
1. 소개
이 튜토리얼에서는 주변을 보고 이를 설명해 줄 수 있는 핸즈프리 음성 기반 AI 에이전트인 ClarityCam을 빌드합니다. ClarityCam은 시각장애인 및 저시력 사용자를 위한 강력한 도구를 제공하는 등 접근성을 핵심으로 설계되었지만, 여기서 배우는 원칙은 최신 범용 음성 애플리케이션을 만드는 데 필수적입니다.

이 프로젝트는 네이티브 적응형 인터페이스 (NAI)라는 강력한 설계 철학을 기반으로 합니다. 접근성을 사후 고려 사항으로 취급하는 대신 NAI는 접근성을 기반으로 합니다. 이 접근 방식을 사용하면 AI 에이전트가 인터페이스가 됩니다. AI 에이전트는 다양한 사용자에 맞게 조정되고, 음성 및 시각과 같은 멀티모달 입력을 처리하며, 고유한 요구사항에 따라 사람들을 선제적으로 안내합니다.
NAI로 첫 번째 AI 에이전트 빌드:

이 세션의 목표는 다음과 같습니다.
- 접근성을 기본값으로 설계: 네이티브 적응형 인터페이스 (NAI) 원칙을 적용하여 모든 사용자에게 동일한 경험을 제공하는 AI 시스템을 만듭니다.
- 사용자 의도 분류: 자연어 명령어를 에이전트의 구조화된 작업으로 변환하는 강력한 의도 분류기를 빌드합니다.
- 대화 컨텍스트 유지: 단기 메모리를 구현하여 에이전트가 후속 질문과 참조 명령어 (예: '색상이 뭐야?')를 이해할 수 있도록 합니다.
- 효과적인 프롬프트 엔지니어링: Gemini와 같은 멀티모달 모델에 대해 정확하고 신뢰할 수 있는 이미지 분석을 보장하기 위해 집중적이고 컨텍스트가 풍부한 프롬프트를 작성합니다.
- 모호성 처리 및 사용자 안내: 범위 외 요청에 대한 적절한 오류 처리를 설계하고 사용자를 사전 대응적으로 온보딩하여 신뢰와 자신감을 구축합니다.
- 멀티 에이전트 시스템 조정: 음성 처리, 분석, 음성 합성 등 복잡한 태스크를 처리하기 위해 협업하는 전문 에이전트 모음을 사용하여 애플리케이션을 구조화합니다.
2. 대략적인 디자인
ClarityCam은 기본적으로 사용자가 간단하게 사용할 수 있도록 설계되었지만, 협업하는 정교한 AI 에이전트 시스템을 기반으로 작동합니다. 아키텍처를 살펴보겠습니다.

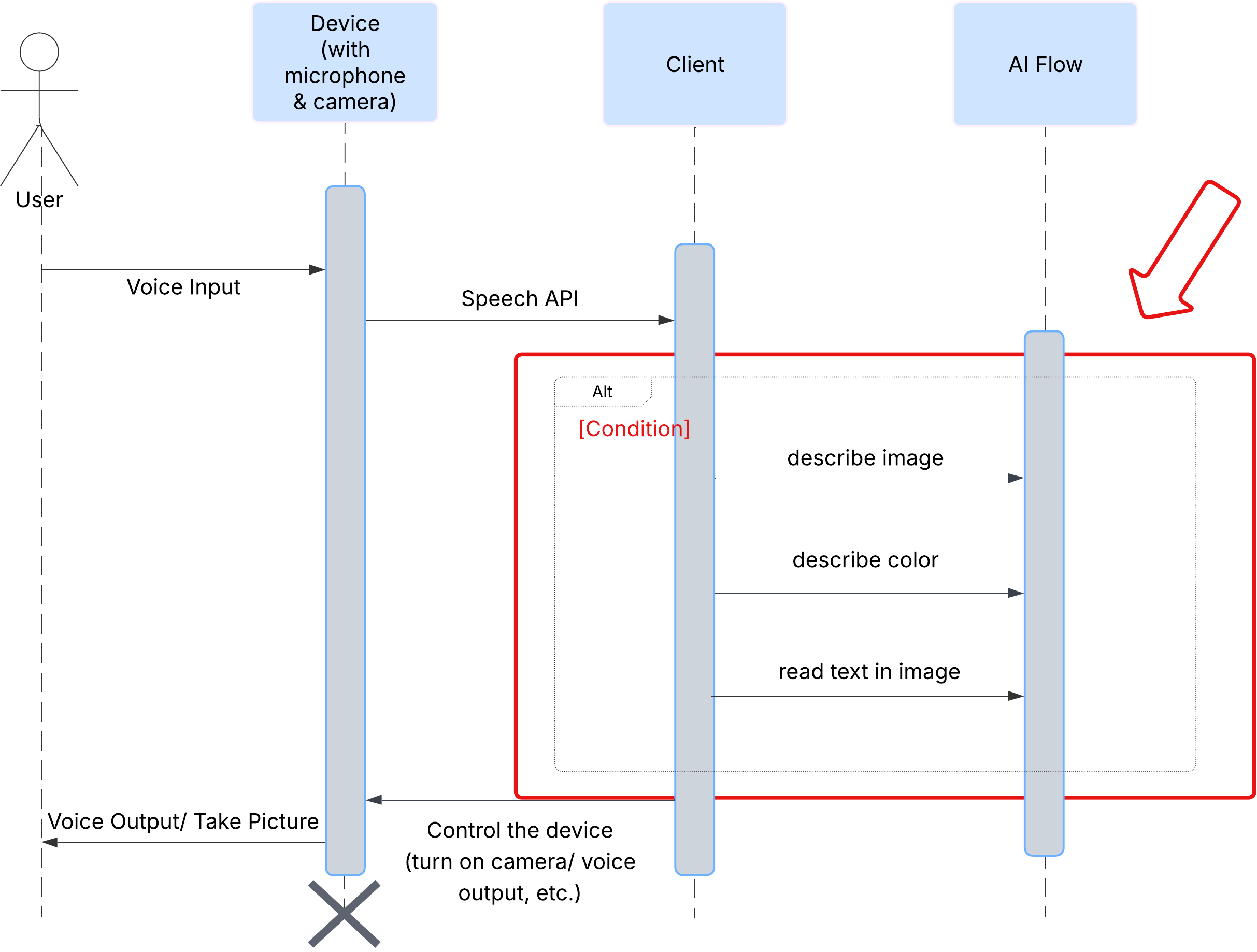
사용자 환경
먼저 사용자가 ClarityCam과 상호작용하는 방식을 살펴보겠습니다. 전체 환경이 핸즈프리 및 대화형입니다. 사용자가 명령을 말하면 에이전트가 음성 설명이나 작업으로 응답합니다. 이 시퀀스 다이어그램은 사용자의 초기 음성 명령부터 기기의 최종 오디오 응답까지의 일반적인 상호작용 흐름을 보여줍니다.
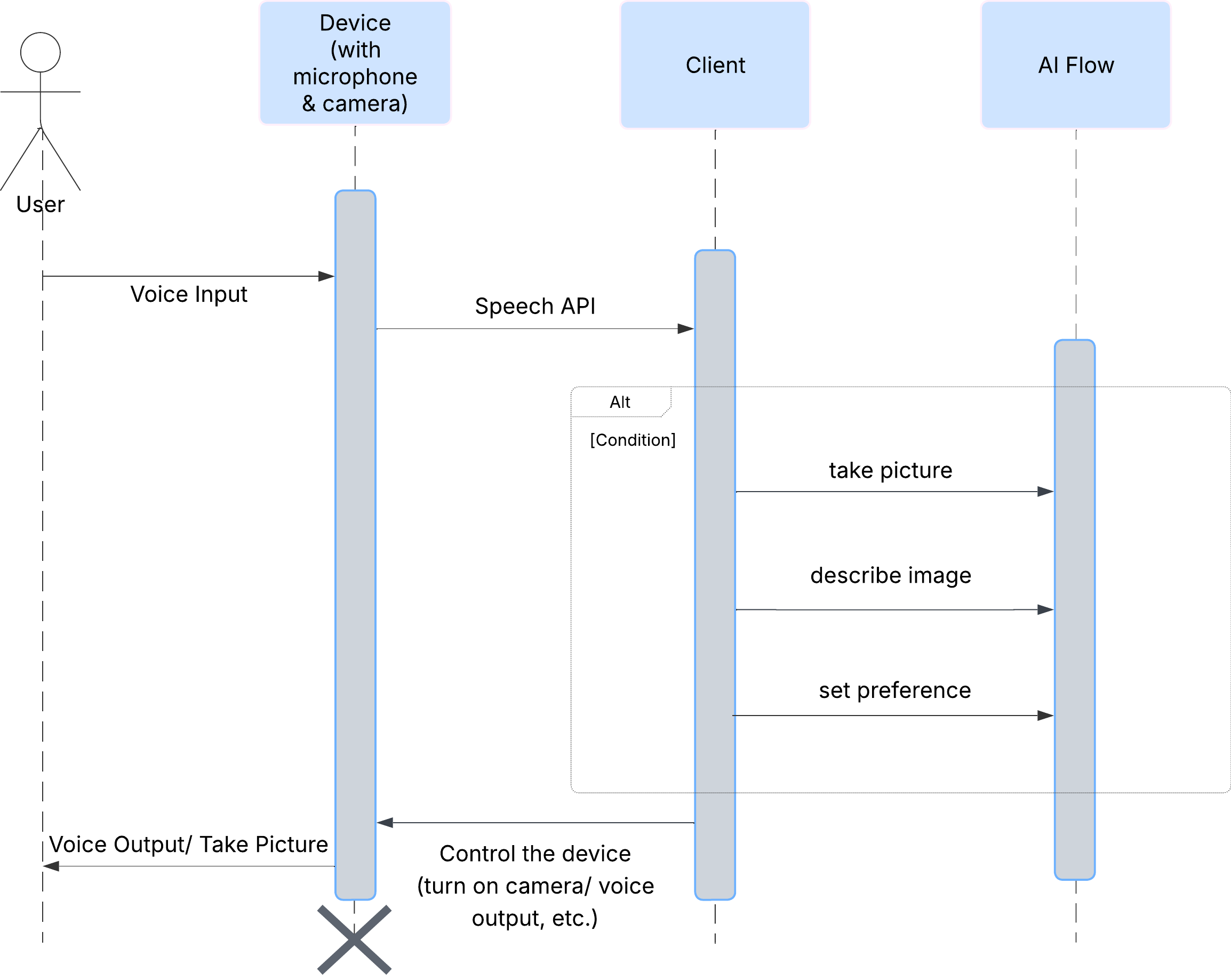
AI 에이전트 아키텍처
겉으로 드러나지 않는 부분에서 멀티 에이전트 시스템은 조화롭게 작동하여 경험을 구현합니다. 명령어가 수신되면 중앙 오케스트레이터 에이전트가 인텐트 이해, 이미지 분석, 응답 형성을 담당하는 전문 에이전트에게 작업을 위임합니다. 이 AI 흐름 다이어그램은 이러한 에이전트가 협업하는 방식을 자세히 설명합니다. 다음 섹션에서 이 아키텍처를 구현합니다.
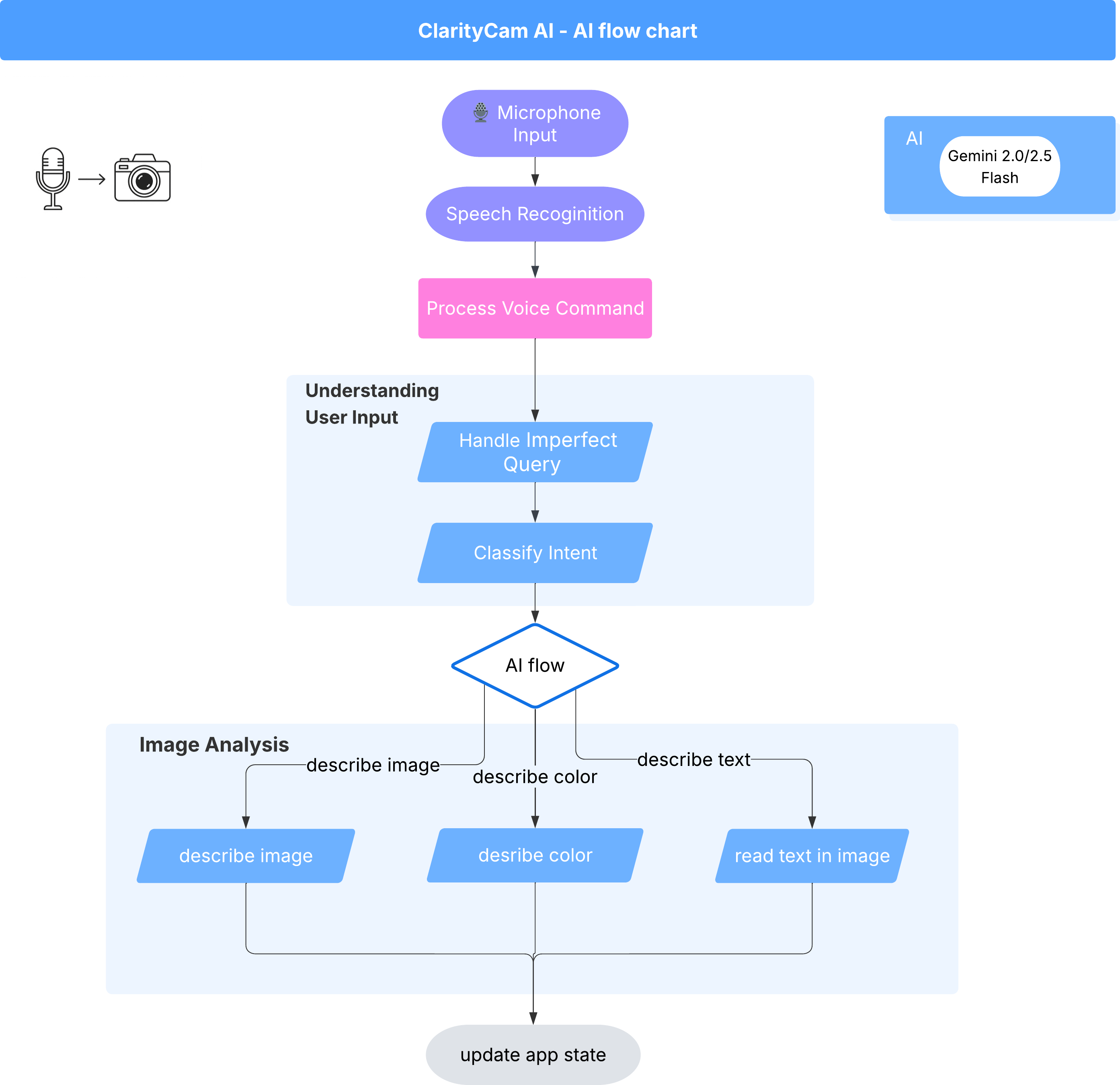
프로젝트 파일 둘러보기
코드를 작성하기 전에 프로젝트의 파일 구조를 살펴보겠습니다. 파일이 많은 것처럼 보일 수 있지만 이 튜토리얼 전체에서 두 가지 특정 영역에만 집중하면 됩니다.
다음은 프로젝트의 간단한 지도입니다.
accessibilityAI/src/
├── 📁 app/
│ ├── layout.tsx # An overall page shell (you can ignore this).
│ └── page.tsx # ⬅️ MODIFY THIS: The main user interface for our app.
│
├── 📁 ai/
│ ├── 📁flows # ⬅️ MODIFY THIS: The core AI logic and server functions.
│ └── intent-classifier.ts # ⬅️ MODIFY THIS: Where we'll edit our AI prompts.
| └── ai-instance.ts
| └── dev.ts
│
├── 📁 components/ # Contains pre-built UI components (ignore this).
│
├── 📁 hooks/
│
├── 📁 lib/
│
└── 📁 types/
기술 스택
Google 시스템은 강력한 클라우드 서비스와 최첨단 AI 모델을 결합한 확장 가능한 최신 기술 스택을 기반으로 빌드됩니다. 사용할 주요 구성요소는 다음과 같습니다.
- Google Cloud Platform (GCP): 에이전트를 위한 서버리스 인프라를 제공합니다.
- Cloud Run: 개별 에이전트를 컨테이너화된 확장 가능한 마이크로서비스로 배포합니다.
- Artifact Registry: 에이전트의 Docker 이미지를 안전하게 저장하고 관리합니다.
- Secret Manager: 민감한 사용자 인증 정보와 API 키를 안전하게 처리합니다.
- 대규모 언어 모델 (LLM): 시스템의 '두뇌' 역할을 합니다.
- Google의 Gemini 모델: 사용자 의도 분류부터 이미지 콘텐츠 분석, 지능형 설명 제공에 이르기까지 모든 작업에 Gemini 제품군의 강력한 멀티모달 기능을 사용합니다.
3. 설정 및 기본 요건
결제 계정 사용 설정 이 Codelab을 실행하려면 크레딧이 있는 결제 계정이 필요합니다. 이 Codelab 상단의 배너에 있는 크레딧을 사용하여 시작하세요. 이미 결제 계정에 연결되어 있다면 이 단계를 건너뛰어도 됩니다.
새 GCP 프로젝트 만들기
- Google Cloud 콘솔로 이동하여 새 프로젝트를 만듭니다.
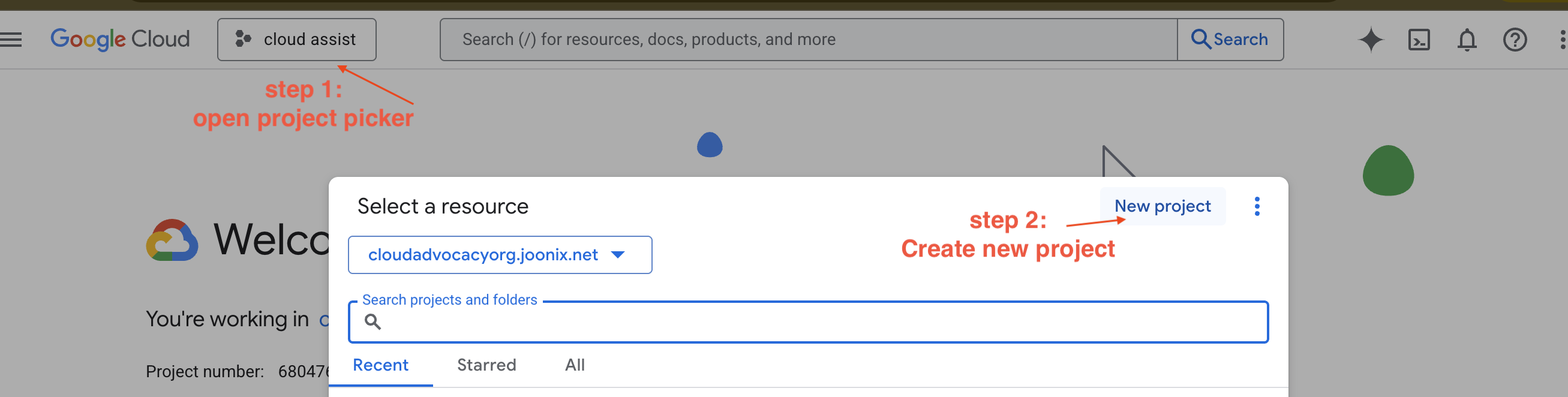
- Google Cloud 콘솔로 이동하여 새 프로젝트를 만듭니다.
- 왼쪽 패널을 열고
Billing을 클릭하여 결제 계정이 이 GCP 계정에 연결되어 있는지 확인합니다.
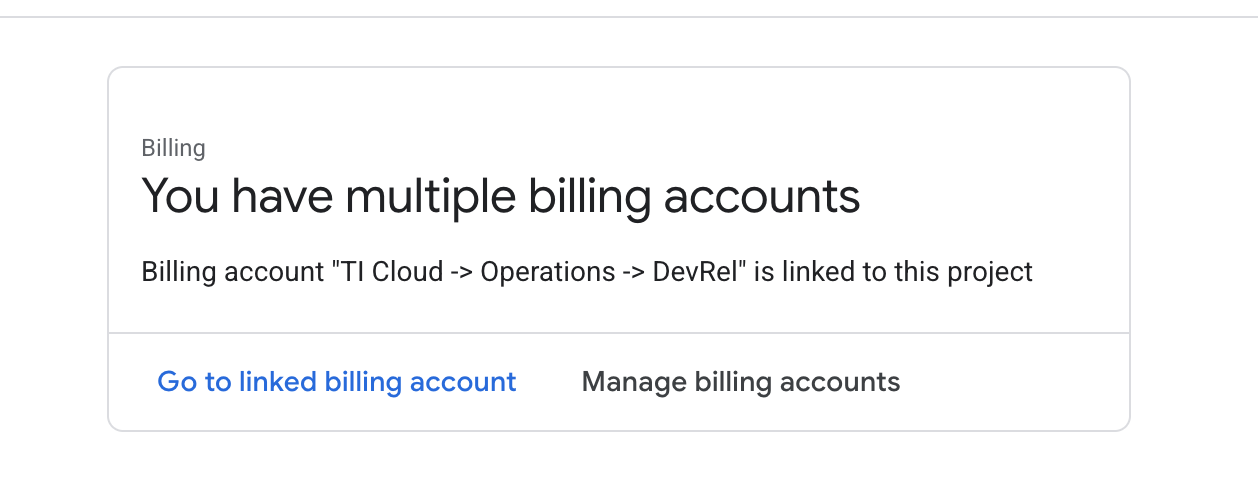
이 페이지가 표시되면 manage billing account를 확인하고 Google Cloud 무료 체험판을 선택하여 연결합니다.
Gemini API 키 만들기
키를 보호하려면 키가 있어야 합니다.
- Google AI Studio(https://aistudio.google.com/)로 이동합니다.
- Google 계정으로 로그인합니다.
- 'API 키 가져오기' 버튼을 클릭합니다. 이 버튼은 일반적으로 왼쪽 탐색 창이나 오른쪽 상단에 있습니다.
- 'API 키' 대화상자에서 '새 프로젝트에서 API 키 만들기'를 클릭합니다.
- 새 API 키가 생성됩니다. 이 키를 즉시 복사하여 비밀번호 관리자나 보안 메모와 같은 안전한 곳에 임시로 저장합니다. 이 값은 다음 단계에서 사용됩니다.
로컬 개발 워크플로 (머신에서 테스트)
npm run dev를 실행하고 앱이 작동할 수 있어야 합니다. 이때 .env가 사용됩니다.
- 파일에 API 키 추가:
.env라는 새 파일을 만들고 이 파일에 다음 줄을 추가합니다.
YOUR_API_KEY_HERE를 AI Studio에서 가져와 .env에 저장한 키로 바꿔야 합니다.
GOOGLE_GENAI_API_KEY="YOUR_API_KEY_HERE"
[선택사항] IDE 및 환경 설정
이 튜토리얼에서는 VS Code 또는 IntelliJ와 같은 익숙한 개발 환경에서 로컬 터미널을 사용하여 작업할 수 있습니다. 하지만 표준화된 사전 구성 환경을 보장하기 위해 Google Cloud Shell을 사용하는 것이 좋습니다.
다음 단계는 Cloud Shell 컨텍스트를 위해 작성되었습니다. 대신 로컬 환경을 사용하려면 git, nvm, npm, gcloud가 설치되어 있고 올바르게 구성되어 있어야 합니다.
Cloud Shell 편집기에서 작업하기
👉Google Cloud 콘솔 상단에서 Cloud Shell 활성화를 클릭합니다 (Cloud Shell 창 상단의 터미널 모양 아이콘). 
👉'편집기 열기' 버튼 (연필이 있는 열린 폴더 모양)을 클릭합니다. 그러면 창에 Cloud Shell 코드 편집기가 열립니다. 왼쪽에 파일 탐색기가 표시됩니다. 
👉그림과 같이 하단 상태 표시줄에서 Cloud Code 로그인 버튼을 클릭합니다. 안내에 따라 플러그인을 승인합니다. 상태 표시줄에 Cloud Code - 프로젝트 없음이 표시되면 이를 선택한 다음 드롭다운에서 'Google Cloud 프로젝트 선택'을 선택하고 생성한 프로젝트 목록에서 특정 Google Cloud 프로젝트를 선택합니다. 
👉클라우드 IDE에서 터미널을 엽니다. 
👉터미널에서 다음 명령어를 사용하여 이미 인증되었는지, 프로젝트가 프로젝트 ID로 설정되어 있는지 확인합니다.
gcloud auth list
👉 GitHub에서 natively-accessible-interface 프로젝트를 클론합니다.
git clone https://github.com/cuppibla/AccessibilityAgent.git
👉<YOUR_PROJECT_ID>를 프로젝트 ID로 바꿔 실행합니다. Google Cloud 콘솔의 프로젝트 부분에서 프로젝트 ID를 확인할 수 있습니다. ❗️❗️project id와 project number를 혼동하지 마세요❗️❗️
echo <YOUR_PROJECT_ID> > ~/project_id.txt
gcloud config set project $(cat ~/project_id.txt)
👉다음 명령어를 실행하여 필요한 Google Cloud API를 사용 설정합니다. 실행하는 데 약 2분이 걸릴 수 있습니다.
gcloud services enable compute.googleapis.com \
storage.googleapis.com \
run.googleapis.com \
artifactregistry.googleapis.com \
aiplatform.googleapis.com \
eventarc.googleapis.com \
sqladmin.googleapis.com \
secretmanager.googleapis.com \
cloudbuild.googleapis.com \
cloudresourcemanager.googleapis.com \
cloudfunctions.googleapis.com \
cloudaicompanion.googleapis.com
몇 분 정도 걸릴 수 있습니다.
권한 설정
👉서비스 계정 권한을 설정합니다. 터미널에서 다음을 실행합니다.
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
export SERVICE_ACCOUNT_NAME=$(gcloud compute project-info describe --format="value(defaultServiceAccount)")
echo "Here's your SERVICE_ACCOUNT_NAME $SERVICE_ACCOUNT_NAME"
👉 권한 부여 터미널에서 다음을 실행합니다.
#Cloud Storage (Read/Write):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/storage.objectAdmin"
#Pub/Sub (Publish/Receive):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/pubsub.publisher"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/pubsub.subscriber"
#Cloud SQL (Read/Write):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/cloudsql.editor"
#Eventarc (Receive Events):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/iam.serviceAccountTokenCreator"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/eventarc.eventReceiver"
#Vertex AI (User):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/aiplatform.user"
#Secret Manager (Read):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/secretmanager.secretAccessor"
4. 사용자 입력 이해 - 의도 분류기
AI 에이전트가 작업을 수행하려면 먼저 사용자가 원하는 바를 정확하게 이해해야 합니다. 실제 입력은 모호하거나, 오타가 포함되어 있거나, 대화형 언어를 사용하는 등 복잡한 경우가 많습니다.
이 섹션에서는 원시 사용자 입력을 명확하고 실행 가능한 명령어로 변환하는 중요한 '수신' 구성요소를 빌드합니다.
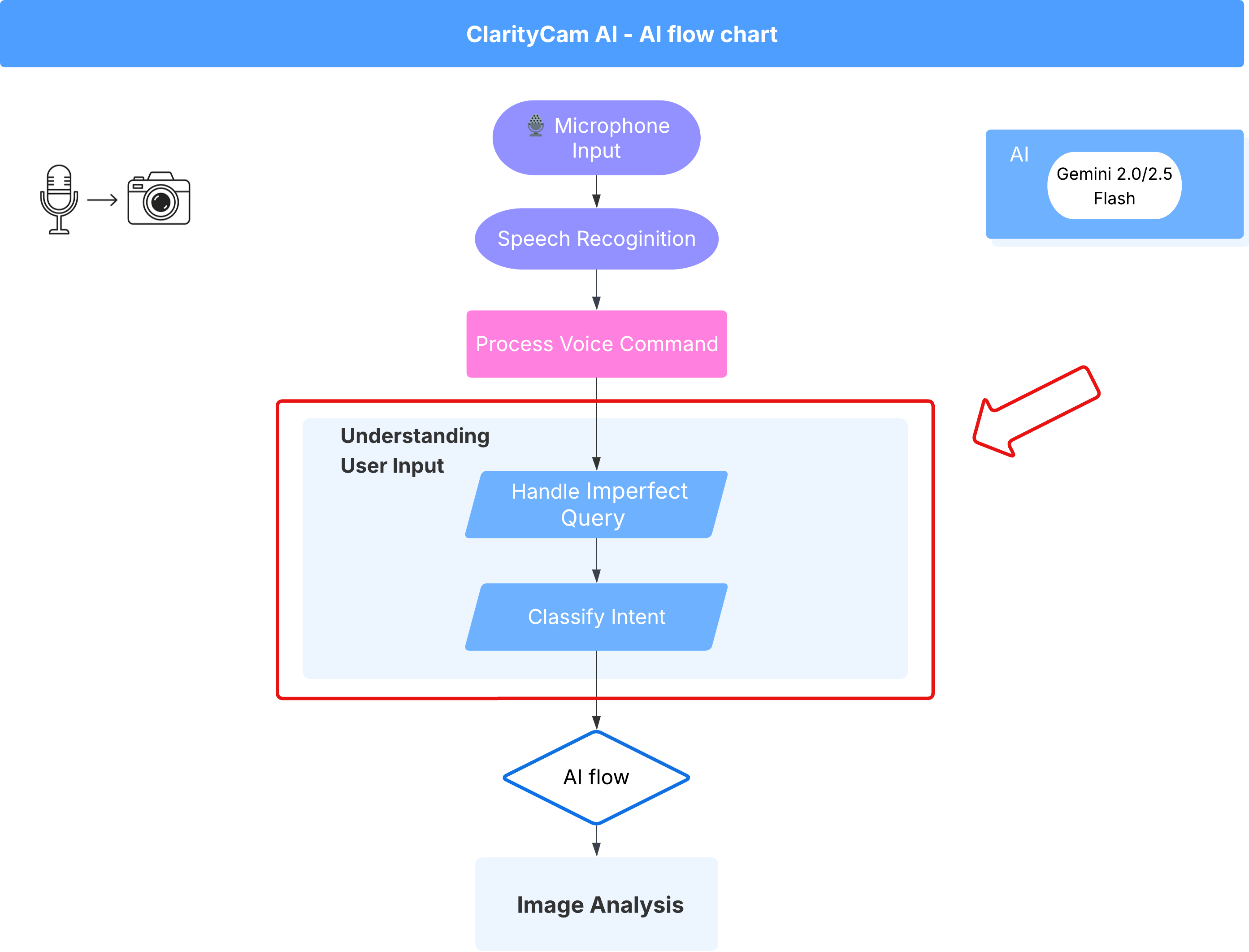
의도 분류기 추가
이제 분류기를 지원하는 AI 로직을 정의합니다.
👉 작업: Cloud Shell IDE에서 ~/src/ai/intent-classifier/ 디렉터리로 이동합니다.
1단계: 에이전트의 어휘 정의 (IntentCategory)
먼저 에이전트가 수행할 수 있는 모든 가능한 작업의 명확한 목록을 만들어야 합니다.
👉 작업: 자리표시자 // REPLACE ME PART 1: add IntentCategory here를 다음 코드로 바꿉니다.
👉 아래 코드를 사용합니다.
export type IntentCategory =
// Image Analysis Intents
| "DescribeImage"
| "AskAboutImage"
| "ReadTextInImage"
| "IdentifyColorsInImage"
// Control Intents
| "TakePicture"
| "StartCamera"
| "SelectImage"
| "StopSpeaking"
// Preference Intents
| "SetDescriptionDetailed"
| "SetDescriptionConcise"
// Fallback Intents
| "GeneralInquiry" // User has a general question about the agent's functions or polite interaction
| "OutOfScopeRequest" // User's request is clearly outside the agent's defined capabilities
| "Unknown"; // Intent could not be determined with confidence
설명
이 TypeScript 코드는 IntentCategory라는 맞춤 유형을 만듭니다. 이는 에이전트가 이해할 수 있는 모든 가능한 작업 또는 '인텐트'를 정의하는 엄격한 목록입니다. 이는 무한한 수의 사용자 문구 ('보이는 것을 말해 줘', '사진에 뭐가 있어?')를 명확하고 예측 가능한 명령어 집합으로 변환하므로 중요한 첫 번째 단계입니다. 분류기의 목표는 모든 사용자 질문을 이러한 특정 카테고리 중 하나에 매핑하는 것입니다.
2단계
정확한 결정을 내리려면 AI가 자체 기능과 한계를 알아야 합니다. 이 정보는 자세한 텍스트 블록으로 제공됩니다.
👉 작업: 자리표시자 REPLACE ME PART 2: add AGENT_CAPABILITIES_AND_LIMITATIONS here를 다음 코드로 바꿉니다.
아래 코드를 바꿉니다. // REPLACE ME PART 2: add AGENT_CAPABILITIES_AND_LIMITATIONS here:
👉 아래 코드를 사용하여
const AGENT_CAPABILITIES_AND_LIMITATIONS = `
**Core Capabilities (What the Agent CAN DO):**
* **Image Analysis:**
* DescribeImage: Provide a general description of the current image.
* AskAboutImage: Answer a specific question about the visual content of the current image (e.g., "Is there a dog?", "What color is the car?").
* ReadTextInImage: Read any text found in the current image.
* IdentifyColorsInImage: Identify the dominant colors of the current image.
* **Image Input Control:**
* TakePicture: Capture an image using the currently active camera stream.
* StartCamera: Activate the camera (e.g., "use camera", "take another picture").
* SelectImage: Allow the user to choose an image file from their device.
* **Voice & Audio Control:**
* StopSpeaking: Stop the current text-to-speech output.
* **Preference Management:**
* SetDescriptionDetailed: Make future image descriptions more detailed.
* SetDescriptionConcise: Make future image descriptions less detailed or concise.
* **General Interaction:**
* GeneralInquiry: Handle conversational phrases (e.g., "hello", "thank you") or questions about its own capabilities (e.g., "what can you do?", "help").
**Limitations (What the Agent CANNOT DO and should be classified as OutOfScopeRequest):**
* Cannot generate or create new images.
* Cannot edit or modify existing images (e.g., "remove background," "make the car blue").
* Cannot analyze video files or live video beyond capturing a single frame.
* Cannot provide general knowledge or answer questions unrelated to the provided image's visual content (e.g., "What's the weather?", "Who is the president?", "Tell me a joke", "What time is it?").
* Cannot perform mathematical calculations or complex data analysis.
* Cannot translate languages as a primary function.
* Cannot remember information from past images or vastly different previous queries in the same session.
* Cannot control other device settings or applications.
* Cannot perform web searches.
`;
중요한 이유:
이 텍스트는 사용자가 읽는 것이 아니라 Google의 AI 모델을 위한 것입니다. 정확한 결정을 내리는 데 필요한 컨텍스트를 언어 모델(LLM)에 제공하기 위해 다음 단계에서 이 '직무 설명'을 프롬프트에 직접 입력합니다. 이 컨텍스트가 없으면 LLM이 '날씨는 어때?'를 AskAboutImage로 잘못 분류할 수 있습니다. 이 컨텍스트를 통해 날씨가 이미지의 시각적 요소가 아님을 알 수 있으며 범위 외로 올바르게 분류됩니다.
3단계
이제 Gemini 모델이 분류를 실행하기 위해 따를 전체 명령어 세트를 작성합니다.
👉 작업: // REPLACE ME PART 3 - classifyIntentPrompt를 다음 코드로 바꿉니다.
아래 코드를 사용합니다.
const classifyIntentPrompt = ai.definePrompt({
name: 'classifyIntentPrompt',
input: { schema: ClassifyIntentInputSchema },
output: { schema: ClassifyIntentOutputSchema },
prompt: `You are classifying the user's intent for ClarityCam, a voice-controlled AI application focused on image analysis.
Analyze the user query: '{userQuery}'.
First, understand ClarityCam's capabilities and limitations:
${AGENT_CAPABILITIES_AND_LIMITATIONS}
Now, classify the user's PRIMARY intent into ONE of the following categories:
* **DescribeImage**: User wants a general description of the current image.
* **AskAboutImage**: User is asking a specific question directly related to the visual content of the current image.
* **ReadTextInImage**: User wants any text read from the current image.
* **IdentifyColorsInImage**: User wants the dominant colors of the current image.
* **TakePicture**: User wants to capture an image using an active camera.
* **StartCamera**: User wants to activate the camera.
* **SelectImage**: User wants to choose an image file.
* **StopSpeaking**: User wants the current text-to-speech output to stop.
* **SetDescriptionDetailed**: User wants future image descriptions to be more detailed.
* **SetDescriptionConcise**: User wants future image descriptions to be less detailed.
* **GeneralInquiry**: The query is a simple conversational filler (e.g., "hello", "thanks"), a polite closing, or a direct question about the agent's functions (e.g., "what can you do?", "how does this work?", "help").
* **OutOfScopeRequest**: The query asks the agent to perform an action clearly listed under its "Limitations" or otherwise demonstrably outside its defined image analysis and control functions. Examples: "Tell me a joke," "What's the weather in London?", "Generate an image of a cat," "Can you edit my photo to make it brighter?", "Send this image to my friends","Translate 'hello' to Spanish."
Output ONLY the category name.
If the query is ambiguous but seems generally related to polite interaction or asking about the agent itself, prefer 'GeneralInquiry'.
If the query is clearly asking for something the agent CANNOT do, use 'OutOfScopeRequest'.
If truly unclassifiable even with these guidelines, use 'Unknown'.`,
config: {
temperature: 0.05, // Very low temperature for highly deterministic classification
}
});
이 프롬프트에서 마법 같은 일이 일어납니다. AI의 역할을 알려주고, 필요한 맥락을 제공하고, 원하는 출력을 정의하는 분류기의 '두뇌'입니다. 다음과 같은 주요 프롬프트 엔지니어링 기법을 참고하세요.
- 역할극: 명확한 작업을 설정하기 위해 '분류하고 있어...'로 시작합니다.
- 컨텍스트 삽입:
AGENT_CAPABILITIES_AND_LIMITATIONS변수를 프롬프트에 동적으로 삽입합니다. - 엄격한 출력 형식 지정: '카테고리 이름만 출력해'라는 요청 사항은 코드에서 쉽게 사용할 수 있는 깔끔하고 예측 가능한 대답을 얻는 데 매우 중요합니다.
- 낮은 온도: 분류의 경우 창의적인 답변이 아닌 결정적이고 논리적인 답변이 필요합니다. 온도를 매우 낮은 값 (0.05)으로 설정하면 모델의 집중도가 높아지고 일관성이 유지됩니다.
4단계: 앱을 AI 흐름에 연결
마지막으로 기본 애플리케이션 파일에서 새 AI 분류기를 호출합니다.
👉 작업: ~/src/app/page.tsx 파일로 이동합니다. processVoiceCommand 함수 내에서 여기의 // REPLACE ME PART 1: add classificationResult를 다음으로 바꿉니다.
const classificationResult = await classifyIntentFlow({ userQuery: commandToProcess });
intent = classificationResult.intent as IntentCategory;
이 코드는 프런트엔드 애플리케이션과 백엔드 AI 로직 간의 중요한 연결고리입니다. 사용자의 음성 명령 (commandToProcess)을 가져와 방금 빌드한 classifyIntentFlow에 전송하고 AI가 분류된 의도를 반환할 때까지 기다립니다.
이제 인텐트 변수가 정리된 구조화된 명령어 (예: DescribeImage)를 보유합니다. 이 결과는 애플리케이션의 로직을 실행하고 다음에 취할 조치를 결정하기 위해 이어지는 switch 문에서 사용됩니다. AI의 '생각'이 앱의 '행동'으로 바뀌는 방식입니다.
사용자 인터페이스 실행
이제 애플리케이션이 실제로 작동하는지 확인해 보겠습니다. 개발 서버를 시작해 보겠습니다.
👉 터미널에서 다음 명령어를 실행합니다. npm run dev 참고: npm run dev를 실행하기 전에 npm install를 실행해야 할 수도 있습니다.
잠시 후 다음과 비슷한 출력이 표시됩니다. 이는 서버가 성공적으로 실행되고 있음을 의미합니다.
▲ Next.js 15.2.3 (Turbopack)
- Local: http://localhost:9003
- Network: http://10.88.0.4:9003
- Environments: .env
✓ Starting...
✓ Ready in 1512ms
○ Compiling / ...
✓ Compiled / in 26.6s
이제 로컬 URL (http://localhost:9003)을 클릭하여 브라우저에서 애플리케이션을 엽니다.
SightGuide 사용자 인터페이스가 표시됩니다. 현재 버튼은 로직에 연결되어 있지 않으므로 클릭해도 아무 작업도 발생하지 않습니다. 이 단계에서 예상되는 결과입니다. 다음 섹션에서 이러한 요소를 구현해 보겠습니다.
UI를 확인했으므로 터미널로 돌아가 Ctrl + C를 눌러 개발 서버를 중지한 후 계속 진행합니다.
5. 사용자 입력 이해 - 불완전한 쿼리 확인
불완전한 쿼리 확인 추가
1부: 프롬프트 정의('무엇')
먼저 AI에 대한 안내를 정의해 보겠습니다. 프롬프트는 AI 호출을 위한 '레시피'입니다. 모델에 원하는 작업을 정확하게 알려줍니다.
👉 작업: IDE에서 ~/src/ai/flows/check_typo/로 이동합니다.
아래 코드를 바꿉니다. // REPLACE ME PART 1: add prompt here:
👉 아래 코드를 사용하여
const prompt = ai.definePrompt({
name: 'checkTypoPrompt',
input: {
schema: CheckTypoInputSchema,
},
output: {
schema: CheckTypoOutputSchema,
},
prompt: `You are a helpful AI assistant that checks user text for typos and suggests corrections.
- If you find typos, respond with the corrected text.
- If there are no typos, or if you are unsure about a correction, respond with the original text unchanged.
User text: {text}
Corrected text:
`,
});
이 코드 블록은 AI를 위한 재사용 가능한 템플릿(checkTypoPrompt)을 정의합니다. 입력 및 출력 스키마는 이 작업의 데이터 계약을 정의합니다. 이렇게 하면 오류를 방지하고 시스템을 예측 가능하게 만들 수 있습니다.
2부: 흐름 만들기('방법')
이제 '레시피' (프롬프트)가 있으므로 실제로 실행할 수 있는 함수를 만들어야 합니다. Genkit에서는 이를 흐름이라고 합니다. 흐름은 애플리케이션의 나머지 부분에서 쉽게 호출할 수 있는 실행 가능한 함수로 프롬프트를 래핑합니다.
👉 작업: 동일한 ~/src/ai/flows/check_typo/ 파일에서 아래 코드를 바꿉니다. // REPLACE ME PART 2: add flow here:
👉 아래 코드를 사용하여
const checkTypoFlow = ai.defineFlow<
typeof CheckTypoInputSchema,
typeof CheckTypoOutputSchema
>(
{
name: 'checkTypoFlow',
inputSchema: CheckTypoInputSchema,
outputSchema: CheckTypoOutputSchema,
},
async input => {
const {output} = await prompt(input);
return output!;
}
);
3부: 맞춤법 검사기 사용하기
AI 흐름이 완료되었으므로 이제 애플리케이션의 기본 로직에 통합할 수 있습니다. 사용자의 명령을 받은 직후에 호출하여 추가 처리 전에 텍스트가 정리되도록 합니다.
👉작업: ~/src/app/ai/flows/check-typo.ts로 이동하여 export async function checkTypo 함수를 찾습니다. return 문에 대한 주석 처리를 삭제합니다.
return; 대신 return checkTypoFlow(input);을 사용하세요.
👉작업: ~/src/app/page.tsx로 이동하여 processVoiceCommand 함수를 찾습니다. 아래 코드를 바꿉니다. REPLACE ME PART 2: add typoResult here:
👉 아래 코드를 사용하여
const typoResult = await checkTypo({ text: rawCommand });
if (typoResult && typoResult.correctedText && typoResult.correctedText.trim().length > 0) {
const originalTrimmedLower = rawCommand.trim().toLowerCase();
const correctedTrimmedLower = typoResult.correctedText.trim().toLowerCase();
if (correctedTrimmedLower !== originalTrimmedLower) {
commandToProcess = typoResult.correctedText;
typoCorrectionAnnouncement = `I think you said: ${commandToProcess}. `;
}
}
이번 변경으로 모든 사용자 명령에 대해 더 강력한 데이터 처리 파이프라인이 생성되었습니다.
음성 명령 흐름 (읽기 전용, 조치 필요 없음)
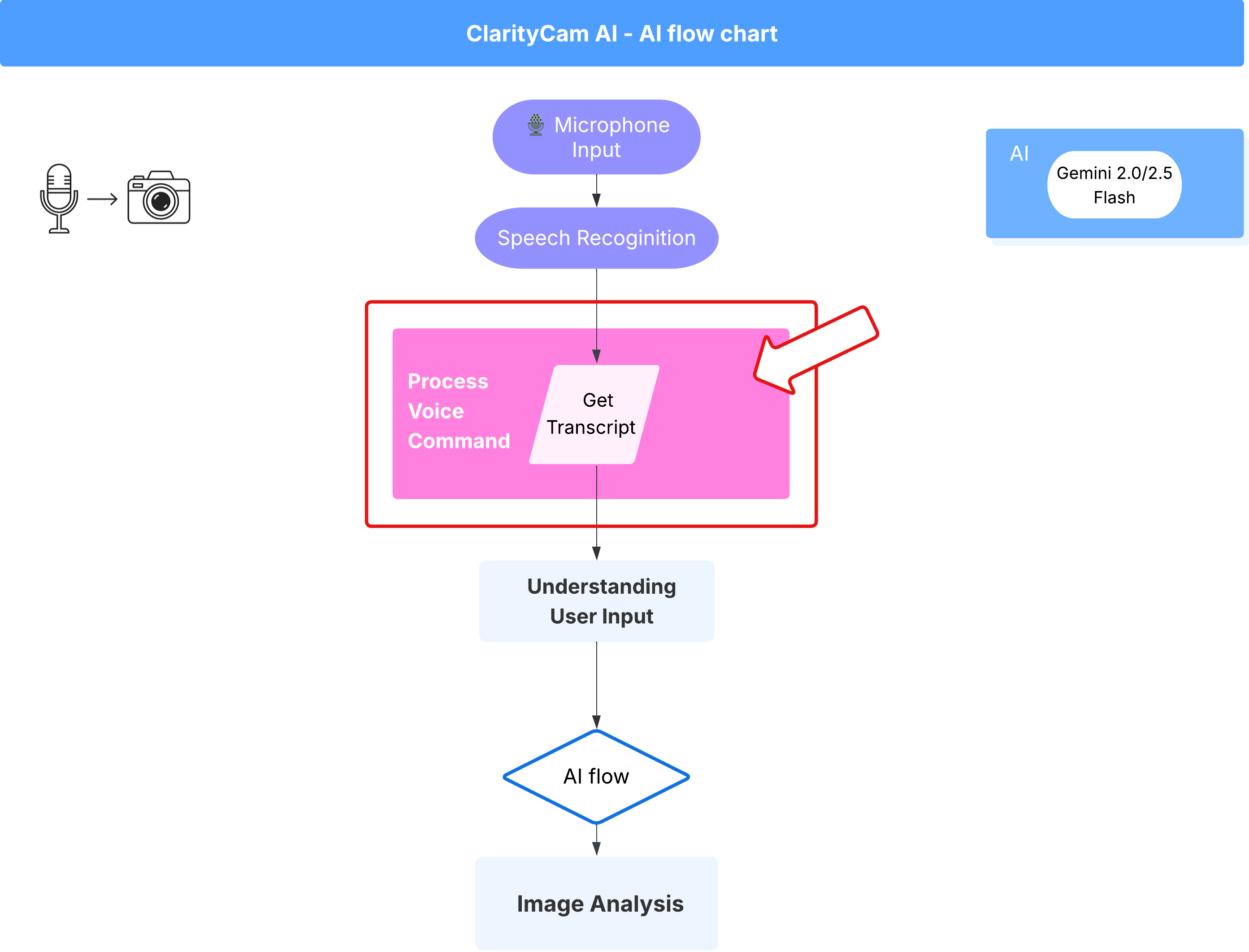
이제 핵심 '이해' 구성요소 (오타 검사기 및 의도 분류기)가 있으므로 애플리케이션의 기본 음성 처리 로직에 어떻게 적합한지 살펴보겠습니다.
모든 것은 사용자가 말할 때 시작됩니다. 브라우저의 Web Speech API는 음성을 수신하고 사용자가 말을 마치면 들은 내용의 텍스트 스크립트를 제공합니다. 다음 코드는 이 프로세스를 처리합니다.
👉읽기 전용: ~/src/app/page.tsx로 이동하고 handleResult 함수 내부로 이동합니다. 아래 코드를 찾습니다.
for (let i = event.resultIndex; i < event.results.length; ++i) {
if (event.results[i].isFinal) {
finalTranscript += event.results[i][0].transcript;
}
}
if (finalTranscript) {
console.log("Final Transcript:", finalTranscript);
processVoiceCommand(finalTranscript);
}
오타 수정 테스트
이제 재미있는 부분을 살펴볼까요? 새로운 오타 수정 기능이 완벽한 음성 명령과 불완전한 음성 명령을 어떻게 처리하는지 살펴보겠습니다.
애플리케이션 시작
먼저 개발 서버를 다시 실행해 보겠습니다. 터미널에서 npm run dev을 실행합니다.
앱 열기
서버가 준비되면 브라우저를 열고 로컬 주소 (예: http://localhost:9003)로 이동합니다.
음성 명령 활성화
Start Listening 버튼을 클릭합니다. 브라우저에서 마이크 사용 권한을 요청할 수 있습니다. 허용을 클릭하세요.
불완전한 명령어 테스트
이제 AI가 이를 파악할 수 있는지 확인하기 위해 약간 결함이 있는 명령어를 의도적으로 입력해 보겠습니다. 마이크에 대고 명확하게 말합니다.
'내 사진 찍어 줘'
결과 관찰하기
아직 생성된 실험이 없습니다. '내 사진 찍어줘'라고 말해도 애플리케이션에서 카메라를 올바르게 활성화해야 합니다. checkTypo 흐름은 백그라운드에서 문구를 '사진 촬영'으로 수정하고 classifyIntentFlow는 수정된 명령어를 이해합니다.
이를 통해 오타 수정 기능이 완벽하게 작동하여 앱이 훨씬 더 안정적이고 사용자 친화적이라는 것을 확인할 수 있습니다. 완료되면 사진을 찍어 카메라를 중지하거나 터미널에서 서버를 중지하면 됩니다 (Ctrl + C).
6. AI 기반 이미지 분석 - 이미지 설명
이제 에이전트가 요청을 이해할 수 있으므로 에이전트에게 시각을 부여할 차례입니다. 이 섹션에서는 모든 이미지 분석을 담당하는 핵심 구성요소인 Vision Agent의 기능을 빌드합니다. 가장 중요한 기능인 이미지 설명부터 시작하여 텍스트를 읽는 기능을 추가할 예정입니다.
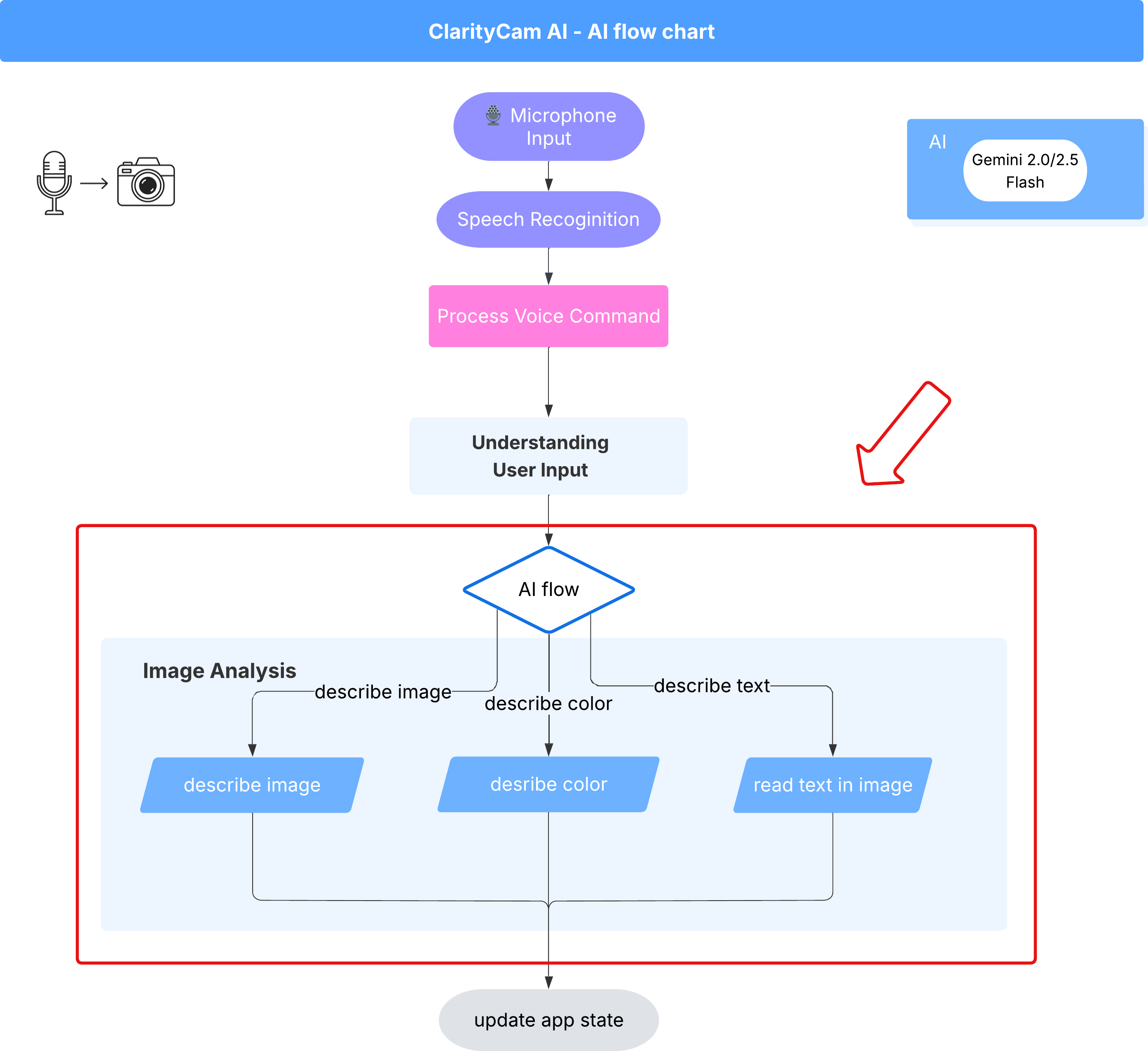
기능 1: 이미지 설명
이는 상담사의 기본 기능입니다. 정적인 설명만 생성하는 것이 아니라 사용자 환경설정에 따라 세부정보 수준을 조정할 수 있는 동적 플로우를 구축합니다. 이는 Natively Adaptive Interface (NAI) 철학의 핵심 부분입니다.
👉 작업: Cloud Shell IDE에서 ~/src/ai/flows/describe_image/ 파일로 이동하여 다음 코드를 주석 처리 삭제합니다.
1단계: 동적 프롬프트 템플릿 빌드하기
먼저 입력에 따라 안내를 변경할 수 있는 정교한 프롬프트 템플릿을 만듭니다.
아래 코드의 주석 처리를 해제합니다.
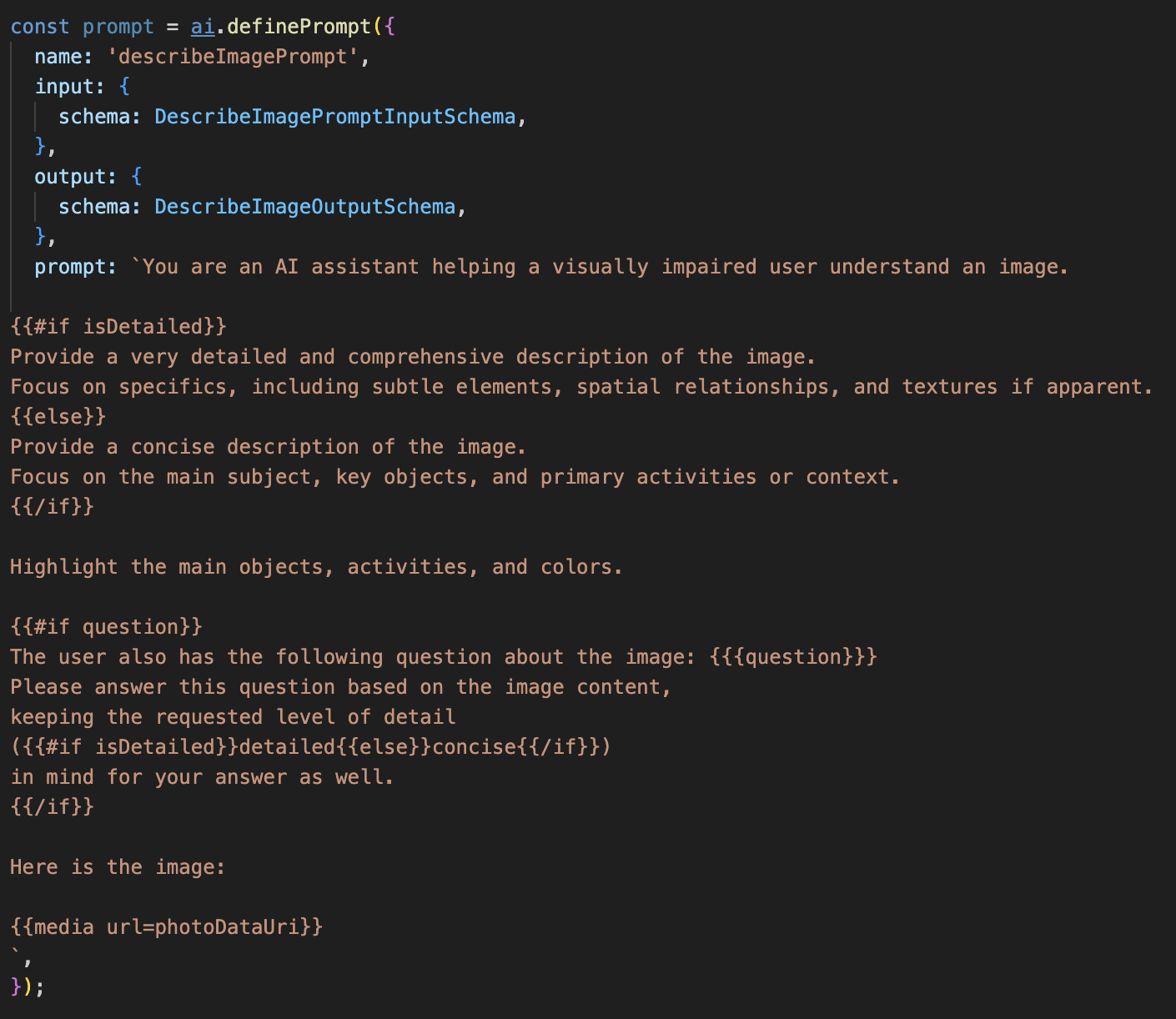
이 코드는 Dot-Mustache라는 템플릿 언어를 사용하는 문자열 변수 prompt를 정의합니다. 이를 통해 조건부 로직을 프롬프트에 직접 삽입할 수 있습니다.
{#if isDetailed}...{else}...{/if}: 조건부 블록입니다. 이 프롬프트에 전송하는 입력 데이터에 isDetailed: true 속성이 포함되어 있으면 AI는 '매우 상세한' 지침을 받게 됩니다. 그렇지 않으면 '간결한' 안내가 표시됩니다. 상담사가 사용자 선호도에 적응하는 방식입니다.
{#if question}...{/if}: 이 블록은 입력 데이터에 질문 속성이 포함된 경우에만 포함됩니다. 이를 통해 일반적인 설명과 구체적인 질문에 모두 동일한 강력한 프롬프트를 사용할 수 있습니다.
{media url=photoDataUri}: 멀티모달 모델이 분석할 수 있도록 이미지 데이터를 프롬프트에 직접 삽입하는 Genkit의 특수 구문입니다.
2단계: 스마트 흐름 만들기
다음으로 새 템플릿을 사용할 프롬프트와 흐름을 정의합니다. 이 흐름에는 사용자의 선호도를 템플릿이 이해할 수 있는 불리언으로 변환하는 로직이 포함되어 있습니다.
👉 작업: Cloud Shell IDE의 동일한 ~/src/ai/flows/describe_image/ 파일에서 다음 코드를 바꿉니다. // REPLACE ME PART 1: add flow here
👉 아래 코드를 사용합니다.
// Define the prompt using the template from Step 1
const prompt = ai.definePrompt({
name: 'describeImagePrompt',
input: { schema: DescribeImagePromptInputSchema },
output: { schema: DescribeImageOutputSchema },
prompt: promptTemplate,
});
// Define the flow
const describeImageFlow = ai.defineFlow<
typeof DescribeImageInputSchema,
typeof DescribeImageOutputSchema
>(
{
name: 'describeImageFlow',
inputSchema: DescribeImageInputSchema,
outputSchema: DescribeImageOutputSchema,
},
async (pageInput) => {
const preference = pageInput.detailPreference || "concise";
// Prepare the input for the prompt, including the new boolean flag
const promptInputData = {
...pageInput,
isDetailed: preference === "detailed",
};
const { output } = await prompt(promptInputData);
return output!;
}
);
이는 프런트엔드와 AI 프롬프트 간의 스마트한 중개자 역할을 합니다.
- 애플리케이션에서
pageInput를 수신합니다. 여기에는 사용자의 환경설정이 문자열 (예:"detailed")로 포함됩니다. - 그런 다음 새 객체
promptInputData를 만듭니다. - 가장 중요한 줄은
isDetailed: preference === "detailed"입니다. 이 줄은 환경설정 문자열에 따라true또는false불리언 값을 만드는 중요한 작업을 실행합니다. - 마지막으로 이 향상된 데이터로
prompt을 호출합니다. 이제 1단계의 프롬프트 템플릿에서isDetailed불리언을 사용하여 AI에 전송되는 요청 사항을 동적으로 변경할 수 있습니다.
3단계: 프런트엔드 연결하기
이제 page.tsx의 사용자 인터페이스에서 이 흐름을 트리거해 보겠습니다.
👉작업: ~/src/app/ai/flows/describe-image.ts로 이동하여 export async function describeImage 함수를 찾습니다. return 문에 대한 주석 처리를 삭제합니다.
return; 대신 return describeImageFlow(input);을 사용하세요.
👉작업: ~/src/app/page.tsx에서 handleAnalyze 함수를 찾아 // REPLACE ME PART 2: DESCRIBE IMAGE 코드를 다음 코드로 바꿉니다.
👉 다음 코드를 사용합니다.
case "description":
result = await describeImage({
photoDataUri,
question,
detailPreference: descriptionPreference
});
outputText = question ? `Answer: ${result.description}` : `Description: ${result.description}`;
break;
사용자의 인텐트가 설명을 가져오려는 경우 이 코드가 실행됩니다. React 구성요소에서 이미지 데이터와 중요한 descriptionPreference 상태 변수를 전달하여 describeImage 흐름을 호출합니다. 이는 퍼즐의 마지막 조각으로, UI에 저장된 사용자의 환경설정을 이에 따라 동작을 조정하는 AI 흐름에 직접 연결합니다.
이미지 설명 기능 테스트
사진을 촬영하는 것부터 AI가 인식하는 내용을 듣는 것까지 이미지 설명 기능이 작동하는 모습을 살펴보겠습니다.
애플리케이션 시작
먼저 개발 서버를 다시 실행해 보겠습니다. 👉 터미널에서 다음 명령어를 실행합니다. npm run dev 참고: npm run dev를 실행하기 전에 npm install를 실행해야 할 수도 있습니다.
앱 열기
서버가 준비되면 브라우저를 열고 로컬 주소 (예: http://localhost:9003)로 이동합니다.
카메라 활성화
듣기 시작 버튼을 클릭하고 메시지가 표시되면 마이크 액세스 권한을 부여합니다. 그런 다음 첫 번째 명령어를 말합니다.
'사진 찍어 줘'
애플리케이션이 기기의 카메라를 활성화합니다. 이제 화면에 라이브 동영상 피드가 표시됩니다.
사진 촬영
카메라가 활성화된 상태에서 설명하려는 대상을 향하도록 카메라를 배치합니다. 이제 명령어를 다시 말하여 이미지를 캡처합니다.
'사진 찍어 줘'
라이브 동영상이 방금 촬영한 정적 사진으로 대체됩니다.
설명 요청하기
화면에 새 사진이 표시되면 최종 명령어를 입력합니다.
'사진 설명'
결과 듣기
앱에 처리 상태가 표시된 후 이미지에 대한 AI 생성 설명이 음성으로 제공됩니다. 텍스트는 '상태 및 결과' 카드에도 표시됩니다.
완료되면 사진을 찍거나 터미널에서 서버를 중지 (Ctrl + C)하여 카메라를 중지할 수 있습니다.
7. AI 기반 이미지 분석 - 텍스트 설명 (OCR)
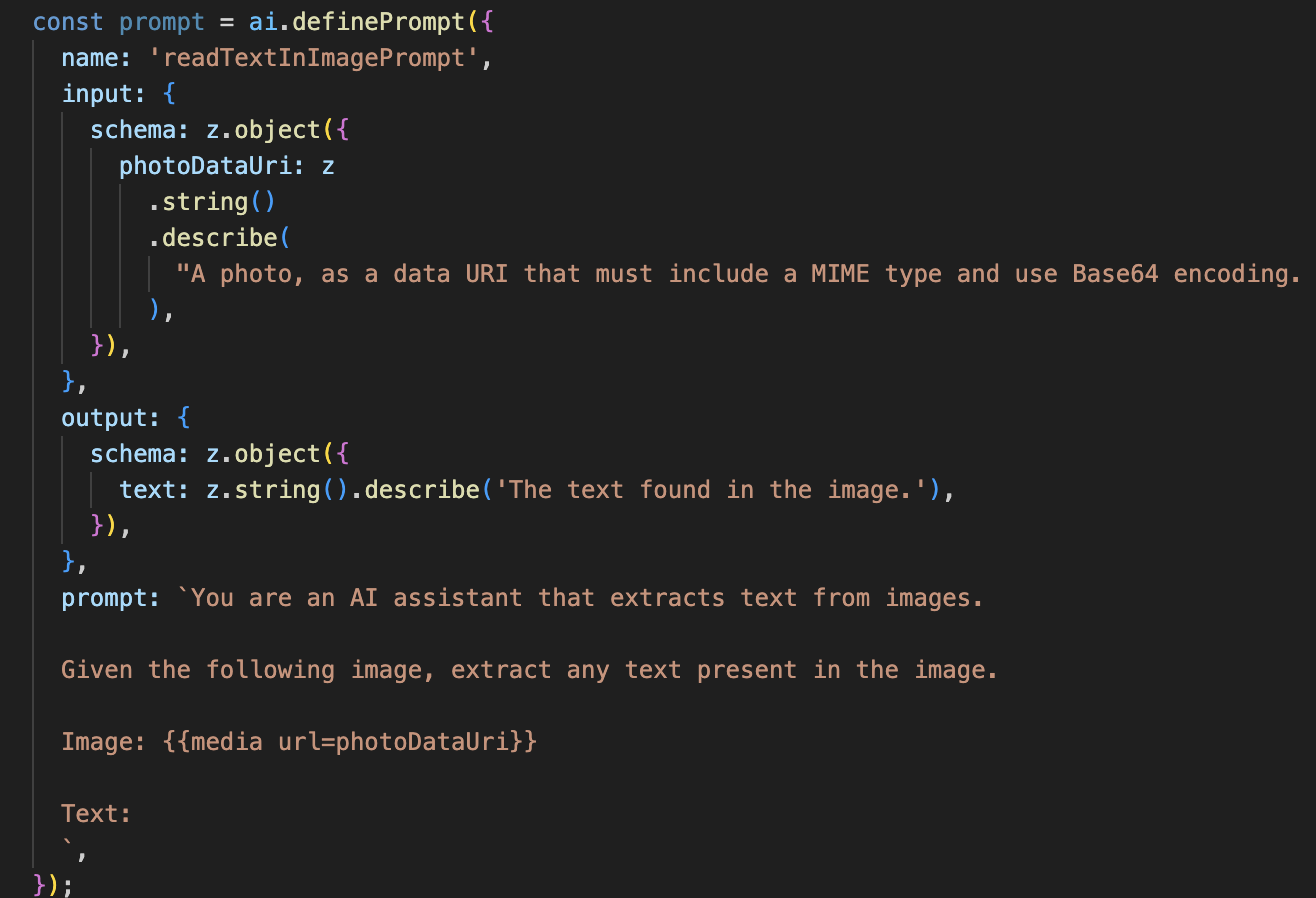
다음으로 Vision Agent에 광학 문자 인식 (OCR) 기능을 추가합니다. 이를 통해 모든 이미지에서 텍스트를 읽을 수 있습니다.
👉 작업: IDE에서 ~/src/ai/flows/read-text-in-image/로 이동하여 아래 코드를 주석 처리 삭제합니다.
👉 조치: IDE의 동일한 ~/src/ai/flows/read-text-in-image/ 파일에서 // REPLACE ME: Creating Prmopt를
👉 아래 코드를 사용합니다.
const readTextInImageFlow = ai.defineFlow<
typeof ReadTextInImageInputSchema,
typeof ReadTextInImageOutputSchema
>(
{
name: 'readTextInImageFlow',
inputSchema: ReadTextInImageInputSchema,
outputSchema: ReadTextInImageOutputSchema,
},
async input => {
const {output} = await prompt(input);
return output!;
}
);
이 AI 흐름은 훨씬 간단하며 특정 작업에 집중된 도구를 사용한다는 원칙을 강조합니다.
- 프롬프트: 설명 프롬프트와 달리 이 프롬프트는 정적이며 매우 구체적입니다. 이 프롬프트의 유일한 역할은 AI가 OCR 엔진으로 작동하도록 지시하는 것입니다('이미지에 있는 텍스트를 추출해').
- 스키마: 입력 및 출력 스키마도 간단하며 이미지를 예상하고 텍스트 문자열 하나를 반환합니다.
OCR용 프런트엔드 연결
마지막으로 page.tsx에서 이 새로운 기능을 연결해 보겠습니다.
👉작업: ~/src/app/ai/flows/read-text-in-image.ts로 이동하여 export async function readTextInImage 함수를 찾습니다. return 문에 대한 주석 처리를 삭제합니다.
return; 대신 return readTextInImageFlow(input);을 사용하세요.
👉 작업: ~/src/app/page.tsx에서 handleAnalyze 함수와 switch 문을 찾습니다.
REPLACE ME PART 3: READ TEXT 바꾸기
아래 코드를 사용합니다.
case "text":
result = await readTextInImage({ photoDataUri });
outputText = result.text ? `Text Found: ${result.text}` : "No text found.";
break;
사용자의 의도가 ReadTextInImage인 경우 이 코드가 트리거됩니다. 간단한 readTextInImage 흐름을 호출합니다. result.text ? ... : ... 줄은 출력을 처리하는 깔끔한 방법으로, AI가 이미지에서 텍스트를 찾을 수 없는 경우 사용자에게 유용한 메시지를 제공합니다.
텍스트 읽기 (OCR) 기능 테스트
텍스트 읽어주기 기능을 테스트하려면 다음 단계를 따르세요. 카메라를 텍스트가 명확한 물체에 조준해야 합니다.
npm run dev로 애플리케이션을 실행하고 브라우저에서 엽니다.- '듣기 시작'을 클릭하고 메시지가 표시되면 마이크 액세스 권한을 부여합니다.
- 카메라를 활성화합니다. '사진 찍어 줘'라고 말합니다. 화면에 라이브 동영상 피드가 표시됩니다.
- 사진을 촬영합니다. 읽고 싶은 텍스트를 카메라로 가리키고 '사진 찍어줘'라는 명령어를 다시 말합니다. 동영상이 정지된 사진으로 대체됩니다.
- 텍스트를 요청합니다. 사진이 캡처되었으므로 마지막 명령어를 입력합니다. '이미지의 텍스트는 뭐야?'
- 결과 확인 잠시 후 앱에서 사진을 분석하고 감지된 텍스트를 소리 내어 읽어 줍니다. 텍스트를 찾을 수 없으면 알려줍니다.
강력한 OCR 기능이 작동하는지 확인할 수 있습니다. 완료되면 Ctrl + C로 서버를 중지합니다.
8. 고급 AI 개선 기능 - 읽기 전용 ✨
훌륭한 AI 에이전트는 요청 사항을 따를 수 있습니다. 훌륭한 AI 에이전트는 직관적이고 신뢰할 수 있으며 유용합니다. 이 섹션에서는 에이전트의 기능을 향상하는 세 가지 고급 개선사항을 중점적으로 살펴보겠습니다.
다음과 같은 방법을 살펴봅니다.
Add Context & Memory를 사용하여 자연스러운 대화형 후속 질문을 처리합니다.Reduce Hallucination를 사용하여 더 안정적이고 신뢰할 수 있는 에이전트를 구축합니다.Make the Agent Proactive를 사용하여 접근성이 높고 사용자 친화적인 환경을 제공합니다.Add preference setting을 사용하여 이미지 설명 맞춤설정
개선사항 1: 컨텍스트 및 메모리
자연스러운 대화는 일련의 고립된 명령이 아니라 흐름이 있습니다. 사용자가 '사진에 뭐가 있어?'라고 묻고 상담사가 '빨간색 자동차'라고 대답하면 사용자는 '자동차'를 다시 말하지 않고 '무슨 색이야?'라고 자연스럽게 후속 질문을 할 수 있습니다. 에이전트가 이 컨텍스트를 이해하려면 단기 메모리가 필요합니다.
구현 방법 (요약)
이 기능은 이미 describeImage 흐름에 내장되어 있습니다. 이 섹션에서는 해당 패턴의 작동 방식을 간략하게 설명합니다. page.tsx에서 describeImage 함수를 호출할 때 대화 기록을 전달합니다.
👉 코드 쇼케이스 (page.tsx에서):
const result = await describeImage({
photoDataUri,
question: commandToProcess,
detailPreference: descriptionPreference,
previousUserQueryOnImage: lastUserQuery ?? undefined,
previousAIResponseOnImage: lastAIResponse ?? undefined,
});
previousUserQueryOnImage및previousAIResponseOnImage: 이 두 속성은 에이전트의 단기 기억입니다. 마지막 상호작용을 AI에 전달하면 모호하거나 참조적인 후속 질문을 이해하는 데 필요한 컨텍스트가 제공됩니다.- 적응형 프롬프트: 이 컨텍스트는 describe_image 흐름의 프롬프트에서 사용됩니다. 프롬프트는 새 답변을 구성할 때 이전 대화를 고려하도록 설계되어 상담사가 지능적으로 응답할 수 있습니다.
개선사항 2: 할루시네이션 감소
AI가 사실을 발명하거나 보유하지 않은 기능을 보유하고 있다고 주장하는 경우 '할루시네이션'이 발생합니다. 사용자의 신뢰를 구축하려면 에이전트가 자체 한계를 알고 범위 외 요청을 적절하게 거부할 수 있어야 합니다.
구현 방법 (요약)
모델에 명확한 경계를 지정하는 것이 엉뚱한 대답을 방지하는 가장 효과적인 방법입니다. Google은 의도 분류기를 빌드할 때 이를 달성했습니다.
👉 코드 쇼케이스 (intent-classifier 흐름에서):
// Define Agent Capabilities and Limitations for the prompt
const AGENT_CAPABILITIES_AND_LIMITATIONS = `
**Core Capabilities (What the Agent CAN DO):**
* **Image Analysis:**
* DescribeImage: Provide a general description of the current image...
**Limitations (What the Agent CANNOT DO...):**
* Cannot generate or create new images.
* Cannot provide general knowledge or answer questions unrelated to the image...
* Cannot perform web searches.
`;
이 상수는 분류 프롬프트에서 AI에 제공하는 '직무 설명' 역할을 합니다.
- 모델 그라운딩: AI에 할 수 없는 작업을 명시적으로 알려주면 현실에 '그라운딩'됩니다. '날씨가 어때?'와 같은 질문을 보면 제한사항 목록과 일치하는지 확신하고 인텐트를 OutOfScopeRequest로 분류할 수 있습니다.
- 신뢰 구축: 솔직하게 '도와드릴 수 없습니다'라고 말할 수 있는 상담사는 추측을 시도하다가 틀리는 상담사보다 훨씬 더 신뢰할 수 있습니다. 이는 안전하고 신뢰할 수 있는 AI 설계의 기본 원칙입니다. `
개선사항 3: 사전 대응형 에이전트 만들기
접근성 우선 애플리케이션의 경우 시각적 신호에 의존할 수 없습니다. 사용자가 청취 모드를 활성화하면 에이전트가 준비되어 명령을 기다리고 있다는 즉각적인 비시각적 확인이 필요합니다. 이제 이 중요한 의견을 제공하기 위해 사전 대응형 소개를 추가하겠습니다.
1단계: 첫 번째 청취를 추적하는 상태 추가
먼저 사용자가 세션 중에 "Start Listening" 버튼을 처음 누른 것인지 알 수 있는 방법이 필요합니다.
👉 ~/src/app/page.tsx에서 ClarityCam 구성요소 상단 근처에 있는 다음 새 상태 변수를 확인합니다.
export default function ClarityCam() {
// ... other state variables
const [descriptionPreference, setDescriptionPreference] = useState<DescriptionPreference>("concise");
// Add this new line
const [isFirstListen, setIsFirstListen] = useState(true);
// ... rest of the component
}
새 상태 변수 isFirstListen를 도입하고 true으로 초기화했습니다. 이 플래그는 일회성 환영 메시지를 트리거하는 데 사용됩니다.
2단계: toggleListening 함수 업데이트하기
이제 마이크를 처리하는 함수를 수정하여 인사말을 재생해 보겠습니다.
👉 ~/src/app/page.tsx에서 toggleListening 함수를 찾아 다음 if 블록을 확인합니다.
const toggleListening = useCallback(() => {
// ... existing logic to setup speech recognition
if (isListening || isAttemptingStart) {
// ... existing logic to stop listening
} else {
stopSpeaking(); // Stop any ongoing TTS
// Add this new block
if (isFirstListen) {
setIsFirstListen(false);
const introMessage = "Hello! I am ClarityCam, your AI assistant. I'm now listening. You can ask me to 'describe the image', 'read text', 'take a picture', or ask questions about what's in an image.";
speakText(introMessage);
} else {
speakText("Listening..."); // Optional: provide feedback on subsequent clicks
}
// ... rest of the logic to start listening
}
}, [/*...existing dependencies...*/, isFirstListen]); // Don't forget to add isFirstListen to the dependency array!
- 플래그 확인: if (isFirstListen) 블록은 첫 번째 활성화인지 확인합니다.
- 반복 방지: 블록 내에서 가장 먼저 setIsFirstListen(false)을 호출합니다. 이렇게 하면 세션당 소개 메시지가 한 번만 재생됩니다.
- 안내 제공: introMessage는 최대한 유용하도록 신중하게 작성됩니다. 사용자에게 인사하고, 에이전트를 이름으로 식별하고, 이제 활성 상태임을 확인 ('이제 듣고 있습니다')하고, 사용할 수 있는 음성 명령의 명확한 예를 제공합니다.
- 청각적 피드백: 마지막으로 speakText(introMessage)가 이 중요한 정보를 전달하여 사용자가 화면을 보지 않아도 즉각적인 확신과 안내를 제공합니다.
개선사항 4: 사용자 환경설정에 적응 (요약)
진정한 스마트 에이전트는 단순히 응답하는 것이 아니라 사용자의 요구사항을 학습하고 이에 적응합니다. Google에서 구축한 가장 강력한 기능 중 하나는 사용자가 '더 자세히'와 같은 명령어를 사용하여 이미지 설명의 자세한 정도를 즉석에서 변경할 수 있다는 점입니다.
구현 방법 (요약) 이 기능은 describeImage 흐름을 위해 생성된 동적 프롬프트로 구동됩니다. 조건부 논리를 사용하여 사용자의 환경설정에 따라 AI에 전송되는 안내를 변경합니다.
👉 코드 쇼케이스 (describe_image의 promptTemplate):
const settingPreferenceTemplate = `
{#if isDetailed}
Provide a very detailed and comprehensive description of the image. Focus on specifics, including subtle elements, spatial relationships, and textures if apparent.
{else}
Provide a concise description of the image. Focus on the main subject, key objects, and primary activities or context.
{/if}
Highlight the main objects, activities, and colors.
...
`;
- 조건부 로직:
{#if isDetailed}...{else}...{/if}블록이 핵심입니다. describeImageFlow가 프런트엔드에서 detailPreference를 수신하면 isDetailed 불리언 (true 또는 false)이 생성됩니다. - 적응형 안내: 이 불리언 플래그는 AI 모델이 수신하는 안내 집합을 결정합니다. isDetailed가 true이면 모델은 매우 상세하게 설명하도록 지시를 받습니다. false인 경우 간결하게 작성하도록 안내합니다.
- 사용자 제어: 이 패턴은 사용자의 음성 명령 (예: '설명을 간결하게 해줘', SetDescriptionConcise 인텐트로 분류됨)을 AI의 근본적인 행동 변화에 직접 연결하여 에이전트가 진정으로 반응하고 개인화된 느낌을 주도록 합니다.
9. 클라우드에 배포
Google Cloud Build를 사용하여 Docker 이미지 빌드
gcloud builds submit . --tag gcr.io/$PROJECT_ID/accessibilityai-nextjs-app:latest
accessibilityai-nextjs-app은 추천 이미지 이름입니다.- . 현재 디렉터리 (
accessibilityAI/)를 빌드 소스로 사용합니다.
Google Cloud Run에 이미지 배포
- API 키와 기타 보안 비밀이 Secret Manager에 준비되어 있는지 확인합니다. 예를 들면
GOOGLE_GENAI_API_KEY입니다.
이 YOUR_ACTUAL_GOOGLE_AI_KEY_VALUE를 실제 Gemini API 키 값으로 바꿉니다.
echo "YOUR_ACTUAL_GOOGLE_AI_KEY_VALUE" | gcloud secrets create GOOGLE_GENAI_API_KEY --data-file=- --project=YOUR_PROJECT_ID
Cloud Run 서비스의 런타임 서비스 계정 (예: PROJECT_NUMBER-compute@developer.gserviceaccount.com 또는 전용 계정)에 이 보안 비밀에 대한 'Secret Manager 보안 비밀 접근자' 역할을 부여합니다.
- 배포 명령어:
gcloud run deploy accessibilityai-app-service \
--image gcr.io/$PROJECT_ID/accessibilityai-nextjs-app:latest \
--platform managed \
--region us-central1 \
--allow-unauthenticated \
--port 3000 \
--set-secrets=GOOGLE_GENAI_API_KEY=GOOGLE_GENAI_API_KEY:latest \
--set-env-vars NODE_ENV="production"