
1. Visão geral
Um agente é um programa autônomo que conversa com um modelo de IA para realizar uma operação baseada em metas usando as ferramentas e o contexto disponíveis. Ele também é capaz de tomar decisões autônomas com base na verdade.
Quando seu aplicativo tem vários agentes trabalhando juntos de forma autônoma e conforme necessário para atender ao propósito maior, com cada um deles sendo independente e responsável por uma área de foco específica, ele se torna um sistema multiagente.
O Kit de Desenvolvimento de Agente (ADK)
O Kit de Desenvolvimento de Agente (ADK) é um framework flexível e modular para desenvolver e implantar agentes de IA. O ADK permite criar aplicativos sofisticados ao combinar várias instâncias de agentes distintos em um sistema multiagente (MAS, na sigla em inglês).
No ADK, um sistema multiagente é um aplicativo em que diferentes agentes, muitas vezes formando uma hierarquia, colaboram ou se coordenam para alcançar um objetivo maior. Estruturar seu aplicativo dessa forma oferece vantagens significativas, incluindo modularidade, especialização, reutilização, capacidade de manutenção e a possibilidade de definir fluxos de controle estruturados usando agentes de fluxo de trabalho dedicados.
Considerações importantes para um sistema multiagente
Primeiro, é importante ter um entendimento e raciocínio adequados da especialização de cada agente. — "você sabe por que precisa de um subagente específico para algo", resolva isso primeiro.
Segundo, como juntar tudo com um agente raiz para encaminhar e entender cada uma das respostas.
Terceiro, há vários tipos de encaminhamento de agente que podem ser encontrados aqui nesta documentação. Confira qual deles é mais adequado ao fluxo do seu aplicativo. Além disso, quais são os vários contextos e estados necessários para o controle de fluxo do seu sistema multiagente?
O que você vai criar
Vamos criar um sistema multiagente para lidar com reformas de cozinha. É isso que vamos fazer. Vamos criar um sistema com três agentes.
- Agente de proposta de reforma
- Agente de verificação de conformidade e permissões
- Agente de verificação do status do pedido
Agente de proposta de reforma, para gerar o documento de proposta de reforma da cozinha.
Agente de permissões e compliance, para cuidar de tarefas relacionadas a permissões e compliance.
Agente de verificação do status do pedido, para verificar o status do pedido de materiais trabalhando no banco de dados de gerenciamento de pedidos que configuramos no AlloyDB.
Teremos um agente raiz que vai orquestrar esses agentes com base no requisito.
Requisitos
2. Antes de começar
Criar um projeto
- No console do Google Cloud, na página de seletor de projetos, selecione ou crie um projeto do Google Cloud.
- Verifique se o faturamento está ativado para seu projeto do Cloud. Saiba como verificar se o faturamento está ativado em um projeto .
- Clique neste link para ativar o Cloud Shell. É possível alternar entre o terminal do Cloud Shell (para executar comandos da nuvem) e o editor (para criar projetos) clicando no botão correspondente no Cloud Shell.
- Depois de se conectar ao Cloud Shell, verifique se sua conta já está autenticada e se o projeto está configurado com o ID do seu projeto usando o seguinte comando:
gcloud auth list
- Execute o comando a seguir no Cloud Shell para confirmar se o comando gcloud sabe sobre seu projeto.
gcloud config list project
- Se o projeto não estiver definido, use este comando:
gcloud config set project <YOUR_PROJECT_ID>
- Verifique se você tem o Python 3.9 ou uma versão mais recente.
- Ative as seguintes APIs executando os comandos abaixo:
gcloud services enable artifactregistry.googleapis.com \cloudbuild.googleapis.com \run.googleapis.com \aiplatform.googleapis.com
- Consulte a documentação para ver o uso e os comandos gcloud.
3. Protótipo
Você pode pular esta etapa se decidir usar o modelo Gemini 2.5 Pro no projeto.
Acesse o Google AI Studio. Comece a digitar seu comando. Este é meu comando:
I want to renovate my kitchen, basically just remodel it. I don't know where to start. So I want to use Gemini to generate a plan. For that I need a good prompt. Give me a short yet detailed prompt that I can use.
Ajuste e configure os parâmetros à direita para ter uma resposta ideal.
Com base nessa descrição simples, o Gemini criou um comando incrivelmente detalhado para iniciar minha reforma. Na prática, estamos usando o Gemini para receber respostas ainda melhores do AI Studio e dos nossos modelos. Você também pode selecionar modelos diferentes para usar, com base no seu caso de uso.
Escolhemos o Gemini 2.5 Pro. Esse é um modelo de pensamento, o que significa que recebemos ainda mais tokens de saída, neste caso, até 65 mil tokens, para análises longas e documentos detalhados. A caixa de raciocínio do Gemini aparece quando você ativa o Gemini 2.5 Pro, que tem recursos de raciocínio nativos e pode receber solicitações de contexto longo.
Confira o snippet da resposta abaixo:
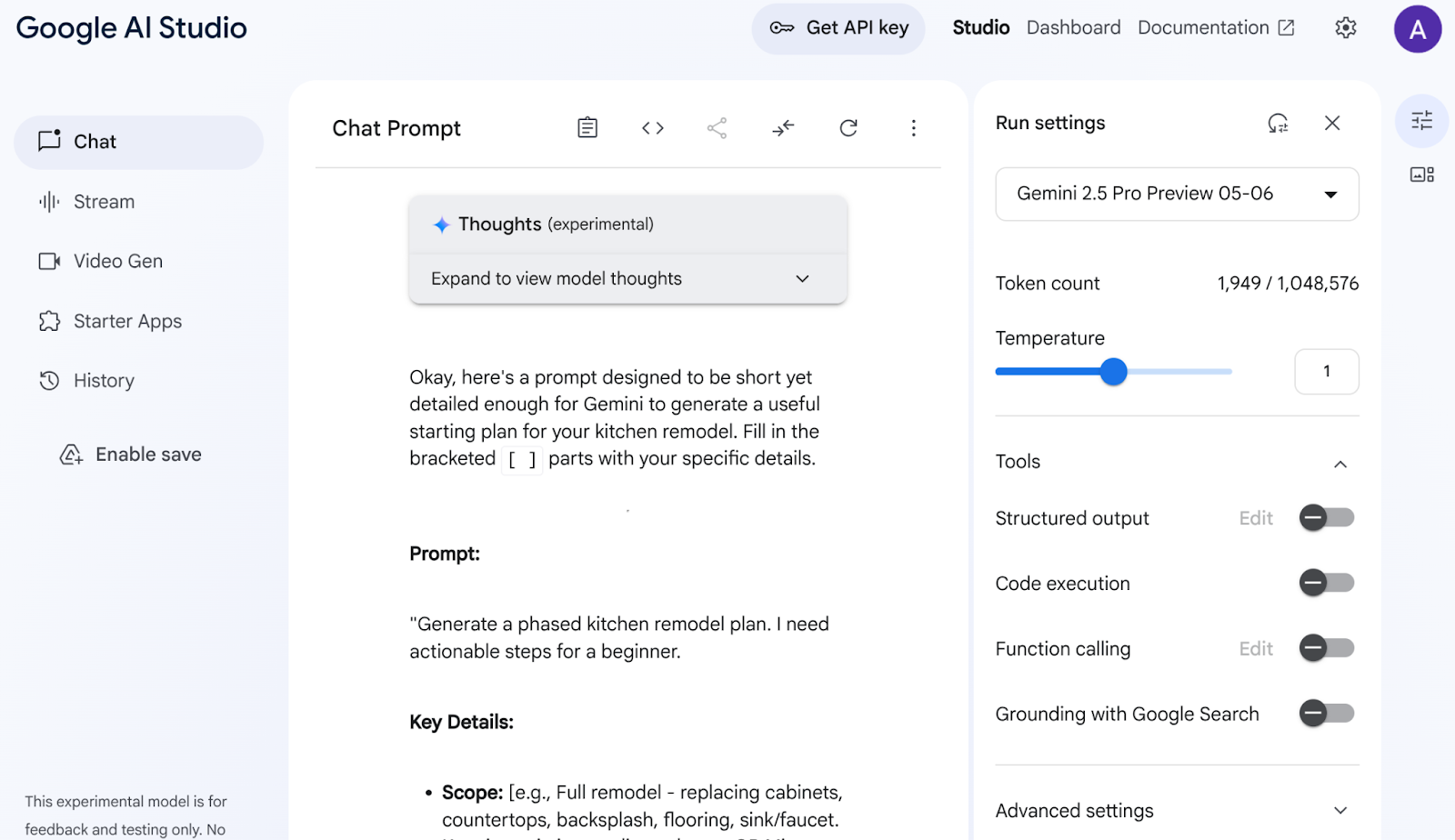
O AI Studio analisou meus dados e produziu todos esses itens, como armários, bancadas, revestimento, piso, pia, coesão, paleta de cores e seleção de materiais. O Gemini está até citando fontes!
Repita o processo com diferentes opções de modelo até ficar satisfeito com o resultado. Mas por que passar por tudo isso quando você tem o Gemini 2.5? :)
De qualquer forma, agora tente ver a ideia ganhar vida com um comando diferente:
Add flat and circular light accessories above the island area for my current kitchen in the attached image.
Anexe um link para a imagem da sua cozinha atual (ou qualquer imagem de cozinha de exemplo). Mude o modelo para "Geração de imagens da prévia do Gemini 2.0 Flash" para ter acesso à geração de imagens.
Recebi esta saída:

Esse é o poder do Gemini!
Desde entender vídeos até gerar imagens nativas e embasar informações reais com a Pesquisa Google, há coisas que só podem ser criadas com a tecnologia do Gemini.
No AI Studio, é possível pegar esse protótipo, extrair a chave de API e dimensioná-lo para um aplicativo de agente completo usando o poder do ADK da Vertex AI.
4. Configuração do ADK
- Criar e ativar o ambiente virtual (recomendado)
No terminal do Cloud Shell, crie um ambiente virtual:
python -m venv .venv
Ative o ambiente virtual:
source .venv/bin/activate
- Instale o ADK
pip install google-adk
5. Estrutura do projeto
- No Terminal do Cloud Shell, crie um diretório no local desejado do projeto.
mkdir agentic-apps
cd agentic-apps
mkdir renovation-agent
- Acesse o Editor do Cloud Shell e crie a seguinte estrutura de projeto criando os arquivos (vazios para começar):
renovation-agent/
__init__.py
agent.py
.env
requirements.txt
6. Código-fonte
- Acesse "init.py" e atualize com o seguinte conteúdo:
from . import agent
- Acesse agent.py e atualize o arquivo com o seguinte conteúdo do caminho abaixo:
https://github.com/AbiramiSukumaran/adk-renovation-agent/blob/main/agent.py
Em agent.py, importamos as dependências necessárias, recuperamos os parâmetros de configuração do arquivo .env e definimos o root_agent, que orquestra os três subagentes que criamos neste aplicativo. Há várias ferramentas que ajudam com as funções principais e de suporte desses subagentes.
- Verifique se você tem o bucket do Cloud Storage
Isso é para armazenar o documento de proposta gerado pelo agente. Crie e conceda acesso para que o sistema multiagente criado com a Vertex AI possa acessá-lo. Confira como fazer isso:
https://cloud.google.com/storage/docs/creating-buckets#console
Nomeie o bucket como "next-demo-store". Se você escolher outro nome, atualize o valor de STORAGE_BUCKET no arquivo .env (na etapa "Configuração de variáveis de ambiente").
- Para configurar o acesso ao bucket, acesse o console do Cloud Storage e seu bucket de armazenamento. No nosso caso, o nome do bucket é "next-demo-storage": https://console.cloud.google.com/storage/browser/next-demo-storage.
Navegue até Permissões -> Ver principais -> Conceder acesso. Selecione "allUsers" como principais e "Usuário de objetos do Storage" como papel.
Make sure to not enable "prevent public access". Since this is a demo/study application we are going with a public bucket. Remember to configure permission settings appropriately when you are building your application.
- Criar lista de dependências
Liste todas as dependências em requirements.txt. Você pode copiar isso do repositório.
Explicação do código-fonte do sistema multiagente
O arquivo agent.py define a estrutura e o comportamento do nosso sistema multiagente de reforma da cozinha usando o Kit de Desenvolvimento de Agente (ADK). Vamos detalhar os principais componentes:
Definições de agente
RenovationProposalAgent
Esse agente é responsável por criar o documento de proposta de reforma da cozinha. Ele também pode receber parâmetros de entrada, como tamanho da cozinha, estilo desejado, orçamento e preferências do cliente. Com base nessas informações, ele usa um modelo de linguagem grande (LLM) Gemini 2.5 para gerar uma proposta detalhada. A proposta gerada é armazenada em um bucket do Cloud Storage.
PermitsAndComplianceCheckAgent
Esse agente se concentra em garantir que o projeto de reforma obedeça aos códigos e regulamentações de construção locais. Ele recebe informações sobre a reforma proposta (por exemplo, mudanças estruturais, trabalho elétrico, modificações hidráulicas) e usa o LLM para verificar os requisitos de permissão e as regras de conformidade. O agente usa informações de uma base de conhecimento, que pode ser personalizada para acessar APIs externas e coletar regulamentações relevantes.
OrderingAgent
Esse agente, que pode ser comentado se você não quiser implementar agora, verifica o status do pedido de materiais e equipamentos necessários para a reforma. Para ativar, crie uma função do Cloud Run conforme descrito nas etapas de configuração. Em seguida, o agente vai chamar essa função do Cloud Run, que interage com um banco de dados do AlloyDB que contém informações de pedidos. Isso demonstra a integração com um sistema de banco de dados para rastrear dados em tempo real.
Agente raiz (Orchestrator)
O root_agent atua como o orquestrador central do sistema multiagente. Ele recebe a solicitação inicial de reforma e determina quais subagentes invocar com base nas necessidades da solicitação. Por exemplo, se a solicitação exigir a verificação dos requisitos de permissão, ela vai chamar o PermitsAndComplianceCheckAgent. Se o usuário quiser verificar o status do pedido, o OrderingAgent será chamado (se estiver ativado).
O root_agent coleta as respostas dos subagentes e as combina para fornecer uma resposta abrangente ao usuário. Isso pode envolver resumir a proposta, listar as permissões necessárias e fornecer atualizações sobre o status do pedido.
Fluxo de dados e conceitos principais
O usuário inicia uma solicitação pela interface do ADK (terminal ou interface da Web).
- A solicitação é recebida pelo root_agent.
- O root_agent analisa a solicitação e a encaminha para os subagentes adequados.
- Os subagentes usam LLMs, bases de conhecimento, APIs e bancos de dados para processar a solicitação e gerar respostas.
- Os subagentes retornam as respostas para o root_agent.
- O root_agent combina as respostas e fornece uma saída final ao usuário.
LLMs (modelos de linguagem grandes)
Os agentes dependem muito dos LLMs para gerar texto, responder a perguntas e realizar tarefas de raciocínio. Os LLMs são os "cérebros" por trás da capacidade dos agentes de entender e responder às solicitações dos usuários. Estamos usando o Gemini 2.5 neste aplicativo.
Google Cloud Storage
Usado para armazenar os documentos de proposta de reforma gerados. Você precisa criar um bucket e conceder as permissões necessárias para que os agentes acessem o bucket.
Cloud Run (opcional)
O OrderingAgent usa uma função do Cloud Run para interagir com o AlloyDB. O Cloud Run oferece um ambiente sem servidor para executar código em resposta a solicitações HTTP.
AlloyDB
Se você estiver usando o OrderingAgent, precisará configurar um banco de dados do AlloyDB para armazenar informações de pedidos. Vamos falar sobre os detalhes na próxima seção, "Configuração do banco de dados".
Arquivo.env
O arquivo .env armazena informações sensíveis, como chaves de API, credenciais de banco de dados e nomes de buckets. É crucial manter esse arquivo seguro e não confirmá-lo no seu repositório. Ele também armazena as configurações dos agentes e do projeto na nuvem do Google Cloud. O root_agent ou as funções de suporte normalmente leem valores desse arquivo. Verifique se todas as variáveis necessárias estão definidas corretamente no arquivo .env. Isso inclui o nome do bucket do Cloud Storage
7. Configuração do banco de dados
Em uma das ferramentas usadas pelo ordering_agent, chamada "check_status", acessamos o banco de dados de pedidos do AlloyDB para conferir o status dos pedidos. Nesta seção, vamos configurar um cluster e uma instância de banco de dados do AlloyDB.
criar um cluster e uma instância
- Navegue até a página do AlloyDB no console do Cloud. Uma maneira fácil de encontrar a maioria das páginas no console do Cloud é pesquisar usando a barra de pesquisa do console.
- Selecione CRIAR CLUSTER nessa página:

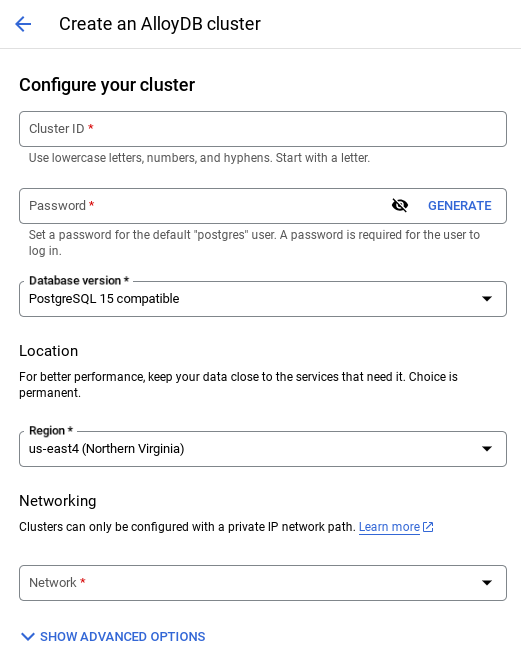
- Você vai ver uma tela como a abaixo. Crie um cluster e uma instância com os seguintes valores. Verifique se os valores correspondem caso você esteja clonando o código do aplicativo do repositório:
- ID do cluster: "
vector-cluster" - password: "
alloydb" - PostgreSQL 15 / mais recente recomendado
- Região: "
us-central1" - Rede: "
default"
- Ao selecionar a rede padrão, uma tela como a abaixo vai aparecer.
Selecione CONFIGURAR CONEXÃO.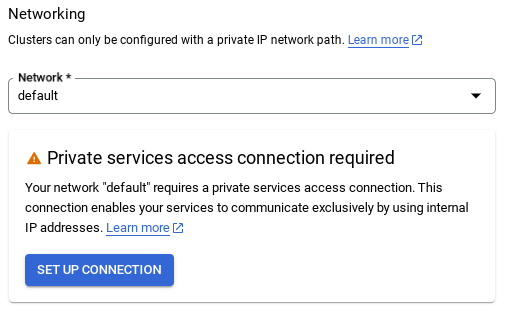
- Em seguida, selecione Usar um intervalo de IP alocado automaticamente e clique em "Continuar". Depois de revisar as informações, selecione CRIAR CONEXÃO.
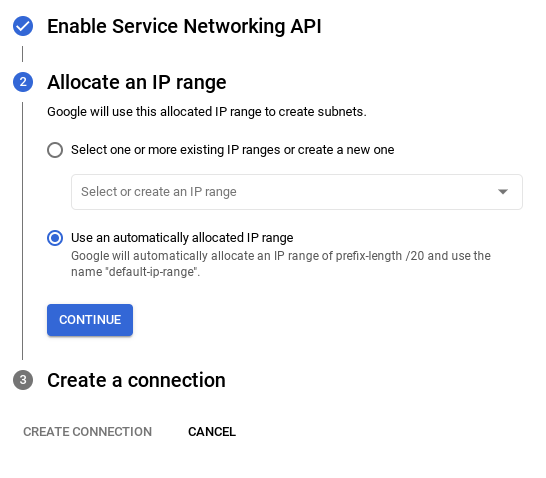
- Depois que a rede for configurada, você poderá continuar criando o cluster. Clique em CRIAR CLUSTER para concluir a configuração do cluster, conforme mostrado abaixo:
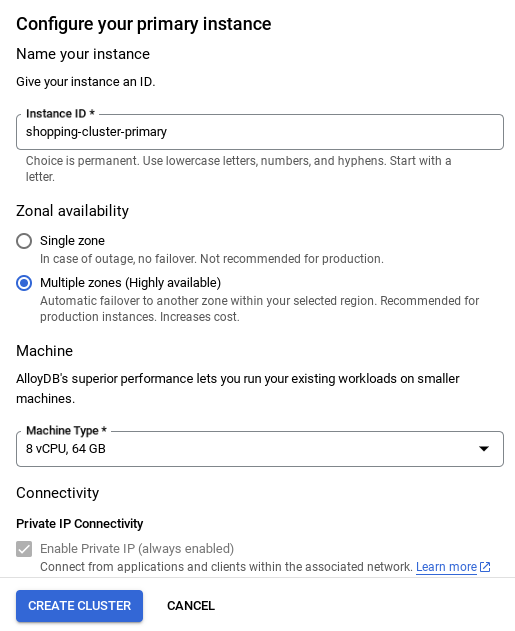
Mude o ID da instância (que pode ser encontrado no momento da configuração do cluster / instância) para
vector-instance. Se não for possível mudar, use o ID da instância em todas as referências futuras.
A criação do cluster leva cerca de 10 minutos. Quando a operação for concluída, uma tela vai mostrar a visão geral do cluster que você acabou de criar.
Ingestão de dados
Agora é hora de adicionar uma tabela com os dados da loja. Acesse o AlloyDB, selecione o cluster principal e o AlloyDB Studio:
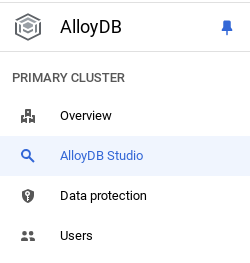
Talvez seja necessário aguardar a conclusão da criação da instância. Depois disso, faça login no AlloyDB usando as credenciais criadas ao criar o cluster. Use os seguintes dados para autenticar no PostgreSQL:
- Nome de usuário : "
postgres" - Banco de dados : "
postgres" - Senha : "
alloydb"
Depois de se autenticar no AlloyDB Studio, os comandos SQL são inseridos no editor. É possível adicionar várias janelas do Editor usando o sinal de mais à direita da última janela.
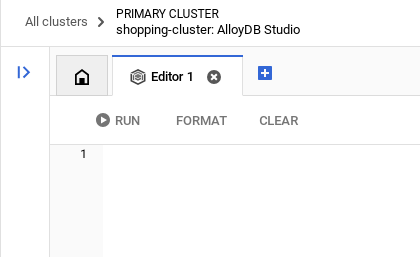
Você vai inserir comandos para o AlloyDB nas janelas do editor, usando as opções "Executar", "Formatar" e "Limpar" conforme necessário.
Criar uma tabela
É possível criar uma tabela usando a instrução DDL abaixo no AlloyDB Studio:
-- Table DDL for Procurement Material Order Status
CREATE TABLE material_order_status (
order_id VARCHAR(50) PRIMARY KEY,
material_name VARCHAR(100) NOT NULL,
supplier_name VARCHAR(100) NOT NULL,
order_date DATE NOT NULL,
estimated_delivery_date DATE,
actual_delivery_date DATE,
quantity_ordered INT NOT NULL,
quantity_received INT,
unit_price DECIMAL(10, 2) NOT NULL,
total_amount DECIMAL(12, 2),
order_status VARCHAR(50) NOT NULL, -- e.g., "Ordered", "Shipped", "Delivered", "Cancelled"
delivery_address VARCHAR(255),
contact_person VARCHAR(100),
contact_phone VARCHAR(20),
tracking_number VARCHAR(100),
notes TEXT,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
quality_check_passed BOOLEAN, -- Indicates if the material passed quality control
quality_check_notes TEXT, -- Notes from the quality control check
priority VARCHAR(20), -- e.g., "High", "Medium", "Low"
project_id VARCHAR(50), -- Link to a specific project
receiver_name VARCHAR(100), -- Name of the person who received the delivery
return_reason TEXT, -- Reason for returning material if applicable
po_number VARCHAR(50) -- Purchase order number
);
Inserir registros
Copie a instrução de consulta insert do script database_script.sql mencionado acima para o editor.
Clique em Executar.
Agora que o conjunto de dados está pronto, vamos criar um aplicativo Java do Cloud Run Functions para extrair o status.
Criar uma função do Cloud Run em Java para extrair informações sobre o status do pedido
- Crie uma função do Cloud Run aqui: https://console.cloud.google.com/run/create?deploymentType=function
- Defina o nome da função como "check-status" e escolha "Java 17" como ambiente de execução.
- Como é um aplicativo de demonstração, você pode definir a autenticação como Permitir invocações não autenticadas.
- Escolha Java 17 como ambiente de execução e o editor in-line para o código-fonte.
- Neste ponto, o código de marcador de posição será carregado no editor.
Substituir o código do marcador de posição
- Mude o nome do arquivo Java para "ProposalOrdersTool.java" e o nome da classe para "ProposalOrdersTool".
- Substitua o código de marcador de posição em ProposalOrdersTool.java e pom.xml pelo código dos respectivos arquivos na pasta "Função do Cloud Run" neste repositório.
- Em ProposalOrdersTool.java, encontre a seguinte linha de código e substitua os valores de marcador pelos valores da sua configuração:
String ALLOYDB_INSTANCE_NAME = "projects/<<YOUR_PROJECT_ID>>/locations/us-central1/clusters/<<YOUR_CLUSTER>>/instances/<<YOUR_INSTANCE>>";
- Clique em "Criar".
- A função do Cloud Run será criada e implantada.
ETAPA IMPORTANTE:
Depois da implantação, para permitir que a função do Cloud acesse a instância de banco de dados do AlloyDB, vamos criar o conector de VPC.
Depois de configurar a implantação, você poderá ver as funções no console do Google Cloud Run Functions. Pesquise a função recém-criada (check-status), clique nela e em EDITAR E IMPLANTAR NOVAS REVISÕES (identificado pelo ícone de edição (lápis) na parte de cima do console do Cloud Run Functions) e mude o seguinte:
- Acesse a guia "Rede":
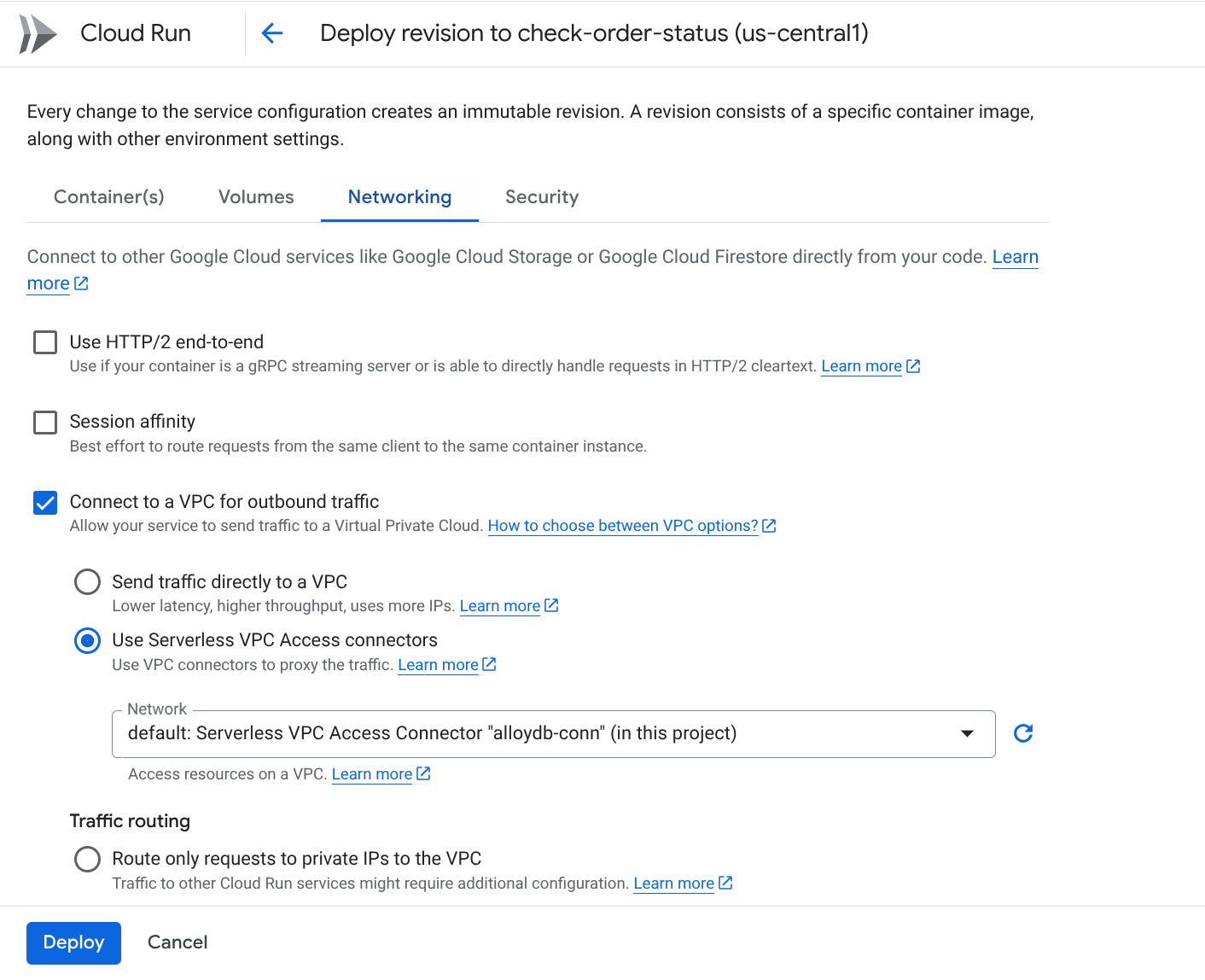
- Selecione Conectar a uma VPC para tráfego de saída e Usar conectores de acesso VPC sem servidor.
- No menu suspenso "Rede", clique nele e selecione a opção Adicionar novo conector VPC (se você ainda não tiver configurado o padrão) e siga as instruções na caixa de diálogo que aparece:
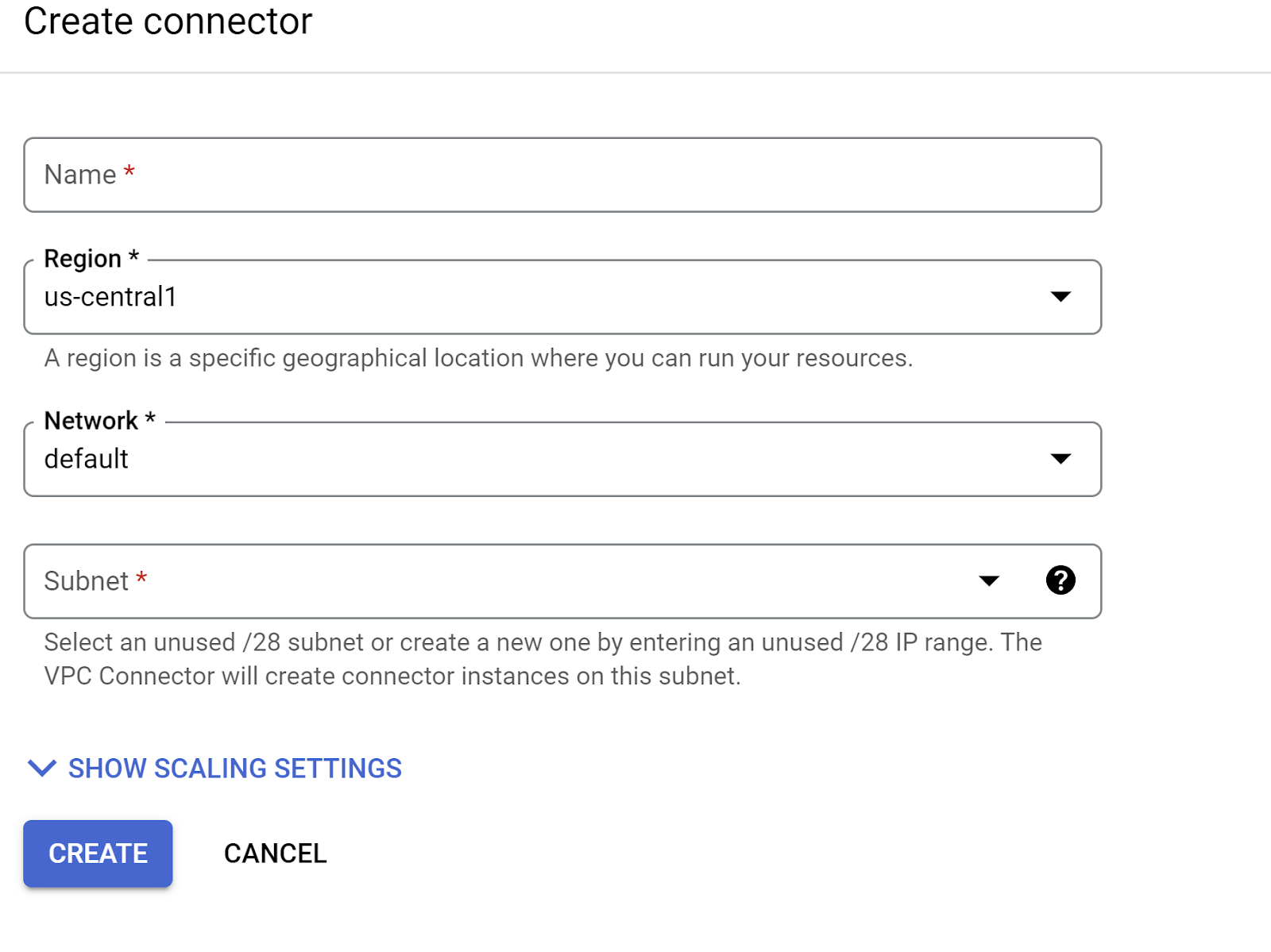
- Forneça um nome para o conector da VPC e verifique se a região é a mesma da sua instância. Deixe o valor da rede como padrão e defina a sub-rede como "Intervalo de IP personalizado" com o intervalo de IP 10.8.0.0 ou algo semelhante que esteja disponível.
- Expanda MOSTRAR CONFIGURAÇÕES DE ESCALONAMENTO e verifique se a configuração está exatamente assim:
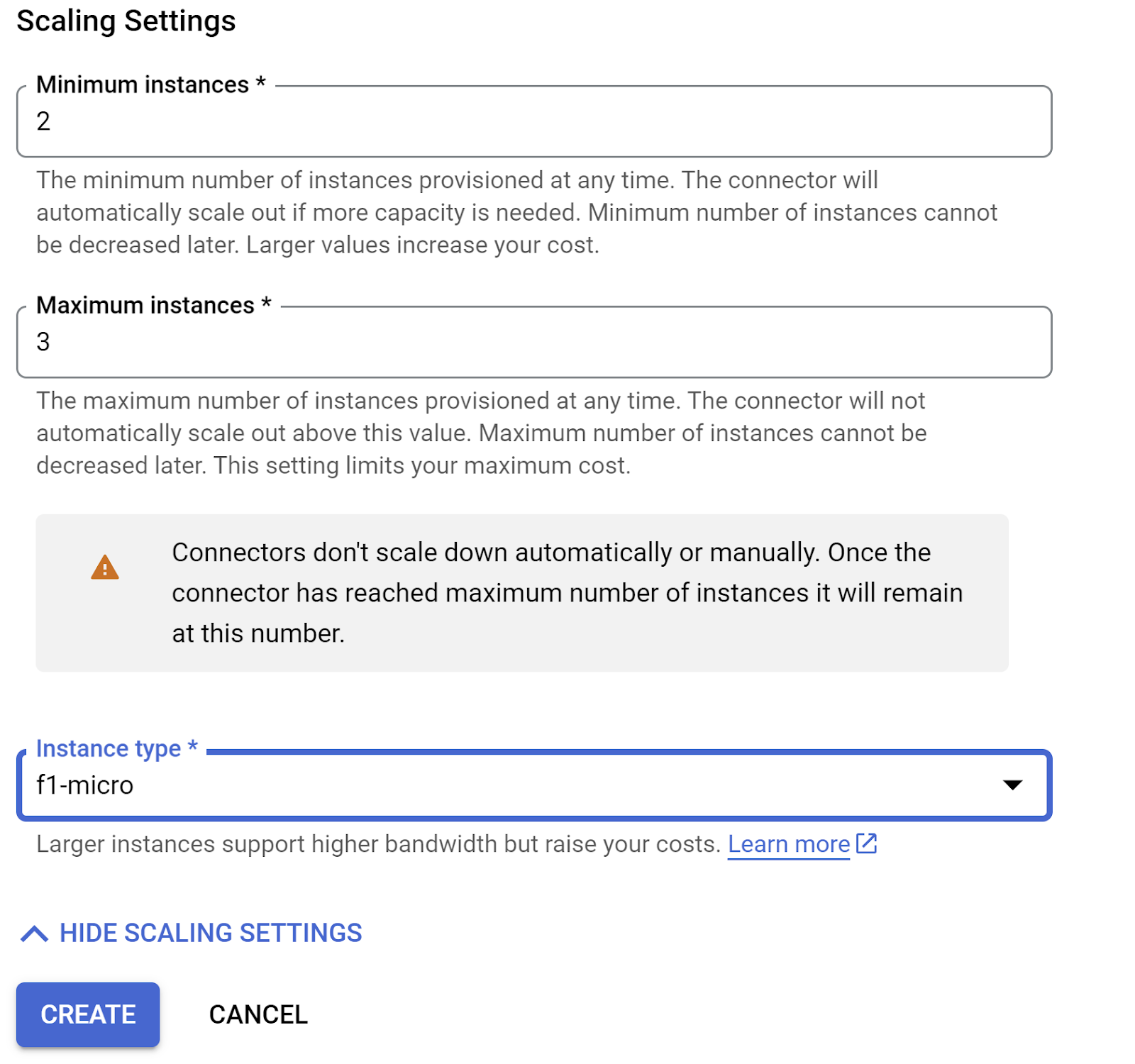
- Clique em CRIAR. O conector vai aparecer nas configurações de saída.
- Selecione o conector recém-criado.
- Opte por todo o tráfego ser roteado por esse conector de VPC.
- Clique em PRÓXIMA e em IMPLANTAR.
- Depois que a função do Cloud atualizada for implantada, o endpoint gerado vai aparecer.
- Para testar, clique no botão "TESTAR" na parte de cima do console do Cloud Run Functions e execute o comando resultante no terminal do Cloud Shell.
- O endpoint implantado é o URL que você precisa atualizar na variável
CHECK_ORDER_STATUS_ENDPOINTdo arquivo .env.
8. Configuração do modelo
A capacidade do agente de entender as solicitações do usuário e gerar respostas é alimentada por um modelo de linguagem grande (LLM). Seu agente precisa fazer chamadas seguras para esse serviço de LLM externo, o que exige credenciais de autenticação. Sem uma autenticação válida, o serviço de LLM vai negar as solicitações do agente, e ele não vai funcionar.
- Receba uma chave de API do Google AI Studio.
- Na próxima etapa, em que você configura o arquivo .env, substitua
<<your API KEY>>pelo valor real da sua chave de API.
9. Configuração de variáveis de ambiente
- Configure os valores dos parâmetros no arquivo .env do modelo neste repositório. No meu caso, o .env tem estas variáveis:
GOOGLE_GENAI_USE_VERTEXAI=FALSE
GOOGLE_API_KEY=<<your API KEY>>
GOOGLE_CLOUD_LOCATION=us-central1 <<or your region>>
GOOGLE_CLOUD_PROJECT=<<your project id>>
PROJECT_ID=<<your project id>>
GOOGLE_CLOUD_REGION=us-central1 <<or your region>>
STORAGE_BUCKET=next-demo-store <<or your storage bucket name>>
CHECK_ORDER_STATUS_ENDPOINT=<<YOUR_ENDPOINT_TO_CLOUD FUNCTION_TO_READ_ORDER_DATA_FROM_ALLOYDB>>
Substitua os marcadores pelos seus valores.
10. Executar o agente
- Usando o terminal, navegue até o diretório pai do projeto do agente:
cd renovation-agent
- Instale todas as dependências
pip install -r requirements.txt
- Execute o comando a seguir no terminal do Cloud Shell para executar o agente:
adk run .
- Execute o seguinte comando para executar em uma interface da Web provisionada pelo ADK:
adk web
- Teste com os seguintes comandos:
user>>
Hello. Generate Proposal Document for the kitchen remodel requirement. I have no other specification.
11. Resultado
@ Sistema multiagente para tarefas de reforma de cozinha
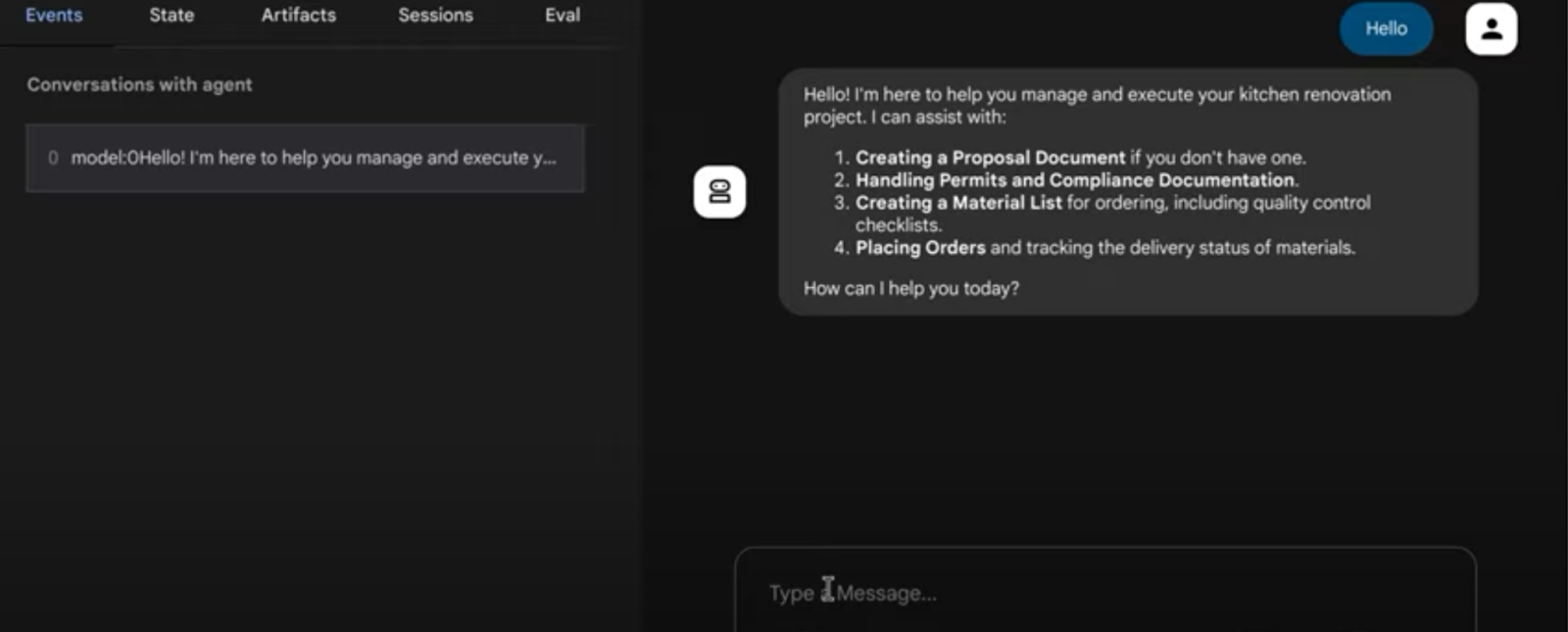
12. Implantação no Agent Engine
Agora que você testou o sistema multiagente e ele está funcionando bem, vamos torná-lo sem servidor e disponível na nuvem para que qualquer pessoa ou aplicativo possa usá-lo. Remova o comentário do snippet de código abaixo no agent.py do repo e você estará pronto para implantar seu sistema multiagente:
# Agent Engine Deployment:
# Create a remote app for our multiagent with agent Engine.
# This may take 1-2 minutes to finish.
# Uncomment the below segment when you're ready to deploy.
app = AdkApp(
agent=root_agent,
enable_tracing=True,
)
vertexai.init(
project=PROJECT_ID,
location=GOOGLE_CLOUD_LOCATION,
staging_bucket=STAGING_BUCKET,
)
remote_app = agent_engines.create(
app,
requirements=[
"google-cloud-aiplatform[agent_engines,adk]>=1.88",
"google-adk",
"pysqlite3-binary",
"toolbox-langchain==0.1.0",
"pdfplumber",
"google-cloud-aiplatform",
"cloudpickle==3.1.1",
"pydantic==2.10.6",
"pytest",
"overrides",
"scikit-learn",
"reportlab",
"google-auth",
"google-cloud-storage",
],
)
# Deployment to Agent Engine related code ends
Execute o agent.py na pasta do projeto novamente com o seguinte comando:
>> cd adk-renovation-agent
>> python agent.py
Esse processo leva alguns minutos. Quando terminar, você vai receber um endpoint parecido com este:
'projects/123456789/locations/us-central1/reasoningEngines/123456'
É possível testar o agente implantado com o seguinte código ao adicionar um novo arquivo " test.py"
import vertexai
from vertexai.preview import reasoning_engines
from vertexai import agent_engines
import os
import warnings
from dotenv import load_dotenv
load_dotenv()
GOOGLE_CLOUD_PROJECT = os.environ["GOOGLE_CLOUD_PROJECT"]
GOOGLE_CLOUD_LOCATION = os.environ["GOOGLE_CLOUD_LOCATION"]
GOOGLE_API_KEY = os.environ["GOOGLE_API_KEY"]
GOOGLE_GENAI_USE_VERTEXAI=os.environ["GOOGLE_GENAI_USE_VERTEXAI"]
AGENT_NAME = "adk_renovation_agent"
MODEL_NAME = "gemini-2.5-pro-preview-03-25"
warnings.filterwarnings("ignore")
PROJECT_ID = GOOGLE_CLOUD_PROJECT
reasoning_engine_id = "<<YOUR_DEPLOYED_ENGINE_ID>>"
vertexai.init(project=PROJECT_ID, location="us-central1")
agent = agent_engines.get(reasoning_engine_id)
print("**********************")
print(agent)
print("**********************")
for event in agent.stream_query(
user_id="test_user",
message="I want you to check order status.",
):
print(event)
No código acima, substitua o valor do marcador de posição "<<YOUR_DEPLOYED_ENGINE_ID>>" e execute o comando "python test.py". Assim, você poderá interagir com um sistema multiagente implantado no Agent Engine e renovar sua cozinha.
13. Opções de implantação de uma linha
Agora que você testou o sistema multiagente implantado, vamos aprender métodos mais simples que abstraem a etapa de implantação que fizemos na etapa anterior: OPÇÕES DE IMPLANTAÇÃO DE UMA LINHA:
- Para o Cloud Run:
Sintaxe:
adk deploy cloud_run \
--project=<<YOUR_PROJECT_ID>> \
--region=us-central1 \
--service_name=<<YOUR_SERVICE_NAME>> \
--app_name=<<YOUR_APP_NAME>> \
--with_ui \
./<<YOUR_AGENT_PROJECT_NAME>>
Neste caso:
adk deploy cloud_run \
--project=<<YOUR_PROJECT_ID>> \
--region=us-central1 \
--service_name=renovation-agent \
--app_name=renovation-app \
--with_ui \
./renovation-agent
Você pode usar o endpoint implantado para integrações downstream.
- Para o Agent Engine:
Sintaxe:
adk deploy agent_engine \
--project <your-project-id> \
--region us-central1 \
--staging_bucket gs://<your-google-cloud-storage-bucket> \
--trace_to_cloud \
path/to/agent/folder
Neste caso:
adk deploy agent_engine --project <<YOUR_PROJECT_ID>> --region us-central1 --staging_bucket gs://<<YOUR_BUCKET_NAME>> --trace_to_cloud renovation-agent
Um novo agente vai aparecer na interface do Agent Engine no console do Google Cloud. Consulte este blog para mais detalhes.
14. Limpar
Para evitar cobranças na sua conta do Google Cloud pelos recursos usados nesta postagem, siga estas etapas:
- No console do Google Cloud, acesse a página Gerenciar recursos.
- Na lista de projetos, selecione o projeto que você quer excluir e clique em Excluir.
- Na caixa de diálogo, digite o ID do projeto e clique em Encerrar para excluí-lo.
15. Parabéns
Parabéns! Você criou e interagiu com seu primeiro agente usando o ADK.