
1. Introdução
Neste tutorial, você vai criar a ClarityCam, um agente de IA sem usar as mãos e controlado por voz que pode ver o mundo e explicar para você. Embora a ClarityCam tenha sido projetada com acessibilidade como base, oferecendo uma ferramenta poderosa para usuários cegos e com baixa visão, os princípios que você vai aprender são essenciais para criar qualquer aplicativo de voz moderno e de uso geral.

Esse projeto é baseado em uma filosofia de design poderosa chamada Interface nativamente adaptativa (NAI, na sigla em inglês). Em vez de tratar a acessibilidade como algo secundário, a NAI a torna a base. Com essa abordagem, o agente de IA é a interface: ele se adapta a diferentes usuários, processa entradas multimodais, como voz e visão, e orienta as pessoas de maneira proativa com base nas necessidades exclusivas delas.
Como criar seu primeiro agente de IA com a NAI:

Ao final desta sessão, você vai saber:
- Projetar com acessibilidade como padrão: aplique os princípios da interface adaptativa nativa (NAI, na sigla em inglês) para criar sistemas de IA que ofereçam experiências equivalentes para todos os usuários.
- Classificar a intenção do usuário: crie um classificador de intenção robusto que traduza comandos em linguagem natural em ações estruturadas para seu agente.
- Manter o contexto da conversa: implemente a memória de curto prazo para permitir que o agente entenda perguntas complementares e comandos referenciais (por exemplo, "Qual é a cor?").
- Criar comandos eficazes: elabore comandos focados e ricos em contexto para um modelo multimodal como o Gemini e garantir uma análise de imagens precisa e confiável.
- Lidar com ambiguidade e orientar o usuário: crie um tratamento de erros adequado para solicitações fora do escopo e integre os usuários de maneira proativa para criar confiança.
- Orquestre um sistema multiagente: estruture seu aplicativo usando uma coleção de agentes especializados que colaboram para lidar com tarefas complexas, como processamento, análise e síntese de voz.
2. Design de alto nível
A ClarityCam foi projetada para ser simples para o usuário, mas é alimentada por um sistema sofisticado de agentes de IA colaborativos. Vamos detalhar a arquitetura.

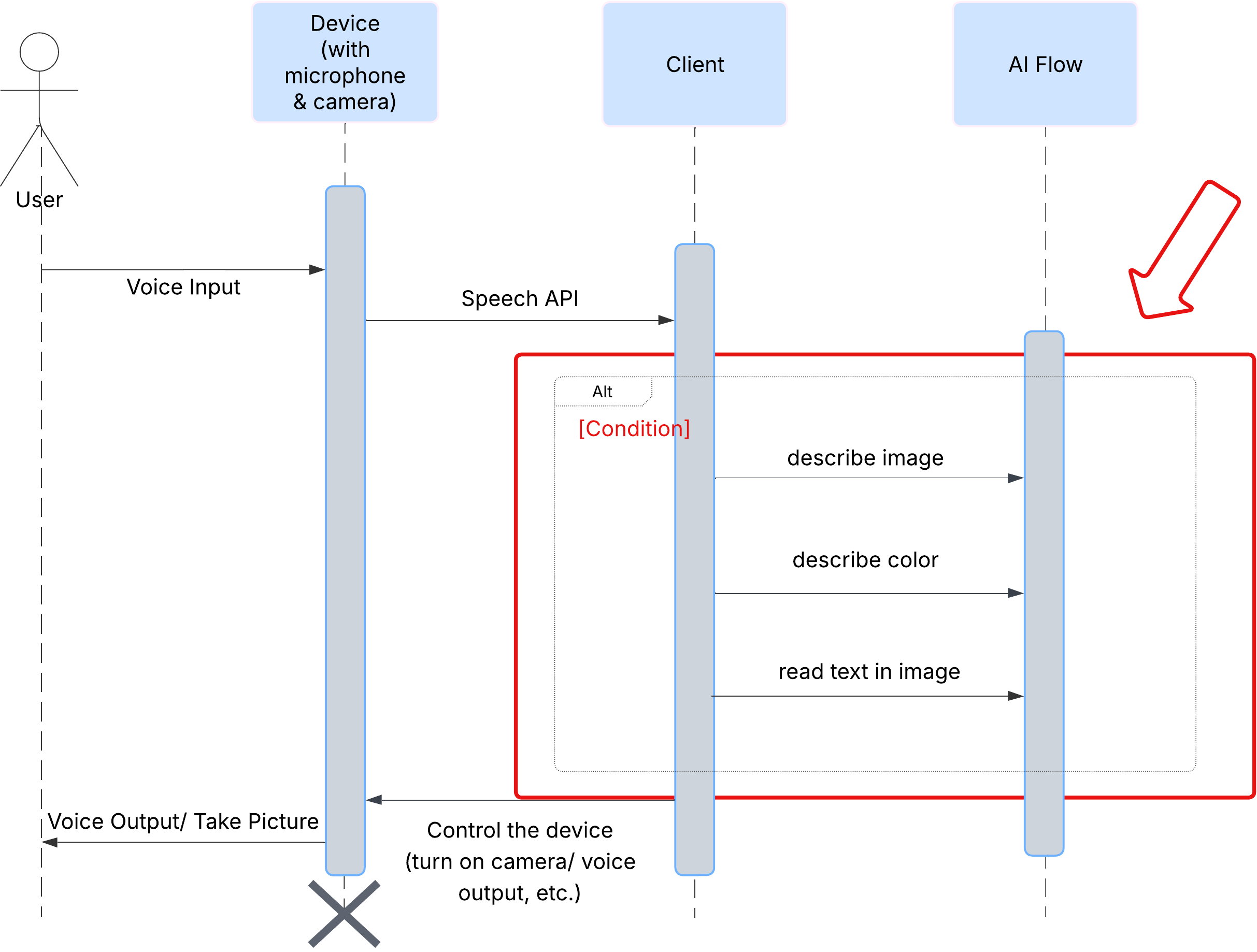
Experiência do usuário
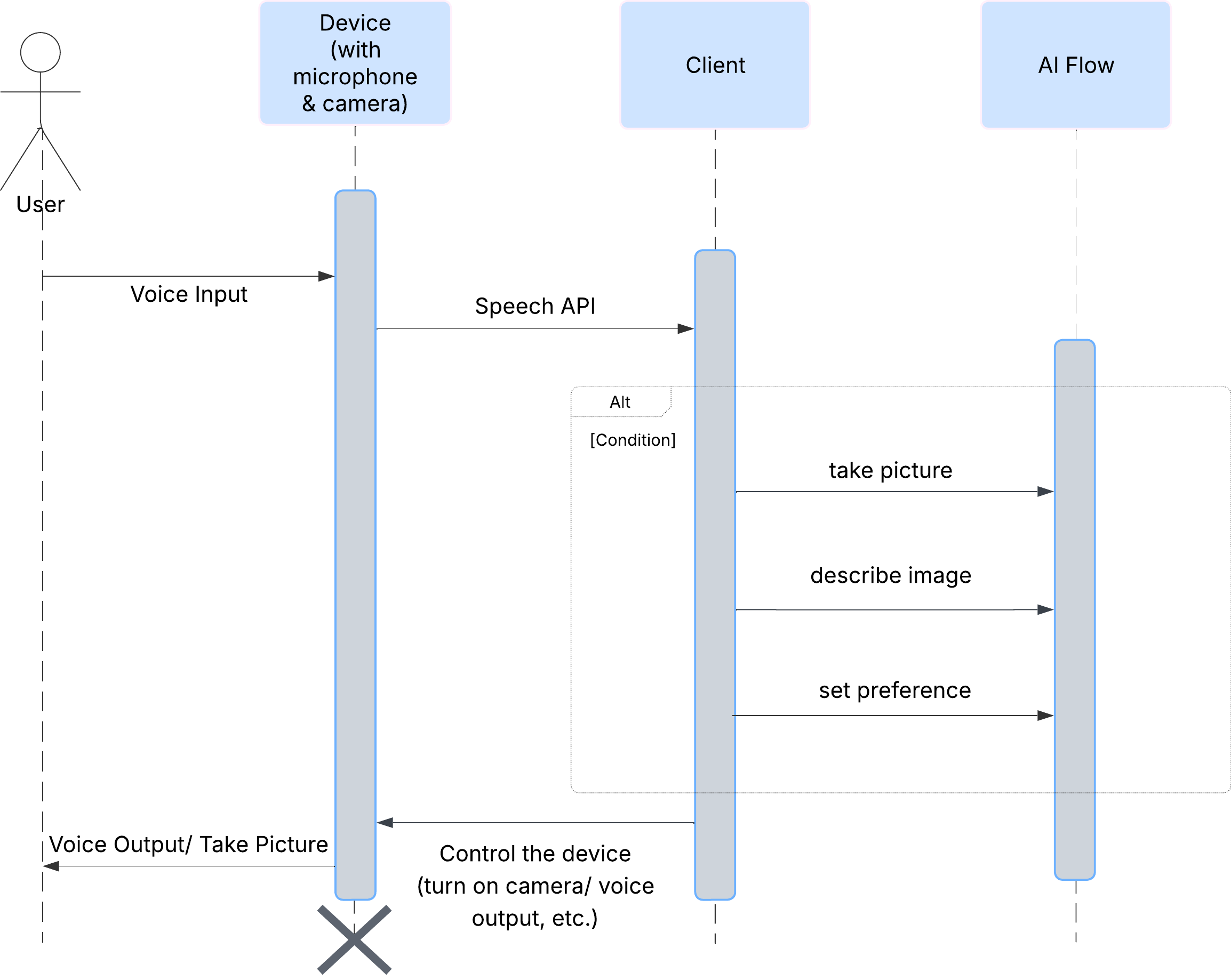
Primeiro, vamos analisar como um usuário interage com a ClarityCam. Toda a experiência é viva-voz e de conversa. O usuário fala um comando, e o agente responde com uma descrição ou ação falada. Este diagrama de sequência mostra um fluxo de interação típico, desde o comando de voz inicial do usuário até a resposta de áudio final do dispositivo.
A arquitetura do agente de IA
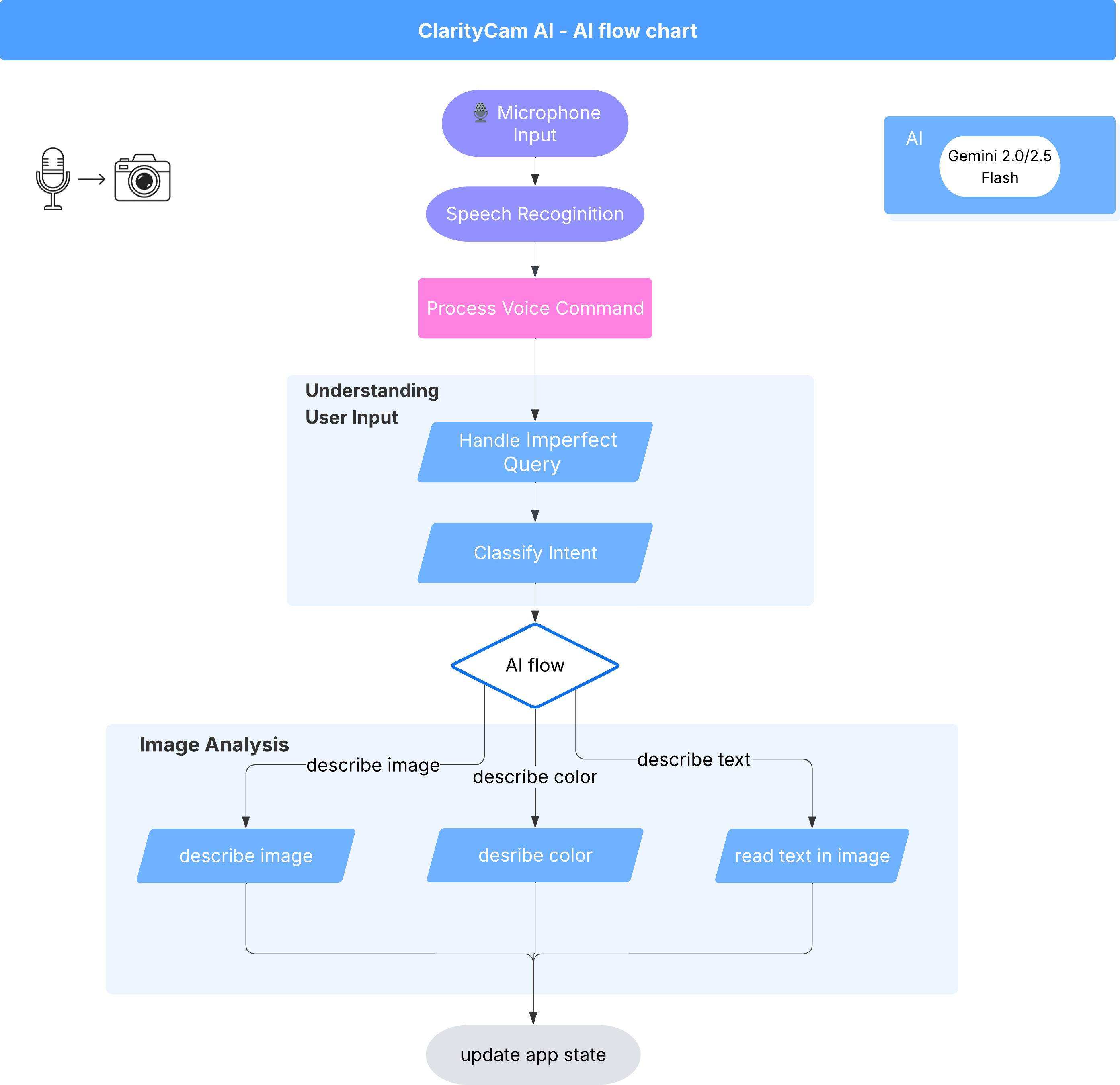
Por trás da interface, um sistema multiagente trabalha em conjunto para dar vida à experiência. Quando um comando é recebido, um agente orquestrador central delega tarefas a agentes especializados responsáveis por entender a intenção, analisar imagens e formar uma resposta. Este diagrama de fluxo de IA mostra como esses agentes colaboram. Vamos implementar essa arquitetura nas seções a seguir.
Um tour rápido pelos arquivos do projeto
Antes de começar a escrever o código, vamos conhecer a estrutura de arquivos do nosso projeto. Pode parecer que há muitos arquivos, mas você só precisa se concentrar em duas áreas específicas para todo este tutorial.
Confira um mapa simplificado do nosso projeto.
accessibilityAI/src/
├── 📁 app/
│ ├── layout.tsx # An overall page shell (you can ignore this).
│ └── page.tsx # ⬅️ MODIFY THIS: The main user interface for our app.
│
├── 📁 ai/
│ ├── 📁flows # ⬅️ MODIFY THIS: The core AI logic and server functions.
│ └── intent-classifier.ts # ⬅️ MODIFY THIS: Where we'll edit our AI prompts.
| └── ai-instance.ts
| └── dev.ts
│
├── 📁 components/ # Contains pre-built UI components (ignore this).
│
├── 📁 hooks/
│
├── 📁 lib/
│
└── 📁 types/
A pilha de tecnologia
Nosso sistema é criado em uma pilha de tecnologia moderna e escalonável que combina serviços de nuvem eficientes e modelos de IA de última geração. Estes são os principais componentes que vamos usar:
- Google Cloud Platform (GCP): fornece a infraestrutura sem servidor para nossos agentes.
- Cloud Run: implanta nossos agentes individuais como microsserviços conteinerizados e escalonáveis.
- Artifact Registry: armazena e gerencia com segurança as imagens do Docker para nossos agentes.
- Secret Manager: processa com segurança credenciais sensíveis e chaves de API.
- Modelos de linguagem grandes (LLMs): funcionam como o "cérebro" do sistema.
- Modelos do Gemini do Google: usamos os recursos multimodais avançados da família Gemini para tudo, desde a classificação da intenção do usuário até a análise do conteúdo de imagens e a descrição inteligente.
3. Configuração e pré-requisitos
Ativar uma conta de faturamento: para executar este codelab, você precisa de uma conta de faturamento com algum crédito. Use os créditos do banner na parte de cima deste codelab para começar. Se você já estiver conectado a uma conta de faturamento, pule esta etapa.
Criar um projeto do GCP
- Acesse o Console do Google Cloud e crie um projeto.
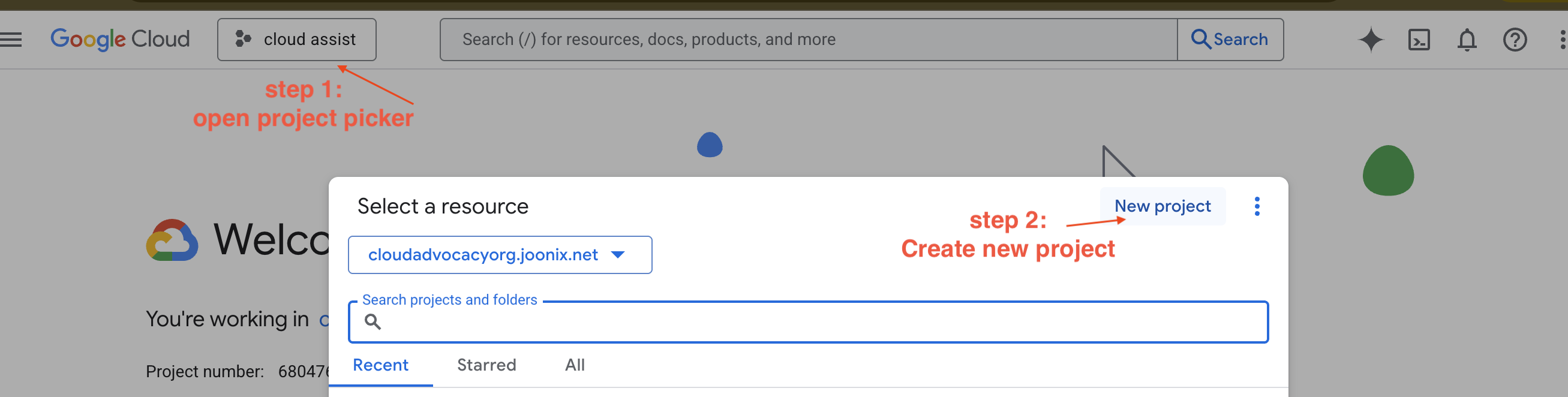
- Acesse o Console do Google Cloud e crie um projeto.
- Abra o painel à esquerda, clique em
Billinge verifique se a conta de faturamento está vinculada a essa conta do GCP.
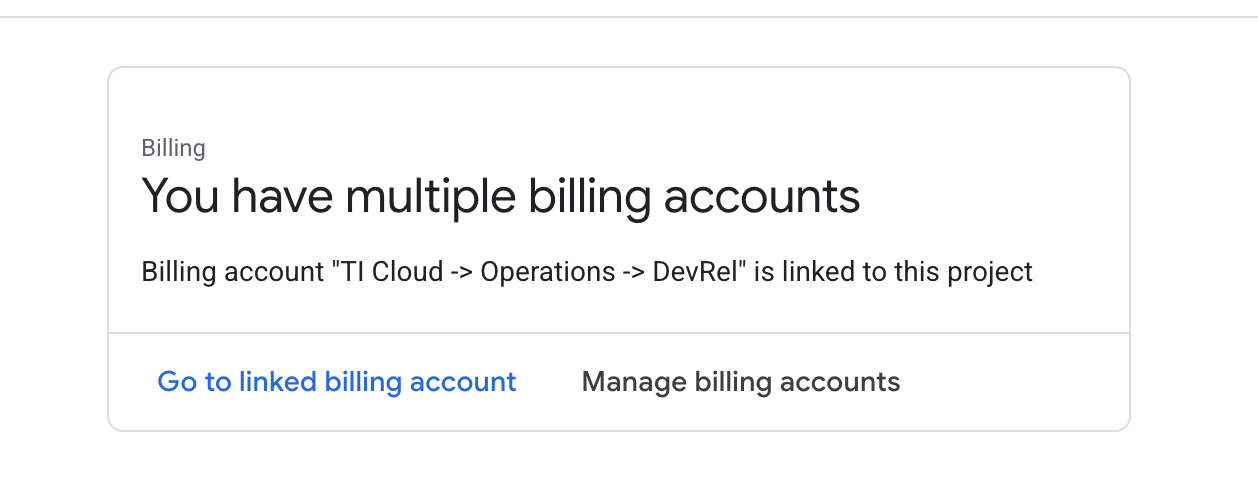
Se esta página aparecer, verifique o manage billing account, escolha o teste do Google Cloud e vincule a ele.
Crie sua chave da API Gemini
Antes de proteger a chave, você precisa ter uma.
- Acesse o Google AI Studio : https://aistudio.google.com/
- Faça login usando sua Conta do Google.
- Clique no botão Receber chave de API, geralmente encontrado no painel de navegação à esquerda ou no canto superior direito.
- Na caixa de diálogo Chaves de API, clique em "Criar chave de API em um novo projeto".
- Uma nova chave de API será gerada para você. Copie essa chave imediatamente e armazene-a em um lugar seguro temporariamente, como um gerenciador de senhas ou uma nota segura. Esse é o valor que você vai usar nas próximas etapas.
O fluxo de trabalho de desenvolvimento local (teste na sua máquina)
Você precisa conseguir executar npm run dev e fazer o app funcionar. É aí que entra o .env.
- Adicione a chave de API ao arquivo: crie um arquivo chamado
.enve adicione a seguinte linha a ele.
Substitua YOUR_API_KEY_HERE pela chave que você recebeu do AI Studio e salve em .env:
GOOGLE_GENAI_API_KEY="YOUR_API_KEY_HERE"
[Opcional] Configurar IDE e ambiente
Para este tutorial, você pode trabalhar em um ambiente de desenvolvimento conhecido, como o VS Code ou o IntelliJ, com seu terminal local. No entanto, recomendamos usar o Google Cloud Shell para garantir um ambiente padronizado e pré-configurado.
As etapas a seguir foram escritas para o contexto do Cloud Shell. Se você preferir usar o ambiente local, verifique se git, nvm, npm e gcloud estão instalados e configurados corretamente.
Trabalhar no editor do Cloud Shell
👉Clique em Ativar o Cloud Shell na parte de cima do console do Google Cloud. É o ícone em forma de terminal na parte de cima do painel do Cloud Shell. 
👉Clique no botão "Abrir Editor" (parece uma pasta aberta com um lápis). Isso vai abrir o editor de código do Cloud Shell na janela. Um explorador de arquivos vai aparecer no lado esquerdo. 
👉Clique no botão Fazer login no Cloud Code na barra de status inferior, conforme mostrado. Autorize o plug-in conforme instruído. Se a barra de status mostrar Cloud Code – sem projeto, clique na opção e escolha o projeto do Google Cloud com que você quer trabalhar no menu suspenso "Selecionar um projeto do Google Cloud". 
👉Abra o terminal no IDE na nuvem, 
👉No terminal, verifique se você já está autenticado e se o projeto está definido como seu ID do projeto usando o seguinte comando:
gcloud auth list
👉 Clone o projeto natively-accessible-interface do GitHub:
git clone https://github.com/cuppibla/AccessibilityAgent.git
👉Execute o comando make e substitua <YOUR_PROJECT_ID> pelo ID do seu projeto. É possível encontrar o ID do projeto no console do Google Cloud, na parte do projeto. ❗️❗️Não confunda project id com project number❗️❗️:
echo <YOUR_PROJECT_ID> > ~/project_id.txt
gcloud config set project $(cat ~/project_id.txt)
👉Execute o comando a seguir para ativar as APIs do Cloud necessárias. Isso pode levar cerca de dois minutos.
gcloud services enable compute.googleapis.com \
storage.googleapis.com \
run.googleapis.com \
artifactregistry.googleapis.com \
aiplatform.googleapis.com \
eventarc.googleapis.com \
sqladmin.googleapis.com \
secretmanager.googleapis.com \
cloudbuild.googleapis.com \
cloudresourcemanager.googleapis.com \
cloudfunctions.googleapis.com \
cloudaicompanion.googleapis.com
Isso pode levar alguns minutos.
Configurar permissão
👉Configure a permissão da conta de serviço. No terminal, execute :
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
export SERVICE_ACCOUNT_NAME=$(gcloud compute project-info describe --format="value(defaultServiceAccount)")
echo "Here's your SERVICE_ACCOUNT_NAME $SERVICE_ACCOUNT_NAME"
Conceda permissões. No terminal, execute :
#Cloud Storage (Read/Write):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/storage.objectAdmin"
#Pub/Sub (Publish/Receive):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/pubsub.publisher"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/pubsub.subscriber"
#Cloud SQL (Read/Write):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/cloudsql.editor"
#Eventarc (Receive Events):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/iam.serviceAccountTokenCreator"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/eventarc.eventReceiver"
#Vertex AI (User):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/aiplatform.user"
#Secret Manager (Read):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/secretmanager.secretAccessor"
4. Entender a entrada do usuário: classificador de intenção
Antes de agir, o agente de IA precisa entender com precisão o que o usuário quer. A entrada do mundo real geralmente é confusa: pode ser vaga, incluir erros de digitação ou usar linguagem coloquial.
Nesta seção, vamos criar os componentes de "escuta" essenciais que transformam a entrada do usuário bruta em um comando claro e prático.
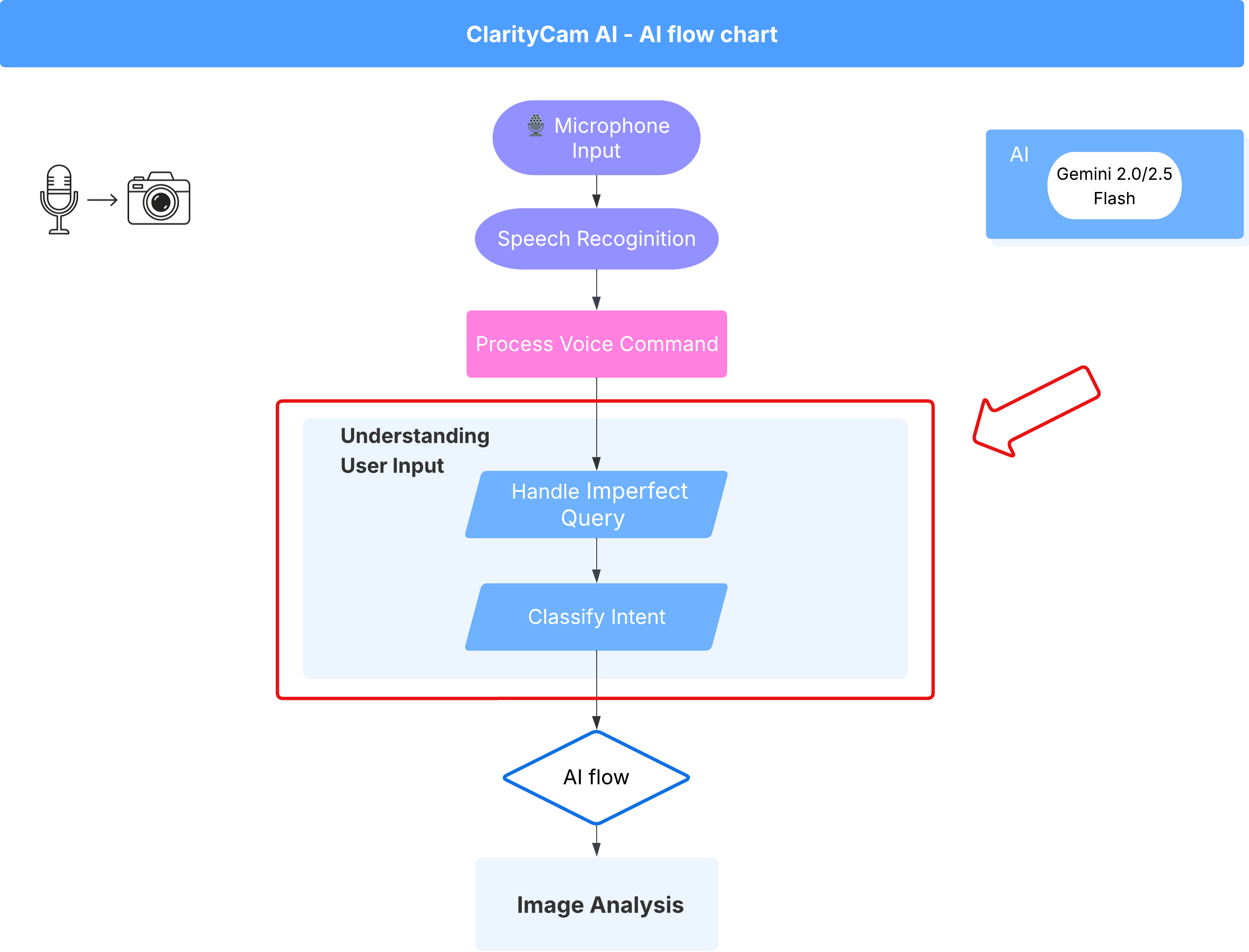
Adicionar um classificador de intents
Agora vamos definir a lógica de IA que alimenta nosso classificador.
👉 Ação: no Cloud Shell IDE, navegue até o diretório ~/src/ai/intent-classifier/.
Etapa 1: definir o vocabulário do agente (IntentCategory)
Primeiro, precisamos criar uma lista definitiva de todas as ações possíveis que nosso agente pode realizar.
👉 Ação: substitua o marcador de posição // REPLACE ME PART 1: add IntentCategory here pelo seguinte código:
👉 com o código abaixo:
export type IntentCategory =
// Image Analysis Intents
| "DescribeImage"
| "AskAboutImage"
| "ReadTextInImage"
| "IdentifyColorsInImage"
// Control Intents
| "TakePicture"
| "StartCamera"
| "SelectImage"
| "StopSpeaking"
// Preference Intents
| "SetDescriptionDetailed"
| "SetDescriptionConcise"
// Fallback Intents
| "GeneralInquiry" // User has a general question about the agent's functions or polite interaction
| "OutOfScopeRequest" // User's request is clearly outside the agent's defined capabilities
| "Unknown"; // Intent could not be determined with confidence
Explicação
Esse código TypeScript cria um tipo personalizado chamado "IntentCategory". É uma lista estrita que define todas as ações ou "intents" possíveis que nosso agente pode entender. Essa é uma primeira etapa crucial porque transforma um número potencialmente infinito de frases do usuário ("me diga o que você vê", "o que tem na foto?") em um conjunto de comandos limpo e previsível. O objetivo do nosso classificador é mapear qualquer consulta do usuário para uma dessas categorias específicas.
Etapa 2
Para tomar decisões precisas, nossa IA precisa conhecer as próprias capacidades e limitações. Vamos fornecer essas informações como um bloco de texto detalhado.
👉 Ação: substitua o marcador REPLACE ME PART 2: add AGENT_CAPABILITIES_AND_LIMITATIONS here pelo seguinte código:
Substitua o código abaixo: // REPLACE ME PART 2: add AGENT_CAPABILITIES_AND_LIMITATIONS here:
👉 com o código abaixo
const AGENT_CAPABILITIES_AND_LIMITATIONS = `
**Core Capabilities (What the Agent CAN DO):**
* **Image Analysis:**
* DescribeImage: Provide a general description of the current image.
* AskAboutImage: Answer a specific question about the visual content of the current image (e.g., "Is there a dog?", "What color is the car?").
* ReadTextInImage: Read any text found in the current image.
* IdentifyColorsInImage: Identify the dominant colors of the current image.
* **Image Input Control:**
* TakePicture: Capture an image using the currently active camera stream.
* StartCamera: Activate the camera (e.g., "use camera", "take another picture").
* SelectImage: Allow the user to choose an image file from their device.
* **Voice & Audio Control:**
* StopSpeaking: Stop the current text-to-speech output.
* **Preference Management:**
* SetDescriptionDetailed: Make future image descriptions more detailed.
* SetDescriptionConcise: Make future image descriptions less detailed or concise.
* **General Interaction:**
* GeneralInquiry: Handle conversational phrases (e.g., "hello", "thank you") or questions about its own capabilities (e.g., "what can you do?", "help").
**Limitations (What the Agent CANNOT DO and should be classified as OutOfScopeRequest):**
* Cannot generate or create new images.
* Cannot edit or modify existing images (e.g., "remove background," "make the car blue").
* Cannot analyze video files or live video beyond capturing a single frame.
* Cannot provide general knowledge or answer questions unrelated to the provided image's visual content (e.g., "What's the weather?", "Who is the president?", "Tell me a joke", "What time is it?").
* Cannot perform mathematical calculations or complex data analysis.
* Cannot translate languages as a primary function.
* Cannot remember information from past images or vastly different previous queries in the same session.
* Cannot control other device settings or applications.
* Cannot perform web searches.
`;
Por que isso é importante:
Esse texto não é para o usuário ler, mas sim para nosso modelo de IA. Vamos inserir essa "descrição do trabalho" diretamente no comando (na próxima etapa) para dar ao modelo de linguagem (LLM) o contexto necessário para tomar decisões precisas. Sem esse contexto, o LLM pode classificar incorretamente "qual é a previsão do tempo?" como AskAboutImage. Com esse contexto, ele sabe que o clima não é um elemento visual na imagem e o classifica corretamente como fora do escopo.
Etapa 3
Agora vamos escrever o conjunto completo de instruções que o modelo do Gemini vai seguir para realizar a classificação.
👉 Ação: substitua o // REPLACE ME PART 3 - classifyIntentPrompt pelo seguinte código:
com o código abaixo
const classifyIntentPrompt = ai.definePrompt({
name: 'classifyIntentPrompt',
input: { schema: ClassifyIntentInputSchema },
output: { schema: ClassifyIntentOutputSchema },
prompt: `You are classifying the user's intent for ClarityCam, a voice-controlled AI application focused on image analysis.
Analyze the user query: '{userQuery}'.
First, understand ClarityCam's capabilities and limitations:
${AGENT_CAPABILITIES_AND_LIMITATIONS}
Now, classify the user's PRIMARY intent into ONE of the following categories:
* **DescribeImage**: User wants a general description of the current image.
* **AskAboutImage**: User is asking a specific question directly related to the visual content of the current image.
* **ReadTextInImage**: User wants any text read from the current image.
* **IdentifyColorsInImage**: User wants the dominant colors of the current image.
* **TakePicture**: User wants to capture an image using an active camera.
* **StartCamera**: User wants to activate the camera.
* **SelectImage**: User wants to choose an image file.
* **StopSpeaking**: User wants the current text-to-speech output to stop.
* **SetDescriptionDetailed**: User wants future image descriptions to be more detailed.
* **SetDescriptionConcise**: User wants future image descriptions to be less detailed.
* **GeneralInquiry**: The query is a simple conversational filler (e.g., "hello", "thanks"), a polite closing, or a direct question about the agent's functions (e.g., "what can you do?", "how does this work?", "help").
* **OutOfScopeRequest**: The query asks the agent to perform an action clearly listed under its "Limitations" or otherwise demonstrably outside its defined image analysis and control functions. Examples: "Tell me a joke," "What's the weather in London?", "Generate an image of a cat," "Can you edit my photo to make it brighter?", "Send this image to my friends","Translate 'hello' to Spanish."
Output ONLY the category name.
If the query is ambiguous but seems generally related to polite interaction or asking about the agent itself, prefer 'GeneralInquiry'.
If the query is clearly asking for something the agent CANNOT do, use 'OutOfScopeRequest'.
If truly unclassifiable even with these guidelines, use 'Unknown'.`,
config: {
temperature: 0.05, // Very low temperature for highly deterministic classification
}
});
É aqui que a mágica acontece. É o "cérebro" do nosso classificador, informando à IA qual é a função dela, fornecendo o contexto necessário e definindo a saída desejada. Confira estas técnicas importantes de engenharia de comando:
- Interpretação de papéis: começa com "Você está classificando..." para definir uma tarefa clara.
- Injeção de contexto: insere dinamicamente a variável
AGENT_CAPABILITIES_AND_LIMITATIONSno comando. - Formatação estrita da saída: a instrução "Gere APENAS o nome da categoria" é essencial para receber uma resposta limpa e previsível que pode ser usada facilmente no código.
- Temperatura baixa: para classificação, queremos respostas deterministas e lógicas, não criativas. Definir a temperatura com um valor muito baixo (0,05) garante que o modelo seja altamente focado e consistente.
Etapa 4: conectar o app ao fluxo de IA
Por fim, vamos chamar nosso novo classificador de IA do arquivo principal do aplicativo.
👉 Ação: navegue até o arquivo ~/src/app/page.tsx. Dentro da função "processVoiceCommand", substitua // REPLACE ME PART 1: add classificationResult pelo seguinte:
const classificationResult = await classifyIntentFlow({ userQuery: commandToProcess });
intent = classificationResult.intent as IntentCategory;
Esse código é a ponte crucial entre o aplicativo de front-end e a lógica de IA de back-end. Ele recebe o comando de voz do usuário (commandToProcess), envia para o classifyIntentFlow que você acabou de criar e aguarda a IA retornar a intenção classificada.
A variável de intent agora contém um comando limpo e estruturado (como "DescribeImage"). Esse resultado será usado na instrução switch a seguir para direcionar a lógica do aplicativo e decidir qual ação tomar em seguida. É assim que o "pensamento" da IA se transforma no "fazer" do app.
Como iniciar a interface do usuário
É hora de ver nosso aplicativo em ação. Vamos iniciar o servidor de desenvolvimento.
👉 No terminal, execute o seguinte comando: npm run dev. Observação: talvez seja necessário executar npm install antes de npm run dev.
Depois de um momento, você vai ver uma saída semelhante a esta, o que significa que o servidor está sendo executado corretamente:
▲ Next.js 15.2.3 (Turbopack)
- Local: http://localhost:9003
- Network: http://10.88.0.4:9003
- Environments: .env
✓ Starting...
✓ Ready in 1512ms
○ Compiling / ...
✓ Compiled / in 26.6s
Agora, clique no URL local (http://localhost:9003) para abrir o aplicativo no navegador.
A interface do usuário do SightGuide vai aparecer. Por enquanto, os botões não estão conectados a nenhuma lógica. Portanto, clicar neles não vai fazer nada. É exatamente isso que esperamos nesta fase. Vamos dar vida a eles na próxima seção.
Agora que você já viu a interface, volte ao terminal e pressione Ctrl + C para interromper o servidor de desenvolvimento antes de continuar.
5. Entender a entrada do usuário: verificação de consultas imperfeitas
Adição da verificação de consultas imperfeitas
Parte 1: como definir o comando (o "o quê")
Primeiro, vamos definir as instruções para nossa IA. O comando é a "receita" da nossa chamada de IA. Ele informa ao modelo exatamente o que queremos que ele faça.
👉 Ação: no ambiente de desenvolvimento integrado, navegue até ~/src/ai/flows/check_typo/.
Substitua o código abaixo: // REPLACE ME PART 1: add prompt here:
👉 com o código abaixo
const prompt = ai.definePrompt({
name: 'checkTypoPrompt',
input: {
schema: CheckTypoInputSchema,
},
output: {
schema: CheckTypoOutputSchema,
},
prompt: `You are a helpful AI assistant that checks user text for typos and suggests corrections.
- If you find typos, respond with the corrected text.
- If there are no typos, or if you are unsure about a correction, respond with the original text unchanged.
User text: {text}
Corrected text:
`,
});
Esse bloco de código define um modelo reutilizável para nossa IA chamado checkTypoPrompt. Os esquemas de entrada e saída definem o contrato de dados para essa tarefa. Isso evita erros e torna nosso sistema previsível.
Parte 2: como criar o fluxo
Agora que temos nossa "receita" (o comando), precisamos criar uma função que possa executá-la. No Genkit, isso é chamado de fluxo. Um fluxo envolve nosso comando em uma função executável que o restante do aplicativo pode chamar facilmente.
👉 Ação: no mesmo arquivo ~/src/ai/flows/check_typo/, substitua o código abaixo: // REPLACE ME PART 2: add flow here:
👉 com o código abaixo
const checkTypoFlow = ai.defineFlow<
typeof CheckTypoInputSchema,
typeof CheckTypoOutputSchema
>(
{
name: 'checkTypoFlow',
inputSchema: CheckTypoInputSchema,
outputSchema: CheckTypoOutputSchema,
},
async input => {
const {output} = await prompt(input);
return output!;
}
);
Parte 3: como usar o verificador de erros de digitação
Com o fluxo de IA concluído, podemos integrá-lo à lógica principal do aplicativo. Vamos chamá-lo logo após receber o comando do usuário, garantindo que o texto esteja limpo antes de qualquer outro processamento.
👉Ação:navegue até ~/src/app/ai/flows/check-typo.ts e encontre a função export async function checkTypo. Remova a marca de comentário da instrução de retorno:
Em vez de return;, faça return checkTypoFlow(input);
👉Ação:navegue até ~/src/app/page.tsx e encontre a função processVoiceCommand. Substitua o código abaixo: REPLACE ME PART 2: add typoResult here:
👉 com o código abaixo
const typoResult = await checkTypo({ text: rawCommand });
if (typoResult && typoResult.correctedText && typoResult.correctedText.trim().length > 0) {
const originalTrimmedLower = rawCommand.trim().toLowerCase();
const correctedTrimmedLower = typoResult.correctedText.trim().toLowerCase();
if (correctedTrimmedLower !== originalTrimmedLower) {
commandToProcess = typoResult.correctedText;
typoCorrectionAnnouncement = `I think you said: ${commandToProcess}. `;
}
}
Com essa mudança, criamos um pipeline de tratamento de dados mais robusto para cada comando do usuário.
Fluxo de comando de voz (somente leitura, nenhuma ação necessária)
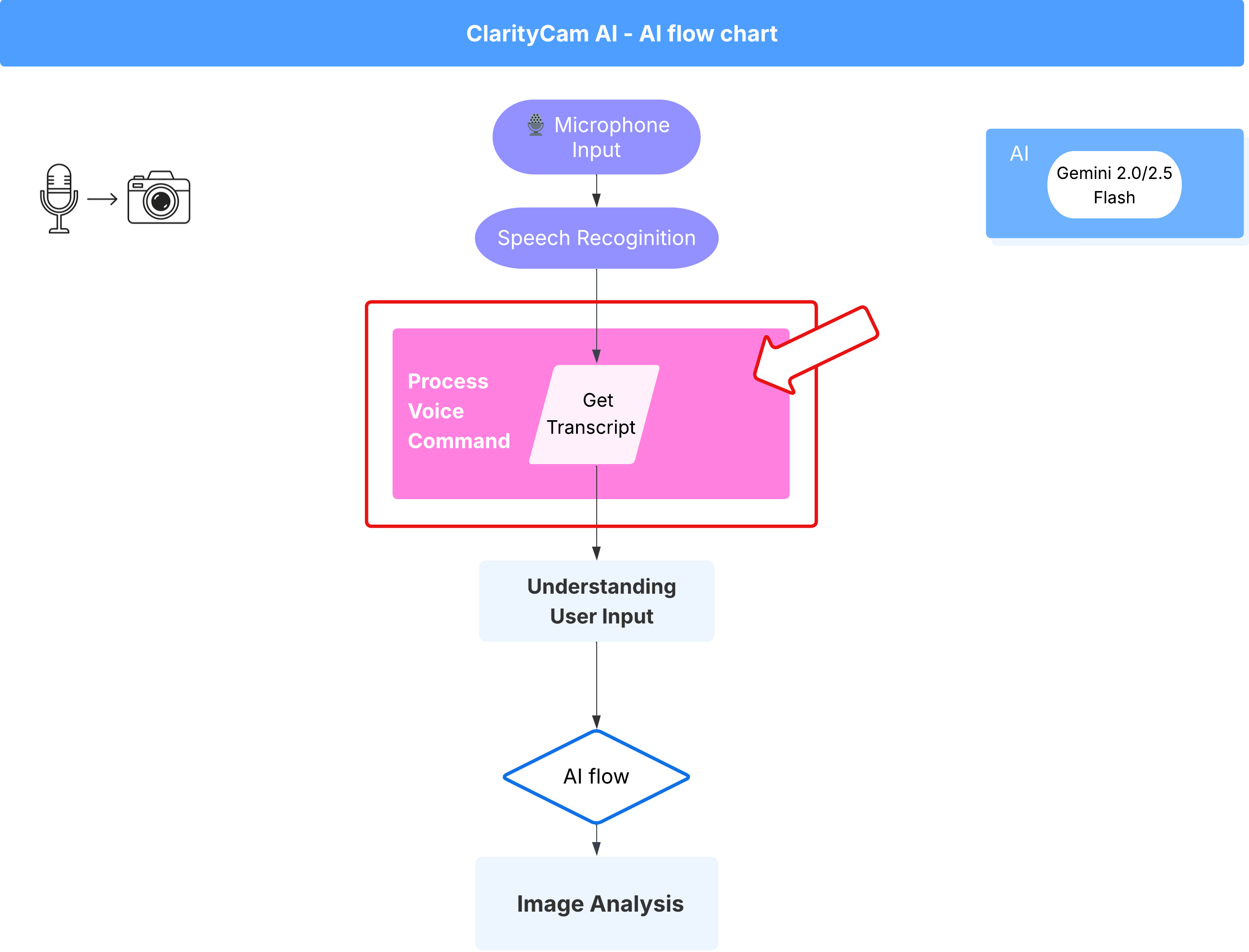
Agora que temos os componentes principais de "entendimento" (o verificador de erros tipográficos e o classificador de intents), vamos ver como eles se encaixam na lógica principal de processamento de voz do aplicativo.
Tudo começa quando o usuário fala. A API Web Speech do navegador ouve a fala e, quando o usuário termina de falar, fornece uma transcrição em texto do que foi ouvido. O código a seguir processa isso.
👉Somente leitura:navegue até ~/src/app/page.tsx e dentro da função handleResult. Encontre o código abaixo:
for (let i = event.resultIndex; i < event.results.length; ++i) {
if (event.results[i].isFinal) {
finalTranscript += event.results[i][0].transcript;
}
}
if (finalTranscript) {
console.log("Final Transcript:", finalTranscript);
processVoiceCommand(finalTranscript);
}
Testando nossa correção de erros de digitação
A diversão começa agora! Vamos ver como nosso novo recurso de correção de erros tipográficos lida com comandos de voz perfeitos e imperfeitos.
Iniciar o aplicativo
Primeiro, vamos executar o servidor de desenvolvimento novamente. No terminal, execute: npm run dev
Abra o app
Quando o servidor estiver pronto, abra o navegador e navegue até o endereço local (por exemplo, http://localhost:9003).
Ativar os comandos de voz
Clique no botão Start Listening. O navegador provavelmente vai pedir permissão para usar o microfone. Clique em "Permitir".
Testar um comando imperfeito
Agora, vamos dar um comando um pouco falho para ver se a IA consegue entender. Fale com clareza no microfone:
"Tire uma foto minha"
Observar o resultado
É aqui que tudo acontece. Mesmo que você tenha dito "Tire uma foto minha", o aplicativo vai ativar a câmera corretamente. O fluxo checkTypo corrige sua frase para "tirar uma foto" nos bastidores, e o classifyIntentFlow entende o comando corrigido.
Isso confirma que nosso recurso de correção de erros de digitação está funcionando perfeitamente, tornando o app muito mais robusto e fácil de usar. Quando terminar, pare a câmera tirando uma foto ou simplesmente interrompa o servidor no terminal (Ctrl + C).
6. Análise de imagens com tecnologia de IA: descrever a imagem
Agora que nosso agente consegue entender solicitações, é hora de dar olhos a ele. Nesta seção, vamos desenvolver os recursos do nosso agente de visão, o componente principal responsável por toda a análise de imagens. Vamos começar com o recurso mais importante, que é descrever uma imagem, e depois adicionar a capacidade de ler texto.
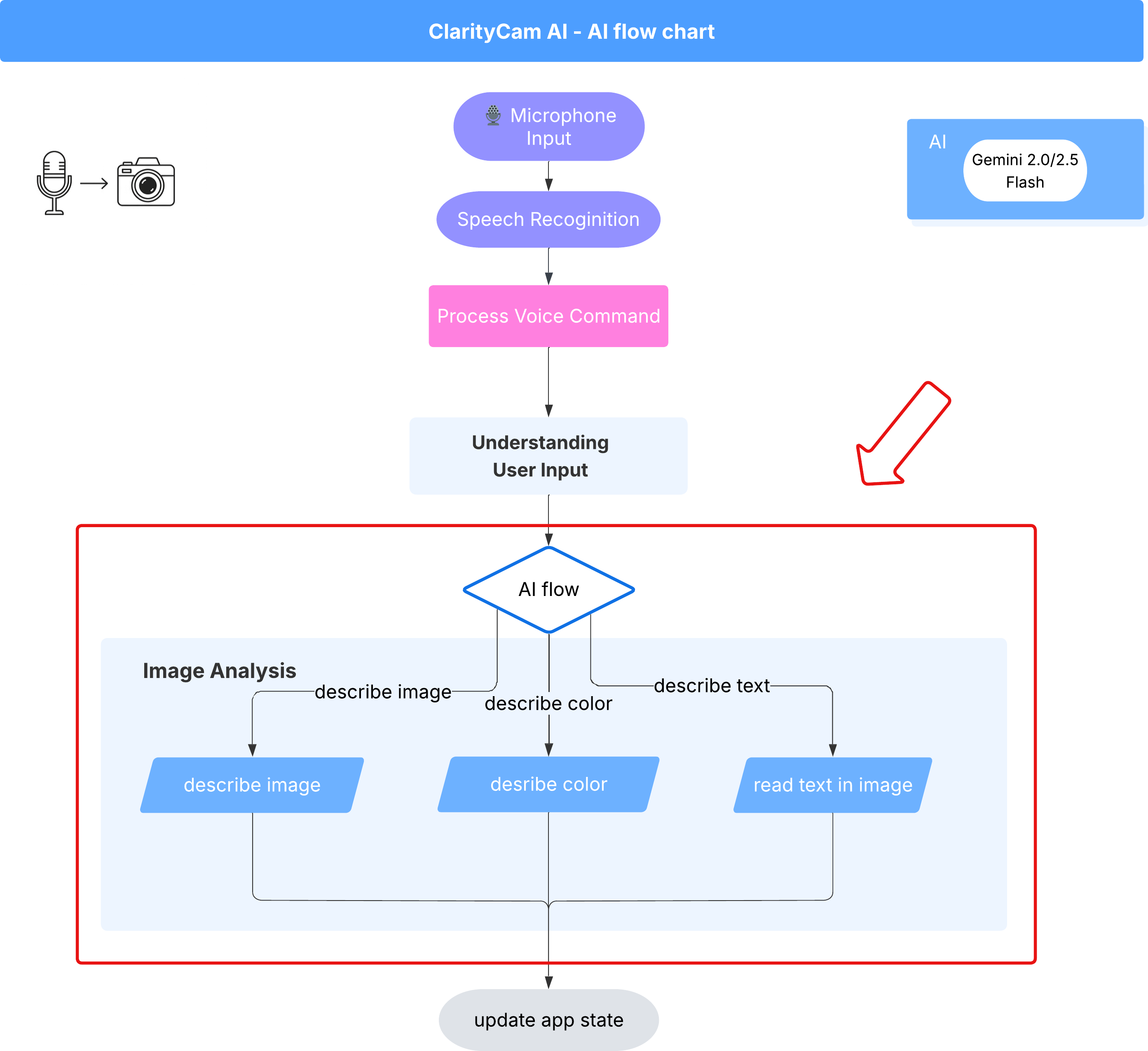
Recurso 1: descrever uma imagem
Essa é a função principal do agente. Não vamos apenas gerar uma descrição estática. Vamos criar um fluxo dinâmico que pode adaptar o nível de detalhes com base nas preferências do usuário. Essa é uma parte fundamental da filosofia de interface nativamente adaptativa (NAI, na sigla em inglês).
👉 Ação: no Cloud Shell IDE, navegue até o arquivo ~/src/ai/flows/describe_image/ e remova a marca de comentário do código a seguir.
Etapa 1: criar um modelo de comando dinâmico
Primeiro, vamos criar um modelo de solicitação sofisticado que pode mudar as instruções com base na entrada recebida.
Remova a marca de comentário do código abaixo
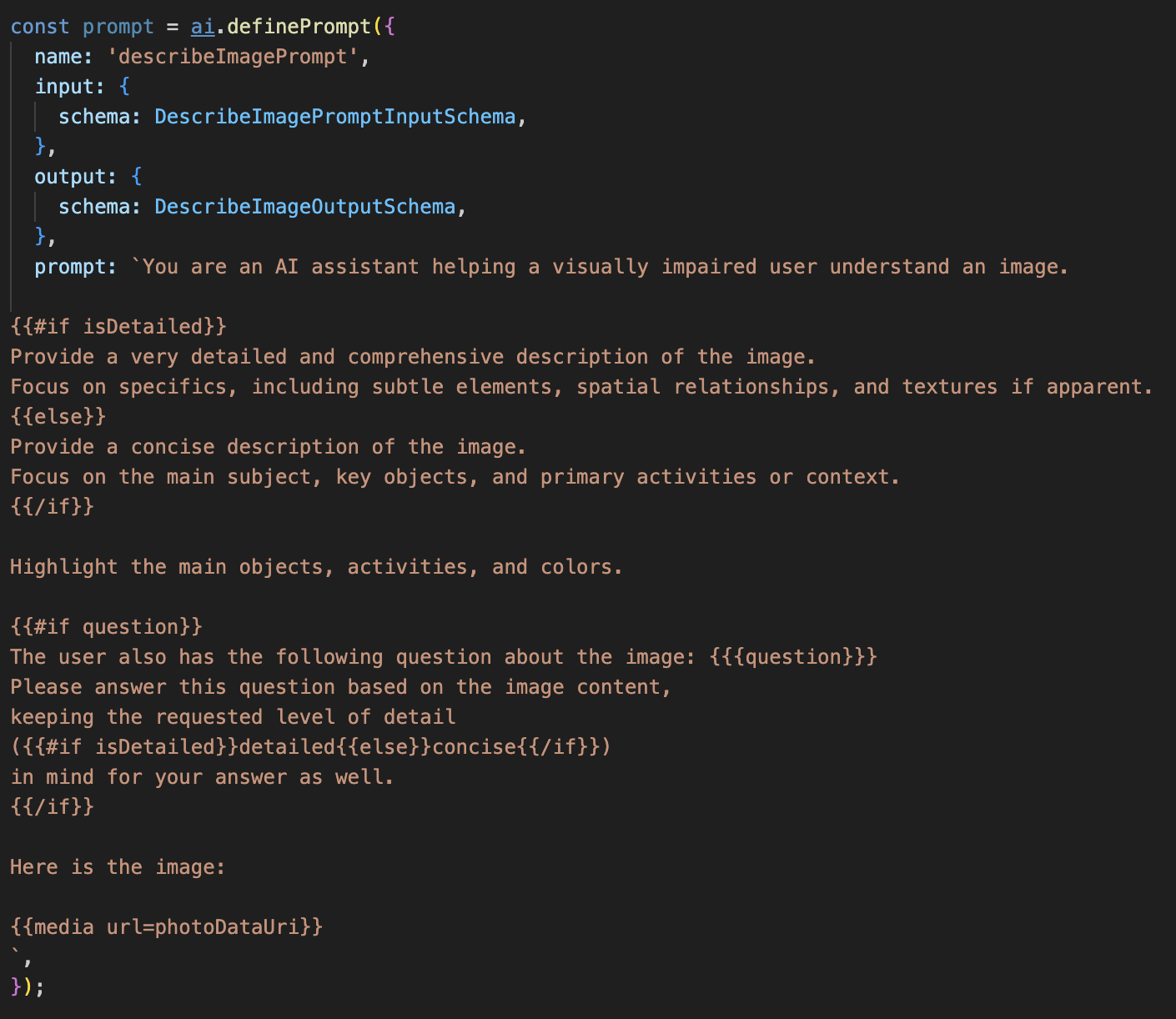
Esse código define uma variável de string, "prompt", que usa uma linguagem de modelo chamada Dot-Mustache. Isso permite incorporar lógica condicional diretamente no nosso comando.
{#if isDetailed}...{else}...{/if}: este é um bloco condicional. Se os dados de entrada que enviamos a esse comando contiverem uma propriedade "isDetailed: true", a IA vai receber o conjunto de instruções "muito detalhado". Caso contrário, ele vai receber as instruções "concisas". É assim que nosso agente se adapta à preferência do usuário.
{#if question}...{/if}: esse bloco só será incluído se os dados de entrada tiverem uma propriedade de pergunta. Isso nos permite usar o mesmo comando eficiente para descrições gerais e perguntas específicas.
{media url=photoDataUri}: essa é a sintaxe especial do Genkit para incorporar dados de imagem diretamente no comando para o modelo multimodal analisar.
Etapa 2: criar o fluxo inteligente
Em seguida, definimos o comando e o fluxo que vão usar nosso novo modelo. Esse fluxo contém um pouco de lógica para traduzir a preferência do usuário em um booleano que nosso modelo pode entender.
👉 Ação: no Cloud Shell IDE, no mesmo arquivo ~/src/ai/flows/describe_image/, substitua o código a seguir. // REPLACE ME PART 1: add flow here
👉 Com o código abaixo:
// Define the prompt using the template from Step 1
const prompt = ai.definePrompt({
name: 'describeImagePrompt',
input: { schema: DescribeImagePromptInputSchema },
output: { schema: DescribeImageOutputSchema },
prompt: promptTemplate,
});
// Define the flow
const describeImageFlow = ai.defineFlow<
typeof DescribeImageInputSchema,
typeof DescribeImageOutputSchema
>(
{
name: 'describeImageFlow',
inputSchema: DescribeImageInputSchema,
outputSchema: DescribeImageOutputSchema,
},
async (pageInput) => {
const preference = pageInput.detailPreference || "concise";
// Prepare the input for the prompt, including the new boolean flag
const promptInputData = {
...pageInput,
isDetailed: preference === "detailed",
};
const { output } = await prompt(promptInputData);
return output!;
}
);
Ele atua como um intermediário inteligente entre o front-end e o comando de IA.
- Ele recebe
pageInputdo nosso aplicativo, que inclui a preferência do usuário como uma string (por exemplo,"detailed"). - Em seguida, ele cria um novo objeto,
promptInputData. - A linha mais importante é
isDetailed: preference === "detailed". Essa linha faz o trabalho crucial de criar um valor booleanotrueoufalsecom base na string de preferência. - Por fim, ele chama o
promptcom esses dados aprimorados. O modelo de comando da etapa 1 agora pode usar o booleanoisDetailedpara mudar dinamicamente as instruções enviadas à IA.
Etapa 3: conectar o front-end
Agora, vamos acionar esse fluxo na interface do usuário em page.tsx.
👉Ação:navegue até ~/src/app/ai/flows/describe-image.ts e encontre a função export async function describeImage. Remova a marca de comentário da instrução de retorno:
Em vez de return;, faça return describeImageFlow(input);
👉Ação:em ~/src/app/page.tsx, encontre a função handleAnalyze e substitua o código // REPLACE ME PART 2: DESCRIBE IMAGE
👉 com o seguinte código:
case "description":
result = await describeImage({
photoDataUri,
question,
detailPreference: descriptionPreference
});
outputText = question ? `Answer: ${result.description}` : `Description: ${result.description}`;
break;
Quando a intenção de um usuário é receber uma descrição, esse código é executado. Ele chama nosso fluxo describeImage, transmitindo os dados da imagem e, principalmente, a variável de estado descriptionPreference do nosso componente React. Essa é a peça final do quebra-cabeça, conectando a preferência do usuário armazenada na interface diretamente ao fluxo de IA que vai adaptar o comportamento de acordo com ela.
Testando o recurso de descrição de imagens
Vamos conferir a funcionalidade de descrição de imagens em ação, desde a captura de uma foto até a audição do que a IA vê.
Iniciar o aplicativo
Primeiro, vamos executar o servidor de desenvolvimento novamente. 👉 No terminal, execute o seguinte comando: npm run dev. Observação: talvez seja necessário executar npm install antes de npm run dev.
Abra o app
Quando o servidor estiver pronto, abra o navegador e navegue até o endereço local (por exemplo, http://localhost:9003).
Ativar a câmera
Clique no botão "Começar a ouvir" e conceda acesso ao microfone se solicitado. Em seguida, diga seu primeiro comando:
"Tirar uma foto"
O aplicativo vai ativar a câmera do dispositivo. Agora você vai ver a transmissão de vídeo ao vivo na tela.
Capturar a foto
Com a câmera ativada, posicione-a no que você quer descrever. Agora, diga o comando uma segunda vez para capturar a imagem:
"Tirar uma foto"
O vídeo ao vivo será substituído pela foto estática que você acabou de tirar.
Pedir a descrição
Com a nova foto na tela, dê o comando final:
"Descreva a imagem"
Ouvir o resultado
O app vai mostrar um status de processamento, e depois você vai ouvir a descrição gerada por IA da sua imagem. O texto também vai aparecer no card "Status e resultado".
Quando terminar, pare a câmera tirando uma foto ou simplesmente interrompa o servidor no terminal (Ctrl + C).
7. Análise de imagens com tecnologia de IA: descrever texto (OCR)
Em seguida, vamos adicionar a capacidade de reconhecimento óptico de caracteres (OCR) ao nosso agente do Vision. Isso permite que ele leia texto de qualquer imagem.
👉 Ação: no seu ambiente de desenvolvimento integrado (IDE), navegue até ~/src/ai/flows/read-text-in-image/ e remova a marca de comentário do código abaixo:
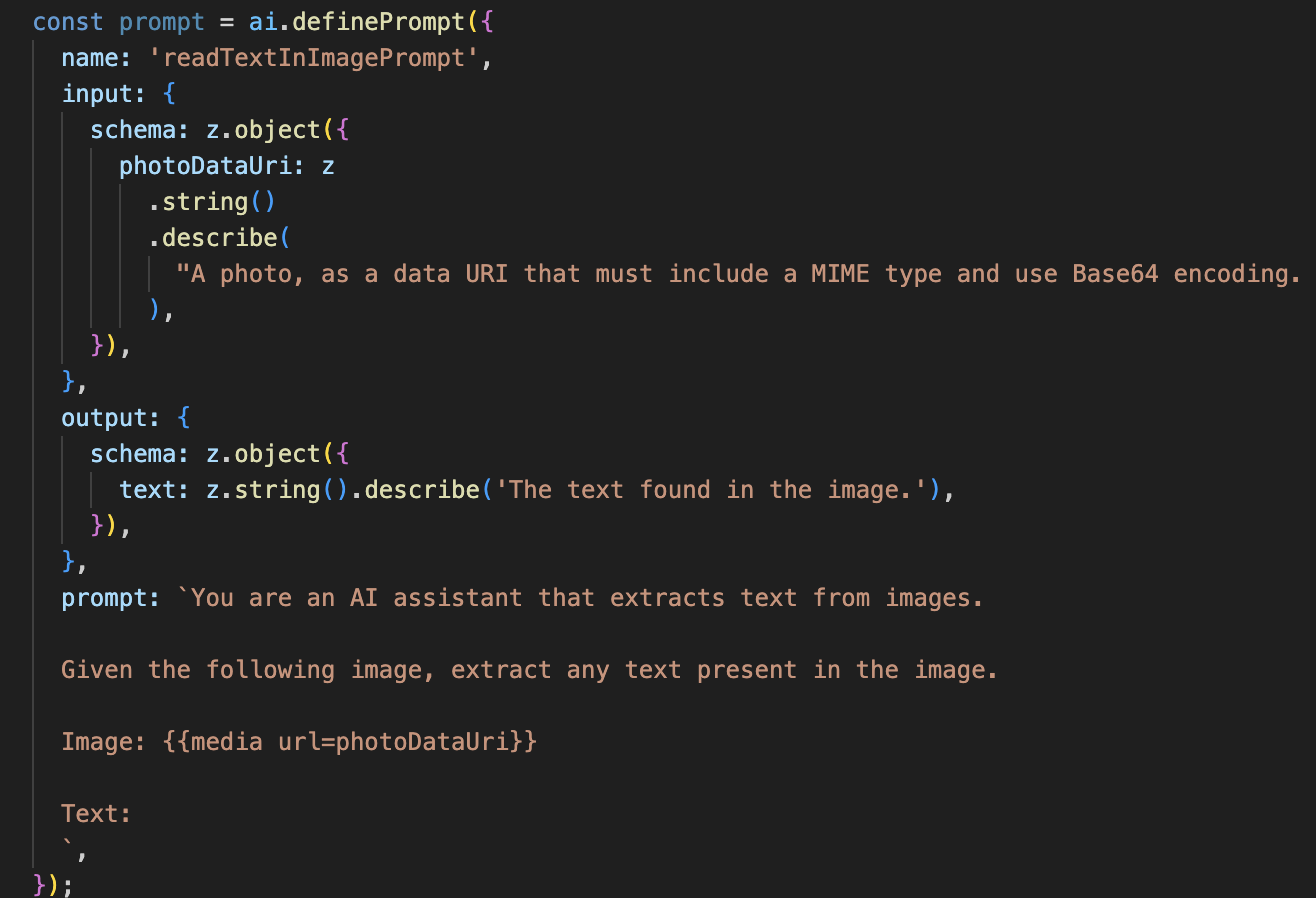
👉 Ação: no IDE, no mesmo arquivo ~/src/ai/flows/read-text-in-image/, substitua // REPLACE ME: Creating Prmopt
👉 com o código abaixo:
const readTextInImageFlow = ai.defineFlow<
typeof ReadTextInImageInputSchema,
typeof ReadTextInImageOutputSchema
>(
{
name: 'readTextInImageFlow',
inputSchema: ReadTextInImageInputSchema,
outputSchema: ReadTextInImageOutputSchema,
},
async input => {
const {output} = await prompt(input);
return output!;
}
);
Esse fluxo de IA é muito mais simples, destacando o princípio de usar ferramentas focadas para trabalhos específicos.
- O comando: ao contrário do comando de descrição, este é estático e altamente específico. A única função dele é instruir a IA a agir como um mecanismo de OCR: "extraia qualquer texto presente na imagem".
- Os esquemas: os esquemas de entrada e saída também são simples, esperando uma imagem e retornando uma única string de texto.
Conectar o front-end para OCR
Por fim, vamos conectar esse novo recurso em page.tsx.
👉Ação:navegue até ~/src/app/ai/flows/read-text-in-image.ts e encontre a função export async function readTextInImage. Remova a marca de comentário da instrução de retorno:
Em vez de return;, faça return readTextInImageFlow(input);
👉 Ação: em ~/src/app/page.tsx, encontre a função handleAnalyze e a instrução switch.
Substituir REPLACE ME PART 3: READ TEXT
com o código abaixo:
case "text":
result = await readTextInImage({ photoDataUri });
outputText = result.text ? `Text Found: ${result.text}` : "No text found.";
break;
Quando a intenção do usuário é ReadTextInImage, esse código é acionado. Ele chama nosso fluxo readTextInImage simples. A linha result.text ? ... : ... é uma maneira simples de processar a saída, fornecendo uma mensagem útil ao usuário se a IA não conseguir encontrar texto na imagem.
Testar o recurso Ler texto (OCR)
Siga estas etapas para testar o recurso de leitura de texto. Lembre-se de apontar a câmera para um objeto com texto legível.
- Execute o aplicativo com
npm run deve abra no navegador. - Clique em "Começar a ouvir" e conceda acesso ao microfone quando solicitado.
- Ative a câmera. Diga o comando "Tirar uma foto". O feed de vídeo ao vivo vai aparecer na tela.
- Tire a foto. Aponte a câmera para o texto que você quer ler e diga o comando novamente: "Tirar uma foto". O vídeo será substituído por uma foto estática.
- Peça o texto. Agora que uma foto foi tirada, dê o comando final: "Qual é o texto na imagem?"
- Verifique o resultado Depois de um momento, o app vai analisar a foto e ler o texto detectado em voz alta. Se não for possível encontrar nenhum texto, você vai receber uma notificação.
Isso confirma que o recurso de OCR está funcionando. Quando terminar, pare o servidor com Ctrl + C.
8. Aprimoramentos avançados de IA - Somente leitura ✨
Um bom agente de IA consegue seguir instruções. Um bom agente de IA parece intuitivo, confiável e útil. Nesta seção, vamos nos concentrar em três melhorias avançadas que aumentam as capacidades do nosso agente.
Vamos aprender a:
Add Context & Memorypara lidar com acompanhamentos naturais e conversacionais.Reduce Hallucinationpara criar um agente mais confiável.Make the Agent Proactivepara oferecer uma experiência mais acessível e fácil de usar.Add preference settingpara personalizar a descrição da imagem
Melhoria 1: contexto e memória
Uma conversa natural não é uma série de comandos isolados, ela flui. Se um usuário perguntar: "O que tem na foto?" e o agente responder: "Um carro vermelho", a continuação natural da conversa pode ser: "Qual é a cor dele?", sem dizer "carro" novamente. Nosso agente precisa de memória de curto prazo para entender esse contexto.
Como implementamos (resumo)
Já criamos essa capacidade no nosso fluxo describeImage. Esta seção é um resumo de como esse padrão funciona. Quando chamamos a função describeImage em page.tsx, transmitimos a ela o histórico da conversa.
👉 Mostruário de código (de page.tsx):
const result = await describeImage({
photoDataUri,
question: commandToProcess,
detailPreference: descriptionPreference,
previousUserQueryOnImage: lastUserQuery ?? undefined,
previousAIResponseOnImage: lastAIResponse ?? undefined,
});
previousUserQueryOnImageepreviousAIResponseOnImage: essas duas propriedades são a memória de curto prazo do nosso agente. Ao transmitir a última interação para a IA, damos a ela o contexto necessário para entender perguntas de acompanhamento vagas ou referenciais.- O comando adaptativo: esse contexto é usado pelo comando no nosso fluxo "describe_image". O comando foi criado para considerar a conversa anterior ao formar uma nova resposta, permitindo que o agente responda de forma inteligente.
Melhoria 2: redução de alucinações
Uma IA "alucina" quando inventa fatos ou afirma ter recursos que não possui. Para criar confiança no usuário, é fundamental que nosso agente conheça os próprios limites e possa recusar solicitações fora do escopo de maneira adequada.
Como implementamos (resumo)
A maneira mais eficaz de evitar alucinações é dar limites claros ao modelo. Conseguimos isso ao criar nosso classificador de intents.
👉 Vitrine de código (do fluxo intent-classifier):
// Define Agent Capabilities and Limitations for the prompt
const AGENT_CAPABILITIES_AND_LIMITATIONS = `
**Core Capabilities (What the Agent CAN DO):**
* **Image Analysis:**
* DescribeImage: Provide a general description of the current image...
**Limitations (What the Agent CANNOT DO...):**
* Cannot generate or create new images.
* Cannot provide general knowledge or answer questions unrelated to the image...
* Cannot perform web searches.
`;
Essa constante funciona como uma "descrição de cargo" que enviamos à IA no comando de classificação.
- Embasamento do modelo: ao dizer explicitamente à IA o que ela não pode fazer, nós a "embasamos" na realidade. Quando ele vê uma consulta como "Qual é a previsão do tempo?", pode associá-la com confiança à lista de limitações e classificar a intent como OutOfScopeRequest.
- Construir confiança: um agente que pode dizer honestamente "Não posso ajudar com isso" é muito mais confiável do que um que tenta adivinhar e erra. Esse é um princípio fundamental do design de IA segura e confiável. `
Melhoria 3: como criar um agente proativo
Para um aplicativo com foco na acessibilidade, não podemos depender de indicadores visuais. Quando um usuário ativa o modo de escuta, ele precisa de uma confirmação imediata e não visual de que o agente está pronto e aguardando um comando. Agora vamos adicionar uma introdução proativa para fornecer esse feedback crucial.
Etapa 1: adicionar um estado para rastrear a primeira escuta
Primeiro, precisamos saber se é a primeira vez que o usuário pressiona o botão "Start Listening" durante a sessão.
👉 Em ~/src/app/page.tsx, confira a nova variável de estado perto da parte de cima do componente ClarityCam.
export default function ClarityCam() {
// ... other state variables
const [descriptionPreference, setDescriptionPreference] = useState<DescriptionPreference>("concise");
// Add this new line
const [isFirstListen, setIsFirstListen] = useState(true);
// ... rest of the component
}
Introduzimos uma nova variável de estado, isFirstListen, e a inicializamos como true. Vamos usar essa flag para acionar nossa mensagem de boas-vindas única.
Etapa 2: atualizar a função "toggleListening"
Agora, vamos modificar a função que processa o microfone para tocar nossa saudação.
👉 Em ~/src/app/page.tsx, encontre a função toggleListening e veja o seguinte bloco if.
const toggleListening = useCallback(() => {
// ... existing logic to setup speech recognition
if (isListening || isAttemptingStart) {
// ... existing logic to stop listening
} else {
stopSpeaking(); // Stop any ongoing TTS
// Add this new block
if (isFirstListen) {
setIsFirstListen(false);
const introMessage = "Hello! I am ClarityCam, your AI assistant. I'm now listening. You can ask me to 'describe the image', 'read text', 'take a picture', or ask questions about what's in an image.";
speakText(introMessage);
} else {
speakText("Listening..."); // Optional: provide feedback on subsequent clicks
}
// ... rest of the logic to start listening
}
}, [/*...existing dependencies...*/, isFirstListen]); // Don't forget to add isFirstListen to the dependency array!
- Verifique a flag: o bloco if (isFirstListen) verifica se esta é a primeira ativação.
- Evitar repetição: a primeira coisa que ele faz dentro do bloco é chamar setIsFirstListen(false). Isso garante que a mensagem de introdução seja reproduzida apenas uma vez por sessão.
- Fornecer orientação: a introMessage é cuidadosamente elaborada para ser o mais útil possível. Ele cumprimenta o usuário, identifica o agente pelo nome, confirma que está ativo ("Estou ouvindo") e oferece exemplos claros de comandos de voz que podem ser usados.
- Feedback auditivo: por fim, o speakText(introMessage) fornece essas informações cruciais, oferecendo garantia e orientação imediatas sem exigir que o usuário veja a tela.
Melhoria 4: adaptação às preferências do usuário (resumo)
Um agente verdadeiramente inteligente não apenas responde, mas aprende e se adapta às necessidades do usuário. Um dos recursos mais eficientes que criamos é a capacidade de o usuário mudar a riqueza de detalhes das descrições de imagens na hora com comandos como "Seja mais detalhado".
Como implementamos (resumo): esse recurso é alimentado pelo comando dinâmico que criamos para o fluxo "describeImage". Ela usa lógica condicional para mudar as instruções enviadas à IA com base na preferência do usuário.
👉 Mostruário de código (o promptTemplate de describe_image):
const settingPreferenceTemplate = `
{#if isDetailed}
Provide a very detailed and comprehensive description of the image. Focus on specifics, including subtle elements, spatial relationships, and textures if apparent.
{else}
Provide a concise description of the image. Focus on the main subject, key objects, and primary activities or context.
{/if}
Highlight the main objects, activities, and colors.
...
`;
- Lógica condicional: o bloco
{#if isDetailed}...{else}...{/if}é fundamental. Quando nosso describeImageFlow recebe o detailPreference do front-end, ele cria um booleano isDetailed (verdadeiro ou falso). - Instruções adaptáveis: essa flag booleana determina qual conjunto de instruções o modelo de IA recebe. Se "isDetailed" for verdadeiro, o modelo vai receber instruções para ser altamente descritivo. Se for "false", o modelo vai ser conciso.
- Controle do usuário: esse padrão conecta diretamente um comando de voz do usuário (por exemplo, "faça descrições concisas", que é classificado como a intenção "SetDescriptionConcise") a uma mudança fundamental no comportamento da IA, fazendo com que o agente pareça realmente responsivo e personalizado.
9. Implantação na nuvem
Criar a imagem do Docker usando o Google Cloud Build
gcloud builds submit . --tag gcr.io/$PROJECT_ID/accessibilityai-nextjs-app:latest
accessibilityai-nextjs-appé um nome de imagem sugerido.- O arquivo . usa o diretório atual (
accessibilityAI/) como a origem do build.
Implantar a imagem no Google Cloud Run
- Verifique se as chaves de API e outros secrets estão prontos no Secret Manager. Por exemplo,
GOOGLE_GENAI_API_KEY.
Substitua YOUR_ACTUAL_GOOGLE_AI_KEY_VALUE pelo valor da sua chave de API Gemini.
echo "YOUR_ACTUAL_GOOGLE_AI_KEY_VALUE" | gcloud secrets create GOOGLE_GENAI_API_KEY --data-file=- --project=YOUR_PROJECT_ID
Conceda à conta de serviço do ambiente de execução do serviço do Cloud Run (por exemplo, PROJECT_NUMBER-compute@developer.gserviceaccount.com ou uma conta dedicada) o papel "Acessador de secrets do Secret Manager" para esse secret.
- Comando de implantação:
gcloud run deploy accessibilityai-app-service \
--image gcr.io/$PROJECT_ID/accessibilityai-nextjs-app:latest \
--platform managed \
--region us-central1 \
--allow-unauthenticated \
--port 3000 \
--set-secrets=GOOGLE_GENAI_API_KEY=GOOGLE_GENAI_API_KEY:latest \
--set-env-vars NODE_ENV="production"