
1. はじめに
このチュートリアルでは、世界を見て説明できるハンズフリーの音声駆動型 AI エージェントである ClarityCam を構築します。ClarityCam は、視覚障がいのあるユーザー向けの強力なツールとして、ユーザー補助機能を中核に設計されていますが、このコースで学ぶ原則は、最新の汎用音声アプリケーションを作成するうえで不可欠です。

このプロジェクトは、ネイティブに適応するインターフェース(NAI)と呼ばれる強力な設計理念に基づいて構築されています。NAI は、ユーザー補助を後から追加するのではなく、基盤として扱っています。このアプローチでは、AI エージェントがインターフェースとなります。さまざまなユーザーに適応し、音声や視覚などのマルチモーダル入力を処理し、ユーザーの独自のニーズに基づいてプロアクティブにガイドします。
NAI を使用して最初の AI エージェントを構築する:

このセッションを修了すると、次のことができるようになります。
- アクセシビリティをデフォルトとして設計する: ネイティブ適応型インターフェース(NAI)の原則を適用して、すべてのユーザーに同等のエクスペリエンスを提供する AI システムを作成します。
- ユーザー インテントの分類: 自然言語コマンドをエージェントの構造化されたアクションに変換する、堅牢なインテント分類子を構築します。
- 会話のコンテキストを維持する: 短期記憶を実装して、エージェントがフォローアップの質問や参照コマンド(「何色ですか?」など)を理解できるようにします。
- 効果的なプロンプトを設計する: Gemini などのマルチモーダル モデル用に、正確で信頼性の高い画像分析を保証する、コンテキストが豊富で焦点を絞ったプロンプトを作成します。
- 曖昧さを処理してユーザーをガイドする: 範囲外のリクエストに対して適切なエラー処理を設計し、ユーザーを積極的にオンボーディングして信頼と自信を築きます。
- マルチエージェント システムをオーケストレートする: 音声処理、分析、音声合成などの複雑なタスクを処理するために連携する専門エージェントのコレクションを使用して、アプリケーションを構造化します。
2. 設計の概要
ClarityCam は、ユーザーにとってシンプルになるように設計されていますが、連携する AI エージェントの高度なシステムによって動作しています。アーキテクチャを分解してみましょう。

ユーザー エクスペリエンス
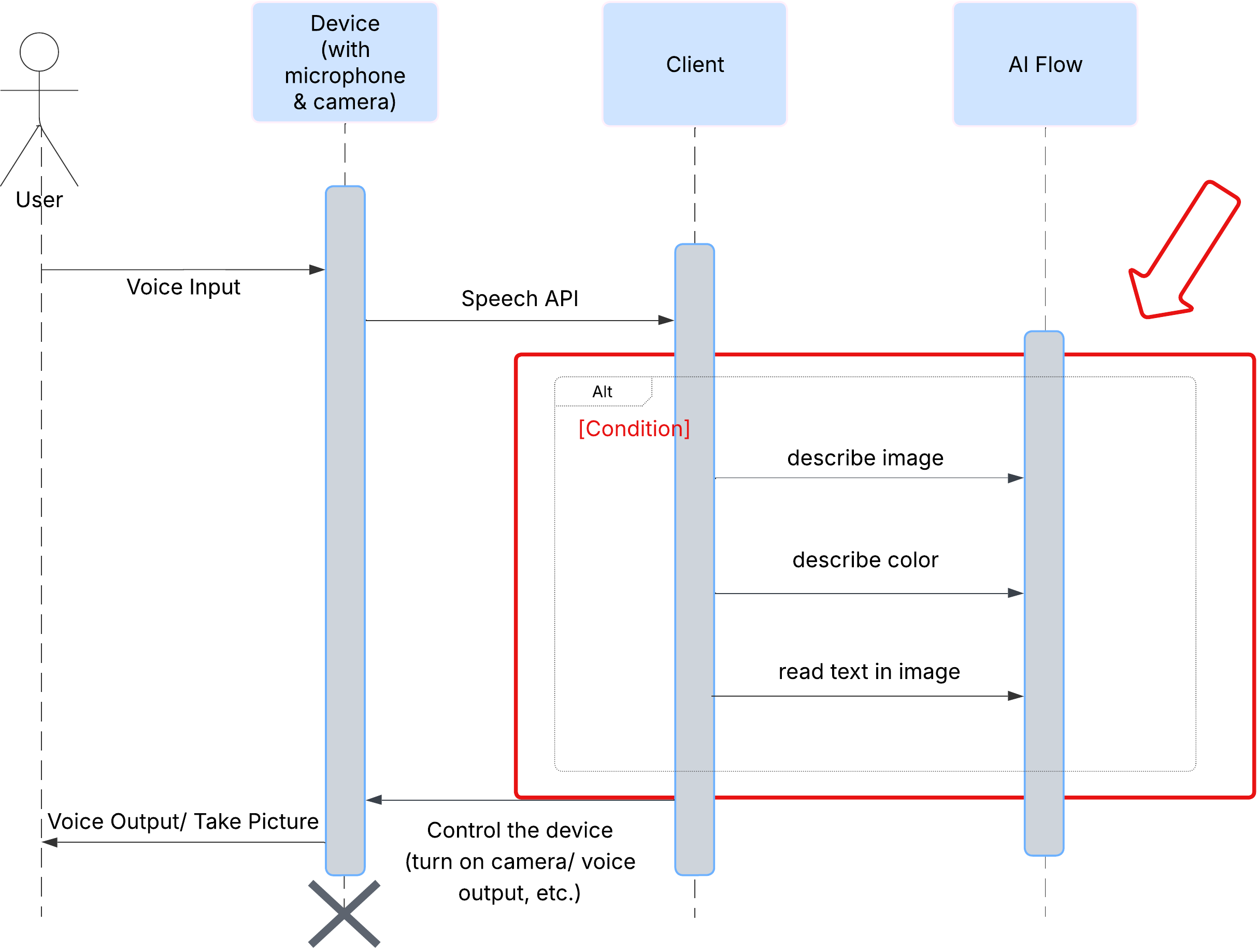
まず、ユーザーが ClarityCam をどのように操作するかを見てみましょう。操作はすべてハンズフリーで、会話形式で行われます。ユーザーがコマンドを発話すると、エージェントが発話による説明やアクションで応答します。このシーケンス図は、ユーザーの最初の音声コマンドからデバイスからの最終的な音声レスポンスまでの一般的なインタラクション フローを示しています。
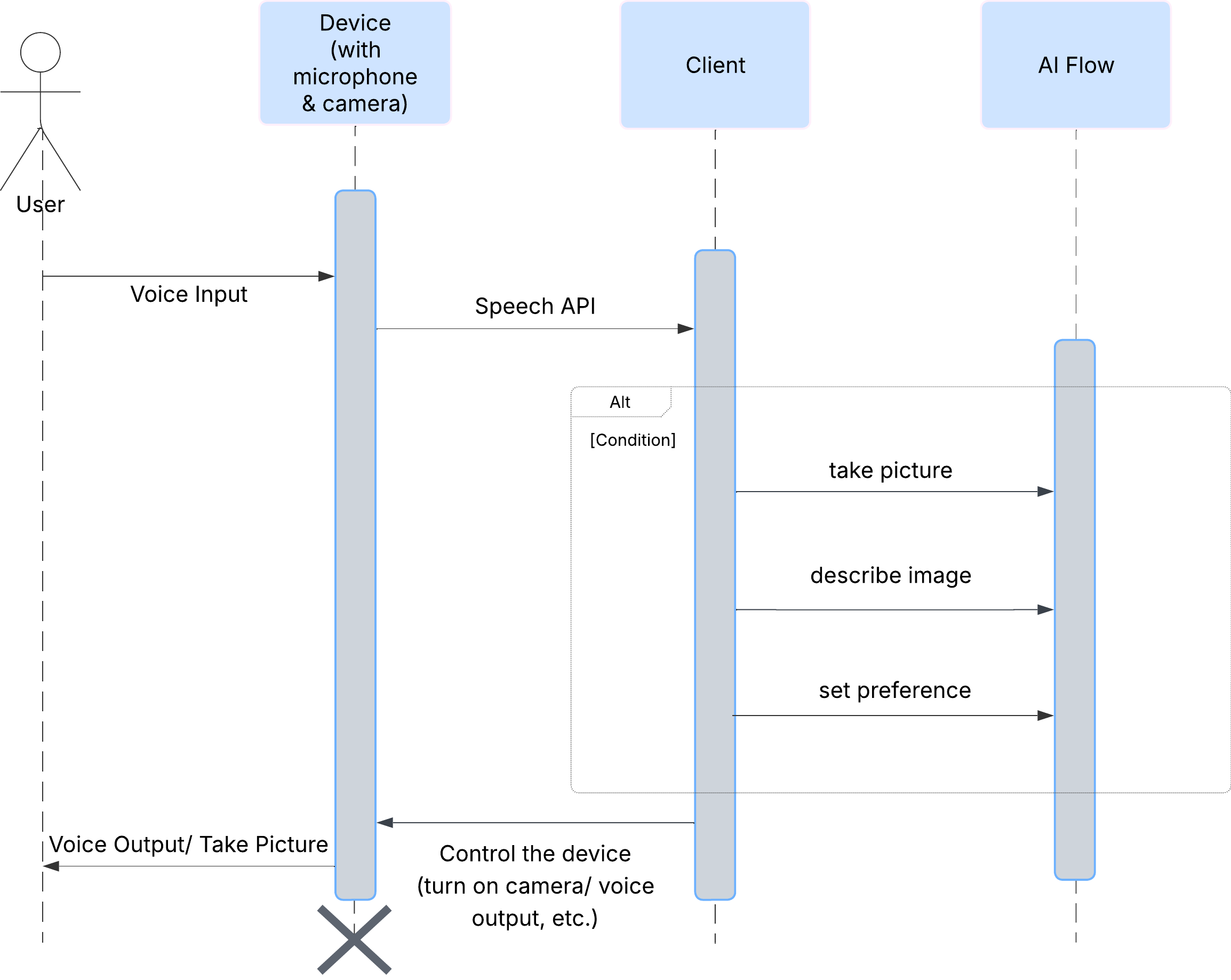
AI エージェントのアーキテクチャ
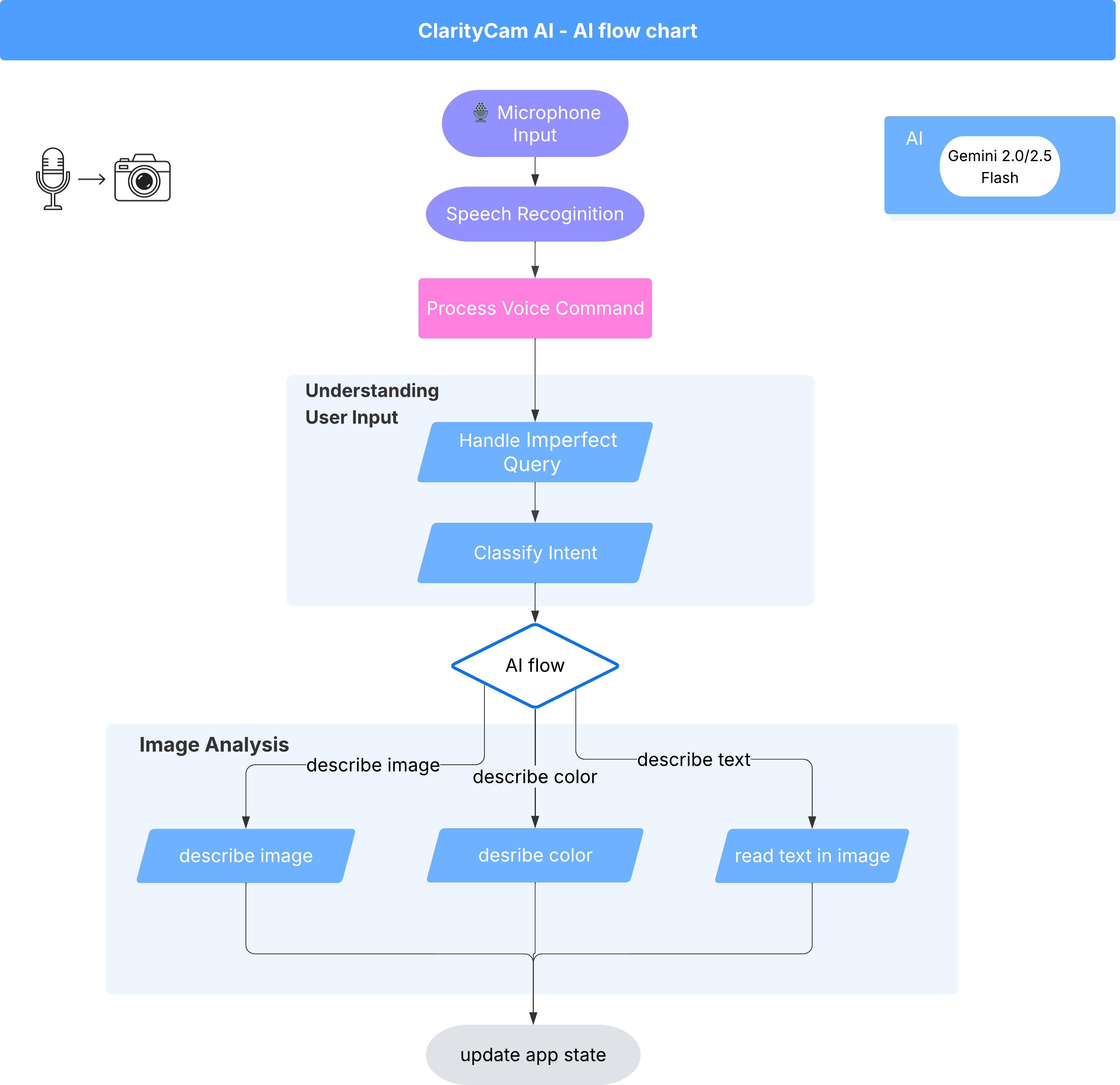
このエクスペリエンスを実現するために、マルチエージェント システムが連携して動作しています。コマンドを受信すると、中央の Orchestrator エージェントは、インテントの理解、画像の分析、レスポンスの作成を担当する専門のエージェントにタスクを委任します。この AI フロー図は、これらのエージェントがどのように連携しているかを示しています。次のセクションでは、このアーキテクチャを実装します。
プロジェクト ファイルの概要
コードを記述する前に、プロジェクトのファイル構造について説明します。ファイルがたくさんあるように見えますが、このチュートリアル全体で注目する必要があるのは 2 つの特定の領域だけです。
プロジェクトの簡略化された地図を以下に示します。
accessibilityAI/src/
├── 📁 app/
│ ├── layout.tsx # An overall page shell (you can ignore this).
│ └── page.tsx # ⬅️ MODIFY THIS: The main user interface for our app.
│
├── 📁 ai/
│ ├── 📁flows # ⬅️ MODIFY THIS: The core AI logic and server functions.
│ └── intent-classifier.ts # ⬅️ MODIFY THIS: Where we'll edit our AI prompts.
| └── ai-instance.ts
| └── dev.ts
│
├── 📁 components/ # Contains pre-built UI components (ignore this).
│
├── 📁 hooks/
│
├── 📁 lib/
│
└── 📁 types/
テクノロジー スタック
Google のシステムは、強力なクラウド サービスと最先端の AI モデルを組み合わせた、最新のスケーラブルな技術スタック上に構築されています。使用する主なコンポーネントは次のとおりです。
- Google Cloud Platform(GCP): エージェント用のサーバーレス インフラストラクチャを提供します。
- Cloud Run: 個々のエージェントをコンテナ化されたスケーラブルなマイクロサービスとしてデプロイします。
- Artifact Registry: エージェントの Docker イメージを安全に保存して管理します。
- Secret Manager: 機密性の高い認証情報と API キーを安全に処理します。
- 大規模言語モデル(LLM): システムの「頭脳」として機能します。
- Google の Gemini モデル: Gemini ファミリーの強力なマルチモーダル機能を活用して、ユーザーの意図の分類から画像コンテンツの分析、インテリジェントな説明の提供まで、あらゆる処理を行っています。
3. 設定と前提条件
請求先アカウントを有効にする: この Codelab を実行するには、クレジットが残っている請求先アカウントが必要です。この Codelab の上部にあるバナーのクレジットを使用して、開始します。請求先アカウントにすでに接続している場合は、この手順をスキップできます。
新しい GCP プロジェクトを作成する
- Google Cloud コンソールに移動し、新しいプロジェクトを作成します。
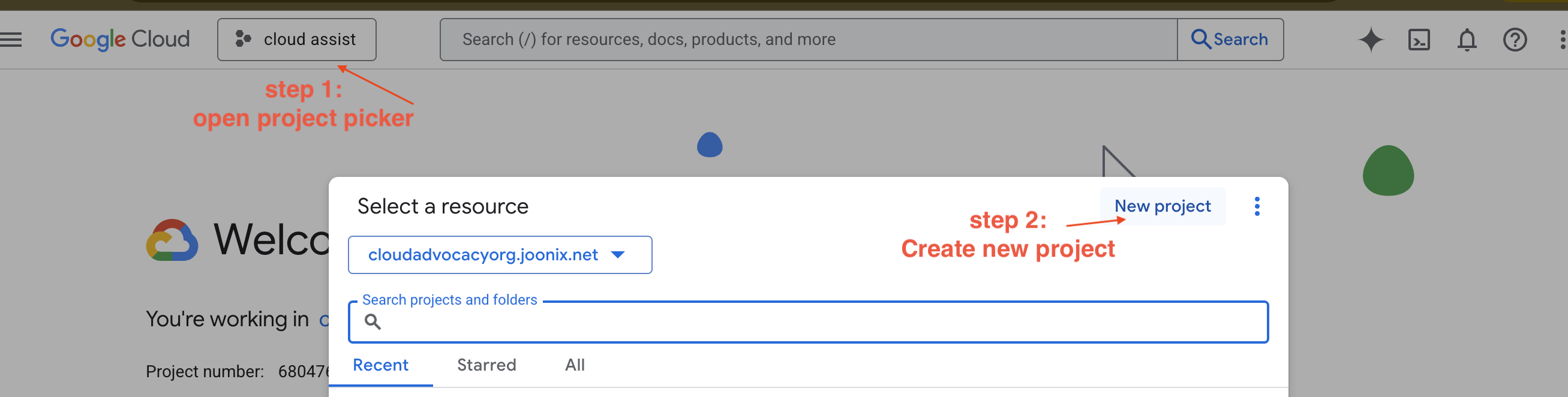
- Google Cloud コンソールに移動し、新しいプロジェクトを作成します。
- 左側のパネルを開き、
Billingをクリックして、請求先アカウントがこの GCP アカウントにリンクされているかどうかを確認します。
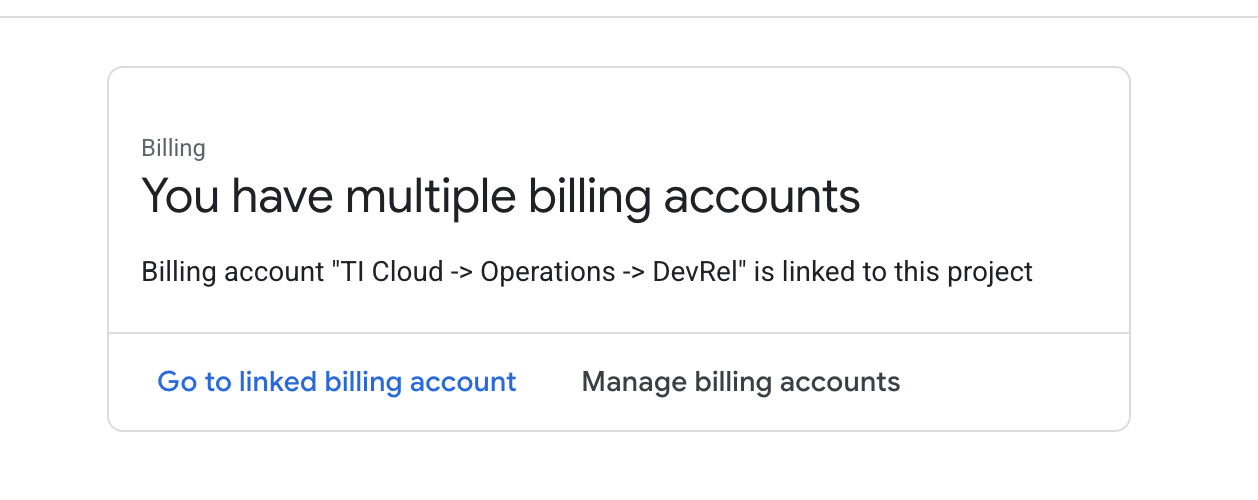
このページが表示されたら、manage billing account をオンにして、Google Cloud トライアル One を選択してリンクします。
Gemini API キーを作成する
鍵を保護するには、鍵が必要です。
- Google AI Studio(https://aistudio.google.com/)に移動します。
- Google アカウントを使用してログインします。
- [API キーを取得] ボタンをクリックします。通常、このボタンは左側のナビゲーション ペインまたは右上にあります。
- [API キー] ダイアログで、[新しいプロジェクトで API キーを作成] をクリックします。
- 新しい API キーが生成されます。このキーをすぐにコピーして、安全な場所に一時的に保存します(パスワード マネージャーや安全なメモなど)。これは次のステップで使用する値です。
ローカル開発ワークフロー(マシンでのテスト)
npm run dev を実行してアプリを動作させる必要があります。ここで .env が役立ちます。
- API キーをファイルに追加する:
.envという名前の新しいファイルを作成し、このファイルに次の行を追加します。
YOUR_API_KEY_HERE は、AI Studio から取得して .env に保存したキーに置き換えてください。
GOOGLE_GENAI_API_KEY="YOUR_API_KEY_HERE"
[省略可] IDE と環境を設定する
このチュートリアルでは、VS Code や IntelliJ などの使い慣れた開発環境でローカル ターミナルを使用できます。ただし、標準化された事前構成済みの環境を確保するには、Google Cloud Shell を使用することを強くおすすめします。
次の手順は、Cloud Shell のコンテキストで記述されています。ローカル環境を使用する場合は、git、nvm、npm、gcloud がインストールされ、正しく構成されていることを確認してください。
Cloud Shell エディタで作業する
👉Google Cloud コンソールの最上部にある [Cloud Shell をアクティブにする] をクリックします(Cloud Shell ペインの上部にあるターミナル型のアイコンです)。
👉[エディタを開く] ボタン(鉛筆のアイコンが付いた開いたフォルダのアイコン)をクリックします。ウィンドウに Cloud Shell コードエディタが開きます。左側にファイル エクスプローラが表示されます。
👉下のステータスバーにある [Cloud Code Sign-in] ボタンをクリックします。指示に従ってプラグインを承認します。ステータスバーに「Cloud Code - no project」と表示されている場合は、それを選択し、プルダウンの [Google Cloud プロジェクトを選択] で、作成したプロジェクトのリストから特定の Google Cloud プロジェクトを選択します。
👉クラウド IDE でターミナルを開きます。
👉ターミナルで、次のコマンドを使用して、すでに認証済みであることと、プロジェクトがプロジェクト ID に設定されていることを確認します。
gcloud auth list
👉 GitHub から natively-accessible-interface プロジェクトのクローンを作成します。
git clone https://github.com/cuppibla/AccessibilityAgent.git
👉 実行する前に、<YOUR_PROJECT_ID> をプロジェクト ID に置き換えてください(プロジェクト ID は Google Cloud コンソールのプロジェクト部分で確認できます。❗️❗️project id と project number を混同しないようにしてください❗️❗️)。
echo <YOUR_PROJECT_ID> > ~/project_id.txt
gcloud config set project $(cat ~/project_id.txt)
👉次のコマンドを実行して、必要な Google Cloud API を有効にします(実行に 2 分ほどかかることがあります)。
gcloud services enable compute.googleapis.com \
storage.googleapis.com \
run.googleapis.com \
artifactregistry.googleapis.com \
aiplatform.googleapis.com \
eventarc.googleapis.com \
sqladmin.googleapis.com \
secretmanager.googleapis.com \
cloudbuild.googleapis.com \
cloudresourcemanager.googleapis.com \
cloudfunctions.googleapis.com \
cloudaicompanion.googleapis.com
これには数分かかることがあります。
権限の設定
👉サービス アカウントの権限を設定します。ターミナルで次のコマンドを実行します。
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
export SERVICE_ACCOUNT_NAME=$(gcloud compute project-info describe --format="value(defaultServiceAccount)")
echo "Here's your SERVICE_ACCOUNT_NAME $SERVICE_ACCOUNT_NAME"
👉 権限を付与します。ターミナルで次のコマンドを実行します。
#Cloud Storage (Read/Write):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/storage.objectAdmin"
#Pub/Sub (Publish/Receive):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/pubsub.publisher"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/pubsub.subscriber"
#Cloud SQL (Read/Write):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/cloudsql.editor"
#Eventarc (Receive Events):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/iam.serviceAccountTokenCreator"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/eventarc.eventReceiver"
#Vertex AI (User):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/aiplatform.user"
#Secret Manager (Read):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/secretmanager.secretAccessor"
4. ユーザー入力の理解 - インテント分類子
AI エージェントが行動する前に、まずユーザーの意図を正確に理解する必要があります。現実世界の入力は雑多であることが多く、曖昧であったり、タイプミスが含まれていたり、会話的な言葉遣いが使われていたりします。
このセクションでは、ユーザー入力を明確で実行可能なコマンドに変換する重要な「リスニング」コンポーネントを構築します。
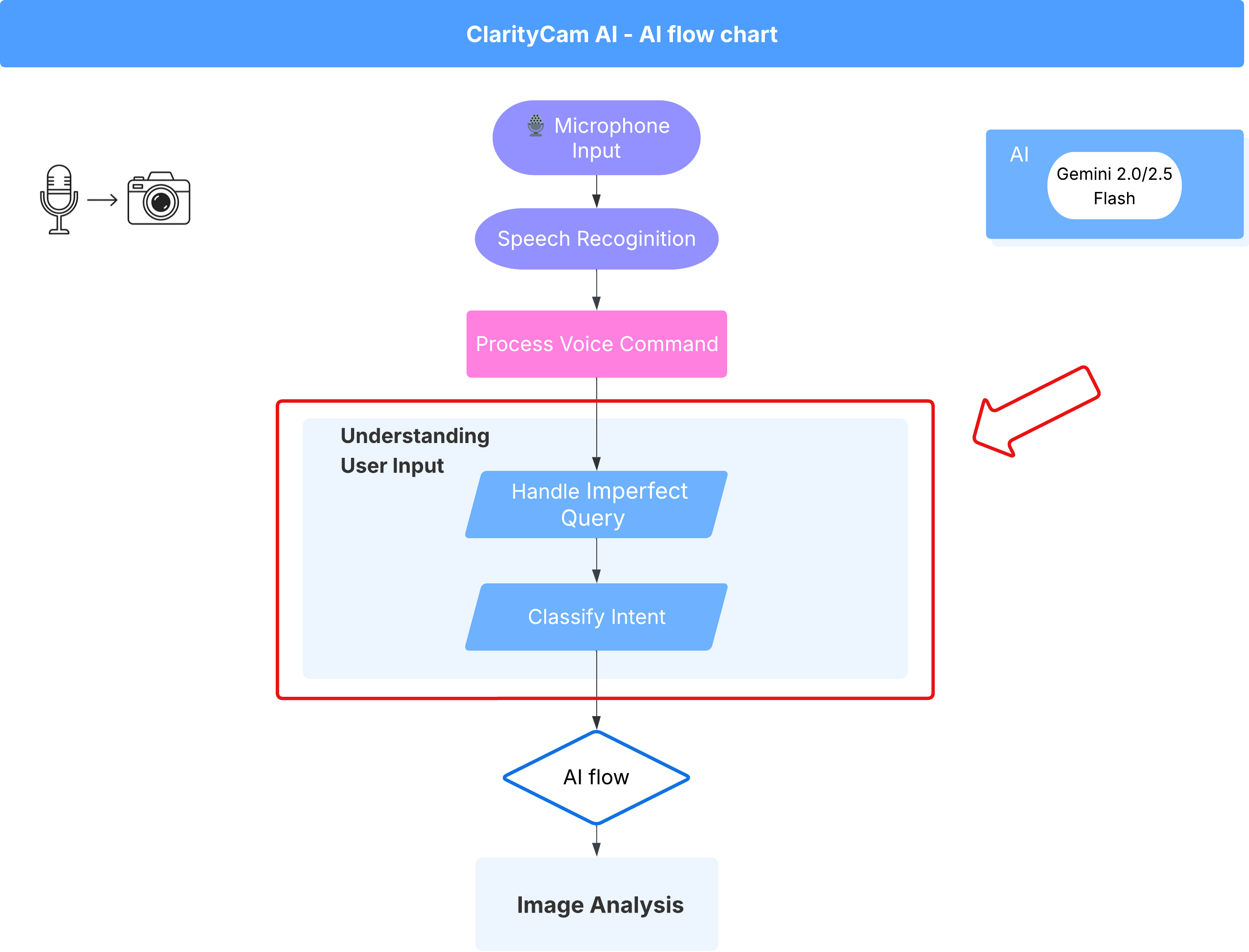
インテント分類器を追加する
次に、分類機能を強化する AI ロジックを定義します。
👉 操作: Cloud Shell IDE で、~/src/ai/intent-classifier/ ディレクトリに移動します。
ステップ 1: エージェントの語彙を定義する(IntentCategory)
まず、エージェントが実行できるすべてのアクションの明確なリストを作成する必要があります。
👉 対応: プレースホルダ // REPLACE ME PART 1: add IntentCategory here を次のコードに置き換えます。
👉 以下のコードに置き換えます。
export type IntentCategory =
// Image Analysis Intents
| "DescribeImage"
| "AskAboutImage"
| "ReadTextInImage"
| "IdentifyColorsInImage"
// Control Intents
| "TakePicture"
| "StartCamera"
| "SelectImage"
| "StopSpeaking"
// Preference Intents
| "SetDescriptionDetailed"
| "SetDescriptionConcise"
// Fallback Intents
| "GeneralInquiry" // User has a general question about the agent's functions or polite interaction
| "OutOfScopeRequest" // User's request is clearly outside the agent's defined capabilities
| "Unknown"; // Intent could not be determined with confidence
説明
この TypeScript コードは、IntentCategory というカスタムタイプを作成します。これは、エージェントが理解できるすべての可能なアクション(インテント)を定義する厳密なリストです。これは、ユーザーのフレーズ(「何が見えるか教えて」、「写真には何が写っているか」など)を無限に増やせる可能性のあるものから、明確で予測可能なコマンドのセットに変換する重要な最初のステップです。分類器の目標は、ユーザーのクエリをこれらの特定のカテゴリのいずれかにマッピングすることです。
ステップ 2
正確な判断を下すには、AI が自身の能力と限界を把握している必要があります。この情報は詳細なテキスト ブロックとして提供されます。
👉 アクション: プレースホルダ「REPLACE ME PART 2: add AGENT_CAPABILITIES_AND_LIMITATIONS here」を次のコードに置き換えます。
次のコード // REPLACE ME PART 2: add AGENT_CAPABILITIES_AND_LIMITATIONS here を置き換えます。
👉 以下のコードを使用します。
const AGENT_CAPABILITIES_AND_LIMITATIONS = `
**Core Capabilities (What the Agent CAN DO):**
* **Image Analysis:**
* DescribeImage: Provide a general description of the current image.
* AskAboutImage: Answer a specific question about the visual content of the current image (e.g., "Is there a dog?", "What color is the car?").
* ReadTextInImage: Read any text found in the current image.
* IdentifyColorsInImage: Identify the dominant colors of the current image.
* **Image Input Control:**
* TakePicture: Capture an image using the currently active camera stream.
* StartCamera: Activate the camera (e.g., "use camera", "take another picture").
* SelectImage: Allow the user to choose an image file from their device.
* **Voice & Audio Control:**
* StopSpeaking: Stop the current text-to-speech output.
* **Preference Management:**
* SetDescriptionDetailed: Make future image descriptions more detailed.
* SetDescriptionConcise: Make future image descriptions less detailed or concise.
* **General Interaction:**
* GeneralInquiry: Handle conversational phrases (e.g., "hello", "thank you") or questions about its own capabilities (e.g., "what can you do?", "help").
**Limitations (What the Agent CANNOT DO and should be classified as OutOfScopeRequest):**
* Cannot generate or create new images.
* Cannot edit or modify existing images (e.g., "remove background," "make the car blue").
* Cannot analyze video files or live video beyond capturing a single frame.
* Cannot provide general knowledge or answer questions unrelated to the provided image's visual content (e.g., "What's the weather?", "Who is the president?", "Tell me a joke", "What time is it?").
* Cannot perform mathematical calculations or complex data analysis.
* Cannot translate languages as a primary function.
* Cannot remember information from past images or vastly different previous queries in the same session.
* Cannot control other device settings or applications.
* Cannot perform web searches.
`;
重要である理由:
このテキストはユーザーが読むものではなく、AI モデルのためのものです。この「職務記述書」は、次のステップでプロンプトに直接入力され、言語モデル(LLM)が正確な判断を下すために必要なコンテキストを提供します。このコンテキストがないと、LLM は「天気はどう?」を AskAboutImage として誤って分類する可能性があります。このコンテキストにより、天気は画像内の視覚要素ではないことが認識され、範囲外として正しく分類されます。
ステップ 3
次に、Gemini モデルが分類を実行するために従う一連の指示を記述します。
👉 対応: // REPLACE ME PART 3 - classifyIntentPrompt を次のコードに置き換えます。
以下のコードで
const classifyIntentPrompt = ai.definePrompt({
name: 'classifyIntentPrompt',
input: { schema: ClassifyIntentInputSchema },
output: { schema: ClassifyIntentOutputSchema },
prompt: `You are classifying the user's intent for ClarityCam, a voice-controlled AI application focused on image analysis.
Analyze the user query: '{userQuery}'.
First, understand ClarityCam's capabilities and limitations:
${AGENT_CAPABILITIES_AND_LIMITATIONS}
Now, classify the user's PRIMARY intent into ONE of the following categories:
* **DescribeImage**: User wants a general description of the current image.
* **AskAboutImage**: User is asking a specific question directly related to the visual content of the current image.
* **ReadTextInImage**: User wants any text read from the current image.
* **IdentifyColorsInImage**: User wants the dominant colors of the current image.
* **TakePicture**: User wants to capture an image using an active camera.
* **StartCamera**: User wants to activate the camera.
* **SelectImage**: User wants to choose an image file.
* **StopSpeaking**: User wants the current text-to-speech output to stop.
* **SetDescriptionDetailed**: User wants future image descriptions to be more detailed.
* **SetDescriptionConcise**: User wants future image descriptions to be less detailed.
* **GeneralInquiry**: The query is a simple conversational filler (e.g., "hello", "thanks"), a polite closing, or a direct question about the agent's functions (e.g., "what can you do?", "how does this work?", "help").
* **OutOfScopeRequest**: The query asks the agent to perform an action clearly listed under its "Limitations" or otherwise demonstrably outside its defined image analysis and control functions. Examples: "Tell me a joke," "What's the weather in London?", "Generate an image of a cat," "Can you edit my photo to make it brighter?", "Send this image to my friends","Translate 'hello' to Spanish."
Output ONLY the category name.
If the query is ambiguous but seems generally related to polite interaction or asking about the agent itself, prefer 'GeneralInquiry'.
If the query is clearly asking for something the agent CANNOT do, use 'OutOfScopeRequest'.
If truly unclassifiable even with these guidelines, use 'Unknown'.`,
config: {
temperature: 0.05, // Very low temperature for highly deterministic classification
}
});
このプロンプトで魔法が起こります。これは分類子の「脳」であり、AI に役割を伝え、必要なコンテキストを提供し、望ましい出力を定義します。プロンプト エンジニアリングの主な手法は次のとおりです。
- ロールプレイング: 「あなたは分類しています...」で始まり、明確なタスクを設定します。
- コンテキストの挿入:
AGENT_CAPABILITIES_AND_LIMITATIONS変数をプロンプトに動的に挿入します。 - 厳密な出力形式: 「カテゴリ名のみを出力してください」という指示は、コードで簡単に使用できるクリーンで予測可能なレスポンスを取得するために重要です。
- Temperature: 分類では、創造的な回答ではなく、確定的で論理的な回答が必要です。Temperature を非常に低い値(0.05)に設定すると、モデルの焦点が絞られ、一貫性が高まります。
ステップ 4: アプリを AI Flow に接続する
最後に、メイン アプリケーション ファイルから新しい AI 分類子を呼び出します。
👉 アクション: ~/src/app/page.tsx ファイルに移動します。processVoiceCommand 関数内で、// REPLACE ME PART 1: add classificationResult を次のように置き換えます。
const classificationResult = await classifyIntentFlow({ userQuery: commandToProcess });
intent = classificationResult.intent as IntentCategory;
このコードは、フロントエンド アプリケーションとバックエンド AI ロジックの重要な橋渡しとなります。ユーザーの音声コマンド(commandToProcess)を取得し、作成した classifyIntentFlow に送信して、2 つの AI が分類されたインテントを返すのを待ちます。
インテント変数には、クリーンで構造化されたコマンド(DescribeImage など)が保持されるようになりました。この結果は、後続の switch ステートメントで使用され、アプリケーションのロジックを駆動して、次に実行するアクションを決定します。AI の「思考」がアプリの「動作」に変換される仕組みです。
ユーザー インターフェースを起動する
アプリケーションの動作を確認しましょう。開発用サーバーを起動しましょう。
👉 ターミナルで、次のコマンドを実行します。npm run dev 注: npm run dev を実行する前に npm install の実行が必要になる場合があります。
しばらくすると、次のような出力が表示されます。これは、サーバーが正常に実行されていることを意味します。
▲ Next.js 15.2.3 (Turbopack)
- Local: http://localhost:9003
- Network: http://10.88.0.4:9003
- Environments: .env
✓ Starting...
✓ Ready in 1512ms
○ Compiling / ...
✓ Compiled / in 26.6s
ローカル URL(http://localhost:9003)をクリックして、ブラウザでアプリケーションを開きます。
SightGuide のユーザー インターフェースが表示されます。現時点では、ボタンはロジックに接続されていないため、クリックしても何も起こりません。これは、この段階で想定されることです。次のセクションでは、これらの要素を実際に使用します。
UI を確認したら、ターミナルに戻り、Ctrl + C を押して開発用サーバーを停止してから、続行します。
5. ユーザー入力の理解 - 不完全なクエリのチェック
不完全なクエリチェックを追加
パート 1: プロンプトの定義(「何」)
まず、AI の指示を定義しましょう。プロンプトは AI 呼び出しの「レシピ」です。モデルに何をしてほしいかを正確に伝えます。
👉 対応: IDE で ~/src/ai/flows/check_typo/ に移動します。
次のコード // REPLACE ME PART 1: add prompt here を置き換えます。
👉 以下のコードを使用します。
const prompt = ai.definePrompt({
name: 'checkTypoPrompt',
input: {
schema: CheckTypoInputSchema,
},
output: {
schema: CheckTypoOutputSchema,
},
prompt: `You are a helpful AI assistant that checks user text for typos and suggests corrections.
- If you find typos, respond with the corrected text.
- If there are no typos, or if you are unsure about a correction, respond with the original text unchanged.
User text: {text}
Corrected text:
`,
});
このコードブロックは、checkTypoPrompt という AI の再利用可能なテンプレートを定義しています。入力スキーマと出力スキーマは、このタスクのデータ コントラクトを定義します。これにより、エラーを防ぎ、システムを予測可能にすることができます。
パート 2: フローの作成(方法)
「レシピ」(プロンプト)ができたので、実際に実行できる関数を作成する必要があります。Genkit では、これはフローと呼ばれます。フローは、アプリケーションの他の部分が簡単に呼び出すことができる実行可能な関数でプロンプトをラップします。
👉 操作: 同じ ~/src/ai/flows/check_typo/ ファイルで、次のコード // REPLACE ME PART 2: add flow here を置き換えます。
👉 以下のコードを使用します。
const checkTypoFlow = ai.defineFlow<
typeof CheckTypoInputSchema,
typeof CheckTypoOutputSchema
>(
{
name: 'checkTypoFlow',
inputSchema: CheckTypoInputSchema,
outputSchema: CheckTypoOutputSchema,
},
async input => {
const {output} = await prompt(input);
return output!;
}
);
パート 3: 誤字脱字チェッカーを実際に使用する
AI フローが完成したので、アプリケーションのメイン ロジックに統合します。ユーザーのコマンドを受け取った直後に呼び出し、それ以上の処理を行う前にテキストがクリーンであることを確認します。
👉対応: ~/src/app/ai/flows/check-typo.ts に移動して、export async function checkTypo 関数を見つけます。return 文のコメントを解除します。
return; の代わりに return checkTypoFlow(input); を使用する
👉対応: ~/src/app/page.tsx に移動して、processVoiceCommand 関数を見つけます。次のコード REPLACE ME PART 2: add typoResult here を置き換えます。
👉 以下のコードを使用します。
const typoResult = await checkTypo({ text: rawCommand });
if (typoResult && typoResult.correctedText && typoResult.correctedText.trim().length > 0) {
const originalTrimmedLower = rawCommand.trim().toLowerCase();
const correctedTrimmedLower = typoResult.correctedText.trim().toLowerCase();
if (correctedTrimmedLower !== originalTrimmedLower) {
commandToProcess = typoResult.correctedText;
typoCorrectionAnnouncement = `I think you said: ${commandToProcess}. `;
}
}
この変更により、すべてのユーザー コマンドに対してより堅牢なデータ処理パイプラインが作成されました。
音声コマンドのフロー(読み取り専用、対応不要)
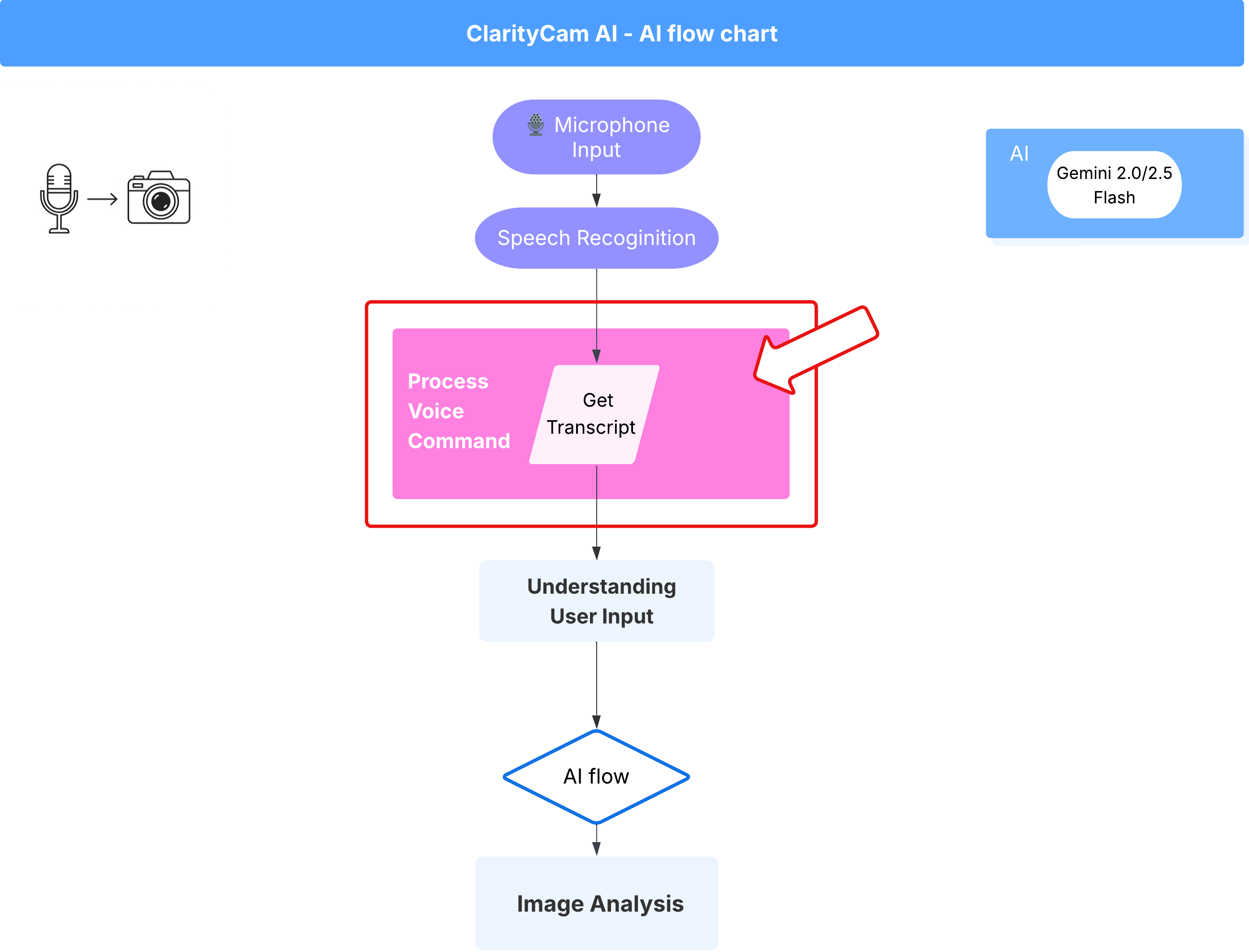
これで、コアの「理解」コンポーネント(Typo Checker と Intent Classifier)ができました。次に、これらのコンポーネントがアプリのメインの音声処理ロジックにどのように組み込まれるかを見ていきましょう。
すべてはユーザーが話すことから始まります。ブラウザの Web Speech API は音声をリッスンし、ユーザーが話し終えると、聞いた内容のテキスト文字起こしを提供します。次のコードは、このプロセスを処理します。
👉読み取り専用: ~/src/app/page.tsx に移動し、handleResult 関数内に移動します。次のコードを見つけます。
for (let i = event.resultIndex; i < event.results.length; ++i) {
if (event.results[i].isFinal) {
finalTranscript += event.results[i][0].transcript;
}
}
if (finalTranscript) {
console.log("Final Transcript:", finalTranscript);
processVoiceCommand(finalTranscript);
}
誤字脱字修正機能をテストする
ここからが面白いところです。新しい誤字脱字修正機能が、完璧な音声コマンドと不完全な音声コマンドの両方をどのように処理するかを見てみましょう。
アプリケーションを開始する
まず、開発用サーバーを再び実行します。ターミナルで npm run dev を実行します。
アプリを開く
サーバーの準備ができたら、ブラウザを開いてローカル アドレス(http://localhost:9003 など)に移動します。
音声コマンドを有効にする
[Start Listening] ボタンをクリックします。 ブラウザでマイクの使用許可を求められることがあります。[許可] をクリックしてください。
不完全なコマンドをテストする
ここで、AI が理解できるかどうかを確認するために、少し欠陥のあるコマンドを意図的に入力してみましょう。マイクにはっきりと話しかけてください。
「私の写真」
結果を確認する
ここで魔法が起こります。「写真を撮って」と話しかけると、アプリがカメラを正しく起動します。checkTypo フローは、フレーズを「写真を撮って」に舞台裏で修正し、classifyIntentFlow は修正されたコマンドを理解します。
これにより、誤字脱字修正機能が完璧に動作し、アプリの堅牢性とユーザー フレンドリーさが大幅に向上することが確認できます。完了したら、写真を撮るか、ターミナルでサーバーを停止(Ctrl + C)して、カメラを停止できます。
6. AI を活用した画像分析 - 画像の説明
エージェントがリクエストを理解できるようになったので、次はエージェントに目を与えます。このセクションでは、すべての画像分析を担当するコア コンポーネントである Vision エージェントの機能を構築します。まず、最も重要な機能である画像の描写から始め、次にテキストの読み取り機能を追加します。
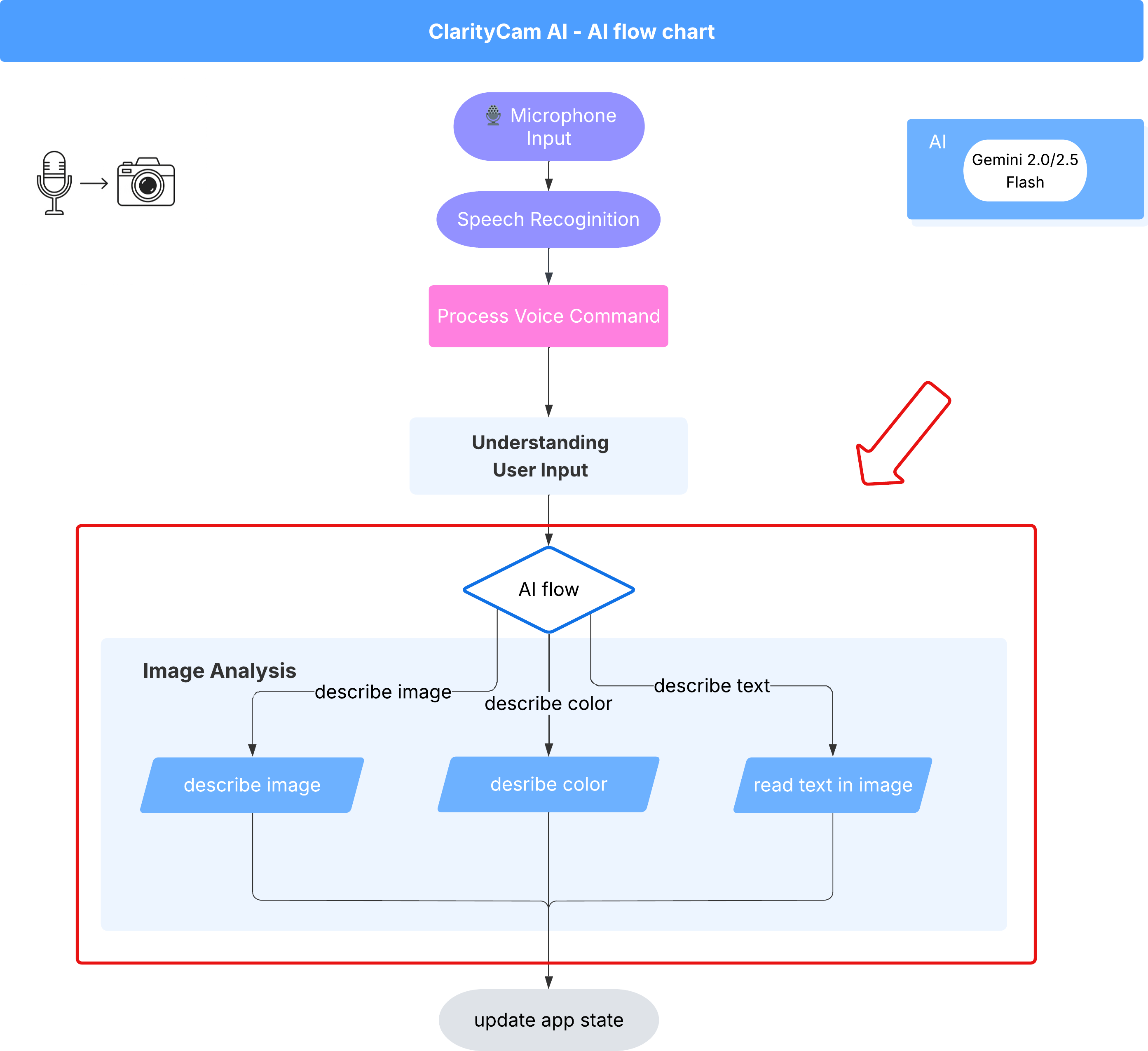
機能 1: 画像の説明
これがエージェントの主な機能です。静的な説明を生成するだけでなく、ユーザーの好みに応じて詳細レベルを調整できる動的なフローを構築します。これは、Natively Adaptive Interface(NAI)の理念の重要な部分です。
👉 操作: Cloud Shell IDE で ~/src/ai/flows/describe_image/ ファイルに移動し、次のコードのコメントを解除します。
ステップ 1: 動的プロンプト テンプレートを構築する
まず、受け取った入力に基づいて指示を変更できる高度なプロンプト テンプレートを作成します。
以下のコードのコメントを解除します。
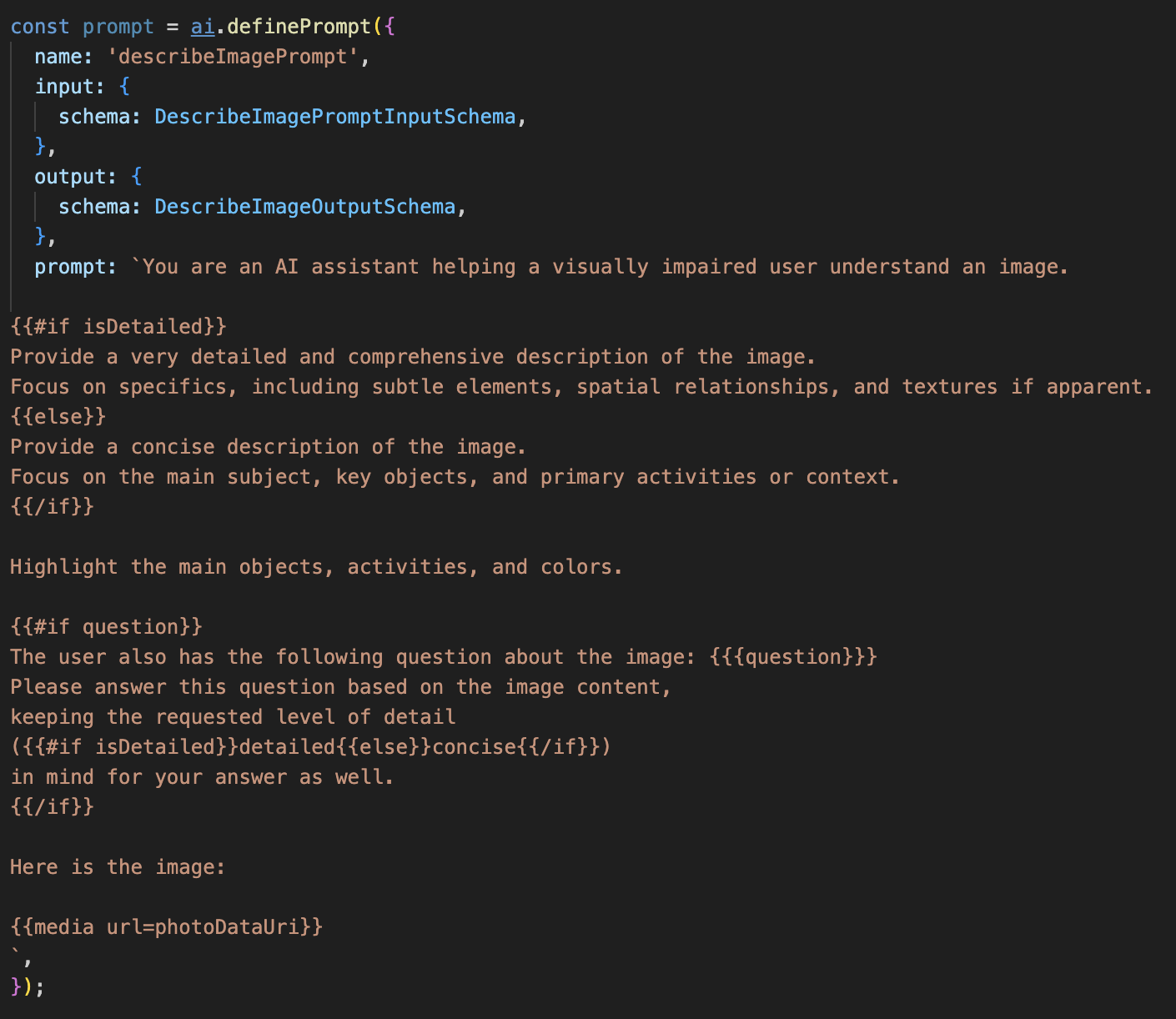
このコードでは、Dot-Mustache というテンプレート言語を使用する文字列変数 prompt を定義しています。これにより、条件ロジックをプロンプトに直接埋め込むことができます。
{#if isDetailed}...{else}...{/if}: これは条件付きブロックです。このプロンプトに送信する入力データに isDetailed: true というプロパティが含まれている場合、AI は「非常に詳細な」一連の指示を受け取ります。それ以外の場合は、簡潔な指示が届きます。このようにして、エージェントはユーザーの好みに適応します。
{#if question}...{/if}: このブロックは、入力データに質問プロパティが含まれている場合にのみ含まれます。これにより、一般的な説明と具体的な質問の両方に同じ強力なプロンプトを使用できます。
{media url=photoDataUri}: これは、マルチモーダル モデルが分析するプロンプトに画像データを直接埋め込むための Genkit の特別な構文です。
ステップ 2: スマートフローを作成する
次に、新しいテンプレートを使用するプロンプトとフローを定義します。このフローには、ユーザーの設定をテンプレートが理解できるブール値に変換するロジックが含まれています。
👉 アクション: Cloud Shell IDE の同じ ~/src/ai/flows/describe_image/ ファイルで、次のコードを置き換えます。// REPLACE ME PART 1: add flow here
👉 次のコードを使用します。
// Define the prompt using the template from Step 1
const prompt = ai.definePrompt({
name: 'describeImagePrompt',
input: { schema: DescribeImagePromptInputSchema },
output: { schema: DescribeImageOutputSchema },
prompt: promptTemplate,
});
// Define the flow
const describeImageFlow = ai.defineFlow<
typeof DescribeImageInputSchema,
typeof DescribeImageOutputSchema
>(
{
name: 'describeImageFlow',
inputSchema: DescribeImageInputSchema,
outputSchema: DescribeImageOutputSchema,
},
async (pageInput) => {
const preference = pageInput.detailPreference || "concise";
// Prepare the input for the prompt, including the new boolean flag
const promptInputData = {
...pageInput,
isDetailed: preference === "detailed",
};
const { output } = await prompt(promptInputData);
return output!;
}
);
これは、フロントエンドと AI プロンプトの間のスマートな仲介役として機能します。
- アプリから
pageInputを受け取ります。これには、ユーザーの設定が文字列("detailed"など)として含まれています。 - 次に、新しいオブジェクト
promptInputDataを作成します。 - 最も重要な行は
isDetailed: preference === "detailed"です。この行は、設定文字列に基づいてtrueまたはfalseのブール値を作成するという重要な処理を行います。 - 最後に、この拡張データを使用して
promptを呼び出します。ステップ 1 のプロンプト テンプレートで、isDetailedブール値を使用して、AI に送信される指示を動的に変更できるようになりました。
ステップ 3: フロントエンドを接続する
それでは、page.tsx のユーザー インターフェースからこのフローをトリガーしましょう。
👉対応: ~/src/app/ai/flows/describe-image.ts に移動して、export async function describeImage 関数を見つけます。return 文のコメントを解除します。
return; の代わりに return describeImageFlow(input); を使用する
👉対応: ~/src/app/page.tsx で handleAnalyze 関数を見つけ、コード // REPLACE ME PART 2: DESCRIBE IMAGE を
👉 次のコードを使用します。
case "description":
result = await describeImage({
photoDataUri,
question,
detailPreference: descriptionPreference
});
outputText = question ? `Answer: ${result.description}` : `Description: ${result.description}`;
break;
ユーザーが説明を取得しようとすると、このコードが実行されます。この関数は describeImage フローを呼び出し、画像データと、重要なことに、React コンポーネントの descriptionPreference 状態変数を渡します。これはパズルの最後のピースであり、UI に保存されたユーザーの設定を、それに応じて動作を適応させる AI フローに直接接続します。
画像の説明機能のテスト
写真を撮影してから AI が認識した内容を聞くまでの、画像の説明機能の動作を見てみましょう。
アプリケーションを開始する
まず、開発用サーバーを再び実行します。👉 ターミナルで、次のコマンドを実行します。npm run dev 注: npm run dev を実行する前に npm install の実行が必要になる場合があります。
アプリを開く
サーバーの準備ができたら、ブラウザを開いてローカル アドレス(http://localhost:9003 など)に移動します。
カメラを有効にする
[聞き取りを開始] ボタンをクリックし、マイクへのアクセスを求められたら許可します。次に、最初のコマンドを言います。
「写真を撮って」
アプリによってデバイスのカメラが起動します。画面にライブ動画フィードが表示されます。
写真を撮影する
カメラを起動し、説明したいものにカメラを向けます。もう一度コマンドを発して、画像をキャプチャします。
「写真を撮って」
ライブ動画が、先ほど撮影した静止画像に置き換えられます。
説明を求める
画面に新しい写真が表示されたら、最後のコマンドを入力します。
「Describe the picture」
結果を聞く
アプリに処理ステータスが表示され、その後、画像の AI 生成の説明が聞こえます。このテキストは [ステータスと結果] カードにも表示されます。
完了したら、写真を撮ってカメラを停止するか、ターミナルでサーバーを停止します(Ctrl+C)。
7. AI による画像分析 - テキストの説明(OCR)
次に、Vision エージェントに光学式文字認識(OCR)機能を追加します。これにより、あらゆる画像からテキストを読み取ることができます。
👉 操作: IDE で ~/src/ai/flows/read-text-in-image/ に移動し、次のコードのコメントを解除します。
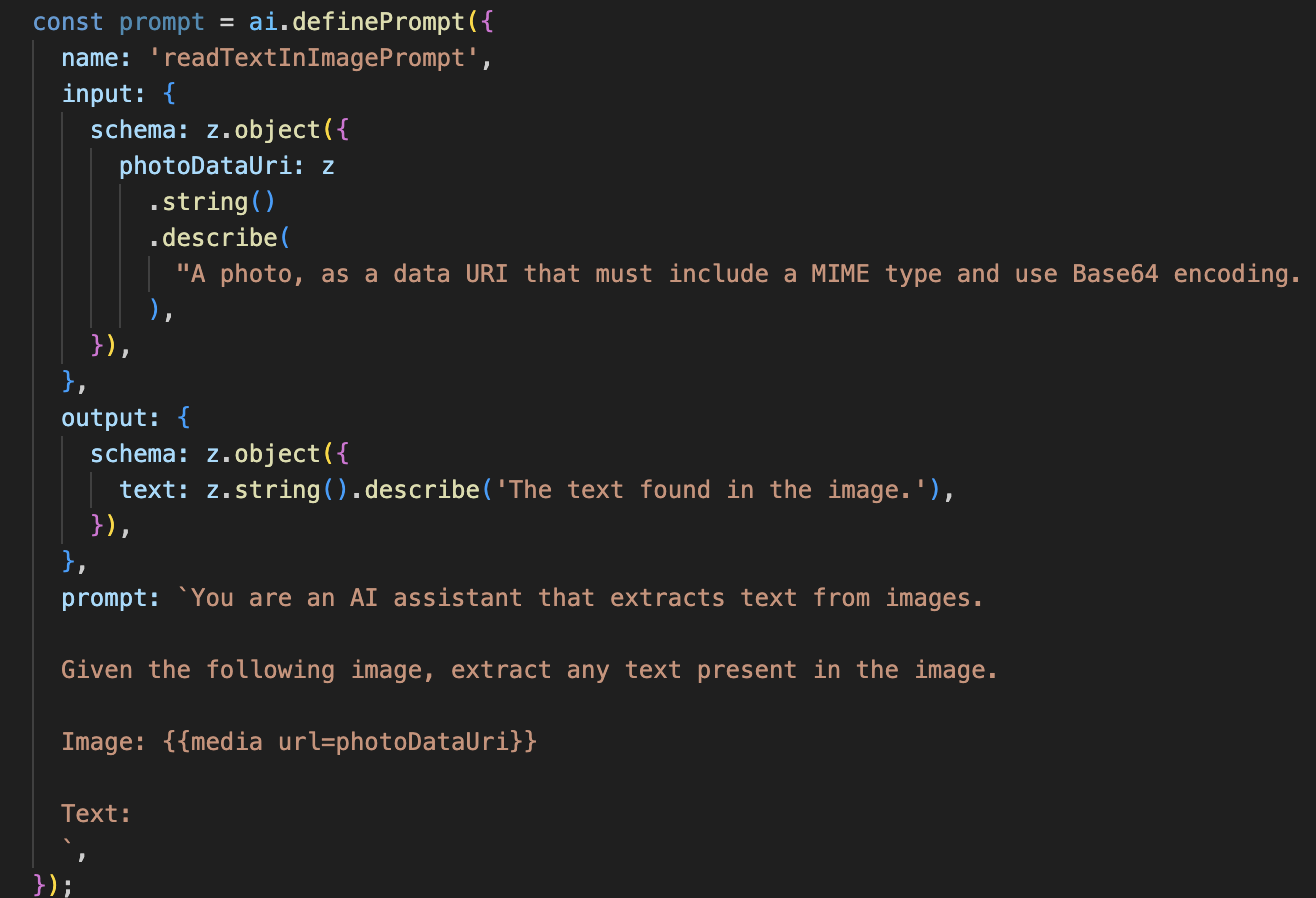
👉 操作: IDE の同じ ~/src/ai/flows/read-text-in-image/ ファイルで、// REPLACE ME: Creating Prmopt を置き換えます。
👉 次のコードを使用します。
const readTextInImageFlow = ai.defineFlow<
typeof ReadTextInImageInputSchema,
typeof ReadTextInImageOutputSchema
>(
{
name: 'readTextInImageFlow',
inputSchema: ReadTextInImageInputSchema,
outputSchema: ReadTextInImageOutputSchema,
},
async input => {
const {output} = await prompt(input);
return output!;
}
);
この AI フローははるかにシンプルで、特定のジョブに特化したツールを使用するという原則を強調しています。
- プロンプト: 説明プロンプトとは異なり、このプロンプトは静的で非常に具体的です。このプロンプトの役割は、AI に OCR エンジンとして動作するよう指示することだけです(「画像内のテキストを抽出する」)。
- スキーマ: 入力スキーマと出力スキーマもシンプルで、画像を想定し、テキストの単一の文字列を返します。
OCR 用のフロントエンドを接続する
最後に、page.tsx でこの新機能を接続します。
👉対応: ~/src/app/ai/flows/read-text-in-image.ts に移動して、export async function readTextInImage 関数を見つけます。return 文のコメントを解除します。
return; の代わりに return readTextInImageFlow(input); を使用する
👉 アクション: ~/src/app/page.tsx で、handleAnalyze 関数と switch ステートメントを見つけます。
REPLACE ME PART 3: READ TEXT を置き換えます
次のコードに置き換えます。
case "text":
result = await readTextInImage({ photoDataUri });
outputText = result.text ? `Text Found: ${result.text}` : "No text found.";
break;
ユーザーのインテントが ReadTextInImage の場合、このコードがトリガーされます。これは、シンプルな readTextInImage フローを呼び出します。result.text ? ... : ... 行は出力を処理するクリーンな方法です。AI が画像内のテキストを見つけられなかった場合に、ユーザーに役立つメッセージを提供します。
テキスト読み上げ(OCR)機能をテストする
テキスト読み上げ機能をテストする手順は次のとおりです。カメラを、テキストがはっきりと写る被写体に向けるようにしてください。
npm run devでアプリケーションを実行し、ブラウザで開きます。- [聞き取りを開始] をクリックし、メッセージが表示されたらマイクへのアクセスを許可します。
- カメラを起動します。「写真を撮って」とコマンドを発します。画面にライブ動画フィードが表示されます。
- 写真を撮影します。読み上げたいテキストにカメラを向け、もう一度「写真を撮って」とコマンドを言います。動画が静止写真に置き換わります。
- テキストをリクエストします。写真がキャプチャされたら、最後のコマンド「画像内のテキストは何ですか?」と入力します。
- 結果を確認する: しばらくすると、アプリが写真を分析し、検出されたテキストを読み上げます。テキストが見つからない場合は、その旨が通知されます。
これで、強力な OCR 機能が動作していることが確認できました。完了したら、Ctrl + C でサーバーを停止します。
8. 高度な AI 補正 - 読み取り専用 ✨
優れた AI エージェントは指示に従うことができます。優れた AI エージェントは、直感的で信頼でき、役に立つものです。このセクションでは、エージェントの機能を強化する 3 つの高度な機能に焦点を当てます。
以下について説明します。
Add Context & Memoryを使用して、自然な会話形式のフォローアップを処理します。Reduce Hallucinationを使用して、より信頼性の高いエージェントを構築します。Make the Agent Proactiveを使用して、よりアクセスしやすくユーザー フレンドリーなエクスペリエンスを提供します。Add preference setting: 画像の説明をカスタマイズします
強化 1: コンテキストとメモリ
自然な会話は、一連の独立したコマンドではなく、流れがあります。ユーザーが「写真には何が写っていますか?」と尋ね、エージェントが「赤い車です」と答えた場合、ユーザーは「何色ですか?」と尋ねる可能性があります。このとき、ユーザーは「車」という言葉を繰り返さないでしょう。エージェントがこのコンテキストを理解するには、短期記憶が必要です。
実装方法(まとめ)
この機能は、describeImage フローにすでに組み込まれています。このセクションでは、このパターンの仕組みをまとめます。page.tsx から describeImage 関数を呼び出すときに、会話履歴を渡します。
👉 コードのショーケース(page.tsx から):
const result = await describeImage({
photoDataUri,
question: commandToProcess,
detailPreference: descriptionPreference,
previousUserQueryOnImage: lastUserQuery ?? undefined,
previousAIResponseOnImage: lastAIResponse ?? undefined,
});
previousUserQueryOnImageとpreviousAIResponseOnImage: これら 2 つのプロパティは、エージェントの短期記憶です。最後のやり取りを AI に渡すことで、曖昧なフォローアップの質問や参照的なフォローアップの質問を理解するために必要なコンテキストが AI に提供されます。- 適応型プロンプト: このコンテキストは、describe_image フローのプロンプトで使用されます。このプロンプトは、新しい回答を作成する際に以前の会話を考慮するように設計されているため、エージェントはインテリジェントな回答をすることができます。
機能強化 2: ハルシネーションの低減
AI が事実を捏造したり、持っていない能力があると主張したりする場合、AI は「ハルシネーション」を起こしていると言えます。ユーザーの信頼を得るには、エージェントが自身の限界を把握し、範囲外のリクエストを適切に拒否できることが重要です。
実装方法(まとめ)
ハルシネーションを防ぐ最も効果的な方法は、モデルに明確な境界線を設定することです。これは、インテント分類器を構築したときに実現しました。
👉 コードのショーケース(intent-classifier フローから):
// Define Agent Capabilities and Limitations for the prompt
const AGENT_CAPABILITIES_AND_LIMITATIONS = `
**Core Capabilities (What the Agent CAN DO):**
* **Image Analysis:**
* DescribeImage: Provide a general description of the current image...
**Limitations (What the Agent CANNOT DO...):**
* Cannot generate or create new images.
* Cannot provide general knowledge or answer questions unrelated to the image...
* Cannot perform web searches.
`;
この定数は、分類プロンプトで AI に渡す「職務記述書」として機能します。
- モデルのグラウンディング: AI にできないことを明示的に伝えることで、AI を現実に「グラウンディング」します。「今日の天気は?」などのクエリが検出されると、制限事項のリストと照合して、インテントを OutOfScopeRequest として分類できます。
- 信頼を築く: 「その件についてはサポートできません」と正直に言えるエージェントは、推測して間違えるエージェントよりもはるかに信頼できます。これは、安全で信頼性の高い AI 設計の基本原則です。`
機能強化 3: プロアクティブ エージェントの作成
アクセシビリティを重視したアプリケーションでは、視覚的な手がかりに頼ることはできません。ユーザーがリスニング モードを有効にすると、エージェントが準備完了してコマンドを待機していることを視覚以外の方法で直ちに確認する必要があります。この重要なフィードバックを提供するために、事前対応型の導入を追加します。
ステップ 1: 初回リスニングを追跡する状態を追加する
まず、ユーザーがセッション中に "Start Listening" ボタンを初めて押したかどうかを判断する方法が必要です。
👉 ~/src/app/page.tsx で、ClarityCam コンポーネントの上部付近に次の新しい状態変数があります。
export default function ClarityCam() {
// ... other state variables
const [descriptionPreference, setDescriptionPreference] = useState<DescriptionPreference>("concise");
// Add this new line
const [isFirstListen, setIsFirstListen] = useState(true);
// ... rest of the component
}
新しい状態変数 isFirstListen を導入し、true に初期化しました。このフラグは、1 回限りのウェルカム メッセージをトリガーするために使用します。
ステップ 2: toggleListening 関数を更新する
次に、マイクを処理する関数を変更して、挨拶を再生します。
👉 ~/src/app/page.tsx で toggleListening 関数を見つけて、次の if ブロックを確認します。
const toggleListening = useCallback(() => {
// ... existing logic to setup speech recognition
if (isListening || isAttemptingStart) {
// ... existing logic to stop listening
} else {
stopSpeaking(); // Stop any ongoing TTS
// Add this new block
if (isFirstListen) {
setIsFirstListen(false);
const introMessage = "Hello! I am ClarityCam, your AI assistant. I'm now listening. You can ask me to 'describe the image', 'read text', 'take a picture', or ask questions about what's in an image.";
speakText(introMessage);
} else {
speakText("Listening..."); // Optional: provide feedback on subsequent clicks
}
// ... rest of the logic to start listening
}
}, [/*...existing dependencies...*/, isFirstListen]); // Don't forget to add isFirstListen to the dependency array!
- フラグを確認する: if (isFirstListen) ブロックは、これが初回のアクティベーションかどうかを確認します。
- 繰り返しを防止: ブロック内で最初に setIsFirstListen(false) を呼び出します。これにより、セッションごとに紹介メッセージが 1 回だけ再生されるようになります。
- ガイダンスを提供する: introMessage は、できるだけ役に立つように慎重に作成されています。ユーザーに挨拶し、エージェントの名前を特定し、現在アクティブであることを確認し(「現在リッスン中です」)、使用できる音声コマンドの明確な例を提供します。
- 音声フィードバック: 最後に、speakText(introMessage) によってこの重要な情報が伝えられ、ユーザーが画面を見る必要なく、すぐに安心感とガイダンスが得られます。
機能強化 4: ユーザー設定への適応(まとめ)
真にスマートなエージェントは、応答するだけでなく、ユーザーのニーズを学習して適応します。最も強力な機能の一つとして、ユーザーが「もっと詳しく」などのコマンドを使用して、画像の説明の冗長性をその場で変更できる機能があります。
実装方法(まとめ)この機能は、describeImage フロー用に作成した動的プロンプトによって実現されています。条件付きロジックを使用して、ユーザーの設定に基づいて AI に送信される指示を変更します。
👉 コードショーケース(describe_image の promptTemplate):
const settingPreferenceTemplate = `
{#if isDetailed}
Provide a very detailed and comprehensive description of the image. Focus on specifics, including subtle elements, spatial relationships, and textures if apparent.
{else}
Provide a concise description of the image. Focus on the main subject, key objects, and primary activities or context.
{/if}
Highlight the main objects, activities, and colors.
...
`;
- 条件付きロジック:
{#if isDetailed}...{else}...{/if}ブロックが重要です。describeImageFlow がフロントエンドから detailPreference を受け取ると、isDetailed ブール値(true または false)が作成されます。 - Adaptive Instructions: このブール値フラグは、AI モデルが受け取る指示のセットを決定します。isDetailed が true の場合、モデルは詳細な説明を行うように指示されます。false の場合は、簡潔にするよう指示されます。
- ユーザー制御: このパターンでは、ユーザーの音声コマンド(「説明を簡潔にして」など。これは SetDescriptionConcise インテントとして分類されます)を AI の動作の根本的な変更に直接接続することで、エージェントが真にレスポンシブでパーソナライズされたものになります。
9. クラウドへのデプロイ
Google Cloud Build を使用して Docker イメージをビルドする
gcloud builds submit . --tag gcr.io/$PROJECT_ID/accessibilityai-nextjs-app:latest
accessibilityai-nextjs-appは、推奨されるイメージ名です。- 。現在のディレクトリ(
accessibilityAI/)をビルドソースとして使用します。
Google Cloud Run にイメージをデプロイする
- API キーなどのシークレットが Secret Manager で準備できていることを確認します。例:
GOOGLE_GENAI_API_KEY
YOUR_ACTUAL_GOOGLE_AI_KEY_VALUE は、実際の Gemini API キーの値に置き換えます。
echo "YOUR_ACTUAL_GOOGLE_AI_KEY_VALUE" | gcloud secrets create GOOGLE_GENAI_API_KEY --data-file=- --project=YOUR_PROJECT_ID
このシークレットに対する「Secret Manager のシークレット アクセサー」ロールを、Cloud Run サービスのランタイム サービス アカウント(PROJECT_NUMBER-compute@developer.gserviceaccount.com や専用のサービス アカウントなど)に付与します。
- デプロイ コマンド:
gcloud run deploy accessibilityai-app-service \
--image gcr.io/$PROJECT_ID/accessibilityai-nextjs-app:latest \
--platform managed \
--region us-central1 \
--allow-unauthenticated \
--port 3000 \
--set-secrets=GOOGLE_GENAI_API_KEY=GOOGLE_GENAI_API_KEY:latest \
--set-env-vars NODE_ENV="production"