
1. Einführung
In dieser Anleitung erstellen Sie ClarityCam, einen sprachgesteuerten KI-Agenten, der die Welt sehen und Ihnen erklären kann. ClarityCam wurde mit dem Fokus auf Barrierefreiheit entwickelt und ist ein leistungsstarkes Tool für blinde Nutzer und Nutzer mit eingeschränktem Sehvermögen. Die Prinzipien, die Sie in diesem Kurs kennenlernen, sind jedoch für die Entwicklung jeder modernen Sprachanwendung für allgemeine Zwecke unerlässlich.

Dieses Projekt basiert auf einer leistungsstarken Designphilosophie namens Natively Adaptive Interface (NAI). Bei NAI wird Barrierefreiheit nicht als nachträgliche Überlegung behandelt, sondern als Grundlage. Bei diesem Ansatz ist der KI-Agent die Schnittstelle. Er passt sich an verschiedene Nutzer an, verarbeitet multimodale Eingaben wie Sprache und Vision und gibt proaktiv Anleitungen basierend auf den individuellen Bedürfnissen der Nutzer.
Ersten KI-Agenten mit NAI erstellen:

Am Ende dieses Trainings können Sie:
- Barrierefreiheit als Standard festlegen: Wenden Sie die Prinzipien der nativ adaptiven Benutzeroberfläche (Natively Adaptive Interface, NAI) an, um KI-Systeme zu entwickeln, die allen Nutzern gleichwertige Funktionen bieten.
- Nutzerabsicht klassifizieren: Erstellen Sie einen robusten Intent-Klassifikator, der Befehle in natürlicher Sprache in strukturierte Aktionen für Ihren Agenten übersetzt.
- Konversationskontext beibehalten: Implementieren Sie ein Kurzzeitgedächtnis, damit Ihr Agent Folgefragen und referenzielle Befehle (z.B. „Welche Farbe hat es?“) verstehen kann.
- Effektive Prompts erstellen: Erstellen Sie fokussierte, kontextreiche Prompts für ein multimodales Modell wie Gemini, um eine genaue und zuverlässige Bildanalyse zu gewährleisten.
- Mehrdeutigkeiten behandeln und Nutzer anleiten: Entwickeln Sie eine elegante Fehlerbehandlung für Anfragen, die nicht abgedeckt werden, und führen Sie Nutzer proaktiv ein, um Vertrauen aufzubauen.
- Multi-Agenten-System orchestrieren: Strukturieren Sie Ihre Anwendung mit einer Sammlung spezialisierter Agents, die zusammenarbeiten, um komplexe Aufgaben wie Sprachverarbeitung, Analyse und Sprachsynthese zu erledigen.
2. High-Level-Design
ClarityCam ist für den Nutzer einfach zu bedienen, basiert aber auf einem ausgeklügelten System von zusammenarbeitenden KI-Agents. Sehen wir uns die Architektur genauer an.

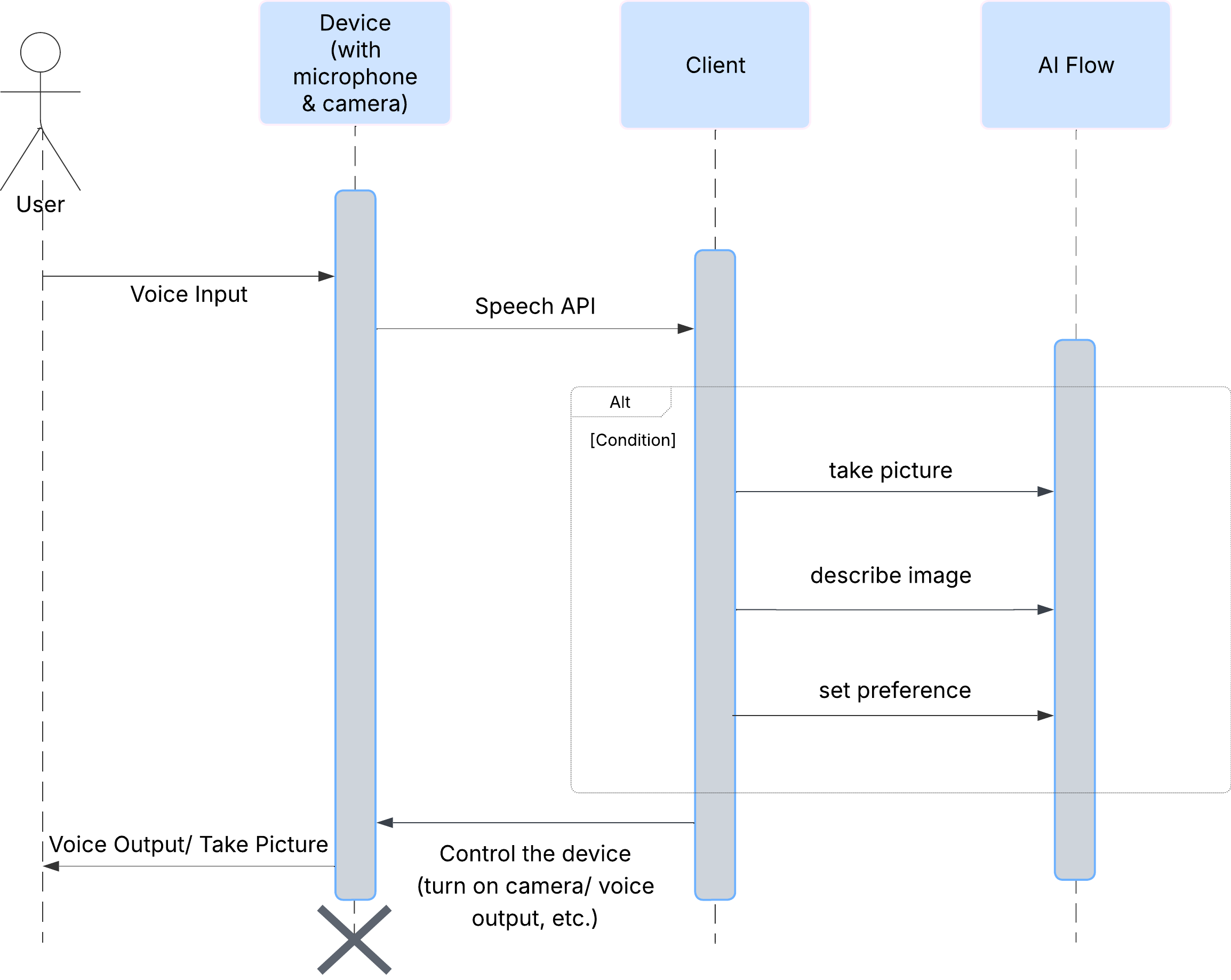
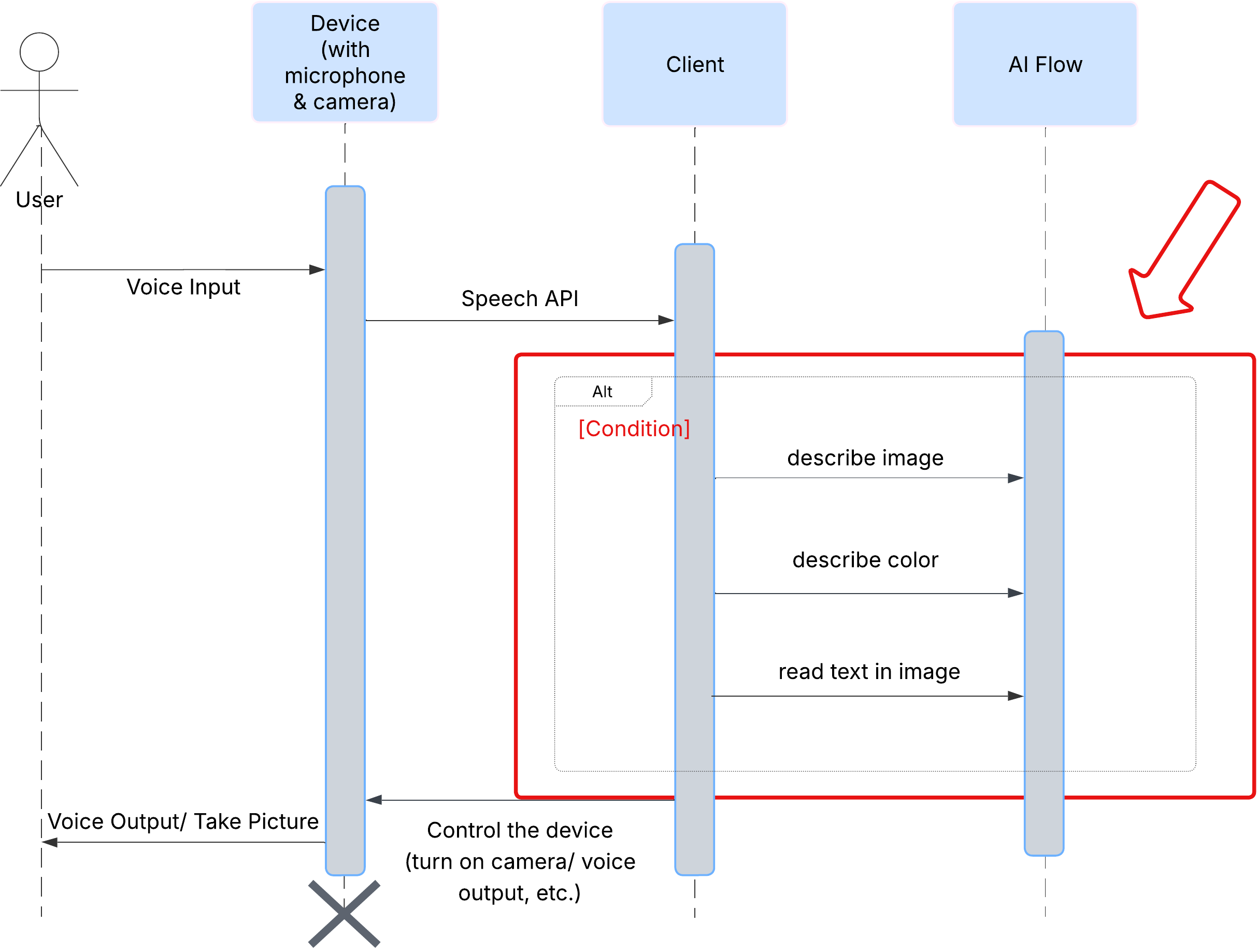
User Experience
Sehen wir uns zuerst an, wie ein Nutzer mit ClarityCam interagiert. Die gesamte Interaktion erfolgt per Sprachbefehl und im Konversationsmodus. Der Nutzer spricht einen Befehl und der Agent antwortet mit einer gesprochenen Beschreibung oder Aktion. Dieses Sequenzdiagramm zeigt einen typischen Interaktionsablauf vom ersten Sprachbefehl des Nutzers bis zur endgültigen Audioantwort des Geräts.
Die KI-Agentenarchitektur
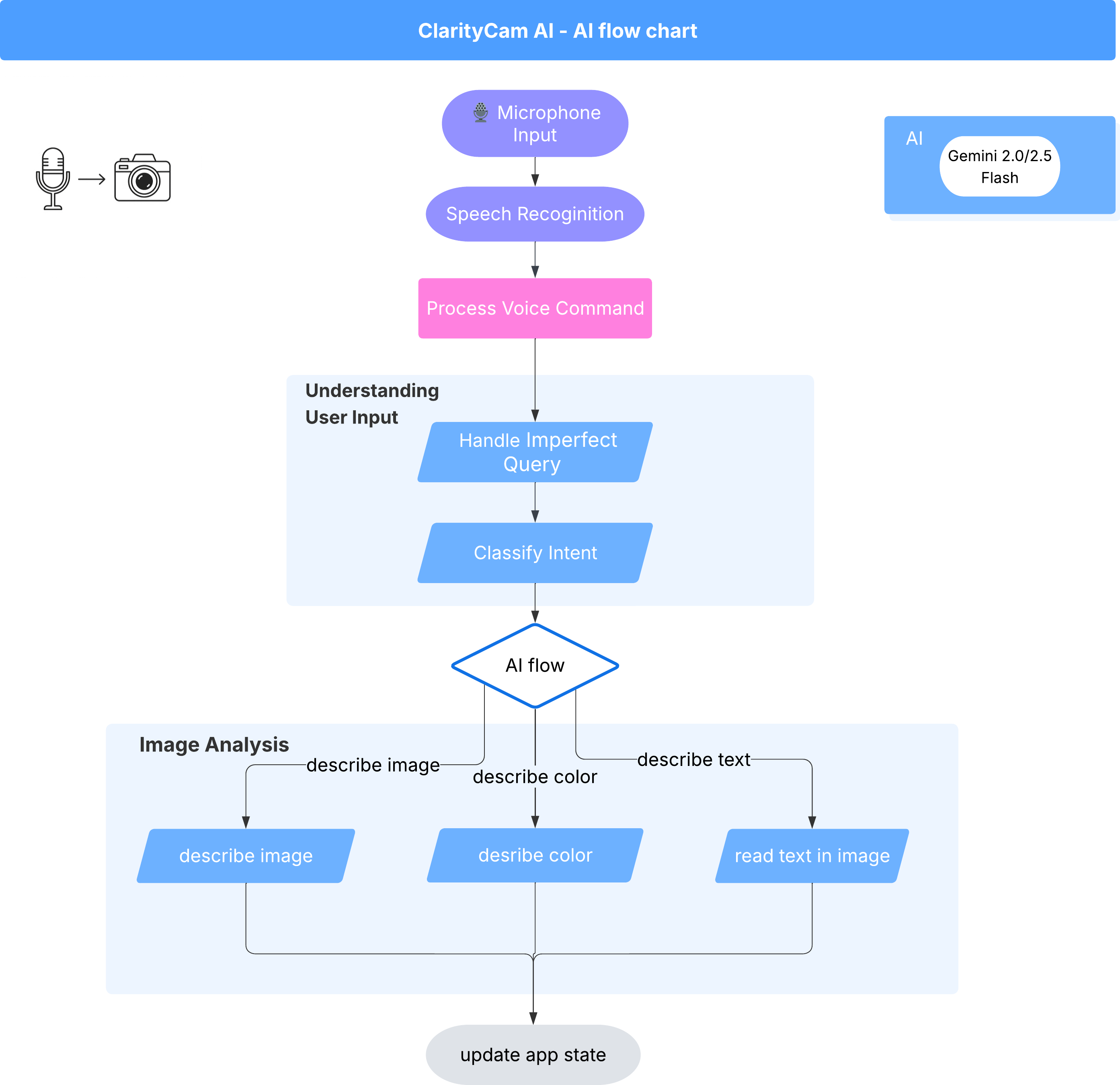
Im Hintergrund arbeitet ein Multi-Agent-System zusammen, um die Erfahrung zu ermöglichen. Wenn ein Befehl empfangen wird, delegiert ein zentraler Orchestrator-Agent Aufgaben an spezialisierte Agenten, die für das Erkennen von Intentionen, das Analysieren von Bildern und das Formulieren einer Antwort zuständig sind. Dieses KI-Ablaufdiagramm bietet einen detaillierten Einblick in die Zusammenarbeit dieser Agents. Wir werden diese Architektur in den folgenden Abschnitten implementieren.
Kurze Einführung in die Projektdateien
Bevor wir mit dem Schreiben von Code beginnen, sehen wir uns die Dateistruktur unseres Projekts an. Es sieht vielleicht so aus, als gäbe es viele Dateien, aber für diese Anleitung müssen Sie sich nur auf zwei bestimmte Bereiche konzentrieren.
Hier ist eine vereinfachte Karte unseres Projekts.
accessibilityAI/src/
├── 📁 app/
│ ├── layout.tsx # An overall page shell (you can ignore this).
│ └── page.tsx # ⬅️ MODIFY THIS: The main user interface for our app.
│
├── 📁 ai/
│ ├── 📁flows # ⬅️ MODIFY THIS: The core AI logic and server functions.
│ └── intent-classifier.ts # ⬅️ MODIFY THIS: Where we'll edit our AI prompts.
| └── ai-instance.ts
| └── dev.ts
│
├── 📁 components/ # Contains pre-built UI components (ignore this).
│
├── 📁 hooks/
│
├── 📁 lib/
│
└── 📁 types/
Der Technologie-Stack
Unser System basiert auf einem modernen, skalierbaren Technologie-Stack, der leistungsstarke Cloud-Dienste und hochmoderne KI-Modelle kombiniert. Das sind die wichtigsten Komponenten, die wir verwenden werden:
- Google Cloud Platform (GCP): Bietet die serverlose Infrastruktur für unsere Agents.
- Cloud Run: Stellt unsere einzelnen Agents als containerisierte, skalierbare Mikrodienste bereit.
- Artifact Registry: Hier werden die Docker-Images für unsere Agents sicher gespeichert und verwaltet.
- Secret Manager: Verarbeitet sensible Anmeldedaten und API-Schlüssel sicher.
- Large Language Models (LLMs): Sie fungieren als „Gehirn“ des Systems.
- Gemini-Modelle von Google: Wir nutzen die leistungsstarken multimodalen Funktionen der Gemini-Familie für alles, von der Klassifizierung der Nutzerabsicht bis hin zur Analyse von Bildinhalten und der Bereitstellung intelligenter Beschreibungen.
3. Einrichtung und Voraussetzungen
Rechnungskonto aktivieren: Für dieses Codelab benötigen Sie ein Rechnungskonto mit Guthaben. Verwenden Sie die Guthabenpunkte aus dem Banner oben in diesem Codelab, um loszulegen. Wenn Sie bereits mit einem Rechnungskonto verbunden sind, können Sie diesen Schritt überspringen.
Neues GCP-Projekt erstellen
- Rufen Sie die Google Cloud Console auf und erstellen Sie ein neues Projekt.
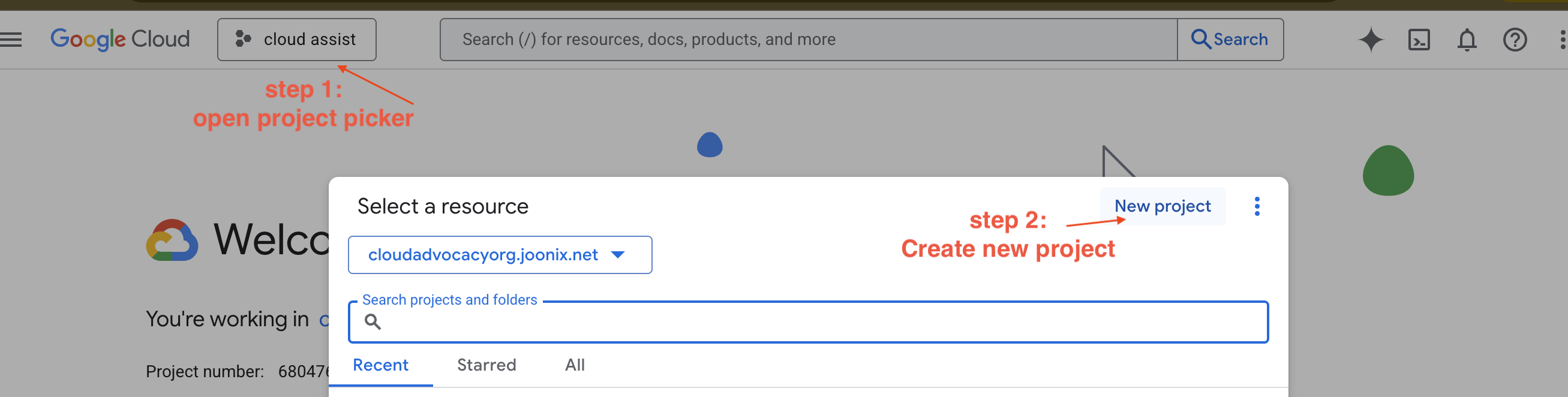
- Rufen Sie die Google Cloud Console auf und erstellen Sie ein neues Projekt.
- Öffnen Sie den linken Bereich, klicken Sie auf
Billingund prüfen Sie, ob das Rechnungskonto mit diesem GCP-Konto verknüpft ist.
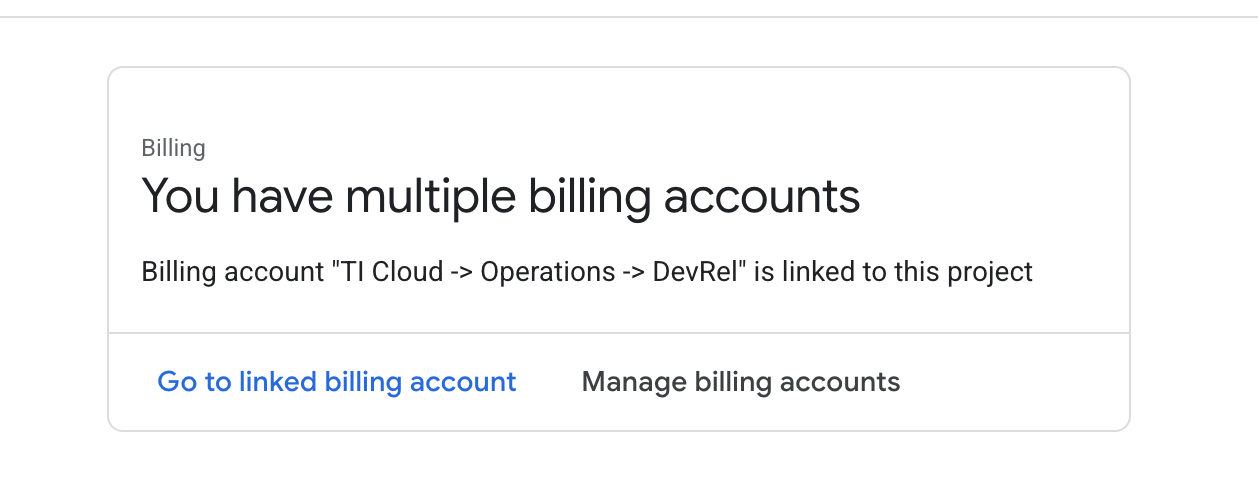
Wenn Sie diese Seite sehen, prüfen Sie das manage billing account, wählen Sie das Google Cloud-Probeabo aus und verknüpfen Sie es.
Gemini API-Schlüssel erstellen
Bevor Sie den Schlüssel sichern können, müssen Sie einen haben.
- Rufen Sie Google AI Studio auf : https://aistudio.google.com/.
- Melde dich mit deinem Google-Konto an.
- Klicken Sie auf die Schaltfläche API-Schlüssel abrufen, die sich normalerweise im linken Navigationsbereich oder oben rechts befindet.
- Klicken Sie im Dialogfeld API-Schlüssel auf „API-Schlüssel in neuem Projekt erstellen“.
- Ein neuer API-Schlüssel wird für Sie generiert. Kopieren Sie diesen Schlüssel sofort und speichern Sie ihn vorübergehend an einem sicheren Ort, z. B. in einem Passwortmanager oder einer sicheren Notiz. Diesen Wert benötigen Sie in den nächsten Schritten.
Workflow für die lokale Entwicklung (auf dem eigenen Computer testen)
Sie müssen npm run dev ausführen können und Ihre App muss funktionieren. Hier kommt .env ins Spiel.
- Fügen Sie den API-Schlüssel in die Datei ein: Erstellen Sie eine neue Datei mit dem Namen
.envund fügen Sie die folgende Zeile in diese Datei ein.
Achten Sie darauf, dass Sie YOUR_API_KEY_HERE durch den Schlüssel ersetzen, den Sie von AI Studio erhalten und in .env gespeichert haben:
GOOGLE_GENAI_API_KEY="YOUR_API_KEY_HERE"
[Optional] IDE und Umgebung einrichten
In dieser Anleitung können Sie in einer vertrauten Entwicklungsumgebung wie VS Code oder IntelliJ mit Ihrem lokalen Terminal arbeiten. Wir empfehlen jedoch dringend, Google Cloud Shell zu verwenden, um eine standardisierte, vorkonfigurierte Umgebung zu gewährleisten.
Die folgenden Schritte sind für den Cloud Shell-Kontext geschrieben. Wenn Sie stattdessen Ihre lokale Umgebung verwenden möchten, müssen git, nvm, npm und gcloud installiert und richtig konfiguriert sein.
Mit dem Cloud Shell-Editor arbeiten
👉 Klicken Sie oben in der Google Cloud Console auf Cloud Shell aktivieren (das Terminalsymbol oben im Cloud Shell-Bereich),  .
.
👉 Klicken Sie auf die Schaltfläche Editor öffnen (sie sieht aus wie ein geöffneter Ordner mit einem Stift). Dadurch wird der Cloud Shell-Code-Editor im Fenster geöffnet. Auf der linken Seite wird ein Datei-Explorer angezeigt. 
👉 Klicken Sie in der unteren Statusleiste auf den Button Cloud Code-Anmeldung, wie dargestellt. Autorisieren Sie das Plug-in wie beschrieben. Wenn in der Statusleiste Cloud Code – kein Projekt angezeigt wird, wählen Sie diese Option im Drop-down-Menü „Google Cloud-Projekt auswählen“ aus und wählen Sie dann das gewünschte Google Cloud-Projekt aus der Liste der Projekte aus, die Sie erstellt haben. 
👉 Öffnen Sie das Terminal in der Cloud-IDE  .
.
👉 Prüfen Sie im Terminal mit dem folgenden Befehl, ob Sie bereits authentifiziert sind und das Projekt auf Ihre Projekt-ID festgelegt ist:
gcloud auth list
👉 Klonen Sie das natively-accessible-interface-Projekt aus GitHub:
git clone https://github.com/cuppibla/AccessibilityAgent.git
👉 Ersetzen Sie <YOUR_PROJECT_ID> durch Ihre Projekt-ID. Sie finden Ihre Projekt-ID in der Google Cloud Console im Projektbereich. ❗️❗️Achten Sie darauf, project id und project number nicht zu verwechseln.❗️❗️
echo <YOUR_PROJECT_ID> > ~/project_id.txt
gcloud config set project $(cat ~/project_id.txt)
👉 Führen Sie den folgenden Befehl aus, um die erforderlichen Google Cloud APIs zu aktivieren. Das kann etwa 2 Minuten dauern.
gcloud services enable compute.googleapis.com \
storage.googleapis.com \
run.googleapis.com \
artifactregistry.googleapis.com \
aiplatform.googleapis.com \
eventarc.googleapis.com \
sqladmin.googleapis.com \
secretmanager.googleapis.com \
cloudbuild.googleapis.com \
cloudresourcemanager.googleapis.com \
cloudfunctions.googleapis.com \
cloudaicompanion.googleapis.com
Das kann einige Minuten dauern.
Berechtigung einrichten
👉 Dienstkontoberechtigungen einrichten Führen Sie im Terminal folgenden Befehl aus :
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
export SERVICE_ACCOUNT_NAME=$(gcloud compute project-info describe --format="value(defaultServiceAccount)")
echo "Here's your SERVICE_ACCOUNT_NAME $SERVICE_ACCOUNT_NAME"
👉 Berechtigungen erteilen Führen Sie im Terminal folgenden Befehl aus :
#Cloud Storage (Read/Write):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/storage.objectAdmin"
#Pub/Sub (Publish/Receive):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/pubsub.publisher"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/pubsub.subscriber"
#Cloud SQL (Read/Write):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/cloudsql.editor"
#Eventarc (Receive Events):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/iam.serviceAccountTokenCreator"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/eventarc.eventReceiver"
#Vertex AI (User):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/aiplatform.user"
#Secret Manager (Read):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/secretmanager.secretAccessor"
4. Nutzeranfragen verstehen – Intention klassifizieren
Bevor unser KI-Agent aktiv werden kann, muss er erst genau verstehen, was der Nutzer möchte. Eingaben aus der Praxis sind oft unstrukturiert. Sie können vage sein, Tippfehler enthalten oder in Umgangssprache formuliert sein.
In diesem Abschnitt erstellen wir die wichtigen „Zuhör“-Komponenten, die rohe Nutzereingaben in einen klaren, umsetzbaren Befehl umwandeln.
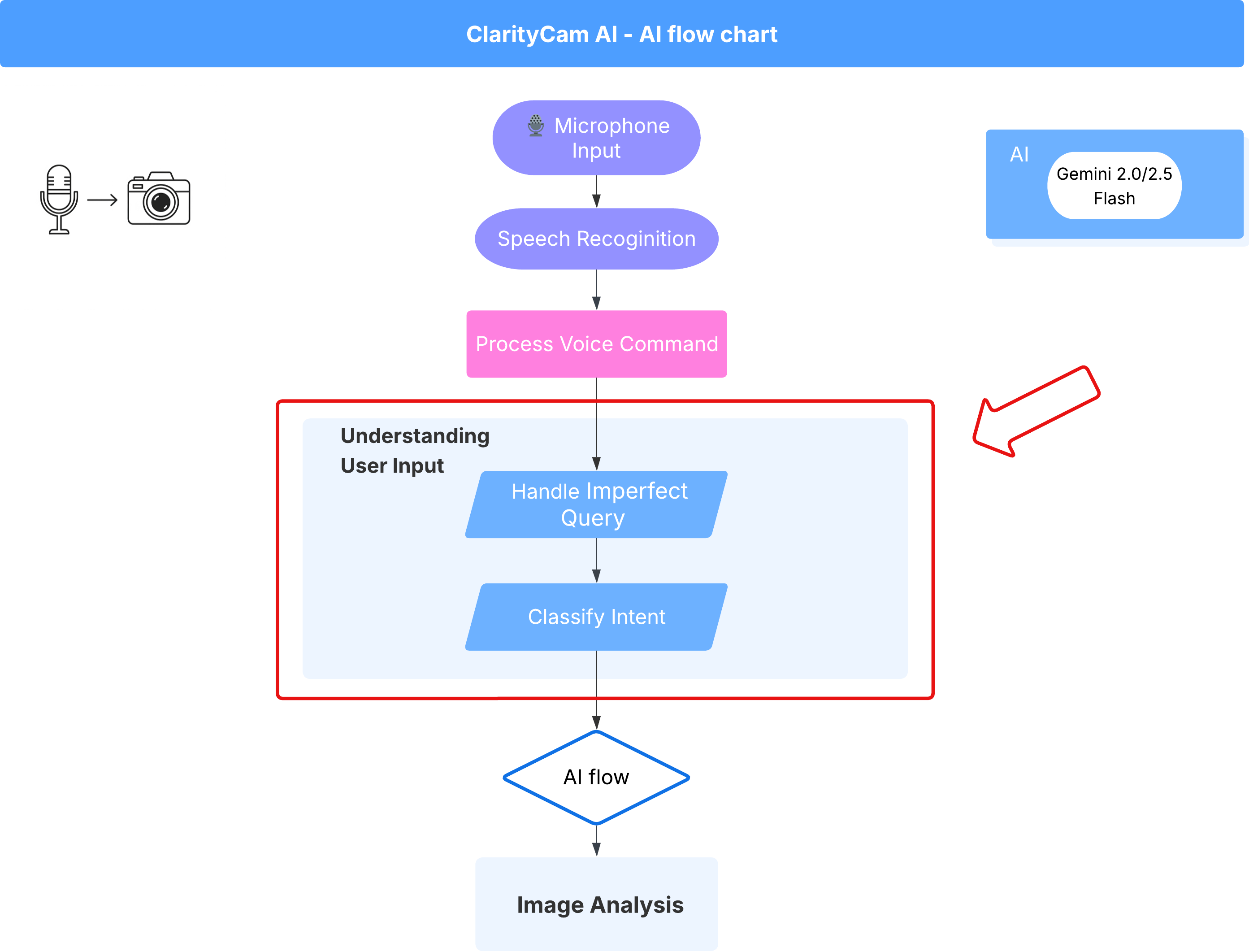
Intent Classifier hinzufügen
Als Nächstes definieren wir die KI-Logik, die unserem Classifier zugrunde liegt.
👉 Aktion: Öffnen Sie in Ihrer Cloud Shell IDE das Verzeichnis ~/src/ai/intent-classifier/.
Schritt 1: Wortschatz des KI-Agenten definieren (IntentCategory)
Zuerst müssen wir eine endgültige Liste aller möglichen Aktionen erstellen, die unser Agent ausführen kann.
👉 Aktion: Ersetzen Sie den Platzhalter // REPLACE ME PART 1: add IntentCategory here durch den folgenden Code:
👉 mit dem folgenden Code:
export type IntentCategory =
// Image Analysis Intents
| "DescribeImage"
| "AskAboutImage"
| "ReadTextInImage"
| "IdentifyColorsInImage"
// Control Intents
| "TakePicture"
| "StartCamera"
| "SelectImage"
| "StopSpeaking"
// Preference Intents
| "SetDescriptionDetailed"
| "SetDescriptionConcise"
// Fallback Intents
| "GeneralInquiry" // User has a general question about the agent's functions or polite interaction
| "OutOfScopeRequest" // User's request is clearly outside the agent's defined capabilities
| "Unknown"; // Intent could not be determined with confidence
Erklärung
Mit diesem TypeScript-Code wird ein benutzerdefinierter Typ namens „IntentCategory“ erstellt. Es ist eine strikte Liste, in der jede mögliche Aktion oder jeder „Intent“ definiert ist, die unser Agent verstehen kann. Das ist ein wichtiger erster Schritt, da eine potenziell unendliche Anzahl von Nutzerformulierungen („Erzähl mir, was du siehst“, „Was ist auf dem Bild?“) in eine übersichtliche, vorhersagbare Menge von Befehlen umgewandelt wird. Unser Ziel ist es, jede Nutzeranfrage einer dieser spezifischen Kategorien zuzuordnen.
Schritt 2
Damit unsere KI fundierte Entscheidungen treffen kann, muss sie ihre eigenen Fähigkeiten und Einschränkungen kennen. Wir stellen diese Informationen als detaillierten Textblock zur Verfügung.
👉 Aktion: Ersetzen Sie den Platzhalter REPLACE ME PART 2: add AGENT_CAPABILITIES_AND_LIMITATIONS here durch den folgenden Code:
Ersetzen Sie den folgenden Code: // REPLACE ME PART 2: add AGENT_CAPABILITIES_AND_LIMITATIONS here:
👉 mit dem Code unten
const AGENT_CAPABILITIES_AND_LIMITATIONS = `
**Core Capabilities (What the Agent CAN DO):**
* **Image Analysis:**
* DescribeImage: Provide a general description of the current image.
* AskAboutImage: Answer a specific question about the visual content of the current image (e.g., "Is there a dog?", "What color is the car?").
* ReadTextInImage: Read any text found in the current image.
* IdentifyColorsInImage: Identify the dominant colors of the current image.
* **Image Input Control:**
* TakePicture: Capture an image using the currently active camera stream.
* StartCamera: Activate the camera (e.g., "use camera", "take another picture").
* SelectImage: Allow the user to choose an image file from their device.
* **Voice & Audio Control:**
* StopSpeaking: Stop the current text-to-speech output.
* **Preference Management:**
* SetDescriptionDetailed: Make future image descriptions more detailed.
* SetDescriptionConcise: Make future image descriptions less detailed or concise.
* **General Interaction:**
* GeneralInquiry: Handle conversational phrases (e.g., "hello", "thank you") or questions about its own capabilities (e.g., "what can you do?", "help").
**Limitations (What the Agent CANNOT DO and should be classified as OutOfScopeRequest):**
* Cannot generate or create new images.
* Cannot edit or modify existing images (e.g., "remove background," "make the car blue").
* Cannot analyze video files or live video beyond capturing a single frame.
* Cannot provide general knowledge or answer questions unrelated to the provided image's visual content (e.g., "What's the weather?", "Who is the president?", "Tell me a joke", "What time is it?").
* Cannot perform mathematical calculations or complex data analysis.
* Cannot translate languages as a primary function.
* Cannot remember information from past images or vastly different previous queries in the same session.
* Cannot control other device settings or applications.
* Cannot perform web searches.
`;
Warum ist das wichtig?
Dieser Text ist nicht für den Nutzer, sondern für unser KI-Modell. Wir geben diese „Stellenbeschreibung“ direkt in unseren Prompt ein (im nächsten Schritt), damit das Sprachmodell (LLM) den Kontext erhält, den es für fundierte Entscheidungen benötigt. Ohne diesen Kontext könnte das LLM „Wie ist das Wetter?“ fälschlicherweise als „AskAboutImage“ klassifizieren. Mit diesem Kontext weiß die KI, dass das Wetter kein visuelles Element im Bild ist, und klassifiziert es korrekt als nicht relevant.
Schritt 3
Jetzt schreiben wir die vollständigen Anweisungen, die das Gemini-Modell befolgen wird, um die Klassifizierung durchzuführen.
👉 Aktion: Ersetzen Sie // REPLACE ME PART 3 - classifyIntentPrompt durch den folgenden Code:
mit dem folgenden Code
const classifyIntentPrompt = ai.definePrompt({
name: 'classifyIntentPrompt',
input: { schema: ClassifyIntentInputSchema },
output: { schema: ClassifyIntentOutputSchema },
prompt: `You are classifying the user's intent for ClarityCam, a voice-controlled AI application focused on image analysis.
Analyze the user query: '{userQuery}'.
First, understand ClarityCam's capabilities and limitations:
${AGENT_CAPABILITIES_AND_LIMITATIONS}
Now, classify the user's PRIMARY intent into ONE of the following categories:
* **DescribeImage**: User wants a general description of the current image.
* **AskAboutImage**: User is asking a specific question directly related to the visual content of the current image.
* **ReadTextInImage**: User wants any text read from the current image.
* **IdentifyColorsInImage**: User wants the dominant colors of the current image.
* **TakePicture**: User wants to capture an image using an active camera.
* **StartCamera**: User wants to activate the camera.
* **SelectImage**: User wants to choose an image file.
* **StopSpeaking**: User wants the current text-to-speech output to stop.
* **SetDescriptionDetailed**: User wants future image descriptions to be more detailed.
* **SetDescriptionConcise**: User wants future image descriptions to be less detailed.
* **GeneralInquiry**: The query is a simple conversational filler (e.g., "hello", "thanks"), a polite closing, or a direct question about the agent's functions (e.g., "what can you do?", "how does this work?", "help").
* **OutOfScopeRequest**: The query asks the agent to perform an action clearly listed under its "Limitations" or otherwise demonstrably outside its defined image analysis and control functions. Examples: "Tell me a joke," "What's the weather in London?", "Generate an image of a cat," "Can you edit my photo to make it brighter?", "Send this image to my friends","Translate 'hello' to Spanish."
Output ONLY the category name.
If the query is ambiguous but seems generally related to polite interaction or asking about the agent itself, prefer 'GeneralInquiry'.
If the query is clearly asking for something the agent CANNOT do, use 'OutOfScopeRequest'.
If truly unclassifiable even with these guidelines, use 'Unknown'.`,
config: {
temperature: 0.05, // Very low temperature for highly deterministic classification
}
});
Dieser Prompt ist der Schlüssel zum Erfolg. Er ist das „Gehirn“ unseres Klassifikators, das der KI ihre Rolle zuweist, den erforderlichen Kontext bereitstellt und die gewünschte Ausgabe definiert. Hier einige wichtige Prompt-Engineering-Techniken:
- Rollenspiel: Es beginnt mit „Du klassifizierst…“, um eine klare Aufgabe zu formulieren.
- Kontexteinfügung: Die Variable
AGENT_CAPABILITIES_AND_LIMITATIONSwird dynamisch in den Prompt eingefügt. - Strikte Ausgabeformatierung: Die Anweisung „Gib NUR den Kategorienamen aus“ ist entscheidend, um eine saubere, vorhersagbare Antwort zu erhalten, die wir problemlos in unserem Code verwenden können.
- Niedrige Temperatur: Bei der Klassifizierung sind deterministische, logische Antworten erwünscht, keine kreativen. Wenn Sie die Temperatur auf einen sehr niedrigen Wert (0,05) einstellen, ist das Modell sehr fokussiert und konsistent.
Schritt 4: App mit dem KI-Ablauf verbinden
Rufen wir nun unseren neuen KI-Klassifikator aus der Hauptanwendungsdatei auf.
👉 Aktion: Rufen Sie Ihre Datei ~/src/app/page.tsx auf. Ersetzen Sie in der Funktion „processVoiceCommand“ // REPLACE ME PART 1: add classificationResult durch Folgendes:
const classificationResult = await classifyIntentFlow({ userQuery: commandToProcess });
intent = classificationResult.intent as IntentCategory;
Dieser Code ist die entscheidende Brücke zwischen Ihrer Frontend-Anwendung und Ihrer Backend-KI-Logik. Es nimmt den Sprachbefehl des Nutzers (commandToProcess) entgegen, sendet ihn an die classifyIntentFlow, die Sie gerade erstellt haben, und wartet darauf, dass die KI den klassifizierten Intent zurückgibt.
Die Intent-Variable enthält jetzt einen bereinigten, strukturierten Befehl (z. B. „DescribeImage“). Dieses Ergebnis wird in der folgenden Switch-Anweisung verwendet, um die Logik der Anwendung zu steuern und zu entscheiden, welche Aktion als Nächstes ausgeführt werden soll. So wird das „Denken“ der KI in das „Handeln“ der App umgewandelt.
Benutzeroberfläche starten
Jetzt ist es an der Zeit, unsere Anwendung in Aktion zu sehen. Starten wir den Entwicklungsserver.
👉 Führen Sie im Terminal den folgenden Befehl aus: npm run dev Hinweis: Möglicherweise müssen Sie npm install ausführen, bevor Sie npm run dev ausführen.
Nach kurzer Zeit wird eine Ausgabe ähnlich der folgenden angezeigt. Das bedeutet, dass der Server erfolgreich ausgeführt wird:
▲ Next.js 15.2.3 (Turbopack)
- Local: http://localhost:9003
- Network: http://10.88.0.4:9003
- Environments: .env
✓ Starting...
✓ Ready in 1512ms
○ Compiling / ...
✓ Compiled / in 26.6s
Klicken Sie nun auf die lokale URL (http://localhost:9003), um die Anwendung in Ihrem Browser zu öffnen.
Sie sollten jetzt die SightGuide-Benutzeroberfläche sehen. Die Schaltflächen sind noch nicht mit einer Logik verknüpft. Wenn Sie darauf klicken, passiert also nichts. Genau das erwarten wir in dieser Phase. Im nächsten Abschnitt werden wir sie zum Leben erwecken.
Nachdem Sie sich die Benutzeroberfläche angesehen haben, kehren Sie zum Terminal zurück und drücken Sie Ctrl + C, um den Entwicklungsserver zu beenden, bevor wir fortfahren.
5. Nutzereingabe verstehen – Überprüfung unvollkommener Anfragen
Prüfung auf unvollkommene Suchanfragen hinzufügen
Teil 1: Prompt definieren (das „Was“)
Zuerst definieren wir die Anweisungen für unsere KI. Der Prompt ist das „Rezept“ für unseren KI-Aufruf. Er teilt dem Modell genau mit, was wir von ihm erwarten.
👉 Aktion: Rufen Sie in Ihrer IDE ~/src/ai/flows/check_typo/ auf.
Ersetzen Sie den folgenden Code: // REPLACE ME PART 1: add prompt here:
👉 mit dem Code unten
const prompt = ai.definePrompt({
name: 'checkTypoPrompt',
input: {
schema: CheckTypoInputSchema,
},
output: {
schema: CheckTypoOutputSchema,
},
prompt: `You are a helpful AI assistant that checks user text for typos and suggests corrections.
- If you find typos, respond with the corrected text.
- If there are no typos, or if you are unsure about a correction, respond with the original text unchanged.
User text: {text}
Corrected text:
`,
});
Dieser Codeblock definiert eine wiederverwendbare Vorlage für unsere KI namens checkTypoPrompt. Die Ein- und Ausgabeschemas definieren den Datenvertrag für diese Aufgabe. So werden Fehler vermieden und unser System wird berechenbar.
Teil 2: Ablauf erstellen (das „Wie“)
Nachdem wir unser „Rezept“ (den Prompt) haben, müssen wir eine Funktion erstellen, die es tatsächlich ausführen kann. In Genkit wird dies als Flow bezeichnet. In einem Flow wird unser Prompt in eine ausführbare Funktion eingebunden, die vom Rest unserer Anwendung einfach aufgerufen werden kann.
👉 Aktion: Ersetzen Sie in derselben Datei ~/src/ai/flows/check_typo/ den folgenden Code: // REPLACE ME PART 2: add flow here:
👉 mit dem Code unten
const checkTypoFlow = ai.defineFlow<
typeof CheckTypoInputSchema,
typeof CheckTypoOutputSchema
>(
{
name: 'checkTypoFlow',
inputSchema: CheckTypoInputSchema,
outputSchema: CheckTypoOutputSchema,
},
async input => {
const {output} = await prompt(input);
return output!;
}
);
Teil 3: Rechtschreibprüfung verwenden
Nachdem wir den KI-Ablauf fertiggestellt haben, können wir ihn jetzt in die Hauptlogik unserer Anwendung einbinden. Wir rufen sie direkt nach Erhalt des Nutzerbefehls auf, um sicherzustellen, dass der Text vor der weiteren Verarbeitung bereinigt wird.
👉Aktion:Rufen Sie ~/src/app/ai/flows/check-typo.ts auf und suchen Sie nach der Funktion export async function checkTypo. Entfernen Sie die Kommentare aus der return-Anweisung:
Statt return; Do return checkTypoFlow(input);
👉Aktion:Rufen Sie ~/src/app/page.tsx auf und suchen Sie nach der Funktion processVoiceCommand. Ersetzen Sie den folgenden Code: REPLACE ME PART 2: add typoResult here:
👉 mit dem Code unten
const typoResult = await checkTypo({ text: rawCommand });
if (typoResult && typoResult.correctedText && typoResult.correctedText.trim().length > 0) {
const originalTrimmedLower = rawCommand.trim().toLowerCase();
const correctedTrimmedLower = typoResult.correctedText.trim().toLowerCase();
if (correctedTrimmedLower !== originalTrimmedLower) {
commandToProcess = typoResult.correctedText;
typoCorrectionAnnouncement = `I think you said: ${commandToProcess}. `;
}
}
Mit dieser Änderung haben wir eine robustere Datenverarbeitungs-Pipeline für jeden Nutzerbefehl erstellt.
Ablauf von Sprachbefehlen (nur lesen, keine Maßnahmen erforderlich)
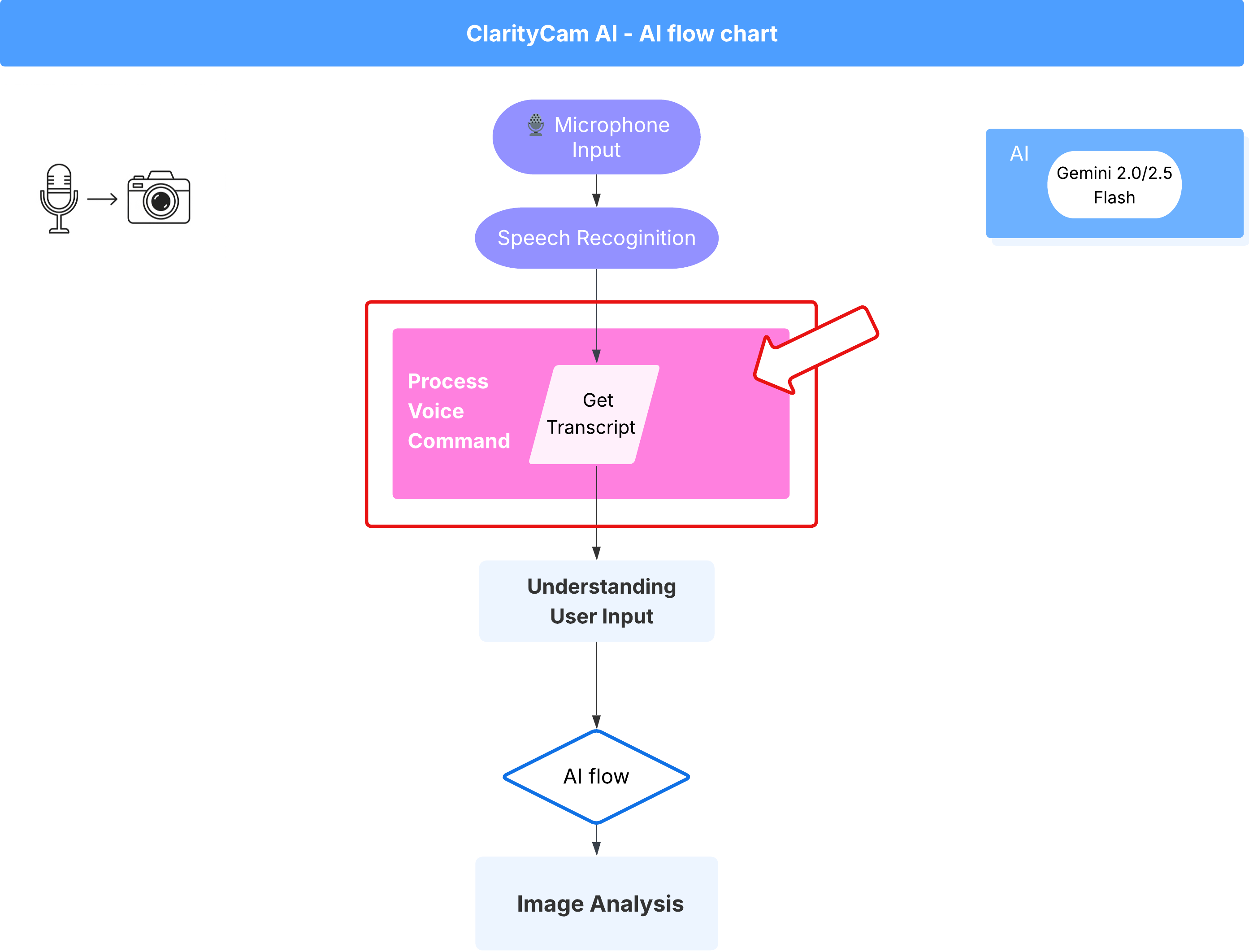
Nachdem wir nun die wichtigsten Komponenten für das „Verstehen“ (Rechtschreibprüfung und Intent-Klassifizierung) kennengelernt haben, sehen wir uns an, wie sie in die Hauptlogik der Sprachverarbeitung der Anwendung passen.
Alles beginnt, wenn der Nutzer spricht. Die Web Speech API des Browsers hört auf Sprache und stellt, sobald der Nutzer aufgehört hat zu sprechen, ein Texttranskript des Gehörten bereit. Der folgende Code übernimmt diesen Vorgang.
👉 Nur lesen:Rufen Sie ~/src/app/page.tsx und die Funktion handleResult auf. Suchen Sie den folgenden Code:
for (let i = event.resultIndex; i < event.results.length; ++i) {
if (event.results[i].isFinal) {
finalTranscript += event.results[i][0].transcript;
}
}
if (finalTranscript) {
console.log("Final Transcript:", finalTranscript);
processVoiceCommand(finalTranscript);
}
Rechtschreibkorrektur auf die Probe stellen
Jetzt kommen wir zur Darstellung der Ergebnisse in einer Präsentation. Sehen wir uns an, wie unsere neue Funktion zur Korrektur von Tippfehlern sowohl perfekte als auch unvollkommene Sprachbefehle verarbeitet.
Anwendung starten
Zuerst müssen wir den Entwicklungsserver wieder zum Laufen bringen. Führen Sie im Terminal folgenden Befehl aus: npm run dev
App öffnen
Wenn der Server bereit ist, öffnen Sie Ihren Browser und rufen Sie die lokale Adresse auf (z.B. http://localhost:9003).
Sprachbefehle aktivieren
Klicken Sie auf Start Listening. Ihr Browser wird Sie wahrscheinlich um die Berechtigung zur Verwendung Ihres Mikrofons bitten. Klicken Sie auf „Zulassen“.
Unvollkommenen Befehl testen
Jetzt geben wir der KI absichtlich einen etwas fehlerhaften Befehl, um zu sehen, ob sie ihn korrigieren kann. Deutlich ins Mikrofon sprechen:
„Picture take of me“ (Mach ein Foto von mir)
Ergebnis beobachten
Es sind noch keine Tests verfügbar. Auch wenn Sie „Mach ein Foto von mir“ gesagt haben, sollte die Kamera durch die Anwendung korrekt aktiviert werden. Im checkTypo-Ablauf wird Ihr Satz im Hintergrund in „take a picture“ (Foto aufnehmen) korrigiert und der classifyIntent-Ablauf versteht dann den korrigierten Befehl.
Das bestätigt, dass unsere Funktion zur Korrektur von Tippfehlern einwandfrei funktioniert und die App dadurch viel robuster und nutzerfreundlicher ist. Wenn Sie fertig sind, können Sie die Kamera stoppen, indem Sie ein Foto aufnehmen oder den Server einfach in Ihrem Terminal beenden (Ctrl + C).
6. KI-basierte Bildanalyse – „Bild beschreiben“
Nachdem unser Agent Anfragen verstehen kann, ist es an der Zeit, ihm Augen zu geben. In diesem Abschnitt erweitern wir die Funktionen unseres Vision Agent, der für die gesamte Bildanalyse zuständig ist. Wir beginnen mit der wichtigsten Funktion, nämlich der Beschreibung von Bildern, und fügen dann die Möglichkeit hinzu, Text zu lesen.
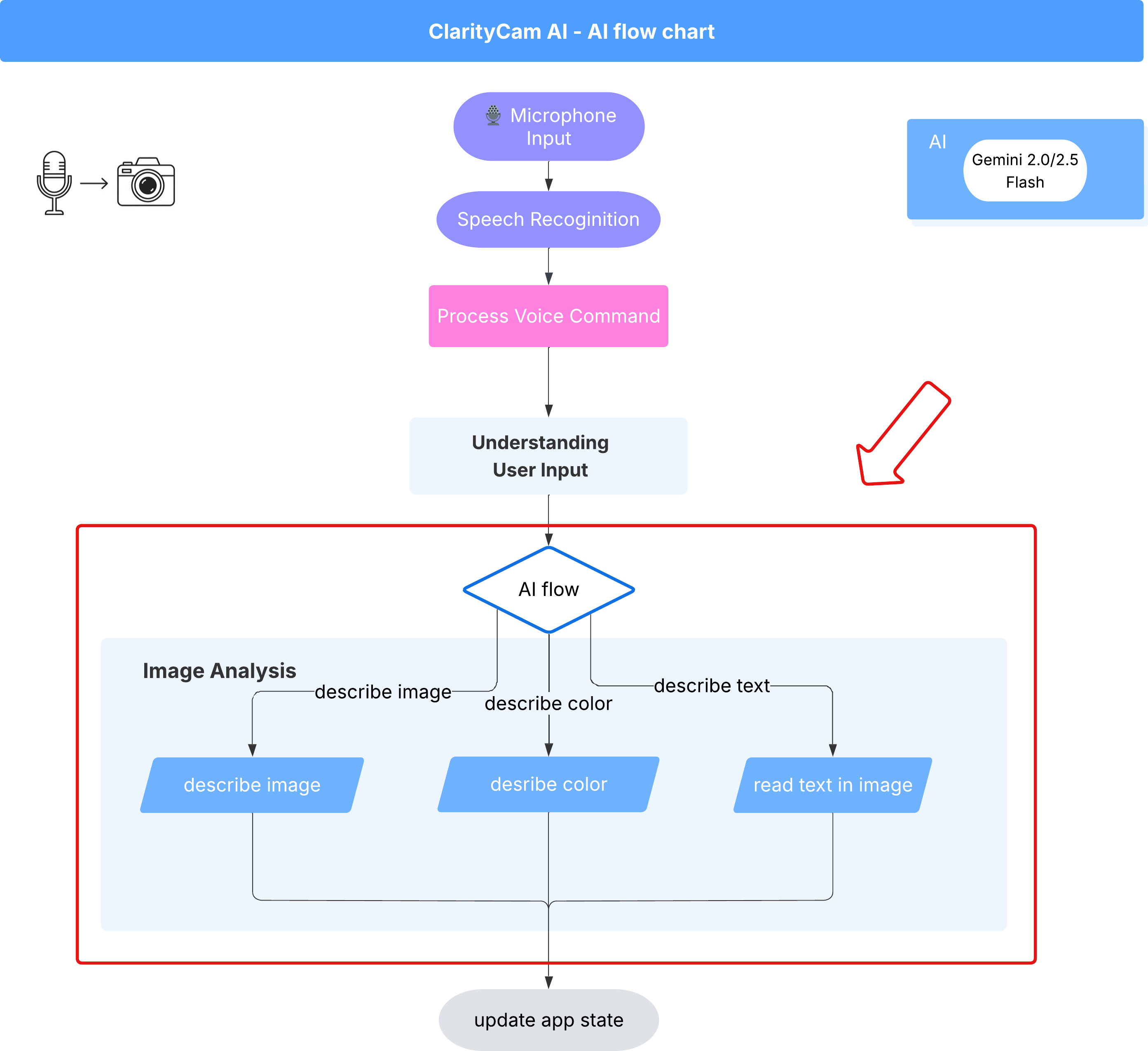
Funktion 1: Bild beschreiben
Das ist die Hauptfunktion des Agents. Wir erstellen nicht nur eine statische Beschreibung, sondern einen dynamischen Ablauf, dessen Detaillierungsgrad sich an die Nutzerpräferenzen anpassen kann. Das ist ein wichtiger Teil der Philosophie von Natively Adaptive Interfaces (NAI).
👉 Aktion: Rufen Sie in Ihrer Cloud Shell-IDE die Datei ~/src/ai/flows/describe_image/ auf und entfernen Sie die Auskommentierung des folgenden Codes.
Schritt 1: Dynamische Prompt-Vorlage erstellen
Zuerst erstellen wir eine ausgefeilte Promptvorlage, deren Anweisungen sich je nach Eingabe ändern können.
Entfernen Sie die Kommentarzeichen aus dem folgenden Code.
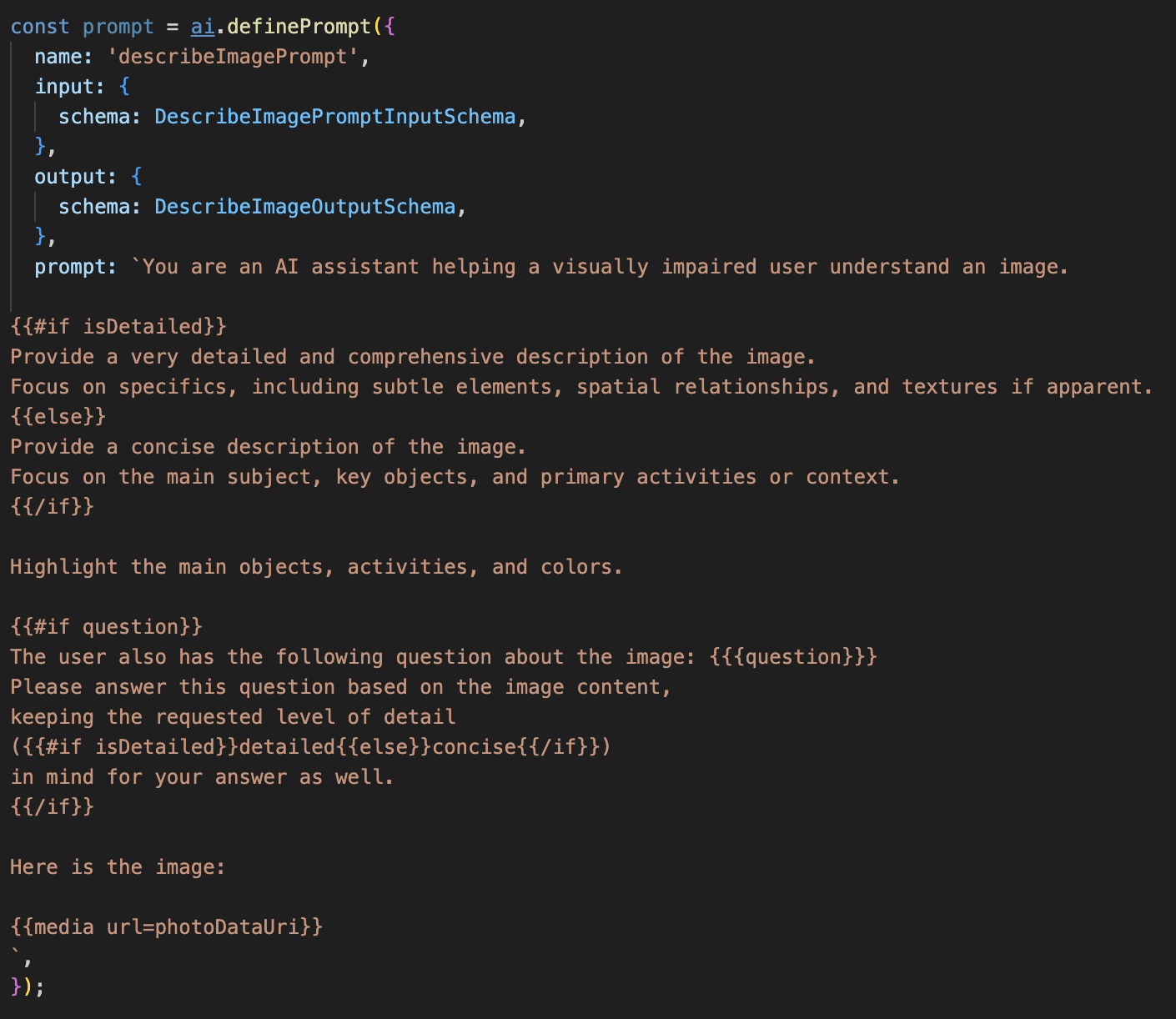
In diesem Code wird eine String-Variable namens „prompt“ definiert, die eine Vorlagensprache namens Dot-Mustache verwendet. So können wir bedingte Logik direkt in unseren Prompt einbetten.
{#if isDetailed}...{else}...{/if}: Dies ist ein bedingter Block. Wenn die Eingabedaten, die wir an diesen Prompt senden, das Attribut „isDetailed: true“ enthalten, erhält die KI die „sehr detaillierte“ Anleitung. Andernfalls erhält sie die Anweisung „concise“. So passt sich unser Agent an die Nutzereinstellungen an.
{#if question}...{/if}: Dieser Block wird nur eingefügt, wenn unsere Eingabedaten eine Frage-Property enthalten. So können wir denselben leistungsstarken Prompt sowohl für allgemeine Beschreibungen als auch für spezifische Fragen verwenden.
{media url=photoDataUri}: Dies ist die spezielle Genkit-Syntax zum Einbetten von Bilddaten direkt in den Prompt, damit das multimodale Modell sie analysieren kann.
Schritt 2: Smart Flow erstellen
Als Nächstes definieren wir den Prompt und den Ablauf, in dem unsere neue Vorlage verwendet wird. Dieser Ablauf enthält etwas Logik, um die Nutzereinstellung in einen booleschen Wert zu übersetzen, den unsere Vorlage verstehen kann.
👉 Aktion: Ersetzen Sie in Ihrer Cloud Shell-IDE in derselben Datei ~/src/ai/flows/describe_image/ den folgenden Code. // REPLACE ME PART 1: add flow here
👉 Mit dem folgenden Code:
// Define the prompt using the template from Step 1
const prompt = ai.definePrompt({
name: 'describeImagePrompt',
input: { schema: DescribeImagePromptInputSchema },
output: { schema: DescribeImageOutputSchema },
prompt: promptTemplate,
});
// Define the flow
const describeImageFlow = ai.defineFlow<
typeof DescribeImageInputSchema,
typeof DescribeImageOutputSchema
>(
{
name: 'describeImageFlow',
inputSchema: DescribeImageInputSchema,
outputSchema: DescribeImageOutputSchema,
},
async (pageInput) => {
const preference = pageInput.detailPreference || "concise";
// Prepare the input for the prompt, including the new boolean flag
const promptInputData = {
...pageInput,
isDetailed: preference === "detailed",
};
const { output } = await prompt(promptInputData);
return output!;
}
);
Diese Funktion fungiert als intelligenter Vermittler zwischen dem Frontend und dem KI-Prompt.
- Sie empfängt
pageInputvon unserer Anwendung, die die Einstellung des Nutzers als String enthält (z.B."detailed"). - Anschließend wird ein neues Objekt erstellt:
promptInputData. - Die wichtigste Zeile ist
isDetailed: preference === "detailed". In dieser Zeile wird der boolesche Werttrueoderfalsebasierend auf dem Einstellungsstring erstellt. - Schließlich wird
promptmit diesen erweiterten Daten aufgerufen. Im Prompt-Template aus Schritt 1 kann jetzt der boolesche WertisDetailedverwendet werden, um die an die KI gesendeten Anweisungen dynamisch zu ändern.
Schritt 3: Frontend verbinden
Lösen wir diesen Ablauf nun über die Benutzeroberfläche in „page.tsx“ aus.
👉Aktion:Rufen Sie ~/src/app/ai/flows/describe-image.ts auf und suchen Sie nach der Funktion export async function describeImage. Entfernen Sie die Kommentare aus der return-Anweisung:
Statt return; Do return describeImageFlow(input);
👉Maßnahme:Suchen Sie in ~/src/app/page.tsx nach der Funktion handleAnalyze und ersetzen Sie den Code // REPLACE ME PART 2: DESCRIBE IMAGE
👉 mit dem folgenden Code:
case "description":
result = await describeImage({
photoDataUri,
question,
detailPreference: descriptionPreference
});
outputText = question ? `Answer: ${result.description}` : `Description: ${result.description}`;
break;
Wenn ein Nutzer eine Beschreibung erhalten möchte, wird dieser Code ausgeführt. Es ruft unseren describeImage-Flow auf und übergibt die Bilddaten und vor allem die Statusvariable descriptionPreference aus unserer React-Komponente. Das ist das letzte Puzzleteil, mit dem die in der Benutzeroberfläche gespeicherte Nutzereinstellung direkt mit dem KI-Ablauf verbunden wird, der sein Verhalten entsprechend anpasst.
Funktion „Bildbeschreibung“ testen
Sehen wir uns die Funktion zur Bildbeschreibung in Aktion an – vom Aufnehmen eines Fotos bis hin zu dem, was die KI sieht.
Anwendung starten
Zuerst müssen wir den Entwicklungsserver wieder zum Laufen bringen. 👉 Führen Sie im Terminal den folgenden Befehl aus: npm run dev Hinweis: Möglicherweise müssen Sie npm install ausführen, bevor Sie npm run dev ausführen.
App öffnen
Wenn der Server bereit ist, öffnen Sie Ihren Browser und rufen Sie die lokale Adresse auf (z.B. http://localhost:9003).
Kamera aktivieren
Klicken Sie auf die Schaltfläche „Zuhören starten“ und gewähren Sie den Mikrofonzugriff, wenn Sie dazu aufgefordert werden. Sagen Sie dann Ihren ersten Befehl:
„Mach ein Foto.“
Die Anwendung aktiviert die Kamera Ihres Geräts. Auf dem Bildschirm sollte jetzt der Live-Videofeed zu sehen sein.
Foto aufnehmen
Richten Sie die Kamera auf das Objekt, das Sie beschreiben möchten. Sagen Sie den Befehl nun ein zweites Mal, um das Bild aufzunehmen:
„Mach ein Foto.“
Das Live-Video wird durch das statische Foto ersetzt, das Sie gerade aufgenommen haben.
Nach der Beschreibung fragen
Wenn das neue Foto auf dem Display angezeigt wird, gib den letzten Befehl:
„Beschreibe das Bild“
Ergebnis anhören
In der App wird ein Verarbeitungsstatus angezeigt und dann hören Sie die KI-generierte Beschreibung Ihres Bildes. Der Text wird auch auf der Karte „Status und Ergebnis“ angezeigt.
Wenn Sie fertig sind, können Sie die Kamera anhalten, indem Sie ein Bild aufnehmen oder den Server einfach im Terminal beenden (Strg + C).
7. KI-basierte Bildanalyse – Text beschreiben (OCR)
Als Nächstes fügen wir unserem Vision-Agent die Funktion zur optischen Zeichenerkennung (Optical Character Recognition, OCR) hinzu. So kann Text aus beliebigen Bildern gelesen werden.
👉 Aktion: Gehen Sie in Ihrer IDE zu ~/src/ai/flows/read-text-in-image/ und entfernen Sie die Kommentarzeichen aus dem folgenden Code:
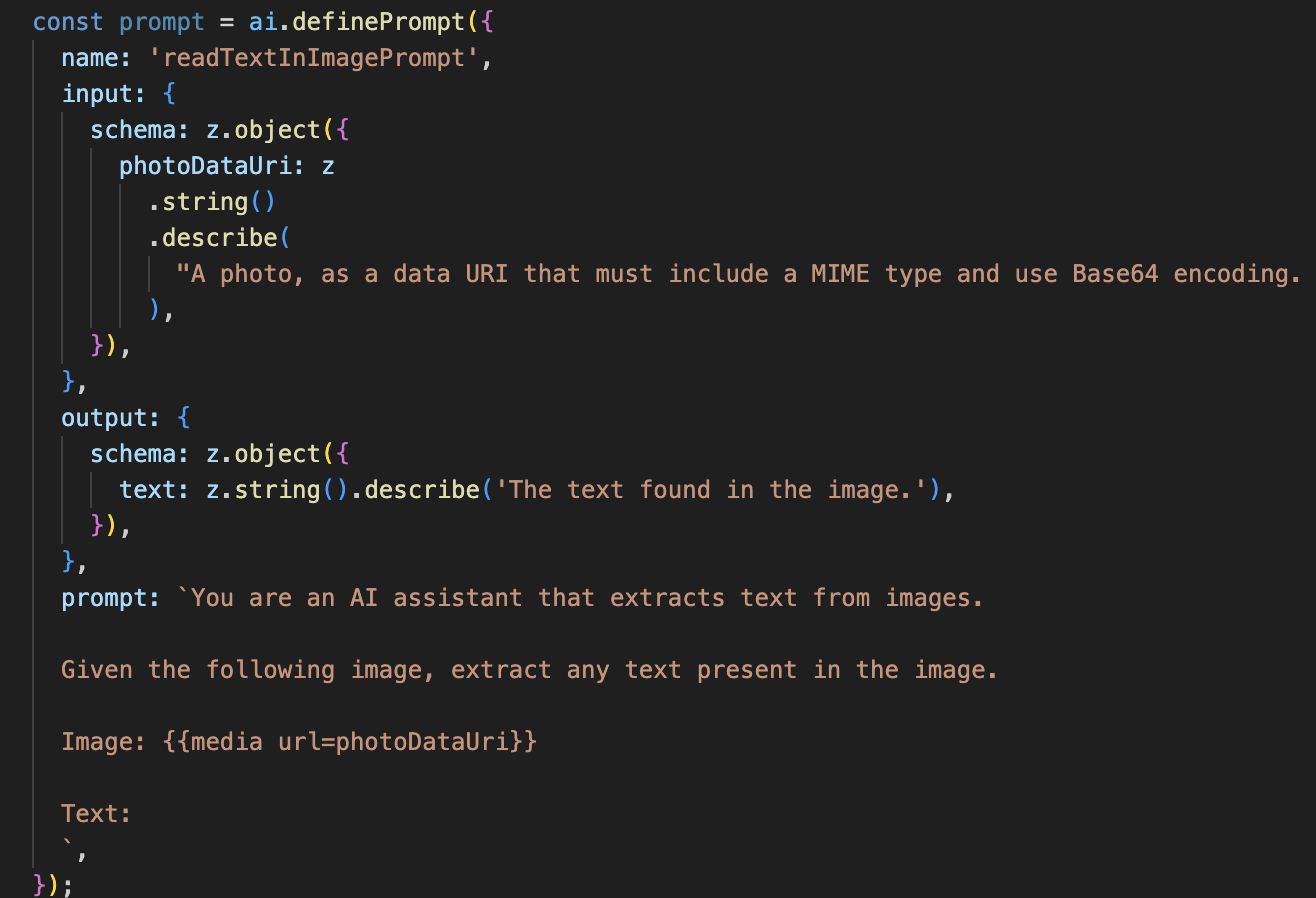
👉 Maßnahme: Ersetzen Sie in Ihrer IDE in derselben ~/src/ai/flows/read-text-in-image/-Datei // REPLACE ME: Creating Prmopt
👉 mit dem folgenden Code:
const readTextInImageFlow = ai.defineFlow<
typeof ReadTextInImageInputSchema,
typeof ReadTextInImageOutputSchema
>(
{
name: 'readTextInImageFlow',
inputSchema: ReadTextInImageInputSchema,
outputSchema: ReadTextInImageOutputSchema,
},
async input => {
const {output} = await prompt(input);
return output!;
}
);
Dieser KI-Ablauf ist viel einfacher und unterstreicht das Prinzip, dass für bestimmte Aufgaben spezielle Tools verwendet werden sollten.
- Der Prompt: Im Gegensatz zu unserem Prompt für die Beschreibung ist dieser statisch und sehr spezifisch. Seine einzige Aufgabe besteht darin, die KI anzuweisen, als OCR-Engine zu fungieren: „Extrahiere den gesamten Text, der im Bild vorhanden ist.“
- Die Schemas: Die Eingabe- und Ausgabeschemas sind ebenfalls einfach. Es wird ein Bild erwartet und ein einzelner Textstring zurückgegeben.
Frontend für OCR verbinden
Verbinden wir diese neue Funktion nun mit page.tsx.
👉Aktion:Rufen Sie ~/src/app/ai/flows/read-text-in-image.ts auf und suchen Sie nach der Funktion export async function readTextInImage. Entfernen Sie die Kommentare aus der return-Anweisung:
Statt return; Do return readTextInImageFlow(input);
👉 Maßnahme: Suchen Sie in ~/src/app/page.tsx nach der Funktion handleAnalyze und der switch-Anweisung.
REPLACE ME PART 3: READ TEXT ersetzen
mit dem folgenden Code:
case "text":
result = await readTextInImage({ photoDataUri });
outputText = result.text ? `Text Found: ${result.text}` : "No text found.";
break;
Dieser Code wird ausgelöst, wenn die Absicht des Nutzers ReadTextInImage ist. Dabei wird unser einfacher readTextInImage-Ablauf aufgerufen. Die Zeile result.text ? ... : ... ist eine saubere Möglichkeit, die Ausgabe zu verarbeiten. Sie enthält eine hilfreiche Meldung für den Nutzer, wenn die KI keinen Text im Bild finden konnte.
Funktion „Text vorlesen (OCR)“ testen
So testen Sie die Funktion zum Vorlesen von Text: Richten Sie die Kamera auf ein Objekt mit gut lesbarem Text.
- Führen Sie die Anwendung mit
npm run devaus und öffnen Sie sie in Ihrem Browser. - Klicken Sie auf „Zuhören starten“ und gewähren Sie den Mikrofonzugriff, wenn Sie dazu aufgefordert werden.
- Aktivieren Sie die Kamera. Sagen Sie den Befehl „Mach ein Foto“. Der Live-Videofeed sollte auf dem Bildschirm angezeigt werden.
- Machen Sie ein Foto. Richten Sie die Kamera auf den Text, der vorgelesen werden soll, und sagen Sie den Befehl noch einmal: „Mach ein Foto“. Das Video wird durch ein statisches Foto ersetzt.
- Bitten Sie um den Text. Nachdem ein Foto aufgenommen wurde, geben Sie den endgültigen Befehl ein: „What is the text in the image?“ (Was ist der Text auf dem Bild?).
- Ergebnis ansehen Nach einem Moment analysiert die App das Foto und liest den erkannten Text vor. Wenn kein Text gefunden wird, werden Sie darüber informiert.
Das bestätigt, dass die leistungsstarke OCR-Funktion funktioniert. Wenn Sie fertig sind, beenden Sie den Server mit Ctrl + C.
8. Erweiterte KI-Funktionen – Nur lesen ✨
Ein guter KI-Agent kann Anweisungen befolgen. Ein guter KI‑Agent fühlt sich intuitiv, vertrauenswürdig und hilfreich an. In diesem Abschnitt konzentrieren wir uns auf drei erweiterte Verbesserungen, die die Fähigkeiten unseres Kundenservicemitarbeiters verbessern.
Wir werden uns ansehen, wie Sie:
Add Context & Memory, um natürliche, konversationelle Folgefragen zu beantworten.Reduce Hallucination, um einen zuverlässigeren und vertrauenswürdigeren Agent zu erstellen.Make the Agent Proactive, um die Bedienung zu vereinfachen und die Barrierefreiheit zu verbessern.Add preference setting, um die Bildbeschreibung anzupassen
Verbesserung 1: Kontext und Speicherkapazität
Eine natürliche Unterhaltung besteht nicht aus einer Reihe isolierter Befehle, sondern aus einem Fluss von Äußerungen. Wenn ein Nutzer fragt: „Was ist auf dem Bild zu sehen?“ und der Agent antwortet: „Ein rotes Auto“, könnte die natürliche Folgefrage des Nutzers lauten: „Welche Farbe hat es?“, ohne das Wort „Auto“ noch einmal zu erwähnen. Unser KI-Agent benötigt ein Kurzzeitgedächtnis, um diesen Kontext zu verstehen.
Umsetzung (Zusammenfassung)
Wir haben diese Funktion bereits in unseren Ablauf „Bild beschreiben“ integriert. In diesem Abschnitt wird noch einmal zusammengefasst, wie dieses Muster funktioniert. Wenn wir unsere Funktion „describeImage“ über „page.tsx“ aufrufen, übergeben wir ihr den Unterhaltungsverlauf.
👉 Code Showcase (von page.tsx):
const result = await describeImage({
photoDataUri,
question: commandToProcess,
detailPreference: descriptionPreference,
previousUserQueryOnImage: lastUserQuery ?? undefined,
previousAIResponseOnImage: lastAIResponse ?? undefined,
});
previousUserQueryOnImageundpreviousAIResponseOnImage: Diese beiden Eigenschaften sind das Kurzzeitgedächtnis unseres Agenten. Indem wir die letzte Interaktion an die KI weitergeben, erhält sie den Kontext, der erforderlich ist, um vage oder referenzielle Folgefragen zu verstehen.- Der adaptive Prompt: Dieser Kontext wird vom Prompt in unserem describe_image-Ablauf verwendet. Der Prompt ist so konzipiert, dass die vorherige Unterhaltung bei der Formulierung einer neuen Antwort berücksichtigt wird, sodass der Kundenservicemitarbeiter intelligent reagieren kann.
Verbesserung 2: Weniger Halluzinationen
Eine KI „halluziniert“, wenn sie Fakten erfindet oder behauptet, Fähigkeiten zu haben, die sie nicht besitzt. Um das Vertrauen der Nutzer zu gewinnen, ist es wichtig, dass unser Agent seine eigenen Grenzen kennt und Anfragen, die nicht in seinen Aufgabenbereich fallen, höflich ablehnen kann.
Umsetzung (Zusammenfassung)
Die effektivste Methode, um Halluzinationen zu verhindern, besteht darin, dem Modell klare Grenzen zu setzen. Das haben wir mit unserem Intent Classifier erreicht.
👉 Code Showcase (aus dem intent-classifier-Ablauf):
// Define Agent Capabilities and Limitations for the prompt
const AGENT_CAPABILITIES_AND_LIMITATIONS = `
**Core Capabilities (What the Agent CAN DO):**
* **Image Analysis:**
* DescribeImage: Provide a general description of the current image...
**Limitations (What the Agent CANNOT DO...):**
* Cannot generate or create new images.
* Cannot provide general knowledge or answer questions unrelated to the image...
* Cannot perform web searches.
`;
Diese Konstante dient als „Stellenbeschreibung“, die wir der KI im Klassifizierungsprompt übergeben.
- Modell fundieren: Indem wir der KI explizit mitteilen, was sie nicht tun darf, „fundieren“ wir sie in der Realität. Wenn das Modell eine Anfrage wie „Wie ist das Wetter?“ sieht, kann es sie zuverlässig mit seiner Liste von Einschränkungen abgleichen und den Intent als „OutOfScopeRequest“ klassifizieren.
- Vertrauen aufbauen: Ein Agent, der ehrlich sagen kann: „Dabei kann ich dir nicht helfen“, ist viel vertrauenswürdiger als einer, der versucht, die Antwort zu erraten und falsch liegt. Dies ist ein grundlegendes Prinzip für die Entwicklung sicherer und zuverlässiger KI. `
Verbesserung 3: Proaktiven Agent erstellen
Bei einer barrierefreien Anwendung können wir uns nicht auf visuelle Hinweise verlassen. Wenn ein Nutzer den Zuhörmodus aktiviert, benötigt er eine sofortige, nicht visuelle Bestätigung, dass der Agent bereit ist und auf einen Befehl wartet. Wir fügen jetzt eine proaktive Einführung hinzu, um dieses wichtige Feedback zu geben.
Schritt 1: Status zum Erfassen des ersten Hörens hinzufügen
Zuerst müssen wir herausfinden, ob der Nutzer die Schaltfläche "Start Listening" während seiner Sitzung zum ersten Mal gedrückt hat.
👉 In ~/src/app/page.tsx finden Sie die folgende neue Statusvariable oben in Ihrer ClarityCam-Komponente.
export default function ClarityCam() {
// ... other state variables
const [descriptionPreference, setDescriptionPreference] = useState<DescriptionPreference>("concise");
// Add this new line
const [isFirstListen, setIsFirstListen] = useState(true);
// ... rest of the component
}
Wir haben eine neue Statusvariable isFirstListen eingeführt und sie mit true initialisiert. Wir verwenden dieses Flag, um unsere einmalige Willkommensnachricht auszulösen.
Schritt 2: Funktion „toggleListening“ aktualisieren
Ändern wir nun die Funktion, die das Mikrofon verwaltet, um unsere Begrüßung abzuspielen.
👉 Suchen Sie in ~/src/app/page.tsx nach der Funktion toggleListening und sehen Sie sich den folgenden if-Block an.
const toggleListening = useCallback(() => {
// ... existing logic to setup speech recognition
if (isListening || isAttemptingStart) {
// ... existing logic to stop listening
} else {
stopSpeaking(); // Stop any ongoing TTS
// Add this new block
if (isFirstListen) {
setIsFirstListen(false);
const introMessage = "Hello! I am ClarityCam, your AI assistant. I'm now listening. You can ask me to 'describe the image', 'read text', 'take a picture', or ask questions about what's in an image.";
speakText(introMessage);
} else {
speakText("Listening..."); // Optional: provide feedback on subsequent clicks
}
// ... rest of the logic to start listening
}
}, [/*...existing dependencies...*/, isFirstListen]); // Don't forget to add isFirstListen to the dependency array!
- Flag prüfen: Der Block „if (isFirstListen)“ prüft, ob dies die erste Aktivierung ist.
- Wiederholung verhindern: Als Erstes wird im Block setIsFirstListen(false) aufgerufen. So wird die Einführungsnachricht nur einmal pro Sitzung abgespielt.
- Anleitung geben: Die Intro-Nachricht ist so formuliert, dass sie möglichst hilfreich ist. Der Agent begrüßt den Nutzer, nennt seinen Namen, bestätigt, dass er jetzt aktiv ist („Ich höre jetzt zu“) und gibt klare Beispiele für Sprachbefehle, die der Nutzer verwenden kann.
- Akustisches Feedback: Mit speakText(introMessage) werden diese wichtigen Informationen ausgegeben. So erhalten Nutzer sofort Bestätigung und Anleitung, ohne auf den Bildschirm schauen zu müssen.
Verbesserung 4: Anpassung an Nutzereinstellungen (Zusammenfassung)
Ein wirklich intelligenter Agent reagiert nicht nur, sondern lernt und passt sich an die Bedürfnisse des Nutzers an. Eine der leistungsstärksten Funktionen, die wir entwickelt haben, ist die Möglichkeit für den Nutzer, die Ausführlichkeit der Bildbeschreibungen spontan mit Befehlen wie „Sei detaillierter“ zu ändern.
Umsetzung (Zusammenfassung): Diese Funktion basiert auf dem dynamischen Prompt, den wir für unseren describeImage-Ablauf erstellt haben. Dabei wird bedingte Logik verwendet, um die an die KI gesendeten Anweisungen basierend auf den Einstellungen des Nutzers zu ändern.
👉 Code-Showcase (die promptTemplate aus describe_image):
const settingPreferenceTemplate = `
{#if isDetailed}
Provide a very detailed and comprehensive description of the image. Focus on specifics, including subtle elements, spatial relationships, and textures if apparent.
{else}
Provide a concise description of the image. Focus on the main subject, key objects, and primary activities or context.
{/if}
Highlight the main objects, activities, and colors.
...
`;
- Bedingte Logik: Der
{#if isDetailed}...{else}...{/if}-Block ist der Schlüssel. Wenn unser describeImageFlow die detailPreference vom Frontend empfängt, wird ein boolescher Wert „isDetailed“ (wahr oder falsch) erstellt. - Adaptive Anweisungen: Dieses boolesche Flag bestimmt, welche Anweisungen das KI-Modell erhält. Wenn „isDetailed“ auf „true“ gesetzt ist, wird das Modell angewiesen, sehr detailliert zu sein. Wenn sie falsch ist, soll sie kurz und prägnant sein.
- Nutzersteuerung: Dieses Muster verbindet den Sprachbefehl eines Nutzers (z. B. „Fasse Beschreibungen kurz“, was als Intention „SetDescriptionConcise“ klassifiziert wird) direkt mit einer grundlegenden Änderung des KI-Verhaltens. Dadurch wirkt der Agent wirklich reaktionsschnell und personalisiert.
9. Bereitstellung in der Cloud
Docker-Image mit Google Cloud Build erstellen
gcloud builds submit . --tag gcr.io/$PROJECT_ID/accessibilityai-nextjs-app:latest
accessibilityai-nextjs-appist ein vorgeschlagener Bildname.- Die verwendet das aktuelle Verzeichnis (
accessibilityAI/) als Build-Quelle.
Image in Google Cloud Run bereitstellen
- Achten Sie darauf, dass Ihre API-Schlüssel und andere Secrets in Secret Manager verfügbar sind. Beispiel:
GOOGLE_GENAI_API_KEY.
Ersetzen Sie YOUR_ACTUAL_GOOGLE_AI_KEY_VALUE durch den tatsächlichen Wert Ihres Gemini API-Schlüssels.
echo "YOUR_ACTUAL_GOOGLE_AI_KEY_VALUE" | gcloud secrets create GOOGLE_GENAI_API_KEY --data-file=- --project=YOUR_PROJECT_ID
Weisen Sie dem Laufzeitdienstkonto Ihres Cloud Run-Dienstes (z.B. PROJECT_NUMBER-compute@developer.gserviceaccount.com oder ein dediziertes Dienstkonto) die Rolle „Secret Manager Secret Accessor“ für dieses Secret zu.
- Bereitstellungsbefehl:
gcloud run deploy accessibilityai-app-service \
--image gcr.io/$PROJECT_ID/accessibilityai-nextjs-app:latest \
--platform managed \
--region us-central1 \
--allow-unauthenticated \
--port 3000 \
--set-secrets=GOOGLE_GENAI_API_KEY=GOOGLE_GENAI_API_KEY:latest \
--set-env-vars NODE_ENV="production"