
1. מבוא
במדריך הזה תבנו את ClarityCam, סוכן AI שמופעל באמצעות קול, ללא צורך במגע, שיכול לראות את העולם ולהסביר לכם אותו. העיצוב של ClarityCam מבוסס על נגישות – הכלי מספק פתרון יעיל למשתמשים עיוורים או עם ליקויי ראייה – אבל העקרונות שתלמדו חשובים ליצירת כל אפליקציית קול מודרנית לשימוש כללי.

הפרויקט הזה מבוסס על פילוסופיית עיצוב עוצמתית שנקראת ממשק מותאם באופן טבעי (NAI). במקום להתייחס לנגישות כאל מחשבה משנית, ב-NAI היא הבסיס. בגישה הזו, סוכן ה-AI הוא הממשק – הוא מותאם למשתמשים שונים, מטפל בקלט מולטי-מודאלי כמו קול וראייה, ומספק לאנשים הנחיות באופן פרואקטיבי על סמך הצרכים הייחודיים שלהם.
יצירת סוכן ה-AI הראשון באמצעות NAI:

בסוף הסשן הזה, תוכלו:
- עיצוב עם נגישות כברירת מחדל: שימוש בעקרונות של ממשק מותאם באופן טבעי (NAI) כדי ליצור מערכות AI שמספקות חוויות שוות לכל המשתמשים.
- סיווג כוונת המשתמש: בניית מסווג כוונות חזק שמתרגם פקודות בשפה טבעית לפעולות מובנות עבור הסוכן.
- שמירה על ההקשר בשיחה: הטמעת זיכרון לטווח קצר כדי לאפשר לסוכן להבין שאלות המשך ופקודות שמתייחסות למשהו שנאמר קודם (למשל, "באיזה צבע זה?").
- יצירת הנחיות יעילות: כדי להבטיח ניתוח תמונות מדויק ואמין, חשוב ליצור הנחיות ממוקדות ועשירות בהקשר למודל multimodal כמו Gemini.
- טיפול במצבים של חוסר ודאות והדרכת המשתמשים: חשוב לתכנן טיפול יעיל בשגיאות שמתרחשות בבקשות שלא נמצאות בהיקף, ולעזור למשתמשים להתחיל להשתמש במוצר כדי לבנות אמון וביטחון.
- תזמור של מערכת מרובת סוכנים: אפשר לבנות את האפליקציה באמצעות אוסף של סוכנים מיוחדים שמשתפים פעולה כדי לטפל במשימות מורכבות כמו עיבוד קולי, ניתוח וסינתזת דיבור.
2. High-Level Design
הבסיס של ClarityCam הוא פשוט למשתמש, אבל הוא מבוסס על מערכת מתוחכמת של סוכני AI שפועלים בשיתוף פעולה. ננסה להסביר את הארכיטקטורה.

חווית משתמש
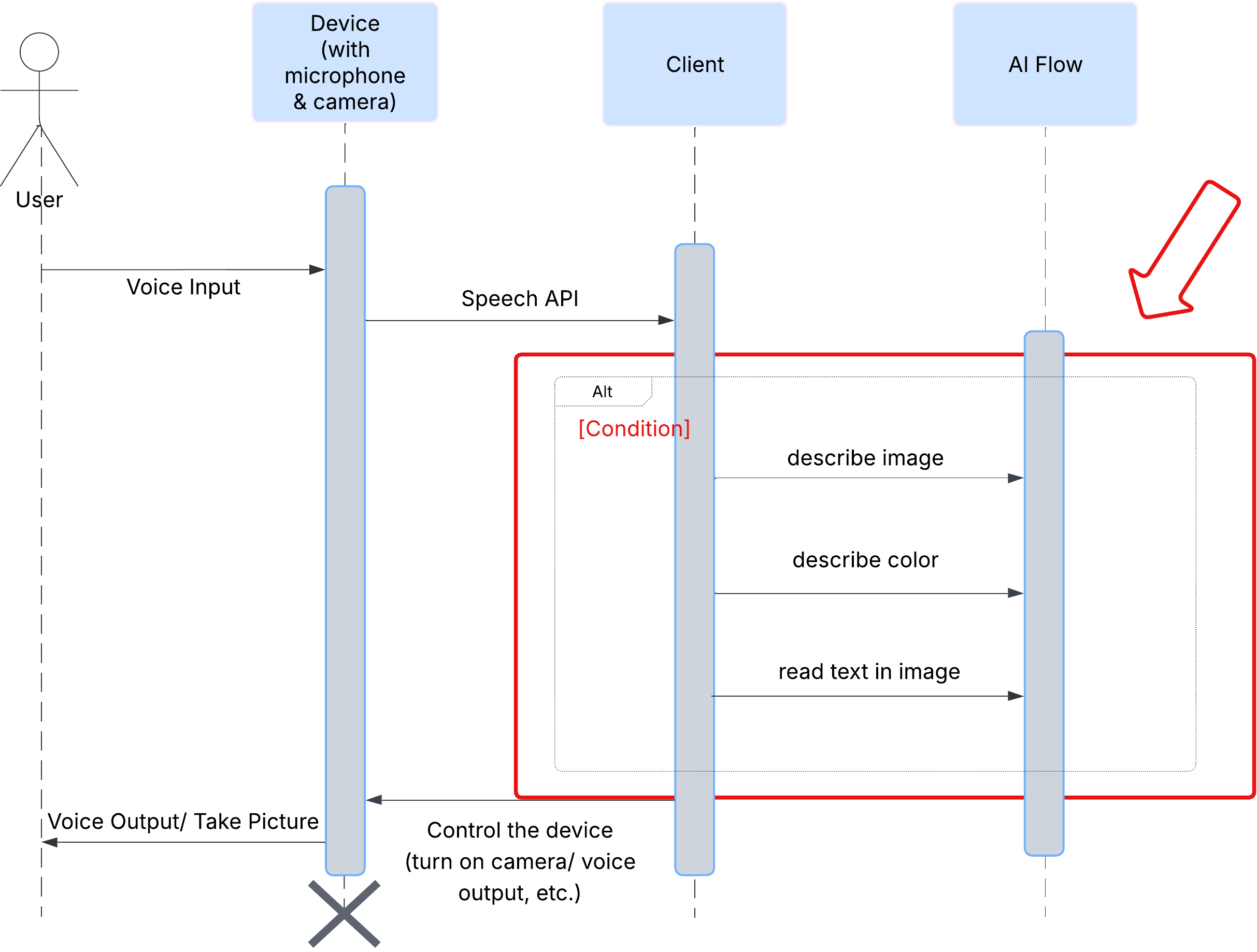
קודם כל, נראה איך משתמש מקיים אינטראקציה עם ClarityCam. כל התהליך מתבצע ללא מגע יד ובאמצעות שיחה. המשתמש אומר פקודה, והסוכן מגיב עם תיאור או פעולה בדיבור. בתרשים הרצף הזה מוצג תהליך אינטראקציה טיפוסי, מהפקודה הקולית הראשונית של המשתמש ועד לתגובה הקולית הסופית מהמכשיר.
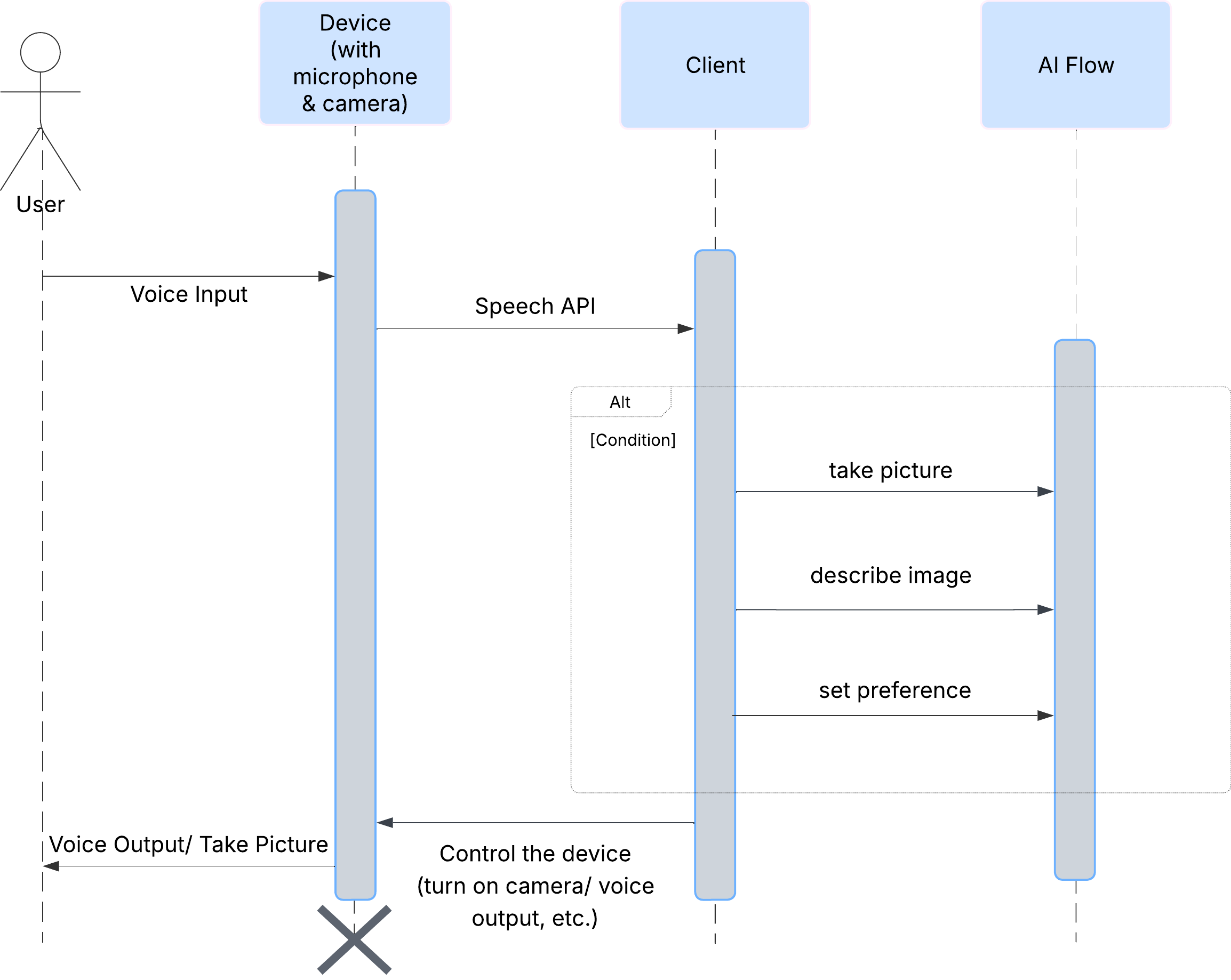
ארכיטקטורת סוכן ה-AI
מתחת לפני השטח, מערכת מרובת סוכנים פועלת יחד כדי להפיח חיים בחוויה. כשמתקבלת פקודה, סוכן מרכזי של Orchestrator מעביר משימות לסוכנים מומחים שאחראים על הבנת הכוונה, ניתוח תמונות וגיבוש תשובה. תרשים זרימת ה-AI הזה מספק מידע מעמיק על האופן שבו הסוכנים האלה משתפים פעולה. בקטעים הבאים נסביר איך ליישם את הארכיטקטורה הזו.
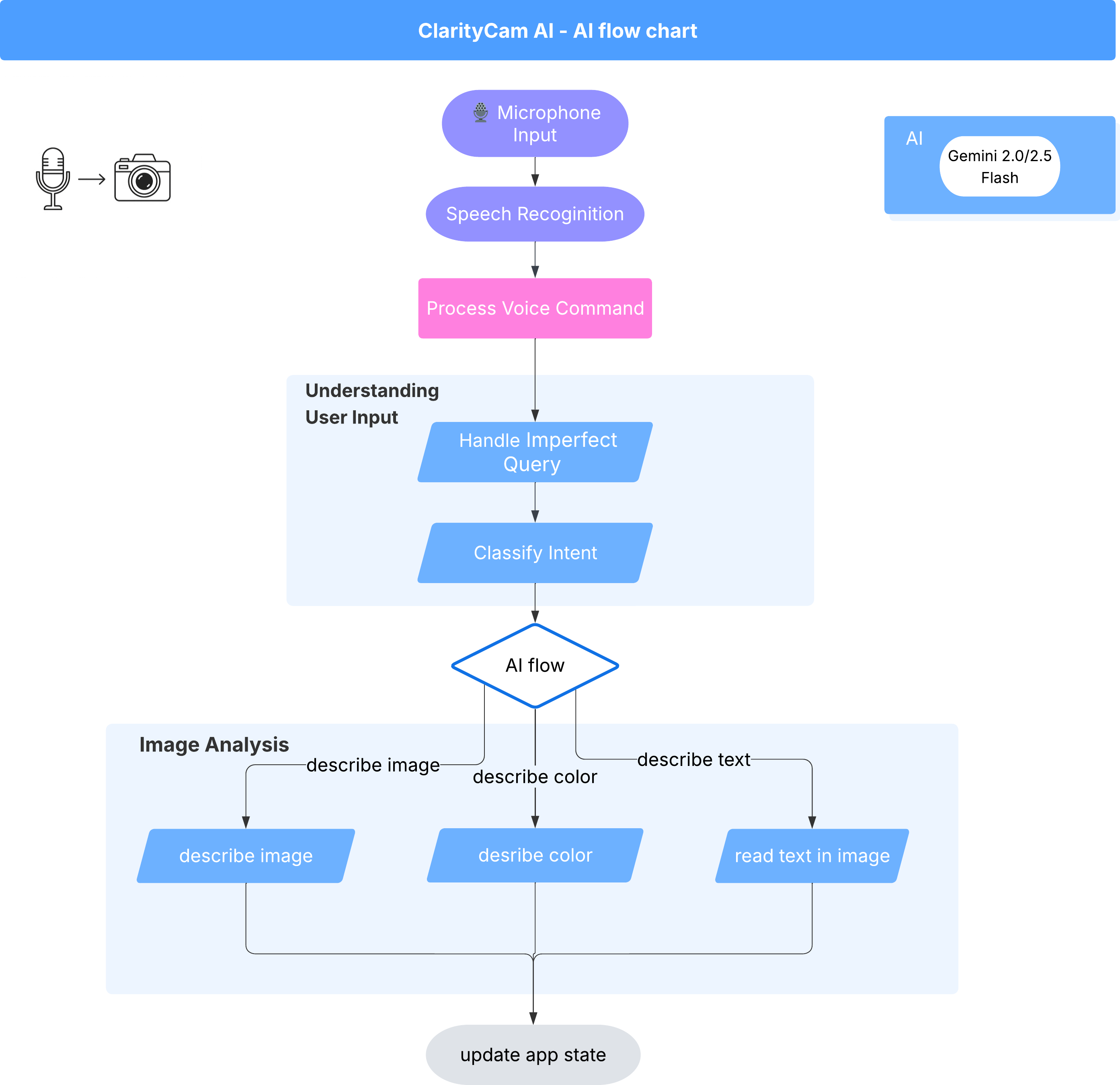
סיור קצר בקבצים של הפרויקט
לפני שמתחילים לכתוב קוד, כדאי להכיר את מבנה הקבצים של הפרויקט. יכול להיות שייראו הרבה קבצים, אבל צריך להתמקד רק בשני אזורים ספציפיים במדריך הזה.
זו מפה פשוטה של הפרויקט שלנו.
accessibilityAI/src/
├── 📁 app/
│ ├── layout.tsx # An overall page shell (you can ignore this).
│ └── page.tsx # ⬅️ MODIFY THIS: The main user interface for our app.
│
├── 📁 ai/
│ ├── 📁flows # ⬅️ MODIFY THIS: The core AI logic and server functions.
│ └── intent-classifier.ts # ⬅️ MODIFY THIS: Where we'll edit our AI prompts.
| └── ai-instance.ts
| └── dev.ts
│
├── 📁 components/ # Contains pre-built UI components (ignore this).
│
├── 📁 hooks/
│
├── 📁 lib/
│
└── 📁 types/
הסטאק הטכנולוגי
המערכת שלנו מבוססת על סטאק תוכנות מודרני וניתן להרחבה, שמשלב שירותי ענן מתקדמים ומודלים של AI חדשניים. אלה הרכיבים העיקריים שבהם נשתמש:
- Google Cloud Platform (GCP): מספק את התשתית ללא שרתים עבור הסוכנים שלנו.
- Cloud Run: פורס את הסוכנים האישיים שלנו כמיקרו-שירותים בקונטיינרים שאפשר להרחיב.
- Artifact Registry: אחסון וניהול מאובטחים של קובצי אימג' של Docker עבור הסוכנים שלנו.
- Secret Manager: ניהול מאובטח של פרטי כניסה רגישים ומפתחות API.
- מודלים גדולים של שפה (LLM): משמשים כ'מוח' של המערכת.
- המודלים של Gemini מבית Google: אנחנו משתמשים ביכולות המולטימודאליות המתקדמות של משפחת Gemini לכל דבר, החל מסיווג כוונת המשתמש ועד לניתוח תוכן תמונות ומתן תיאורים חכמים.
3. הגדרה ותנאים מוקדמים
הפעלת חשבון לחיוב כדי להשתמש ב-codelab הזה, צריך חשבון לחיוב עם קרדיט. כדי להתחיל, משתמשים בקרדיטים שמופיעים בבאנר בחלק העליון של ה-codelab. אם כבר קישרתם חשבון לחיוב, אתם יכולים לדלג על השלב הזה.
יצירת פרויקט חדש ב-GCP
- נכנסים אל מסוף Google Cloud ויוצרים פרויקט חדש.
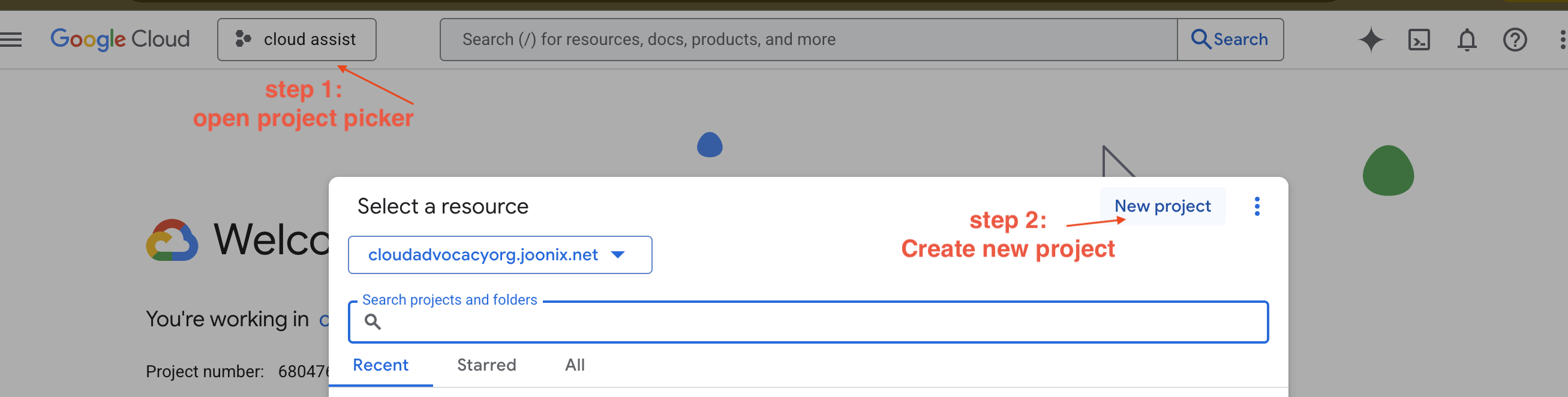
- נכנסים אל מסוף Google Cloud ויוצרים פרויקט חדש.
- פותחים את החלונית הימנית, לוחצים על
Billingובודקים אם החשבון לחיוב מקושר לחשבון GCP הזה.
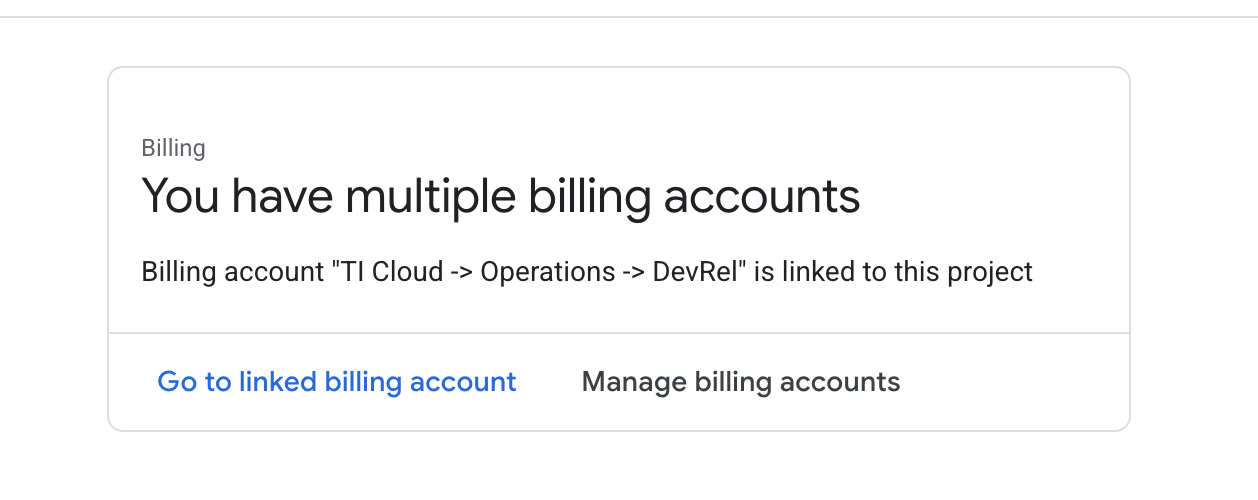
אם הדף הזה מוצג, מסמנים את התיבה manage billing account, בוחרים באפשרות Google Cloud Trial One ומקשרים אליה.
יצירת מפתח Gemini API
כדי לאבטח את המפתח, צריך קודם שיהיה לכם מפתח.
- עוברים אל Google AI Studio : https://aistudio.google.com/
- נכנסים באמצעות חשבון Google.
- לוחצים על הלחצן Get API key (קבלת מפתח API), שנמצא בדרך כלל בחלונית הניווט בצד ימין או בפינה השמאלית העליונה.
- בתיבת הדו-שיח מפתחות API, לוחצים על 'יצירת מפתח API בפרויקט חדש'.
- המערכת תיצור בשבילכם מפתח API חדש. מעתיקים את המפתח הזה באופן מיידי ושומרים אותו במקום בטוח באופן זמני (למשל, במנהל סיסמאות או בהערה מאובטחת). זה הערך שתשתמשו בו בשלבים הבאים.
תהליך העבודה בפיתוח מקומי (בדיקה במחשב)
צריך להיות לכם אפשרות להריץ את npm run dev ולגרום לאפליקציה לפעול. כאן נכנס לתמונה .env.
- מוסיפים את מפתח ה-API לקובץ: יוצרים קובץ חדש בשם
.envומוסיפים לו את השורה הבאה.
חשוב להקפיד להחליף את YOUR_API_KEY_HERE במפתח שקיבלתם מ-AI Studio ושמרתם ב-.env:
GOOGLE_GENAI_API_KEY="YOUR_API_KEY_HERE"
[אופציונלי] הגדרה של סביבת פיתוח משולבת (IDE) וסביבה
במדריך הזה, אפשר לעבוד בסביבת פיתוח מוכרת כמו VS Code או IntelliJ עם הטרמינל המקומי. עם זאת, מומלץ מאוד להשתמש ב-Google Cloud Shell כדי להבטיח סביבה סטנדרטית שהוגדרה מראש.
השלבים הבאים מתייחסים להקשר של Cloud Shell. אם בחרתם להשתמש בסביבה המקומית שלכם, ודאו שהאפליקציות git, nvm, npm ו-gcloud מותקנות ומוגדרות בצורה תקינה.
עבודה ב-Cloud Shell Editor
👈 לוחצים על Activate Cloud Shell בחלק העליון של מסוף Google Cloud (זהו סמל הטרמינל בחלק העליון של חלונית Cloud Shell), 
👈 לוחצים על הלחצן 'פתיחת הכלי לעריכה' (הוא נראה כמו תיקייה פתוחה עם עיפרון). ייפתח חלון עם Cloud Shell Code Editor. בצד ימין יופיע סייר הקבצים. 
👈 לוחצים על הלחצן Cloud Code Sign-in (כניסה באמצעות קוד בענן) בשורת הסטטוס התחתונה, כמו שמוצג. נותנים הרשאה לפלאגין לפי ההוראות. אם בשורת הסטטוס מופיע Cloud Code - no project, בוחרים באפשרות הזו, ואז בתפריט הנפתח 'Select a Google Cloud Project' בוחרים את הפרויקט הספציפי ב-Google Cloud מתוך רשימת הפרויקטים שיצרתם. 
👈פותחים את הטרמינל בסביבת הפיתוח המשולבת (IDE) בענן, 
👈 בטרמינל, מוודאים שכבר עברתם אימות ושהפרויקט מוגדר למזהה הפרויקט שלכם באמצעות הפקודה הבאה:
gcloud auth list
👈 משכפלים את הפרויקט natively-accessible-interface מ-GitHub:
git clone https://github.com/cuppibla/AccessibilityAgent.git
👈חשוב להחליף את <YOUR_PROJECT_ID> במזהה הפרויקט שלכם (אפשר למצוא את מזהה הפרויקט במסוף Google Cloud, בחלק של הפרויקט. ❗️❗️חשוב לא לבלבל בין project id לבין project number❗️❗️):
echo <YOUR_PROJECT_ID> > ~/project_id.txt
gcloud config set project $(cat ~/project_id.txt)
👉מריצים את הפקודה הבאה כדי להפעיל את ממשקי ה-API הנדרשים של Google Cloud: (הפעולה הזו עשויה להימשך כ-2 דקות)
gcloud services enable compute.googleapis.com \
storage.googleapis.com \
run.googleapis.com \
artifactregistry.googleapis.com \
aiplatform.googleapis.com \
eventarc.googleapis.com \
sqladmin.googleapis.com \
secretmanager.googleapis.com \
cloudbuild.googleapis.com \
cloudresourcemanager.googleapis.com \
cloudfunctions.googleapis.com \
cloudaicompanion.googleapis.com
הפעולה עשויה להימשך כמה דקות.
הגדרת הרשאות
👈הגדרת הרשאה לחשבון שירות. בטרמינל, מריצים את הפקודה :
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
export SERVICE_ACCOUNT_NAME=$(gcloud compute project-info describe --format="value(defaultServiceAccount)")
echo "Here's your SERVICE_ACCOUNT_NAME $SERVICE_ACCOUNT_NAME"
👈 מתן הרשאות. בטרמינל, מריצים את הפקודה :
#Cloud Storage (Read/Write):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/storage.objectAdmin"
#Pub/Sub (Publish/Receive):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/pubsub.publisher"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/pubsub.subscriber"
#Cloud SQL (Read/Write):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/cloudsql.editor"
#Eventarc (Receive Events):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/iam.serviceAccountTokenCreator"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/eventarc.eventReceiver"
#Vertex AI (User):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/aiplatform.user"
#Secret Manager (Read):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/secretmanager.secretAccessor"
4. הבנת קלט משתמשים – סיווג כוונות
לפני שנציג ה-AI שלנו יפעל, הוא צריך להבין במדויק מה המשתמש רוצה. קלט מהעולם האמיתי הוא לרוב מבולגן – הוא יכול להיות מעורפל, לכלול שגיאות הקלדה או להשתמש בשפה שיחתית.
בקטע הזה נבנה את רכיבי ה'האזנה' החשובים שממירים קלט של משתמשים גולמי לפקודה ברורה וניתנת לביצוע.
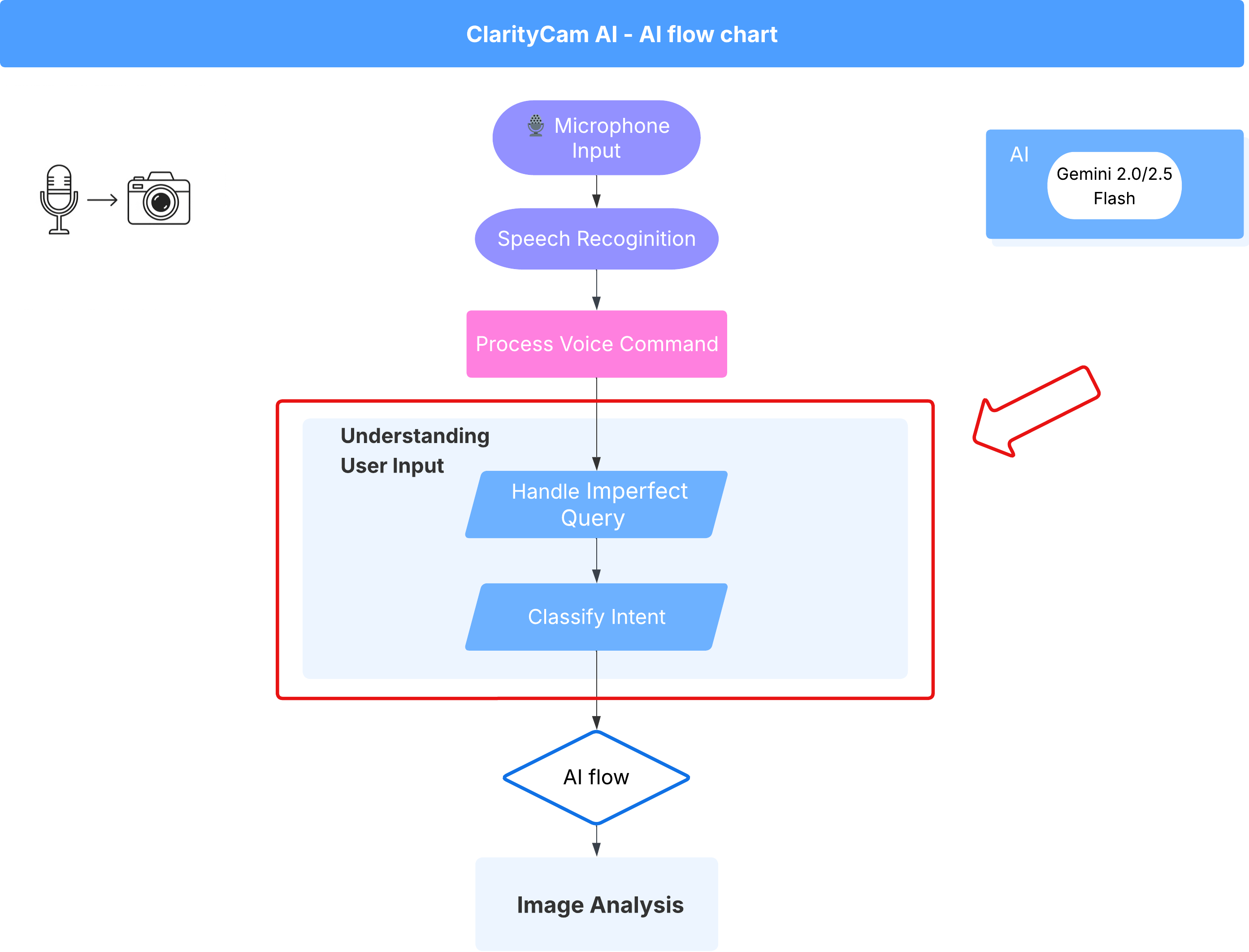
הוספת מסווג כוונות
עכשיו נגדיר את לוגיקת ה-AI שמפעילה את מסווג התוכן שלנו.
👈 Action: בסביבת הפיתוח המשולבת (IDE) של Cloud Shell, עוברים לספרייה ~/src/ai/intent-classifier/
שלב 1: הגדרת אוצר המילים של הסוכן (IntentCategory)
קודם כל, אנחנו צריכים ליצור רשימה סופית של כל הפעולות האפשריות שהסוכן יכול לבצע.
👈 פעולה: מחליפים את ה-placeholder // REPLACE ME PART 1: add IntentCategory here בקוד הבא:
👉 עם הקוד הבא:
export type IntentCategory =
// Image Analysis Intents
| "DescribeImage"
| "AskAboutImage"
| "ReadTextInImage"
| "IdentifyColorsInImage"
// Control Intents
| "TakePicture"
| "StartCamera"
| "SelectImage"
| "StopSpeaking"
// Preference Intents
| "SetDescriptionDetailed"
| "SetDescriptionConcise"
// Fallback Intents
| "GeneralInquiry" // User has a general question about the agent's functions or polite interaction
| "OutOfScopeRequest" // User's request is clearly outside the agent's defined capabilities
| "Unknown"; // Intent could not be determined with confidence
הסבר
קוד ה-TypeScript הזה יוצר סוג מותאם אישית שנקרא IntentCategory. זו רשימה מוגדרת שמפרטת כל פעולה אפשרית, או 'כוונה', שהסוכן שלנו יכול להבין. זהו שלב ראשון קריטי, כי הוא הופך מספר פוטנציאלי אינסופי של ביטויי משתמשים ("תגיד לי מה אתה רואה", "מה יש בתמונה?") לקבוצה נקייה וצפויה של פקודות. המטרה של המסווג שלנו היא למפות כל שאילתת משתמש לאחת מהקטגוריות הספציפיות האלה.
שלב 2
כדי לקבל החלטות מדויקות, הבינה המלאכותית שלנו צריכה לדעת מה היכולות והמגבלות שלה. המידע הזה יופיע כבלוק טקסט מפורט.
👉 פעולה: מחליפים את הפלייס הולדר REPLACE ME PART 2: add AGENT_CAPABILITIES_AND_LIMITATIONS here בקוד הבא:
מחליפים את הקוד שלמטה: // REPLACE ME PART 2: add AGENT_CAPABILITIES_AND_LIMITATIONS here:
👉 עם הקוד שמופיע למטה
const AGENT_CAPABILITIES_AND_LIMITATIONS = `
**Core Capabilities (What the Agent CAN DO):**
* **Image Analysis:**
* DescribeImage: Provide a general description of the current image.
* AskAboutImage: Answer a specific question about the visual content of the current image (e.g., "Is there a dog?", "What color is the car?").
* ReadTextInImage: Read any text found in the current image.
* IdentifyColorsInImage: Identify the dominant colors of the current image.
* **Image Input Control:**
* TakePicture: Capture an image using the currently active camera stream.
* StartCamera: Activate the camera (e.g., "use camera", "take another picture").
* SelectImage: Allow the user to choose an image file from their device.
* **Voice & Audio Control:**
* StopSpeaking: Stop the current text-to-speech output.
* **Preference Management:**
* SetDescriptionDetailed: Make future image descriptions more detailed.
* SetDescriptionConcise: Make future image descriptions less detailed or concise.
* **General Interaction:**
* GeneralInquiry: Handle conversational phrases (e.g., "hello", "thank you") or questions about its own capabilities (e.g., "what can you do?", "help").
**Limitations (What the Agent CANNOT DO and should be classified as OutOfScopeRequest):**
* Cannot generate or create new images.
* Cannot edit or modify existing images (e.g., "remove background," "make the car blue").
* Cannot analyze video files or live video beyond capturing a single frame.
* Cannot provide general knowledge or answer questions unrelated to the provided image's visual content (e.g., "What's the weather?", "Who is the president?", "Tell me a joke", "What time is it?").
* Cannot perform mathematical calculations or complex data analysis.
* Cannot translate languages as a primary function.
* Cannot remember information from past images or vastly different previous queries in the same session.
* Cannot control other device settings or applications.
* Cannot perform web searches.
`;
למה זה חשוב:
הטקסט הזה לא מיועד לקריאה על ידי המשתמש, אלא למודל ה-AI שלנו. אנחנו נזין את 'תיאור התפקיד' הזה ישירות להנחיה שלנו (בשלב הבא) כדי לספק למודל השפה (LLM) את ההקשר שהוא צריך כדי לקבל החלטות מדויקות. בלי ההקשר הזה, יכול להיות שה-LLM יסווג באופן שגוי את השאלה 'מה מזג האוויר?' כ-AskAboutImage. בהקשר הזה, המודל יודע שמזג האוויר הוא לא רכיב חזותי בתמונה, ומסווג אותו בצורה נכונה כלא רלוונטי.
שלב 3
עכשיו נכתוב את קבוצת ההוראות המלאה שמודל Gemini יפעל לפיה כדי לבצע את הסיווג.
👈 Action: מחליפים את // REPLACE ME PART 3 - classifyIntentPrompt בקוד הבא:
עם הקוד הבא
const classifyIntentPrompt = ai.definePrompt({
name: 'classifyIntentPrompt',
input: { schema: ClassifyIntentInputSchema },
output: { schema: ClassifyIntentOutputSchema },
prompt: `You are classifying the user's intent for ClarityCam, a voice-controlled AI application focused on image analysis.
Analyze the user query: '{userQuery}'.
First, understand ClarityCam's capabilities and limitations:
${AGENT_CAPABILITIES_AND_LIMITATIONS}
Now, classify the user's PRIMARY intent into ONE of the following categories:
* **DescribeImage**: User wants a general description of the current image.
* **AskAboutImage**: User is asking a specific question directly related to the visual content of the current image.
* **ReadTextInImage**: User wants any text read from the current image.
* **IdentifyColorsInImage**: User wants the dominant colors of the current image.
* **TakePicture**: User wants to capture an image using an active camera.
* **StartCamera**: User wants to activate the camera.
* **SelectImage**: User wants to choose an image file.
* **StopSpeaking**: User wants the current text-to-speech output to stop.
* **SetDescriptionDetailed**: User wants future image descriptions to be more detailed.
* **SetDescriptionConcise**: User wants future image descriptions to be less detailed.
* **GeneralInquiry**: The query is a simple conversational filler (e.g., "hello", "thanks"), a polite closing, or a direct question about the agent's functions (e.g., "what can you do?", "how does this work?", "help").
* **OutOfScopeRequest**: The query asks the agent to perform an action clearly listed under its "Limitations" or otherwise demonstrably outside its defined image analysis and control functions. Examples: "Tell me a joke," "What's the weather in London?", "Generate an image of a cat," "Can you edit my photo to make it brighter?", "Send this image to my friends","Translate 'hello' to Spanish."
Output ONLY the category name.
If the query is ambiguous but seems generally related to polite interaction or asking about the agent itself, prefer 'GeneralInquiry'.
If the query is clearly asking for something the agent CANNOT do, use 'OutOfScopeRequest'.
If truly unclassifiable even with these guidelines, use 'Unknown'.`,
config: {
temperature: 0.05, // Very low temperature for highly deterministic classification
}
});
ההנחיה הזו היא המקום שבו הקסם קורה. ההנחיה היא ה"מוח" של המסווג שלנו. היא אומרת ל-AI מה התפקיד שלו, מספקת את ההקשר הנדרש ומגדירה את הפלט הרצוי. שימו לב לטכניקות העיקריות הבאות של הנדסת הנחיות:
- משחק תפקידים: מתחיל במילים "אתה מסווג..." כדי להגדיר משימה ברורה.
- הזרקת הקשר: המערכת מוסיפה באופן דינמי את המשתנה
AGENT_CAPABILITIES_AND_LIMITATIONSלהנחיה. - פורמט פלט מדויק: ההוראה 'תחזיר רק את שם הקטגוריה' היא קריטית כדי לקבל תגובה ברורה וצפויה שנוכל להשתמש בה בקוד שלנו בקלות.
- רמת אקראיות נמוכה: לסיווג, אנחנו רוצים תשובות דטרמיניסטיות והגיוניות, ולא תשובות יצירתיות. הגדרת רמת האקראיות לערך נמוך מאוד (0.05) מבטיחה שהמודל יתמקד מאוד ויהיה עקבי.
שלב 4: חיבור האפליקציה לזרימת ה-AI
לבסוף, נקרא למסווג ה-AI החדש שלנו מקובץ האפליקציה הראשי.
👈 פעולה: עוברים לקובץ ~/src/app/page.tsx. בתוך הפונקציה processVoiceCommand, מחליפים את // REPLACE ME PART 1: add classificationResult כאן בקוד הבא:
const classificationResult = await classifyIntentFlow({ userQuery: commandToProcess });
intent = classificationResult.intent as IntentCategory;
הקוד הזה הוא הגשר החשוב בין אפליקציית ה-frontend לבין לוגיקת ה-AI של ה-backend. הוא מקבל את הפקודה הקולית של המשתמש (commandToProcess), שולח אותה אל classifyIntentFlow שיצרתם זה עתה וממתין עד ש-AI יחזיר את הכוונה המסווגת.
משתנה הכוונה מכיל עכשיו פקודה נקייה ומובנית (כמו DescribeImage). התוצאה הזו תשמש בהמשך בהוראת ה-switch כדי להפעיל את הלוגיקה של האפליקציה ולהחליט איזו פעולה לבצע בהמשך. כך ה"חשיבה" של ה-AI הופכת ל"פעולה" של האפליקציה.
הפעלת ממשק המשתמש
הגיע הזמן לראות את האפליקציה שלנו בפעולה! נתחיל את שרת הפיתוח.
👈 בטרמינל, מריצים את הפקודה הבאה: npm run dev הערה: יכול להיות שתצטרכו להריץ את הפקודה npm install לפני שתריצו את הפקודה npm run dev
אחרי רגע, יוצג פלט דומה לזה שמופיע כאן, מה שאומר שהשרת פועל בהצלחה:
▲ Next.js 15.2.3 (Turbopack)
- Local: http://localhost:9003
- Network: http://10.88.0.4:9003
- Environments: .env
✓ Starting...
✓ Ready in 1512ms
○ Compiling / ...
✓ Compiled / in 26.6s
עכשיו לוחצים על כתובת ה-URL המקומית (http://localhost:9003) כדי לפתוח את האפליקציה בדפדפן.
ממשק המשתמש של SightGuide אמור להופיע. בשלב הזה, הכפתורים לא מחוברים ללוגיקה כלשהי, ולכן לחיצה עליהם לא תעשה כלום. זה בדיוק מה שאנחנו מצפים בשלב הזה. נראה איך זה קורה בקטע הבא.
עכשיו, אחרי שראיתם את ממשק המשתמש, חוזרים למסוף ולוחצים על Ctrl + C כדי לעצור את שרת הפיתוח לפני שממשיכים.
5. הבנת קלט משתמשים – בדיקת שאילתות לא מושלמת
הוספת בדיקת שאילתה לא מושלמת
חלק 1: הגדרת ההנחיה (החלק של 'מה')
קודם כול, נגדיר את ההוראות ל-AI. ההנחיה היא ה "מתכון" לשיחת ה-AI שלנו – היא אומרת למודל בדיוק מה אנחנו רוצים שהוא יעשה.
👈 Action: בסביבת הפיתוח המשולבת, עוברים אל ~/src/ai/flows/check_typo/.
מחליפים את הקוד שלמטה: // REPLACE ME PART 1: add prompt here:
👉 עם הקוד שמופיע למטה
const prompt = ai.definePrompt({
name: 'checkTypoPrompt',
input: {
schema: CheckTypoInputSchema,
},
output: {
schema: CheckTypoOutputSchema,
},
prompt: `You are a helpful AI assistant that checks user text for typos and suggests corrections.
- If you find typos, respond with the corrected text.
- If there are no typos, or if you are unsure about a correction, respond with the original text unchanged.
User text: {text}
Corrected text:
`,
});
בלוק הקוד הזה מגדיר תבנית לשימוש חוזר עבור ה-AI שלנו שנקרא checkTypoPrompt. סכימות הקלט והפלט מגדירות את חוזה הנתונים של המשימה הזו. כך נמנעות שגיאות והמערכת שלנו צפויה.
חלק 2: יצירת ה-Flow (הסבר)
עכשיו, אחרי שיש לנו את ה'מתכון' (ההנחיה), אנחנו צריכים ליצור פונקציה שיכולה לבצע אותו. ב-Genkit, זה נקרא flow (תהליך). ה-Flow עוטף את ההנחיה שלנו בפונקציה שניתנת להרצה, ששאר האפליקציה יכולה לקרוא לה בקלות.
👈 פעולה: באותו קובץ ~/src/ai/flows/check_typo/, מחליפים את הקוד שבהמשך: // REPLACE ME PART 2: add flow here:
👉 עם הקוד שמופיע למטה
const checkTypoFlow = ai.defineFlow<
typeof CheckTypoInputSchema,
typeof CheckTypoOutputSchema
>(
{
name: 'checkTypoFlow',
inputSchema: CheckTypoInputSchema,
outputSchema: CheckTypoOutputSchema,
},
async input => {
const {output} = await prompt(input);
return output!;
}
);
חלק 3: שימוש בבודק השגיאות
אחרי שסיימנו את תהליך ה-AI, אנחנו יכולים לשלב אותו בלוגיקה הראשית של האפליקציה. הסריקה תתבצע מיד אחרי קבלת הפקודה מהמשתמש, כדי לוודא שהטקסט נקי לפני עיבוד נוסף.
👉פעולה: עוברים אל ~/src/app/ai/flows/check-typo.ts ומחפשים את הפונקציה export async function checkTypo. מבטלים את ההערה של פקודת החזרה:
במקום return; Do return checkTypoFlow(input);
👉פעולה: עוברים אל ~/src/app/page.tsx ומחפשים את הפונקציה processVoiceCommand. מחליפים את הקוד שלמטה: REPLACE ME PART 2: add typoResult here:
👉 עם הקוד שמופיע למטה
const typoResult = await checkTypo({ text: rawCommand });
if (typoResult && typoResult.correctedText && typoResult.correctedText.trim().length > 0) {
const originalTrimmedLower = rawCommand.trim().toLowerCase();
const correctedTrimmedLower = typoResult.correctedText.trim().toLowerCase();
if (correctedTrimmedLower !== originalTrimmedLower) {
commandToProcess = typoResult.correctedText;
typoCorrectionAnnouncement = `I think you said: ${commandToProcess}. `;
}
}
בעקבות השינוי הזה, יצרנו פייפליין חזק יותר לעיבוד נתונים לכל פקודת משתמש.
תהליך עבודה של פקודות קוליות (לקריאה בלבד, לא נדרשת פעולה)
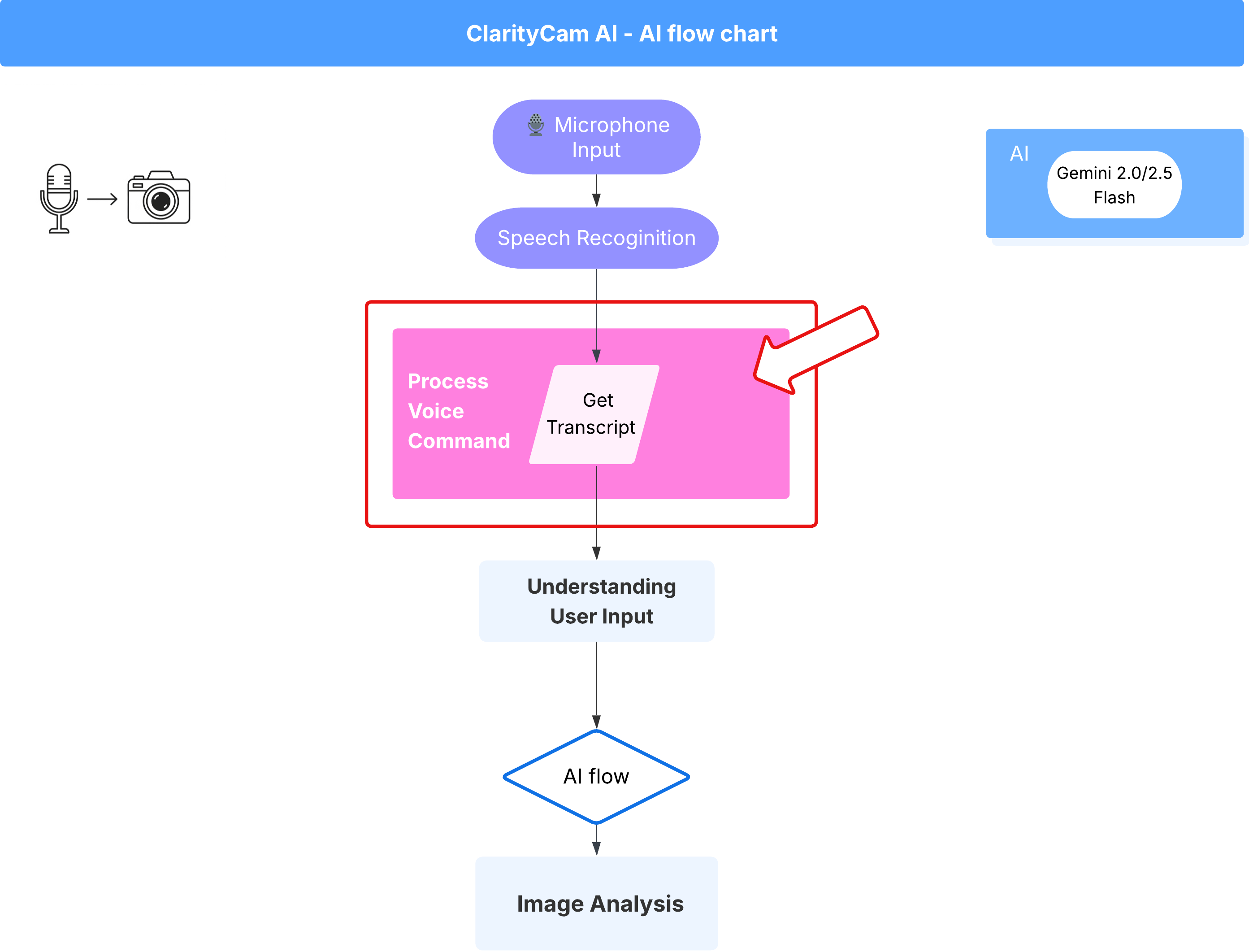
עכשיו, אחרי שיש לנו את רכיבי הליבה של ה'הבנה' (בודק השגיאות והמסווג של ה-Intent), נראה איך הם משתלבים בלוגיקה העיקרית של עיבוד הקול באפליקציה.
הכול מתחיל כשהמשתמש מדבר. ממשק Web Speech API של הדפדפן מאזין לדיבור, וכשהמשתמש מסיים לדבר, הוא מספק תמליל טקסט של מה שהוא שמע. הקוד הבא מטפל בתהליך הזה.
👈Read Only: עוברים אל ~/src/app/page.tsx ובתוך הפונקציה handleResult. הקוד מופיע כאן:
for (let i = event.resultIndex; i < event.results.length; ++i) {
if (event.results[i].isFinal) {
finalTranscript += event.results[i][0].transcript;
}
}
if (finalTranscript) {
console.log("Final Transcript:", finalTranscript);
processVoiceCommand(finalTranscript);
}
בודקים את תיקון שגיאות ההקלדה שלנו
ועכשיו לחלק הכיפי! נבדוק איך התכונה החדשה לתיקון שגיאות הקלדה מטפלת בפקודות קוליות מושלמות ולא מושלמות.
הפעלת האפליקציה
קודם כול, צריך להפעיל מחדש את שרת הפיתוח. בטרמינל, מריצים את הפקודה: npm run dev
פתיחת האפליקציה
כשהשרת מוכן, פותחים את הדפדפן ועוברים לכתובת המקומית (למשל, http://localhost:9003).
הפעלת פקודות קוליות
לוחצים על הלחצן Start Listening. בדרך כלל הדפדפן יבקש הרשאה להשתמש במיקרופון. צריך ללחוץ על 'אישור'.
בדיקת פקודה לא מושלמת
עכשיו ניתן לו בכוונה פקודה עם פגם קל כדי לראות אם ה-AI שלנו יצליח להבין אותה. מדברים בבירור למיקרופון:
"Picture take of me" (צלם תמונה שלי)
בדיקת התוצאה
כאן הקסם קורה! גם אם אמרת "תצלם אותי", האפליקציה אמורה להפעיל את המצלמה בצורה תקינה. תהליך העבודה של checkTypo מתקן את הביטוי ל-"take a picture" (צלם תמונה) מאחורי הקלעים, ותהליך העבודה של classifyIntentFlow מבין את הפקודה המתוקנת.
הנתונים האלה מאשרים שהתכונה שלנו לתיקון שגיאות הקלדה פועלת בצורה מושלמת, והופכת את האפליקציה ליציבה וידידותית יותר למשתמש. כשמסיימים, אפשר לצלם תמונה כדי להפסיק את המצלמה או פשוט להפסיק את השרת במסוף (Ctrl + C).
6. ניתוח תמונות מבוסס-AI – תיאור התמונה
עכשיו שהסוכן שלנו יכול להבין בקשות, הגיע הזמן לתת לו עיניים. בקטע הזה נרחיב את היכולות של סוכן הראייה, הרכיב המרכזי שאחראי לכל ניתוח התמונות. נתחיל עם התכונה הכי חשובה שלו – תיאור תמונה – ואז נוסיף את היכולת לקרוא טקסט.
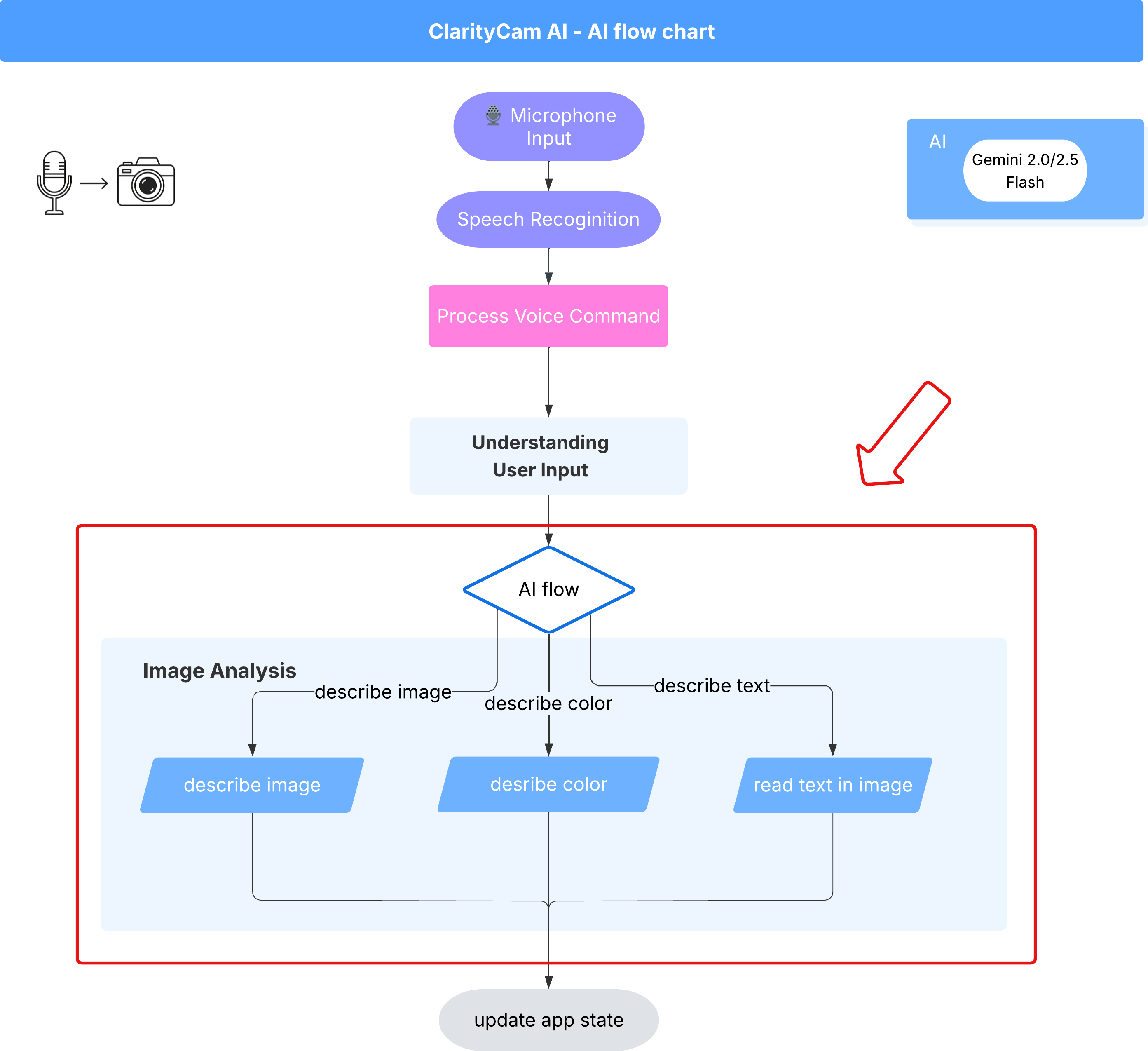
תכונה 1: תיאור תמונה
זו הפונקציה העיקרית של הסוכן. אנחנו לא רק ניצור תיאור סטטי, אלא נבנה תהליך דינמי שיוכל להתאים את רמת הפירוט שלו על סמך העדפות המשתמש. זהו חלק מרכזי בפילוסופיה של ממשק שמותאם באופן טבעי (NAI).
👈 פעולה: בסביבת הפיתוח המשולבת (IDE) של Cloud Shell, עוברים לקובץ ~/src/ai/flows/describe_image/ ומסירים את ההערה מהקוד הבא.
שלב 1: יצירת תבנית של הנחיה דינמית
קודם כל, ניצור תבנית הנחיה מתוחכמת שיכולה לשנות את ההוראות שלה על סמך הקלט שהיא מקבלת.
מבטלים את ההערה בקוד שלמטה
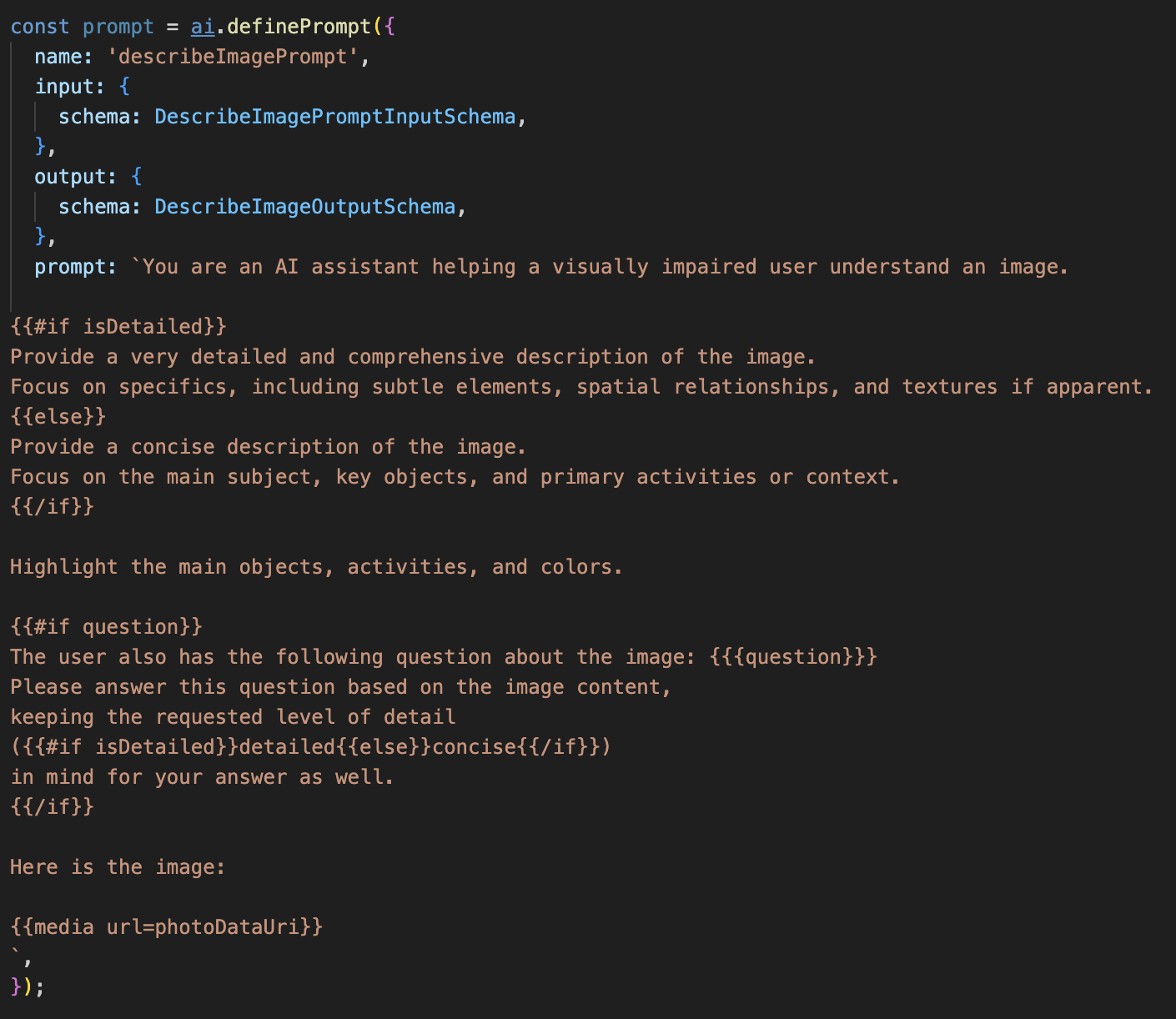
הקוד הזה מגדיר משתנה מחרוזת, prompt, שמשתמש בשפת תבניות שנקראת Dot-Mustache. כך אנחנו יכולים להטמיע לוגיקה מותנית ישירות בהנחיה.
{#if isDetailed}...{else}...{/if}: זהו בלוק של תנאי. אם נתוני הקלט שאנחנו שולחים להנחיה הזו מכילים את המאפיין isDetailed: true, ה-AI יקבל את קבוצת ההוראות 'מפורטות מאוד'. אחרת, הוא יקבל את ההוראות 'התמציתיות'. כך הסוכן שלנו מתאים את עצמו להעדפות המשתמשים.
{#if question}...{/if}: הבלוק הזה ייכלל רק אם נתוני הקלט שלנו מכילים מאפיין של שאלה. כך אנחנו יכולים להשתמש באותו הנחיה עוצמתית גם לתיאורים כלליים וגם לשאלות ספציפיות.
{media url=photoDataUri}: זהו התחביר המיוחד של Genkit להטמעת נתוני תמונה ישירות בהנחיה לניתוח על ידי המודל הרב-אופני.
שלב 2: יצירת התהליך החכם
לאחר מכן, מגדירים את ההנחיה ואת התהליך שישתמשו בתבנית החדשה. התהליך הזה כולל קצת לוגיקה כדי לתרגם את ההעדפה של המשתמש לערך בוליאני שהתבנית שלנו יכולה להבין.
👈 פעולה: בסביבת הפיתוח המשולבת (IDE) של Cloud Shell, מחליפים את הקוד הבא בקובץ ~/src/ai/flows/describe_image/. // REPLACE ME PART 1: add flow here
👉 עם הקוד שבהמשך:
// Define the prompt using the template from Step 1
const prompt = ai.definePrompt({
name: 'describeImagePrompt',
input: { schema: DescribeImagePromptInputSchema },
output: { schema: DescribeImageOutputSchema },
prompt: promptTemplate,
});
// Define the flow
const describeImageFlow = ai.defineFlow<
typeof DescribeImageInputSchema,
typeof DescribeImageOutputSchema
>(
{
name: 'describeImageFlow',
inputSchema: DescribeImageInputSchema,
outputSchema: DescribeImageOutputSchema,
},
async (pageInput) => {
const preference = pageInput.detailPreference || "concise";
// Prepare the input for the prompt, including the new boolean flag
const promptInputData = {
...pageInput,
isDetailed: preference === "detailed",
};
const { output } = await prompt(promptInputData);
return output!;
}
);
השער הזה משמש כמתווך חכם בין הקצה הקדמי לבין הנחיית ה-AI.
- היא מקבלת
pageInputמהאפליקציה שלנו, שכולל את ההעדפה של המשתמש כמחרוזת (לדוגמה,"detailed"). - לאחר מכן נוצר אובייקט חדש,
promptInputData. - השורה הכי חשובה היא
isDetailed: preference === "detailed". השורה הזו מבצעת את העבודה החשובה של יצירת ערך בוליאניtrueאוfalseעל סמך מחרוזת ההעדפות. - לבסוף, היא קוראת ל-
promptעם הנתונים המשופרים האלה. עכשיו אפשר להשתמש בתבנית ההנחיה משלב 1 כדי לשנות באופן דינמי את ההוראות שנשלחות ל-AI באמצעותisDetailedboolean.
שלב 3: קישור חזית האתר
עכשיו נפעיל את התהליך הזה מממשק המשתמש שלנו בקובץ page.tsx.
👉פעולה: עוברים אל ~/src/app/ai/flows/describe-image.ts ומחפשים את הפונקציה export async function describeImage. מבטלים את ההערה של פקודת החזרה:
במקום return; Do return describeImageFlow(input);
👈פעולה: ב-~/src/app/page.tsx, מאתרים את הפונקציה handleAnalyze, מחליפים את הקוד // REPLACE ME PART 2: DESCRIBE IMAGE
👈 עם הקוד הבא:
case "description":
result = await describeImage({
photoDataUri,
question,
detailPreference: descriptionPreference
});
outputText = question ? `Answer: ${result.description}` : `Description: ${result.description}`;
break;
הקוד הזה מופעל כשהמשתמש רוצה לקבל תיאור. היא קוראת לזרימת העבודה describeImage שלנו, מעבירה את נתוני התמונה וחשוב מכך, את משתנה הסטטוס descriptionPreference מרכיב React שלנו. זהו החלק האחרון בפאזל, שמקשר את ההעדפה של המשתמש שמאוחסנת בממשק המשתמש ישירות לזרימת ה-AI, שתתאים את ההתנהגות שלה בהתאם.
בדיקת התכונה 'תיאור תמונה'
בואו נראה את הפונקציונליות של תיאור התמונה בפעולה, החל מצילום תמונה ועד לשמיעת מה ש-AI רואה.
הפעלת האפליקציה
קודם כול, צריך להפעיל מחדש את שרת הפיתוח. 👈 בטרמינל, מריצים את הפקודה הבאה: npm run dev הערה: יכול להיות שתצטרכו להריץ את הפקודה npm install לפני שתריצו את הפקודה npm run dev
פתיחת האפליקציה
כשהשרת מוכן, פותחים את הדפדפן ועוברים לכתובת המקומית (למשל, http://localhost:9003).
הפעלת המצלמה
לוחצים על הלחצן 'התחלת ההאזנה' ומאשרים גישה למיקרופון אם מתבקשים. אחר כך אומרים את הפקודה הראשונה:
"Take a picture" (צלם תמונה)
האפליקציה תפעיל את המצלמה של המכשיר. עכשיו אמור להופיע פיד הווידאו בשידור חי על המסך.
צילום התמונה
כשהמצלמה פעילה, מכוונים אותה למה שרוצים לתאר. עכשיו, אומרים את הפקודה בפעם השנייה כדי לצלם את התמונה:
"Take a picture" (צלם תמונה)
הווידאו בשידור חי יוחלף בתמונה הסטטית שצילמתם עכשיו.
בקשת התיאור
כשהתמונה החדשה מופיעה במסך, נותנים את הפקודה הסופית:
"Describe the picture" (תאר את התמונה)
האזנה לתוצאה
באפליקציה יוצג סטטוס העיבוד, ואז תשמעו את התיאור של התמונה שנוצר על ידי AI. הטקסט יופיע גם בכרטיס 'סטטוס ותוצאה'.
כשמסיימים, אפשר לצלם תמונה כדי לעצור את המצלמה או פשוט לעצור את השרת במסוף (Ctrl + C).
7. ניתוח תמונות מבוסס-AI – תיאור טקסט (OCR)
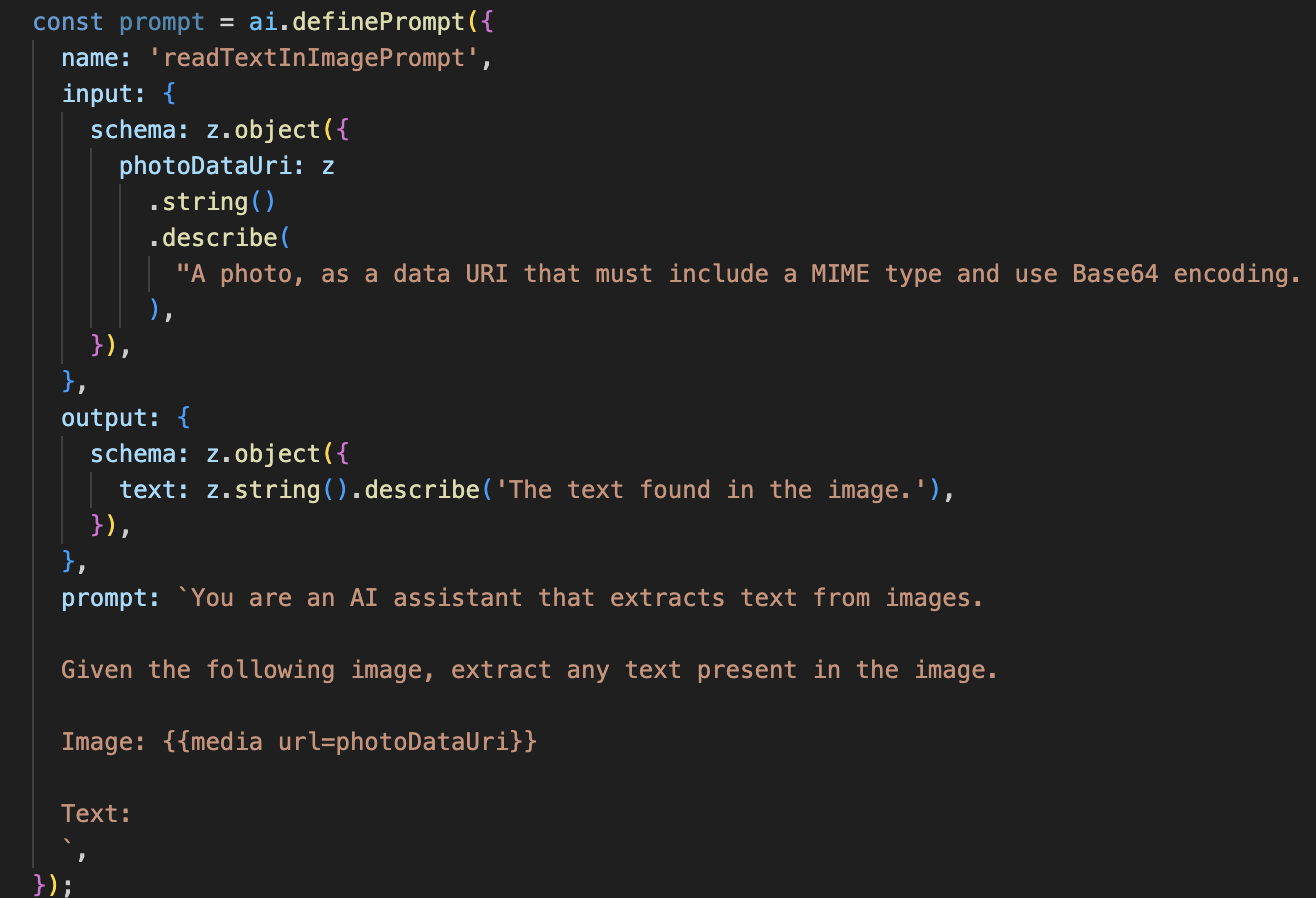
בשלב הבא, נוסיף יכולת זיהוי תווים אופטי (OCR) לסוכן Vision שלנו. כך אפשר לקרוא טקסט מכל תמונה.
👈 פעולה: בסביבת הפיתוח המשולבת, עוברים אל ~/src/ai/flows/read-text-in-image/, מסירים את ההערה מהקוד הבא:
👈 פעולה: בסביבת הפיתוח המשולבת, באותו קובץ ~/src/ai/flows/read-text-in-image/, מחליפים את // REPLACE ME: Creating Prmopt
👈 עם הקוד הבא:
const readTextInImageFlow = ai.defineFlow<
typeof ReadTextInImageInputSchema,
typeof ReadTextInImageOutputSchema
>(
{
name: 'readTextInImageFlow',
inputSchema: ReadTextInImageInputSchema,
outputSchema: ReadTextInImageOutputSchema,
},
async input => {
const {output} = await prompt(input);
return output!;
}
);
התהליך הזה מבוסס על AI והוא הרבה יותר פשוט, וממחיש את העיקרון של שימוש בכלים ממוקדים למשימות ספציפיות.
- ההנחיה: בניגוד להנחיית התיאור שלנו, ההנחיה הזו סטטית וספציפית מאוד. התפקיד היחיד שלו הוא להנחות את ה-AI לפעול כמנוע OCR: "תמצה כל טקסט שמופיע בתמונה".
- הסכימות: סכימות הקלט והפלט פשוטות גם הן. הן מצפות לתמונה ומחזירות מחרוזת טקסט יחידה.
חיבור הקצה הקדמי ל-OCR
לבסוף, נחבר את היכולת החדשה הזו ב-page.tsx.
👉פעולה: עוברים אל ~/src/app/ai/flows/read-text-in-image.ts ומחפשים את הפונקציה export async function readTextInImage. מבטלים את ההערה של פקודת החזרה:
במקום return; Do return readTextInImageFlow(input);
👈 פעולה: ב-~/src/app/page.tsx, מחפשים את הפונקציה handleAnalyze ואת ההצהרה switch.
החלפה של REPLACE ME PART 3: READ TEXT
עם הקוד הבא:
case "text":
result = await readTextInImage({ photoDataUri });
outputText = result.text ? `Text Found: ${result.text}` : "No text found.";
break;
הקוד הזה מופעל כשהכוונה של המשתמש היא ReadTextInImage. הוא קורא לזרימת העבודה הפשוטה readTextInImage שלנו. השורה result.text ? ... : ... היא דרך נקייה לטפל בפלט, ומספקת למשתמש הודעה מועילה אם ה-AI לא הצליח למצוא טקסט בתמונה.
בדיקת התכונה 'קריאת טקסט (OCR)'
כדי לבדוק את התכונה להקראת טקסט, פועלים לפי השלבים הבאים. חשוב לזכור לכוון את המצלמה לאובייקט עם טקסט ברור.
- מריצים את האפליקציה עם
npm run devופותחים אותה בדפדפן. - לוחצים על 'התחלת האזנה' ומאשרים גישה למיקרופון כשמתבקשים.
- מפעילים את המצלמה. אומרים את הפקודה: "Take a picture" (צלם תמונה). פיד הווידאו בשידור חי אמור להופיע על המסך.
- מצלמים את התמונה. מכוונים את המצלמה לטקסט שרוצים לקרוא ואומרים שוב את הפקודה: "צלם תמונה". הסרטון יוחלף בתמונה סטטית.
- מבקשים את הטקסט. אחרי שמצלמים תמונה, נותנים את הפקודה הסופית: "What is the text in the image?" (מה הטקסט בתמונה?).
- בודקים את התוצאה אחרי רגע, האפליקציה תנתח את התמונה ותקריא את הטקסט שזוהה. אם לא נמצא טקסט, תקבלו על כך הודעה.
כך תוכלו לוודא שתכונת ה-OCR המתקדמת פועלת. כשמסיימים, עוצרים את השרת באמצעות Ctrl + C.
8. שיפורים מתקדמים באמצעות AI – קריאה בלבד ✨
סוכן AI טוב יכול לפעול לפי הוראות. סוכן AI טוב הוא אינטואיטיבי, מהימן ומועיל. בקטע הזה נתמקד בשלושה שיפורים מתקדמים שמשדרגים את היכולות של הסוכן שלנו.
נראה איך:
Add Context & Memoryכדי לנהל שיחות טבעיות עם שאלות המשך.Reduce Hallucinationכדי ליצור סוכן אמין יותר.Make the Agent Proactiveכדי לספק חוויה נגישה וידידותית יותר למשתמש.Add preference settingכדי להתאים אישית את תיאור התמונה
שיפור 1: הקשר וזיכרון
שיחה טבעית היא לא סדרה של פקודות מבודדות, אלא שיחה רציפה. אם משתמש שואל: "מה יש בתמונה?" והסוכן עונה: "מכונית אדומה", יכול להיות שהמשתמש ישאל באופן טבעי: "איזה צבע זה?" בלי להגיד שוב "מכונית". הנציג שלנו צריך זיכרון לטווח קצר כדי להבין את ההקשר הזה.
איך הטמענו את זה (סיכום)
כבר שילבנו את היכולת הזו בתהליך העבודה של describeImage. בקטע הזה נסכם את אופן הפעולה של התבנית. כשמפעילים את הפונקציה describeImage מהקובץ page.tsx, מעבירים לה את היסטוריית השיחה.
👈 Code Showcase (מתוך page.tsx):
const result = await describeImage({
photoDataUri,
question: commandToProcess,
detailPreference: descriptionPreference,
previousUserQueryOnImage: lastUserQuery ?? undefined,
previousAIResponseOnImage: lastAIResponse ?? undefined,
});
-
previousUserQueryOnImage&previousAIResponseOnImage: שני הנכסים האלה הם הזיכרון לטווח קצר של הסוכן. העברת האינטראקציה האחרונה ל-AI מספקת לו את ההקשר שדרוש לו כדי להבין שאלות המשך מעורפלות או שאלות שמתייחסות למשהו שנאמר קודם. - הנחיה דינמית: ההקשר הזה משמש את ההנחיה בתהליך describe_image. ההנחיה מתוכננת כך שתתחשב בשיחה הקודמת כשמנסחים תשובה חדשה, כדי שהנציג יוכל להגיב בצורה חכמה.
שיפור 2: צמצום ההזיות
המונח 'הזיה' מתייחס למצב שבו AI ממציא עובדות או טוען שיש לו יכולות שאין לו. כדי לבנות אמון בקרב המשתמשים, חשוב שהסוכן יכיר את המגבלות שלו וידע לדחות בנימוס בקשות שלא נמצאות בתחום ההתמחות שלו.
איך הטמענו את זה (סיכום)
הדרך היעילה ביותר למנוע הזיות היא להגדיר למודל גבולות ברורים. השגנו את זה כשבנינו את מערכת סיווג הכוונות שלנו.
👈 Code Showcase (מתוך התהליך intent-classifier):
// Define Agent Capabilities and Limitations for the prompt
const AGENT_CAPABILITIES_AND_LIMITATIONS = `
**Core Capabilities (What the Agent CAN DO):**
* **Image Analysis:**
* DescribeImage: Provide a general description of the current image...
**Limitations (What the Agent CANNOT DO...):**
* Cannot generate or create new images.
* Cannot provide general knowledge or answer questions unrelated to the image...
* Cannot perform web searches.
`;
הקבוע הזה משמש כ "תיאור משרה" שאנחנו מזינים ל-AI בהנחיה לסיווג.
- הארקה של המודל: אנחנו "מארקים" את ה-AI במציאות על ידי ציון מפורש של מה שהוא לא יכול לעשות. כשהוא מזהה שאילתה כמו "מה מזג האוויר?", הוא יכול להתאים אותה בביטחון לרשימת המגבלות שלו ולסווג את הכוונה כ-OutOfScopeRequest.
- בניית אמון: סוכן שיכול לומר בכנות "אין לי אפשרות לעזור לך בנושא הזה" הוא מהימן הרבה יותר מסוכן שמנסה לנחש וטועה. זהו עיקרון בסיסי בתכנון של AI בטוח ואמין. `
שיפור 3: יצירת סוכן פרואקטיבי
באפליקציה שמתמקדת בנגישות, אי אפשר להסתמך על רמזים חזותיים. כשמשתמש מפעיל את מצב ההאזנה, הוא צריך לקבל אישור מיידי ולא ויזואלי שהנציג מוכן וממתין לפקודה. מעכשיו נוסיף הקדמה יזומה כדי לספק את המשוב החשוב הזה.
שלב 1: הוספת מצב למעקב אחר ההאזנה הראשונה
קודם כל, אנחנו צריכים לדעת אם זו הפעם הראשונה שהמשתמש לוחץ על הלחצן "Start Listening" במהלך הסשן.
👈 ב-~/src/app/page.tsx, משתנה המצב החדש הבא מופיע בחלק העליון של רכיב ClarityCam.
export default function ClarityCam() {
// ... other state variables
const [descriptionPreference, setDescriptionPreference] = useState<DescriptionPreference>("concise");
// Add this new line
const [isFirstListen, setIsFirstListen] = useState(true);
// ... rest of the component
}
הוספנו משתנה מצב חדש, isFirstListen, והגדרנו את הערך שלו ל-true. אנחנו נשתמש בסימון הזה כדי להפעיל את הודעת קבלת הפנים החד-פעמית שלנו.
שלב 2: מעדכנים את הפונקציה toggleListening
עכשיו נשנה את הפונקציה שמטפלת במיקרופון כדי להשמיע את ההודעה שלנו.
👈 ב-~/src/app/page.tsx, מחפשים את הפונקציה toggleListening ורואים את הבלוק if הבא.
const toggleListening = useCallback(() => {
// ... existing logic to setup speech recognition
if (isListening || isAttemptingStart) {
// ... existing logic to stop listening
} else {
stopSpeaking(); // Stop any ongoing TTS
// Add this new block
if (isFirstListen) {
setIsFirstListen(false);
const introMessage = "Hello! I am ClarityCam, your AI assistant. I'm now listening. You can ask me to 'describe the image', 'read text', 'take a picture', or ask questions about what's in an image.";
speakText(introMessage);
} else {
speakText("Listening..."); // Optional: provide feedback on subsequent clicks
}
// ... rest of the logic to start listening
}
}, [/*...existing dependencies...*/, isFirstListen]); // Don't forget to add isFirstListen to the dependency array!
- בדיקת הדגל: הבלוק if (isFirstListen) בודק אם זו ההפעלה הראשונה.
- Prevent Repetition: הפעולה הראשונה שמתבצעת בתוך הבלוק היא קריאה ל-setIsFirstListen(false). כך מוודאים שההודעה המקדימה תושמע רק פעם אחת בכל סשן.
- מתן הנחיות: הודעת הפתיחה מנוסחת בקפידה כדי להיות מועילה ככל האפשר. הוא מברך את המשתמש, מזהה את הסוכן בשם, מאשר שהוא פעיל עכשיו ("אני מקשיב עכשיו") ומספק דוגמאות ברורות לפקודות קוליות שאפשר להשתמש בהן.
- משוב קולי: לבסוף, הפונקציה speakText(introMessage) מעבירה את המידע החשוב הזה, ומספקת למשתמשים מידע והנחיות באופן מיידי בלי שהם יצטרכו להסתכל על המסך.
שיפור 4: התאמה להעדפות המשתמשים (סיכום)
סוכן חכם באמת לא רק מגיב, אלא לומד ומתאים את עצמו לצרכים של המשתמש. אחת התכונות הכי שימושיות שפיתחנו היא היכולת של המשתמש לשנות את דרגת המלל של תיאורי התמונות תוך כדי תנועה באמצעות פקודות כמו 'תאר בפירוט רב יותר'.
איך הטמענו את התכונה (סיכום) התכונה הזו מבוססת על ההנחיה הדינמית שיצרנו לתהליך describeImage. הוא משתמש בלוגיקה מותנית כדי לשנות את ההוראות שנשלחות ל-AI על סמך ההעדפה של המשתמש.
👈 Code Showcase (ה-promptTemplate מתוך describe_image):
const settingPreferenceTemplate = `
{#if isDetailed}
Provide a very detailed and comprehensive description of the image. Focus on specifics, including subtle elements, spatial relationships, and textures if apparent.
{else}
Provide a concise description of the image. Focus on the main subject, key objects, and primary activities or context.
{/if}
Highlight the main objects, activities, and colors.
...
`;
- לוגיקה של משפט תנאי: בלוק
{#if isDetailed}...{else}...{/if}הוא המפתח. כשהפונקציה describeImageFlow מקבלת את הפרמטר detailPreference מהקצה הקדמי, היא יוצרת ערך בוליאני isDetailed (TRUE או FALSE). - הוראות דינמיות: דגל בוליאני שקובע איזו קבוצת הוראות מקבל מודל ה-AI. אם הערך של isDetailed הוא True, המודל מקבל הוראה להיות תיאורי מאוד. אם התשובה היא False, היא צריכה להיות תמציתית.
- שליטה של המשתמש: התבנית הזו מקשרת ישירות בין פקודה קולית של משתמש (למשל, 'תכתוב תיאורים תמציתיים', שמסווגת ככוונת המשתמש SetDescriptionConcise) לבין שינוי מהותי בהתנהגות של ה-AI, כך שהסוכן מרגיש באמת מגיב ומותאם אישית.
9. פריסה בענן
יצירת קובץ אימג' של Docker באמצעות Google Cloud Build
gcloud builds submit . --tag gcr.io/$PROJECT_ID/accessibilityai-nextjs-app:latest
-
accessibilityai-nextjs-appהוא שם מוצע של תמונה. - לא ניתן לעבד את קובץ ה- משתמש בספרייה הנוכחית (
accessibilityAI/) כמקור הבנייה.
פריסת האימג' ב-Google Cloud Run
- מוודאים שמפתחות ה-API וסודות אחרים מוכנים ב-Secret Manager. לדוגמה,
GOOGLE_GENAI_API_KEY.
מחליפים את הערך YOUR_ACTUAL_GOOGLE_AI_KEY_VALUE בערך בפועל של מפתח ה-API של Gemini.
echo "YOUR_ACTUAL_GOOGLE_AI_KEY_VALUE" | gcloud secrets create GOOGLE_GENAI_API_KEY --data-file=- --project=YOUR_PROJECT_ID
צריך להעניק לחשבון השירות של זמן הריצה של שירות Cloud Run (לדוגמה, PROJECT_NUMBER-compute@developer.gserviceaccount.com או חשבון ייעודי) את התפקיד Secret Manager Secret Accessor (גישה לסודות ב-Secret Manager) עבור הסוד הזה.
- פקודת פריסה:
gcloud run deploy accessibilityai-app-service \
--image gcr.io/$PROJECT_ID/accessibilityai-nextjs-app:latest \
--platform managed \
--region us-central1 \
--allow-unauthenticated \
--port 3000 \
--set-secrets=GOOGLE_GENAI_API_KEY=GOOGLE_GENAI_API_KEY:latest \
--set-env-vars NODE_ENV="production"