
1. Übersicht
In diesem Codelab erstellen Sie ein komplexes Multi-Agent-System für die Anlageforschung, das die Leistungsfähigkeit des Agent Development Kit (ADK) von Google, der Neo4j-Graphendatenbank und der Model Context Protocol (MCP) Toolbox kombiniert. In diesem praktischen Tutorial wird gezeigt, wie Sie intelligente Agents erstellen, die den Datenkontext anhand von Beziehungen im Diagramm verstehen und sehr genaue Antworten auf Anfragen liefern.
Warum GraphRAG + Multi-Agenten-Systeme?
GraphRAG (Graph-based Retrieval-Augmented Generation) verbessert herkömmliche RAG-Ansätze, indem die umfassende Beziehungsstruktur von Knowledge Graphs genutzt wird. Anstatt nur nach ähnlichen Dokumenten zu suchen, können GraphRAG-Agents:
- Komplexe Beziehungen zwischen Entitäten durchlaufen
- Kontext anhand der Diagrammstruktur verstehen
- Erklärbare Ergebnisse auf Grundlage verbundener Daten liefern
- Mehrstufige Problemlösung im Knowledge Graph ausführen
Multi-Agenten-Systeme bieten folgende Möglichkeiten:
- Komplexe Probleme in spezialisierte Teilaufgaben zerlegen
- Modulare, wartungsfreundliche KI-Anwendungen erstellen
- Parallele Verarbeitung und effiziente Ressourcennutzung aktivieren
- Hierarchische Reasoning-Muster mit Orchestrierung erstellen
Umfang
Sie erstellen ein vollständiges System für die Anlageforschung mit folgenden Funktionen:
- Graph Database Agent: Führt Cypher-Abfragen aus und versteht das Neo4j-Schema.
- Investor Research Agent: Ermittelt Investorenbeziehungen und Anlageportfolios
- Investment Research Agent: Greift über MCP-Tools auf umfassende Knowledge Graphs zu.
- Root-Agent: Orchestriert alle untergeordneten Agents intelligent.
Das System kann komplexe Fragen beantworten, z. B.:
- „Wer sind die wichtigsten Konkurrenten von YouTube?“
- „Welche Unternehmen werden im Januar 2023 positiv erwähnt?“
- „Wer hat in ByteDance investiert und wo haben diese Investoren noch investiert?“
Architekturübersicht
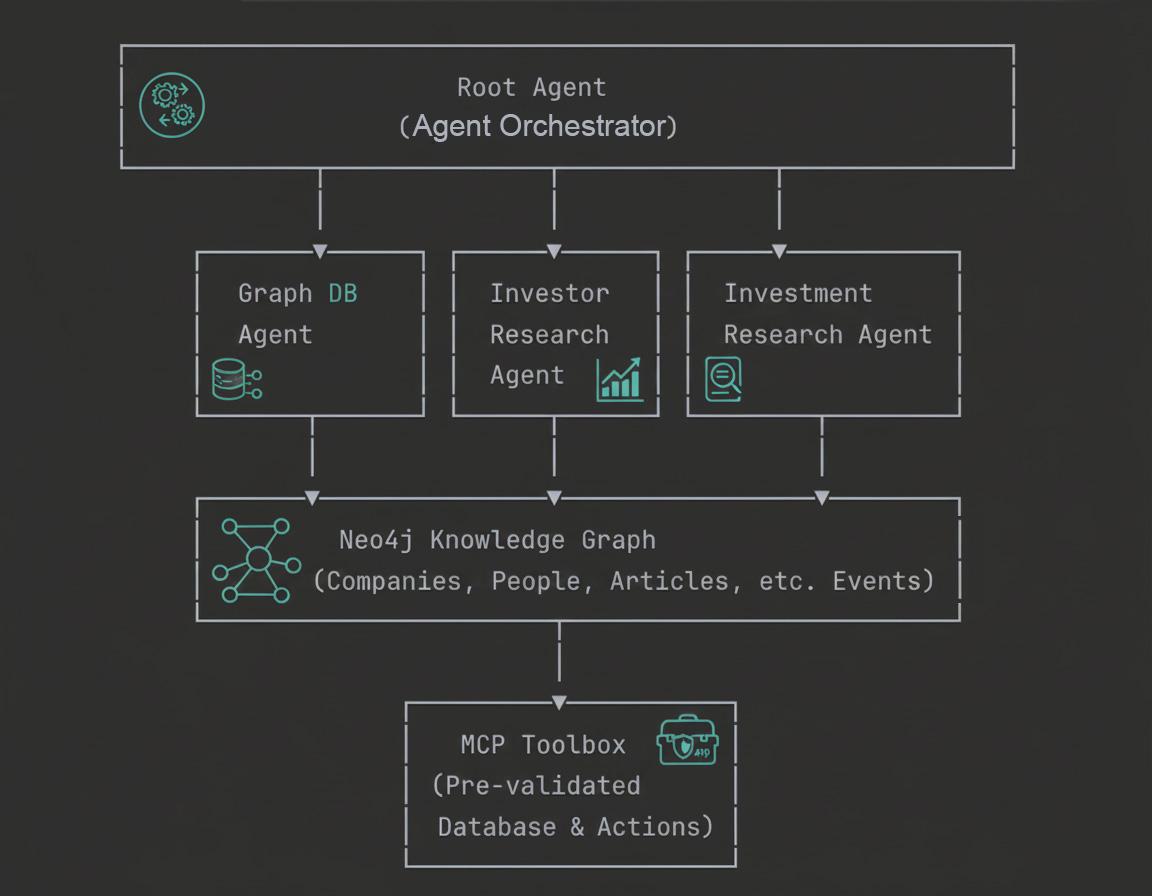
In diesem Codelab lernen Sie sowohl die konzeptionellen Grundlagen als auch die praktische Implementierung von GraphRAG-Agents für Unternehmen kennen.
Lerninhalte
- Multi-Agent-Systeme mit dem Agent Development Kit (ADK) von Google erstellen
- Neo4j-Grafikdatenbank in das ADK für GraphRAG-Anwendungen einbinden
- Implementieren der MCP-Toolbox (Model Context Protocol) für vorab validierte Datenbankabfragen
- Benutzerdefinierte Tools und Funktionen für intelligente Agenten erstellen
- Agentenhierarchien und Orchestrierungsmuster entwerfen
- Agent-Anweisungen für optimale Leistung strukturieren
- Multi-Agent-Interaktionen effektiv debuggen
Voraussetzungen
- Chrome-Webbrowser
- Ein Gmail-Konto
- Ein Google Cloud-Projekt mit aktivierter Abrechnung
- Grundkenntnisse in Terminalbefehlen und Python (sind hilfreich, aber nicht erforderlich)
In diesem Codelab, das sich an Entwickler aller Erfahrungsstufen (auch Anfänger) richtet, werden Python und Neo4j in der Beispielanwendung verwendet. Grundkenntnisse in Python und Graphdatenbanken können hilfreich sein, sind aber nicht erforderlich, um die Konzepte zu verstehen oder dem Kurs zu folgen.
2. GraphRAG und Multi-Agenten-Systeme
Bevor wir uns mit der Implementierung befassen, sollten wir uns die wichtigsten Konzepte ansehen, die diesem System zugrunde liegen.
Neo4j ist eine führende native Graphendatenbank, in der Daten als Netzwerk von Knoten (Entitäten) und Beziehungen (Verbindungen zwischen Entitäten) gespeichert werden. Sie eignet sich daher ideal für Anwendungsfälle, in denen es wichtig ist, Verbindungen zu verstehen, z. B. Empfehlungen, Betrugserkennung und Knowledge Graphs. Im Gegensatz zu relationalen oder dokumentbasierten Datenbanken, die auf starren Tabellen oder hierarchischen Strukturen basieren, ermöglicht das flexible Graphmodell von Neo4j eine intuitive und effiziente Darstellung komplexer, miteinander verbundener Daten.
Anstatt Daten wie in relationalen Datenbanken in Zeilen und Tabellen zu organisieren, verwendet Neo4j ein Graphenmodell, in dem Informationen als Knoten (Entitäten) und Beziehungen (Verbindungen zwischen diesen Entitäten) dargestellt werden. Dieses Modell ist besonders intuitiv für die Arbeit mit Daten, die von Natur aus miteinander verknüpft sind, z. B. Personen, Orte, Produkte oder in unserem Fall Filme, Schauspieler und Genres.
Beispiel: In einem Filmdataset:
- Ein Knoten kann eine
Movie,ActoroderDirectordarstellen. - Eine Beziehung kann
ACTED_INoderDIRECTEDsein.
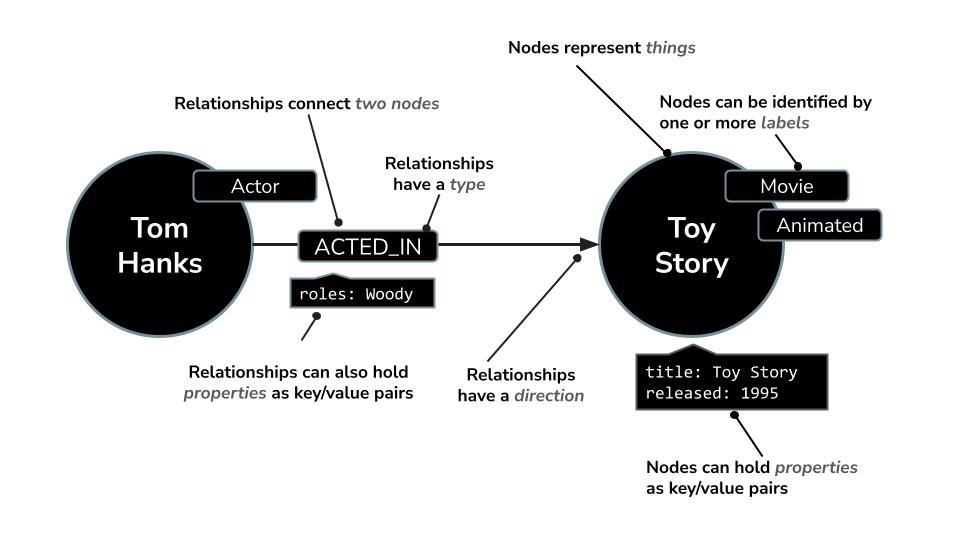
So können Sie ganz einfach Fragen stellen wie:
- In welchen Filmen hat dieser Schauspieler mitgespielt?
- Wer hat mit Christopher Nolan zusammengearbeitet?
- Welche ähnlichen Filme gibt es basierend auf gemeinsamen Schauspielern oder Genres?
Was ist GraphRAG?
Retrieval-Augmented Generation (RAG) verbessert LLM-Antworten, indem relevante Informationen aus externen Quellen abgerufen werden. Bei der herkömmlichen RAG-Methode wird in der Regel:
- Dokumente in Vektoren einbetten
- Suchen nach ähnlichen Vektoren
- Übergeben abgerufene Dokumente an das LLM
GraphRAG erweitert diesen Ansatz durch die Verwendung von Knowledge Graphs:
- Entitäten und Beziehungen einbetten
- Durchläuft Diagrammverbindungen
- Ruft Kontextinformationen über mehrere Schritte ab
- Strukturierte, nachvollziehbare Ergebnisse
Warum Graphen für KI-Agenten?
Beispiel: „Wer sind die Wettbewerber von YouTube und welche Investoren haben sowohl YouTube als auch seine Wettbewerber finanziert?“
Was passiert bei einem herkömmlichen RAG-Ansatz?
- Nach Dokumenten über YouTube-Konkurrenten suchen
- Separate Suche nach Informationen für Investoren
- Schwierigkeiten, diese beiden Informationen in Verbindung zu bringen
- Implizite Beziehungen werden möglicherweise nicht berücksichtigt
So funktioniert GraphRAG:
MATCH (org:Organization {name: "OpenAI"})-[:HAS_COMPETITOR]-(competitor:Organization)
MATCH (org)-[:HAS_INVESTOR]->(investor:Person)
MATCH (competitor)-[:HAS_INVESTOR]->(investor)
RETURN org, competitor, investor
Im Diagramm werden Beziehungen auf natürliche Weise dargestellt, sodass Multi-Hop-Abfragen einfach und effizient sind.
Multi-Agenten-Systeme im ADK
Das Agent Development Kit (ADK) ist das Open-Source-Framework von Google zum Erstellen und Bereitstellen von produktionsreifen KI-Agenten. Es bietet intuitive Primitiven für die Orchestrierung von Multi-Agent-Systemen, die Toolintegration und das Workflowmanagement, sodass sich spezialisierte Agents einfach zu komplexen Systemen zusammenstellen lassen. Das ADK funktioniert nahtlos mit Gemini und unterstützt die Bereitstellung in Cloud Run, Kubernetes oder einer beliebigen Infrastruktur.
Das Agent Development Kit (ADK) bietet Primitiven zum Erstellen von Multi-Agent-Systemen:
- Agent-Hierarchie:
# Root agent coordinates specialized agents
root_agent = LlmAgent(
name="RootAgent",
sub_agents=[
graph_db_agent,
investor_agent,
investment_agent
]
)
- Spezialisierte Kundenservicemitarbeiter: Jeder Kundenservicemitarbeiter hat
- Spezifische Tools: Funktionen, die aufgerufen werden können
- Klare Anweisungen: Rolle und Funktionen
- Domänenwissen: Wissen über den Bereich
- Orchestrierungsmuster:
- Sequenziell: Agenten in der richtigen Reihenfolge ausführen
- Parallel: Mehrere Agents gleichzeitig ausführen
- Bedingt: Routing basierend auf dem Anfragetyp
MCP Toolbox for Databases
Das Model Context Protocol (MCP) ist ein offener Standard zum Verbinden von KI-Systemen mit externen Datenquellen und Tools. Die MCP Toolbox for Databases ist die Implementierung von Google, die die deklarative Verwaltung von Datenbankabfragen ermöglicht. So können Sie vorab validierte, von Experten erstellte Abfragen als wiederverwendbare Tools definieren. Anstatt LLMs potenziell unsichere Anfragen generieren zu lassen, stellt die MCP Toolbox vorab genehmigte Anfragen mit Parameterüberprüfung bereit. So werden Sicherheit, Leistung und Zuverlässigkeit gewährleistet und gleichzeitig die Flexibilität für KI-Agenten beibehalten.
Traditioneller Ansatz:
# LLM generates query (may be incorrect/unsafe)
query = llm.generate("SELECT * FROM users WHERE...")
db.execute(query) # Risk of errors/SQL injection
MCP-Ansatz:
# Pre-validated query definition
- name: get_industries
description: Fetch all industries from database
query: |
MATCH (i:Industry)
RETURN i.name, i.id
Vorteile:
- Von Experten vorab validiert
- Schutz vor Injection-Angriffen
- Leistungsoptimiert
- Zentral verwaltet
- In mehreren Agents wiederverwendbar
Abschluss
Die Kombination aus GraphRAG, Multi-Agenten-Framework von ADK und MCP ergibt ein leistungsstarkes System:
- Der Root-Agent empfängt die Nutzeranfrage.
- Weiterleitung an einen spezialisierten Kundenservicemitarbeiter basierend auf dem Anfragetyp
- Der Agent verwendet MCP-Tools, um Daten sicher abzurufen.
- Die Diagrammstruktur bietet umfangreichen Kontext.
- Das LLM generiert eine fundierte, nachvollziehbare Antwort.
Nachdem wir uns mit der Architektur vertraut gemacht haben, können wir mit der Entwicklung beginnen.
3. Google Cloud-Projekt einrichten
Projekt erstellen
- Wählen Sie in der Google Cloud Console auf der Seite zur Projektauswahl ein Google Cloud-Projekt aus oder erstellen Sie eines.
- Die Abrechnung für das Cloud-Projekt muss aktiviert sein. So prüfen Sie, ob die Abrechnung für ein Projekt aktiviert ist .
- Sie verwenden Cloud Shell, eine Befehlszeilenumgebung, die in Google Cloud ausgeführt wird. Klicken Sie oben in der Google Cloud Console auf „Cloud Shell aktivieren“. Sie können zwischen dem Cloud Shell-Terminal (zum Ausführen von Cloud-Befehlen) und dem Editor (zum Erstellen von Projekten) wechseln, indem Sie in Cloud Shell auf die entsprechende Schaltfläche klicken.

- Sobald die Verbindung mit der Cloud Shell hergestellt ist, prüfen Sie mit dem folgenden Befehl, ob Sie bereits authentifiziert sind und für das Projekt schon Ihre Projekt-ID eingestellt ist:
gcloud auth list
- Führen Sie den folgenden Befehl in Cloud Shell aus, um zu bestätigen, dass der gcloud-Befehl Ihr Projekt kennt.
gcloud config list project
- Wenn Ihr Projekt nicht festgelegt ist, verwenden Sie den folgenden Befehl, um es festzulegen:
gcloud config set project <YOUR_PROJECT_ID>
Informationen zu gcloud-Befehlen und deren Verwendung finden Sie in der Dokumentation.
Super! Wir können nun mit dem nächsten Schritt fortfahren: dem Analysieren des Datasets.
4. Das Dataset „Unternehmen“
In diesem Codelab verwenden wir eine schreibgeschützte Neo4j-Datenbank, die mit Investitions- und Unternehmensdaten aus dem Knowledge Graph von Diffbot vorab gefüllt wurde.
Das Dataset enthält:
- 237.358 Knoten,die Folgendes darstellen:
- Organisationen (Unternehmen)
- Personen (Führungskräfte, Mitarbeiter)
- Artikel (Nachrichten und Erwähnungen)
- Branchen
- Technologien
- Investoren
- Beziehungen, einschließlich:
HAS_INVESTOR– InvestmentverbindungenHAS_COMPETITOR– WettbewerbsbeziehungenMENTIONS– ArtikelreferenzenHAS_CEO– ArbeitsverhältnisseHAS_CATEGORY– Branchenklassifizierungen
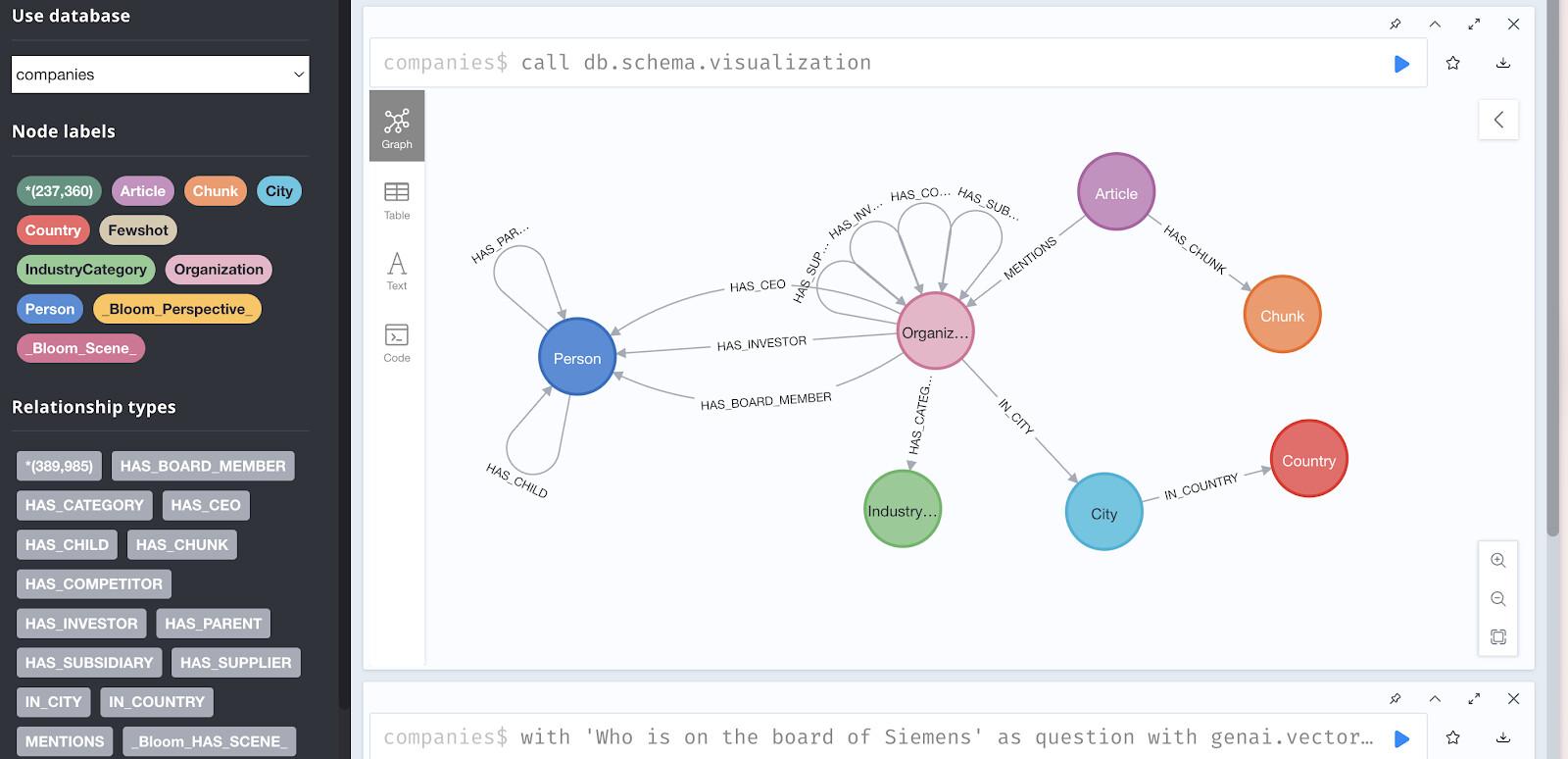
Auf die Demodatenbank zugreifen
In diesem Codelab verwenden wir eine gehostete Demo-Instanz. Fügen Sie diese Anmeldedaten Ihren Notizen hinzu:
URI: neo4j+s://demo.neo4jlabs.com
Username: companies
Password: companies
Database: companies
Browserzugriff:
Sie können die Daten unter https://demo.neo4jlabs.com:7473 visuell darstellen.
Melden Sie sich mit denselben Anmeldedaten an und führen Sie Folgendes aus:
// Sample query to explore the graph
MATCH (c:Organization)-[:HAS_COMPETITOR]-(competitor:Organization)
RETURN c.name, competitor.name
LIMIT 10
Graphstruktur visualisieren
Führen Sie diese Abfrage im Neo4j-Browser aus, um Beziehungsmuster zu sehen:
// Find investors and their portfolio companies
MATCH (company:Organization)-[:HAS_INVESTOR]->(investor:Person)
WITH investor, collect(company.name) as portfolio
RETURN investor.name, size(portfolio) as num_investments, portfolio
ORDER BY num_investments DESC
LIMIT 5
Diese Abfrage gibt die fünf aktivsten Investoren und ihre Portfolios zurück.
Warum diese Datenbank für GraphRAG?
Dieses Dataset eignet sich hervorragend für die Demonstration von GraphRAG, da:
- Umfangreiche Beziehungen: Komplexe Verbindungen zwischen Entitäten
- Reale Daten: tatsächliche Unternehmen, Personen und Nachrichtenartikel
- Multi-Hop-Abfragen: Erfordert das Durchlaufen mehrerer Beziehungstypen
- Zeitbezogene Daten: Artikel mit Zeitstempeln für zeitbasierte Analysen
- Sentimentanalyse: Vorab berechnete Sentiment-Scores für Artikel
Nachdem Sie sich mit der Datenstruktur vertraut gemacht haben, können Sie Ihre Entwicklungsumgebung einrichten.
5. Repository klonen und Umgebung konfigurieren
Repository klonen
Führen Sie im Cloud Shell-Terminal folgenden Befehl aus:
# Clone the repository
git clone https://github.com/sidagarwal04/neo4j-adk-multiagents.git
# Navigate into the directory
cd neo4j-adk-multiagents
Repository-Struktur ansehen
Sehen Sie sich das Projektlayout an:
neo4j-adk-multiagents/
├── investment_agent/ # Main agent code
│ ├── agent.py # Agent definitions
│ ├── tools.py # Custom tool functions
│ └── .adk/ # ADK configuration
│ └── tools.yaml # MCP tool definitions
├── main.py # Application entry point
├── setup_tools_yaml.py # Configuration generator
├── requirements.txt # Python dependencies
├── example.env # Environment template
└── README.md # Project documentation
Virtuelle Umgebung einrichten
Erstellen und aktivieren Sie eine virtuelle Python-Umgebung mit uv:
# Install uv if not already installed
pip install uv
# Create virtual environment
uv venv
# Activate the environment
source .venv/bin/activate # On macOS/Linux
# or
.venv\Scripts\activate # On Windows
(.venv) sollte nun vor der Eingabeaufforderung in Ihrem Terminal angezeigt werden.
Abhängigkeiten installieren
Installieren Sie alle erforderlichen Pakete:
uv pip install -r requirements.txt
Wichtige Abhängigkeiten:
txtgoogle-adk>=1.21.0 # Agent Development Kit
neo4j>=6.0.3 # Neo4j Python driver
python-dotenv>=1.0.0 # Environment variables
google-cloud-aiplatform>=1.30.0 # Vertex AI
Umgebungsvariablen konfigurieren
- Erstellen Sie die Datei **
.env**:
cp example.env .env
- Bearbeiten Sie die Datei **
.env**:
Wenn Sie Cloud Shell verwenden, klicken Sie in der Symbolleiste auf „Editor öffnen“, rufen Sie .env auf und aktualisieren Sie Folgendes:
So machen Sie die verborgene Datei .env sichtbar:
Klicken Sie im Google Cloud Shell-Editor auf View > Toggle Hidden files.
# Neo4j Configuration (Demo Database)
NEO4J_URI=neo4j+s://demo.neo4jlabs.com
NEO4J_USERNAME=companies
NEO4J_PASSWORD=companies
NEO4J_DATABASE=companies
# Google AI Configuration
# Choose ONE of the following options:
# Option 1: Google AI API (Recommended)
GOOGLE_GENAI_USE_VERTEXAI=0
GOOGLE_API_KEY=your_api_key_here # Get from https://aistudio.google.com/app/apikey
# Option 2: Vertex AI (If using GCP)
# GOOGLE_GENAI_USE_VERTEXAI=1
# GOOGLE_CLOUD_PROJECT=your-project-id
# GOOGLE_CLOUD_LOCATION=us-central1
# ADK Configuration
GOOGLE_ADK_MODEL=gemini-3.1-flash-lite-preview # or gemini-3-flash-preview
# MCP Toolbox Configuration
MCP_TOOLBOX_URL=https://toolbox-990868019953.us-central1.run.app/mcp/sse
- MCP Toolbox-Konfiguration generieren:
Führen Sie das Setupscript aus, um die Datei tools.yaml aus Ihren Umgebungsvariablen zu erstellen:
python setup_tools_yaml.py
Dadurch wird investment_agent/.adk/tools.yaml mit Ihren Neo4j-Anmeldedaten generiert, die für MCP-Tools richtig konfiguriert sind.
Konfiguration überprüfen
Prüfen Sie, ob alles richtig eingerichtet ist:
# Verify .env file exists
ls -la .env
# Verify tools.yaml was generated
ls -la investment_agent/.adk/tools.yaml
# Test Python environment
python -c "import google.adk; print('ADK installed successfully')"
# Test Neo4j connection
python -c "from neo4j import GraphDatabase; print('Neo4j driver installed')"
Ihre Entwicklungsumgebung ist jetzt vollständig konfiguriert. Als Nächstes sehen wir uns die Architektur mit mehreren Agenten an.
6. Architektur mit mehreren Agenten
Das Vier-Agenten-System
Unser System für die Anlageforschung nutzt eine hierarchische Multi-Agent-Architektur mit vier spezialisierten Agents, die zusammenarbeiten, um komplexe Anfragen zu Unternehmen, Investoren und Marktinformationen zu beantworten.
┌──────────────┐
│ Root Agent │ ◄── User Query
└──────┬───────┘
│
┌────────────────┼────────────────┐
│ │ │
┌─────▼─────┐ ┌────▼─────┐ ┌────▼──────────┐
│ Graph DB │ │ Investor │ │ Investment │
│ Agent │ │ Research │ │ Research │
└───────────┘ │ Agent │ │ Agent │
└──────────┘ └───────────────┘
- Root-Agent (Orchestrator):
Der Root-Agent fungiert als intelligenter Koordinator des gesamten Systems. Er empfängt Nutzeranfragen, analysiert die Absicht und leitet Anfragen an den am besten geeigneten spezialisierten Agenten weiter. Stellen Sie sich vor, Sie sind ein Projektmanager, der weiß, welches Teammitglied am besten für die jeweilige Aufgabe geeignet ist. Außerdem werden Antworten zusammengefasst, Ergebnisse auf Anfrage als Tabellen oder Diagramme formatiert und der Gesprächskontext über mehrere Anfragen hinweg beibehalten. Der Stamm-Agent bevorzugt immer spezialisierte Agents gegenüber dem allgemeinen Datenbank-Agenten, damit Anfragen von der kompetentesten verfügbaren Komponente bearbeitet werden.
- Graph Database Agent:
Der Graph Database Agent ist Ihre direkte Verbindung zu den leistungsstarken Graph-Funktionen von Neo4j. Es versteht das Datenbankschema, generiert Cypher-Abfragen aus natürlicher Sprache und führt komplexe Graphdurchläufe aus. Dieser Agent ist auf strukturelle Fragen, Aggregationen und Multi-Hop-Schlussfolgerungen im Knowledge Graph spezialisiert. Er ist der Fallback-Experte, wenn für Anfragen benutzerdefinierte Logik erforderlich ist, die mit vordefinierten Tools nicht verarbeitet werden kann. Daher ist er für explorative Analysen und komplexe analytische Anfragen unerlässlich, die im Systemdesign nicht berücksichtigt wurden.
- Investor Research Agent:
Der Investor Research Agent konzentriert sich ausschließlich auf Investitionsbeziehungen und Portfolioanalysen. Es kann ermitteln, wer in bestimmte Unternehmen investiert hat, indem es den genauen Namen abgleicht, vollständige Investorenportfolios mit allen Investitionen abrufen und Investitionsmuster in verschiedenen Branchen analysieren. Diese Spezialisierung macht es äußerst effizient bei der Beantwortung von Fragen wie „Wer hat in ByteDance investiert?“ oder „In was hat Sequoia Capital noch investiert?“. Der Agent verwendet benutzerdefinierte Python-Funktionen, mit denen die Neo4j-Datenbank direkt nach Beziehungen im Zusammenhang mit Investoren abgefragt wird.
- Investment Research Agent:
Der Investment Research Agent nutzt die MCP-Toolbox (Model Context Protocol), um auf vorab validierte, von Experten erstellte Anfragen zuzugreifen. Sie kann alle verfügbaren Branchen abrufen, Unternehmen in bestimmten Branchen finden, Artikel mit Sentimentanalyse finden, Erwähnungen von Organisationen in Nachrichten entdecken und Informationen zu Personen abrufen, die in Unternehmen arbeiten. Im Gegensatz zum Graph Database Agent, der Abfragen dynamisch generiert, verwendet dieser Agent sichere, optimierte, vordefinierte Abfragen, die zentral verwaltet und validiert werden. Das macht es sowohl sicher als auch leistungsstark für gängige Forschungs-Workflows.
7. Multi-Agenten-System ausführen und testen
Anwendung starten
Nachdem Sie nun die Architektur kennen, können wir das gesamte System ausführen und damit interagieren.
ADK-Weboberfläche starten:
# Make sure you're in the project directory with activated virtual environment
cd ~/neo4j-adk-multiagents
source .venv/bin/activate # If not already activated
# Launch the application
uv run adk web
Die Ausgabe sollte etwa so aussehen:
INFO: Started server process [2542]
INFO: Waiting for application startup.
+----------------------------------------------------------------+
| ADK Web Server started |
| |
| For local testing, access at http://127.0.0.1:8000. |
+----------------------------------------------------------------+
INFO: Application startup complete.
INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
Abfragen und erwartetes Verhalten testen
Sehen wir uns die Funktionen des Systems anhand von immer komplexeren Anfragen an:
Einfache Anfragen (einzelner Agent)
Abfrage 1: Branchen entdecken
What industries are available in the database?
Erwartetes Verhalten:
- Root-Agent leitet Anfragen an den Investment Research-Agent weiter
- Verwendet das MCP-Tool:
get_industries() - Gibt eine formatierte Liste aller Branchen zurück.
Was ist zu beobachten?
Maximieren Sie in der ADK-Benutzeroberfläche die Ausführungsdetails, um Folgendes zu sehen:
- Entscheidung zur Auswahl von KI-Agenten
- Toolaufruf:
get_industries() - Rohdaten aus Neo4j
- Formatierte Antwort
Abfrage 2: Investoren finden
Who invested in ByteDance?
Erwartetes Verhalten:
- Der Root-Agent identifiziert dies als anlegerbezogene Anfrage.
- Weiterleitung an den Investor Research Agent
- Verwendet Tool:
find_investor_by_name("ByteDance") - Gibt Investoren mit ihren Typen (Person/Organisation) zurück
Erwartete Antwort:
I found 2 investors in ByteDance:
1. Rong Yue (Person)
2. Wendi Murdoch (Person)
Would you like to know more about their investment portfolios?
Abfrage 3: Unternehmen nach Branche**
I found 2 investors in ByteDance:
1. Rong Yue (Person)
2. Wendi Murdoch (Person)
Would you like to know more about their investment portfolios?
"Show me companies in the Artificial Intelligence industry"
Erwartetes Verhalten:
- Root-Agent leitet Anfragen an den Investment Research-Agent weiter
- Verwendet das MCP-Tool:
get_companies_in_industry("Artificial Intelligence") - Gibt eine Liste von KI-Unternehmen mit IDs und Gründungsdaten zurück.
Was du beobachten solltest:
- Achten Sie darauf, wie der Agent den genauen Namen der Branche verwendet.
- Die Ergebnisse sind begrenzt, um eine Überforderung durch die Ausgabe zu vermeiden.
- Die Daten sind zur besseren Lesbarkeit übersichtlich formatiert.
Zwischenabfragen (mehrere Schritte innerhalb eines Agents)
Abfrage 4: Sentimentanalyse
Find articles with positive sentiment from January 2023
Erwartetes Verhalten:
- Zugriff auf den Investment Research Agent
- Verwendet das MCP-Tool:
get_articles_with_sentiment(0.7, 2023, 1) - Gibt Artikel mit Titeln, Sentiment-Werten und Veröffentlichungsdaten zurück
Tipp zur Fehlerbehebung:
Sehen Sie sich die Parameter für den Tool-Aufruf an:
min_sentiment: 0,7 (der Agent interpretiert „positiv“ als >= 0,7)year: 2023month: 1
Abfrage 5: Komplexe Datenbankabfrage
How many companies are in the database?
Erwartetes Verhalten:
- Root-Agent leitet Anfragen an Graph Database Agent weiter
- Der Agent ruft zuerst
get_neo4j_schema()auf, um die Struktur zu verstehen. - Generiert Cypher:
MATCH (c:Company) RETURN count(c) - Führt die Abfrage aus und gibt die Anzahl zurück
Erwartete Antwort:
There are 8,064 companies in the database.
Erweiterte Anfragen (Koordination mehrerer Agents)
Abfrage 6: Portfolioanalyse
Who invested in ByteDance and what else have they invested in?
Erwartetes Verhalten:
Dies ist eine zweiteilige Anfrage, die eine Abstimmung mit dem Kundenservicemitarbeiter erfordert:
- Schritt 1: Root Agent → Investor Research Agent
- Ruft
find_investor_by_name("ByteDance")auf - Ruft die Investorenliste ab: [Rong Yue, Wendi Murdoch]
- Schritt 2: Für jeden Investor → Investor Research Agent
- Ruft
find_investor_by_id(investor_id)auf - Ruft das vollständige Portfolio ab
- Schritt 3: Root-Agent aggregiert und formatiert
Erwartete Antwort:
I found 2 investors in ByteDance. Here are their portfolios:
1. Rong Yue (Person)
- ByteDance
- Inspur
2. Wendi Murdoch (Person)
- ByteDance
- (No other investments in database)
Was du beobachten solltest:
- Mehrere Toolaufrufe in Folge
- Kontext wird zwischen Schritten beibehalten
- Intelligent zusammengefasste Ergebnisse
Abfrage 7: Recherche in mehreren Domains
What are 5 AI companies mentioned in positive articles, and who are their CEOs?
Erwartetes Verhalten:
Für diese komplexe Anfrage sind mehrere KI-Agents und Tools erforderlich:
- Schritt 1: Investment Research Agent
get_companies_in_industry("Artificial Intelligence")- Gibt eine Liste von KI-Unternehmen zurück
- Schritt 2: Investment Research Agent
get_articles_with_sentiment(0.8)- Es werden positive Artikel zurückgegeben.
- Schritt 3: Root-Agent-Filter
- Identifiziert, welche KI-Unternehmen in positiven Artikeln erwähnt werden
- Wählt die 5 besten aus
- Schritt 4: Investment Research Agent
get_people_in_organizations([company_names], "CEO")- Gibt Informationen zum CEO zurück
- Schritt 5: Root-Agent-Format als Tabelle
Erwartete Antwort:
Here are 5 AI companies with positive news and their CEOs:
| Company | Industry | CEO | Avg Sentiment |
|---------|----------|-----|---------------|
| OpenAI | Artificial Intelligence | Sam Altman | 0.92 |
| Anthropic | Artificial Intelligence | Dario Amodei | 0.89 |
| ... | ... | ... | ... |
Was ist zu beobachten?
- Mehrere Toolaufrufe über verschiedene Agents hinweg
- Logik für Datenfilterung und ‐kombination
- Professionelle Tabellenformatierung
Abfrage 8: Wettbewerbsanalyse
Who are YouTube's main competitors?
Erwartetes Verhalten:
- Root Agent leitet Anfragen an den Graph Database Agent weiter (Beziehungsabfrage)
- Der Agent generiert GraphRAG-optimierten Cypher-Code:
MATCH (c:Company {name: "YouTube"})-[:COMPETES_WITH]->(competitor)
RETURN competitor.name as competitor_name
- Gibt eine Liste der konkurrierenden Unternehmen zurück.
Erwartete Antwort:
YouTube's main competitors are:
- TikTok (ByteDance)
- Dailymotion
- Twitter
- BuzzFeed
- Mixer
- OpenAI (for video content)
Kontextbezogene Folgeanfragen
Abfrage 9: Folgefrage (nach Abfrage 8)
Which investors funded both YouTube and its competitors?
Erwartetes Verhalten:
- Der Root-Agent merkt sich den vorherigen Kontext (YouTube und seine Mitbewerber).
- Weiterleitung an den Investor Research Agent
- Für YouTube und jeden Mitbewerber werden Investoren gefunden.
- Identifiziert Investoren, die in mehreren Unternehmen vertreten sind
Erwartete Antwort:
Based on our previous analysis of YouTube's competitors, I found these
investors who funded multiple companies in this competitive landscape:
Sequoia Capital invested in:
- YouTube
- TikTok (ByteDance)
- Twitter
Accel Partners invested in:
- YouTube
- BuzzFeed
This suggests these investors have strategic positions across the video content platform ecosystem.
Abfrage 10: Zusammenfassung der Recherche
Summarize our research findings so far
Erwartetes Verhalten:
- Root-Agent prüft den Unterhaltungsverlauf
- Die wichtigsten Erkenntnisse aus früheren Anfragen werden zusammengefasst.
- Bietet eine kohärente Zusammenfassung
Erwartete Antwort:
Here's a summary of our investment research session:
1. Industry Overview: We explored the Artificial Intelligence industry
with 150+ companies in the database.
2. ByteDance Analysis:
- Investors: Rong Yue, Wendi Murdoch
- Rong Yue also invested in Inspur
3. Market Sentiment: We analyzed articles from January 2023, finding
strong positive sentiment (avg 0.85) for tech companies.
4. Competitive Landscape: YouTube faces competition from TikTok,
Dailymotion, and others, with some investors (Sequoia, Accel) holding
positions across competing platforms.
5. Key Players: Identified CEOs of major AI companies with positive media coverage.
Agent-Interaktionen in der Debugging-Ansicht
Die ADK-Weboberfläche bietet detaillierte Informationen zur Ausführung. Achten Sie auf Folgendes:
- Ereignisverlauf
Chronologischer Ablauf:
[USER] Query received
[ROOT_AGENT] Analyzing query intent
[ROOT_AGENT] Routing to investment_research_agent
[INVESTMENT_RESEARCH_AGENT] Tool call: get_companies_in_industry
[TOOL] Executing with params: {"industry_name": "Artificial Intelligence"}
[TOOL] Returned 47 results
[INVESTMENT_RESEARCH_AGENT] Formatting response
[ROOT_AGENT] Presenting to user
- Details zum Aufrufen von Tools
Klicken Sie auf einen beliebigen Toolaufruf, um Folgendes zu sehen:
- Funktionsname
- Eingabeparameter
- Rückgabewert
- Ausführungszeit
- Fehler
- Entscheidungsfindung durch Agenten
Logik des LLM beobachten:
- Warum wurde ein bestimmter KI-Agent ausgewählt?
- Wie die Anfrage interpretiert wurde
- Welche Tools wurden berücksichtigt?
- Warum Ergebnisse auf eine bestimmte Weise formatiert wurden
Häufige Beobachtungen und Statistiken
- Muster für das Weiterleiten von Anfragen:
- Keywords wie „Investor“, „investiert“ → Investor Research Agent
- Keywords wie „Branche“, „Unternehmen“, „Artikel“ → Investment Research Agent
- Aggregationen, Anzahl, komplexe Logik → Graph Database Agent
- Hinweise zur Leistung:
- MCP-Tools sind in der Regel schneller (voroptimierte Anfragen).
- Die Generierung komplexer Cypher-Abfragen dauert länger (LLM-Denkzeit).
- Mehrere Toolaufrufe erhöhen die Latenz, liefern aber umfassendere Ergebnisse.
- Fehlerbehandlung:
- Wenn eine Abfrage fehlschlägt:
- Der KI-Agent erklärt, was schiefgelaufen ist
- Es werden Korrekturen vorgeschlagen, z. B. „Name des Unternehmens nicht gefunden, Rechtschreibung prüfen“.
- Möglicherweise werden alternative Ansätze ausprobiert
Tipps für effektive Tests
- Einfach anfangen: Testen Sie die Hauptfunktion jedes Agenten, bevor Sie komplexe Anfragen stellen.
- Follow-ups verwenden: Testen Sie die Kontextbeibehaltung mit Folgefragen.
- Routing beobachten: Sehen Sie sich an, welcher Agent die einzelnen Anfragen bearbeitet, um die Logik zu verstehen.
- Tool-Aufrufe prüfen: Prüfen Sie, ob Parameter korrekt aus natürlicher Sprache extrahiert werden.
- Grenzfälle testen: Versuchen Sie es mit mehrdeutigen Anfragen, Rechtschreibfehlern oder ungewöhnlichen Anfragen.
Sie haben jetzt ein voll funktionsfähiges Multi-Agent-GraphRAG-System. Experimentieren Sie mit eigenen Fragen, um die Möglichkeiten zu erkunden.
8. Bereinigen
So vermeiden Sie, dass Ihrem Google Cloud-Konto die in diesem Beitrag verwendeten Ressourcen in Rechnung gestellt werden:
- Wechseln Sie in der Google Cloud Console zur Seite Ressourcen verwalten.
- Wählen Sie in der Projektliste das Projekt aus, das Sie löschen möchten, und klicken Sie auf Löschen.
- Geben Sie im Dialogfeld die Projekt-ID ein und klicken Sie auf Herunterfahren, um das Projekt zu löschen.
9. Glückwunsch
🎉 Glückwunsch! Sie haben mit dem Agent Development Kit von Google, Neo4j und der MCP Toolbox ein Multi-Agenten-GraphRAG-System in Produktionsqualität erstellt.
Durch die Kombination der intelligenten Orchestrierungsfunktionen von ADK mit dem beziehungsreichen Datenmodell von Neo4j und der Sicherheit vorab validierter MCP-Abfragen haben Sie ein ausgeklügeltes System geschaffen, das über einfache Datenbankabfragen hinausgeht. Es versteht den Kontext, zieht Schlussfolgerungen aus komplexen Beziehungen und koordiniert spezialisierte Agenten, um umfassende, genaue Statistiken zu liefern.
In diesem Codelab haben Sie Folgendes erreicht:
✅ Multi-Agenten-System erstellt mit dem Agent Development Kit (ADK) von Google mit hierarchischer Orchestrierung
✅ Integrierte Neo4j-Grafikdatenbank für beziehungsbezogene Abfragen und Multi-Hop-Reasoning
✅ MCP Toolbox für sichere, vorab validierte Datenbankabfragen als wiederverwendbare Tools implementiert
✅ Spezialisierte KI-Agents erstellt für die Investorenrecherche, Anlageanalyse und den Betrieb von Graphdatenbanken
✅ Intelligentes Routing, das Anfragen automatisch an den am besten geeigneten Expert-Agenten weiterleitet
✅ Komplexe Datentypen werden verarbeitet mit korrekter Neo4j-Typserialisierung für eine nahtlose Python-Integration.
✅ Best Practices für die Produktion für das Agent-Design, die Fehlerbehandlung und das System-Debugging angewendet
Wie geht es weiter?
Diese Multi-Agent-GraphRAG-Architektur ist nicht auf die Anlageforschung beschränkt, sondern kann auf Folgendes ausgeweitet werden:
- Finanzdienstleistungen: Portfolio-Optimierung, Risikobewertung, Betrugserkennung
- Gesundheitswesen: Koordination der Patientenversorgung, Analyse von Arzneimittelwechselwirkungen, klinische Forschung
- E-Commerce: Personalisierte Empfehlungen, Optimierung der Lieferkette, Kundenstatistiken
- Recht und Compliance: Vertragsanalyse, Überwachung von Vorschriften, Recherche von Rechtsprechung
- Wissenschaftliche Forschung: Literaturrecherche, Zusammenarbeit, Zitationsanalyse
- Enterprise Intelligence: Wettbewerbsanalysen, Marktforschung, Organisations-Knowledge Graphs
Überall dort, wo Sie komplexe, miteinander verbundene Daten + Fachwissen + Schnittstellen für natürliche Sprache haben, kann diese Kombination aus ADK-Multi-Agent-Systemen + Neo4j-Knowledge-Graphs + MCP-validierten Abfragen die nächste Generation intelligenter Unternehmensanwendungen ermöglichen.
Da sich das Agent Development Kit von Google und die Gemini-Modelle ständig weiterentwickeln, können Sie noch anspruchsvollere Schlussfolgerungsmuster, Echtzeitdatenintegration und multimodale Funktionen einbinden, um wirklich intelligente, kontextbezogene Systeme zu entwickeln.
Weiter gehts mit dem Entdecken und Entwickeln – bringen Sie Ihre intelligenten Agentenanwendungen auf das nächste Level.
Noch mehr praktische Tutorials zum Knowledge Graph finden Sie in der Neo4j GraphAcademy. Zusätzliche Agent-Muster finden Sie im ADK Samples Repository.
🚀 Bereit für Ihr nächstes intelligentes Agentsystem?