
1. مقدمة
في هذا البرنامج التعليمي، ستنشئ ClarityCam، وهو وكيل ذكاء اصطناعي يعمل بدون استخدام اليدين ويستجيب للأوامر الصوتية، ويمكنه رؤية العالم وشرحه لك. على الرغم من أنّ ClarityCam مصمَّمة مع التركيز على أدوات تسهيل الاستخدام، إذ توفّر أداة فعّالة للمستخدمين المكفوفين والمصابين بضعف في النظر، إلا أنّ المبادئ التي ستتعلّمها ضرورية لإنشاء أي تطبيق صوتي حديث ومتعدّد الأغراض.

يستند هذا المشروع إلى فلسفة تصميم فعّالة تُعرف باسم واجهة المستخدم المتكيّفة بشكلٍ طبيعي (NAI). بدلاً من التعامل مع تسهيل الاستخدام كأمر ثانوي، تجعل NAI منه الأساس. باستخدام هذا الأسلوب، يصبح وكيل الذكاء الاصطناعي هو الواجهة، إذ يتكيّف مع المستخدمين المختلفين ويتعامل مع الإدخال المتعدّد الوسائط، مثل الصوت والصورة، ويقدّم إرشادات استباقية للمستخدمين استنادًا إلى احتياجاتهم الفريدة.
إنشاء أول وكيل ذكاء اصطناعي باستخدام NAI:

مع نهاية هذه الجلسة، سيكون بإمكانك:
- التصميم مع إتاحة ميزات تسهيل الاستخدام تلقائيًا: طبِّق مبادئ "الواجهة التكيّفية الأصلية" (NAI) لإنشاء أنظمة ذكاء اصطناعي توفّر تجارب مكافئة لجميع المستخدمين.
- تصنيف نية المستخدم: أنشئ أداة تصنيف قوية للنية تترجم طلبات اللغة الطبيعية إلى إجراءات منظَّمة لتنفيذها من خلال برنامجك.
- الحفاظ على سياق المحادثة: يمكنك تنفيذ ذاكرة قصيرة الأمد لتمكين الوكيل من فهم الأسئلة اللاحقة والأوامر المرجعية (مثل "ما هو لونها؟").
- صياغة طلبات فعّالة: صياغة طلبات مركّزة وغنية بالسياق لنموذج متعدّد الوسائط مثل Gemini لضمان تحليل دقيق وموثوق للصور
- التعامل مع الغموض وتوجيه المستخدم: صمِّم طريقة سلسة للتعامل مع الأخطاء في الطلبات غير المشمولة بالنطاق، ووجِّه المستخدمين بشكل استباقي لبناء الثقة والاطمئنان.
- تنظيم نظام متعدد الوكلاء: يمكنك تنظيم تطبيقك باستخدام مجموعة من الوكلاء المتخصّصين الذين يتعاونون للتعامل مع المهام المعقّدة، مثل معالجة الصوت وتحليله وتركيبه.
2. التصميم العالي المستوى
في جوهرها، تم تصميم ClarityCam لتكون بسيطة بالنسبة إلى المستخدم، ولكنها تستند إلى نظام متطوّر من برامج الذكاء الاصطناعي المتعاونة. دعونا نوضّح البنية.

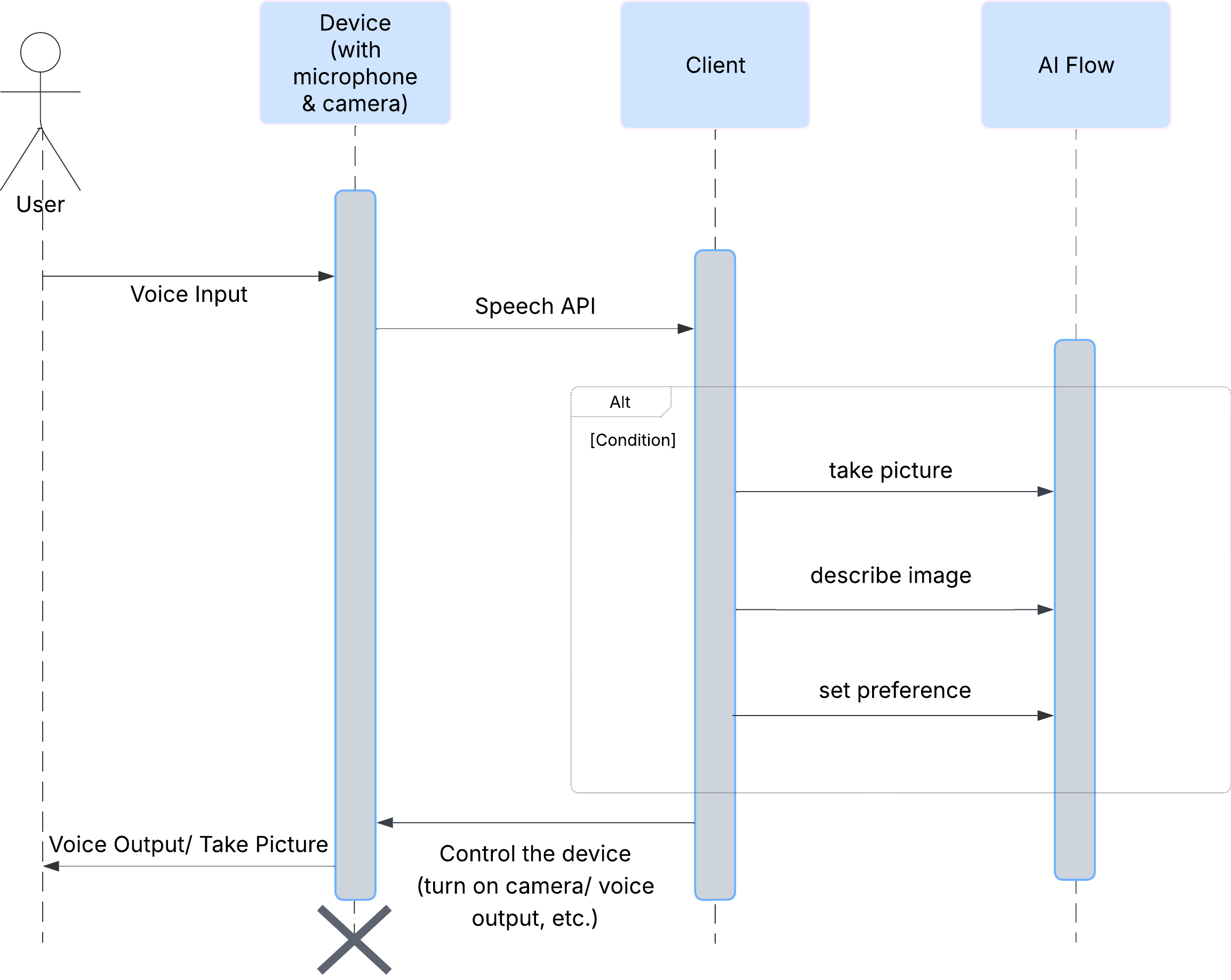
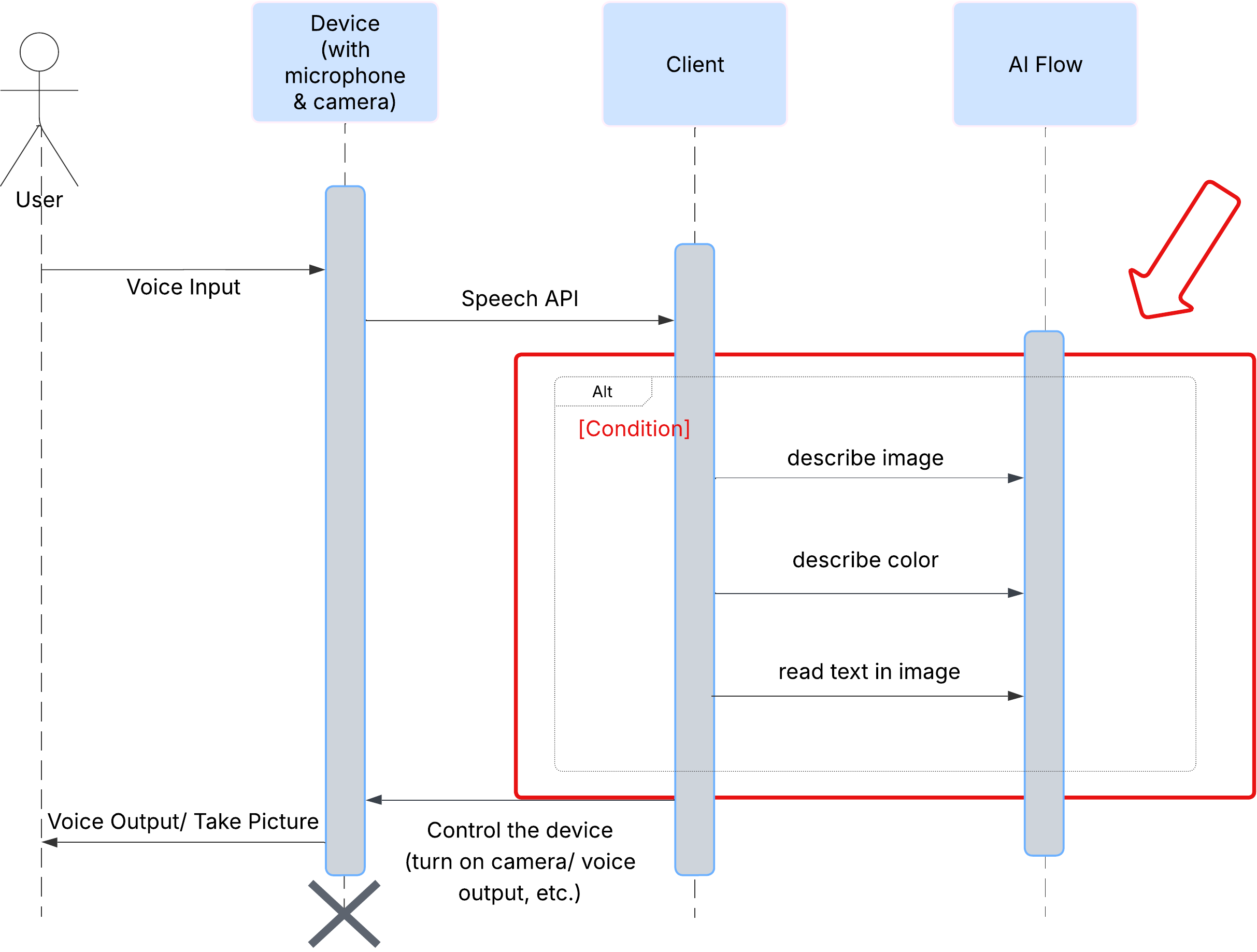
انطباع المستخدم
لنلقِ نظرة أولاً على كيفية تفاعل المستخدم مع ClarityCam. تتوفّر التجربة بأكملها بدون لمس الجهاز وبطريقة حوارية. يقول المستخدم طلبًا صوتيًا، ويردّ الوكيل بوصف أو إجراء صوتي. يعرض مخطط التسلسل هذا مسار تفاعل نموذجيًا، بدءًا من الأمر الصوتي الأوّلي الذي يطلبه المستخدم وصولاً إلى الرد الصوتي النهائي من الجهاز.
بنية وكيل الذكاء الاصطناعي
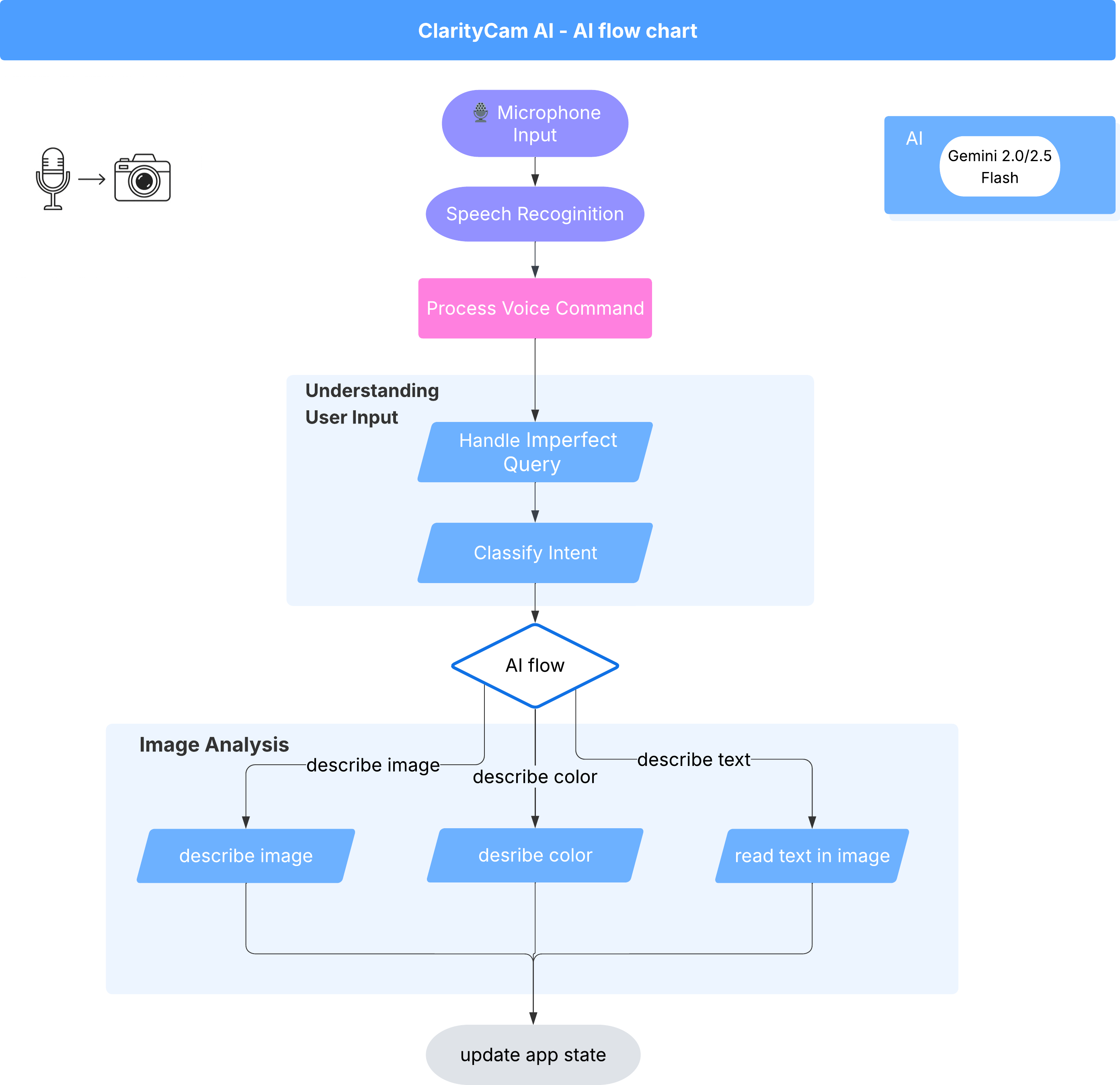
في الخلفية، يعمل نظام مستند إلى عدّة وكلاء بشكل متزامن لتقديم هذه التجربة. عند تلقّي أمر، يفوّض وكيل مركزي في Orchestrator المهام إلى وكلاء متخصصين مسؤولين عن فهم النية وتحليل الصور وإنشاء ردّ. يقدّم مخطط تدفق الذكاء الاصطناعي هذا نظرة متعمّقة لطريقة تعاون هؤلاء الوكلاء. سننفّذ هذه البنية في الأقسام التالية.
جولة سريعة في ملفات المشروع
قبل البدء في كتابة الرمز، لنطّلع على بنية ملفات مشروعنا. قد يبدو أنّ هناك الكثير من الملفات، ولكن عليك التركيز على مجالَين محدّدين فقط في هذا البرنامج التعليمي بأكمله.
في ما يلي خريطة مبسَّطة لمشروعنا.
accessibilityAI/src/
├── 📁 app/
│ ├── layout.tsx # An overall page shell (you can ignore this).
│ └── page.tsx # ⬅️ MODIFY THIS: The main user interface for our app.
│
├── 📁 ai/
│ ├── 📁flows # ⬅️ MODIFY THIS: The core AI logic and server functions.
│ └── intent-classifier.ts # ⬅️ MODIFY THIS: Where we'll edit our AI prompts.
| └── ai-instance.ts
| └── dev.ts
│
├── 📁 components/ # Contains pre-built UI components (ignore this).
│
├── 📁 hooks/
│
├── 📁 lib/
│
└── 📁 types/
حزمة التكنولوجيا
يستند نظامنا إلى حزمة تكنولوجية حديثة وقابلة للتوسّع تجمع بين خدمات سحابية فعّالة ونماذج ذكاء اصطناعي متطوّرة. في ما يلي المكوّنات الرئيسية التي سنستخدمها:
- Google Cloud Platform (GCP): توفّر البنية الأساسية بدون خادم لوكلائنا.
- Cloud Run: تنشر الوكلاء الفرديين كخدمات دقيقة قابلة للتوسيع ومحفوظة في حاويات.
- Artifact Registry: تخزِّن صور Docker لوكلائنا وتديرها بشكل آمن.
- Secret Manager: تتعامل هذه الخدمة بأمان مع بيانات الاعتماد الحساسة ومفاتيح واجهة برمجة التطبيقات.
- النماذج اللغوية الكبيرة (LLM): تعمل هذه النماذج كـ "عقول" للنظام.
- نماذج Gemini من Google: نستفيد من الإمكانات المتعددة الوسائط القوية التي توفّرها عائلة Gemini في كل شيء، بدءًا من تصنيف نية المستخدم إلى تحليل محتوى الصور وتقديم أوصاف ذكية.
3- الإعداد والمتطلبات الأساسية
تفعيل حساب الفوترة: لتنفيذ هذا الدرس العملي، تحتاج إلى حساب فوترة يتضمّن بعض الرصيد. استخدِم الرصيد من البانر في أعلى هذا الدرس التطبيقي للبدء. إذا كنت مرتبطًا بحساب فوترة، يمكنك تخطّي هذه الخطوة.
إنشاء مشروع جديد على Google Cloud Platform
- انتقِل إلى Google Cloud Console وأنشِئ مشروعًا جديدًا.
- انتقِل إلى Google Cloud Console وأنشِئ مشروعًا جديدًا.
- افتح اللوحة اليمنى، وانقر على
Billing، وتحقّق ممّا إذا كان حساب الفوترة مرتبطًا بحساب Google Cloud Platform هذا.
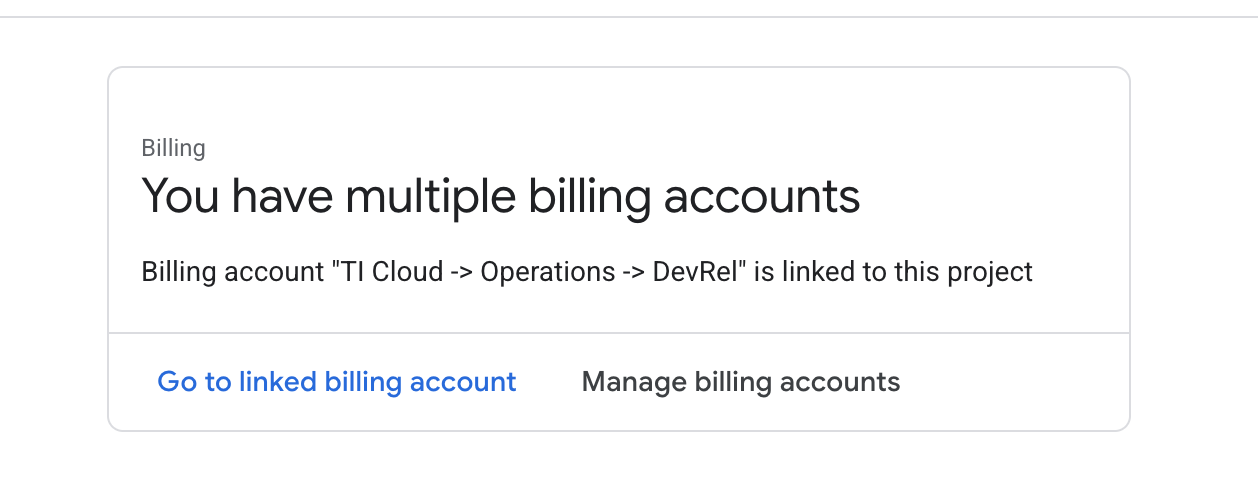
إذا ظهرت لك هذه الصفحة، ضَع علامة في المربّع manage billing account، واختَر Google Cloud Trial One واربطه بحسابك.
إنشاء مفتاح Gemini API
قبل أن تتمكّن من تأمين المفتاح، يجب أن يكون لديك مفتاح.
- انتقِل إلى Google AI Studio : https://aistudio.google.com/
- سجِّل الدخول باستخدام حسابك على Google.
- انقر على الزر "الحصول على مفتاح واجهة برمجة التطبيقات"، والذي يظهر عادةً في لوحة التنقّل على يمين الصفحة أو في أعلى يسارها.
- في مربّع الحوار "مفاتيح واجهة برمجة التطبيقات"، انقر على "إنشاء مفتاح واجهة برمجة التطبيقات في مشروع جديد".
- سيتم إنشاء مفتاح واجهة برمجة تطبيقات جديد لك. انسخ هذا المفتاح على الفور وخزِّنه مؤقتًا في مكان آمن (مثل برنامج مدير كلمات المرور أو ملاحظة آمنة). هذه هي القيمة التي ستستخدِمها في الخطوات التالية.
سير عمل التطوير المحلي (الاختبار على جهازك)
يجب أن تتمكّن من تشغيل npm run dev وأن يعمل تطبيقك. وهنا يأتي دور .env.
- أضِف مفتاح واجهة برمجة التطبيقات إلى الملف: أنشئ ملفًا جديدًا باسم
.envوأضِف السطر التالي إلى هذا الملف.
تأكَّد من استبدال YOUR_API_KEY_HERE بالمفتاح الذي حصلت عليه من AI Studio وحفظته في .env:
GOOGLE_GENAI_API_KEY="YOUR_API_KEY_HERE"
[اختياري] إعداد بيئة التطوير المتكاملة (IDE) والبيئة
في هذا البرنامج التعليمي، يمكنك العمل في بيئة تطوير مألوفة، مثل VS Code أو IntelliJ، باستخدام الوحدة الطرفية المحلية. ومع ذلك، ننصحك بشدة باستخدام Google Cloud Shell لضمان توفّر بيئة موحّدة ومُعدّة مسبقًا.
تمت كتابة الخطوات التالية في سياق Cloud Shell. إذا اخترت استخدام بيئتك المحلية بدلاً من ذلك، يُرجى التأكّد من تثبيت git وnvm وnpm وgcloud وإعدادها بشكلٍ صحيح.
العمل على "محرّر Cloud Shell"
👉انقر على تفعيل Cloud Shell في أعلى "وحدة تحكّم Google Cloud" (رمز شكل الوحدة الطرفية في أعلى لوحة Cloud Shell)، 
👉انقر على الزر "فتح المحرّر" (يبدو كملف مفتوح مع قلم رصاص). سيؤدي ذلك إلى فتح "محرِّر Cloud Shell للرموز" في النافذة. سيظهر لك مستكشف الملفات على الجانب الأيمن. 
👉انقر على الزر تسجيل الدخول باستخدام رمز السحابة الإلكترونية في شريط الحالة أسفل الصفحة كما هو موضّح. امنح المصادقة للمكوّن الإضافي حسب التعليمات. إذا ظهرت لك الرسالة Cloud Code - no project في شريط الحالة، انقر عليها ثم انقر على "اختيار مشروع Google Cloud" في القائمة المنسدلة، ثم اختَر مشروع Google Cloud المحدّد من قائمة المشاريع التي أنشأتها. 
👉افتح نافذة المحطة الطرفية في بيئة التطوير المتكاملة المستندة إلى السحابة الإلكترونية، 
👉في نافذة الأوامر، تأكَّد من أنّك قد أثبتّ هويتك وأنّ المشروع مضبوط على رقم تعريف مشروعك باستخدام الأمر التالي:
gcloud auth list
👉 استنسِخ مشروع natively-accessible-interface من GitHub:
git clone https://github.com/cuppibla/AccessibilityAgent.git
وتأكَّد من استبدال <YOUR_PROJECT_ID> برقم تعريف مشروعك (يمكنك العثور على رقم تعريف مشروعك في Google Cloud Console، قسم المشروع، ❗️❗️تأكَّد من عدم الخلط بين project id وproject number❗️❗️):
echo <YOUR_PROJECT_ID> > ~/project_id.txt
gcloud config set project $(cat ~/project_id.txt)
👈نفِّذ الأمر التالي لتفعيل واجهات Google Cloud APIs اللازمة: (قد يستغرق تنفيذ هذا الأمر حوالي دقيقتَين)
gcloud services enable compute.googleapis.com \
storage.googleapis.com \
run.googleapis.com \
artifactregistry.googleapis.com \
aiplatform.googleapis.com \
eventarc.googleapis.com \
sqladmin.googleapis.com \
secretmanager.googleapis.com \
cloudbuild.googleapis.com \
cloudresourcemanager.googleapis.com \
cloudfunctions.googleapis.com \
cloudaicompanion.googleapis.com
قد تستغرق هذه العملية بضع دقائق.
إعداد الأذونات
👉إعداد إذن حساب الخدمة في الوحدة الطرفية، شغِّل الأمر التالي :
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
export SERVICE_ACCOUNT_NAME=$(gcloud compute project-info describe --format="value(defaultServiceAccount)")
echo "Here's your SERVICE_ACCOUNT_NAME $SERVICE_ACCOUNT_NAME"
👉 منح الأذونات في الوحدة الطرفية، شغِّل الأمر التالي :
#Cloud Storage (Read/Write):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/storage.objectAdmin"
#Pub/Sub (Publish/Receive):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/pubsub.publisher"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/pubsub.subscriber"
#Cloud SQL (Read/Write):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/cloudsql.editor"
#Eventarc (Receive Events):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/iam.serviceAccountTokenCreator"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/eventarc.eventReceiver"
#Vertex AI (User):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/aiplatform.user"
#Secret Manager (Read):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/secretmanager.secretAccessor"
4. فهم مدخلات المستخدم - أداة تصنيف النية
قبل أن يتمكّن وكيل الذكاء الاصطناعي من اتّخاذ أي إجراء، يجب أن يفهم أولاً بدقة ما يريده المستخدم. غالبًا ما تكون البيانات التي يتم إدخالها من العالم الحقيقي غير منظَّمة، فقد تكون غامضة أو تتضمّن أخطاء إملائية أو تستخدم لغة محادثة.
في هذا القسم، سننشئ مكوّنات "الاستماع" المهمة التي تحوّل بيانات أدخلها المستخدم الأولية إلى أمر واضح وقابل للتنفيذ.
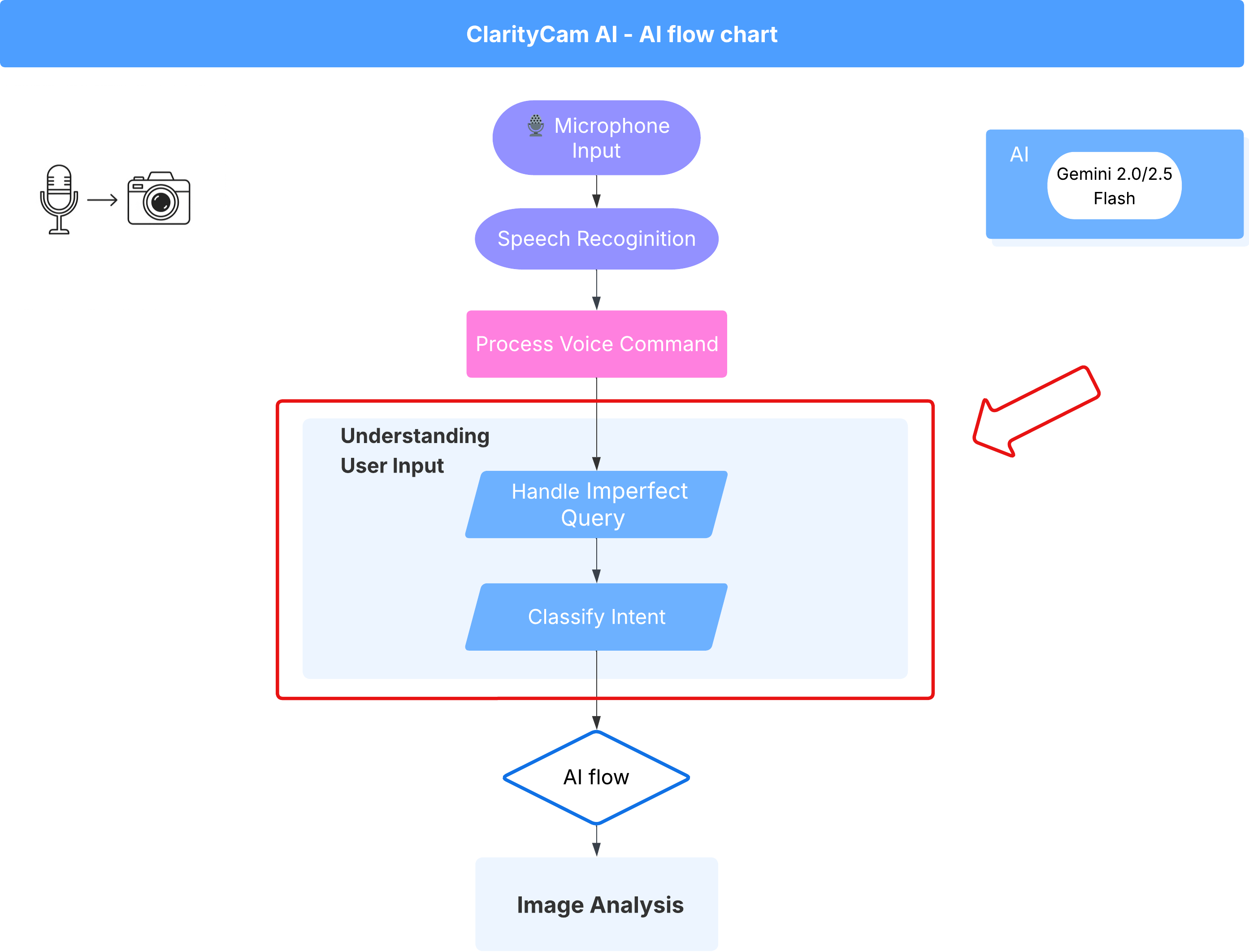
إضافة أداة تصنيف الأهداف
سنحدّد الآن منطق الذكاء الاصطناعي الذي يشغّل أداة التصنيف.
👉 الإجراء: في بيئة التطوير المتكاملة (IDE) في Cloud Shell، انتقِل إلى الدليل ~/src/ai/intent-classifier/
الخطوة 1: تحديد مفردات الوكيل (IntentCategory)
أولاً، علينا إنشاء قائمة نهائية بكل الإجراءات المحتملة التي يمكن أن ينفّذها الوكيل.
👉 الإجراء: استبدِل العنصر النائب // REPLACE ME PART 1: add IntentCategory here بالرمز التالي:
👉 باستخدام الرمز أدناه:
export type IntentCategory =
// Image Analysis Intents
| "DescribeImage"
| "AskAboutImage"
| "ReadTextInImage"
| "IdentifyColorsInImage"
// Control Intents
| "TakePicture"
| "StartCamera"
| "SelectImage"
| "StopSpeaking"
// Preference Intents
| "SetDescriptionDetailed"
| "SetDescriptionConcise"
// Fallback Intents
| "GeneralInquiry" // User has a general question about the agent's functions or polite interaction
| "OutOfScopeRequest" // User's request is clearly outside the agent's defined capabilities
| "Unknown"; // Intent could not be determined with confidence
الشرح
تنشئ تعليمة TypeScript البرمجية هذه نوعًا مخصّصًا يُسمى IntentCategory. وهي قائمة صارمة تحدّد كل إجراء محتمل، أو "هدف"، يمكن أن يفهمه برنامجنا. هذه خطوة أولى مهمة لأنّها تحوّل عددًا لا نهائيًا من عبارات المستخدمين المحتملة ("أخبرني بما تراه" و"ماذا يوجد في الصورة؟") إلى مجموعة واضحة وقابلة للتوقّع من الأوامر. يهدف المصنّف إلى ربط أي طلب بحث من المستخدم بإحدى هذه الفئات المحدّدة.
الخطوة 2
لاتّخاذ قرارات دقيقة، يجب أن يعرف الذكاء الاصطناعي قدراته وقيوده. سنقدّم هذه المعلومات ككتلة نصية مفصّلة.
👉 الإجراء: استبدِل العنصر النائب REPLACE ME PART 2: add AGENT_CAPABILITIES_AND_LIMITATIONS هنا بالرمز التالي:
استبدِل الرمز أدناه: // REPLACE ME PART 2: add AGENT_CAPABILITIES_AND_LIMITATIONS here:
👉 باستخدام الرمز أدناه
const AGENT_CAPABILITIES_AND_LIMITATIONS = `
**Core Capabilities (What the Agent CAN DO):**
* **Image Analysis:**
* DescribeImage: Provide a general description of the current image.
* AskAboutImage: Answer a specific question about the visual content of the current image (e.g., "Is there a dog?", "What color is the car?").
* ReadTextInImage: Read any text found in the current image.
* IdentifyColorsInImage: Identify the dominant colors of the current image.
* **Image Input Control:**
* TakePicture: Capture an image using the currently active camera stream.
* StartCamera: Activate the camera (e.g., "use camera", "take another picture").
* SelectImage: Allow the user to choose an image file from their device.
* **Voice & Audio Control:**
* StopSpeaking: Stop the current text-to-speech output.
* **Preference Management:**
* SetDescriptionDetailed: Make future image descriptions more detailed.
* SetDescriptionConcise: Make future image descriptions less detailed or concise.
* **General Interaction:**
* GeneralInquiry: Handle conversational phrases (e.g., "hello", "thank you") or questions about its own capabilities (e.g., "what can you do?", "help").
**Limitations (What the Agent CANNOT DO and should be classified as OutOfScopeRequest):**
* Cannot generate or create new images.
* Cannot edit or modify existing images (e.g., "remove background," "make the car blue").
* Cannot analyze video files or live video beyond capturing a single frame.
* Cannot provide general knowledge or answer questions unrelated to the provided image's visual content (e.g., "What's the weather?", "Who is the president?", "Tell me a joke", "What time is it?").
* Cannot perform mathematical calculations or complex data analysis.
* Cannot translate languages as a primary function.
* Cannot remember information from past images or vastly different previous queries in the same session.
* Cannot control other device settings or applications.
* Cannot perform web searches.
`;
سبب الأهمية:
هذا النص ليس مخصّصًا للمستخدم، بل لنموذج الذكاء الاصطناعي. سنقدّم "الوصف الوظيفي" هذا مباشرةً إلى الطلب (في الخطوة التالية) لمنح النموذج اللغوي (LLM) السياق الذي يحتاج إليه لاتخاذ قرارات دقيقة. وبدون هذا السياق، قد يصنّف النموذج اللغوي الكبير طلب البحث "ما هي حالة الطقس؟" بشكل غير صحيح على أنّه AskAboutImage. وبفضل هذا السياق، يعرف النموذج أنّ الطقس ليس عنصرًا مرئيًا في الصورة ويصنّفه بشكل صحيح على أنّه خارج نطاق البحث.
الخطوة 3
الآن، سنكتب المجموعة الكاملة من التعليمات التي سيتّبعها نموذج Gemini لإجراء التصنيف.
👉 الإجراء: استبدِل // REPLACE ME PART 3 - classifyIntentPrompt بالرمز التالي:
باستخدام الرمز أدناه
const classifyIntentPrompt = ai.definePrompt({
name: 'classifyIntentPrompt',
input: { schema: ClassifyIntentInputSchema },
output: { schema: ClassifyIntentOutputSchema },
prompt: `You are classifying the user's intent for ClarityCam, a voice-controlled AI application focused on image analysis.
Analyze the user query: '{userQuery}'.
First, understand ClarityCam's capabilities and limitations:
${AGENT_CAPABILITIES_AND_LIMITATIONS}
Now, classify the user's PRIMARY intent into ONE of the following categories:
* **DescribeImage**: User wants a general description of the current image.
* **AskAboutImage**: User is asking a specific question directly related to the visual content of the current image.
* **ReadTextInImage**: User wants any text read from the current image.
* **IdentifyColorsInImage**: User wants the dominant colors of the current image.
* **TakePicture**: User wants to capture an image using an active camera.
* **StartCamera**: User wants to activate the camera.
* **SelectImage**: User wants to choose an image file.
* **StopSpeaking**: User wants the current text-to-speech output to stop.
* **SetDescriptionDetailed**: User wants future image descriptions to be more detailed.
* **SetDescriptionConcise**: User wants future image descriptions to be less detailed.
* **GeneralInquiry**: The query is a simple conversational filler (e.g., "hello", "thanks"), a polite closing, or a direct question about the agent's functions (e.g., "what can you do?", "how does this work?", "help").
* **OutOfScopeRequest**: The query asks the agent to perform an action clearly listed under its "Limitations" or otherwise demonstrably outside its defined image analysis and control functions. Examples: "Tell me a joke," "What's the weather in London?", "Generate an image of a cat," "Can you edit my photo to make it brighter?", "Send this image to my friends","Translate 'hello' to Spanish."
Output ONLY the category name.
If the query is ambiguous but seems generally related to polite interaction or asking about the agent itself, prefer 'GeneralInquiry'.
If the query is clearly asking for something the agent CANNOT do, use 'OutOfScopeRequest'.
If truly unclassifiable even with these guidelines, use 'Unknown'.`,
config: {
temperature: 0.05, // Very low temperature for highly deterministic classification
}
});
هذا الطلب هو المكان الذي يحدث فيه السحر. وهي "عقل" المصنّف، إذ تحدّد دور الذكاء الاصطناعي وتوفّر السياق اللازم وتعرّف النتيجة المطلوبة. في ما يلي بعض أساليب هندسة الطلبات الرئيسية:
- لعب الأدوار: يبدأ بعبارة "أنت تصنّف..." لتحديد مهمة واضحة.
- إدخال السياق: يتم إدراج المتغيّر
AGENT_CAPABILITIES_AND_LIMITATIONSديناميكيًا في الطلب. - تنسيق الناتج الصارم: إنّ التعليمات "عرض اسم الفئة فقط" ضرورية للحصول على ردّ واضح يمكن توقّعه ويمكننا استخدامه بسهولة في الرمز البرمجي.
- درجة العشوائية المنخفضة: عند التصنيف، نريد إجابات حتمية ومنطقية، وليس إجابات إبداعية. يضمن ضبط درجة العشوائية على قيمة منخفضة جدًا (0.05) أن يكون النموذج مركّزًا ومتسقًا إلى حد كبير.
الخطوة 4: ربط التطبيق بتدفق الذكاء الاصطناعي
أخيرًا، لنستدعِ أداة التصنيف الجديدة المستندة إلى الذكاء الاصطناعي من ملف التطبيق الرئيسي.
👉 الإجراء: انتقِل إلى ملف ~/src/app/page.tsx. داخل الدالة processVoiceCommand، استبدِل // REPLACE ME PART 1: add classificationResult هنا بما يلي:
const classificationResult = await classifyIntentFlow({ userQuery: commandToProcess });
intent = classificationResult.intent as IntentCategory;
يشكّل هذا الرمز حلقة الوصل الأساسية بين تطبيق الواجهة الأمامية ومنطق الذكاء الاصطناعي في الواجهة الخلفية. يأخذ الأمر الصوتي للمستخدم (commandToProcess)، ويرسله إلى classifyIntentFlow الذي أنشأته للتو، وينتظر أن يعرض الذكاء الاصطناعي النية المصنّفة.
يحتوي متغيّر الغرض الآن على أمر منظَّم وواضح (مثل DescribeImage). سيتم استخدام هذه النتيجة في عبارة التبديل التالية لتوجيه منطق التطبيق وتحديد الإجراء الذي يجب اتّخاذه بعد ذلك. وهي الطريقة التي يتم من خلالها تحويل "تفكير" الذكاء الاصطناعي إلى "إجراء" في التطبيق.
تشغيل واجهة المستخدم
حان الوقت لتجربة تطبيقنا. لنبدأ خادم التطوير.
👉 في الوحدة الطرفية، شغِّل الأمر التالي: npm run dev ملاحظة: قد تحتاج إلى تنفيذ npm install قبل تنفيذ npm run dev
بعد لحظات، ستظهر لك نتيجة مشابهة لما يلي، ما يعني أنّ الخادم يعمل بنجاح:
▲ Next.js 15.2.3 (Turbopack)
- Local: http://localhost:9003
- Network: http://10.88.0.4:9003
- Environments: .env
✓ Starting...
✓ Ready in 1512ms
○ Compiling / ...
✓ Compiled / in 26.6s
الآن، انقر على عنوان URL المحلي (http://localhost:9003) لفتح التطبيق في المتصفّح.
من المفترض أن تظهر لك واجهة مستخدم SightGuide. في الوقت الحالي، لا ترتبط الأزرار بأي منطق، لذا لن يؤدي النقر عليها إلى أي إجراء. وهذا ما نتوقّعه بالضبط في هذه المرحلة. سنوضّح لك طريقة تنفيذ ذلك في القسم التالي.
بعد أن تعرّفت على واجهة المستخدم، ارجع إلى نافذة الأوامر واضغط على Ctrl + C لإيقاف خادم التطوير قبل المتابعة.
5- فهم إدخال المستخدم - التحقّق من طلب البحث غير الكامل
إضافة ميزة "التحقّق من طلب البحث غير المثالي"
الجزء 1: تحديد الطلب (ما هو المطلوب؟)
أولاً، لنحدّد التعليمات التي يجب أن يتّبعها الذكاء الاصطناعي. الطلب هو "الوصفة" التي نقدّمها لمكالمة الذكاء الاصطناعي، فهو يوضّح للنموذج بالضبط ما نريد منه أن يفعله.
👉 الإجراء: في بيئة التطوير المتكاملة (IDE)، انتقِل إلى ~/src/ai/flows/check_typo/.
استبدِل الرمز أدناه: // REPLACE ME PART 1: add prompt here:
👉 باستخدام الرمز أدناه
const prompt = ai.definePrompt({
name: 'checkTypoPrompt',
input: {
schema: CheckTypoInputSchema,
},
output: {
schema: CheckTypoOutputSchema,
},
prompt: `You are a helpful AI assistant that checks user text for typos and suggests corrections.
- If you find typos, respond with the corrected text.
- If there are no typos, or if you are unsure about a correction, respond with the original text unchanged.
User text: {text}
Corrected text:
`,
});
تحدّد مجموعة الرموز هذه نموذجًا قابلاً لإعادة الاستخدام للذكاء الاصطناعي باسم checkTypoPrompt. يحدّد مخطّطا الإدخال والإخراج عقد البيانات لهذه المهمة. يمنع ذلك حدوث أخطاء ويجعل نظامنا قابلاً للتوقّع.
الجزء 2: إنشاء المسار (طريقة التنفيذ)
بعد أن أصبح لدينا "وصفة" (الطلب)، علينا إنشاء دالة يمكنها تنفيذها فعليًا. في Genkit، يُطلق على ذلك اسم "مسار". يغلّف التدفق طلبنا في دالة قابلة للتنفيذ يمكن لبقية تطبيقنا استدعاؤها بسهولة.
👉 الإجراء: في ملف ~/src/ai/flows/check_typo/ نفسه، استبدِل الرمز أدناه: // REPLACE ME PART 2: add flow here:
👉 باستخدام الرمز أدناه
const checkTypoFlow = ai.defineFlow<
typeof CheckTypoInputSchema,
typeof CheckTypoOutputSchema
>(
{
name: 'checkTypoFlow',
inputSchema: CheckTypoInputSchema,
outputSchema: CheckTypoOutputSchema,
},
async input => {
const {output} = await prompt(input);
return output!;
}
);
الجزء 3: استخدام أداة "مدقق الأخطاء الإملائية"
بعد اكتمال مسار الذكاء الاصطناعي، يمكننا الآن دمجه في المنطق الرئيسي لتطبيقنا. سننفّذ عملية التنظيف مباشرةً بعد تلقّي أمر المستخدم، ما يضمن أن يكون النص نظيفًا قبل أي معالجة أخرى.
👉الإجراء: انتقِل إلى ~/src/app/ai/flows/check-typo.ts وابحث عن الدالة export async function checkTypo. أزِل التعليق من عبارة return:
بدلاً من return;، افعل return checkTypoFlow(input);
👉الإجراء: انتقِل إلى ~/src/app/page.tsx وابحث عن الدالة processVoiceCommand. استبدِل الرمز أدناه: REPLACE ME PART 2: add typoResult here:
👉 باستخدام الرمز أدناه
const typoResult = await checkTypo({ text: rawCommand });
if (typoResult && typoResult.correctedText && typoResult.correctedText.trim().length > 0) {
const originalTrimmedLower = rawCommand.trim().toLowerCase();
const correctedTrimmedLower = typoResult.correctedText.trim().toLowerCase();
if (correctedTrimmedLower !== originalTrimmedLower) {
commandToProcess = typoResult.correctedText;
typoCorrectionAnnouncement = `I think you said: ${commandToProcess}. `;
}
}
من خلال هذا التغيير، أنشأنا مسارًا أكثر فعالية لمعالجة البيانات لكل أمر يصدره المستخدم.
مسار الطلب الصوتي (للقراءة فقط، لا يلزم اتّخاذ أي إجراء)
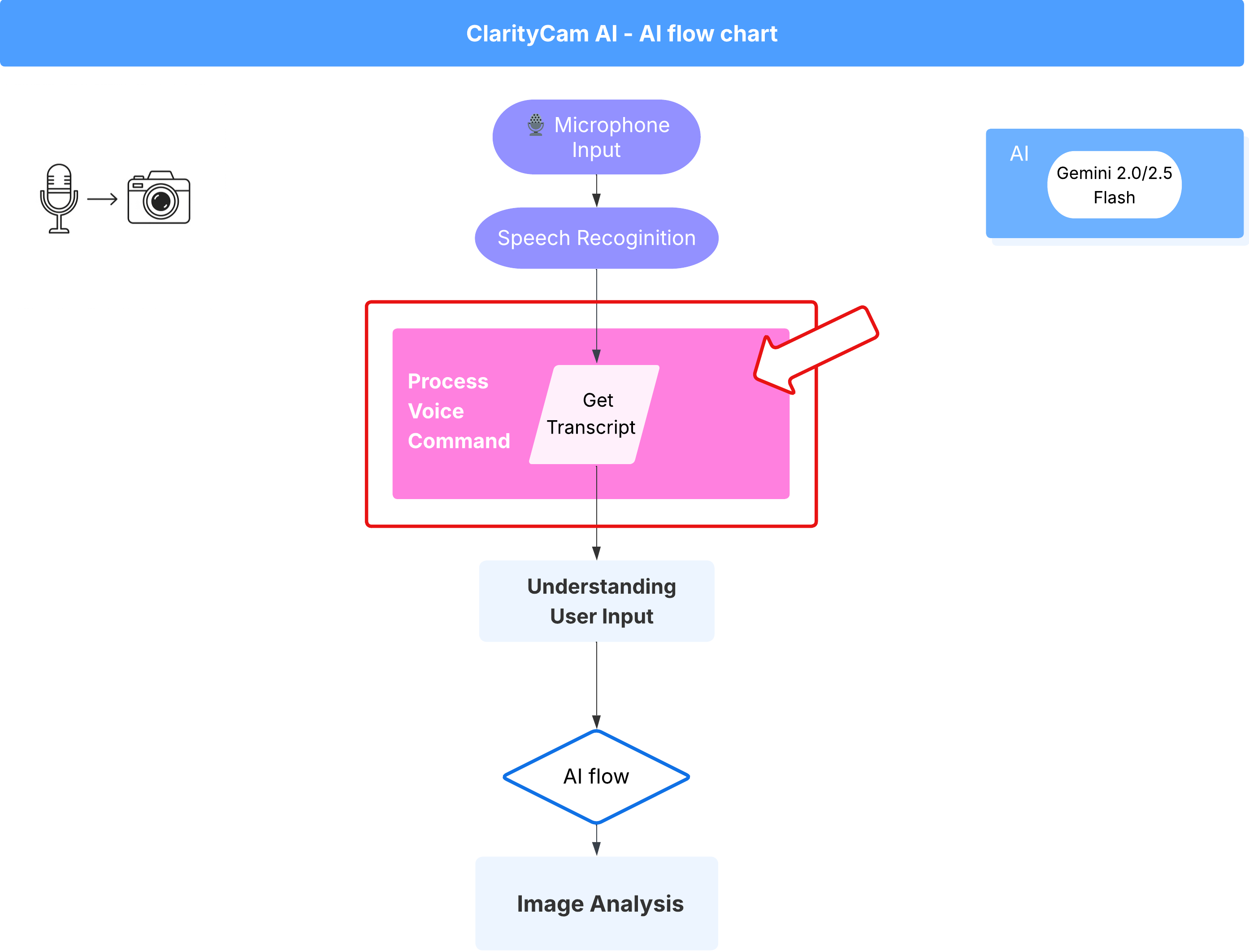
بعد أن تناولنا مكوّنَي "الفهم" الأساسيَّين (مدقّق الأخطاء الإملائية ومصنّف النية)، لنرَ كيف يتناسبان مع منطق معالجة الصوت الرئيسي للتطبيق.
يبدأ كل شيء عندما يتحدث المستخدم. تستمع واجهة Web Speech API في المتصفّح إلى الكلام، وعندما ينتهي المستخدم من التحدث، تقدّم النص لما سمعته. تتعامل التعليمة البرمجية التالية مع هذه العملية.
👉للقراءة فقط: انتقِل إلى ~/src/app/page.tsx وداخل الدالة handleResult. ابحث عن الرمز أدناه:
for (let i = event.resultIndex; i < event.results.length; ++i) {
if (event.results[i].isFinal) {
finalTranscript += event.results[i][0].transcript;
}
}
if (finalTranscript) {
console.log("Final Transcript:", finalTranscript);
processVoiceCommand(finalTranscript);
}
اختبار ميزة تصحيح الأخطاء الإملائية
الآن نصل إلى الجانب الشيق! لنتعرّف على كيفية تعامل ميزة تصحيح الأخطاء الإملائية الجديدة مع الأوامر الصوتية الصحيحة وغير الصحيحة.
بدء التطبيق
لنبدأ أولاً بإعادة تشغيل خادم التطوير. في الوحدة الطرفية، شغِّل الأمر التالي: npm run dev
فتح التطبيق
بعد أن يصبح الخادم جاهزًا، افتح المتصفّح وانتقِل إلى العنوان المحلي (مثل http://localhost:9003).
تفعيل الطلبات الصوتية
انقر على الزر Start Listening. من المحتمل أن يطلب المتصفّح إذنًا لاستخدام الميكروفون. يُرجى النقر على "سماح".
اختبار أمر غير مثالي
الآن، لنقدّم له أمرًا معيبًا قليلاً لنرى ما إذا كان بإمكان الذكاء الاصطناعي فهمه. تحدَّث بوضوح في الميكروفون:
"التقط صورة لي"
مراقبة النتيجة
هذا هو المكان الذي يحدث فيه السحر! حتى إذا قلت "التقط صورة لي"، من المفترض أن يفعّل التطبيق الكاميرا بشكل صحيح. يصحّح مسار checkTypo عبارتك إلى "التقاط صورة" في الخلفية، ثم يفهم مسار classifyIntentFlow الأمر المصحّح.
يؤكّد هذا على أنّ ميزة تصحيح الأخطاء الإملائية تعمل بشكل مثالي، ما يجعل التطبيق أكثر فعالية وسهولة في الاستخدام. عند الانتهاء، يمكنك إيقاف الكاميرا من خلال التقاط صورة أو إيقاف الخادم ببساطة في نافذة الأوامر (Ctrl + C).
6. تحليل الصور باستخدام الذكاء الاصطناعي - وصف الصورة
بعد أن أصبح بإمكان الوكيل فهم الطلبات، حان الوقت لمنحه القدرة على الرؤية. في هذا القسم، سنعمل على تطوير إمكانات Vision Agent، وهو المكوّن الأساسي المسؤول عن جميع عمليات تحليل الصور. سنبدأ بأهم ميزة، وهي وصف صورة، ثم سنضيف إمكانية قراءة النص.
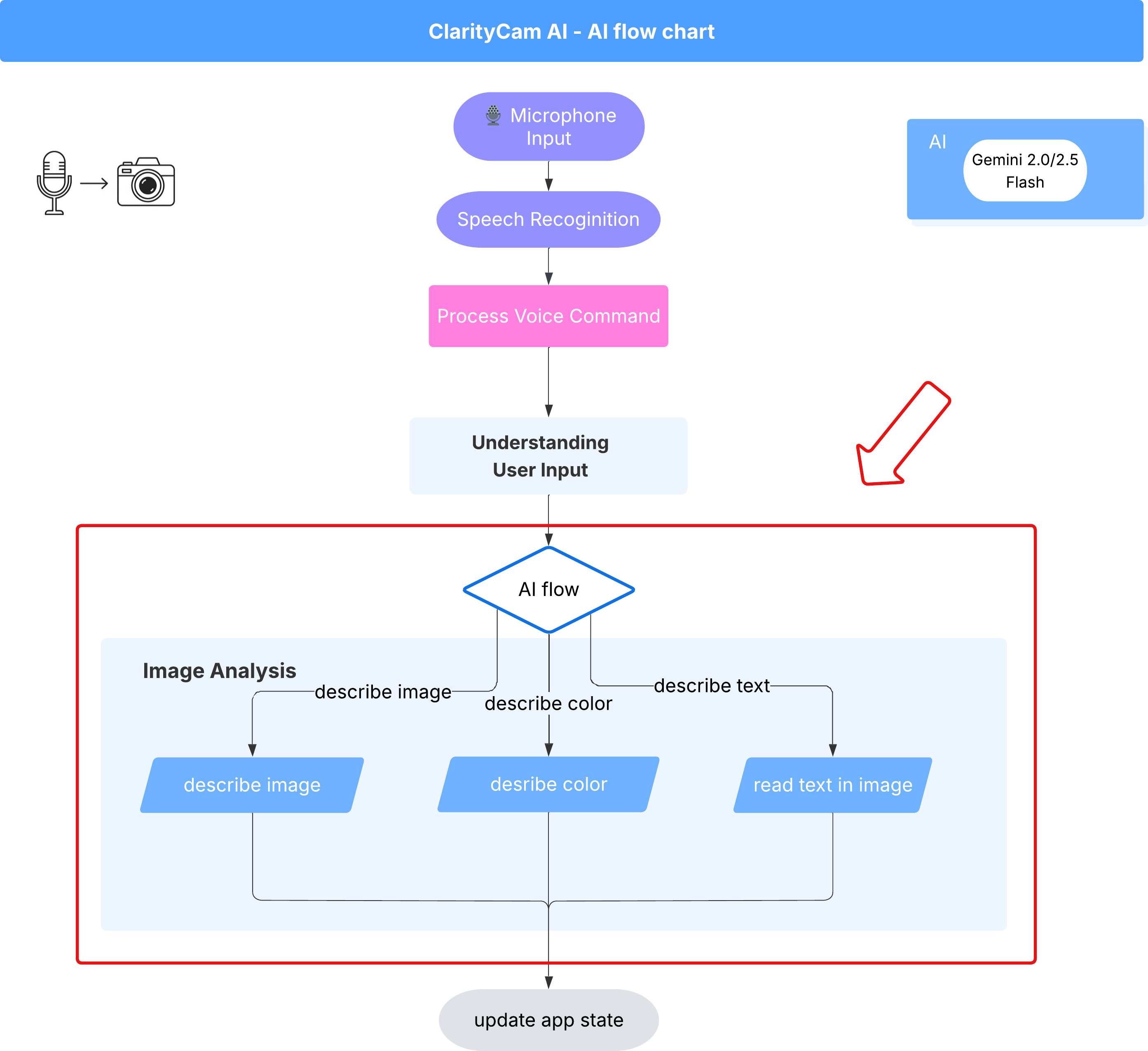
الميزة 1: وصف صورة
هذه هي الوظيفة الأساسية للوكيل. لن نكتفي بإنشاء وصف ثابت، بل سنصمّم مسارًا ديناميكيًا يمكنه تعديل مستوى التفاصيل استنادًا إلى الإعدادات المفضّلة للمستخدم. هذا جزء أساسي من فلسفة "الواجهة الذاتية التكيّف" (NAI).
👉 الإجراء: في بيئة التطوير المتكاملة (IDE) في Cloud Shell، انتقِل إلى ملف ~/src/ai/flows/describe_image/ وأزِل التعليق من الرمز التالي.
الخطوة 1: إنشاء نموذج طلب ديناميكي
أولاً، سننشئ نموذج طلب متطوّرًا يمكنه تغيير تعليماته استنادًا إلى المعلومات التي يتلقّاها.
إزالة التعليق من الرمز أدناه
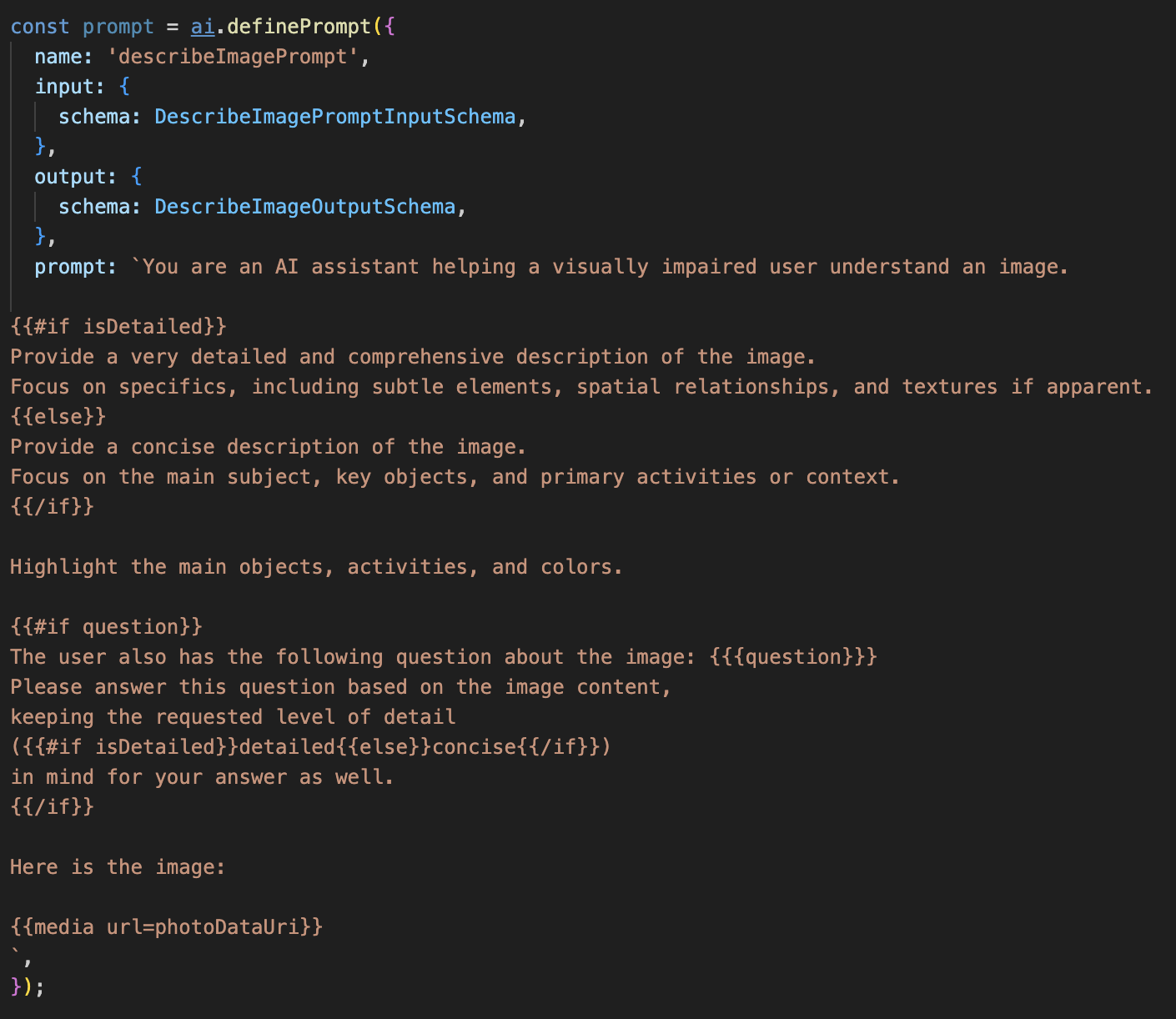
يحدّد هذا الرمز متغيّر سلسلة، وهو prompt، يستخدم لغة نموذجية تُسمى Dot-Mustache. يتيح لنا ذلك تضمين منطق شرطي مباشرةً في الطلب.
{#if isDetailed}...{else}...{/if}: هذا حظر مشروط. إذا كانت بيانات الإدخال التي نرسلها إلى هذا الطلب تحتوي على السمة isDetailed: true، سيتلقّى الذكاء الاصطناعي مجموعة التعليمات "مفصّلة جدًا". وفي ما عدا ذلك، سيتلقّى التعليمات "الموجزة". إليك كيف يتكيّف وكيلنا مع الإعدادات المفضّلة للمستخدم.
{#if question}...{/if}: لن يتم تضمين هذه الكتلة إلا إذا كانت بيانات الإدخال تحتوي على سمة سؤال. يتيح لنا ذلك استخدام الطلب الفعّال نفسه لكلّ من الأوصاف العامة والأسئلة المحدّدة.
{media url=photoDataUri}: هذه هي صيغة Genkit الخاصة لتضمين بيانات الصور مباشرةً في الطلب كي يحلّلها النموذج المتعدد الوسائط.
الخطوة 2: إنشاء "المسار الذكي"
بعد ذلك، نحدّد الطلب والتسلسل الذي سيستخدم النموذج الجديد. يحتوي هذا المسار على بعض المنطق لترجمة إعدادات المستخدم المفضّلة إلى قيمة منطقية يمكن أن يفهمها النموذج.
👉 الإجراء: في بيئة التطوير المتكاملة (IDE) في Cloud Shell، استبدِل الرمز التالي في ملف ~/src/ai/flows/describe_image/ نفسه. // REPLACE ME PART 1: add flow here
👉 باستخدام الرمز أدناه:
// Define the prompt using the template from Step 1
const prompt = ai.definePrompt({
name: 'describeImagePrompt',
input: { schema: DescribeImagePromptInputSchema },
output: { schema: DescribeImageOutputSchema },
prompt: promptTemplate,
});
// Define the flow
const describeImageFlow = ai.defineFlow<
typeof DescribeImageInputSchema,
typeof DescribeImageOutputSchema
>(
{
name: 'describeImageFlow',
inputSchema: DescribeImageInputSchema,
outputSchema: DescribeImageOutputSchema,
},
async (pageInput) => {
const preference = pageInput.detailPreference || "concise";
// Prepare the input for the prompt, including the new boolean flag
const promptInputData = {
...pageInput,
isDetailed: preference === "detailed",
};
const { output } = await prompt(promptInputData);
return output!;
}
);
يعمل هذا الإجراء كوسيط ذكي بين الواجهة الأمامية وطلب الذكاء الاصطناعي.
- يتلقّى هذا الحقل القيمة
pageInputمن تطبيقنا، والتي تتضمّن خيار المستخدم المفضّل كسلسلة (مثل"detailed"). - ثم ينشئ عنصرًا جديدًا،
promptInputData. - السطر الأكثر أهمية هو
isDetailed: preference === "detailed". يؤدي هذا السطر المهمة الحاسمة المتمثلة في إنشاء قيمة منطقيةtrueأوfalseاستنادًا إلى سلسلة الإعدادات المفضّلة. - وأخيرًا، يتم استدعاء
promptباستخدام هذه البيانات المحسّنة. يمكن لنموذج الطلب من الخطوة 1 الآن استخدام القيمة المنطقيةisDetailedلتغيير التعليمات المرسَلة إلى الذكاء الاصطناعي بشكل ديناميكي.
الخطوة 3: ربط الواجهة الأمامية
الآن، لنبدأ هذا التدفق من واجهة المستخدم في ملف page.tsx.
👉الإجراء: انتقِل إلى ~/src/app/ai/flows/describe-image.ts وابحث عن الدالة export async function describeImage. أزِل التعليق من عبارة return:
بدلاً من return;، افعل return describeImageFlow(input);
👉الإجراء: في ~/src/app/page.tsx، ابحث عن الدالة handleAnalyze، واستبدِل الرمز // REPLACE ME PART 2: DESCRIBE IMAGE
👉 مع الرمز التالي:
case "description":
result = await describeImage({
photoDataUri,
question,
detailPreference: descriptionPreference
});
outputText = question ? `Answer: ${result.description}` : `Description: ${result.description}`;
break;
عندما يريد المستخدم الحصول على وصف، يتم تنفيذ هذا الرمز. يتم استدعاء مسار describeImage، مع تمرير بيانات الصورة ومتغير حالة descriptionPreference من مكوّن React، وهو أمر بالغ الأهمية. هذه هي الخطوة الأخيرة، وهي تربط خيار المستخدم المخزّن في واجهة المستخدم مباشرةً بتدفق الذكاء الاصطناعي الذي سيعدّل سلوكه وفقًا لذلك.
اختبار ميزة "وصف الصورة"
لنلقِ نظرة على وظيفة وصف الصور أثناء عملها، بدءًا من التقاط صورة إلى سماع ما يراه الذكاء الاصطناعي.
بدء التطبيق
لنبدأ أولاً بإعادة تشغيل خادم التطوير. 👉 في الوحدة الطرفية، شغِّل الأمر التالي: npm run dev ملاحظة: قد تحتاج إلى تنفيذ npm install قبل تنفيذ npm run dev
فتح التطبيق
بعد أن يصبح الخادم جاهزًا، افتح المتصفّح وانتقِل إلى العنوان المحلي (مثل http://localhost:9003).
تفعيل الكاميرا
انقر على الزر "بدء الاستماع" (Start Listening) وامنح إذن الوصول إلى الميكروفون إذا طُلب منك ذلك. بعد ذلك، قُل طلبك الأول:
"أريد التقاط صورة"
سيفعّل التطبيق كاميرا جهازك. من المفترض أن تظهر الآن خلاصة الفيديو المباشر على الشاشة.
التقاط الصورة
بعد تفعيل الكاميرا، وجِّهها إلى ما تريد وصفه. الآن، قُل الأمر مرة ثانية لالتقاط الصورة:
"أريد التقاط صورة"
سيتم استبدال الفيديو المباشر بالصورة الثابتة التي التقطتها للتو.
طلب الوصف
بعد ظهور صورتك الجديدة على الشاشة، أعطِ الأمر النهائي:
"وصف الصورة"
الاستماع إلى النتيجة
سيعرض التطبيق حالة المعالجة، ثم ستستمع إلى الوصف الذي أنشأه الذكاء الاصطناعي لصورتك. سيظهر النص أيضًا في بطاقة "الحالة والنتيجة".
عند الانتهاء، يمكنك إيقاف الكاميرا من خلال التقاط صورة أو إيقاف الخادم ببساطة في الوحدة الطرفية (Ctrl + C).
7. تحليل الصور المستند إلى الذكاء الاصطناعي - وصف النص (التعرّف البصري على الأحرف)
بعد ذلك، سنضيف إمكانية التعرّف البصري على الأحرف (OCR) إلى Vision Agent. يتيح ذلك قراءة النص من أي صورة.
👉 الإجراء: في بيئة التطوير المتكاملة (IDE)، انتقِل إلى ~/src/ai/flows/read-text-in-image/، ثم أزِل التعليق من الرمز البرمجي أدناه:
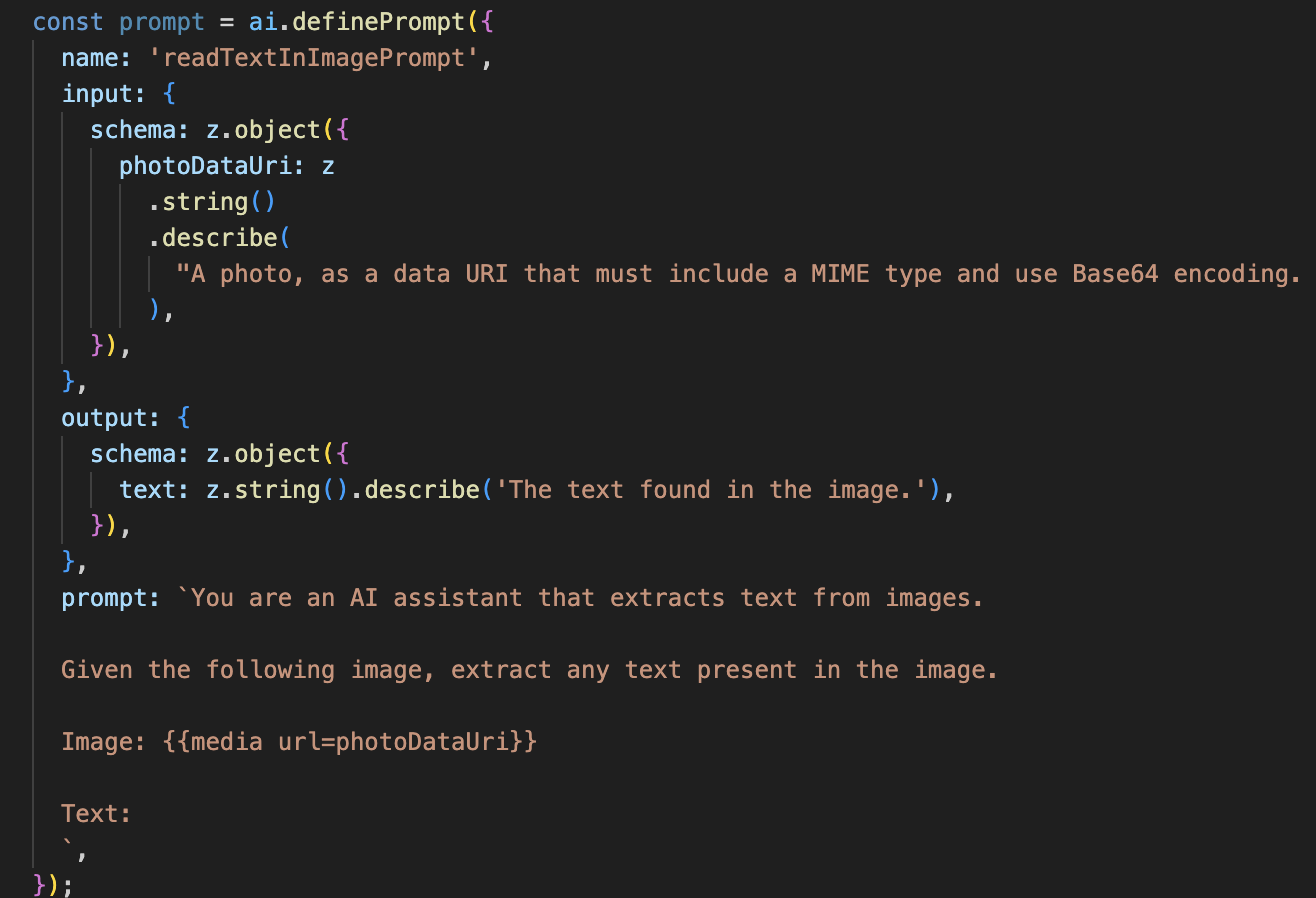
👉 الإجراء: في بيئة التطوير المتكاملة (IDE)، في ملف ~/src/ai/flows/read-text-in-image/ نفسه، استبدِل // REPLACE ME: Creating Prmopt
👉 باستخدام الرمز أدناه:
const readTextInImageFlow = ai.defineFlow<
typeof ReadTextInImageInputSchema,
typeof ReadTextInImageOutputSchema
>(
{
name: 'readTextInImageFlow',
inputSchema: ReadTextInImageInputSchema,
outputSchema: ReadTextInImageOutputSchema,
},
async input => {
const {output} = await prompt(input);
return output!;
}
);
إنّ تدفّق الذكاء الاصطناعي هذا أبسط بكثير، ما يسلّط الضوء على مبدأ استخدام أدوات مركّزة لمهام محدّدة.
- الطلب: يختلف هذا الطلب عن طلب الوصف، فهو ثابت ومحدّد للغاية. مهمتها الوحيدة هي توجيه الذكاء الاصطناعي للعمل كمحرّك تعرّف بصري على الأحرف: "استخرِج أي نص في الصورة".
- المخططات: مخططات الإدخال والإخراج بسيطة أيضًا، إذ تتوقّع صورة وتعرض سلسلة نصية واحدة.
ربط الواجهة الأمامية بميزة التعرّف البصري على الأحرف
أخيرًا، لنربط هذه الإمكانية الجديدة في page.tsx.
👉الإجراء: انتقِل إلى ~/src/app/ai/flows/read-text-in-image.ts وابحث عن الدالة export async function readTextInImage. أزِل التعليق من عبارة return:
بدلاً من return;، افعل return readTextInImageFlow(input);
👉 الإجراء: في ~/src/app/page.tsx، ابحث عن الدالة handleAnalyze وحول العبارة switch.
استبدال REPLACE ME PART 3: READ TEXT
باستخدام الرمز أدناه:
case "text":
result = await readTextInImage({ photoDataUri });
outputText = result.text ? `Text Found: ${result.text}` : "No text found.";
break;
يتم تشغيل هذا الرمز عندما تكون نية المستخدم هي ReadTextInImage. يتم استدعاء مسار readTextInImage البسيط. السطر result.text ? ... : ... هو طريقة واضحة للتعامل مع الناتج، حيث يقدّم رسالة مفيدة للمستخدم إذا لم يتمكّن الذكاء الاصطناعي من العثور على أي نص في الصورة.
اختبار ميزة "قراءة النص" (التعرّف البصري على الأحرف)
اتّبِع الخطوات التالية لاختبار ميزة قراءة النص. احرص على توجيه الكاميرا إلى عنصر يتضمّن نصًا واضحًا.
- شغِّل التطبيق باستخدام
npm run devوافتحه في المتصفّح. - انقر على "بدء الاستماع" وامنح إذن الوصول إلى الميكروفون عندما يُطلب منك ذلك.
- فعِّل الكاميرا. قُل الأمر: "التقاط صورة". من المفترض أن يظهر بث الفيديو المباشر على الشاشة.
- التقِط الصورة. وجِّه الكاميرا نحو النص الذي تريد قراءته، ثم كرِّر الأمر: "التقط صورة". سيتم استبدال الفيديو بصورة ثابتة.
- اطلب النص. بعد التقاط الصورة، أعطِ الأمر النهائي: "ما هو النص في الصورة؟"
- التحقّق من النتيجة بعد لحظات، سيحلّل التطبيق الصورة ويقرأ النص الذي تم رصده بصوتٍ عالٍ. إذا لم يتمكّن من العثور على أي نص، سيُعلمك بذلك.
يؤكّد هذا الإجراء أنّ ميزة "التعرّف البصري على الأحرف" الفعّالة تعمل. عند الانتهاء، أوقِف الخادم باستخدام Ctrl + C.
8. التحسينات المتقدّمة المستندة إلى الذكاء الاصطناعي - للقراءة فقط ✨
يمكن لوكيل الذكاء الاصطناعي الجيد اتّباع التعليمات. يجب أن يكون وكيل الذكاء الاصطناعي الرائع سهل الاستخدام وجديرًا بالثقة ومفيدًا. في هذا القسم، سنركّز على ثلاثة تحسينات متقدّمة ترفع من قدرات وكيلنا.
سنستكشف كيفية:
Add Context & Memoryللتعامل مع المتابعات الطبيعية في المحادثاتReduce Hallucinationلبناء وكيل أكثر موثوقية وجديرًا بالثقة.Make the Agent Proactiveلتوفير تجربة أكثر سهولة في الاستخدام.Add preference settingلتخصيص وصف الصورة
التحسين 1: السياق والذاكرة
المحادثة الطبيعية ليست سلسلة من الطلبات المنفصلة، بل هي متواصلة. إذا سأل المستخدم: "ماذا يوجد في الصورة؟" وأجاب الوكيل: "سيارة حمراء"، قد يكون السؤال التالي الذي يطرحه المستخدم هو: "ما هو لونها؟" بدون أن يذكر كلمة "سيارة" مرة أخرى. يحتاج الوكيل إلى ذاكرة قصيرة المدى لفهم هذا السياق.
كيفية تنفيذ هذه الميزة (ملخّص)
لقد أضفنا هذه الإمكانية إلى مسار عمل ميزة "وصف الصورة". يتضمّن هذا القسم ملخّصًا لطريقة عمل هذا النمط. عندما نستدعي الدالة describeImage من ملف page.tsx، نمرّر إليها سجلّ المحادثات.
👉 Code Showcase (من page.tsx):
const result = await describeImage({
photoDataUri,
question: commandToProcess,
detailPreference: descriptionPreference,
previousUserQueryOnImage: lastUserQuery ?? undefined,
previousAIResponseOnImage: lastAIResponse ?? undefined,
});
previousUserQueryOnImageوpreviousAIResponseOnImage: هاتان السمتان تمثّلان الذاكرة القصيرة الأمد للوكيل. من خلال تمرير التفاعل الأخير إلى الذكاء الاصطناعي، نمنحه السياق اللازم لفهم أسئلة المتابعة الغامضة أو المرجعية.- الطلب التكيّفي: يستخدم الطلب هذا السياق في مسار describe_image. تم تصميم الطلب ليأخذ المحادثة السابقة في الاعتبار عند تكوين إجابة جديدة، ما يسمح للوكيل بالرد بذكاء.
التحسين 2: تقليل الهلوسة
تحدث "هلوسة" الذكاء الاصطناعي عندما يخترع حقائق أو يدّعي امتلاك قدرات لا يملكها. لكسب ثقة المستخدمين، من الضروري أن يعرف الوكيل حدوده وأن يتمكّن من رفض الطلبات غير المشمولة بنطاقه بطريقة سلسة.
كيفية تنفيذ هذه الميزة (ملخّص)
إنّ أكثر الطرق فعاليةً لمنع الهلوسة هي وضع حدود واضحة للنموذج. وقد حقّقنا ذلك عند إنشاء "مصنّف النوايا".
👉 Code Showcase (من مسار intent-classifier):
// Define Agent Capabilities and Limitations for the prompt
const AGENT_CAPABILITIES_AND_LIMITATIONS = `
**Core Capabilities (What the Agent CAN DO):**
* **Image Analysis:**
* DescribeImage: Provide a general description of the current image...
**Limitations (What the Agent CANNOT DO...):**
* Cannot generate or create new images.
* Cannot provide general knowledge or answer questions unrelated to the image...
* Cannot perform web searches.
`;
يعمل هذا الثابت كـ "وصف وظيفي" نقدّمه للذكاء الاصطناعي في طلب التصنيف.
- تحديد المصدر: من خلال إخبار الذكاء الاصطناعي بشكل صريح بما لا يمكنه فعله، نحدّد مصدره في الواقع. عندما يرى طلب بحث مثل "ما هي حالة الطقس؟"، يمكنه مطابقة هذا الطلب بثقة مع قائمة القيود وتصنيف الغرض على أنّه OutOfScopeRequest.
- بناء الثقة: الوكيل الذي يمكنه أن يقول بصدق "لا يمكنني المساعدة في ذلك" يكون أكثر جدارة بالثقة من الوكيل الذي يحاول التخمين ويخطئ. هذا مبدأ أساسي لتصميم ذكاء اصطناعي آمن وموثوق به. `
التحسين 3: إنشاء وكيل استباقي
بالنسبة إلى تطبيق يركّز على تسهيل الاستخدام، لا يمكننا الاعتماد على الإشارات المرئية. عندما يفعّل المستخدم وضع الاستماع، يحتاج إلى تأكيد فوري غير مرئي بأنّ الوكيل جاهز وينتظر تلقّي أمر. سنضيف الآن مقدمة استباقية لتقديم هذه الملاحظات المهمة.
الخطوة 1: إضافة حالة لتتبُّع الاستماع الأول
أولاً، نحتاج إلى طريقة لمعرفة ما إذا كانت هذه هي المرة الأولى التي يضغط فيها المستخدم على الزر "Start Listening" خلال جلسته.
👉 في ~/src/app/page.tsx، اطّلِع على متغيّر الحالة الجديد التالي بالقرب من أعلى مكوّن ClarityCam.
export default function ClarityCam() {
// ... other state variables
const [descriptionPreference, setDescriptionPreference] = useState<DescriptionPreference>("concise");
// Add this new line
const [isFirstListen, setIsFirstListen] = useState(true);
// ... rest of the component
}
لقد أضفنا متغيّر حالة جديدًا، وهو isFirstListen، وأعطيناه القيمة الأولية true. سنستخدم هذه العلامة لتفعيل رسالة الترحيب التي تُعرض لمرة واحدة.
الخطوة 2: تعديل الدالة toggleListening
الآن، لنعدّل الدالة التي تتعامل مع الميكروفون لتشغيل الترحيب.
👉 في ~/src/app/page.tsx، ابحث عن الدالة toggleListening واطّلِع على كتلة if التالية.
const toggleListening = useCallback(() => {
// ... existing logic to setup speech recognition
if (isListening || isAttemptingStart) {
// ... existing logic to stop listening
} else {
stopSpeaking(); // Stop any ongoing TTS
// Add this new block
if (isFirstListen) {
setIsFirstListen(false);
const introMessage = "Hello! I am ClarityCam, your AI assistant. I'm now listening. You can ask me to 'describe the image', 'read text', 'take a picture', or ask questions about what's in an image.";
speakText(introMessage);
} else {
speakText("Listening..."); // Optional: provide feedback on subsequent clicks
}
// ... rest of the logic to start listening
}
}, [/*...existing dependencies...*/, isFirstListen]); // Don't forget to add isFirstListen to the dependency array!
- التحقّق من العلامة: يتحقّق القسم if (isFirstListen) من ما إذا كان هذا هو التفعيل الأول.
- منع التكرار: أول ما يفعله داخل الكتلة هو استدعاء setIsFirstListen(false). يضمن ذلك عدم تشغيل الرسالة التمهيدية إلا مرة واحدة فقط في كل جلسة.
- تقديم إرشادات: تم تصميم introMessage بعناية ليكون مفيدًا قدر الإمكان. يرحّب بالضيف، ويحدّد اسم الوكيل، ويؤكّد أنّه نشط الآن ("أستمع إليك الآن")، ويقدّم أمثلة واضحة على الطلبات الصوتية التي يمكنه استخدامها.
- الملاحظات السمعية: أخيرًا، تقدّم الدالة speakText(introMessage) هذه المعلومات المهمة، ما يوفّر تأكيدًا وإرشادات فورية بدون أن يحتاج المستخدم إلى رؤية الشاشة.
التحسين 4: التكيّف مع الإعدادات المفضّلة للمستخدم (ملخّص)
لا يكتفي الوكيل الذكي بالرد على الطلبات، بل يتعلّم ويتكيّف مع احتياجات المستخدم. إحدى أقوى الميزات التي أنشأناها هي إمكانية تغيير مستوى الإسهاب في أوصاف الصور أثناء التنقل باستخدام أوامر مثل "أريد وصفًا أكثر تفصيلاً".
طريقة التنفيذ (ملخّص) تستند هذه الميزة إلى الطلب الديناميكي الذي أنشأناه لعملية describeImage. تستخدم هذه الميزة منطقًا شرطيًا لتغيير التعليمات المُرسَلة إلى الذكاء الاصطناعي استنادًا إلى إعدادات المستخدم المفضّلة.
👉 عرض الرمز (السمة promptTemplate من describe_image):
const settingPreferenceTemplate = `
{#if isDetailed}
Provide a very detailed and comprehensive description of the image. Focus on specifics, including subtle elements, spatial relationships, and textures if apparent.
{else}
Provide a concise description of the image. Focus on the main subject, key objects, and primary activities or context.
{/if}
Highlight the main objects, activities, and colors.
...
`;
- المنطق الشرطي: يشكّل البلوك
{#if isDetailed}...{else}...{/if}العنصر الأساسي. عندما تتلقّى describeImageFlow detailPreference من الواجهة الأمامية، تنشئ قيمة منطقية isDetailed (صحيح أو خطأ). - التعليمات التكيّفية: تحدّد علامة القيمة المنطقية هذه مجموعة التعليمات التي يتلقّاها نموذج الذكاء الاصطناعي. إذا كانت قيمة isDetailed هي "صحيح"، يتم توجيه النموذج لتقديم وصف تفصيلي. إذا كانت القيمة false، يجب أن تكون موجزة.
- تحكّم المستخدم: يربط هذا النمط مباشرةً بين الأمر الصوتي للمستخدم (مثل "اجعل الأوصاف موجزة"، والذي يتم تصنيفه على أنّه الغرض SetDescriptionConcise) والتغيير الأساسي في سلوك الذكاء الاصطناعي، ما يجعل الوكيل يبدو متجاوبًا ومخصّصًا.
9- النشر على السحابة الإلكترونية
إنشاء صورة Docker باستخدام Google Cloud Build
gcloud builds submit . --tag gcr.io/$PROJECT_ID/accessibilityai-nextjs-app:latest
-
accessibilityai-nextjs-appهو اسم مقترَح للصورة. - لا يمكن معالجة ملف .ZIP يستخدم الدليل الحالي (
accessibilityAI/) كمصدر للإنشاء.
نشر الصورة على Google Cloud Run
- تأكَّد من أنّ مفاتيح واجهة برمجة التطبيقات والأسرار الأخرى جاهزة في Secret Manager. مثلاً:
GOOGLE_GENAI_API_KEY
استبدِل YOUR_ACTUAL_GOOGLE_AI_KEY_VALUE بقيمة مفتاح Gemini API الفعلي.
echo "YOUR_ACTUAL_GOOGLE_AI_KEY_VALUE" | gcloud secrets create GOOGLE_GENAI_API_KEY --data-file=- --project=YOUR_PROJECT_ID
امنح حساب خدمة وقت التشغيل لخدمة Cloud Run (مثل PROJECT_NUMBER-compute@developer.gserviceaccount.com أو حساب مخصّص) دور "أداة الوصول إلى أسرار Secret Manager" لهذا السرّ.
- أمر النشر:
gcloud run deploy accessibilityai-app-service \
--image gcr.io/$PROJECT_ID/accessibilityai-nextjs-app:latest \
--platform managed \
--region us-central1 \
--allow-unauthenticated \
--port 3000 \
--set-secrets=GOOGLE_GENAI_API_KEY=GOOGLE_GENAI_API_KEY:latest \
--set-env-vars NODE_ENV="production"