
1. บทนำ
ในบทแนะนำนี้ คุณจะได้สร้าง ClarityCam ซึ่งเป็น AI Agent แบบแฮนด์ฟรีที่ขับเคลื่อนด้วยเสียงซึ่งมองเห็นโลกและอธิบายให้คุณฟังได้ แม้ว่า ClarityCam จะได้รับการออกแบบโดยคำนึงถึงการช่วยเหลือพิเศษเป็นหลัก ซึ่งเป็นเครื่องมือที่มีประสิทธิภาพสำหรับผู้ใช้ที่ตาบอดและมีสายตาเลือนราง แต่หลักการที่คุณจะได้เรียนรู้ก็มีความสำคัญต่อการสร้างแอปพลิเคชันเสียงอเนกประสงค์ที่ทันสมัย

โปรเจ็กต์นี้สร้างขึ้นตามปรัชญาการออกแบบอันทรงพลังที่เรียกว่าอินเทอร์เฟซที่ปรับเปลี่ยนได้โดยกำเนิด (NAI) NAI ไม่ได้มองว่าการช่วยเหลือพิเศษเป็นเรื่องที่ต้องพิจารณาในภายหลัง แต่ถือเป็นรากฐานสำคัญ ด้วยแนวทางนี้ AI Agent จึงเป็นอินเทอร์เฟซที่ปรับให้เหมาะกับผู้ใช้แต่ละราย จัดการอินพุตแบบมัลติโมดอล เช่น เสียงและภาพ และแนะนําผู้คนอย่างกระตือรือร้นตามความต้องการเฉพาะตัว
การสร้าง AI Agent ตัวแรกด้วย NAI:

เมื่อสิ้นสุดเซสชันนี้ คุณจะทำสิ่งต่อไปนี้ได้
- ออกแบบโดยให้การช่วยเหลือพิเศษเป็นค่าเริ่มต้น: ใช้หลักการของอินเทอร์เฟซที่ปรับเปลี่ยนได้โดยกำเนิด (NAI) เพื่อสร้างระบบ AI ที่มอบประสบการณ์การใช้งานที่เทียบเท่ากันสำหรับผู้ใช้ทุกคน
- จัดประเภทความตั้งใจของผู้ใช้: สร้างตัวแยกประเภทความตั้งใจที่มีประสิทธิภาพซึ่งแปลคําสั่งภาษาธรรมชาติเป็นการกระทําที่มีโครงสร้างสําหรับเอเจนต์
- รักษาบริบทการสนทนา: ใช้หน่วยความจำระยะสั้นเพื่อให้ตัวแทนเข้าใจคำถามติดตามผลและคำสั่งอ้างอิง (เช่น "มีสีอะไรบ้าง")
- สร้างพรอมต์ที่มีประสิทธิภาพ: สร้างพรอมต์ที่เน้นและมีบริบทที่สมบูรณ์สำหรับโมเดลแบบหลายรูปแบบ เช่น Gemini เพื่อให้มั่นใจว่าการวิเคราะห์รูปภาพจะแม่นยำและเชื่อถือได้
- จัดการความคลุมเครือและแนะนําผู้ใช้: ออกแบบการจัดการข้อผิดพลาดที่เหมาะสมสําหรับคําขอนอกขอบเขต และเริ่มต้นใช้งานผู้ใช้เชิงรุกเพื่อสร้างความน่าเชื่อถือและความมั่นใจ
- จัดระเบียบระบบหลาย Agent: จัดโครงสร้างแอปพลิเคชันโดยใช้คอลเล็กชันของ Agent เฉพาะทางที่ทำงานร่วมกันเพื่อจัดการงานที่ซับซ้อน เช่น การประมวลผลเสียง การวิเคราะห์ และการสังเคราะห์เสียงพูด
2. การออกแบบระดับสูง
ClarityCam ได้รับการออกแบบมาให้ใช้งานง่ายสำหรับผู้ใช้ แต่ขับเคลื่อนด้วยระบบที่ซับซ้อนของ AI Agent ที่ทำงานร่วมกัน มาดูรายละเอียดสถาปัตยกรรมกัน

ประสบการณ์ของผู้ใช้
ก่อนอื่น มาดูวิธีที่ผู้ใช้โต้ตอบกับ ClarityCam กัน ประสบการณ์การใช้งานทั้งหมดเป็นแบบแฮนด์ฟรีและสนทนาได้ ผู้ใช้พูดคำสั่ง และเอเจนต์จะตอบกลับด้วยคำอธิบายหรือการดำเนินการที่พูด แผนภาพลำดับนี้แสดงโฟลว์การโต้ตอบทั่วไป ตั้งแต่คำสั่งเสียงเริ่มต้นของผู้ใช้ไปจนถึงการตอบกลับด้วยเสียงสุดท้ายจากอุปกรณ์
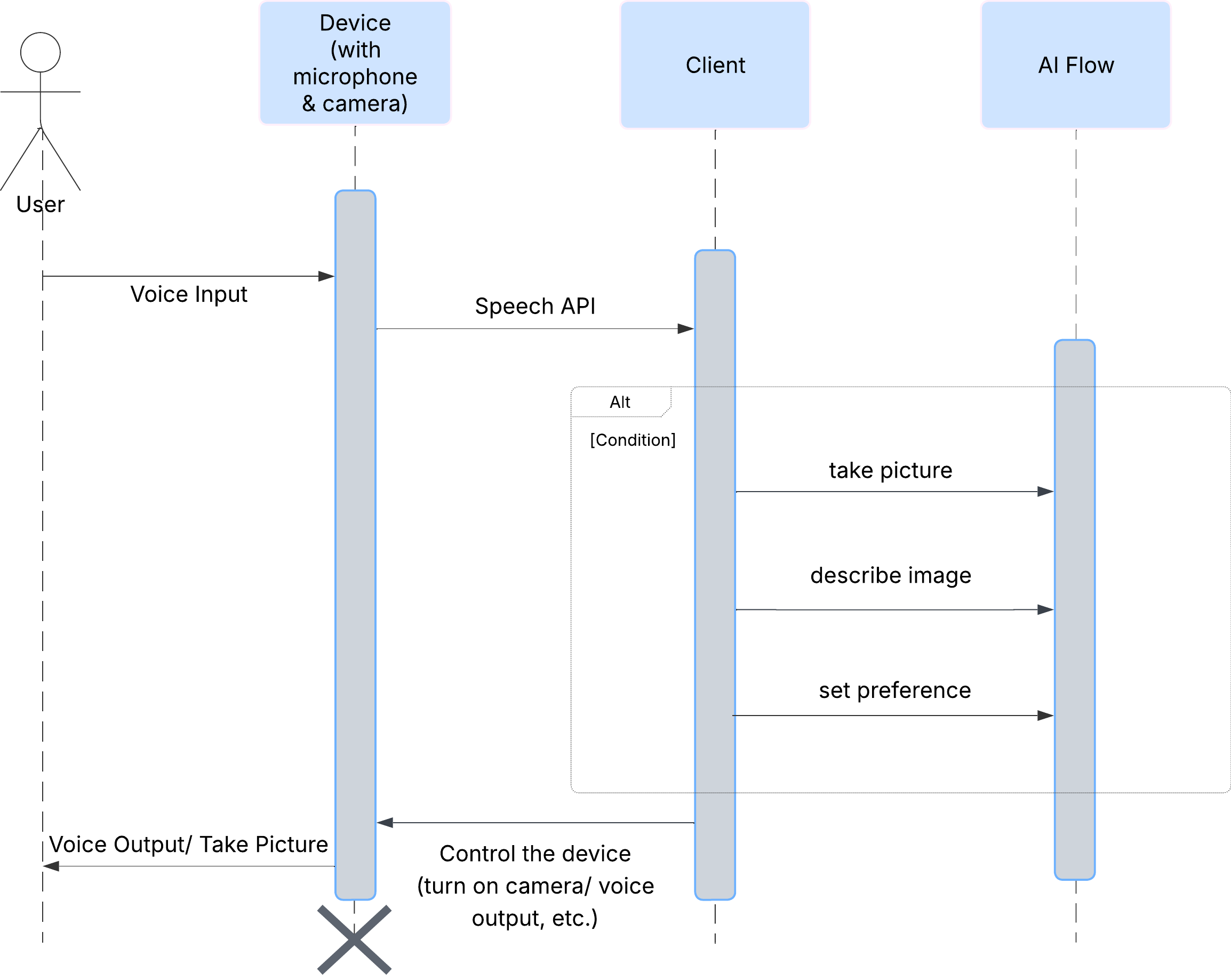
สถาปัตยกรรมของ AI Agent
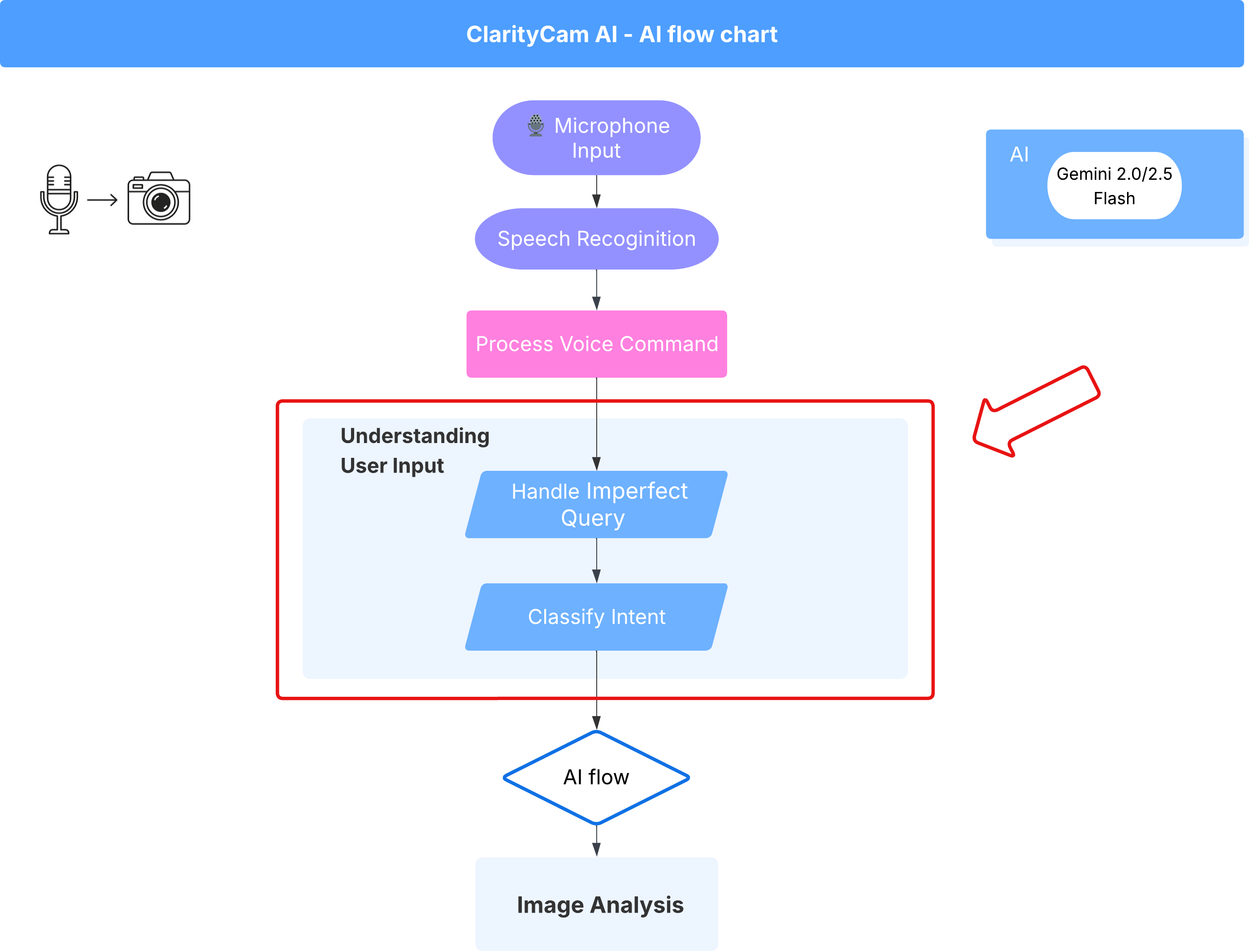
เบื้องหลังการทำงานคือระบบหลายเอเจนต์ที่ทำงานร่วมกันเพื่อสร้างประสบการณ์การใช้งาน เมื่อได้รับคำสั่ง ตัวแทน Orchestrator ส่วนกลางจะมอบหมายงานให้กับตัวแทนเฉพาะทางที่รับผิดชอบในการทำความเข้าใจเจตนา วิเคราะห์รูปภาพ และสร้างคำตอบ แผนภาพโฟลว์ AI นี้จะให้ข้อมูลเจาะลึกเกี่ยวกับวิธีที่เอเจนต์เหล่านี้ทำงานร่วมกัน เราจะใช้สถาปัตยกรรมนี้ในส่วนต่อไปนี้
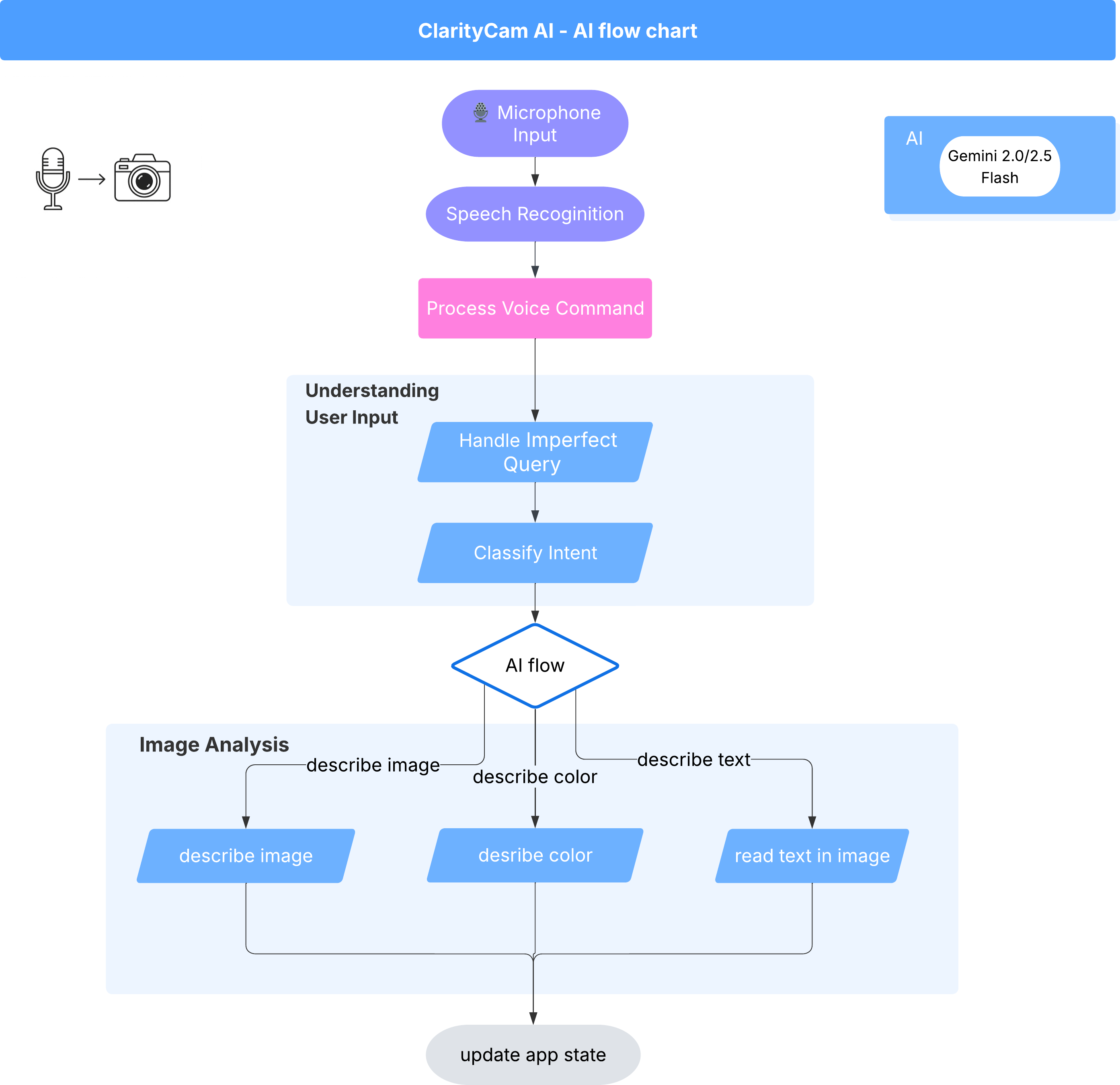
การแนะนำสั้นๆ เกี่ยวกับไฟล์โปรเจ็กต์
ก่อนเริ่มเขียนโค้ด เรามาทำความคุ้นเคยกับโครงสร้างไฟล์ของโปรเจ็กต์กันก่อน แม้ว่าจะมีไฟล์จำนวนมาก แต่คุณจะต้องโฟกัสที่2 ส่วนที่เฉพาะเจาะจงเท่านั้นสำหรับบทแนะนำนี้ทั้งหมด
นี่คือแผนที่แบบง่ายของโปรเจ็กต์ของเรา
accessibilityAI/src/
├── 📁 app/
│ ├── layout.tsx # An overall page shell (you can ignore this).
│ └── page.tsx # ⬅️ MODIFY THIS: The main user interface for our app.
│
├── 📁 ai/
│ ├── 📁flows # ⬅️ MODIFY THIS: The core AI logic and server functions.
│ └── intent-classifier.ts # ⬅️ MODIFY THIS: Where we'll edit our AI prompts.
| └── ai-instance.ts
| └── dev.ts
│
├── 📁 components/ # Contains pre-built UI components (ignore this).
│
├── 📁 hooks/
│
├── 📁 lib/
│
└── 📁 types/
Technology Stack
ระบบของเราสร้างขึ้นบนชุดซอฟต์แวร์โครงสร้างพื้นฐานที่ทันสมัยและปรับขนาดได้ ซึ่งรวมบริการคลาวด์ที่มีประสิทธิภาพและโมเดล AI ที่ทันสมัย องค์ประกอบหลักที่เราจะใช้มีดังนี้
- Google Cloud Platform (GCP): มีโครงสร้างพื้นฐานแบบ Serverless สำหรับ Agent ของเรา
- Cloud Run: ทำให้ Agent แต่ละตัวของเราใช้งานได้เป็น Microservice ที่ปรับขนาดได้ซึ่งสร้างโดยใช้คอนเทนเนอร์
- Artifact Registry: จัดเก็บและจัดการอิมเมจ Docker สำหรับ Agent ของเราอย่างปลอดภัย
- Secret Manager: จัดการข้อมูลเข้าสู่ระบบและคีย์ API ที่ละเอียดอ่อนอย่างปลอดภัย
- โมเดลภาษาขนาดใหญ่ (LLM): ทำหน้าที่เป็น "สมอง" ของระบบ
- โมเดล Gemini ของ Google: เราใช้ความสามารถแบบมัลติโมดัลอันทรงพลังของกลุ่ม Gemini สำหรับทุกอย่าง ตั้งแต่การจัดประเภทความตั้งใจของผู้ใช้ไปจนถึงการวิเคราะห์เนื้อหารูปภาพและการให้คำอธิบายอัจฉริยะ
3. การตั้งค่าและข้อกำหนดเบื้องต้น
เปิดใช้บัญชีสำหรับการเรียกเก็บเงิน หากต้องการเรียกใช้ Codelab นี้ คุณต้องมีบัญชีสำหรับการเรียกเก็บเงินที่มีเครดิตอยู่ ใช้เครดิตจากแบนเนอร์ที่ด้านบนของ Codelab นี้เพื่อเริ่มต้นใช้งาน หากเชื่อมต่อกับบัญชีสำหรับการเรียกเก็บเงินอยู่แล้ว ให้ข้ามขั้นตอนนี้
สร้างโปรเจ็กต์ GCP ใหม่
- ไปที่คอนโซล Google Cloud แล้วสร้างโปรเจ็กต์ใหม่

- ไปที่คอนโซล Google Cloud แล้วสร้างโปรเจ็กต์ใหม่
- เปิดแผงด้านซ้าย คลิก
Billingแล้วตรวจสอบว่าบัญชีสำหรับการเรียกเก็บเงินลิงก์กับบัญชี gcp นี้หรือไม่
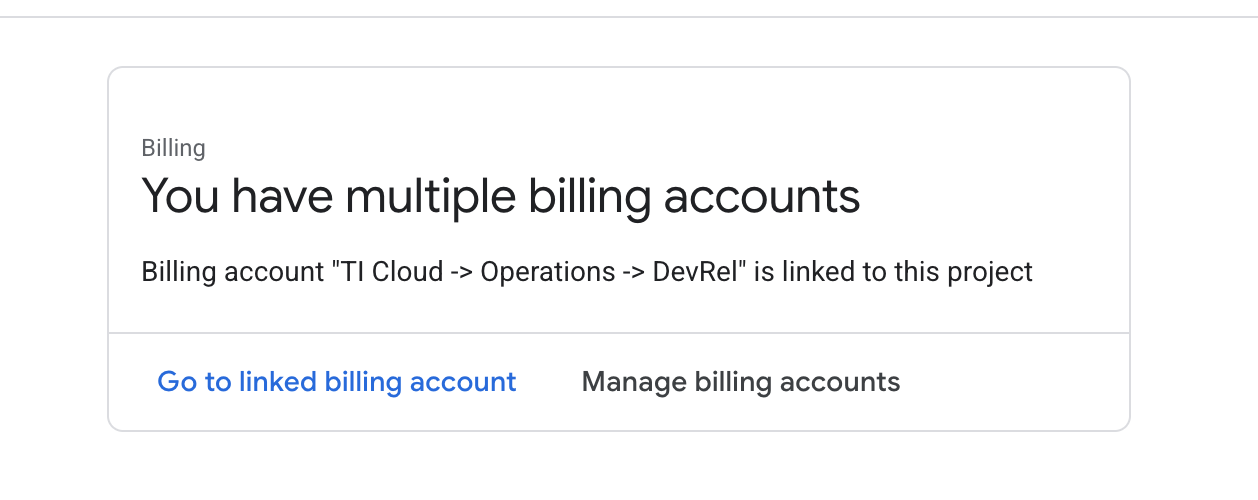
หากเห็นหน้านี้ ให้ตรวจสอบ manage billing account เลือก Google Cloud Trial One และลิงก์กับบัญชีดังกล่าว
สร้างคีย์ Gemini API
คุณต้องมีคีย์ก่อนจึงจะรักษาความปลอดภัยของคีย์ได้
- ไปที่ Google AI Studio : https://aistudio.google.com/
- ลงชื่อเข้าใช้ด้วยบัญชี Google
- คลิกปุ่ม "รับคีย์ API" ซึ่งมักจะอยู่ในแผงการนำทางด้านซ้ายมือหรือที่มุมขวาบน
- ในกล่องโต้ตอบ "คีย์ API" ให้คลิก "สร้างคีย์ API ในโปรเจ็กต์ใหม่"
- ระบบจะสร้างคีย์ API ใหม่ให้คุณ คัดลอกคีย์นี้ทันทีและจัดเก็บไว้ในที่ปลอดภัยชั่วคราว (เช่น เครื่องมือจัดการรหัสผ่านหรือโน้ตที่ปลอดภัย) ค่านี้เป็นค่าที่คุณจะใช้ในขั้นตอนถัดไป
เวิร์กโฟลว์การพัฒนาในเครื่อง (การทดสอบในเครื่องของคุณ)
คุณต้องเรียกใช้ npm run dev และทำให้แอปทำงานได้ .env จึงเข้ามามีบทบาทในจุดนี้
- เพิ่มคีย์ API ลงในไฟล์: สร้างไฟล์ใหม่ชื่อ
.envแล้วเพิ่มบรรทัดต่อไปนี้ลงในไฟล์นี้
อย่าลืมแทนที่ YOUR_API_KEY_HERE ด้วยคีย์ที่คุณได้รับจาก AI Studio และบันทึกลงใน .env
GOOGLE_GENAI_API_KEY="YOUR_API_KEY_HERE"
[ไม่บังคับ] ตั้งค่า IDE และสภาพแวดล้อม
สำหรับบทแนะนำนี้ คุณสามารถทำงานในสภาพแวดล้อมในการพัฒนาซอฟต์แวร์ที่คุ้นเคย เช่น VS Code หรือ IntelliJ ด้วยเทอร์มินัลในเครื่อง อย่างไรก็ตาม เราขอแนะนำอย่างยิ่งให้ใช้ Google Cloud Shell เพื่อให้มั่นใจว่าสภาพแวดล้อมเป็นไปตามมาตรฐานและมีการกำหนดค่าไว้ล่วงหน้า
ขั้นตอนต่อไปนี้เขียนขึ้นสำหรับบริบทของ Cloud Shell หากเลือกใช้สภาพแวดล้อมในเครื่องแทน โปรดตรวจสอบว่าคุณได้ติดตั้งและกำหนดค่า git, nvm, npm และ gcloud อย่างถูกต้อง
ทำงานใน Cloud Shell Editor
👉คลิกเปิดใช้งาน Cloud Shell ที่ด้านบนของคอนโซล Google Cloud (ไอคอนรูปเทอร์มินัลที่ด้านบนของแผง Cloud Shell) 
👉คลิกปุ่ม "เปิดเอดิเตอร์" (มีลักษณะเป็นโฟลเดอร์ที่เปิดอยู่พร้อมดินสอ) ซึ่งจะเปิดตัวแก้ไขโค้ด Cloud Shell ในหน้าต่าง คุณจะเห็น File Explorer ทางด้านซ้าย 
👉คลิกปุ่มลงชื่อเข้าใช้ Cloud Code ในแถบสถานะด้านล่างตามที่แสดง ให้สิทธิ์ปลั๊กอินตามวิธีการ หากเห็น Cloud Code - ไม่มีโปรเจ็กต์ในแถบสถานะ ให้เลือกข้อความดังกล่าว จากนั้นเลือก "เลือกโปรเจ็กต์ Google Cloud" ในเมนูแบบเลื่อนลง แล้วเลือกโปรเจ็กต์ Google Cloud ที่ต้องการจากรายการโปรเจ็กต์ที่คุณสร้าง 
👉เปิดเทอร์มินัลใน Cloud IDE 
👉ในเทอร์มินัล ให้ตรวจสอบว่าคุณได้รับการตรวจสอบสิทธิ์แล้วและตั้งค่าโปรเจ็กต์เป็นรหัสโปรเจ็กต์โดยใช้คำสั่งต่อไปนี้
gcloud auth list
👉 โคลนโปรเจ็กต์ natively-accessible-interface จาก GitHub
git clone https://github.com/cuppibla/AccessibilityAgent.git
👉และอย่าลืมแทนที่ <YOUR_PROJECT_ID> ด้วยรหัสโปรเจ็กต์ของคุณ (คุณดูรหัสโปรเจ็กต์ได้ใน Google Cloud Console ส่วนโปรเจ็กต์ ❗️❗️อย่าสับสนระหว่าง project id กับ project number❗️❗️)
echo <YOUR_PROJECT_ID> > ~/project_id.txt
gcloud config set project $(cat ~/project_id.txt)
👉เรียกใช้คำสั่งต่อไปนี้เพื่อเปิดใช้ Google Cloud APIs ที่จำเป็น (การดำเนินการนี้อาจใช้เวลาประมาณ 2 นาที)
gcloud services enable compute.googleapis.com \
storage.googleapis.com \
run.googleapis.com \
artifactregistry.googleapis.com \
aiplatform.googleapis.com \
eventarc.googleapis.com \
sqladmin.googleapis.com \
secretmanager.googleapis.com \
cloudbuild.googleapis.com \
cloudresourcemanager.googleapis.com \
cloudfunctions.googleapis.com \
cloudaicompanion.googleapis.com
การดำเนินการนี้อาจใช้เวลาสักครู่
การตั้งค่าสิทธิ์
👉ตั้งค่าสิทธิ์ของบัญชีบริการ ในเทอร์มินัล ให้เรียกใช้คำสั่งต่อไปนี้
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
export SERVICE_ACCOUNT_NAME=$(gcloud compute project-info describe --format="value(defaultServiceAccount)")
echo "Here's your SERVICE_ACCOUNT_NAME $SERVICE_ACCOUNT_NAME"
👉 ให้สิทธิ์ ในเทอร์มินัล ให้เรียกใช้คำสั่งต่อไปนี้
#Cloud Storage (Read/Write):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/storage.objectAdmin"
#Pub/Sub (Publish/Receive):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/pubsub.publisher"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/pubsub.subscriber"
#Cloud SQL (Read/Write):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/cloudsql.editor"
#Eventarc (Receive Events):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/iam.serviceAccountTokenCreator"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/eventarc.eventReceiver"
#Vertex AI (User):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/aiplatform.user"
#Secret Manager (Read):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/secretmanager.secretAccessor"
4. การทำความเข้าใจอินพุตของผู้ใช้ - ตัวแยกประเภทเจตนา
ก่อนที่ AI Agent จะดำเนินการได้ เอเจนต์ต้องเข้าใจสิ่งที่ผู้ใช้ต้องการอย่างถูกต้องเสียก่อน ข้อมูลในโลกแห่งความเป็นจริงมักจะยุ่งเหยิง อาจไม่ชัดเจน มีการพิมพ์ผิด หรือใช้ภาษาแบบสนทนา
ในส่วนนี้ เราจะสร้างคอมโพเนนต์ "การฟัง" ที่สำคัญซึ่งจะเปลี่ยนข้อมูลจากผู้ใช้ดิบๆ ให้เป็นคำสั่งที่ชัดเจนและนำไปใช้ได้
การเพิ่มตัวแยกประเภทความตั้งใจ
ตอนนี้เราจะกำหนดตรรกะ AI ที่ขับเคลื่อนตัวแยกประเภท
👉 การดำเนินการ: ใน IDE ของ Cloud Shell ให้ไปที่ไดเรกทอรี ~/src/ai/intent-classifier/
ขั้นตอนที่ 1: กำหนดคำศัพท์ของเอเจนต์ (IntentCategory)
ก่อนอื่น เราต้องสร้างรายการการดำเนินการที่เป็นไปได้ทั้งหมดที่เอเจนต์ของเราทำได้
👉 การดำเนินการ: แทนที่ตัวยึดตำแหน่ง // REPLACE ME PART 1: add IntentCategory here ด้วยโค้ดต่อไปนี้
👉 โดยใช้รหัสด้านล่าง
export type IntentCategory =
// Image Analysis Intents
| "DescribeImage"
| "AskAboutImage"
| "ReadTextInImage"
| "IdentifyColorsInImage"
// Control Intents
| "TakePicture"
| "StartCamera"
| "SelectImage"
| "StopSpeaking"
// Preference Intents
| "SetDescriptionDetailed"
| "SetDescriptionConcise"
// Fallback Intents
| "GeneralInquiry" // User has a general question about the agent's functions or polite interaction
| "OutOfScopeRequest" // User's request is clearly outside the agent's defined capabilities
| "Unknown"; // Intent could not be determined with confidence
คำอธิบาย
โค้ด TypeScript นี้สร้างประเภทที่กำหนดเองชื่อ IntentCategory ซึ่งเป็นรายการที่เข้มงวดซึ่งกำหนดการดำเนินการที่เป็นไปได้ทั้งหมด หรือ "Intent" ที่เอเจนต์ของเราเข้าใจ นี่เป็นขั้นตอนแรกที่สำคัญเนื่องจากจะเปลี่ยนวลีของผู้ใช้ที่อาจมีจำนวนไม่สิ้นสุด ("บอกฉันหน่อยว่าคุณเห็นอะไร" "ในรูปมีอะไร") ให้เป็นชุดคำสั่งที่สะอาดและคาดการณ์ได้ เป้าหมายของตัวแยกประเภทคือการเชื่อมโยงคำค้นหาของผู้ใช้กับหมวดหมู่ใดหมวดหมู่หนึ่งโดยเฉพาะ
ขั้นตอนที่ 2
AI ของเราต้องทราบความสามารถและข้อจำกัดของตนเองเพื่อประกอบการตัดสินใจที่ถูกต้อง เราจะให้ข้อมูลนี้เป็นบล็อกข้อความแบบละเอียด
👉 การดำเนินการ: แทนที่ตัวยึดตำแหน่ง REPLACE ME PART 2: add AGENT_CAPABILITIES_AND_LIMITATIONS here ด้วยโค้ดต่อไปนี้
แทนที่รหัสด้านล่าง // REPLACE ME PART 2: add AGENT_CAPABILITIES_AND_LIMITATIONS here:
👉 เมื่อใช้รหัสที่ระบุไว้ด้านล่าง
const AGENT_CAPABILITIES_AND_LIMITATIONS = `
**Core Capabilities (What the Agent CAN DO):**
* **Image Analysis:**
* DescribeImage: Provide a general description of the current image.
* AskAboutImage: Answer a specific question about the visual content of the current image (e.g., "Is there a dog?", "What color is the car?").
* ReadTextInImage: Read any text found in the current image.
* IdentifyColorsInImage: Identify the dominant colors of the current image.
* **Image Input Control:**
* TakePicture: Capture an image using the currently active camera stream.
* StartCamera: Activate the camera (e.g., "use camera", "take another picture").
* SelectImage: Allow the user to choose an image file from their device.
* **Voice & Audio Control:**
* StopSpeaking: Stop the current text-to-speech output.
* **Preference Management:**
* SetDescriptionDetailed: Make future image descriptions more detailed.
* SetDescriptionConcise: Make future image descriptions less detailed or concise.
* **General Interaction:**
* GeneralInquiry: Handle conversational phrases (e.g., "hello", "thank you") or questions about its own capabilities (e.g., "what can you do?", "help").
**Limitations (What the Agent CANNOT DO and should be classified as OutOfScopeRequest):**
* Cannot generate or create new images.
* Cannot edit or modify existing images (e.g., "remove background," "make the car blue").
* Cannot analyze video files or live video beyond capturing a single frame.
* Cannot provide general knowledge or answer questions unrelated to the provided image's visual content (e.g., "What's the weather?", "Who is the president?", "Tell me a joke", "What time is it?").
* Cannot perform mathematical calculations or complex data analysis.
* Cannot translate languages as a primary function.
* Cannot remember information from past images or vastly different previous queries in the same session.
* Cannot control other device settings or applications.
* Cannot perform web searches.
`;
ความสำคัญ:
ข้อความนี้ไม่ได้มีไว้ให้ผู้ใช้อ่าน แต่มีไว้สำหรับโมเดล AI ของเรา เราจะป้อน "คำบรรยายลักษณะงาน" นี้ลงในพรอมต์โดยตรง (ในขั้นตอนถัดไป) เพื่อให้โมเดลภาษา (LLM) มีบริบทที่จำเป็นต่อการตัดสินใจที่ถูกต้อง หากไม่มีบริบทนี้ LLM อาจจัดประเภท "สภาพอากาศเป็นอย่างไร" เป็น AskAboutImage อย่างไม่ถูกต้อง บริบทนี้ช่วยให้โมเดลทราบว่าสภาพอากาศไม่ใช่องค์ประกอบภาพในรูปภาพ และจัดประเภทได้อย่างถูกต้องว่าอยู่นอกขอบเขต
ขั้นตอนที่ 3
ตอนนี้เราจะเขียนชุดคำสั่งที่สมบูรณ์ซึ่งโมเดล Gemini จะใช้เพื่อทำการแยกประเภท
👉 การดำเนินการ: แทนที่ // REPLACE ME PART 3 - classifyIntentPrompt ด้วยโค้ดต่อไปนี้
โดยใช้โค้ดด้านล่าง
const classifyIntentPrompt = ai.definePrompt({
name: 'classifyIntentPrompt',
input: { schema: ClassifyIntentInputSchema },
output: { schema: ClassifyIntentOutputSchema },
prompt: `You are classifying the user's intent for ClarityCam, a voice-controlled AI application focused on image analysis.
Analyze the user query: '{userQuery}'.
First, understand ClarityCam's capabilities and limitations:
${AGENT_CAPABILITIES_AND_LIMITATIONS}
Now, classify the user's PRIMARY intent into ONE of the following categories:
* **DescribeImage**: User wants a general description of the current image.
* **AskAboutImage**: User is asking a specific question directly related to the visual content of the current image.
* **ReadTextInImage**: User wants any text read from the current image.
* **IdentifyColorsInImage**: User wants the dominant colors of the current image.
* **TakePicture**: User wants to capture an image using an active camera.
* **StartCamera**: User wants to activate the camera.
* **SelectImage**: User wants to choose an image file.
* **StopSpeaking**: User wants the current text-to-speech output to stop.
* **SetDescriptionDetailed**: User wants future image descriptions to be more detailed.
* **SetDescriptionConcise**: User wants future image descriptions to be less detailed.
* **GeneralInquiry**: The query is a simple conversational filler (e.g., "hello", "thanks"), a polite closing, or a direct question about the agent's functions (e.g., "what can you do?", "how does this work?", "help").
* **OutOfScopeRequest**: The query asks the agent to perform an action clearly listed under its "Limitations" or otherwise demonstrably outside its defined image analysis and control functions. Examples: "Tell me a joke," "What's the weather in London?", "Generate an image of a cat," "Can you edit my photo to make it brighter?", "Send this image to my friends","Translate 'hello' to Spanish."
Output ONLY the category name.
If the query is ambiguous but seems generally related to polite interaction or asking about the agent itself, prefer 'GeneralInquiry'.
If the query is clearly asking for something the agent CANNOT do, use 'OutOfScopeRequest'.
If truly unclassifiable even with these guidelines, use 'Unknown'.`,
config: {
temperature: 0.05, // Very low temperature for highly deterministic classification
}
});
ข้อความแจ้งนี้เป็นจุดที่เกิดการทำงาน ซึ่งเป็น "สมอง" ของตัวแยกประเภทของเรา โดยจะบอกบทบาทของ AI ให้บริบทที่จำเป็น และกำหนดเอาต์พุตที่ต้องการ โปรดทราบเทคนิควิศวกรรมพรอมต์ (Prompt Engineering) ที่สำคัญต่อไปนี้
- การสวมบทบาท: เริ่มต้นด้วย "คุณกำลังจัดประเภท..." เพื่อกำหนดงานที่ชัดเจน
- การแทรกบริบท: แทรกตัวแปร
AGENT_CAPABILITIES_AND_LIMITATIONSลงในพรอมต์แบบไดนามิก - การจัดรูปแบบเอาต์พุตอย่างเคร่งครัด: คำสั่ง "แสดงเฉพาะชื่อหมวดหมู่" มีความสำคัญอย่างยิ่งต่อการได้รับคำตอบที่ชัดเจนและคาดการณ์ได้ ซึ่งเราสามารถนำไปใช้ในโค้ดได้อย่างง่ายดาย
- อุณหภูมิต่ำ: สำหรับการจัดประเภท เราต้องการคำตอบที่แน่นอนและสมเหตุสมผล ไม่ใช่คำตอบที่สร้างสรรค์ การตั้งค่าอุณหภูมิเป็นค่าที่ต่ำมาก (0.05) จะช่วยให้มั่นใจได้ว่าโมเดลจะมีความแม่นยำและสอดคล้องกันสูง
ขั้นตอนที่ 4: เชื่อมต่อแอปกับโฟลว์ AI
สุดท้ายนี้ เราจะเรียกใช้เครื่องมือคัดแยก AI ใหม่จากไฟล์แอปพลิเคชันหลัก
👉 การดำเนินการ: ไปที่~/src/app/page.tsxไฟล์ ในฟังก์ชัน processVoiceCommand ให้แทนที่ // REPLACE ME PART 1: add classificationResult ด้วยโค้ดต่อไปนี้
const classificationResult = await classifyIntentFlow({ userQuery: commandToProcess });
intent = classificationResult.intent as IntentCategory;
โค้ดนี้เป็นสะพานที่สำคัญระหว่างแอปพลิเคชันฟรอนท์เอนด์กับตรรกะ AI แบ็กเอนด์ โดยจะรับคำสั่งเสียงของผู้ใช้ (commandToProcess) ส่งไปยัง classifyIntentFlow ที่คุณเพิ่งสร้าง และรอให้ AI2 ส่งคืนความตั้งใจที่จัดประเภทแล้ว
ตอนนี้ตัวแปรเจตนาจะมีคำสั่งที่ชัดเจนและเป็นโครงสร้าง (เช่น DescribeImage) ระบบจะใช้ผลลัพธ์นี้ในคำสั่ง switch ที่ตามมาเพื่อขับเคลื่อนตรรกะของแอปพลิเคชันและตัดสินใจว่าจะดำเนินการใดต่อไป ซึ่งเป็นวิธีที่ "การคิด" ของ AI เปลี่ยนเป็น "การทำงาน" ของแอป
การเปิดตัวอินเทอร์เฟซผู้ใช้
ได้เวลาดูการทำงานของแอปพลิเคชันแล้ว มาเริ่มเซิร์ฟเวอร์การพัฒนา
👉 ในเทอร์มินัล ให้เรียกใช้คำสั่งต่อไปนี้ npm run dev หมายเหตุ: คุณอาจต้องเรียกใช้ npm install ก่อนเรียกใช้ npm run dev
หลังจากผ่านไปสักครู่ คุณจะเห็นเอาต์พุตที่คล้ายกับเอาต์พุตนี้ ซึ่งหมายความว่าเซิร์ฟเวอร์ทำงานได้สำเร็จ
▲ Next.js 15.2.3 (Turbopack)
- Local: http://localhost:9003
- Network: http://10.88.0.4:9003
- Environments: .env
✓ Starting...
✓ Ready in 1512ms
○ Compiling / ...
✓ Compiled / in 26.6s
ตอนนี้ ให้คลิก URL ในเครื่อง (http://localhost:9003) เพื่อเปิดแอปพลิเคชันในเบราว์เซอร์
คุณควรเห็นอินเทอร์เฟซผู้ใช้ของ SightGuide ตอนนี้ปุ่มยังไม่ได้เชื่อมต่อกับตรรกะใดๆ ดังนั้นการคลิกปุ่มจึงไม่ทําให้เกิดการดําเนินการใดๆ ซึ่งเป็นสิ่งที่เราคาดหวังในขั้นตอนนี้ เราจะทำให้ตัวละครเหล่านี้มีชีวิตชีวาขึ้นมาในส่วนถัดไป
ตอนนี้คุณได้เห็น UI แล้ว ให้กลับไปที่เทอร์มินัลแล้วกด Ctrl + C เพื่อหยุดเซิร์ฟเวอร์การพัฒนาก่อนที่เราจะดำเนินการต่อ
5. ทำความเข้าใจอินพุตของผู้ใช้ - การตรวจสอบคำค้นหาที่ไม่สมบูรณ์
เพิ่มการตรวจสอบคำค้นหาที่ไม่สมบูรณ์
ส่วนที่ 1: การกำหนดพรอมต์ ("อะไร")
ก่อนอื่น เรามากำหนดคำสั่งสำหรับ AI กัน พรอมต์คือ "สูตร" สำหรับการเรียกใช้ AI ซึ่งจะบอกโมเดลอย่างชัดเจนว่าเราต้องการให้ทำอะไร
👉 การดำเนินการ: ใน IDE ให้ไปที่ ~/src/ai/flows/check_typo/
แทนที่รหัสด้านล่าง // REPLACE ME PART 1: add prompt here:
👉 เมื่อใช้รหัสที่ระบุไว้ด้านล่าง
const prompt = ai.definePrompt({
name: 'checkTypoPrompt',
input: {
schema: CheckTypoInputSchema,
},
output: {
schema: CheckTypoOutputSchema,
},
prompt: `You are a helpful AI assistant that checks user text for typos and suggests corrections.
- If you find typos, respond with the corrected text.
- If there are no typos, or if you are unsure about a correction, respond with the original text unchanged.
User text: {text}
Corrected text:
`,
});
โค้ดบล็อกนี้กำหนดเทมเพลตที่นำกลับมาใช้ใหม่ได้สำหรับ AI ของเราที่ชื่อ checkTypoPrompt สคีมาอินพุตและเอาต์พุตจะกำหนดสัญญาข้อมูลสำหรับงานนี้ ซึ่งจะช่วยป้องกันข้อผิดพลาดและทำให้ระบบของเราคาดการณ์ได้
ส่วนที่ 2: การสร้างโฟลว์ ("วิธี")
ตอนนี้เรามี "สูตร" (พรอมต์) แล้ว เราต้องสร้างฟังก์ชันที่สามารถดำเนินการได้จริง ใน Genkit เราเรียกการดำเนินการนี้ว่าโฟลว์ โฟลว์จะห่อหุ้มพรอมต์ของเราในฟังก์ชันที่เรียกใช้งานได้ ซึ่งส่วนอื่นๆ ของแอปพลิเคชันสามารถเรียกใช้ได้อย่างง่ายดาย
👉 การดำเนินการ: ในไฟล์ ~/src/ai/flows/check_typo/ เดียวกัน ให้แทนที่โค้ดด้านล่าง // REPLACE ME PART 2: add flow here:
👉 เมื่อใช้รหัสที่ระบุไว้ด้านล่าง
const checkTypoFlow = ai.defineFlow<
typeof CheckTypoInputSchema,
typeof CheckTypoOutputSchema
>(
{
name: 'checkTypoFlow',
inputSchema: CheckTypoInputSchema,
outputSchema: CheckTypoOutputSchema,
},
async input => {
const {output} = await prompt(input);
return output!;
}
);
ส่วนที่ 3: การใช้เครื่องมือตรวจตัวสะกด
เมื่อขั้นตอน AI เสร็จสมบูรณ์แล้ว เราก็สามารถผสานรวมเข้ากับตรรกะหลักของแอปพลิเคชันได้ เราจะเรียกใช้ฟังก์ชันนี้ทันทีหลังจากได้รับคำสั่งของผู้ใช้ เพื่อให้มั่นใจว่าข้อความจะสะอาดก่อนที่จะประมวลผลต่อไป
👉การดำเนินการ: ไปที่ ~/src/app/ai/flows/check-typo.ts แล้วค้นหาฟังก์ชัน export async function checkTypo ยกเลิกการแสดงความคิดเห็นของคำสั่ง return
แทนที่จะใช้ return; ให้ใช้ return checkTypoFlow(input);
👉การดำเนินการ: ไปที่ ~/src/app/page.tsx แล้วค้นหาฟังก์ชัน processVoiceCommand แทนที่รหัสด้านล่าง REPLACE ME PART 2: add typoResult here:
👉 เมื่อใช้รหัสที่ระบุไว้ด้านล่าง
const typoResult = await checkTypo({ text: rawCommand });
if (typoResult && typoResult.correctedText && typoResult.correctedText.trim().length > 0) {
const originalTrimmedLower = rawCommand.trim().toLowerCase();
const correctedTrimmedLower = typoResult.correctedText.trim().toLowerCase();
if (correctedTrimmedLower !== originalTrimmedLower) {
commandToProcess = typoResult.correctedText;
typoCorrectionAnnouncement = `I think you said: ${commandToProcess}. `;
}
}
การเปลี่ยนแปลงนี้ช่วยให้เราสร้างไปป์ไลน์การประมวลผลข้อมูลที่แข็งแกร่งยิ่งขึ้นสำหรับคำสั่งของผู้ใช้ทุกคำสั่ง
โฟลว์คำสั่งเสียง (อ่านอย่างเดียว ไม่ต้องดำเนินการใดๆ)
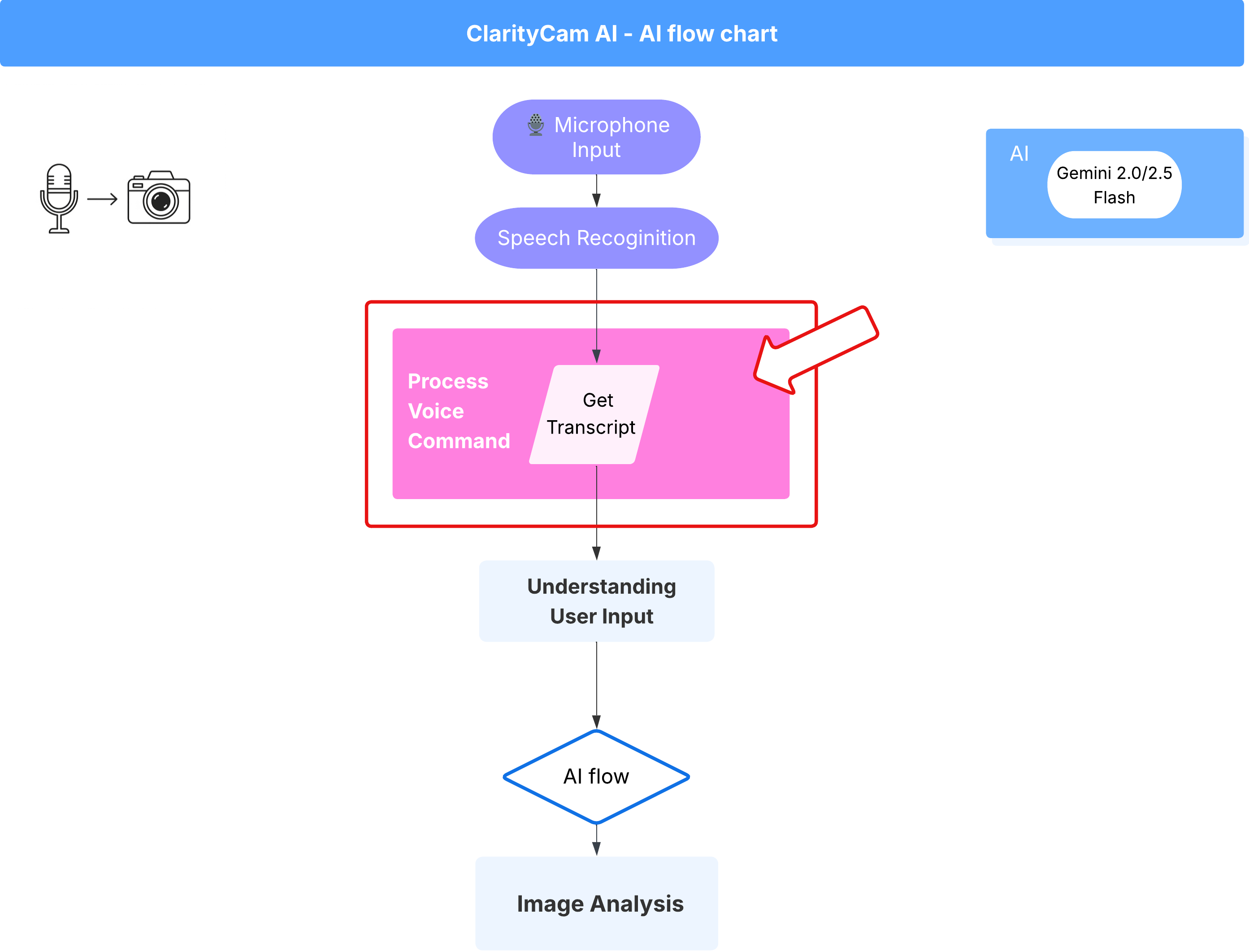
ตอนนี้เรามีคอมโพเนนต์หลักที่ "เข้าใจ" (เครื่องมือตรวจตัวสะกดและเครื่องมือแยกประเภทเจตนา) แล้ว มาดูกันว่าคอมโพเนนต์เหล่านี้เข้ากับตรรกะการประมวลผลเสียงหลักของแอปพลิเคชันได้อย่างไร
ทุกอย่างจะเริ่มต้นเมื่อผู้ใช้พูด Web Speech API ของเบราว์เซอร์จะฟังคำพูด และเมื่อผู้ใช้พูดจบแล้ว จะแสดงข้อความถอดเสียงของสิ่งที่ได้ยิน โค้ดต่อไปนี้จะจัดการกระบวนการนี้
👉อ่านอย่างเดียว: ไปที่ ~/src/app/page.tsx และภายในฟังก์ชัน handleResult ค้นหารหัสด้านล่าง
for (let i = event.resultIndex; i < event.results.length; ++i) {
if (event.results[i].isFinal) {
finalTranscript += event.results[i][0].transcript;
}
}
if (finalTranscript) {
console.log("Final Transcript:", finalTranscript);
processVoiceCommand(finalTranscript);
}
การทดสอบการแก้ไขคำที่สะกดผิด
มาถึงช่วงสนุกๆ กันแล้ว มาดูกันว่าฟีเจอร์แก้ไขคำที่พิมพ์ผิดใหม่ของเราจัดการกับคำสั่งเสียงที่สมบูรณ์และไม่สมบูรณ์ได้อย่างไร
เริ่มแอปพลิเคชัน
ก่อนอื่น มาเรียกใช้เซิร์ฟเวอร์การพัฒนาอีกครั้งกัน ในเทอร์มินัล ให้เรียกใช้คำสั่ง npm run dev
เปิดแอป
เมื่อเซิร์ฟเวอร์พร้อมแล้ว ให้เปิดเบราว์เซอร์แล้วไปที่ที่อยู่ภายใน (เช่น http://localhost:9003)
เปิดใช้งานคำสั่งเสียง
คลิกปุ่ม Start Listening เบราว์เซอร์อาจขอสิทธิ์ในการใช้ไมโครโฟน โปรดคลิกอนุญาต
ทดสอบคำสั่งที่ไม่สมบูรณ์
ตอนนี้เรามาลองป้อนคำสั่งที่มีข้อบกพร่องเล็กน้อยเพื่อดูว่า AI จะเข้าใจหรือไม่ พูดใส่ไมโครโฟนให้ชัดเจน
"ถ่ายรูปฉันหน่อย"
สังเกตผลลัพธ์
นี่คือที่ที่เวทมนตร์เริ่มทำงาน! แม้ว่าคุณจะพูดว่า "ถ่ายรูปฉัน" แต่คุณควรเห็นแอปพลิเคชันเปิดใช้งานกล้องอย่างถูกต้อง โฟลว์ checkTypo จะแก้ไขวลีของคุณเป็น "ถ่ายรูป" เบื้องหลัง และ classifyIntentFlow จะเข้าใจคำสั่งที่แก้ไขแล้ว
ซึ่งเป็นการยืนยันว่าฟีเจอร์แก้ไขคำที่พิมพ์ผิดของเราทำงานได้อย่างสมบูรณ์ ทำให้แอปมีความเสถียรและใช้งานง่ายยิ่งขึ้น เมื่อเสร็จแล้ว คุณสามารถหยุดกล้องได้โดยการถ่ายรูปหรือเพียงแค่หยุดเซิร์ฟเวอร์ในเทอร์มินัล (Ctrl + C)
6. การวิเคราะห์รูปภาพที่ทำงานด้วยระบบ AI - อธิบายรูปภาพ
เมื่อตัวแทนเข้าใจคำขอแล้ว ก็ถึงเวลาให้ตัวแทนมองเห็น ในส่วนนี้ เราจะสร้างความสามารถของ Vision Agent ซึ่งเป็นคอมโพเนนต์หลักที่รับผิดชอบการวิเคราะห์รูปภาพทั้งหมด เราจะเริ่มจากฟีเจอร์ที่สำคัญที่สุด นั่นคือการอธิบายรูปภาพ แล้วเพิ่มความสามารถในการอ่านข้อความ
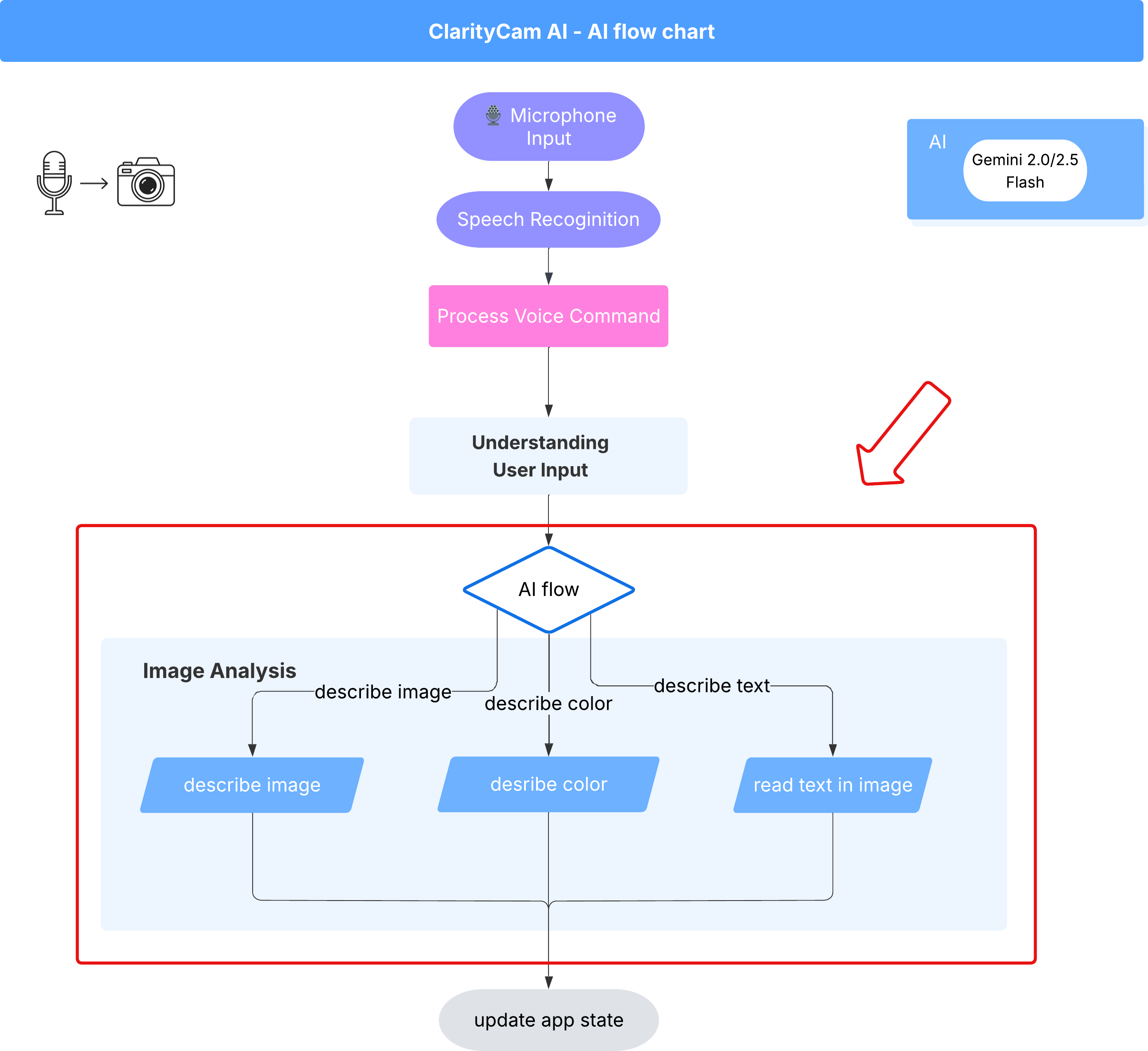
ฟีเจอร์ 1: อธิบายรูปภาพ
ซึ่งเป็นฟังก์ชันหลักของเอเจนต์ เราไม่ได้สร้างคำอธิบายแบบคงที่เท่านั้น แต่จะสร้างขั้นตอนแบบไดนามิกที่ปรับระดับรายละเอียดตามค่ากำหนดของผู้ใช้ได้ ซึ่งเป็นส่วนสำคัญของปรัชญา Natively Adaptive Interface (NAI)
👉 การดำเนินการ: ใน Cloud Shell IDE ให้ไปที่ไฟล์ ~/src/ai/flows/describe_image/ แล้วยกเลิกการแสดงความคิดเห็นในโค้ดต่อไปนี้
ขั้นตอนที่ 1: สร้างเทมเพลตพรอมต์แบบไดนามิก
ก่อนอื่น เราจะสร้างเทมเพลตพรอมต์ที่ซับซ้อนซึ่งสามารถเปลี่ยนวิธีการตามอินพุตที่ได้รับ
Uncommentโค้ดด้านล่าง
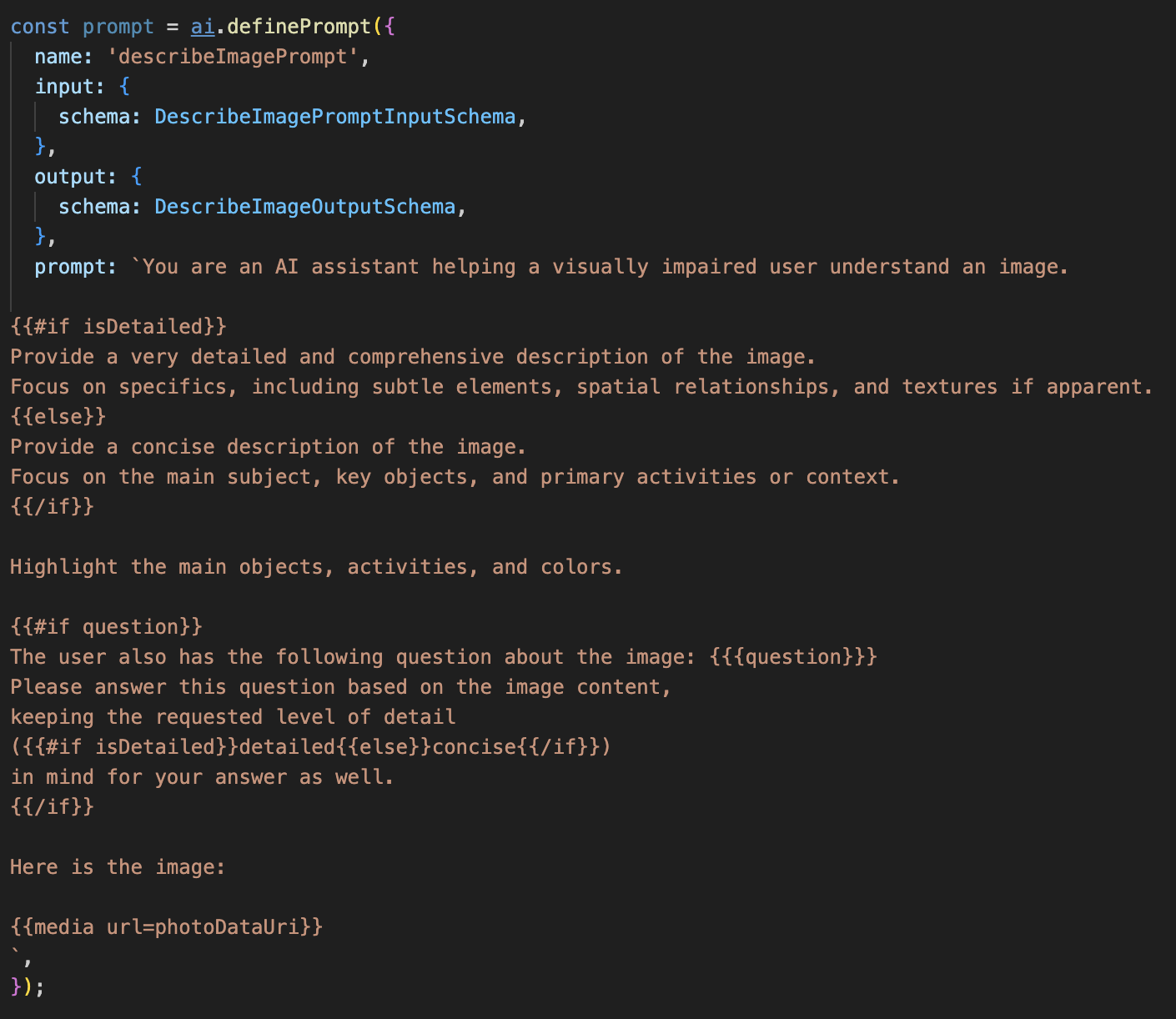
โค้ดนี้กำหนดตัวแปรสตริง พรอมต์ ที่ใช้ภาษาเทมเพลตที่เรียกว่า Dot-Mustache ซึ่งช่วยให้เราฝังตรรกะแบบมีเงื่อนไขลงในพรอมต์ได้โดยตรง
{#if isDetailed}...{else}...{/if}: นี่คือการบล็อกแบบมีเงื่อนไข หากข้อมูลอินพุตที่เราส่งไปยังพรอมต์นี้มีพร็อพเพอร์ตี้ isDetailed: true AI จะได้รับชุดคำสั่ง "ละเอียดมาก" ไม่เช่นนั้นจะได้รับคำสั่ง "กระชับ" นี่คือวิธีที่เอเจนต์ปรับให้เข้ากับค่ากำหนดของผู้ใช้
{#if question}...{/if}: บล็อกนี้จะรวมอยู่ก็ต่อเมื่อข้อมูลอินพุตมีพร็อพเพอร์ตี้คำถาม ซึ่งช่วยให้เราใช้พรอมต์ที่มีประสิทธิภาพเดียวกันได้ทั้งสำหรับคำอธิบายทั่วไปและคำถามเฉพาะ
{media url=photoDataUri}: นี่คือไวยากรณ์ Genkit แบบพิเศษสำหรับการฝังข้อมูลรูปภาพลงในพรอมต์โดยตรงเพื่อให้โมเดลมัลติโมดัลวิเคราะห์
ขั้นตอนที่ 2: สร้างโฟลว์อัจฉริยะ
จากนั้น เราจะกำหนดพรอมต์และโฟลว์ที่จะใช้เทมเพลตใหม่ โฟลว์นี้มีตรรกะเล็กน้อยในการแปลค่ากำหนดของผู้ใช้เป็นบูลีนที่เทมเพลตของเราเข้าใจได้
👉 การดำเนินการ: ใน IDE ของ Cloud Shell ให้แทนที่โค้ดต่อไปนี้ใน~/src/ai/flows/describe_image/ไฟล์เดียวกัน// REPLACE ME PART 1: add flow here
👉 โดยใช้โค้ดด้านล่าง
// Define the prompt using the template from Step 1
const prompt = ai.definePrompt({
name: 'describeImagePrompt',
input: { schema: DescribeImagePromptInputSchema },
output: { schema: DescribeImageOutputSchema },
prompt: promptTemplate,
});
// Define the flow
const describeImageFlow = ai.defineFlow<
typeof DescribeImageInputSchema,
typeof DescribeImageOutputSchema
>(
{
name: 'describeImageFlow',
inputSchema: DescribeImageInputSchema,
outputSchema: DescribeImageOutputSchema,
},
async (pageInput) => {
const preference = pageInput.detailPreference || "concise";
// Prepare the input for the prompt, including the new boolean flag
const promptInputData = {
...pageInput,
isDetailed: preference === "detailed",
};
const { output } = await prompt(promptInputData);
return output!;
}
);
ซึ่งทำหน้าที่เป็นตัวกลางอัจฉริยะระหว่างส่วนหน้าและพรอมต์ AI
- โดยจะได้รับ
pageInputจากแอปพลิเคชันของเรา ซึ่งรวมถึงค่ากำหนดของผู้ใช้เป็นสตริง (เช่น"detailed") - จากนั้นระบบจะสร้างออบเจ็กต์ใหม่
promptInputData - บรรทัดที่สำคัญที่สุดคือ
isDetailed: preference === "detailed"บรรทัดนี้จะทำงานที่สำคัญในการสร้างค่าบูลีนtrueหรือfalseตามสตริงค่ากำหนด - สุดท้าย โมเดลจะเรียกใช้
promptด้วยข้อมูลที่ปรับปรุงแล้วนี้ ตอนนี้เทมเพลตพรอมต์จากขั้นตอนที่ 1 สามารถใช้บูลีนisDetailedเพื่อเปลี่ยนวิธีการที่ส่งไปยัง AI แบบไดนามิกได้แล้ว
ขั้นตอนที่ 3: เชื่อมต่อส่วนหน้า
ตอนนี้เรามาทริกเกอร์โฟลว์นี้จากอินเทอร์เฟซผู้ใช้ใน page.tsx กัน
👉การดำเนินการ: ไปที่ ~/src/app/ai/flows/describe-image.ts แล้วค้นหาฟังก์ชัน export async function describeImage ยกเลิกการแสดงความคิดเห็นของคำสั่ง return
แทนที่จะใช้ return; ให้ใช้ return describeImageFlow(input);
👉การดำเนินการ: ใน ~/src/app/page.tsx ให้ค้นหาฟังก์ชัน handleAnalyze แล้วแทนที่โค้ด // REPLACE ME PART 2: DESCRIBE IMAGE
👉 โดยใช้รหัสต่อไปนี้
case "description":
result = await describeImage({
photoDataUri,
question,
detailPreference: descriptionPreference
});
outputText = question ? `Answer: ${result.description}` : `Description: ${result.description}`;
break;
เมื่อผู้ใช้ต้องการรับคำอธิบาย ระบบจะเรียกใช้โค้ดนี้ โดยจะเรียกใช้describeImageโฟลว์ของเรา ส่งต่อข้อมูลรูปภาพ และที่สำคัญคือdescriptionPreferenceตัวแปรสถานะจากคอมโพเนนต์ React นี่เป็นจิ๊กซอว์ชิ้นสุดท้ายที่เชื่อมต่อค่ากําหนดของผู้ใช้ที่จัดเก็บไว้ใน UI กับโฟลว์ AI โดยตรง ซึ่งจะปรับลักษณะการทํางานตามนั้น
การทดสอบฟีเจอร์คำอธิบายรูปภาพ
มาดูการทำงานของฟังก์ชันคำอธิบายรูปภาพกัน ตั้งแต่การถ่ายรูปไปจนถึงการฟังสิ่งที่ AI เห็น
เริ่มแอปพลิเคชัน
ก่อนอื่น มาเรียกใช้เซิร์ฟเวอร์การพัฒนาอีกครั้งกัน 👉 ในเทอร์มินัล ให้เรียกใช้คำสั่งต่อไปนี้ npm run dev หมายเหตุ: คุณอาจต้องเรียกใช้ npm install ก่อนเรียกใช้ npm run dev
เปิดแอป
เมื่อเซิร์ฟเวอร์พร้อมแล้ว ให้เปิดเบราว์เซอร์แล้วไปที่ที่อยู่ภายใน (เช่น http://localhost:9003)
เปิดใช้งานกล้อง
คลิกปุ่มเริ่มฟังและให้สิทธิ์เข้าถึงไมโครโฟนหากมีข้อความแจ้ง จากนั้นพูดคำสั่งแรก
"ถ่ายรูป"
แอปพลิเคชันจะเปิดใช้งานกล้องของอุปกรณ์ ตอนนี้คุณควรเห็นฟีดวิดีโอสดบนหน้าจอ
ถ่ายภาพ
เมื่อกล้องทำงานอยู่ ให้วางกล้องไว้ที่สิ่งที่คุณต้องการอธิบาย ตอนนี้ให้พูดคำสั่งอีกครั้งเพื่อจับภาพ
"ถ่ายรูป"
ระบบจะแทนที่วิดีโอสดด้วยภาพนิ่งที่คุณเพิ่งถ่าย
ขอคำอธิบาย
เมื่อรูปภาพใหม่ปรากฏบนหน้าจอแล้ว ให้ป้อนคำสั่งสุดท้ายดังนี้
"อธิบายรูปภาพ"
ฟังผลลัพธ์
แอปจะแสดงสถานะการประมวลผล จากนั้นคุณจะได้ยินคำอธิบายที่ AI สร้างขึ้นของรูปภาพ ข้อความจะปรากฏในการ์ด "สถานะและผลลัพธ์" ด้วย
เมื่อเสร็จแล้ว คุณสามารถหยุดกล้องได้โดยการถ่ายรูปหรือหยุดเซิร์ฟเวอร์ในเทอร์มินัล (Ctrl + C)
7. การวิเคราะห์รูปภาพด้วยระบบ AI - อธิบายข้อความ (OCR)
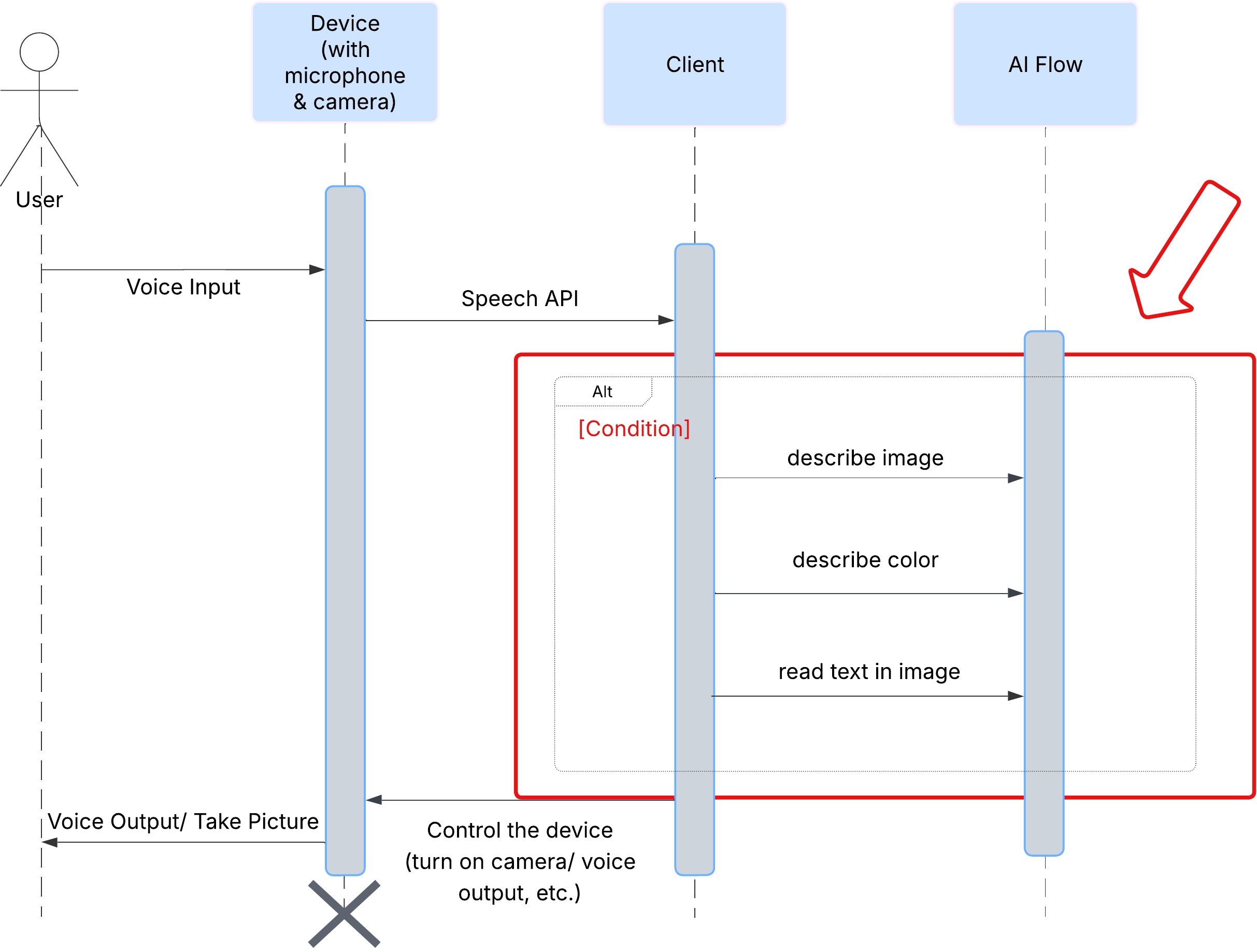
จากนั้นเราจะเพิ่มความสามารถในการรู้จำอักขระด้วยภาพ (OCR) ลงใน Vision Agent ซึ่งจะช่วยให้อ่านข้อความจากรูปภาพใดก็ได้
👉 การดำเนินการ: ใน IDE ให้ไปที่ ~/src/ai/flows/read-text-in-image/ แล้วยกเลิกการแสดงความคิดเห็นในโค้ดด้านล่าง
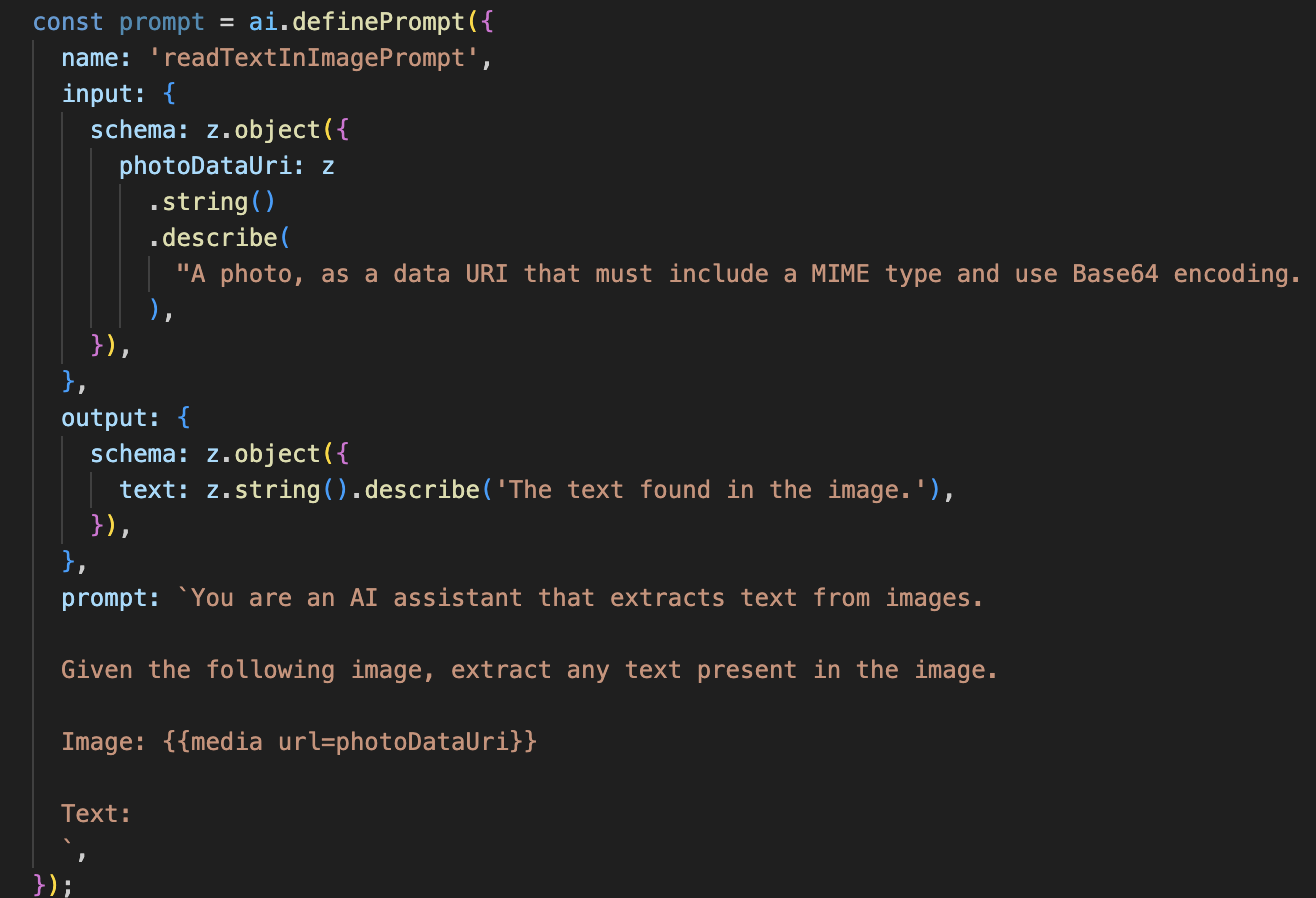
👉 การดำเนินการ: ใน IDE ให้แทนที่ // REPLACE ME: Creating Prmopt ใน~/src/ai/flows/read-text-in-image/ไฟล์เดียวกัน
👉 โดยใช้โค้ดด้านล่าง
const readTextInImageFlow = ai.defineFlow<
typeof ReadTextInImageInputSchema,
typeof ReadTextInImageOutputSchema
>(
{
name: 'readTextInImageFlow',
inputSchema: ReadTextInImageInputSchema,
outputSchema: ReadTextInImageOutputSchema,
},
async input => {
const {output} = await prompt(input);
return output!;
}
);
ขั้นตอนการทำงานของ AI นี้เรียบง่ายกว่ามาก โดยเน้นหลักการใช้เครื่องมือที่มุ่งเน้นสำหรับงานที่เฉพาะเจาะจง
- พรอมต์: พรอมต์นี้จะคงที่และมีความเฉพาะเจาะจงสูง ซึ่งแตกต่างจากพรอมต์คำอธิบาย หน้าที่เดียวของพรอมต์นี้คือการสั่งให้ AI ทำหน้าที่เป็นเครื่องมือ OCR โดยระบุว่า "ดึงข้อความทั้งหมดที่อยู่ในรูปภาพ"
- สคีมา: สคีมาอินพุตและเอาต์พุตก็เรียบง่ายเช่นกัน โดยคาดหวังรูปภาพและส่งคืนสตริงข้อความเดียว
การเชื่อมต่อส่วนหน้าสำหรับ OCR
สุดท้าย มาเชื่อมต่อความสามารถใหม่นี้ใน page.tsx กัน
👉การดำเนินการ: ไปที่ ~/src/app/ai/flows/read-text-in-image.ts แล้วค้นหาฟังก์ชัน export async function readTextInImage ยกเลิกการแสดงความคิดเห็นของคำสั่ง return
แทนที่จะใช้ return; ให้ใช้ return readTextInImageFlow(input);
👉 การดำเนินการ: ใน ~/src/app/page.tsx ให้ค้นหาฟังก์ชัน handleAnalyze และรอบๆ คำสั่ง switch
แทนที่ REPLACE ME PART 3: READ TEXT
โดยใช้โค้ดด้านล่าง
case "text":
result = await readTextInImage({ photoDataUri });
outputText = result.text ? `Text Found: ${result.text}` : "No text found.";
break;
เมื่อความตั้งใจของผู้ใช้คือ ReadTextInImage ระบบจะทริกเกอร์โค้ดนี้ โดยจะเรียกใช้readTextInImageโฟลว์แบบง่ายๆ บรรทัด result.text ? ... : ... เป็นวิธีที่ชัดเจนในการจัดการเอาต์พุต โดยจะแสดงข้อความที่เป็นประโยชน์ต่อผู้ใช้หาก AI ไม่พบข้อความใดๆ ในรูปภาพ
การทดสอบฟีเจอร์อ่านข้อความ (OCR)
ทำตามขั้นตอนต่อไปนี้เพื่อทดสอบฟีเจอร์การอ่านข้อความ อย่าลืมเล็งกล้องไปที่วัตถุที่มีข้อความชัดเจน
- เรียกใช้แอปพลิเคชันด้วย
npm run devแล้วเปิดในเบราว์เซอร์ - คลิก "เริ่มฟัง" และให้สิทธิ์เข้าถึงไมโครโฟนเมื่อได้รับแจ้ง
- เปิดใช้งานกล้อง พูดคำสั่ง "ถ่ายรูป" คุณควรเห็นฟีดวิดีโอสดปรากฏบนหน้าจอ
- ถ่ายรูป เล็งกล้องไปที่ข้อความที่ต้องการอ่าน แล้วพูดคำสั่งอีกครั้งว่า "ถ่ายรูป" ระบบจะแทนที่วิดีโอด้วยรูปภาพนิ่ง
- ขอข้อความ เมื่อถ่ายรูปภาพแล้ว ให้ป้อนคำสั่งสุดท้ายว่า "ข้อความในรูปภาพคืออะไร"
- ตรวจสอบผลลัพธ์ หลังจากนั้นไม่นาน แอปจะวิเคราะห์รูปภาพและอ่านออกเสียงข้อความที่ตรวจพบ หากไม่พบข้อความใดๆ ระบบจะแจ้งให้คุณทราบ
ซึ่งเป็นการยืนยันว่าฟีเจอร์ OCR ที่มีประสิทธิภาพทำงานได้ เมื่อเสร็จแล้ว ให้หยุดเซิร์ฟเวอร์ด้วย Ctrl + C
8. การปรับปรุง AI ขั้นสูง - อ่านอย่างเดียว ✨
AI Agent ที่ดีจะทำตามคำสั่งได้ เอเจนต์ AI ที่ดีจะใช้งานง่าย น่าเชื่อถือ และมีประโยชน์ ในส่วนนี้ เราจะมุ่งเน้นไปที่การปรับปรุงขั้นสูง 3 อย่างที่จะช่วยยกระดับความสามารถของเอเจนต์
เราจะสำรวจวิธีการต่อไปนี้
Add Context & Memoryเพื่อจัดการการติดตามผลที่เป็นธรรมชาติและเป็นบทสนทนาReduce Hallucinationเพื่อสร้างเอเจนต์ที่เชื่อถือได้และไว้วางใจได้มากขึ้นMake the Agent Proactiveเพื่อมอบประสบการณ์การใช้งานที่สะดวกและเป็นมิตรกับผู้ใช้มากขึ้นAdd preference settingเพื่อปรับแต่งคำอธิบายรูปภาพ
การปรับปรุงที่ 1: บริบทและหน่วยความจำ
การสนทนาที่เป็นธรรมชาติไม่ใช่ชุดคำสั่งที่แยกจากกัน แต่เป็นการสนทนาที่ต่อเนื่อง หากผู้ใช้ถามว่า "ในรูปภาพมีอะไร" และตัวแทนตอบว่า "รถสีแดง" ผู้ใช้อาจถามต่อว่า "สีอะไร" โดยไม่ต้องพูดคำว่า "รถ" อีก ตัวแทนของเราต้องใช้ความจำระยะสั้นเพื่อทำความเข้าใจบริบทนี้
วิธีที่เรานำมาใช้ (สรุป)
เราได้สร้างความสามารถนี้ไว้ในโฟลว์ describeImage แล้ว ส่วนนี้เป็นการสรุปวิธีการทำงานของรูปแบบดังกล่าว เมื่อเรียกฟังก์ชัน describeImage จาก page.tsx เราจะส่งประวัติการสนทนาไปยังฟังก์ชันดังกล่าว
👉 Code Showcase (ตั้งแต่ page.tsx):
const result = await describeImage({
photoDataUri,
question: commandToProcess,
detailPreference: descriptionPreference,
previousUserQueryOnImage: lastUserQuery ?? undefined,
previousAIResponseOnImage: lastAIResponse ?? undefined,
});
previousUserQueryOnImageและpreviousAIResponseOnImage: พร็อพเพอร์ตี้ทั้ง 2 รายการนี้คือหน่วยความจำระยะสั้นของเอเจนต์ การส่งการโต้ตอบสุดท้ายไปยัง AI จะช่วยให้ AI มีบริบทที่จำเป็นต่อการทำความเข้าใจคำถามติดตามผลที่คลุมเครือหรืออ้างอิง- พรอมต์แบบปรับเปลี่ยนได้: พรอมต์ในโฟลว์ describe_image จะใช้บริบทนี้ พรอมต์ได้รับการออกแบบมาให้พิจารณาการสนทนาก่อนหน้าเมื่อสร้างคำตอบใหม่ เพื่อให้ตัวแทนตอบกลับได้อย่างชาญฉลาด
การปรับปรุง 2: ลดการหลอน
AI "ไม่สมเหตุสมผล" เมื่อคิดข้อเท็จจริงขึ้นมาเองหรืออ้างว่ามีความสามารถที่ไม่มี การสร้างความไว้วางใจของผู้ใช้เป็นสิ่งสำคัญอย่างยิ่งที่เอเจนต์ของเราต้องทราบขีดจำกัดของตนเองและสามารถปฏิเสธคำขอนอกขอบเขตได้อย่างราบรื่น
วิธีที่เรานำมาใช้ (สรุป)
วิธีที่มีประสิทธิภาพที่สุดในการป้องกันการหลอนคือการกำหนดขอบเขตที่ชัดเจนให้กับโมเดล เราทำได้เมื่อสร้างตัวแยกประเภทเจตนา
👉 การแสดงโค้ด (จากโฟลว์ของ intent-classifier):
// Define Agent Capabilities and Limitations for the prompt
const AGENT_CAPABILITIES_AND_LIMITATIONS = `
**Core Capabilities (What the Agent CAN DO):**
* **Image Analysis:**
* DescribeImage: Provide a general description of the current image...
**Limitations (What the Agent CANNOT DO...):**
* Cannot generate or create new images.
* Cannot provide general knowledge or answer questions unrelated to the image...
* Cannot perform web searches.
`;
ค่าคงที่นี้ทำหน้าที่เป็น "คำอธิบายงาน" ที่เราป้อนให้กับ AI ในพรอมต์การจัดประเภท
- การเชื่อมต่อโมเดลกับความเป็นจริง: การบอก AI อย่างชัดเจนว่าทำอะไรไม่ได้เป็นการ "เชื่อมต่อ" AI กับความเป็นจริง เมื่อเห็นคำค้นหา เช่น "อากาศเป็นยังไง" โมเดลจะจับคู่คำค้นหากับรายการข้อจำกัดได้อย่างมั่นใจ และจัดประเภทเจตนาเป็น OutOfScopeRequest
- สร้างความน่าเชื่อถือ: เอเจนต์ที่พูดอย่างตรงไปตรงมาว่า "ฉันช่วยเรื่องนั้นไม่ได้" จะน่าเชื่อถือมากกว่าเอเจนต์ที่พยายามคาดเดาและตอบผิด นี่คือหลักการพื้นฐานของการออกแบบ AI ที่ปลอดภัยและเชื่อถือได้ `
การปรับปรุงที่ 3: การสร้างเอเจนต์เชิงรุก
สำหรับแอปพลิเคชันที่เน้นการช่วยเหลือพิเศษเป็นอันดับแรก เราไม่สามารถพึ่งพาสัญญาณภาพได้ เมื่อผู้ใช้เปิดใช้งานโหมดการฟัง ผู้ใช้จะต้องได้รับการยืนยันทันทีแบบไม่ใช้ภาพว่าเอเจนต์พร้อมและรอรับคำสั่ง ตอนนี้เราจะเพิ่มการแนะนำเชิงรุกเพื่อให้ความคิดเห็นที่สำคัญนี้
ขั้นตอนที่ 1: เพิ่มสถานะเพื่อติดตามการฟังครั้งแรก
ก่อนอื่น เราต้องมีวิธีทราบว่านี่เป็นครั้งแรกที่ผู้ใช้กดปุ่ม "Start Listening" ในระหว่างเซสชันหรือไม่
👉 ใน ~/src/app/page.tsx ให้ดูตัวแปรสถานะใหม่ต่อไปนี้ที่ด้านบนของคอมโพเนนต์ ClarityCam
export default function ClarityCam() {
// ... other state variables
const [descriptionPreference, setDescriptionPreference] = useState<DescriptionPreference>("concise");
// Add this new line
const [isFirstListen, setIsFirstListen] = useState(true);
// ... rest of the component
}
เราได้เปิดตัวตัวแปรสถานะใหม่ isFirstListen และเริ่มต้นด้วย true เราจะใช้ Flag นี้เพื่อทริกเกอร์ข้อความต้อนรับแบบครั้งเดียว
ขั้นตอนที่ 2: อัปเดตฟังก์ชัน toggleListening
ตอนนี้เรามาแก้ไขฟังก์ชันที่จัดการไมโครโฟนเพื่อเล่นคำทักทายกัน
👉 ใน ~/src/app/page.tsx ให้ค้นหาฟังก์ชัน toggleListening แล้วดูบล็อก if ต่อไปนี้
const toggleListening = useCallback(() => {
// ... existing logic to setup speech recognition
if (isListening || isAttemptingStart) {
// ... existing logic to stop listening
} else {
stopSpeaking(); // Stop any ongoing TTS
// Add this new block
if (isFirstListen) {
setIsFirstListen(false);
const introMessage = "Hello! I am ClarityCam, your AI assistant. I'm now listening. You can ask me to 'describe the image', 'read text', 'take a picture', or ask questions about what's in an image.";
speakText(introMessage);
} else {
speakText("Listening..."); // Optional: provide feedback on subsequent clicks
}
// ... rest of the logic to start listening
}
}, [/*...existing dependencies...*/, isFirstListen]); // Don't forget to add isFirstListen to the dependency array!
- ตรวจสอบ Flag: บล็อก if (isFirstListen) จะตรวจสอบว่านี่เป็นการเปิดใช้งานครั้งแรกหรือไม่
- ป้องกันการทำซ้ำ: สิ่งแรกที่ฟังก์ชันนี้ทำภายในบล็อกคือการเรียกใช้ setIsFirstListen(false) ซึ่งจะช่วยให้มั่นใจได้ว่าข้อความแนะนำจะเล่นเพียงครั้งเดียวต่อเซสชัน
- ให้คำแนะนำ: เราออกแบบ introMessage อย่างรอบคอบเพื่อให้มีประโยชน์มากที่สุด โดยจะทักทายผู้ใช้ ระบุชื่อตัวแทน ยืนยันว่าตอนนี้พร้อมใช้งานแล้ว ("ตอนนี้ฉันพร้อมรับฟัง") และให้ตัวอย่างคำสั่งเสียงที่ชัดเจนซึ่งผู้ใช้สามารถใช้ได้
- การตอบกลับด้วยเสียง: สุดท้ายนี้ speakText(introMessage) จะให้ข้อมูลที่สำคัญนี้ ซึ่งเป็นการให้ความมั่นใจและคำแนะนำในทันทีโดยไม่ต้องให้ผู้ใช้ดูหน้าจอ
การปรับปรุงที่ 4: การปรับให้เข้ากับค่ากำหนดของผู้ใช้ (สรุป)
เอเจนต์อัจฉริยะอย่างแท้จริงไม่ได้เพียงแค่ตอบสนอง แต่ยังเรียนรู้และปรับตัวให้เข้ากับความต้องการของผู้ใช้ด้วย ฟีเจอร์ที่มีประสิทธิภาพมากที่สุดอย่างหนึ่งที่เราสร้างขึ้นคือความสามารถของผู้ใช้ในการเปลี่ยนความละเอียดของคำอธิบายรูปภาพได้ทันทีด้วยคำสั่งต่างๆ เช่น "อธิบายให้ละเอียดขึ้น"
วิธีที่เรานำไปใช้ (สรุป) ความสามารถนี้ทำงานด้วยพรอมต์แบบไดนามิกที่เราสร้างขึ้นสำหรับโฟลว์ describeImage โดยใช้ตรรกะแบบมีเงื่อนไขเพื่อเปลี่ยนคำสั่งที่ส่งไปยัง AI ตามค่ากำหนดของผู้ใช้
👉 การแสดงโค้ด (promptTemplate จาก describe_image):
const settingPreferenceTemplate = `
{#if isDetailed}
Provide a very detailed and comprehensive description of the image. Focus on specifics, including subtle elements, spatial relationships, and textures if apparent.
{else}
Provide a concise description of the image. Focus on the main subject, key objects, and primary activities or context.
{/if}
Highlight the main objects, activities, and colors.
...
`;
- ตรรกะแบบมีเงื่อนไข: บล็อก
{#if isDetailed}...{else}...{/if}คือกุญแจสำคัญ เมื่อ describeImageFlow ได้รับ detailPreference จากส่วนหน้า ระบบจะสร้างบูลีน isDetailed (จริงหรือเท็จ) - คำสั่งแบบปรับอัตโนมัติ: แฟล็กบูลีนนี้จะกำหนดชุดคำสั่งที่โมเดล AI ได้รับ หาก isDetailed เป็นจริง ระบบจะสั่งให้โมเดลอธิบายอย่างละเอียด หากเป็นเท็จ ระบบจะแนะนำให้เขียนอย่างกระชับ
- การควบคุมของผู้ใช้: รูปแบบนี้เชื่อมต่อคำสั่งเสียงของผู้ใช้โดยตรง (เช่น "เขียนคำอธิบายให้กระชับ" ซึ่งจัดเป็นเจตนา SetDescriptionConcise) กับการเปลี่ยนแปลงพื้นฐานในลักษณะการทำงานของ AI ซึ่งทําให้เอเจนต์รู้สึกตอบสนองและปรับเปลี่ยนในแบบของคุณอย่างแท้จริง
9. การติดตั้งใช้งานในระบบคลาวด์
สร้างอิมเมจ Docker โดยใช้ Google Cloud Build
gcloud builds submit . --tag gcr.io/$PROJECT_ID/accessibilityai-nextjs-app:latest
accessibilityai-nextjs-appเป็นชื่อรูปภาพที่แนะนำ- ประมวลผลไฟล์ . ใช้ไดเรกทอรีปัจจุบัน (
accessibilityAI/) เป็นแหล่งที่มาของบิลด์
ติดตั้งใช้งานอิมเมจใน Google Cloud Run
- ตรวจสอบว่าคีย์ API และข้อมูลลับอื่นๆ พร้อมใช้งานใน Secret Manager เช่น
GOOGLE_GENAI_API_KEY
แทนที่ YOUR_ACTUAL_GOOGLE_AI_KEY_VALUE นี้ด้วยค่าคีย์ Gemini API จริง
echo "YOUR_ACTUAL_GOOGLE_AI_KEY_VALUE" | gcloud secrets create GOOGLE_GENAI_API_KEY --data-file=- --project=YOUR_PROJECT_ID
มอบบทบาท "Secret Manager Secret Accessor" ให้กับบัญชีบริการรันไทม์ของบริการ Cloud Run (เช่น PROJECT_NUMBER-compute@developer.gserviceaccount.com หรือบัญชีเฉพาะ) สำหรับข้อมูลลับนี้
- คำสั่งการติดตั้งใช้งาน
gcloud run deploy accessibilityai-app-service \
--image gcr.io/$PROJECT_ID/accessibilityai-nextjs-app:latest \
--platform managed \
--region us-central1 \
--allow-unauthenticated \
--port 3000 \
--set-secrets=GOOGLE_GENAI_API_KEY=GOOGLE_GENAI_API_KEY:latest \
--set-env-vars NODE_ENV="production"