
1. Wprowadzenie
W tym samouczku utworzysz ClarityCam, czyli sterowanego głosem agenta AI, który może widzieć świat i wyjaśniać go użytkownikowi. Aplikacja ClarityCam została zaprojektowana z myślą o ułatwieniach dostępu – jest to potężne narzędzie dla osób niewidomych i niedowidzących. Zasady, których się nauczysz, są jednak niezbędne do tworzenia nowoczesnych aplikacji głosowych do zwykłych obciążeń.

Ten projekt opiera się na zaawansowanej filozofii projektowania o nazwie Natywnie adaptacyjny interfejs (NAI). Zamiast traktować ułatwienia dostępu jako dodatek, NAI czyni je podstawą. W tym podejściu interfejsem jest agent AI, który dostosowuje się do różnych użytkowników, obsługuje dane wejściowe w różnych formatach, takie jak głos i obraz, oraz proaktywnie prowadzi użytkowników w oparciu o ich indywidualne potrzeby.
Tworzenie pierwszego agenta AI za pomocą NAI:

Po zakończeniu tej sesji będziecie w stanie:
- Projektowanie z ułatwieniami dostępu jako domyślnymi: stosuj zasady natywnie adaptacyjnego interfejsu (NAI), aby tworzyć systemy AI, które zapewniają wszystkim użytkownikom równoważne doświadczenia.
- Klasyfikowanie intencji użytkownika: utwórz niezawodny klasyfikator intencji, który tłumaczy polecenia w języku naturalnym na uporządkowane działania dla Twojego agenta.
- Zachowaj kontekst rozmowy: wdróż pamięć krótkotrwałą, aby umożliwić agentowi rozumienie pytań uzupełniających i poleceń odwołujących się do poprzednich wypowiedzi (np. „Jakiego jest koloru?”).
- Twórz skuteczne prompty: opracowuj prompty o dużej ilości szczegółów i kontekstu dla modelu multimodalnego, takiego jak Gemini, aby zapewnić dokładną i niezawodną analizę obrazów.
- Radzenie sobie z niejednoznacznością i prowadzenie użytkownika: zaprojektuj eleganckie mechanizmy obsługi błędów w przypadku żądań wykraczających poza zakres i proaktywnie wprowadzaj użytkowników, aby budować zaufanie i pewność.
- Orkiestracja systemu wieloagentowego: możesz zaprojektować aplikację, korzystając z kolekcji wyspecjalizowanych agentów, którzy współpracują ze sobą, aby wykonywać złożone zadania, takie jak przetwarzanie głosu, analiza i synteza mowy.
2. Projekt wysokiego poziomu
ClarityCam jest z założenia prosty w obsłudze, ale opiera się na zaawansowanym systemie współpracujących agentów AI. Przyjrzyjmy się architekturze.

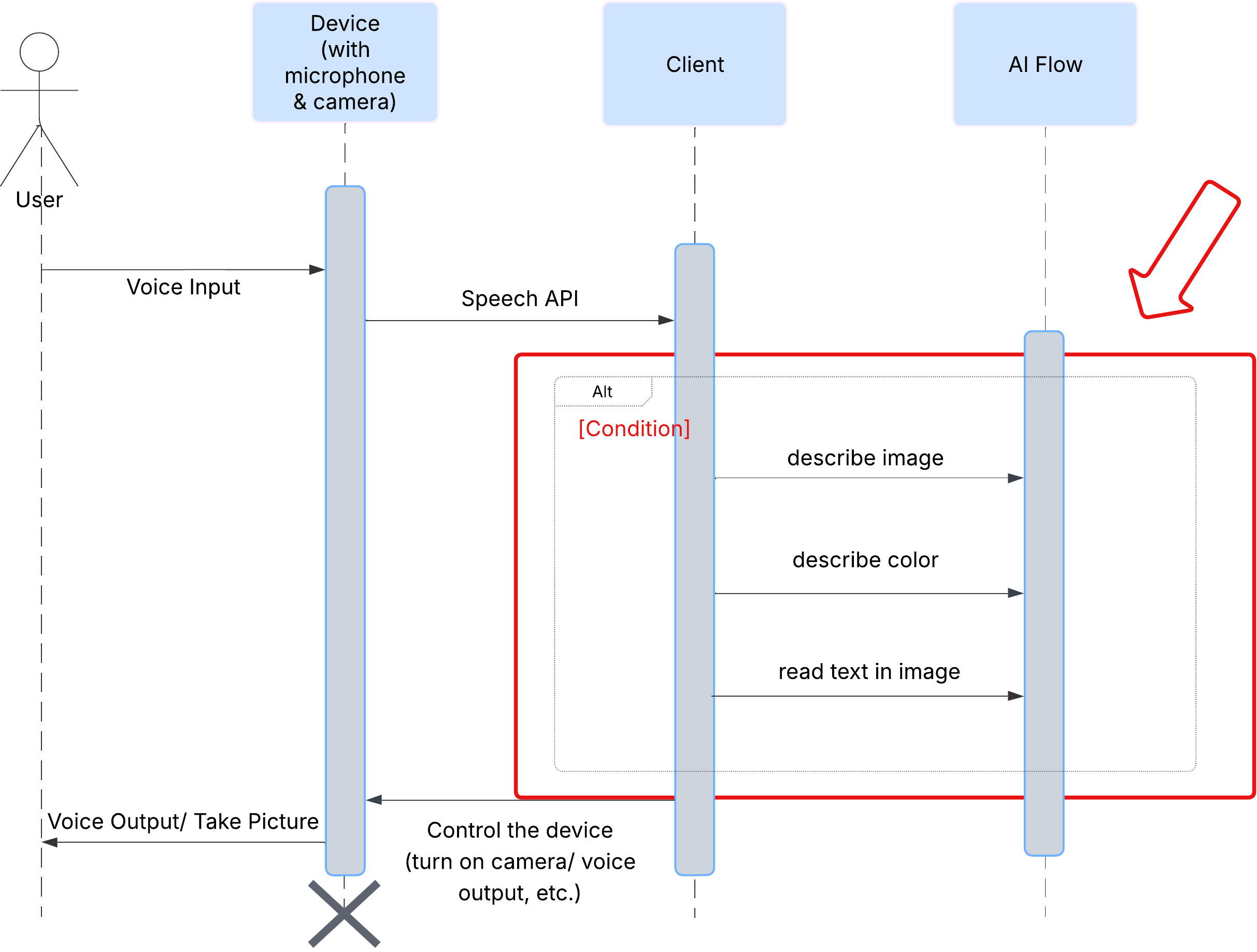
Jakość usług
Najpierw przyjrzyjmy się, jak użytkownik wchodzi w interakcję z ClarityCam. Cały proces jest obsługiwany bez użycia rąk i w formie rozmowy. Użytkownik wypowiada polecenie, a agent odpowiada opisem lub działaniem. Ten diagram sekwencji przedstawia typowy przepływ interakcji od początkowego polecenia głosowego użytkownika do końcowej odpowiedzi audio z urządzenia.
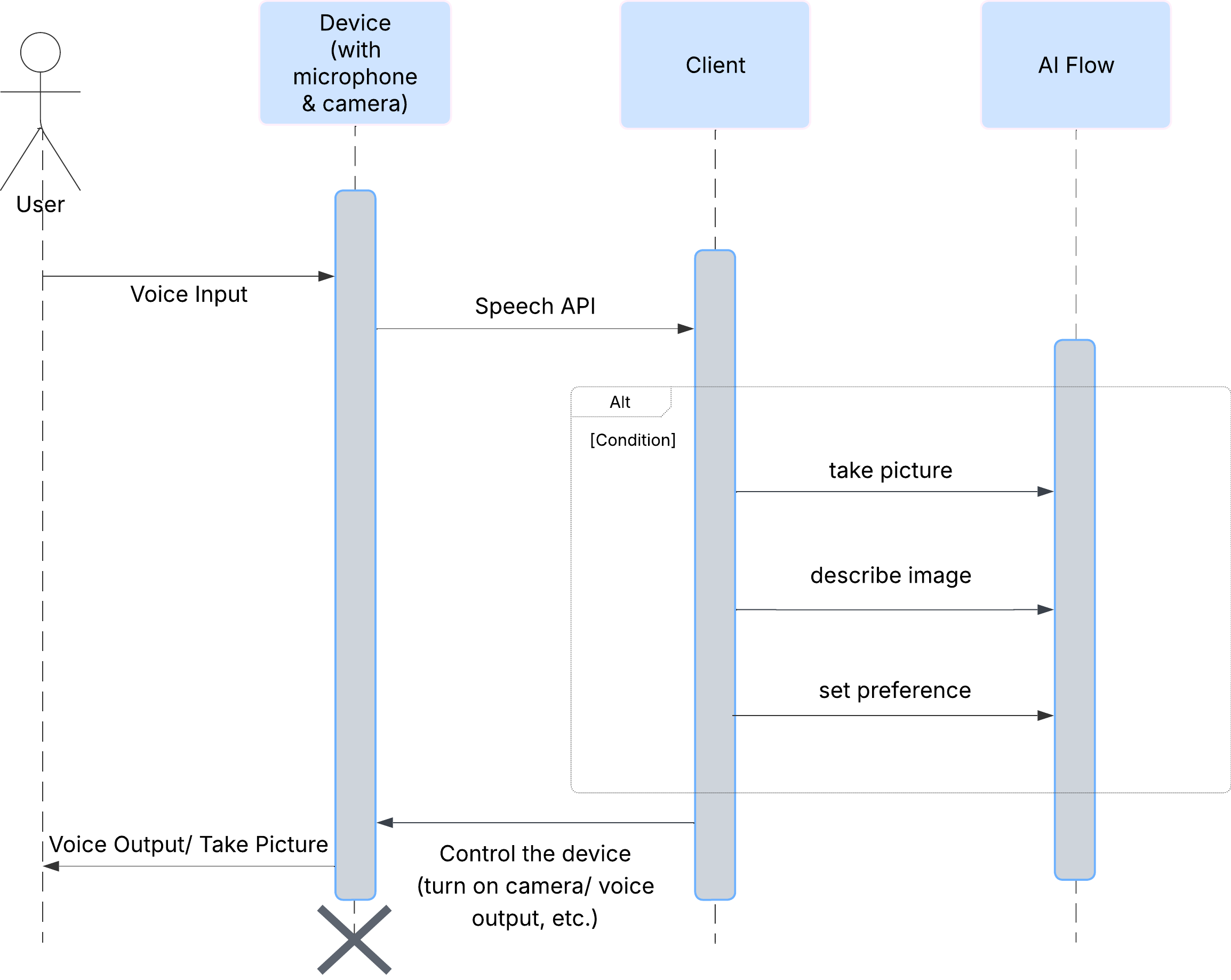
Architektura agenta AI
Pod powierzchnią działa system wieloagentowy, który sprawia, że wszystko ożywa. Gdy polecenie zostanie odebrane, centralny agent Orchestrator deleguje zadania do wyspecjalizowanych agentów odpowiedzialnych za zrozumienie intencji, analizowanie obrazów i tworzenie odpowiedzi. Ten diagram przepływu AI zawiera szczegółowe informacje o tym, jak współpracują ze sobą te agenty. W kolejnych sekcjach wdrożymy tę architekturę.
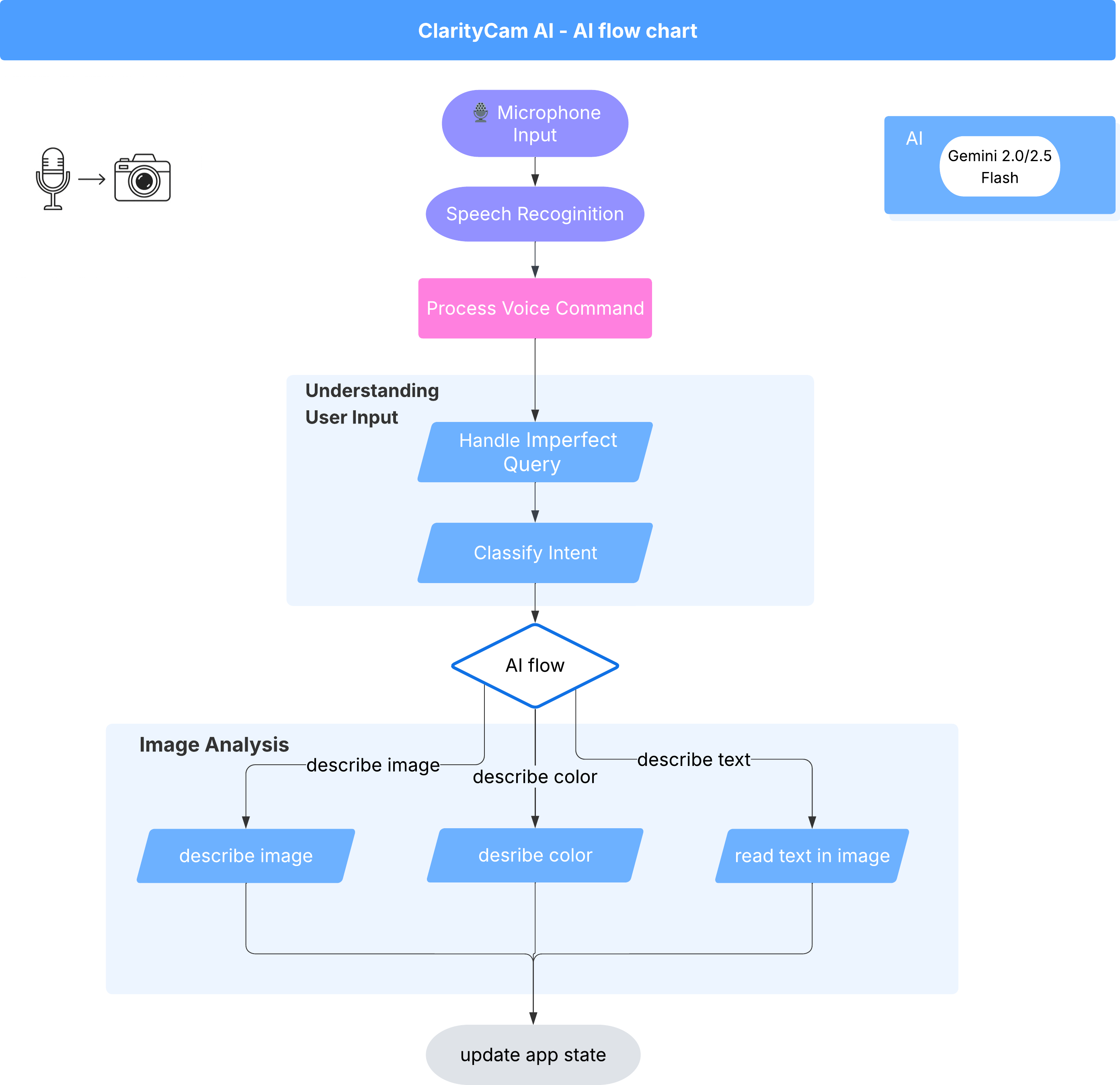
Krótkie omówienie plików projektu
Zanim zaczniemy pisać kod, zapoznajmy się ze strukturą plików w naszym projekcie. Może się wydawać, że jest dużo plików, ale w tym samouczku musisz skupić się tylko na 2 obszarach.
Oto uproszczona mapa naszego projektu.
accessibilityAI/src/
├── 📁 app/
│ ├── layout.tsx # An overall page shell (you can ignore this).
│ └── page.tsx # ⬅️ MODIFY THIS: The main user interface for our app.
│
├── 📁 ai/
│ ├── 📁flows # ⬅️ MODIFY THIS: The core AI logic and server functions.
│ └── intent-classifier.ts # ⬅️ MODIFY THIS: Where we'll edit our AI prompts.
| └── ai-instance.ts
| └── dev.ts
│
├── 📁 components/ # Contains pre-built UI components (ignore this).
│
├── 📁 hooks/
│
├── 📁 lib/
│
└── 📁 types/
Stos technologiczny
Nasz system jest oparty na nowoczesnym, skalowalnym stosie technologicznym, który łączy zaawansowane usługi w chmurze i najnowocześniejsze modele AI. Oto kluczowe komponenty, których będziemy używać:
- Google Cloud Platform (GCP): zapewnia bezserwerową infrastrukturę dla naszych agentów.
- Cloud Run: wdraża poszczególne agenty jako skonteneryzowane, skalowalne mikroserwisy.
- Artifact Registry: bezpiecznie przechowuje obrazy Dockera dla naszych agentów i nimi zarządza.
- Secret Manager: bezpiecznie obsługuje dane logowania i klucze interfejsu API.
- Duże modele językowe (LLM): pełnią rolę „mózgu” systemu.
- Modele Gemini od Google: korzystamy z zaawansowanych funkcji multimodalnych rodziny Gemini do różnych zadań, od klasyfikowania intencji użytkowników po analizowanie treści obrazów i tworzenie inteligentnych opisów.
3. Konfiguracja i wymagania wstępne
Włącz konto rozliczeniowe: aby wykonać to ćwiczenie, musisz mieć konto rozliczeniowe z pewną ilością środków. Aby rozpocząć, użyj środków z banera u góry tego modułu. Jeśli masz już połączenie z kontem rozliczeniowym, możesz pominąć ten krok.
Tworzenie nowego projektu GCP
- Otwórz konsolę Google Cloud i utwórz nowy projekt.
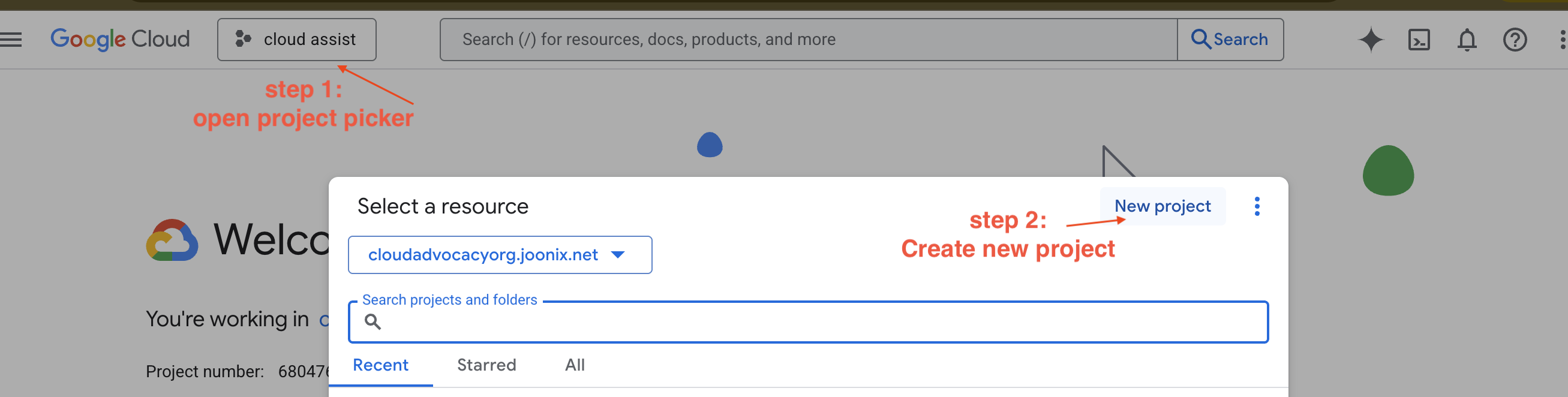
- Otwórz konsolę Google Cloud i utwórz nowy projekt.
- Otwórz panel po lewej stronie, kliknij
Billingi sprawdź, czy konto rozliczeniowe jest połączone z tym kontem GCP.
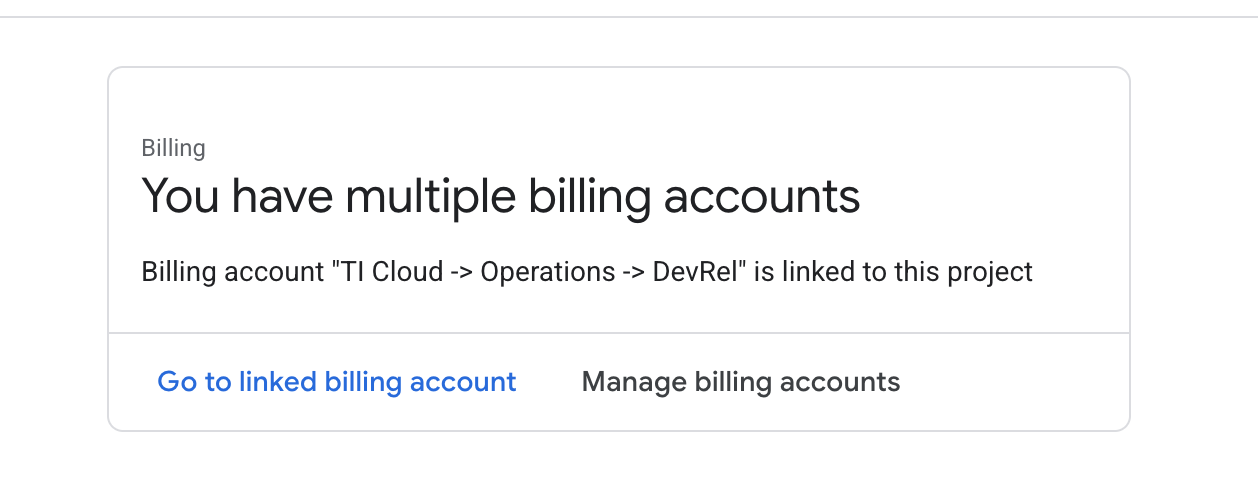
Jeśli widzisz tę stronę, sprawdź manage billing account, wybierz Google Cloud Trial One i połącz go.
Tworzenie klucza interfejsu Gemini API
Zanim zabezpieczysz klucz, musisz go mieć.
- Otwórz Google AI Studio : https://aistudio.google.com/
- Zaloguj się przy użyciu swojego konta Google.
- Kliknij przycisk „Uzyskaj klucz API”, który zwykle znajduje się w panelu nawigacji po lewej stronie lub w prawym górnym rogu.
- W oknie „Klucze interfejsu API” kliknij „Utwórz klucz interfejsu API w nowym projekcie”.
- Wygenerujemy dla Ciebie nowy klucz interfejsu API. Natychmiast skopiuj ten klucz i tymczasowo zapisz go w bezpiecznym miejscu (np. w menedżerze haseł lub bezpiecznej notatce). Tej wartości użyjesz w kolejnych krokach.
Procedura lokalnego tworzenia (testowanie na własnym komputerze)
Musisz mieć możliwość uruchomienia npm run dev i sprawnego działania aplikacji. W tym momencie pojawia się .env.
- Dodaj klucz interfejsu API do pliku: utwórz nowy plik o nazwie
.envi dodaj do niego ten wiersz.
Zastąp YOUR_API_KEY_HERE kluczem uzyskanym z AI Studio i zapisz go w .env:
GOOGLE_GENAI_API_KEY="YOUR_API_KEY_HERE"
[Opcjonalnie] Skonfiguruj środowisko IDE
W tym samouczku możesz pracować w znanym środowisku programistycznym, takim jak VS Code lub IntelliJ, korzystając z lokalnego terminala. Zdecydowanie zalecamy jednak używanie Google Cloud Shell, aby zapewnić standardowe, wstępnie skonfigurowane środowisko.
Poniższe instrukcje dotyczą środowiska Cloud Shell. Jeśli zdecydujesz się użyć środowiska lokalnego, upewnij się, że masz zainstalowane i prawidłowo skonfigurowane narzędzia git, nvm, npm i gcloud.
Praca w edytorze Cloud Shell
👉 U góry konsoli Google Cloud kliknij Aktywuj Cloud Shell (jest to ikona terminala u góry panelu Cloud Shell). 
👉Kliknij przycisk „Otwórz edytor” (wygląda jak otwarty folder z ołówkiem). W oknie otworzy się edytor kodu Cloud Shell. Po lewej stronie zobaczysz eksplorator plików. 
👉 Na pasku stanu u dołu kliknij przycisk Zaloguj się w Cloud Code, jak pokazano na ilustracji. Autoryzuj wtyczkę zgodnie z instrukcjami. Jeśli na pasku stanu widzisz Cloud Code – brak projektu, wybierz tę opcję, a następnie w menu „Wybierz projekt Google Cloud” wybierz konkretny projekt Google Cloud z listy utworzonych projektów. 
👉Otwórz terminal w chmurowym IDE. 
👉W terminalu sprawdź, czy uwierzytelnianie zostało już przeprowadzone, a projekt jest już ustawiony na Twój identyfikator projektu. Użyj tego polecenia:
gcloud auth list
👉 Sklonuj natively-accessible-interface projekt z GitHuba:
git clone https://github.com/cuppibla/AccessibilityAgent.git
👉 Uruchom polecenie make, pamiętając o zastąpieniu ciągu <YOUR_PROJECT_ID> identyfikatorem projektu (znajdziesz go w konsoli Google Cloud w sekcji projektu. ❗️❗️Uważaj, aby nie pomylić znaków project id i project number❗️❗️):
echo <YOUR_PROJECT_ID> > ~/project_id.txt
gcloud config set project $(cat ~/project_id.txt)
👉Aby włączyć wymagane interfejsy Cloud APIs Google Cloud, uruchom to polecenie: (może to potrwać około 2 minut)
gcloud services enable compute.googleapis.com \
storage.googleapis.com \
run.googleapis.com \
artifactregistry.googleapis.com \
aiplatform.googleapis.com \
eventarc.googleapis.com \
sqladmin.googleapis.com \
secretmanager.googleapis.com \
cloudbuild.googleapis.com \
cloudresourcemanager.googleapis.com \
cloudfunctions.googleapis.com \
cloudaicompanion.googleapis.com
Może to potrwać kilka minut.
Konfigurowanie uprawnień
👉Skonfiguruj uprawnienia konta usługi. W terminalu uruchom :
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
export SERVICE_ACCOUNT_NAME=$(gcloud compute project-info describe --format="value(defaultServiceAccount)")
echo "Here's your SERVICE_ACCOUNT_NAME $SERVICE_ACCOUNT_NAME"
👉 Przyznaj uprawnienia. W terminalu uruchom :
#Cloud Storage (Read/Write):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/storage.objectAdmin"
#Pub/Sub (Publish/Receive):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/pubsub.publisher"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/pubsub.subscriber"
#Cloud SQL (Read/Write):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/cloudsql.editor"
#Eventarc (Receive Events):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/iam.serviceAccountTokenCreator"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/eventarc.eventReceiver"
#Vertex AI (User):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/aiplatform.user"
#Secret Manager (Read):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/secretmanager.secretAccessor"
4. Interpretowanie danych wejściowych użytkownika – klasyfikator intencji
Zanim nasz agent AI podejmie działanie, musi najpierw dokładnie zrozumieć, czego oczekuje użytkownik. Dane wejściowe z rzeczywistego świata są często nieuporządkowane – mogą być niejasne, zawierać błędy pisowni lub być napisane językiem potocznym.
W tej sekcji utworzymy kluczowe komponenty „nasłuchujące”, które przekształcają surowe dane wejściowe użytkownika w jasne, wykonalne polecenie.
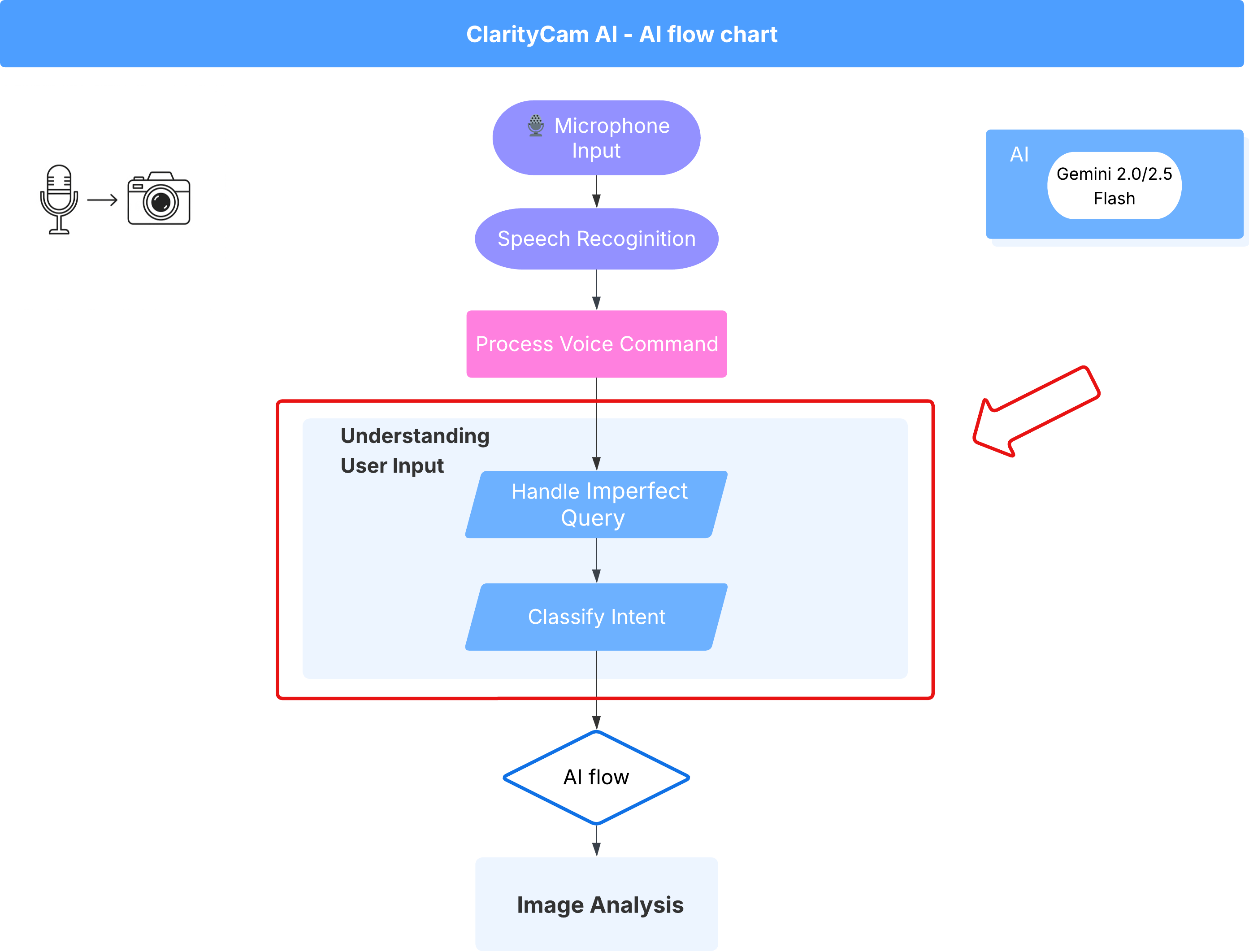
Dodawanie klasyfikatora intencji
Teraz zdefiniujemy logikę AI, która zasila nasz klasyfikator.
👉 Działanie: w środowisku IDE Cloud Shell przejdź do katalogu ~/src/ai/intent-classifier/.
Krok 1. Zdefiniuj słownictwo agenta (IntentCategory)
Najpierw musimy utworzyć ostateczną listę wszystkich możliwych działań, jakie może wykonać nasz agent.
👉 Działanie: zastąp symbol zastępczy // REPLACE ME PART 1: add IntentCategory here tym kodem:
👉 z poniższym kodem:
export type IntentCategory =
// Image Analysis Intents
| "DescribeImage"
| "AskAboutImage"
| "ReadTextInImage"
| "IdentifyColorsInImage"
// Control Intents
| "TakePicture"
| "StartCamera"
| "SelectImage"
| "StopSpeaking"
// Preference Intents
| "SetDescriptionDetailed"
| "SetDescriptionConcise"
// Fallback Intents
| "GeneralInquiry" // User has a general question about the agent's functions or polite interaction
| "OutOfScopeRequest" // User's request is clearly outside the agent's defined capabilities
| "Unknown"; // Intent could not be determined with confidence
Wyjaśnienie
Ten kod TypeScript tworzy typ niestandardowy o nazwie IntentCategory. Jest to ścisła lista, która określa każde możliwe działanie lub „intencję”, jaką może zrozumieć nasz agent. To kluczowy pierwszy krok, ponieważ przekształca potencjalnie nieskończoną liczbę fraz użytkownika („powiedz mi, co widzisz”, „co jest na zdjęciu?”) w jasny, przewidywalny zestaw poleceń. Celem naszego klasyfikatora jest przypisanie każdego zapytania użytkownika do jednej z tych kategorii.
Krok 2
Aby podejmować trafne decyzje, nasza AI musi znać swoje możliwości i ograniczenia. Podamy te informacje w formie szczegółowego bloku tekstu.
👉 Działanie: zastąp symbol zastępczy REPLACE ME PART 2: add AGENT_CAPABILITIES_AND_LIMITATIONS here tym kodem:
Zastąp poniższy kod: // REPLACE ME PART 2: add AGENT_CAPABILITIES_AND_LIMITATIONS here:
👉 z poniższym kodem
const AGENT_CAPABILITIES_AND_LIMITATIONS = `
**Core Capabilities (What the Agent CAN DO):**
* **Image Analysis:**
* DescribeImage: Provide a general description of the current image.
* AskAboutImage: Answer a specific question about the visual content of the current image (e.g., "Is there a dog?", "What color is the car?").
* ReadTextInImage: Read any text found in the current image.
* IdentifyColorsInImage: Identify the dominant colors of the current image.
* **Image Input Control:**
* TakePicture: Capture an image using the currently active camera stream.
* StartCamera: Activate the camera (e.g., "use camera", "take another picture").
* SelectImage: Allow the user to choose an image file from their device.
* **Voice & Audio Control:**
* StopSpeaking: Stop the current text-to-speech output.
* **Preference Management:**
* SetDescriptionDetailed: Make future image descriptions more detailed.
* SetDescriptionConcise: Make future image descriptions less detailed or concise.
* **General Interaction:**
* GeneralInquiry: Handle conversational phrases (e.g., "hello", "thank you") or questions about its own capabilities (e.g., "what can you do?", "help").
**Limitations (What the Agent CANNOT DO and should be classified as OutOfScopeRequest):**
* Cannot generate or create new images.
* Cannot edit or modify existing images (e.g., "remove background," "make the car blue").
* Cannot analyze video files or live video beyond capturing a single frame.
* Cannot provide general knowledge or answer questions unrelated to the provided image's visual content (e.g., "What's the weather?", "Who is the president?", "Tell me a joke", "What time is it?").
* Cannot perform mathematical calculations or complex data analysis.
* Cannot translate languages as a primary function.
* Cannot remember information from past images or vastly different previous queries in the same session.
* Cannot control other device settings or applications.
* Cannot perform web searches.
`;
Dlaczego to ważne:
Ten tekst nie jest przeznaczony dla użytkownika, ale dla naszego modelu AI. Ten „opis stanowiska” zostanie bezpośrednio przekazany do promptu (w następnym kroku), aby zapewnić modelowi językowemu kontekst potrzebny do podejmowania trafnych decyzji. Bez tego kontekstu LLM może błędnie zaklasyfikować zapytanie „Jaka jest pogoda?” jako AskAboutImage. Dzięki temu kontekstowi wie, że pogoda nie jest elementem wizualnym na obrazie, i prawidłowo klasyfikuje ją jako wykraczającą poza zakres.
Krok 3
Teraz napiszemy pełny zestaw instrukcji, których model Gemini będzie używać do klasyfikacji.
👉 Działanie: zastąp znak // REPLACE ME PART 3 - classifyIntentPrompt tym kodem:
z poniższym kodem.
const classifyIntentPrompt = ai.definePrompt({
name: 'classifyIntentPrompt',
input: { schema: ClassifyIntentInputSchema },
output: { schema: ClassifyIntentOutputSchema },
prompt: `You are classifying the user's intent for ClarityCam, a voice-controlled AI application focused on image analysis.
Analyze the user query: '{userQuery}'.
First, understand ClarityCam's capabilities and limitations:
${AGENT_CAPABILITIES_AND_LIMITATIONS}
Now, classify the user's PRIMARY intent into ONE of the following categories:
* **DescribeImage**: User wants a general description of the current image.
* **AskAboutImage**: User is asking a specific question directly related to the visual content of the current image.
* **ReadTextInImage**: User wants any text read from the current image.
* **IdentifyColorsInImage**: User wants the dominant colors of the current image.
* **TakePicture**: User wants to capture an image using an active camera.
* **StartCamera**: User wants to activate the camera.
* **SelectImage**: User wants to choose an image file.
* **StopSpeaking**: User wants the current text-to-speech output to stop.
* **SetDescriptionDetailed**: User wants future image descriptions to be more detailed.
* **SetDescriptionConcise**: User wants future image descriptions to be less detailed.
* **GeneralInquiry**: The query is a simple conversational filler (e.g., "hello", "thanks"), a polite closing, or a direct question about the agent's functions (e.g., "what can you do?", "how does this work?", "help").
* **OutOfScopeRequest**: The query asks the agent to perform an action clearly listed under its "Limitations" or otherwise demonstrably outside its defined image analysis and control functions. Examples: "Tell me a joke," "What's the weather in London?", "Generate an image of a cat," "Can you edit my photo to make it brighter?", "Send this image to my friends","Translate 'hello' to Spanish."
Output ONLY the category name.
If the query is ambiguous but seems generally related to polite interaction or asking about the agent itself, prefer 'GeneralInquiry'.
If the query is clearly asking for something the agent CANNOT do, use 'OutOfScopeRequest'.
If truly unclassifiable even with these guidelines, use 'Unknown'.`,
config: {
temperature: 0.05, // Very low temperature for highly deterministic classification
}
});
To w tym miejscu dzieje się magia. To „mózg” naszego klasyfikatora, który informuje AI o jej roli, zapewnia niezbędny kontekst i określa pożądane dane wyjściowe. Oto najważniejsze techniki tworzenia promptów:
- Odgrywanie ról: zaczyna się od słów „Klasyfikujesz…”, aby jasno określić zadanie.
- Wstawianie kontekstu: dynamicznie wstawia zmienną
AGENT_CAPABILITIES_AND_LIMITATIONSdo promptu. - Ścisłe formatowanie danych wyjściowych: instrukcja „Podaj TYLKO nazwę kategorii” jest kluczowa, aby uzyskać przejrzystą i przewidywalną odpowiedź, którą możemy łatwo wykorzystać w naszym kodzie.
- Niska temperatura: w przypadku klasyfikacji oczekujemy deterministycznych, logicznych odpowiedzi, a nie kreatywnych. Ustawienie bardzo niskiej temperatury (0,05) sprawia, że model jest bardzo skoncentrowany i spójny.
Krok 4. Połącz aplikację z przepływem AI
Na koniec wywołajmy nasz nowy klasyfikator AI z głównego pliku aplikacji.
👉 Działanie: przejdź do pliku ~/src/app/page.tsx. W funkcji processVoiceCommand zastąp // REPLACE ME PART 1: add classificationResult tym kodem:
const classificationResult = await classifyIntentFlow({ userQuery: commandToProcess });
intent = classificationResult.intent as IntentCategory;
Ten kod jest kluczowym pomostem między aplikacją frontendową a logiką AI backendu. Otrzymuje polecenie głosowe użytkownika (commandToProcess), wysyła je do utworzonego przez Ciebie classifyIntentFlow i czeka, aż AI zwróci sklasyfikowaną intencję.
Zmienna intencji zawiera teraz czyste, uporządkowane polecenie (np. DescribeImage). Ten wynik zostanie użyty w instrukcji switch, która następuje po nim, aby sterować logiką aplikacji i decydować, jakie działanie należy podjąć w dalszej kolejności. W ten sposób „myślenie” AI przekształca się w „działanie” aplikacji.
Uruchamianie interfejsu
Czas zobaczyć naszą aplikację w akcji. Uruchommy serwer programistyczny.
👉 W terminalu uruchom to polecenie: npm run dev Uwaga: przed uruchomieniem polecenia npm run dev może być konieczne uruchomienie polecenia npm install.
Po chwili zobaczysz dane wyjściowe podobne do tych, co oznacza, że serwer działa prawidłowo:
▲ Next.js 15.2.3 (Turbopack)
- Local: http://localhost:9003
- Network: http://10.88.0.4:9003
- Environments: .env
✓ Starting...
✓ Ready in 1512ms
○ Compiling / ...
✓ Compiled / in 26.6s
Teraz kliknij lokalny adres URL (http://localhost:9003), aby otworzyć aplikację w przeglądarce.
Powinien pojawić się interfejs SightGuide. Na razie przyciski nie są powiązane z żadną logiką, więc kliknięcie ich nie spowoduje żadnej reakcji. Tego właśnie oczekujemy na tym etapie. W następnej sekcji pokażemy, jak to zrobić.
Teraz, gdy znasz już interfejs, wróć do terminala i naciśnij Ctrl + C, aby zatrzymać serwer programistyczny.
5. Interpretowanie danych wejściowych użytkownika – sprawdzanie niedokładnych zapytań
Dodawanie sprawdzania niedokładnych zapytań
Część 1. Określanie prompta (czyli „co”)
Najpierw określmy instrukcje dla naszej AI. Prompt to „przepis” na wywołanie AI – mówi modelowi dokładnie, co ma zrobić.
👉 Działanie: w środowisku IDE przejdź do ~/src/ai/flows/check_typo/.
Zastąp poniższy kod: // REPLACE ME PART 1: add prompt here:
👉 z poniższym kodem
const prompt = ai.definePrompt({
name: 'checkTypoPrompt',
input: {
schema: CheckTypoInputSchema,
},
output: {
schema: CheckTypoOutputSchema,
},
prompt: `You are a helpful AI assistant that checks user text for typos and suggests corrections.
- If you find typos, respond with the corrected text.
- If there are no typos, or if you are unsure about a correction, respond with the original text unchanged.
User text: {text}
Corrected text:
`,
});
Ten blok kodu definiuje szablon wielokrotnego użytku dla naszej AI o nazwie checkTypoPrompt. Schematy wejściowy i wyjściowy definiują umowę dotyczącą danych dla tego zadania. Zapobiega to błędom i sprawia, że nasz system jest przewidywalny.
Część 2. Tworzenie przepływu (czyli „jak”)
Mamy już „przepis” (prompt), teraz musimy utworzyć funkcję, która będzie go wykonywać. W Genkit nazywa się to przepływem. Przepływ opakowuje prompt w wykonywalną funkcję, którą reszta aplikacji może łatwo wywołać.
👉 Działanie: w tym samym pliku ~/src/ai/flows/check_typo/ zastąp ten kod: // REPLACE ME PART 2: add flow here:
👉 z poniższym kodem
const checkTypoFlow = ai.defineFlow<
typeof CheckTypoInputSchema,
typeof CheckTypoOutputSchema
>(
{
name: 'checkTypoFlow',
inputSchema: CheckTypoInputSchema,
outputSchema: CheckTypoOutputSchema,
},
async input => {
const {output} = await prompt(input);
return output!;
}
);
Część 3. Używanie narzędzia do sprawdzania pisowni
Po ukończeniu przepływu AI możemy teraz zintegrować go z główną logiką aplikacji. Wywołamy go od razu po otrzymaniu polecenia użytkownika, aby upewnić się, że tekst jest czysty przed dalszym przetwarzaniem.
👉Działanie: otwórz ~/src/app/ai/flows/check-typo.ts i znajdź funkcję export async function checkTypo. Usuń znacznik komentarza z instrukcji powrotu:
Zamiast return; Zrób return checkTypoFlow(input);
👉Działanie: otwórz ~/src/app/page.tsx i znajdź funkcję processVoiceCommand. Zastąp poniższy kod: REPLACE ME PART 2: add typoResult here:
👉 z poniższym kodem
const typoResult = await checkTypo({ text: rawCommand });
if (typoResult && typoResult.correctedText && typoResult.correctedText.trim().length > 0) {
const originalTrimmedLower = rawCommand.trim().toLowerCase();
const correctedTrimmedLower = typoResult.correctedText.trim().toLowerCase();
if (correctedTrimmedLower !== originalTrimmedLower) {
commandToProcess = typoResult.correctedText;
typoCorrectionAnnouncement = `I think you said: ${commandToProcess}. `;
}
}
Dzięki tej zmianie utworzyliśmy bardziej niezawodny potok przetwarzania danych dla każdego polecenia użytkownika.
Przepływ poleceń głosowych (tylko do odczytu, nie wymaga działania)
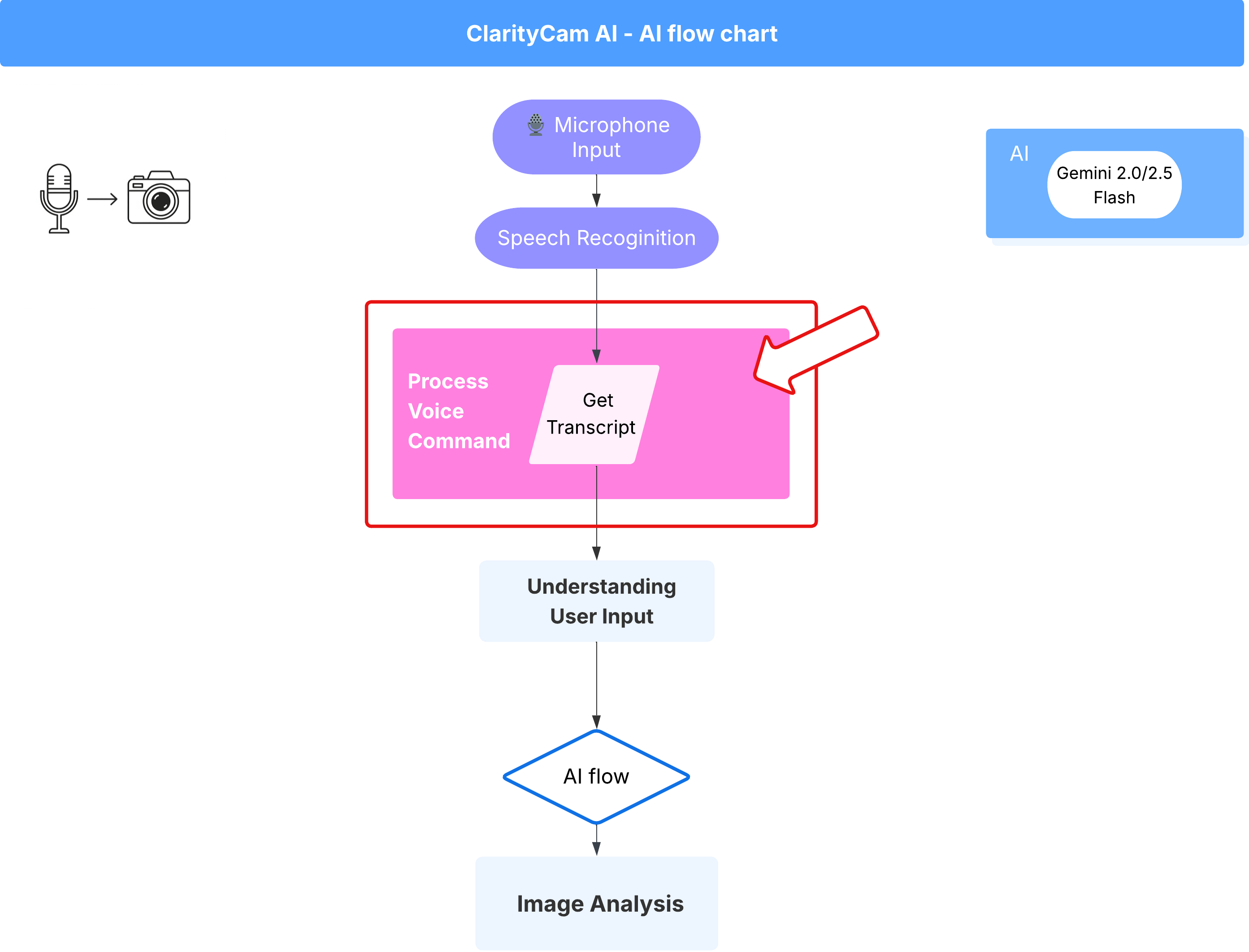
Mamy już podstawowe komponenty „rozumienia” (sprawdzanie pisowni i klasyfikator intencji). Zobaczmy teraz, jak pasują one do głównej logiki przetwarzania głosu w aplikacji.
Wszystko zaczyna się, gdy użytkownik zaczyna mówić. Interfejs Web Speech API przeglądarki nasłuchuje mowy, a gdy użytkownik skończy mówić, udostępnia transkrypcję tekstową tego, co usłyszał. Ten proces obsługuje poniższy kod.
👉Tylko do odczytu: przejdź do funkcji ~/src/app/page.tsx i handleResult. Znajdź kod poniżej:
for (let i = event.resultIndex; i < event.results.length; ++i) {
if (event.results[i].isFinal) {
finalTranscript += event.results[i][0].transcript;
}
}
if (finalTranscript) {
console.log("Final Transcript:", finalTranscript);
processVoiceCommand(finalTranscript);
}
Testowanie naszej funkcji poprawiania literówek
A teraz czas na zabawę! Sprawdźmy, jak nasza nowa funkcja korekty literówek radzi sobie z poleceniami głosowymi, które są poprawne i niepoprawne.
Uruchom aplikację
Najpierw ponownie uruchom serwer programistyczny. W terminalu uruchom to polecenie: npm run dev
Otwórz aplikację
Gdy serwer będzie gotowy, otwórz przeglądarkę i przejdź do adresu lokalnego (np. http://localhost:9003).
Włączanie poleceń głosowych
Kliknij przycisk Start Listening. Przeglądarka prawdopodobnie poprosi o zezwolenie na korzystanie z mikrofonu. Kliknij Zezwól.
Testowanie niedoskonałego polecenia
Teraz celowo wydajmy nieco wadliwe polecenie, aby sprawdzić, czy nasza AI sobie z nim poradzi. Mów wyraźnie do mikrofonu:
„Zdjęcie, na którym jestem”
Obserwowanie wyniku
To tutaj rodzi się magia! Nawet jeśli powiesz „Zrób mi zdjęcie”, aplikacja powinna prawidłowo aktywować aparat. Proces checkTypo poprawia w tle frazę na „zrób zdjęcie”, a proces classifyIntentFlow rozpoznaje poprawione polecenie.
Potwierdza to, że nasza funkcja korekty literówek działa bez zarzutu, dzięki czemu aplikacja jest znacznie bardziej niezawodna i przyjazna dla użytkownika. Gdy skończysz, możesz wyłączyć aparat, robiąc zdjęcie lub po prostu zatrzymując serwer w terminalu (Ctrl + C).
6. Analiza obrazów oparta na AI – opisywanie obrazów
Skoro nasz agent rozumie już żądania, czas dać mu oczy. W tej sekcji rozbudujemy możliwości naszego agenta Vision, czyli głównego komponentu odpowiedzialnego za analizę obrazów. Zaczniemy od najważniejszej funkcji, czyli opisywania obrazów, a potem dodamy możliwość odczytywania tekstu.
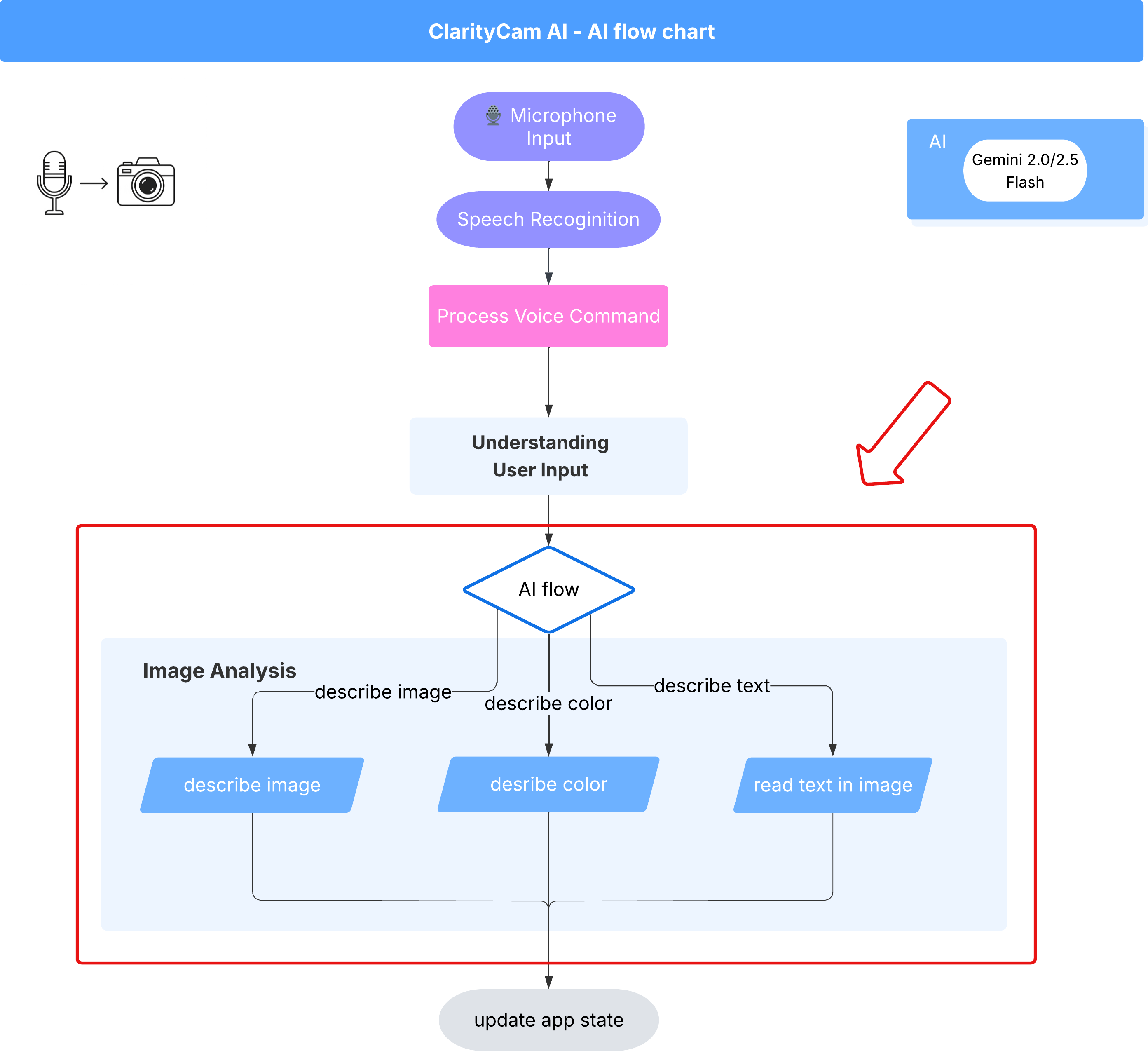
Funkcja 1. Opisywanie obrazu
Jest to główna funkcja agenta. Nie wygenerujemy tylko statycznego opisu, ale stworzymy dynamiczny przepływ, który może dostosowywać poziom szczegółowości do preferencji użytkownika. To kluczowy element filozofii interfejsu z natywną adaptacją (NAI).
👉 Działanie: w środowisku IDE Cloud Shell otwórz plik ~/src/ai/flows/describe_image/ i usuń znacznik komentarza z tego kodu.
Krok 1. Tworzenie szablonu dynamicznego prompta
Najpierw utworzymy zaawansowany szablon promptu, który może zmieniać instrukcje w zależności od otrzymanych danych wejściowych.
Odkomentuj poniższy kod.
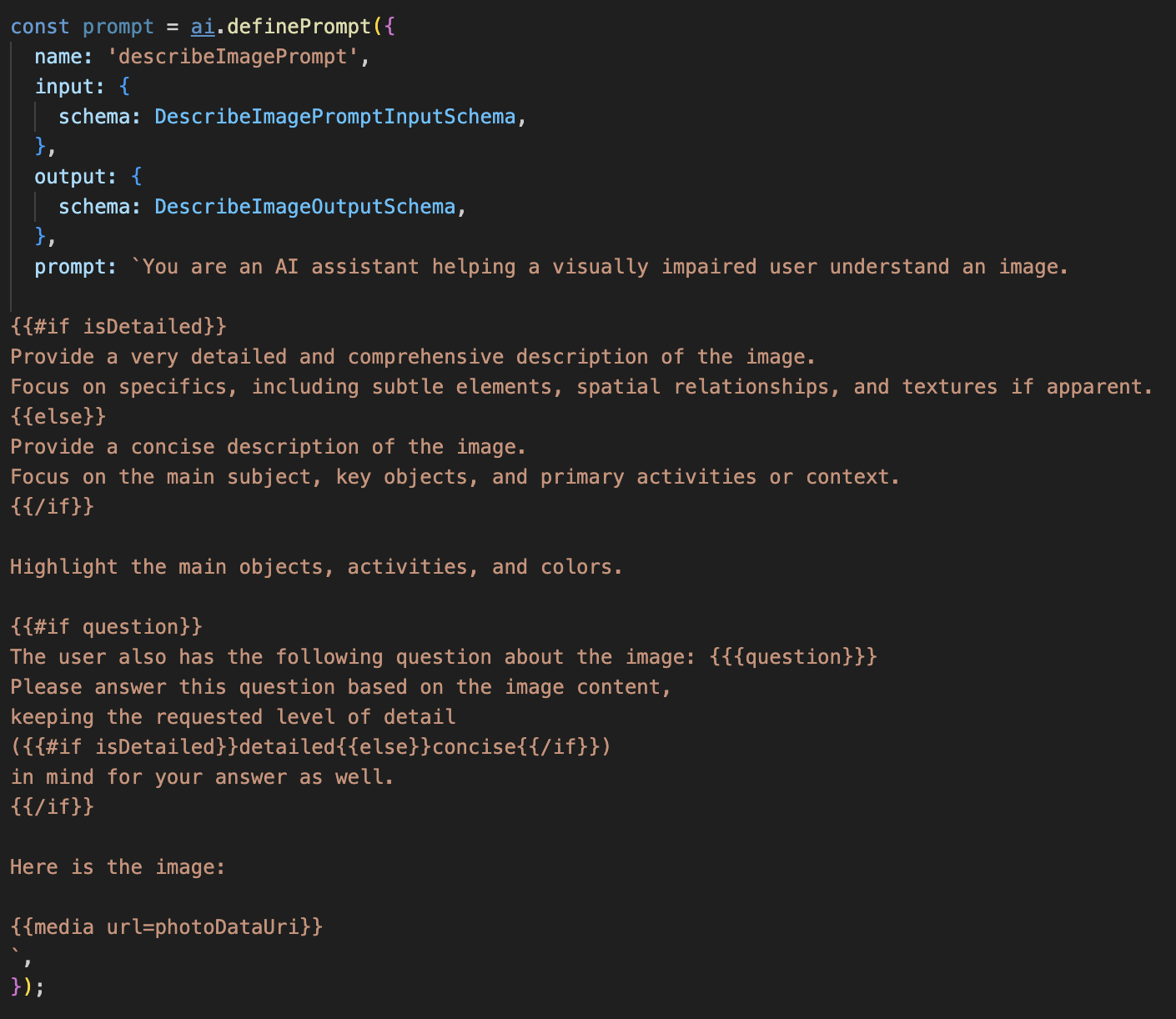
Ten kod definiuje zmienną tekstową prompt, która korzysta z języka szablonów o nazwie Dot-Mustache. Dzięki temu możemy osadzać logikę warunkową bezpośrednio w prompcie.
{#if isDetailed}...{else}...{/if}: Jest to blok warunkowy. Jeśli dane wejściowe, które wysyłamy do tego promptu, zawierają właściwość isDetailed: true, AI otrzyma „bardzo szczegółowy” zestaw instrukcji. W przeciwnym razie otrzyma instrukcje „zwięzłe”. W ten sposób nasz agent dostosowuje się do preferencji użytkownika.
{#if question}...{/if}: ten blok będzie uwzględniony tylko wtedy, gdy dane wejściowe zawierają właściwość pytania. Dzięki temu możemy używać tego samego skutecznego prompta zarówno w przypadku ogólnych opisów, jak i konkretnych pytań.
{media url=photoDataUri}: jest to specjalna składnia Genkitu, która umożliwia osadzanie danych obrazu bezpośrednio w prompcie, aby model multimodalny mógł je analizować.
Krok 2. Tworzenie inteligentnego przepływu
Następnie zdefiniujemy prompt i przepływ, który będzie korzystać z naszego nowego szablonu. Ten proces zawiera nieco logiki, która tłumaczy preferencje użytkownika na wartość logiczną zrozumiałą dla naszego szablonu.
👉 Działanie: w środowisku IDE Cloud Shell w tym samym pliku ~/src/ai/flows/describe_image/ zastąp poniższy kod. // REPLACE ME PART 1: add flow here
👉 Z tym kodem:
// Define the prompt using the template from Step 1
const prompt = ai.definePrompt({
name: 'describeImagePrompt',
input: { schema: DescribeImagePromptInputSchema },
output: { schema: DescribeImageOutputSchema },
prompt: promptTemplate,
});
// Define the flow
const describeImageFlow = ai.defineFlow<
typeof DescribeImageInputSchema,
typeof DescribeImageOutputSchema
>(
{
name: 'describeImageFlow',
inputSchema: DescribeImageInputSchema,
outputSchema: DescribeImageOutputSchema,
},
async (pageInput) => {
const preference = pageInput.detailPreference || "concise";
// Prepare the input for the prompt, including the new boolean flag
const promptInputData = {
...pageInput,
isDetailed: preference === "detailed",
};
const { output } = await prompt(promptInputData);
return output!;
}
);
Działa ona jako inteligentny pośrednik między interfejsem a promptem AI.
- Otrzymuje ona z naszej aplikacji wartość
pageInput, która zawiera preferencje użytkownika w postaci ciągu znaków (np."detailed"). - Następnie tworzy nowy obiekt
promptInputData. - Najważniejsza linia to
isDetailed: preference === "detailed". Ta linia wykonuje kluczową pracę, tworząc wartość logicznątruelubfalsena podstawie ciągu preferencji. - Na koniec wywołuje funkcję
promptz tymi ulepszonymi danymi. Szablon promptu z kroku 1 może teraz używać wartości logicznejisDetaileddo dynamicznej zmiany instrukcji wysyłanych do AI.
Krok 3. Łączenie interfejsu
Teraz wywołajmy ten proces z interfejsu w pliku page.tsx.
👉Działanie: otwórz ~/src/app/ai/flows/describe-image.ts i znajdź funkcję export async function describeImage. Usuń znacznik komentarza z instrukcji powrotu:
Zamiast return; Zrób return describeImageFlow(input);
👉Działanie: w ~/src/app/page.tsx znajdź funkcję handleAnalyze i zastąp kod // REPLACE ME PART 2: DESCRIBE IMAGE
👉 z tym kodem:
case "description":
result = await describeImage({
photoDataUri,
question,
detailPreference: descriptionPreference
});
outputText = question ? `Answer: ${result.description}` : `Description: ${result.description}`;
break;
Ten kod jest wykonywany, gdy intencją użytkownika jest uzyskanie opisu. Wywołuje nasz describeImageprzepływ, przekazując dane obrazu i co najważniejsze, descriptionPreferencezmienną stanu z naszego komponentu React. To ostatni element układanki, który łączy preferencje użytkownika przechowywane w interfejsie bezpośrednio z procesem AI, który odpowiednio dostosuje swoje działanie.
Testowanie funkcji opisu obrazu
Zobaczmy, jak działa funkcja opisu obrazu – od zrobienia zdjęcia po usłyszenie tego, co widzi AI.
Uruchom aplikację
Najpierw ponownie uruchom serwer programistyczny. 👉 W terminalu uruchom to polecenie: npm run dev Uwaga: przed uruchomieniem polecenia npm run dev może być konieczne uruchomienie polecenia npm install.
Otwórz aplikację
Gdy serwer będzie gotowy, otwórz przeglądarkę i przejdź do adresu lokalnego (np. http://localhost:9003).
Aktywowanie kamery
Kliknij przycisk Zacznij słuchać i w razie potrzeby przyznaj dostęp do mikrofonu. Następnie wypowiedz pierwsze polecenie:
„Zrób zdjęcie”.
Aplikacja włączy kamerę urządzenia. Na ekranie powinien być teraz widoczny obraz na żywo.
Zrób zdjęcie
Włącz kamerę i skieruj ją na to, co chcesz opisać. Teraz powtórz polecenie, aby zrobić zdjęcie:
„Zrób zdjęcie”.
Obraz na żywo zostanie zastąpiony statycznym zdjęciem, które właśnie zostało zrobione.
Poproś o opis
Gdy nowe zdjęcie pojawi się na ekranie, wydaj ostateczne polecenie:
„Opisz obraz”
Odsłuchanie wyniku
Aplikacja wyświetli stan przetwarzania, a następnie usłyszysz wygenerowany przez AI opis obrazu. Tekst pojawi się też na karcie „Stan i wynik”.
Gdy skończysz, możesz wyłączyć kamerę, robiąc zdjęcie, lub po prostu zatrzymać serwer w terminalu (Ctrl + C).
7. Analiza obrazów oparta na AI – opisywanie tekstu (OCR)
Następnie dodamy do naszego agenta Vision funkcję optycznego rozpoznawania znaków (OCR). Dzięki temu może odczytywać tekst z dowolnego obrazu.
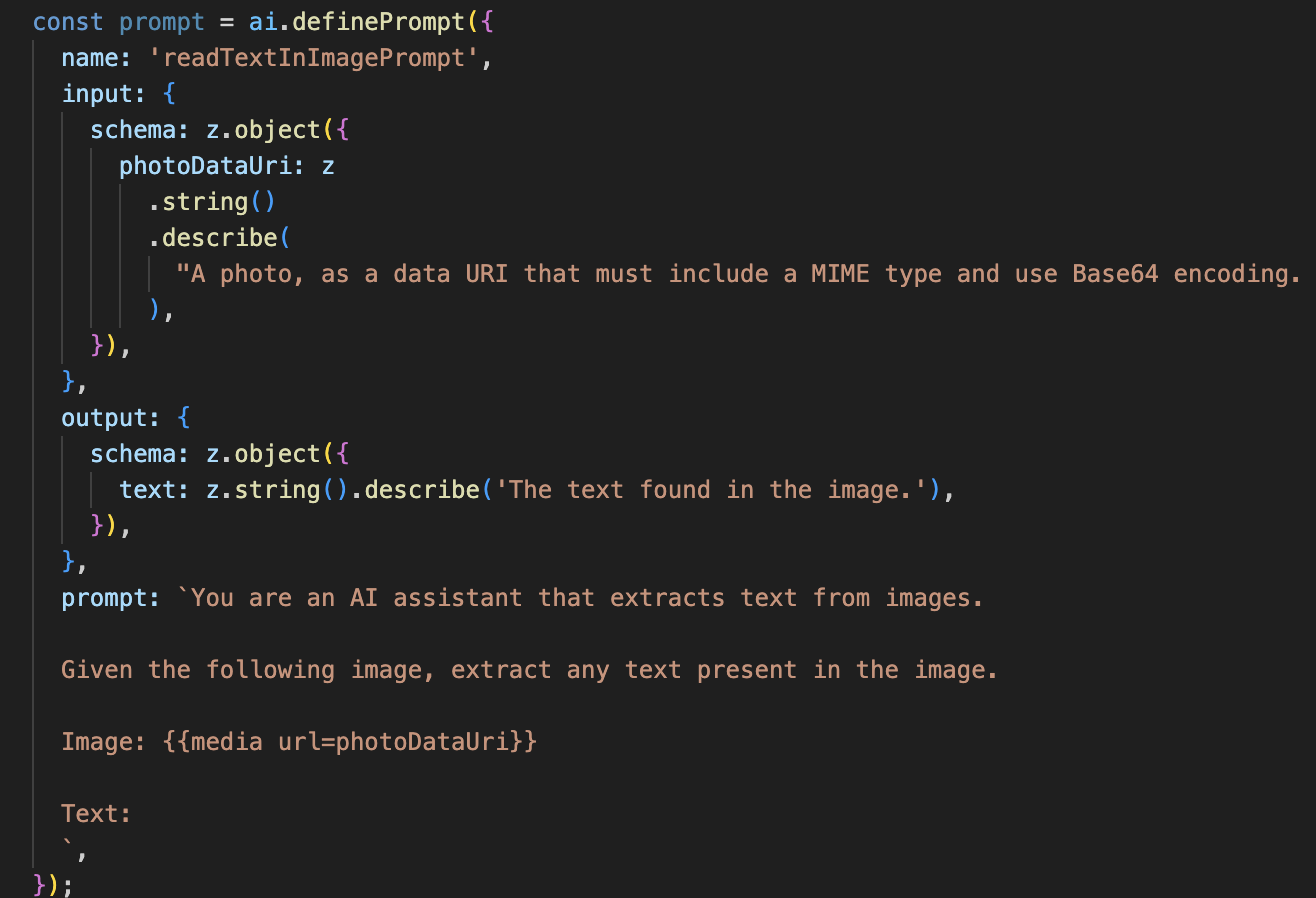
👉 Działanie: w IDE otwórz ~/src/ai/flows/read-text-in-image/ i odkomentuj poniższy kod:
👉 Działanie: w środowisku IDE w tym samym pliku ~/src/ai/flows/read-text-in-image/ zastąp // REPLACE ME: Creating Prmopt
👉 z kodem poniżej:
const readTextInImageFlow = ai.defineFlow<
typeof ReadTextInImageInputSchema,
typeof ReadTextInImageOutputSchema
>(
{
name: 'readTextInImageFlow',
inputSchema: ReadTextInImageInputSchema,
outputSchema: ReadTextInImageOutputSchema,
},
async input => {
const {output} = await prompt(input);
return output!;
}
);
Ten proces AI jest znacznie prostszy, co podkreśla zasadę używania wyspecjalizowanych narzędzi do konkretnych zadań.
- Prompt: w przeciwieństwie do promptu opisu ten jest statyczny i bardzo szczegółowy. Jego jedynym zadaniem jest poinstruowanie AI, aby działała jako silnik OCR: „wyodrębnij cały tekst z obrazu”.
- Schematy: schematy wejściowe i wyjściowe są również proste – oczekują obrazu i zwracają pojedynczy ciąg tekstu.
Łączenie frontendu z OCR
Na koniec połączmy tę nową funkcję w page.tsx.
👉Działanie: otwórz ~/src/app/ai/flows/read-text-in-image.ts i znajdź funkcję export async function readTextInImage. Usuń znacznik komentarza z instrukcji powrotu:
Zamiast return; Zrób return readTextInImageFlow(input);
👉 Działanie: w ~/src/app/page.tsx znajdź funkcję handleAnalyze i instrukcję switch.
Zastąp REPLACE ME PART 3: READ TEXT
z kodem poniżej:
case "text":
result = await readTextInImage({ photoDataUri });
outputText = result.text ? `Text Found: ${result.text}` : "No text found.";
break;
Gdy intencją użytkownika jest ReadTextInImage, ten kod jest wywoływany. Wywołuje on nasz prosty readTextInImage. Wiersz result.text ? ... : ... to prosty sposób na obsługę danych wyjściowych. Jeśli AI nie znajdzie żadnego tekstu na obrazie, wyświetli użytkownikowi pomocny komunikat.
Testowanie funkcji odczytywania tekstu (OCR)
Aby przetestować funkcję odczytywania tekstu, wykonaj te czynności. Pamiętaj, aby skierować aparat na obiekt z wyraźnym tekstem.
- Uruchom aplikację za pomocą polecenia
npm run devi otwórz ją w przeglądarce. - Kliknij Rozpocznij słuchanie i gdy pojawi się prośba, przyznaj dostęp do mikrofonu.
- Włącz kamerę. Wypowiedz polecenie „Zrób zdjęcie”. Na ekranie powinien pojawić się obraz na żywo.
- Zrób zdjęcie. Skieruj aparat na tekst, który chcesz przeczytać, i ponownie wypowiedz polecenie: „Zrób zdjęcie”. Film zostanie zastąpiony statycznym zdjęciem.
- Poproś o tekst. Po zrobieniu zdjęcia wydaj ostateczne polecenie: „What is the text in the image?” (Jaki tekst znajduje się na obrazie?).
- Sprawdź wynik Po chwili aplikacja przeanalizuje zdjęcie i odczyta wykryty tekst. Jeśli nie znajdzie żadnego tekstu, poinformuje Cię o tym.
Potwierdza to, że zaawansowana funkcja OCR działa. Gdy skończysz, zatrzymaj serwer za pomocą Ctrl + C.
8. Zaawansowane ulepszenia oparte na AI – tylko do odczytu ✨
Dobry agent AI potrafi wykonywać instrukcje. Dobry agent AI jest intuicyjny, godny zaufania i pomocny. W tej sekcji skupimy się na 3 zaawansowanych ulepszeniach, które zwiększają możliwości agenta.
Dowiesz się, jak:
Add Context & Memory, aby obsługiwać naturalne, konwersacyjne pytania uzupełniające.Reduce Hallucination– aby stworzyć bardziej niezawodnego i wiarygodnego agenta.Make the Agent Proactive, aby zapewnić większą dostępność i wygodę.Add preference setting, aby dostosować opis obrazu.
Ulepszenie 1. Kontekst i pamięć
Naturalna rozmowa to nie seria odosobnionych poleceń, ale płynna wymiana zdań. Jeśli użytkownik zapyta „Co jest na zdjęciu?”, a agent odpowie „Czerwony samochód”, naturalną reakcją użytkownika może być pytanie „Jakiego jest koloru?” bez ponownego wspominania „samochodu”. Aby zrozumieć ten kontekst, agent musi mieć pamięć krótkotrwałą.
Jak to wdrożyliśmy (podsumowanie)
Ta funkcja jest już wbudowana w proces opisywania obrazu. Ta sekcja zawiera podsumowanie działania tego wzorca. Gdy wywołujemy funkcję describeImage z pliku page.tsx, przekazujemy do niej historię rozmowy.
👉 Code Showcase (od page.tsx):
const result = await describeImage({
photoDataUri,
question: commandToProcess,
detailPreference: descriptionPreference,
previousUserQueryOnImage: lastUserQuery ?? undefined,
previousAIResponseOnImage: lastAIResponse ?? undefined,
});
previousUserQueryOnImageipreviousAIResponseOnImage: te 2 właściwości to pamięć krótkotrwała agenta. Przekazując ostatnią interakcję do AI, zapewniamy jej kontekst potrzebny do zrozumienia niejasnych lub odwołujących się do wcześniejszych informacji pytań.- Prompt adaptacyjny: ten kontekst jest używany przez prompt w naszym procesie describe_image. Prompt jest zaprojektowany tak, aby podczas tworzenia nowej odpowiedzi uwzględniać poprzednią rozmowę, co pozwala agentowi inteligentnie odpowiadać.
Ulepszenie 2. Ograniczanie halucynacji
Sztuczna inteligencja „halucynuje”, gdy zmyśla fakty lub twierdzi, że ma możliwości, których nie posiada. Aby budować zaufanie użytkowników, nasz agent musi znać swoje ograniczenia i umieć grzecznie odmawiać odpowiedzi na pytania wykraczające poza jego zakres.
Jak to wdrożyliśmy (podsumowanie)
Najskuteczniejszym sposobem zapobiegania halucynacjom jest wyznaczenie modelu wyraźnych granic. Udało nam się to osiągnąć, gdy tworzyliśmy klasyfikator intencji.
👉 Code Showcase (z przepływu intent-classifier):
// Define Agent Capabilities and Limitations for the prompt
const AGENT_CAPABILITIES_AND_LIMITATIONS = `
**Core Capabilities (What the Agent CAN DO):**
* **Image Analysis:**
* DescribeImage: Provide a general description of the current image...
**Limitations (What the Agent CANNOT DO...):**
* Cannot generate or create new images.
* Cannot provide general knowledge or answer questions unrelated to the image...
* Cannot perform web searches.
`;
Ta stała pełni funkcję „opisu stanowiska”, który przekazujemy do AI w prompcie klasyfikacji.
- Uziemienie modelu: wyraźnie informując AI, czego nie może robić, „uziemiamy” ją w rzeczywistości. Gdy zobaczy zapytanie takie jak „Jaka jest pogoda?”, może z pewnością dopasować je do listy ograniczeń i zaklasyfikować intencję jako OutOfScopeRequest.
- Budowanie zaufania: agent, który potrafi szczerze powiedzieć „Nie mogę Ci w tym pomóc”, jest o wiele bardziej wiarygodny niż ten, który próbuje zgadywać i się myli. To podstawowa zasada projektowania bezpiecznych i niezawodnych systemów AI. `
Ulepszenie 3. Tworzenie proaktywnego agenta
W przypadku aplikacji z ułatwieniami dostępu nie możemy polegać na wskazówkach wizualnych. Gdy użytkownik aktywuje tryb słuchania, musi natychmiast otrzymać potwierdzenie, że agent jest gotowy i czeka na polecenie. Teraz dodamy proaktywne wprowadzenie, aby przekazać te kluczowe informacje.
Krok 1. Dodaj stan, aby śledzić pierwsze odtworzenie
Najpierw musimy wiedzieć, czy użytkownik po raz pierwszy w sesji nacisnął przycisk "Start Listening".
👉 W ~/src/app/page.tsx u góry komponentu ClarityCam zobaczysz nową zmienną stanu:
export default function ClarityCam() {
// ... other state variables
const [descriptionPreference, setDescriptionPreference] = useState<DescriptionPreference>("concise");
// Add this new line
const [isFirstListen, setIsFirstListen] = useState(true);
// ... rest of the component
}
Wprowadziliśmy nową zmienną stanu isFirstListen i ustawiliśmy jej wartość początkową na true. Użyjemy tego znacznika, aby wywołać jednorazową wiadomość powitalną.
Krok 2. Zaktualizuj funkcję toggleListening
Teraz zmodyfikujmy funkcję obsługującą mikrofon, aby odtwarzała powitanie.
👉 W ~/src/app/page.tsx znajdź funkcję toggleListening i zobacz ten blok if.
const toggleListening = useCallback(() => {
// ... existing logic to setup speech recognition
if (isListening || isAttemptingStart) {
// ... existing logic to stop listening
} else {
stopSpeaking(); // Stop any ongoing TTS
// Add this new block
if (isFirstListen) {
setIsFirstListen(false);
const introMessage = "Hello! I am ClarityCam, your AI assistant. I'm now listening. You can ask me to 'describe the image', 'read text', 'take a picture', or ask questions about what's in an image.";
speakText(introMessage);
} else {
speakText("Listening..."); // Optional: provide feedback on subsequent clicks
}
// ... rest of the logic to start listening
}
}, [/*...existing dependencies...*/, isFirstListen]); // Don't forget to add isFirstListen to the dependency array!
- Sprawdź flagę: blok if (isFirstListen) sprawdza, czy jest to pierwsza aktywacja.
- Zapobieganie powtórzeniom: pierwszą czynnością w bloku jest wywołanie funkcji setIsFirstListen(false). Dzięki temu wiadomość wprowadzająca będzie odtwarzana tylko raz na sesję.
- Wskazówki: wiadomość wprowadzająca jest starannie przygotowana, aby była jak najbardziej pomocna. Wita użytkownika, przedstawia się z imienia, potwierdza, że jest aktywny („Teraz słucham”), i podaje jasne przykłady poleceń głosowych, których można używać.
- Informacje zwrotne w formie dźwiękowej: na koniec funkcja speakText(introMessage) przekazuje te kluczowe informacje, zapewniając natychmiastowe potwierdzenie i wskazówki bez konieczności patrzenia na ekran.
Ulepszenie 4. Dostosowywanie się do ustawień użytkownika (podsumowanie)
Prawdziwie inteligentny agent nie tylko odpowiada, ale też uczy się i dostosowuje do potrzeb użytkownika. Jedną z najbardziej zaawansowanych funkcji, które stworzyliśmy, jest możliwość zmiany poziomu szczegółowości opisów obrazów w trakcie ich odczytywania za pomocą poleceń takich jak „Podaj więcej szczegółów”.
Jak to zrobiliśmy (podsumowanie) Ta funkcja korzysta z dynamicznego promptu, który utworzyliśmy na potrzeby procesu opisywania obrazów. Wykorzystuje logikę warunkową, aby zmieniać instrukcje wysyłane do AI na podstawie preferencji użytkownika.
👉 Code Showcase (promptTemplate z describe_image):
const settingPreferenceTemplate = `
{#if isDetailed}
Provide a very detailed and comprehensive description of the image. Focus on specifics, including subtle elements, spatial relationships, and textures if apparent.
{else}
Provide a concise description of the image. Focus on the main subject, key objects, and primary activities or context.
{/if}
Highlight the main objects, activities, and colors.
...
`;
- Logika warunkowa: kluczowy jest blok
{#if isDetailed}...{else}...{/if}. Gdy funkcja describeImageFlow otrzyma z interfejsu preferencje dotyczące szczegółów, utworzy wartość logiczną isDetailed (prawda lub fałsz). - Instrukcje adaptacyjne: ten flaga logiczna określa, który zestaw instrukcji otrzymuje model AI. Jeśli parametr isDetailed ma wartość Prawda, model ma generować bardzo szczegółowe opisy. Jeśli jest fałszywa, ma być zwięzła.
- Kontrola użytkownika: ten wzorzec bezpośrednio łączy polecenie głosowe użytkownika (np. „skróć opisy”, które jest klasyfikowane jako intencja SetDescriptionConcise) z zasadniczą zmianą w zachowaniu AI, dzięki czemu agent reaguje w sposób spersonalizowany.
9. Wdrażanie w chmurze
Tworzenie obrazu Dockera za pomocą Google Cloud Build
gcloud builds submit . --tag gcr.io/$PROJECT_ID/accessibilityai-nextjs-app:latest
accessibilityai-nextjs-appto sugerowana nazwa obrazu.- Nie można przetworzyć pliku . używa bieżącego katalogu (
accessibilityAI/) jako źródła kompilacji.
Wdrażanie obrazu w Google Cloud Run
- Sprawdź, czy klucze interfejsu API i inne obiekty tajne są gotowe w usłudze Secret Manager. Na przykład:
GOOGLE_GENAI_API_KEY.
Zastąp ten symbol YOUR_ACTUAL_GOOGLE_AI_KEY_VALUE rzeczywistą wartością klucza interfejsu Gemini API.
echo "YOUR_ACTUAL_GOOGLE_AI_KEY_VALUE" | gcloud secrets create GOOGLE_GENAI_API_KEY --data-file=- --project=YOUR_PROJECT_ID
Przypisz wykonawczemu kontu usługi Cloud Run (np. PROJECT_NUMBER-compute@developer.gserviceaccount.com lub dedykowanemu) rolę „Uzyskujący dostęp do obiektów tajnych w Secret Manager” w przypadku tego obiektu tajnego.
- Polecenie wdrożenia:
gcloud run deploy accessibilityai-app-service \
--image gcr.io/$PROJECT_ID/accessibilityai-nextjs-app:latest \
--platform managed \
--region us-central1 \
--allow-unauthenticated \
--port 3000 \
--set-secrets=GOOGLE_GENAI_API_KEY=GOOGLE_GENAI_API_KEY:latest \
--set-env-vars NODE_ENV="production"