
1. Introduzione
In questo tutorial, creerai ClarityCam, un agente AI vocale e a mani libere che può vedere il mondo e spiegartelo. Sebbene ClarityCam sia progettata con l'accessibilità al centro, fornendo un potente strumento per gli utenti ciechi e ipovedenti, i principi che imparerai sono essenziali per creare qualsiasi applicazione vocale moderna e per uso generico.

Questo progetto si basa su una potente filosofia di progettazione chiamata interfaccia nativamente adattiva (NAI). Anziché considerare l'accessibilità come un aspetto secondario, NAI la rende la base. Con questo approccio, l'agente AI è l'interfaccia: si adatta a diversi utenti, gestisce input multimodali come voce e visione e guida le persone in modo proattivo in base alle loro esigenze specifiche.
Creare il tuo primo agente AI con NAI:

Alla fine di questa sessione sarai in grado di:
- Progettare con l'accessibilità come impostazione predefinita: applica i principi dell'interfaccia adattiva nativa (NAI) per creare sistemi di AI che offrano esperienze equivalenti per tutti gli utenti.
- Classifica l'intento dell'utente: crea un classificatore di intent robusto che traduca i comandi in linguaggio naturale in azioni strutturate per il tuo agente.
- Mantenere il contesto conversazionale: implementa la memoria a breve termine per consentire all'agente di comprendere le domande successive e i comandi referenziali (ad es. "Di che colore è?").
- Progettare prompt efficaci: crea prompt mirati e ricchi di contesto per un modello multimodale come Gemini per garantire un'analisi delle immagini accurata e affidabile.
- Gestisci l'ambiguità e guida l'utente: progetta una gestione degli errori corretta per le richieste fuori ambito e integra in modo proattivo gli utenti per creare fiducia.
- Orchestrare un sistema multi-agente: struttura la tua applicazione utilizzando una raccolta di agenti specializzati che collaborano per gestire attività complesse come l'elaborazione vocale, l'analisi e la sintesi vocale.
2. Progettazione di alto livello
ClarityCam è progettata per essere semplice da usare per l'utente, ma è alimentata da un sofisticato sistema di agenti AI che collaborano. Analizziamo l'architettura.

Esperienza utente
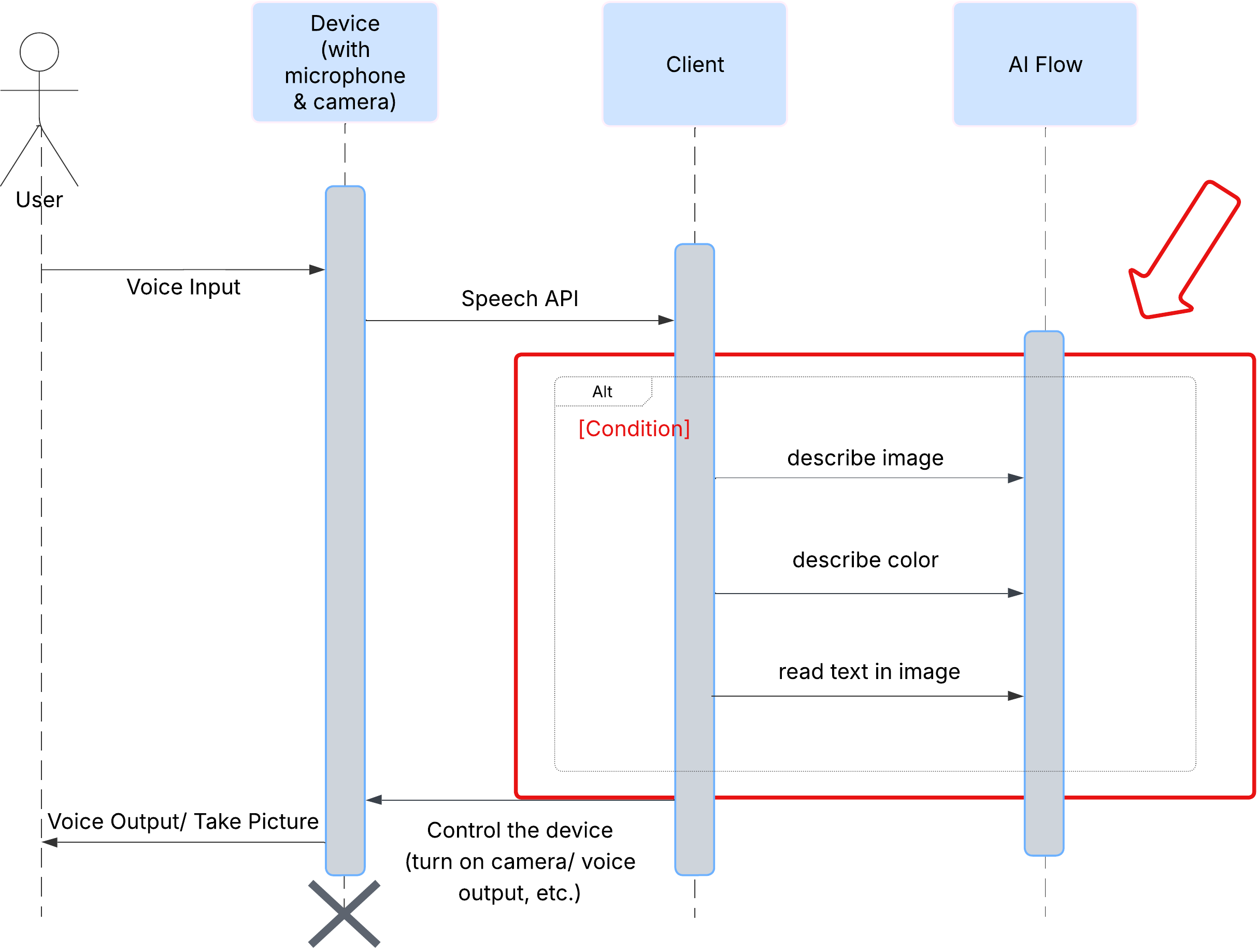
Innanzitutto, vediamo come un utente interagisce con ClarityCam. L'intera esperienza è a mani libere e conversazionale. L'utente pronuncia un comando e l'agente risponde con una descrizione o un'azione vocale. Questo diagramma di sequenza mostra un flusso di interazione tipico, dal comando vocale iniziale dell'utente alla risposta audio finale del dispositivo.
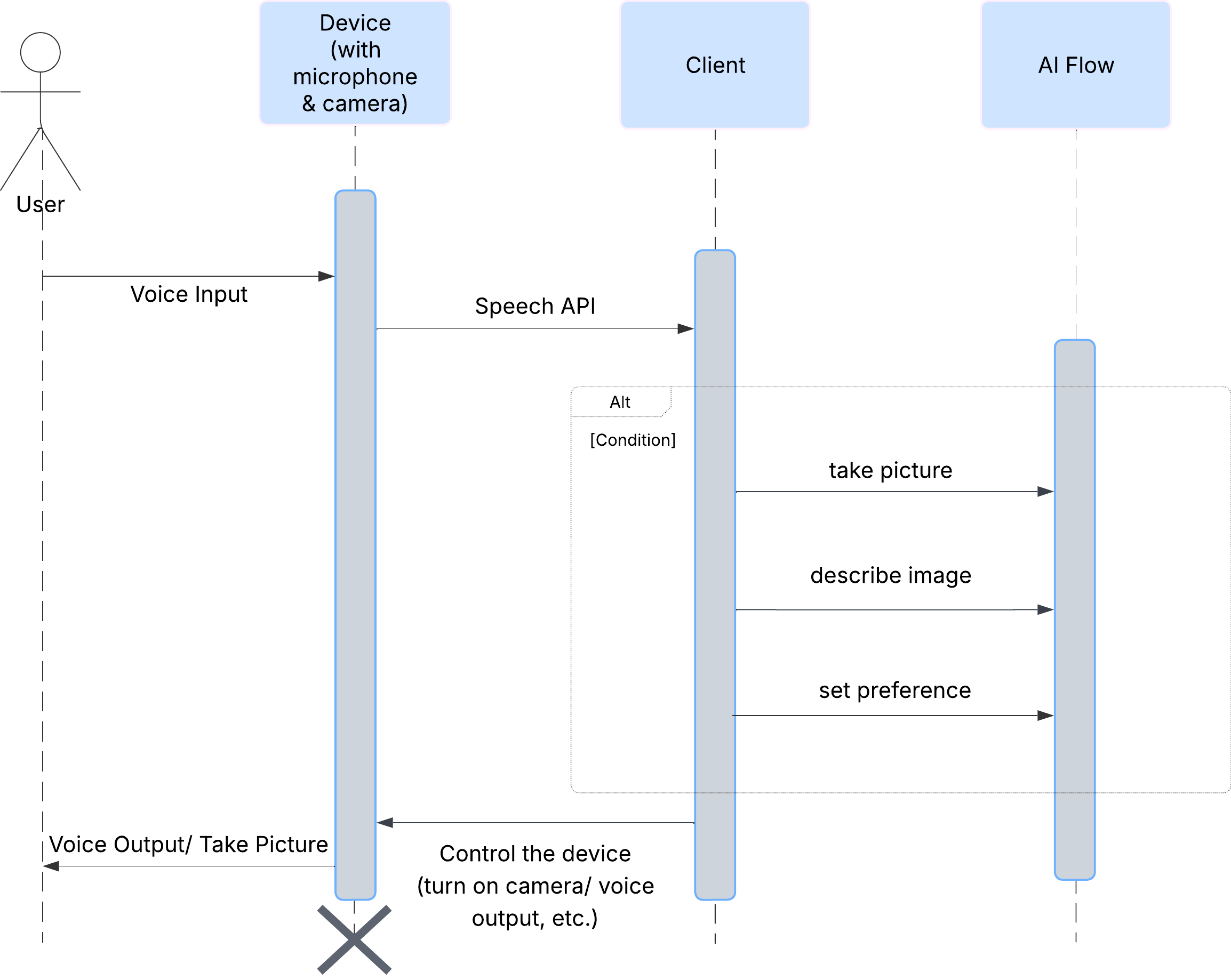
Architettura dell'agente AI
Sotto la superficie, un sistema multi-agente lavora in concerto per dare vita all'esperienza. Quando viene ricevuto un comando, un agente Orchestrator centrale delega le attività ad agenti specializzati responsabili della comprensione dell'intent, dell'analisi delle immagini e della formazione di una risposta. Questo diagramma di flusso dell'AI fornisce un approfondimento sulla collaborazione tra questi agenti. Implementeremo questa architettura nelle sezioni seguenti.
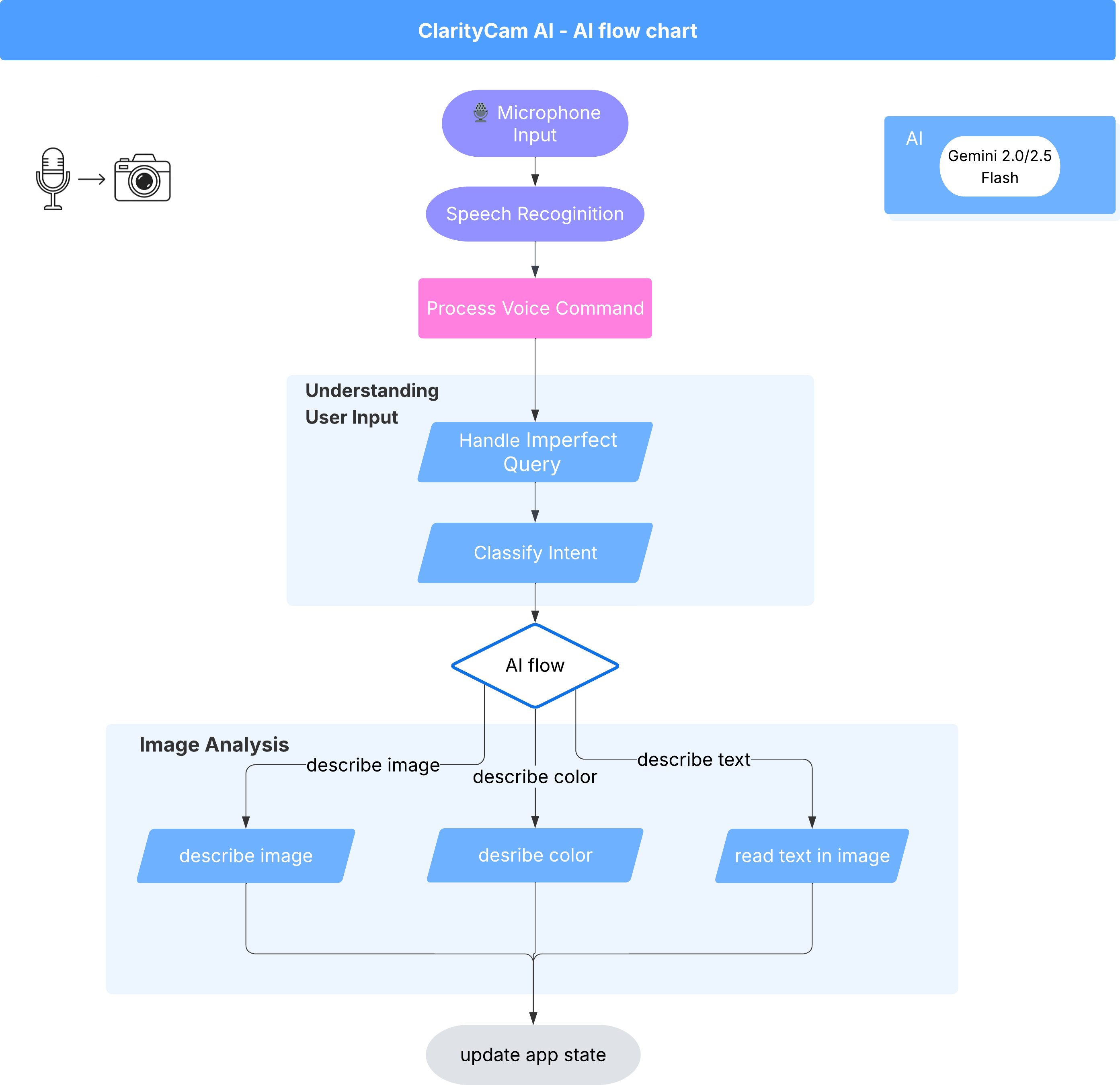
Un rapido tour dei file di progetto
Prima di iniziare a scrivere il codice, familiarizziamo con la struttura dei file del nostro progetto. Potrebbe sembrare che ci siano molti file, ma per questo tutorial devi concentrarti solo su due aree specifiche.
Ecco una mappa semplificata del nostro progetto.
accessibilityAI/src/
├── 📁 app/
│ ├── layout.tsx # An overall page shell (you can ignore this).
│ └── page.tsx # ⬅️ MODIFY THIS: The main user interface for our app.
│
├── 📁 ai/
│ ├── 📁flows # ⬅️ MODIFY THIS: The core AI logic and server functions.
│ └── intent-classifier.ts # ⬅️ MODIFY THIS: Where we'll edit our AI prompts.
| └── ai-instance.ts
| └── dev.ts
│
├── 📁 components/ # Contains pre-built UI components (ignore this).
│
├── 📁 hooks/
│
├── 📁 lib/
│
└── 📁 types/
Lo stack tecnologico
Il nostro sistema è basato su uno stack tecnologico moderno e scalabile che combina potenti servizi cloud e modelli di AI all'avanguardia. Questi sono i componenti chiave che utilizzeremo:
- Google Cloud Platform (GCP): fornisce l'infrastruttura serverless per i nostri agenti.
- Cloud Run: esegue il deployment dei singoli agenti come microservizi scalabili e containerizzati.
- Artifact Registry: archivia e gestisce in modo sicuro le immagini Docker per i nostri agenti.
- Secret Manager: gestisce in modo sicuro le credenziali sensibili e le chiavi API.
- Modelli linguistici di grandi dimensioni (LLM): fungono da "cervello" del sistema.
- Modelli Gemini di Google: utilizziamo le potenti funzionalità multimodali della famiglia Gemini per qualsiasi attività, dalla classificazione dell'intento dell'utente all'analisi dei contenuti delle immagini e alla fornitura di descrizioni intelligenti.
3. Configurazione e prerequisiti
Abilita l'account di fatturazione. Per eseguire questo codelab, devi disporre di un account di fatturazione con un po' di credito. Per iniziare, utilizza i crediti del banner nella parte superiore di questo codelab. Se hai già collegato un account di fatturazione, puoi saltare questo passaggio.
Crea un nuovo progetto GCP
- Vai alla console Google Cloud e crea un nuovo progetto.
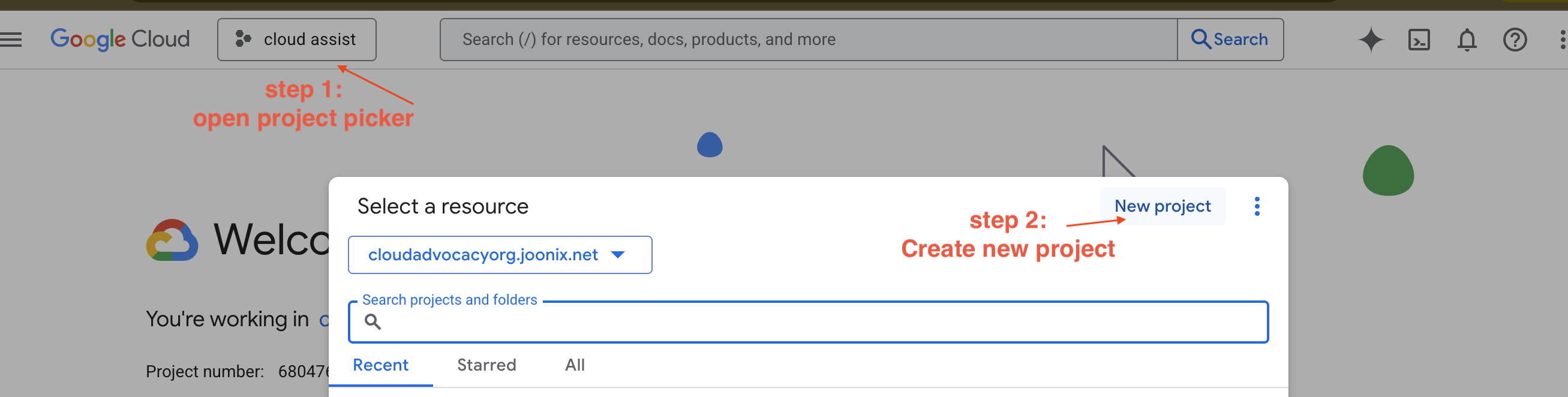
- Vai alla console Google Cloud e crea un nuovo progetto.
- Apri il riquadro a sinistra, fai clic su
Billinge verifica se l'account di fatturazione è collegato a questo account GCP.
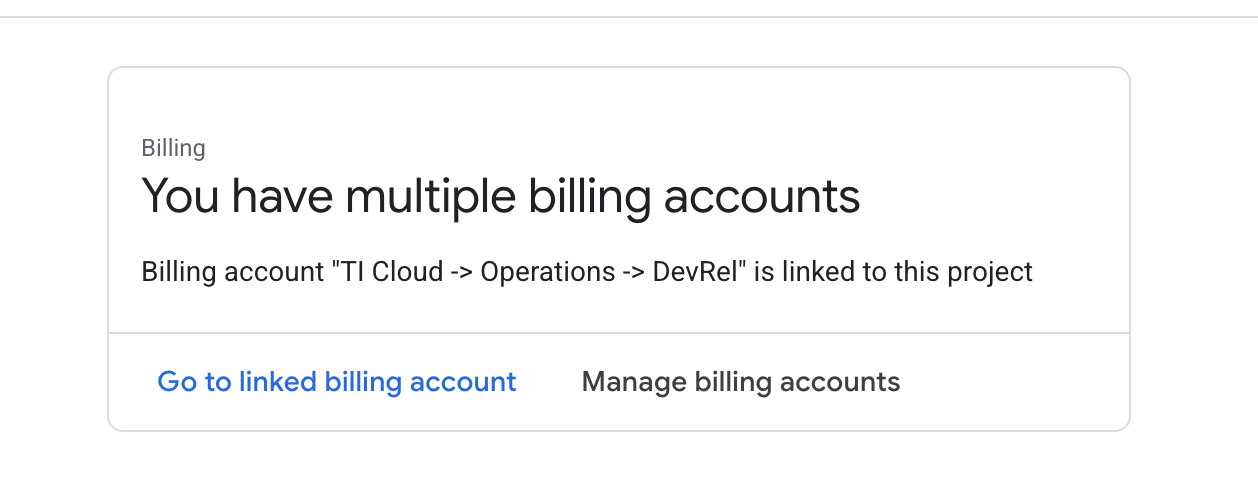
Se visualizzi questa pagina, controlla manage billing account, scegli la prova di Google Cloud e collegala.
Crea la tua chiave API Gemini
Prima di poter proteggere la chiave, devi averne una.
- Vai a Google AI Studio : https://aistudio.google.com/
- Esegui l'accesso con il tuo Account Google.
- Fai clic sul pulsante "Ottieni chiave API", che di solito si trova nel riquadro di navigazione a sinistra o nell'angolo in alto a destra.
- Nella finestra di dialogo "Chiavi API", fai clic su "Crea chiave API nel nuovo progetto".
- Verrà generata una nuova chiave API. Copia immediatamente questa chiave e conservala temporaneamente in un luogo sicuro (ad esempio un software di gestione delle password o una nota protetta). Questo è il valore che utilizzerai nei passaggi successivi.
Flusso di lavoro di sviluppo locale (test sul tuo computer)
Devi essere in grado di eseguire npm run dev e far funzionare la tua app. È qui che entra in gioco .env.
- Aggiungi la chiave API al file: crea un nuovo file denominato
.enve aggiungi la seguente riga.
Assicurati di sostituire YOUR_API_KEY_HERE con la chiave che hai ottenuto da AI Studio e salvato in .env:
GOOGLE_GENAI_API_KEY="YOUR_API_KEY_HERE"
[Facoltativo] Configura IDE e ambiente
Per questo tutorial, puoi lavorare in un ambiente di sviluppo familiare come VS Code o IntelliJ con il tuo terminale locale. Tuttavia, ti consigliamo vivamente di utilizzare Google Cloud Shell per garantire un ambiente standardizzato e preconfigurato.
I passaggi seguenti sono scritti per il contesto di Cloud Shell. Se scegli di utilizzare l'ambiente locale, assicurati di aver installato e configurato correttamente git, nvm, npm e gcloud.
Utilizzare l'editor di Cloud Shell
👉 Fai clic su Attiva Cloud Shell nella parte superiore della console Google Cloud (l'icona a forma di terminale nella parte superiore del riquadro Cloud Shell), 
👉 Fai clic sul pulsante "Apri editor" (ha l'aspetto di una cartella aperta con una matita). Si aprirà l'editor di codice di Cloud Shell nella finestra. Vedrai un esploratore di file sul lato sinistro. 
👉 Fai clic sul pulsante Accedi a Cloud Code nella barra di stato in basso, come mostrato. Autorizza il plug-in come indicato. Se nella barra di stato vedi Cloud Code - no project, selezionalo, poi seleziona "Select a Google Cloud Project" (Seleziona un progetto Google Cloud) nel menu a discesa e infine seleziona il progetto Google Cloud specifico dall'elenco dei progetti che hai creato. 
👉 Apri il terminale nell'IDE cloud, 
👉 Nel terminale, verifica di essere già autenticato e che il progetto sia impostato sul tuo ID progetto utilizzando il seguente comando:
gcloud auth list
👉 Clona il progetto natively-accessible-interface da GitHub:
git clone https://github.com/cuppibla/AccessibilityAgent.git
👉 E assicurati di sostituire <YOUR_PROJECT_ID> con l'ID progetto (puoi trovarlo nella console Google Cloud, nella sezione del progetto. ❗️❗️Assicurati di non confondere project id e project number❗️❗️):
echo <YOUR_PROJECT_ID> > ~/project_id.txt
gcloud config set project $(cat ~/project_id.txt)
👉 Esegui il seguente comando per abilitare le API Google Cloud necessarie: (l'esecuzione potrebbe richiedere circa 2 minuti)
gcloud services enable compute.googleapis.com \
storage.googleapis.com \
run.googleapis.com \
artifactregistry.googleapis.com \
aiplatform.googleapis.com \
eventarc.googleapis.com \
sqladmin.googleapis.com \
secretmanager.googleapis.com \
cloudbuild.googleapis.com \
cloudresourcemanager.googleapis.com \
cloudfunctions.googleapis.com \
cloudaicompanion.googleapis.com
L'operazione potrebbe richiedere alcuni minuti.
Configurazione dell'autorizzazione
👉 Configura l'autorizzazione per il service account. Nel terminale, esegui :
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
export SERVICE_ACCOUNT_NAME=$(gcloud compute project-info describe --format="value(defaultServiceAccount)")
echo "Here's your SERVICE_ACCOUNT_NAME $SERVICE_ACCOUNT_NAME"
👉 Concedi le autorizzazioni. Nel terminale, esegui :
#Cloud Storage (Read/Write):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/storage.objectAdmin"
#Pub/Sub (Publish/Receive):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/pubsub.publisher"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/pubsub.subscriber"
#Cloud SQL (Read/Write):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/cloudsql.editor"
#Eventarc (Receive Events):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/iam.serviceAccountTokenCreator"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/eventarc.eventReceiver"
#Vertex AI (User):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/aiplatform.user"
#Secret Manager (Read):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/secretmanager.secretAccessor"
4. Comprendere l'input dell'utente - Classificatore di intent
Prima di poter agire, il nostro agente AI deve prima capire con precisione cosa vuole l'utente. L'input del mondo reale è spesso disordinato: può essere vago, includere errori di battitura o utilizzare un linguaggio colloquiale.
In questa sezione, creeremo i componenti di "ascolto " fondamentali che trasformano l'input utente non elaborato in un comando chiaro e azionabile.
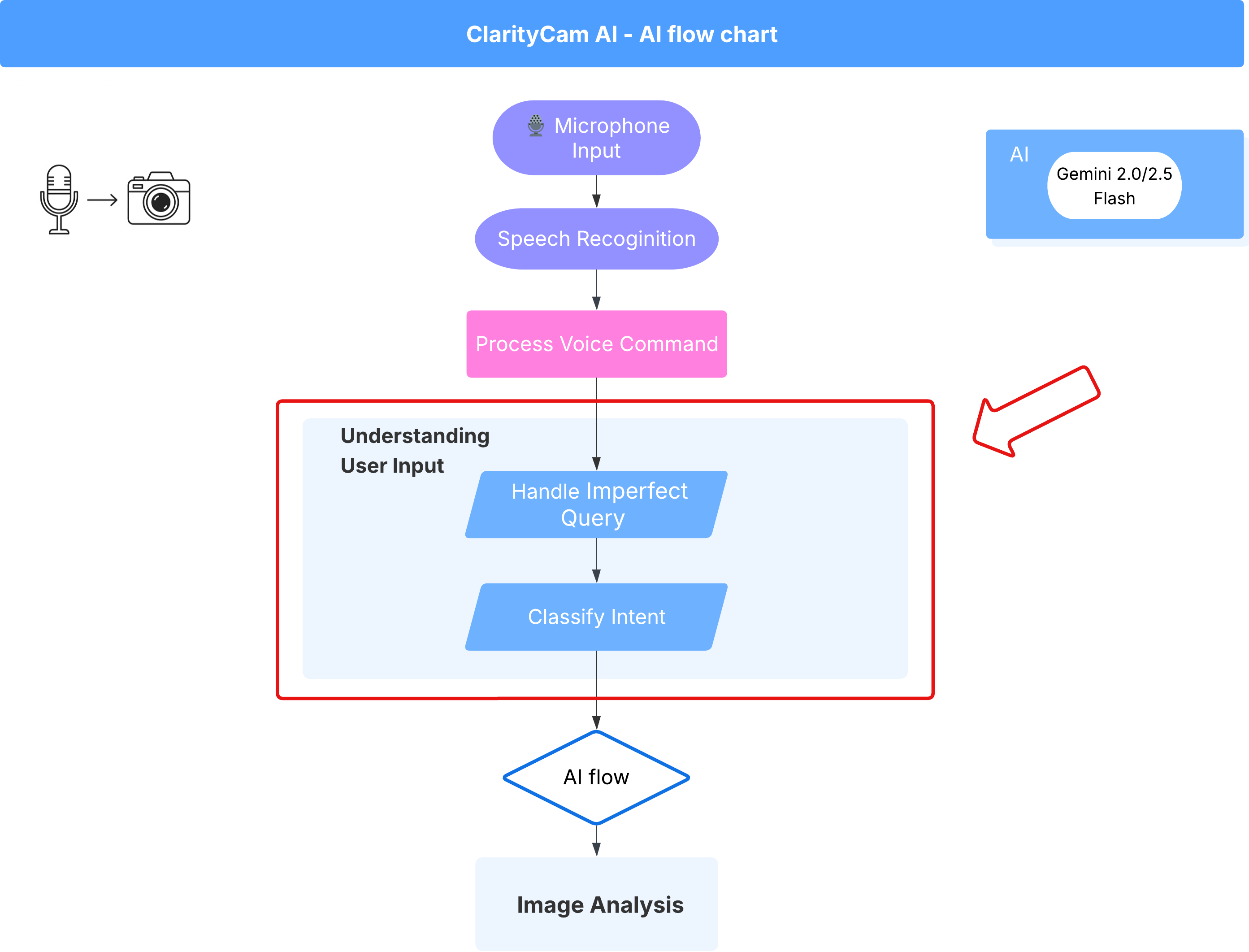
Aggiunta di un classificatore di intent
Ora definiamo la logica dell'AI che alimenta il nostro classificatore.
👉 Azione: nell'IDE Cloud Shell, vai alla directory ~/src/ai/intent-classifier/
Passaggio 1: definisci il vocabolario dell'agente (IntentCategory)
Innanzitutto, dobbiamo creare un elenco definitivo di ogni possibile azione che il nostro agente può eseguire.
👉 Azione: sostituisci il segnaposto // REPLACE ME PART 1: add IntentCategory here con il seguente codice:
👉 con il codice riportato di seguito:
export type IntentCategory =
// Image Analysis Intents
| "DescribeImage"
| "AskAboutImage"
| "ReadTextInImage"
| "IdentifyColorsInImage"
// Control Intents
| "TakePicture"
| "StartCamera"
| "SelectImage"
| "StopSpeaking"
// Preference Intents
| "SetDescriptionDetailed"
| "SetDescriptionConcise"
// Fallback Intents
| "GeneralInquiry" // User has a general question about the agent's functions or polite interaction
| "OutOfScopeRequest" // User's request is clearly outside the agent's defined capabilities
| "Unknown"; // Intent could not be determined with confidence
Spiegazione
Questo codice TypeScript crea un tipo personalizzato chiamato IntentCategory. È un elenco rigoroso che definisce ogni possibile azione, o "intent", che il nostro agente può comprendere. Questo è un primo passo fondamentale perché trasforma un numero potenzialmente infinito di frasi dell'utente ("dimmi cosa vedi", "cosa c'è nella foto?") in un insieme di comandi pulito e prevedibile. L'obiettivo del nostro classificatore è mappare qualsiasi query utente a una di queste categorie specifiche.
Passaggio 2
Per prendere decisioni accurate, la nostra AI deve conoscere le proprie capacità e i propri limiti. Forniremo queste informazioni come un blocco di testo dettagliato.
👉 Azione: sostituisci il segnaposto REPLACE ME PART 2: add AGENT_CAPABILITIES_AND_LIMITATIONS here con il seguente codice:
Sostituisci il codice riportato di seguito: // REPLACE ME PART 2: add AGENT_CAPABILITIES_AND_LIMITATIONS here:
👉 con il codice riportato di seguito
const AGENT_CAPABILITIES_AND_LIMITATIONS = `
**Core Capabilities (What the Agent CAN DO):**
* **Image Analysis:**
* DescribeImage: Provide a general description of the current image.
* AskAboutImage: Answer a specific question about the visual content of the current image (e.g., "Is there a dog?", "What color is the car?").
* ReadTextInImage: Read any text found in the current image.
* IdentifyColorsInImage: Identify the dominant colors of the current image.
* **Image Input Control:**
* TakePicture: Capture an image using the currently active camera stream.
* StartCamera: Activate the camera (e.g., "use camera", "take another picture").
* SelectImage: Allow the user to choose an image file from their device.
* **Voice & Audio Control:**
* StopSpeaking: Stop the current text-to-speech output.
* **Preference Management:**
* SetDescriptionDetailed: Make future image descriptions more detailed.
* SetDescriptionConcise: Make future image descriptions less detailed or concise.
* **General Interaction:**
* GeneralInquiry: Handle conversational phrases (e.g., "hello", "thank you") or questions about its own capabilities (e.g., "what can you do?", "help").
**Limitations (What the Agent CANNOT DO and should be classified as OutOfScopeRequest):**
* Cannot generate or create new images.
* Cannot edit or modify existing images (e.g., "remove background," "make the car blue").
* Cannot analyze video files or live video beyond capturing a single frame.
* Cannot provide general knowledge or answer questions unrelated to the provided image's visual content (e.g., "What's the weather?", "Who is the president?", "Tell me a joke", "What time is it?").
* Cannot perform mathematical calculations or complex data analysis.
* Cannot translate languages as a primary function.
* Cannot remember information from past images or vastly different previous queries in the same session.
* Cannot control other device settings or applications.
* Cannot perform web searches.
`;
Perché è importante:
Questo testo non è destinato alla lettura da parte dell'utente, ma al nostro modello di AI. Inseriremo questa "descrizione del lavoro" direttamente nel prompt (nel passaggio successivo) per fornire al modello linguistico (LLM) il contesto necessario per prendere decisioni accurate. Senza questo contesto, il LLM potrebbe classificare erroneamente "Che tempo fa?" come AskAboutImage. Con questo contesto, sa che il meteo non è un elemento visivo nell'immagine e lo classifica correttamente come fuori ambito.
Passaggio 3
Ora scriveremo l'insieme completo di istruzioni che il modello Gemini seguirà per eseguire la classificazione.
👉 Azione: sostituisci // REPLACE ME PART 3 - classifyIntentPrompt con il seguente codice:
con il codice riportato di seguito
const classifyIntentPrompt = ai.definePrompt({
name: 'classifyIntentPrompt',
input: { schema: ClassifyIntentInputSchema },
output: { schema: ClassifyIntentOutputSchema },
prompt: `You are classifying the user's intent for ClarityCam, a voice-controlled AI application focused on image analysis.
Analyze the user query: '{userQuery}'.
First, understand ClarityCam's capabilities and limitations:
${AGENT_CAPABILITIES_AND_LIMITATIONS}
Now, classify the user's PRIMARY intent into ONE of the following categories:
* **DescribeImage**: User wants a general description of the current image.
* **AskAboutImage**: User is asking a specific question directly related to the visual content of the current image.
* **ReadTextInImage**: User wants any text read from the current image.
* **IdentifyColorsInImage**: User wants the dominant colors of the current image.
* **TakePicture**: User wants to capture an image using an active camera.
* **StartCamera**: User wants to activate the camera.
* **SelectImage**: User wants to choose an image file.
* **StopSpeaking**: User wants the current text-to-speech output to stop.
* **SetDescriptionDetailed**: User wants future image descriptions to be more detailed.
* **SetDescriptionConcise**: User wants future image descriptions to be less detailed.
* **GeneralInquiry**: The query is a simple conversational filler (e.g., "hello", "thanks"), a polite closing, or a direct question about the agent's functions (e.g., "what can you do?", "how does this work?", "help").
* **OutOfScopeRequest**: The query asks the agent to perform an action clearly listed under its "Limitations" or otherwise demonstrably outside its defined image analysis and control functions. Examples: "Tell me a joke," "What's the weather in London?", "Generate an image of a cat," "Can you edit my photo to make it brighter?", "Send this image to my friends","Translate 'hello' to Spanish."
Output ONLY the category name.
If the query is ambiguous but seems generally related to polite interaction or asking about the agent itself, prefer 'GeneralInquiry'.
If the query is clearly asking for something the agent CANNOT do, use 'OutOfScopeRequest'.
If truly unclassifiable even with these guidelines, use 'Unknown'.`,
config: {
temperature: 0.05, // Very low temperature for highly deterministic classification
}
});
Questo prompt è il punto in cui avviene la magia. È il "cervello" del nostro classificatore, che indica all'AI il suo ruolo, fornisce il contesto necessario e definisce l'output desiderato. Tieni presente queste tecniche chiave di prompt engineering:
- Role-playing: inizia con "Stai classificando…" per impostare un compito chiaro.
- Inserimento del contesto: inserisce dinamicamente la variabile
AGENT_CAPABILITIES_AND_LIMITATIONSnel prompt. - Formattazione rigorosa dell'output: l'istruzione "Restituisci SOLO il nome della categoria" è fondamentale per ottenere una risposta pulita e prevedibile che possiamo utilizzare facilmente nel nostro codice.
- Temperatura bassa: per la classificazione, vogliamo risposte deterministiche e logiche, non creative. Se imposti la temperatura su un valore molto basso (0,05), il modello sarà molto concentrato e coerente.
Passaggio 4: collega l'app al flusso AI
Infine, chiamiamo il nuovo classificatore AI dal file dell'applicazione principale.
👉 Azione: vai al file ~/src/app/page.tsx. All'interno della funzione processVoiceCommand, sostituisci // REPLACE ME PART 1: add classificationResult con quanto segue:
const classificationResult = await classifyIntentFlow({ userQuery: commandToProcess });
intent = classificationResult.intent as IntentCategory;
Questo codice è il ponte cruciale tra l'applicazione frontend e la logica AI di backend. Prende il comando vocale dell'utente (commandToProcess), lo invia all'classifyIntentFlow che hai appena creato e attende che l'AI restituisca l'intent classificato.
La variabile intent ora contiene un comando pulito e strutturato (ad esempio DescribeImage). Questo risultato verrà utilizzato nell'istruzione switch che segue per guidare la logica dell'applicazione e decidere quale azione intraprendere successivamente. È così che il "pensiero" dell'AI si trasforma nell'azione dell'app.
Avvio dell'interfaccia utente
È il momento di vedere la nostra applicazione in azione. Avviamo il server di sviluppo.
👉 Nel terminale, esegui questo comando: npm run dev Nota: potresti dover eseguire npm install prima di eseguire npm run dev
Dopo qualche istante, vedrai un output simile a questo, il che significa che il server è in esecuzione:
▲ Next.js 15.2.3 (Turbopack)
- Local: http://localhost:9003
- Network: http://10.88.0.4:9003
- Environments: .env
✓ Starting...
✓ Ready in 1512ms
○ Compiling / ...
✓ Compiled / in 26.6s
Ora fai clic sull'URL locale (http://localhost:9003) per aprire l'applicazione nel browser.
Dovresti visualizzare l'interfaccia utente di SightGuide. Per ora, i pulsanti non sono collegati a nessuna logica, quindi fare clic non produrrà alcun effetto. È esattamente quello che ci aspettiamo in questa fase. Li vedremo in azione nella prossima sezione.
Ora che hai visto la UI, torna al terminale e premi Ctrl + C per arrestare il server di sviluppo prima di continuare.
5. Comprendere l'input utente - Controllo delle query imperfette
Aggiunta del controllo delle query imperfette
Parte 1: definizione del prompt (il "cosa")
Innanzitutto, definiamo le istruzioni per la nostra AI. Il prompt è la "ricetta" per la nostra chiamata all'AI: indica al modello esattamente cosa vogliamo che faccia.
👉 Azione: nel tuo IDE, vai a ~/src/ai/flows/check_typo/.
Sostituisci il codice riportato di seguito: // REPLACE ME PART 1: add prompt here:
👉 con il codice riportato di seguito
const prompt = ai.definePrompt({
name: 'checkTypoPrompt',
input: {
schema: CheckTypoInputSchema,
},
output: {
schema: CheckTypoOutputSchema,
},
prompt: `You are a helpful AI assistant that checks user text for typos and suggests corrections.
- If you find typos, respond with the corrected text.
- If there are no typos, or if you are unsure about a correction, respond with the original text unchanged.
User text: {text}
Corrected text:
`,
});
Questo blocco di codice definisce un modello riutilizzabile per la nostra AI chiamata checkTypoPrompt. Gli schemi di input e output definiscono il contratto di dati per questa attività. In questo modo si evitano errori e il nostro sistema è prevedibile.
Parte 2: creazione del flusso (il "come")
Ora che abbiamo la nostra "ricetta" (il prompt), dobbiamo creare una funzione che possa eseguirla. In Genkit, questa operazione è chiamata flusso. Un flusso racchiude il prompt in una funzione eseguibile che il resto dell'applicazione può chiamare facilmente.
👉 Azione: nello stesso file ~/src/ai/flows/check_typo/, sostituisci il codice riportato di seguito: // REPLACE ME PART 2: add flow here:
👉 con il codice riportato di seguito
const checkTypoFlow = ai.defineFlow<
typeof CheckTypoInputSchema,
typeof CheckTypoOutputSchema
>(
{
name: 'checkTypoFlow',
inputSchema: CheckTypoInputSchema,
outputSchema: CheckTypoOutputSchema,
},
async input => {
const {output} = await prompt(input);
return output!;
}
);
Parte 3: utilizzare il controllo ortografico
Ora che il flusso di AI è completo, possiamo integrarlo nella logica principale della nostra applicazione. Lo chiameremo subito dopo aver ricevuto il comando dell'utente, assicurandoci che il testo sia pulito prima di qualsiasi ulteriore elaborazione.
👉Azione: vai a ~/src/app/ai/flows/check-typo.ts e trova la funzione export async function checkTypo. Rimuovi il commento dalla dichiarazione return:
Invece di return;, fai return checkTypoFlow(input);
👉Azione: vai a ~/src/app/page.tsx e trova la funzione processVoiceCommand. Sostituisci il codice riportato di seguito: REPLACE ME PART 2: add typoResult here:
👉 con il codice riportato di seguito
const typoResult = await checkTypo({ text: rawCommand });
if (typoResult && typoResult.correctedText && typoResult.correctedText.trim().length > 0) {
const originalTrimmedLower = rawCommand.trim().toLowerCase();
const correctedTrimmedLower = typoResult.correctedText.trim().toLowerCase();
if (correctedTrimmedLower !== originalTrimmedLower) {
commandToProcess = typoResult.correctedText;
typoCorrectionAnnouncement = `I think you said: ${commandToProcess}. `;
}
}
Con questa modifica, abbiamo creato una pipeline di elaborazione dei dati più solida per ogni comando utente.
Flusso di comando vocale (sola lettura, nessuna azione necessaria)
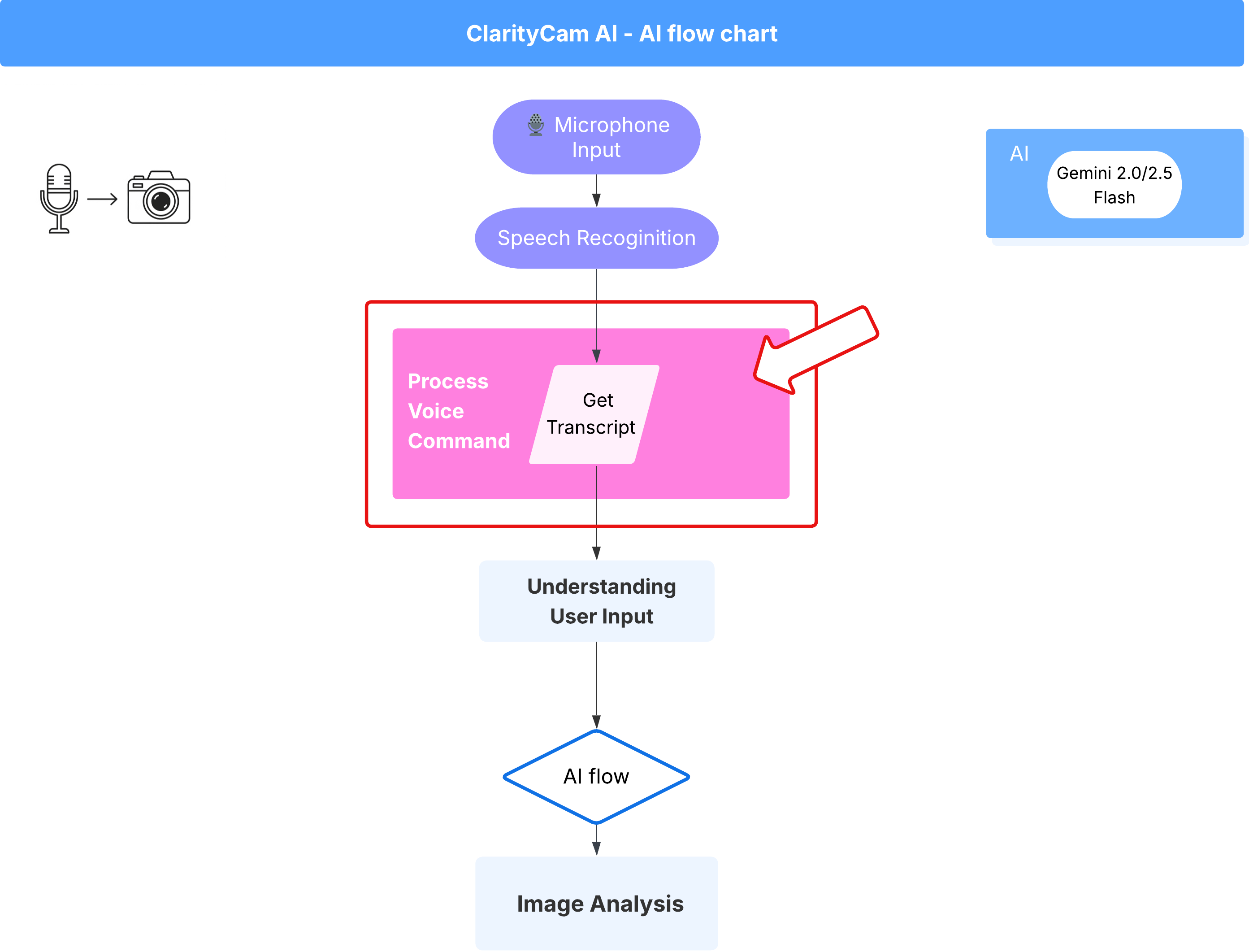
Ora che abbiamo i componenti principali di "comprensione" (il controllo ortografico e il classificatore di intent), vediamo come si inseriscono nella logica principale di elaborazione vocale dell'applicazione.
Tutto inizia quando l'utente parla. L'API Web Speech del browser ascolta la voce e, una volta che l'utente ha finito di parlare, fornisce una trascrizione testuale di ciò che ha sentito. Il seguente codice gestisce questo processo.
👉Sola lettura:vai a ~/src/app/page.tsx e all'interno della funzione handleResult. Trova il codice di seguito:
for (let i = event.resultIndex; i < event.results.length; ++i) {
if (event.results[i].isFinal) {
finalTranscript += event.results[i][0].transcript;
}
}
if (finalTranscript) {
console.log("Final Transcript:", finalTranscript);
processVoiceCommand(finalTranscript);
}
Mettere alla prova la nostra correzione di errori ortografici
E ora la parte divertente. Vediamo come la nostra nuova funzionalità di correzione degli errori di battitura gestisce i comandi vocali perfetti e imperfetti.
Avviare l'applicazione
Innanzitutto, riavviamo il server di sviluppo. Nel terminale, esegui: npm run dev
Apri l'app
Quando il server è pronto, apri il browser e vai all'indirizzo locale (ad es. http://localhost:9003).
Attivare i comandi vocali
Fai clic sul pulsante Start Listening. Il browser probabilmente ti chiederà l'autorizzazione per utilizzare il microfono. Fai clic su Consenti.
Testare un comando imperfetto
Ora, diamo intenzionalmente un comando leggermente imperfetto per vedere se la nostra AI riesce a capirlo. Parla in modo chiaro nel microfono:
"Picture take of me" (scatta una mia foto)
Osserva il risultato
È qui che avviene la magia! Anche se hai detto "Scatta una foto di me", dovresti vedere l'applicazione attivare correttamente la fotocamera. Il flusso checkTypo corregge la frase in "scatta una foto" in background, mentre classifyIntentFlow comprende il comando corretto.
Ciò conferma che la nostra funzionalità di correzione degli errori di battitura funziona perfettamente, rendendo l'app molto più solida e facile da usare. Al termine, puoi fermare la videocamera scattando una foto o semplicemente interrompendo il server nel terminale (Ctrl + C).
6. Analisi delle immagini basata sull'AI - Descrivi l'immagine
Ora che il nostro agente può comprendere le richieste, è il momento di dargli degli occhi. In questa sezione, svilupperemo le funzionalità del nostro Vision Agent, il componente principale responsabile di tutta l'analisi delle immagini. Inizieremo con la sua funzionalità più importante, la descrizione di un'immagine, per poi aggiungere la possibilità di leggere il testo.
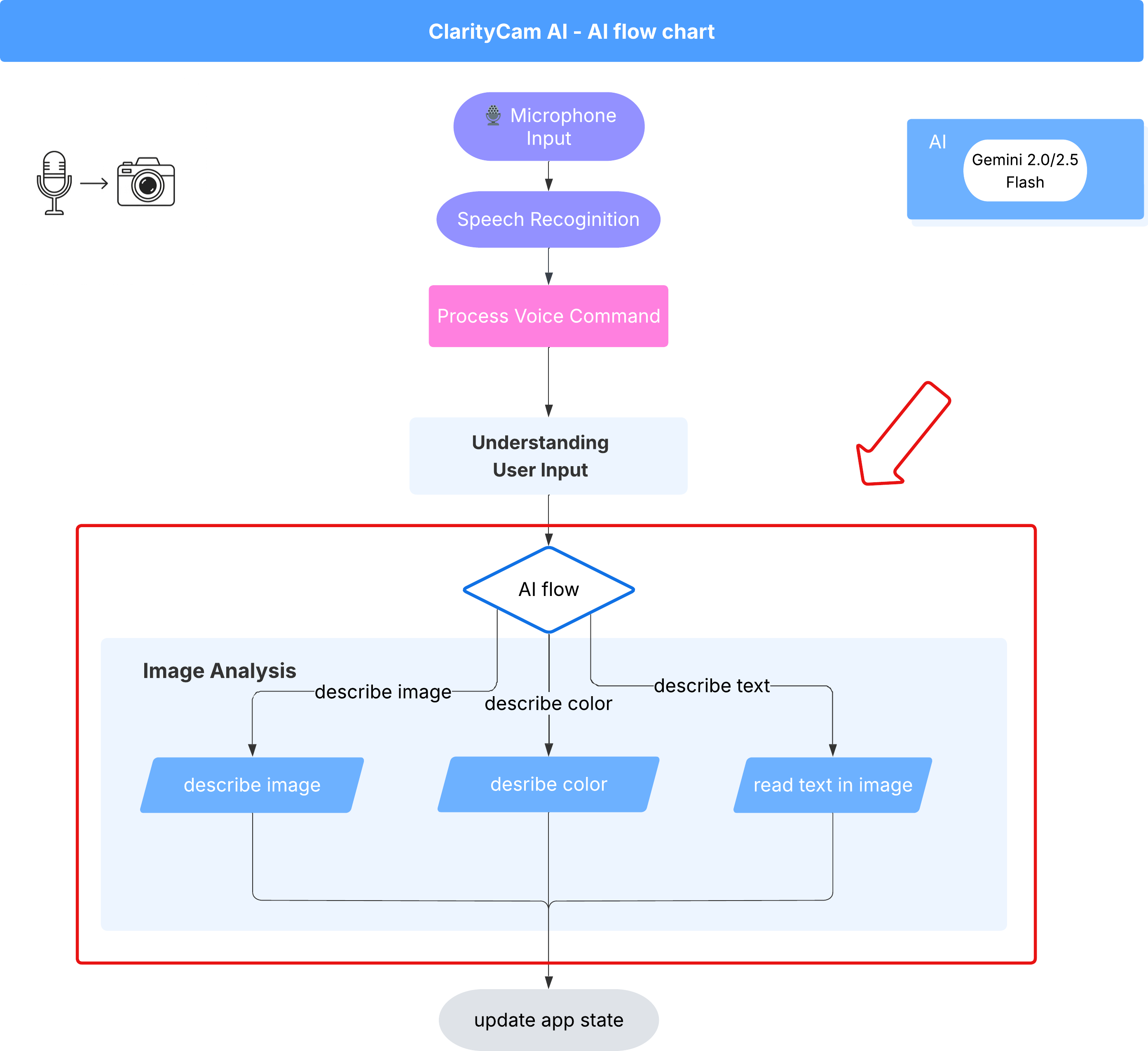
Funzionalità 1: descrivere un'immagine
Questa è la funzione principale dell'agente. Non genereremo solo una descrizione statica, ma creeremo un flusso dinamico in grado di adattare il livello di dettaglio in base alle preferenze dell'utente. Si tratta di un aspetto fondamentale della filosofia dell'interfaccia adattiva nativa (NAI).
👉 Azione: nell'IDE Cloud Shell, vai al file ~/src/ai/flows/describe_image/ e rimuovi il commento dal seguente codice.
Passaggio 1: crea un modello di prompt dinamico
Innanzitutto, creeremo un modello di prompt sofisticato che può modificare le sue istruzioni in base all'input ricevuto.
Rimuovi il commento dal codice riportato di seguito.
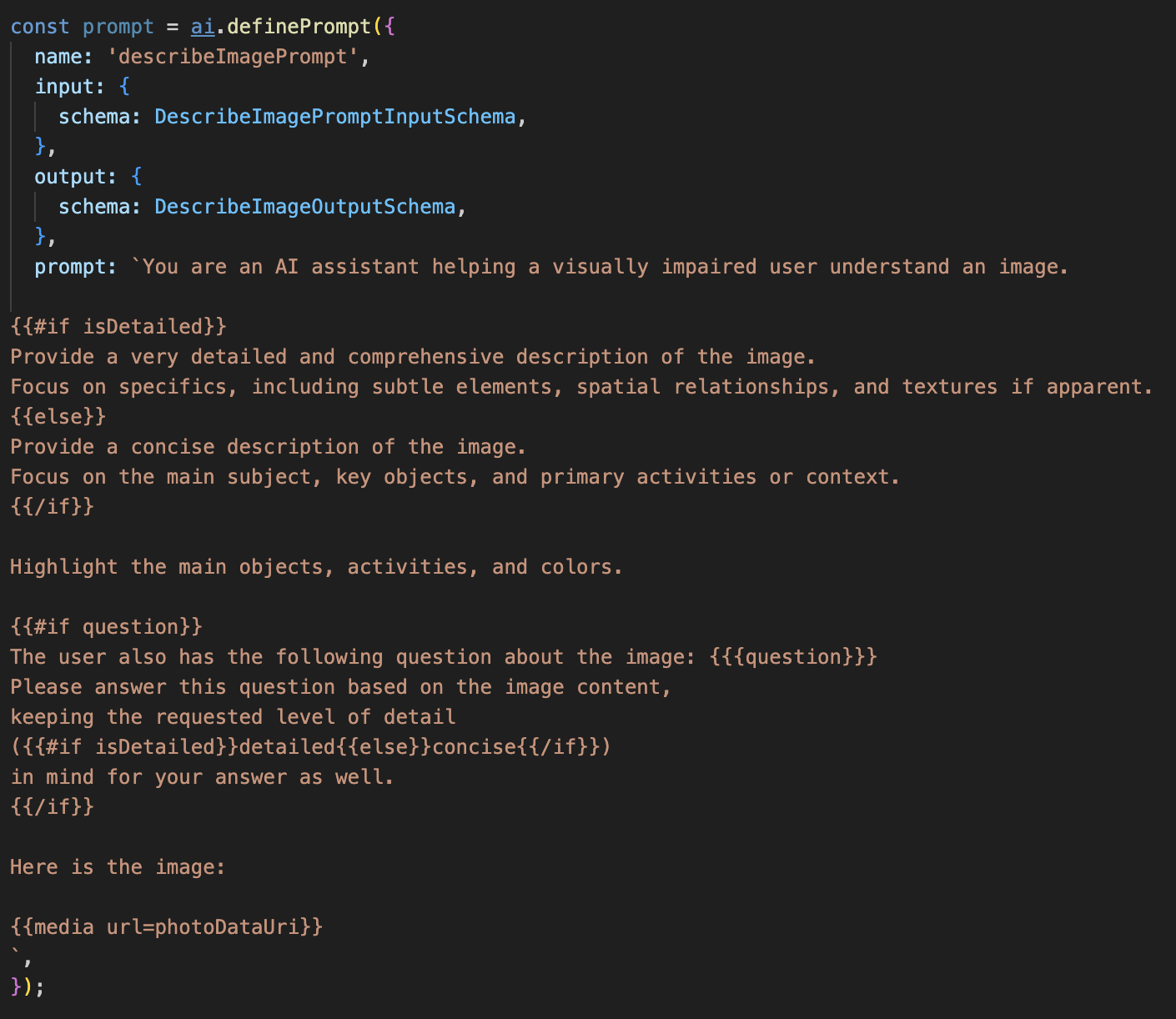
Questo codice definisce una variabile stringa, prompt, che utilizza un linguaggio di modello chiamato Dot-Mustache. In questo modo, possiamo incorporare la logica condizionale direttamente nel prompt.
{#if isDetailed}...{else}...{/if}: questo è un blocco condizionale. Se i dati di input che inviamo a questo prompt contengono una proprietà isDetailed: true, l'AI riceverà il set di istruzioni "molto dettagliato". In caso contrario, riceverà le istruzioni "concise". Ecco come il nostro agente si adatta alle preferenze dell'utente.
{#if question}...{/if}: questo blocco verrà incluso solo se i dati di input contengono una proprietà di domanda. In questo modo, possiamo utilizzare lo stesso prompt efficace sia per le descrizioni generali che per le domande specifiche.
{media url=photoDataUri}: Questa è la sintassi speciale di Genkit per incorporare i dati delle immagini direttamente nel prompt affinché il modello multimodale li analizzi.
Passaggio 2: crea lo Smart Flow
Successivamente, definiamo il prompt e il flusso che utilizzerà il nostro nuovo modello. Questo flusso contiene un po' di logica per tradurre la preferenza dell'utente in un valore booleano comprensibile al nostro modello.
👉 Azione: nell'IDE Cloud Shell, nello stesso file ~/src/ai/flows/describe_image/, sostituisci il seguente codice. // REPLACE ME PART 1: add flow here
👉 Con il codice riportato di seguito:
// Define the prompt using the template from Step 1
const prompt = ai.definePrompt({
name: 'describeImagePrompt',
input: { schema: DescribeImagePromptInputSchema },
output: { schema: DescribeImageOutputSchema },
prompt: promptTemplate,
});
// Define the flow
const describeImageFlow = ai.defineFlow<
typeof DescribeImageInputSchema,
typeof DescribeImageOutputSchema
>(
{
name: 'describeImageFlow',
inputSchema: DescribeImageInputSchema,
outputSchema: DescribeImageOutputSchema,
},
async (pageInput) => {
const preference = pageInput.detailPreference || "concise";
// Prepare the input for the prompt, including the new boolean flag
const promptInputData = {
...pageInput,
isDetailed: preference === "detailed",
};
const { output } = await prompt(promptInputData);
return output!;
}
);
Funge da intermediario intelligente tra il frontend e il prompt AI.
- Riceve
pageInputdalla nostra applicazione, che include la preferenza dell'utente come stringa (ad es."detailed"). - Quindi crea un nuovo oggetto,
promptInputData. - La riga più importante è
isDetailed: preference === "detailed". Questa riga svolge il lavoro cruciale di creare un valore booleanotrueofalsein base alla stringa delle preferenze. - Infine, chiama
promptcon questi dati migliorati. Il modello di prompt del passaggio 1 ora può utilizzare il valore booleanoisDetailedper modificare dinamicamente le istruzioni inviate all'AI.
Passaggio 3: collega il frontend
Ora attiviamo questo flusso dalla nostra interfaccia utente in page.tsx.
👉Azione: vai a ~/src/app/ai/flows/describe-image.ts e trova la funzione export async function describeImage. Rimuovi il commento dalla dichiarazione return:
Invece di return;, fai return describeImageFlow(input);
👉Azione: in ~/src/app/page.tsx, trova la funzione handleAnalyze, sostituisci il codice // REPLACE ME PART 2: DESCRIBE IMAGE
👉 con il seguente codice:
case "description":
result = await describeImage({
photoDataUri,
question,
detailPreference: descriptionPreference
});
outputText = question ? `Answer: ${result.description}` : `Description: ${result.description}`;
break;
Quando l'intento di un utente è ottenere una descrizione, questo codice viene eseguito. Chiama il nostro flusso describeImage, passando i dati dell'immagine e, cosa fondamentale, la variabile di stato descriptionPreference del nostro componente React. Questo è l'ultimo pezzo del puzzle, che collega la preferenza dell'utente memorizzata nell'UI direttamente al flusso di AI che adatterà il proprio comportamento di conseguenza.
Test della funzionalità di descrizione delle immagini
Vediamo la funzionalità di descrizione delle immagini in azione, dall'acquisizione di una foto all'ascolto di ciò che vede l'AI.
Avviare l'applicazione
Innanzitutto, riavviamo il server di sviluppo. 👉 Nel terminale, esegui questo comando: npm run dev Nota: potresti dover eseguire npm install prima di eseguire npm run dev
Apri l'app
Quando il server è pronto, apri il browser e vai all'indirizzo locale (ad es. http://localhost:9003).
Attivare la videocamera
Fai clic sul pulsante Avvia ascolto e concedi l'accesso al microfono se richiesto. Poi, di' il tuo primo comando:
"Scatta una foto"
L'applicazione attiverà la fotocamera del dispositivo. Ora dovresti vedere il feed video in diretta sullo schermo.
Acquisire la foto
Con la videocamera attiva, posizionala su ciò che vuoi descrivere. Ora, pronuncia il comando una seconda volta per acquisire l'immagine:
"Scatta una foto"
Il video in diretta verrà sostituito dalla foto statica che hai appena scattato.
Chiedere la descrizione
Con la nuova foto sullo schermo, dai il comando finale:
"Descrivi l'immagine"
Ascolta il risultato
L'app mostrerà lo stato di elaborazione e poi ascolterai la descrizione dell'immagine creata con l'AI. Il testo verrà visualizzato anche nella scheda "Stato e risultato".
Al termine, puoi fermare la videocamera scattando una foto o semplicemente arrestando il server nel terminale (Ctrl + C).
7. Analisi delle immagini basata sull'AI - Descrivi testo (OCR)
Successivamente, aggiungeremo la funzionalità di riconoscimento ottico dei caratteri (OCR) al nostro agente Vision. In questo modo può leggere il testo di qualsiasi immagine.
👉 Azione: nel tuo IDE, vai a ~/src/ai/flows/read-text-in-image/, rimuovi il commento dal codice riportato di seguito:
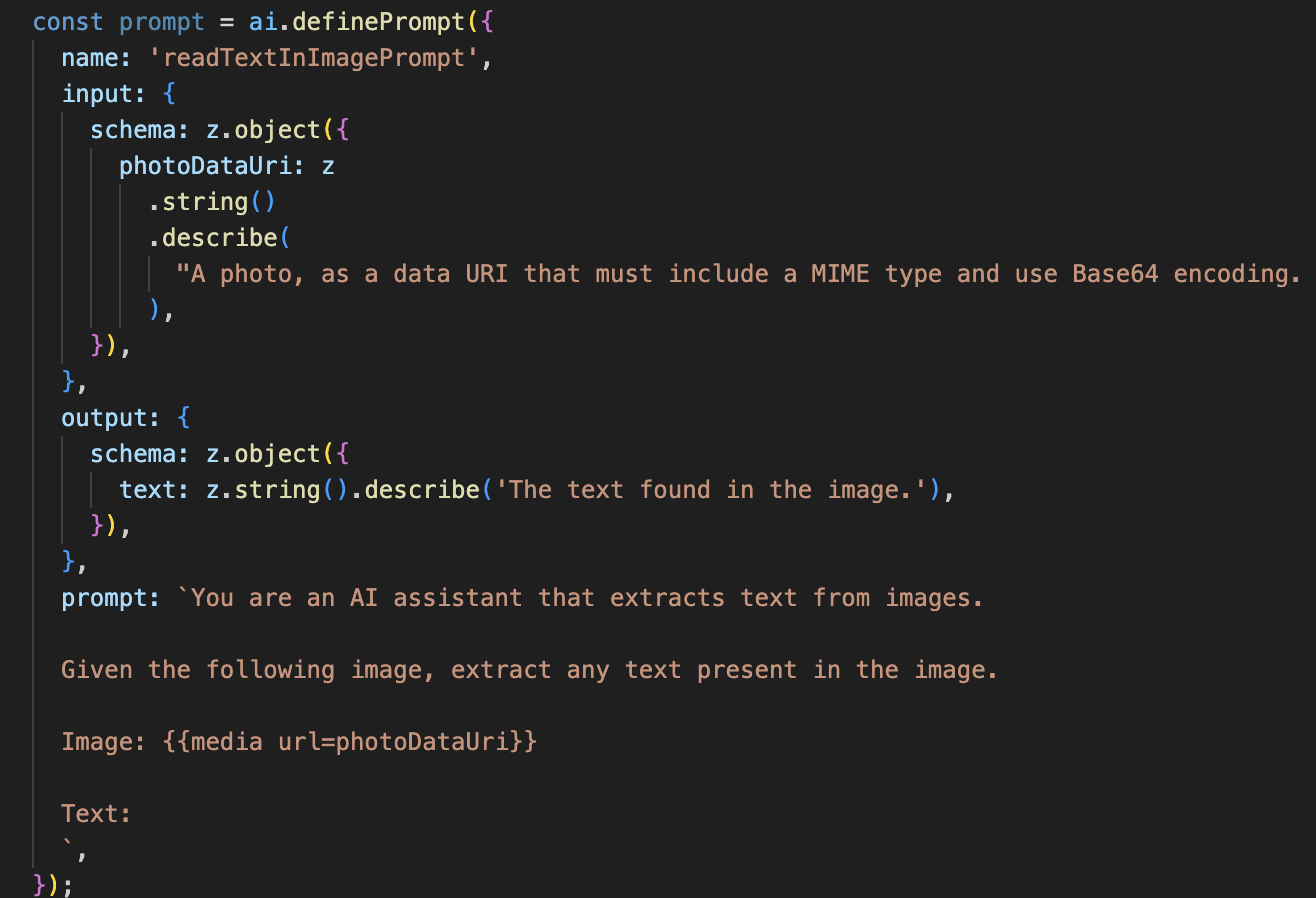
👉 Azione: nel tuo IDE, nello stesso file ~/src/ai/flows/read-text-in-image/, sostituisci // REPLACE ME: Creating Prmopt
👉 con il codice riportato di seguito:
const readTextInImageFlow = ai.defineFlow<
typeof ReadTextInImageInputSchema,
typeof ReadTextInImageOutputSchema
>(
{
name: 'readTextInImageFlow',
inputSchema: ReadTextInImageInputSchema,
outputSchema: ReadTextInImageOutputSchema,
},
async input => {
const {output} = await prompt(input);
return output!;
}
);
Questo flusso di AI è molto più semplice e mette in evidenza il principio dell'utilizzo di strumenti mirati per lavori specifici.
- Il prompt: a differenza del prompt di descrizione, questo è statico e molto specifico. Il suo unico compito è quello di istruire l'AI ad agire come motore OCR: "estrai qualsiasi testo presente nell'immagine".
- Gli schemi: anche gli schemi di input e output sono semplici, in quanto prevedono un'immagine e restituiscono una singola stringa di testo.
Connessione del frontend per l'OCR
Infine, colleghiamo questa nuova funzionalità in page.tsx.
👉Azione: vai a ~/src/app/ai/flows/read-text-in-image.ts e trova la funzione export async function readTextInImage. Rimuovi il commento dalla dichiarazione return:
Invece di return;, fai return readTextInImageFlow(input);
👉 Azione: in ~/src/app/page.tsx, trova la funzione handleAnalyze e l'istruzione switch.
Sostituisci REPLACE ME PART 3: READ TEXT
con il codice riportato di seguito:
case "text":
result = await readTextInImage({ photoDataUri });
outputText = result.text ? `Text Found: ${result.text}` : "No text found.";
break;
Quando l'intent dell'utente è ReadTextInImage, questo codice viene attivato. Chiama il nostro semplice flusso readTextInImage. La riga result.text ? ... : ... è un modo semplice per gestire l'output, fornendo un messaggio utile all'utente se l'AI non è riuscita a trovare testo nell'immagine.
Test della funzionalità Leggi testo (OCR)
Segui questi passaggi per testare la funzionalità di lettura del testo. Ricorda di puntare la fotocamera su un oggetto con un testo chiaro.
- Esegui l'applicazione con
npm run deve aprila nel browser. - Fai clic su Avvia ascolto e concedi l'accesso al microfono quando richiesto.
- Attiva la videocamera. Pronuncia il comando "Scatta una foto". Dovresti vedere il feed video in diretta sullo schermo.
- Scatta la foto. Punta la fotocamera sul testo che vuoi leggere e ripeti il comando: "Scatta una foto". Il video verrà sostituito da una foto statica.
- Chiedi il testo. Ora che è stata scattata una foto, dai il comando finale: "Qual è il testo nell'immagine?"
- Controlla il risultato Dopo qualche istante, l'app analizzerà la foto e leggerà ad alta voce il testo rilevato. Se non riesce a trovare alcun testo, ti avviserà.
Ciò conferma che la potente funzionalità OCR è in funzione. Quando hai finito, arresta il server con Ctrl + C.
8. Miglioramenti avanzati dell'AI - Sola lettura ✨
Un buon agente AI può seguire le istruzioni. Un ottimo agente AI è intuitivo, affidabile e utile. In questa sezione, ci concentreremo su tre miglioramenti avanzati che potenziano le capacità del nostro agente.
Esploreremo come:
Add Context & Memoryper gestire i follow-up naturali e conversazionali.Reduce Hallucinationper creare un agente più affidabile e attendibile.Make the Agent Proactiveper offrire un'esperienza più accessibile e intuitiva.Add preference settingper personalizzare la descrizione dell'immagine
Miglioramento 1: contesto e memoria
Una conversazione naturale non è una serie di comandi isolati, ma un flusso. Se un utente chiede: "Che cosa c'è nella foto?" e l'agente risponde: "Un'auto rossa", il naturale follow-up dell'utente potrebbe essere: "Di che colore è?" senza dire di nuovo "auto". Il nostro agente ha bisogno della memoria a breve termine per comprendere questo contesto.
Come è stato implementato (riepilogo)
Abbiamo già integrato questa funzionalità nel nostro flusso describeImage. Questa sezione riassume il funzionamento del pattern. Quando chiamiamo la funzione describeImage da page.tsx, le trasmettiamo la cronologia della conversazione.
👉 Code Showcase (dal giorno page.tsx):
const result = await describeImage({
photoDataUri,
question: commandToProcess,
detailPreference: descriptionPreference,
previousUserQueryOnImage: lastUserQuery ?? undefined,
previousAIResponseOnImage: lastAIResponse ?? undefined,
});
previousUserQueryOnImageepreviousAIResponseOnImage: queste due proprietà rappresentano la memoria a breve termine dell'agente. Passando l'ultima interazione all'AI, le forniamo il contesto necessario per comprendere domande di follow-up vaghe o referenziali.- Il prompt adattivo: questo contesto viene utilizzato dal prompt nel nostro flusso describe_image. Il prompt è progettato per prendere in considerazione la conversazione precedente quando viene formulata una nuova risposta, consentendo all'agente di rispondere in modo intelligente.
Miglioramento 2: riduzione delle allucinazioni
Un'AI"ha allucinazioni" quando inventa fatti o afferma di avere capacità che non possiede. Per creare fiducia negli utenti, è fondamentale che il nostro agente conosca i propri limiti e possa rifiutare con garbo le richieste fuori ambito.
Come è stato implementato (riepilogo)
Il modo più efficace per evitare le allucinazioni è fornire al modello limiti chiari. Abbiamo raggiunto questo obiettivo quando abbiamo creato il nostro classificatore di intenti.
👉 Code Showcase (dal flusso intent-classifier):
// Define Agent Capabilities and Limitations for the prompt
const AGENT_CAPABILITIES_AND_LIMITATIONS = `
**Core Capabilities (What the Agent CAN DO):**
* **Image Analysis:**
* DescribeImage: Provide a general description of the current image...
**Limitations (What the Agent CANNOT DO...):**
* Cannot generate or create new images.
* Cannot provide general knowledge or answer questions unrelated to the image...
* Cannot perform web searches.
`;
Questa costante funge da "descrizione del lavoro" che forniamo all'AI nel prompt di classificazione.
- Ancoraggio del modello: dicendo esplicitamente all'AI cosa non può fare, la "ancoriamo" alla realtà. Quando rileva una query come "Che tempo fa?", può associarla con sicurezza al suo elenco di limitazioni e classificare l'intent come OutOfScopeRequest.
- Creare fiducia: un agente che può dire onestamente "Non posso aiutarti" è molto più affidabile di uno che cerca di indovinare e sbaglia. Si tratta di un principio fondamentale della progettazione di un'AI sicura e affidabile. `
Miglioramento 3: creazione di un agente proattivo
Per un'applicazione che dà la priorità all'accessibilità, non possiamo fare affidamento su segnali visivi. Quando un utente attiva la modalità di ascolto, ha bisogno di una conferma immediata e non visiva che l'agente è pronto e in attesa di un comando. Ora aggiungeremo un'introduzione proattiva per fornire questo feedback fondamentale.
Passaggio 1: aggiungi uno stato per monitorare il primo ascolto
Innanzitutto, abbiamo bisogno di un modo per sapere se è la prima volta che l'utente preme il pulsante "Start Listening" durante la sessione.
👉 In ~/src/app/page.tsx, visualizza la seguente nuova variabile di stato nella parte superiore del componente ClarityCam.
export default function ClarityCam() {
// ... other state variables
const [descriptionPreference, setDescriptionPreference] = useState<DescriptionPreference>("concise");
// Add this new line
const [isFirstListen, setIsFirstListen] = useState(true);
// ... rest of the component
}
Abbiamo introdotto una nuova variabile di stato, isFirstListen, e l'abbiamo inizializzata su true. Utilizzeremo questo flag per attivare il nostro messaggio di benvenuto una tantum.
Passaggio 2: aggiorna la funzione toggleListening
Ora modifichiamo la funzione che gestisce il microfono per riprodurre il nostro saluto.
👉 In ~/src/app/page.tsx, trova la funzione toggleListening e visualizza il seguente blocco if.
const toggleListening = useCallback(() => {
// ... existing logic to setup speech recognition
if (isListening || isAttemptingStart) {
// ... existing logic to stop listening
} else {
stopSpeaking(); // Stop any ongoing TTS
// Add this new block
if (isFirstListen) {
setIsFirstListen(false);
const introMessage = "Hello! I am ClarityCam, your AI assistant. I'm now listening. You can ask me to 'describe the image', 'read text', 'take a picture', or ask questions about what's in an image.";
speakText(introMessage);
} else {
speakText("Listening..."); // Optional: provide feedback on subsequent clicks
}
// ... rest of the logic to start listening
}
}, [/*...existing dependencies...*/, isFirstListen]); // Don't forget to add isFirstListen to the dependency array!
- Controlla il flag: il blocco if (isFirstListen) controlla se si tratta della prima attivazione.
- Prevent Repetition: la prima cosa che fa all'interno del blocco è chiamare setIsFirstListen(false). In questo modo, il messaggio introduttivo verrà riprodotto una sola volta per sessione.
- Fornire indicazioni: il messaggio introduttivo è realizzato con cura per essere il più utile possibile. Saluta l'utente, identifica l'agente per nome, conferma che è ora attivo ("Ti ascolto") e fornisce esempi chiari di comandi vocali che può utilizzare.
- Feedback uditivo: infine, speakText(introMessage) fornisce queste informazioni cruciali, offrendo rassicurazione e indicazioni immediate senza richiedere all'utente di guardare lo schermo.
Miglioramento 4: adattamento alle preferenze degli utenti (riepilogo)
Un agente veramente intelligente non si limita a rispondere, ma impara e si adatta alle esigenze dell'utente. Una delle funzionalità più potenti che abbiamo creato è la possibilità per l'utente di modificare al volo la verbosità delle descrizioni delle immagini con comandi come "Fornisci maggiori dettagli".
Come l'abbiamo implementata (riepilogo) Questa funzionalità è basata sul prompt dinamico che abbiamo creato per il nostro flusso describeImage. Utilizza la logica condizionale per modificare le istruzioni inviate all'AI in base alle preferenze dell'utente.
👉 Code Showcase (il promptTemplate di describe_image):
const settingPreferenceTemplate = `
{#if isDetailed}
Provide a very detailed and comprehensive description of the image. Focus on specifics, including subtle elements, spatial relationships, and textures if apparent.
{else}
Provide a concise description of the image. Focus on the main subject, key objects, and primary activities or context.
{/if}
Highlight the main objects, activities, and colors.
...
`;
- Logica condizionale: il blocco
{#if isDetailed}...{else}...{/if}è fondamentale. Quando describeImageFlow riceve detailPreference dal frontend, crea un valore booleano isDetailed (true o false). - Adaptive Instructions: questo flag booleano determina quale insieme di istruzioni riceve il modello di AI. Se isDetailed è true, al modello viene chiesto di essere molto descrittivo. Se è falso, è stato chiesto di essere concisi.
- Controllo utente: questo pattern collega direttamente il comando vocale di un utente (ad es. "rendi le descrizioni concise", che viene classificato come intent SetDescriptionConcise) a una modifica fondamentale del comportamento dell'AI, rendendo l'agente davvero reattivo e personalizzato.
9. Deployment nel cloud
Crea l'immagine Docker utilizzando Google Cloud Build
gcloud builds submit . --tag gcr.io/$PROJECT_ID/accessibilityai-nextjs-app:latest
accessibilityai-nextjs-appè un nome di immagine suggerito.- Impossibile elaborare lo . utilizza la directory corrente (
accessibilityAI/) come origine della build.
Esegui il deployment dell'immagine in Google Cloud Run
- Assicurati che le chiavi API e gli altri secret siano pronti in Secret Manager. Ad esempio,
GOOGLE_GENAI_API_KEY.
Sostituisci YOUR_ACTUAL_GOOGLE_AI_KEY_VALUE con il valore effettivo della tua chiave API Gemini.
echo "YOUR_ACTUAL_GOOGLE_AI_KEY_VALUE" | gcloud secrets create GOOGLE_GENAI_API_KEY --data-file=- --project=YOUR_PROJECT_ID
Concedi al service account di runtime del servizio Cloud Run (ad es. PROJECT_NUMBER-compute@developer.gserviceaccount.com o uno dedicato) il ruolo "Secret Manager Secret Accessor" per questo secret.
- Comando di deployment:
gcloud run deploy accessibilityai-app-service \
--image gcr.io/$PROJECT_ID/accessibilityai-nextjs-app:latest \
--platform managed \
--region us-central1 \
--allow-unauthenticated \
--port 3000 \
--set-secrets=GOOGLE_GENAI_API_KEY=GOOGLE_GENAI_API_KEY:latest \
--set-env-vars NODE_ENV="production"