
۱. مرور کلی
در این آزمایشگاه کد، شما یک سیستم تحقیق سرمایهگذاری چندعاملی پیچیده خواهید ساخت که قدرت کیت توسعه عامل گوگل (ADK)، پایگاه داده گراف Neo4j و جعبه ابزار پروتکل زمینه مدل (MCP) را با هم ترکیب میکند. این آموزش عملی نشان میدهد که چگونه میتوان عاملهای هوشمندی ایجاد کرد که زمینه دادهها را از طریق روابط گراف درک میکنند و پاسخهای پرسوجوی بسیار دقیقی ارائه میدهند.
چرا GraphRAG + سیستمهای چندعامله؟
GraphRAG (تولید افزوده بازیابی مبتنی بر گراف) با بهرهگیری از ساختار روابط غنی گرافهای دانش، رویکردهای سنتی RAG را بهبود میبخشد. به جای جستجوی صرف اسناد مشابه، عاملهای GraphRAG میتوانند:
- روابط پیچیده بین موجودیتها را بررسی کنید
- درک زمینه از طریق ساختار نمودار
- ارائه نتایج قابل توضیح بر اساس دادههای متصل
- اجرای استدلال چندگامی در سراسر نمودار دانش
سیستمهای چندعاملی به شما این امکان را میدهند که:
- تجزیه مسائل پیچیده به زیر وظایف تخصصی
- ساخت برنامههای هوش مصنوعی ماژولار و قابل نگهداری
- پردازش موازی و استفاده کارآمد از منابع را فعال کنید
- ایجاد الگوهای استدلال سلسله مراتبی با ارکستراسیون
آنچه خواهید ساخت
شما یک سیستم تحقیق سرمایهگذاری کامل ایجاد خواهید کرد که شامل موارد زیر است:
- عامل پایگاه داده گراف : کوئریهای Cypher را اجرا میکند و طرح Neo4j را درک میکند.
- نماینده تحقیقات سرمایهگذار : روابط سرمایهگذاران و سبدهای سرمایهگذاری را کشف میکند
- نماینده تحقیقات سرمایهگذاری : از طریق ابزارهای MCP به نمودارهای دانش جامع دسترسی پیدا میکند.
- عامل ریشه : همه عاملهای فرعی را هوشمندانه هماهنگ میکند
این سیستم به سوالات پیچیدهای مانند موارد زیر پاسخ خواهد داد:
- «رقبای اصلی یوتیوب چه کسانی هستند؟»
- «در ژانویه ۲۰۲۳، چه شرکتهایی با دیدگاه مثبت ذکر شدهاند؟»
- «چه کسی در ByteDance سرمایهگذاری کرده و در کجاهای دیگر سرمایهگذاری کردهاند؟»
نمای کلی معماری
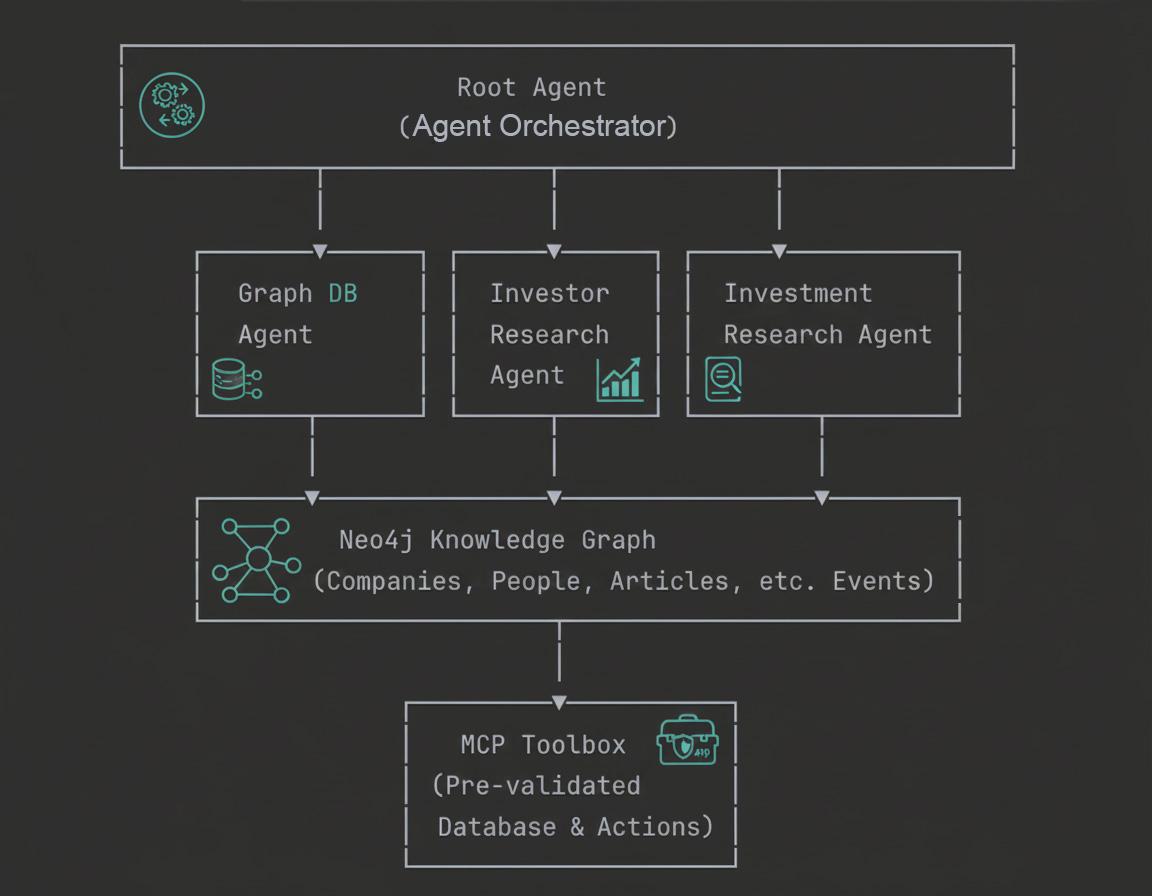
از طریق این آزمایشگاه کد، شما هم مبانی مفهومی و هم پیادهسازی عملی ساخت عاملهای GraphRAG در سطح سازمانی را خواهید آموخت.
آنچه یاد خواهید گرفت
- نحوه ساخت سیستمهای چندعاملی با استفاده از کیت توسعه عامل گوگل (ADK)
- نحوه ادغام پایگاه داده گراف Neo4j با ADK برای برنامههای GraphRAG
- نحوه پیادهسازی جعبه ابزار پروتکل زمینه مدل (MCP) برای کوئریهای از پیش اعتبارسنجیشده پایگاه داده
- نحوه ایجاد ابزارها و توابع سفارشی برای عاملهای هوشمند
- نحوه طراحی سلسله مراتب عاملها و الگوهای ارکستراسیون
- نحوه ساختاردهی دستورالعملهای عامل برای عملکرد بهینه
- چگونه تعاملات چند عاملی را به طور موثر اشکال زدایی کنیم
آنچه نیاز دارید
- مرورگر وب کروم
- یک حساب جیمیل
- یک پروژه گوگل کلود با قابلیت پرداخت صورتحساب
- آشنایی اولیه با دستورات ترمینال و پایتون (مفید است اما الزامی نیست)
این آزمایشگاه کد که برای توسعهدهندگان در تمام سطوح (از جمله مبتدیان) طراحی شده است، در برنامه نمونه خود از پایتون و Neo4j استفاده میکند. اگرچه آشنایی اولیه با پایتون و پایگاههای داده گراف میتواند مفید باشد، اما برای درک مفاهیم یا دنبال کردن آن نیازی به تجربه قبلی نیست.
۲. درک GraphRAG و سیستمهای چندعاملی
قبل از پرداختن به پیادهسازی، بیایید مفاهیم کلیدی که این سیستم را قدرتمند میکنند را درک کنیم.
Neo4j یک پایگاه داده گراف بومی پیشرو است که دادهها را به صورت شبکهای از گرهها (موجودیتها) و روابط (ارتباطات بین موجودیتها) ذخیره میکند و آن را برای مواردی که درک ارتباطات کلیدی است - مانند توصیهها، تشخیص تقلب، گرافهای دانش و موارد دیگر - ایدهآل میکند. برخلاف پایگاههای داده رابطهای یا مبتنی بر سند که به جداول سفت و سخت یا ساختارهای سلسله مراتبی متکی هستند، مدل گراف انعطافپذیر Neo4j امکان نمایش شهودی و کارآمد دادههای پیچیده و به هم پیوسته را فراهم میکند.
به جای سازماندهی دادهها در ردیفها و جداول مانند پایگاههای داده رابطهای، Neo4j از یک مدل گراف استفاده میکند که در آن اطلاعات به صورت گرهها (موجودیتها) و روابط (ارتباطات بین آن موجودیتها) نمایش داده میشوند. این مدل، کار با دادههایی که ذاتاً به هم مرتبط هستند - مانند افراد، مکانها، محصولات یا در مورد ما، فیلمها، بازیگران و ژانرها - را فوقالعاده شهودی میکند.
برای مثال، در یک مجموعه داده فیلم:
- یک گره میتواند نمایانگر یک
Movie،ActorیاDirectorباشد - یک رابطه میتواند
ACTED_INیاDIRECTEDباشد.
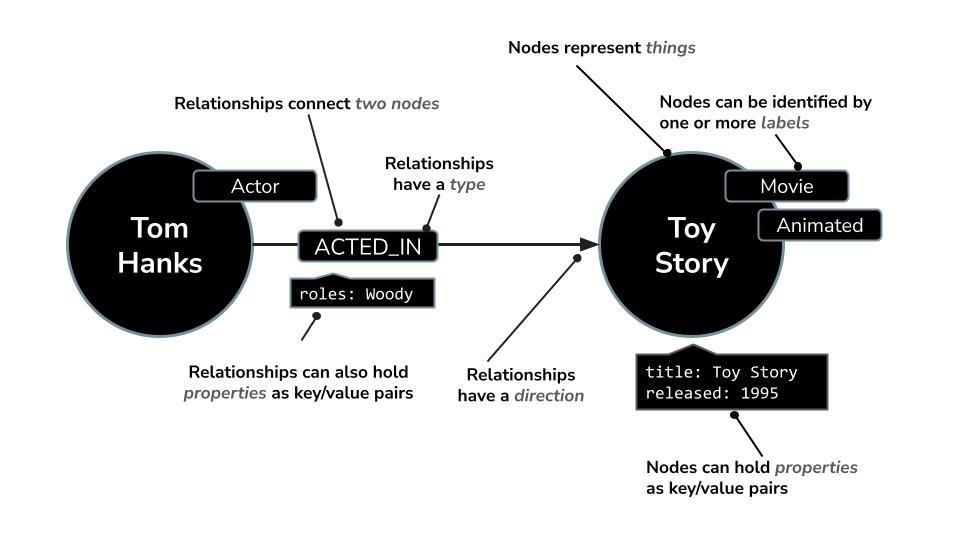
این ساختار به شما امکان میدهد به راحتی سوالاتی مانند موارد زیر را بپرسید:
- این بازیگر در کدام فیلمها بازی کرده است؟
- چه کسانی با کریستوفر نولان همکاری داشتهاند؟
- فیلمهای مشابه بر اساس بازیگران یا ژانرهای مشترک کدامند؟
گرافرَگ چیست؟
تولید افزوده بازیابی (RAG) با بازیابی اطلاعات مرتبط از منابع خارجی، پاسخهای LLM را بهبود میبخشد. RAG سنتی معمولاً:
- اسناد را در بردارها جاسازی میکند
- جستجوی بردارهای مشابه
- اسناد بازیابی شده را به LLM منتقل می کند
GraphRAG این را با استفاده از نمودارهای دانش گسترش میدهد:
- موجودیتها و روابط را جاسازی میکند
- اتصالات گراف را پیمایش میکند
- اطلاعات زمینهای چندگامی را بازیابی میکند
- نتایج ساختاریافته و قابل توضیح ارائه میدهد
چرا نمودارها برای عاملهای هوش مصنوعی؟
این سوال را در نظر بگیرید: «رقبای یوتیوب چه کسانی هستند و کدام سرمایهگذاران هم یوتیوب و هم رقبای آن را تأمین مالی کردهاند؟»
آنچه در رویکرد سنتی RAG اتفاق میافتد:
- جستجو برای اسناد مربوط به رقبای یوتیوب
- به طور جداگانه برای اطلاعات سرمایهگذار جستجو میکند
- برای ارتباط دادن این دو بخش از اطلاعات مشکل دارد
- ممکن است روابط ضمنی را از دست بدهد
آنچه در رویکرد GraphRAG اتفاق میافتد:
MATCH (org:Organization {name: "OpenAI"})-[:HAS_COMPETITOR]-(competitor:Organization)
MATCH (org)-[:HAS_INVESTOR]->(investor:Person)
MATCH (competitor)-[:HAS_INVESTOR]->(investor)
RETURN org, competitor, investor
این نمودار به طور طبیعی روابط را نشان میدهد و پرسوجوهای چندگامی را سرراست و کارآمد میکند.
سیستمهای چندعاملی در ADK
کیت توسعه عامل (ADK) چارچوب متنباز گوگل برای ساخت و استقرار عاملهای هوش مصنوعی در سطح تولید است. این کیت، اصول اولیه بصری برای تنظیم چندعاملی، ادغام ابزار و مدیریت گردش کار را فراهم میکند و ترکیب عاملهای تخصصی را در سیستمهای پیچیده آسان میسازد. ADK به طور یکپارچه با Gemini کار میکند و از استقرار در Cloud Run، Kubernetes یا هر زیرساختی پشتیبانی میکند.
کیت توسعه عامل (ADK) اصول اولیه برای ساخت سیستمهای چندعاملی را فراهم میکند:
- سلسله مراتب عامل:
# Root agent coordinates specialized agents
root_agent = LlmAgent(
name="RootAgent",
sub_agents=[
graph_db_agent,
investor_agent,
investment_agent
]
)
- نمایندگان تخصصی: هر نماینده دارای
- ابزارهای خاص: توابعی که میتواند فراخوانی کند
- دستورالعملهای واضح: نقش و قابلیتهای آن
- تخصص در حوزه: دانش مربوط به آن حوزه
- الگوهای ارکستراسیون:
- ترتیبی: عاملها را به ترتیب اجرا کنید
- موازی: چندین عامل را همزمان اجرا کنید
- شرطی: مسیر بر اساس نوع پرس و جو
جعبه ابزار MCP برای پایگاههای داده
پروتکل زمینه مدل (MCP) یک استاندارد باز برای اتصال سیستمهای هوش مصنوعی به منابع داده و ابزارهای خارجی است. جعبه ابزار MCP برای پایگاههای داده، پیادهسازی گوگل است که مدیریت پرسوجوی پایگاه داده اعلانی را امکانپذیر میکند و به شما امکان میدهد پرسوجوهای از پیش اعتبارسنجیشده و نوشتهشده توسط متخصص را به عنوان ابزارهای قابل استفاده مجدد تعریف کنید. جعبه ابزار MCP به جای اینکه به LLMها اجازه دهد پرسوجوهای بالقوه ناامن تولید کنند، پرسوجوهای از پیش تأییدشده را با اعتبارسنجی پارامتر ارائه میدهد و امنیت، عملکرد و قابلیت اطمینان را تضمین میکند و در عین حال انعطافپذیری را برای عوامل هوش مصنوعی حفظ میکند.
رویکرد سنتی:
# LLM generates query (may be incorrect/unsafe)
query = llm.generate("SELECT * FROM users WHERE...")
db.execute(query) # Risk of errors/SQL injection
رویکرد MCP:
# Pre-validated query definition
- name: get_industries
description: Fetch all industries from database
query: |
MATCH (i:Industry)
RETURN i.name, i.id
مزایا:
- از قبل توسط کارشناسان تایید شده است
- ایمن در برابر حملات تزریق
- عملکرد بهینه شده
- مدیریت متمرکز
- قابل استفاده مجدد در بین عاملها
کنار هم قرار دادن همه چیز
ترکیب GraphRAG + چارچوب چندعاملی ADK + MCP یک سیستم قدرتمند ایجاد میکند:
- نماینده ریشه درخواست کاربر را دریافت میکند
- مسیرهای منتهی به نماینده تخصصی بر اساس نوع پرس و جو
- نماینده از ابزارهای MCP برای دریافت ایمن دادهها استفاده میکند
- ساختار نمودار، زمینه غنی را فراهم میکند
- LLM پاسخی منطقی و قابل توضیح تولید میکند
حالا که معماری را فهمیدیم، بیایید شروع به ساختن کنیم!
۳. راهاندازی پروژه ابری گوگل
ایجاد یک پروژه
- در کنسول گوگل کلود ، در صفحه انتخاب پروژه، یک پروژه گوگل کلود را انتخاب یا ایجاد کنید.
- مطمئن شوید که صورتحساب برای پروژه ابری شما فعال است. یاد بگیرید که چگونه بررسی کنید که آیا صورتحساب در یک پروژه فعال است یا خیر .
- شما از Cloud Shell ، یک محیط خط فرمان که در Google Cloud اجرا میشود، استفاده خواهید کرد. در بالای کنسول Google Cloud روی Activate Cloud Shell کلیک کنید. میتوانید با کلیک روی دکمه مربوطه از Cloud Shell، بین Cloud Shell Terminal (برای اجرای دستورات ابری) و Editor (برای ساخت پروژهها) جابجا شوید.

- پس از اتصال به Cloud Shell، با استفاده از دستور زیر بررسی میکنید که آیا از قبل احراز هویت شدهاید و پروژه روی شناسه پروژه شما تنظیم شده است یا خیر:
gcloud auth list
- دستور زیر را در Cloud Shell اجرا کنید تا تأیید شود که دستور gcloud از پروژه شما اطلاع دارد.
gcloud config list project
- اگر پروژه شما تنظیم نشده است، از دستور زیر برای تنظیم آن استفاده کنید:
gcloud config set project <YOUR_PROJECT_ID>
برای دستورات و نحوهی استفاده از gcloud به مستندات مراجعه کنید.
عالی! اکنون آمادهایم تا به مرحله بعدی برویم - درک مجموعه دادهها.
۴. درک مجموعه دادههای شرکتها
برای این آزمایشگاه کد، ما از یک پایگاه داده Neo4j فقط خواندنی استفاده میکنیم که از قبل با دادههای سرمایهگذاری و شرکت از نمودار دانش Diffbot پر شده است.
مجموعه دادهها شامل موارد زیر است:
- ۲۳۷,۳۵۸ گره به نمایندگی از:
- سازمانها (شرکتها)
- افراد (مدیران، کارمندان)
- مقالات (اخبار و یادداشتها)
- صنایع
- فناوریها
- سرمایهگذاران
- روابط شامل:
-
HAS_INVESTOR- ارتباطات سرمایهگذاری -
HAS_COMPETITOR- روابط رقابتی -
MENTIONS- منابع مقاله -
HAS_CEO- روابط استخدامی -
HAS_CATEGORY- طبقهبندیهای صنعتی
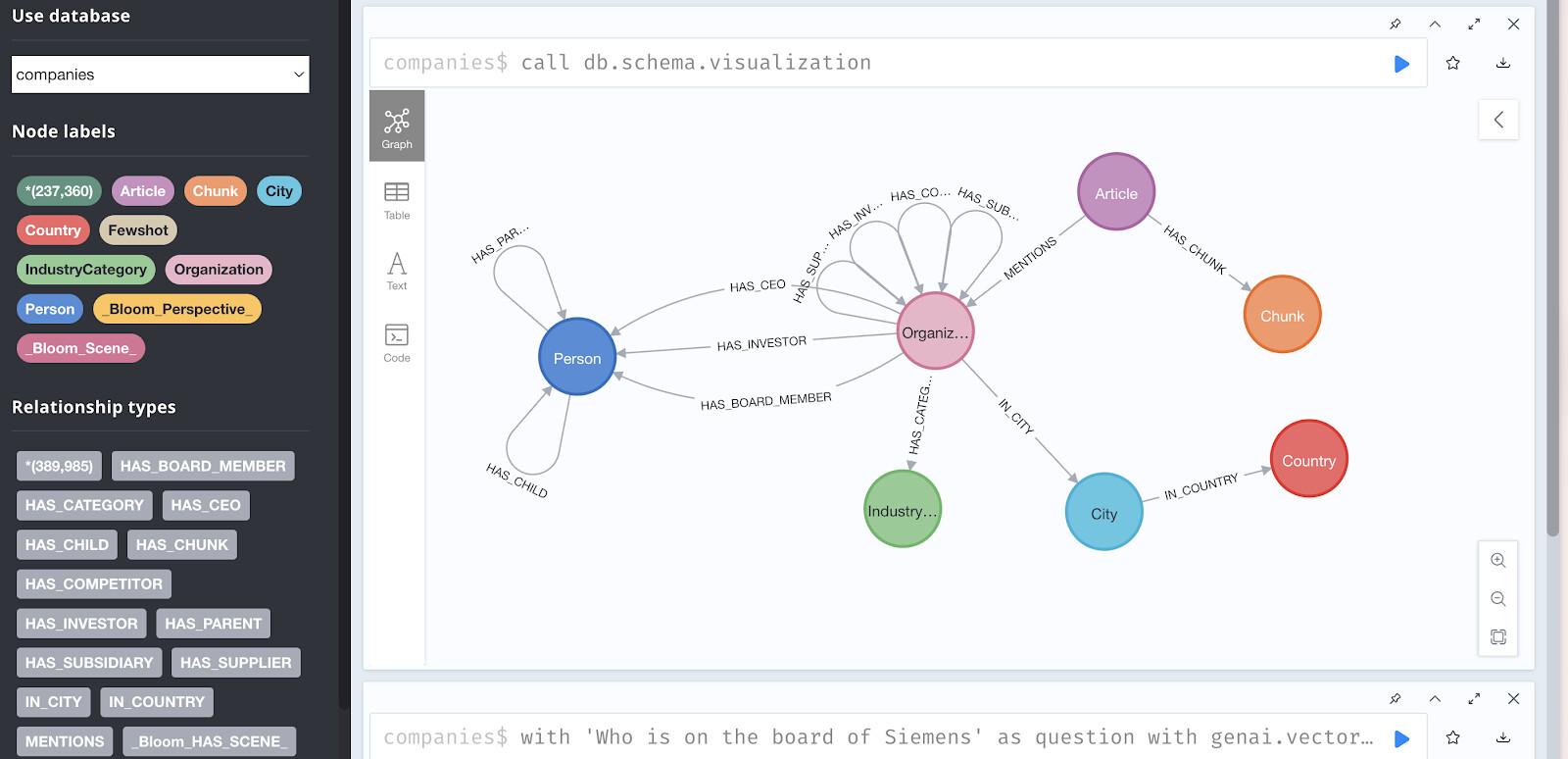
دسترسی به پایگاه داده نسخه آزمایشی
برای این آزمایشگاه کد، ما از یک نمونه آزمایشی میزبانیشده استفاده خواهیم کرد. این اطلاعات کاربری را به یادداشتهای خود اضافه کنید:
URI: neo4j+s://demo.neo4jlabs.com
Username: companies
Password: companies
Database: companies
دسترسی مرورگر:
شما میتوانید دادهها را به صورت بصری در آدرس زیر بررسی کنید: https://demo.neo4jlabs.com:7473
با همان اطلاعات کاربری وارد شوید و دستور زیر را اجرا کنید:
// Sample query to explore the graph
MATCH (c:Organization)-[:HAS_COMPETITOR]-(competitor:Organization)
RETURN c.name, competitor.name
LIMIT 10
تجسم ساختار گراف
برای مشاهده الگوهای رابطه، این کوئری را در مرورگر Neo4j امتحان کنید:
// Find investors and their portfolio companies
MATCH (company:Organization)-[:HAS_INVESTOR]->(investor:Person)
WITH investor, collect(company.name) as portfolio
RETURN investor.name, size(portfolio) as num_investments, portfolio
ORDER BY num_investments DESC
LIMIT 5
این کوئری ۵ سرمایهگذار فعال و پرتفوی آنها را برمیگرداند.
چرا این پایگاه داده برای GraphRAG مناسب است؟
این مجموعه داده برای نمایش GraphRAG عالی است زیرا:
- روابط غنی : ارتباطات پیچیده بین موجودیتها
- دادههای دنیای واقعی : شرکتها، افراد و مقالات خبری واقعی
- پرسوجوهای چندگامی : نیاز به پیمایش چندین نوع رابطه دارد
- دادههای زمانی : مقالاتی با مهر زمانی برای تحلیل مبتنی بر زمان
- تحلیل احساسات : امتیازهای احساسی از پیش محاسبهشده برای مقالات
حالا که ساختار دادهها را درک کردید، بیایید محیط توسعه خود را راهاندازی کنیم!
۵. کلون کردن مخزن و پیکربندی محیط
مخزن را کلون کنید
در ترمینال Cloud Shell خود، دستور زیر را اجرا کنید:
# Clone the repository
git clone https://github.com/sidagarwal04/neo4j-adk-multiagents.git
# Navigate into the directory
cd neo4j-adk-multiagents
ساختار مخزن را بررسی کنید
برای درک طرح پروژه، لحظهای وقت بگذارید:
neo4j-adk-multiagents/
├── investment_agent/ # Main agent code
│ ├── agent.py # Agent definitions
│ ├── tools.py # Custom tool functions
│ └── .adk/ # ADK configuration
│ └── tools.yaml # MCP tool definitions
├── main.py # Application entry point
├── setup_tools_yaml.py # Configuration generator
├── requirements.txt # Python dependencies
├── example.env # Environment template
└── README.md # Project documentation
راهاندازی محیط مجازی
ایجاد و فعالسازی یک محیط مجازی پایتون با استفاده از uv:
# Install uv if not already installed
pip install uv
# Create virtual environment
uv venv
# Activate the environment
source .venv/bin/activate # On macOS/Linux
# or
.venv\Scripts\activate # On Windows
باید ببینید که (.venv) به اعلان ترمینال شما اضافه شده است.
نصب وابستگیها
نصب تمام بستههای مورد نیاز:
uv pip install -r requirements.txt
وابستگیهای کلیدی عبارتند از:
txtgoogle-adk>=1.21.0 # Agent Development Kit
neo4j>=6.0.3 # Neo4j Python driver
python-dotenv>=1.0.0 # Environment variables
google-cloud-aiplatform>=1.30.0 # Vertex AI
پیکربندی متغیرهای محیطی
- فایل
.envخود را ایجاد کنید :
cp example.env .env
- فایل
.envرا ویرایش کنید :
اگر از Cloud Shell استفاده میکنید، روی Open Editor در نوار ابزار کلیک کنید، سپس به .env بروید و بهروزرسانی کنید:
برای آشکار کردن فایل مخفی .env :
در ویرایشگر پوسته گوگل کلود، روی View > Toggle Hidden files کلیک کنید.
# Neo4j Configuration (Demo Database)
NEO4J_URI=neo4j+s://demo.neo4jlabs.com
NEO4J_USERNAME=companies
NEO4J_PASSWORD=companies
NEO4J_DATABASE=companies
# Google AI Configuration
# Choose ONE of the following options:
# Option 1: Google AI API (Recommended)
GOOGLE_GENAI_USE_VERTEXAI=0
GOOGLE_API_KEY=your_api_key_here # Get from https://aistudio.google.com/app/apikey
# Option 2: Vertex AI (If using GCP)
# GOOGLE_GENAI_USE_VERTEXAI=1
# GOOGLE_CLOUD_PROJECT=your-project-id
# GOOGLE_CLOUD_LOCATION=us-central1
# ADK Configuration
GOOGLE_ADK_MODEL=gemini-3.1-flash-lite-preview # or gemini-3-flash-preview
# MCP Toolbox Configuration
MCP_TOOLBOX_URL=https://toolbox-990868019953.us-central1.run.app/mcp/sse
- پیکربندی جعبه ابزار MCP را ایجاد کنید:
اسکریپت راهاندازی را اجرا کنید تا فایل tools.yaml از متغیرهای محیطی شما ایجاد شود:
python setup_tools_yaml.py
این دستور، investment_agent/.adk/tools.yaml را با اعتبارنامههای Neo4j شما که به درستی برای ابزارهای MCP پیکربندی شدهاند، ایجاد میکند.
پیکربندی را تأیید کنید
بررسی کنید که همه چیز به درستی تنظیم شده باشد:
# Verify .env file exists
ls -la .env
# Verify tools.yaml was generated
ls -la investment_agent/.adk/tools.yaml
# Test Python environment
python -c "import google.adk; print('ADK installed successfully')"
# Test Neo4j connection
python -c "from neo4j import GraphDatabase; print('Neo4j driver installed')"
محیط توسعه شما اکنون کاملاً پیکربندی شده است! در ادامه، به معماری چندعاملی خواهیم پرداخت.
۶. درک معماری چندعاملی
سیستم چهار عاملی
سیستم تحقیقات سرمایهگذاری ما از یک معماری سلسله مراتبی چندعاملی با چهار عامل تخصصی استفاده میکند که برای پاسخ به پرسشهای پیچیده در مورد شرکتها، سرمایهگذاران و اطلاعات بازار با یکدیگر همکاری میکنند.
┌──────────────┐
│ Root Agent │ ◄── User Query
└──────┬───────┘
│
┌────────────────┼────────────────┐
│ │ │
┌─────▼─────┐ ┌────▼─────┐ ┌────▼──────────┐
│ Graph DB │ │ Investor │ │ Investment │
│ Agent │ │ Research │ │ Research │
└───────────┘ │ Agent │ │ Agent │
└──────────┘ └───────────────┘
- عامل ریشه (هماهنگکننده):
عامل ریشه (Root Agent) به عنوان هماهنگکننده هوشمند کل سیستم عمل میکند. این عامل، درخواستهای کاربر را دریافت میکند، هدف را تجزیه و تحلیل میکند و درخواستها را به مناسبترین عامل تخصصی هدایت میکند. آن را به عنوان یک مدیر پروژه در نظر بگیرید که میفهمد کدام عضو تیم برای هر کار مناسبتر است. همچنین، جمعآوری پاسخها، قالببندی نتایج به صورت جداول یا نمودارها در صورت درخواست و حفظ زمینه مکالمه در چندین پرسوجو را انجام میدهد. عامل ریشه همیشه عاملهای تخصصی را بر عامل پایگاه داده عمومی ترجیح میدهد و تضمین میکند که پرسوجوها توسط متخصصترین جزء موجود مدیریت میشوند.
- عامل پایگاه داده گراف:
عامل پایگاه داده گراف، رابط مستقیم شما با قابلیتهای قدرتمند گراف Neo4j است. این عامل، طرحواره پایگاه داده را درک میکند، پرسوجوهای Cypher را از زبان طبیعی تولید میکند و پیمایشهای پیچیده گراف را اجرا میکند. این عامل در سوالات ساختاری، تجمیع و استدلال چندگامی در سراسر گراف دانش تخصص دارد. این عامل، متخصص پشتیبان است، زمانی که پرسوجوها به منطق سفارشی نیاز دارند که ابزارهای از پیش تعریفشده نمیتوانند از عهده آن برآیند، و این امر آن را برای تجزیه و تحلیل اکتشافی و پرسوجوهای تحلیلی پیچیدهای که در طراحی سیستم پیشبینی نشده بودند، ضروری میکند.
- نماینده تحقیقات سرمایهگذار:
نماینده تحقیقات سرمایهگذار منحصراً بر روابط سرمایهگذاری و تحلیل پرتفوی تمرکز دارد. این نماینده میتواند با استفاده از تطبیق دقیق نام، کشف کند که چه کسی در شرکتهای خاص سرمایهگذاری کرده است، پرتفویهای کامل سرمایهگذاران را که تمام سرمایهگذاریهای آنها را نشان میدهد، بازیابی کند و الگوهای سرمایهگذاری را در صنایع مختلف تجزیه و تحلیل کند. این تخصص، آن را در پاسخ به سؤالاتی مانند «چه کسی در ByteDance سرمایهگذاری کرده است؟» یا «Sequoia Capital در چه چیزهای دیگری سرمایهگذاری کرده است؟» بسیار کارآمد میکند. این نماینده از توابع سفارشی پایتون استفاده میکند که مستقیماً از پایگاه داده Neo4j برای روابط مرتبط با سرمایهگذاران پرس و جو میکنند.
- نماینده تحقیقات سرمایهگذاری:
عامل تحقیقات سرمایهگذاری از جعبه ابزار پروتکل زمینه مدل (MCP) برای دسترسی به پرسوجوهای از پیش اعتبارسنجیشده و نوشتهشده توسط متخصصان استفاده میکند. این عامل میتواند تمام صنایع موجود را بازیابی کند، شرکتهای موجود در صنایع خاص را بازیابی کند، مقالاتی با تحلیل احساسات پیدا کند، نامهای سازمان را در اخبار کشف کند و اطلاعاتی در مورد افراد شاغل در شرکتها به دست آورد. برخلاف عامل پایگاه داده گراف که پرسوجوها را به صورت پویا تولید میکند، این عامل از پرسوجوهای ایمن، بهینهشده و از پیش تعریفشدهای استفاده میکند که به صورت مرکزی مدیریت و اعتبارسنجی میشوند. این امر باعث میشود که این عامل برای گردشهای کاری تحقیقاتی رایج، هم ایمن و هم کارآمد باشد.
۷. اجرا و آزمایش سیستم چندعاملی
برنامه را اجرا کنید
حالا که معماری را درک کردید، بیایید کل سیستم را اجرا کنیم و با آن تعامل داشته باشیم.
رابط وب ADK را شروع کنید:
# Make sure you're in the project directory with activated virtual environment
cd ~/neo4j-adk-multiagents
source .venv/bin/activate # If not already activated
# Launch the application
uv run adk web
شما باید خروجی مشابه زیر را ببینید:
INFO: Started server process [2542]
INFO: Waiting for application startup.
+----------------------------------------------------------------+
| ADK Web Server started |
| |
| For local testing, access at http://127.0.0.1:8000. |
+----------------------------------------------------------------+
INFO: Application startup complete.
INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
کوئریهای آزمایشی و رفتار مورد انتظار
بیایید قابلیتهای سیستم را با پرسوجوهای پیچیدهتر بررسی کنیم:
پرسوجوهای پایه (تک عامل)
سوال ۱: کشف صنایع
What industries are available in the database?
رفتار مورد انتظار:
- مسیرهای نماینده ریشه به نماینده تحقیقات سرمایهگذاری
- از ابزار MCP استفاده میکند:
get_industries() - فهرستی قالببندیشده از تمام صنایع را برمیگرداند
چه مواردی را باید رعایت کرد:
در رابط کاربری ADK، جزئیات اجرا را باز کنید تا موارد زیر را ببینید:
- تصمیم انتخاب نماینده
- فراخوانی ابزار:
get_industries() - نتایج خام از Neo4j
- پاسخ قالببندیشده
سوال دوم: پیدا کردن سرمایهگذاران
Who invested in ByteDance?
رفتار مورد انتظار:
- Root Agent این را به عنوان یک پرس و جو مربوط به سرمایه گذار شناسایی می کند
- مسیرهای دسترسی به نماینده تحقیقات سرمایهگذار
- ابزار مورد استفاده:
find_investor_by_name("ByteDance") - سرمایهگذاران را به همراه نوع آنها (شخص/سازمان) برمیگرداند
پاسخ مورد انتظار:
I found 2 investors in ByteDance:
1. Rong Yue (Person)
2. Wendi Murdoch (Person)
Would you like to know more about their investment portfolios?
پرسش ۳: شرکتها بر اساس صنعت**
I found 2 investors in ByteDance:
1. Rong Yue (Person)
2. Wendi Murdoch (Person)
Would you like to know more about their investment portfolios?
"Show me companies in the Artificial Intelligence industry"
رفتار مورد انتظار:
- مسیرهای نماینده ریشه به نماینده تحقیقات سرمایهگذاری
- از ابزار MCP استفاده میکند:
get_companies_in_industry("Artificial Intelligence") - فهرست شرکتهای هوش مصنوعی را به همراه شناسه و تاریخ تأسیس ارائه میدهد.
چه مواردی را باید رعایت کرد:
- توجه داشته باشید که چگونه نماینده از تطبیق دقیق نام صنعت استفاده میکند
- نتایج برای جلوگیری از خروجی بیش از حد محدود هستند
- دادهها برای خوانایی به وضوح قالببندی شدهاند
پرسوجوهای میانی (چند مرحلهای در یک عامل)
پرسش ۴: تحلیل احساسات
Find articles with positive sentiment from January 2023
رفتار مورد انتظار:
- مسیرهای دسترسی به نماینده تحقیقات سرمایهگذاری
- از ابزار MCP استفاده میکند:
get_articles_with_sentiment(0.7, 2023, 1) - مقالات را با عناوین، امتیازهای احساسی و تاریخ انتشار برمیگرداند
نکته اشکال زدایی:
به پارامترهای فراخوانی ابزار نگاه کنید:
-
min_sentiment: 0.7 (عامل "مثبت" را >= 0.7 تفسیر میکند) -
year: ۲۰۲۳ -
month: ۱
پرس و جوی ۵: پرس و جوی پیچیده پایگاه داده
How many companies are in the database?
رفتار مورد انتظار:
- مسیرهای عامل ریشه به عامل پایگاه داده گراف
- عامل ابتدا
get_neo4j_schema()را فراخوانی میکند تا ساختار را درک کند. - تولید سایفر:
MATCH (c:Company) RETURN count(c) - پرس و جو را اجرا میکند و تعداد را برمیگرداند
پاسخ مورد انتظار:
There are 8,064 companies in the database.
پرسوجوهای پیشرفته (هماهنگی چندعاملی)
پرسش ششم: تحلیل سبد سهام
Who invested in ByteDance and what else have they invested in?
رفتار مورد انتظار:
این یک پرس و جوی دو بخشی است که نیاز به هماهنگی اپراتور دارد:
- مرحله 1 : نماینده ریشه → نماینده تحقیقات سرمایهگذار
- فراخوانیهای
find_investor_by_name("ByteDance") - فهرست سرمایهگذاران را دریافت میکند: [رونگ یو، وندی مرداک]
- مرحله ۲ : برای هر سرمایهگذار → نماینده تحقیقات سرمایهگذار
- فراخوانیهای
find_investor_by_id(investor_id) - نمونه کارها را به طور کامل بازیابی میکند
- مرحله 3 : تجمیعها و قالببندیهای عامل ریشه
پاسخ مورد انتظار:
I found 2 investors in ByteDance. Here are their portfolios:
1. Rong Yue (Person)
- ByteDance
- Inspur
2. Wendi Murdoch (Person)
- ByteDance
- (No other investments in database)
چه مواردی را باید رعایت کرد:
- فراخوانیهای متوالی چندین ابزار
- حفظ زمینه بین مراحل
- نتایج به صورت هوشمندانه جمعآوری میشوند
پرسش ۷: تحقیقات چند دامنهای
What are 5 AI companies mentioned in positive articles, and who are their CEOs?
رفتار مورد انتظار:
این پرسوجوی پیچیده به عوامل و ابزارهای متعددی نیاز دارد:
- مرحله 1 : نماینده تحقیقات سرمایهگذاری
-
get_companies_in_industry("Artificial Intelligence") - فهرست بازگشت شرکتهای هوش مصنوعی
- مرحله 2 : نماینده تحقیقات سرمایهگذاری
-
get_articles_with_sentiment(0.8) - مقالات مثبت را برمیگرداند
- مرحله 3 : فیلترهای Root Agent
- مشخص میکند که کدام شرکتهای هوش مصنوعی در مقالات مثبت ظاهر میشوند
- 5 نفر برتر را انتخاب میکند
- مرحله ۴ : نماینده تحقیقات سرمایهگذاری
-
get_people_in_organizations([company_names], "CEO") - اطلاعات مدیرعامل را برمیگرداند
- مرحله 5 : Root Agent به صورت جدول قالببندی میکند
پاسخ مورد انتظار:
Here are 5 AI companies with positive news and their CEOs:
| Company | Industry | CEO | Avg Sentiment |
|---------|----------|-----|---------------|
| OpenAI | Artificial Intelligence | Sam Altman | 0.92 |
| Anthropic | Artificial Intelligence | Dario Amodei | 0.89 |
| ... | ... | ... | ... |
چه مواردی را باید رعایت کرد:
- فراخوانیهای چندگانه ابزار بین عاملهای مختلف
- فیلتر کردن دادهها و منطق ترکیب
- قالببندی حرفهای جداول
سوال ۸: تحلیل رقابتی
Who are YouTube's main competitors?
رفتار مورد انتظار:
- مسیرهای عامل ریشه به عامل پایگاه داده گراف (پرس و جوی رابطه)
- عامل، سایفرِ بهبودیافته با GraphRAG تولید میکند:
MATCH (c:Company {name: "YouTube"})-[:COMPETES_WITH]->(competitor)
RETURN competitor.name as competitor_name
- فهرست بازگشت کالاهای شرکتهای رقیب
پاسخ مورد انتظار:
YouTube's main competitors are:
- TikTok (ByteDance)
- Dailymotion
- Twitter
- BuzzFeed
- Mixer
- OpenAI (for video content)
پرسوجوهای پیگیری آگاه از متن
پرسش ۹: پرسش تکمیلی (بعد از پرسش ۸)
Which investors funded both YouTube and its competitors?
رفتار مورد انتظار:
- Root Agent زمینه قبلی (یوتیوب و رقبای آن) را به خاطر میسپارد
- مسیرهای دسترسی به نماینده تحقیقات سرمایهگذار
- برای یوتیوب و هر رقیب، سرمایهگذاران را پیدا میکند
- سرمایهگذارانی را که در چندین شرکت حضور دارند، شناسایی میکند
پاسخ مورد انتظار:
Based on our previous analysis of YouTube's competitors, I found these
investors who funded multiple companies in this competitive landscape:
Sequoia Capital invested in:
- YouTube
- TikTok (ByteDance)
- Twitter
Accel Partners invested in:
- YouTube
- BuzzFeed
This suggests these investors have strategic positions across the video content platform ecosystem.
پرسش دهم: خلاصه تحقیق
Summarize our research findings so far
رفتار مورد انتظار:
- بررسی سابقه مکالمات توسط Root Agent
- یافتههای کلیدی از پرسشهای قبلی را ترکیب میکند
- خلاصهای منسجم ارائه میدهد
پاسخ مورد انتظار:
Here's a summary of our investment research session:
1. Industry Overview: We explored the Artificial Intelligence industry
with 150+ companies in the database.
2. ByteDance Analysis:
- Investors: Rong Yue, Wendi Murdoch
- Rong Yue also invested in Inspur
3. Market Sentiment: We analyzed articles from January 2023, finding
strong positive sentiment (avg 0.85) for tech companies.
4. Competitive Landscape: YouTube faces competition from TikTok,
Dailymotion, and others, with some investors (Sequoia, Accel) holding
positions across competing platforms.
5. Key Players: Identified CEOs of major AI companies with positive media coverage.
درک تعاملات عاملها در نمای اشکالزدایی
رابط وب ADK امکان مشاهده جزئیات اجرا را فراهم میکند. در اینجا به موارد زیر اشاره میکنیم:
- جدول زمانی رویداد
جریان زمانی را نشان میدهد:
[USER] Query received
[ROOT_AGENT] Analyzing query intent
[ROOT_AGENT] Routing to investment_research_agent
[INVESTMENT_RESEARCH_AGENT] Tool call: get_companies_in_industry
[TOOL] Executing with params: {"industry_name": "Artificial Intelligence"}
[TOOL] Returned 47 results
[INVESTMENT_RESEARCH_AGENT] Formatting response
[ROOT_AGENT] Presenting to user
- جزئیات فراخوانی ابزار
برای دیدن موارد زیر، روی هر فراخوانی ابزار کلیک کنید:
- نام تابع
- پارامترهای ورودی
- مقدار بازگشتی
- زمان اجرا
- هرگونه خطا
- تصمیمگیری عامل
به استدلال LLM توجه کنید:
- چرا یک نماینده خاص را انتخاب کرد
- چگونه پرس و جو را تفسیر کرد
- چه ابزارهایی را در نظر گرفته است
- چرا نتایج را به شکلی خاص قالببندی کرد
مشاهدات و بینشهای رایج
- الگوهای مسیریابی پرس و جو:
- کلمات کلیدی مانند "سرمایهگذار"، "سرمایهگذاری شده" → Investor Research Agent
- کلمات کلیدی مانند «صنعت»، «شرکتها»، «مقالات» → نماینده تحقیقات سرمایهگذاری
- تجمیعها، شمارشها، منطق پیچیده → عامل پایگاه داده گراف
- یادداشتهای عملکرد:
- ابزارهای MCP معمولاً سریعتر هستند (پرسوجوهای از پیش بهینهشده)
- تولید سایفر پیچیده زمان بیشتری میبرد (زمان تفکر LLM)
- فراخوانیهای چندگانه ابزار، تأخیر ایجاد میکنند اما نتایج غنیتری ارائه میدهند
- مدیریت خطا:
- اگر یک پرس و جو با شکست مواجه شود:
- نماینده توضیح میدهد که چه مشکلی پیش آمده است
- اصلاحات را پیشنهاد میدهد (مثلاً «نام شرکت یافت نشد، املای آن را بررسی کنید»)
- ممکن است رویکردهای جایگزین را امتحان کند
نکاتی برای تست موثر
- شروع ساده : قبل از پرسوجوهای پیچیده، عملکرد اصلی هر عامل را آزمایش کنید
- از سوالات پیگیری استفاده کنید : با سوالات پیگیری، میزان حفظ متن را بسنجید.
- مشاهده مسیریابی : برای درک منطق، ببینید کدام عامل هر پرسوجو را مدیریت میکند.
- بررسی فراخوانیهای ابزار : تأیید کنید که پارامترها به درستی از زبان طبیعی استخراج شدهاند
- موارد لبه آزمایش : پرسوجوهای مبهم، غلطهای املایی یا درخواستهای غیرمعمول را امتحان کنید
اکنون شما یک سیستم GraphRAG چندعامله کاملاً کاربردی دارید! با سوالات خودتان آزمایش کنید تا قابلیتهای آن را بررسی کنید.
۸. تمیز کردن
برای جلوگیری از تحمیل هزینه به حساب Google Cloud خود برای منابع استفاده شده در این پست، این مراحل را دنبال کنید:
- در کنسول گوگل کلود، به صفحه مدیریت منابع بروید.
- در لیست پروژهها، پروژهای را که میخواهید حذف کنید انتخاب کنید و سپس روی «حذف» کلیک کنید.
- در کادر محاورهای، شناسه پروژه را تایپ کنید و سپس برای حذف پروژه، روی خاموش کردن کلیک کنید.
۹. تبریک
🎉 تبریک! شما با موفقیت یک سیستم GraphRAG چندعامله با کیفیت در مرحله تولید با استفاده از کیت توسعه عامل گوگل، Neo4j و جعبه ابزار MCP ساختید!
با ترکیب قابلیتهای هوشمند تنظیم ADK با مدل داده غنی از روابط Neo4j و ایمنی پرسوجوهای MCP از پیش اعتبارسنجیشده، شما یک سیستم پیچیده ایجاد کردهاید که فراتر از پرسوجوهای ساده پایگاه داده عمل میکند - این سیستم زمینه و دلایل روابط پیچیده را درک میکند و عوامل تخصصی را برای ارائه بینشهای جامع و دقیق هماهنگ میکند.
در این آزمایشگاه کد، شما موارد زیر را انجام دادید:
✅ ساخت یک سیستم چندعاملی با استفاده از کیت توسعه عامل (ADK) گوگل با هماهنگی سلسله مراتبی
✅ پایگاه داده گراف Neo4j یکپارچه برای بهرهگیری از پرسوجوهای آگاه از رابطه و استدلال چندگامی
✅ پیادهسازی جعبه ابزار MCP برای کوئریهای پایگاه داده ایمن و از پیش اعتبارسنجیشده به عنوان ابزارهای قابل استفاده مجدد
✅ ایجاد کارگزاران تخصصی برای تحقیقات سرمایهگذاری، تحلیل سرمایهگذاری و عملیات پایگاه داده نموداری
✅ مسیریابی هوشمند طراحی شده که به طور خودکار پرس و جوها را به مناسبترین کارشناس ارجاع میدهد
✅ انواع دادههای پیچیده را با سریالسازی مناسب نوع Neo4j برای ادغام یکپارچه پایتون مدیریت کرد.
✅ بهترین شیوههای تولید کاربردی برای طراحی عامل، مدیریت خطا و اشکالزدایی سیستم
قدم بعدی چیست؟
این معماری GraphRAG چندعامله محدود به تحقیقات سرمایهگذاری نیست - میتواند به موارد زیر نیز گسترش یابد:
- خدمات مالی : بهینهسازی سبد سهام، ارزیابی ریسک، تشخیص کلاهبرداری
- مراقبتهای بهداشتی : هماهنگی مراقبت از بیمار، تجزیه و تحلیل تداخلات دارویی، تحقیقات بالینی
- تجارت الکترونیک : توصیههای شخصیسازیشده، بهینهسازی زنجیره تأمین، بینش مشتری
- حقوقی و انطباق : تحلیل قرارداد، نظارت نظارتی، تحقیقات رویهای قضایی
- تحقیقات دانشگاهی : بررسی متون، کشف همکاری، تحلیل استنادی
- هوش سازمانی : تحلیل رقابتی، تحقیقات بازار، نمودارهای دانش سازمانی
هر جایی که دادههای پیچیده و بههمپیوسته + تخصص در حوزه کاری + رابطهای زبان طبیعی داشته باشید، این ترکیب سیستمهای چندعامله ADK + نمودارهای دانش Neo4j + پرسوجوهای معتبر MCP میتواند نسل بعدی برنامههای کاربردی هوشمند سازمانی را تقویت کند.
همچنان که کیت توسعه عامل گوگل و مدلهای Gemini به تکامل خود ادامه میدهند، شما قادر خواهید بود الگوهای استدلال پیچیدهتر، ادغام دادههای بلادرنگ و قابلیتهای چندوجهی را برای ساخت سیستمهای واقعاً هوشمند و آگاه از متن، در خود جای دهید.
به کاوش ادامه دهید، به ساختن ادامه دهید و برنامههای عامل هوشمند خود را به سطح بعدی ببرید!
آموزشهای کاربردیتر گراف دانش را در Neo4j GraphAcademy جستجو کنید و الگوهای عامل بیشتری را در مخزن نمونههای ADK کشف کنید.
🚀 آمادهاید تا سیستم عامل هوشمند بعدی خود را بسازید؟