
1. Giriş
Bu eğiticide, dünyayı görebilen ve size açıklayabilen, eller serbest ve sesle çalışan bir yapay zeka ajanı olan ClarityCam'i oluşturacaksınız. ClarityCam, erişilebilirlik temel alınarak tasarlanmıştır ve görme engelli veya az gören kullanıcılar için güçlü bir araçtır. Ancak öğreneceğiniz ilkeler, modern ve genel amaçlı tüm ses uygulamalarını oluşturmak için gereklidir.

Bu proje, Doğal Olarak Uyarlanabilir Arayüz (NAI) adı verilen güçlü bir tasarım felsefesi üzerine kurulmuştur. NAI, erişilebilirliği sonradan eklenen bir özellik olarak ele almak yerine temel bir unsur olarak kabul eder. Bu yaklaşımla yapay zeka aracısı arayüz olarak işlev görür. Farklı kullanıcılara uyum sağlar, ses ve görüntü gibi çok formatlı girişleri işler ve benzersiz ihtiyaçlarına göre kullanıcılara proaktif olarak rehberlik eder.
NAI ile İlk Yapay Zeka Temsilcinizi Oluşturma:

Bu oturumun sonunda şunları yapabileceksiniz:
- Erişilebilirliği Varsayılan Olarak Tasarlama: Tüm kullanıcılara eşdeğer deneyimler sunan yapay zeka sistemleri oluşturmak için Doğal Olarak Uyarlanabilir Arayüz (NAI) ilkelerini uygulayın.
- Kullanıcı Amacını Sınıflandırma: Doğal dil komutlarını aracınız için yapılandırılmış işlemlere çeviren güçlü bir amaç sınıflandırıcı oluşturun.
- Sohbet Bağlamını Koruma: Kısa süreli hafıza uygulayarak temsilcinizin ek soruları ve referans komutlarını (ör. "Hangi renkte?") anlamasını sağlayın.
- Etkili istemler oluşturun: Doğru ve güvenilir görüntü analizi için Gemini gibi çok formatlı bir modelde odaklanmış, bağlam açısından zengin istemler oluşturun.
- Belirsizliği Ele Alma ve Kullanıcıya Yol Gösterme: Kapsam dışı istekler için zarif bir hata işleme tasarımı yapın ve güven oluşturmak için kullanıcıları proaktif bir şekilde dahil edin.
- Çok Temsilcili Bir Sistemi Düzenleme: Uygulamanızı, ses işleme, analiz ve konuşma sentezi gibi karmaşık görevleri yönetmek için birlikte çalışan bir dizi uzmanlaşmış temsilci kullanarak yapılandırın.
2. Üst Düzey Tasarım
ClarityCam, temelde kullanıcı için basit olacak şekilde tasarlanmıştır ancak işbirliği yapan yapay zeka aracıları tarafından desteklenen gelişmiş bir sistemle çalışır. Mimariyi inceleyelim.

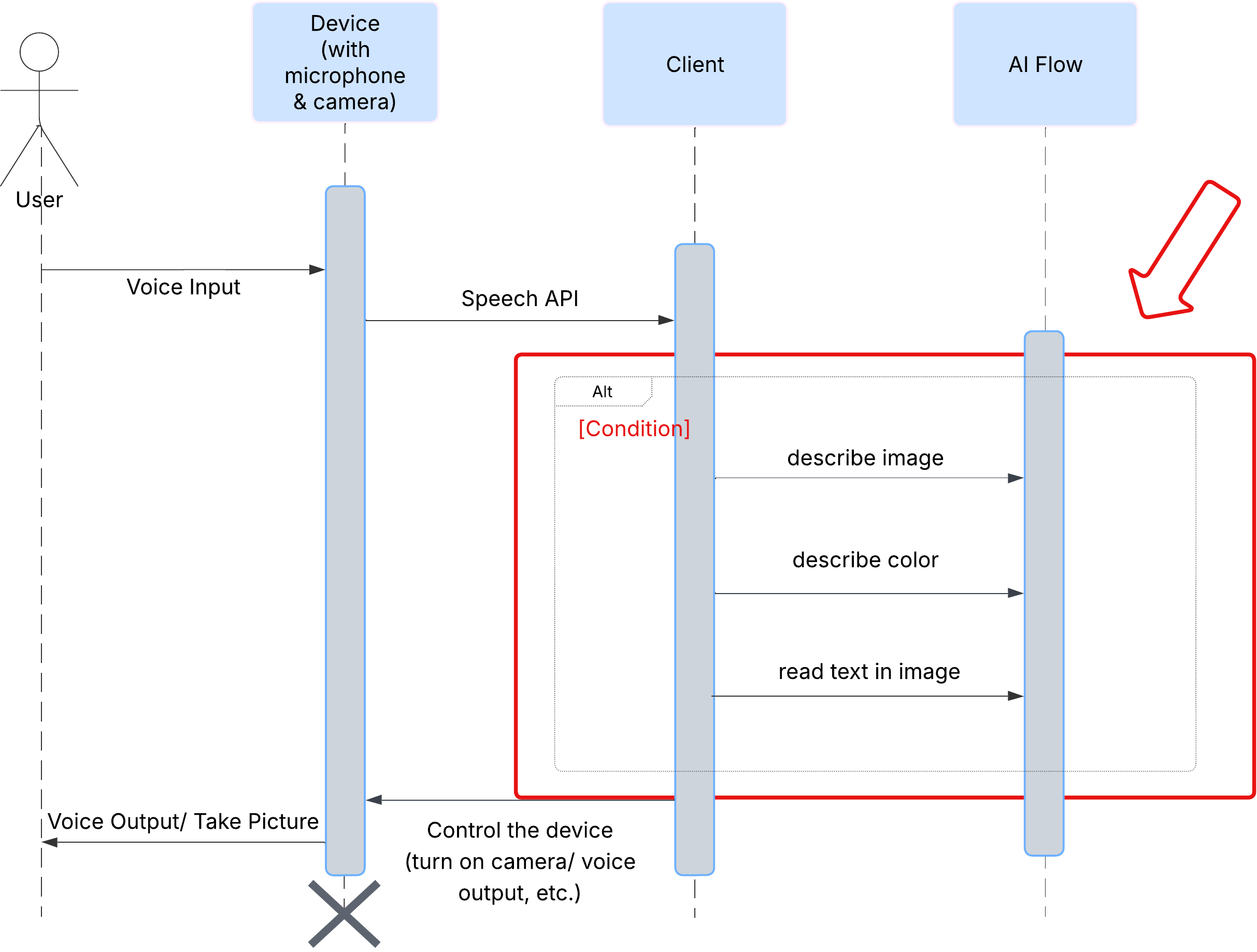
Kullanıcı Deneyimi
Öncelikle, kullanıcının ClarityCam ile nasıl etkileşimde bulunduğuna bakalım. Tüm deneyim eller serbest ve sohbet odaklıdır. Kullanıcı bir komut veriyor ve temsilci, sözlü bir açıklama veya işlemle yanıt veriyor. Bu sıra şeması, kullanıcının ilk sesli komutundan cihazın son sesli yanıtına kadar olan tipik bir etkileşim akışını gösterir.
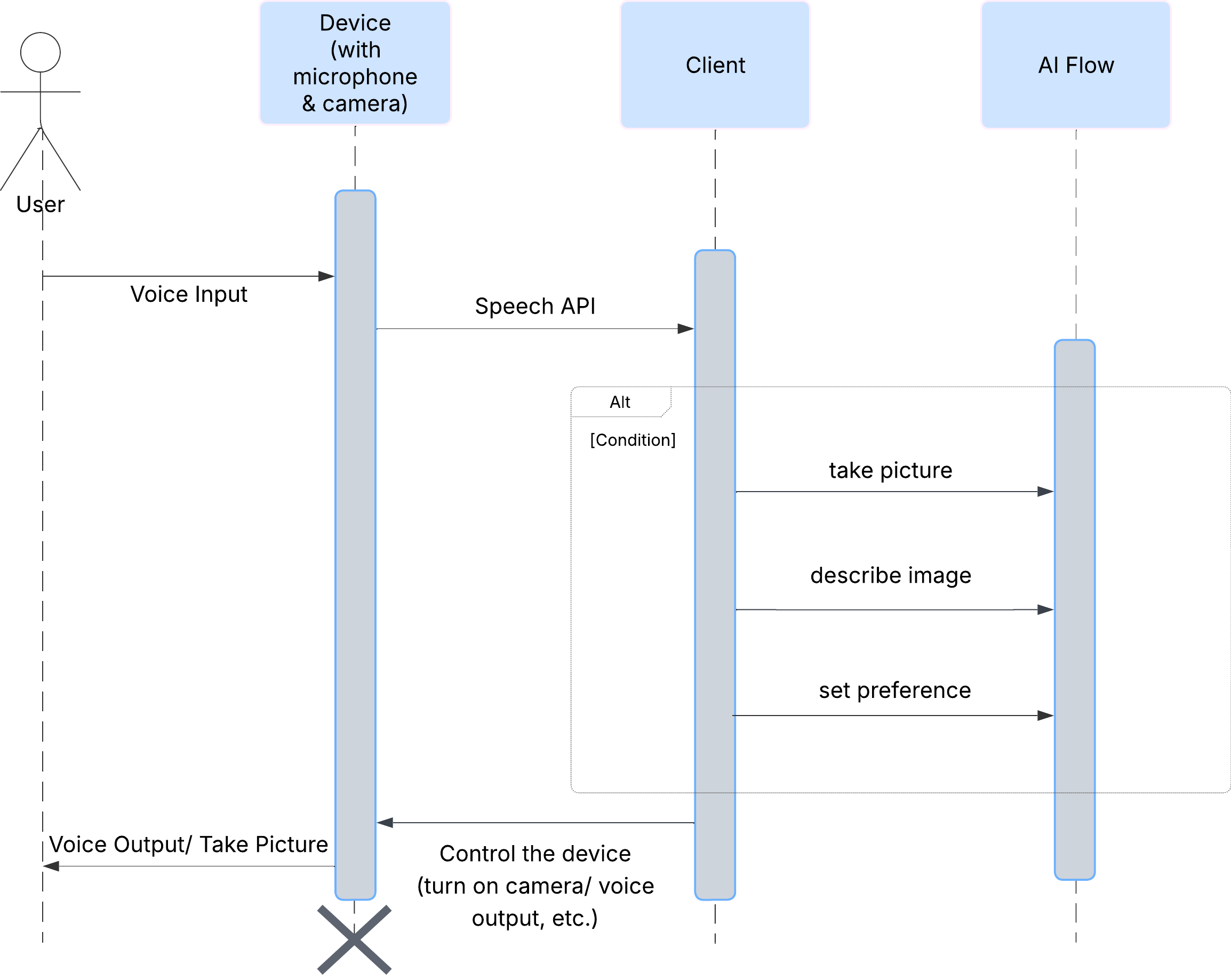
Yapay Zeka Temsilcisi Mimarisi
Yüzeyin altında, deneyimi hayata geçirmek için çoklu aracı sistemi uyum içinde çalışır. Bir komut alındığında merkezi bir Orchestrator aracısı, görevleri amacı anlamak, görüntüleri analiz etmek ve yanıt oluşturmaktan sorumlu uzmanlaşmış aracılara devreder. Bu yapay zeka akış şeması, bu aracıların nasıl birlikte çalıştığına dair ayrıntılı inceleme sağlar. Bu mimariyi sonraki bölümlerde uygulayacağız.
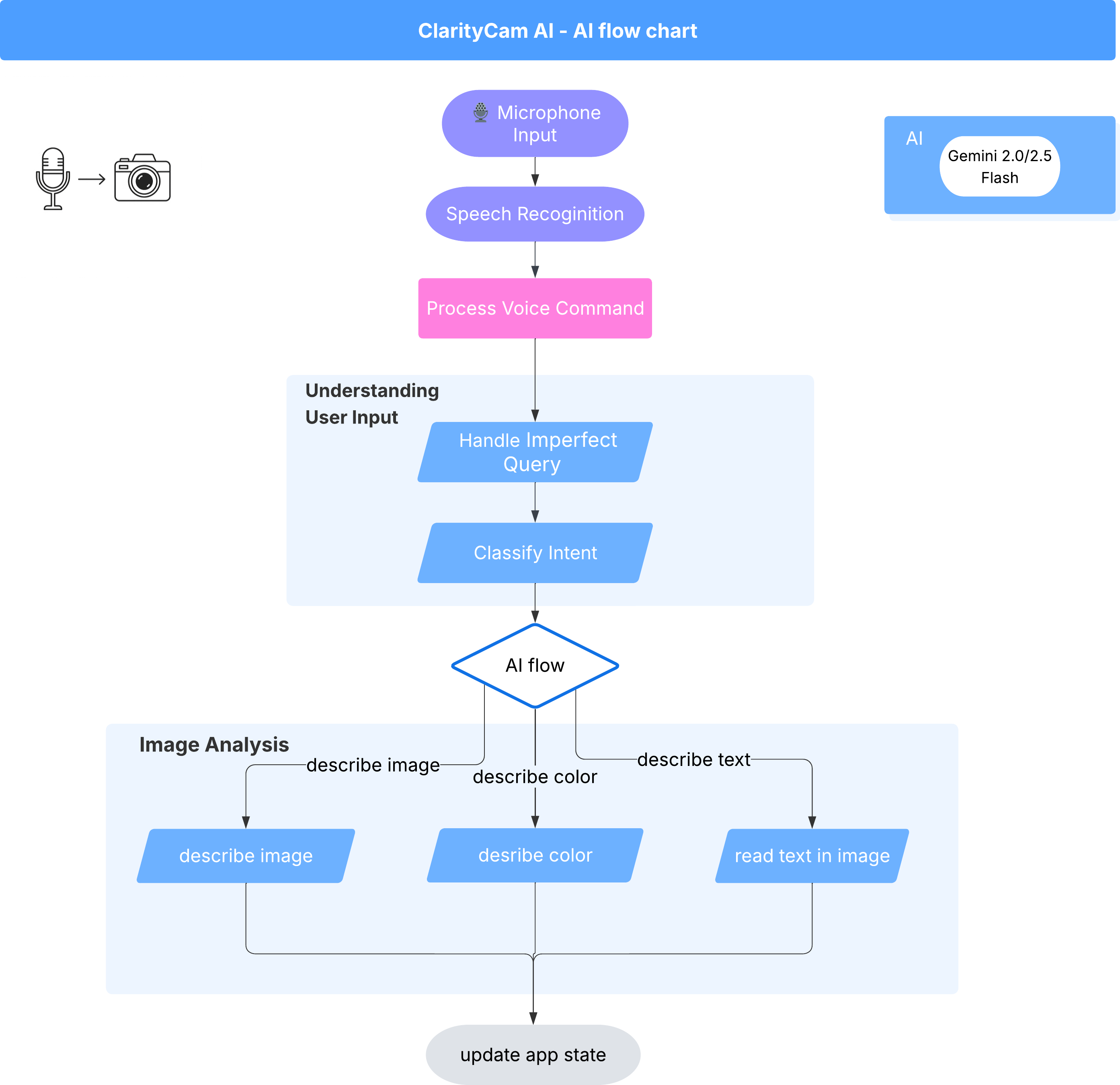
Proje Dosyalarına Hızlı Bir Bakış
Kod yazmaya başlamadan önce projemizin dosya yapısını tanıyalım. Çok sayıda dosya varmış gibi görünebilir ancak bu eğitimin tamamı için yalnızca iki belirli alana odaklanmanız gerekir.
Projemizin basitleştirilmiş haritasını aşağıda bulabilirsiniz.
accessibilityAI/src/
├── 📁 app/
│ ├── layout.tsx # An overall page shell (you can ignore this).
│ └── page.tsx # ⬅️ MODIFY THIS: The main user interface for our app.
│
├── 📁 ai/
│ ├── 📁flows # ⬅️ MODIFY THIS: The core AI logic and server functions.
│ └── intent-classifier.ts # ⬅️ MODIFY THIS: Where we'll edit our AI prompts.
| └── ai-instance.ts
| └── dev.ts
│
├── 📁 components/ # Contains pre-built UI components (ignore this).
│
├── 📁 hooks/
│
├── 📁 lib/
│
└── 📁 types/
Teknoloji Yığını
Sistemimiz, güçlü bulut hizmetlerini ve son teknoloji yapay zeka modellerini birleştiren modern ve ölçeklenebilir bir teknoloji yığını üzerine kurulmuştur. Kullanacağımız temel bileşenler şunlardır:
- Google Cloud Platform (GCP): Aracılarımız için sunucusuz altyapı sağlar.
- Cloud Run: Ayrı ayrı aracıları container'a alınmış, ölçeklenebilir mikro hizmetler olarak dağıtır.
- Artifact Registry: Aracıları için Docker görüntülerini güvenli bir şekilde depolar ve yönetir.
- Secret Manager: Hassas kimlik bilgilerini ve API anahtarlarını güvenli bir şekilde işler.
- Büyük dil modelleri (LLM'ler): Sistemin "beyni" olarak işlev görür.
- Google'ın Gemini Modelleri: Kullanıcı niyetini sınıflandırmadan görüntü içeriğini analiz etmeye ve akıllı açıklamalar sağlamaya kadar her şey için Gemini ailesinin güçlü çok formatlı özelliklerini kullanırız.
3. Kurulum ve Ön Koşullar
Faturalandırma Hesabını Etkinleştirme Bu codelab'i çalıştırmak için biraz kredisi olan bir faturalandırma hesabına ihtiyacınız var. Başlamak için bu codelab'in üst kısmındaki banner'da yer alan kredileri kullanın. Zaten bir faturalandırma hesabına bağlıysanız bu adımı atlayabilirsiniz.
Yeni bir GCP projesi oluşturma
- Google Cloud Console'a gidip yeni bir proje oluşturun.
- Google Cloud Console'a gidip yeni bir proje oluşturun.
- Sol paneli açın,
Billingsimgesini tıklayın ve faturalandırma hesabının bu GCP hesabına bağlı olup olmadığını kontrol edin.
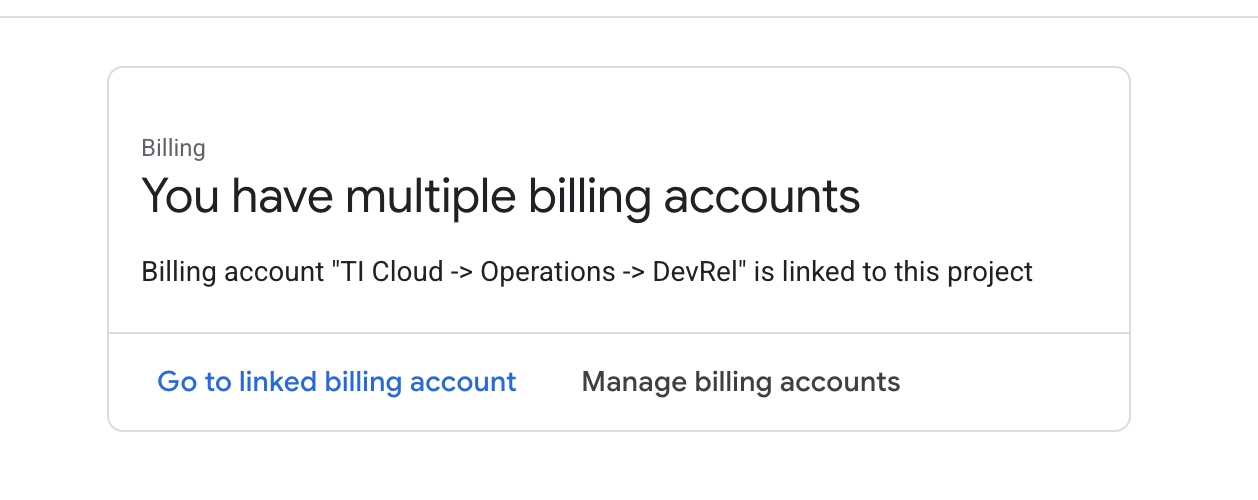
Bu sayfayı görüyorsanız manage billing account seçeneğini işaretleyin, Google Cloud deneme sürümünü seçin ve bu sürüme bağlanın.
Gemini API anahtarınızı oluşturma
Anahtarı güvence altına alabilmek için önce anahtarınızın olması gerekir.
- Google AI Studio'ya gidin : https://aistudio.google.com/
- Google hesabınızla oturum açın.
- Genellikle soldaki gezinme bölmesinde veya sağ üst köşede bulunan "API anahtarı al" düğmesini tıklayın.
- "API anahtarları" iletişim kutusunda "Yeni projede API anahtarı oluştur"u tıklayın.
- Sizin için yeni bir API anahtarı oluşturulur. Bu anahtarı hemen kopyalayın ve geçici olarak güvenli bir yerde (ör. şifre yöneticisi veya güvenli not) saklayın. Bu, sonraki adımlarda kullanacağınız değerdir.
Yerel Geliştirme İş Akışı (Makinenizde Test Etme)
npm run dev'yı çalıştırabilmeniz ve uygulamanızın çalışması gerekir. Bu noktada .env devreye girer.
- API anahtarını dosyaya ekleyin:
.envadlı yeni bir dosya oluşturun ve bu dosyaya aşağıdaki satırı ekleyin.
YOUR_API_KEY_HERE kısmını, AI Studio'dan aldığınız ve .env konumuna kaydettiğiniz anahtarla değiştirdiğinizden emin olun:
GOOGLE_GENAI_API_KEY="YOUR_API_KEY_HERE"
[İsteğe bağlı] IDE ve ortamı ayarlama
Bu eğitimde, yerel terminalinizle birlikte VS Code veya IntelliJ gibi tanıdık bir geliştirme ortamında çalışabilirsiniz. Ancak standartlaştırılmış ve önceden yapılandırılmış bir ortam sağlamak için Google Cloud Shell'i kullanmanızı önemle tavsiye ederiz.
Aşağıdaki adımlar Cloud Shell bağlamı için yazılmıştır. Bunun yerine yerel ortamınızı kullanmayı tercih ederseniz lütfen git, nvm, npm ve gcloud'ün yüklendiğinden ve doğru şekilde yapılandırıldığından emin olun.
Cloud Shell Düzenleyici'de çalışma
👉Google Cloud Console'un üst kısmında Cloud Shell'i etkinleştir'i tıklayın (Cloud Shell bölmesinin üst kısmındaki terminal şeklindeki simge). 
👉 "Düzenleyici" düğmesini tıklayın (kalemli açık bir klasöre benzer). Bu işlem, pencerede Cloud Shell kod düzenleyiciyi açar. Sol tarafta bir dosya gezgini görürsünüz. 
👉Gösterildiği gibi, alt durum çubuğundaki Cloud Code ile Oturum Açma düğmesini tıklayın. Eklentiyi talimatlara uygun şekilde yetkilendirin. Durum çubuğunda Cloud Code - no project (Cloud Code - proje yok) ifadesini görürseniz bunu seçin, ardından açılır listede "Google Cloud projesi seçin"i ve oluşturduğunuz projeler listesinden belirli bir Google Cloud projesini seçin. 
👉Bulut IDE'de terminali açın. 
👉Terminalde, aşağıdaki komutu kullanarak kimliğinizin doğrulandığını ve projenin proje kimliğinize ayarlandığını doğrulayın:
gcloud auth list
👉 natively-accessible-interface projesini GitHub'dan kopyalayın:
git clone https://github.com/cuppibla/AccessibilityAgent.git
👉Ayrıca <YOUR_PROJECT_ID> yerine proje kimliğinizi girdiğinizden emin olun (proje kimliğinizi Google Cloud Console'un proje bölümünde bulabilirsiniz. ❗️❗️project id ile project number'ü karıştırmamaya dikkat edin❗️❗️):
echo <YOUR_PROJECT_ID> > ~/project_id.txt
gcloud config set project $(cat ~/project_id.txt)
👉Gerekli Google Cloud API'lerini etkinleştirmek için aşağıdaki komutu çalıştırın: (Bu işlemin tamamlanması yaklaşık 2 dakika sürebilir)
gcloud services enable compute.googleapis.com \
storage.googleapis.com \
run.googleapis.com \
artifactregistry.googleapis.com \
aiplatform.googleapis.com \
eventarc.googleapis.com \
sqladmin.googleapis.com \
secretmanager.googleapis.com \
cloudbuild.googleapis.com \
cloudresourcemanager.googleapis.com \
cloudfunctions.googleapis.com \
cloudaicompanion.googleapis.com
Bu işlem birkaç dakika sürebilir.
İzin ayarlama
👉Hizmet hesabı iznini ayarlayın. Terminalde şunu çalıştırın :
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
export SERVICE_ACCOUNT_NAME=$(gcloud compute project-info describe --format="value(defaultServiceAccount)")
echo "Here's your SERVICE_ACCOUNT_NAME $SERVICE_ACCOUNT_NAME"
İzin verin. Terminalde şunu çalıştırın :
#Cloud Storage (Read/Write):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/storage.objectAdmin"
#Pub/Sub (Publish/Receive):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/pubsub.publisher"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/pubsub.subscriber"
#Cloud SQL (Read/Write):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/cloudsql.editor"
#Eventarc (Receive Events):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/iam.serviceAccountTokenCreator"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/eventarc.eventReceiver"
#Vertex AI (User):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/aiplatform.user"
#Secret Manager (Read):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/secretmanager.secretAccessor"
4. Kullanıcı Girişini Anlama - Amaç Sınıflandırıcı
Yapay zeka ajanımızın harekete geçebilmesi için önce kullanıcının ne istediğini doğru bir şekilde anlaması gerekir. Gerçek dünyadaki girişler genellikle karmaşıktır. Belirsiz olabilir, yazım hataları içerebilir veya sohbet dilinde olabilir.
Bu bölümde, ham kullanıcı girişini net ve uygulanabilir bir komuta dönüştüren kritik "dinleme" bileşenlerini oluşturacağız.
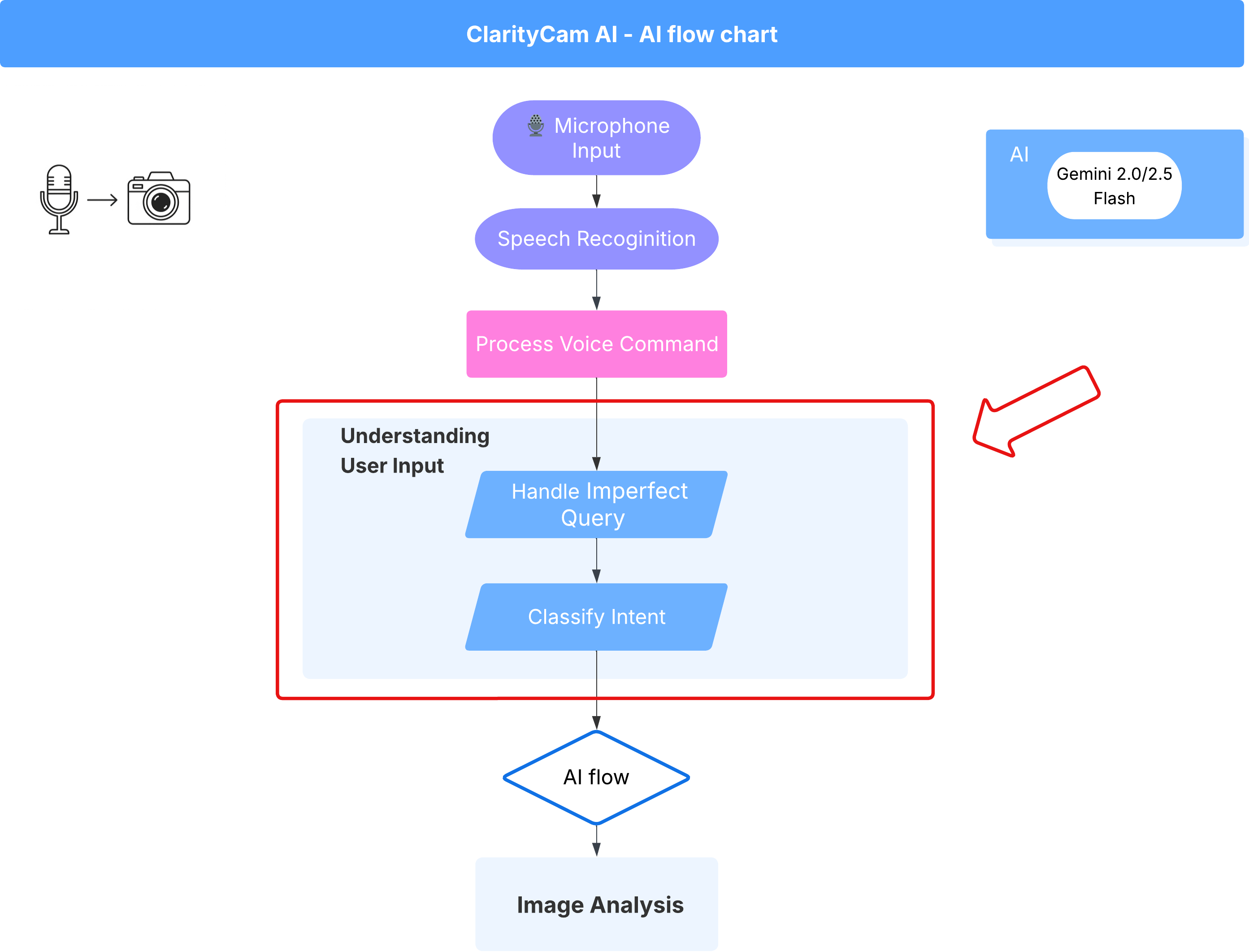
Amaç sınıflandırıcı ekleme
Şimdi sınıflandırıcımızı destekleyen yapay zeka mantığını tanımlayacağız.
👉 İşlem: Cloud Shell IDE'nizde ~/src/ai/intent-classifier/ dizinine gidin.
1. adım: Aracının kelime dağarcığını tanımlayın (IntentCategory)
Öncelikle, aracımızın gerçekleştirebileceği her olası işlemin kesin bir listesini oluşturmamız gerekir.
👉 İşlem: Yer tutucu // REPLACE ME PART 1: add IntentCategory here öğesini aşağıdaki kodla değiştirin:
👉 Aşağıdaki kodla:
export type IntentCategory =
// Image Analysis Intents
| "DescribeImage"
| "AskAboutImage"
| "ReadTextInImage"
| "IdentifyColorsInImage"
// Control Intents
| "TakePicture"
| "StartCamera"
| "SelectImage"
| "StopSpeaking"
// Preference Intents
| "SetDescriptionDetailed"
| "SetDescriptionConcise"
// Fallback Intents
| "GeneralInquiry" // User has a general question about the agent's functions or polite interaction
| "OutOfScopeRequest" // User's request is clearly outside the agent's defined capabilities
| "Unknown"; // Intent could not be determined with confidence
Açıklama
Bu TypeScript kodu, IntentCategory adlı özel bir tür oluşturur. Bu liste, temsilcimizin anlayabileceği her olası işlemi veya "amacı" tanımlayan katı bir listedir. Bu, olası sonsuz sayıda kullanıcı ifadesini ("Ne görüyorsun?", "Resimde ne var?") temiz ve tahmin edilebilir bir komut grubuna dönüştürdüğü için çok önemli bir ilk adımdır. Sınıflandırıcımızın amacı, tüm kullanıcı sorgularını bu belirli kategorilerden biriyle eşleştirmektir.
2. Adım
Yapay zekamızın doğru kararlar verebilmesi için kendi yeteneklerini ve sınırlamalarını bilmesi gerekir. Bu bilgileri ayrıntılı bir metin bloğu olarak sunacağız.
👉 İşlem: REPLACE ME PART 2: add AGENT_CAPABILITIES_AND_LIMITATIONS here yer tutucusunu aşağıdaki kodla değiştirin:
Aşağıdaki kodu değiştirin: // REPLACE ME PART 2: add AGENT_CAPABILITIES_AND_LIMITATIONS here:
👉 Aşağıdaki kodu kullanarak
const AGENT_CAPABILITIES_AND_LIMITATIONS = `
**Core Capabilities (What the Agent CAN DO):**
* **Image Analysis:**
* DescribeImage: Provide a general description of the current image.
* AskAboutImage: Answer a specific question about the visual content of the current image (e.g., "Is there a dog?", "What color is the car?").
* ReadTextInImage: Read any text found in the current image.
* IdentifyColorsInImage: Identify the dominant colors of the current image.
* **Image Input Control:**
* TakePicture: Capture an image using the currently active camera stream.
* StartCamera: Activate the camera (e.g., "use camera", "take another picture").
* SelectImage: Allow the user to choose an image file from their device.
* **Voice & Audio Control:**
* StopSpeaking: Stop the current text-to-speech output.
* **Preference Management:**
* SetDescriptionDetailed: Make future image descriptions more detailed.
* SetDescriptionConcise: Make future image descriptions less detailed or concise.
* **General Interaction:**
* GeneralInquiry: Handle conversational phrases (e.g., "hello", "thank you") or questions about its own capabilities (e.g., "what can you do?", "help").
**Limitations (What the Agent CANNOT DO and should be classified as OutOfScopeRequest):**
* Cannot generate or create new images.
* Cannot edit or modify existing images (e.g., "remove background," "make the car blue").
* Cannot analyze video files or live video beyond capturing a single frame.
* Cannot provide general knowledge or answer questions unrelated to the provided image's visual content (e.g., "What's the weather?", "Who is the president?", "Tell me a joke", "What time is it?").
* Cannot perform mathematical calculations or complex data analysis.
* Cannot translate languages as a primary function.
* Cannot remember information from past images or vastly different previous queries in the same session.
* Cannot control other device settings or applications.
* Cannot perform web searches.
`;
Bu neden önemli?
Bu metin, kullanıcıların okuması için değil, yapay zeka modelimiz için hazırlanmıştır. Dil modeline (LLM) doğru kararlar vermesi için gereken bağlamı sağlamak amacıyla bu "iş açıklamasını" doğrudan istemimize (bir sonraki adımda) aktaracağız. Bu bağlam olmadan, büyük dil modeli "hava nasıl?" sorgusunu AskAboutImage olarak yanlış sınıflandırabilir. Bu bağlam sayesinde, hava durumunun resimde görsel bir öğe olmadığını bilir ve bunu kapsam dışı olarak doğru şekilde sınıflandırır.
3. Adım
Şimdi, sınıflandırmayı gerçekleştirmek için Gemini modelinin uygulayacağı talimatların tamamını yazacağız.
👉 İşlem: // REPLACE ME PART 3 - classifyIntentPrompt simgesini aşağıdaki kodla değiştirin:
aşağıdaki kodla
const classifyIntentPrompt = ai.definePrompt({
name: 'classifyIntentPrompt',
input: { schema: ClassifyIntentInputSchema },
output: { schema: ClassifyIntentOutputSchema },
prompt: `You are classifying the user's intent for ClarityCam, a voice-controlled AI application focused on image analysis.
Analyze the user query: '{userQuery}'.
First, understand ClarityCam's capabilities and limitations:
${AGENT_CAPABILITIES_AND_LIMITATIONS}
Now, classify the user's PRIMARY intent into ONE of the following categories:
* **DescribeImage**: User wants a general description of the current image.
* **AskAboutImage**: User is asking a specific question directly related to the visual content of the current image.
* **ReadTextInImage**: User wants any text read from the current image.
* **IdentifyColorsInImage**: User wants the dominant colors of the current image.
* **TakePicture**: User wants to capture an image using an active camera.
* **StartCamera**: User wants to activate the camera.
* **SelectImage**: User wants to choose an image file.
* **StopSpeaking**: User wants the current text-to-speech output to stop.
* **SetDescriptionDetailed**: User wants future image descriptions to be more detailed.
* **SetDescriptionConcise**: User wants future image descriptions to be less detailed.
* **GeneralInquiry**: The query is a simple conversational filler (e.g., "hello", "thanks"), a polite closing, or a direct question about the agent's functions (e.g., "what can you do?", "how does this work?", "help").
* **OutOfScopeRequest**: The query asks the agent to perform an action clearly listed under its "Limitations" or otherwise demonstrably outside its defined image analysis and control functions. Examples: "Tell me a joke," "What's the weather in London?", "Generate an image of a cat," "Can you edit my photo to make it brighter?", "Send this image to my friends","Translate 'hello' to Spanish."
Output ONLY the category name.
If the query is ambiguous but seems generally related to polite interaction or asking about the agent itself, prefer 'GeneralInquiry'.
If the query is clearly asking for something the agent CANNOT do, use 'OutOfScopeRequest'.
If truly unclassifiable even with these guidelines, use 'Unknown'.`,
config: {
temperature: 0.05, // Very low temperature for highly deterministic classification
}
});
İstem, sihrin gerçekleştiği yerdir. Bu, sınıflandırıcımızın "beynidir". Yapay zekaya rolünü söyler, gerekli bağlamı sağlar ve istenen çıktıyı tanımlar. Şu önemli istem mühendisliği tekniklerine dikkat edin:
- Rol yapma: Net bir görev belirlemek için "Şunu sınıflandırıyorsun..." ile başlar.
- Bağlam Ekleme:
AGENT_CAPABILITIES_AND_LIMITATIONSdeğişkenini isteme dinamik olarak ekler. - Katı Çıkış Biçimlendirmesi: "YALNIZCA kategori adını çıkış olarak ver" talimatı, kodumuzda kolayca kullanabileceğimiz temiz ve tahmin edilebilir bir yanıt almak için çok önemlidir.
- Düşük sıcaklık: Sınıflandırma için yaratıcı değil, belirleyici ve mantıklı yanıtlar istiyoruz. Sıcaklığı çok düşük bir değere (0,05) ayarlamak modelin son derece odaklanmış ve tutarlı olmasını sağlar.
4. adım: Uygulamayı yapay zeka akışına bağlayın
Son olarak, yeni yapay zeka sınıflandırıcımızı ana uygulama dosyasından çağıralım.
👉 İşlem: ~/src/app/page.tsx dosyanıza gidin. processVoiceCommand işlevinin içinde // REPLACE ME PART 1: add classificationResult ifadesini aşağıdakilerle değiştirin:
const classificationResult = await classifyIntentFlow({ userQuery: commandToProcess });
intent = classificationResult.intent as IntentCategory;
Bu kod, ön uç uygulamanız ile arka uç yapay zeka mantığınız arasındaki önemli köprüdür. Kullanıcının sesli komutunu (commandToProcess) alıp yeni oluşturduğunuz classifyIntentFlow'ye gönderir ve yapay zekanın sınıflandırılmış amacı döndürmesini bekler.
Niyet değişkeni artık temiz ve yapılandırılmış bir komut (ör. DescribeImage) içeriyor. Bu sonuç, uygulamanın mantığını yönlendirmek ve bir sonraki adımda hangi işlemin yapılacağına karar vermek için sonraki switch ifadesinde kullanılır. Bu, yapay zekanın "düşünme" sürecinin uygulamanın "yapma" sürecine dönüştürülme şeklidir.
Kullanıcı arayüzünü başlatma
Uygulamamızı iş başında görme zamanı geldi. Geliştirme sunucusunu başlatalım.
👉 Terminalinizde aşağıdaki komutu çalıştırın: npm run dev Not: npm run dev komutunu çalıştırmadan önce npm install komutunu çalıştırmanız gerekebilir.
Bir süre sonra aşağıdakine benzer bir çıkış görürsünüz. Bu, sunucunun başarıyla çalıştığı anlamına gelir:
▲ Next.js 15.2.3 (Turbopack)
- Local: http://localhost:9003
- Network: http://10.88.0.4:9003
- Environments: .env
✓ Starting...
✓ Ready in 1512ms
○ Compiling / ...
✓ Compiled / in 26.6s
Şimdi uygulamayı tarayıcınızda açmak için yerel URL'yi (http://localhost:9003) tıklayın.
SightGuide kullanıcı arayüzünü görmeniz gerekir. Şimdilik düğmeler herhangi bir mantığa bağlı olmadığından bunları tıkladığınızda hiçbir şey olmaz. Bu aşamada tam olarak bunu bekliyoruz. Bir sonraki bölümde bunları nasıl kullanacağımızı göreceğiz.
Kullanıcı arayüzünü gördüğünüz için terminalinize dönün ve devam etmeden önce geliştirme sunucusunu durdurmak için Ctrl + C tuşuna basın.
5. Kullanıcı Girişini Anlama - Kusurlu Sorgu Kontrolü
Eksik Sorgu Kontrolü Ekleme
1. Bölüm: İstem Tanımlama ("Ne")
Öncelikle yapay zekamızın talimatlarını tanımlayalım. İstem, yapay zeka çağrımızın "tarifi"dir. Modele tam olarak ne yapmasını istediğimizi söyler.
👉 İşlem: Entegre geliştirme ortamınızda ~/src/ai/flows/check_typo/ konumuna gidin.
Aşağıdaki kodu değiştirin: // REPLACE ME PART 1: add prompt here:
👉 Aşağıdaki kodu kullanarak
const prompt = ai.definePrompt({
name: 'checkTypoPrompt',
input: {
schema: CheckTypoInputSchema,
},
output: {
schema: CheckTypoOutputSchema,
},
prompt: `You are a helpful AI assistant that checks user text for typos and suggests corrections.
- If you find typos, respond with the corrected text.
- If there are no typos, or if you are unsure about a correction, respond with the original text unchanged.
User text: {text}
Corrected text:
`,
});
Bu kod bloğu, checkTypoPrompt adlı yapay zekamız için yeniden kullanılabilir bir şablon tanımlar. Giriş ve çıkış şemaları, bu görev için veri sözleşmesini tanımlar. Bu sayede hatalar önlenir ve sistemimiz öngörülebilir hale gelir.
2. Bölüm: Akışı Oluşturma ("Nasıl")
Artık "tarifimiz" (istem) olduğuna göre, bunu gerçekten yürütebilecek bir işlev oluşturmamız gerekiyor. Genkit'te buna akış denir. Akış, istemimizi, uygulamamızın geri kalanının kolayca çağırabileceği yürütülebilir bir işlevle sarmalar.
👉 İşlem: Aynı ~/src/ai/flows/check_typo/ dosyasında aşağıdaki kodu değiştirin: // REPLACE ME PART 2: add flow here:
👉 Aşağıdaki kodu kullanarak
const checkTypoFlow = ai.defineFlow<
typeof CheckTypoInputSchema,
typeof CheckTypoOutputSchema
>(
{
name: 'checkTypoFlow',
inputSchema: CheckTypoInputSchema,
outputSchema: CheckTypoOutputSchema,
},
async input => {
const {output} = await prompt(input);
return output!;
}
);
3. Bölüm: Yazım Hatası Denetleyicisi'ni kullanma
Yapay zeka akışımız tamamlandığına göre artık bunu uygulamamızın ana mantığına entegre edebiliriz. Kullanıcı komutunu aldıktan hemen sonra metni temizleyerek başka bir işleme tabi tutacağız.
👉İşlem: ~/src/app/ai/flows/check-typo.ts bölümüne gidin ve export async function checkTypo işlevini bulun. Dönüş ifadesinin yorumunu kaldırın:
return; yerine return checkTypoFlow(input);
👉İşlem: ~/src/app/page.tsx bölümüne gidin ve processVoiceCommand işlevini bulun. Aşağıdaki kodu değiştirin: REPLACE ME PART 2: add typoResult here:
👉 Aşağıdaki kodu kullanarak
const typoResult = await checkTypo({ text: rawCommand });
if (typoResult && typoResult.correctedText && typoResult.correctedText.trim().length > 0) {
const originalTrimmedLower = rawCommand.trim().toLowerCase();
const correctedTrimmedLower = typoResult.correctedText.trim().toLowerCase();
if (correctedTrimmedLower !== originalTrimmedLower) {
commandToProcess = typoResult.correctedText;
typoCorrectionAnnouncement = `I think you said: ${commandToProcess}. `;
}
}
Bu değişiklikle birlikte, her kullanıcı komutu için daha sağlam bir veri işleme hattı oluşturduk.
Sesli Komut Akışı (Yalnızca Okuma, İşlem Gerekmez)
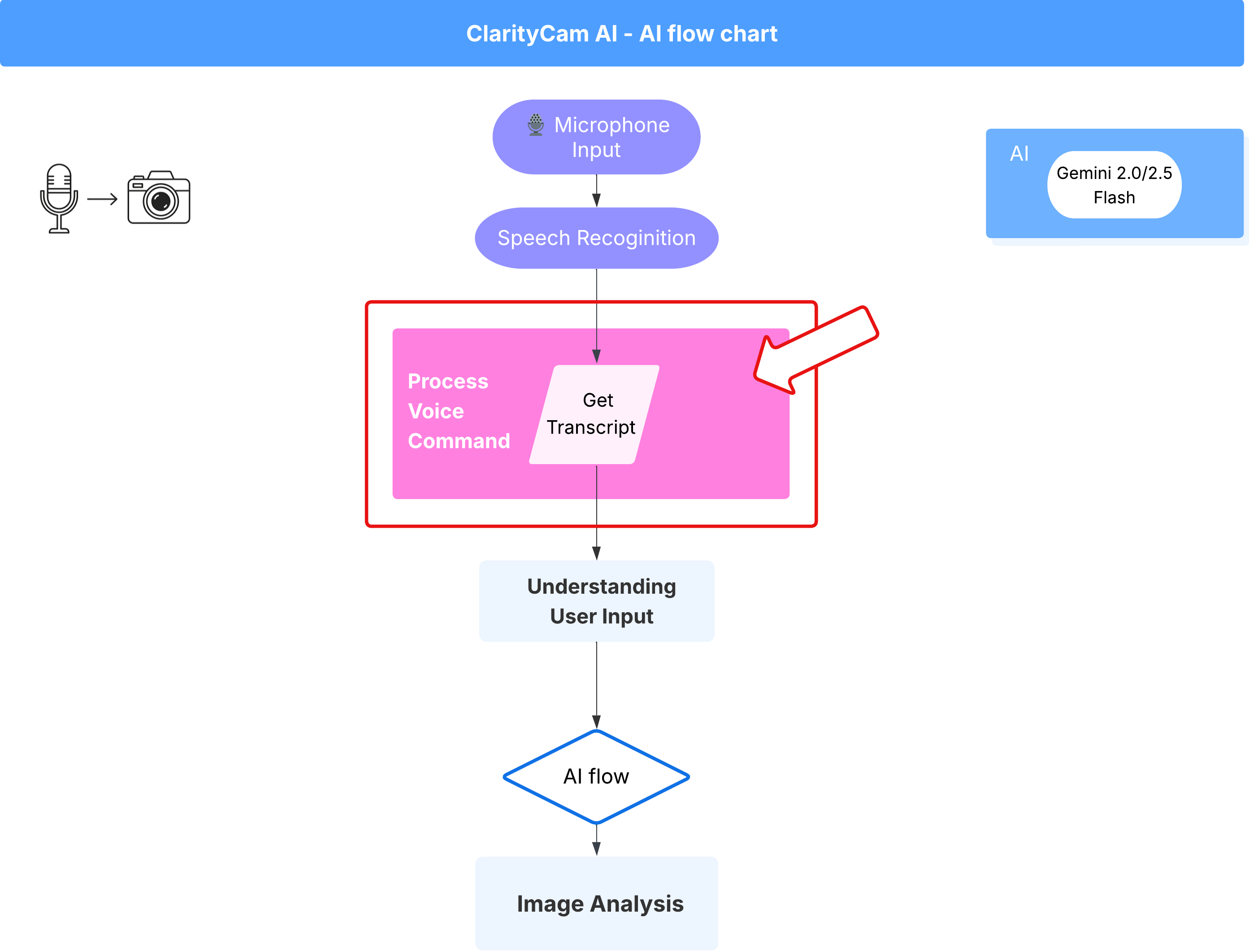
Temel "anlama" bileşenlerimizi (Yazım Denetleyici ve Amaç Sınıflandırıcı) ele aldığımıza göre, bunların uygulamanın ana ses işleme mantığına nasıl uyduğunu görelim.
Her şey kullanıcının konuşmasıyla başlar. Tarayıcının Web Speech API'si konuşmayı dinler ve kullanıcı konuşmayı bitirdiğinde duyduklarının metin transkriptini sağlar. Bu işlem aşağıdaki kodla gerçekleştirilir.
👉Salt Okuma: ~/src/app/page.tsx ve handleResult fonksiyonuna gidin. Aşağıdaki kodu bulun:
for (let i = event.resultIndex; i < event.results.length; ++i) {
if (event.results[i].isFinal) {
finalTranscript += event.results[i][0].transcript;
}
}
if (finalTranscript) {
console.log("Final Transcript:", finalTranscript);
processVoiceCommand(finalTranscript);
}
Yazım Hatası Düzeltme Özelliğimizi Test Etme
Şimdi de işin eğlenceli kısmına geçelim. Yeni yazım hatası düzeltme özelliğimizin hem mükemmel hem de kusurlu sesli komutları nasıl işlediğine bakalım.
Uygulamayı Başlatma
Öncelikle geliştirme sunucusunu tekrar çalıştıralım. Terminalinizde şu komutu çalıştırın: npm run dev
Uygulamayı açma
Sunucu hazır olduğunda tarayıcınızı açıp yerel adrese (ör. http://localhost:9003) gidin.
Sesli komutları etkinleştirme
Start Listening düğmesini tıklayın. Tarayıcınız büyük olasılıkla mikrofonunuzu kullanmak için izin isteyecektir. Lütfen İzin ver'i tıklayın.
Kusurlu Bir Komutu Test Etme
Şimdi de yapay zekamızın bunu anlayıp anlamayacağını görmek için biraz hatalı bir komut verelim. Mikrofonunuza net bir şekilde konuşun:
"Picture take of me" (Benim fotoğrafımı çek)
Sonucu Gözlemleme
Tüm sihir burada gerçekleşir! "Fotoğrafımı çek" dediğinizde uygulama kamerayı doğru şekilde etkinleştirmelidir. checkTypo akışı, ifadenizi arka planda "take a picture" (fotoğraf çek) olarak düzeltir. classifyIntentFlow ise düzeltilmiş komutu anlar.
Bu, yazım hatası düzeltme özelliğimizin mükemmel şekilde çalıştığını, uygulamayı çok daha sağlam ve kullanıcı dostu hale getirdiğini doğruluyor. İşiniz bittiğinde fotoğraf çekerek kamerayı durdurabilir veya terminalinizde sunucuyu durdurabilirsiniz (Ctrl + C).
6. Yapay Zeka Destekli Resim Analizi - Resmi Açıklama
Temsilcimiz artık istekleri anlayabildiğine göre ona göz verme zamanı. Bu bölümde, tüm görüntü analizlerinden sorumlu temel bileşen olan Vision Agent'ımızın özelliklerini geliştireceğiz. En önemli özelliği olan görüntü açıklamasıyla başlayıp ardından metin okuma özelliğini ekleyeceğiz.
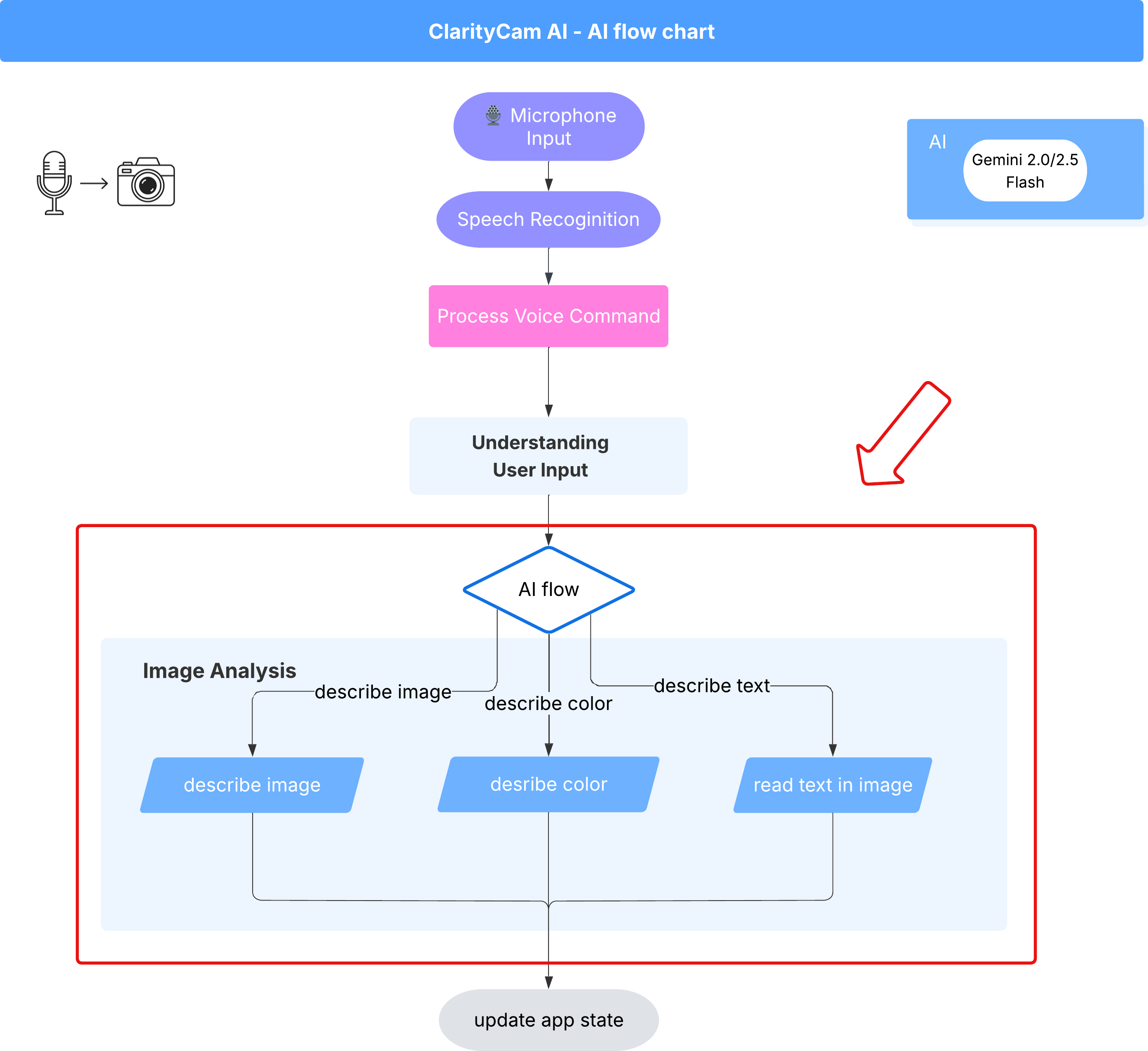
1. Özellik: Resim Açıklama
Bu, aracının birincil işlevidir. Yalnızca statik bir açıklama oluşturmayacağız. Ayrıntı düzeyini kullanıcı tercihlerine göre ayarlayabilen dinamik bir akış oluşturacağız. Bu, Natively Adaptive Interface (NAI) felsefesinin önemli bir parçasıdır.
👉 İşlem: Cloud Shell IDE'nizde ~/src/ai/flows/describe_image/ dosyasına gidin ve aşağıdaki kodun yorum işaretini kaldırın.
1. adım: Dinamik istem şablonu oluşturma
İlk olarak, aldığı girişe göre talimatlarını değiştirebilen gelişmiş bir istem şablonu oluşturacağız.
Aşağıdaki kodun yorum işaretini kaldırın.
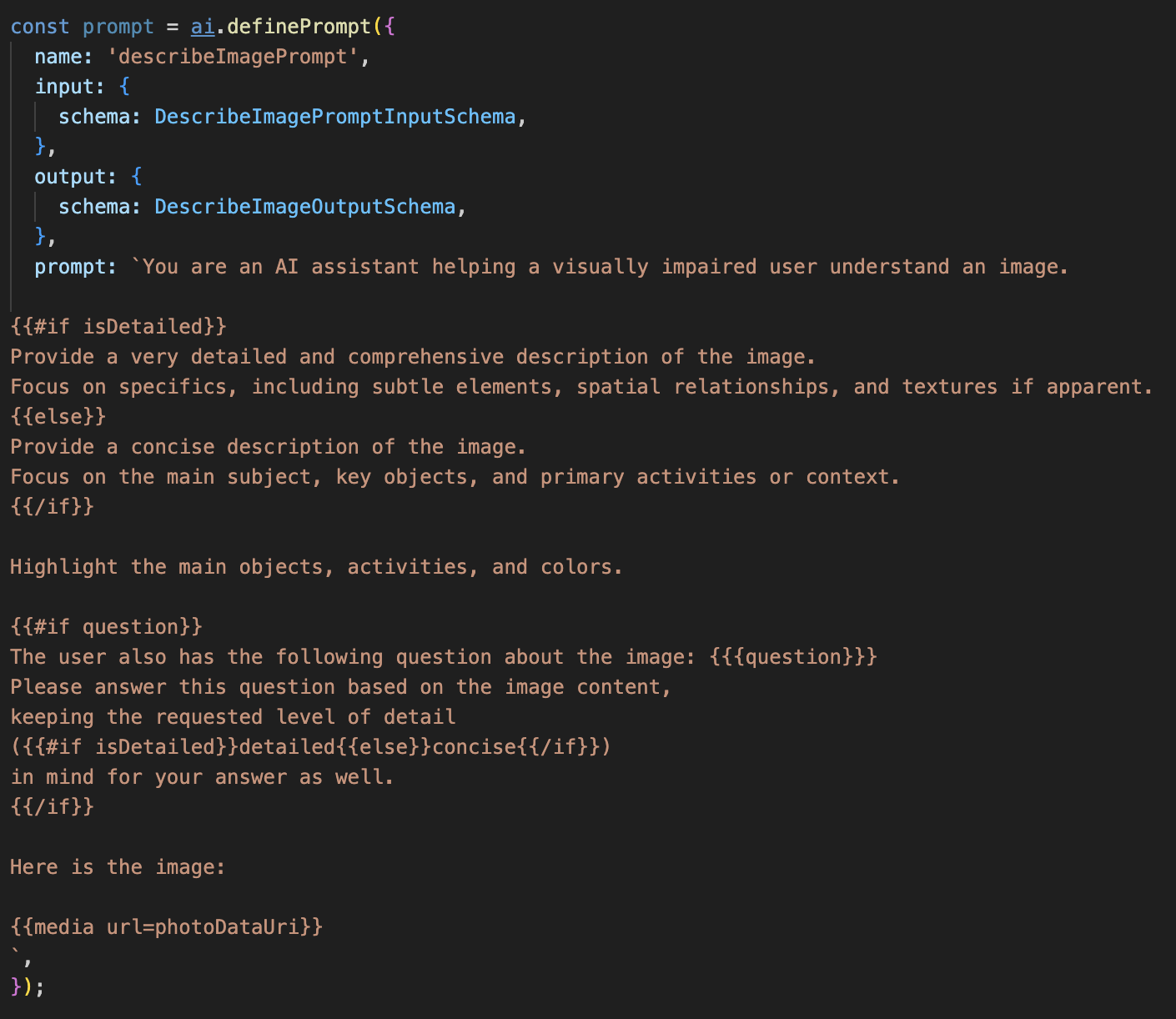
Bu kod, Dot-Mustache adlı bir şablon dilini kullanan bir dize değişkeni (istem) tanımlar. Bu sayede, koşullu mantığı doğrudan istemimize yerleştirebiliriz.
{#if isDetailed}...{else}...{/if}: Bu, koşullu bir bloktur. Bu isteme gönderdiğimiz giriş verileri isDetailed: true özelliğini içeriyorsa yapay zeka, "çok ayrıntılı" talimat grubunu alır. Aksi takdirde, "özlü" talimatları alır. Aracımız, kullanıcı tercihine bu şekilde uyum sağlar.
{#if question}...{/if}: Bu blok yalnızca giriş verilerimizde soru özelliği varsa eklenir. Bu sayede hem genel açıklamalar hem de belirli sorular için aynı güçlü istemi kullanabiliriz.
{media url=photoDataUri}: Bu, çok formatlı modelin analiz etmesi için görsel verilerini doğrudan isteme yerleştirmeye yönelik özel Genkit söz dizimidir.
2. adım: Akıllı akışı oluşturma
Ardından, istemi ve yeni şablonumuzu kullanacak akışı tanımlıyoruz. Bu akış, kullanıcının tercihini şablonumuzun anlayabileceği bir Boole değerine çevirmek için biraz mantık içerir.
👉 İşlem: Cloud Shell IDE'nizde, aynı ~/src/ai/flows/describe_image/ dosyasında aşağıdaki kodu değiştirin. // REPLACE ME PART 1: add flow here
👉 Aşağıdaki kodla:
// Define the prompt using the template from Step 1
const prompt = ai.definePrompt({
name: 'describeImagePrompt',
input: { schema: DescribeImagePromptInputSchema },
output: { schema: DescribeImageOutputSchema },
prompt: promptTemplate,
});
// Define the flow
const describeImageFlow = ai.defineFlow<
typeof DescribeImageInputSchema,
typeof DescribeImageOutputSchema
>(
{
name: 'describeImageFlow',
inputSchema: DescribeImageInputSchema,
outputSchema: DescribeImageOutputSchema,
},
async (pageInput) => {
const preference = pageInput.detailPreference || "concise";
// Prepare the input for the prompt, including the new boolean flag
const promptInputData = {
...pageInput,
isDetailed: preference === "detailed",
};
const { output } = await prompt(promptInputData);
return output!;
}
);
Bu, ön uç ile yapay zeka istemi arasında akıllı bir aracı görevi görür.
- Uygulamamızdan
pageInputalır.Bu, kullanıcının tercihini dize olarak içerir (ör."detailed"). - Ardından,
promptInputDataadlı yeni bir nesne oluşturur. - En önemli satır
isDetailed: preference === "detailed"'dır. Bu satır, tercih dizesine göretrueveyafalseBoole değeri oluşturma gibi önemli bir işlevi yerine getirir. - Son olarak, bu geliştirilmiş verilerle
promptişlevini çağırır. 1. adımdaki istem şablonu artık yapay zekaya gönderilen talimatları dinamik olarak değiştirmek içinisDetailedboole değerini kullanabilir.
3. adım: Ön ucu bağlama
Şimdi bu akışı page.tsx dosyasındaki kullanıcı arayüzümüzden tetikleyelim.
👉İşlem: ~/src/app/ai/flows/describe-image.ts bölümüne gidin ve export async function describeImage işlevini bulun. Dönüş ifadesinin yorumunu kaldırın:
return; yerine return describeImageFlow(input);
👉İşlem: ~/src/app/page.tsx içinde handleAnalyze işlevini bulun, // REPLACE ME PART 2: DESCRIBE IMAGE kodunu şu kodla değiştirin:
👉 aşağıdaki kodla:
case "description":
result = await describeImage({
photoDataUri,
question,
detailPreference: descriptionPreference
});
outputText = question ? `Answer: ${result.description}` : `Description: ${result.description}`;
break;
Kullanıcının amacı açıklama almak olduğunda bu kod yürütülür. Bu işlev, describeImage akışımızı çağırır, resim verilerini ve en önemlisi descriptionPreference React bileşenimizdeki durum değişkenini iletir. Bu, kullanıcının kullanıcı arayüzünde depolanan tercihini, davranışını buna göre uyarlayacak yapay zeka akışına doğrudan bağlayan son parçadır.
Görüntü Açıklaması Özelliğini Test Etme
Fotoğraf çekmekten yapay zekanın gördüklerini dinlemeye kadar, resim açıklaması işlevimizin nasıl çalıştığını görelim.
Uygulamayı Başlatma
Öncelikle geliştirme sunucusunu tekrar çalıştıralım. 👉 Terminalinizde aşağıdaki komutu çalıştırın: npm run dev Not: npm run dev komutunu çalıştırmadan önce npm install komutunu çalıştırmanız gerekebilir.
Uygulamayı açma
Sunucu hazır olduğunda tarayıcınızı açıp yerel adrese (ör. http://localhost:9003) gidin.
Kamerayı etkinleştirme
Dinlemeye Başla düğmesini tıklayın ve istenirse mikrofona erişim izni verin. Ardından ilk komutunuzu söyleyin:
"Fotoğraf çek"
Uygulama, cihazınızın kamerasını etkinleştirir. Artık ekranda canlı video feed'ini görmeniz gerekir.
Fotoğrafı Çekme
Kamerayı etkinleştirin ve tarif etmek istediğiniz öğeye doğru tutun. Şimdi, resmi çekmek için komutu ikinci kez söyleyin:
"Fotoğraf çek"
Canlı video, az önce çektiğiniz statik fotoğrafla değiştirilir.
Açıklama isteme
Ekranda yeni fotoğrafınız varken son komutu verin:
"Resmi açıkla"
Sonucu Dinleme
Uygulama, işleme durumunu gösterir. Ardından, resminizin yapay zeka tarafından üretilmiş açıklamasını dinleyebilirsiniz. Metin, "Durum ve Sonuç" kartında da gösterilir.
İşlemi tamamladığınızda fotoğraf çekerek veya terminalinizde sunucuyu durdurarak (Ctrl + C) kamerayı kapatabilirsiniz.
7. Yapay Zeka Destekli Resim Analizi - Metin Açıklama (OCR)
Ardından, Vision Aracımıza optik karakter tanıma (OCR) özelliği ekleyeceğiz. Bu sayede, herhangi bir resimdeki metni okuyabilir.
👉 İşlem: IDE'nizde ~/src/ai/flows/read-text-in-image/ bölümüne gidin ve aşağıdaki kodun yorum işaretini kaldırın:
👉 İşlem: Entegre geliştirme ortamınızda, aynı ~/src/ai/flows/read-text-in-image/ dosyasında // REPLACE ME: Creating Prmopt
👉 Aşağıdaki kodla:
const readTextInImageFlow = ai.defineFlow<
typeof ReadTextInImageInputSchema,
typeof ReadTextInImageOutputSchema
>(
{
name: 'readTextInImageFlow',
inputSchema: ReadTextInImageInputSchema,
outputSchema: ReadTextInImageOutputSchema,
},
async input => {
const {output} = await prompt(input);
return output!;
}
);
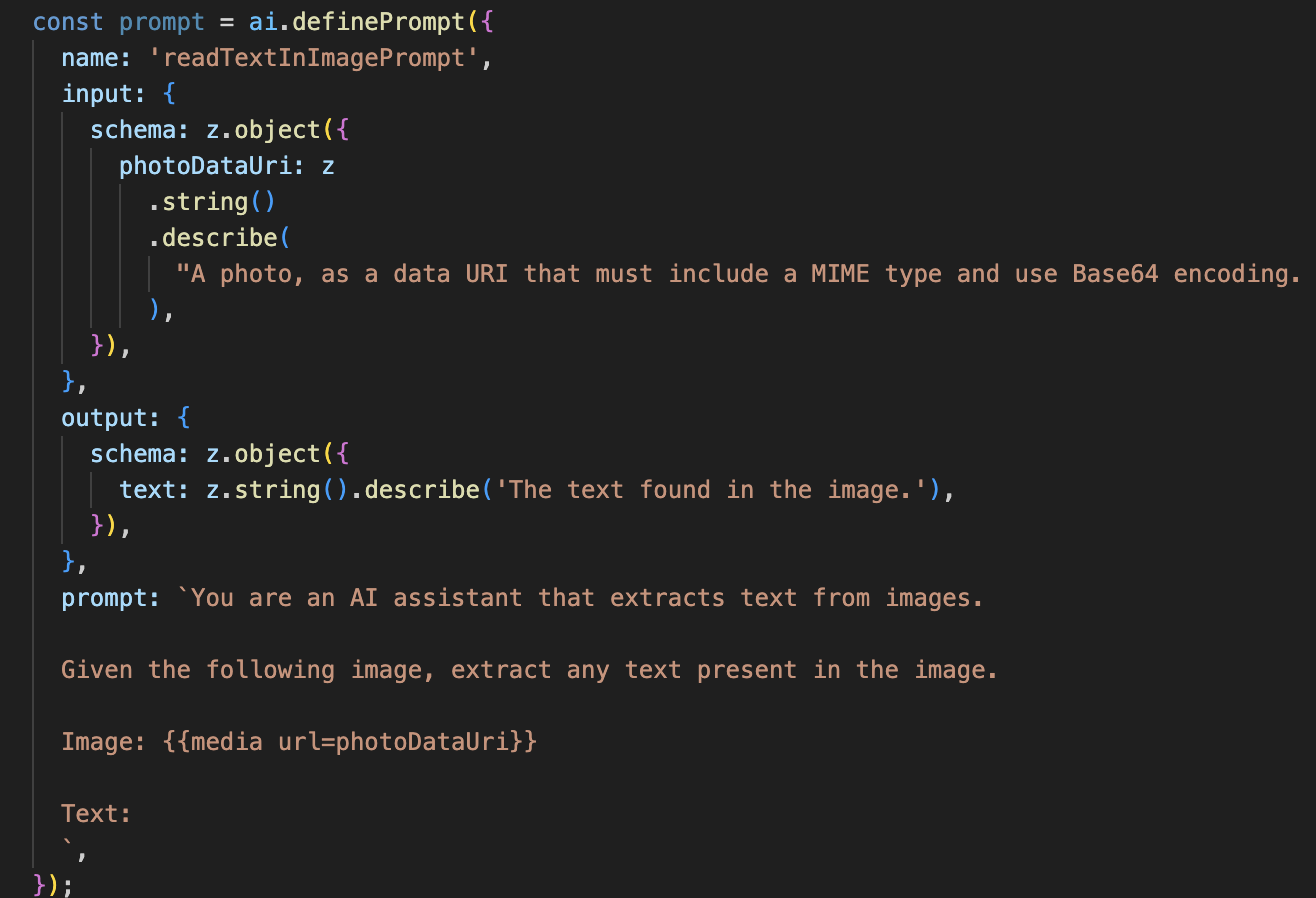
Bu yapay zeka akışı çok daha basittir ve belirli işler için odaklanılmış araçlar kullanma ilkesini vurgular.
- İstem: Açıklama istemimizden farklı olarak bu istem statik ve son derece spesifiktir. Tek görevi, yapay zekaya OCR motoru gibi davranması talimatını vermektir: "Resimde bulunan tüm metinleri ayıkla."
- Şemalar: Giriş ve çıkış şemaları da basittir. Giriş olarak bir resim beklenir ve çıkış olarak tek bir metin dizesi döndürülür.
OCR için ön ucu bağlama
Son olarak, page.tsx'daki bu yeni özelliği bağlayalım.
👉İşlem: ~/src/app/ai/flows/read-text-in-image.ts bölümüne gidin ve export async function readTextInImage işlevini bulun. Dönüş ifadesinin yorumunu kaldırın:
return; yerine return readTextInImageFlow(input);
👉 İşlem: ~/src/app/page.tsx içinde handleAnalyze işlevini ve switch ifadesini bulun.
REPLACE ME PART 3: READ TEXT sütununu değiştirin
aşağıdaki kodla:
case "text":
result = await readTextInImage({ photoDataUri });
outputText = result.text ? `Text Found: ${result.text}` : "No text found.";
break;
Kullanıcının amacı ReadTextInImage olduğunda bu kod tetiklenir. Basit readTextInImage akışımızı çağırır. result.text ? ... : ... satırı, çıktıyı temiz bir şekilde işlemek için kullanılır. Yapay zeka, resimde herhangi bir metin bulamazsa kullanıcıya faydalı bir mesaj gösterir.
Metni Okuma (OCR) Özelliğini Test Etme
Metin okuma özelliğini test etmek için aşağıdaki adımları uygulayın. Kameranızı net metin içeren bir nesneye doğru tutmayı unutmayın.
- Uygulamayı
npm run devile çalıştırın ve tarayıcınızda açın. - Dinlemeye Başla'yı tıklayın ve istendiğinde mikrofon erişimine izin verin.
- Kamerayı etkinleştirin. “Fotoğraf çek” komutunu söyleyin. Canlı video feed'inin ekranda görünmesi gerekir.
- Fotoğrafı çekin. Kameranızı okumak istediğiniz metne doğru tutun ve komutu tekrar söyleyin: "Fotoğraf çek". Video, statik bir fotoğrafla değiştirilir.
- Metni isteyin. Fotoğraf çekildikten sonra son komutu verin: "Resimdeki metin nedir?"
- Sonucu kontrol etme Uygulama, bir süre sonra fotoğrafı analiz eder ve algılanan metni sesli okur. Metin bulamazsa sizi bilgilendirir.
Bu, güçlü OCR özelliğinin çalıştığını doğrular. İşiniz bittiğinde Ctrl + C ile sunucuyu durdurun.
8. Gelişmiş Yapay Zeka İyileştirmeleri - Yalnızca Okuma ✨
İyi bir yapay zeka ajanı talimatları uygulayabilir. Mükemmel bir yapay zeka aracısı sezgisel, güvenilir ve faydalı olmalıdır. Bu bölümde, aracımızın yeteneklerini geliştiren üç gelişmiş iyileştirmeye odaklanacağız.
Şunların nasıl yapılacağını inceleyeceğiz:
Add Context & Memoryile doğal ve sohbet tarzında ek sorular sorun.Reduce Hallucinationdaha güvenilir bir aracı oluşturmak için kullanılır.Make the Agent Proactivedaha erişilebilir ve kullanıcı dostu bir deneyim sunmak içinAdd preference settingsimgesini tıklayarak resim açıklamasını özelleştirin.
Geliştirme 1: Bağlam ve Bellek
Doğal bir sohbet, birbirinden bağımsız komutlar dizisi değildir. Sohbet akıcı olmalıdır. Bir kullanıcı "Resimde ne var?" diye sorarsa ve temsilci "Kırmızı bir araba" diye yanıt verirse kullanıcı, "Araba" kelimesini tekrar kullanmadan "Ne renk?" diye sorabilir. Temsilcimizin bu bağlamı anlamak için kısa süreli hafızaya ihtiyacı var.
Nasıl Uyguladık? (Özet)
Bu özelliği, describeImage akışımıza ekledik. Bu bölümde, söz konusu kalıbın işleyiş şekli özetlenmektedir. describeImage işlevimizi page.tsx dosyasından çağırdığımızda, bu işleve görüşme geçmişini iletiyoruz.
👉 Code Showcase (page.tsx'dan):
const result = await describeImage({
photoDataUri,
question: commandToProcess,
detailPreference: descriptionPreference,
previousUserQueryOnImage: lastUserQuery ?? undefined,
previousAIResponseOnImage: lastAIResponse ?? undefined,
});
previousUserQueryOnImagevepreviousAIResponseOnImage: Bu iki özellik, aracımızın kısa süreli hafızasıdır. Son etkileşimi yapay zekaya ileterek, belirsiz veya referans içeren takip sorularını anlaması için gereken bağlamı sağlıyoruz.- Uyarlanabilir İstem: Bu bağlam, describe_image akışımızdaki istem tarafından kullanılır. İstem, yeni bir yanıt oluştururken önceki görüşmeyi dikkate alacak şekilde tasarlanmıştır. Böylece temsilci akıllıca yanıt verebilir.
Geliştirme 2: Halüsinasyonları Azaltma
Yapay zeka, gerçekleri uydurduğunda veya sahip olmadığı yeteneklere sahip olduğunu iddia ettiğinde "halüsinasyon" görüyor demektir. Kullanıcıların güvenini kazanmak için aracımızın kendi sınırlarını bilmesi ve kapsam dışı istekleri nazikçe reddedebilmesi çok önemlidir.
Nasıl Uyguladık? (Özet)
Halüsinasyonu önlemenin en etkili yolu, modele net sınırlar vermektir. Bu, Niyet Sınıflandırıcımızı oluştururken elde ettiğimiz bir sonuçtur.
👉 Code Showcase (intent-classifier akışından):
// Define Agent Capabilities and Limitations for the prompt
const AGENT_CAPABILITIES_AND_LIMITATIONS = `
**Core Capabilities (What the Agent CAN DO):**
* **Image Analysis:**
* DescribeImage: Provide a general description of the current image...
**Limitations (What the Agent CANNOT DO...):**
* Cannot generate or create new images.
* Cannot provide general knowledge or answer questions unrelated to the image...
* Cannot perform web searches.
`;
Bu sabit, sınıflandırma isteminde yapay zekaya sağladığımız bir "iş açıklaması" görevi görür.
- Modeli Temellendirme: Yapay zekaya ne yapamayacağını açıkça söyleyerek onu gerçeklikle "temellendiririz". "Hava nasıl?" gibi bir sorgu gördüğünde bunu sınırlamalar listesiyle güvenle eşleştirebilir ve amacı OutOfScopeRequest olarak sınıflandırabilir.
- Güven Oluşturma: "Bu konuda yardımcı olamıyorum" diyebilen bir temsilci, tahmin etmeye çalışıp yanlış cevap veren bir temsilciye kıyasla çok daha güvenilirdir. Bu, güvenli ve güvenilir yapay zeka tasarımının temel ilkesidir. `
Geliştirme 3: Proaktif bir temsilci oluşturma
Erişilebilirliğe öncelik veren bir uygulamada görsel ipuçlarına güvenemeyiz. Kullanıcılar dinleme modunu etkinleştirdiğinde, temsilcinin hazır olduğunu ve komut beklediğini anında ve görsel olmayan bir şekilde onaylamaları gerekir. Bu önemli geri bildirimi sağlamak için artık proaktif bir giriş ekleyeceğiz.
1. adım: İlk dinlemeyi izlemek için bir durum ekleyin
Öncelikle, kullanıcının oturumu sırasında "Start Listening" düğmesine ilk kez basıp basmadığını bilmemiz gerekir.
👉 ~/src/app/page.tsx içinde, ClarityCam bileşeninizin üst kısmına yakın bir yerde aşağıdaki yeni durum değişkenini göreceksiniz.
export default function ClarityCam() {
// ... other state variables
const [descriptionPreference, setDescriptionPreference] = useState<DescriptionPreference>("concise");
// Add this new line
const [isFirstListen, setIsFirstListen] = useState(true);
// ... rest of the component
}
Yeni bir durum değişkeni olan isFirstListen'yı kullanıma sunduk ve true olarak başlattık. Tek seferlik karşılama mesajımızı tetiklemek için bu işareti kullanırız.
2. adım: toggleListening işlevini güncelleyin
Şimdi de karşılama mesajımızı çalmak için mikrofonu işleyen işlevi değiştirelim.
👉 ~/src/app/page.tsx içinde toggleListening işlevini bulun ve aşağıdaki if bloğunu inceleyin.
const toggleListening = useCallback(() => {
// ... existing logic to setup speech recognition
if (isListening || isAttemptingStart) {
// ... existing logic to stop listening
} else {
stopSpeaking(); // Stop any ongoing TTS
// Add this new block
if (isFirstListen) {
setIsFirstListen(false);
const introMessage = "Hello! I am ClarityCam, your AI assistant. I'm now listening. You can ask me to 'describe the image', 'read text', 'take a picture', or ask questions about what's in an image.";
speakText(introMessage);
} else {
speakText("Listening..."); // Optional: provide feedback on subsequent clicks
}
// ... rest of the logic to start listening
}
}, [/*...existing dependencies...*/, isFirstListen]); // Don't forget to add isFirstListen to the dependency array!
- İşareti Kontrol Edin: if (isFirstListen) bloğu, bunun ilk etkinleştirme olup olmadığını kontrol eder.
- Tekrarı Önleme: Blok içinde yapılan ilk işlem, setIsFirstListen(false) işlevini çağırmaktır. Bu sayede, tanıtım mesajı oturum başına yalnızca bir kez oynatılır.
- Rehberlik sağlama: introMessage, mümkün olduğunca faydalı olacak şekilde dikkatle hazırlanır. Kullanıcıyı selamlar, temsilciyi adıyla tanımlar, etkin olduğunu onaylar ("Artık dinliyorum") ve kullanabileceği sesli komutlarla ilgili net örnekler verir.
- İşitsel geri bildirim: Son olarak, speakText(introMessage) bu önemli bilgiyi sunarak kullanıcının ekrana bakmasını gerektirmeden anında güvence ve rehberlik sağlar.
Geliştirme 4: Kullanıcı Tercihlerine Uyarlanma (Özet)
Gerçekten akıllı bir temsilci yalnızca yanıt vermekle kalmaz, kullanıcının ihtiyaçlarını öğrenir ve bunlara uyum sağlar. Geliştirdiğimiz en güçlü özelliklerden biri, kullanıcının "Daha ayrıntılı ol" gibi komutlarla resim açıklamalarının ayrıntı düzeyini anında değiştirebilmesidir.
Nasıl Uyguladık? (Özet) Bu özellik, describeImage akışımız için oluşturduğumuz dinamik istem tarafından desteklenir. Kullanıcının tercihine göre yapay zekaya gönderilen talimatları değiştirmek için koşullu mantık kullanır.
👉 Code Showcase (describe_image içindeki promptTemplate):
const settingPreferenceTemplate = `
{#if isDetailed}
Provide a very detailed and comprehensive description of the image. Focus on specifics, including subtle elements, spatial relationships, and textures if apparent.
{else}
Provide a concise description of the image. Focus on the main subject, key objects, and primary activities or context.
{/if}
Highlight the main objects, activities, and colors.
...
`;
- Koşullu Mantık:
{#if isDetailed}...{else}...{/if}bloğu önemlidir. describeImageFlow, ön uçtan detailPreference'ı aldığında isDetailed adlı bir Boole değeri (doğru veya yanlış) oluşturur. - Uyarlanabilir Talimatlar: Bu boole işareti, yapay zeka modelinin hangi talimat grubunu alacağını belirler. isDetailed doğruysa modele son derece açıklayıcı olması talimatı verilir. Yanlışsa kısa olması istenir.
- Kullanıcı Kontrolü: Bu kalıp, kullanıcının sesli komutunu (ör. "açıklamaları kısa yap", SetDescriptionConcise amacı olarak sınıflandırılır) doğrudan yapay zekanın davranışındaki temel bir değişikliğe bağlayarak aracının gerçekten duyarlı ve kişiselleştirilmiş olmasını sağlar.
9. Buluta dağıtım
Google Cloud Build kullanarak Docker görüntüsü oluşturma
gcloud builds submit . --tag gcr.io/$PROJECT_ID/accessibilityai-nextjs-app:latest
accessibilityai-nextjs-app, önerilen bir resim adıdır.- Kendisi Derleme kaynağı olarak geçerli dizini (
accessibilityAI/) kullanır.
Görüntüyü Google Cloud Run'a dağıtma
- API anahtarlarınızın ve diğer gizli anahtarlarınızın Secret Manager'da hazır olduğundan emin olun. Örneğin,
GOOGLE_GENAI_API_KEY.
Bu YOUR_ACTUAL_GOOGLE_AI_KEY_VALUE kısmını gerçek Gemini API anahtarınızın değeriyle değiştirin.
echo "YOUR_ACTUAL_GOOGLE_AI_KEY_VALUE" | gcloud secrets create GOOGLE_GENAI_API_KEY --data-file=- --project=YOUR_PROJECT_ID
Cloud Run hizmetinizin çalışma zamanı hizmet hesabına (ör. PROJECT_NUMBER-compute@developer.gserviceaccount.com veya özel bir hesap) bu gizli için "Secret Manager Secret Accessor" rolünü verin.
- Dağıtma komutu:
gcloud run deploy accessibilityai-app-service \
--image gcr.io/$PROJECT_ID/accessibilityai-nextjs-app:latest \
--platform managed \
--region us-central1 \
--allow-unauthenticated \
--port 3000 \
--set-secrets=GOOGLE_GENAI_API_KEY=GOOGLE_GENAI_API_KEY:latest \
--set-env-vars NODE_ENV="production"