem (do tworzenia projektów), klikając odpowiedni przycisk w Cloud Shell.
- Po połączeniu z Cloud Shell sprawdź, czy uwierzytelnianie zostało już przeprowadzone, a projekt jest już ustawiony na Twój identyfikator projektu, używając tego polecenia:
gcloud auth list
- Aby potwierdzić, że polecenie gcloud zna Twój projekt, uruchom w Cloud Shell to polecenie:
gcloud config list project
- Jeśli projekt nie jest ustawiony, użyj tego polecenia, aby go ustawić:
gcloud config set project <YOUR_PROJECT_ID>
- Upewnij się, że masz Pythona w wersji 3.9 lub nowszej.
- Włącz te interfejsy API, uruchamiając te polecenia:
gcloud services enable artifactregistry.googleapis.com \cloudbuild.googleapis.com \run.googleapis.com \aiplatform.googleapis.com
- Informacje o poleceniach gcloud i ich użyciu znajdziesz w dokumentacji.
3. Prototyp
Możesz pominąć ten krok, jeśli zdecydujesz się użyć w projekcie modelu „Gemini 2.5 Pro”.
Otwórz Google AI Studio. Zacznij wpisywać prompta. Oto mój prompt:
I want to renovate my kitchen, basically just remodel it. I don't know where to start. So I want to use Gemini to generate a plan. For that I need a good prompt. Give me a short yet detailed prompt that I can use.
Dostosuj i skonfiguruj parametry po prawej stronie, aby uzyskać optymalną odpowiedź.
Na podstawie tego prostego opisu Gemini stworzył dla mnie niezwykle szczegółowego prompta, który pomógł mi rozpocząć remont. W efekcie używamy Gemini, aby uzyskiwać jeszcze lepsze odpowiedzi z AI Studio i naszych modeli. Możesz też wybrać różne modele do użycia w zależności od przypadku użycia.
Wybraliśmy Gemini 2.5 Pro. Jest to model Thinking, co oznacza, że otrzymujemy jeszcze więcej tokenów wyjściowych, w tym przypadku do 65 tys., na potrzeby długich analiz i szczegółowych dokumentów. Pole myślenia Gemini pojawia się po włączeniu Gemini 2.5 Pro, który ma natywne możliwości rozumowania i może przyjmować długie żądania kontekstowe.
Fragment odpowiedzi znajdziesz poniżej:
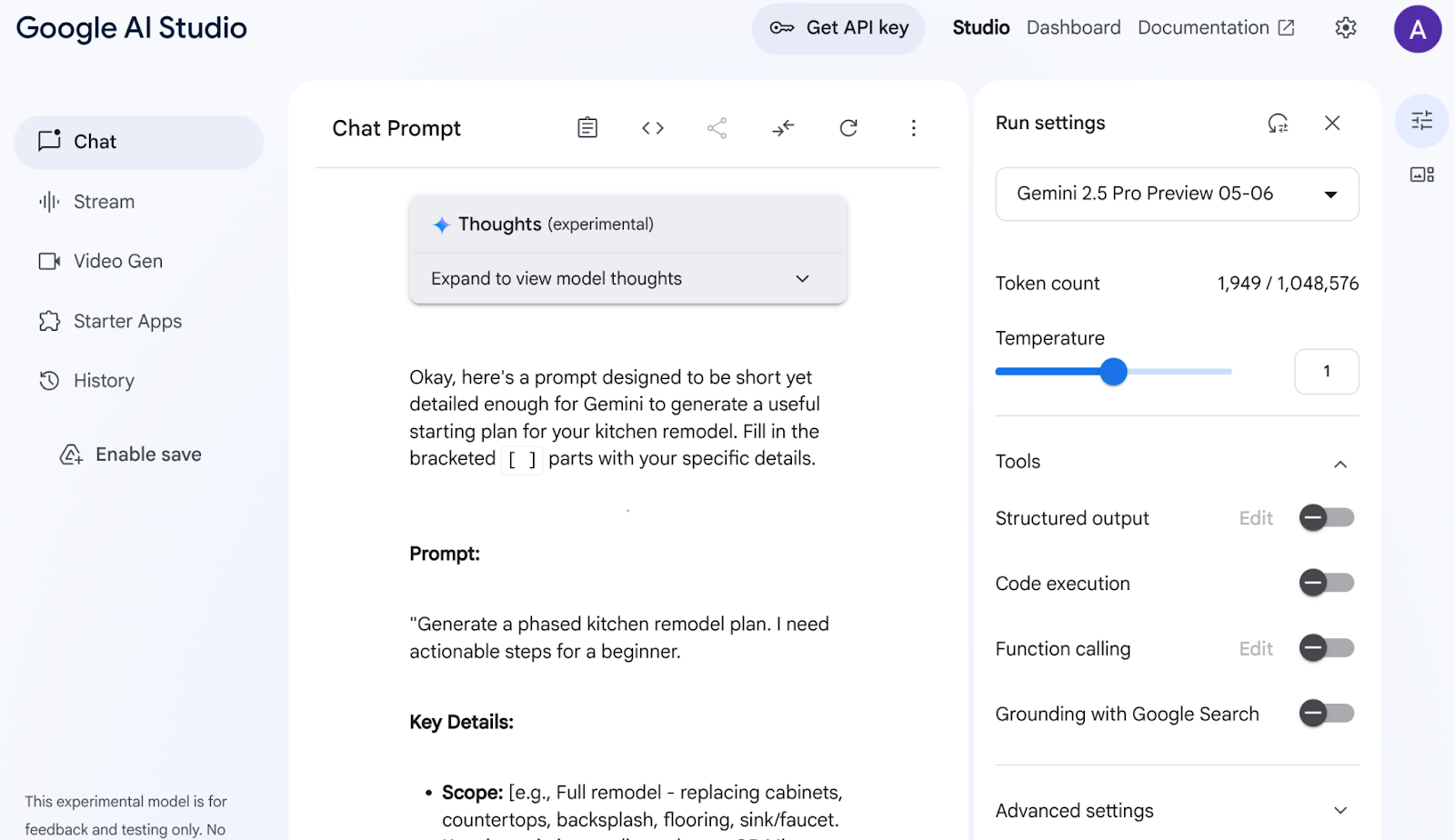
AI Studio przeanalizowało moje dane i wygenerowało wszystkie te elementy, takie jak szafki, blaty, backsplash, podłogi, zlewozmywak, spójność, paleta kolorów i wybór materiałów. Gemini podaje nawet źródła.
Powtarzaj te czynności, wybierając różne modele, aż uzyskasz zadowalający efekt. Ale po co to wszystko, skoro masz Gemini 2.5 :)
Spróbuj teraz zobaczyć, jak pomysł ożywa dzięki innemu promptowi:
Add flat and circular light accessories above the island area for my current kitchen in the attached image.
Dołącz link do zdjęcia obecnej kuchni (lub dowolnego przykładowego zdjęcia kuchni). Zmień model na „Gemini 2.0 Flash Preview Image Generation”, aby mieć dostęp do generowania obrazów.
Otrzymuję te dane wyjściowe:

To jest właśnie moc Gemini.
Od rozumienia filmów po natywne generowanie obrazów i oparcie prawdziwych informacji na faktach za pomocą wyszukiwarki Google – są rzeczy, które można stworzyć tylko dzięki Gemini.
W AI Studio możesz wziąć ten prototyp, pobrać klucz interfejsu API i skalować go do pełnej aplikacji opartej na agentach, korzystając z możliwości pakietu Vertex AI ADK.
4. Konfiguracja ADK
- Tworzenie i aktywowanie środowiska wirtualnego (zalecane)
W terminalu Cloud Shell utwórz środowisko wirtualne:
python -m venv .venv
Aktywuj środowisko wirtualne:
source .venv/bin/activate
- Instalowanie pakietu ADK
pip install google-adk
5. Struktura projektu
- W terminalu Cloud Shell utwórz katalog w wybranej lokalizacji projektu.
mkdir agentic-apps
cd agentic-apps
mkdir renovation-agent
- Otwórz edytor Cloud Shell i utwórz tę strukturę projektu, tworząc pliki (na początku puste):
renovation-agent/
__init__.py
agent.py
.env
requirements.txt
6. Kod źródłowy
- Otwórz plik „init.py” i zaktualizuj go, wklejając poniższą treść:
from . import agent
- Otwórz plik agent.py i zastąp jego zawartość treścią z tej ścieżki:
https://github.com/AbiramiSukumaran/adk-renovation-agent/blob/main/agent.py
W pliku agent.py importujemy niezbędne zależności, pobieramy parametry konfiguracji z pliku .env i definiujemy agenta głównego, który koordynuje 3 podrzędnych agentów, których chcemy utworzyć w tej aplikacji. Istnieje kilka narzędzi, które pomagają w realizacji podstawowych i pomocniczych funkcji tych podmiotów.
- Sprawdź, czy masz zasobnik Cloud Storage
Służy do przechowywania dokumentu z propozycją wygenerowanego przez agenta. Utwórz go i przyznaj dostęp, aby system wieloagentowy utworzony za pomocą Vertex AI mógł z niego korzystać. Aby to zrobić:
https://cloud.google.com/storage/docs/creating-buckets#console
Nazwij zasobnik „next-demo-store”. Jeśli nadasz mu inną nazwę, pamiętaj, aby zaktualizować wartość STORAGE_BUCKET w pliku .env (w kroku Konfiguracja zmiennych środowiskowych).
- Aby skonfigurować dostęp do zasobnika, otwórz konsolę Cloud Storage i wybierz zasobnik Storage (w naszym przypadku nazwa zasobnika to „next-demo-storage”): https://console.cloud.google.com/storage/browser/next-demo-storage.
Kliknij kolejno Uprawnienia –> Wyświetl podmioty zabezpieczeń –> Przyznaj dostęp. Wybierz Podmioty zabezpieczeń jako „allUsers” i Rolę jako „Użytkownik obiektów Cloud Storage”.
Make sure to not enable "prevent public access". Since this is a demo/study application we are going with a public bucket. Remember to configure permission settings appropriately when you are building your application.
- Tworzenie listy zależności
Wymień wszystkie zależności w pliku requirements.txt. Możesz go skopiować z repozytorium.
Wyjaśnienie kodu źródłowego systemu wieloagentowego
Plik agent.py definiuje strukturę i działanie naszego systemu wieloagentowego do remontu kuchni za pomocą pakietu Agent Development Kit (ADK). Przyjrzyjmy się kluczowym komponentom:
Definicje agentów
RenovationProposalAgent
Ten agent odpowiada za utworzenie dokumentu z ofertą remontu kuchni. Opcjonalnie przyjmuje parametry wejściowe, takie jak rozmiar kuchni, pożądany styl, budżet i preferencje klienta. Na podstawie tych informacji używa dużego modelu językowego (LLM) Gemini 2.5 do wygenerowania szczegółowej propozycji. Wygenerowana propozycja jest następnie przechowywana w zasobniku Google Cloud Storage.
PermitsAndComplianceCheckAgent
Ten agent dba o to, aby projekt remontu był zgodny z lokalnymi przepisami budowlanymi i regulacjami prawnymi. Otrzymuje informacje o planowanym remoncie (np. zmiany konstrukcyjne, prace elektryczne, modyfikacje instalacji wodno-kanalizacyjnej) i za pomocą LLM sprawdza wymagania dotyczące pozwolenia i przepisy dotyczące zgodności. Agent korzysta z informacji z bazy wiedzy (którą możesz dostosować, aby uzyskiwać dostęp do zewnętrznych interfejsów API i zbierać odpowiednie przepisy).
OrderingAgent
Ten agent (możesz go zakomentować, jeśli nie chcesz go teraz wdrażać) sprawdza stan zamówienia materiałów i sprzętu potrzebnych do remontu. Aby ją włączyć, musisz utworzyć funkcję Cloud Run zgodnie z instrukcjami konfiguracji. Następnie agent wywoła tę funkcję Cloud Run, która wchodzi w interakcję z bazą danych AlloyDB zawierającą informacje o zamówieniach. Pokazuje to integrację z systemem bazy danych w celu śledzenia danych w czasie rzeczywistym.
Agent główny (aranżer)
Główny agent pełni rolę centralnego aranżera systemu wieloagentowego. Otrzymuje początkową prośbę o remont i na jej podstawie określa, które podagenty należy wywołać. Jeśli na przykład prośba wymaga sprawdzenia wymagań dotyczących zezwoleń, wywoła ona agenta PermitsAndComplianceCheckAgent. Jeśli użytkownik chce sprawdzić stan zamówienia, wywoła OrderingAgent (jeśli jest włączony).
Główny agent zbiera odpowiedzi od podrzędnych agentów i łączy je, aby przekazać użytkownikowi wyczerpującą odpowiedź. Może to obejmować podsumowanie propozycji, wymienienie wymaganych zezwoleń i przesyłanie aktualizacji stanu zamówienia.
Przepływ danych i kluczowe pojęcia
Użytkownik inicjuje żądanie za pomocą interfejsu ADK (terminala lub interfejsu internetowego).
- Żądanie jest odbierane przez agenta głównego.
- Główny agent analizuje żądanie i kieruje je do odpowiednich podagentów.
- Podagenci używają LLM, baz wiedzy, interfejsów API i baz danych do przetwarzania żądań i generowania odpowiedzi.
- Podagenci przesyłają odpowiedzi do głównego agenta.
- Główny agent łączy odpowiedzi i przekazuje użytkownikowi ostateczny wynik.
LLM (duże modele językowe)
Agenci w dużej mierze polegają na LLM w zakresie generowania tekstu, odpowiadania na pytania i wykonywania zadań wymagających rozumowania. LLM to „mózgi” agentów, które umożliwiają im rozumienie żądań użytkowników i odpowiadanie na nie. W tej aplikacji używamy Gemini 2.5.
Google Cloud Storage
Służy do przechowywania wygenerowanych dokumentów z propozycją remontu. Musisz utworzyć zasobnik i przyznać agentom niezbędne uprawnienia dostępu do niego.
Cloud Run (opcjonalnie)
OrderingAgent korzysta z funkcji Cloud Run do komunikacji z AlloyDB. Cloud Run udostępnia środowisko bezserwerowe do wykonywania kodu w odpowiedzi na żądania HTTP.
AlloyDB
Jeśli używasz OrderingAgent, musisz skonfigurować bazę danych AlloyDB do przechowywania informacji o zamówieniach. Szczegóły znajdziesz w następnej sekcji „Konfiguracja bazy danych”.
plik.env
Plik .env przechowuje informacje poufne, takie jak klucze interfejsu API, dane logowania do bazy danych i nazwy zasobników. Ważne jest, aby chronić ten plik i nie przesyłać go do repozytorium. Przechowuje też ustawienia konfiguracji agentów i projektu w chmurze Google. Funkcja root_agent lub funkcje pomocnicze zwykle odczytują wartości z tego pliku. Sprawdź, czy w pliku .env wszystkie wymagane zmienne są prawidłowo ustawione. Obejmuje to nazwę zasobnika Cloud Storage.
7. Konfiguracja bazy danych
W jednym z narzędzi używanych przez agenta zamawiania, o nazwie „check_status”, uzyskujemy dostęp do bazy danych zamówień AlloyDB, aby sprawdzić stan zamówień. W tej sekcji skonfigurujemy klaster i instancję bazy danych AlloyDB.
Tworzenie klastra i instancji
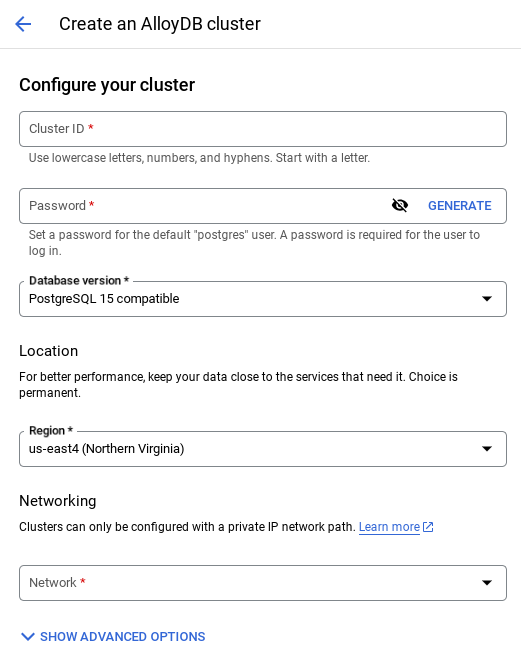
- Otwórz stronę AlloyDB w konsoli Cloud. Najprostszym sposobem na znalezienie większości stron w Cloud Console jest wyszukanie ich za pomocą paska wyszukiwania w konsoli.
- Na tej stronie kliknij UTWÓRZ KLASTER:

- Wyświetli się ekran podobny do tego poniżej. Utwórz klaster i instancję z tymi wartościami (upewnij się, że wartości są zgodne, jeśli klonujesz kod aplikacji z repozytorium):
- id klastra: „
vector-cluster” - password: "
alloydb" - PostgreSQL 15 / najnowsza zalecana
- Region: "
us-central1" - Sieć: „
default”
- Po wybraniu sieci domyślnej zobaczysz ekran podobny do tego poniżej.
Kliknij SKONFIGURUJ POŁĄCZENIE.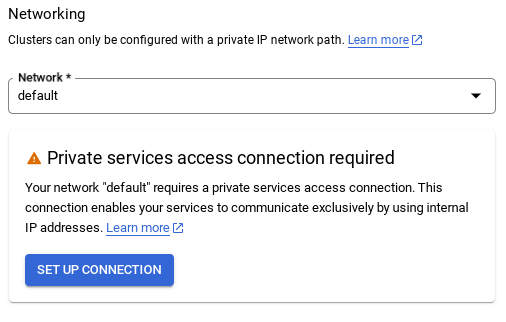
- Następnie wybierz „Użyj automatycznie przydzielonego zakresu adresów IP” i kliknij Dalej. Po sprawdzeniu informacji kliknij UTWÓRZ POŁĄCZENIE.
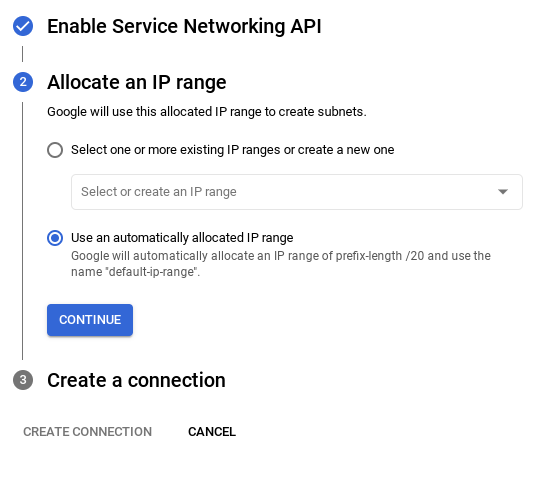
- Po skonfigurowaniu sieci możesz kontynuować tworzenie klastra. Kliknij UTWÓRZ KLASTER, aby dokończyć konfigurowanie klastra, jak pokazano poniżej:
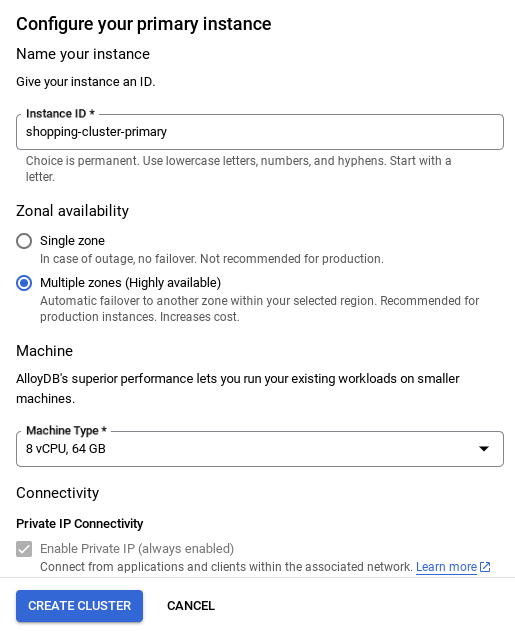
Pamiętaj, aby zmienić identyfikator instancji (który możesz znaleźć podczas konfigurowania klastra lub instancji) na
vector-instance. Jeśli nie możesz go zmienić, pamiętaj, aby we wszystkich kolejnych odwołaniach używać identyfikatora instancji.
Pamiętaj, że utworzenie klastra zajmie około 10 minut. Po zakończeniu procesu wyświetli się ekran z omówieniem utworzonego klastra.
Pozyskiwanie danych
Teraz dodaj tabelę z danymi o sklepie. Otwórz AlloyDB, wybierz klaster główny, a następnie AlloyDB Studio:
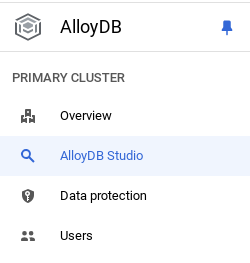
Może być konieczne poczekanie na zakończenie tworzenia instancji. Gdy to zrobisz, zaloguj się w AlloyDB przy użyciu danych logowania utworzonych podczas tworzenia klastra. Do uwierzytelniania w PostgreSQL użyj tych danych:
- Nazwa użytkownika: „
postgres” - Baza danych: „
postgres” - Hasło: „
alloydb”
Po pomyślnym uwierzytelnieniu w AlloyDB Studio polecenia SQL są wpisywane w Edytorze. Możesz dodać wiele okien Edytora, klikając znak plusa po prawej stronie ostatniego okna.
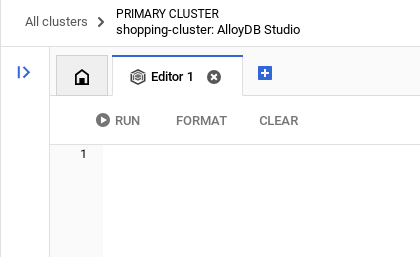
Polecenia dla AlloyDB będziesz wpisywać w oknach edytora, w razie potrzeby korzystając z opcji Uruchom, Formatuj i Wyczyść.
Tworzenie tabeli
Tabelę możesz utworzyć za pomocą instrukcji DDL poniżej w AlloyDB Studio:
-- Table DDL for Procurement Material Order Status
CREATE TABLE material_order_status (
order_id VARCHAR(50) PRIMARY KEY,
material_name VARCHAR(100) NOT NULL,
supplier_name VARCHAR(100) NOT NULL,
order_date DATE NOT NULL,
estimated_delivery_date DATE,
actual_delivery_date DATE,
quantity_ordered INT NOT NULL,
quantity_received INT,
unit_price DECIMAL(10, 2) NOT NULL,
total_amount DECIMAL(12, 2),
order_status VARCHAR(50) NOT NULL, -- e.g., "Ordered", "Shipped", "Delivered", "Cancelled"
delivery_address VARCHAR(255),
contact_person VARCHAR(100),
contact_phone VARCHAR(20),
tracking_number VARCHAR(100),
notes TEXT,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
quality_check_passed BOOLEAN, -- Indicates if the material passed quality control
quality_check_notes TEXT, -- Notes from the quality control check
priority VARCHAR(20), -- e.g., "High", "Medium", "Low"
project_id VARCHAR(50), -- Link to a specific project
receiver_name VARCHAR(100), -- Name of the person who received the delivery
return_reason TEXT, -- Reason for returning material if applicable
po_number VARCHAR(50) -- Purchase order number
);
Wstawianie rekordów
Skopiuj instrukcję zapytania insert ze skryptu database_script.sql wspomnianego powyżej do edytora.
Kliknij Wykonaj.
Zbiór danych jest już gotowy, więc możemy utworzyć aplikację Cloud Run Functions w języku Java, aby wyodrębnić stan.
Tworzenie funkcji Cloud Run w Javie do wyodrębniania informacji o stanie zamówienia
- Utwórz funkcję Cloud Run tutaj: https://console.cloud.google.com/run/create?deploymentType=function
- Nadaj funkcji nazwę „check-status” i jako środowisko wykonawcze wybierz „Java 17”.
- W przypadku aplikacji demonstracyjnej możesz ustawić uwierzytelnianie na „Zezwalaj na nieuwierzytelnione wywołania”.
- Wybierz Java 17 jako środowisko wykonawcze i Edytor wbudowany jako kod źródłowy.
- W tym momencie w edytorze zostanie wczytany kod zastępczy.
Zastąpienie kodu zastępczego
- Zmień nazwę pliku Java na „ProposalOrdersTool.java”, a nazwę klasy na „ProposalOrdersTool”.
- Zastąp kod zastępczy w plikach ProposalOrdersTool.java i pom.xml kodem z odpowiednich plików w folderze „Cloud Run Function” w tym repozytorium.
- W pliku ProposalOrdersTool.java znajdź ten wiersz kodu i zastąp wartości zastępcze wartościami z konfiguracji:
String ALLOYDB_INSTANCE_NAME = "projects/<<YOUR_PROJECT_ID>>/locations/us-central1/clusters/<<YOUR_CLUSTER>>/instances/<<YOUR_INSTANCE>>";
- Kliknij Utwórz.
- Funkcja Cloud Run zostanie utworzona i wdrożona.
WAŻNY KROK:
Po wdrożeniu, aby umożliwić funkcji w Cloud Functions dostęp do instancji bazy danych AlloyDB, utworzymy oprogramowanie sprzęgające VPC.
Gdy przygotujesz się do wdrożenia, funkcje powinny być widoczne w konsoli funkcji Google Cloud Run. Wyszukaj nowo utworzoną funkcję (check-status), kliknij ją, a potem kliknij EDIT AND DEPLOY NEW REVISIONS (EDYTUJ I WDRAŻAJ NOWE WERSJE) (oznaczone ikoną EDYCJA (ołówka) u góry konsoli Cloud Run Functions) i zmień te ustawienia:
- Otwórz kartę Sieć:
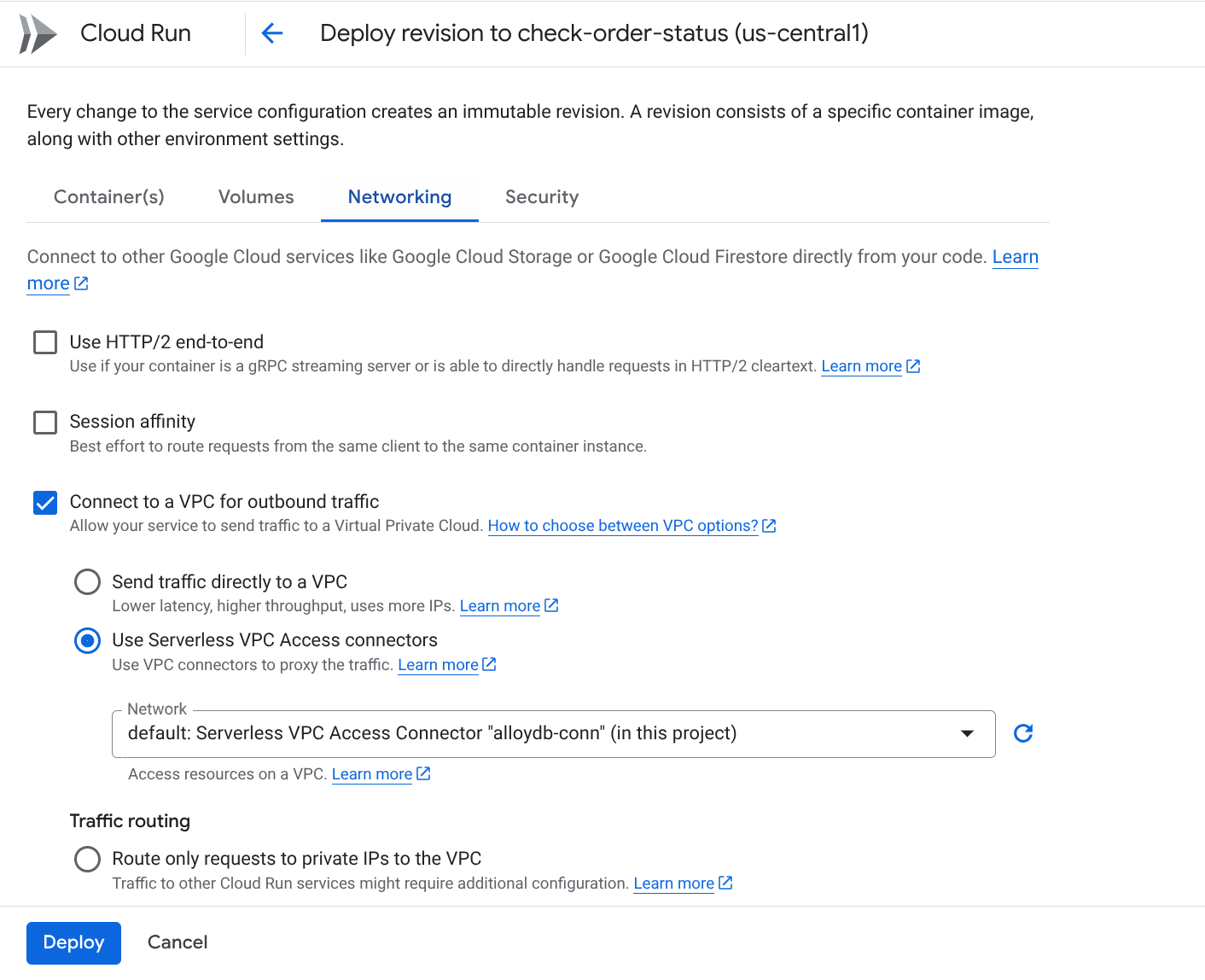
- Kliknij „Łącz się z siecią VPC w przypadku ruchu wychodzącego”, a następnie „Używaj oprogramowania sprzęgającego bezserwerowego dostępu do VPC”.
- W menu Sieć kliknij menu Sieć i wybierz opcję „Dodaj nowe połączenie VPC” (jeśli nie masz jeszcze skonfigurowanego połączenia domyślnego) i postępuj zgodnie z instrukcjami wyświetlanymi w wyskakującym okienku:
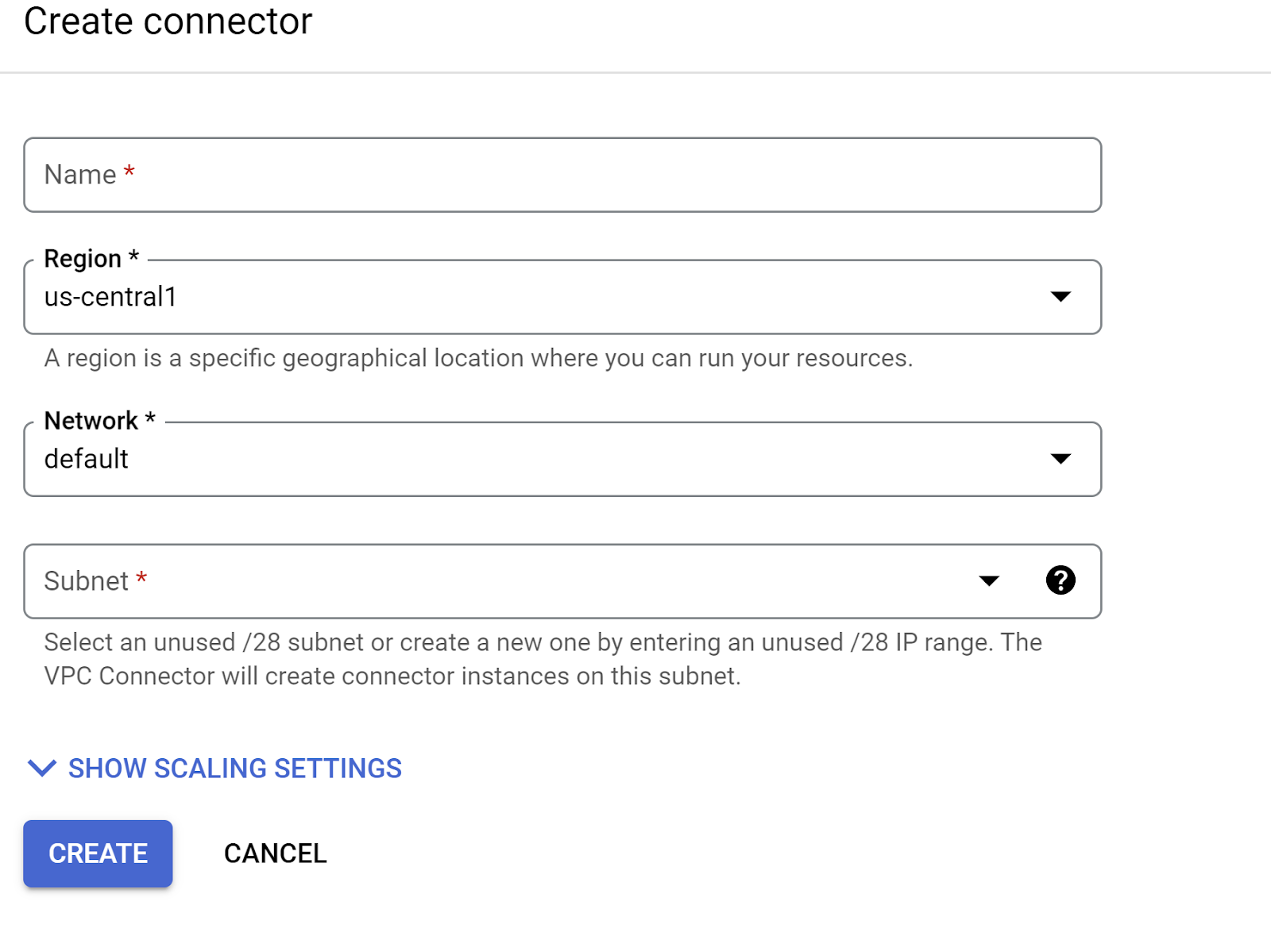
- Podaj nazwę oprogramowania sprzęgającego VPC i upewnij się, że region jest taki sam jak w przypadku instancji. Pozostaw domyślną wartość Sieć i ustaw Podsieć jako Niestandardowy zakres adresów IP z zakresem adresów IP 10.8.0.0 lub podobnym, który jest dostępny.
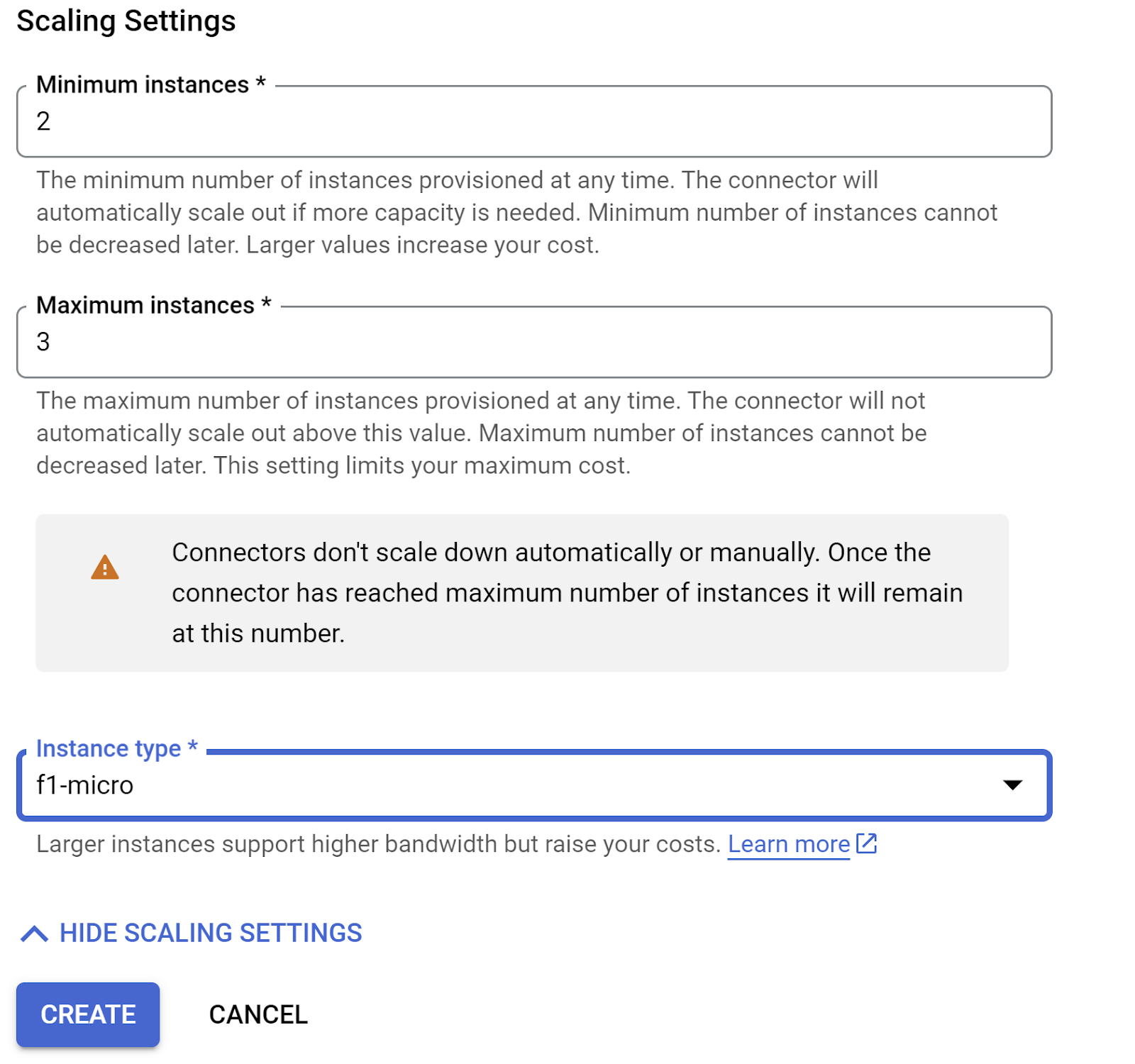
- Rozwiń POKAŻ USTAWIENIA SKALOWANIA i upewnij się, że konfiguracja jest dokładnie taka:
- Kliknij UTWÓRZ. Ten łącznik powinien być teraz widoczny w ustawieniach ruchu wychodzącego.
- Wybierz nowo utworzone oprogramowanie sprzęgające.
- Wybierz opcję kierowania całego ruchu przez to oprogramowanie sprzęgające VPC.
- Kliknij DALEJ, a potem WDRÓŻ.
- Po wdrożeniu zaktualizowanej funkcji w Cloud Functions powinien pojawić się wygenerowany punkt końcowy.
- Możesz ją przetestować, klikając przycisk TEST u góry konsoli Cloud Run Functions i wykonując wynikowe polecenie w terminalu Cloud Shell.
- Wdrożony punkt końcowy to adres URL, który musisz zaktualizować w zmiennej
CHECK_ORDER_STATUS_ENDPOINTw pliku .env.
8. Konfiguracja modelu
Zdolność agenta do rozumienia próśb użytkowników i generowania odpowiedzi jest oparta na dużym modelu językowym (LLM). Agent musi wykonywać bezpieczne wywołania tej zewnętrznej usługi LLM, co wymaga danych uwierzytelniających. Bez prawidłowego uwierzytelnienia usługa LLM odrzuci żądania agenta, a agent nie będzie mógł działać.
- Uzyskaj klucz interfejsu API z Google AI Studio.
- W następnym kroku, w którym skonfigurujesz plik .env, zastąp
<<your API KEY>>rzeczywistą wartością klucza API.
9. Konfigurowanie zmiennych środowiskowych
- Skonfiguruj wartości parametrów w pliku .env w tym repozytorium. W moim przypadku plik .env zawiera te zmienne:
GOOGLE_GENAI_USE_VERTEXAI=FALSE
GOOGLE_API_KEY=<<your API KEY>>
GOOGLE_CLOUD_LOCATION=us-central1 <<or your region>>
GOOGLE_CLOUD_PROJECT=<<your project id>>
PROJECT_ID=<<your project id>>
GOOGLE_CLOUD_REGION=us-central1 <<or your region>>
STORAGE_BUCKET=next-demo-store <<or your storage bucket name>>
CHECK_ORDER_STATUS_ENDPOINT=<<YOUR_ENDPOINT_TO_CLOUD FUNCTION_TO_READ_ORDER_DATA_FROM_ALLOYDB>>
Zastąp symbole zastępcze swoimi wartościami.
10. Uruchamianie agenta
- W terminalu przejdź do katalogu nadrzędnego projektu agenta:
cd renovation-agent
- Instalowanie wszystkich zależności
pip install -r requirements.txt
- Aby uruchomić agenta, możesz wykonać w terminalu Cloud Shell to polecenie:
adk run .
- Aby uruchomić go w interfejsie ADK, wykonaj to polecenie:
adk web
- Przeprowadź testy, korzystając z tych promptów:
user>>
Hello. Generate Proposal Document for the kitchen remodel requirement. I have no other specification.
11. Wynik
@ System wielu agentów do zadań związanych z remontem kuchni
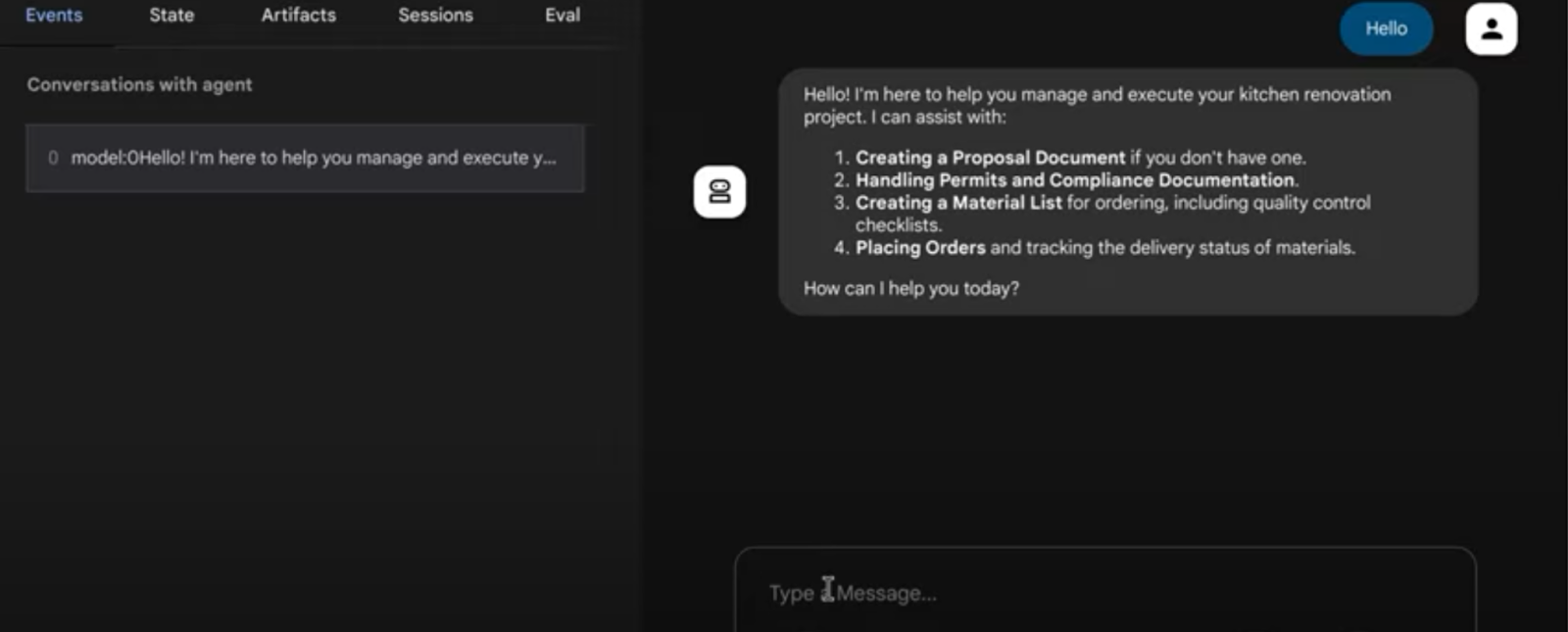
12. Wdrażanie w Agent Engine
Po przetestowaniu systemu z wieloma agentami i upewnieniu się, że działa on prawidłowo, przekształćmy go w usługę bezserwerową dostępną w chmurze dla każdego użytkownika i każdej aplikacji. Odkomentuj poniższy fragment kodu w pliku agent.py z repozytorium i możesz wdrożyć system z wieloma agentami:
# Agent Engine Deployment:
# Create a remote app for our multiagent with agent Engine.
# This may take 1-2 minutes to finish.
# Uncomment the below segment when you're ready to deploy.
app = AdkApp(
agent=root_agent,
enable_tracing=True,
)
vertexai.init(
project=PROJECT_ID,
location=GOOGLE_CLOUD_LOCATION,
staging_bucket=STAGING_BUCKET,
)
remote_app = agent_engines.create(
app,
requirements=[
"google-cloud-aiplatform[agent_engines,adk]>=1.88",
"google-adk",
"pysqlite3-binary",
"toolbox-langchain==0.1.0",
"pdfplumber",
"google-cloud-aiplatform",
"cloudpickle==3.1.1",
"pydantic==2.10.6",
"pytest",
"overrides",
"scikit-learn",
"reportlab",
"google-auth",
"google-cloud-storage",
],
)
# Deployment to Agent Engine related code ends
Ponownie uruchom plik agent.py z poziomu folderu projektu za pomocą tego polecenia:
>> cd adk-renovation-agent
>> python agent.py
Wykonanie tego kodu zajmie kilka minut. Gdy to zrobisz, otrzymasz punkt końcowy w formacie:
'projects/123456789/locations/us-central1/reasoningEngines/123456'
Aby przetestować wdrożonego agenta, dodaj nowy plik „test.py” z tym kodem:
import vertexai
from vertexai.preview import reasoning_engines
from vertexai import agent_engines
import os
import warnings
from dotenv import load_dotenv
load_dotenv()
GOOGLE_CLOUD_PROJECT = os.environ["GOOGLE_CLOUD_PROJECT"]
GOOGLE_CLOUD_LOCATION = os.environ["GOOGLE_CLOUD_LOCATION"]
GOOGLE_API_KEY = os.environ["GOOGLE_API_KEY"]
GOOGLE_GENAI_USE_VERTEXAI=os.environ["GOOGLE_GENAI_USE_VERTEXAI"]
AGENT_NAME = "adk_renovation_agent"
MODEL_NAME = "gemini-2.5-pro-preview-03-25"
warnings.filterwarnings("ignore")
PROJECT_ID = GOOGLE_CLOUD_PROJECT
reasoning_engine_id = "<<YOUR_DEPLOYED_ENGINE_ID>>"
vertexai.init(project=PROJECT_ID, location="us-central1")
agent = agent_engines.get(reasoning_engine_id)
print("**********************")
print(agent)
print("**********************")
for event in agent.stream_query(
user_id="test_user",
message="I want you to check order status.",
):
print(event)
W powyższym kodzie zastąp wartość symbolu zastępczego „<<YOUR_DEPLOYED_ENGINE_ID>>” i uruchom polecenie „python test.py”. W ten sposób możesz wchodzić w interakcje z systemem wieloagentowym wdrożonym w Agent Engine i przygotować się do remontu kuchni.
13. Opcje wdrażania w jednym wierszu
Po przetestowaniu wdrożonego systemu z wieloma agentami poznajmy prostsze metody, które abstrahują od kroku wdrażania wykonanego w poprzednim kroku: OPCJE WDRAŻANIA ZA POMOCĄ JEDNEJ LINII KODU:
- W Cloud Run:
Składnia:
adk deploy cloud_run \
--project=<<YOUR_PROJECT_ID>> \
--region=us-central1 \
--service_name=<<YOUR_SERVICE_NAME>> \
--app_name=<<YOUR_APP_NAME>> \
--with_ui \
./<<YOUR_AGENT_PROJECT_NAME>>
W tym przypadku:
adk deploy cloud_run \
--project=<<YOUR_PROJECT_ID>> \
--region=us-central1 \
--service_name=renovation-agent \
--app_name=renovation-app \
--with_ui \
./renovation-agent
Wdrożonego punktu końcowego możesz używać w integracjach podrzędnych.
- Do Agent Engine:
Składnia:
adk deploy agent_engine \
--project <your-project-id> \
--region us-central1 \
--staging_bucket gs://<your-google-cloud-storage-bucket> \
--trace_to_cloud \
path/to/agent/folder
W tym przypadku:
adk deploy agent_engine --project <<YOUR_PROJECT_ID>> --region us-central1 --staging_bucket gs://<<YOUR_BUCKET_NAME>> --trace_to_cloud renovation-agent
W interfejsie Agent Engine w konsoli Google Cloud powinien być widoczny nowy agent. Więcej informacji znajdziesz na tym blogu.
14. Czyszczenie danych
Aby uniknąć obciążenia konta Google Cloud opłatami za zasoby użyte w tym poście, wykonaj te czynności:
- W konsoli Google Cloud otwórz stronę Zarządzanie zasobami.
- Z listy projektów wybierz projekt do usunięcia, a potem kliknij Usuń.
- W oknie wpisz identyfikator projektu i kliknij Wyłącz, aby usunąć projekt.
15. Gratulacje
Gratulacje! Udało Ci się utworzyć pierwszego agenta za pomocą pakietu ADK i wejść z nim w interakcję.