
1. Pengantar
Dalam tutorial ini, Anda akan membuat ClarityCam, agen AI handsfree yang digerakkan oleh suara yang dapat melihat dunia dan menjelaskannya kepada Anda. Meskipun ClarityCam dirancang dengan aksesibilitas sebagai intinya—menyediakan alat canggih bagi pengguna tunanetra dan pengguna dengan penglihatan rendah—prinsip yang akan Anda pelajari sangat penting untuk membuat aplikasi suara modern serbaguna.

Project ini dibangun berdasarkan filosofi desain canggih yang disebut Antarmuka Adaptif Secara Native (NAI). Alih-alih memperlakukan aksesibilitas sebagai sesuatu yang tidak penting, NAI menjadikannya sebagai fondasi. Dengan pendekatan ini, agen AI menjadi antarmuka—agen AI beradaptasi dengan berbagai pengguna, menangani input multimodal seperti suara dan penglihatan, serta secara proaktif memandu orang berdasarkan kebutuhan unik mereka.
Membangun Agen AI Pertama Anda dengan NAI:

Di akhir sesi ini, Anda akan dapat:
- Merancang dengan Aksesibilitas sebagai Default: Terapkan prinsip Antarmuka Adaptif Secara Native (NAI) untuk membuat sistem AI yang memberikan pengalaman yang setara bagi semua pengguna.
- Mengklasifikasikan Maksud Pengguna: Bangun pengklasifikasi maksud yang andal yang menerjemahkan perintah bahasa alami menjadi tindakan terstruktur untuk agen Anda.
- Mempertahankan Konteks Percakapan: Terapkan memori jangka pendek agar agen Anda dapat memahami pertanyaan lanjutan dan perintah referensial (misalnya, "Warnanya apa?").
- Membuat Perintah yang Efektif: Buat perintah yang fokus dan kaya konteks untuk model multimodal seperti Gemini guna memastikan analisis gambar yang akurat dan andal.
- Menangani Ambigu dan Memandu Pengguna: Desain penanganan error yang baik untuk permintaan di luar cakupan dan secara proaktif memandu pengguna untuk membangun kepercayaan dan keyakinan.
- Mengorkestrasi Sistem Multi-Agen: Susun aplikasi Anda menggunakan kumpulan agen khusus yang berkolaborasi untuk menangani tugas kompleks seperti pemrosesan suara, analisis, dan sintesis ucapan.
2. Desain Tingkat Tinggi
Pada intinya, ClarityCam dirancang agar mudah digunakan oleh pengguna, tetapi didukung oleh sistem canggih dari agen AI yang berkolaborasi. Mari kita uraikan arsitekturnya.

Pengalaman Pengguna
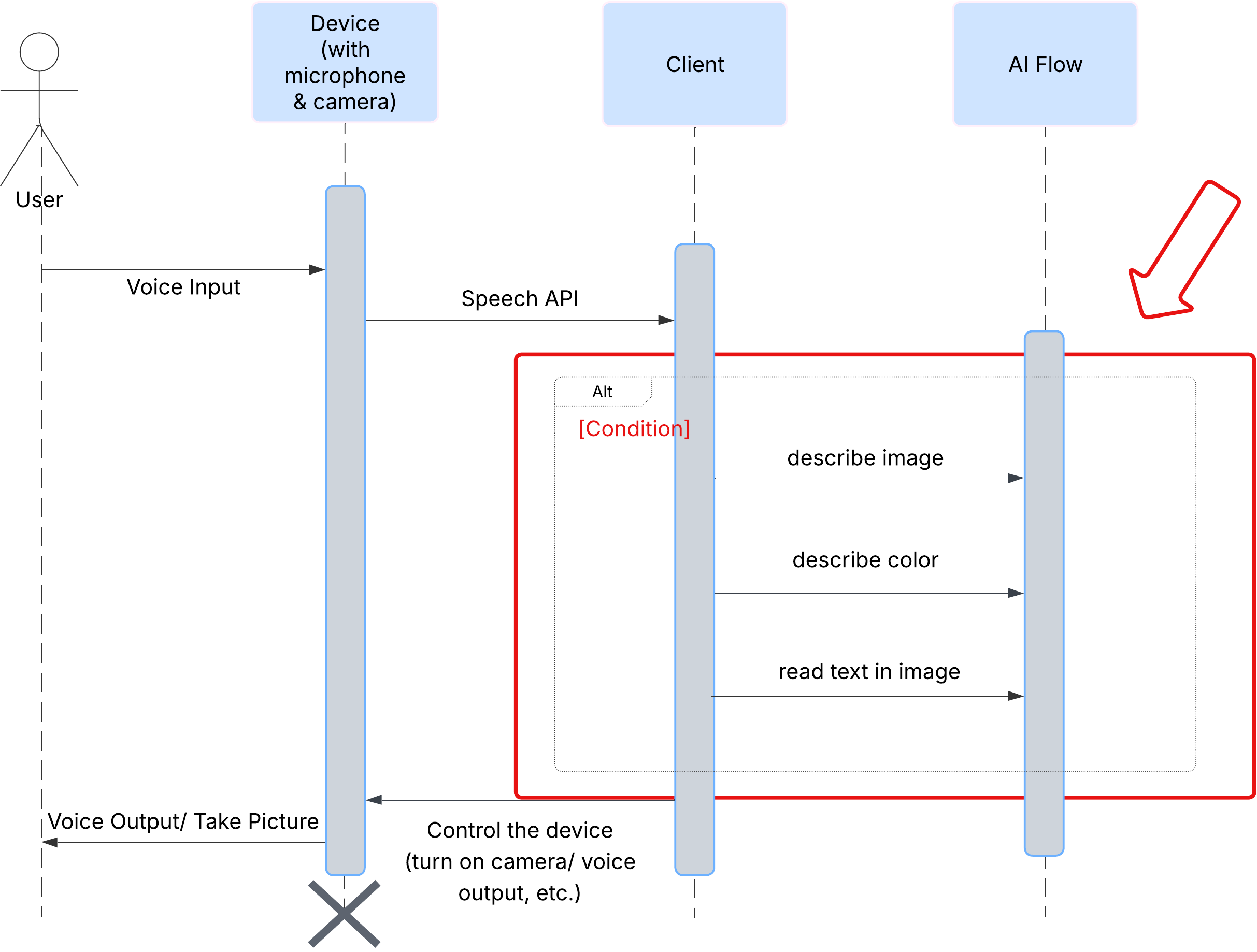
Pertama, mari kita lihat cara pengguna berinteraksi dengan ClarityCam. Seluruh pengalaman ini bersifat hands-free dan percakapan. Pengguna mengucapkan perintah, dan agen merespons dengan deskripsi atau tindakan yang diucapkan. Diagram urutan ini menunjukkan alur interaksi umum, dari perintah suara awal pengguna hingga respons audio akhir dari perangkat.
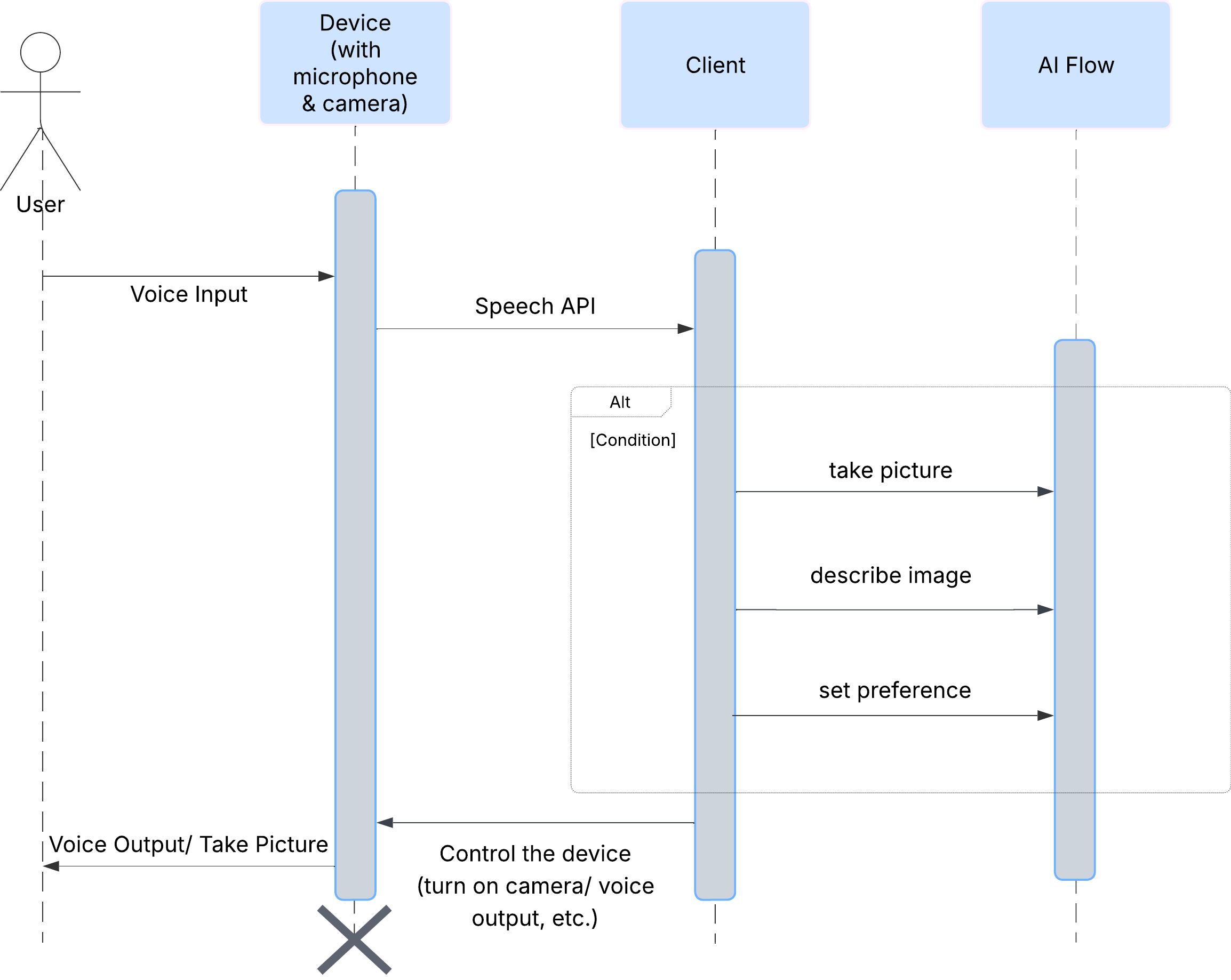
Arsitektur Agen AI
Di balik layar, sistem multi-agen bekerja sama untuk menghadirkan pengalaman tersebut. Saat perintah diterima, agen Orchestrator pusat akan mendelegasikan tugas ke agen khusus yang bertanggung jawab untuk memahami maksud, menganalisis gambar, dan membuat respons. Diagram alur AI ini memberikan pembahasan mendalam tentang cara agen ini berkolaborasi. Kita akan menerapkan arsitektur ini di bagian berikutnya.
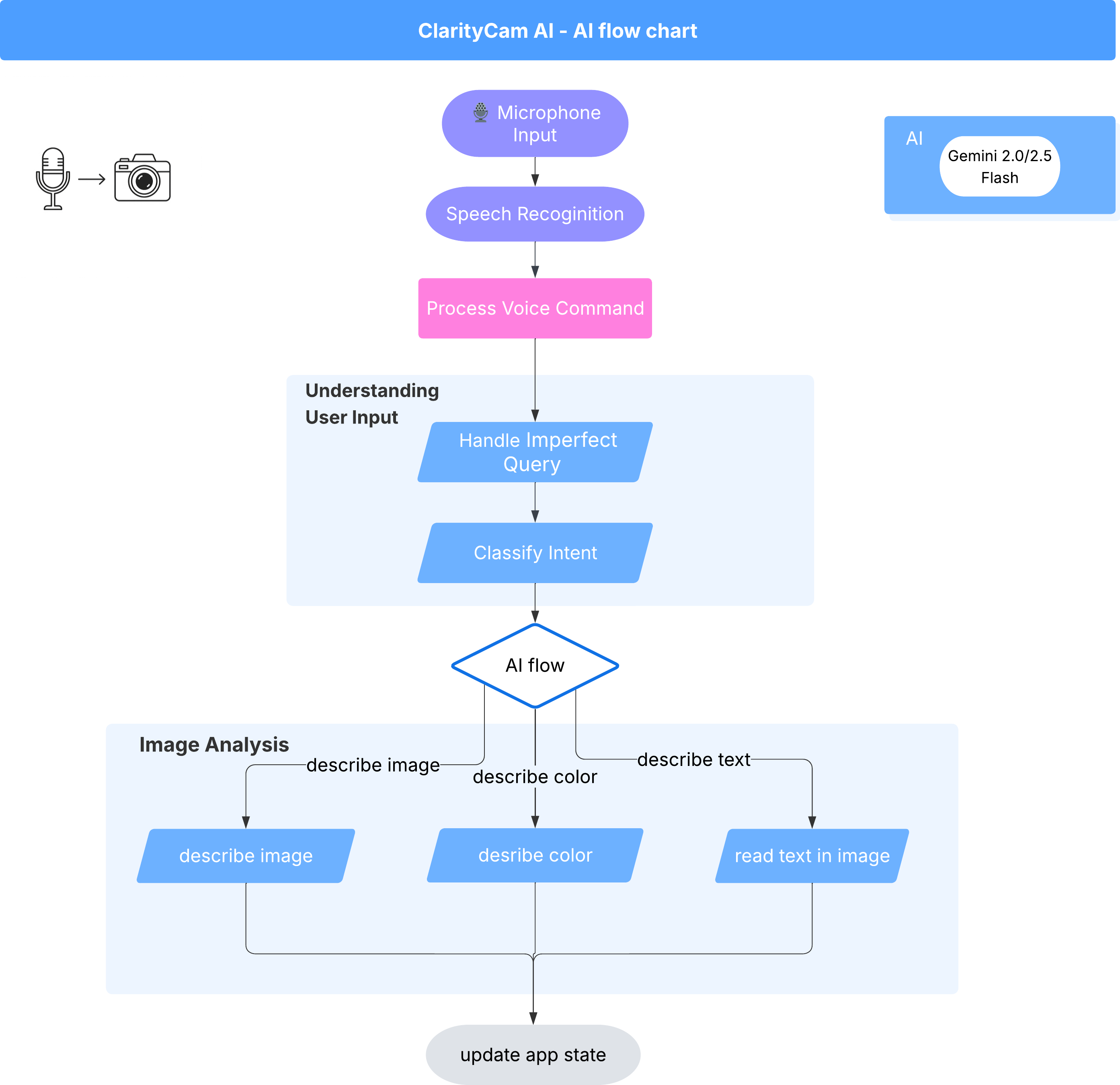
Tur Singkat File Project
Sebelum mulai menulis kode, mari kita pahami struktur file project kita. Mungkin terlihat ada banyak file, tetapi Anda hanya perlu berfokus pada dua area tertentu untuk seluruh tutorial ini.
Berikut adalah peta sederhana project kami.
accessibilityAI/src/
├── 📁 app/
│ ├── layout.tsx # An overall page shell (you can ignore this).
│ └── page.tsx # ⬅️ MODIFY THIS: The main user interface for our app.
│
├── 📁 ai/
│ ├── 📁flows # ⬅️ MODIFY THIS: The core AI logic and server functions.
│ └── intent-classifier.ts # ⬅️ MODIFY THIS: Where we'll edit our AI prompts.
| └── ai-instance.ts
| └── dev.ts
│
├── 📁 components/ # Contains pre-built UI components (ignore this).
│
├── 📁 hooks/
│
├── 📁 lib/
│
└── 📁 types/
Technology Stack
Sistem kami dibangun di atas stack teknologi modern dan skalabel yang menggabungkan layanan cloud yang andal dan model AI canggih. Berikut adalah komponen utama yang akan kita gunakan:
- Google Cloud Platform (GCP): Menyediakan infrastruktur serverless untuk agen kami.
- Cloud Run: Men-deploy setiap agen kami sebagai microservice dalam container yang skalabel.
- Artifact Registry: Menyimpan dan mengelola image Docker untuk agen kami secara aman.
- Secret Manager: Menangani kredensial sensitif dan kunci API dengan aman.
- Model Bahasa Besar (LLM): Berfungsi sebagai "otak" sistem.
- Model Gemini Google: Kami menggunakan kemampuan multimodal yang canggih dari rangkaian model Gemini untuk berbagai hal, mulai dari mengklasifikasikan niat pengguna hingga menganalisis konten gambar dan memberikan deskripsi yang cerdas.
3. Penyiapan dan Prasyarat
Aktifkan Akun Penagihan Untuk menjalankan codelab ini, Anda memerlukan akun penagihan dengan beberapa kredit. Gunakan kredit dari banner di bagian atas codelab ini untuk memulai. Jika sudah terhubung ke akun penagihan, Anda dapat melewati langkah ini.
Membuat Project GCP Baru
- Buka Konsol Google Cloud dan buat project baru.
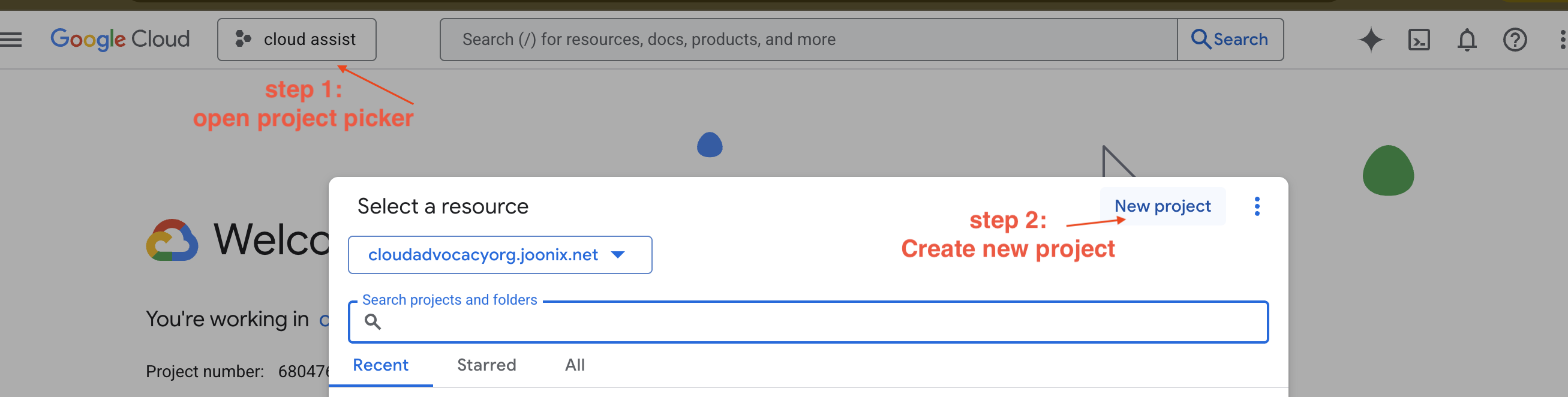
- Buka Konsol Google Cloud dan buat project baru.
- Buka panel kiri, klik
Billing, periksa apakah akun penagihan ditautkan ke akun GCP ini.
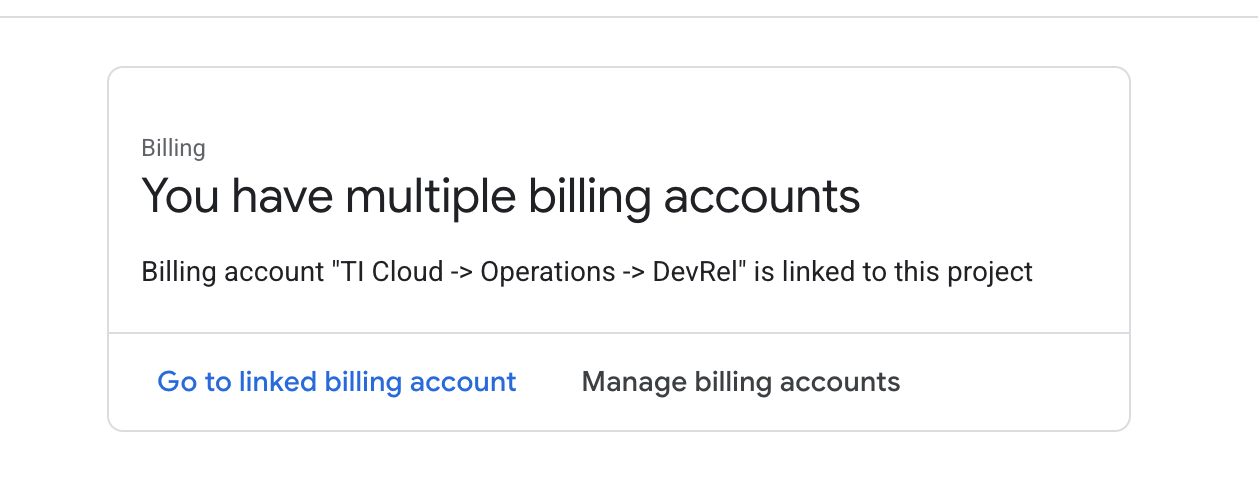
Jika Anda melihat halaman ini, periksa manage billing account, pilih Uji Coba Google Cloud dan tautkan ke halaman tersebut.
Membuat Kunci Gemini API Anda
Sebelum dapat mengamankan kunci, Anda harus memilikinya.
- Buka Google AI Studio : https://aistudio.google.com/
- Login dengan Akun Google Anda.
- Klik tombol "Dapatkan kunci API", yang biasanya ada di panel navigasi sebelah kiri atau di pojok kanan atas.
- Di dialog "Kunci API", klik "Buat kunci API di project baru".
- Kunci API baru akan dibuat untuk Anda. Segera salin kunci ini dan simpan di tempat yang aman untuk sementara (seperti pengelola sandi atau catatan aman). Nilai ini akan Anda gunakan pada langkah berikutnya.
Alur Kerja Pengembangan Lokal (Pengujian di Komputer Anda)
Anda harus dapat menjalankan npm run dev dan membuat aplikasi Anda berfungsi. Di sinilah .env berperan.
- Tambahkan Kunci API ke file: Buat file baru bernama
.envdan tambahkan baris berikut ke file ini.
Pastikan untuk mengganti YOUR_API_KEY_HERE dengan kunci yang Anda dapatkan dari AI Studio dan menyimpannya ke .env:
GOOGLE_GENAI_API_KEY="YOUR_API_KEY_HERE"
[Opsional] Menyiapkan IDE& Lingkungan
Untuk tutorial ini, Anda dapat bekerja di lingkungan pengembangan yang sudah dikenal seperti VS Code atau IntelliJ dengan terminal lokal. Namun, sebaiknya gunakan Google Cloud Shell untuk memastikan lingkungan yang standar dan telah dikonfigurasi sebelumnya.
Langkah-langkah berikut ditulis untuk konteks Cloud Shell. Jika Anda memilih untuk menggunakan lingkungan lokal, pastikan Anda telah menginstal dan mengonfigurasi git, nvm, npm, dan gcloud dengan benar.
Bekerja di Cloud Shell Editor
👉Klik Activate Cloud Shell di bagian atas Konsol Google Cloud (ikon berbentuk terminal di bagian atas panel Cloud Shell), 
👉Klik tombol "Open Editor" (terlihat seperti folder terbuka dengan pensil). Tindakan ini akan membuka Editor Kode Cloud Shell di jendela. Anda akan melihat file explorer di sisi kiri. 
👉Klik tombol Cloud Code Sign-in di status bar bawah seperti yang ditunjukkan. Otorisasi plugin seperti yang ditunjukkan. Jika Anda melihat Cloud Code - no project di status bar, pilih opsi tersebut, lalu di drop-down 'Select a Google Cloud Project', pilih Project Google Cloud tertentu dari daftar project yang Anda buat. 
👉Buka terminal di IDE cloud, 
👉Di terminal, verifikasi bahwa Anda sudah diautentikasi dan project telah disetel ke project ID Anda menggunakan perintah berikut:
gcloud auth list
👉 Clone project natively-accessible-interface dari GitHub:
git clone https://github.com/cuppibla/AccessibilityAgent.git
👉Jalankan dan pastikan untuk mengganti <YOUR_PROJECT_ID> dengan project ID Anda (Anda dapat menemukan project ID di konsol Google Cloud, bagian project, ❗️❗️pastikan untuk tidak mencampuradukkan project id VS project number❗️❗️):
echo <YOUR_PROJECT_ID> > ~/project_id.txt
gcloud config set project $(cat ~/project_id.txt)
👉Jalankan perintah berikut untuk mengaktifkan Google Cloud API yang diperlukan: (Proses ini mungkin memerlukan waktu sekitar 2 menit untuk dijalankan)
gcloud services enable compute.googleapis.com \
storage.googleapis.com \
run.googleapis.com \
artifactregistry.googleapis.com \
aiplatform.googleapis.com \
eventarc.googleapis.com \
sqladmin.googleapis.com \
secretmanager.googleapis.com \
cloudbuild.googleapis.com \
cloudresourcemanager.googleapis.com \
cloudfunctions.googleapis.com \
cloudaicompanion.googleapis.com
Proses ini mungkin memerlukan waktu beberapa menit.
Menyiapkan izin
👉Siapkan izin akun layanan. Di terminal, jalankan :
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
export SERVICE_ACCOUNT_NAME=$(gcloud compute project-info describe --format="value(defaultServiceAccount)")
echo "Here's your SERVICE_ACCOUNT_NAME $SERVICE_ACCOUNT_NAME"
👉 Berikan Izin. Di terminal, jalankan :
#Cloud Storage (Read/Write):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/storage.objectAdmin"
#Pub/Sub (Publish/Receive):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/pubsub.publisher"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/pubsub.subscriber"
#Cloud SQL (Read/Write):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/cloudsql.editor"
#Eventarc (Receive Events):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/iam.serviceAccountTokenCreator"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/eventarc.eventReceiver"
#Vertex AI (User):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/aiplatform.user"
#Secret Manager (Read):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/secretmanager.secretAccessor"
4. Memahami Input Pengguna - Pengklasifikasi Maksud (Intent Classifier)
Sebelum agen AI kami dapat bertindak, agen tersebut harus terlebih dahulu memahami secara akurat apa yang diinginkan pengguna. Input dunia nyata sering kali tidak rapi—dapat berupa kata-kata yang tidak jelas, menyertakan kesalahan ketik, atau menggunakan bahasa percakapan.
Di bagian ini, kita akan membuat komponen "pendengar" penting yang mengubah input pengguna mentah menjadi perintah yang jelas dan dapat ditindaklanjuti.
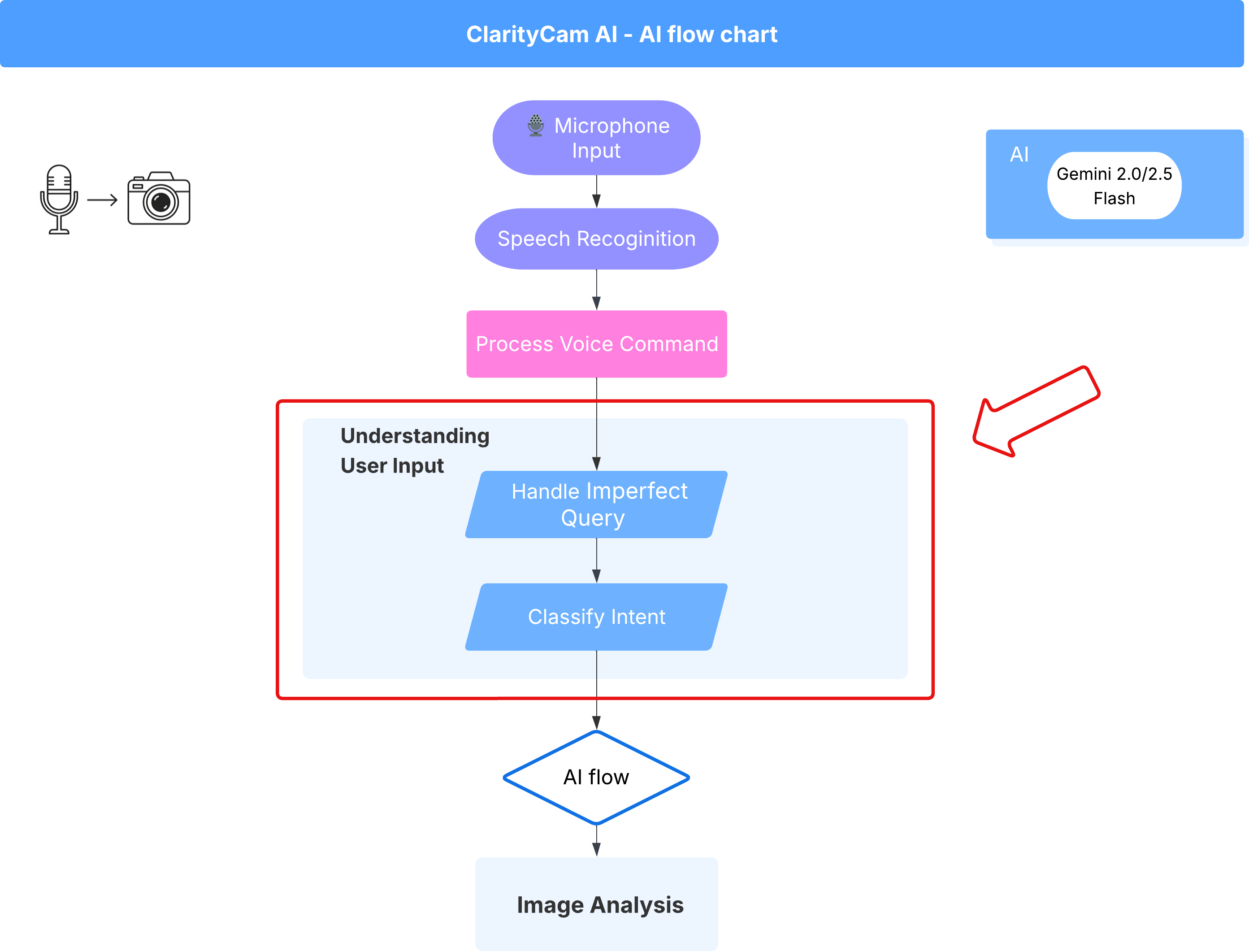
Menambahkan Pengklasifikasi Intent
Sekarang kita akan menentukan logika AI yang mendukung pengklasifikasi kita.
👉 Tindakan: Di Cloud Shell IDE, buka direktori ~/src/ai/intent-classifier/
Langkah 1: Tentukan Kosakata Agen (IntentCategory)
Pertama, kita perlu membuat daftar pasti dari setiap kemungkinan tindakan yang dapat dilakukan agen kita.
👉 Tindakan: Ganti placeholder // REPLACE ME PART 1: add IntentCategory here dengan kode berikut:
👉 dengan kode di bawah:
export type IntentCategory =
// Image Analysis Intents
| "DescribeImage"
| "AskAboutImage"
| "ReadTextInImage"
| "IdentifyColorsInImage"
// Control Intents
| "TakePicture"
| "StartCamera"
| "SelectImage"
| "StopSpeaking"
// Preference Intents
| "SetDescriptionDetailed"
| "SetDescriptionConcise"
// Fallback Intents
| "GeneralInquiry" // User has a general question about the agent's functions or polite interaction
| "OutOfScopeRequest" // User's request is clearly outside the agent's defined capabilities
| "Unknown"; // Intent could not be determined with confidence
Explanation
Kode TypeScript ini membuat jenis kustom bernama IntentCategory. Ini adalah daftar ketat yang menentukan setiap kemungkinan tindakan, atau "intent", yang dapat dipahami oleh agen kita. Ini adalah langkah pertama yang penting karena mengubah frasa pengguna yang berpotensi tak terbatas ("beri tahu saya apa yang Anda lihat", "apa yang ada di foto?") menjadi serangkaian perintah yang bersih dan dapat diprediksi. Tujuan pengklasifikasi kami adalah memetakan kueri pengguna ke salah satu kategori tertentu ini.
Langkah 2
Untuk membuat keputusan yang akurat, AI kami perlu mengetahui kemampuan dan batasannya sendiri. Kami akan memberikan informasi ini sebagai blok teks mendetail.
👉 Tindakan: Ganti placeholder REPLACE ME PART 2: add AGENT_CAPABILITIES_AND_LIMITATIONS here dengan kode berikut:
Ganti kode di bawah: // REPLACE ME PART 2: add AGENT_CAPABILITIES_AND_LIMITATIONS here:
👉 dengan kode di bawah
const AGENT_CAPABILITIES_AND_LIMITATIONS = `
**Core Capabilities (What the Agent CAN DO):**
* **Image Analysis:**
* DescribeImage: Provide a general description of the current image.
* AskAboutImage: Answer a specific question about the visual content of the current image (e.g., "Is there a dog?", "What color is the car?").
* ReadTextInImage: Read any text found in the current image.
* IdentifyColorsInImage: Identify the dominant colors of the current image.
* **Image Input Control:**
* TakePicture: Capture an image using the currently active camera stream.
* StartCamera: Activate the camera (e.g., "use camera", "take another picture").
* SelectImage: Allow the user to choose an image file from their device.
* **Voice & Audio Control:**
* StopSpeaking: Stop the current text-to-speech output.
* **Preference Management:**
* SetDescriptionDetailed: Make future image descriptions more detailed.
* SetDescriptionConcise: Make future image descriptions less detailed or concise.
* **General Interaction:**
* GeneralInquiry: Handle conversational phrases (e.g., "hello", "thank you") or questions about its own capabilities (e.g., "what can you do?", "help").
**Limitations (What the Agent CANNOT DO and should be classified as OutOfScopeRequest):**
* Cannot generate or create new images.
* Cannot edit or modify existing images (e.g., "remove background," "make the car blue").
* Cannot analyze video files or live video beyond capturing a single frame.
* Cannot provide general knowledge or answer questions unrelated to the provided image's visual content (e.g., "What's the weather?", "Who is the president?", "Tell me a joke", "What time is it?").
* Cannot perform mathematical calculations or complex data analysis.
* Cannot translate languages as a primary function.
* Cannot remember information from past images or vastly different previous queries in the same session.
* Cannot control other device settings or applications.
* Cannot perform web searches.
`;
Mengapa ini penting:
Teks ini bukan untuk dibaca pengguna, melainkan untuk model AI kami. Kita akan memasukkan "deskripsi pekerjaan" ini langsung ke dalam perintah (di langkah berikutnya) untuk memberikan konteks yang diperlukan Model Bahasa (LLM) dalam membuat keputusan yang akurat. Tanpa konteks ini, LLM mungkin salah mengklasifikasikan "bagaimana cuacanya?" sebagai AskAboutImage. Dengan konteks ini, model mengetahui bahwa cuaca bukanlah elemen visual dalam gambar dan mengklasifikasikannya dengan benar sebagai di luar cakupan.
Langkah 3
Sekarang kita akan menulis serangkaian petunjuk lengkap yang akan diikuti model Gemini untuk melakukan klasifikasi.
👉 Tindakan: Ganti // REPLACE ME PART 3 - classifyIntentPrompt dengan kode berikut:
dengan kode di bawah
const classifyIntentPrompt = ai.definePrompt({
name: 'classifyIntentPrompt',
input: { schema: ClassifyIntentInputSchema },
output: { schema: ClassifyIntentOutputSchema },
prompt: `You are classifying the user's intent for ClarityCam, a voice-controlled AI application focused on image analysis.
Analyze the user query: '{userQuery}'.
First, understand ClarityCam's capabilities and limitations:
${AGENT_CAPABILITIES_AND_LIMITATIONS}
Now, classify the user's PRIMARY intent into ONE of the following categories:
* **DescribeImage**: User wants a general description of the current image.
* **AskAboutImage**: User is asking a specific question directly related to the visual content of the current image.
* **ReadTextInImage**: User wants any text read from the current image.
* **IdentifyColorsInImage**: User wants the dominant colors of the current image.
* **TakePicture**: User wants to capture an image using an active camera.
* **StartCamera**: User wants to activate the camera.
* **SelectImage**: User wants to choose an image file.
* **StopSpeaking**: User wants the current text-to-speech output to stop.
* **SetDescriptionDetailed**: User wants future image descriptions to be more detailed.
* **SetDescriptionConcise**: User wants future image descriptions to be less detailed.
* **GeneralInquiry**: The query is a simple conversational filler (e.g., "hello", "thanks"), a polite closing, or a direct question about the agent's functions (e.g., "what can you do?", "how does this work?", "help").
* **OutOfScopeRequest**: The query asks the agent to perform an action clearly listed under its "Limitations" or otherwise demonstrably outside its defined image analysis and control functions. Examples: "Tell me a joke," "What's the weather in London?", "Generate an image of a cat," "Can you edit my photo to make it brighter?", "Send this image to my friends","Translate 'hello' to Spanish."
Output ONLY the category name.
If the query is ambiguous but seems generally related to polite interaction or asking about the agent itself, prefer 'GeneralInquiry'.
If the query is clearly asking for something the agent CANNOT do, use 'OutOfScopeRequest'.
If truly unclassifiable even with these guidelines, use 'Unknown'.`,
config: {
temperature: 0.05, // Very low temperature for highly deterministic classification
}
});
Di sinilah keajaiban perintah ini terjadi. Ini adalah "otak" pengklasifikasi kami, yang memberi tahu AI perannya, memberikan konteks yang diperlukan, dan menentukan output yang diinginkan. Perhatikan teknik rekayasa perintah utama berikut:
- Bermain Peran: Dimulai dengan "Anda mengklasifikasikan..." untuk menetapkan tugas yang jelas.
- Penyisipan Konteks: Secara dinamis menyisipkan variabel
AGENT_CAPABILITIES_AND_LIMITATIONSke dalam perintah. - Pemformatan Output yang Ketat: Instruksi "Output HANYA nama kategori" sangat penting untuk mendapatkan respons yang bersih dan dapat diprediksi yang dapat dengan mudah kita gunakan dalam kode kita.
- Temperatur Rendah: Untuk klasifikasi, kita menginginkan jawaban yang deterministik dan logis, bukan yang kreatif. Menetapkan suhu ke nilai yang sangat rendah (0,05) memastikan model sangat fokus dan konsisten.
Langkah 4: Hubungkan Aplikasi ke Alur AI
Terakhir, mari panggil pengklasifikasi AI baru dari file aplikasi utama.
👉 Tindakan: Buka file ~/src/app/page.tsx Anda. Di dalam fungsi processVoiceCommand, ganti // REPLACE ME PART 1: add classificationResult di sini dengan kode berikut:
const classificationResult = await classifyIntentFlow({ userQuery: commandToProcess });
intent = classificationResult.intent as IntentCategory;
Kode ini adalah jembatan penting antara aplikasi frontend dan logika AI backend Anda. Aplikasi ini mengambil perintah suara pengguna (commandToProcess), mengirimkannya ke classifyIntentFlow yang baru saja Anda buat, dan menunggu AI mengembalikan maksud yang diklasifikasikan.
Variabel intent kini menyimpan perintah yang bersih dan terstruktur (seperti DescribeImage). Hasil ini akan digunakan dalam pernyataan switch berikutnya untuk mendorong logika aplikasi dan memutuskan tindakan yang akan diambil selanjutnya. Dengan cara ini, "pemikiran" AI diubah menjadi "tindakan" aplikasi.
Meluncurkan Antarmuka Pengguna
Saatnya melihat aplikasi kita beraksi. Mulai server pengembangan.
👉 Di terminal, jalankan perintah berikut: npm run dev Catatan: Anda mungkin perlu menjalankan npm install sebelum menjalankan npm run dev
Setelah beberapa saat, Anda akan melihat output yang mirip dengan ini, yang berarti server berhasil berjalan:
▲ Next.js 15.2.3 (Turbopack)
- Local: http://localhost:9003
- Network: http://10.88.0.4:9003
- Environments: .env
✓ Starting...
✓ Ready in 1512ms
○ Compiling / ...
✓ Compiled / in 26.6s
Sekarang, klik URL lokal (http://localhost:9003) untuk membuka aplikasi di browser Anda.
Anda akan melihat antarmuka pengguna SightGuide. Untuk saat ini, tombol tidak terhubung ke logika apa pun, jadi mengkliknya tidak akan melakukan apa pun. Itulah yang kami harapkan pada tahap ini. Kita akan mewujudkannya di bagian berikutnya.
Setelah melihat UI, kembali ke terminal Anda dan tekan Ctrl + C untuk menghentikan server pengembangan sebelum kita melanjutkan
5. Memahami Input Pengguna - Pemeriksaan Kueri yang Tidak Sempurna
Menambahkan Pemeriksaan Kueri Tidak Sempurna
Bagian 1: Menentukan Perintah (The "What")
Pertama, mari kita definisikan petunjuk untuk AI kita. Perintah adalah "resep" untuk panggilan AI kita—perintah ini memberi tahu model secara persis apa yang kita inginkan.
👉 Tindakan: Di IDE, buka ~/src/ai/flows/check_typo/.
Ganti kode di bawah: // REPLACE ME PART 1: add prompt here:
👉 dengan kode di bawah
const prompt = ai.definePrompt({
name: 'checkTypoPrompt',
input: {
schema: CheckTypoInputSchema,
},
output: {
schema: CheckTypoOutputSchema,
},
prompt: `You are a helpful AI assistant that checks user text for typos and suggests corrections.
- If you find typos, respond with the corrected text.
- If there are no typos, or if you are unsure about a correction, respond with the original text unchanged.
User text: {text}
Corrected text:
`,
});
Blok kode ini menentukan template yang dapat digunakan kembali untuk AI kita yang disebut checkTypoPrompt. Skema input dan output menentukan kontrak data untuk tugas ini. Hal ini mencegah terjadinya error dan membuat sistem kita dapat diprediksi.
Bagian 2: Membuat Flow (Cara)
Setelah memiliki "resep" (perintah), kita perlu membuat fungsi yang dapat mengeksekusinya. Di Genkit, hal ini disebut alur. Flow membungkus perintah kita dalam fungsi yang dapat dieksekusi yang dapat dengan mudah dipanggil oleh aplikasi kita.
👉 Tindakan: Di file ~/src/ai/flows/check_typo/ yang sama, ganti kode di bawah: // REPLACE ME PART 2: add flow here:
👉 dengan kode di bawah
const checkTypoFlow = ai.defineFlow<
typeof CheckTypoInputSchema,
typeof CheckTypoOutputSchema
>(
{
name: 'checkTypoFlow',
inputSchema: CheckTypoInputSchema,
outputSchema: CheckTypoOutputSchema,
},
async input => {
const {output} = await prompt(input);
return output!;
}
);
Bagian 3: Menggunakan Pemeriksa Kesalahan Ketik
Setelah alur AI selesai, kita dapat mengintegrasikannya ke dalam logika utama aplikasi. Kita akan memanggilnya tepat setelah menerima perintah pengguna, memastikan teks bersih sebelum diproses lebih lanjut.
👉Tindakan: Buka ~/src/app/ai/flows/check-typo.ts dan temukan fungsi export async function checkTypo. Hapus tanda komentar pada pernyataan return:
Bukan return; Lakukan return checkTypoFlow(input);
👉Tindakan: Buka ~/src/app/page.tsx dan temukan fungsi processVoiceCommand. Ganti kode di bawah: REPLACE ME PART 2: add typoResult here:
👉 dengan kode di bawah
const typoResult = await checkTypo({ text: rawCommand });
if (typoResult && typoResult.correctedText && typoResult.correctedText.trim().length > 0) {
const originalTrimmedLower = rawCommand.trim().toLowerCase();
const correctedTrimmedLower = typoResult.correctedText.trim().toLowerCase();
if (correctedTrimmedLower !== originalTrimmedLower) {
commandToProcess = typoResult.correctedText;
typoCorrectionAnnouncement = `I think you said: ${commandToProcess}. `;
}
}
Dengan perubahan ini, kami telah membuat pipeline pemrosesan data yang lebih andal untuk setiap perintah pengguna.
Alur Perintah Suara (Hanya Baca, Tidak Perlu Tindakan)
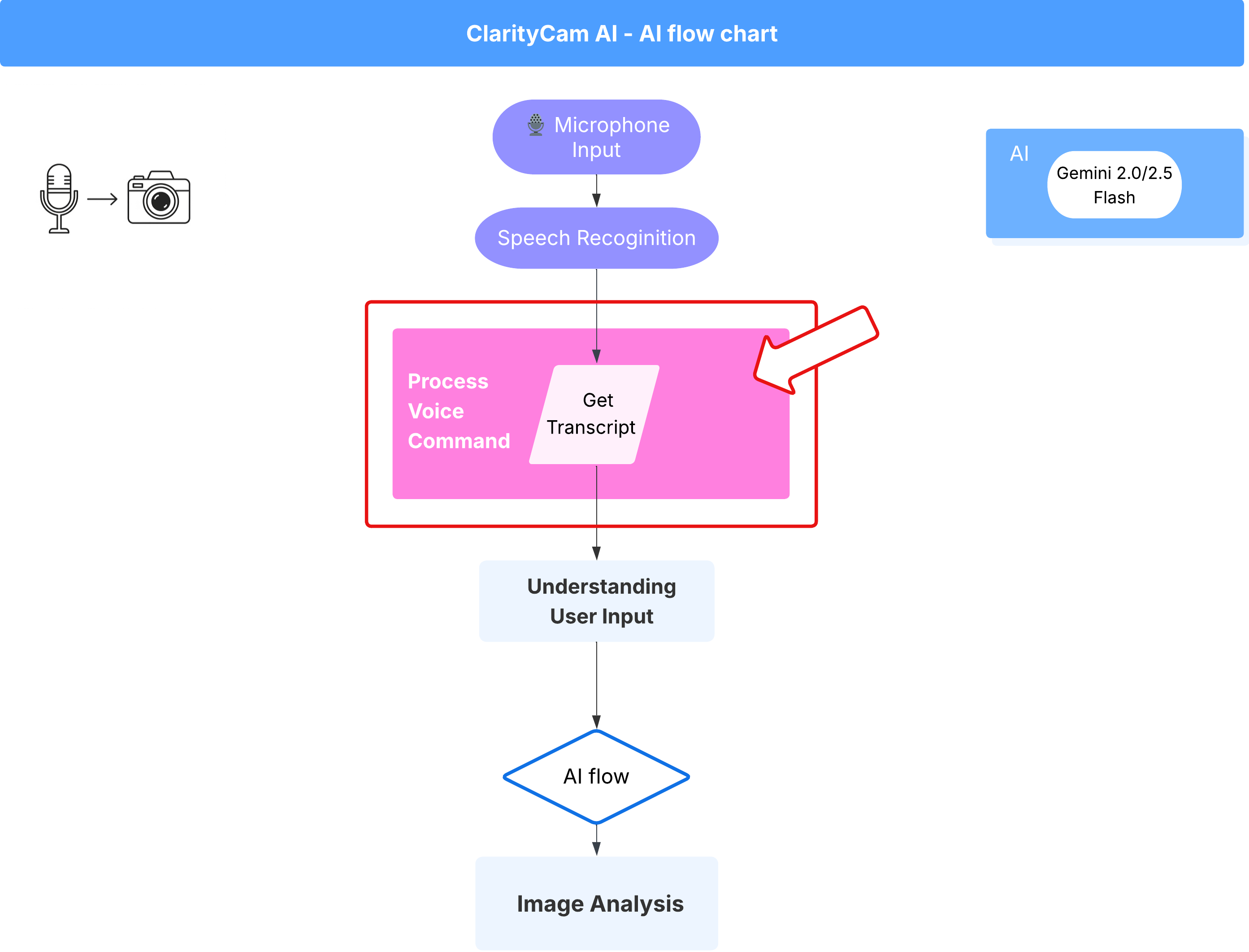
Setelah memiliki komponen "pemahaman" inti (Pemeriksa Kesalahan Ketik dan Pengklasifikasi Maksud), mari kita lihat cara komponen tersebut sesuai dengan logika pemrosesan suara utama aplikasi.
Semuanya dimulai saat pengguna berbicara. Web Speech API browser mendengarkan ucapan dan, setelah pengguna selesai berbicara, akan memberikan transkrip teks dari apa yang didengarnya. Kode berikut menangani proses ini.
👉Hanya Baca: Buka ~/src/app/page.tsx dan di dalam fungsi handleResult. Temukan kode di bawah ini:
for (let i = event.resultIndex; i < event.results.length; ++i) {
if (event.results[i].isFinal) {
finalTranscript += event.results[i][0].transcript;
}
}
if (finalTranscript) {
console.log("Final Transcript:", finalTranscript);
processVoiceCommand(finalTranscript);
}
Menguji Koreksi Kesalahan Ketik Kami
Sekarang saatnya bersenang-senang! Mari kita lihat cara fitur koreksi kesalahan ketik baru kami menangani perintah suara yang sempurna dan tidak sempurna.
Mulai Aplikasi
Pertama, jalankan kembali server pengembangan. Di terminal Anda, jalankan: npm run dev
Buka Aplikasi
Setelah server siap, buka browser Anda dan buka alamat lokal (misalnya, http://localhost:9003).
Mengaktifkan Perintah Suara
Klik tombol Start Listening. Browser Anda kemungkinan akan meminta izin untuk menggunakan mikrofon Anda. Klik Izinkan.
Menguji Perintah yang Tidak Sempurna
Sekarang, mari kita sengaja memberikan perintah yang sedikit salah untuk melihat apakah AI kita dapat memahaminya. Bicaralah dengan jelas ke mikrofon Anda:
"Ambil foto saya"
Mengamati Hasilnya
Di sinilah keajaiban terjadi! Meskipun Anda mengatakan "Ambil fotoku", Anda akan melihat aplikasi mengaktifkan kamera dengan benar. Alur checkTypo mengoreksi frasa Anda menjadi "take a picture" di balik layar, dan classifyIntentFlow kemudian memahami perintah yang telah dikoreksi.
Hal ini mengonfirmasi bahwa fitur koreksi salah ketik kami berfungsi dengan sempurna, sehingga aplikasi menjadi jauh lebih andal dan mudah digunakan. Setelah selesai, Anda dapat menghentikan kamera dengan mengambil gambar atau cukup menghentikan server di terminal (Ctrl + C).
6. Analisis Gambar yang Didukung AI - Mendeskripsikan Gambar
Setelah agen kita dapat memahami permintaan, saatnya memberinya mata. Di bagian ini, kita akan mengembangkan kemampuan Vision Agent, komponen inti yang bertanggung jawab atas semua analisis gambar. Kita akan mulai dengan fitur terpentingnya—mendeskripsikan gambar—lalu menambahkan kemampuan untuk membaca teks.
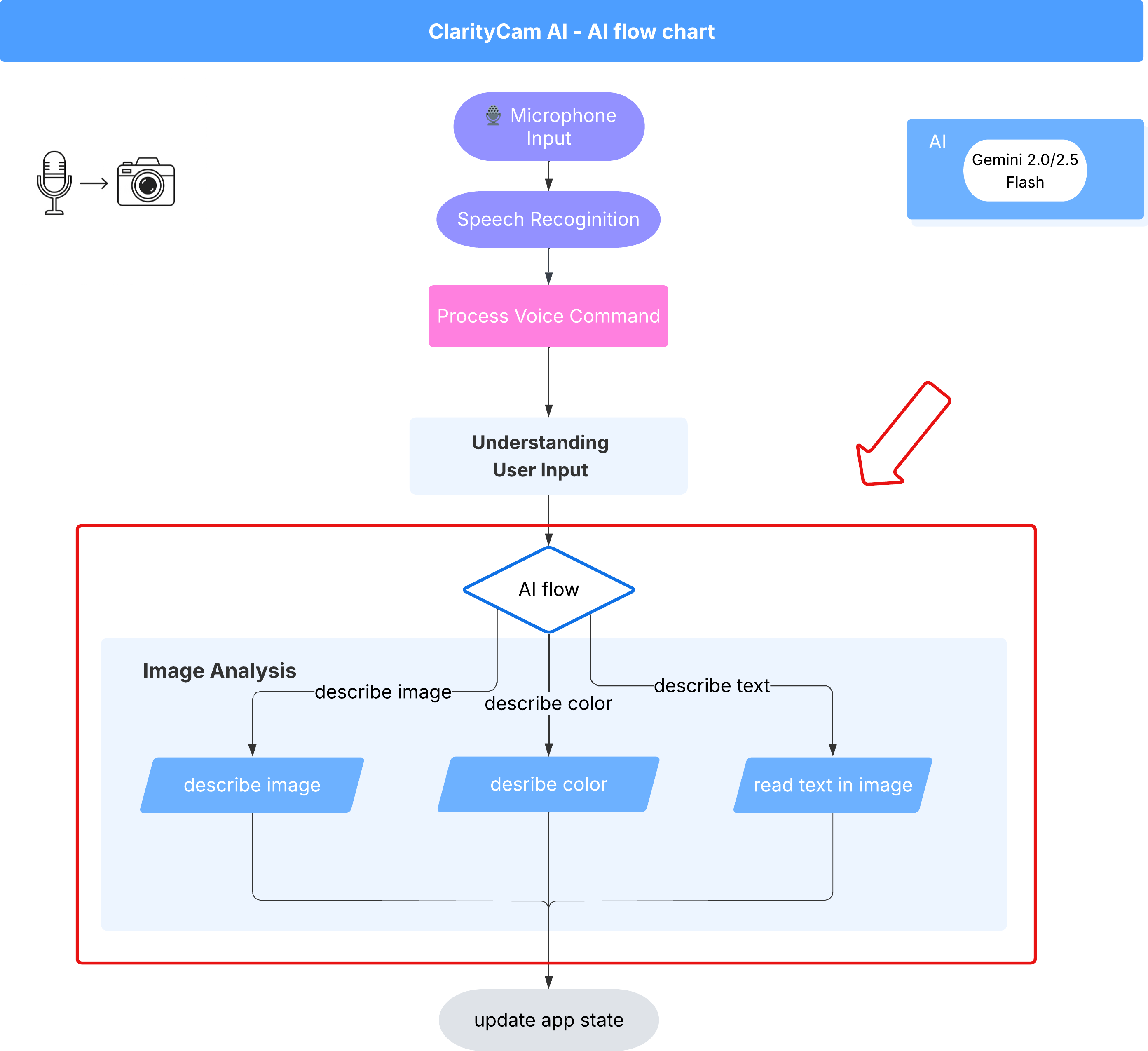
Fitur 1: Mendeskripsikan Gambar
Ini adalah fungsi utama agen. Kami tidak hanya membuat deskripsi statis, tetapi juga membangun alur dinamis yang dapat menyesuaikan tingkat detailnya berdasarkan preferensi pengguna. Ini adalah bagian penting dari filosofi Natively Adaptive Interface (NAI).
👉 Tindakan: Di IDE Cloud Shell, buka file ~/src/ai/flows/describe_image/ dan hapus komentar kode berikut.
Langkah 1: Membuat Template Perintah Dinamis
Pertama, kita akan membuat template perintah canggih yang dapat mengubah instruksinya berdasarkan input yang diterimanya.
Hapus komentar kode di bawah
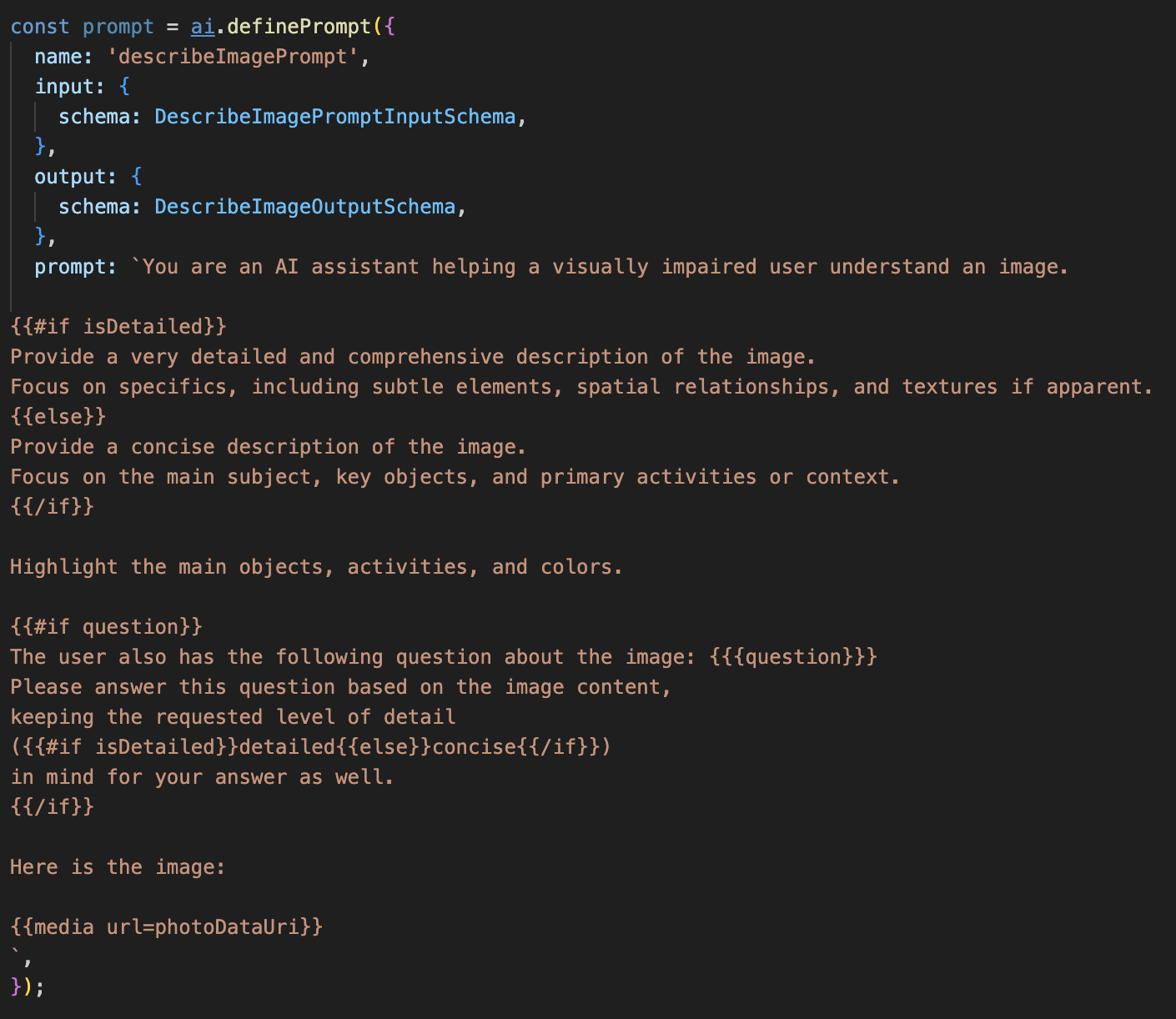
Kode ini menentukan variabel string, prompt, yang menggunakan bahasa template bernama Dot-Mustache. Dengan demikian, kita dapat menyematkan logika bersyarat langsung ke perintah.
{#if isDetailed}...{else}...{/if}: Ini adalah blok bersyarat. Jika data input yang kita kirim ke perintah ini berisi properti isDetailed: true, AI akan menerima serangkaian petunjuk "sangat mendetail". Jika tidak, model akan menerima petunjuk "singkat". Berikut cara agen kami beradaptasi dengan preferensi pengguna.
{#if question}...{/if}: Blok ini hanya akan disertakan jika data input kita berisi properti pertanyaan. Dengan begitu, kita dapat menggunakan perintah yang sama dan efektif untuk deskripsi umum dan pertanyaan spesifik.
{media url=photoDataUri}: Ini adalah sintaksis Genkit khusus untuk menyematkan data gambar langsung ke dalam perintah agar dianalisis oleh model multimodal.
Langkah 2: Membuat Smart Flow
Selanjutnya, kita akan menentukan perintah dan alur yang akan menggunakan template baru. Alur ini berisi sedikit logika untuk menerjemahkan preferensi pengguna ke dalam boolean yang dapat dipahami template kita.
👉 Tindakan: Di IDE Cloud Shell Anda, pada file ~/src/ai/flows/describe_image/ yang sama, ganti kode berikut. // REPLACE ME PART 1: add flow here
👉 Dengan kode di bawah:
// Define the prompt using the template from Step 1
const prompt = ai.definePrompt({
name: 'describeImagePrompt',
input: { schema: DescribeImagePromptInputSchema },
output: { schema: DescribeImageOutputSchema },
prompt: promptTemplate,
});
// Define the flow
const describeImageFlow = ai.defineFlow<
typeof DescribeImageInputSchema,
typeof DescribeImageOutputSchema
>(
{
name: 'describeImageFlow',
inputSchema: DescribeImageInputSchema,
outputSchema: DescribeImageOutputSchema,
},
async (pageInput) => {
const preference = pageInput.detailPreference || "concise";
// Prepare the input for the prompt, including the new boolean flag
const promptInputData = {
...pageInput,
isDetailed: preference === "detailed",
};
const { output } = await prompt(promptInputData);
return output!;
}
);
Alat ini berfungsi sebagai perantara cerdas antara frontend dan perintah AI.
- Fungsi ini menerima
pageInputdari aplikasi kita, yang mencakup preferensi pengguna sebagai string (misalnya,"detailed"). - Kemudian, objek tersebut membuat objek baru,
promptInputData. - Baris yang paling penting adalah
isDetailed: preference === "detailed". Baris ini melakukan tugas penting dalam membuat nilai booleantrueataufalseberdasarkan string preferensi. - Terakhir, API ini memanggil
promptdengan data yang disempurnakan ini. Template perintah dari Langkah 1 kini dapat menggunakan booleanisDetaileduntuk mengubah petunjuk yang dikirim ke AI secara dinamis.
Langkah 3: Menghubungkan Frontend
Sekarang, mari kita picu alur ini dari antarmuka pengguna di page.tsx.
👉Tindakan: Buka ~/src/app/ai/flows/describe-image.ts dan temukan fungsi export async function describeImage. Hapus tanda komentar pada pernyataan return:
Bukan return; Lakukan return describeImageFlow(input);
👉Tindakan: Di ~/src/app/page.tsx, temukan fungsi handleAnalyze, ganti kode // REPLACE ME PART 2: DESCRIBE IMAGE
👉 dengan kode berikut:
case "description":
result = await describeImage({
photoDataUri,
question,
detailPreference: descriptionPreference
});
outputText = question ? `Answer: ${result.description}` : `Description: ${result.description}`;
break;
Saat maksud pengguna adalah mendapatkan deskripsi, kode ini akan dieksekusi. Fungsi ini memanggil alur describeImage kami, meneruskan data gambar dan, yang terpenting, variabel status descriptionPreference dari komponen React kami. Ini adalah bagian terakhir dari teka-teki, yang menghubungkan preferensi pengguna yang disimpan di UI langsung ke alur AI yang akan menyesuaikan perilakunya.
Menguji Fitur Deskripsi Gambar
Mari kita lihat fungsi deskripsi gambar kita beraksi, mulai dari mengambil foto hingga mendengar apa yang dilihat AI.
Mulai Aplikasi
Pertama, jalankan kembali server pengembangan. 👉 Di terminal, jalankan perintah berikut: npm run dev Catatan: Anda mungkin perlu menjalankan npm install sebelum menjalankan npm run dev
Buka Aplikasi
Setelah server siap, buka browser Anda dan buka alamat lokal (misalnya, http://localhost:9003).
Mengaktifkan Kamera
Klik tombol Mulai Mendengarkan dan berikan akses mikrofon jika diminta. Kemudian, ucapkan perintah pertama Anda:
"Ambil foto"
Aplikasi akan mengaktifkan kamera perangkat Anda. Anda kini akan melihat feed video live di layar.
Mengambil Foto
Dengan kamera aktif, posisikan kamera ke apa pun yang ingin Anda deskripsikan. Sekarang, ucapkan perintah untuk kedua kalinya guna mengambil gambar:
"Ambil foto"
Video live akan digantikan dengan foto statis yang baru saja Anda ambil.
Meminta Deskripsi
Dengan foto baru Anda di layar, berikan perintah terakhir:
"Jelaskan gambar"
Mendengarkan Hasil
Aplikasi akan menampilkan status pemrosesan, lalu Anda akan mendengar deskripsi gambar yang dibuat AI. Teks juga akan muncul di kartu "Status & Hasil".
Setelah selesai, Anda dapat menghentikan kamera dengan mengambil foto atau cukup menghentikan server di terminal (Ctrl + C).
7. Analisis Gambar yang Didukung AI - Mendeskripsikan Teks (OCR)
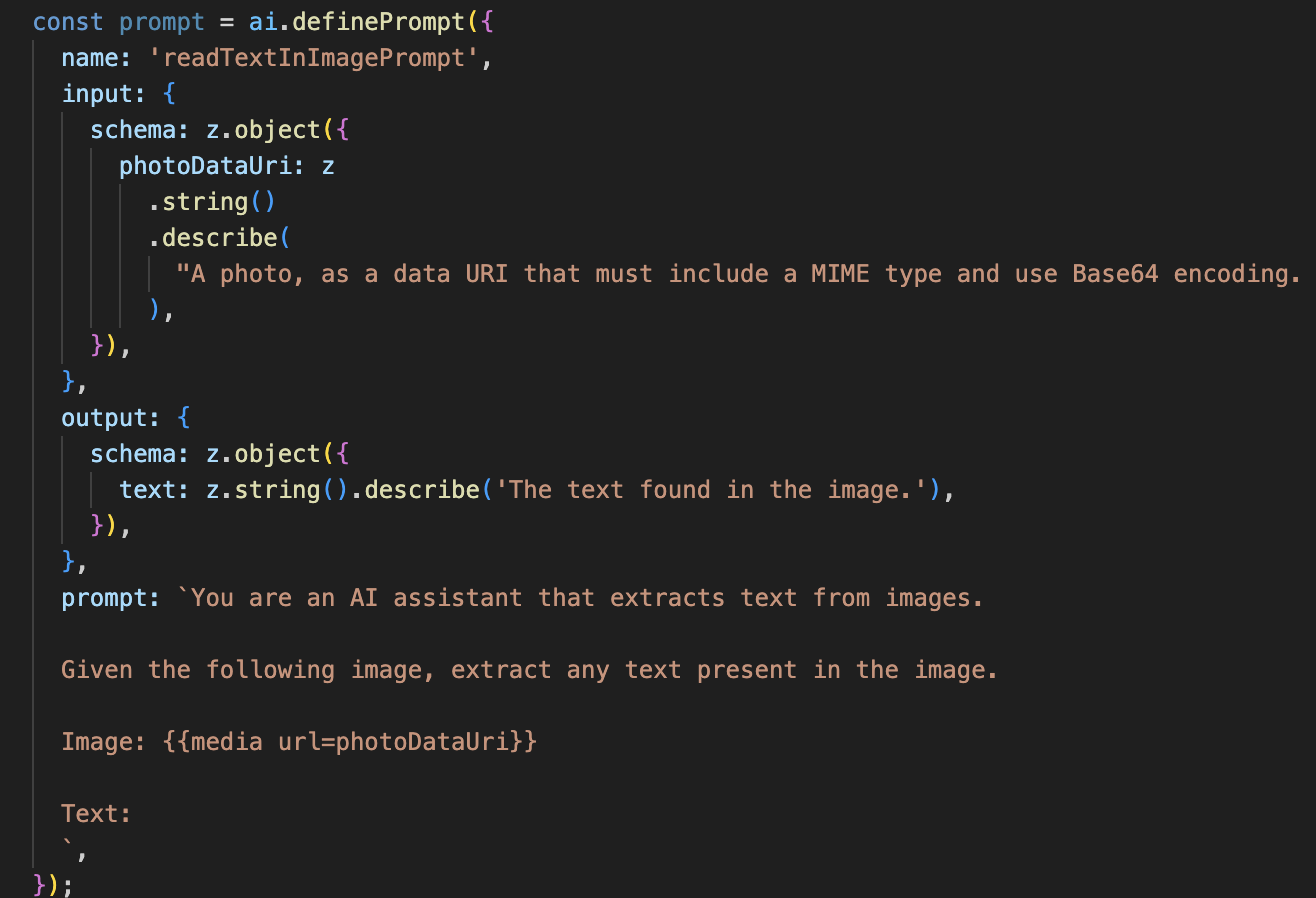
Selanjutnya, kami akan menambahkan kemampuan Pengenalan Karakter Optik (OCR) ke Vision Agent kami. Hal ini memungkinkan Gemini membaca teks dari gambar apa pun.
👉 Tindakan: Di IDE Anda, buka ~/src/ai/flows/read-text-in-image/, Hapus komentar kode di bawah:
👉 Tindakan: Di IDE Anda, di file ~/src/ai/flows/read-text-in-image/ yang sama, ganti // REPLACE ME: Creating Prmopt
👉 dengan kode di bawah:
const readTextInImageFlow = ai.defineFlow<
typeof ReadTextInImageInputSchema,
typeof ReadTextInImageOutputSchema
>(
{
name: 'readTextInImageFlow',
inputSchema: ReadTextInImageInputSchema,
outputSchema: ReadTextInImageOutputSchema,
},
async input => {
const {output} = await prompt(input);
return output!;
}
);
Alur AI ini jauh lebih sederhana, yang menyoroti prinsip penggunaan alat yang terfokus untuk tugas tertentu.
- Perintah: Tidak seperti perintah deskripsi kami, perintah ini bersifat statis dan sangat spesifik. Satu-satunya tugasnya adalah menginstruksikan AI untuk bertindak sebagai mesin OCR: "ekstrak teks apa pun yang ada dalam gambar".
- Skema: Skema input dan output juga sederhana, mengharapkan gambar dan menampilkan satu string teks.
Menghubungkan Frontend untuk OCR
Terakhir, mari hubungkan kemampuan baru ini di page.tsx.
👉Tindakan: Buka ~/src/app/ai/flows/read-text-in-image.ts dan temukan fungsi export async function readTextInImage. Hapus tanda komentar pada pernyataan return:
Bukan return; Lakukan return readTextInImageFlow(input);
👉 Tindakan: Di ~/src/app/page.tsx, temukan fungsi handleAnalyze dan di sekitar pernyataan switch.
Ganti REPLACE ME PART 3: READ TEXT
dengan kode di bawah:
case "text":
result = await readTextInImage({ photoDataUri });
outputText = result.text ? `Text Found: ${result.text}` : "No text found.";
break;
Saat maksud pengguna adalah ReadTextInImage, kode ini akan dipicu. Ini memanggil alur readTextInImage sederhana kita. Baris result.text ? ... : ... adalah cara yang tepat untuk menangani output, dengan memberikan pesan yang berguna kepada pengguna jika AI tidak dapat menemukan teks apa pun dalam gambar.
Menguji Fitur Baca Teks (OCR)
Ikuti langkah-langkah berikut untuk menguji fitur pembacaan teks. Ingatlah untuk mengarahkan kamera ke objek dengan teks yang jelas.
- Jalankan aplikasi dengan
npm run devdan buka di browser Anda. - Klik Mulai Mendengarkan dan berikan akses mikrofon saat diminta.
- Aktifkan kamera. Ucapkan perintah: "Ambil foto". Anda akan melihat feed video live muncul di layar.
- Ambil foto. Arahkan kamera ke teks yang ingin Anda baca, lalu ucapkan perintah lagi: "Ambil foto". Video akan digantikan dengan foto statis.
- Minta teksnya. Setelah foto diambil, berikan perintah terakhir: "Apa teks dalam gambar?"
- Periksa Hasil Setelah beberapa saat, aplikasi akan menganalisis foto dan membacakan teks yang terdeteksi. Jika tidak dapat menemukan teks apa pun, Anda akan diberi tahu.
Hal ini mengonfirmasi bahwa fitur OCR yang canggih berfungsi. Setelah selesai, hentikan server dengan Ctrl + C.
8. Peningkatan Kualitas AI Tingkat Lanjut - Hanya Baca ✨
Agen AI yang baik dapat mengikuti petunjuk. Agen AI yang hebat terasa intuitif, dapat dipercaya, dan bermanfaat. Di bagian ini, kita akan berfokus pada tiga peningkatan lanjutan yang meningkatkan kemampuan agen kita.
Kita akan mempelajari cara:
Add Context & Memoryuntuk menangani tindak lanjut percakapan yang alami.Reduce Hallucinationuntuk membangun agen yang lebih andal dan tepercaya.Make the Agent Proactiveuntuk memberikan pengalaman yang lebih mudah diakses dan ramah pengguna.Add preference settinguntuk menyesuaikan deskripsi gambar
Peningkatan 1: Konteks & Memori
Percakapan alami bukanlah serangkaian perintah yang terpisah; percakapan mengalir. Jika pengguna bertanya, "Apa yang ada di dalam gambar?" dan agen menjawab, "Mobil merah", tindak lanjut alami pengguna mungkin adalah, "Apa warnanya?" tanpa mengatakan "mobil" lagi. Agen kita memerlukan memori jangka pendek untuk memahami konteks ini.
Cara Kami Menerapkannya (Rangkuman)
Kami telah membangun kemampuan ini ke dalam alur describeImage kami. Bagian ini adalah ringkasan cara kerja pola tersebut. Saat memanggil fungsi describeImage dari page.tsx, kita meneruskan histori percakapan.
👉 Galeri Kode (dari page.tsx):
const result = await describeImage({
photoDataUri,
question: commandToProcess,
detailPreference: descriptionPreference,
previousUserQueryOnImage: lastUserQuery ?? undefined,
previousAIResponseOnImage: lastAIResponse ?? undefined,
});
previousUserQueryOnImage&previousAIResponseOnImage: Kedua properti ini adalah memori jangka pendek agen kita. Dengan meneruskan interaksi terakhir ke AI, kita memberikan konteks yang diperlukan untuk memahami pertanyaan lanjutan yang tidak jelas atau merujuk.- Perintah Adaptif: Konteks ini digunakan oleh perintah dalam alur describe_image kami. Perintah ini dirancang untuk mempertimbangkan percakapan sebelumnya saat membentuk jawaban baru, sehingga memungkinkan agen merespons secara cerdas.
Peningkatan 2: Mengurangi Halusinasi
AI "berhalusinasi" saat AI membuat-buat fakta atau mengklaim memiliki kemampuan yang tidak dimilikinya. Untuk membangun kepercayaan pengguna, sangat penting bagi agen kami untuk mengetahui batas kemampuannya sendiri dan dapat menolak permintaan di luar cakupan dengan baik.
Cara Kami Menerapkannya (Rangkuman)
Cara paling efektif untuk mencegah halusinasi adalah dengan memberikan batasan yang jelas pada model. Kami mencapai hal ini saat membangun Pengklasifikasi Maksud (Intent Classifier).
👉 Showcase Kode (dari alur intent-classifier):
// Define Agent Capabilities and Limitations for the prompt
const AGENT_CAPABILITIES_AND_LIMITATIONS = `
**Core Capabilities (What the Agent CAN DO):**
* **Image Analysis:**
* DescribeImage: Provide a general description of the current image...
**Limitations (What the Agent CANNOT DO...):**
* Cannot generate or create new images.
* Cannot provide general knowledge or answer questions unrelated to the image...
* Cannot perform web searches.
`;
Konstanta ini berfungsi sebagai "deskripsi pekerjaan" yang kita masukkan ke AI dalam perintah klasifikasi.
- Mendasari Model: Dengan secara eksplisit memberi tahu AI tentang hal yang tidak boleh dilakukannya, kita "mendasari" AI dalam kenyataan. Saat melihat kueri seperti "Bagaimana cuacanya?", model dapat mencocokkannya dengan yakin ke daftar batasannya dan mengklasifikasikan maksudnya sebagai OutOfScopeRequest.
- Membangun Kepercayaan: Agen yang dapat dengan jujur mengatakan, "Saya tidak dapat membantu," jauh lebih dapat dipercaya daripada agen yang mencoba menebak dan salah. Hal ini merupakan prinsip mendasar dari desain AI yang aman dan andal. `
Peningkatan 3: Membuat Agen Proaktif
Untuk aplikasi yang mengutamakan aksesibilitas, kita tidak dapat mengandalkan isyarat visual. Saat pengguna mengaktifkan mode mendengarkan, mereka memerlukan konfirmasi langsung non-visual bahwa agen sudah siap dan menunggu perintah. Sekarang kita akan menambahkan pengantar proaktif untuk memberikan masukan penting ini.
Langkah 1: Tambahkan Status untuk Melacak Pemutaran Pertama
Pertama, kita memerlukan cara untuk mengetahui apakah ini adalah pertama kalinya pengguna menekan tombol "Start Listening" selama sesi mereka.
👉 Di ~/src/app/page.tsx, lihat variabel status baru berikut di dekat bagian atas komponen ClarityCam Anda.
export default function ClarityCam() {
// ... other state variables
const [descriptionPreference, setDescriptionPreference] = useState<DescriptionPreference>("concise");
// Add this new line
const [isFirstListen, setIsFirstListen] = useState(true);
// ... rest of the component
}
Kita telah memperkenalkan variabel status baru, isFirstListen, dan melakukan inisialisasi menjadi true. Kita akan menggunakan tanda ini untuk memicu pesan selamat datang satu kali.
Langkah 2: Perbarui Fungsi toggleListening
Sekarang, mari kita ubah fungsi yang menangani mikrofon untuk memutar ucapan selamat datang kita.
👉 Di ~/src/app/page.tsx, temukan fungsi toggleListening dan lihat blok if berikut.
const toggleListening = useCallback(() => {
// ... existing logic to setup speech recognition
if (isListening || isAttemptingStart) {
// ... existing logic to stop listening
} else {
stopSpeaking(); // Stop any ongoing TTS
// Add this new block
if (isFirstListen) {
setIsFirstListen(false);
const introMessage = "Hello! I am ClarityCam, your AI assistant. I'm now listening. You can ask me to 'describe the image', 'read text', 'take a picture', or ask questions about what's in an image.";
speakText(introMessage);
} else {
speakText("Listening..."); // Optional: provide feedback on subsequent clicks
}
// ... rest of the logic to start listening
}
}, [/*...existing dependencies...*/, isFirstListen]); // Don't forget to add isFirstListen to the dependency array!
- Periksa Flag: Blok if (isFirstListen) memeriksa apakah ini adalah aktivasi pertama.
- Mencegah Pengulangan: Hal pertama yang dilakukan di dalam blok adalah memanggil setIsFirstListen(false). Hal ini memastikan pesan pengantar hanya akan diputar sekali per sesi.
- Memberikan Panduan: introMessage dibuat dengan cermat agar dapat membantu semaksimal mungkin. Agent menyapa pengguna, mengidentifikasi agent berdasarkan nama, mengonfirmasi bahwa agent kini aktif ("Saya sekarang mendengarkan"), dan memberikan contoh jelas perintah suara yang dapat digunakan.
- Respons Audio: Terakhir, speakText(introMessage) menyampaikan informasi penting ini, memberikan jaminan dan panduan langsung tanpa mengharuskan pengguna melihat layar.
Peningkatan 4: Menyesuaikan dengan Preferensi Pengguna (Ringkasan)
Agen yang benar-benar cerdas tidak hanya merespons, tetapi juga mempelajari dan beradaptasi dengan kebutuhan pengguna. Salah satu fitur paling canggih yang kami buat adalah kemampuan pengguna untuk mengubah kejelasan deskripsi gambar secara langsung dengan perintah seperti "Lebih rinci".
Cara Kami Menerapkannya (Ringkasan) Kemampuan ini didukung oleh perintah dinamis yang kami buat untuk alur describeImage. Fitur ini menggunakan logika bersyarat untuk mengubah petunjuk yang dikirim ke AI berdasarkan preferensi pengguna.
👉 Code Showcase (promptTemplate dari describe_image):
const settingPreferenceTemplate = `
{#if isDetailed}
Provide a very detailed and comprehensive description of the image. Focus on specifics, including subtle elements, spatial relationships, and textures if apparent.
{else}
Provide a concise description of the image. Focus on the main subject, key objects, and primary activities or context.
{/if}
Highlight the main objects, activities, and colors.
...
`;
- Logika Bersyarat: Blok
{#if isDetailed}...{else}...{/if}adalah kuncinya. Saat describeImageFlow menerima detailPreference dari frontend, describeImageFlow akan membuat boolean isDetailed (benar atau salah). - Petunjuk Adaptif: Flag boolean ini menentukan kumpulan petunjuk yang diterima model AI. Jika isDetailed bernilai benar (true), model akan diinstruksikan untuk memberikan deskripsi yang sangat mendetail. Jika salah, maka harus diringkas.
- Kontrol Pengguna: Pola ini menghubungkan perintah suara pengguna secara langsung (misalnya, "buat deskripsi lebih ringkas", yang diklasifikasikan sebagai maksud SetDescriptionConcise) dengan perubahan mendasar dalam perilaku AI, sehingga membuat agen terasa benar-benar responsif dan dipersonalisasi.
9. Deployment ke Cloud
Membangun Image Docker menggunakan Google Cloud Build
gcloud builds submit . --tag gcr.io/$PROJECT_ID/accessibilityai-nextjs-app:latest
accessibilityai-nextjs-appadalah nama gambar yang disarankan.- File . menggunakan direktori saat ini (
accessibilityAI/) sebagai sumber build.
Men-deploy Image ke Google Cloud Run
- Pastikan kunci API dan secret lainnya sudah siap di Secret Manager. Misalnya,
GOOGLE_GENAI_API_KEY.
Ganti YOUR_ACTUAL_GOOGLE_AI_KEY_VALUE ini dengan nilai kunci Gemini API Anda yang sebenarnya.
echo "YOUR_ACTUAL_GOOGLE_AI_KEY_VALUE" | gcloud secrets create GOOGLE_GENAI_API_KEY --data-file=- --project=YOUR_PROJECT_ID
Beri akun layanan runtime layanan Cloud Run Anda (misalnya, PROJECT_NUMBER-compute@developer.gserviceaccount.com atau akun khusus) peran "Secret Manager Secret Accessor" untuk secret ini.
- Perintah deployment:
gcloud run deploy accessibilityai-app-service \
--image gcr.io/$PROJECT_ID/accessibilityai-nextjs-app:latest \
--platform managed \
--region us-central1 \
--allow-unauthenticated \
--port 3000 \
--set-secrets=GOOGLE_GENAI_API_KEY=GOOGLE_GENAI_API_KEY:latest \
--set-env-vars NODE_ENV="production"