
1. Introduction
Dans ce tutoriel, vous allez créer ClarityCam, un agent d'IA mains libres et à commande vocale qui peut voir le monde et vous l'expliquer. Bien que ClarityCam soit conçu avec l'accessibilité comme principe fondamental (il s'agit d'un outil puissant pour les utilisateurs aveugles et malvoyants), les principes que vous apprendrez sont essentiels pour créer n'importe quelle application vocale moderne à usage général.

Ce projet repose sur une puissante philosophie de conception appelée Interface nativement adaptative (NAI). Au lieu de considérer l'accessibilité comme une réflexion secondaire, NAI en fait le fondement. Avec cette approche, l'agent IA est l'interface. Il s'adapte aux différents utilisateurs, gère les entrées multimodales comme la voix et la vision, et guide les personnes de manière proactive en fonction de leurs besoins spécifiques.
Créer votre premier agent d'IA avec NAI :

À la fin de cette session, vous saurez :
- Concevez des systèmes d'IA en intégrant l'accessibilité par défaut : appliquez les principes de l'interface nativement adaptative (NAI) pour créer des systèmes d'IA qui offrent des expériences équivalentes à tous les utilisateurs.
- Classifier l'intention de l'utilisateur : créez un classificateur d'intention robuste qui traduit les commandes en langage naturel en actions structurées pour votre agent.
- Maintenir le contexte conversationnel : implémentez une mémoire à court terme pour permettre à votre agent de comprendre les questions complémentaires et les commandes référentielles (par exemple, "De quelle couleur est-il ?").
- Concevez des requêtes efficaces : créez des requêtes ciblées et riches en contexte pour un modèle multimodal comme Gemini afin de garantir une analyse d'image précise et fiable.
- Gérer l'ambiguïté et guider l'utilisateur : concevez une gestion des erreurs élégante pour les requêtes hors champ et intégrez les utilisateurs de manière proactive pour renforcer la confiance.
- Orchestrer un système multi-agents : structurez votre application à l'aide d'une collection d'agents spécialisés qui collaborent pour gérer des tâches complexes telles que le traitement, l'analyse et la synthèse vocale.
2. Conception de haut niveau
ClarityCam est conçu pour être simple à utiliser, mais il repose sur un système sophistiqué d'agents IA collaboratifs. Décomposons l'architecture.

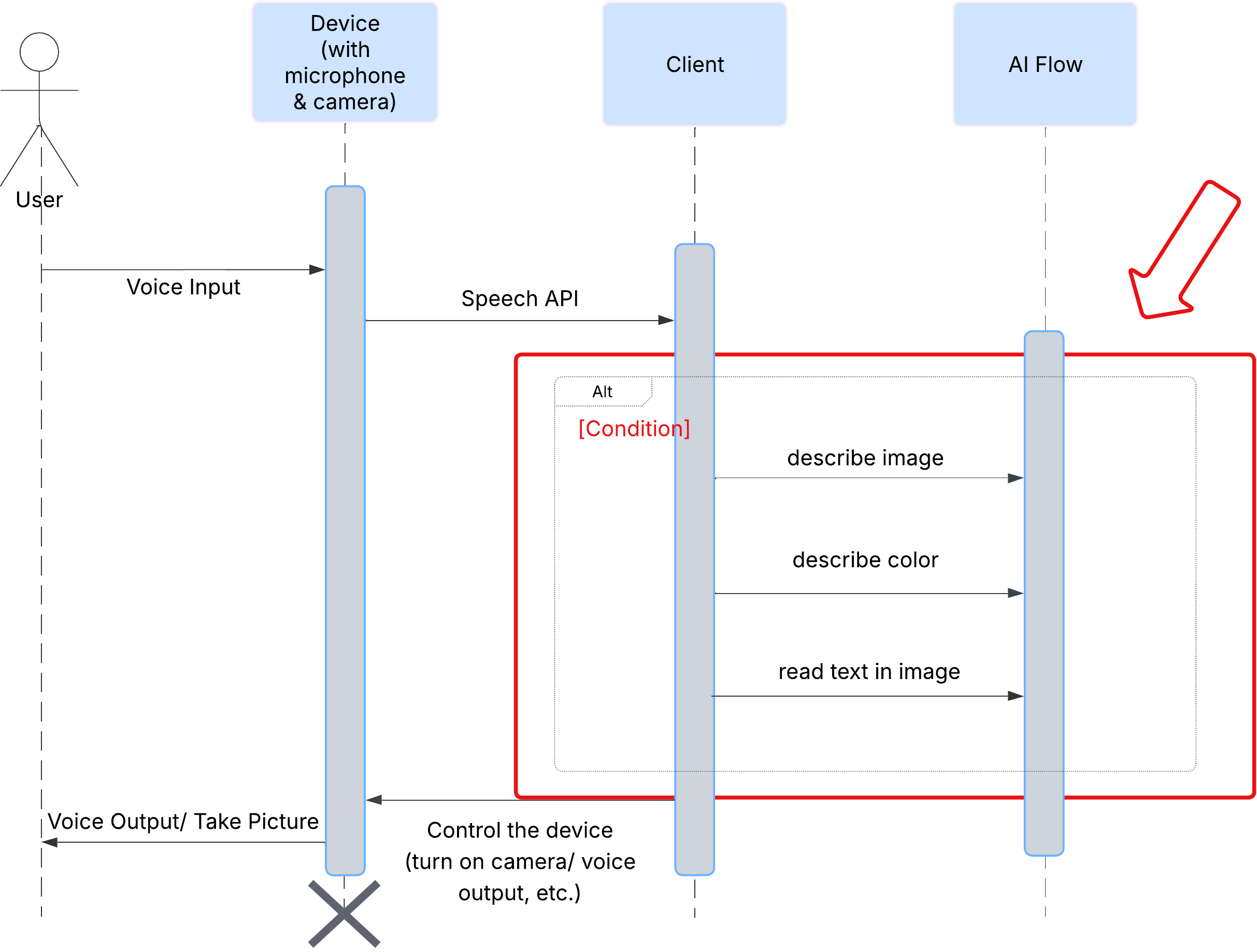
Expérience utilisateur
Commençons par examiner comment un utilisateur interagit avec ClarityCam. L'ensemble de l'expérience est mains libres et conversationnel. L'utilisateur énonce une commande et l'agent répond par une description ou une action vocale. Ce diagramme de séquence montre un flux d'interaction typique, de la commande vocale initiale de l'utilisateur à la réponse audio finale de l'appareil.
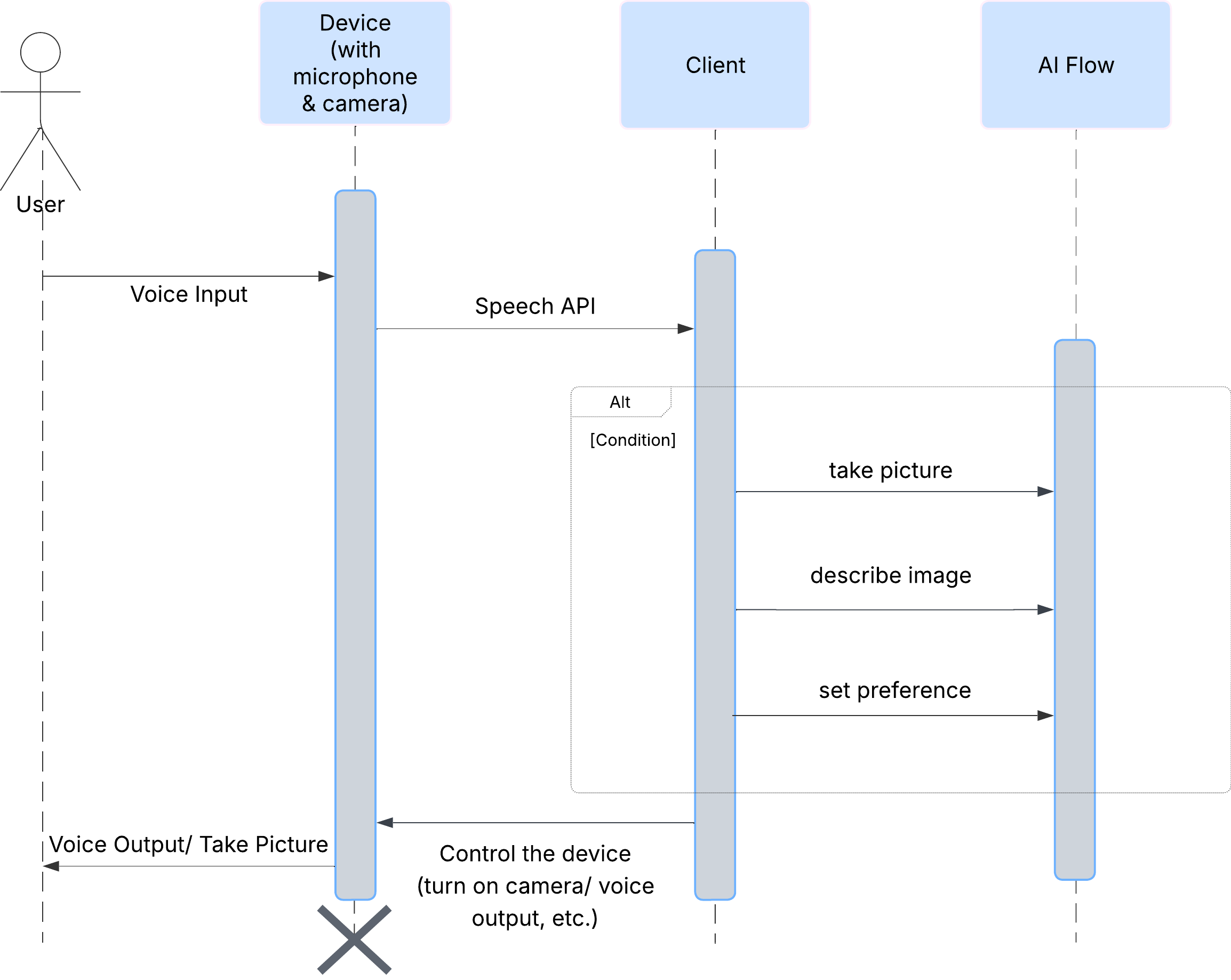
Architecture de l'agent IA
Sous la surface, un système multi-agent fonctionne de concert pour donner vie à l'expérience. Lorsqu'une commande est reçue, un agent Orchestrator central délègue des tâches à des agents spécialisés chargés de comprendre l'intention, d'analyser les images et de formuler une réponse. Ce diagramme de flux d'IA explique en détail comment ces agents collaborent. Nous allons implémenter cette architecture dans les sections suivantes.
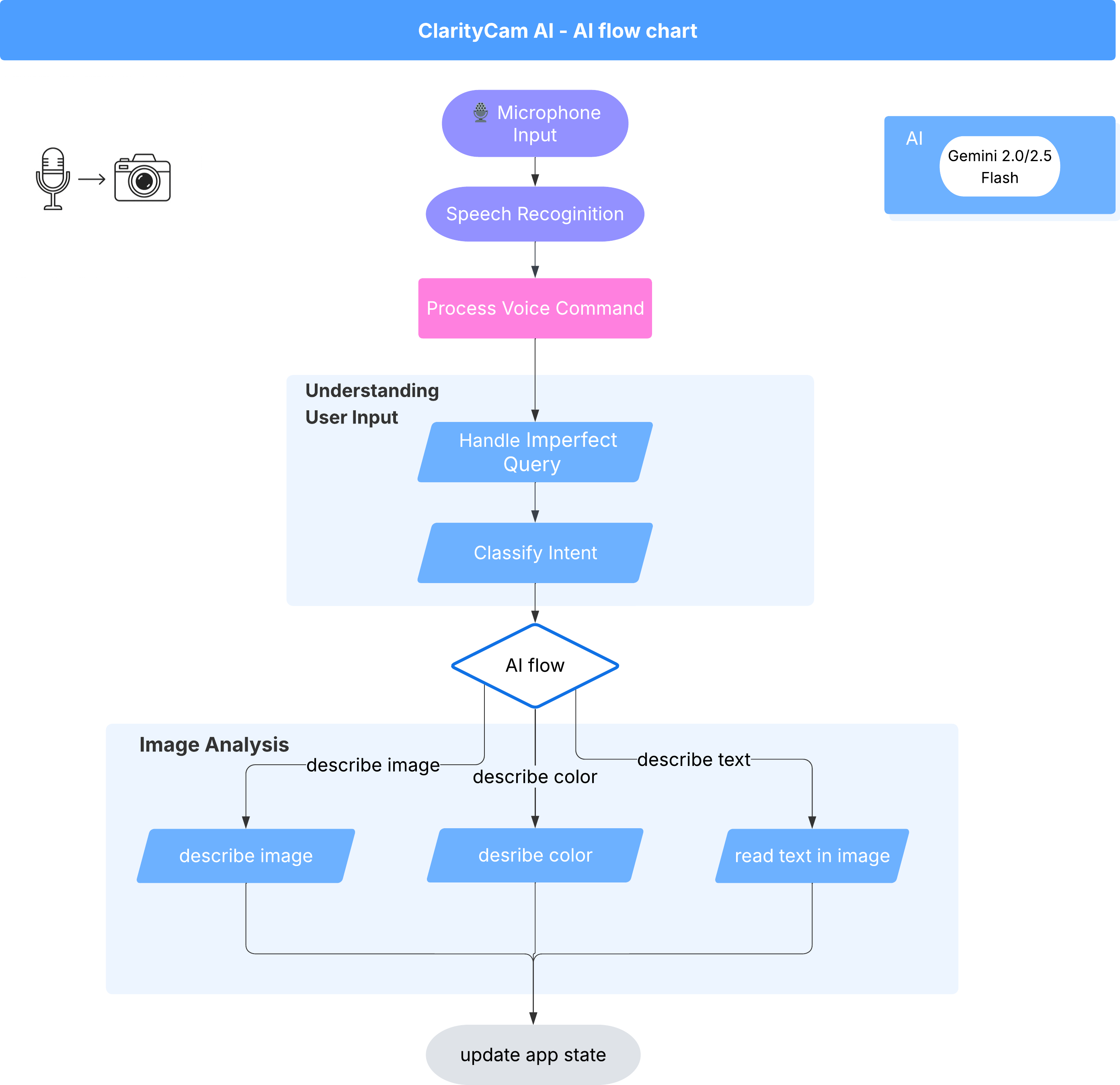
Présentation rapide des fichiers du projet
Avant de commencer à écrire du code, familiarisons-nous avec la structure des fichiers de notre projet. Il peut sembler qu'il y a beaucoup de fichiers, mais vous n'avez besoin de vous concentrer que sur deux zones spécifiques pour l'ensemble de ce tutoriel.
Voici une carte simplifiée de notre projet.
accessibilityAI/src/
├── 📁 app/
│ ├── layout.tsx # An overall page shell (you can ignore this).
│ └── page.tsx # ⬅️ MODIFY THIS: The main user interface for our app.
│
├── 📁 ai/
│ ├── 📁flows # ⬅️ MODIFY THIS: The core AI logic and server functions.
│ └── intent-classifier.ts # ⬅️ MODIFY THIS: Where we'll edit our AI prompts.
| └── ai-instance.ts
| └── dev.ts
│
├── 📁 components/ # Contains pre-built UI components (ignore this).
│
├── 📁 hooks/
│
├── 📁 lib/
│
└── 📁 types/
Pile technologique
Notre système repose sur une pile technologique moderne et évolutive qui combine des services cloud puissants et des modèles d'IA de pointe. Voici les principaux composants que nous allons utiliser :
- Google Cloud Platform (GCP) : fournit l'infrastructure sans serveur pour nos agents.
- Cloud Run : déploie nos agents individuels sous forme de microservices conteneurisés et évolutifs.
- Artifact Registry : stocke et gère de manière sécurisée les images Docker de nos agents.
- Secret Manager : gère de manière sécurisée les identifiants et les clés API sensibles.
- Grands modèles de langage (LLM) : ils agissent comme le "cerveau" du système.
- Modèles Gemini de Google : nous utilisons les puissantes capacités multimodales de la famille Gemini pour tout, de la classification de l'intention de l'utilisateur à l'analyse du contenu des images et à la fourniture de descriptions intelligentes.
3. Configuration et prérequis
Activer un compte de facturation : pour suivre cet atelier de programmation, vous avez besoin d'un compte de facturation avec un certain crédit. Utilisez les crédits de la bannière en haut de cet atelier de programmation pour commencer. Si vous êtes déjà associé à un compte de facturation, vous pouvez ignorer cette étape.
Créer un projet GCP
- Accédez à la console Google Cloud et créez un projet.
- Accédez à la console Google Cloud et créez un projet.
- Ouvrez le panneau de gauche, cliquez sur
Billinget vérifiez si le compte de facturation est associé à ce compte GCP.
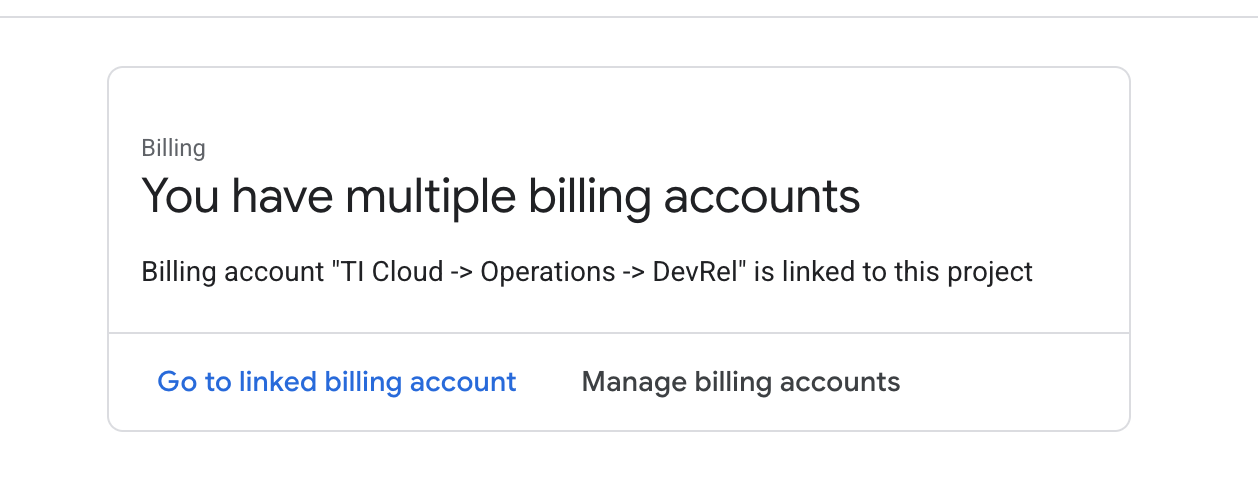
Si cette page s'affiche, cochez la case manage billing account, puis sélectionnez l'essai Google Cloud et associez-le.
Créer votre clé API Gemini
Avant de pouvoir sécuriser une clé, vous devez en avoir une.
- Accédez à Google AI Studio : https://aistudio.google.com/.
- Connectez-vous à l'aide de votre compte Google.
- Cliquez sur le bouton Obtenir une clé API, généralement situé dans le volet de navigation de gauche ou en haut à droite.
- Dans la boîte de dialogue Clés API, cliquez sur "Créer une clé API dans un nouveau projet".
- Une nouvelle clé API sera générée pour vous. Copiez immédiatement cette clé et stockez-la temporairement dans un endroit sûr (comme un gestionnaire de mots de passe ou une note sécurisée). Il s'agit de la valeur que vous utiliserez dans les étapes suivantes.
Workflow de développement local (test sur votre ordinateur)
Vous devez pouvoir exécuter npm run dev et faire fonctionner votre application. C'est là qu'intervient .env.
- Ajoutez la clé API au fichier : créez un fichier appelé
.envet ajoutez-y la ligne suivante.
Veillez à remplacer YOUR_API_KEY_HERE par la clé que vous avez obtenue dans AI Studio et enregistrée dans .env :
GOOGLE_GENAI_API_KEY="YOUR_API_KEY_HERE"
[Facultatif] Configurer l'IDE et l'environnement
Pour ce tutoriel, vous pouvez travailler dans un environnement de développement familier comme VS Code ou IntelliJ avec votre terminal local. Toutefois, nous vous recommandons vivement d'utiliser Google Cloud Shell pour garantir un environnement standardisé et préconfiguré.
Les étapes suivantes sont écrites pour le contexte Cloud Shell. Si vous choisissez d'utiliser votre environnement local, assurez-vous que git, nvm, npm et gcloud sont installés et correctement configurés.
Travailler dans l'éditeur Cloud Shell
👉 Cliquez sur Activer Cloud Shell en haut de la console Google Cloud (icône en forme de terminal en haut du volet Cloud Shell),  .
.
👉 Cliquez sur le bouton "Ouvrir l'éditeur" (icône en forme de dossier ouvert avec un crayon). L'éditeur de code Cloud Shell s'ouvre dans la fenêtre. Un explorateur de fichiers s'affiche sur la gauche. 
👉 Cliquez sur le bouton Cloud Code – Se connecter dans la barre d'état inférieure (voir ci-dessous). Autorisez le plug-in comme indiqué. Si Cloud Code – Aucun projet est affiché dans la barre d'état, cliquez dessus. Dans le menu déroulant "Sélectionner un projet Google Cloud", sélectionnez le projet Google Cloud que vous avez créé. 
👉 Ouvrez le terminal dans l'IDE cloud,  .
.
👉 Dans le terminal, vérifiez que vous êtes déjà authentifié et que le projet est défini sur votre ID de projet à l'aide de la commande suivante :
gcloud auth list
👉 Clonez le projet natively-accessible-interface à partir de GitHub :
git clone https://github.com/cuppibla/AccessibilityAgent.git
👉 Exécutez la commande en veillant à remplacer <YOUR_PROJECT_ID> par l'ID de votre projet (vous le trouverez dans la console Google Cloud, dans la section "Projet"). ❗️❗️Veillez à ne pas confondre project id et project number.❗️❗️
echo <YOUR_PROJECT_ID> > ~/project_id.txt
gcloud config set project $(cat ~/project_id.txt)
👉 Exécutez la commande suivante pour activer les API Google Cloud nécessaires (l'exécution peut prendre environ deux minutes) :
gcloud services enable compute.googleapis.com \
storage.googleapis.com \
run.googleapis.com \
artifactregistry.googleapis.com \
aiplatform.googleapis.com \
eventarc.googleapis.com \
sqladmin.googleapis.com \
secretmanager.googleapis.com \
cloudbuild.googleapis.com \
cloudresourcemanager.googleapis.com \
cloudfunctions.googleapis.com \
cloudaicompanion.googleapis.com
Cette opération peut prendre quelques minutes.
Configurer les autorisations
👉 Configurez les autorisations du compte de service. Dans le terminal, exécutez la commande suivante :
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
export SERVICE_ACCOUNT_NAME=$(gcloud compute project-info describe --format="value(defaultServiceAccount)")
echo "Here's your SERVICE_ACCOUNT_NAME $SERVICE_ACCOUNT_NAME"
👉 Accorder des autorisations. Dans le terminal, exécutez la commande suivante :
#Cloud Storage (Read/Write):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/storage.objectAdmin"
#Pub/Sub (Publish/Receive):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/pubsub.publisher"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/pubsub.subscriber"
#Cloud SQL (Read/Write):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/cloudsql.editor"
#Eventarc (Receive Events):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/iam.serviceAccountTokenCreator"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/eventarc.eventReceiver"
#Vertex AI (User):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/aiplatform.user"
#Secret Manager (Read):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/secretmanager.secretAccessor"
4. Comprendre les entrées utilisateur : classificateur d'intention
Avant que notre agent IA puisse agir, il doit d'abord comprendre précisément ce que l'utilisateur souhaite. Les entrées du monde réel sont souvent désordonnées : elles peuvent être vagues, contenir des fautes de frappe ou utiliser un langage conversationnel.
Dans cette section, nous allons créer les composants d'"écoute" essentiels qui transforment les entrées utilisateur brutes en commandes claires et exploitables.
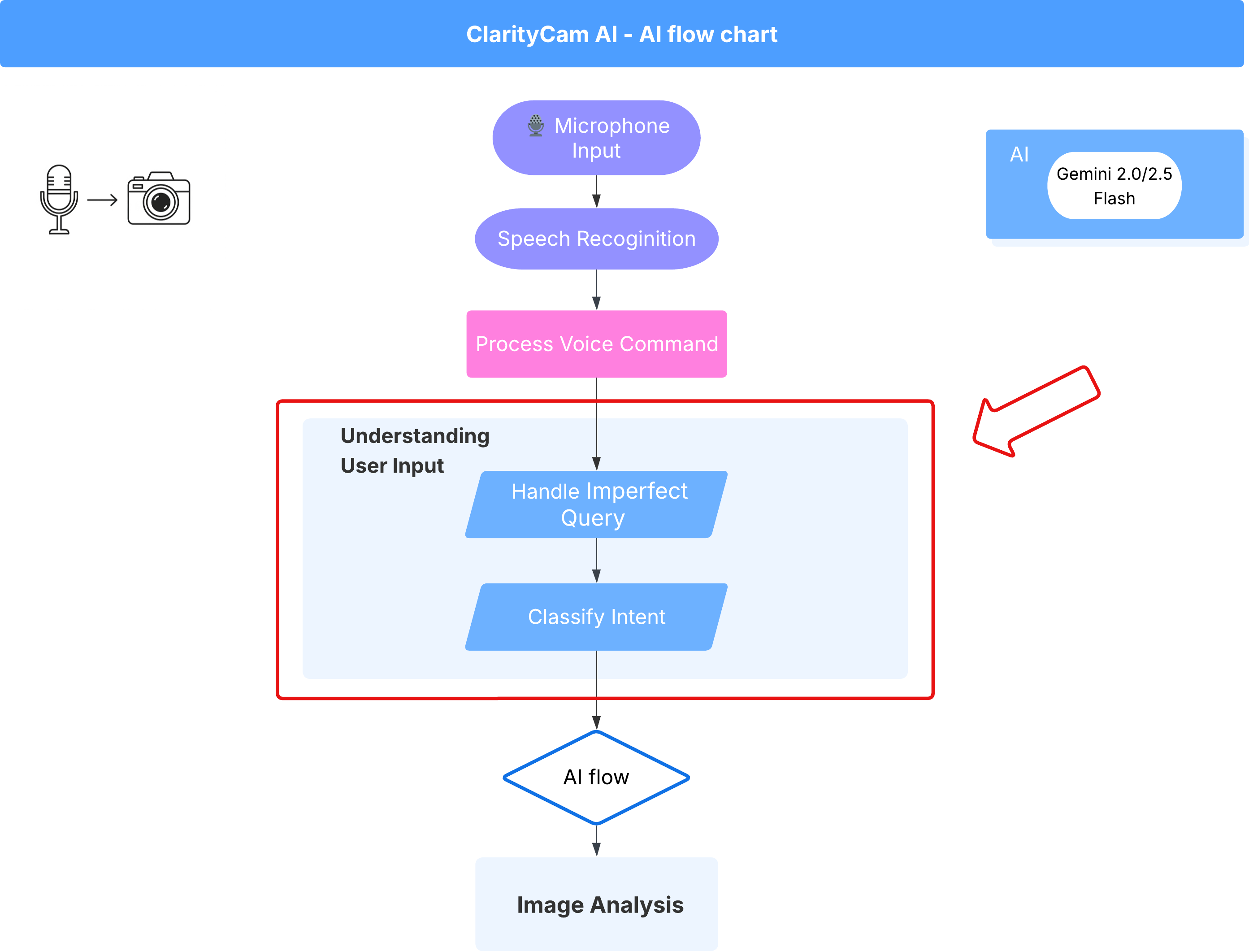
Ajouter un classificateur d'intent
Nous allons maintenant définir la logique d'IA qui alimente notre classificateur.
👉 Action : Dans votre IDE Cloud Shell, accédez au répertoire ~/src/ai/intent-classifier/.
Étape 1 : Définir le vocabulaire de l'agent (IntentCategory)
Tout d'abord, nous devons créer une liste exhaustive de toutes les actions possibles de notre agent.
👉 Action : Remplacez l'espace réservé // REPLACE ME PART 1: add IntentCategory here par le code suivant :
👉 avec le code ci-dessous :
export type IntentCategory =
// Image Analysis Intents
| "DescribeImage"
| "AskAboutImage"
| "ReadTextInImage"
| "IdentifyColorsInImage"
// Control Intents
| "TakePicture"
| "StartCamera"
| "SelectImage"
| "StopSpeaking"
// Preference Intents
| "SetDescriptionDetailed"
| "SetDescriptionConcise"
// Fallback Intents
| "GeneralInquiry" // User has a general question about the agent's functions or polite interaction
| "OutOfScopeRequest" // User's request is clearly outside the agent's defined capabilities
| "Unknown"; // Intent could not be determined with confidence
Explication
Ce code TypeScript crée un type personnalisé appelé IntentCategory. Il s'agit d'une liste stricte qui définit toutes les actions ou "intents" possibles que notre agent peut comprendre. Il s'agit d'une première étape cruciale, car elle transforme un nombre potentiellement infini d'expressions utilisateur ("dis-moi ce que tu vois", "qu'y a-t-il sur la photo ?") en un ensemble de commandes clair et prévisible. L'objectif de notre classificateur est de mapper toute requête utilisateur à l'une de ces catégories spécifiques.
Étape 2
Pour prendre des décisions précises, notre IA doit connaître ses propres capacités et limites. Nous vous fournirons ces informations sous la forme d'un bloc de texte détaillé.
👉 Action : Remplacez l'espace réservé REPLACE ME PART 2 : add AGENT_CAPABILITIES_AND_LIMITATIONS here par le code suivant :
Remplacez le code ci-dessous : // REPLACE ME PART 2: add AGENT_CAPABILITIES_AND_LIMITATIONS here :
👉 avec le code ci-dessous
const AGENT_CAPABILITIES_AND_LIMITATIONS = `
**Core Capabilities (What the Agent CAN DO):**
* **Image Analysis:**
* DescribeImage: Provide a general description of the current image.
* AskAboutImage: Answer a specific question about the visual content of the current image (e.g., "Is there a dog?", "What color is the car?").
* ReadTextInImage: Read any text found in the current image.
* IdentifyColorsInImage: Identify the dominant colors of the current image.
* **Image Input Control:**
* TakePicture: Capture an image using the currently active camera stream.
* StartCamera: Activate the camera (e.g., "use camera", "take another picture").
* SelectImage: Allow the user to choose an image file from their device.
* **Voice & Audio Control:**
* StopSpeaking: Stop the current text-to-speech output.
* **Preference Management:**
* SetDescriptionDetailed: Make future image descriptions more detailed.
* SetDescriptionConcise: Make future image descriptions less detailed or concise.
* **General Interaction:**
* GeneralInquiry: Handle conversational phrases (e.g., "hello", "thank you") or questions about its own capabilities (e.g., "what can you do?", "help").
**Limitations (What the Agent CANNOT DO and should be classified as OutOfScopeRequest):**
* Cannot generate or create new images.
* Cannot edit or modify existing images (e.g., "remove background," "make the car blue").
* Cannot analyze video files or live video beyond capturing a single frame.
* Cannot provide general knowledge or answer questions unrelated to the provided image's visual content (e.g., "What's the weather?", "Who is the president?", "Tell me a joke", "What time is it?").
* Cannot perform mathematical calculations or complex data analysis.
* Cannot translate languages as a primary function.
* Cannot remember information from past images or vastly different previous queries in the same session.
* Cannot control other device settings or applications.
* Cannot perform web searches.
`;
Pourquoi est-ce important ?
Ce texte n'est pas destiné à l'utilisateur, mais à notre modèle d'IA. Nous allons directement insérer cette "description du poste" dans notre requête (à l'étape suivante) pour fournir au modèle de langage (LLM) le contexte dont il a besoin pour prendre des décisions précises. Sans ce contexte, le LLM peut classer à tort "Quel temps fait-il ?" comme AskAboutImage. Grâce à ce contexte, il sait que la météo n'est pas un élément visuel de l'image et la classe correctement comme hors champ.
Étape 3
Nous allons maintenant écrire l'ensemble complet d'instructions que le modèle Gemini suivra pour effectuer la classification.
👉 Action : Remplacez // REPLACE ME PART 3 - classifyIntentPrompt par le code suivant :
avec le code ci-dessous.
const classifyIntentPrompt = ai.definePrompt({
name: 'classifyIntentPrompt',
input: { schema: ClassifyIntentInputSchema },
output: { schema: ClassifyIntentOutputSchema },
prompt: `You are classifying the user's intent for ClarityCam, a voice-controlled AI application focused on image analysis.
Analyze the user query: '{userQuery}'.
First, understand ClarityCam's capabilities and limitations:
${AGENT_CAPABILITIES_AND_LIMITATIONS}
Now, classify the user's PRIMARY intent into ONE of the following categories:
* **DescribeImage**: User wants a general description of the current image.
* **AskAboutImage**: User is asking a specific question directly related to the visual content of the current image.
* **ReadTextInImage**: User wants any text read from the current image.
* **IdentifyColorsInImage**: User wants the dominant colors of the current image.
* **TakePicture**: User wants to capture an image using an active camera.
* **StartCamera**: User wants to activate the camera.
* **SelectImage**: User wants to choose an image file.
* **StopSpeaking**: User wants the current text-to-speech output to stop.
* **SetDescriptionDetailed**: User wants future image descriptions to be more detailed.
* **SetDescriptionConcise**: User wants future image descriptions to be less detailed.
* **GeneralInquiry**: The query is a simple conversational filler (e.g., "hello", "thanks"), a polite closing, or a direct question about the agent's functions (e.g., "what can you do?", "how does this work?", "help").
* **OutOfScopeRequest**: The query asks the agent to perform an action clearly listed under its "Limitations" or otherwise demonstrably outside its defined image analysis and control functions. Examples: "Tell me a joke," "What's the weather in London?", "Generate an image of a cat," "Can you edit my photo to make it brighter?", "Send this image to my friends","Translate 'hello' to Spanish."
Output ONLY the category name.
If the query is ambiguous but seems generally related to polite interaction or asking about the agent itself, prefer 'GeneralInquiry'.
If the query is clearly asking for something the agent CANNOT do, use 'OutOfScopeRequest'.
If truly unclassifiable even with these guidelines, use 'Unknown'.`,
config: {
temperature: 0.05, // Very low temperature for highly deterministic classification
}
});
C'est dans cette requête que la magie opère. C'est le "cerveau" de notre classificateur. Il indique à l'IA son rôle, lui fournit le contexte nécessaire et définit le résultat souhaité. Voici quelques techniques clés d'ingénierie des requêtes :
- Jeu de rôle : la tâche est clairement définie par la phrase "Vous devez classer…".
- Injection de contexte : elle insère dynamiquement la variable
AGENT_CAPABILITIES_AND_LIMITATIONSdans la requête. - Mise en forme stricte de la sortie : l'instruction "N'affichez QUE le nom de la catégorie" est essentielle pour obtenir une réponse claire et prévisible que nous pouvons facilement utiliser dans notre code.
- Température basse : pour la classification, nous souhaitons obtenir des réponses déterministes et logiques, et non créatives. Définir la température sur une valeur très faible (0,05) garantit que le modèle est très concentré et cohérent.
Étape 4 : Connectez l'application au flux d'IA
Enfin, appelons notre nouveau classificateur d'IA à partir du fichier d'application principal.
👉 Action : Accédez à votre fichier ~/src/app/page.tsx. Dans la fonction processVoiceCommand, remplacez // REPLACE ME PART 1: add classificationResult par ce qui suit :
const classificationResult = await classifyIntentFlow({ userQuery: commandToProcess });
intent = classificationResult.intent as IntentCategory;
Ce code constitue le pont essentiel entre votre application frontend et votre logique d'IA backend. Il prend la commande vocale de l'utilisateur (commandToProcess), l'envoie au classifyIntentFlow que vous venez de créer et attend que l'IA renvoie l'intention classée.
La variable d'intention contient désormais une commande propre et structurée (comme DescribeImage). Ce résultat sera utilisé dans l'instruction switch qui suit pour piloter la logique de l'application et décider de la prochaine action à effectuer. C'est ainsi que la "pensée " de l'IA se transforme en "action " de l'application.
Lancer l'interface utilisateur
Il est temps de voir notre application en action ! Démarrons le serveur de développement.
👉 Dans votre terminal, exécutez la commande suivante : npm run dev Remarque : Vous devrez peut-être exécuter npm install avant d'exécuter npm run dev.
Au bout d'un moment, un résultat semblable à celui-ci s'affiche, ce qui signifie que le serveur fonctionne correctement :
▲ Next.js 15.2.3 (Turbopack)
- Local: http://localhost:9003
- Network: http://10.88.0.4:9003
- Environments: .env
✓ Starting...
✓ Ready in 1512ms
○ Compiling / ...
✓ Compiled / in 26.6s
Cliquez ensuite sur l'URL locale (http://localhost:9003) pour ouvrir l'application dans votre navigateur.
L'interface utilisateur de SightGuide devrait s'afficher. Pour l'instant, les boutons ne sont associés à aucune logique. Par conséquent, cliquer dessus n'aura aucun effet. C'est exactement ce à quoi nous nous attendons à ce stade. Nous allons les mettre en œuvre dans la section suivante.
Maintenant que vous avez vu l'UI, revenez à votre terminal et appuyez sur Ctrl + C pour arrêter le serveur de développement avant de continuer.
5. Comprendre les saisies utilisateur : vérification imparfaite des requêtes
Ajouter la vérification des requêtes imparfaites
Partie 1 : Définir la requête (le "quoi")
Commençons par définir les instructions pour notre IA. La requête est la "recette" de notre appel d'IA. Elle indique au modèle exactement ce que nous voulons qu'il fasse.
👉 Action : Dans votre IDE, accédez à ~/src/ai/flows/check_typo/.
Remplacez le code ci-dessous : // REPLACE ME PART 1: add prompt here :
👉 avec le code ci-dessous
const prompt = ai.definePrompt({
name: 'checkTypoPrompt',
input: {
schema: CheckTypoInputSchema,
},
output: {
schema: CheckTypoOutputSchema,
},
prompt: `You are a helpful AI assistant that checks user text for typos and suggests corrections.
- If you find typos, respond with the corrected text.
- If there are no typos, or if you are unsure about a correction, respond with the original text unchanged.
User text: {text}
Corrected text:
`,
});
Ce bloc de code définit un modèle réutilisable pour notre IA, appelé checkTypoPrompt. Les schémas d'entrée et de sortie définissent le contrat de données pour cette tâche. Cela évite les erreurs et rend notre système prévisible.
Partie 2 : Créer le flux (le "comment")
Maintenant que nous avons notre "recette" (le prompt), nous devons créer une fonction qui peut l'exécuter. Dans Genkit, on appelle cela un flux. Un flux encapsule notre requête dans une fonction exécutable que le reste de notre application peut facilement appeler.
👉 Action : Dans le même fichier ~/src/ai/flows/check_typo/, remplacez le code ci-dessous : // REPLACE ME PART 2: add flow here :
👉 avec le code ci-dessous
const checkTypoFlow = ai.defineFlow<
typeof CheckTypoInputSchema,
typeof CheckTypoOutputSchema
>(
{
name: 'checkTypoFlow',
inputSchema: CheckTypoInputSchema,
outputSchema: CheckTypoOutputSchema,
},
async input => {
const {output} = await prompt(input);
return output!;
}
);
Partie 3 : Mettre le vérificateur de fautes d'orthographe à l'œuvre
Maintenant que notre flux d'IA est terminé, nous pouvons l'intégrer à la logique principale de notre application. Nous l'appellerons immédiatement après avoir reçu la commande de l'utilisateur, en veillant à ce que le texte soit propre avant tout traitement ultérieur.
👉Action : accédez à ~/src/app/ai/flows/check-typo.ts et recherchez la fonction export async function checkTypo. Annulez la mise en commentaire de l'instruction return :
Au lieu de return;, faites return checkTypoFlow(input);
👉Action : accédez à ~/src/app/page.tsx et recherchez la fonction processVoiceCommand. Remplacez le code ci-dessous : REPLACE ME PART 2: add typoResult here :
👉 avec le code ci-dessous
const typoResult = await checkTypo({ text: rawCommand });
if (typoResult && typoResult.correctedText && typoResult.correctedText.trim().length > 0) {
const originalTrimmedLower = rawCommand.trim().toLowerCase();
const correctedTrimmedLower = typoResult.correctedText.trim().toLowerCase();
if (correctedTrimmedLower !== originalTrimmedLower) {
commandToProcess = typoResult.correctedText;
typoCorrectionAnnouncement = `I think you said: ${commandToProcess}. `;
}
}
Grâce à ce changement, nous avons créé un pipeline de traitement des données plus robuste pour chaque commande utilisateur.
Flux de commandes vocales (lecture seule, aucune action requise)
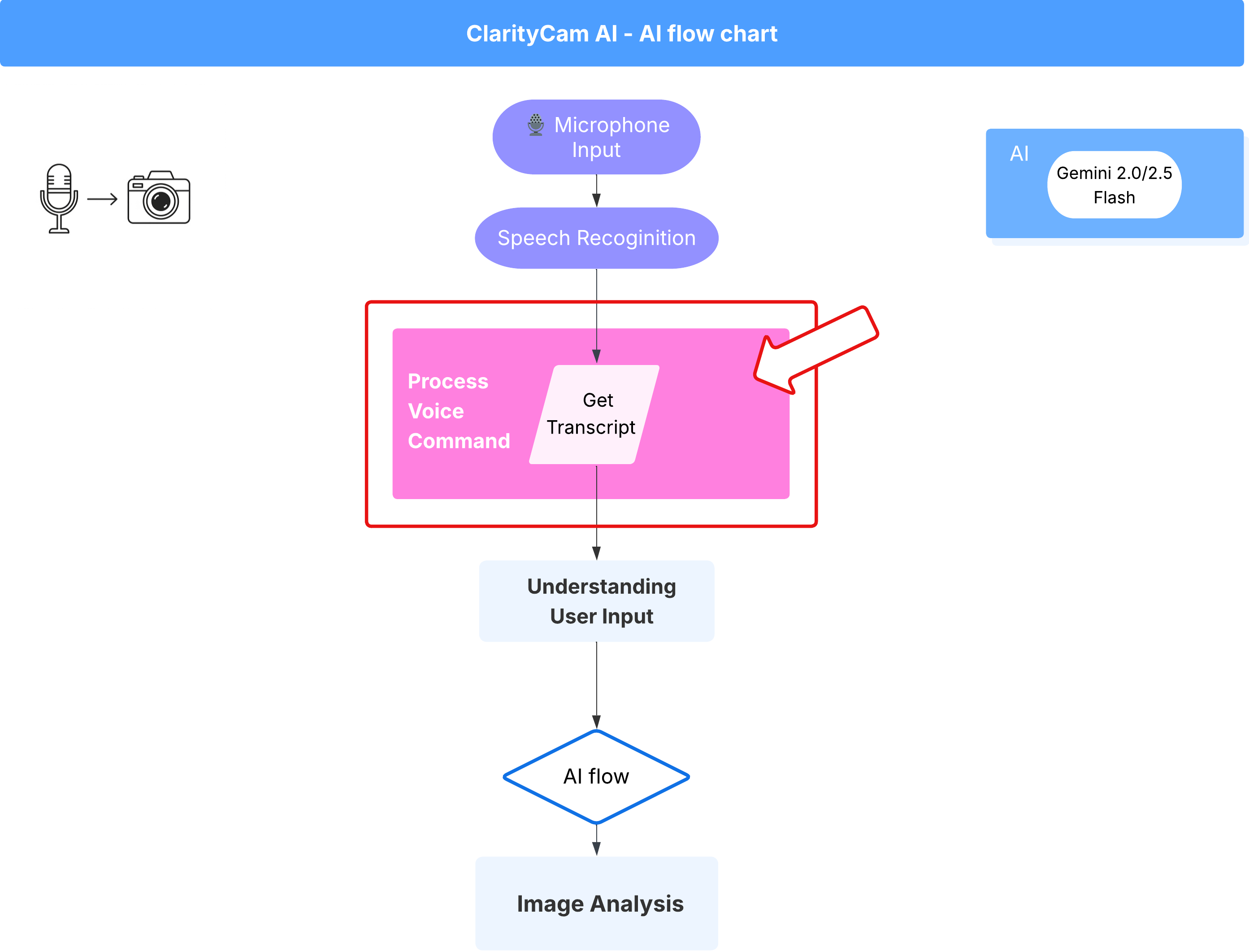
Maintenant que nous avons nos composants de "compréhension" de base (le vérificateur d'orthographe et le classificateur d'intentions), voyons comment ils s'intègrent à la logique de traitement vocal principale de l'application.
Tout commence lorsque l'utilisateur parle. L'API Web Speech du navigateur écoute la parole et, une fois que l'utilisateur a fini de parler, fournit une transcription textuelle de ce qu'elle a entendu. Le code suivant gère ce processus.
👉 Lecture seule : accédez à ~/src/app/page.tsx et à la fonction handleResult. Recherchez le code ci-dessous :
for (let i = event.resultIndex; i < event.results.length; ++i) {
if (event.results[i].isFinal) {
finalTranscript += event.results[i][0].transcript;
}
}
if (finalTranscript) {
console.log("Final Transcript:", finalTranscript);
processVoiceCommand(finalTranscript);
}
Mettre notre correction des fautes de frappe à l'épreuve
Passons maintenant à la partie la plus intéressante : Voyons comment notre nouvelle fonctionnalité de correction typographique gère les commandes vocales parfaites et imparfaites.
Démarrer l'application
Commençons par relancer le serveur de développement. Dans votre terminal, exécutez la commande suivante : npm run dev
Ouvrez l'application.
Une fois le serveur prêt, ouvrez votre navigateur et accédez à l'adresse locale (par exemple, http://localhost:9003).
Activer les commandes vocales
Cliquez sur le bouton Start Listening. Votre navigateur vous demandera probablement l'autorisation d'utiliser votre micro. Veuillez cliquer sur "Autoriser".
Tester une commande imparfaite
Maintenant, donnons-lui intentionnellement une commande légèrement erronée pour voir si notre IA peut la comprendre. Parlez clairement dans votre micro :
"Prends une photo de moi"
Observer le résultat
C'est ici que la magie se produit ! Même si vous avez dit "Prends-moi en photo", l'application devrait activer correctement la caméra. Le flux checkTypo corrige votre expression en "prendre une photo" en arrière-plan, puis le flux classifyIntentFlow comprend la commande corrigée.
Cela confirme que notre fonctionnalité de correction des fautes de frappe fonctionne parfaitement, ce qui rend l'application beaucoup plus robuste et conviviale. Lorsque vous avez terminé, vous pouvez arrêter la caméra en prenant une photo ou simplement arrêter le serveur dans votre terminal (Ctrl + C).
6. Analyse d'images optimisée par l'IA : décrire l'image
Maintenant que notre agent peut comprendre les requêtes, il est temps de lui donner des yeux. Dans cette section, nous allons développer les capacités de notre agent Vision, le composant principal responsable de l'analyse des images. Nous allons commencer par sa fonctionnalité la plus importante, à savoir la description d'une image, puis nous ajouterons la possibilité de lire du texte.
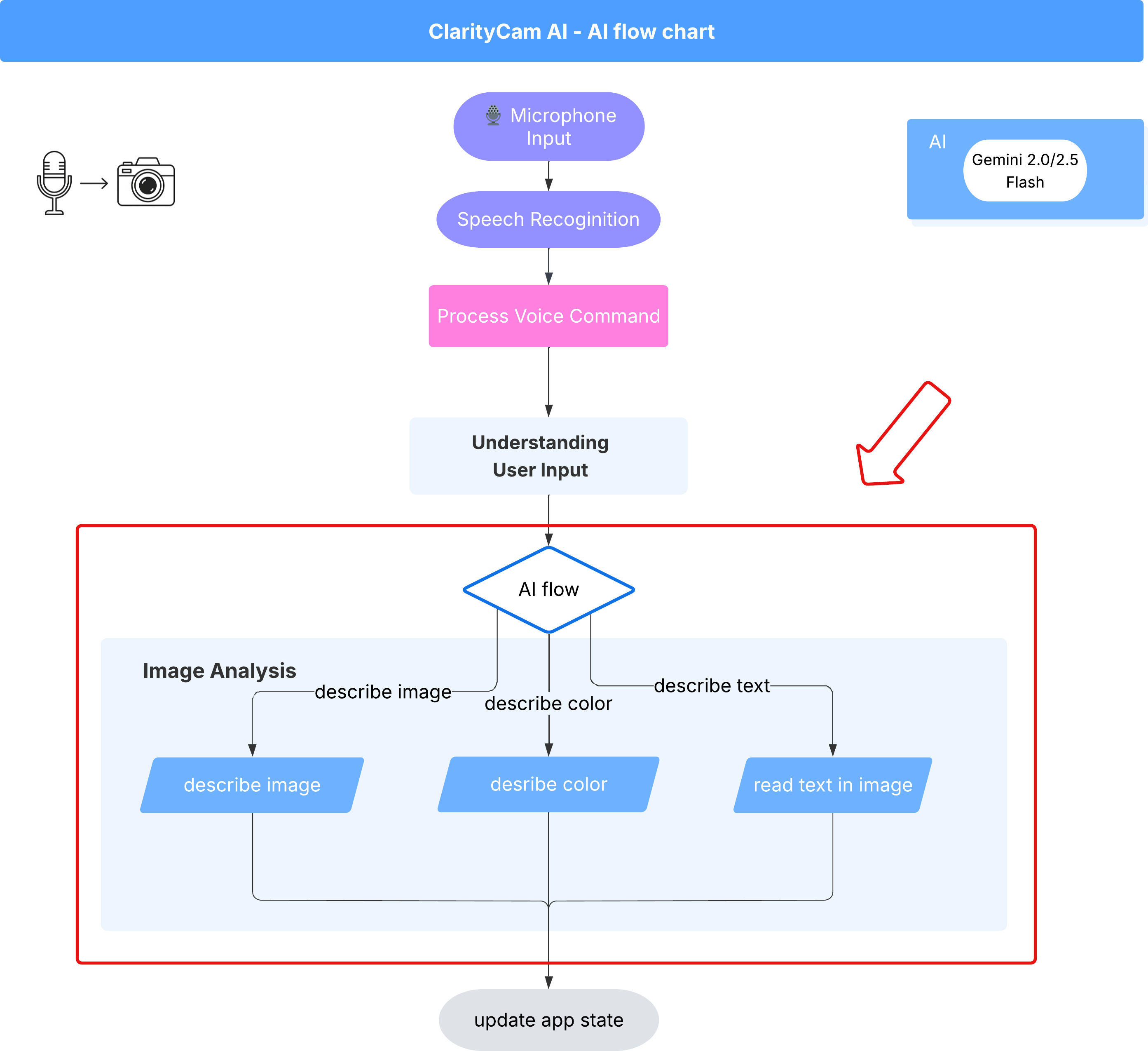
Fonctionnalité 1 : Description d'une image
Il s'agit de la fonction principale de l'agent. Nous ne nous contenterons pas de générer une description statique. Nous créerons un flux dynamique qui pourra adapter son niveau de détail en fonction des préférences de l'utilisateur. Il s'agit d'un élément clé de la philosophie de l'interface adaptative native (NAI, Natively Adaptive Interface).
👉 Action : Dans votre IDE Cloud Shell, accédez au fichier ~/src/ai/flows/describe_image/ et supprimez la mise en commentaire du code suivant.
Étape 1 : Créer un modèle d'invite dynamique
Nous allons commencer par créer un modèle de requête sophistiqué qui peut modifier ses instructions en fonction de l'entrée qu'il reçoit.
Décommentez le code ci-dessous.
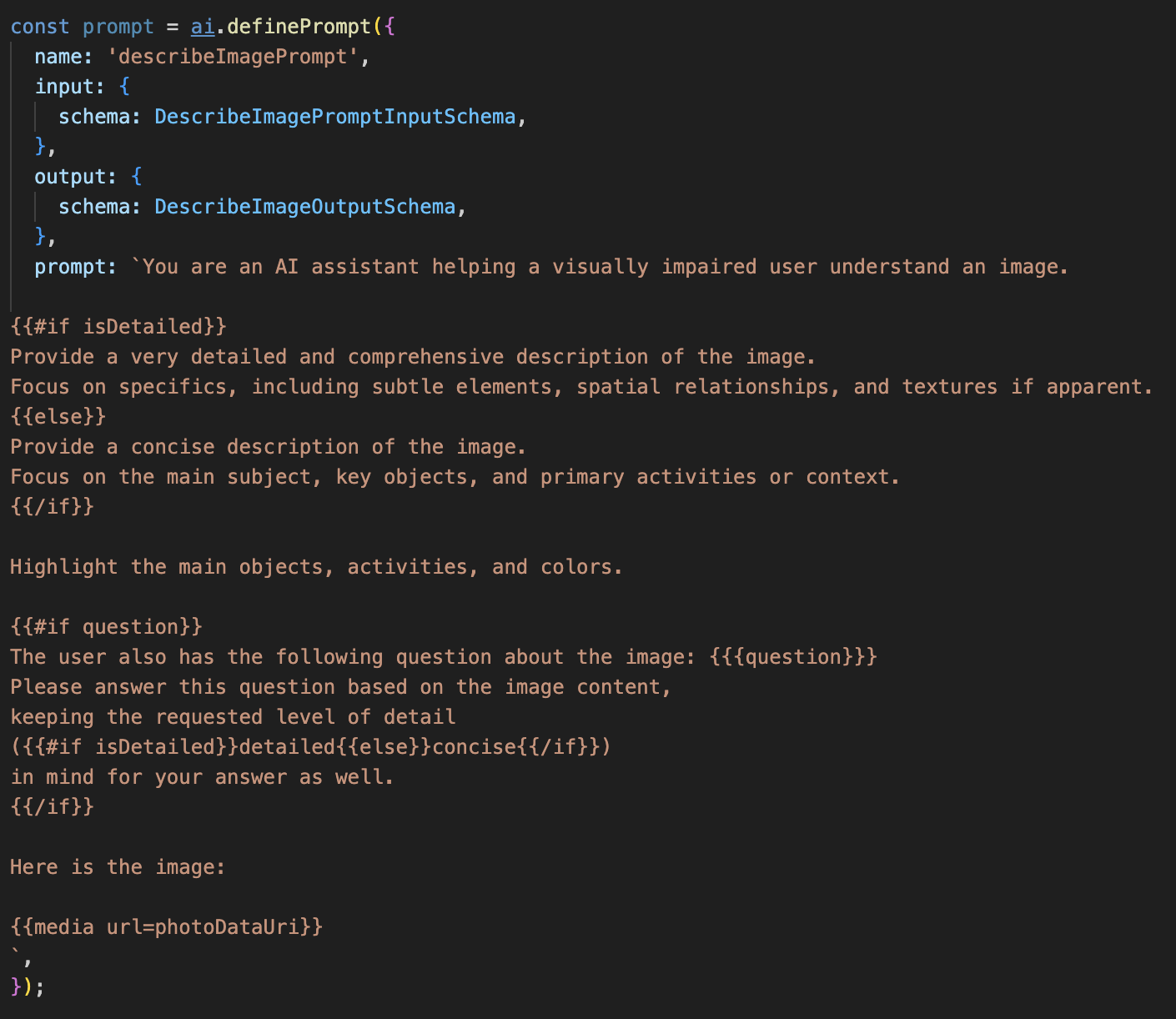
Ce code définit une variable de chaîne, "prompt", qui utilise un langage de modèle appelé Dot-Mustache. Cela nous permet d'intégrer une logique conditionnelle directement dans notre requête.
{#if isDetailed}...{else}...{/if} : il s'agit d'un bloc conditionnel. Si les données d'entrée que nous envoyons à cette requête contiennent une propriété "isDetailed: true", l'IA recevra l'ensemble d'instructions "très détaillé". Sinon, il recevra les instructions "concises". Voici comment notre agent s'adapte aux préférences de l'utilisateur.
{#if question}...{/if} : ce bloc ne sera inclus que si nos données d'entrée contiennent une propriété de question. Cela nous permet d'utiliser la même requête puissante pour les descriptions générales et les questions spécifiques.
{media url=photoDataUri} : il s'agit de la syntaxe spéciale de Genkit permettant d'intégrer des données d'image directement dans la requête pour que le modèle multimodal puisse les analyser.
Étape 2 : Créer le flux intelligent
Ensuite, nous définissons le prompt et le flux qui utiliseront notre nouveau modèle. Ce flux contient un peu de logique pour traduire la préférence de l'utilisateur en un booléen que notre modèle peut comprendre.
👉 Action : Dans votre IDE Cloud Shell, dans le même fichier ~/src/ai/flows/describe_image/, remplacez le code suivant. // REPLACE ME PART 1: add flow here
👉 Avec le code ci-dessous :
// Define the prompt using the template from Step 1
const prompt = ai.definePrompt({
name: 'describeImagePrompt',
input: { schema: DescribeImagePromptInputSchema },
output: { schema: DescribeImageOutputSchema },
prompt: promptTemplate,
});
// Define the flow
const describeImageFlow = ai.defineFlow<
typeof DescribeImageInputSchema,
typeof DescribeImageOutputSchema
>(
{
name: 'describeImageFlow',
inputSchema: DescribeImageInputSchema,
outputSchema: DescribeImageOutputSchema,
},
async (pageInput) => {
const preference = pageInput.detailPreference || "concise";
// Prepare the input for the prompt, including the new boolean flag
const promptInputData = {
...pageInput,
isDetailed: preference === "detailed",
};
const { output } = await prompt(promptInputData);
return output!;
}
);
Il sert d'intermédiaire intelligent entre l'interface et la requête d'IA.
- Il reçoit
pageInputde notre application, qui inclut la préférence de l'utilisateur sous forme de chaîne (par exemple,"detailed"). - Il crée ensuite un objet
promptInputData. - La ligne la plus importante est
isDetailed: preference === "detailed". Cette ligne effectue le travail crucial de création d'une valeur booléennetrueoufalseen fonction de la chaîne de préférence. - Enfin, il appelle
promptavec ces données améliorées. Le modèle de prompt de l'étape 1 peut désormais utiliser le booléenisDetailedpour modifier de manière dynamique les instructions envoyées à l'IA.
Étape 3 : Connecter le frontend
Maintenant, déclenchons ce flux à partir de notre interface utilisateur dans page.tsx.
👉Action : accédez à ~/src/app/ai/flows/describe-image.ts et recherchez la fonction export async function describeImage. Annulez la mise en commentaire de l'instruction return :
Au lieu de return;, faites return describeImageFlow(input);
👉 Action : Dans ~/src/app/page.tsx, recherchez la fonction handleAnalyze et remplacez le code // REPLACE ME PART 2: DESCRIBE IMAGE
👉 avec le code suivant :
case "description":
result = await describeImage({
photoDataUri,
question,
detailPreference: descriptionPreference
});
outputText = question ? `Answer: ${result.description}` : `Description: ${result.description}`;
break;
Ce code est exécuté lorsque l'utilisateur souhaite obtenir une description. Il appelle notre flux describeImage, en transmettant les données d'image et, surtout, la variable d'état descriptionPreference de notre composant React. Il s'agit de la dernière pièce du puzzle, qui relie la préférence de l'utilisateur stockée dans l'UI directement au flux d'IA qui adaptera son comportement en conséquence.
Tester la fonctionnalité de description d'images
Découvrons notre fonctionnalité de description d'images en action, de la prise de photo à l'écoute de ce que l'IA voit.
Démarrer l'application
Commençons par relancer le serveur de développement. 👉 Dans votre terminal, exécutez la commande suivante : npm run dev Remarque : Vous devrez peut-être exécuter npm install avant d'exécuter npm run dev.
Ouvrez l'application.
Une fois le serveur prêt, ouvrez votre navigateur et accédez à l'adresse locale (par exemple, http://localhost:9003).
Activer la caméra
Cliquez sur le bouton "Écouter" et accordez l'accès au micro si vous y êtes invité. Énoncez ensuite votre première commande :
"Prends une photo"
L'application active l'appareil photo de votre appareil. Vous devriez désormais voir le flux vidéo en direct à l'écran.
Prendre la photo
Activez la caméra et pointez-la sur ce que vous souhaitez décrire. Dites ensuite la commande une deuxième fois pour capturer l'image :
"Prends une photo"
La vidéo en direct sera remplacée par la photo statique que vous venez de prendre.
Demander la description
Une fois votre nouvelle photo affichée à l'écran, donnez la commande finale :
"Décris l'image"
Écouter le résultat
L'application affiche l'état du traitement, puis vous entendrez la description de votre image générée par l'IA. Le texte apparaîtra également dans la fiche "État et résultat".
Lorsque vous avez terminé, vous pouvez arrêter la caméra en prenant une photo ou simplement arrêter le serveur dans votre terminal (Ctrl+C).
7. Analyse d'images optimisée par l'IA : décrire du texte (OCR)
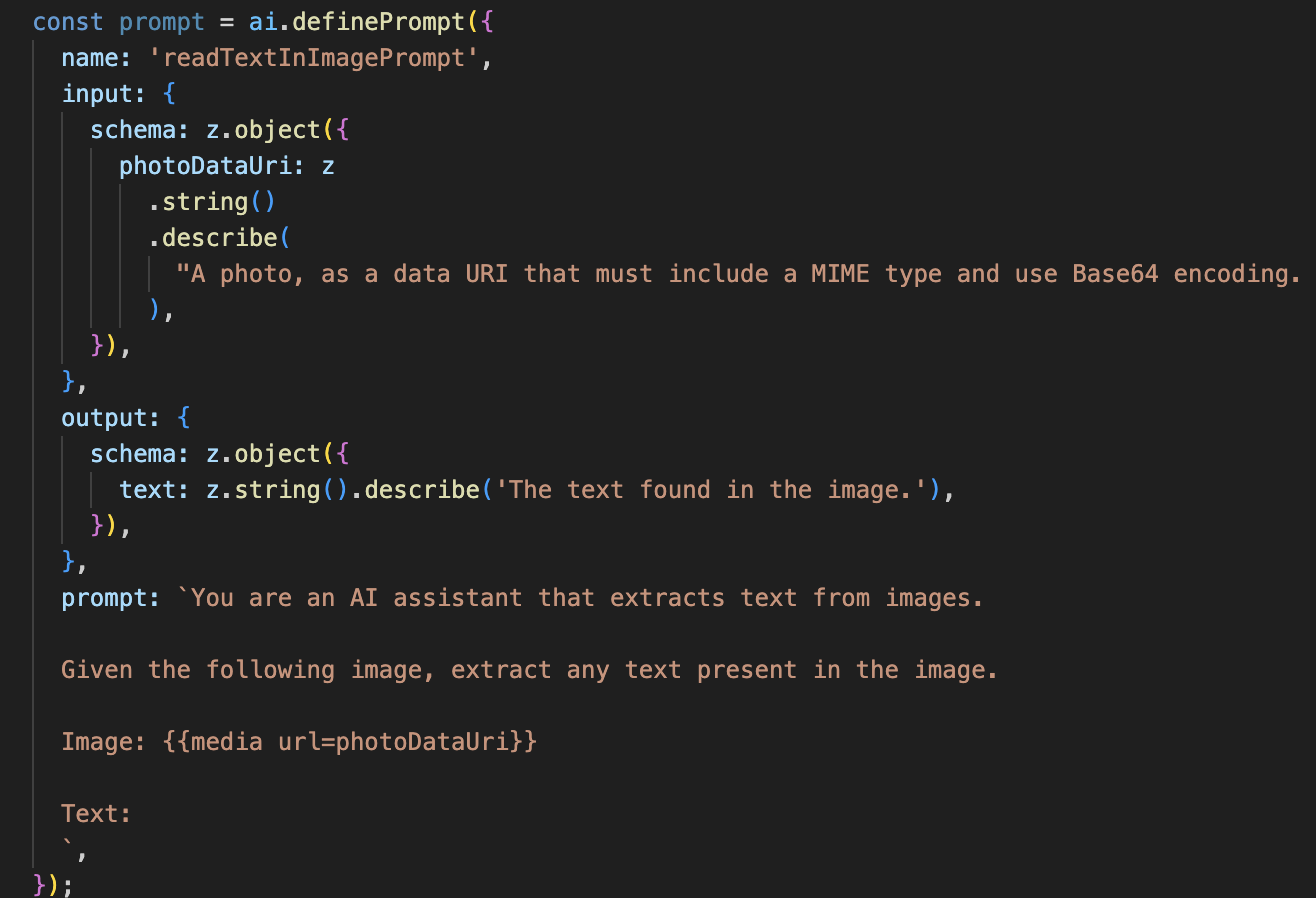
Nous ajouterons ensuite la reconnaissance optique des caractères (OCR) à notre agent Vision. Il peut ainsi lire le texte de n'importe quelle image.
👉 Action : Dans votre IDE, accédez à ~/src/ai/flows/read-text-in-image/, décommentez le code ci-dessous :
👉 Action : Dans votre IDE, dans le même fichier ~/src/ai/flows/read-text-in-image/, remplacez // REPLACE ME: Creating Prmopt
👉 avec le code ci-dessous :
const readTextInImageFlow = ai.defineFlow<
typeof ReadTextInImageInputSchema,
typeof ReadTextInImageOutputSchema
>(
{
name: 'readTextInImageFlow',
inputSchema: ReadTextInImageInputSchema,
outputSchema: ReadTextInImageOutputSchema,
},
async input => {
const {output} = await prompt(input);
return output!;
}
);
Ce flux d'IA est beaucoup plus simple et met en évidence le principe d'utilisation d'outils ciblés pour des tâches spécifiques.
- Le prompt : contrairement à notre prompt de description, celui-ci est statique et très spécifique. Son seul rôle est d'indiquer à l'IA d'agir comme un moteur OCR : "extraire tout texte présent dans l'image".
- Schémas : les schémas d'entrée et de sortie sont également simples. Ils attendent une image et renvoient une seule chaîne de texte.
Connecter l'interface pour l'OCR
Enfin, connectons cette nouvelle fonctionnalité dans page.tsx.
👉Action : accédez à ~/src/app/ai/flows/read-text-in-image.ts et recherchez la fonction export async function readTextInImage. Annulez la mise en commentaire de l'instruction return :
Au lieu de return;, faites return readTextInImageFlow(input);
👉 Action : Dans ~/src/app/page.tsx, recherchez la fonction handleAnalyze et autour de l'instruction switch.
Remplacer "REPLACE ME PART 3: READ TEXT"
avec le code ci-dessous :
case "text":
result = await readTextInImage({ photoDataUri });
outputText = result.text ? `Text Found: ${result.text}` : "No text found.";
break;
Ce code est déclenché lorsque l'intention de l'utilisateur est ReadTextInImage. Il appelle notre flux readTextInImage simple. La ligne result.text ? ... : ... est un moyen simple de gérer la sortie, en fournissant un message utile à l'utilisateur si l'IA n'a pas pu trouver de texte dans l'image.
Tester la fonctionnalité Lire le texte (OCR)
Pour tester la fonctionnalité de lecture de texte, procédez comme suit. N'oubliez pas de diriger l'appareil photo vers un objet dont le texte est bien lisible.
- Exécutez l'application avec
npm run devet ouvrez-la dans votre navigateur. - Cliquez sur "Commencer à écouter" et accordez l'accès au micro lorsque vous y êtes invité.
- Activez la caméra. Dites la commande "Prendre une photo". Le flux vidéo en direct devrait s'afficher à l'écran.
- Prenez la photo. Dirigez l'appareil photo vers le texte que vous souhaitez lire, puis répétez la commande : "Prends une photo". La vidéo sera remplacée par une photo statique.
- Demandez le texte. Maintenant que vous avez pris une photo, donnez la commande finale : "Quel est le texte de l'image ?"
- Vérifier le résultat Au bout de quelques instants, l'application analyse la photo et lit le texte détecté à voix haute. Si aucun texte n'est détecté, vous en serez informé.
Cela confirme que la puissante fonctionnalité d'OCR fonctionne. Lorsque vous avez terminé, arrêtez le serveur avec Ctrl + C.
8. Fonctionnalités avancées d'amélioration par l'IA : lecture seule ✨
Un bon agent d'IA peut suivre des instructions. Un bon agent IA doit être intuitif, fiable et utile. Dans cette section, nous allons nous concentrer sur trois améliorations avancées qui renforcent les capacités de notre agent.
Nous allons voir comment :
Add Context & Memorypour gérer les demandes de suivi naturelles et conversationnelles.Reduce Hallucinationpour créer un agent plus fiable et digne de confiance.Make the Agent Proactivepour offrir une expérience plus accessible et conviviale.Add preference settingpour personnaliser la description de l'image
Amélioration 1 : Contexte et mémoire
Une conversation naturelle n'est pas une série de commandes isolées, mais un échange fluide. Si un utilisateur demande "Qu'y a-t-il sur la photo ?" et que l'agent répond "Une voiture rouge", l'utilisateur peut ensuite demander "De quelle couleur est-elle ?" sans répéter le mot "voiture". Notre agent a besoin d'une mémoire à court terme pour comprendre ce contexte.
Comment nous l'avons implémenté (récapitulatif)
Nous avons déjà intégré cette fonctionnalité à notre flux describeImage. Cette section récapitule le fonctionnement de ce modèle. Lorsque nous appelons notre fonction describeImage à partir de page.tsx, nous lui transmettons l'historique des conversations.
👉 Code Showcase (depuis page.tsx) :
const result = await describeImage({
photoDataUri,
question: commandToProcess,
detailPreference: descriptionPreference,
previousUserQueryOnImage: lastUserQuery ?? undefined,
previousAIResponseOnImage: lastAIResponse ?? undefined,
});
previousUserQueryOnImageetpreviousAIResponseOnImage: ces deux propriétés correspondent à la mémoire à court terme de notre agent. En transmettant la dernière interaction à l'IA, nous lui fournissons le contexte dont elle a besoin pour comprendre les questions de suivi vagues ou référentielles.- Le prompt adaptatif : ce contexte est utilisé par le prompt dans notre flux describe_image. Le prompt est conçu pour tenir compte de la conversation précédente lors de la formulation d'une nouvelle réponse, ce qui permet à l'agent de répondre de manière intelligente.
Amélioration 2 : Réduction des hallucinations
Une IA "hallucine" lorsqu'elle invente des faits ou prétend avoir des capacités qu'elle ne possède pas. Pour gagner la confiance des utilisateurs, il est essentiel que notre agent connaisse ses propres limites et puisse refuser poliment les demandes hors champ.
Comment nous l'avons implémenté (récapitulatif)
Le moyen le plus efficace d'éviter les hallucinations est de définir des limites claires pour le modèle. C'est ce que nous avons fait lorsque nous avons créé notre classificateur d'intentions.
👉 Présentation du code (à partir du flux intent-classifier) :
// Define Agent Capabilities and Limitations for the prompt
const AGENT_CAPABILITIES_AND_LIMITATIONS = `
**Core Capabilities (What the Agent CAN DO):**
* **Image Analysis:**
* DescribeImage: Provide a general description of the current image...
**Limitations (What the Agent CANNOT DO...):**
* Cannot generate or create new images.
* Cannot provide general knowledge or answer questions unrelated to the image...
* Cannot perform web searches.
`;
Cette constante sert de "description de poste" que nous fournissons à l'IA dans l'invite de classification.
- Ancrer le modèle : en indiquant explicitement à l'IA ce qu'elle ne peut pas faire, nous l'ancrons dans la réalité. Lorsqu'il reçoit une requête comme "Quel temps fait-il ?", il peut l'associer de manière fiable à sa liste de limites et classer l'intention comme OutOfScopeRequest.
- Gagner la confiance des utilisateurs : un agent qui peut honnêtement dire "Je ne peux pas vous aider" est beaucoup plus fiable qu'un agent qui essaie de deviner et se trompe. Il s'agit d'un principe fondamental pour concevoir une IA sûre et fiable. `
Amélioration 3 : Créer un agent proactif
Pour une application axée sur l'accessibilité, nous ne pouvons pas nous fier aux repères visuels. Lorsqu'un utilisateur active le mode écoute, il a besoin d'une confirmation immédiate et non visuelle que l'agent est prêt et attend une commande. Nous allons maintenant ajouter une introduction proactive pour fournir ces commentaires essentiels.
Étape 1 : Ajoutez un état pour suivre la première écoute
Tout d'abord, nous avons besoin d'un moyen de savoir si l'utilisateur a appuyé sur le bouton "Start Listening" pour la toute première fois au cours de sa session.
👉 Dans ~/src/app/page.tsx, consultez la nouvelle variable d'état en haut de votre composant ClarityCam.
export default function ClarityCam() {
// ... other state variables
const [descriptionPreference, setDescriptionPreference] = useState<DescriptionPreference>("concise");
// Add this new line
const [isFirstListen, setIsFirstListen] = useState(true);
// ... rest of the component
}
Nous avons introduit une nouvelle variable d'état, isFirstListen, et l'avons initialisée sur true. Nous utiliserons ce signalement pour déclencher notre message de bienvenue unique.
Étape 2 : Mettez à jour la fonction toggleListening
Modifions maintenant la fonction qui gère le micro pour qu'elle lise notre salutation.
👉 Dans ~/src/app/page.tsx, recherchez la fonction toggleListening et le bloc if suivant.
const toggleListening = useCallback(() => {
// ... existing logic to setup speech recognition
if (isListening || isAttemptingStart) {
// ... existing logic to stop listening
} else {
stopSpeaking(); // Stop any ongoing TTS
// Add this new block
if (isFirstListen) {
setIsFirstListen(false);
const introMessage = "Hello! I am ClarityCam, your AI assistant. I'm now listening. You can ask me to 'describe the image', 'read text', 'take a picture', or ask questions about what's in an image.";
speakText(introMessage);
} else {
speakText("Listening..."); // Optional: provide feedback on subsequent clicks
}
// ... rest of the logic to start listening
}
}, [/*...existing dependencies...*/, isFirstListen]); // Don't forget to add isFirstListen to the dependency array!
- Vérifiez l'indicateur : le bloc if (isFirstListen) vérifie s'il s'agit de la première activation.
- Empêcher la répétition : la première chose qu'il fait à l'intérieur du bloc est d'appeler setIsFirstListen(false). Cela garantit que le message d'introduction ne sera lu qu'une seule fois par session.
- Fournir des conseils : le message d'introduction est soigneusement conçu pour être aussi utile que possible. Il salue l'utilisateur, identifie l'agent par son nom, confirme qu'il est désormais actif ("Je suis à votre écoute") et fournit des exemples clairs de commandes vocales qu'il peut utiliser.
- Retour audio : enfin, speakText(introMessage) fournit ces informations cruciales, en offrant une assurance et des conseils immédiats sans que l'utilisateur ait besoin de regarder l'écran.
Amélioration 4 : S'adapter aux préférences des utilisateurs (récapitulatif)
Un agent vraiment intelligent ne se contente pas de répondre : il apprend et s'adapte aux besoins de l'utilisateur. L'une des fonctionnalités les plus puissantes que nous avons développées permet à l'utilisateur de modifier la précision des descriptions d'images à la volée à l'aide de commandes telles que "Sois plus précis".
Comment nous l'avons implémentée (récapitulatif) : cette fonctionnalité est optimisée par la requête dynamique que nous avons créée pour notre flux describeImage. Elle utilise une logique conditionnelle pour modifier les instructions envoyées à l'IA en fonction des préférences de l'utilisateur.
👉 Présentation du code (promptTemplate de describe_image) :
const settingPreferenceTemplate = `
{#if isDetailed}
Provide a very detailed and comprehensive description of the image. Focus on specifics, including subtle elements, spatial relationships, and textures if apparent.
{else}
Provide a concise description of the image. Focus on the main subject, key objects, and primary activities or context.
{/if}
Highlight the main objects, activities, and colors.
...
`;
- Logique conditionnelle : le bloc
{#if isDetailed}...{else}...{/if}est essentiel. Lorsque notre describeImageFlow reçoit la préférence de détail du frontend, il crée un booléen isDetailed (true ou false). - Instructions adaptatives : ce indicateur booléen détermine l'ensemble d'instructions que reçoit le modèle d'IA. Si la valeur de isDetailed est "true", le modèle est invité à être très descriptif. Si la valeur est "false", la réponse doit être concise.
- Contrôle par l'utilisateur : ce modèle relie directement une commande vocale de l'utilisateur (par exemple, "faire des descriptions concises", qui est classée comme intention SetDescriptionConcise) à un changement fondamental dans le comportement de l'IA, ce qui donne l'impression que l'agent est vraiment réactif et personnalisé.
9. Déploiement dans le cloud
Créer l'image Docker à l'aide de Google Cloud Build
gcloud builds submit . --tag gcr.io/$PROJECT_ID/accessibilityai-nextjs-app:latest
accessibilityai-nextjs-appest un nom d'image suggéré.- Impossible utilise le répertoire actuel (
accessibilityAI/) comme source de compilation.
Déployer l'image sur Google Cloud Run
- Assurez-vous que vos clés API et autres secrets sont prêts dans Secret Manager. Par exemple :
GOOGLE_GENAI_API_KEY.
Remplacez YOUR_ACTUAL_GOOGLE_AI_KEY_VALUE par la valeur de votre clé API Gemini.
echo "YOUR_ACTUAL_GOOGLE_AI_KEY_VALUE" | gcloud secrets create GOOGLE_GENAI_API_KEY --data-file=- --project=YOUR_PROJECT_ID
Attribuez le rôle "Accesseur de secrets Secret Manager " au compte de service d'exécution de votre service Cloud Run (par exemple, PROJECT_NUMBER-compute@developer.gserviceaccount.com ou un compte dédié) pour ce secret.
- Commande de déploiement :
gcloud run deploy accessibilityai-app-service \
--image gcr.io/$PROJECT_ID/accessibilityai-nextjs-app:latest \
--platform managed \
--region us-central1 \
--allow-unauthenticated \
--port 3000 \
--set-secrets=GOOGLE_GENAI_API_KEY=GOOGLE_GENAI_API_KEY:latest \
--set-env-vars NODE_ENV="production"