
1. खास जानकारी
इस कोडलैब में, आपको एक बेहतर मल्टी-एजेंट इन्वेस्टमेंट रिसर्च सिस्टम बनाने का तरीका बताया जाएगा. इसमें Google के एजेंट डेवलपमेंट किट (एडीके), Neo4j Graph Database, और मॉडल कॉन्टेक्स्ट प्रोटोकॉल (एमसीपी) टूलबॉक्स का इस्तेमाल किया जाता है. इस प्रैक्टिकल ट्यूटोरियल में, ऐसे इंटेलिजेंट एजेंट बनाने का तरीका बताया गया है जो ग्राफ़ रिलेशनशिप के ज़रिए डेटा के कॉन्टेक्स्ट को समझते हैं और क्वेरी के ज़्यादा सटीक जवाब देते हैं.
GraphRAG + मल्टी-एजेंट सिस्टम का इस्तेमाल क्यों करें?
GraphRAG (ग्राफ़ पर आधारित Retrieval-Augmented Generation), नॉलेज ग्राफ़ के बेहतर संबंध स्ट्रक्चर का फ़ायदा उठाकर, RAG के पारंपरिक तरीकों को बेहतर बनाता है. GraphRAG एजेंट, सिर्फ़ मिलते-जुलते दस्तावेज़ों को खोजने के बजाय ये काम कर सकते हैं:
- इकाइयों के बीच जटिल संबंधों को समझना
- ग्राफ़ स्ट्रक्चर के ज़रिए कॉन्टेक्स्ट को समझना
- कनेक्ट किए गए डेटा के आधार पर, ऐसे नतीजे देना जिनके बारे में बताया जा सके
- नॉलेज ग्राफ़ में मल्टी-हॉप रीज़निंग को लागू करना
मल्टी-एजेंट सिस्टम की मदद से, ये काम किए जा सकते हैं:
- मुश्किल समस्याओं को खास उप-टास्क में बांटना
- मॉड्यूलर और रखरखाव में आसान एआई ऐप्लिकेशन बनाना
- पैरलल प्रोसेसिंग और संसाधनों का बेहतर इस्तेमाल करने की सुविधा चालू करें
- ऑर्केस्ट्रेशन की मदद से, हैरारकी वाली तार्किक विवेचना (लॉजिकल रीज़निंग) के पैटर्न बनाना
आपको क्या बनाने को मिलेगा
आपको एक पूरा इन्वेस्टमेंट रिसर्च सिस्टम बनाना होगा. इसमें ये सुविधाएं शामिल होंगी:
- ग्राफ़ डेटाबेस एजेंट: यह Cypher क्वेरी को लागू करता है और Neo4j स्कीमा को समझता है
- इन्वेस्टर रिसर्च एजेंट: यह निवेशकों के साथ संबंधों और निवेश पोर्टफ़ोलियो के बारे में जानकारी देता है
- निवेश से जुड़ी रिसर्च करने वाला एजेंट: एमसीपी टूल की मदद से, नॉलेज ग्राफ़ की पूरी जानकारी ऐक्सेस करता है
- रूट एजेंट: सभी सब-एजेंट को स्मार्ट तरीके से मैनेज करता है
सिस्टम, इस तरह के मुश्किल सवालों के जवाब देगा:
- "YouTube के मुख्य प्रतिस्पर्धी कौन हैं?"
- "जनवरी 2023 में, किन कंपनियों के बारे में सकारात्मक बातें की गई हैं?"
- "ByteDance में किसने निवेश किया है और उन्होंने और कहां निवेश किया है?"
आर्किटेक्चर की खास जानकारी
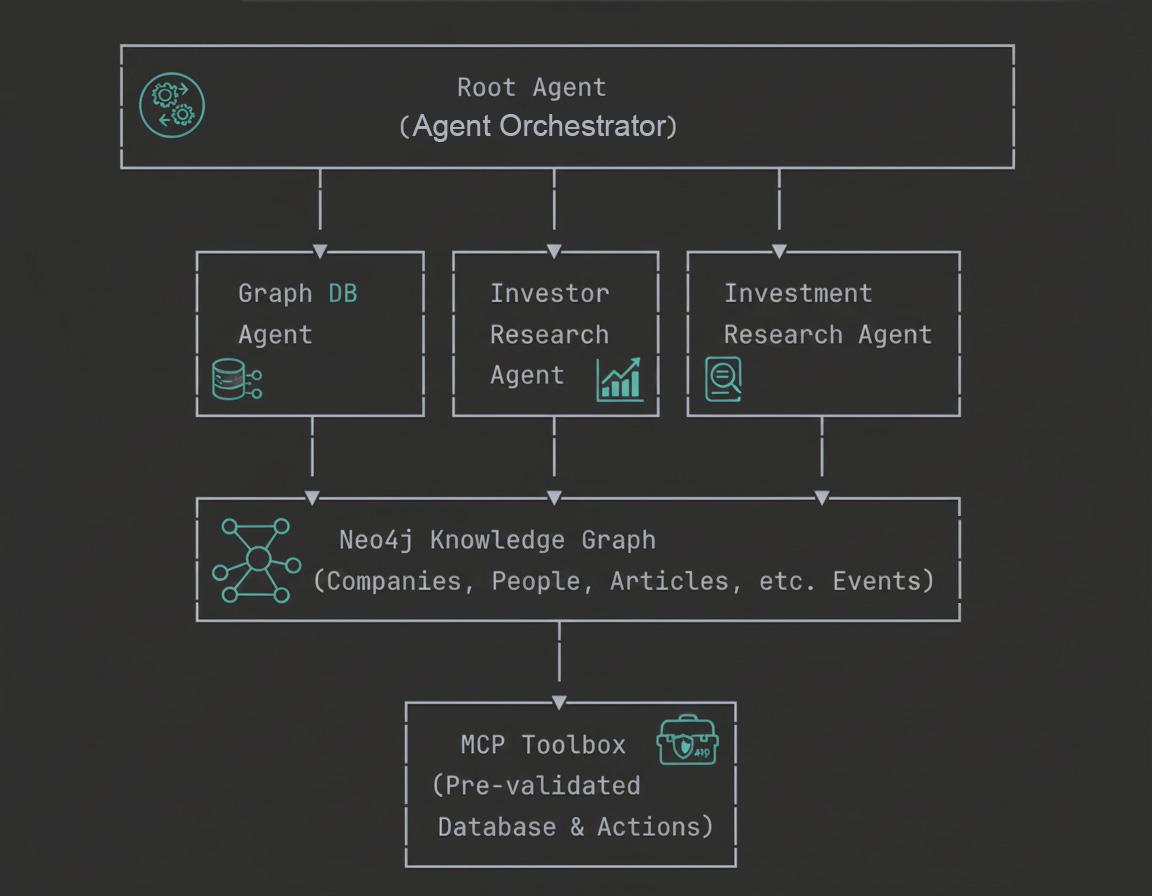
इस कोडलैब में, आपको एंटरप्राइज़-ग्रेड GraphRAG एजेंट बनाने के कॉन्सेप्ट और उन्हें लागू करने के तरीके के बारे में जानकारी मिलेगी.
आपको क्या सीखने को मिलेगा
- Google के Agent Development Kit (ADK) का इस्तेमाल करके, मल्टी-एजेंट सिस्टम बनाने का तरीका
- GraphRAG ऐप्लिकेशन के लिए, Neo4j ग्राफ़ डेटाबेस को ADK के साथ इंटिग्रेट करने का तरीका
- पहले से पुष्टि की गई डेटाबेस क्वेरी के लिए, मॉडल कॉन्टेक्स्ट प्रोटोकॉल (एमसीपी) टूलबॉक्स को लागू करने का तरीका
- इंटेलिजेंट एजेंट के लिए कस्टम टूल और फ़ंक्शन बनाने का तरीका
- एजेंट हैरारकी और ऑर्केस्ट्रेशन पैटर्न डिज़ाइन करने का तरीका
- बेहतर परफ़ॉर्मेंस के लिए, एजेंट को निर्देश देने का तरीका
- मल्टी-एजेंट इंटरैक्शन को असरदार तरीके से डीबग करने का तरीका
आपको इन चीज़ों की ज़रूरत होगी
- Chrome वेब ब्राउज़र
- Gmail खाता
- बिलिंग की सुविधा वाला Google Cloud प्रोजेक्ट
- टर्मिनल कमांड और Python की बुनियादी जानकारी (ज़रूरी नहीं, लेकिन मददगार)
यह कोडलैब, सभी लेवल के डेवलपर (शुरुआती डेवलपर भी शामिल हैं) के लिए बनाया गया है. इसमें सैंपल ऐप्लिकेशन में Python और Neo4j का इस्तेमाल किया गया है. Python और ग्राफ़ डेटाबेस के बारे में बुनियादी जानकारी होना मददगार हो सकता है. हालांकि, कॉन्सेप्ट को समझने या साथ-साथ काम करने के लिए, पहले से कोई अनुभव होना ज़रूरी नहीं है.
2. GraphRAG और मल्टी-एजेंट सिस्टम के बारे में जानकारी
इसे लागू करने से पहले, आइए इस सिस्टम को बेहतर बनाने वाले मुख्य कॉन्सेप्ट के बारे में जानते हैं.
Neo4j, एक लोकप्रिय नेटिव ग्राफ़ डेटाबेस है. यह डेटा को नोड (इकाइयां) और रिलेशनशिप (इकाइयों के बीच कनेक्शन) के नेटवर्क के तौर पर सेव करता है. इसलिए, यह उन मामलों में इस्तेमाल करने के लिए सबसे सही है जहां कनेक्शन को समझना ज़रूरी है. जैसे, सुझाव देना, धोखाधड़ी का पता लगाना, नॉलेज ग्राफ़ वगैरह. रिलेशनल या दस्तावेज़ पर आधारित डेटाबेस, टेबल या क्रमबद्ध स्ट्रक्चर पर निर्भर करते हैं. हालांकि, Neo4j का फ़्लेक्सिबल ग्राफ़ मॉडल, जटिल और आपस में जुड़े डेटा को आसानी से और असरदार तरीके से दिखाने की सुविधा देता है.
रिलेशनल डेटाबेस की तरह, Neo4j डेटा को लाइनों और टेबल में व्यवस्थित करने के बजाय, ग्राफ़ मॉडल का इस्तेमाल करता है. इसमें जानकारी को नोड (इकाइयां) और संबंधों (उन इकाइयों के बीच कनेक्शन) के तौर पर दिखाया जाता है. यह मॉडल, ऐसे डेटा के साथ काम करने के लिए बहुत आसान है जो स्वाभाविक रूप से एक-दूसरे से जुड़ा होता है. जैसे, लोग, जगहें, प्रॉडक्ट या हमारे मामले में, फ़िल्में, कलाकार, और शैलियां.
उदाहरण के लिए, किसी फ़िल्म के डेटासेट में:
- कोई नोड,
Movie,ActorयाDirectorको दिखा सकता है - संबंध
ACTED_INयाDIRECTEDहो सकता है
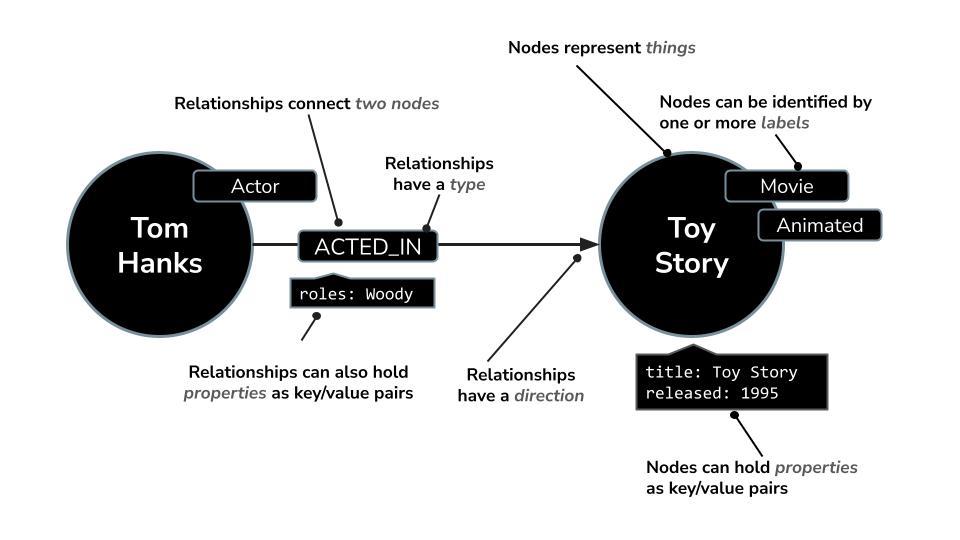
इस स्ट्रक्चर की मदद से, आसानी से इस तरह के सवाल पूछे जा सकते हैं:
- इस अभिनेता ने किन फ़िल्मों में काम किया है?
- क्रिस्टोफ़र नोलन के साथ किन लोगों ने काम किया है?
- शेयर किए गए कलाकारों या शैलियों के आधार पर, मिलती-जुलती फ़िल्में कौनसी हैं?
GraphRAG क्या है?
रिट्रीवल ऑगमेंटेड जनरेशन (आरएजी) तकनीक, एलएलएम के जवाबों को बेहतर बनाती है. इसके लिए, यह बाहरी सोर्स से काम की जानकारी इकट्ठा करती है. आम तौर पर, पारंपरिक आरएजी में:
- यह दस्तावेज़ों को वेक्टर में बदलता है
- मिलते-जुलते वेक्टर खोजता है
- यह खोजे गए दस्तावेज़ों को एलएलएम को भेजता है
GraphRAG, नॉलेज ग्राफ़ का इस्तेमाल करके इस प्रोसेस को और बेहतर बनाता है:
- इकाइयों और उनके बीच के संबंधों को शामिल करता है
- ग्राफ़ कनेक्शन को ट्रैवर्स करता है
- यह एक से ज़्यादा चरणों में कॉन्टेक्स्ट के हिसाब से जानकारी वापस लाता है
- स्ट्रक्चर्ड और समझने में आसान नतीजे मिलते हैं
एआई एजेंट के लिए ग्राफ़ क्यों ज़रूरी हैं?
इस सवाल पर विचार करें: "YouTube के प्रतिस्पर्धी कौन हैं और किन निवेशकों ने YouTube और उसके प्रतिस्पर्धियों, दोनों को फ़ंड किया है?"
पारंपरिक RAG के तरीके में क्या होता है:
- YouTube के प्रतिस्पर्धियों के बारे में दस्तावेज़ खोजता है
- यह निवेशक की जानकारी को अलग से खोजता है
- इन दोनों जानकारियों को आपस में जोड़ने में समस्या आ रही है
- ऐसा हो सकता है कि इसमें छिपे हुए संबंधों की जानकारी न हो
GraphRAG के तरीके में क्या होता है:
MATCH (org:Organization {name: "OpenAI"})-[:HAS_COMPETITOR]-(competitor:Organization)
MATCH (org)-[:HAS_INVESTOR]->(investor:Person)
MATCH (competitor)-[:HAS_INVESTOR]->(investor)
RETURN org, competitor, investor
ग्राफ़, संबंधों को आसानी से दिखाता है. इससे मल्टी-हॉप क्वेरी को आसानी से और असरदार तरीके से हल किया जा सकता है.
ADK में मल्टी-एजेंट सिस्टम
एजेंट डेवलपमेंट किट (एडीके), Google का ओपन-सोर्स फ़्रेमवर्क है. इसका इस्तेमाल, प्रोडक्शन-ग्रेड एआई एजेंट बनाने और उन्हें डिप्लॉय करने के लिए किया जाता है. यह मल्टी-एजेंट ऑर्केस्ट्रेशन, टूल इंटिग्रेशन, और वर्कफ़्लो मैनेजमेंट के लिए, इस्तेमाल में आसान प्रिमिटिव उपलब्ध कराता है. इससे, खास एजेंट को बेहतर सिस्टम में कंपोज़ करना आसान हो जाता है. ADK, Gemini के साथ आसानी से काम करता है. साथ ही, इसे Cloud Run, Kubernetes या किसी भी इन्फ़्रास्ट्रक्चर पर डिप्लॉय किया जा सकता है.
Agent Development Kit (ADK) में, मल्टी-एजेंट सिस्टम बनाने के लिए प्रिमिटिव उपलब्ध हैं:
- एजेंट का क्रम:
# Root agent coordinates specialized agents
root_agent = LlmAgent(
name="RootAgent",
sub_agents=[
graph_db_agent,
investor_agent,
investment_agent
]
)
- किसी खास विषय से जुड़े एजेंट: हर एजेंट के पास
- खास टूल: ऐसे फ़ंक्शन जिन्हें यह कॉल कर सकता है
- साफ़ तौर पर निर्देश: इसकी भूमिका और क्षमताएं
- डोमेन की विशेषज्ञता: अपने क्षेत्र की जानकारी
- ऑर्केस्ट्रेशन पैटर्न:
- क्रम से: एजेंट को क्रम से लागू करें
- पैरलल: एक साथ कई एजेंट चलाएं
- शर्त के साथ: क्वेरी टाइप के आधार पर रूट करना
डेटाबेस के लिए एमसीपी टूलबॉक्स
मॉडल कॉन्टेक्स्ट प्रोटोकॉल (एमसीपी) एक ओपन स्टैंडर्ड है. इसका इस्तेमाल, एआई सिस्टम को बाहरी डेटा सोर्स और टूल से कनेक्ट करने के लिए किया जाता है. डेटाबेस के लिए एमसीपी टूलबॉक्स, Google का एक ऐसा टूल है जो डेटाबेस क्वेरी को मैनेज करने की सुविधा देता है. इसकी मदद से, पहले से पुष्टि की गई और विशेषज्ञों की लिखी गई क्वेरी को फिर से इस्तेमाल किए जा सकने वाले टूल के तौर पर तय किया जा सकता है. एलएलएम को संभावित रूप से असुरक्षित क्वेरी जनरेट करने की अनुमति देने के बजाय, एमसीपी टूलबॉक्स पहले से मंज़ूरी पा चुकी क्वेरी दिखाता है. साथ ही, पैरामीटर की पुष्टि करता है. इससे सुरक्षा, परफ़ॉर्मेंस, और भरोसेमंद तरीके से काम करने की क्षमता बनी रहती है. साथ ही, एआई एजेंट के लिए फ़्लेक्सिबिलिटी भी बनी रहती है.
परंपरागत तरीका:
# LLM generates query (may be incorrect/unsafe)
query = llm.generate("SELECT * FROM users WHERE...")
db.execute(query) # Risk of errors/SQL injection
एमसीपी का तरीका:
# Pre-validated query definition
- name: get_industries
description: Fetch all industries from database
query: |
MATCH (i:Industry)
RETURN i.name, i.id
फ़ायदे:
- विशेषज्ञों ने पहले से ही पुष्टि की हो
- इंजेक्शन अटैक से सुरक्षित
- परफ़ॉर्मेंस के लिए ऑप्टिमाइज़ किया गया
- एक ही जगह से मैनेज किया गया
- इसे अलग-अलग एजेंट के लिए फिर से इस्तेमाल किया जा सकता है
कुल मिलाकर ज़रूरी जानकारी
ADK + MCP के GraphRAG + मल्टी-एजेंट फ़्रेमवर्क को मिलाकर एक दमदार सिस्टम बनाया जा सकता है:
- रूट एजेंट को उपयोगकर्ता की क्वेरी मिलती है
- क्वेरी के टाइप के आधार पर, खास एजेंट को रूट करता है
- एजेंट, डेटा को सुरक्षित तरीके से फ़ेच करने के लिए MCP टूल का इस्तेमाल करता है
- ग्राफ़ स्ट्रक्चर से ज़्यादा कॉन्टेक्स्ट मिलता है
- एलएलएम, सटीक और भरोसेमंद जवाब जनरेट करता है
अब हम आर्किटेक्चर के बारे में जान चुके हैं. तो चलिए, अब इसे बनाना शुरू करते हैं!
3. Google Cloud प्रोजेक्ट सेट अप करना
प्रोजेक्ट बनाना
- Google Cloud Console में, प्रोजेक्ट चुनने वाले पेज पर, Google Cloud प्रोजेक्ट चुनें या बनाएं.
- पक्का करें कि आपके Cloud प्रोजेक्ट के लिए बिलिंग चालू हो. किसी प्रोजेक्ट के लिए बिलिंग चालू है या नहीं, यह देखने का तरीका जानें .
- आपको Cloud Shell का इस्तेमाल करना होगा. यह Google Cloud में चलने वाला कमांड-लाइन एनवायरमेंट है. Google Cloud Console में सबसे ऊपर मौजूद, Cloud Shell चालू करें पर क्लिक करें. Cloud Shell में जाकर, Cloud Shell टर्मिनल (क्लाउड कमांड चलाने के लिए) और एडिटर (प्रोजेक्ट बनाने के लिए) के बीच टॉगल किया जा सकता है. इसके लिए, Cloud Shell में मौजूद बटन पर क्लिक करें.

- Cloud Shell से कनेक्ट होने के बाद, यह देखने के लिए कि आपकी पुष्टि हो चुकी है और प्रोजेक्ट को आपके प्रोजेक्ट आईडी पर सेट किया गया है, इस कमांड का इस्तेमाल करें:
gcloud auth list
- यह पुष्टि करने के लिए कि gcloud कमांड को आपके प्रोजेक्ट के बारे में पता है, Cloud Shell में यह कमांड चलाएं.
gcloud config list project
- अगर आपका प्रोजेक्ट सेट नहीं है, तो इसे सेट करने के लिए इस निर्देश का इस्तेमाल करें:
gcloud config set project <YOUR_PROJECT_ID>
gcloud कमांड और उनके इस्तेमाल के बारे में जानने के लिए, दस्तावेज़ देखें.
बहुत बढ़िया ! अब हम अगले चरण पर जाने के लिए तैयार हैं. यानी, डेटासेट को समझना.
4. कंपनियों के डेटासेट के बारे में जानकारी
इस कोडलैब के लिए, हम read-only Neo4j डेटाबेस का इस्तेमाल कर रहे हैं. इसमें Diffbot के नॉलेज ग्राफ़ से, निवेश और कंपनी का डेटा पहले से भरा हुआ है.
डेटासेट में यह जानकारी शामिल होती है:
- 2,37,358 नोड, जो इन चीज़ों को दिखाते हैं:
- संगठन (कंपनियां)
- लोग (कार्यकारी, कर्मचारी)
- लेख (खबरें और ज़िक्र)
- उद्योग
- तकनीक
- निवेशक
- इनके साथ संबंध:
HAS_INVESTOR- निवेश से जुड़े कनेक्शनHAS_COMPETITOR- प्रतिस्पर्धी संबंधMENTIONS- लेख के रेफ़रंसHAS_CEO- रोज़गार से जुड़े संबंधHAS_CATEGORY- इंडस्ट्री की कैटगरी
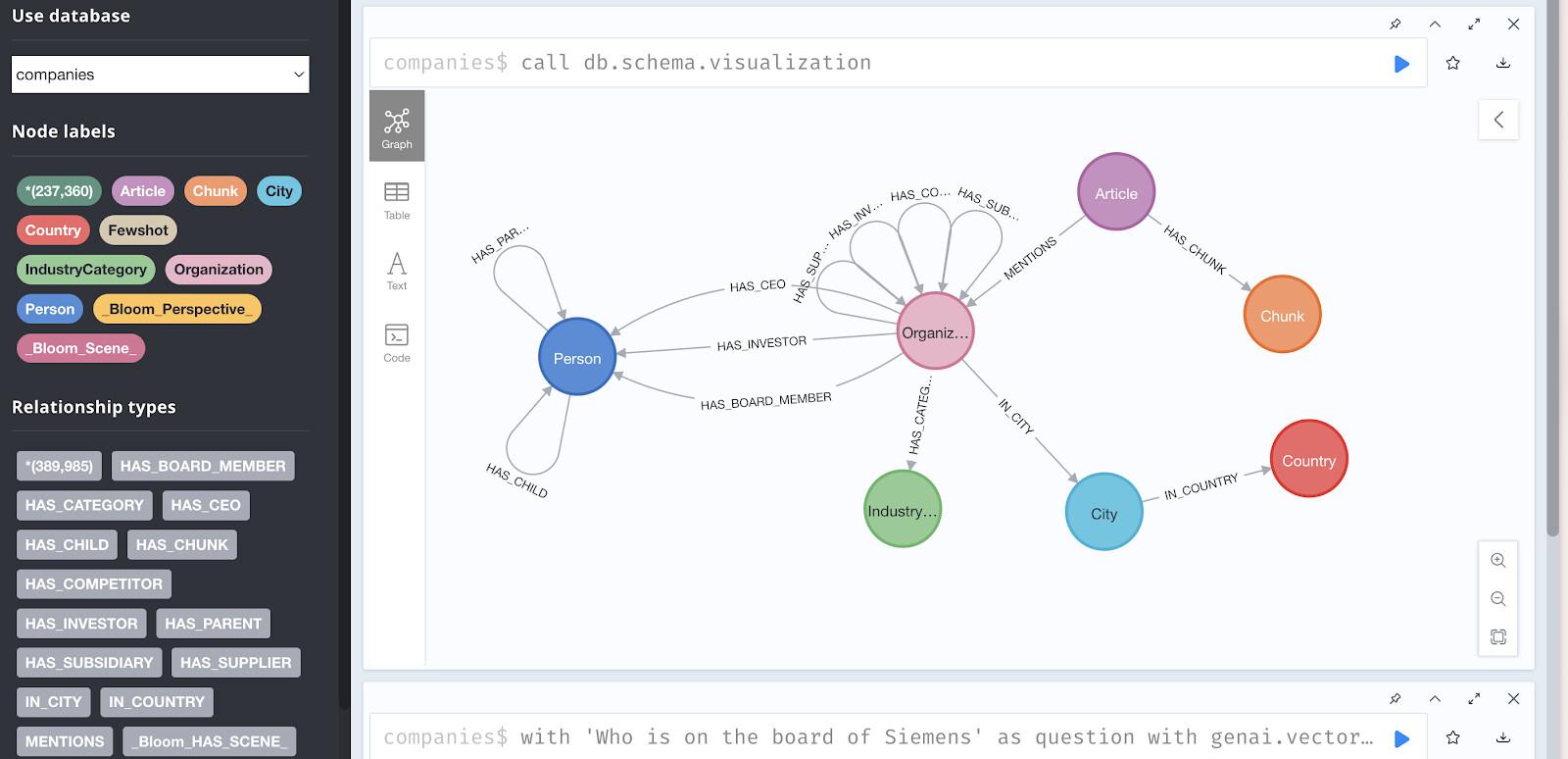
डेमो डेटाबेस ऐक्सेस करना
इस कोडलैब के लिए, हम होस्ट किए गए डेमो इंस्टेंस का इस्तेमाल करेंगे. इन क्रेडेंशियल को अपने नोट में जोड़ें:
URI: neo4j+s://demo.neo4jlabs.com
Username: companies
Password: companies
Database: companies
ब्राउज़र से ऐक्सेस करना:
डेटा को विज़ुअलाइज़ करके देखने के लिए, यहां जाएं: https://demo.neo4jlabs.com:7473
उसी क्रेडेंशियल से लॉग इन करें और यह कमांड चलाएं:
// Sample query to explore the graph
MATCH (c:Organization)-[:HAS_COMPETITOR]-(competitor:Organization)
RETURN c.name, competitor.name
LIMIT 10
ग्राफ़ स्ट्रक्चर को विज़ुअलाइज़ करना
रिलेशनशिप पैटर्न देखने के लिए, Neo4j Browser में यह क्वेरी आज़माएं:
// Find investors and their portfolio companies
MATCH (company:Organization)-[:HAS_INVESTOR]->(investor:Person)
WITH investor, collect(company.name) as portfolio
RETURN investor.name, size(portfolio) as num_investments, portfolio
ORDER BY num_investments DESC
LIMIT 5
इस क्वेरी से, सबसे ज़्यादा सक्रिय पांच निवेशकों और उनके पोर्टफ़ोलियो की जानकारी मिलती है.
GraphRAG के लिए इस डेटाबेस का इस्तेमाल क्यों किया जाता है?
यह डेटासेट, GraphRAG को दिखाने के लिए सबसे सही है, क्योंकि:
- रिच रिलेशनशिप: इकाइयों के बीच जटिल कनेक्शन
- असल दुनिया का डेटा: असली कंपनियां, लोग, और समाचार लेख
- मल्टी-हॉप क्वेरी: इसके लिए, कई तरह के संबंधों को पार करना ज़रूरी होता है
- समय के हिसाब से डेटा: समय के हिसाब से विश्लेषण करने के लिए टाइमस्टैंप वाले लेख
- भावनाओं का विश्लेषण: लेखों के लिए पहले से कैलकुलेट किए गए सेंटीमेंट स्कोर
अब जब आपको डेटा स्ट्रक्चर के बारे में पता चल गया है, तो आइए अपना डेवलपमेंट एनवायरमेंट सेट अप करें!
5. रिपॉज़िटरी क्लोन करना और एनवायरमेंट कॉन्फ़िगर करना
रिपॉज़िटरी का क्लोन बनाना
अपने Cloud Shell टर्मिनल में, यह कमांड चलाएं:
# Clone the repository
git clone https://github.com/sidagarwal04/neo4j-adk-multiagents.git
# Navigate into the directory
cd neo4j-adk-multiagents
रिपॉज़िटरी के स्ट्रक्चर के बारे में जानें
प्रोजेक्ट के लेआउट को समझने के लिए, कुछ समय निकालें:
neo4j-adk-multiagents/
├── investment_agent/ # Main agent code
│ ├── agent.py # Agent definitions
│ ├── tools.py # Custom tool functions
│ └── .adk/ # ADK configuration
│ └── tools.yaml # MCP tool definitions
├── main.py # Application entry point
├── setup_tools_yaml.py # Configuration generator
├── requirements.txt # Python dependencies
├── example.env # Environment template
└── README.md # Project documentation
वर्चुअल एनवायरमेंट सेट अप करना
uv का इस्तेमाल करके, Python का वर्चुअल एनवायरमेंट बनाएं और उसे चालू करें:
# Install uv if not already installed
pip install uv
# Create virtual environment
uv venv
# Activate the environment
source .venv/bin/activate # On macOS/Linux
# or
.venv\Scripts\activate # On Windows
आपको अपने टर्मिनल प्रॉम्प्ट के पहले (.venv) दिखेगा.
डिपेंडेंसी इंस्टॉल करना
सभी ज़रूरी पैकेज इंस्टॉल करें:
uv pip install -r requirements.txt
मुख्य डिपेंडेंसी में ये शामिल हैं:
txtgoogle-adk>=1.21.0 # Agent Development Kit
neo4j>=6.0.3 # Neo4j Python driver
python-dotenv>=1.0.0 # Environment variables
google-cloud-aiplatform>=1.30.0 # Vertex AI
एनवायरमेंट वैरिएबल कॉन्फ़िगर करना
- अपनी **
.env** **फ़ाइल बनाएं:**
cp example.env .env
- **
.env** **फ़ाइल में बदलाव करने के लिए:**
अगर Cloud Shell का इस्तेमाल किया जा रहा है, तो टूलबार में मौजूद Open Editor पर क्लिक करें. इसके बाद, .env पर जाएं और इसे अपडेट करें:
छिपी हुई .env फ़ाइल को दिखाने के लिए:
Google Cloud Shell Editor में, View > Toggle Hidden files पर क्लिक करें.
# Neo4j Configuration (Demo Database)
NEO4J_URI=neo4j+s://demo.neo4jlabs.com
NEO4J_USERNAME=companies
NEO4J_PASSWORD=companies
NEO4J_DATABASE=companies
# Google AI Configuration
# Choose ONE of the following options:
# Option 1: Google AI API (Recommended)
GOOGLE_GENAI_USE_VERTEXAI=0
GOOGLE_API_KEY=your_api_key_here # Get from https://aistudio.google.com/app/apikey
# Option 2: Vertex AI (If using GCP)
# GOOGLE_GENAI_USE_VERTEXAI=1
# GOOGLE_CLOUD_PROJECT=your-project-id
# GOOGLE_CLOUD_LOCATION=us-central1
# ADK Configuration
GOOGLE_ADK_MODEL=gemini-3.1-flash-lite-preview # or gemini-3-flash-preview
# MCP Toolbox Configuration
MCP_TOOLBOX_URL=https://toolbox-990868019953.us-central1.run.app/mcp/sse
- एमसीपी टूलबॉक्स का कॉन्फ़िगरेशन जनरेट करें:
अपने एनवायरमेंट वैरिएबल से tools.yaml फ़ाइल बनाने के लिए, सेटअप स्क्रिप्ट चलाएं:
python setup_tools_yaml.py
इससे investment_agent/.adk/tools.yaml जनरेट होता है. इसमें एमसीपी टूल के लिए, आपके Neo4j क्रेडेंशियल सही तरीके से कॉन्फ़िगर किए जाते हैं.
कॉन्फ़िगरेशन की पुष्टि करना
देखें कि सब कुछ सही तरीके से सेट अप किया गया हो:
# Verify .env file exists
ls -la .env
# Verify tools.yaml was generated
ls -la investment_agent/.adk/tools.yaml
# Test Python environment
python -c "import google.adk; print('ADK installed successfully')"
# Test Neo4j connection
python -c "from neo4j import GraphDatabase; print('Neo4j driver installed')"
आपका डेवलपमेंट एनवायरमेंट अब पूरी तरह से कॉन्फ़िगर हो गया है! इसके बाद, हम मल्टी-एजेंट आर्किटेक्चर के बारे में ज़्यादा जानेंगे.
6. मल्टी-एजेंट आर्किटेक्चर के बारे में जानकारी
चार एजेंट वाला सिस्टम
निवेश के बारे में रिसर्च करने वाला हमारा सिस्टम, एक हैरारिकल मल्टी-एजेंट आर्किटेक्चर का इस्तेमाल करता है. इसमें चार विशेषज्ञ एजेंट एक साथ काम करते हैं. ये एजेंट, कंपनियों, निवेशकों, और मार्केट इंटेलिजेंस के बारे में मुश्किल सवालों के जवाब देते हैं.
┌──────────────┐
│ Root Agent │ ◄── User Query
└──────┬───────┘
│
┌────────────────┼────────────────┐
│ │ │
┌─────▼─────┐ ┌────▼─────┐ ┌────▼──────────┐
│ Graph DB │ │ Investor │ │ Investment │
│ Agent │ │ Research │ │ Research │
└───────────┘ │ Agent │ │ Agent │
└──────────┘ └───────────────┘
- रूट एजेंट (ऑर्केस्ट्रेटर):
रूट एजेंट, पूरे सिस्टम के लिए एक इंटेलिजेंट कोऑर्डिनेटर के तौर पर काम करता है. यह उपयोगकर्ता की क्वेरी लेता है, उसके इंटेंट का विश्लेषण करता है, और अनुरोधों को सबसे सही स्पेशलाइज़्ड एजेंट को रूट करता है. इसे एक प्रोजेक्ट मैनेजर की तरह समझें, जिसे यह पता होता है कि हर टास्क के लिए कौनसी टीम का सदस्य सबसे सही है. यह जवाबों को इकट्ठा करने, अनुरोध किए जाने पर नतीजों को टेबल या चार्ट के तौर पर फ़ॉर्मैट करने, और कई क्वेरी के बीच बातचीत के कॉन्टेक्स्ट को बनाए रखने का काम भी करता है. रूट एजेंट, सामान्य डेटाबेस एजेंट के बजाय हमेशा खास एजेंट को प्राथमिकता देता है. इससे यह पक्का होता है कि क्वेरी को सबसे ज़्यादा विशेषज्ञता वाले कॉम्पोनेंट से हैंडल किया जाए.
- ग्राफ़ डेटाबेस एजेंट:
Graph Database Agent, Neo4j की दमदार ग्राफ़ क्षमताओं से सीधे तौर पर कनेक्ट होता है. यह डेटाबेस स्कीमा को समझता है, नैचुरल लैंग्वेज से साइफ़र क्वेरी जनरेट करता है, और मुश्किल ग्राफ़ ट्रैवर्सल को लागू करता है. यह एजेंट, स्ट्रक्चरल सवालों, एग्रीगेशन, और नॉलेज ग्राफ़ में मल्टी-हॉप रीज़निंग में माहिर है. यह तब काम आता है, जब क्वेरी के लिए कस्टम लॉजिक की ज़रूरत होती है. पहले से तय किए गए टूल, इस लॉजिक को हैंडल नहीं कर सकते. इसलिए, यह एक्सप्लोरेटरी विश्लेषण और जटिल विश्लेषणात्मक क्वेरी के लिए ज़रूरी है. ये क्वेरी, सिस्टम डिज़ाइन में शामिल नहीं की गई थीं.
- निवेशक रिसर्च एजेंट:
इन्वेस्टर रिसर्च एजेंट, सिर्फ़ निवेश से जुड़े संबंधों और पोर्टफ़ोलियो के विश्लेषण पर फ़ोकस करता है. यह सटीक नाम मैचिंग का इस्तेमाल करके, यह पता लगा सकता है कि किन लोगों ने किसी कंपनी में निवेश किया है. साथ ही, यह निवेशकों के पूरे पोर्टफ़ोलियो को वापस पा सकता है, जिसमें उनके सभी निवेश दिखते हैं. इसके अलावा, यह अलग-अलग उद्योगों में निवेश के पैटर्न का विश्लेषण भी कर सकता है. इस स्पेशलाइज़ेशन की वजह से, यह "ByteDance में किसने निवेश किया?" या "Sequoia Capital ने और किन कंपनियों में निवेश किया?" जैसे सवालों के जवाब बहुत आसानी से दे पाता है. एजेंट, कस्टम Python फ़ंक्शन का इस्तेमाल करता है. ये फ़ंक्शन, सीधे तौर पर Neo4j डेटाबेस से निवेशक से जुड़े संबंधों के बारे में क्वेरी करते हैं.
- निवेश से जुड़ी रिसर्च करने वाला एजेंट:
निवेश से जुड़ी रिसर्च करने वाला एजेंट, मॉडल कॉन्टेक्स्ट प्रोटोकॉल (एमसीपी) टूलबॉक्स का इस्तेमाल करके, विशेषज्ञों की लिखी हुई और पहले से पुष्टि की गई क्वेरी ऐक्सेस करता है. यह सभी उपलब्ध उद्योगों की जानकारी इकट्ठा कर सकता है. साथ ही, किसी खास उद्योग में शामिल कंपनियों की जानकारी भी इकट्ठा कर सकता है. यह भावना विश्लेषण वाले लेख ढूंढ सकता है. इसके अलावा, यह खबरों में संगठनों के बारे में दी गई जानकारी का पता लगा सकता है. साथ ही, यह कंपनियों में काम करने वाले लोगों के बारे में जानकारी इकट्ठा कर सकता है. Graph Database Agent, क्वेरी को डाइनैमिक तरीके से जनरेट करता है. हालांकि, यह एजेंट सुरक्षित, ऑप्टिमाइज़ की गई, और पहले से तय की गई क्वेरी का इस्तेमाल करता है. इन क्वेरी को केंद्रीय रूप से मैनेज और पुष्टि की जाती है. इससे, रिसर्च के सामान्य वर्कफ़्लो के लिए यह सुरक्षित और बेहतर परफ़ॉर्म करने वाला बन जाता है.
7. मल्टी-एजेंट सिस्टम को चलाना और उसकी जांच करना
ऐप्लिकेशन लॉन्च करना
अब आपको आर्किटेक्चर के बारे में पता चल गया है. इसलिए, आइए पूरे सिस्टम को चलाकर देखते हैं और इससे इंटरैक्ट करते हैं.
ADK के वेब इंटरफ़ेस का इस्तेमाल शुरू करें:
# Make sure you're in the project directory with activated virtual environment
cd ~/neo4j-adk-multiagents
source .venv/bin/activate # If not already activated
# Launch the application
uv run adk web
आपको इससे मिलता-जुलता आउटपुट दिखेगा:
INFO: Started server process [2542]
INFO: Waiting for application startup.
+----------------------------------------------------------------+
| ADK Web Server started |
| |
| For local testing, access at http://127.0.0.1:8000. |
+----------------------------------------------------------------+
INFO: Application startup complete.
INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
क्वेरी की जांच करना और नतीजे किस तरह से मिल सकते हैं
आइए, मुश्किल क्वेरी के साथ सिस्टम की क्षमताओं के बारे में जानें:
बुनियादी क्वेरी (सिंगल एजेंट)
पहली क्वेरी: इंडस्ट्री के बारे में जानकारी पाना
What industries are available in the database?
अनुमानित व्यवहार:
- रूट एजेंट, इन्वेस्टमेंट रिसर्च एजेंट को रूट करता है
- MCP टूल का इस्तेमाल करता है:
get_industries() - इससे सभी उद्योगों की फ़ॉर्मैट की गई सूची मिलती है
इन बातों पर ध्यान दें:
एडीके के यूज़र इंटरफ़ेस (यूआई) में, लागू करने से जुड़ी जानकारी को बड़ा करके यह देखा जा सकता है:
- एजेंट चुनने के बारे में फ़ैसला
- टूल कॉल:
get_industries() - Neo4j से मिले रॉ नतीजे
- फ़ॉर्मैट किया गया जवाब
Query 2: निवेशकों को ढूंढना
Who invested in ByteDance?
अनुमानित व्यवहार:
- रूट एजेंट ने इसे निवेशक से जुड़ी क्वेरी के तौर पर पहचाना है
- निवेशक के लिए रिसर्च एजेंट से संपर्क करने के तरीके
- टूल का इस्तेमाल किया गया:
find_investor_by_name("ByteDance") - यह क्वेरी, निवेशकों को उनके टाइप (व्यक्ति/संगठन) के साथ दिखाती है
अनुमानित जवाब:
I found 2 investors in ByteDance:
1. Rong Yue (Person)
2. Wendi Murdoch (Person)
Would you like to know more about their investment portfolios?
तीसरी क्वेरी: इंडस्ट्री के हिसाब से कंपनियां**
I found 2 investors in ByteDance:
1. Rong Yue (Person)
2. Wendi Murdoch (Person)
Would you like to know more about their investment portfolios?
"Show me companies in the Artificial Intelligence industry"
अनुमानित व्यवहार:
- रूट एजेंट, इन्वेस्टमेंट रिसर्च एजेंट को रूट करता है
- MCP टूल का इस्तेमाल करता है:
get_companies_in_industry("Artificial Intelligence") - एआई कंपनियों की सूची दिखाता है, जिसमें उनके आईडी और स्थापना की तारीखें शामिल होती हैं
इन बातों पर ध्यान दें:
- ध्यान दें कि एजेंट, इंडस्ट्री के सटीक नाम से मेल खाने वाली जानकारी का इस्तेमाल कैसे करता है
- ज़्यादा नतीजे दिखाने से बचने के लिए, नतीजों की संख्या सीमित रखी जाती है
- डेटा को आसानी से पढ़ने के लिए, साफ़ तौर पर फ़ॉर्मैट किया गया हो
बीच की क्वेरी (एक ही एजेंट के ज़रिए कई चरणों में की गई क्वेरी)
क्वेरी 4: सेंटीमेंट का विश्लेषण
Find articles with positive sentiment from January 2023
अनुमानित व्यवहार:
- निवेश से जुड़ी रिसर्च करने वाले एजेंट से संपर्क करने के तरीके
- MCP टूल का इस्तेमाल करता है:
get_articles_with_sentiment(0.7, 2023, 1) - यह फ़ंक्शन, टाइटल, भावना के स्कोर, और पब्लिकेशन की तारीखों के साथ लेख दिखाता है
डीबग करने से जुड़ी अहम जानकारी:
टूल शुरू करने के पैरामीटर देखें:
min_sentiment: 0.7 (एजेंट "पॉज़िटिव" को >= 0.7 के तौर पर इंटरप्रेट करता है)year: 2023month: 1
क्वेरी 5: जटिल डेटाबेस क्वेरी
How many companies are in the database?
अनुमानित व्यवहार:
- रूट एजेंट, Graph Database Agent को रूट करता है
- एजेंट, स्ट्रक्चर को समझने के लिए सबसे पहले
get_neo4j_schema()को कॉल करता है - Cypher जनरेट करता है:
MATCH (c:Company) RETURN count(c) - यह क्वेरी को एक्ज़ीक्यूट करता है और गिनती दिखाता है
अनुमानित जवाब:
There are 8,064 companies in the database.
ऐडवांस क्वेरी (एक से ज़्यादा एजेंट के साथ मिलकर काम करना)
क्वेरी 6: पोर्टफ़ोलियो का विश्लेषण
Who invested in ByteDance and what else have they invested in?
अनुमानित व्यवहार:
यह दो हिस्सों वाली क्वेरी है. इसके लिए, एजेंट के साथ समन्वय करना ज़रूरी है:
- पहला चरण: रूट एजेंट → निवेशक से जुड़ी रिसर्च करने वाला एजेंट
- कॉल
find_investor_by_name("ByteDance") - निवेशकों की सूची मिलती है: [रॉन्ग यू, वेंडी मर्डोक]
- दूसरा चरण: हर निवेशक के लिए → निवेशक रिसर्च एजेंट
- कॉल
find_investor_by_id(investor_id) - पूरा पोर्टफ़ोलियो वापस पाता है
- तीसरा चरण: रूट एजेंट, डेटा इकट्ठा करता है और उसे फ़ॉर्मैट करता है
अनुमानित जवाब:
I found 2 investors in ByteDance. Here are their portfolios:
1. Rong Yue (Person)
- ByteDance
- Inspur
2. Wendi Murdoch (Person)
- ByteDance
- (No other investments in database)
इन बातों पर ध्यान दें:
- एक के बाद एक कई टूल कॉल
- एक चरण से दूसरे चरण के बीच कॉन्टेक्स्ट बनाए रखना
- नतीजों को समझदारी से एग्रीगेट किया गया है
क्वेरी 7: कई डोमेन पर रिसर्च करना
What are 5 AI companies mentioned in positive articles, and who are their CEOs?
अनुमानित व्यवहार:
इस मुश्किल क्वेरी के लिए, कई एजेंट और टूल की ज़रूरत होती है:
- पहला चरण: निवेश से जुड़ी रिसर्च करने वाला एजेंट
get_companies_in_industry("Artificial Intelligence")- एआई कंपनियों की सूची दिखाता है
- दूसरा चरण: इन्वेस्टमेंट रिसर्च एजेंट
get_articles_with_sentiment(0.8)- सकारात्मक लेख दिखाता है
- तीसरा चरण: रूट एजेंट फ़िल्टर
- इससे यह पता चलता है कि सकारात्मक लेखों में किन एआई कंपनियों का नाम शामिल है
- इससे टॉप 5 को चुना जाएगा
- चौथा चरण: इन्वेस्टमेंट रिसर्च एजेंट
get_people_in_organizations([company_names], "CEO")- सीईओ की जानकारी दिखाता है
- पांचवां चरण: रूट एजेंट, टेबल के तौर पर फ़ॉर्मैट करता है
अनुमानित जवाब:
Here are 5 AI companies with positive news and their CEOs:
| Company | Industry | CEO | Avg Sentiment |
|---------|----------|-----|---------------|
| OpenAI | Artificial Intelligence | Sam Altman | 0.92 |
| Anthropic | Artificial Intelligence | Dario Amodei | 0.89 |
| ... | ... | ... | ... |
इन बातों पर ध्यान दें:
- अलग-अलग एजेंट के लिए कई टूल कॉल
- डेटा को फ़िल्टर करना और कॉम्बिनेशन लॉजिक
- टेबल को प्रोफ़ेशनल तरीके से फ़ॉर्मैट करना
क्वेरी 8: प्रतिस्पर्धी विश्लेषण
Who are YouTube's main competitors?
अनुमानित व्यवहार:
- रूट एजेंट, Graph Database Agent को रूट करता है (रिलेशनशिप क्वेरी)
- एजेंट, GraphRAG की मदद से बेहतर किया गया साइफ़र जनरेट करता है:
MATCH (c:Company {name: "YouTube"})-[:COMPETES_WITH]->(competitor)
RETURN competitor.name as competitor_name
- इससे, आपके जैसे प्रॉडक्ट बेचने वाली कंपनियों की सूची मिलती है
अनुमानित जवाब:
YouTube's main competitors are:
- TikTok (ByteDance)
- Dailymotion
- Twitter
- BuzzFeed
- Mixer
- OpenAI (for video content)
कॉन्टेक्स्ट के हिसाब से फ़ॉलो-अप क्वेरी
Query 9: फ़ॉलो-अप सवाल (Query 8 के बाद)
Which investors funded both YouTube and its competitors?
अनुमानित व्यवहार:
- रूट एजेंट को पिछले कॉन्टेक्स्ट (YouTube और उसके प्रतिस्पर्धी) के बारे में जानकारी होती है
- निवेशक के लिए रिसर्च एजेंट से संपर्क करने के तरीके
- YouTube और उसके हर प्रतिस्पर्धी के लिए, निवेशकों को ढूंढता है
- यह कुकी, एक से ज़्यादा कंपनियों में निवेश करने वाले निवेशकों की पहचान करती है
अनुमानित जवाब:
Based on our previous analysis of YouTube's competitors, I found these
investors who funded multiple companies in this competitive landscape:
Sequoia Capital invested in:
- YouTube
- TikTok (ByteDance)
- Twitter
Accel Partners invested in:
- YouTube
- BuzzFeed
This suggests these investors have strategic positions across the video content platform ecosystem.
क्वेरी 10: रिसर्च की खास जानकारी
Summarize our research findings so far
अनुमानित व्यवहार:
- रूट एजेंट, बातचीत के इतिहास की समीक्षा करता है
- पिछली क्वेरी के अहम नतीजों को एक जगह लिखा जा रहा है
- जवाब में दी गई खास जानकारी में एकरूपता होती है
अनुमानित जवाब:
Here's a summary of our investment research session:
1. Industry Overview: We explored the Artificial Intelligence industry
with 150+ companies in the database.
2. ByteDance Analysis:
- Investors: Rong Yue, Wendi Murdoch
- Rong Yue also invested in Inspur
3. Market Sentiment: We analyzed articles from January 2023, finding
strong positive sentiment (avg 0.85) for tech companies.
4. Competitive Landscape: YouTube faces competition from TikTok,
Dailymotion, and others, with some investors (Sequoia, Accel) holding
positions across competing platforms.
5. Key Players: Identified CEOs of major AI companies with positive media coverage.
डीबग व्यू में एजेंट इंटरैक्शन को समझना
ADK का वेब इंटरफ़ेस, एक्ज़ीक्यूशन की पूरी जानकारी देता है. यहां देखें कि आपको क्या-क्या देखना है:
- इवेंट की टाइमलाइन
इसमें क्रम से फ़्लो दिखाया गया है:
[USER] Query received
[ROOT_AGENT] Analyzing query intent
[ROOT_AGENT] Routing to investment_research_agent
[INVESTMENT_RESEARCH_AGENT] Tool call: get_companies_in_industry
[TOOL] Executing with params: {"industry_name": "Artificial Intelligence"}
[TOOL] Returned 47 results
[INVESTMENT_RESEARCH_AGENT] Formatting response
[ROOT_AGENT] Presenting to user
- टूल को शुरू करने की जानकारी
किसी भी टूल कॉल पर क्लिक करके, यह जानकारी देखी जा सकती है:
- प्रकार्य का नाम
- इनपुट पैरामीटर
- रिटर्न वैल्यू
- लागू करने का समय
- कोई भी गड़बड़ी
- एजेंट के फ़ैसले लेने की क्षमता
एलएलएम के तर्क को देखें:
- इसने किसी एजेंट को क्यों चुना
- क्वेरी को कैसे समझा गया
- इसमें किन टूल का इस्तेमाल किया गया
- नतीजों को किसी खास तरीके से फ़ॉर्मैट क्यों किया गया
सामान्य ऑब्ज़र्वेशन और अहम जानकारी
- क्वेरी रूटिंग पैटर्न:
- "निवेशक" और "निवेश किया गया" जैसे कीवर्ड → निवेशक के बारे में रिसर्च करने वाला एजेंट
- "इंडस्ट्री," "कंपनियां," "लेख" जैसे कीवर्ड → इन्वेस्टमेंट रिसर्च एजेंट
- एग्रीगेशन, गिनती, जटिल लॉजिक → ग्राफ़ डेटाबेस एजेंट
- परफ़ॉर्मेंस से जुड़ी अहम जानकारी:
- आम तौर पर, एमसीपी टूल ज़्यादा तेज़ होते हैं (पहले से ऑप्टिमाइज़ की गई क्वेरी)
- मुश्किल साइफ़र जनरेट करने में ज़्यादा समय लगता है (एलएलएम को सोचने में लगने वाला समय)
- एक से ज़्यादा टूल कॉल करने से, नतीजे मिलने में देरी होती है. हालांकि, इससे ज़्यादा बेहतर नतीजे मिलते हैं
- गड़बड़ी ठीक करना:
- अगर कोई क्वेरी फ़ेल हो जाती है, तो:
- एजेंट बताता है कि क्या गड़बड़ी हुई
- सुधार के सुझाव देता है. जैसे, "कंपनी का नाम नहीं मिला, स्पेलिंग की जांच करें"
- अन्य तरीकों का इस्तेमाल किया जा सकता है
असरदार टेस्टिंग के लिए सलाह
- आसान सवालों से शुरुआत करें: मुश्किल क्वेरी पूछने से पहले, हर एजेंट के मुख्य फ़ंक्शन की जांच करें
- फ़ॉलो-अप का इस्तेमाल करना: फ़ॉलो-अप सवालों के ज़रिए, कॉन्टेक्स्ट को बनाए रखने की सुविधा को टेस्ट करना
- ऑब्ज़र्व राउटिंग: यह देखने के लिए कि कौनसे एजेंट ने किस क्वेरी को हैंडल किया, इस विकल्प को चुनें. इससे आपको लॉजिक समझने में मदद मिलेगी
- टूल कॉल की जांच करना: पुष्टि करें कि पैरामीटर, सामान्य भाषा से सही तरीके से निकाले गए हों
- असामान्य मामलों की जांच करना: ऐसी क्वेरी आज़माएं जिनके जवाब साफ़ तौर पर नहीं दिए जा सकते, जिनमें स्पेलिंग की गलतियां हों या जो सामान्य न हों
अब आपके पास पूरी तरह से काम करने वाला मल्टी-एजेंट GraphRAG सिस्टम है! इसकी क्षमताओं के बारे में जानने के लिए, अपने सवालों के साथ एक्सपेरिमेंट करें.
8. व्यवस्थित करें
इस पोस्ट में इस्तेमाल की गई संसाधनों के लिए, अपने Google Cloud खाते से शुल्क न लिए जाने के लिए, यह तरीका अपनाएं:
- Google Cloud Console में, संसाधन मैनेज करें पेज पर जाएं.
- प्रोजेक्ट की सूची में, वह प्रोजेक्ट चुनें जिसे आपको मिटाना है. इसके बाद, मिटाएं पर क्लिक करें.
- डायलॉग बॉक्स में, प्रोजेक्ट आईडी टाइप करें. इसके बाद, प्रोजेक्ट मिटाने के लिए बंद करें पर क्लिक करें.
9. बधाई हो
🎉 बधाई हो! आपने Google के Agent Development Kit, Neo4j, और MCP Toolbox का इस्तेमाल करके, प्रोडक्शन-क्वालिटी वाला मल्टी-एजेंट GraphRAG सिस्टम बना लिया है!
आपने ADK की इंटेलिजेंट ऑर्केस्ट्रेशन क्षमताओं को Neo4j के संबंध-आधारित डेटा मॉडल और पहले से पुष्टि की गई MCP क्वेरी की सुरक्षा के साथ जोड़कर, एक बेहतर सिस्टम बनाया है. यह सिस्टम, डेटाबेस की सामान्य क्वेरी से आगे बढ़कर काम करता है. यह कॉन्टेक्स्ट को समझता है, जटिल संबंधों के बारे में वजहें बताता है, और खास एजेंट को कोऑर्डिनेट करके पूरी और सटीक जानकारी देता है.
इस कोडलैब में, आपने ये काम किए:
✅ Google के Agent Development Kit (ADK) का इस्तेमाल करके, क्रम के हिसाब से ऑर्केस्ट्रेशन के साथ मल्टी-एजेंट सिस्टम बनाया गया हो
✅ Neo4j ग्राफ़ डेटाबेस इंटिग्रेट किया गया है, ताकि संबंध के बारे में जानकारी देने वाली क्वेरी और मल्टी-हॉप रीज़निंग का फ़ायदा लिया जा सके
✅ एमसीपी टूलबॉक्स लागू किया गया है, ताकि डेटाबेस की क्वेरी को सुरक्षित तरीके से पहले से ही पुष्टि किए गए टूल के तौर पर इस्तेमाल किया जा सके
✅ निवेशक की रिसर्च, निवेश के विश्लेषण, और ग्राफ़ डेटाबेस के कामों के लिए खास एजेंट बनाए गए हैं
✅ इंटेलिजेंट राउटिंग की सुविधा, जो क्वेरी को सबसे सही विशेषज्ञ एजेंट को अपने-आप सौंप देती है
✅ जटिल डेटा टाइप मैनेज किए गए. साथ ही, Python के साथ आसानी से इंटिग्रेट करने के लिए, Neo4j टाइप का सही सीरियललाइज़ेशन किया गया
✅ एजेंट डिज़ाइन, गड़बड़ी ठीक करने, और सिस्टम डीबग करने के लिए, प्रोडक्शन के सबसे सही तरीके लागू किए गए हों
अगला चरण?
यह मल्टी-एजेंट GraphRAG आर्किटेक्चर, सिर्फ़ निवेश से जुड़ी रिसर्च के लिए नहीं है. इसे इन कामों के लिए भी इस्तेमाल किया जा सकता है:
- वित्तीय सेवाएं: पोर्टफ़ोलियो ऑप्टिमाइज़ेशन, जोखिम का आकलन, धोखाधड़ी का पता लगाना
- स्वास्थ्य सेवा: मरीज़ की देखभाल से जुड़ी जानकारी को व्यवस्थित करना, दवाओं के आपसी असर का विश्लेषण करना, क्लिनिकल रिसर्च
- ई-कॉमर्स: दिलचस्पी के हिसाब से सुझाव, सप्लाई चेन को ऑप्टिमाइज़ करना, खरीदार की अहम जानकारी
- कानूनी और अनुपालन: अनुबंध का विश्लेषण, कानूनी नियमों की निगरानी, केस लॉ रिसर्च
- रिसर्च: साहित्य की समीक्षा, साथ मिलकर काम करने वाले लोगों की खोज, उद्धरणों का विश्लेषण
- एंटरप्राइज़ इंटेलिजेंस: कॉम्पिटिटिव ऐनालिसिस, मार्केट रिसर्च, और संगठन के नॉलेज ग्राफ़
जहां भी आपके पास जटिल इंटरकनेक्टेड डेटा + डोमेन की विशेषज्ञता + नैचुरल लैंग्वेज इंटरफ़ेस है वहां ADK मल्टी-एजेंट सिस्टम + Neo4j नॉलेज ग्राफ़ + MCP से पुष्टि की गई क्वेरी का यह कॉम्बिनेशन, एंटरप्राइज़ के इंटेलिजेंट ऐप्लिकेशन की अगली जनरेशन को बेहतर बना सकता है.
Google की एजेंट डेवलपमेंट किट और Gemini मॉडल में लगातार सुधार हो रहा है. इसलिए, आपको ज़्यादा बेहतर तरीके से काम करने वाले सिस्टम बनाने में मदद मिलेगी. इसके लिए, आपको इन सुविधाओं का इस्तेमाल करने का मौका मिलेगा: डेटा को बेहतर तरीके से प्रोसेस करके सवालों के जवाब देना, रीयल-टाइम में डेटा इंटिग्रेट करना, और मल्टी-मॉडल क्षमताओं का इस्तेमाल करना.
एक्सप्लोर करना और बनाना जारी रखें और अपने इंटेलिजेंट एजेंट ऐप्लिकेशन को नई ऊंचाइयों पर ले जाएं!
Neo4j GraphAcademy पर जाकर, नॉलेज ग्राफ़ के बारे में ज़्यादा ट्यूटोरियल देखें. साथ ही, ADK के सैंपल रिपॉज़िटरी में एजेंट के अन्य पैटर्न के बारे में जानें.
🚀 क्या आप अपना अगला इंटेलिजेंट एजेंट सिस्टम बनाने के लिए तैयार हैं?