
1. Présentation
Dans cet atelier de programmation, vous allez créer un système sophistiqué de recherche d'investissement multi-agents qui combine la puissance de Google Agent Development Kit (ADK), de la base de données graphiques Neo4j et de la boîte à outils Model Context Protocol (MCP). Ce tutoriel pratique explique comment créer des agents intelligents qui comprennent le contexte des données grâce aux relations graphiques et fournissent des réponses très précises aux requêtes.
Pourquoi utiliser GraphRAG et des systèmes multi-agents ?
GraphRAG (génération augmentée par récupération basée sur des graphes) améliore les approches RAG traditionnelles en exploitant la structure relationnelle riche des graphes de connaissances. Au lieu de se contenter de rechercher des documents similaires, les agents GraphRAG peuvent :
- Parcourir des relations complexes entre les entités
- Comprendre le contexte grâce à la structure du graphique
- Fournir des résultats explicables basés sur les données connectées
- Exécuter un raisonnement multihop dans le Knowledge Graph
Les systèmes multi-agents vous permettent de :
- Décomposer les problèmes complexes en sous-tâches spécialisées
- Créer des applications d'IA modulaires et faciles à gérer
- Activer le traitement parallèle et l'utilisation efficace des ressources
- Créer des modèles de raisonnement hiérarchiques avec l'orchestration
Objectifs de l'atelier
Vous allez créer un système complet de recherche sur les investissements, qui comprendra :
- Agent de base de données de graphes : exécute des requêtes Cypher et comprend le schéma Neo4j
- Agent de recherche sur les investisseurs : découvre les relations avec les investisseurs et les portefeuilles d'investissement
- Agent de recherche sur les investissements : accède à des graphes de connaissances complets grâce aux outils MCP.
- Agent racine : orchestre intelligemment tous les sous-agents
Le système répondra à des questions complexes telles que :
- "Quels sont les principaux concurrents de YouTube ?"
- "Quelles entreprises sont mentionnées de manière positive en janvier 2023 ?"
- "Qui a investi dans ByteDance et dans quoi d'autre a-t-il investi ?"
Présentation de l'architecture
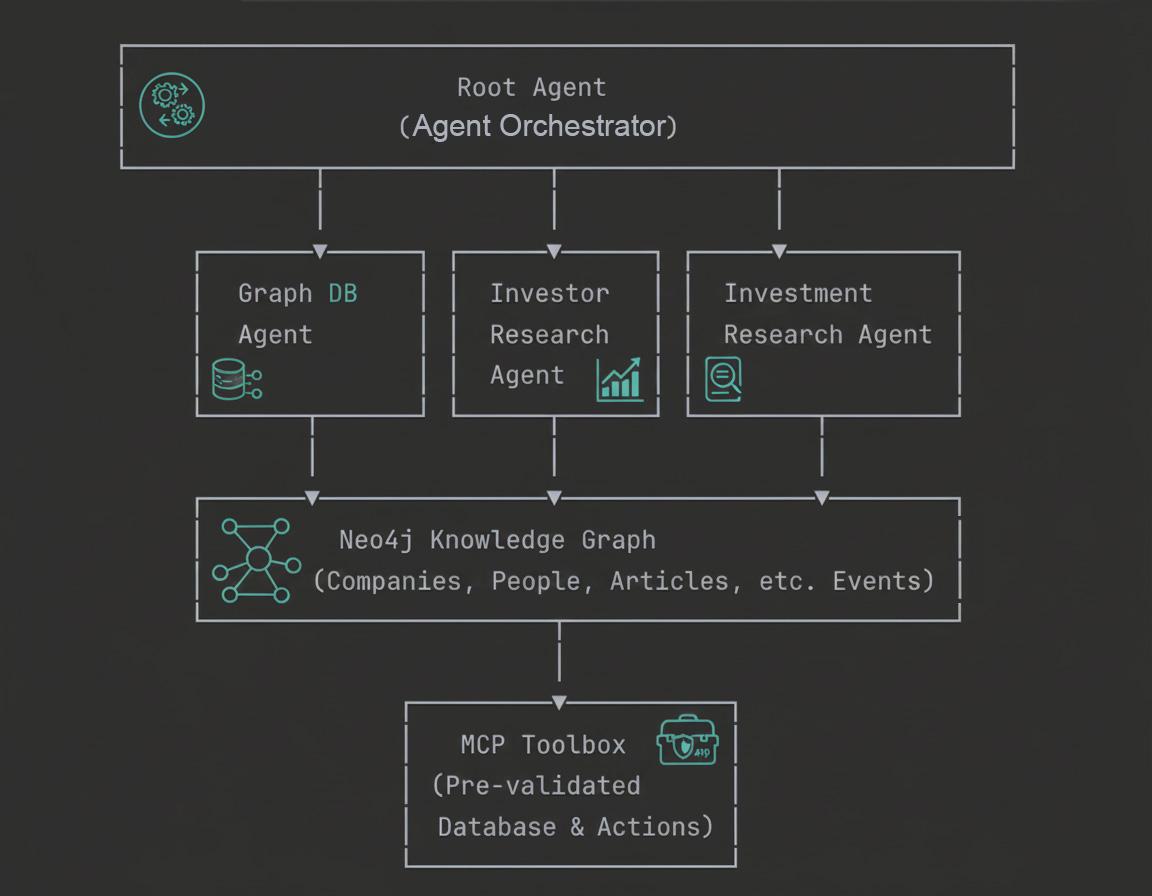
Dans cet atelier de programmation, vous allez découvrir les bases conceptuelles et l'implémentation pratique de la création d'agents GraphRAG de niveau entreprise.
Points abordés
- Créer des systèmes multi-agents à l'aide de Google Agent Development Kit (ADK)
- Intégrer la base de données de graphes Neo4j à ADK pour les applications GraphRAG
- Implémenter MCP (Model Context Protocol) Toolbox pour les requêtes de base de données prévalidées
- Créer des outils et des fonctions personnalisés pour les agents intelligents
- Concevoir des hiérarchies d'agents et des schémas d'orchestration
- Structurer les instructions de l'agent pour des performances optimales
- Déboguer efficacement les interactions multi-agents
Prérequis
- Navigateur Web Chrome
- Un compte Gmail
- Un projet Google Cloud avec facturation activée
- Connaissances de base des commandes de terminal et de Python (non obligatoires, mais recommandées)
Cet atelier de programmation, conçu pour les développeurs de tous niveaux (y compris les débutants), utilise Python et Neo4j dans son exemple d'application. Bien qu'une connaissance de base de Python et des bases de données graphiques puisse être utile, aucune expérience préalable n'est requise pour comprendre les concepts ou suivre le cours.
2. Comprendre GraphRAG et les systèmes multi-agents
Avant de nous pencher sur l'implémentation, comprenons les concepts clés qui alimentent ce système.
Neo4j est une base de données de graphes native de premier plan qui stocke les données sous forme de réseau de nœuds (entités) et de relations (connexions entre les entités). Elle est idéale pour les cas d'utilisation où la compréhension des connexions est essentielle, comme les recommandations, la détection des fraudes, les knowledge graphs, etc. Contrairement aux bases de données relationnelles ou basées sur des documents qui reposent sur des tables rigides ou des structures hiérarchiques, le modèle de graphe flexible de Neo4j permet une représentation intuitive et efficace des données complexes et interconnectées.
Au lieu d'organiser les données en lignes et en tableaux comme les bases de données relationnelles, Neo4j utilise un modèle de graphe, où les informations sont représentées sous forme de nœuds (entités) et de relations (connexions entre ces entités). Ce modèle permet de travailler de manière très intuitive avec des données intrinsèquement liées, comme des personnes, des lieux, des produits ou, dans notre cas, des films, des acteurs et des genres.
Par exemple, dans un ensemble de données de films :
- Un nœud peut représenter un
Movie, unActorou unDirector. - Une relation peut être
ACTED_INouDIRECTED.
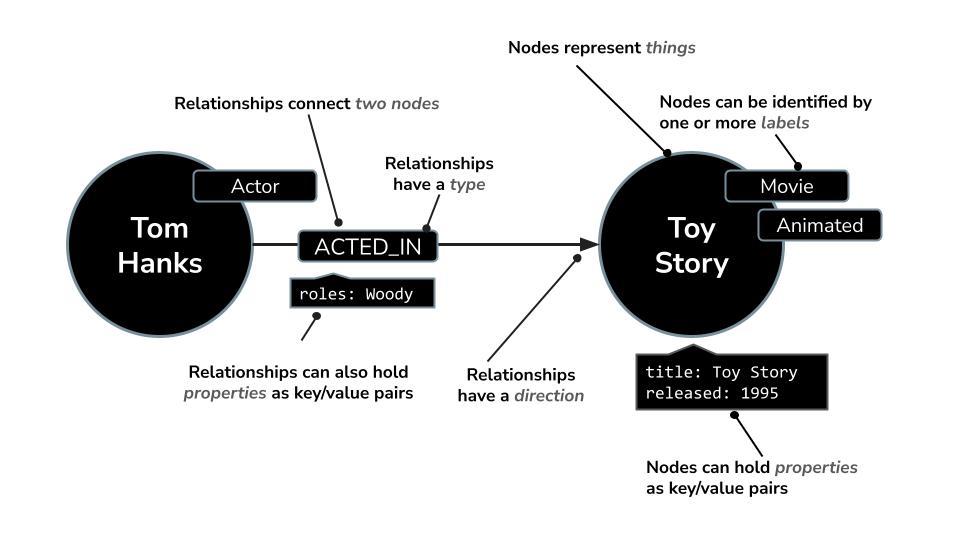
Cette structure vous permet de poser facilement des questions telles que :
- Dans quels films cet acteur a-t-il joué ?
- Qui a travaillé avec Christopher Nolan ?
- Quels sont les films similaires en fonction des acteurs ou des genres en commun ?
Qu'est-ce que GraphRAG ?
La génération augmentée par récupération (RAG) améliore les réponses des LLM en récupérant des informations pertinentes à partir de sources externes. Le RAG traditionnel :
- Intègre des documents dans des vecteurs
- Recherches de vecteurs similaires
- Transmet les documents récupérés au LLM
GraphRAG va plus loin en utilisant des graphes de connaissances :
- Intégrer des entités et des relations
- Parcourt les connexions du graphique
- Récupérer des informations contextuelles multisauts
- Fournit des résultats structurés et explicables
Pourquoi utiliser des graphiques pour les agents d'IA ?
Prenons l'exemple de la question suivante : "Quels sont les concurrents de YouTube et quels investisseurs ont financé à la fois YouTube et ses concurrents ?"
Voici ce qui se passe dans une approche RAG traditionnelle :
- Recherches de documents sur les concurrents de YouTube
- Recherches distinctes pour les informations sur les investisseurs
- Difficulté à établir un lien entre ces deux informations
- Peut passer à côté des relations implicites
Voici ce qui se passe dans une approche GraphRAG :
MATCH (org:Organization {name: "OpenAI"})-[:HAS_COMPETITOR]-(competitor:Organization)
MATCH (org)-[:HAS_INVESTOR]->(investor:Person)
MATCH (competitor)-[:HAS_INVESTOR]->(investor)
RETURN org, competitor, investor
Le graphique représente naturellement les relations, ce qui rend les requêtes multitours simples et efficaces.
Systèmes multi-agents dans ADK
Agent Development Kit (ADK) est le framework Open Source de Google permettant de créer et de déployer des agents d'IA de niveau production. Il fournit des primitives intuitives pour l'orchestration multi-agents, l'intégration d'outils et la gestion des workflows, ce qui facilite la composition d'agents spécialisés dans des systèmes sophistiqués. L'ADK fonctionne parfaitement avec Gemini et permet le déploiement sur Cloud Run, Kubernetes ou toute autre infrastructure.
Agent Development Kit (ADK) fournit des primitives pour créer des systèmes multi-agents :
- Hiérarchie des agents :
# Root agent coordinates specialized agents
root_agent = LlmAgent(
name="RootAgent",
sub_agents=[
graph_db_agent,
investor_agent,
investment_agent
]
)
- Agents spécialisés : chaque agent possède
- Outils spécifiques : fonctions qu'il peut appeler
- Instructions claires : rôle et fonctionnalités
- Expertise du domaine : connaissance de son domaine
- Schémas d'orchestration :
- Séquentiel : exécute les agents dans l'ordre
- Parallèle : exécutez plusieurs agents simultanément.
- Conditionnel : routage en fonction du type de requête
MCP Toolbox for Databases
Le protocole MCP (Model Context Protocol) est une norme ouverte permettant de connecter des systèmes d'IA à des sources de données et des outils externes. MCP Toolbox for Databases est l'implémentation de Google qui permet la gestion déclarative des requêtes de base de données. Vous pouvez ainsi définir des requêtes prévalidées et rédigées par des experts comme des outils réutilisables. Au lieu de laisser les LLM générer des requêtes potentiellement dangereuses, MCP Toolbox propose des requêtes préapprouvées avec validation des paramètres. Cela garantit la sécurité, les performances et la fiabilité tout en préservant la flexibilité des agents d'IA.
Approche traditionnelle :
# LLM generates query (may be incorrect/unsafe)
query = llm.generate("SELECT * FROM users WHERE...")
db.execute(query) # Risk of errors/SQL injection
Approche MCP :
# Pre-validated query definition
- name: get_industries
description: Fetch all industries from database
query: |
MATCH (i:Industry)
RETURN i.name, i.id
Avantages :
- Prévalidé par des experts
- Protection contre les attaques par injection
- Performances optimisées
- Géré de manière centralisée
- Réutilisable dans plusieurs agents
Synthèse
La combinaison de GraphRAG, du framework multi-agents d'ADK et de MCP crée un système puissant :
- L'agent racine reçoit la requête de l'utilisateur.
- Acheminement vers un agent spécialisé en fonction du type de requête
- L'agent utilise les outils MCP pour récupérer les données de manière sécurisée.
- La structure du graphique fournit un contexte riche
- Le LLM génère une réponse ancrée et explicable
Maintenant que nous comprenons l'architecture, commençons à créer !
3. Configurer un projet Google Cloud
Créer un projet
- Dans la console Google Cloud, sur la page du sélecteur de projet, sélectionnez ou créez un projet Google Cloud.
- Assurez-vous que la facturation est activée pour votre projet Cloud. Découvrez comment vérifier si la facturation est activée sur un projet .
- Vous allez utiliser Cloud Shell, un environnement de ligne de commande exécuté dans Google Cloud. Cliquez sur "Activer Cloud Shell" en haut de la console Google Cloud. Vous pouvez basculer entre le terminal Cloud Shell (pour exécuter des commandes cloud) et l'éditeur (pour créer des projets) en cliquant sur le bouton correspondant dans Cloud Shell.

- Une fois connecté à Cloud Shell, vérifiez que vous êtes déjà authentifié et que le projet est défini sur votre ID de projet à l'aide de la commande suivante :
gcloud auth list
- Exécutez la commande suivante dans Cloud Shell pour vérifier que la commande gcloud connaît votre projet.
gcloud config list project
- Si votre projet n'est pas défini, utilisez la commande suivante pour le définir :
gcloud config set project <YOUR_PROJECT_ID>
Consultez la documentation pour connaître les commandes gcloud ainsi que leur utilisation.
Super ! Nous sommes maintenant prêts à passer à l'étape suivante : comprendre l'ensemble de données.
4. Comprendre l'ensemble de données "Companies"
Pour cet atelier de programmation, nous utilisons une base de données Neo4j en lecture seule préremplie avec des données sur les investissements et les entreprises provenant du Knowledge Graph de Diffbot.
L'ensemble de données contient les éléments suivants :
- 237 358 nœuds représentant :
- Organisations (entreprises)
- Personnes (cadres, employés)
- Articles (actualités et mentions)
- Secteurs
- Technologies
- Investisseurs
- Relations, y compris :
HAS_INVESTOR: connexions d'investissementHAS_COMPETITOR– Relations de concurrenceMENTIONS: références d'articlesHAS_CEO– Relations de travailHAS_CATEGORY: classifications sectorielles
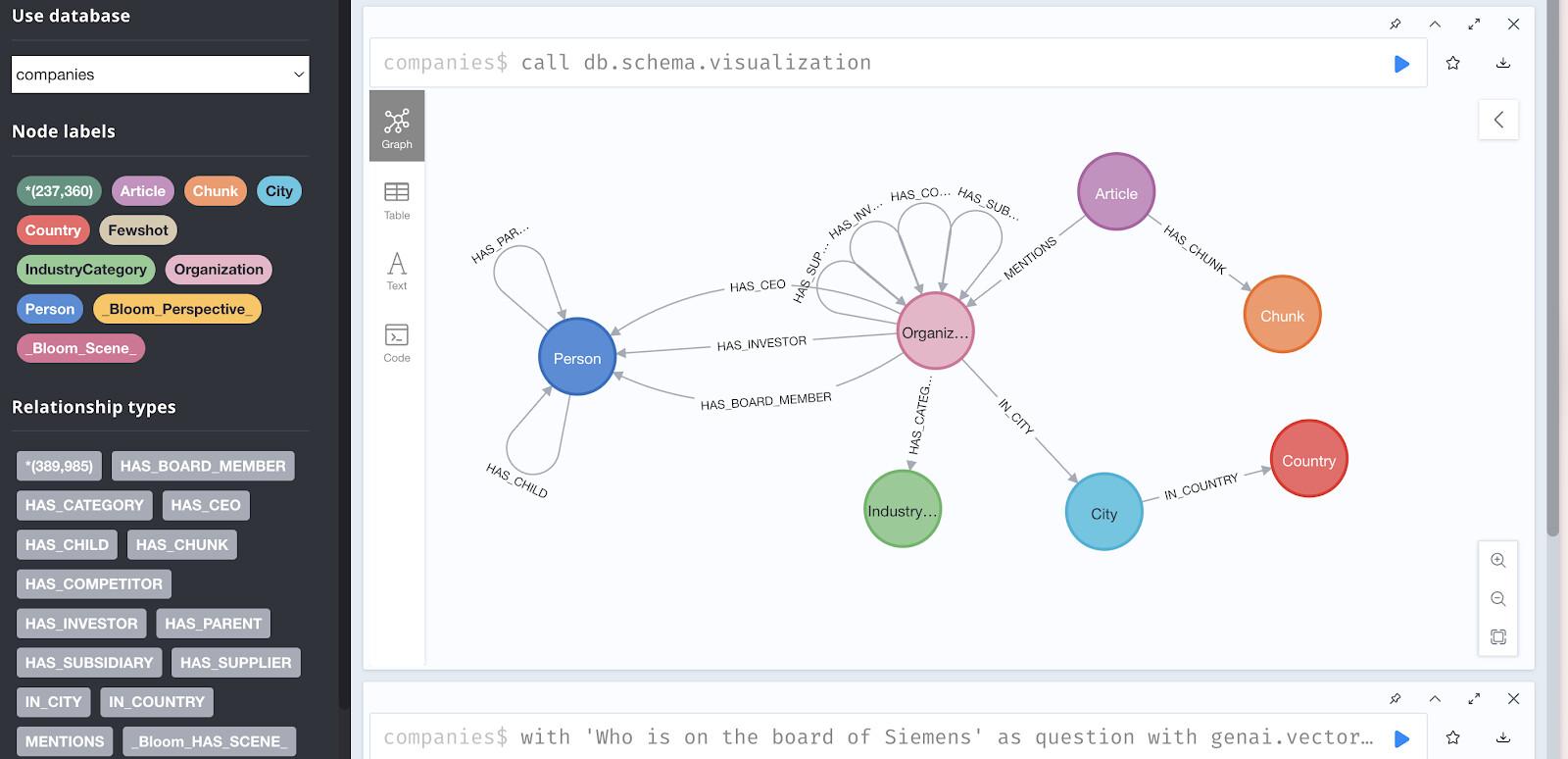
Accéder à la base de données de démonstration
Pour cet atelier de programmation, nous allons utiliser une instance de démonstration hébergée. Ajoutez ces identifiants à vos notes :
URI: neo4j+s://demo.neo4jlabs.com
Username: companies
Password: companies
Database: companies
Accès au navigateur :
Vous pouvez explorer les données visuellement à l'adresse suivante : https://demo.neo4jlabs.com:7473.
Connectez-vous avec les mêmes identifiants et essayez d'exécuter :
// Sample query to explore the graph
MATCH (c:Organization)-[:HAS_COMPETITOR]-(competitor:Organization)
RETURN c.name, competitor.name
LIMIT 10
Visualiser la structure du graphique
Essayez cette requête dans le navigateur Neo4j pour afficher les modèles de relations :
// Find investors and their portfolio companies
MATCH (company:Organization)-[:HAS_INVESTOR]->(investor:Person)
WITH investor, collect(company.name) as portfolio
RETURN investor.name, size(portfolio) as num_investments, portfolio
ORDER BY num_investments DESC
LIMIT 5
Cette requête renvoie les cinq investisseurs les plus actifs et leurs portefeuilles.
Pourquoi cette base de données pour GraphRAG ?
Cet ensemble de données est idéal pour illustrer GraphRAG, car :
- Relations complexes : connexions complexes entre les entités
- Données réelles : entreprises, personnes et articles d'actualité réels
- Requêtes multihops : nécessitent de parcourir plusieurs types de relations
- Données temporelles : articles avec des codes temporels pour l'analyse temporelle
- Analyse des sentiments : scores de sentiment précalculés pour les articles
Maintenant que vous comprenez la structure des données, configurons votre environnement de développement.
5. Cloner le dépôt et configurer l'environnement
Cloner le dépôt
Dans votre terminal Cloud Shell, exécutez la commande suivante :
# Clone the repository
git clone https://github.com/sidagarwal04/neo4j-adk-multiagents.git
# Navigate into the directory
cd neo4j-adk-multiagents
Explorer la structure du dépôt
Prenez quelques instants pour comprendre la mise en page du projet :
neo4j-adk-multiagents/
├── investment_agent/ # Main agent code
│ ├── agent.py # Agent definitions
│ ├── tools.py # Custom tool functions
│ └── .adk/ # ADK configuration
│ └── tools.yaml # MCP tool definitions
├── main.py # Application entry point
├── setup_tools_yaml.py # Configuration generator
├── requirements.txt # Python dependencies
├── example.env # Environment template
└── README.md # Project documentation
Configurer l'environnement virtuel
Créez et activez un environnement virtuel Python à l'aide de uv :
# Install uv if not already installed
pip install uv
# Create virtual environment
uv venv
# Activate the environment
source .venv/bin/activate # On macOS/Linux
# or
.venv\Scripts\activate # On Windows
(.venv) devrait s'afficher au début de l'invite de votre terminal.
Installer des dépendances
Installez tous les packages requis :
uv pip install -r requirements.txt
Voici les principales dépendances :
txtgoogle-adk>=1.21.0 # Agent Development Kit
neo4j>=6.0.3 # Neo4j Python driver
python-dotenv>=1.0.0 # Environment variables
google-cloud-aiplatform>=1.30.0 # Vertex AI
Configurer les variables d'environnement
- Créez votre fichier **
.env** :
cp example.env .env
- Modifiez le fichier **
.env** :
Si vous utilisez Cloud Shell, cliquez sur "Ouvrir l'éditeur" dans la barre d'outils, puis accédez à .env et mettez à jour :
Pour afficher le fichier .env masqué :
Cliquez sur View > Toggle Hidden files dans l'éditeur Google Cloud Shell.
# Neo4j Configuration (Demo Database)
NEO4J_URI=neo4j+s://demo.neo4jlabs.com
NEO4J_USERNAME=companies
NEO4J_PASSWORD=companies
NEO4J_DATABASE=companies
# Google AI Configuration
# Choose ONE of the following options:
# Option 1: Google AI API (Recommended)
GOOGLE_GENAI_USE_VERTEXAI=0
GOOGLE_API_KEY=your_api_key_here # Get from https://aistudio.google.com/app/apikey
# Option 2: Vertex AI (If using GCP)
# GOOGLE_GENAI_USE_VERTEXAI=1
# GOOGLE_CLOUD_PROJECT=your-project-id
# GOOGLE_CLOUD_LOCATION=us-central1
# ADK Configuration
GOOGLE_ADK_MODEL=gemini-3.1-flash-lite-preview # or gemini-3-flash-preview
# MCP Toolbox Configuration
MCP_TOOLBOX_URL=https://toolbox-990868019953.us-central1.run.app/mcp/sse
- Générez la configuration MCP Toolbox :
Exécutez le script de configuration pour créer le fichier tools.yaml à partir de vos variables d'environnement :
python setup_tools_yaml.py
Cela génère investment_agent/.adk/tools.yaml avec vos identifiants Neo4j correctement configurés pour les outils MCP.
Vérifier la configuration
Vérifiez que tout est correctement configuré :
# Verify .env file exists
ls -la .env
# Verify tools.yaml was generated
ls -la investment_agent/.adk/tools.yaml
# Test Python environment
python -c "import google.adk; print('ADK installed successfully')"
# Test Neo4j connection
python -c "from neo4j import GraphDatabase; print('Neo4j driver installed')"
Votre environnement de développement est maintenant entièrement configuré. Nous allons ensuite nous pencher sur l'architecture multi-agents.
6. Comprendre l'architecture multi-agents
Le système à quatre agents
Notre système de recherche sur les investissements utilise une architecture multi-agents hiérarchique avec quatre agents spécialisés qui travaillent ensemble pour répondre à des requêtes complexes sur les entreprises, les investisseurs et les informations sur le marché.
┌──────────────┐
│ Root Agent │ ◄── User Query
└──────┬───────┘
│
┌────────────────┼────────────────┐
│ │ │
┌─────▼─────┐ ┌────▼─────┐ ┌────▼──────────┐
│ Graph DB │ │ Investor │ │ Investment │
│ Agent │ │ Research │ │ Research │
└───────────┘ │ Agent │ │ Agent │
└──────────┘ └───────────────┘
- Agent racine (orchestrateur) :
L'agent racine sert de coordinateur intelligent pour l'ensemble du système. Il reçoit les requêtes des utilisateurs, analyse l'intention et achemine les requêtes vers l'agent spécialisé le plus approprié. Imaginez-le comme un gestionnaire de projet qui sait quel membre de l'équipe est le mieux adapté à chaque tâche. Il gère également l'agrégation des réponses, la mise en forme des résultats sous forme de tableaux ou de graphiques sur demande, et le maintien du contexte conversationnel pour plusieurs requêtes. L'agent racine préfère toujours les agents spécialisés à l'agent de base de données général, ce qui garantit que les requêtes sont traitées par le composant le plus expert disponible.
- Agent de base de données de graphes :
L'agent de base de données de graphes est votre connexion directe aux puissantes fonctionnalités de graphes de Neo4j. Il comprend le schéma de la base de données, génère des requêtes Cypher à partir du langage naturel et exécute des traversées de graphes complexes. Cet agent est spécialisé dans les questions structurelles, les agrégations et le raisonnement multihop dans le Knowledge Graph. Il s'agit de l'expert de secours lorsque les requêtes nécessitent une logique personnalisée que les outils prédéfinis ne peuvent pas gérer. Il est donc essentiel pour l'analyse exploratoire et les requêtes analytiques complexes qui n'ont pas été anticipées dans la conception du système.
- Agent de recherche sur les investisseurs :
L'agent de recherche sur les investisseurs se concentre exclusivement sur les relations d'investissement et l'analyse de portefeuille. Il peut identifier les investisseurs de certaines entreprises en utilisant une correspondance exacte des noms, récupérer des portefeuilles d'investisseurs complets montrant tous leurs investissements et analyser les tendances d'investissement dans différents secteurs. Cette spécialisation lui permet de répondre très efficacement à des questions telles que "Qui a investi dans ByteDance ?" ou "Dans quoi d'autre Sequoia Capital a-t-il investi ?" L'agent utilise des fonctions Python personnalisées qui interrogent directement la base de données Neo4j pour obtenir des relations liées aux investisseurs.
- Agent de recherche sur les investissements :
L'agent Investment Research utilise la boîte à outils MCP (Model Context Protocol) pour accéder à des requêtes prévalidées et rédigées par des experts. Il peut récupérer tous les secteurs disponibles, extraire les entreprises de secteurs spécifiques, trouver des articles avec une analyse des sentiments, découvrir les mentions d'organisations dans les actualités et obtenir des informations sur les personnes travaillant dans des entreprises. Contrairement à l'agent de base de données graphiques qui génère des requêtes de manière dynamique, cet agent utilise des requêtes prédéfinies sécurisées et optimisées, gérées et validées de manière centralisée. Cela le rend à la fois sécurisé et performant pour les workflows de recherche courants.
7. Exécuter et tester le système multi-agents
Lancer l'application
Maintenant que vous comprenez l'architecture, exécutons le système complet et interagissons avec lui.
Démarrez l'interface Web ADK :
# Make sure you're in the project directory with activated virtual environment
cd ~/neo4j-adk-multiagents
source .venv/bin/activate # If not already activated
# Launch the application
uv run adk web
Un résultat semblable à celui-ci s'affiche :
INFO: Started server process [2542]
INFO: Waiting for application startup.
+----------------------------------------------------------------+
| ADK Web Server started |
| |
| For local testing, access at http://127.0.0.1:8000. |
+----------------------------------------------------------------+
INFO: Application startup complete.
INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
Requêtes de test et comportement attendu
Explorons les capacités du système avec des requêtes de complexité croissante :
Requêtes de base (agent unique)
Requête 1 : Découvrir les secteurs d'activité
What industries are available in the database?
Comportement attendu :
- L'agent racine redirige vers l'agent Investment Research
- Utilise l'outil MCP :
get_industries() - Renvoie une liste formatée de tous les secteurs d'activité.
Éléments à observer :
Dans l'interface utilisateur de l'ADK, développez les détails de l'exécution pour afficher les éléments suivants :
- Décision de sélection de l'agent
- Appel d'outil :
get_industries() - Résultats bruts de Neo4j
- Réponse formatée
Requête 2 : Trouver des investisseurs
Who invested in ByteDance?
Comportement attendu :
- L'agent racine identifie cette requête comme liée aux investisseurs.
- Routes vers l'agent de recherche sur les investisseurs
- Utilise l'outil :
find_investor_by_name("ByteDance") - Renvoie les investisseurs avec leurs types (Personne/Organisation)
Réponse attendue :
I found 2 investors in ByteDance:
1. Rong Yue (Person)
2. Wendi Murdoch (Person)
Would you like to know more about their investment portfolios?
Requête 3 : Entreprises par secteur**
I found 2 investors in ByteDance:
1. Rong Yue (Person)
2. Wendi Murdoch (Person)
Would you like to know more about their investment portfolios?
"Show me companies in the Artificial Intelligence industry"
Comportement attendu :
- L'agent racine redirige vers l'agent Investment Research
- Utilise l'outil MCP :
get_companies_in_industry("Artificial Intelligence") - Renvoie la liste des entreprises d'IA avec leurs ID et leurs dates de création
Éléments à observer :
- Notez comment l'agent utilise la correspondance exacte du nom du secteur.
- Les résultats sont limités pour éviter une sortie trop importante.
- Les données sont mises en forme de manière claire pour être lisibles.
Requêtes intermédiaires (en plusieurs étapes au sein d'un même agent)
Requête 4 : Analyse des sentiments
Find articles with positive sentiment from January 2023
Comportement attendu :
- Accéder à l'agent Investment Research
- Utilise l'outil MCP :
get_articles_with_sentiment(0.7, 2023, 1) - Renvoie des articles avec des titres, des scores de sentiment et des dates de publication
Conseil de débogage :
Examinez les paramètres d'appel d'outil :
min_sentiment: 0,7 (l'agent interprète "positif" comme étant >= 0,7)year: 2023month: 1
Requête 5 : Requête de base de données complexe
How many companies are in the database?
Comportement attendu :
- L'agent racine redirige les requêtes vers l'agent de base de données graphiques
- L'agent appelle
get_neo4j_schema()en premier pour comprendre la structure. - Génère du code Cypher :
MATCH (c:Company) RETURN count(c) - Exécute la requête et renvoie le nombre
Réponse attendue :
There are 8,064 companies in the database.
Requêtes avancées (coordination multi-agents)
Requête 6 : Analyse du portefeuille
Who invested in ByteDance and what else have they invested in?
Comportement attendu :
Il s'agit d'une requête en deux parties nécessitant une coordination de l'agent :
- Étape 1 : Agent racine → Agent de recherche sur les investisseurs
- Appels
find_investor_by_name("ByteDance") - Obtenir la liste des investisseurs : [Rong Yue, Wendi Murdoch]
- Étape 2 : Pour chaque investisseur → Agent de recherche sur les investisseurs
- Appels
find_investor_by_id(investor_id) - Récupère le portefeuille complet
- Étape 3 : L'agent racine agrège et met en forme les données
Réponse attendue :
I found 2 investors in ByteDance. Here are their portfolios:
1. Rong Yue (Person)
- ByteDance
- Inspur
2. Wendi Murdoch (Person)
- ByteDance
- (No other investments in database)
Éléments à observer :
- Plusieurs appels d'outils séquentiels
- Le contexte est conservé entre les étapes
- Résultats agrégés de manière intelligente
Requête 7 : Recherche multidomaine
What are 5 AI companies mentioned in positive articles, and who are their CEOs?
Comportement attendu :
Cette requête complexe nécessite plusieurs agents et outils :
- Étape 1 : Agent de recherche sur les investissements
get_companies_in_industry("Artificial Intelligence")- Renvoie la liste des entreprises d'IA
- Étape 2 : Agent de recherche sur les investissements
get_articles_with_sentiment(0.8)- Renvoie des articles positifs
- Étape 3 : Filtres de l'agent racine
- Identifier les entreprises d'IA qui apparaissent dans des articles positifs
- Sélectionne les cinq premiers
- Étape 4 : Agent de recherche sur les investissements
get_people_in_organizations([company_names], "CEO")- Renvoie des informations sur le PDG
- Étape 5 : L'agent racine met en forme le tableau
Réponse attendue :
Here are 5 AI companies with positive news and their CEOs:
| Company | Industry | CEO | Avg Sentiment |
|---------|----------|-----|---------------|
| OpenAI | Artificial Intelligence | Sam Altman | 0.92 |
| Anthropic | Artificial Intelligence | Dario Amodei | 0.89 |
| ... | ... | ... | ... |
Éléments à observer :
- Plusieurs appels d'outils sur différents agents
- Logique de filtrage et de combinaison des données
- Mise en forme professionnelle des tableaux
Requête 8 : Analyse de la concurrence
Who are YouTube's main competitors?
Comportement attendu :
- L'agent racine est routé vers l'agent de base de données de graphes (requête de relation)
- L'agent génère du code Cypher amélioré par GraphRAG :
MATCH (c:Company {name: "YouTube"})-[:COMPETES_WITH]->(competitor)
RETURN competitor.name as competitor_name
- Renvoie la liste des entreprises concurrentes
Réponse attendue :
YouTube's main competitors are:
- TikTok (ByteDance)
- Dailymotion
- Twitter
- BuzzFeed
- Mixer
- OpenAI (for video content)
Requêtes de suivi contextuelles
Requête 9 : Question complémentaire (après la requête 8)
Which investors funded both YouTube and its competitors?
Comportement attendu :
- L'agent racine se souvient du contexte précédent (YouTube et ses concurrents)
- Routes vers l'agent de recherche sur les investisseurs
- Pour YouTube et chaque concurrent, trouve des investisseurs
- Identifie les investisseurs qui apparaissent dans plusieurs entreprises
Réponse attendue :
Based on our previous analysis of YouTube's competitors, I found these
investors who funded multiple companies in this competitive landscape:
Sequoia Capital invested in:
- YouTube
- TikTok (ByteDance)
- Twitter
Accel Partners invested in:
- YouTube
- BuzzFeed
This suggests these investors have strategic positions across the video content platform ecosystem.
Requête 10 : Résumé de la recherche
Summarize our research findings so far
Comportement attendu :
- L'agent racine examine l'historique des conversations
- Synthétise les principales conclusions des requêtes précédentes
- Fournit un résumé cohérent
Réponse attendue :
Here's a summary of our investment research session:
1. Industry Overview: We explored the Artificial Intelligence industry
with 150+ companies in the database.
2. ByteDance Analysis:
- Investors: Rong Yue, Wendi Murdoch
- Rong Yue also invested in Inspur
3. Market Sentiment: We analyzed articles from January 2023, finding
strong positive sentiment (avg 0.85) for tech companies.
4. Competitive Landscape: YouTube faces competition from TikTok,
Dailymotion, and others, with some investors (Sequoia, Accel) holding
positions across competing platforms.
5. Key Players: Identified CEOs of major AI companies with positive media coverage.
Comprendre les interactions de l'agent dans la vue de débogage
L'interface Web d'ADK offre une visibilité détaillée sur l'exécution. Voici ce que vous devez rechercher :
- Chronologie des événements
Affiche le flux chronologique :
[USER] Query received
[ROOT_AGENT] Analyzing query intent
[ROOT_AGENT] Routing to investment_research_agent
[INVESTMENT_RESEARCH_AGENT] Tool call: get_companies_in_industry
[TOOL] Executing with params: {"industry_name": "Artificial Intelligence"}
[TOOL] Returned 47 results
[INVESTMENT_RESEARCH_AGENT] Formatting response
[ROOT_AGENT] Presenting to user
- Détails de l'appel d'outil
Cliquez sur un appel d'outil pour afficher les informations suivantes :
- Nom de la fonction
- Paramètres d'entrée
- Valeur renvoyée
- Durée d'exécution
- Toutes les erreurs
- Prise de décision par l'agent
Observez le raisonnement du LLM :
- Pourquoi il a choisi un agent spécifique
- Comment elle a interprété la requête
- Outils pris en compte
- Pourquoi les résultats ont été mis en forme d'une certaine manière
Observations et insights courants
- Schémas de routage des requêtes :
- Mots clés tels que "investisseur" et "investi" → Agent de recherche sur les investisseurs
- Mots clés tels que "secteur", "entreprises", "articles" → Agent de recherche sur les investissements
- Agrégations, nombres, logique complexe → Agent de base de données graphiques
- Remarques sur les performances :
- Les outils MCP sont généralement plus rapides (requêtes pré-optimisées).
- La génération de requêtes Cypher complexes prend plus de temps (temps de réflexion du LLM).
- Les appels d'outils multiples ajoutent de la latence, mais fournissent des résultats plus riches.
- Gestion des exceptions :
- Si une requête échoue :
- L'agent explique ce qui s'est mal passé
- Suggère des corrections (par exemple, "Nom de l'entreprise introuvable, vérifiez l'orthographe")
- Peut essayer d'autres approches
Conseils pour des tests efficaces
- Commencez par la base : testez la fonctionnalité de base de chaque agent avant les requêtes complexes.
- Utiliser les requêtes complémentaires : testez la conservation du contexte avec des questions complémentaires.
- Observer le routage : regardez quel agent traite chaque requête pour comprendre la logique.
- Vérifier les appels d'outils : vérifiez que les paramètres sont correctement extraits du langage naturel.
- Testez les cas extrêmes : essayez des requêtes ambiguës, des fautes d'orthographe ou des demandes inhabituelles.
Vous disposez désormais d'un système GraphRAG multi-agent entièrement fonctionnel. Testez vos propres questions pour explorer ses capacités.
8. Effectuer un nettoyage
Pour éviter que les ressources utilisées dans cet article soient facturées sur votre compte Google Cloud, procédez comme suit :
- Dans la console Google Cloud, accédez à la page Gérer les ressources.
- Dans la liste des projets, sélectionnez le projet que vous souhaitez supprimer, puis cliquez sur Supprimer.
- Dans la boîte de dialogue, saisissez l'ID du projet, puis cliquez sur Arrêter pour supprimer le projet.
9. Félicitations
🎉 Félicitations ! Vous avez créé un système GraphRAG multi-agent de qualité de production à l'aide de l'Agent Development Kit de Google, de Neo4j et de MCP Toolbox.
En combinant les capacités d'orchestration intelligente de l'ADK avec le modèle de données riche en relations de Neo4j et la sécurité des requêtes MCP prévalidées, vous avez créé un système sophistiqué qui va au-delà des simples requêtes de base de données. Il comprend le contexte, raisonne sur des relations complexes et coordonne des agents spécialisés pour fournir des insights complets et précis.
Dans cet atelier de programmation, vous avez effectué les opérations suivantes :
✅ Créer un système multi-agents à l'aide de Google Agent Development Kit (ADK) avec orchestration hiérarchique
✅ Base de données de graphes Neo4j intégrée pour exploiter les requêtes tenant compte des relations et le raisonnement multi-sauts
✅ Implémentation de MCP Toolbox pour des requêtes de base de données sécurisées et prévalidées en tant qu'outils réutilisables
✅ Créé des agents spécialisés pour la recherche sur les investisseurs, l'analyse des investissements et les opérations sur les bases de données graphiques
✅ Conception d'un routage intelligent qui délègue automatiquement les requêtes à l'agent expert le plus approprié
✅ Gestion des types de données complexes avec la sérialisation appropriée des types Neo4j pour une intégration Python fluide
✅ Appliquer les bonnes pratiques de production pour la conception d'agents, la gestion des exceptions et le débogage du système
Et maintenant ?
Cette architecture GraphRAG multi-agents ne se limite pas à la recherche sur les investissements. Elle peut être étendue à :
- Services financiers : optimisation de portefeuille, évaluation des risques, détection des fraudes
- Santé : coordination des soins aux patients, analyse des interactions médicamenteuses, recherche clinique
- E-commerce : recommandations personnalisées, optimisation de la chaîne d'approvisionnement, insights sur les clients
- Mentions légales et conformité : analyse des contrats, surveillance réglementaire, recherche de jurisprudence
- Recherche universitaire : revue de littérature, découverte de collaborations, analyse des citations
- Intelligence d'entreprise : analyse de la concurrence, études de marché, graphes de connaissances organisationnels
Partout où vous disposez de données complexes et interconnectées + expertise du domaine + interfaces en langage naturel, cette combinaison de systèmes multi-agents ADK + graphiques de connaissances Neo4j + requêtes validées par MCP peut alimenter la prochaine génération d'applications d'entreprise intelligentes.
À mesure que le kit de développement d'agents et les modèles Gemini de Google continuent d'évoluer, vous pourrez intégrer des schémas de raisonnement encore plus sophistiqués, l'intégration de données en temps réel et des fonctionnalités multimodales pour créer des systèmes véritablement intelligents et contextuels.
Continuez à explorer et à développer pour faire passer vos applications d'agents intelligents au niveau supérieur !
Découvrez d'autres tutoriels pratiques sur les knowledge graphs sur Neo4j GraphAcademy et d'autres modèles d'agents dans le dépôt d'exemples ADK.
🚀 Prêt à créer votre prochain système d'agent intelligent ?