
1. Giới thiệu
Trong hướng dẫn này, bạn sẽ tạo ClarityCam, một tác nhân AI điều khiển bằng giọng nói, không cần dùng tay, có thể nhìn thấy thế giới và giải thích cho bạn. Mặc dù ClarityCam được thiết kế với khả năng hỗ trợ tiếp cận làm cốt lõi (cung cấp một công cụ mạnh mẽ cho người dùng khiếm thị và thị lực kém), nhưng những nguyên tắc mà bạn sẽ học được là điều cần thiết để tạo ra bất kỳ ứng dụng thoại đa năng, hiện đại nào.

Dự án này được xây dựng dựa trên một triết lý thiết kế mạnh mẽ có tên là Giao diện thích ứng tự nhiên (NAI). Thay vì coi khả năng hỗ trợ tiếp cận là một yếu tố bổ sung, NAI coi đây là nền tảng. Với phương pháp này, tác nhân AI là giao diện, thích ứng với nhiều người dùng, xử lý dữ liệu đầu vào đa phương thức như giọng nói và thị giác, đồng thời chủ động hướng dẫn mọi người dựa trên nhu cầu riêng của họ.
Tạo tác nhân AI đầu tiên bằng NAI:

Khi kết thúc phiên đào tạo này, bạn sẽ có thể:
- Thiết kế với chế độ Hỗ trợ tiếp cận là chế độ mặc định: Áp dụng các nguyên tắc về Giao diện thích ứng tự nhiên (NAI) để tạo ra các hệ thống AI mang lại trải nghiệm tương đương cho tất cả người dùng.
- Phân loại ý định của người dùng: Xây dựng một bộ phân loại ý định mạnh mẽ, có thể dịch các lệnh bằng ngôn ngữ tự nhiên thành các hành động có cấu trúc cho tác nhân của bạn.
- Duy trì bối cảnh đàm thoại: Triển khai bộ nhớ ngắn hạn để cho phép trợ lý ảo hiểu các câu hỏi tiếp theo và lệnh tham chiếu (ví dụ: "Màu gì?").
- Soạn câu lệnh hiệu quả: Soạn câu lệnh tập trung, giàu ngữ cảnh cho một mô hình đa phương thức như Gemini để đảm bảo phân tích hình ảnh chính xác và đáng tin cậy.
- Xử lý sự mơ hồ và hướng dẫn người dùng: Thiết kế quy trình xử lý lỗi một cách hiệu quả cho các yêu cầu nằm ngoài phạm vi và chủ động hướng dẫn người dùng để xây dựng lòng tin và sự tự tin.
- Điều phối hệ thống đa tác nhân: Cấu trúc ứng dụng của bạn bằng cách sử dụng một tập hợp các tác nhân chuyên biệt cộng tác với nhau để xử lý các tác vụ phức tạp như xử lý giọng nói, phân tích và tổng hợp lời nói.
2. Thiết kế cấp cao
Về cơ bản, ClarityCam được thiết kế để người dùng có thể sử dụng một cách đơn giản nhưng lại được hỗ trợ bởi một hệ thống phức tạp gồm các tác nhân AI cộng tác. Hãy phân tích kiến trúc này.

Trải nghiệm người dùng
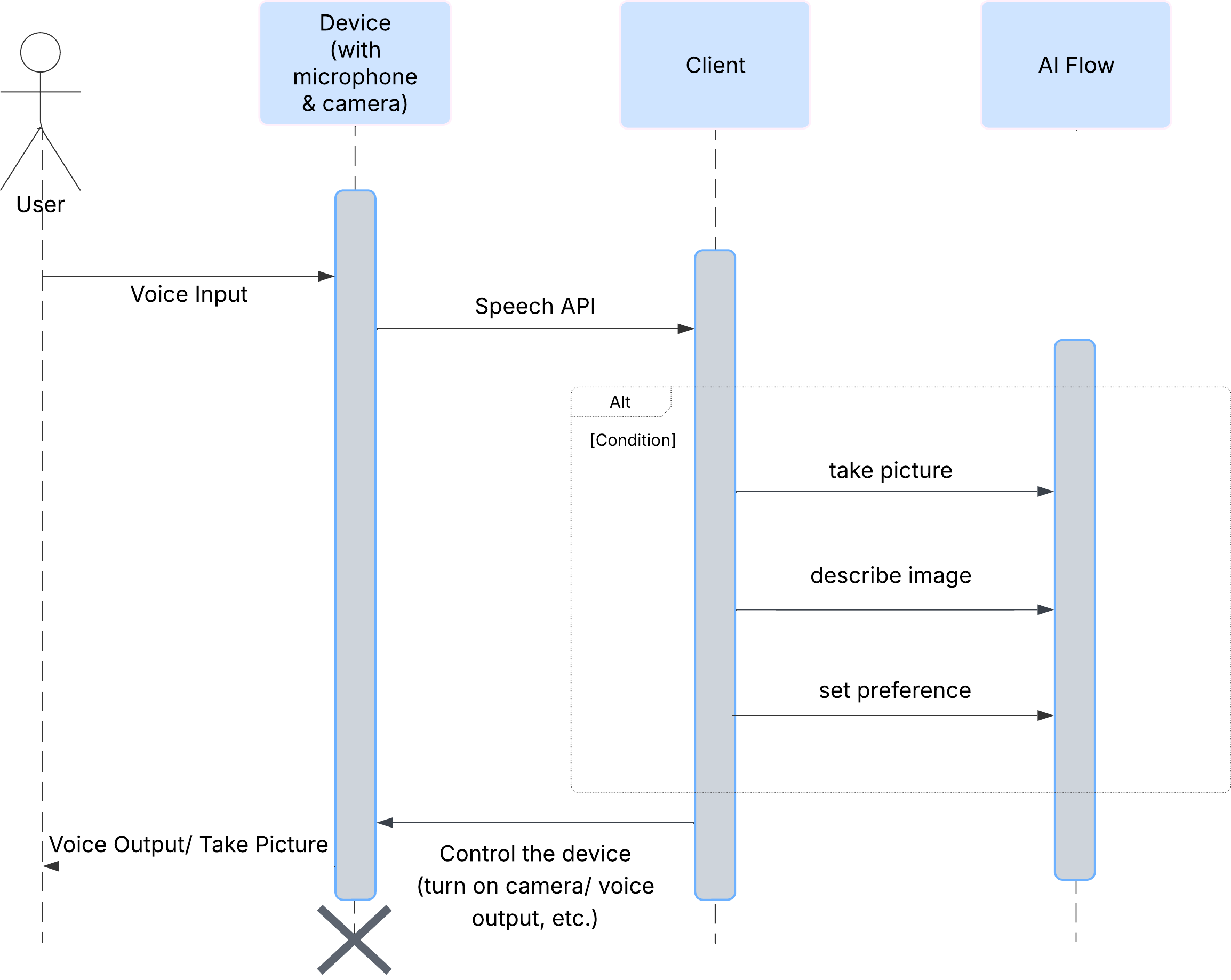
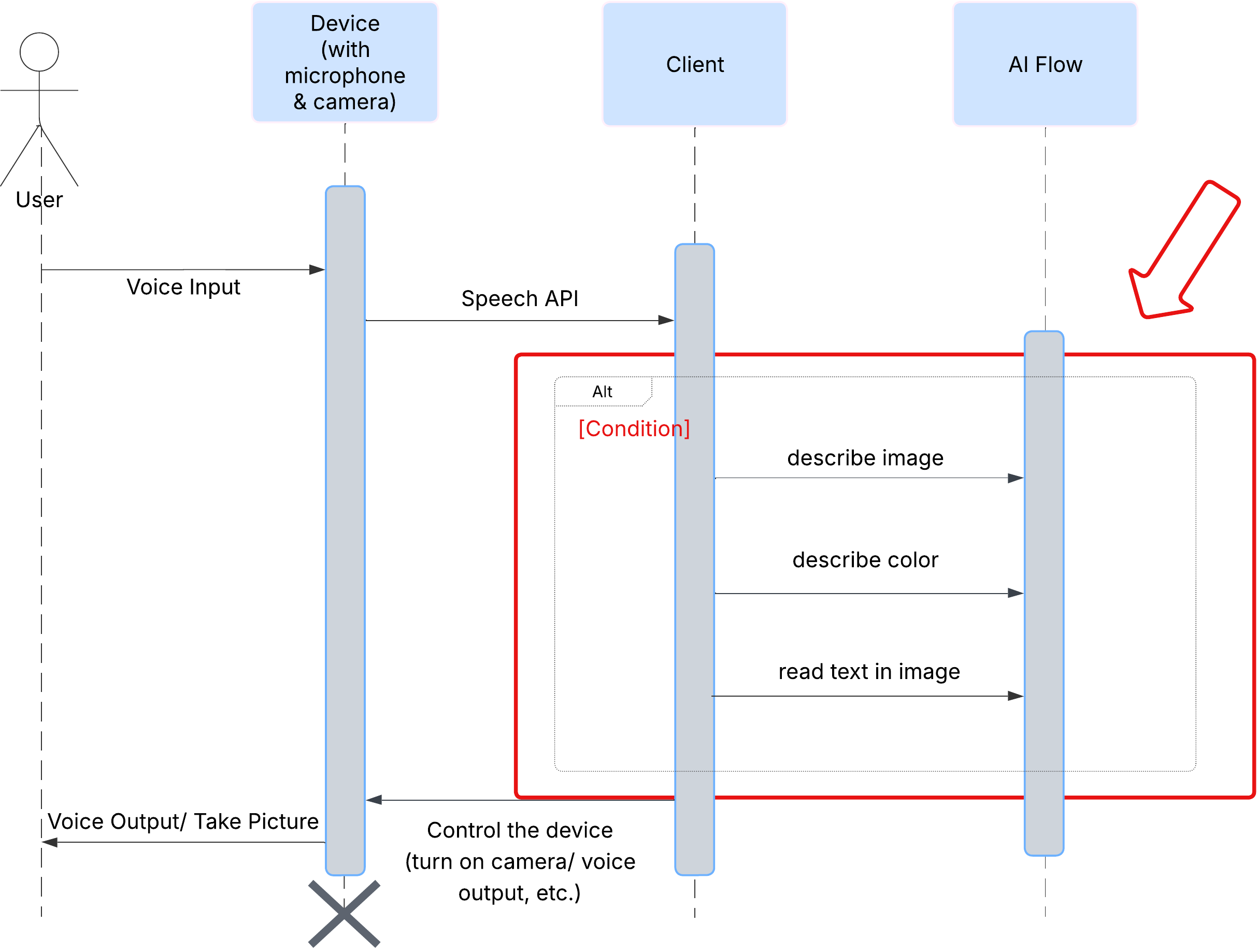
Trước tiên, hãy xem cách người dùng tương tác với ClarityCam. Toàn bộ trải nghiệm đều là đàm thoại và không cần dùng tay. Người dùng nói một lệnh và trợ lý sẽ phản hồi bằng một nội dung mô tả hoặc hành động bằng lời nói. Sơ đồ trình tự này cho thấy một quy trình tương tác điển hình, từ lệnh thoại ban đầu của người dùng cho đến phản hồi âm thanh cuối cùng từ thiết bị.
Cấu trúc tác nhân AI
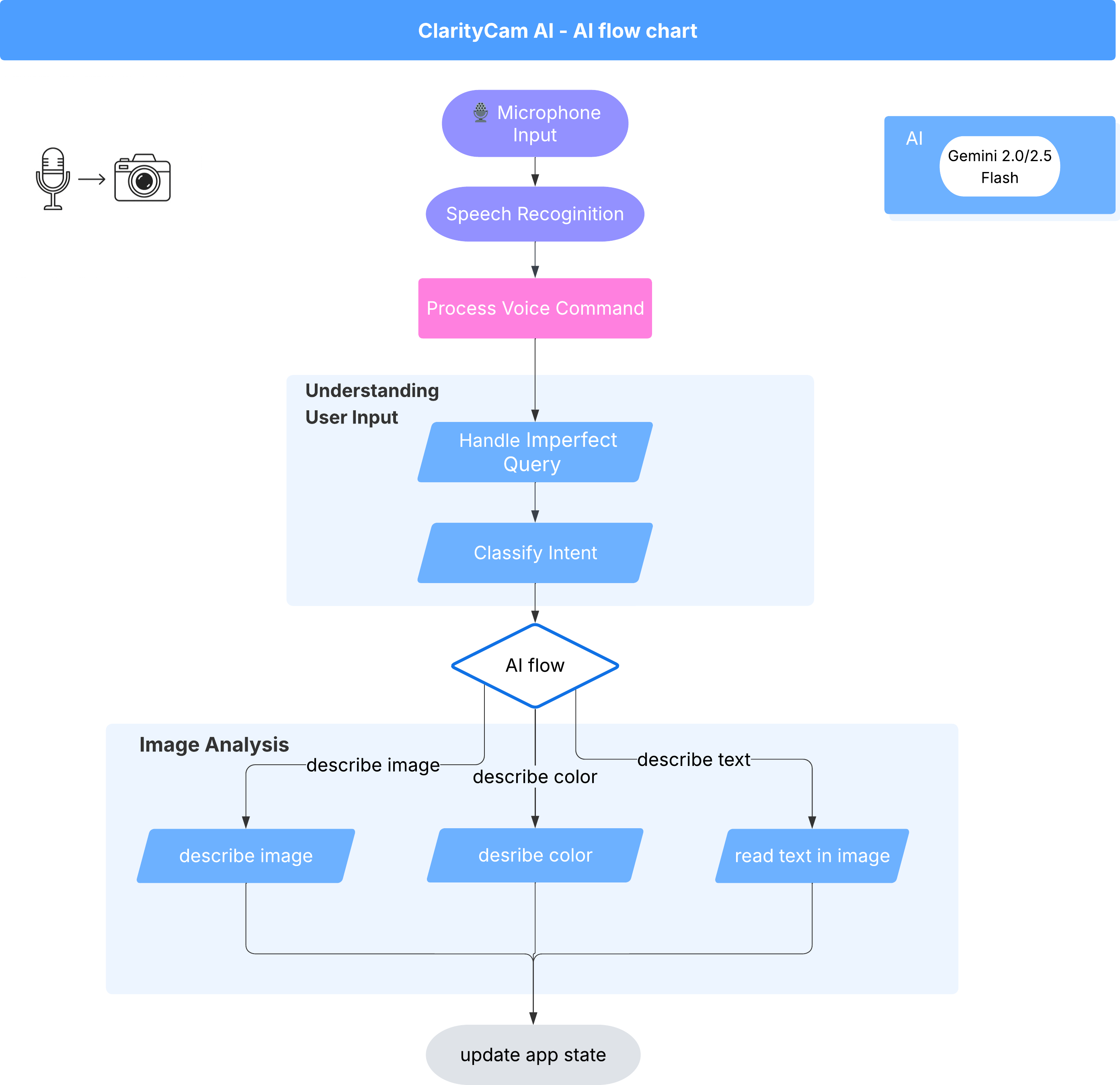
Bên dưới giao diện, một hệ thống đa tác nhân hoạt động đồng bộ để mang đến trải nghiệm sống động. Khi nhận được một lệnh, một tác nhân Orchestrator trung tâm sẽ uỷ quyền các tác vụ cho những tác nhân chuyên biệt chịu trách nhiệm hiểu ý định, phân tích hình ảnh và tạo phản hồi. Sơ đồ quy trình AI này cung cấp nghiên cứu chuyên sâu về cách các tác nhân này cộng tác. Chúng ta sẽ triển khai cấu trúc này trong các phần sau.
Tìm hiểu nhanh về tệp dự án
Trước khi bắt đầu viết mã, hãy làm quen với cấu trúc tệp của dự án. Có vẻ như có rất nhiều tệp, nhưng bạn chỉ cần tập trung vào 2 khu vực cụ thể trong toàn bộ hướng dẫn này!
Sau đây là bản đồ đơn giản về dự án của chúng tôi.
accessibilityAI/src/
├── 📁 app/
│ ├── layout.tsx # An overall page shell (you can ignore this).
│ └── page.tsx # ⬅️ MODIFY THIS: The main user interface for our app.
│
├── 📁 ai/
│ ├── 📁flows # ⬅️ MODIFY THIS: The core AI logic and server functions.
│ └── intent-classifier.ts # ⬅️ MODIFY THIS: Where we'll edit our AI prompts.
| └── ai-instance.ts
| └── dev.ts
│
├── 📁 components/ # Contains pre-built UI components (ignore this).
│
├── 📁 hooks/
│
├── 📁 lib/
│
└── 📁 types/
Bộ phần mềm cơ sở
Hệ thống của chúng tôi được xây dựng trên một bộ phần mềm cơ sở hiện đại, có khả năng mở rộng, kết hợp các dịch vụ đám mây mạnh mẽ và các mô hình AI tiên tiến. Sau đây là các thành phần chính mà chúng ta sẽ sử dụng:
- Google Cloud Platform (GCP): Cung cấp cơ sở hạ tầng không máy chủ cho các tác nhân của chúng tôi.
- Cloud Run: Triển khai các tác nhân riêng lẻ của chúng tôi dưới dạng các dịch vụ vi mô có thể mở rộng và nằm trong vùng chứa.
- Artifact Registry: Lưu trữ và quản lý các hình ảnh Docker cho các tác nhân của chúng tôi một cách an toàn.
- Secret Manager: Xử lý an toàn các thông tin xác thực nhạy cảm và khoá API.
- Mô hình ngôn ngữ lớn (LLM): Đóng vai trò là "bộ não" của hệ thống.
- Các mô hình Gemini của Google: Chúng tôi sử dụng các chức năng đa phương thức mạnh mẽ của họ Gemini cho mọi việc, từ phân loại ý định của người dùng đến phân tích nội dung hình ảnh và cung cấp nội dung mô tả thông minh.
3. Thiết lập và điều kiện tiên quyết
Bật tài khoản thanh toán Để chạy lớp học lập trình này, bạn cần có một tài khoản thanh toán có sẵn một số tín dụng. Hãy sử dụng tín dụng trong biểu ngữ ở đầu lớp học lập trình này để bắt đầu. Nếu đã kết nối với một tài khoản thanh toán, bạn có thể bỏ qua bước này.
Tạo dự án GCP mới
- Truy cập vào Google Cloud Console rồi tạo một dự án mới.
- Truy cập vào Google Cloud Console rồi tạo một dự án mới.
- Mở bảng điều khiển bên trái, nhấp vào
Billing, kiểm tra xem tài khoản thanh toán có được liên kết với tài khoản GCP này hay không.
Nếu bạn thấy trang này, hãy kiểm tra manage billing account, chọn Google Cloud Trial One và liên kết với trang này.
Tạo khoá Gemini API
Trước khi có thể bảo mật khoá, bạn cần phải có khoá.
- Truy cập Google AI Studio : https://aistudio.google.com/
- Đăng nhập bằng Tài khoản Google của bạn.
- Nhấp vào nút "Lấy khoá API". Nút này thường nằm ở ngăn điều hướng bên trái hoặc ở góc trên cùng bên phải.
- Trong hộp thoại "Khoá API", hãy nhấp vào "Tạo khoá API trong dự án mới".
- Một khoá API mới sẽ được tạo cho bạn. Sao chép ngay khoá này và tạm thời lưu trữ ở một nơi an toàn (chẳng hạn như trình quản lý mật khẩu hoặc ghi chú bảo mật). Đây là giá trị bạn sẽ sử dụng trong các bước tiếp theo.
Quy trình phát triển cục bộ (Thử nghiệm trên máy của bạn)
Bạn cần có thể chạy npm run dev và ứng dụng của bạn phải hoạt động. Đây là lúc .env phát huy tác dụng.
- Thêm Khoá API vào tệp: Tạo một tệp mới có tên là
.envrồi thêm dòng sau vào tệp này.
Nhớ thay thế YOUR_API_KEY_HERE bằng khoá mà bạn nhận được từ AI Studio và đã lưu vào .env:
GOOGLE_GENAI_API_KEY="YOUR_API_KEY_HERE"
[Không bắt buộc] Thiết lập IDE và môi trường
Trong hướng dẫn này, bạn có thể làm việc trong một môi trường phát triển quen thuộc như VS Code hoặc IntelliJ bằng thiết bị đầu cuối cục bộ. Tuy nhiên, bạn nên sử dụng Google Cloud Shell để đảm bảo môi trường được chuẩn hoá và định cấu hình sẵn.
Các bước sau đây được viết cho ngữ cảnh Cloud Shell. Nếu bạn chọn sử dụng môi trường cục bộ, vui lòng đảm bảo bạn đã cài đặt và định cấu hình đúng git, nvm, npm và gcloud.
Làm việc trên Cloud Shell Editor
👉Nhấp vào Kích hoạt Cloud Shell ở đầu bảng điều khiển Cloud (Đây là biểu tượng có hình dạng thiết bị đầu cuối ở đầu ngăn Cloud Shell), 
👉Nhấp vào nút "Mở Trình chỉnh sửa" (nút này trông giống như một thư mục đang mở có cây bút chì). Thao tác này sẽ mở Trình chỉnh sửa mã Cloud Shell trong cửa sổ. Bạn sẽ thấy một trình khám phá tệp ở bên trái. 
👉Nhấp vào nút Đăng nhập bằng mã trên đám mây trong thanh trạng thái ở dưới cùng như minh hoạ. Uỷ quyền cho trình bổ trợ theo hướng dẫn. Nếu bạn thấy Cloud Code – no project (Cloud Code – không có dự án) trong thanh trạng thái, hãy chọn mục đó rồi chọn "Select a Google Cloud Project" (Chọn một dự án trên Google Cloud) trong trình đơn thả xuống, sau đó chọn dự án cụ thể trên Google Cloud trong danh sách dự án mà bạn đã tạo. 
👉Mở cửa sổ dòng lệnh trong IDE trên đám mây, 
👉Trong thiết bị đầu cuối, hãy xác minh rằng bạn đã được xác thực và dự án được đặt thành mã dự án của bạn bằng lệnh sau:
gcloud auth list
👉 Sao chép dự án natively-accessible-interface trên GitHub:
git clone https://github.com/cuppibla/AccessibilityAgent.git
👉Và chạy để đảm bảo thay thế <YOUR_PROJECT_ID> bằng mã dự án của bạn (bạn có thể tìm thấy mã dự án trong bảng điều khiển Google Cloud, phần dự án, ❗️❗️đảm bảo không trộn lẫn project id VÀ project number❗️❗️):
echo <YOUR_PROJECT_ID> > ~/project_id.txt
gcloud config set project $(cat ~/project_id.txt)
👉Chạy lệnh sau để bật các Cloud APIs cần thiết của Google Cloud: (Lệnh này có thể mất khoảng 2 phút để chạy)
gcloud services enable compute.googleapis.com \
storage.googleapis.com \
run.googleapis.com \
artifactregistry.googleapis.com \
aiplatform.googleapis.com \
eventarc.googleapis.com \
sqladmin.googleapis.com \
secretmanager.googleapis.com \
cloudbuild.googleapis.com \
cloudresourcemanager.googleapis.com \
cloudfunctions.googleapis.com \
cloudaicompanion.googleapis.com
Quá trình này có thể mất vài phút.
Thiết lập quyền
👉Thiết lập quyền cho tài khoản dịch vụ. Trong thiết bị đầu cuối, hãy chạy :
gcloud config set project $(cat ~/project_id.txt)
export PROJECT_ID=$(gcloud config get project)
export SERVICE_ACCOUNT_NAME=$(gcloud compute project-info describe --format="value(defaultServiceAccount)")
echo "Here's your SERVICE_ACCOUNT_NAME $SERVICE_ACCOUNT_NAME"
Cấp quyền. Trong thiết bị đầu cuối, hãy chạy :
#Cloud Storage (Read/Write):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/storage.objectAdmin"
#Pub/Sub (Publish/Receive):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/pubsub.publisher"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/pubsub.subscriber"
#Cloud SQL (Read/Write):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/cloudsql.editor"
#Eventarc (Receive Events):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/iam.serviceAccountTokenCreator"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/eventarc.eventReceiver"
#Vertex AI (User):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/aiplatform.user"
#Secret Manager (Read):
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT_NAME" \
--role="roles/secretmanager.secretAccessor"
4. Tìm hiểu về hoạt động đầu vào của người dùng – Thuật toán phân loại ý định
Trước khi hành động, trước tiên, tác nhân AI của chúng tôi phải hiểu chính xác những gì người dùng muốn. Thông tin đầu vào trong thế giới thực thường lộn xộn – có thể mơ hồ, có lỗi chính tả hoặc sử dụng ngôn ngữ đàm thoại.
Trong phần này, chúng ta sẽ tạo các thành phần "lắng nghe" quan trọng để chuyển đổi hoạt động đầu vào thô của người dùng thành một lệnh rõ ràng và có thể thực hiện.
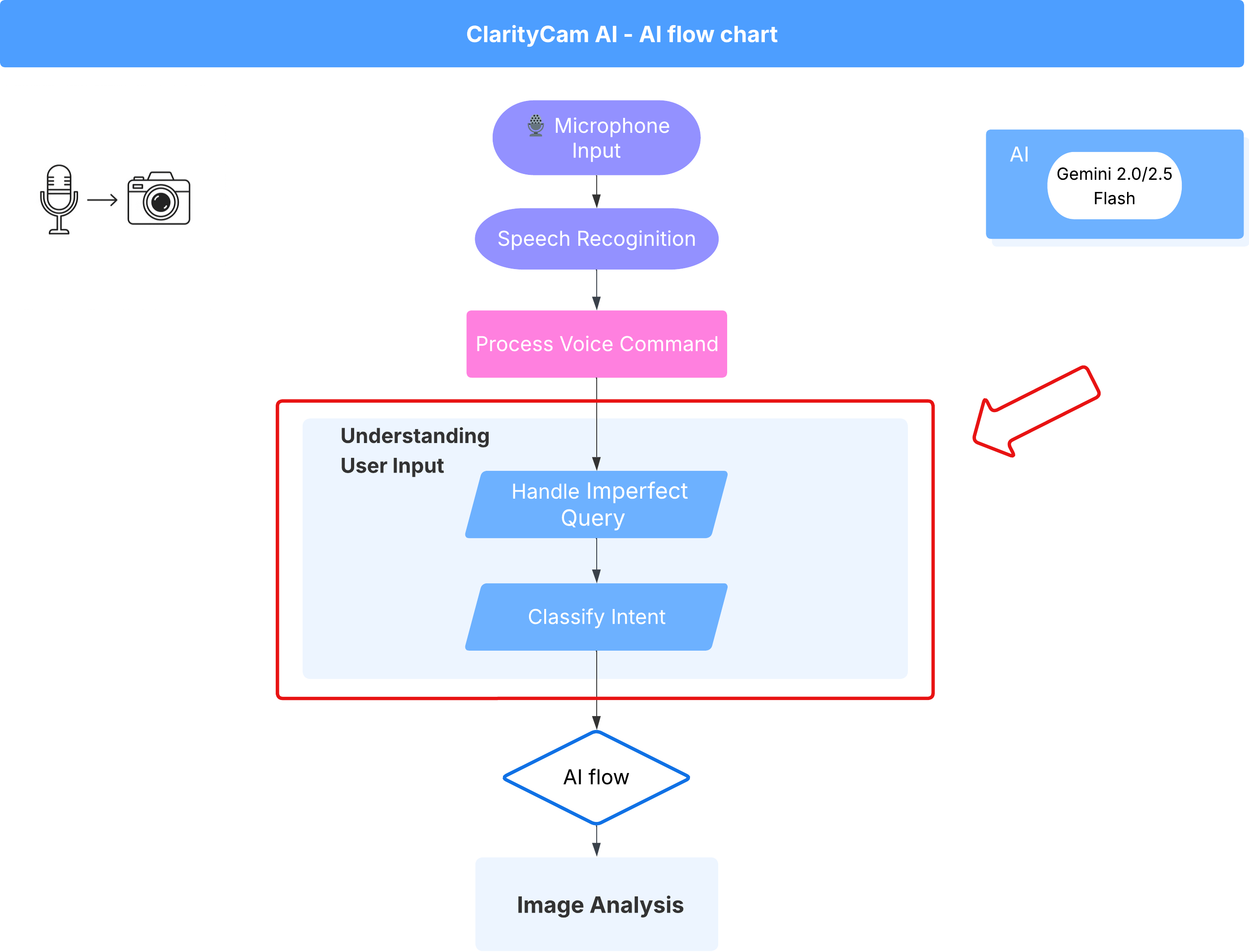
Thêm một Trình phân loại ý định
Bây giờ, chúng ta sẽ xác định logic AI hỗ trợ bộ phân loại.
👉 Hành động: Trong IDE Cloud Shell, hãy chuyển đến thư mục ~/src/ai/intent-classifier/
Bước 1: Xác định từ vựng của Trợ lý (IntentCategory)
Trước tiên, chúng ta cần tạo một danh sách cụ thể về mọi hành động có thể có mà tác nhân của chúng ta có thể thực hiện.
👉 Thao tác: Thay thế phần giữ chỗ // REPLACE ME PART 1: add IntentCategory here bằng đoạn mã sau:
👉 bằng mã bên dưới:
export type IntentCategory =
// Image Analysis Intents
| "DescribeImage"
| "AskAboutImage"
| "ReadTextInImage"
| "IdentifyColorsInImage"
// Control Intents
| "TakePicture"
| "StartCamera"
| "SelectImage"
| "StopSpeaking"
// Preference Intents
| "SetDescriptionDetailed"
| "SetDescriptionConcise"
// Fallback Intents
| "GeneralInquiry" // User has a general question about the agent's functions or polite interaction
| "OutOfScopeRequest" // User's request is clearly outside the agent's defined capabilities
| "Unknown"; // Intent could not be determined with confidence
Giải thích
Đoạn mã TypeScript này tạo một loại tuỳ chỉnh có tên là IntentCategory. Đây là một danh sách nghiêm ngặt xác định mọi hành động có thể có hoặc "ý định" mà tác nhân của chúng tôi có thể hiểu được. Đây là bước đầu tiên quan trọng vì nó chuyển đổi vô số cụm từ của người dùng ("cho tôi biết bạn thấy gì", "bức ảnh này có gì?") thành một tập hợp các lệnh rõ ràng và có thể dự đoán được. Mục tiêu của bộ phân loại là liên kết mọi cụm từ tìm kiếm của người dùng với một trong những danh mục cụ thể này.
Bước 2
Để đưa ra quyết định chính xác, AI của chúng tôi cần biết khả năng và hạn chế của chính mình. Chúng tôi sẽ cung cấp thông tin này dưới dạng một khối văn bản chi tiết.
👉 Hành động: Thay thế phần giữ chỗ REPLACE ME PART 2: add AGENT_CAPABILITIES_AND_LIMITATIONS here bằng đoạn mã sau:
Thay thế mã bên dưới: // REPLACE ME PART 2: add AGENT_CAPABILITIES_AND_LIMITATIONS here:
👉 bằng mã bên dưới
const AGENT_CAPABILITIES_AND_LIMITATIONS = `
**Core Capabilities (What the Agent CAN DO):**
* **Image Analysis:**
* DescribeImage: Provide a general description of the current image.
* AskAboutImage: Answer a specific question about the visual content of the current image (e.g., "Is there a dog?", "What color is the car?").
* ReadTextInImage: Read any text found in the current image.
* IdentifyColorsInImage: Identify the dominant colors of the current image.
* **Image Input Control:**
* TakePicture: Capture an image using the currently active camera stream.
* StartCamera: Activate the camera (e.g., "use camera", "take another picture").
* SelectImage: Allow the user to choose an image file from their device.
* **Voice & Audio Control:**
* StopSpeaking: Stop the current text-to-speech output.
* **Preference Management:**
* SetDescriptionDetailed: Make future image descriptions more detailed.
* SetDescriptionConcise: Make future image descriptions less detailed or concise.
* **General Interaction:**
* GeneralInquiry: Handle conversational phrases (e.g., "hello", "thank you") or questions about its own capabilities (e.g., "what can you do?", "help").
**Limitations (What the Agent CANNOT DO and should be classified as OutOfScopeRequest):**
* Cannot generate or create new images.
* Cannot edit or modify existing images (e.g., "remove background," "make the car blue").
* Cannot analyze video files or live video beyond capturing a single frame.
* Cannot provide general knowledge or answer questions unrelated to the provided image's visual content (e.g., "What's the weather?", "Who is the president?", "Tell me a joke", "What time is it?").
* Cannot perform mathematical calculations or complex data analysis.
* Cannot translate languages as a primary function.
* Cannot remember information from past images or vastly different previous queries in the same session.
* Cannot control other device settings or applications.
* Cannot perform web searches.
`;
Lý do yêu cầu này quan trọng:
Văn bản này không dành cho người dùng đọc mà dành cho mô hình AI của chúng tôi. Chúng ta sẽ đưa "nội dung mô tả công việc" này trực tiếp vào câu lệnh (trong bước tiếp theo) để cung cấp cho Mô hình ngôn ngữ lớn (LLM) ngữ cảnh cần thiết để đưa ra quyết định chính xác. Nếu không có bối cảnh này, LLM có thể phân loại nhầm "thời tiết hôm nay như thế nào?" là AskAboutImage. Với ngữ cảnh này, mô hình biết rằng thời tiết không phải là một phần tử trực quan trong hình ảnh và phân loại chính xác là ngoài phạm vi.
Bước 3
Giờ đây, chúng ta sẽ viết bộ hướng dẫn đầy đủ mà mô hình Gemini sẽ làm theo để thực hiện việc phân loại.
👉 Hành động: Thay thế // REPLACE ME PART 3 - classifyIntentPrompt bằng đoạn mã sau:
bằng mã bên dưới
const classifyIntentPrompt = ai.definePrompt({
name: 'classifyIntentPrompt',
input: { schema: ClassifyIntentInputSchema },
output: { schema: ClassifyIntentOutputSchema },
prompt: `You are classifying the user's intent for ClarityCam, a voice-controlled AI application focused on image analysis.
Analyze the user query: '{userQuery}'.
First, understand ClarityCam's capabilities and limitations:
${AGENT_CAPABILITIES_AND_LIMITATIONS}
Now, classify the user's PRIMARY intent into ONE of the following categories:
* **DescribeImage**: User wants a general description of the current image.
* **AskAboutImage**: User is asking a specific question directly related to the visual content of the current image.
* **ReadTextInImage**: User wants any text read from the current image.
* **IdentifyColorsInImage**: User wants the dominant colors of the current image.
* **TakePicture**: User wants to capture an image using an active camera.
* **StartCamera**: User wants to activate the camera.
* **SelectImage**: User wants to choose an image file.
* **StopSpeaking**: User wants the current text-to-speech output to stop.
* **SetDescriptionDetailed**: User wants future image descriptions to be more detailed.
* **SetDescriptionConcise**: User wants future image descriptions to be less detailed.
* **GeneralInquiry**: The query is a simple conversational filler (e.g., "hello", "thanks"), a polite closing, or a direct question about the agent's functions (e.g., "what can you do?", "how does this work?", "help").
* **OutOfScopeRequest**: The query asks the agent to perform an action clearly listed under its "Limitations" or otherwise demonstrably outside its defined image analysis and control functions. Examples: "Tell me a joke," "What's the weather in London?", "Generate an image of a cat," "Can you edit my photo to make it brighter?", "Send this image to my friends","Translate 'hello' to Spanish."
Output ONLY the category name.
If the query is ambiguous but seems generally related to polite interaction or asking about the agent itself, prefer 'GeneralInquiry'.
If the query is clearly asking for something the agent CANNOT do, use 'OutOfScopeRequest'.
If truly unclassifiable even with these guidelines, use 'Unknown'.`,
config: {
temperature: 0.05, // Very low temperature for highly deterministic classification
}
});
Đây là nơi điều kỳ diệu xảy ra. Đây là "bộ não" của bộ phân loại, cho AI biết vai trò của nó, cung cấp ngữ cảnh cần thiết và xác định đầu ra mong muốn. Lưu ý những kỹ thuật thiết kế câu lệnh chính sau đây:
- Nhập vai: Bắt đầu bằng câu "Bạn đang phân loại..." để đặt ra một nhiệm vụ rõ ràng.
- Chèn ngữ cảnh: Thao tác này sẽ chèn biến
AGENT_CAPABILITIES_AND_LIMITATIONSvào câu lệnh một cách linh hoạt. - Định dạng đầu ra nghiêm ngặt: Chỉ dẫn "CHỈ xuất tên danh mục" là rất quan trọng để nhận được một phản hồi rõ ràng, có thể dự đoán được mà chúng ta có thể dễ dàng sử dụng trong mã của mình.
- Nhiệt độ thấp: Để phân loại, chúng tôi muốn câu trả lời mang tính logic và xác định, chứ không phải câu trả lời mang tính sáng tạo. Việc đặt nhiệt độ ở mức rất thấp (0,05) giúp đảm bảo mô hình tập trung cao độ và nhất quán.
Bước 4: Kết nối ứng dụng với luồng AI
Cuối cùng, hãy gọi trình phân loại AI mới từ tệp ứng dụng chính.
👉 Thao tác: Chuyển đến tệp ~/src/app/page.tsx. Trong hàm processVoiceCommand, hãy thay thế // REPLACE ME PART 1: add classificationResult bằng đoạn mã sau:
const classificationResult = await classifyIntentFlow({ userQuery: commandToProcess });
intent = classificationResult.intent as IntentCategory;
Mã này là cầu nối quan trọng giữa ứng dụng giao diện người dùng và logic AI phụ trợ của bạn. Thao tác này sẽ lấy lệnh thoại của người dùng (commandToProcess), gửi lệnh đó đến classifyIntentFlow mà bạn vừa tạo và đợi AI trả về ý định đã phân loại.
Giờ đây, biến ý định sẽ chứa một lệnh rõ ràng, có cấu trúc (chẳng hạn như DescribeImage). Kết quả này sẽ được dùng trong câu lệnh switch tiếp theo để điều khiển logic của ứng dụng và quyết định hành động cần thực hiện tiếp theo. Đây là cách "suy nghĩ" của AI được chuyển thành "hành động" của ứng dụng.
Khởi chạy giao diện người dùng
Đã đến lúc xem ứng dụng của chúng ta hoạt động! Hãy bắt đầu máy chủ phát triển.
👉 Trong thiết bị đầu cuối, hãy chạy lệnh sau: npm run dev Lưu ý: Bạn có thể cần chạy npm install trước khi chạy npm run dev
Sau giây lát, bạn sẽ thấy kết quả tương tự như sau, tức là máy chủ đang chạy thành công:
▲ Next.js 15.2.3 (Turbopack)
- Local: http://localhost:9003
- Network: http://10.88.0.4:9003
- Environments: .env
✓ Starting...
✓ Ready in 1512ms
○ Compiling / ...
✓ Compiled / in 26.6s
Bây giờ, hãy nhấp vào URL cục bộ (http://localhost:9003) để mở ứng dụng trong trình duyệt.
Bạn sẽ thấy giao diện người dùng của SightGuide! Hiện tại, các nút này chưa được liên kết với bất kỳ logic nào, nên việc nhấp vào các nút này sẽ không có tác dụng gì. Đó chính xác là những gì chúng tôi mong đợi ở giai đoạn này. Chúng ta sẽ làm cho chúng trở nên sống động trong phần tiếp theo!
Bây giờ bạn đã thấy giao diện người dùng, hãy quay lại thiết bị đầu cuối và nhấn Ctrl + C để dừng máy chủ phát triển trước khi chúng ta tiếp tục
5. Tìm hiểu thông tin đầu vào của người dùng – Kiểm tra truy vấn không hoàn hảo
Thêm tính năng Kiểm tra truy vấn không hoàn hảo
Phần 1: Xác định câu lệnh (Phần "Nội dung")
Trước tiên, hãy xác định các chỉ dẫn cho AI của chúng ta. Câu lệnh là "công thức" cho lệnh gọi AI của chúng tôi – câu lệnh này cho mô hình biết chính xác những gì chúng tôi muốn mô hình thực hiện.
👉 Hành động: Trong IDE, hãy chuyển đến ~/src/ai/flows/check_typo/.
Thay thế mã bên dưới: // REPLACE ME PART 1: add prompt here:
👉 bằng mã bên dưới
const prompt = ai.definePrompt({
name: 'checkTypoPrompt',
input: {
schema: CheckTypoInputSchema,
},
output: {
schema: CheckTypoOutputSchema,
},
prompt: `You are a helpful AI assistant that checks user text for typos and suggests corrections.
- If you find typos, respond with the corrected text.
- If there are no typos, or if you are unsure about a correction, respond with the original text unchanged.
User text: {text}
Corrected text:
`,
});
Khối mã này xác định một mẫu có thể dùng lại cho AI của chúng ta, có tên là checkTypoPrompt. Giản đồ đầu vào và đầu ra xác định hợp đồng dữ liệu cho nhiệm vụ này. Việc này giúp ngăn chặn lỗi và giúp hệ thống của chúng tôi hoạt động theo cách có thể dự đoán được.
Phần 2: Tạo Flow (Cách thực hiện)
Giờ đây, khi đã có "công thức" (câu lệnh), chúng ta cần tạo một hàm có thể thực sự thực thi công thức đó. Trong Genkit, thao tác này được gọi là luồng. Luồng này bao bọc lời nhắc của chúng ta trong một hàm có thể thực thi mà phần còn lại của ứng dụng có thể dễ dàng gọi.
👉 Hành động: Trong cùng tệp ~/src/ai/flows/check_typo/, hãy thay thế mã bên dưới: // REPLACE ME PART 2: add flow here:
👉 bằng mã bên dưới
const checkTypoFlow = ai.defineFlow<
typeof CheckTypoInputSchema,
typeof CheckTypoOutputSchema
>(
{
name: 'checkTypoFlow',
inputSchema: CheckTypoInputSchema,
outputSchema: CheckTypoOutputSchema,
},
async input => {
const {output} = await prompt(input);
return output!;
}
);
Phần 3: Sử dụng Trình kiểm tra lỗi chính tả
Sau khi hoàn tất quy trình AI, giờ đây, chúng ta có thể tích hợp quy trình này vào logic chính của ứng dụng. Chúng ta sẽ gọi phương thức này ngay sau khi nhận được lệnh của người dùng, đảm bảo văn bản không có lỗi trước khi xử lý thêm.
👉Hành động: Chuyển đến ~/src/app/ai/flows/check-typo.ts và tìm hàm export async function checkTypo. Huỷ chú thích câu lệnh trả về:
Thay vì return; Do return checkTypoFlow(input);
👉Hành động: Chuyển đến ~/src/app/page.tsx và tìm hàm processVoiceCommand. Thay thế mã bên dưới: REPLACE ME PART 2: add typoResult here:
👉 bằng mã bên dưới
const typoResult = await checkTypo({ text: rawCommand });
if (typoResult && typoResult.correctedText && typoResult.correctedText.trim().length > 0) {
const originalTrimmedLower = rawCommand.trim().toLowerCase();
const correctedTrimmedLower = typoResult.correctedText.trim().toLowerCase();
if (correctedTrimmedLower !== originalTrimmedLower) {
commandToProcess = typoResult.correctedText;
typoCorrectionAnnouncement = `I think you said: ${commandToProcess}. `;
}
}
Với thay đổi này, chúng tôi đã tạo một quy trình xử lý dữ liệu mạnh mẽ hơn cho mọi lệnh của người dùng.
Quy trình Lệnh thoại (Chỉ đọc, không cần làm gì)
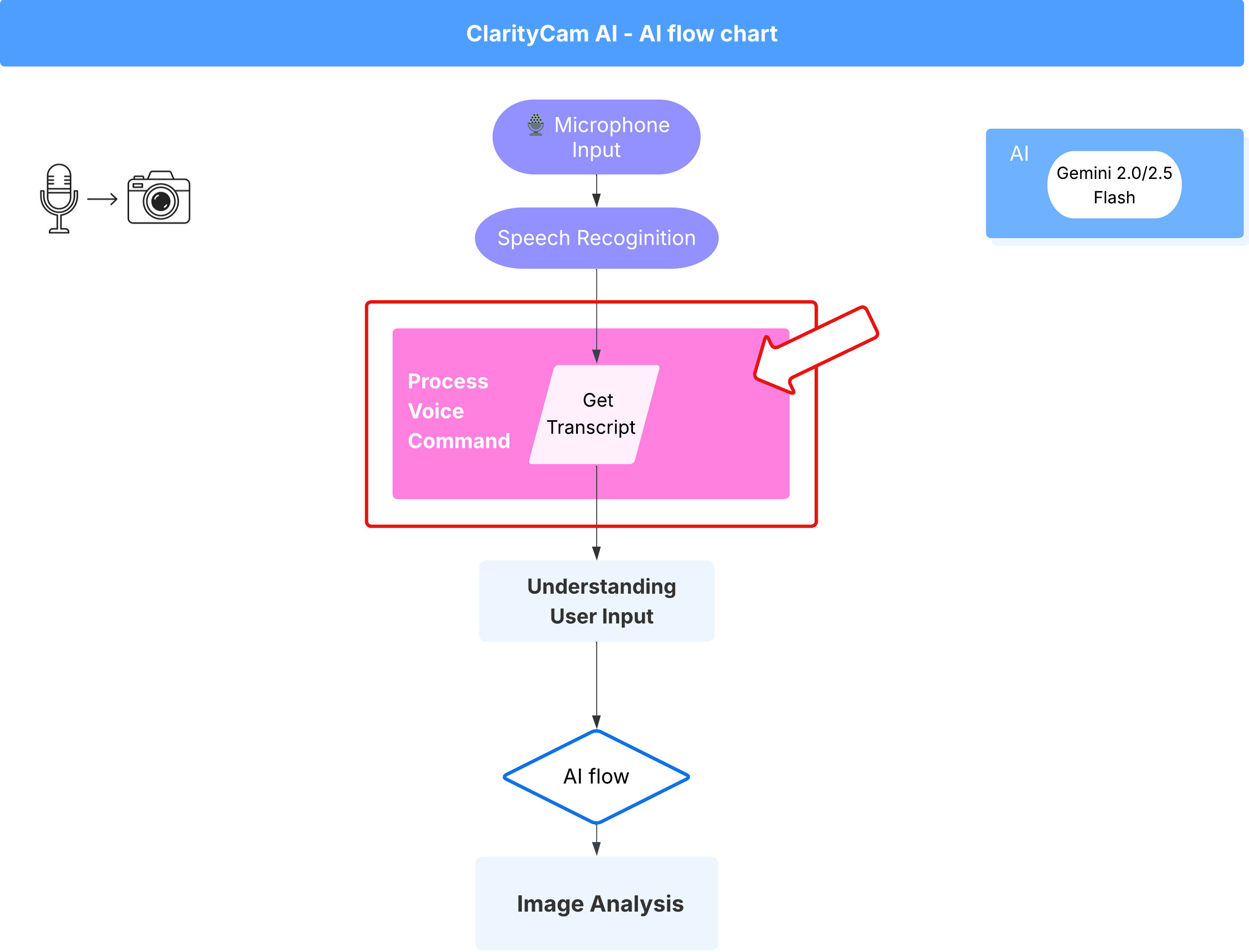
Giờ đây, khi đã có các thành phần "hiểu" cốt lõi (Trình kiểm tra lỗi chính tả và Trình phân loại ý định), hãy xem cách chúng phù hợp với logic xử lý giọng nói chính của ứng dụng.
Mọi thứ bắt đầu khi người dùng nói. Web Speech API của trình duyệt sẽ lắng nghe lời nói và cung cấp bản chép lời bằng văn bản về những gì đã nghe được sau khi người dùng nói xong. Đoạn mã sau đây xử lý quy trình này.
👉Chỉ đọc: Chuyển đến ~/src/app/page.tsx và bên trong hàm handleResult. Tìm mã dưới đây:
for (let i = event.resultIndex; i < event.results.length; ++i) {
if (event.results[i].isFinal) {
finalTranscript += event.results[i][0].transcript;
}
}
if (finalTranscript) {
console.log("Final Transcript:", finalTranscript);
processVoiceCommand(finalTranscript);
}
Kiểm thử tính năng sửa lỗi chính tả
Giờ đến phần thú vị! Hãy xem tính năng sửa lỗi chính tả mới của chúng tôi xử lý cả lệnh thoại hoàn hảo và không hoàn hảo như thế nào.
Bắt đầu ứng dụng
Trước tiên, hãy chạy lại máy chủ phát triển. Trong thiết bị đầu cuối, hãy chạy: npm run dev
Mở ứng dụng
Khi máy chủ đã sẵn sàng, hãy mở trình duyệt rồi chuyển đến địa chỉ cục bộ (ví dụ: http://localhost:9003).
Kích hoạt Lệnh thoại
Nhấp vào nút Start Listening. Trình duyệt của bạn có thể sẽ yêu cầu cấp quyền sử dụng micrô. Vui lòng nhấp vào Cho phép.
Kiểm thử một lệnh không hoàn hảo
Bây giờ, hãy cố tình đưa ra một lệnh có lỗi nhỏ để xem AI của chúng ta có thể nhận ra không. Nói rõ ràng vào micrô:
"Ảnh chụp tôi"
Quan sát kết quả
Đây là nơi tạo thử nghiệm! Mặc dù bạn nói "Chụp ảnh tôi", nhưng bạn sẽ thấy ứng dụng kích hoạt camera đúng cách. Quy trình checkTypo sẽ sửa cụm từ của bạn thành "chụp ảnh" ở chế độ nền, sau đó classifyIntentFlow sẽ hiểu lệnh đã sửa.
Điều này xác nhận rằng tính năng sửa lỗi chính tả của chúng tôi đang hoạt động hoàn hảo, giúp ứng dụng trở nên mạnh mẽ và thân thiện với người dùng hơn nhiều! Khi hoàn tất, bạn có thể dừng camera bằng cách chụp ảnh hoặc chỉ cần dừng máy chủ trong thiết bị đầu cuối (Ctrl + C).
6. Phân tích hình ảnh dựa trên AI – Mô tả hình ảnh
Giờ đây, khi tác nhân của chúng ta có thể hiểu được các yêu cầu, đã đến lúc cung cấp cho tác nhân này khả năng nhìn. Trong phần này, chúng ta sẽ xây dựng các chức năng của Vision Agent, thành phần cốt lõi chịu trách nhiệm phân tích tất cả hình ảnh. Chúng ta sẽ bắt đầu với tính năng quan trọng nhất của Gemini là mô tả hình ảnh, sau đó thêm khả năng đọc văn bản.
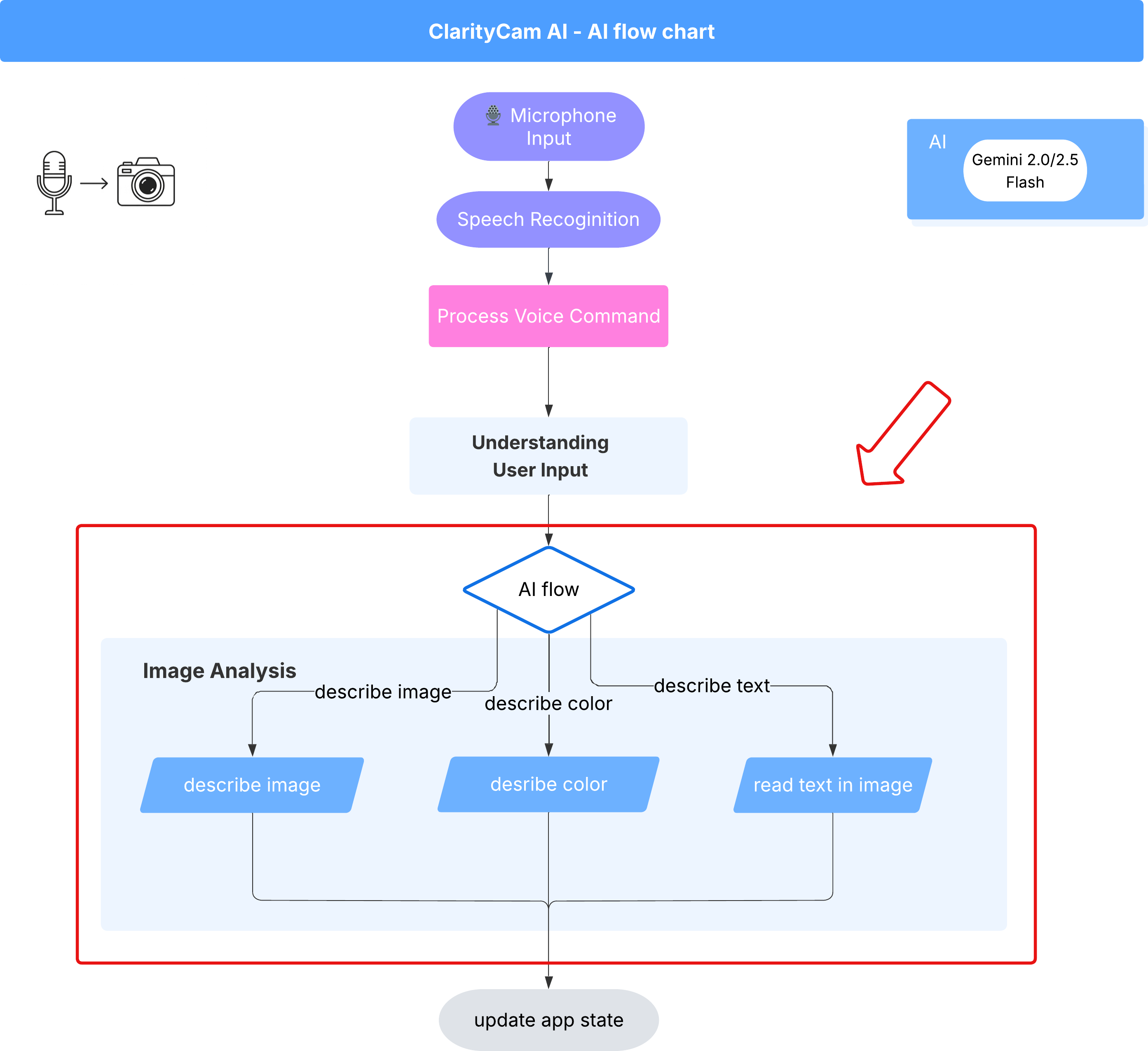
Tính năng 1: Mô tả hình ảnh
Đây là chức năng chính của trợ lý. Chúng tôi sẽ không chỉ tạo một nội dung mô tả tĩnh mà còn xây dựng một quy trình động có thể điều chỉnh mức độ chi tiết dựa trên lựa chọn ưu tiên của người dùng. Đây là một phần quan trọng trong triết lý Giao diện thích ứng tự nhiên (NAI).
👉 Thao tác: Trong IDE Cloud Shell, hãy chuyển đến tệp ~/src/ai/flows/describe_image/ và xoá dấu nhận xét mã sau.
Bước 1: Xây dựng mẫu câu lệnh linh hoạt
Trước tiên, chúng ta sẽ tạo một mẫu câu lệnh phức tạp có thể thay đổi hướng dẫn dựa trên thông tin đầu vào mà mẫu nhận được.
Huỷ chú thích mã bên dưới
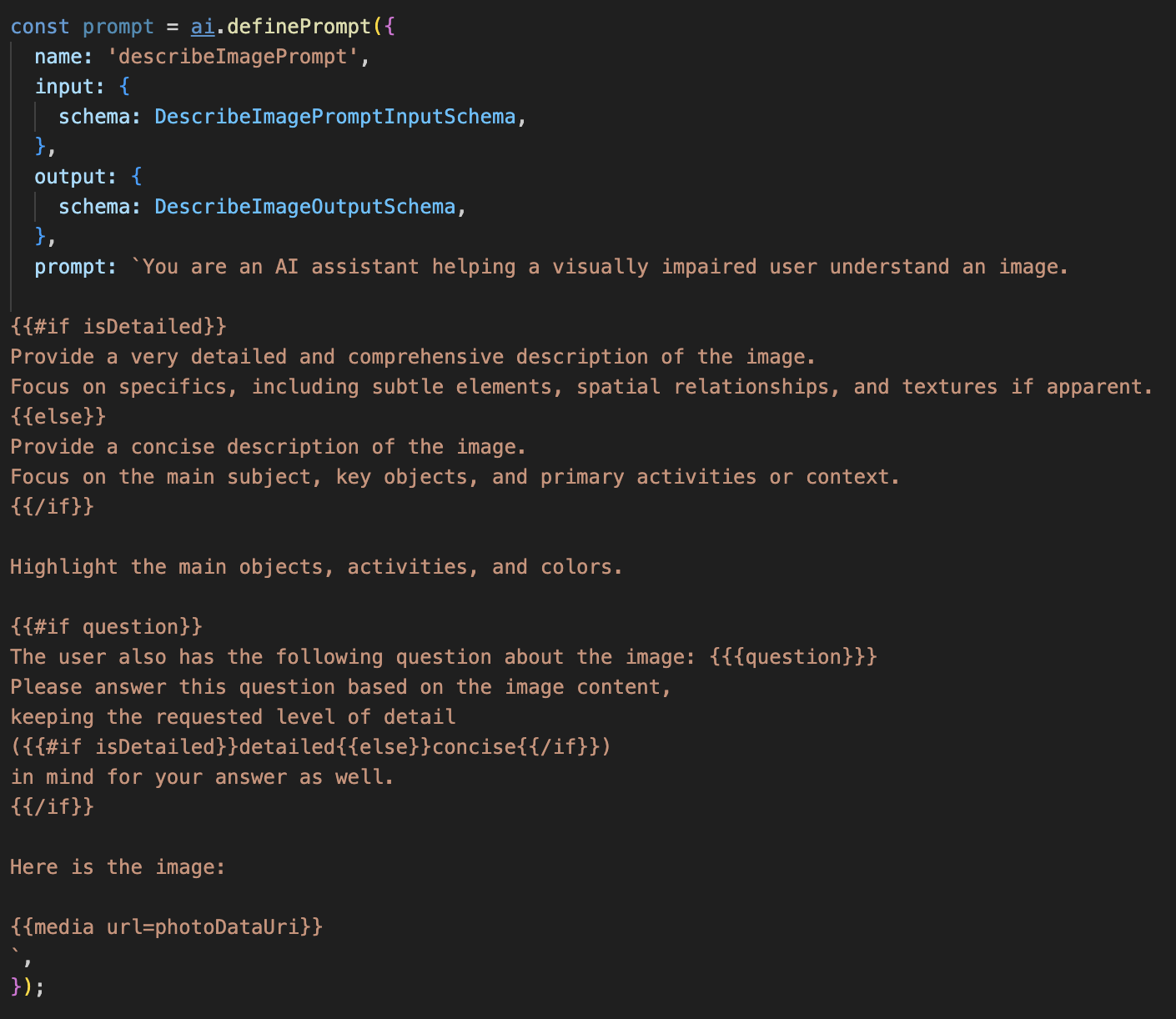
Đoạn mã này xác định một biến chuỗi, câu lệnh, sử dụng một ngôn ngữ mẫu có tên là Dot-Mustache. Điều này cho phép chúng ta nhúng logic có điều kiện trực tiếp vào câu lệnh.
{#if isDetailed}...{else}...{/if}: Đây là một khối có điều kiện. Nếu dữ liệu đầu vào mà chúng tôi gửi đến câu lệnh này có thuộc tính isDetailed: true, thì AI sẽ nhận được bộ hướng dẫn "rất chi tiết". Nếu không, nó sẽ nhận được hướng dẫn "ngắn gọn". Đây là cách mà trợ lý của chúng tôi thích ứng với lựa chọn ưu tiên của người dùng.
{#if question}...{/if}: Khối này sẽ chỉ được đưa vào nếu dữ liệu đầu vào của chúng tôi có thuộc tính câu hỏi. Nhờ đó, chúng tôi có thể sử dụng cùng một câu lệnh hiệu quả cho cả nội dung mô tả chung và câu hỏi cụ thể.
{media url=photoDataUri}: Đây là cú pháp đặc biệt của Genkit để nhúng dữ liệu hình ảnh trực tiếp vào câu lệnh để mô hình đa phương thức phân tích.
Bước 2: Tạo Luồng thông minh
Tiếp theo, chúng ta sẽ xác định câu lệnh và quy trình sẽ sử dụng mẫu mới. Luồng này chứa một chút logic để chuyển đổi lựa chọn ưu tiên của người dùng thành một giá trị boolean mà mẫu của chúng ta có thể hiểu được.
👉 Thao tác: Trong IDE Cloud Shell, tại tệp ~/src/ai/flows/describe_image/, hãy thay thế mã sau. // REPLACE ME PART 1: add flow here
👉 Với mã bên dưới:
// Define the prompt using the template from Step 1
const prompt = ai.definePrompt({
name: 'describeImagePrompt',
input: { schema: DescribeImagePromptInputSchema },
output: { schema: DescribeImageOutputSchema },
prompt: promptTemplate,
});
// Define the flow
const describeImageFlow = ai.defineFlow<
typeof DescribeImageInputSchema,
typeof DescribeImageOutputSchema
>(
{
name: 'describeImageFlow',
inputSchema: DescribeImageInputSchema,
outputSchema: DescribeImageOutputSchema,
},
async (pageInput) => {
const preference = pageInput.detailPreference || "concise";
// Prepare the input for the prompt, including the new boolean flag
const promptInputData = {
...pageInput,
isDetailed: preference === "detailed",
};
const { output } = await prompt(promptInputData);
return output!;
}
);
Thư viện này đóng vai trò là một trung gian thông minh giữa giao diện người dùng và câu lệnh AI.
- Thư viện này nhận
pageInputtừ ứng dụng của chúng tôi, bao gồm cả lựa chọn ưu tiên của người dùng dưới dạng một chuỗi (ví dụ:"detailed"). - Sau đó, nó sẽ tạo một đối tượng mới,
promptInputData. - Dòng quan trọng nhất là
isDetailed: preference === "detailed". Dòng này thực hiện công việc quan trọng là tạo giá trị booleantruehoặcfalsedựa trên chuỗi lựa chọn ưu tiên. - Cuối cùng, nó sẽ gọi
promptbằng dữ liệu nâng cao này. Giờ đây, mẫu câu lệnh ở Bước 1 có thể sử dụng giá trị booleanisDetailedđể thay đổi linh hoạt các chỉ dẫn được gửi đến AI.
Bước 3: Kết nối giao diện người dùng
Bây giờ, hãy kích hoạt quy trình này từ giao diện người dùng trong page.tsx.
👉Hành động: Chuyển đến ~/src/app/ai/flows/describe-image.ts và tìm hàm export async function describeImage. Huỷ chú thích câu lệnh trả về:
Thay vì return; Do return describeImageFlow(input);
👉Hành động: Trong ~/src/app/page.tsx, hãy tìm hàm handleAnalyze, thay thế mã // REPLACE ME PART 2: DESCRIBE IMAGE
👉 bằng mã sau:
case "description":
result = await describeImage({
photoDataUri,
question,
detailPreference: descriptionPreference
});
outputText = question ? `Answer: ${result.description}` : `Description: ${result.description}`;
break;
Khi người dùng có ý định nhận nội dung mô tả, mã này sẽ được thực thi. Thao tác này sẽ gọi luồng describeImage của chúng ta, truyền dữ liệu hình ảnh và quan trọng nhất là biến trạng thái descriptionPreference từ thành phần React. Đây là mảnh ghép cuối cùng, kết nối lựa chọn ưu tiên của người dùng được lưu trữ trong giao diện người dùng trực tiếp với luồng AI sẽ điều chỉnh hành vi cho phù hợp.
Thử nghiệm tính năng Mô tả hình ảnh
Hãy xem chức năng mô tả hình ảnh của chúng ta hoạt động như thế nào, từ việc chụp ảnh cho đến nghe những gì AI nhìn thấy.
Bắt đầu ứng dụng
Trước tiên, hãy chạy lại máy chủ phát triển. 👉 Trong thiết bị đầu cuối, hãy chạy lệnh sau: npm run dev Lưu ý: Bạn có thể cần chạy npm install trước khi chạy npm run dev
Mở ứng dụng
Khi máy chủ đã sẵn sàng, hãy mở trình duyệt rồi chuyển đến địa chỉ cục bộ (ví dụ: http://localhost:9003).
Kích hoạt camera
Nhấp vào nút Bắt đầu nghe và cấp quyền truy cập vào micrô nếu được nhắc. Sau đó, hãy nói lệnh đầu tiên:
"Chụp ảnh"
Ứng dụng sẽ kích hoạt camera trên thiết bị của bạn. Lúc này, bạn sẽ thấy nguồn cấp dữ liệu video trực tiếp trên màn hình.
Chụp ảnh
Khi camera đang hoạt động, hãy hướng camera vào nội dung bạn muốn mô tả. Bây giờ, hãy nói lại lệnh này lần thứ hai để chụp ảnh:
"Chụp ảnh"
Video trực tiếp sẽ được thay thế bằng bức ảnh tĩnh mà bạn vừa chụp.
Yêu cầu cung cấp nội dung mô tả
Khi ảnh mới của bạn xuất hiện trên màn hình, hãy đưa ra lệnh cuối cùng:
"Mô tả bức ảnh"
Nghe kết quả
Ứng dụng sẽ cho biết trạng thái xử lý, sau đó bạn sẽ nghe thấy nội dung mô tả do AI tạo về hình ảnh của mình! Văn bản này cũng sẽ xuất hiện trong thẻ "Trạng thái và kết quả".
Khi chụp xong, bạn có thể dừng camera bằng cách chụp ảnh hoặc chỉ cần dừng máy chủ trong thiết bị đầu cuối (Ctrl + C).
7. Phân tích hình ảnh dựa trên AI – Mô tả văn bản (OCR)
Tiếp theo, chúng ta sẽ thêm chức năng Nhận dạng ký tự quang học (OCR) vào Vision Agent. Nhờ đó, ứng dụng có thể đọc văn bản trong mọi hình ảnh.
👉 Thao tác: Trong IDE, hãy chuyển đến ~/src/ai/flows/read-text-in-image/, Uncomment (Huỷ nhận xét) mã bên dưới:
👉 Việc cần làm: Trong IDE, trong cùng một tệp ~/src/ai/flows/read-text-in-image/, hãy thay thế // REPLACE ME: Creating Prmopt
👉 bằng mã bên dưới:
const readTextInImageFlow = ai.defineFlow<
typeof ReadTextInImageInputSchema,
typeof ReadTextInImageOutputSchema
>(
{
name: 'readTextInImageFlow',
inputSchema: ReadTextInImageInputSchema,
outputSchema: ReadTextInImageOutputSchema,
},
async input => {
const {output} = await prompt(input);
return output!;
}
);
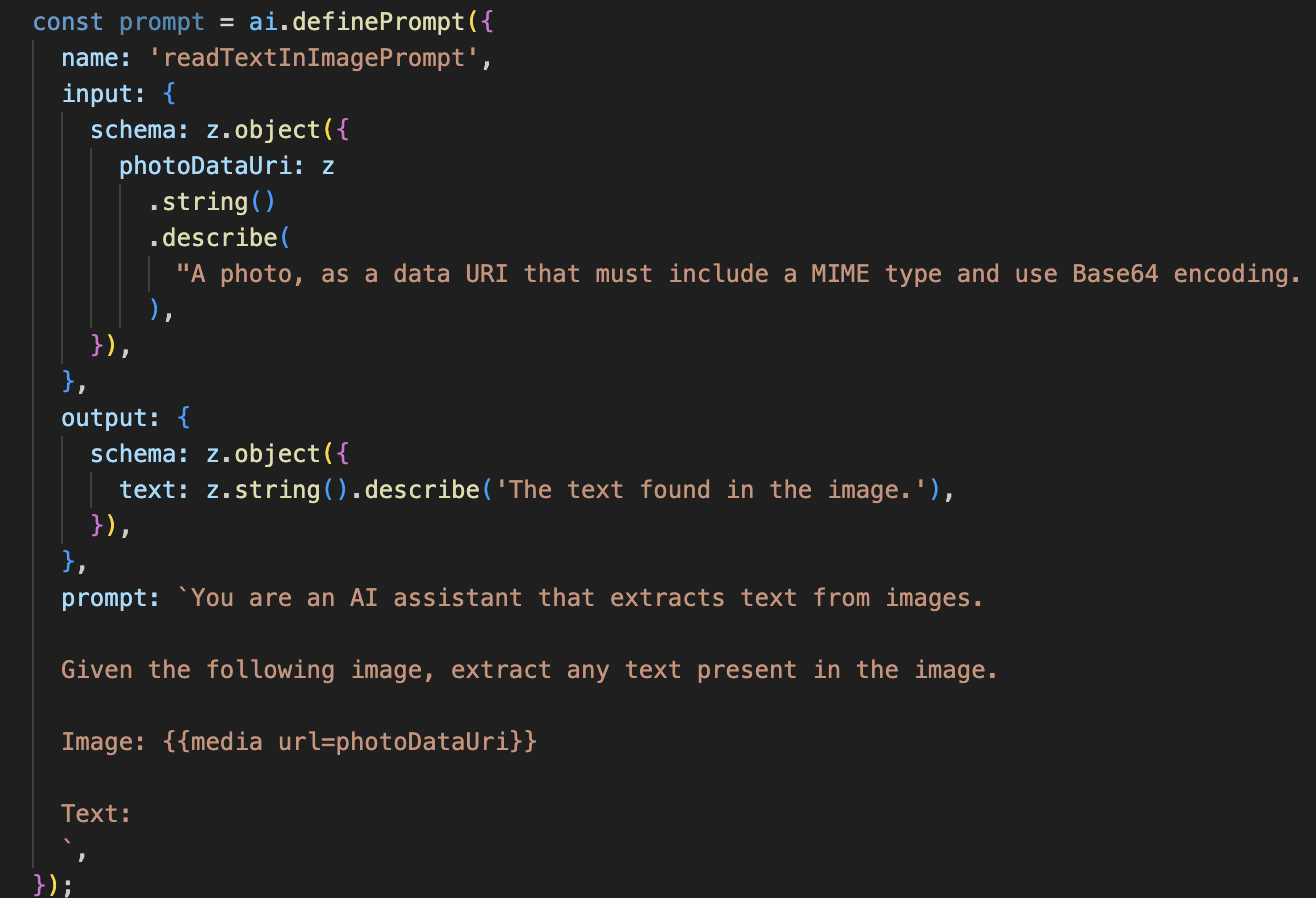
Quy trình AI này đơn giản hơn nhiều, làm nổi bật nguyên tắc sử dụng các công cụ tập trung cho những công việc cụ thể.
- Câu lệnh: Không giống như câu lệnh mô tả, câu lệnh này là tĩnh và rất cụ thể. Công việc duy nhất của nó là hướng dẫn AI (trí tuệ nhân tạo) hoạt động như một công cụ Nhận dạng ký tự quang học (OCR): "trích xuất mọi văn bản có trong hình ảnh".
- Các giản đồ: Giản đồ đầu vào và đầu ra cũng đơn giản, chỉ cần một hình ảnh và trả về một chuỗi văn bản duy nhất.
Kết nối giao diện người dùng cho OCR
Cuối cùng, hãy kết nối chức năng mới này trong page.tsx.
👉Hành động: Chuyển đến ~/src/app/ai/flows/read-text-in-image.ts và tìm hàm export async function readTextInImage. Huỷ chú thích câu lệnh trả về:
Thay vì return; Do return readTextInImageFlow(input);
👉 Thao tác: Trong ~/src/app/page.tsx, hãy tìm hàm handleAnalyze và xung quanh câu lệnh switch.
Thay thế REPLACE ME PART 3: READ TEXT
bằng mã bên dưới:
case "text":
result = await readTextInImage({ photoDataUri });
outputText = result.text ? `Text Found: ${result.text}` : "No text found.";
break;
Khi ý định của người dùng là ReadTextInImage, mã này sẽ được kích hoạt. Thao tác này sẽ gọi quy trình readTextInImage đơn giản của chúng tôi. Dòng result.text ? ... : ... là một cách rõ ràng để xử lý đầu ra, cung cấp thông báo hữu ích cho người dùng nếu AI không tìm thấy văn bản nào trong hình ảnh.
Thử nghiệm tính năng Đọc văn bản (OCR)
Hãy làm theo các bước sau để kiểm thử tính năng đọc văn bản. Nhớ hướng camera vào một đối tượng có văn bản rõ ràng.
- Chạy ứng dụng bằng
npm run devrồi mở ứng dụng đó trong trình duyệt. - Nhấp vào Bắt đầu nghe và cấp quyền truy cập vào micrô khi được nhắc.
- Bật camera. Nói lệnh "Chụp ảnh". Lúc này, bạn sẽ thấy nguồn cấp dữ liệu video trực tiếp xuất hiện trên màn hình.
- Chụp ảnh. Hướng camera vào văn bản bạn muốn đọc rồi nói lại lệnh "Chụp ảnh". Video sẽ được thay thế bằng một bức ảnh tĩnh.
- Yêu cầu văn bản. Sau khi chụp ảnh, hãy đưa ra lệnh cuối cùng: "Văn bản trong hình ảnh là gì?"
- Kiểm tra kết quả Sau một lát, ứng dụng sẽ phân tích bức ảnh và đọc to văn bản được phát hiện. Nếu không tìm thấy văn bản nào, ứng dụng sẽ thông báo cho bạn.
Điều này xác nhận rằng tính năng OCR mạnh mẽ đang hoạt động! Khi bạn hoàn tất, hãy dừng máy chủ bằng Ctrl + C.
8. Các tính năng cải tiến nâng cao bằng AI – Chỉ đọc ✨
Một tác nhân AI hiệu quả có thể làm theo chỉ dẫn. Một tác nhân AI hiệu quả mang lại cảm giác trực quan, đáng tin cậy và hữu ích. Trong phần này, chúng ta sẽ tập trung vào 3 điểm cải tiến nâng cao giúp nâng cao khả năng của trợ lý ảo.
Chúng ta sẽ tìm hiểu cách:
Add Context & Memoryđể xử lý các câu hỏi nối tiếp tự nhiên, mang tính trò chuyện.Reduce Hallucinationđể xây dựng một tác nhân đáng tin cậy hơn.Make the Agent Proactiveđể mang đến trải nghiệm dễ tiếp cận và thân thiện hơn với người dùng.Add preference settingđể tuỳ chỉnh nội dung mô tả hình ảnh
Điểm cải tiến 1: Bối cảnh và bộ nhớ
Một cuộc trò chuyện tự nhiên không phải là một loạt các lệnh riêng lẻ mà là một dòng chảy. Nếu người dùng hỏi "Trong bức ảnh có gì?" và trợ lý trả lời "Một chiếc ô tô màu đỏ", thì câu hỏi tự nhiên tiếp theo của người dùng có thể là "Màu gì?" mà không cần nói lại từ "ô tô". Tác nhân của chúng tôi cần có trí nhớ ngắn hạn để hiểu được bối cảnh này.
Cách chúng tôi triển khai (Tóm tắt)
Chúng tôi đã tích hợp chức năng này vào quy trình describeImage. Phần này tóm tắt cách hoạt động của mẫu đó. Khi gọi hàm describeImage từ page.tsx, chúng ta sẽ truyền nhật ký trò chuyện vào hàm này.
👉 Code Showcase (từ page.tsx):
const result = await describeImage({
photoDataUri,
question: commandToProcess,
detailPreference: descriptionPreference,
previousUserQueryOnImage: lastUserQuery ?? undefined,
previousAIResponseOnImage: lastAIResponse ?? undefined,
});
previousUserQueryOnImagevàpreviousAIResponseOnImage: Đây là bộ nhớ ngắn hạn của tác nhân. Bằng cách truyền lượt tương tác cuối cùng cho AI, chúng ta cung cấp cho AI ngữ cảnh cần thiết để hiểu các câu hỏi tiếp theo mơ hồ hoặc mang tính tham khảo.- Câu lệnh thích ứng: Bối cảnh này được câu lệnh sử dụng trong quy trình describe_image của chúng tôi. Câu lệnh này được thiết kế để xem xét cuộc trò chuyện trước đó khi tạo câu trả lời mới, cho phép trợ lý phản hồi một cách thông minh.
Điểm cải tiến 2: Giảm hiện tượng ảo giác
AI "ảo tưởng" khi bịa đặt thông tin hoặc tuyên bố có những khả năng mà nó không có. Để xây dựng lòng tin của người dùng, điều quan trọng là tác nhân của chúng tôi phải biết giới hạn của chính mình và có thể từ chối một cách lịch sự các yêu cầu nằm ngoài phạm vi.
Cách chúng tôi triển khai (Tóm tắt)
Cách hiệu quả nhất để ngăn chặn hiện tượng ảo tưởng là đưa ra ranh giới rõ ràng cho mô hình. Chúng tôi đã đạt được điều này khi xây dựng Trình phân loại ý định.
👉 Code Showcase (Trình bày mã) (từ quy trình intent-classifier):
// Define Agent Capabilities and Limitations for the prompt
const AGENT_CAPABILITIES_AND_LIMITATIONS = `
**Core Capabilities (What the Agent CAN DO):**
* **Image Analysis:**
* DescribeImage: Provide a general description of the current image...
**Limitations (What the Agent CANNOT DO...):**
* Cannot generate or create new images.
* Cannot provide general knowledge or answer questions unrelated to the image...
* Cannot perform web searches.
`;
Hằng số này đóng vai trò là "mô tả công việc" mà chúng ta cung cấp cho AI trong câu lệnh phân loại.
- Liên kết thực tế cho mô hình: Bằng cách nói rõ cho AI biết những điều mà AI không thể làm, chúng ta sẽ "liên kết thực tế" cho AI. Khi thấy một truy vấn như "Thời tiết thế nào?", mô hình có thể tự tin so khớp truy vấn đó với danh sách các hạn chế của mình và phân loại ý định là OutOfScopeRequest.
- Xây dựng lòng tin: Một trợ lý ảo có thể nói một cách chân thành rằng "Tôi không thể giúp bạn việc đó" sẽ đáng tin cậy hơn nhiều so với một trợ lý ảo cố gắng đoán nhưng lại đoán sai. Đây là một nguyên tắc cơ bản trong thiết kế AI an toàn và đáng tin cậy. `
Điểm cải tiến 3: Tạo một tác nhân chủ động
Đối với một ứng dụng ưu tiên khả năng hỗ trợ tiếp cận, chúng ta không thể dựa vào các tín hiệu trực quan. Khi kích hoạt chế độ nghe, người dùng cần được xác nhận ngay lập tức (không cần hình ảnh) rằng trợ lý đã sẵn sàng và đang chờ lệnh. Giờ đây, chúng tôi sẽ thêm một phần giới thiệu chủ động để cung cấp ý kiến phản hồi quan trọng này.
Bước 1: Thêm trạng thái để theo dõi lượt nghe đầu tiên
Trước tiên, chúng ta cần một cách để biết đây có phải là lần đầu tiên người dùng nhấn nút "Start Listening" trong phiên hoạt động của họ hay không.
👉 Trong ~/src/app/page.tsx, hãy xem biến trạng thái mới sau đây ở gần đầu thành phần ClarityCam.
export default function ClarityCam() {
// ... other state variables
const [descriptionPreference, setDescriptionPreference] = useState<DescriptionPreference>("concise");
// Add this new line
const [isFirstListen, setIsFirstListen] = useState(true);
// ... rest of the component
}
Chúng tôi đã giới thiệu một biến trạng thái mới, isFirstListen và khởi tạo biến này thành true. Chúng tôi sẽ sử dụng cờ này để kích hoạt thông điệp chào mừng một lần.
Bước 2: Cập nhật hàm toggleListening
Bây giờ, hãy sửa đổi hàm xử lý micrô để phát lời chào của chúng ta.
👉 Trong ~/src/app/page.tsx, hãy tìm hàm toggleListening và xem khối if sau.
const toggleListening = useCallback(() => {
// ... existing logic to setup speech recognition
if (isListening || isAttemptingStart) {
// ... existing logic to stop listening
} else {
stopSpeaking(); // Stop any ongoing TTS
// Add this new block
if (isFirstListen) {
setIsFirstListen(false);
const introMessage = "Hello! I am ClarityCam, your AI assistant. I'm now listening. You can ask me to 'describe the image', 'read text', 'take a picture', or ask questions about what's in an image.";
speakText(introMessage);
} else {
speakText("Listening..."); // Optional: provide feedback on subsequent clicks
}
// ... rest of the logic to start listening
}
}, [/*...existing dependencies...*/, isFirstListen]); // Don't forget to add isFirstListen to the dependency array!
- Kiểm tra cờ: Khối if (isFirstListen) kiểm tra xem đây có phải là lần kích hoạt đầu tiên hay không.
- Ngăn lặp lại: Việc đầu tiên mà hàm này thực hiện bên trong khối là gọi setIsFirstListen(false). Điều này đảm bảo thông báo giới thiệu sẽ chỉ phát một lần cho mỗi phiên.
- Đưa ra hướng dẫn: introMessage được thiết kế cẩn thận để hữu ích nhất có thể. Ứng dụng này chào người dùng, xác định tên của trợ lý, xác nhận rằng trợ lý hiện đang hoạt động ("Tôi đang lắng nghe") và đưa ra các ví dụ rõ ràng về lệnh thoại mà người dùng có thể sử dụng.
- Phản hồi bằng âm thanh: Cuối cùng, speakText(introMessage) sẽ truyền tải thông tin quan trọng này, mang đến sự đảm bảo và hướng dẫn ngay lập tức mà không yêu cầu người dùng nhìn vào màn hình.
Điểm cải tiến 4: Thích ứng với lựa chọn ưu tiên của người dùng (Tóm tắt)
Một tác nhân thực sự thông minh không chỉ phản hồi mà còn học hỏi và thích ứng với nhu cầu của người dùng. Một trong những tính năng mạnh mẽ nhất mà chúng tôi đã xây dựng là khả năng cho phép người dùng thay đổi mức độ chi tiết của nội dung mô tả hình ảnh ngay lập tức bằng các lệnh như "Mô tả chi tiết hơn".
Cách chúng tôi triển khai (Tóm tắt) Chức năng này dựa trên câu lệnh linh hoạt mà chúng tôi đã tạo cho quy trình describeImage. Công cụ này sử dụng logic có điều kiện để thay đổi hướng dẫn được gửi đến AI dựa trên lựa chọn ưu tiên của người dùng.
👉 Code Showcase (promptTemplate từ describe_image):
const settingPreferenceTemplate = `
{#if isDetailed}
Provide a very detailed and comprehensive description of the image. Focus on specifics, including subtle elements, spatial relationships, and textures if apparent.
{else}
Provide a concise description of the image. Focus on the main subject, key objects, and primary activities or context.
{/if}
Highlight the main objects, activities, and colors.
...
`;
- Logic có điều kiện: Khối
{#if isDetailed}...{else}...{/if}là yếu tố then chốt. Khi describeImageFlow nhận được detailPreference từ giao diện người dùng, nó sẽ tạo một giá trị boolean isDetailed (true hoặc false). - Hướng dẫn thích ứng: Cờ boolean này xác định tập hợp hướng dẫn mà mô hình AI nhận được. Nếu isDetailed là true, thì mô hình sẽ được hướng dẫn mô tả một cách chi tiết. Nếu thông tin đó là sai, thì bạn nên trình bày ngắn gọn.
- Quyền kiểm soát của người dùng: Mẫu này kết nối trực tiếp lệnh thoại của người dùng (ví dụ: "mô tả ngắn gọn", được phân loại là ý định SetDescriptionConcise) với một thay đổi cơ bản trong hành vi của AI, khiến tác nhân cảm thấy thực sự phản hồi và được cá nhân hoá.
9. Triển khai lên đám mây
Tạo hình ảnh Docker bằng Google Cloud Build
gcloud builds submit . --tag gcr.io/$PROJECT_ID/accessibilityai-nextjs-app:latest
accessibilityai-nextjs-applà tên hình ảnh được đề xuất.- Tệp . sử dụng thư mục hiện tại (
accessibilityAI/) làm nguồn bản dựng.
Triển khai Hình ảnh lên Google Cloud Run
- Đảm bảo khoá API và các bí mật khác của bạn đã sẵn sàng trong Secret Manager. Ví dụ:
GOOGLE_GENAI_API_KEY.
Thay thế YOUR_ACTUAL_GOOGLE_AI_KEY_VALUE này bằng giá trị khoá Gemini API thực tế của bạn.
echo "YOUR_ACTUAL_GOOGLE_AI_KEY_VALUE" | gcloud secrets create GOOGLE_GENAI_API_KEY --data-file=- --project=YOUR_PROJECT_ID
Cấp cho tài khoản dịch vụ thời gian chạy của dịch vụ Cloud Run (ví dụ: PROJECT_NUMBER-compute@developer.gserviceaccount.com hoặc một tài khoản chuyên dụng) vai trò "Secret Manager Secret Accessor" cho bí mật này.
- Lệnh triển khai:
gcloud run deploy accessibilityai-app-service \
--image gcr.io/$PROJECT_ID/accessibilityai-nextjs-app:latest \
--platform managed \
--region us-central1 \
--allow-unauthenticated \
--port 3000 \
--set-secrets=GOOGLE_GENAI_API_KEY=GOOGLE_GENAI_API_KEY:latest \
--set-env-vars NODE_ENV="production"