
1. परिचय
इस ट्यूटोरियल में, आपको ClarityCam बनाने का तरीका बताया जाएगा. यह एक एआई एजेंट है, जिसे बोलकर कंट्रोल किया जा सकता है. यह दुनिया को देख सकता है और आपको इसके बारे में बता सकता है. ClarityCam को सुलभता को ध्यान में रखकर डिज़ाइन किया गया है. यह दृष्टिहीन और कम दृष्टि वाले लोगों के लिए एक बेहतरीन टूल है. हालांकि, आपको जो सिद्धांत सीखने को मिलेंगे वे किसी भी आधुनिक, सामान्य मकसद वाले वॉइस ऐप्लिकेशन को बनाने के लिए ज़रूरी हैं.

यह प्रोजेक्ट, नेटिव अडैप्टिव इंटरफ़ेस (एनएआई) नाम की डिज़ाइन फ़िलॉसफ़ी पर आधारित है. NAI, सुलभता को बाद में जोड़ने के बजाय, इसे अपनी नीति का आधार बनाता है. इस तरीके में, एआई एजेंट इंटरफ़ेस होता है. यह अलग-अलग उपयोगकर्ताओं के हिसाब से काम करता है. साथ ही, यह आवाज़ और विज़न जैसे मल्टीमॉडल इनपुट को हैंडल करता है. इसके अलावा, यह लोगों की ज़रूरतों के हिसाब से उन्हें सलाह देता है.
NAI की मदद से अपना पहला एआई एजेंट बनाना:

इस सेशन के आखिर तक, ये काम किए जा सकेंगे:
- सुलभता को डिफ़ॉल्ट रूप से शामिल करके डिज़ाइन करना: एआई सिस्टम बनाने के लिए, नेटिव अडैप्टिव इंटरफ़ेस (एनएआई) के सिद्धांतों को लागू करें. इससे सभी उपयोगकर्ताओं को एक जैसा अनुभव मिलेगा.
- उपयोगकर्ता के इरादे को क्लासिफ़ाई करना: एक मज़बूत इंटेंट क्लासिफ़ायर बनाएं, जो बोलचाल की भाषा में दिए गए निर्देशों को आपके एजेंट के लिए स्ट्रक्चर्ड ऐक्शन में बदलता है.
- बातचीत के कॉन्टेक्स्ट को बनाए रखना: कम समय के लिए मेमोरी को लागू करें, ताकि आपका एजेंट फ़ॉलो-अप वाले सवालों को समझ सके और रेफ़रंस वाले निर्देशों का पालन कर सके. उदाहरण के लिए, "यह किस रंग का है?"
- असरदार प्रॉम्प्ट तैयार करना: Gemini जैसे मल्टीमॉडल के लिए, कॉन्टेक्स्ट के हिसाब से सटीक और जानकारी से भरपूर प्रॉम्प्ट तैयार करें. इससे इमेज का सटीक और भरोसेमंद विश्लेषण किया जा सकेगा.
- अस्पष्टता को दूर करना और उपयोगकर्ता को गाइड करना: दायरे से बाहर के अनुरोधों के लिए, गड़बड़ी को ठीक करने का बेहतर तरीका डिज़ाइन करें. साथ ही, लोगों का भरोसा जीतने के लिए, उन्हें पहले से ही शामिल करें.
- मल्टी-एजेंट सिस्टम को व्यवस्थित करना: अपने ऐप्लिकेशन को खास एजेंट के कलेक्शन का इस्तेमाल करके स्ट्रक्चर करें. ये एजेंट, आवाज़ को प्रोसेस करने, विश्लेषण करने, और स्पीच सिंथेसिस जैसे मुश्किल टास्क को हैंडल करने के लिए मिलकर काम करते हैं.
2. हाई-लेवल डिज़ाइन
ClarityCam को मुख्य तौर पर, उपयोगकर्ता के लिए आसान बनाने के लिए डिज़ाइन किया गया है. हालांकि, यह एआई एजेंट के एक बेहतर सिस्टम की मदद से काम करता है. आइए, आर्किटेक्चर के बारे में जानते हैं.

उपयोगकर्ता अनुभव
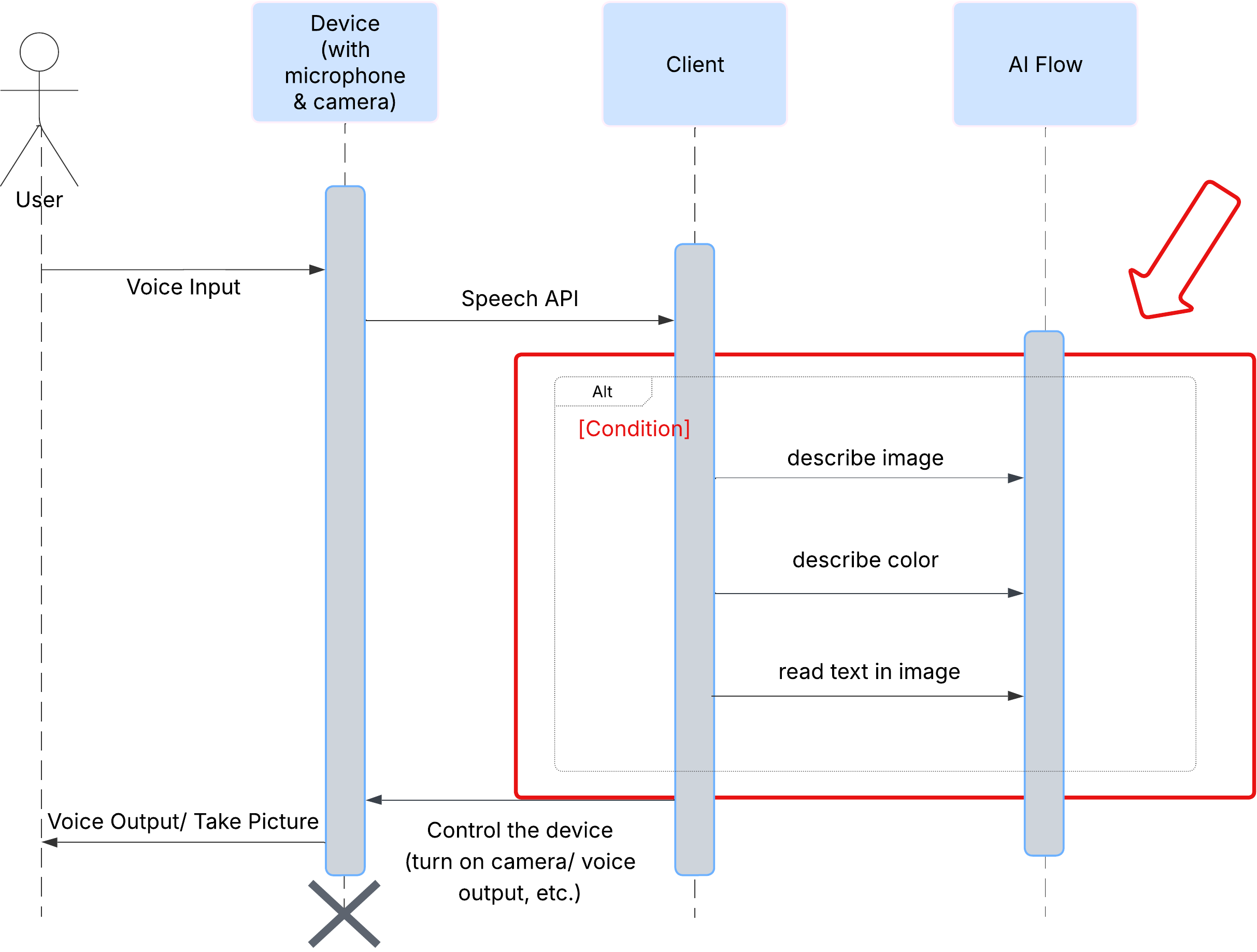
सबसे पहले, यह देखते हैं कि कोई उपयोगकर्ता ClarityCam के साथ कैसे इंटरैक्ट करता है. इस सुविधा को बिना हाथ लगाए और बातचीत करके इस्तेमाल किया जा सकता है. उपयोगकर्ता कोई निर्देश देता है और एजेंट, बोलकर जवाब देता है या कोई कार्रवाई करता है. इस क्रम के डायग्राम में, इंटरैक्शन का सामान्य फ़्लो दिखाया गया है. इसमें उपयोगकर्ता के शुरुआती वॉइस कमांड से लेकर डिवाइस से मिलने वाले फ़ाइनल ऑडियो रिस्पॉन्स तक की जानकारी शामिल है.
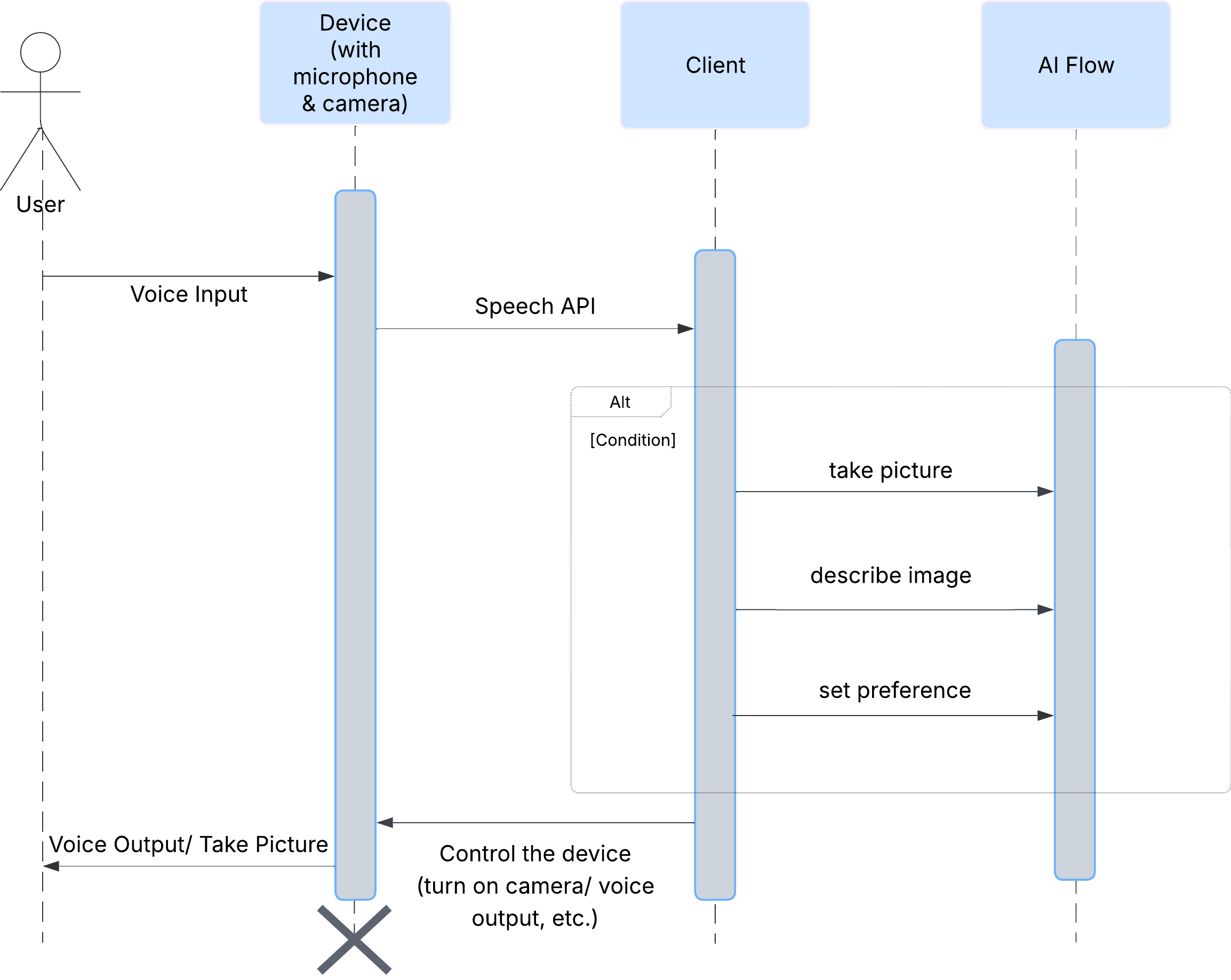
एआई एजेंट का आर्किटेक्चर
इसकी सतह के नीचे, कई एजेंट वाला सिस्टम एक साथ काम करता है, ताकि आपको बेहतर अनुभव मिल सके. कोई कमांड मिलने पर, सेंट्रल ऑर्केस्ट्रेटर एजेंट, टास्क को उन एजेंट को सौंपता है जो इंटेंट को समझने, इमेज का विश्लेषण करने, और जवाब देने में माहिर होते हैं. एआई के इस फ़्लो डायग्राम में, इन एजेंट के साथ मिलकर काम करने के तरीके के बारे में ज़्यादा जानकारी दी गई है. हम इस आर्किटेक्चर को अगले सेक्शन में लागू करेंगे.
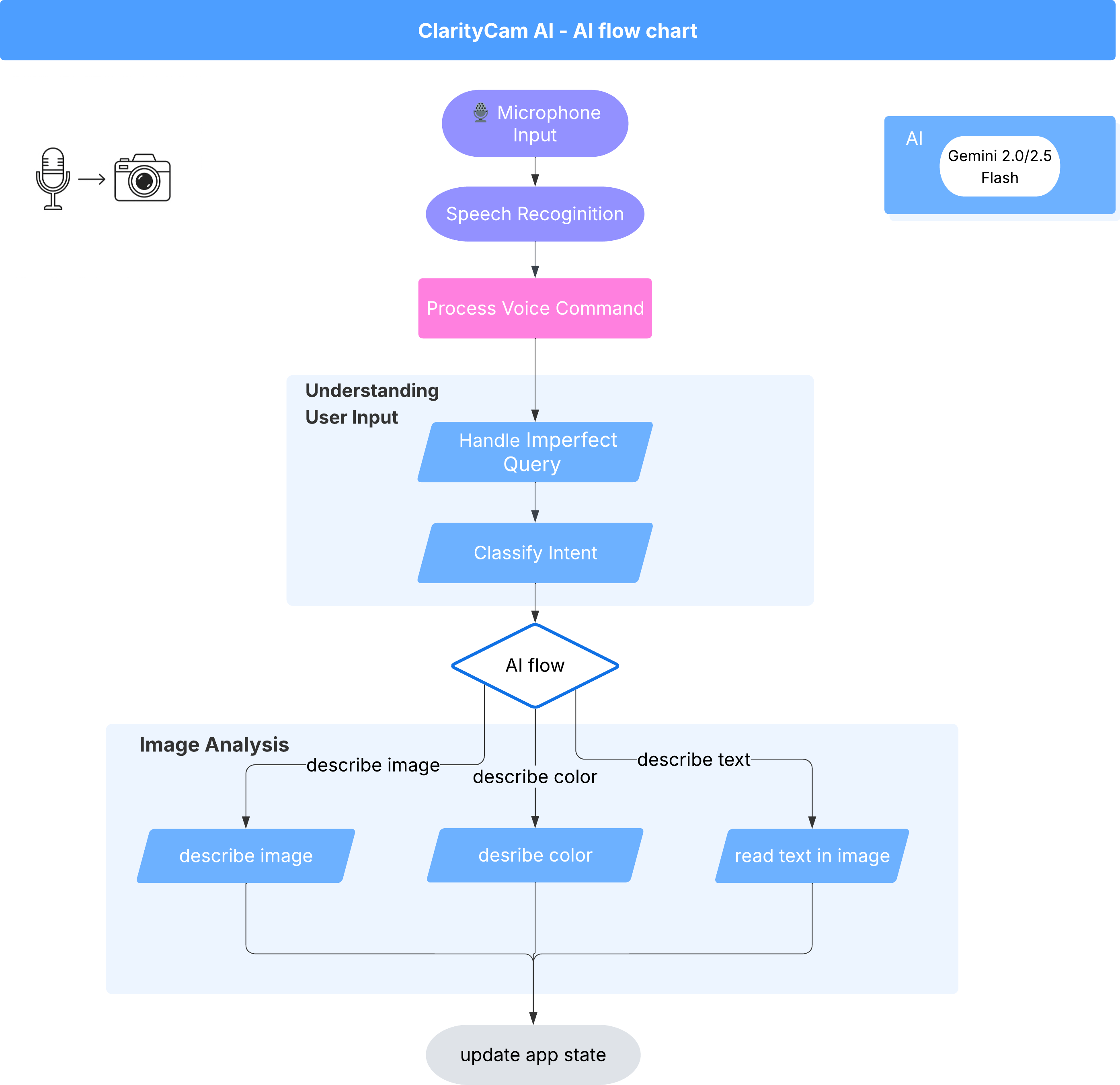
प्रोजेक्ट फ़ाइलों के बारे में खास जानकारी
कोड लिखना शुरू करने से पहले, आइए अपने प्रोजेक्ट के फ़ाइल स्ट्रक्चर के बारे में जान लें. ऐसा लग सकता है कि यहां बहुत सारी फ़ाइलें हैं, लेकिन इस पूरे ट्यूटोरियल के लिए आपको सिर्फ़ दो खास फ़ाइलों पर ध्यान देना है!
यहाँ हमारे प्रोजेक्ट का आसान मैप दिया गया है.
accessibilityAI/src/
├── 📁 app/
│ ├── layout.tsx # An overall page shell (you can ignore this).
│ └── page.tsx # ⬅️ MODIFY THIS: The main user interface for our app.
│
├── 📁 ai/
│ ├── 📁flows # ⬅️ MODIFY THIS: The core AI logic and server functions.
│ └── intent-classifier.ts # ⬅️ MODIFY THIS: Where we'll edit our AI prompts.
| └── ai-instance.ts
| └── dev.ts
│
├── 📁 components/ # Contains pre-built UI components (ignore this).
│
├── 📁 hooks/
│
├── 📁 lib/
│
└── 📁 types/
टेक्नोलॉजी स्टैक
हमारा सिस्टम, आधुनिक और ज़रूरत के हिसाब से अपग्रेड किए जा सकने वाले टेक्नोलॉजी स्टैक पर बनाया गया है. इसमें क्लाउड सेवाएं और एआई मॉडल शामिल हैं. हम इन मुख्य कॉम्पोनेंट का इस्तेमाल करेंगे:
- Google Cloud Platform (GCP): यह हमारे एजेंट के लिए सर्वरलेस इंफ़्रास्ट्रक्चर उपलब्ध कराता है.
- Cloud Run: यह हमारे अलग-अलग एजेंट को कंटेनर वाली, ज़रूरत के हिसाब से स्केल की जा सकने वाली माइक्रोसेवाओं के तौर पर डिप्लॉय करता है.
- Artifact Registry: यह हमारे एजेंट के लिए Docker इमेज को सुरक्षित रूप से सेव और मैनेज करता है.
- Secret Manager: यह संवेदनशील क्रेडेंशियल और एपीआई पासकोड को सुरक्षित तरीके से मैनेज करता है.
- लार्ज लैंग्वेज मॉडल (एलएलएम): ये सिस्टम के "दिमाग" के तौर पर काम करते हैं.
- Google के Gemini मॉडल: हम Gemini मॉडल की मल्टीमॉडल क्षमताओं का इस्तेमाल करते हैं. इनका इस्तेमाल, उपयोगकर्ता के इरादे को समझने से लेकर इमेज के कॉन्टेंट का विश्लेषण करने और स्मार्ट तरीके से जानकारी देने तक के लिए किया जाता है.
3. सेटअप और ज़रूरी शर्तें
बिलिंग खाता चालू करें इस कोडलैब को चलाने के लिए, आपके पास कुछ क्रेडिट वाला बिलिंग खाता होना चाहिए. शुरू करने के लिए, इस कोडलैब के सबसे ऊपर मौजूद बैनर में दिए गए क्रेडिट का इस्तेमाल करें. अगर आपका खाता पहले से ही किसी बिलिंग खाते से कनेक्ट है, तो इस चरण को छोड़ा जा सकता है.
नया GCP प्रोजेक्ट बनाना
- Google Cloud Console पर जाएं और एक नया प्रोजेक्ट बनाएं.
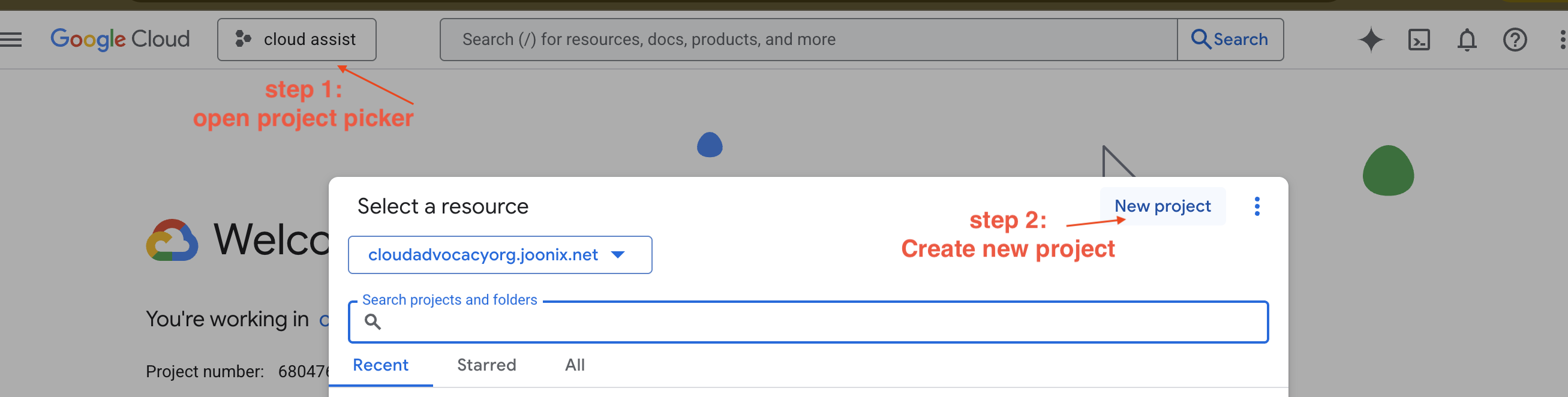
- Google Cloud Console पर जाएं और एक नया प्रोजेक्ट बनाएं.
- बाईं ओर मौजूद पैनल खोलें और
Billingपर क्लिक करें. देखें कि बिलिंग खाता, इस GCP खाते से लिंक है या नहीं.
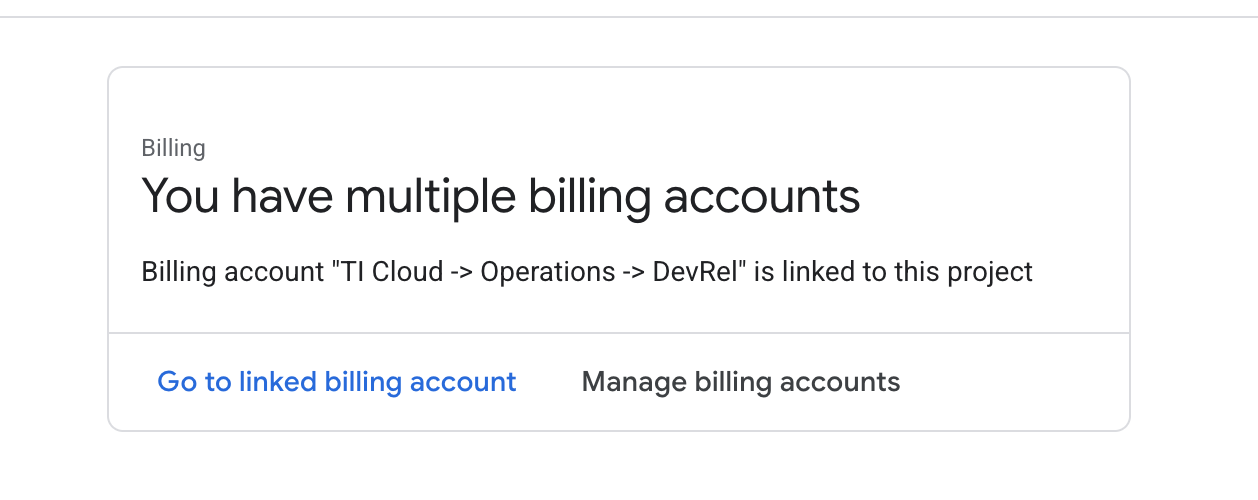
अगर आपको यह पेज दिखता है, तो manage billing account पर जाएं. इसके बाद, Google Cloud की बिना शुल्क आज़माई जा सकने वाली सदस्यता चुनें और उसे लिंक करें.
Gemini API का पासकोड बनाना
कुंजी को सुरक्षित करने से पहले, आपके पास एक कुंजी होनी चाहिए.
- Google AI Studio पर जाएं : https://aistudio.google.com/
- अपने Google खाते से साइन इन करें.
- "एपीआई कुंजी पाएं" बटन पर क्लिक करें. यह बटन आम तौर पर, बाईं ओर मौजूद नेविगेशन पैन या सबसे ऊपर दाएं कोने में होता है.
- "एपीआई पासकोड" डायलॉग में, "नए प्रोजेक्ट में एपीआई पासकोड बनाएं" पर क्लिक करें.
- आपके लिए एक नई एपीआई कुंजी जनरेट की जाएगी. इस कुंजी को तुरंत कॉपी करें और इसे कुछ समय के लिए किसी सुरक्षित जगह पर सेव करें. जैसे, पासवर्ड मैनेजर या सुरक्षित नोट. इस वैल्यू का इस्तेमाल अगले चरणों में किया जाएगा.
लोकल डेवलपमेंट वर्कफ़्लो (अपने कंप्यूटर पर टेस्टिंग)
आपके पास npm run dev को चलाने की सुविधा होनी चाहिए, ताकि आपका ऐप्लिकेशन काम कर सके. ऐसे में, .env आपकी मदद कर सकता है.
- फ़ाइल में एपीआई कुंजी जोड़ें:
.envनाम की एक नई फ़ाइल बनाएं और इस फ़ाइल में यह लाइन जोड़ें.
YOUR_API_KEY_HERE को उस पासकोड से बदलें जो आपको AI Studio से मिला है और जिसे आपने .env में सेव किया है:
GOOGLE_GENAI_API_KEY="YOUR_API_KEY_HERE"
[ज़रूरी नहीं] IDE और एनवायरमेंट सेट अप करना
इस ट्यूटोरियल के लिए, अपने लोकल टर्मिनल के साथ VS Code या IntelliJ जैसे डेवलपमेंट एनवायरमेंट का इस्तेमाल किया जा सकता है. हालांकि, हम Google Cloud Shell का इस्तेमाल करने का सुझाव देते हैं, ताकि यह पक्का किया जा सके कि आपको स्टैंडर्ड और पहले से कॉन्फ़िगर किया गया एनवायरमेंट मिले.
यहां दिया गया तरीका, Cloud Shell के लिए है. अगर आपको अपने लोकल एनवायरमेंट का इस्तेमाल करना है, तो कृपया पक्का करें कि आपने git, nvm, npm, और gcloud को इंस्टॉल किया हो और उन्हें सही तरीके से कॉन्फ़िगर किया हो.
Cloud Shell Editor पर काम करना
👉Google Cloud Console में सबसे ऊपर मौजूद, Cloud Shell चालू करें पर क्लिक करें (यह Cloud Shell पैनल में सबसे ऊपर मौजूद टर्मिनल के आकार का आइकॉन है), 
👉 "एडिटर खोलें" बटन पर क्लिक करें. यह बटन, पेंसिल वाले खुले फ़ोल्डर की तरह दिखता है. इससे विंडो में Cloud Shell Code Editor खुल जाएगा. आपको बाईं ओर फ़ाइल एक्सप्लोरर दिखेगा. 
👉नीचे दिए गए स्टेटस बार में, Cloud Code Sign-in बटन पर क्लिक करें. निर्देशों के मुताबिक, प्लगिन को अनुमति दें. अगर आपको स्टेटस बार में Cloud Code - no project दिखता है, तो उसे चुनें. इसके बाद, ड्रॉप-डाउन में ‘Select a Google Cloud Project' को चुनें. इसके बाद, बनाए गए प्रोजेक्ट की सूची से कोई Google Cloud प्रोजेक्ट चुनें. 
👉क्लाउड आईडीई में टर्मिनल खोलें, 
👉टर्मिनल में, पुष्टि करें कि आपने पहले ही पुष्टि कर ली है और प्रोजेक्ट को अपने प्रोजेक्ट आईडी पर सेट किया गया है. इसके लिए, यह कमांड इस्तेमाल करें:
gcloud auth list
👉 GitHub से natively-accessible-interface प्रोजेक्ट को क्लोन करें:
git clone https://github.com/cuppibla/AccessibilityAgent.git
👉इसके बाद, <YOUR_PROJECT_ID> को अपने प्रोजेक्ट आईडी से बदलें. आपको Google Cloud Console में, प्रोजेक्ट वाले हिस्से में अपना प्रोजेक्ट आईडी मिल सकता है. ❗️❗️ध्यान रखें कि project id और project number को आपस में न मिलाएं❗️❗️:
echo <YOUR_PROJECT_ID> > ~/project_id.txt
gcloud config set project $(cat ~/project_id.txt)
👉ज़रूरी Google Cloud API चालू करने के लिए, यह कमांड चलाएं: (इसे चलने में करीब दो मिनट लग सकते हैं)
gcloud services enable compute.googleapis.com \
storage.googleapis.com \
run.googleapis.com \
artifactregistry.googleapis.com \
aiplatform.googleapis.com \
eventarc.googleapis.com \
sqladmin.googleapis.com \
secretmanager.googleapis.com \
cloudbuild.googleapis.com \
cloudresourcemanager.googleapis.com \
cloudfunctions.googleapis.com \
cloudaicompanion.googleapis.com
इसमें कुछ मिनट लग सकते हैं..
अनुमति सेट अप करना
👉सेवा खाते की अनुमति सेट अप करें. टर्मिनल में यह कमांड चलाएं :
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
export SERVICE_ACCOUNT_NAME=$(gcloud compute project-info describe --format="value(defaultServiceAccount)")
echo "Here's your SERVICE_ACCOUNT_NAME $SERVICE_ACCOUNT_NAME"
👉 अनुमतियां दें. टर्मिनल में यह कमांड चलाएं :
#Cloud Storage (Read/Write):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/storage.objectAdmin"
#Pub/Sub (Publish/Receive):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/pubsub.publisher"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/pubsub.subscriber"
#Cloud SQL (Read/Write):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/cloudsql.editor"
#Eventarc (Receive Events):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/iam.serviceAccountTokenCreator"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/eventarc.eventReceiver"
#Vertex AI (User):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/aiplatform.user"
#Secret Manager (Read):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/secretmanager.secretAccessor"
4. उपयोगकर्ता के इनपुट को समझना - इंटेंट क्लासिफ़ायर
हमारे एआई एजेंट को कार्रवाई करने से पहले, यह समझना होगा कि उपयोगकर्ता को क्या चाहिए. असल दुनिया में, इनपुट अक्सर गड़बड़ होता है. यह अस्पष्ट हो सकता है, इसमें टाइपिंग की गड़बड़ियां हो सकती हैं या इसमें बातचीत वाली भाषा का इस्तेमाल किया जा सकता है.
इस सेक्शन में, हम "सुनने" वाले अहम कॉम्पोनेंट बनाएंगे. ये कॉम्पोनेंट, उपयोगकर्ता के इनपुट को साफ़ तौर पर समझी जा सकने वाली कमांड में बदल देते हैं.
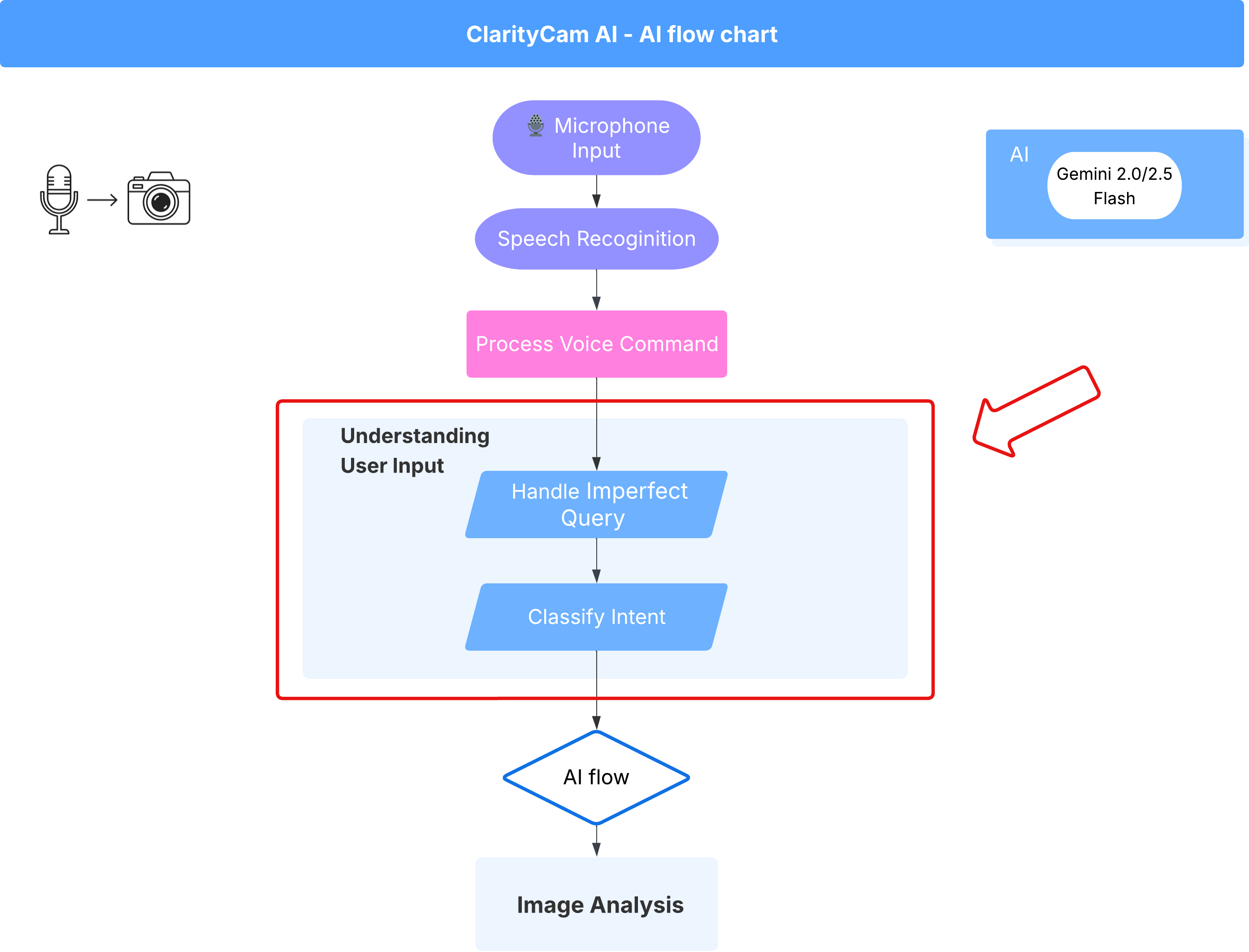
इंटेंट क्लासिफ़ायर जोड़ना
अब हम एआई के उस लॉजिक के बारे में बताएंगे जो क्लासिफ़ायर को काम करने में मदद करता है.
👉 कार्रवाई: Cloud Shell IDE में, ~/src/ai/intent-classifier/ डायरेक्ट्री पर जाएं
पहला चरण: एजेंट के लिए शब्दावली तय करना (IntentCategory)
सबसे पहले, हमें उन सभी संभावित कार्रवाइयों की एक सूची बनानी होगी जिन्हें हमारा एजेंट कर सकता है.
👉 कार्रवाई: प्लेसहोल्डर // REPLACE ME PART 1: add IntentCategory here की जगह यह कोड डालें:
👉 नीचे दिए गए कोड के साथ:
export type IntentCategory =
// Image Analysis Intents
| "DescribeImage"
| "AskAboutImage"
| "ReadTextInImage"
| "IdentifyColorsInImage"
// Control Intents
| "TakePicture"
| "StartCamera"
| "SelectImage"
| "StopSpeaking"
// Preference Intents
| "SetDescriptionDetailed"
| "SetDescriptionConcise"
// Fallback Intents
| "GeneralInquiry" // User has a general question about the agent's functions or polite interaction
| "OutOfScopeRequest" // User's request is clearly outside the agent's defined capabilities
| "Unknown"; // Intent could not be determined with confidence
ज़्यादा जानकारी
इस TypeScript कोड में, IntentCategory नाम का कस्टम टाइप बनाया गया है. यह एक ऐसी सूची है जिसमें हर संभावित कार्रवाई या "इंटेंट" के बारे में बताया गया है जिसे हमारा एजेंट समझ सकता है. यह पहला चरण बहुत ज़रूरी है. इसकी मदद से, उपयोगकर्ता के कई वाक्यांशों ("मुझे बताओ कि तुम्हें क्या दिख रहा है", "इस फ़ोटो में क्या है?") को साफ़ तौर पर समझी जा सकने वाली कमांड में बदला जाता है. हमारे क्लासिफ़ायर का लक्ष्य, किसी भी उपयोगकर्ता की क्वेरी को इनमें से किसी एक कैटगरी में मैप करना है.
दूसरा चरण
सटीक फ़ैसले लेने के लिए, हमारे एआई को अपनी क्षमताओं और सीमाओं के बारे में पता होना चाहिए. हम यह जानकारी, टेक्स्ट ब्लॉक के तौर पर देंगे.
👉 कार्रवाई: REPLACE ME PART 2: add AGENT_CAPABILITIES_AND_LIMITATIONS here प्लेसहोल्डर की जगह यह कोड डालें:
नीचे दिए गए कोड को बदलें: // REPLACE ME PART 2: add AGENT_CAPABILITIES_AND_LIMITATIONS here:
👉 नीचे दिए गए कोड के साथ
const AGENT_CAPABILITIES_AND_LIMITATIONS = `
**Core Capabilities (What the Agent CAN DO):**
* **Image Analysis:**
* DescribeImage: Provide a general description of the current image.
* AskAboutImage: Answer a specific question about the visual content of the current image (e.g., "Is there a dog?", "What color is the car?").
* ReadTextInImage: Read any text found in the current image.
* IdentifyColorsInImage: Identify the dominant colors of the current image.
* **Image Input Control:**
* TakePicture: Capture an image using the currently active camera stream.
* StartCamera: Activate the camera (e.g., "use camera", "take another picture").
* SelectImage: Allow the user to choose an image file from their device.
* **Voice & Audio Control:**
* StopSpeaking: Stop the current text-to-speech output.
* **Preference Management:**
* SetDescriptionDetailed: Make future image descriptions more detailed.
* SetDescriptionConcise: Make future image descriptions less detailed or concise.
* **General Interaction:**
* GeneralInquiry: Handle conversational phrases (e.g., "hello", "thank you") or questions about its own capabilities (e.g., "what can you do?", "help").
**Limitations (What the Agent CANNOT DO and should be classified as OutOfScopeRequest):**
* Cannot generate or create new images.
* Cannot edit or modify existing images (e.g., "remove background," "make the car blue").
* Cannot analyze video files or live video beyond capturing a single frame.
* Cannot provide general knowledge or answer questions unrelated to the provided image's visual content (e.g., "What's the weather?", "Who is the president?", "Tell me a joke", "What time is it?").
* Cannot perform mathematical calculations or complex data analysis.
* Cannot translate languages as a primary function.
* Cannot remember information from past images or vastly different previous queries in the same session.
* Cannot control other device settings or applications.
* Cannot perform web searches.
`;
यह क्यों ज़रूरी है:
यह टेक्स्ट, उपयोगकर्ता के पढ़ने के लिए नहीं है. यह हमारे एआई मॉडल के लिए है. हम इस "नौकरी की जानकारी" को सीधे तौर पर अपने प्रॉम्प्ट (अगले चरण में) में शामिल करेंगे, ताकि भाषा मॉडल (एलएलएम) को सटीक फ़ैसले लेने के लिए ज़रूरी संदर्भ मिल सके. इस कॉन्टेक्स्ट के बिना, एलएलएम "मौसम कैसा है?" को AskAboutImage के तौर पर गलत तरीके से क्लासिफ़ाई कर सकता है. इस कॉन्टेक्स्ट के साथ, यह जानता है कि मौसम, इमेज में मौजूद कोई विज़ुअल एलिमेंट नहीं है. इसलिए, यह इसे सही तरीके से 'स्कोप से बाहर' के तौर पर कैटगरी में रखता है.
तीसरा चरण
अब हम निर्देशों का पूरा सेट लिखेंगे, जिनका पालन करके Gemini मॉडल क्लासिफ़िकेशन करेगा.
👉 कार्रवाई: // REPLACE ME PART 3 - classifyIntentPrompt की जगह यह कोड डालें:
नीचे दिए गए कोड के साथ
const classifyIntentPrompt = ai.definePrompt({
name: 'classifyIntentPrompt',
input: { schema: ClassifyIntentInputSchema },
output: { schema: ClassifyIntentOutputSchema },
prompt: `You are classifying the user's intent for ClarityCam, a voice-controlled AI application focused on image analysis.
Analyze the user query: '{userQuery}'.
First, understand ClarityCam's capabilities and limitations:
${AGENT_CAPABILITIES_AND_LIMITATIONS}
Now, classify the user's PRIMARY intent into ONE of the following categories:
* **DescribeImage**: User wants a general description of the current image.
* **AskAboutImage**: User is asking a specific question directly related to the visual content of the current image.
* **ReadTextInImage**: User wants any text read from the current image.
* **IdentifyColorsInImage**: User wants the dominant colors of the current image.
* **TakePicture**: User wants to capture an image using an active camera.
* **StartCamera**: User wants to activate the camera.
* **SelectImage**: User wants to choose an image file.
* **StopSpeaking**: User wants the current text-to-speech output to stop.
* **SetDescriptionDetailed**: User wants future image descriptions to be more detailed.
* **SetDescriptionConcise**: User wants future image descriptions to be less detailed.
* **GeneralInquiry**: The query is a simple conversational filler (e.g., "hello", "thanks"), a polite closing, or a direct question about the agent's functions (e.g., "what can you do?", "how does this work?", "help").
* **OutOfScopeRequest**: The query asks the agent to perform an action clearly listed under its "Limitations" or otherwise demonstrably outside its defined image analysis and control functions. Examples: "Tell me a joke," "What's the weather in London?", "Generate an image of a cat," "Can you edit my photo to make it brighter?", "Send this image to my friends","Translate 'hello' to Spanish."
Output ONLY the category name.
If the query is ambiguous but seems generally related to polite interaction or asking about the agent itself, prefer 'GeneralInquiry'.
If the query is clearly asking for something the agent CANNOT do, use 'OutOfScopeRequest'.
If truly unclassifiable even with these guidelines, use 'Unknown'.`,
config: {
temperature: 0.05, // Very low temperature for highly deterministic classification
}
});
इस प्रॉम्प्ट में ही, एआई की मदद से जवाब जनरेट किया जाता है. यह हमारे क्लासिफ़ायर का "दिमाग" है. यह एआई को उसकी भूमिका के बारे में बताता है, ज़रूरी कॉन्टेक्स्ट देता है, और मनमुताबिक आउटपुट तय करता है. प्रॉम्प्ट इंजीनियरिंग की इन मुख्य तकनीकों के बारे में जानें:
- भूमिका निभाना: इसमें "आपको इस कॉन्टेंट को इस कैटगरी में रखना है..." से शुरुआत की जाती है, ताकि टास्क को साफ़ तौर पर सेट किया जा सके.
- कॉन्टेक्स्ट इंजेक्शन: यह
AGENT_CAPABILITIES_AND_LIMITATIONSवैरिएबल को प्रॉम्प्ट में डाइनैमिक तरीके से डालता है. - आउटपुट को फ़ॉर्मैट करने के लिए सख्त निर्देश: "सिर्फ़ कैटगरी का नाम आउटपुट करो" निर्देश का पालन करना ज़रूरी है. इससे हमें ऐसा जवाब मिलता है जिसे हम आसानी से अपने कोड में इस्तेमाल कर सकते हैं.
- कम तापमान: वर्गीकरण के लिए, हमें क्रिएटिव नहीं, बल्कि तार्किक जवाब चाहिए. तापमान को बहुत कम वैल्यू (0.05) पर सेट करने से, यह पक्का किया जा सकता है कि मॉडल का फ़ोकस और नतीजे एक जैसे हों.
चौथा चरण: ऐप्लिकेशन को एआई फ़्लो से कनेक्ट करना
आखिर में, मुख्य ऐप्लिकेशन फ़ाइल से हमारे नए एआई क्लासिफ़ायर को कॉल करें.
👉 कार्रवाई: अपनी ~/src/app/page.tsx फ़ाइल पर जाएं. processVoiceCommand फ़ंक्शन में, यहां दिए गए // REPLACE ME PART 1: add classificationResult की जगह यह कोड डालें:
const classificationResult = await classifyIntentFlow({ userQuery: commandToProcess });
intent = classificationResult.intent as IntentCategory;
यह कोड, आपके फ़्रंटएंड ऐप्लिकेशन और बैकएंड एआई लॉजिक के बीच अहम पुल का काम करता है. यह उपयोगकर्ता के वॉइस कमांड (commandToProcess) को लेता है और उसे आपके बनाए गए classifyIntentFlow को भेजता है. इसके बाद, यह एआई के जवाब का इंतज़ार करता है, ताकि वह उपयोगकर्ता के मकसद के हिसाब से जवाब दे सके.
इंटेंट वैरिएबल में अब साफ़ तौर पर स्ट्रक्चर की गई कमांड होती है, जैसे कि DescribeImage. इस नतीजे का इस्तेमाल, स्विच स्टेटमेंट में किया जाएगा. इससे ऐप्लिकेशन के लॉजिक को चलाने और यह तय करने में मदद मिलेगी कि आगे क्या कार्रवाई करनी है. इससे, एआई की "सोचने" की क्षमता को ऐप्लिकेशन की "काम करने" की क्षमता में बदला जाता है.
यूज़र इंटरफ़ेस लॉन्च करना
अब समय आ गया है कि हम अपने ऐप्लिकेशन को काम करते हुए देखें! डेवलपमेंट सर्वर शुरू करें.
👉 अपने टर्मिनल में, यह कमांड चलाएं: npm run dev ध्यान दें: आपको npm run dev चलाने से पहले, npm install चलाना पड़ सकता है
कुछ समय बाद, आपको इससे मिलता-जुलता आउटपुट दिखेगा. इसका मतलब है कि सर्वर सही तरीके से काम कर रहा है:
▲ Next.js 15.2.3 (Turbopack)
- Local: http://localhost:9003
- Network: http://10.88.0.4:9003
- Environments: .env
✓ Starting...
✓ Ready in 1512ms
○ Compiling / ...
✓ Compiled / in 26.6s
अब, अपने ब्राउज़र में ऐप्लिकेशन खोलने के लिए, लोकल यूआरएल (http://localhost:9003) पर क्लिक करें.
आपको SightGuide का यूज़र इंटरफ़ेस दिखेगा! फ़िलहाल, बटन किसी लॉजिक से नहीं जुड़े हैं. इसलिए, उन पर क्लिक करने से कुछ नहीं होगा. इस चरण में, हमें ठीक यही उम्मीद है. हम अगले सेक्शन में, इन सुविधाओं के बारे में ज़्यादा जानकारी देंगे!
अब जब आपने यूज़र इंटरफ़ेस (यूआई) देख लिया है, तो अपने टर्मिनल पर वापस जाएं और Ctrl + C दबाकर डेवलपमेंट सर्वर को बंद करें. इसके बाद, हम आगे की प्रोसेस जारी रखेंगे
5. उपयोगकर्ता के इनपुट को समझना - क्वेरी की जांच करना
क्वेरी की जांच करने की सुविधा जोड़ना
पहला हिस्सा: प्रॉम्प्ट तय करना (क्या करना है)
सबसे पहले, हम अपने एआई के लिए निर्देश तय करेंगे. प्रॉम्प्ट, हमारे एआई कॉल के लिए "रेसिपी" की तरह होता है. इससे मॉडल को पता चलता है कि हमें उससे क्या काम कराना है.
👉 कार्रवाई: अपने आईडीई में, ~/src/ai/flows/check_typo/ पर जाएं.
नीचे दिए गए कोड को बदलें: // REPLACE ME PART 1: add prompt here:
👉 नीचे दिए गए कोड के साथ
const prompt = ai.definePrompt({
name: 'checkTypoPrompt',
input: {
schema: CheckTypoInputSchema,
},
output: {
schema: CheckTypoOutputSchema,
},
prompt: `You are a helpful AI assistant that checks user text for typos and suggests corrections.
- If you find typos, respond with the corrected text.
- If there are no typos, or if you are unsure about a correction, respond with the original text unchanged.
User text: {text}
Corrected text:
`,
});
यह कोड ब्लॉक, हमारे एआई के लिए फिर से इस्तेमाल किया जा सकने वाला टेंप्लेट तय करता है. इसे checkTypoPrompt कहा जाता है. इनपुट और आउटपुट स्कीमा, इस टास्क के लिए डेटा अनुबंध तय करते हैं. इससे गड़बड़ियां नहीं होती हैं और हमारा सिस्टम अनुमान लगाने में मदद करता है.
दूसरा हिस्सा: फ़्लो बनाना (कैसे)
अब हमारे पास "रेसिपी" (प्रॉम्प्ट) है. हमें एक ऐसा फ़ंक्शन बनाना होगा जो इसे लागू कर सके. Genkit में, इसे फ़्लो कहा जाता है. फ़्लो, हमारे प्रॉम्प्ट को एक ऐसे फ़ंक्शन में रैप करता है जिसे हमारा बाकी ऐप्लिकेशन आसानी से कॉल कर सकता है.
👉 कार्रवाई: उसी ~/src/ai/flows/check_typo/ फ़ाइल में, नीचे दिए गए कोड को बदलें: // REPLACE ME PART 2: add flow here:
👉 नीचे दिए गए कोड के साथ
const checkTypoFlow = ai.defineFlow<
typeof CheckTypoInputSchema,
typeof CheckTypoOutputSchema
>(
{
name: 'checkTypoFlow',
inputSchema: CheckTypoInputSchema,
outputSchema: CheckTypoOutputSchema,
},
async input => {
const {output} = await prompt(input);
return output!;
}
);
तीसरा चरण: टाइपो की जांच करने वाले टूल का इस्तेमाल करना
एआई फ़्लो पूरा होने के बाद, अब इसे अपने ऐप्लिकेशन के मुख्य लॉजिक में इंटिग्रेट किया जा सकता है. हम उपयोगकर्ता के निर्देश मिलने के तुरंत बाद इसे कॉल करेंगे. साथ ही, यह पक्का करेंगे कि आगे की प्रोसेसिंग से पहले टेक्स्ट साफ़ हो.
👉कार्रवाई: ~/src/app/ai/flows/check-typo.ts पर जाएं और export async function checkTypo फ़ंक्शन ढूंढें. return स्टेटमेंट से टिप्पणी हटाएं:
return; के बजाय return checkTypoFlow(input); करें
👉कार्रवाई: ~/src/app/page.tsx पर जाएं और processVoiceCommand फ़ंक्शन ढूंढें. नीचे दिए गए कोड को बदलें: REPLACE ME PART 2: add typoResult here:
👉 नीचे दिए गए कोड के साथ
const typoResult = await checkTypo({ text: rawCommand });
if (typoResult && typoResult.correctedText && typoResult.correctedText.trim().length > 0) {
const originalTrimmedLower = rawCommand.trim().toLowerCase();
const correctedTrimmedLower = typoResult.correctedText.trim().toLowerCase();
if (correctedTrimmedLower !== originalTrimmedLower) {
commandToProcess = typoResult.correctedText;
typoCorrectionAnnouncement = `I think you said: ${commandToProcess}. `;
}
}
इस बदलाव के साथ, हमने हर उपयोगकर्ता के निर्देश के लिए डेटा प्रोसेसिंग पाइपलाइन को ज़्यादा बेहतर बनाया है.
बोले गए निर्देश का फ़्लो (सिर्फ़ पढ़ने के लिए, कोई कार्रवाई ज़रूरी नहीं)
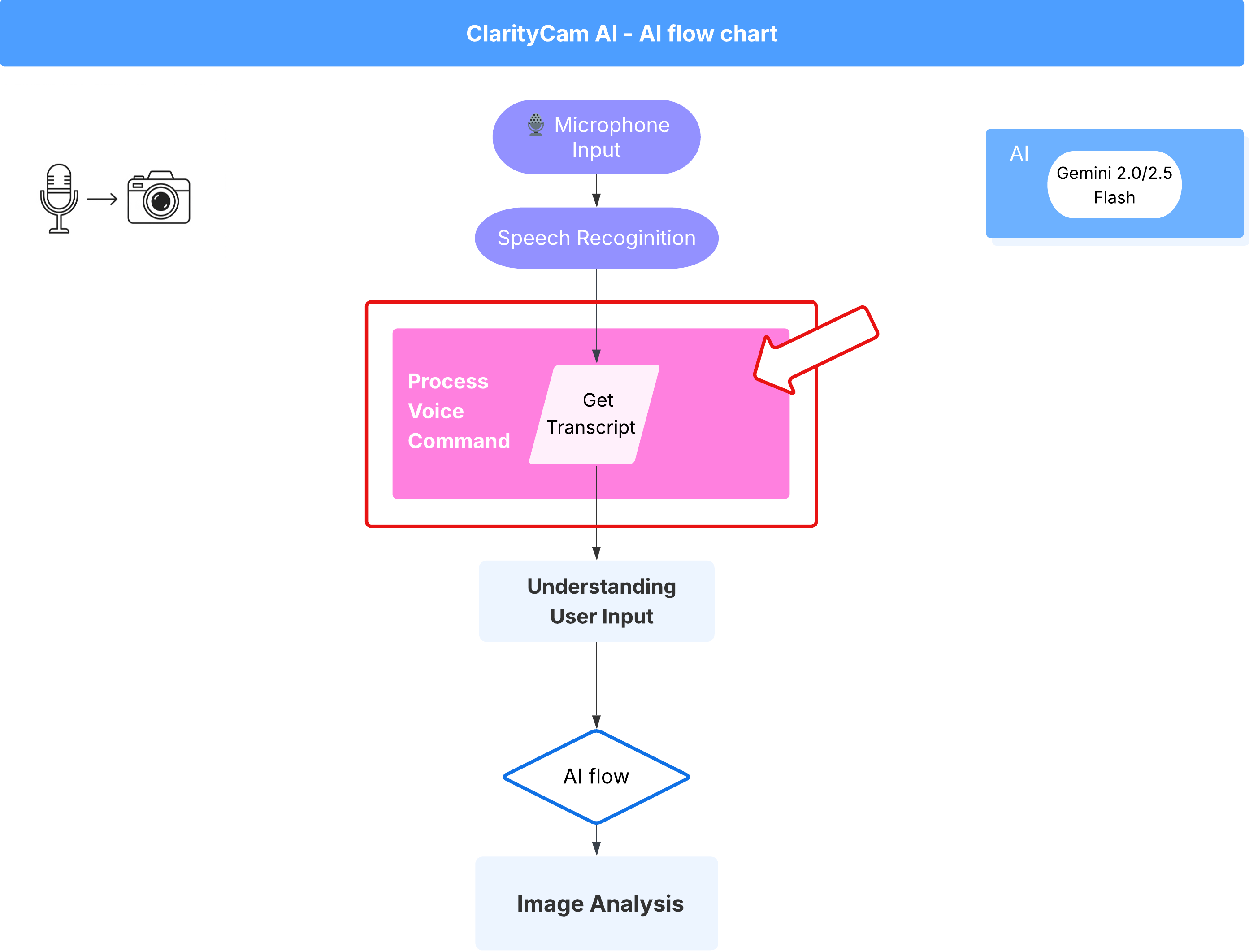
अब हमारे पास "समझने" से जुड़े मुख्य कॉम्पोनेंट (टाइपो ठीक करने वाला और इंटेंट क्लासिफ़ायर) हैं. आइए देखते हैं कि ये ऐप्लिकेशन के मुख्य वॉइस प्रोसेसिंग लॉजिक में कैसे फ़िट होते हैं.
उपयोगकर्ता के बोलने पर ही सब कुछ शुरू होता है. ब्राउज़र का Web Speech API, बोली को सुनता है. जब उपयोगकर्ता बोलना बंद कर देता है, तो यह सुनी गई बोली को टेक्स्ट में बदल देता है. नीचे दिया गया कोड, इस प्रोसेस को मैनेज करता है.
👉सिर्फ़ पढ़ने की अनुमति: ~/src/app/page.tsx और handleResult फ़ंक्शन पर जाएं. नीचे दिया गया कोड ढूंढें:
for (let i = event.resultIndex; i < event.results.length; ++i) {
if (event.results[i].isFinal) {
finalTranscript += event.results[i][0].transcript;
}
}
if (finalTranscript) {
console.log("Final Transcript:", finalTranscript);
processVoiceCommand(finalTranscript);
}
टाइपो ठीक करने की सुविधा की जांच करना
अब मज़ेदार हिस्सा! आइए, देखते हैं कि टाइपिंग में हुई गड़बड़ियों को ठीक करने वाली हमारी नई सुविधा, सटीक और गड़बड़, दोनों तरह के वॉइस कमांड को कैसे हैंडल करती है.
आवेदन शुरू करें
सबसे पहले, डेवलपमेंट सर्वर को फिर से चालू करते हैं. अपने टर्मिनल में, यह कमांड चलाएं: npm run dev
ऐप्लिकेशन खोलें
सर्वर तैयार होने के बाद, अपना ब्राउज़र खोलें और स्थानीय पते (जैसे, http://localhost:9003) पर जाएं.
बोलकर दिए जाने वाले निर्देश की सुविधा चालू करना
Start Listening बटन पर क्लिक करें. आपका ब्राउज़र, माइक्रोफ़ोन इस्तेमाल करने की अनुमति मांग सकता है. कृपया अनुमति दें पर क्लिक करें.
अधूरे निर्देश की जांच करना
अब, हम जान-बूझकर इसे थोड़ा गलत निर्देश देते हैं, ताकि यह देखा जा सके कि हमारा एआई इसे समझ पाता है या नहीं. माइक पर साफ़ आवाज़ में बोलें:
"मेरी फ़ोटो दिखाओ"
नतीजे देखना
यहां से काम शुरू होता है! आपने "मेरी फ़ोटो खींचो" कहा था. इसलिए, आपको ऐप्लिकेशन में कैमरा ठीक से चालू होता हुआ दिखना चाहिए. checkTypo फ़्लो, पर्दे के पीछे आपके वाक्यांश को "तस्वीर खींचो" में बदल देता है. इसके बाद, classifyIntentFlow, सुधारी गई कमांड को समझ लेता है.
इससे पुष्टि होती है कि टाइपिंग की गलतियां ठीक करने वाली हमारी सुविधा ठीक से काम कर रही है. इससे ऐप्लिकेशन ज़्यादा भरोसेमंद और इस्तेमाल में आसान हो जाता है! जब आपको कैमरे का इस्तेमाल बंद करना हो, तब कोई फ़ोटो खींचकर या अपने टर्मिनल में सर्वर को बंद करके (Ctrl + C) कैमरे का इस्तेमाल बंद किया जा सकता है.
6. एआई की मदद से इमेज का विश्लेषण करना - इमेज के बारे में जानकारी देना
अब हमारा एजेंट अनुरोधों को समझ सकता है. इसलिए, अब इसे देखने की सुविधा देने का समय आ गया है. इस सेक्शन में, हम अपने विज़न एजेंट की क्षमताओं को बेहतर बनाएंगे. यह इमेज का विश्लेषण करने वाला मुख्य कॉम्पोनेंट है. हम इसकी सबसे अहम सुविधा, यानी इमेज के बारे में जानकारी देने की सुविधा से शुरुआत करेंगे. इसके बाद, इसमें टेक्स्ट पढ़ने की सुविधा जोड़ी जाएगी.
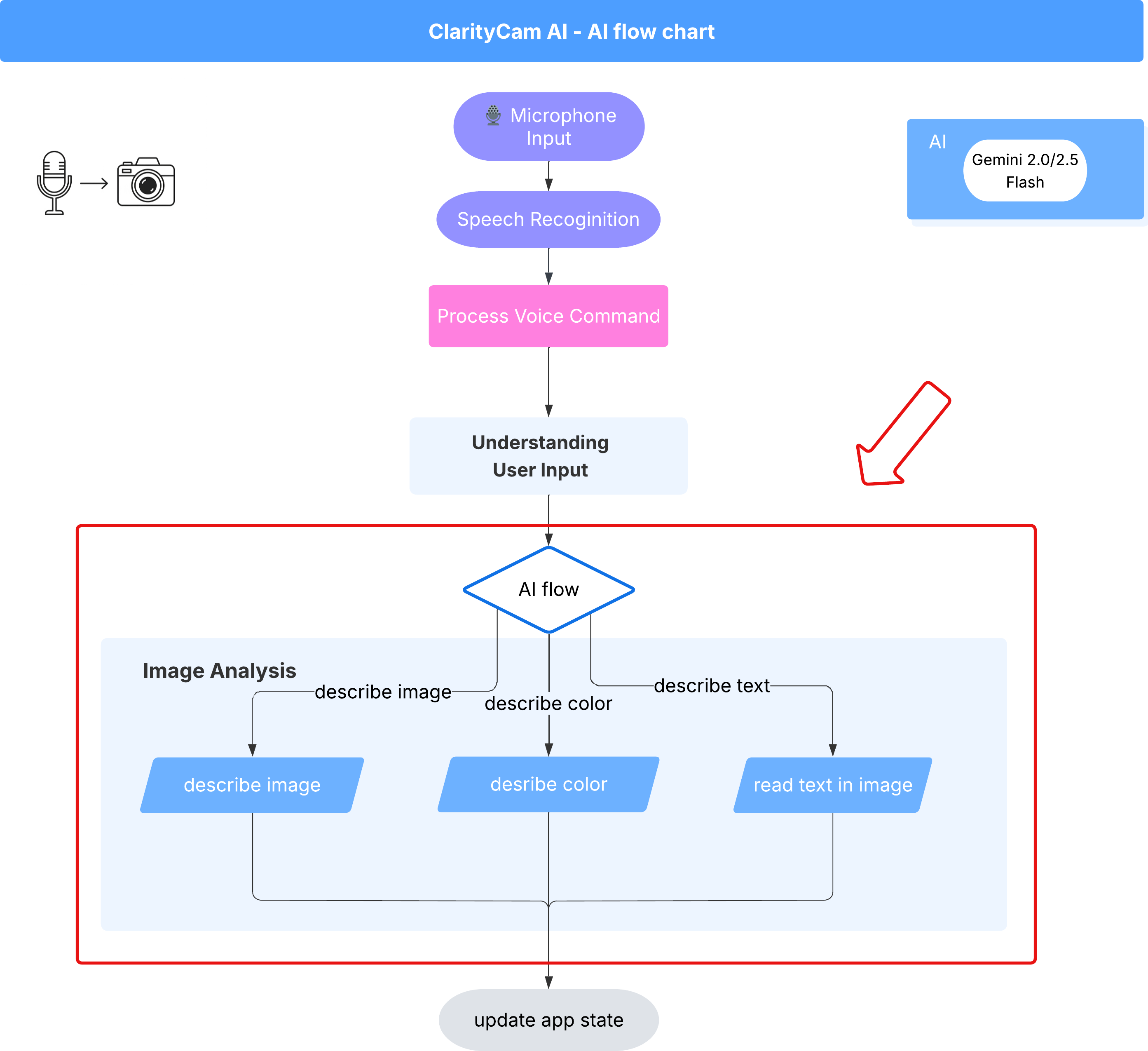
पहली सुविधा: इमेज के बारे में जानकारी देना
यह एजेंट का मुख्य काम है. हम सिर्फ़ स्टैटिक जानकारी जनरेट नहीं करेंगे. हम एक डाइनैमिक फ़्लो तैयार करेंगे, जो उपयोगकर्ता की प्राथमिकताओं के आधार पर जानकारी के लेवल को अडजस्ट कर सकता है. यह Natively Adaptive Interface (NAI) के सिद्धांत का एक अहम हिस्सा है.
👉 कार्रवाई: Cloud Shell IDE में, ~/src/ai/flows/describe_image/ फ़ाइल पर जाएं और यहां दिए गए कोड से कमेंट हटाएं.
पहला चरण: डाइनैमिक प्रॉम्प्ट टेंप्लेट बनाना
सबसे पहले, हम एक बेहतर प्रॉम्प्ट टेंप्लेट बनाएंगे. यह टेंप्लेट, मिले हुए इनपुट के आधार पर अपने निर्देशों में बदलाव कर सकता है.
नीचे दिए गए कोड को अनकमेंट करें
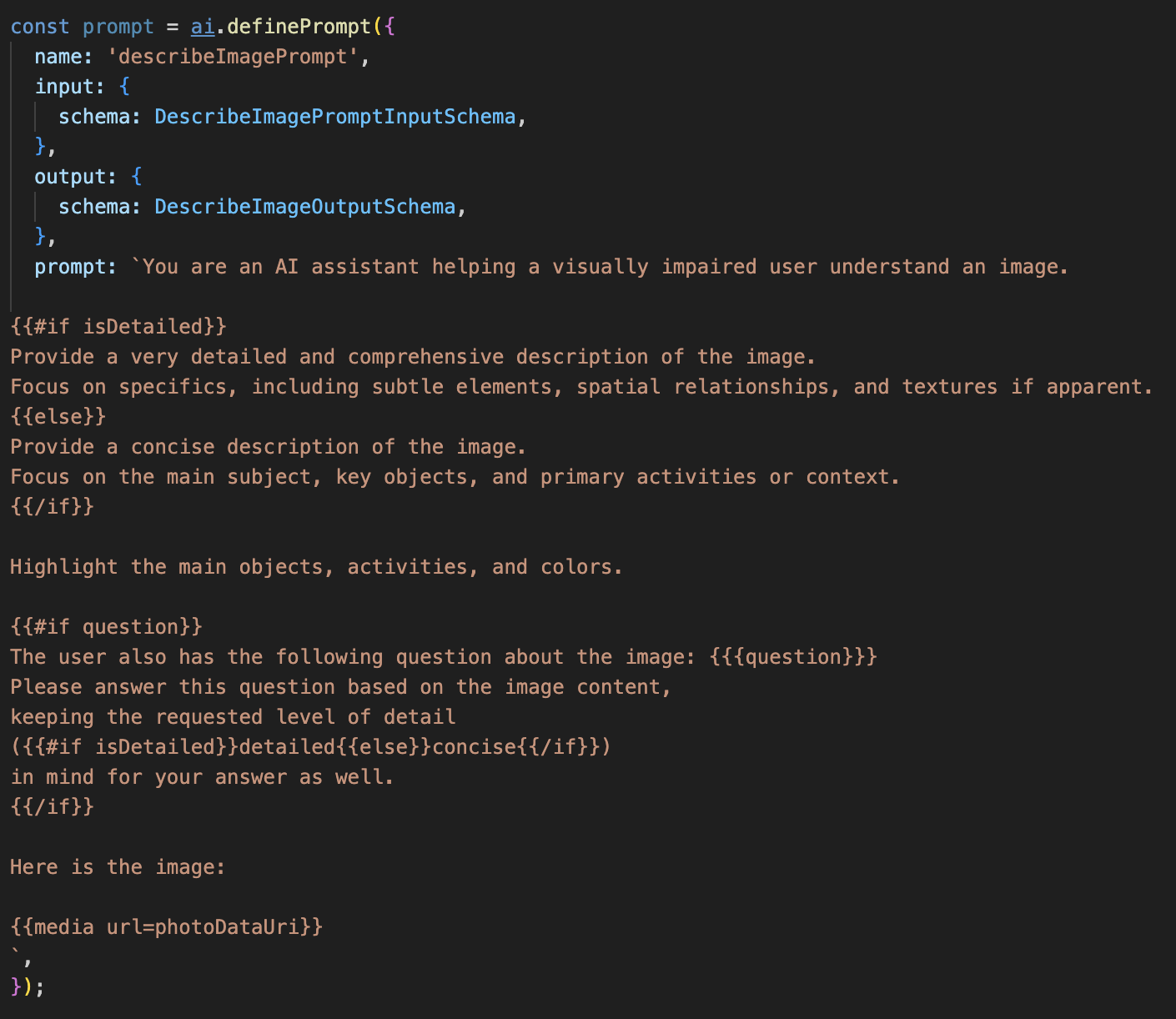
इस कोड में, एक स्ट्रिंग वैरिएबल, प्रॉम्प्ट तय किया गया है. यह Dot-Mustache नाम की टेंप्लेट भाषा का इस्तेमाल करता है. इससे हम सीधे तौर पर अपने प्रॉम्प्ट में शर्त के हिसाब से लॉजिक एम्बेड कर सकते हैं.
{#if isDetailed}...{else}...{/if}: यह एक शर्त वाला ब्लॉक है. अगर इस प्रॉम्प्ट को भेजे गए इनपुट डेटा में isDetailed: true प्रॉपर्टी शामिल है, तो एआई को "बहुत ज़्यादा जानकारी वाली" निर्देशों का सेट मिलेगा. ऐसा न होने पर, इसे "संक्षिप्त" निर्देश मिलेंगे. हमारा एजेंट, उपयोगकर्ता की पसंद के हिसाब से इस तरह काम करता है.
{#if question}...{/if}: इस ब्लॉक को सिर्फ़ तब शामिल किया जाएगा, जब हमारे इनपुट डेटा में सवाल वाली प्रॉपर्टी मौजूद होगी. इससे हमें सामान्य ब्यौरे और खास सवालों, दोनों के लिए एक ही असरदार प्रॉम्प्ट का इस्तेमाल करने की अनुमति मिलती है.
{media url=photoDataUri}: यह Genkit का खास सिंटैक्स है. इसका इस्तेमाल, इमेज डेटा को सीधे तौर पर प्रॉम्प्ट में एम्बेड करने के लिए किया जाता है, ताकि मल्टीमॉडल मॉडल उसका विश्लेषण कर सके.
दूसरा चरण: स्मार्ट फ़्लो बनाना
इसके बाद, हम प्रॉम्प्ट और उस फ़्लो को तय करते हैं जो हमारे नए टेंप्लेट का इस्तेमाल करेगा. इस फ़्लो में कुछ लॉजिक शामिल है, ताकि उपयोगकर्ता की पसंद को ऐसे बूलियन में बदला जा सके जिसे हमारा टेंप्लेट समझ सके.
👉 कार्रवाई: Cloud Shell IDE में, उसी ~/src/ai/flows/describe_image/ फ़ाइल में, यहां दिया गया कोड बदलें. // REPLACE ME PART 1: add flow here
👉 नीचे दिए गए कोड का इस्तेमाल करके:
// Define the prompt using the template from Step 1
const prompt = ai.definePrompt({
name: 'describeImagePrompt',
input: { schema: DescribeImagePromptInputSchema },
output: { schema: DescribeImageOutputSchema },
prompt: promptTemplate,
});
// Define the flow
const describeImageFlow = ai.defineFlow<
typeof DescribeImageInputSchema,
typeof DescribeImageOutputSchema
>(
{
name: 'describeImageFlow',
inputSchema: DescribeImageInputSchema,
outputSchema: DescribeImageOutputSchema,
},
async (pageInput) => {
const preference = pageInput.detailPreference || "concise";
// Prepare the input for the prompt, including the new boolean flag
const promptInputData = {
...pageInput,
isDetailed: preference === "detailed",
};
const { output } = await prompt(promptInputData);
return output!;
}
);
यह फ़्रंटएंड और एआई प्रॉम्प्ट के बीच एक स्मार्ट इंटरमीडियरी के तौर पर काम करता है.
- इसे हमारे ऐप्लिकेशन से
pageInputमिलता है.इसमें उपयोगकर्ता की पसंद को स्ट्रिंग के तौर पर शामिल किया जाता है. उदाहरण के लिए,"detailed". - इसके बाद, यह एक नया ऑब्जेक्ट
promptInputDataबनाता है. - सबसे ज़रूरी लाइन
isDetailed: preference === "detailed"है. यह लाइन, प्राथमिकता वाली स्ट्रिंग के आधार परtrueयाfalseबूलियन वैल्यू बनाने का अहम काम करती है. - आखिर में, यह बेहतर डेटा के साथ
promptको कॉल करता है. पहले चरण में बनाए गए प्रॉम्प्ट टेंप्लेट में, अबisDetailedboolean का इस्तेमाल किया जा सकता है. इससे, एआई को भेजे जाने वाले निर्देशों को डाइनैमिक तरीके से बदला जा सकता है.
तीसरा चरण: फ़्रंटएंड को कनेक्ट करना
अब, page.tsx में मौजूद यूज़र इंटरफ़ेस से इस फ़्लो को ट्रिगर करते हैं.
👉कार्रवाई: ~/src/app/ai/flows/describe-image.ts पर जाएं और export async function describeImage फ़ंक्शन ढूंढें. return स्टेटमेंट से टिप्पणी हटाएं:
return; के बजाय return describeImageFlow(input); करें
👉कार्रवाई: ~/src/app/page.tsx में, handleAnalyze फ़ंक्शन ढूंढें और कोड // REPLACE ME PART 2: DESCRIBE IMAGE को बदलें
👉 इस कोड का इस्तेमाल करके:
case "description":
result = await describeImage({
photoDataUri,
question,
detailPreference: descriptionPreference
});
outputText = question ? `Answer: ${result.description}` : `Description: ${result.description}`;
break;
जब उपयोगकर्ता का मकसद किसी चीज़ के बारे में जानकारी पाना होता है, तब इस कोड को लागू किया जाता है. यह हमारे describeImage फ़्लो को कॉल करता है. साथ ही, इमेज का डेटा और सबसे ज़रूरी, हमारे React कॉम्पोनेंट से descriptionPreference स्टेट वैरिएबल को पास करता है. यह पज़ल का आखिरी हिस्सा है. इसमें, यूज़र इंटरफ़ेस (यूआई) में सेव की गई उपयोगकर्ता की प्राथमिकताओं को सीधे तौर पर एआई फ़्लो से कनेक्ट किया जाता है. इससे एआई, उपयोगकर्ता की प्राथमिकताओं के हिसाब से काम करता है.
इमेज के बारे में जानकारी देने वाली सुविधा की टेस्टिंग
आइए, इमेज के बारे में जानकारी देने वाली सुविधा को ऐक्शन में देखते हैं. इसमें फ़ोटो कैप्चर करने से लेकर, एआई को दिखने वाली चीज़ों के बारे में सुनने तक की जानकारी शामिल है.
आवेदन शुरू करें
सबसे पहले, डेवलपमेंट सर्वर को फिर से चालू करते हैं. 👉 अपने टर्मिनल में, यह कमांड चलाएं: npm run dev ध्यान दें: आपको npm run dev चलाने से पहले, npm install चलाना पड़ सकता है
ऐप्लिकेशन खोलें
सर्वर तैयार होने के बाद, अपना ब्राउज़र खोलें और स्थानीय पते (जैसे, http://localhost:9003) पर जाएं.
कैमरा चालू करना
'सुनना शुरू करें' बटन पर क्लिक करें. अगर आपसे माइक्रोफ़ोन का ऐक्सेस माँगा जाता है, तो उसे दें. इसके बाद, पहला निर्देश दें:
"फ़ोटो खींचो"
ऐप्लिकेशन, आपके डिवाइस का कैमरा चालू कर देगा. अब आपको स्क्रीन पर लाइव वीडियो फ़ीड दिखेगा.
फ़ोटो कैप्चर करना
कैमरा चालू होने पर, उसे उस चीज़ पर फ़ोकस करें जिसके बारे में आपको बताना है. अब इमेज कैप्चर करने के लिए, निर्देश को दूसरी बार बोलें:
"फ़ोटो खींचो"
लाइव वीडियो की जगह, अभी-अभी ली गई स्टैटिक फ़ोटो दिख जाएगी.
ब्यौरे के बारे में पूछना
स्क्रीन पर नई फ़ोटो दिखने के बाद, यह आखिरी निर्देश दें:
"इस तस्वीर के बारे में जानकारी दो"
नतीजा सुनना
ऐप्लिकेशन में, प्रोसेसिंग की स्थिति दिखेगी. इसके बाद, आपको एआई से जनरेट की गई इमेज की जानकारी सुनाई देगी! यह टेक्स्ट, "स्थिति और नतीजा" कार्ड में भी दिखेगा.
जब आपको फ़ोटो खींचनी हो, तब कैमरा बंद किया जा सकता है. इसके अलावा, अपने टर्मिनल में सर्वर को बंद करने के लिए, Ctrl + C दबाएं.
7. एआई की मदद से इमेज का विश्लेषण करना - टेक्स्ट के बारे में जानकारी देना (ओसीआर)
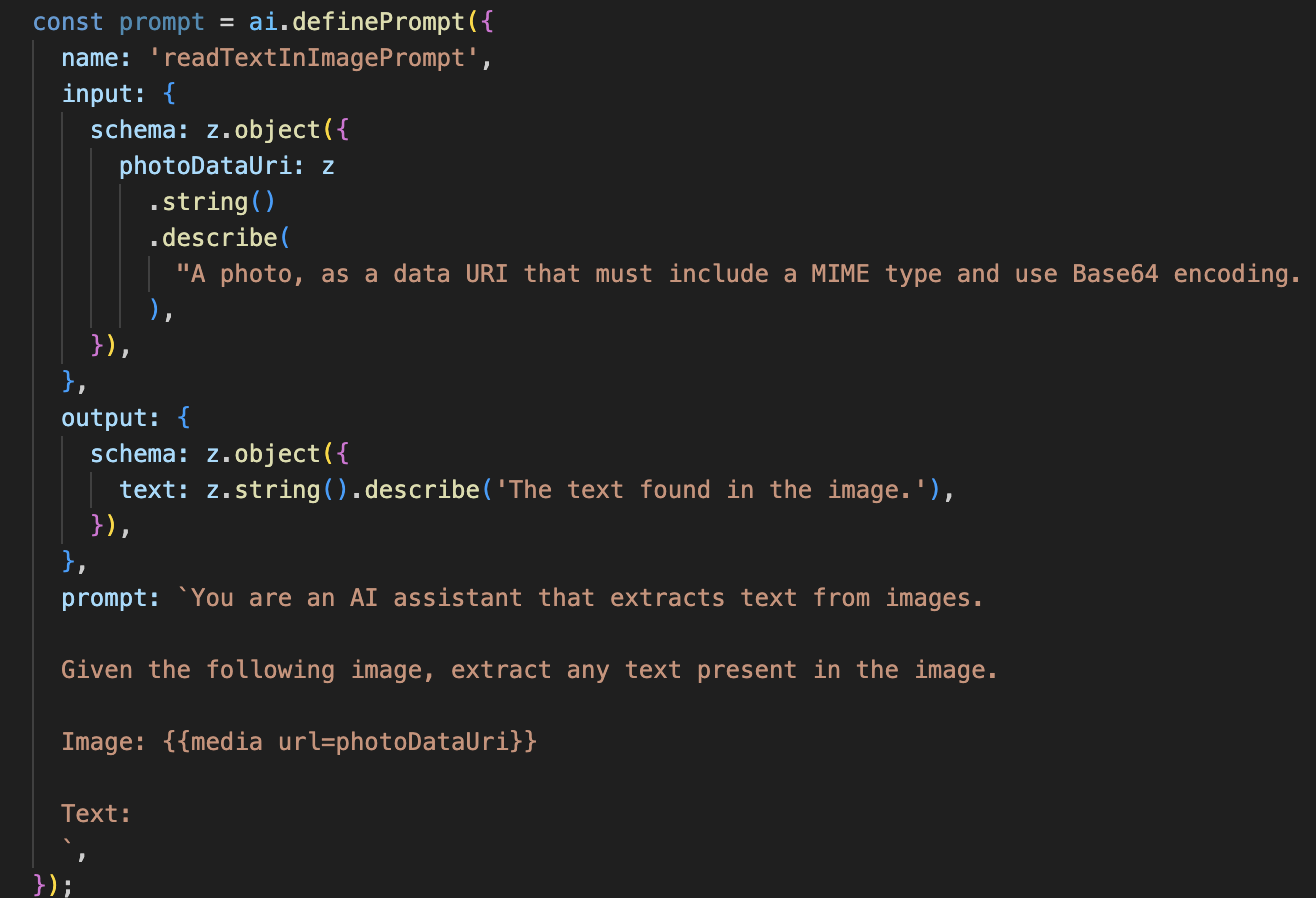
इसके बाद, हम अपने विज़न एजेंट में ऑप्टिकल कैरेक्टर रिकग्निशन (ओसीआर) की सुविधा जोड़ेंगे. इससे, यह किसी भी इमेज से टेक्स्ट पढ़ सकता है.
👉 कार्रवाई: अपने आईडीई में, ~/src/ai/flows/read-text-in-image/ पर जाएं. इसके बाद, यहां दिए गए कोड से Uncomment करें:
👉 कार्रवाई: अपने आईडीई में, उसी ~/src/ai/flows/read-text-in-image/ फ़ाइल में, // REPLACE ME: Creating Prmopt
👉 नीचे दिए गए कोड के साथ:
const readTextInImageFlow = ai.defineFlow<
typeof ReadTextInImageInputSchema,
typeof ReadTextInImageOutputSchema
>(
{
name: 'readTextInImageFlow',
inputSchema: ReadTextInImageInputSchema,
outputSchema: ReadTextInImageOutputSchema,
},
async input => {
const {output} = await prompt(input);
return output!;
}
);
एआई के इस फ़्लो को समझना बहुत आसान है. इसमें, किसी काम को पूरा करने के लिए, खास टूल इस्तेमाल करने के सिद्धांत पर ज़ोर दिया गया है.
- प्रॉम्प्ट: यह प्रॉम्प्ट, ब्यौरे के प्रॉम्प्ट से अलग है. यह स्टैटिक होता है और इसमें बहुत ज़्यादा जानकारी होती है. इसका काम सिर्फ़ एआई को ओसीआर इंजन के तौर पर काम करने का निर्देश देना है: "इमेज में मौजूद किसी भी टेक्स्ट को निकालो."
- स्कीमा: इनपुट और आउटपुट स्कीमा भी आसान हैं. इनमें इमेज की ज़रूरत होती है और बदले में टेक्स्ट की एक स्ट्रिंग मिलती है.
ओसीआर के लिए फ़्रंटएंड को कनेक्ट करना
आखिर में, आइए page.tsx में इस नई सुविधा को कनेक्ट करें.
👉कार्रवाई: ~/src/app/ai/flows/read-text-in-image.ts पर जाएं और export async function readTextInImage फ़ंक्शन ढूंढें. return स्टेटमेंट से टिप्पणी हटाएं:
return; के बजाय return readTextInImageFlow(input); करें
👉 कार्रवाई: ~/src/app/page.tsx में, handleAnalyze फ़ंक्शन और switch स्टेटमेंट ढूंढें.
REPLACE ME PART 3: READ TEXT बदलें
नीचे दिए गए कोड के साथ:
case "text":
result = await readTextInImage({ photoDataUri });
outputText = result.text ? `Text Found: ${result.text}` : "No text found.";
break;
जब उपयोगकर्ता का इरादा ReadTextInImage होता है, तब यह कोड ट्रिगर होता है. यह हमारे आसान readTextInImage फ़्लो को कॉल करता है. लाइन result.text ? ... : ..., आउटपुट को मैनेज करने का एक आसान तरीका है. अगर एआई को इमेज में कोई टेक्स्ट नहीं मिलता है, तो यह उपयोगकर्ता को मददगार मैसेज दिखाता है.
'टेक्स्ट पढ़ें (ओसीआर)' सुविधा की टेस्टिंग
टेक्स्ट पढ़ने की सुविधा को आज़माने के लिए, यह तरीका अपनाएं. अपने कैमरे को किसी ऐसे ऑब्जेक्ट पर पॉइंट करें जिस पर टेक्स्ट साफ़ तौर पर लिखा हो.
npm run devकी मदद से ऐप्लिकेशन चलाएं और इसे अपने ब्राउज़र में खोलें.- 'सुनना शुरू करें' पर क्लिक करें. इसके बाद, मांगे जाने पर माइक्रोफ़ोन का ऐक्सेस दें.
- कैमरा चालू करें. "तस्वीर खींचो" निर्देश दें. आपको स्क्रीन पर लाइव वीडियो फ़ीड दिखेगा.
- फ़ोटो कैप्चर करें. कैमरे को उस टेक्स्ट पर फ़ोकस करें जिसे आपको पढ़ना है. इसके बाद, फिर से यह कमांड दें: "फ़ोटो खींचो" वीडियो की जगह एक स्टैटिक फ़ोटो दिख जाएगी.
- टेक्स्ट के बारे में पूछें. फ़ोटो कैप्चर हो जाने के बाद, फ़ाइनल कमांड दें: "इस इमेज में मौजूद टेक्स्ट क्या है?"
- नतीजा देखें कुछ समय बाद, ऐप्लिकेशन फ़ोटो का विश्लेषण करेगा और उसमें मौजूद टेक्स्ट को पढ़कर सुनाएगा. अगर इसे कोई टेक्स्ट नहीं मिलता है, तो यह आपको इसकी सूचना देगा.
इससे पुष्टि होती है कि ओसीआर की बेहतरीन सुविधा काम कर रही है! जब आपका काम पूरा हो जाए, तो Ctrl + C का इस्तेमाल करके सर्वर को बंद करें.
8. एआई की मदद से बेहतर बनाने की ऐडवांस सुविधाएं - सिर्फ़ पढ़ने की अनुमति ✨
एक अच्छा एआई एजेंट, निर्देशों का पालन कर सकता है. एक बेहतरीन एआई एजेंट, भरोसेमंद और मददगार होता है. इस सेक्शन में, हम तीन बेहतर सुविधाओं पर फ़ोकस करेंगे. इनसे हमारे एजेंट की क्षमताओं को बेहतर बनाया जा सकता है.
हम इन विषयों पर चर्चा करेंगे:
Add Context & Memoryका इस्तेमाल करके, बातचीत के दौरान फ़ॉलो-अप किए जा सकते हैं.Reduce Hallucinationका इस्तेमाल करके, ज़्यादा भरोसेमंद और भरोसे लायक एजेंट बनाया जा सकता है.Make the Agent Proactiveको ज़्यादा सुलभ और इस्तेमाल में आसान बनाने के लिए.Add preference settingपर क्लिक करके, इमेज की जानकारी को अपनी पसंद के मुताबिक बनाएं
बेहतर बनाने से जुड़ी पहली सुविधा: कॉन्टेक्स्ट और मेमोरी
सामान्य बातचीत में, अलग-अलग कमांड नहीं दी जाती हैं, बल्कि एक कमांड के बाद दूसरी कमांड दी जाती है. अगर कोई उपयोगकर्ता पूछता है कि "इस तस्वीर में क्या है?" और एजेंट जवाब देता है कि "एक लाल रंग की कार," तो उपयोगकर्ता का अगला सवाल यह हो सकता है कि "यह किस रंग की है?" इसमें वह "कार" शब्द का इस्तेमाल दोबारा नहीं करेगा. इस कॉन्टेक्स्ट को समझने के लिए, हमारे एजेंट को कुछ देर पहले बताई गई जानकारी याद रखने की ज़रूरत होती है.
हमने इसे कैसे लागू किया (रीकैप)
हमने इस सुविधा को, इमेज के बारे में जानकारी देने वाले फ़्लो में पहले से ही शामिल कर दिया है. इस सेक्शन में, उस पैटर्न के काम करने के तरीके के बारे में फिर से बताया गया है. जब हम page.tsx से describeImage फ़ंक्शन को कॉल करते हैं, तो हम उसे बातचीत का इतिहास पास करते हैं.
👉 कोड शोकेस (page.tsx से):
const result = await describeImage({
photoDataUri,
question: commandToProcess,
detailPreference: descriptionPreference,
previousUserQueryOnImage: lastUserQuery ?? undefined,
previousAIResponseOnImage: lastAIResponse ?? undefined,
});
previousUserQueryOnImageऔरpreviousAIResponseOnImage: ये दोनों प्रॉपर्टी, हमारे एजेंट की कम समय के लिए याद रखने की क्षमता होती है. एआई को आखिरी इंटरैक्शन की जानकारी देने से, उसे ऐसे सवालों के बारे में ज़रूरी कॉन्टेक्स्ट मिल जाता है जो अस्पष्ट होते हैं या जिनमें किसी चीज़ का रेफ़रंस दिया गया होता है.- अडैप्टिव प्रॉम्प्ट: इस कॉन्टेक्स्ट का इस्तेमाल, हमारी describe_image फ़्लो में प्रॉम्प्ट करता है. इस प्रॉम्प्ट को इस तरह से डिज़ाइन किया गया है कि नया जवाब देते समय, पिछली बातचीत को ध्यान में रखा जाए. इससे एजेंट को बेहतर तरीके से जवाब देने में मदद मिलती है.
दूसरा सुधार: मनगढ़ंत जानकारी को कम करना
जब कोई एआई टूल तथ्यों को गलत तरीके से पेश करता है या ऐसी क्षमताओं के बारे में दावा करता है जो उसके पास नहीं हैं, तो उसे "गलत जानकारी" कहा जाता है. लोगों का भरोसा बनाए रखने के लिए, यह ज़रूरी है कि हमारे एजेंट को अपनी सीमाओं के बारे में पता हो. साथ ही, वह दायरे से बाहर के अनुरोधों को आसानी से अस्वीकार कर सके.
हमने इसे कैसे लागू किया (रीकैप)
मॉडल के जवाब में तथ्यों के ग़लत होने की समस्या को रोकने का सबसे असरदार तरीका यह है कि मॉडल को साफ़ तौर पर बताया जाए कि उसे किस तरह के जवाब देने हैं. हमने इंटेंट क्लासिफ़ायर बनाते समय, इस लक्ष्य को हासिल किया था.
👉 Code Showcase (intent-classifier फ़्लो से):
// Define Agent Capabilities and Limitations for the prompt
const AGENT_CAPABILITIES_AND_LIMITATIONS = `
**Core Capabilities (What the Agent CAN DO):**
* **Image Analysis:**
* DescribeImage: Provide a general description of the current image...
**Limitations (What the Agent CANNOT DO...):**
* Cannot generate or create new images.
* Cannot provide general knowledge or answer questions unrelated to the image...
* Cannot perform web searches.
`;
यह कॉन्स्टेंट, "नौकरी की जानकारी" के तौर पर काम करता है. इसे हम क्लासिफ़िकेशन प्रॉम्प्ट में एआई को देते हैं.
- मॉडल को तथ्यों के आधार पर जवाब देना सिखाना: एआई को साफ़ तौर पर यह बताकर कि वह क्या नहीं कर सकता, हम उसे तथ्यों के आधार पर जवाब देना सिखाते हैं. जब इसे "मौसम कैसा है?" जैसी क्वेरी दिखती है, तो यह भरोसे के साथ इसे अपनी सीमाओं की सूची से मैच कर सकता है. साथ ही, क्वेरी के मकसद को OutOfScopeRequest के तौर पर क्लासिफ़ाई कर सकता है.
- भरोसा जीतना: "मैं इस काम में आपकी मदद नहीं कर सकता" कहने वाला एजेंट, अनुमान लगाकर गलत जवाब देने वाले एजेंट की तुलना में ज़्यादा भरोसेमंद होता है. यह सुरक्षित और भरोसेमंद एआई डिज़ाइन का बुनियादी सिद्धांत है. `
तीसरा बेहतर तरीका: प्रोऐक्टिव एजेंट बनाना
सुलभता को ध्यान में रखकर बनाए गए ऐप्लिकेशन के लिए, हम विज़ुअल क्यू पर भरोसा नहीं कर सकते. जब कोई व्यक्ति सुनने का मोड चालू करता है, तो उसे तुरंत यह पुष्टि मिलनी चाहिए कि एजेंट तैयार है और किसी निर्देश का इंतज़ार कर रहा है. यह पुष्टि, विज़ुअल नहीं होनी चाहिए. अब हम इस ज़रूरी सुझाव/राय या शिकायत को देने के लिए, एक जानकारी जोड़ेंगे.
पहला चरण: पहली बार सुने जाने की जानकारी ट्रैक करने के लिए, कोई स्टेट जोड़ना
सबसे पहले, हमें यह पता लगाने का तरीका चाहिए कि क्या उपयोगकर्ता ने अपने सेशन के दौरान पहली बार "Start Listening" बटन दबाया है.
👉 ~/src/app/page.tsx में, ClarityCam कॉम्पोनेंट के सबसे ऊपर मौजूद इस नए स्टेट वैरिएबल को देखें.
export default function ClarityCam() {
// ... other state variables
const [descriptionPreference, setDescriptionPreference] = useState<DescriptionPreference>("concise");
// Add this new line
const [isFirstListen, setIsFirstListen] = useState(true);
// ... rest of the component
}
हमने एक नया स्टेट वैरिएबल, isFirstListen पेश किया है और इसे true पर सेट किया है. हम इस फ़्लैग का इस्तेमाल, एक बार दिखने वाले वेलकम मैसेज को ट्रिगर करने के लिए करेंगे.
दूसरा चरण: toggleListening फ़ंक्शन को अपडेट करना
अब, माइक्रोफ़ोन को मैनेज करने वाले फ़ंक्शन में बदलाव करते हैं, ताकि हम अपनी बधाई वाला मैसेज चला सकें.
👉 ~/src/app/page.tsx में, toggleListening फ़ंक्शन ढूंढें और यहां दिया गया if ब्लॉक देखें.
const toggleListening = useCallback(() => {
// ... existing logic to setup speech recognition
if (isListening || isAttemptingStart) {
// ... existing logic to stop listening
} else {
stopSpeaking(); // Stop any ongoing TTS
// Add this new block
if (isFirstListen) {
setIsFirstListen(false);
const introMessage = "Hello! I am ClarityCam, your AI assistant. I'm now listening. You can ask me to 'describe the image', 'read text', 'take a picture', or ask questions about what's in an image.";
speakText(introMessage);
} else {
speakText("Listening..."); // Optional: provide feedback on subsequent clicks
}
// ... rest of the logic to start listening
}
}, [/*...existing dependencies...*/, isFirstListen]); // Don't forget to add isFirstListen to the dependency array!
- फ़्लैग की जांच करना: if (isFirstListen) ब्लॉक से यह पता चलता है कि यह पहली बार चालू हुआ है या नहीं.
- दोहराव रोकना: ब्लॉक के अंदर, सबसे पहले setIsFirstListen(false) को कॉल किया जाता है. इससे यह पक्का होता है कि शुरुआती मैसेज, हर सेशन में सिर्फ़ एक बार चलेगा.
- निर्देश देना: introMessage को इस तरह से बनाया गया है कि यह ज़्यादा से ज़्यादा मददगार हो. इसमें उपयोगकर्ता का अभिवादन किया जाता है, एजेंट की पहचान नाम से की जाती है, और पुष्टि की जाती है कि यह सुविधा अब चालू है ("मैं अब सुन रहा/रही हूं"). साथ ही, इसमें आवाज़ से दिए जाने वाले निर्देशों के साफ़ तौर पर उदाहरण दिए जाते हैं.
- ऑडिटरी फ़ीडबैक: आखिर में, speakText(introMessage) इस ज़रूरी जानकारी को डिलीवर करता है. इससे उपयोगकर्ता को तुरंत भरोसा मिलता है और उसे दिशा-निर्देश मिलते हैं. इसके लिए, उपयोगकर्ता को स्क्रीन देखने की ज़रूरत नहीं होती.
बेहतर बनाने से जुड़ी चौथी सुविधा: उपयोगकर्ता की प्राथमिकताओं के मुताबिक बदलाव करना (रीकैप)
एक स्मार्ट एजेंट सिर्फ़ जवाब नहीं देता, बल्कि वह उपयोगकर्ता की ज़रूरतों को समझता है और उनके हिसाब से काम करता है. हमने एक ऐसी सुविधा बनाई है जो बहुत काम की है. इसकी मदद से, उपयोगकर्ता इमेज के ब्यौरे की जानकारी को तुरंत बदल सकता है. इसके लिए, उसे "ज़्यादा जानकारी दो" जैसे कमांड देने होंगे.
हमने इसे कैसे लागू किया (रीकैप) यह सुविधा, describeImage फ़्लो के लिए बनाए गए डाइनैमिक प्रॉम्प्ट की मदद से काम करती है. यह उपयोगकर्ता की पसंद के आधार पर, एआई को भेजे गए निर्देशों में बदलाव करने के लिए, शर्त के हिसाब से लॉजिक का इस्तेमाल करता है.
👉 Code Showcase (describe_image से promptTemplate):
const settingPreferenceTemplate = `
{#if isDetailed}
Provide a very detailed and comprehensive description of the image. Focus on specifics, including subtle elements, spatial relationships, and textures if apparent.
{else}
Provide a concise description of the image. Focus on the main subject, key objects, and primary activities or context.
{/if}
Highlight the main objects, activities, and colors.
...
`;
- शर्त वाला फ़ॉर्मूला:
{#if isDetailed}...{else}...{/if}ब्लॉक सबसे अहम है. जब describeImageFlow को फ़्रंटएंड से detailPreference मिलता है, तो यह isDetailed बूलियन (सही या गलत) बनाता है. - अडैप्टिव निर्देश: यह बूलियन फ़्लैग तय करता है कि एआई मॉडल को निर्देशों का कौनसा सेट मिलेगा. अगर isDetailed की वैल्यू 'सही है' पर सेट है, तो मॉडल को ज़्यादा जानकारी देने के लिए कहा जाता है. अगर यह गलत है, तो इसे छोटा रखने का निर्देश दिया गया है.
- उपयोगकर्ता का कंट्रोल: यह पैटर्न, उपयोगकर्ता के वॉइस कमांड (जैसे, "जानकारी को छोटा करो") को सीधे तौर पर एआई के व्यवहार में बुनियादी बदलाव से जोड़ता है.इससे एजेंट को ऐसा लगता है कि वह उपयोगकर्ता की ज़रूरतों के हिसाब से काम कर रहा है. "जानकारी को छोटा करो" को SetDescriptionConcise इंटेंट के तौर पर क्लासिफ़ाई किया जाता है.
9. क्लाउड पर डिप्लॉयमेंट
Google Cloud Build का इस्तेमाल करके, Docker इमेज बनाना
gcloud builds submit . --tag gcr.io/$PROJECT_ID/accessibilityai-nextjs-app:latest
accessibilityai-nextjs-app, सुझाई गई इमेज का नाम है.- . मौजूदा डायरेक्ट्री (
accessibilityAI/) को बिल्ड सोर्स के तौर पर इस्तेमाल करता है.
इमेज को Google Cloud Run पर डिप्लॉय करना
- पक्का करें कि Secret Manager में आपकी एपीआई कुंजियां और अन्य सीक्रेट तैयार हों. उदाहरण के लिए,
GOOGLE_GENAI_API_KEY.
इस YOUR_ACTUAL_GOOGLE_AI_KEY_VALUE को Gemini API के अपने पासकोड की वैल्यू से बदलें.
echo "YOUR_ACTUAL_GOOGLE_AI_KEY_VALUE" | gcloud secrets create GOOGLE_GENAI_API_KEY --data-file=- --project=YOUR_PROJECT_ID
अपनी Cloud Run सेवा के रनटाइम सेवा खाते (जैसे, PROJECT_NUMBER-compute@developer.gserviceaccount.com या कोई खास खाता) को इस सीक्रेट के लिए, "Secret Manager Secret Accessor" की भूमिका असाइन करें.
- डिप्लॉय करने का निर्देश:
gcloud run deploy accessibilityai-app-service \
--image gcr.io/$PROJECT_ID/accessibilityai-nextjs-app:latest \
--platform managed \
--region us-central1 \
--allow-unauthenticated \
--port 3000 \
--set-secrets=GOOGLE_GENAI_API_KEY=GOOGLE_GENAI_API_KEY:latest \
--set-env-vars NODE_ENV="production"