
1. Introducción
En este instructivo, compilarás ClarityCam, un agente de IA manos libres controlado por voz que puede ver el mundo y explicártelo. Si bien ClarityCam se diseñó con la accesibilidad como principio fundamental, ya que proporciona una herramienta potente para las personas ciegas y con visión reducida, los principios que aprenderás son esenciales para crear cualquier aplicación de voz moderna de uso general.

Este proyecto se basa en una potente filosofía de diseño llamada Interfaz adaptable de forma nativa (NAI). En lugar de tratar la accesibilidad como una idea secundaria, la NAI la convierte en la base. Con este enfoque, el agente de IA es la interfaz: se adapta a diferentes usuarios, controla la entrada multimodal, como la voz y la visión, y guía a las personas de forma proactiva según sus necesidades únicas.
Cómo crear tu primer agente de IA con NAI:

Al final de esta sesión, podrás hacer lo siguiente:
- Diseña con la accesibilidad como opción predeterminada: Aplica los principios de la interfaz adaptativa nativa (NAI) para crear sistemas de IA que proporcionen experiencias equivalentes para todos los usuarios.
- Clasifica la intención del usuario: Crea un clasificador de intención sólido que traduzca los comandos en lenguaje natural en acciones estructuradas para tu agente.
- Mantén el contexto de la conversación: Implementa una memoria a corto plazo para que tu agente pueda comprender las preguntas de seguimiento y los comandos referenciales (p.ej., "¿De qué color es?").
- Crea instrucciones eficaces: Elabora instrucciones enfocadas y enriquecidas en contexto para un modelo multimodal como Gemini y, así, garantizar un análisis de imágenes preciso y confiable.
- Maneja la ambigüedad y guía al usuario: Diseña un manejo de errores elegante para las solicitudes fuera del alcance y orienta a los usuarios de forma proactiva para generar confianza.
- Orquesta un sistema multiagente: Estructura tu aplicación con una colección de agentes especializados que colaboran para controlar tareas complejas, como el procesamiento de voz, el análisis y la síntesis de voz.
2. Diseño de alto nivel
En esencia, ClarityCam está diseñada para ser simple para el usuario, pero funciona con un sistema sofisticado de agentes de IA que colaboran entre sí. Desglosemos la arquitectura.

Experiencia del usuario
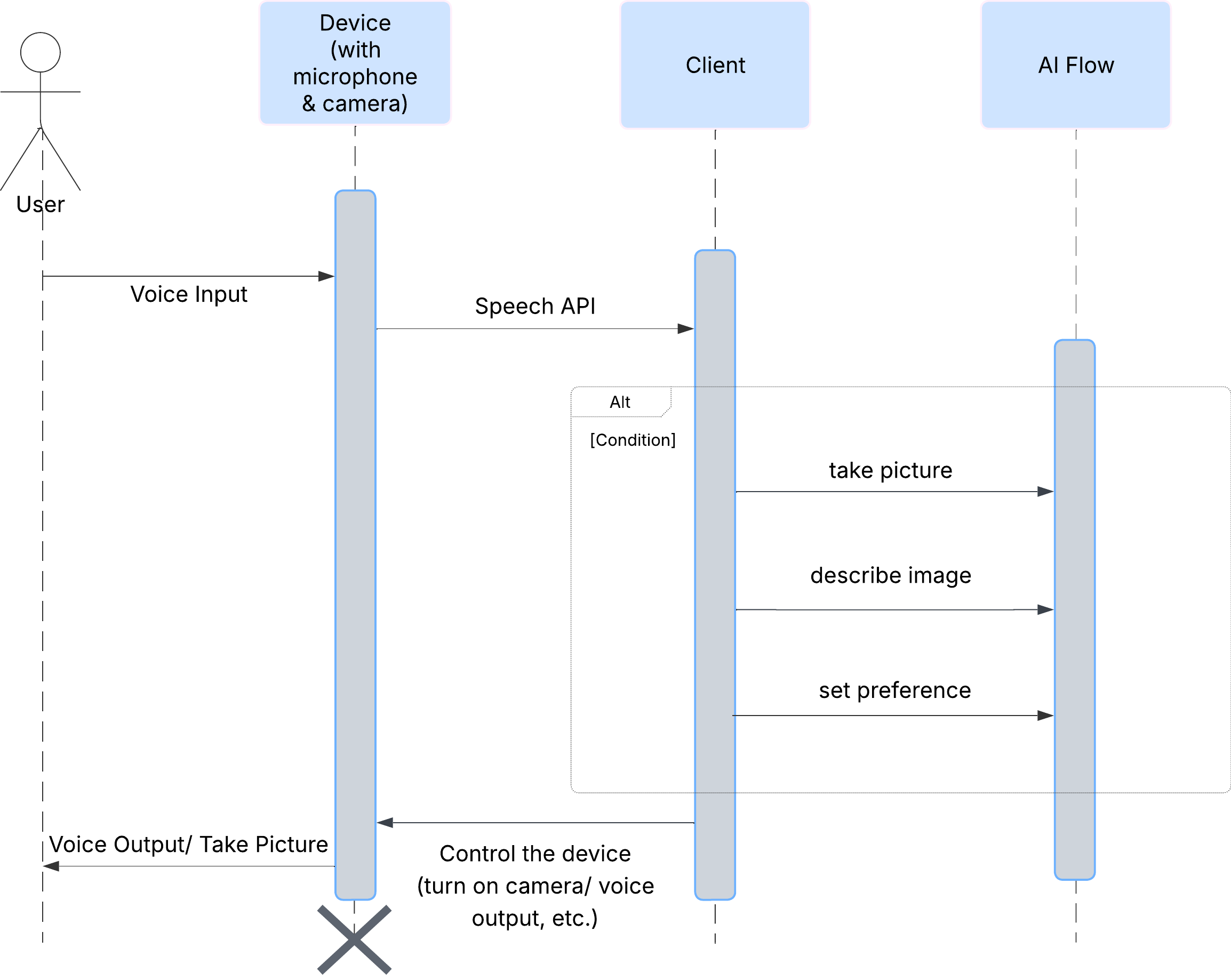
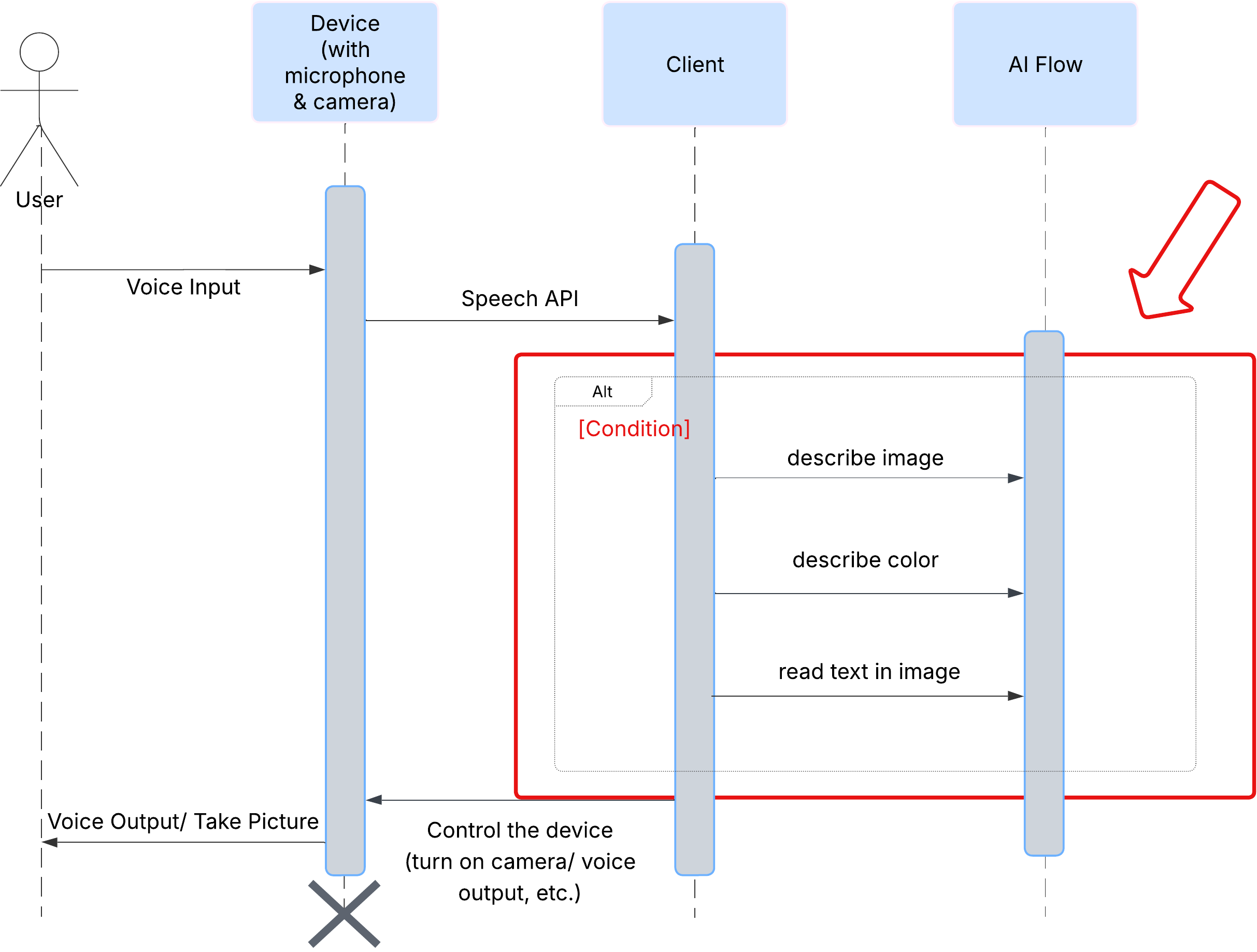
Primero, veamos cómo interactúa un usuario con ClarityCam. Toda la experiencia es conversacional y con manos libres. El usuario dice un comando y el agente responde con una descripción o acción hablada. En este diagrama de secuencia, se muestra un flujo de interacción típico, desde el comando de voz inicial del usuario hasta la respuesta de audio final del dispositivo.
Arquitectura de los agentes de IA
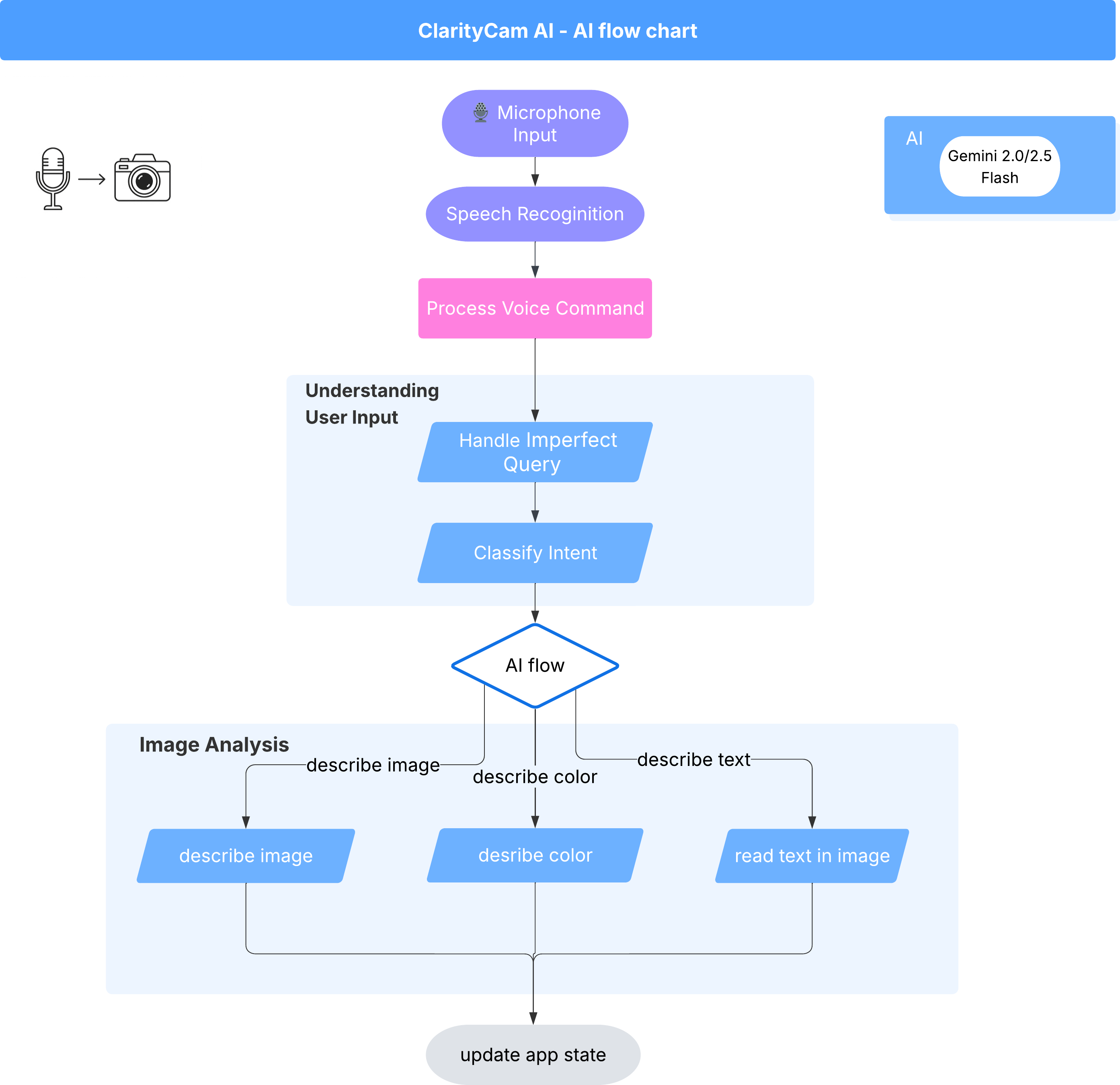
Bajo la superficie, un sistema multiagente trabaja en conjunto para darle vida a la experiencia. Cuando se recibe un comando, un agente central de Orchestrator delega tareas a agentes especializados responsables de comprender la intención, analizar imágenes y formar una respuesta. Este diagrama de flujo de IA proporciona información detallada sobre cómo colaboran estos agentes. Implementaremos esta arquitectura en las siguientes secciones.
Un recorrido rápido por los archivos del proyecto
Antes de comenzar a escribir código, familiaricémonos con la estructura de archivos de nuestro proyecto. Puede parecer que hay muchos archivos, pero solo debes enfocarte en dos áreas específicas para todo este instructivo.
Este es un mapa simplificado de nuestro proyecto.
accessibilityAI/src/
├── 📁 app/
│ ├── layout.tsx # An overall page shell (you can ignore this).
│ └── page.tsx # ⬅️ MODIFY THIS: The main user interface for our app.
│
├── 📁 ai/
│ ├── 📁flows # ⬅️ MODIFY THIS: The core AI logic and server functions.
│ └── intent-classifier.ts # ⬅️ MODIFY THIS: Where we'll edit our AI prompts.
| └── ai-instance.ts
| └── dev.ts
│
├── 📁 components/ # Contains pre-built UI components (ignore this).
│
├── 📁 hooks/
│
├── 📁 lib/
│
└── 📁 types/
La pila tecnológica
Nuestro sistema se basa en una pila tecnológica moderna y escalable que combina potentes servicios en la nube y modelos de IA de vanguardia. Estos son los componentes clave que usaremos:
- Google Cloud Platform (GCP): Proporciona la infraestructura sin servidores para nuestros agentes.
- Cloud Run: Implementa nuestros agentes individuales como microservicios escalables y alojados en contenedores.
- Artifact Registry: Almacena y administra de forma segura las imágenes de Docker para nuestros agentes.
- Secret Manager: Controla de forma segura las credenciales sensibles y las claves de API.
- Modelos de lenguaje grandes (LLM): Actúan como el “cerebro” del sistema.
- Modelos de Gemini de Google: Usamos las potentes capacidades multimodales de la familia Gemini para todo, desde clasificar la intención del usuario hasta analizar el contenido de las imágenes y proporcionar descripciones inteligentes.
3. Configuración y requisitos previos
Habilita la cuenta de facturación. Para ejecutar este codelab, necesitas una cuenta de facturación con algo de crédito. Usa los créditos del banner que se encuentra en la parte superior de este codelab para comenzar. Si ya te conectaste a una cuenta de facturación, puedes omitir este paso.
Crea un proyecto de GCP nuevo
- Ve a la consola de Google Cloud y crea un proyecto nuevo.
- Ve a la consola de Google Cloud y crea un proyecto nuevo.
- Abre el panel izquierdo, haz clic en
Billingy verifica si la cuenta de facturación está vinculada a esta cuenta de GCP.
Si ves esta página, marca la casilla de verificación manage billing account, elige la prueba de Google Cloud One y vincúlala.
Crea tu clave de API de Gemini
Antes de proteger la llave, debes tener una.
- Navega a Google AI Studio : https://aistudio.google.com/
- Accede con tu Cuenta de Google.
- Haz clic en el botón "Obtener clave de API", que suele encontrarse en el panel de navegación de la izquierda o en la esquina superior derecha.
- En el cuadro de diálogo "Claves de API", haz clic en "Crear clave de API en un proyecto nuevo".
- Se generará una nueva clave de API para ti. Copia esta clave de inmediato y guárdala en un lugar seguro de forma temporal (como un Administrador de contraseñas o una nota segura). Este es el valor que usarás en los siguientes pasos.
Flujo de trabajo de desarrollo local (pruebas en tu máquina)
Debes poder ejecutar npm run dev y hacer que funcione tu app. Aquí es donde entra en juego .env.
- Agrega la clave de API al archivo: Crea un archivo nuevo llamado
.envy agrégale la siguiente línea.
Asegúrate de reemplazar YOUR_API_KEY_HERE por la clave que obtuviste de AI Studio y que guardaste en .env:
GOOGLE_GENAI_API_KEY="YOUR_API_KEY_HERE"
[Opcional] Configura el IDE y el entorno
Para este instructivo, puedes trabajar en un entorno de desarrollo conocido, como VS Code o IntelliJ, con tu terminal local. Sin embargo, te recomendamos que uses Google Cloud Shell para garantizar un entorno estandarizado y preconfigurado.
Los siguientes pasos se escribieron para el contexto de Cloud Shell. Si eliges usar tu entorno local, asegúrate de tener instalados y configurados correctamente git, nvm, npm y gcloud.
Trabaja en el editor de Cloud Shell
👉 Haz clic en Activar Cloud Shell en la parte superior de la consola de Google Cloud (es el ícono con forma de terminal en la parte superior del panel de Cloud Shell). 
👉 Haz clic en el botón "Abrir editor" (tiene forma de carpeta abierta con un lápiz). Se abrirá el editor de código de Cloud Shell en la ventana. Verás un explorador de archivos en el lado izquierdo. 
👉 Haz clic en el botón Cloud Code Sign-in en la barra de estado de la parte inferior, como se muestra. Autoriza el complemento según las instrucciones. Si ves Cloud Code - No Project en la barra de estado, selecciónalo y, luego, en el menú desplegable "Select a Google Cloud Project", elige el proyecto específico de Google Cloud de la lista de proyectos que creaste. 
👉Abre la terminal en el IDE de Cloud, 
👉 En la terminal, verifica que ya te hayas autenticado y que el proyecto esté configurado con tu ID del proyecto usando el siguiente comando:
gcloud auth list
👉 Clona el proyecto natively-accessible-interface desde GitHub:
git clone https://github.com/cuppibla/AccessibilityAgent.git
Asegúrate de reemplazar <YOUR_PROJECT_ID> por el ID de tu proyecto (puedes encontrar el ID de tu proyecto en la consola de Google Cloud, en la parte del proyecto. ❗️❗️Asegúrate de no confundir project id con project number❗️❗️):
echo <YOUR_PROJECT_ID> > ~/project_id.txt
gcloud config set project $(cat ~/project_id.txt)
👉 Ejecuta el siguiente comando para habilitar las APIs de Cloud necesarias: (la ejecución puede tardar alrededor de 2 minutos)
gcloud services enable compute.googleapis.com \
storage.googleapis.com \
run.googleapis.com \
artifactregistry.googleapis.com \
aiplatform.googleapis.com \
eventarc.googleapis.com \
sqladmin.googleapis.com \
secretmanager.googleapis.com \
cloudbuild.googleapis.com \
cloudresourcemanager.googleapis.com \
cloudfunctions.googleapis.com \
cloudaicompanion.googleapis.com
Este proceso puede tardar unos minutos.
Cómo configurar permisos
👉Configura el permiso de la cuenta de servicio. En la terminal, ejecuta el siguiente comando :
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
export SERVICE_ACCOUNT_NAME=$(gcloud compute project-info describe --format="value(defaultServiceAccount)")
echo "Here's your SERVICE_ACCOUNT_NAME $SERVICE_ACCOUNT_NAME"
👉 Otorga permisos. En la terminal, ejecuta el siguiente comando :
#Cloud Storage (Read/Write):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/storage.objectAdmin"
#Pub/Sub (Publish/Receive):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/pubsub.publisher"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/pubsub.subscriber"
#Cloud SQL (Read/Write):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/cloudsql.editor"
#Eventarc (Receive Events):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/iam.serviceAccountTokenCreator"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/eventarc.eventReceiver"
#Vertex AI (User):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/aiplatform.user"
#Secret Manager (Read):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/secretmanager.secretAccessor"
4. Cómo comprender la entrada del usuario: clasificador de intención
Antes de que nuestro agente de IA pueda actuar, primero debe comprender con precisión lo que quiere el usuario. Las entradas del mundo real suelen ser desordenadas: pueden ser vagas, incluir errores de escritura o usar lenguaje coloquial.
En esta sección, crearemos los componentes de "escucha" fundamentales que transforman la entrada del usuario sin procesar en un comando claro y práctico.
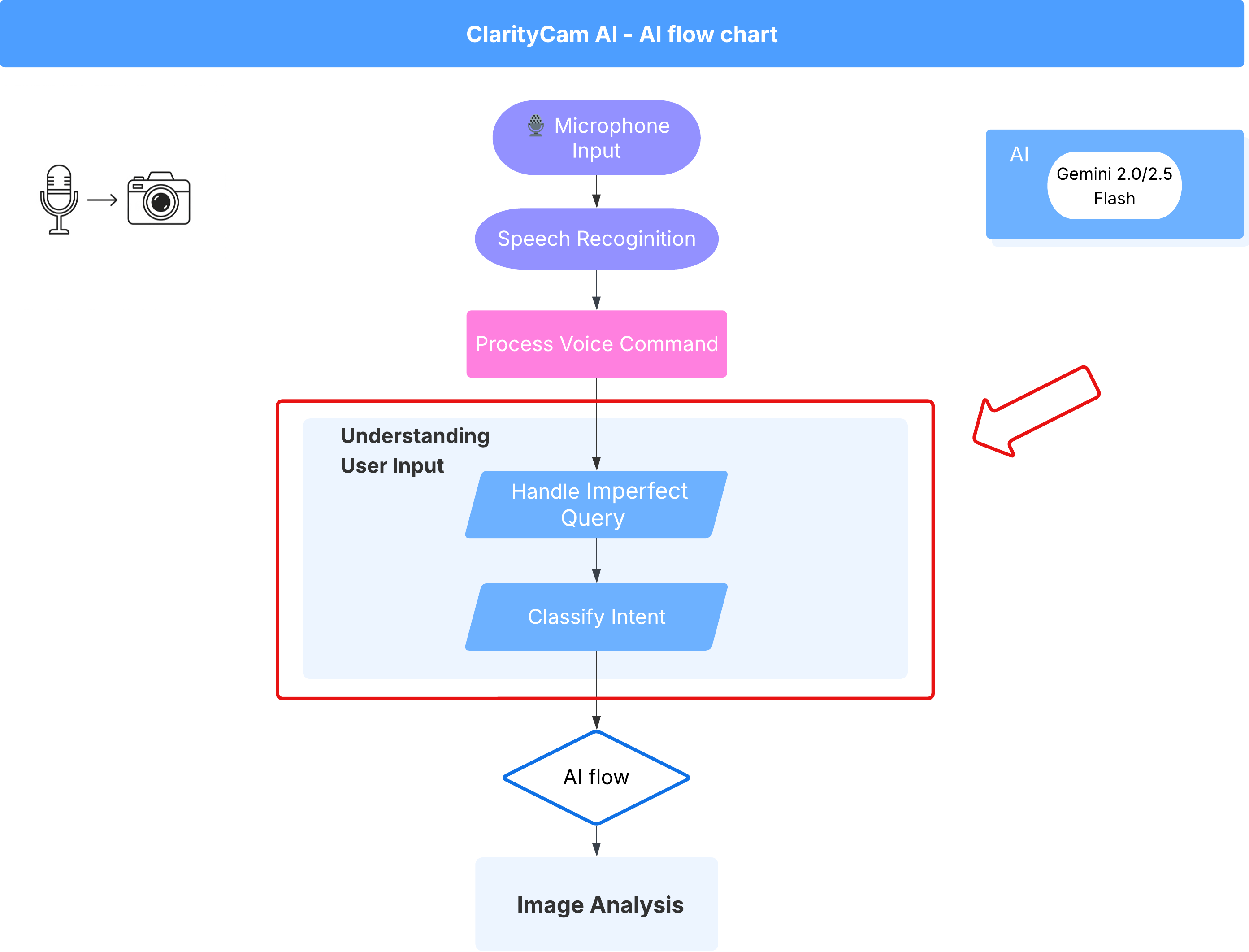
Cómo agregar un clasificador de intents
Ahora definiremos la lógica de IA que impulsa nuestro clasificador.
👉 Acción: En el IDE de Cloud Shell, navega al directorio ~/src/ai/intent-classifier/.
Paso 1: Define el vocabulario del agente (IntentCategory)
Primero, debemos crear una lista definitiva de cada acción posible que nuestro agente puede realizar.
👉 Acción: Reemplaza el marcador de posición // REPLACE ME PART 1: add IntentCategory here por el siguiente código:
👉 con el siguiente código:
export type IntentCategory =
// Image Analysis Intents
| "DescribeImage"
| "AskAboutImage"
| "ReadTextInImage"
| "IdentifyColorsInImage"
// Control Intents
| "TakePicture"
| "StartCamera"
| "SelectImage"
| "StopSpeaking"
// Preference Intents
| "SetDescriptionDetailed"
| "SetDescriptionConcise"
// Fallback Intents
| "GeneralInquiry" // User has a general question about the agent's functions or polite interaction
| "OutOfScopeRequest" // User's request is clearly outside the agent's defined capabilities
| "Unknown"; // Intent could not be determined with confidence
Explicación
Este código de TypeScript crea un tipo personalizado llamado IntentCategory. Es una lista estricta que define cada acción posible, o "intención", que nuestro agente puede comprender. Este es un primer paso fundamental, ya que transforma una cantidad potencialmente infinita de frases del usuario ("dime lo que ves", "¿qué hay en la foto?") en un conjunto de comandos limpio y predecible. El objetivo de nuestro clasificador es asignar cualquier búsqueda del usuario a una de estas categorías específicas.
Paso 2
Para tomar decisiones precisas, nuestra IA debe conocer sus propias capacidades y limitaciones. Proporcionaremos esta información como un bloque de texto detallado.
👉 Acción: Reemplaza el marcador de posición REPLACE ME PART 2: add AGENT_CAPABILITIES_AND_LIMITATIONS here por el siguiente código:
Reemplaza el siguiente código: // REPLACE ME PART 2: add AGENT_CAPABILITIES_AND_LIMITATIONS here:
👉 con el siguiente código
const AGENT_CAPABILITIES_AND_LIMITATIONS = `
**Core Capabilities (What the Agent CAN DO):**
* **Image Analysis:**
* DescribeImage: Provide a general description of the current image.
* AskAboutImage: Answer a specific question about the visual content of the current image (e.g., "Is there a dog?", "What color is the car?").
* ReadTextInImage: Read any text found in the current image.
* IdentifyColorsInImage: Identify the dominant colors of the current image.
* **Image Input Control:**
* TakePicture: Capture an image using the currently active camera stream.
* StartCamera: Activate the camera (e.g., "use camera", "take another picture").
* SelectImage: Allow the user to choose an image file from their device.
* **Voice & Audio Control:**
* StopSpeaking: Stop the current text-to-speech output.
* **Preference Management:**
* SetDescriptionDetailed: Make future image descriptions more detailed.
* SetDescriptionConcise: Make future image descriptions less detailed or concise.
* **General Interaction:**
* GeneralInquiry: Handle conversational phrases (e.g., "hello", "thank you") or questions about its own capabilities (e.g., "what can you do?", "help").
**Limitations (What the Agent CANNOT DO and should be classified as OutOfScopeRequest):**
* Cannot generate or create new images.
* Cannot edit or modify existing images (e.g., "remove background," "make the car blue").
* Cannot analyze video files or live video beyond capturing a single frame.
* Cannot provide general knowledge or answer questions unrelated to the provided image's visual content (e.g., "What's the weather?", "Who is the president?", "Tell me a joke", "What time is it?").
* Cannot perform mathematical calculations or complex data analysis.
* Cannot translate languages as a primary function.
* Cannot remember information from past images or vastly different previous queries in the same session.
* Cannot control other device settings or applications.
* Cannot perform web searches.
`;
Por qué es importante:
Este texto no es para que lo lea el usuario, sino nuestro modelo de IA. Ingresaremos esta "descripción del trabajo" directamente en nuestra instrucción (en el siguiente paso) para brindarle al modelo de lenguaje (LLM) el contexto que necesita para tomar decisiones precisas. Sin este contexto, el LLM podría clasificar incorrectamente "¿Cómo está el clima?" como AskAboutImage. Con este contexto, sabe que el clima no es un elemento visual en la imagen y lo clasifica correctamente como fuera del alcance.
Paso 3
Ahora escribiremos el conjunto completo de instrucciones que seguirá el modelo de Gemini para realizar la clasificación.
👉 Acción: Reemplaza // REPLACE ME PART 3 - classifyIntentPrompt por el siguiente código:
con el siguiente código
const classifyIntentPrompt = ai.definePrompt({
name: 'classifyIntentPrompt',
input: { schema: ClassifyIntentInputSchema },
output: { schema: ClassifyIntentOutputSchema },
prompt: `You are classifying the user's intent for ClarityCam, a voice-controlled AI application focused on image analysis.
Analyze the user query: '{userQuery}'.
First, understand ClarityCam's capabilities and limitations:
${AGENT_CAPABILITIES_AND_LIMITATIONS}
Now, classify the user's PRIMARY intent into ONE of the following categories:
* **DescribeImage**: User wants a general description of the current image.
* **AskAboutImage**: User is asking a specific question directly related to the visual content of the current image.
* **ReadTextInImage**: User wants any text read from the current image.
* **IdentifyColorsInImage**: User wants the dominant colors of the current image.
* **TakePicture**: User wants to capture an image using an active camera.
* **StartCamera**: User wants to activate the camera.
* **SelectImage**: User wants to choose an image file.
* **StopSpeaking**: User wants the current text-to-speech output to stop.
* **SetDescriptionDetailed**: User wants future image descriptions to be more detailed.
* **SetDescriptionConcise**: User wants future image descriptions to be less detailed.
* **GeneralInquiry**: The query is a simple conversational filler (e.g., "hello", "thanks"), a polite closing, or a direct question about the agent's functions (e.g., "what can you do?", "how does this work?", "help").
* **OutOfScopeRequest**: The query asks the agent to perform an action clearly listed under its "Limitations" or otherwise demonstrably outside its defined image analysis and control functions. Examples: "Tell me a joke," "What's the weather in London?", "Generate an image of a cat," "Can you edit my photo to make it brighter?", "Send this image to my friends","Translate 'hello' to Spanish."
Output ONLY the category name.
If the query is ambiguous but seems generally related to polite interaction or asking about the agent itself, prefer 'GeneralInquiry'.
If the query is clearly asking for something the agent CANNOT do, use 'OutOfScopeRequest'.
If truly unclassifiable even with these guidelines, use 'Unknown'.`,
config: {
temperature: 0.05, // Very low temperature for highly deterministic classification
}
});
Aquí es donde ocurre la magia. Es el "cerebro" de nuestro clasificador, ya que le indica a la IA su rol, le proporciona el contexto necesario y define el resultado deseado. Ten en cuenta estas técnicas clave de ingeniería de instrucciones:
- Juego de roles: Comienza con "Estás clasificando…" para establecer una tarea clara.
- Inyección de contexto: Inserta de forma dinámica la variable
AGENT_CAPABILITIES_AND_LIMITATIONSen la instrucción. - Formato de salida estricto: La instrucción "Genera SOLO el nombre de la categoría" es fundamental para obtener una respuesta limpia y predecible que podamos usar fácilmente en nuestro código.
- Temperatura baja: Para la clasificación, queremos respuestas determinísticas y lógicas, no creativas. Establecer la temperatura en un valor muy bajo (0.05) garantiza que el modelo esté muy enfocado y sea coherente.
Paso 4: Conecta la app al flujo de IA
Por último, llamemos a nuestro nuevo clasificador de IA desde el archivo principal de la aplicación.
👉 Acción: Navega a tu archivo ~/src/app/page.tsx. Dentro de la función processVoiceCommand, reemplaza // REPLACE ME PART 1: add classificationResult por lo siguiente:
const classificationResult = await classifyIntentFlow({ userQuery: commandToProcess });
intent = classificationResult.intent as IntentCategory;
Este código es el puente crucial entre tu aplicación de frontend y la lógica de IA de backend. Toma el comando de voz del usuario (commandToProcess), lo envía al classifyIntentFlow que acabas de compilar y espera a que la IA devuelva la intención clasificada.
La variable de intención ahora contiene un comando limpio y estructurado (como DescribeImage). Este resultado se usará en la siguiente instrucción switch para controlar la lógica de la aplicación y decidir qué acción tomar a continuación. Así es como el "pensamiento" de la IA se convierte en el "hacer" de la app.
Cómo iniciar la interfaz de usuario
Es hora de ver nuestra aplicación en acción. Iniciemos el servidor de desarrollo.
👉 En tu terminal, ejecuta el siguiente comando: npm run dev Nota: Es posible que debas ejecutar npm install antes de ejecutar npm run dev.
Después de un momento, verás un resultado similar a este, lo que significa que el servidor se está ejecutando correctamente:
▲ Next.js 15.2.3 (Turbopack)
- Local: http://localhost:9003
- Network: http://10.88.0.4:9003
- Environments: .env
✓ Starting...
✓ Ready in 1512ms
○ Compiling / ...
✓ Compiled / in 26.6s
Ahora, haz clic en la URL local (http://localhost:9003) para abrir la aplicación en tu navegador.
Deberías ver la interfaz de usuario de SightGuide. Por el momento, los botones no están conectados a ninguna lógica, por lo que hacer clic en ellos no hará nada. Eso es exactamente lo que esperamos en esta etapa. Les daremos vida en la próxima sección.
Ahora que viste la IU, vuelve a la terminal y presiona Ctrl + C para detener el servidor de desarrollo antes de continuar.
5. Cómo comprender la entrada del usuario: Verificación de consultas imperfectas
Se agregó la verificación de consultas imperfectas
Parte 1: Definición de la instrucción (el "qué")
Primero, definamos las instrucciones para nuestra IA. La instrucción es la "receta" de nuestra llamada a la IA, ya que le indica al modelo exactamente lo que queremos que haga.
👉 Acción: En tu IDE, navega a ~/src/ai/flows/check_typo/.
Reemplaza el siguiente código: // REPLACE ME PART 1: add prompt here:
👉 con el siguiente código
const prompt = ai.definePrompt({
name: 'checkTypoPrompt',
input: {
schema: CheckTypoInputSchema,
},
output: {
schema: CheckTypoOutputSchema,
},
prompt: `You are a helpful AI assistant that checks user text for typos and suggests corrections.
- If you find typos, respond with the corrected text.
- If there are no typos, or if you are unsure about a correction, respond with the original text unchanged.
User text: {text}
Corrected text:
`,
});
Este bloque de código define una plantilla reutilizable para nuestra IA llamada checkTypoPrompt. Los esquemas de entrada y salida definen el contrato de datos para esta tarea. Esto evita errores y hace que nuestro sistema sea predecible.
Parte 2: Cómo crear el flujo
Ahora que tenemos nuestra "receta" (la instrucción), debemos crear una función que pueda ejecutarla. En Genkit, esto se llama flujo. Un flujo une nuestra instrucción en una función ejecutable a la que el resto de nuestra aplicación puede llamar fácilmente.
👉 Acción: En el mismo archivo ~/src/ai/flows/check_typo/, reemplaza el siguiente código: // REPLACE ME PART 2: add flow here:
👉 con el siguiente código
const checkTypoFlow = ai.defineFlow<
typeof CheckTypoInputSchema,
typeof CheckTypoOutputSchema
>(
{
name: 'checkTypoFlow',
inputSchema: CheckTypoInputSchema,
outputSchema: CheckTypoOutputSchema,
},
async input => {
const {output} = await prompt(input);
return output!;
}
);
Parte 3: Cómo usar el corrector de errores
Ahora que completamos nuestro flujo de IA, podemos integrarlo en la lógica principal de nuestra aplicación. La llamaremos inmediatamente después de recibir el comando del usuario, lo que garantizará que el texto esté limpio antes de cualquier otro procesamiento.
👉Acción: Navega a ~/src/app/ai/flows/check-typo.ts y busca la función export async function checkTypo. Quita los comentarios de la sentencia return:
En lugar de return;, haz return checkTypoFlow(input);.
👉Acción: Navega a ~/src/app/page.tsx y busca la función processVoiceCommand. Reemplaza el siguiente código: REPLACE ME PART 2: add typoResult here:
👉 con el siguiente código
const typoResult = await checkTypo({ text: rawCommand });
if (typoResult && typoResult.correctedText && typoResult.correctedText.trim().length > 0) {
const originalTrimmedLower = rawCommand.trim().toLowerCase();
const correctedTrimmedLower = typoResult.correctedText.trim().toLowerCase();
if (correctedTrimmedLower !== originalTrimmedLower) {
commandToProcess = typoResult.correctedText;
typoCorrectionAnnouncement = `I think you said: ${commandToProcess}. `;
}
}
Con este cambio, creamos una canalización de procesamiento de datos más sólida para cada comando del usuario.
Flujo de comandos por voz (solo lectura, no se requiere ninguna acción)
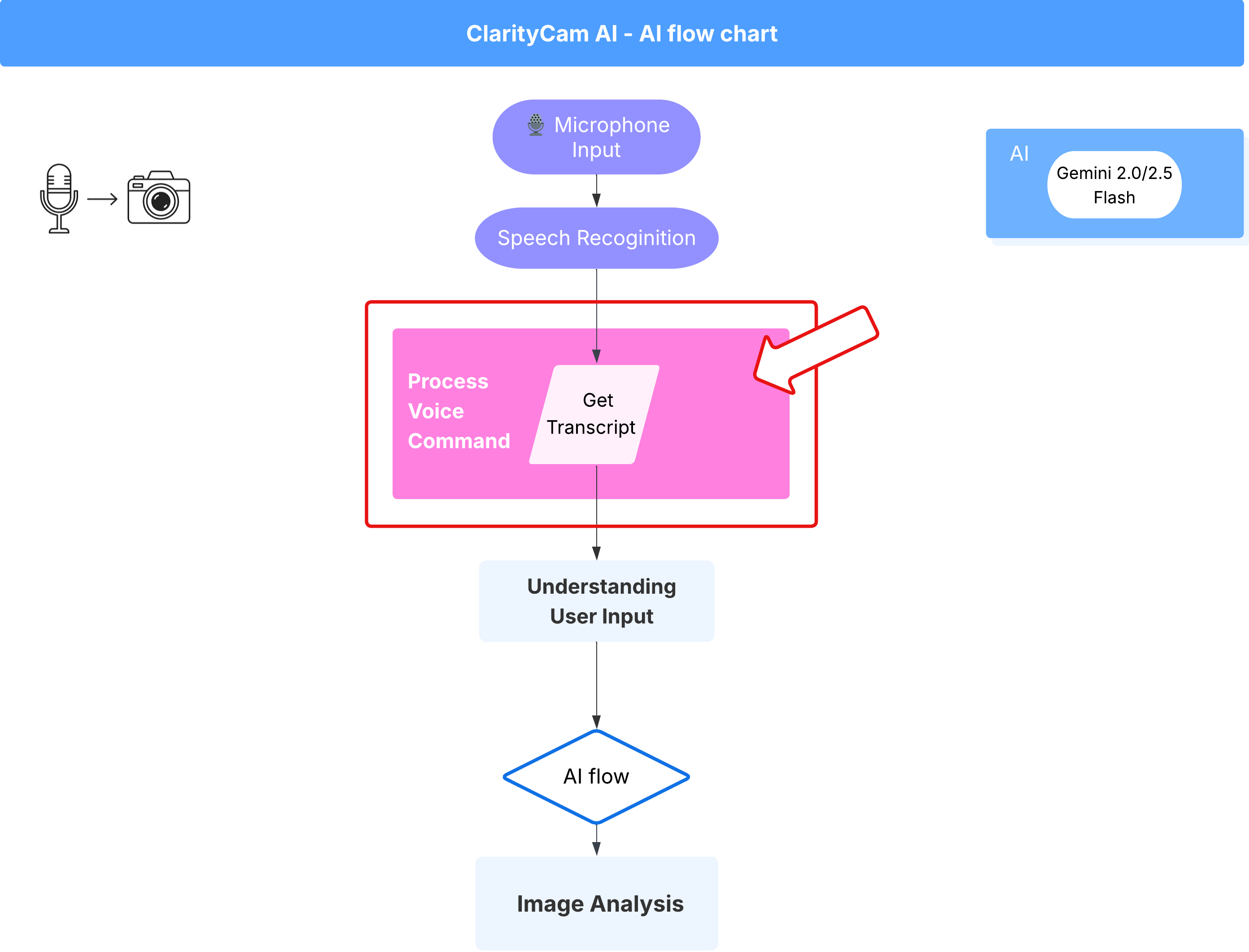
Ahora que tenemos nuestros componentes principales de "comprensión" (el corrector de errores tipográficos y el clasificador de intents), veamos cómo encajan en la lógica principal de procesamiento de voz de la aplicación.
Todo comienza cuando el usuario habla. La API de Web Speech del navegador escucha el habla y, una vez que el usuario termina de hablar, proporciona una transcripción de texto de lo que escuchó. El siguiente código controla este proceso.
👉Solo lectura: Navega a ~/src/app/page.tsx y dentro de la función handleResult. Busca el siguiente código:
for (let i = event.resultIndex; i < event.results.length; ++i) {
if (event.results[i].isFinal) {
finalTranscript += event.results[i][0].transcript;
}
}
if (finalTranscript) {
console.log("Final Transcript:", finalTranscript);
processVoiceCommand(finalTranscript);
}
Ponemos a prueba nuestra corrección de errores tipográficos
Aquí comienza la diversión. Veamos cómo nuestra nueva función de corrección de errores tipográficos controla los comandos de voz perfectos e imperfectos.
Inicia la aplicación
Primero, volvamos a ejecutar el servidor de desarrollo. En tu terminal, ejecuta npm run dev.
Abre la app
Cuando el servidor esté listo, abre tu navegador y navega a la dirección local (p.ej., http://localhost:9003).
Cómo activar los Comandos por voz
Haz clic en el botón Start Listening. Es probable que el navegador te solicite permiso para usar el micrófono. Haz clic en Permitir.
Cómo probar un comando imperfecto
Ahora, démosle intencionalmente un comando ligeramente defectuoso para ver si nuestra IA puede resolverlo. Habla con claridad al micrófono:
"Tómame una foto".
Observa el resultado
Aquí ocurre la magia. Aunque dijiste "Tómame una foto", deberías ver que la aplicación activa la cámara correctamente. El flujo checkTypo corrige tu frase a "toma una foto" tras bambalinas, y el flujo classifyIntentFlow luego comprende el comando corregido.
Esto confirma que nuestra función de corrección de errores de escritura funciona perfectamente, lo que hace que la app sea mucho más sólida y fácil de usar. Cuando termines, puedes detener la cámara tomando una foto o simplemente detener el servidor en la terminal (Ctrl + C).
6. Análisis de imágenes potenciado por IA: Describe la imagen
Ahora que nuestro agente puede comprender solicitudes, es hora de darle ojos. En esta sección, desarrollaremos las capacidades de nuestro Agente de Visión, el componente principal responsable de todo el análisis de imágenes. Comenzaremos con su función más importante, la descripción de imágenes, y, luego, agregaremos la capacidad de leer texto.
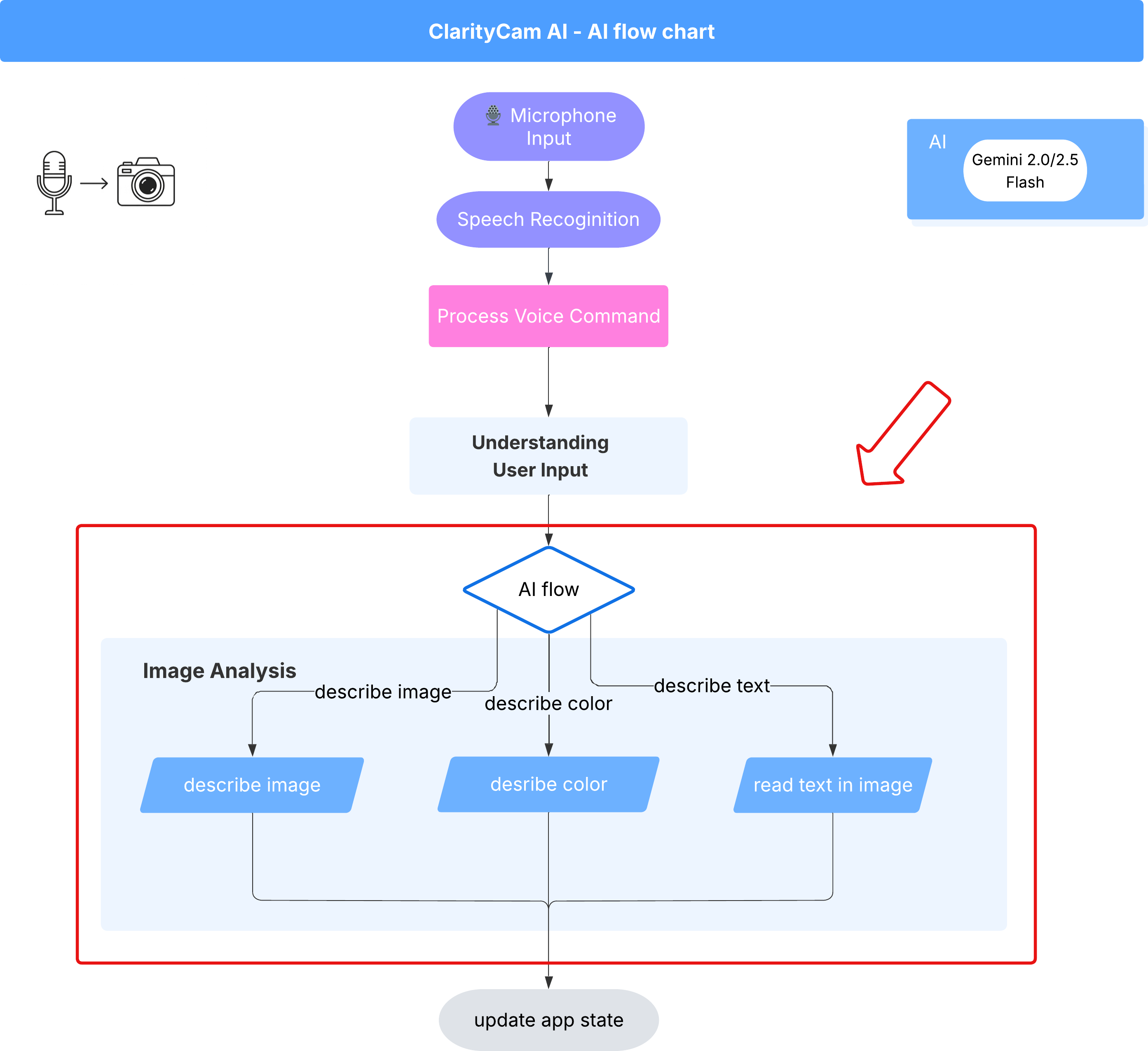
Función 1: Descripción de una imagen
Esta es la función principal del agente. No solo generaremos una descripción estática, sino que crearemos un flujo dinámico que pueda adaptar su nivel de detalle según las preferencias del usuario. Esta es una parte clave de la filosofía de la interfaz adaptable de forma nativa (NAI).
👉 Acción: En tu IDE de Cloud Shell, navega al archivo ~/src/ai/flows/describe_image/ y quita el comentario del siguiente código.
Paso 1: Cómo crear una plantilla de instrucciones dinámicas
Primero, crearemos una plantilla de instrucciones sofisticada que pueda cambiar sus instrucciones según la entrada que reciba.
Quita el comentario del siguiente código
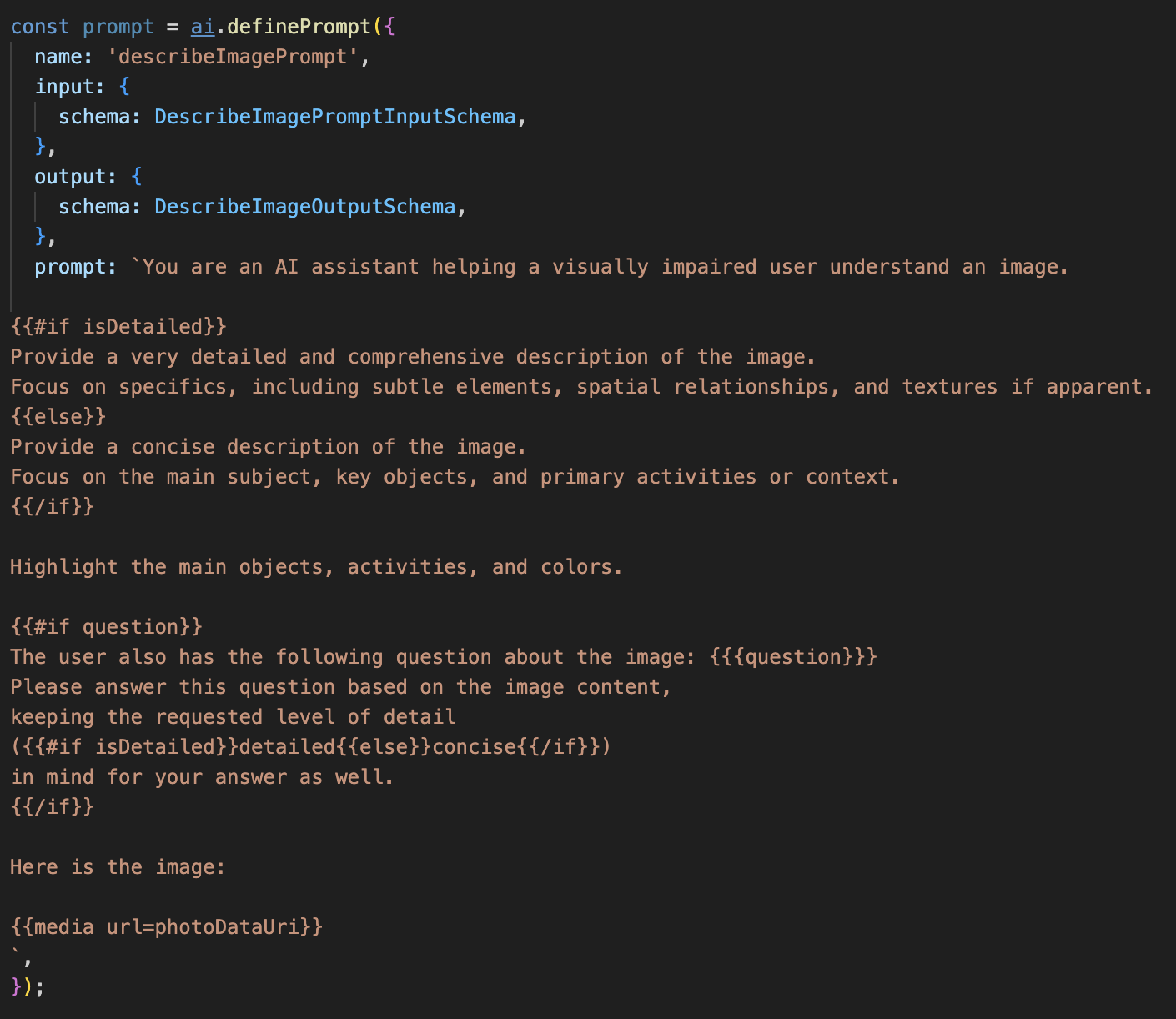
Este código define una variable de cadena, prompt, que usa un lenguaje de plantillas llamado Dot-Mustache. Esto nos permite incorporar lógica condicional directamente en nuestra instrucción.
{#if isDetailed}...{else}...{/if}: Este es un bloque condicional. Si los datos de entrada que enviamos a esta instrucción contienen una propiedad isDetailed: true, la IA recibirá el conjunto de instrucciones "muy detallado". De lo contrario, recibirá las instrucciones "concisas". Así es como nuestro agente se adapta a las preferencias del usuario.
{#if question}...{/if}: Este bloque solo se incluirá si nuestros datos de entrada contienen una propiedad de pregunta. Esto nos permite usar la misma instrucción potente tanto para descripciones generales como para preguntas específicas.
{media url=photoDataUri}: Esta es la sintaxis especial de Genkit para incorporar datos de imágenes directamente en la instrucción para que el modelo multimodal los analice.
Paso 2: Crea el flujo inteligente
A continuación, definimos la instrucción y el flujo que usarán nuestra nueva plantilla. Este flujo contiene un poco de lógica para traducir la preferencia del usuario en un valor booleano que nuestra plantilla pueda comprender.
👉 Acción: En tu IDE de Cloud Shell, en el mismo archivo ~/src/ai/flows/describe_image/, reemplaza el siguiente código. // REPLACE ME PART 1: add flow here
👉 Con el siguiente código:
// Define the prompt using the template from Step 1
const prompt = ai.definePrompt({
name: 'describeImagePrompt',
input: { schema: DescribeImagePromptInputSchema },
output: { schema: DescribeImageOutputSchema },
prompt: promptTemplate,
});
// Define the flow
const describeImageFlow = ai.defineFlow<
typeof DescribeImageInputSchema,
typeof DescribeImageOutputSchema
>(
{
name: 'describeImageFlow',
inputSchema: DescribeImageInputSchema,
outputSchema: DescribeImageOutputSchema,
},
async (pageInput) => {
const preference = pageInput.detailPreference || "concise";
// Prepare the input for the prompt, including the new boolean flag
const promptInputData = {
...pageInput,
isDetailed: preference === "detailed",
};
const { output } = await prompt(promptInputData);
return output!;
}
);
Actúa como un intermediario inteligente entre el frontend y la instrucción de IA.
- Recibe
pageInputde nuestra aplicación, que incluye la preferencia del usuario como una cadena (p.ej.,"detailed"). - Luego, crea un objeto nuevo,
promptInputData. - La línea más importante es
isDetailed: preference === "detailed". Esta línea realiza el trabajo crucial de crear un valor booleanotrueofalsesegún la cadena de preferencia. - Por último, llama a
promptcon estos datos mejorados. La plantilla de instrucciones del paso 1 ahora puede usar el valor booleanoisDetailedpara cambiar de forma dinámica las instrucciones que se envían a la IA.
Paso 3: Conecta el frontend
Ahora, activaremos este flujo desde nuestra interfaz de usuario en page.tsx.
👉Acción: Navega a ~/src/app/ai/flows/describe-image.ts y busca la función export async function describeImage. Quita los comentarios de la sentencia return:
En lugar de return;, haz return describeImageFlow(input);.
👉Acción: En ~/src/app/page.tsx, busca la función handleAnalyze y reemplaza el código // REPLACE ME PART 2: DESCRIBE IMAGE.
👉 con el siguiente código:
case "description":
result = await describeImage({
photoDataUri,
question,
detailPreference: descriptionPreference
});
outputText = question ? `Answer: ${result.description}` : `Description: ${result.description}`;
break;
Cuando la intención del usuario es obtener una descripción, se ejecuta este código. Llama a nuestro flujo describeImage y pasa los datos de la imagen y, lo que es fundamental, la variable de estado descriptionPreference de nuestro componente de React. Esta es la pieza final del rompecabezas, que conecta la preferencia del usuario almacenada en la IU directamente con el flujo de IA que adaptará su comportamiento en consecuencia.
Prueba de la función de descripción de imágenes
Veamos cómo funciona nuestra función de descripción de imágenes, desde la captura de una foto hasta la escucha de lo que ve la IA.
Inicia la aplicación
Primero, volvamos a ejecutar el servidor de desarrollo. 👉 En tu terminal, ejecuta el siguiente comando: npm run dev Nota: Es posible que debas ejecutar npm install antes de ejecutar npm run dev.
Abre la app
Cuando el servidor esté listo, abre tu navegador y navega a la dirección local (p.ej., http://localhost:9003).
Cómo activar la cámara
Haz clic en el botón Comenzar a escuchar y otorga acceso al micrófono si se te solicita. Luego, di tu primer comando:
"Toma una foto".
La aplicación activará la cámara del dispositivo. Ahora deberías ver la transmisión de video en vivo en la pantalla.
Captura la foto
Con la cámara activa, colócala en lo que quieras describir. Ahora, di el comando por segunda vez para capturar la imagen:
"Toma una foto".
El video en vivo se reemplazará por la foto estática que acabas de tomar.
Pide la descripción
Con la nueva foto en la pantalla, da el comando final:
"Describe la imagen".
Escuchar el resultado
La app mostrará un estado de procesamiento y, luego, escucharás la descripción de tu imagen generada por IA. El texto también aparecerá en la tarjeta "Estado y resultado".
Cuando termines, puedes detener la cámara tomando una foto o simplemente detener el servidor en la terminal (Ctrl + C).
7. Análisis de imágenes potenciado por IA: Describe texto (OCR)
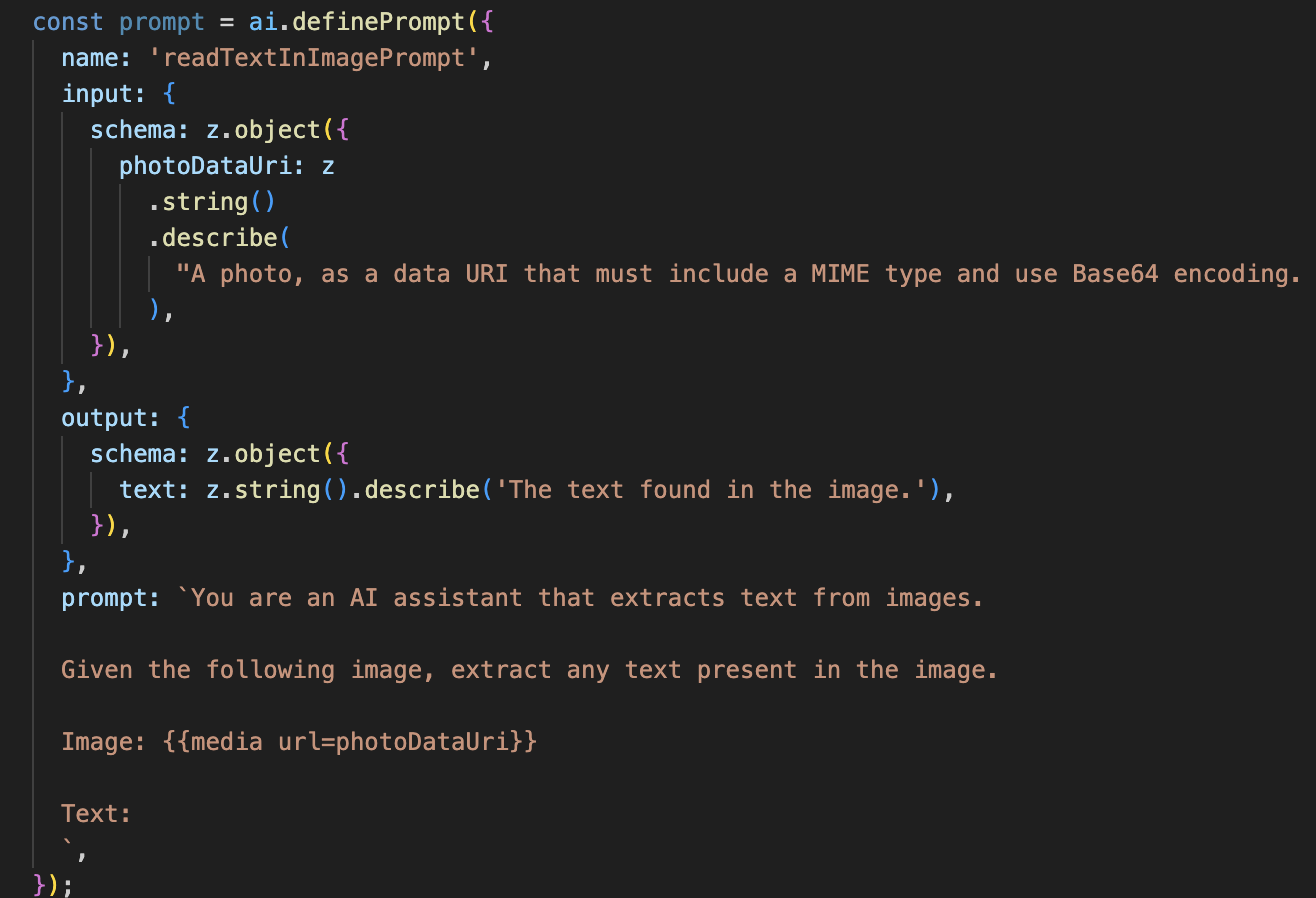
A continuación, agregaremos la capacidad de reconocimiento óptico de caracteres (OCR) a nuestro agente de Vision. Esto le permite leer texto de cualquier imagen.
👉 Acción: En tu IDE, navega a ~/src/ai/flows/read-text-in-image/ y quita el comentario del siguiente código:
👉 Acción: En tu IDE, en el mismo archivo ~/src/ai/flows/read-text-in-image/, reemplaza // REPLACE ME: Creating Prmopt
👉 con el siguiente código:
const readTextInImageFlow = ai.defineFlow<
typeof ReadTextInImageInputSchema,
typeof ReadTextInImageOutputSchema
>(
{
name: 'readTextInImageFlow',
inputSchema: ReadTextInImageInputSchema,
outputSchema: ReadTextInImageOutputSchema,
},
async input => {
const {output} = await prompt(input);
return output!;
}
);
Este flujo de IA es mucho más simple y destaca el principio de usar herramientas enfocadas para trabajos específicos.
- La instrucción: A diferencia de nuestra instrucción de descripción, esta es estática y muy específica. Su único trabajo es indicarle a la IA que actúe como un motor de OCR: "extrae cualquier texto presente en la imagen".
- Los esquemas: Los esquemas de entrada y salida también son simples, ya que esperan una imagen y devuelven una sola cadena de texto.
Cómo conectar el frontend para el OCR
Por último, conectemos esta nueva capacidad en page.tsx.
👉Acción: Navega a ~/src/app/ai/flows/read-text-in-image.ts y busca la función export async function readTextInImage. Quita los comentarios de la sentencia return:
En lugar de return;, haz return readTextInImageFlow(input);.
👉 Acción: En ~/src/app/page.tsx, busca la función handleAnalyze y alrededor de la sentencia switch.
Reemplazar REPLACE ME PART 3: READ TEXT
con el siguiente código:
case "text":
result = await readTextInImage({ photoDataUri });
outputText = result.text ? `Text Found: ${result.text}` : "No text found.";
break;
Este código se activa cuando la intención del usuario es ReadTextInImage. Llama a nuestro flujo readTextInImage simple. La línea result.text ? ... : ... es una forma clara de controlar el resultado, ya que proporciona un mensaje útil al usuario si la IA no pudo encontrar texto en la imagen.
Cómo probar la función de lectura de texto (OCR)
Sigue estos pasos para probar la función de lectura de texto. Recuerda apuntar la cámara a un objeto con texto simple.
- Ejecuta la aplicación con
npm run devy ábrela en tu navegador. - Haz clic en Comenzar a escuchar y otorga acceso al micrófono cuando se te solicite.
- Activa la cámara. Di el comando: "Tomar una foto". Deberías ver el feed de video en vivo en la pantalla.
- Captura la foto. Apunta la cámara hacia el texto que quieres leer y vuelve a decir el comando: "Toma una foto". El video se reemplazará por una foto estática.
- Pídele el texto. Ahora que se capturó una foto, da el comando final: "¿Cuál es el texto de la imagen?".
- Verifica el resultado Después de un momento, la app analizará la foto y leerá el texto detectado en voz alta. Si no encuentra texto, te lo informará.
Esto confirma que la potente función de OCR está funcionando. Cuando termines, detén el servidor con Ctrl + C.
8. Mejoras avanzadas con IA: Solo lectura ✨
Un buen agente de IA puede seguir instrucciones. Un buen agente de IA se siente intuitivo, confiable y útil. En esta sección, nos enfocaremos en tres mejoras avanzadas que potencian las capacidades de nuestro agente.
Exploraremos cómo hacer lo siguiente:
Add Context & Memorypara manejar seguimientos naturales y conversacionalesReduce Hallucinationpara crear un agente más confiable y seguro.Make the Agent Proactivepara brindar una experiencia más accesible y fácil de usarAdd preference settingpara personalizar la descripción de la imagen
Mejora 1: Contexto y memoria
Una conversación natural no es una serie de comandos aislados, sino que fluye. Si un usuario pregunta: "¿Qué hay en la imagen?" y el agente responde: "Un auto rojo", es posible que el usuario pregunte de forma natural: "¿De qué color es?" sin volver a decir "auto". Nuestro agente necesita memoria a corto plazo para comprender este contexto.
Cómo lo implementamos (resumen)
Ya incorporamos esta capacidad en nuestro flujo de describeImage. En esta sección, se resume cómo funciona ese patrón. Cuando llamamos a nuestra función describeImage desde page.tsx, le pasamos el historial de conversación.
👉 Code Showcase (desde page.tsx):
const result = await describeImage({
photoDataUri,
question: commandToProcess,
detailPreference: descriptionPreference,
previousUserQueryOnImage: lastUserQuery ?? undefined,
previousAIResponseOnImage: lastAIResponse ?? undefined,
});
previousUserQueryOnImageypreviousAIResponseOnImage: Estas dos propiedades son la memoria a corto plazo de nuestro agente. Al pasarle la última interacción a la IA, le proporcionamos el contexto necesario para comprender las preguntas de seguimiento vagas o referenciales.- La instrucción adaptable: Este contexto lo usa la instrucción en nuestro flujo de describe_image. La instrucción está diseñada para tener en cuenta la conversación anterior cuando se formula una nueva respuesta, lo que permite que el agente responda de forma inteligente.
Mejora 2: Reducción de alucinaciones
Una IA "alucina" cuando inventa hechos o afirma tener capacidades que no posee. Para generar la confianza de los usuarios, es fundamental que nuestro agente conozca sus propios límites y pueda rechazar con elegancia las solicitudes que están fuera de su alcance.
Cómo lo implementamos (resumen)
La forma más eficaz de evitar las alucinaciones es establecer límites claros para el modelo. Logramos esto cuando creamos nuestro clasificador de intents.
👉 Code Showcase (desde el flujo de intent-classifier):
// Define Agent Capabilities and Limitations for the prompt
const AGENT_CAPABILITIES_AND_LIMITATIONS = `
**Core Capabilities (What the Agent CAN DO):**
* **Image Analysis:**
* DescribeImage: Provide a general description of the current image...
**Limitations (What the Agent CANNOT DO...):**
* Cannot generate or create new images.
* Cannot provide general knowledge or answer questions unrelated to the image...
* Cannot perform web searches.
`;
Esta constante actúa como una "descripción del trabajo" que le proporcionamos a la IA en la instrucción de clasificación.
- Fundamentación del modelo: Al indicarle explícitamente a la IA lo que no puede hacer, la "fundamentamos" en la realidad. Cuando ve una búsqueda como "¿Cómo está el clima?", puede relacionarla con confianza con su lista de limitaciones y clasificar la intención como OutOfScopeRequest.
- Generar confianza: Un agente que puede decir con honestidad "No puedo ayudarte con eso" es mucho más confiable que uno que intenta adivinar y se equivoca. Este es un principio fundamental del diseño de IA segura y confiable. `
Mejora 3: Crea un agente proactivo
En el caso de una aplicación que prioriza la accesibilidad, no podemos depender de las indicaciones visuales. Cuando un usuario activa el modo de escucha, necesita una confirmación inmediata y no visual de que el agente está listo y esperando un comando. Ahora agregaremos una introducción proactiva para proporcionar esta retroalimentación crucial.
Paso 1: Agrega un estado para hacer un seguimiento de la primera escucha
Primero, necesitamos una forma de saber si es la primera vez que el usuario presiona el botón "Start Listening" durante su sesión.
👉 En ~/src/app/page.tsx, verás la siguiente variable de estado nueva cerca de la parte superior de tu componente ClarityCam.
export default function ClarityCam() {
// ... other state variables
const [descriptionPreference, setDescriptionPreference] = useState<DescriptionPreference>("concise");
// Add this new line
const [isFirstListen, setIsFirstListen] = useState(true);
// ... rest of the component
}
Presentamos una nueva variable de estado, isFirstListen, y la inicializamos en true. Usaremos esta marca para activar nuestro mensaje de bienvenida único.
Paso 2: Actualiza la función toggleListening
Ahora, modifiquemos la función que controla el micrófono para que reproduzca nuestro saludo.
👉 En ~/src/app/page.tsx, busca la función toggleListening y observa el siguiente bloque if.
const toggleListening = useCallback(() => {
// ... existing logic to setup speech recognition
if (isListening || isAttemptingStart) {
// ... existing logic to stop listening
} else {
stopSpeaking(); // Stop any ongoing TTS
// Add this new block
if (isFirstListen) {
setIsFirstListen(false);
const introMessage = "Hello! I am ClarityCam, your AI assistant. I'm now listening. You can ask me to 'describe the image', 'read text', 'take a picture', or ask questions about what's in an image.";
speakText(introMessage);
} else {
speakText("Listening..."); // Optional: provide feedback on subsequent clicks
}
// ... rest of the logic to start listening
}
}, [/*...existing dependencies...*/, isFirstListen]); // Don't forget to add isFirstListen to the dependency array!
- Verifica la marca: El bloque if (isFirstListen) verifica si esta es la primera activación.
- Prevent Repetition: Lo primero que hace dentro del bloque es llamar a setIsFirstListen(false). Esto garantiza que el mensaje introductorio solo se reproduzca una vez por sesión.
- Brindar orientación: El mensaje de introducción se redacta cuidadosamente para que sea lo más útil posible. Saluda al usuario, identifica al agente por su nombre, confirma que ahora está activo ("Te estoy escuchando") y proporciona ejemplos claros de los comandos por voz que puede usar.
- Comentarios de audio: Por último, speakText(introMessage) entrega esta información crucial, lo que proporciona seguridad y orientación inmediatas sin necesidad de que el usuario vea la pantalla.
Mejora 4: Adaptación a las preferencias del usuario (recapitulación)
Un agente verdaderamente inteligente no solo responde, sino que aprende y se adapta a las necesidades del usuario. Una de las funciones más potentes que creamos es la capacidad del usuario de cambiar la verbosidad de las descripciones de imágenes sobre la marcha con comandos como "Sé más detallado".
Cómo la implementamos (recapitulativo) Esta capacidad se basa en la instrucción dinámica que creamos para nuestro flujo de describeImage. Utiliza lógica condicional para cambiar las instrucciones que se envían a la IA según las preferencias del usuario.
👉 Code Showcase (el promptTemplate de describe_image):
const settingPreferenceTemplate = `
{#if isDetailed}
Provide a very detailed and comprehensive description of the image. Focus on specifics, including subtle elements, spatial relationships, and textures if apparent.
{else}
Provide a concise description of the image. Focus on the main subject, key objects, and primary activities or context.
{/if}
Highlight the main objects, activities, and colors.
...
`;
- Lógica condicional: El bloque
{#if isDetailed}...{else}...{/if}es la clave. Cuando nuestro flujo describeImageFlow recibe el parámetro detailPreference del frontend, crea un valor booleano isDetailed (verdadero o falso). - Instrucciones adaptativas: Esta marca booleana determina qué conjunto de instrucciones recibe el modelo de IA. Si isDetailed es verdadero, se le indica al modelo que sea muy descriptivo. Si es falso, se le indica que sea conciso.
- Control del usuario: Este patrón conecta directamente un comando por voz del usuario (p.ej., "Haz que las descripciones sean concisas", que se clasifica como la intención SetDescriptionConcise) con un cambio fundamental en el comportamiento de la IA, lo que hace que el agente se sienta verdaderamente responsivo y personalizado.
9. Implementación en la nube
Compila la imagen de Docker con Google Cloud Build
gcloud builds submit . --tag gcr.io/$PROJECT_ID/accessibilityai-nextjs-app:latest
accessibilityai-nextjs-appes un nombre de imagen sugerido.- El archivo ZIP usa el directorio actual (
accessibilityAI/) como la fuente de compilación.
Implementa la imagen en Google Cloud Run
- Asegúrate de que tus claves de API y otros secretos estén listos en Secret Manager. Por ejemplo,
GOOGLE_GENAI_API_KEY.
Reemplaza este YOUR_ACTUAL_GOOGLE_AI_KEY_VALUE por el valor real de tu clave de API de Gemini.
echo "YOUR_ACTUAL_GOOGLE_AI_KEY_VALUE" | gcloud secrets create GOOGLE_GENAI_API_KEY --data-file=- --project=YOUR_PROJECT_ID
Otorga a la cuenta de servicio del entorno de ejecución de tu servicio de Cloud Run (p.ej., PROJECT_NUMBER-compute@developer.gserviceaccount.com o una cuenta dedicada) el rol de "Secret Manager Secret Accessor" para este secreto.
- Comando de implementación:
gcloud run deploy accessibilityai-app-service \
--image gcr.io/$PROJECT_ID/accessibilityai-nextjs-app:latest \
--platform managed \
--region us-central1 \
--allow-unauthenticated \
--port 3000 \
--set-secrets=GOOGLE_GENAI_API_KEY=GOOGLE_GENAI_API_KEY:latest \
--set-env-vars NODE_ENV="production"