
1. Panoramica
In questo codelab, creerai un sofisticato sistema di ricerca sugli investimenti multi-agente che combina la potenza di Agent Development Kit (ADK) di Google, del database a grafi Neo4j e di Model Context Protocol (MCP) Toolbox. Questo tutorial pratico mostra come creare agenti intelligenti che comprendono il contesto dei dati tramite le relazioni del grafico e forniscono risposte alle query estremamente accurate.
Perché GraphRAG + sistemi multiagente?
GraphRAG (Graph-based Retrieval-Augmented Generation) migliora gli approcci RAG tradizionali sfruttando la ricca struttura delle relazioni dei grafi di conoscenza. Invece di cercare solo documenti simili, gli agenti GraphRAG possono:
- Attraversare relazioni complesse tra entità
- Comprendere il contesto tramite la struttura del grafico
- Fornire risultati spiegabili in base ai dati connessi
- Eseguire il ragionamento multihop nel knowledge graph
I sistemi multi-agente ti consentono di:
- Decomporre problemi complessi in sotto-attività specializzate
- Crea applicazioni di AI modulari e gestibili
- Abilitare l'elaborazione parallela e l'utilizzo efficiente delle risorse
- Creare pattern di ragionamento gerarchico con l'orchestrazione
Cosa creerai
Creerai un sistema completo di ricerca sugli investimenti con:
- Agente database a grafo: esegue query Cypher e comprende lo schema Neo4j
- Agente di ricerca degli investitori: scopre le relazioni con gli investitori e i portafogli di investimento
- Agente di ricerca sugli investimenti: accede a grafici di conoscenza completi tramite gli strumenti MCP
- Agente principale: coordina in modo intelligente tutti gli agenti secondari
Il sistema risponderà a domande complesse come:
- "Chi sono i principali concorrenti di YouTube?"
- "Quali aziende sono menzionate con un sentiment positivo a gennaio 2023?"
- "Chi ha investito in ByteDance e in quali altre società ha investito?"
Panoramica dell'architettura
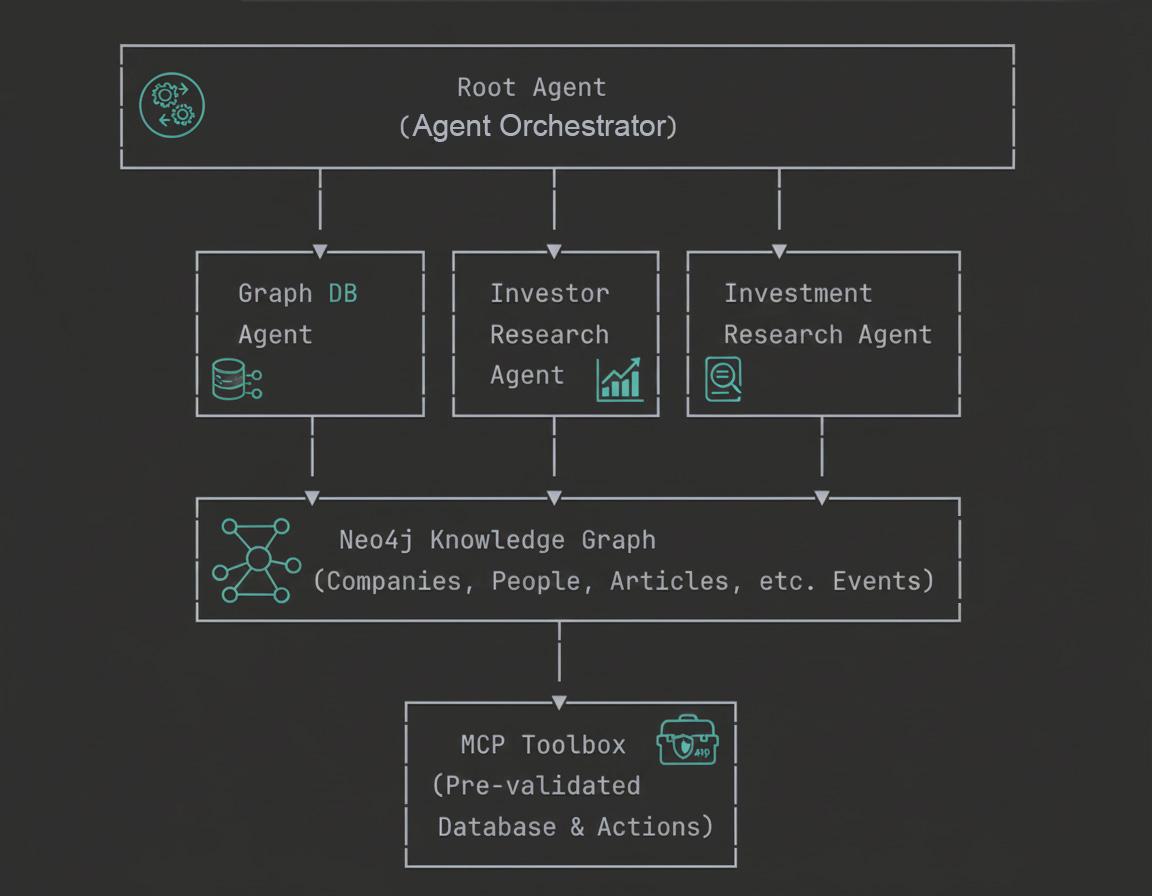
In questo codelab imparerai le basi concettuali e l'implementazione pratica della creazione di agenti GraphRAG di livello enterprise.
Cosa imparerai a fare
- Come creare sistemi multi-agente utilizzando l'Agent Development Kit (ADK) di Google
- Come integrare il database a grafo Neo4j con ADK per le applicazioni GraphRAG
- Come implementare Model Context Protocol (MCP) Toolbox per query di database pre-validate
- Come creare strumenti e funzioni personalizzati per gli agenti intelligenti
- Come progettare gerarchie di agenti e pattern di orchestrazione
- Come strutturare le istruzioni dell'agente per un rendimento ottimale
- Come eseguire il debug delle interazioni multi-agente in modo efficace
Che cosa ti serve
- Browser web Chrome
- Un account Gmail
- Un progetto Google Cloud con la fatturazione abilitata
- Conoscenza di base dei comandi del terminale e di Python (utile ma non obbligatoria)
Questo codelab, progettato per sviluppatori di tutti i livelli (inclusi i principianti), utilizza Python e Neo4j nell'applicazione di esempio. Sebbene una conoscenza di base di Python e dei database grafici possa essere utile, non è necessaria alcuna esperienza precedente per comprendere i concetti o seguire il corso.
2. Informazioni su GraphRAG e sistemi multiagente
Prima di passare all'implementazione, vediamo i concetti chiave che alimentano questo sistema.
Neo4j è un database a grafo nativo leader che archivia i dati come una rete di nodi (entità) e relazioni (connessioni tra entità), il che lo rende ideale per i casi d'uso in cui la comprensione delle connessioni è fondamentale, ad esempio consigli, rilevamento delle frodi, Knowledge Graph e altro ancora. A differenza dei database relazionali o basati su documenti che si basano su tabelle rigide o strutture gerarchiche, il modello a grafo flessibile di Neo4j consente una rappresentazione intuitiva ed efficiente di dati complessi e interconnessi.
Invece di organizzare i dati in righe e tabelle come i database relazionali, Neo4j utilizza un modello a grafo, in cui le informazioni sono rappresentate come nodi (entità) e relazioni (connessioni tra queste entità). Questo modello rende eccezionalmente intuitivo l'utilizzo di dati intrinsecamente collegati, come persone, luoghi, prodotti o, nel nostro caso, film, attori e generi.
Ad esempio, in un set di dati sui film:
- Un nodo può rappresentare un
Movie, unActoro unDirector - Una relazione può essere
ACTED_INoDIRECTED
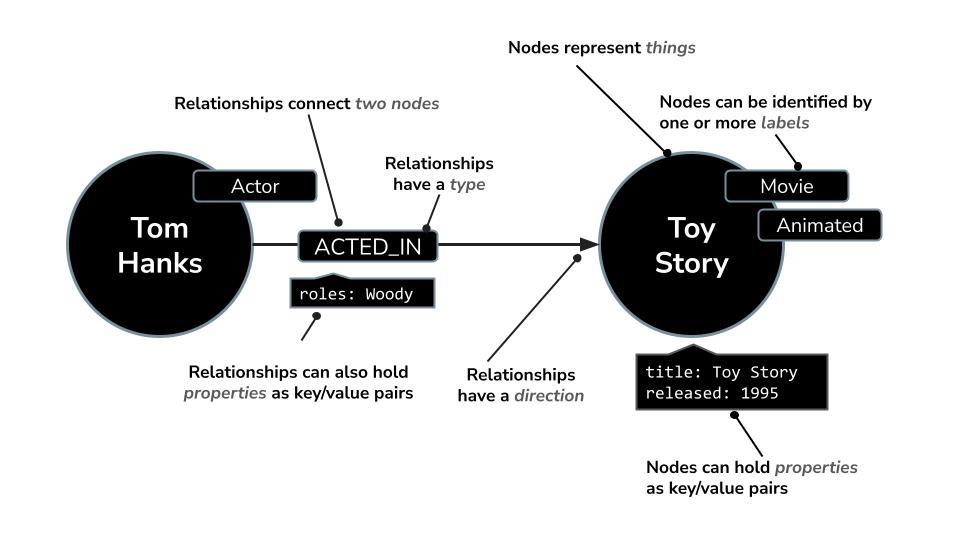
Questa struttura ti consente di porre facilmente domande come:
- In quali film ha recitato questo attore?
- Chi ha lavorato con Christopher Nolan?
- Quali sono i film simili basati su attori o generi condivisi?
Che cos'è GraphRAG?
La Retrieval-Augmented Generation (RAG) migliora le risposte degli LLM recuperando informazioni pertinenti da fonti esterne. La RAG tradizionale in genere:
- Incorpora i documenti in vettori
- Ricerca vettori simili
- Trasferisce i documenti recuperati all'LLM
GraphRAG estende questo concetto utilizzando i grafi della conoscenza:
- Incorpora entità e relazioni
- Attraversa le connessioni del grafico
- Recupera le informazioni contestuali multi-hop
- Fornisce risultati strutturati e spiegabili
Perché i grafici per gli agenti AI?
Considera questa domanda: "Chi sono i concorrenti di YouTube e quali investitori hanno finanziato sia YouTube che i suoi concorrenti?"
Cosa succede in un approccio RAG tradizionale:
- Cerca documenti sui concorrenti di YouTube
- Cerca separatamente le informazioni per gli investitori
- Difficoltà a collegare queste due informazioni
- Potrebbe non rilevare le relazioni implicite
Cosa succede in un approccio GraphRAG:
MATCH (org:Organization {name: "OpenAI"})-[:HAS_COMPETITOR]-(competitor:Organization)
MATCH (org)-[:HAS_INVESTOR]->(investor:Person)
MATCH (competitor)-[:HAS_INVESTOR]->(investor)
RETURN org, competitor, investor
Il grafico rappresenta naturalmente le relazioni, rendendo le query multi-hop semplici ed efficienti.
Sistemi multi-agente in ADK
Agent Development Kit (ADK) è il framework open source di Google per la creazione e il deployment di agenti AI di livello di produzione. Fornisce primitive intuitive per l'orchestrazione multiagente, l'integrazione degli strumenti e la gestione dei workflow, semplificando la composizione di agenti specializzati in sistemi sofisticati. L'ADK funziona perfettamente con Gemini e supporta il deployment su Cloud Run, Kubernetes o qualsiasi infrastruttura.
Agent Development Kit (ADK) fornisce primitive per la creazione di sistemi multi-agente:
- Gerarchia degli agenti:
# Root agent coordinates specialized agents
root_agent = LlmAgent(
name="RootAgent",
sub_agents=[
graph_db_agent,
investor_agent,
investment_agent
]
)
- Agenti specializzati: ogni agente ha
- Strumenti specifici: funzioni che può chiamare
- Istruzioni chiare: il suo ruolo e le sue funzionalità
- Competenza nel dominio: conoscenza del suo settore
- Pattern di orchestrazione:
- Sequenziale: esegui gli agenti in ordine
- Parallel: Run multiple agents simultaneously
- Condizionale: route in base al tipo di query
MCP Toolbox per database
Il Model Context Protocol (MCP) è uno standard aperto per connettere i sistemi AI a origini dati e strumenti esterni. MCP Toolbox for Databases è l'implementazione di Google che consente la gestione dichiarativa delle query di database, permettendoti di definire query pre-validate e create da esperti come strumenti riutilizzabili. Anziché consentire agli LLM di generare query potenzialmente non sicure, MCP Toolbox fornisce query pre-approvate con la convalida dei parametri, garantendo sicurezza, prestazioni e affidabilità, mantenendo al contempo la flessibilità per gli agenti AI.
Approccio tradizionale:
# LLM generates query (may be incorrect/unsafe)
query = llm.generate("SELECT * FROM users WHERE...")
db.execute(query) # Risk of errors/SQL injection
Approccio MCP:
# Pre-validated query definition
- name: get_industries
description: Fetch all industries from database
query: |
MATCH (i:Industry)
RETURN i.name, i.id
Vantaggi:
- Pre-validato da esperti
- Protezione dagli attacchi di injection
- Prestazioni ottimizzate
- Gestito centralmente
- Riutilizzabile in più agenti
Finalizza la tua creazione
La combinazione di GraphRAG + framework multi-agente di ADK + MCP crea un sistema potente:
- L'agente principale riceve la query dell'utente
- Inoltra le richieste a un agente specializzato in base al tipo di query
- L'agente utilizza gli strumenti MCP per recuperare i dati in modo sicuro
- La struttura del grafico fornisce un contesto ricco
- L'LLM genera una risposta fondata e spiegabile
Ora che abbiamo compreso l'architettura, iniziamo a creare.
3. Configura il progetto Google Cloud
Crea un progetto
- Nella console Google Cloud, nella pagina di selezione del progetto, seleziona o crea un progetto Google Cloud.
- Verifica che la fatturazione sia attivata per il tuo progetto Cloud. Scopri come verificare se la fatturazione è abilitata per un progetto .
- Utilizzerai Cloud Shell, un ambiente a riga di comando in esecuzione in Google Cloud. Fai clic su Attiva Cloud Shell nella parte superiore della console Google Cloud. Puoi passare dal terminale Cloud Shell (per eseguire comandi cloud) all'editor (per creare progetti) facendo clic sul pulsante corrispondente in Cloud Shell.

- Una volta eseguita la connessione a Cloud Shell, verifica di essere già autenticato e che il progetto sia impostato sul tuo ID progetto utilizzando il seguente comando:
gcloud auth list
- Esegui questo comando in Cloud Shell per verificare che il comando gcloud conosca il tuo progetto.
gcloud config list project
- Se il progetto non è impostato, utilizza il seguente comando per impostarlo:
gcloud config set project <YOUR_PROJECT_ID>
Consulta la documentazione per i comandi e l'utilizzo di gcloud.
Ottimo. Ora possiamo passare al passaggio successivo: comprendere il set di dati.
4. Informazioni sul set di dati Aziende
Per questo codelab, utilizziamo un database Neo4j di sola lettura precompilato con dati di investimenti e aziende provenienti dal Knowledge Graph di Diffbot.
Il set di dati contiene:
- 237.358 nodi che rappresentano:
- Organizzazioni (aziende)
- Persone (dirigenti, dipendenti)
- Articoli (notizie e menzioni)
- Settori
- Tecnologie
- Investitori
- Relazioni, tra cui:
HAS_INVESTOR- Investment connectionsHAS_COMPETITOR- Competitive relationshipsMENTIONS- Riferimenti agli articoliHAS_CEO- Rapporti di lavoroHAS_CATEGORY- Classificazioni di settore
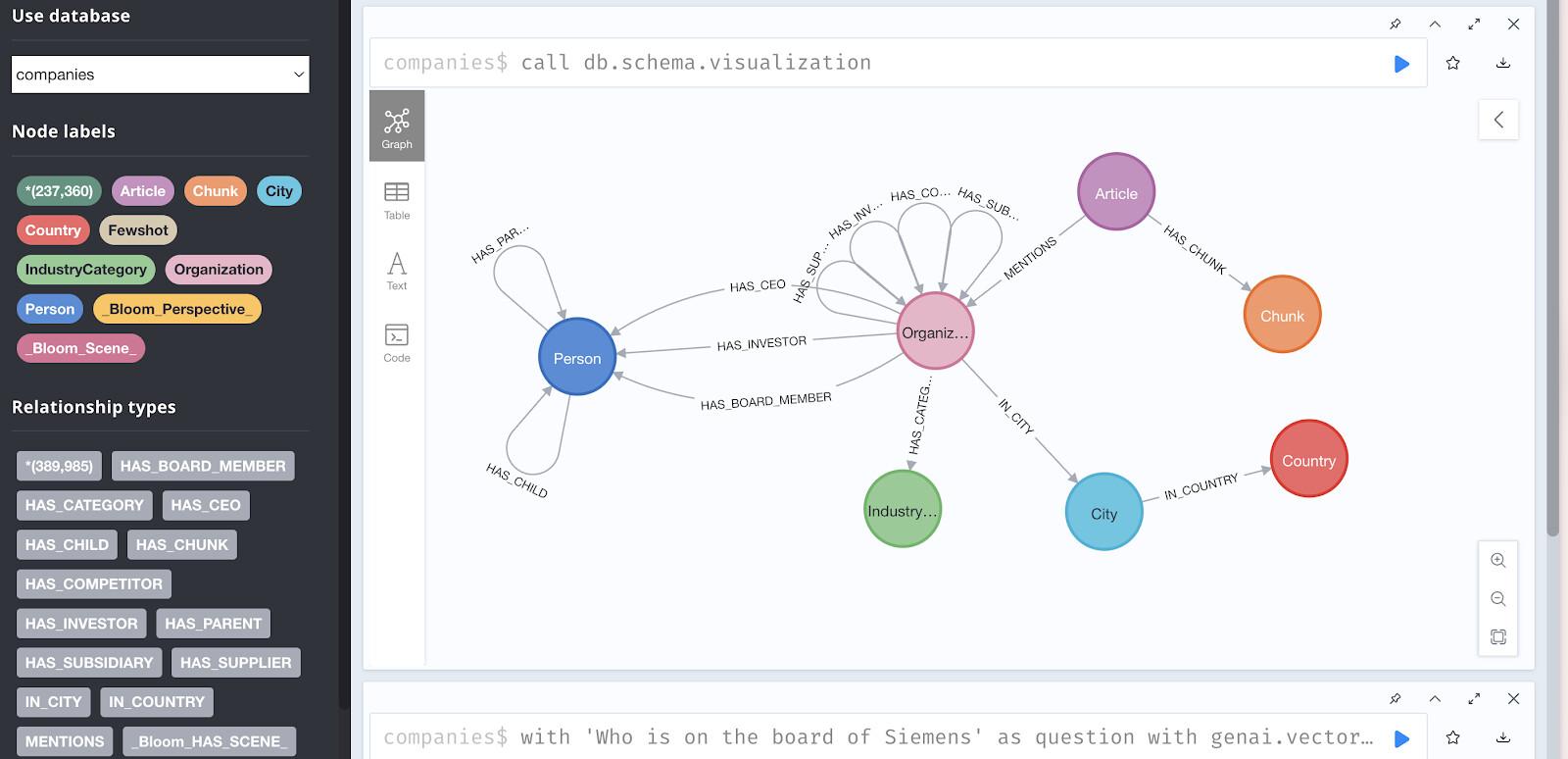
Accedere al database demo
Per questo codelab, utilizzeremo un'istanza demo ospitata. Aggiungi queste credenziali alle tue note:
URI: neo4j+s://demo.neo4jlabs.com
Username: companies
Password: companies
Database: companies
Accesso al browser:
Puoi esplorare i dati visivamente all'indirizzo: https://demo.neo4jlabs.com:7473
Accedi con le stesse credenziali e prova a eseguire:
// Sample query to explore the graph
MATCH (c:Organization)-[:HAS_COMPETITOR]-(competitor:Organization)
RETURN c.name, competitor.name
LIMIT 10
Visualizzare la struttura del grafico
Prova questa query in Neo4j Browser per visualizzare i pattern di relazione:
// Find investors and their portfolio companies
MATCH (company:Organization)-[:HAS_INVESTOR]->(investor:Person)
WITH investor, collect(company.name) as portfolio
RETURN investor.name, size(portfolio) as num_investments, portfolio
ORDER BY num_investments DESC
LIMIT 5
Questa query restituisce i 5 investitori più attivi e i loro portafogli.
Perché questo database per GraphRAG?
Questo set di dati è perfetto per dimostrare GraphRAG perché:
- Relazioni avanzate: connessioni complesse tra entità
- Dati reali: aziende, persone e articoli di notizie reali
- Query multihop: richiede l'attraversamento di più tipi di relazione
- Dati temporali: articoli con timestamp per l'analisi basata sul tempo
- Analisi del sentiment: punteggi del sentiment precalcolati per gli articoli
Ora che hai compreso la struttura dei dati, configuriamo l'ambiente di sviluppo.
5. Clona il repository e configura l'ambiente
Clona il repository
Nel terminale Cloud Shell, esegui:
# Clone the repository
git clone https://github.com/sidagarwal04/neo4j-adk-multiagents.git
# Navigate into the directory
cd neo4j-adk-multiagents
Esplora la struttura del repository
Dedica un momento alla comprensione del layout del progetto:
neo4j-adk-multiagents/
├── investment_agent/ # Main agent code
│ ├── agent.py # Agent definitions
│ ├── tools.py # Custom tool functions
│ └── .adk/ # ADK configuration
│ └── tools.yaml # MCP tool definitions
├── main.py # Application entry point
├── setup_tools_yaml.py # Configuration generator
├── requirements.txt # Python dependencies
├── example.env # Environment template
└── README.md # Project documentation
Configura l'ambiente virtuale
Crea e attiva un ambiente virtuale Python utilizzando uv:
# Install uv if not already installed
pip install uv
# Create virtual environment
uv venv
# Activate the environment
source .venv/bin/activate # On macOS/Linux
# or
.venv\Scripts\activate # On Windows
Dovresti vedere (.venv) anteposto al prompt del terminale.
Installa le dipendenze
Installa tutti i pacchetti richiesti:
uv pip install -r requirements.txt
Le principali dipendenze includono:
txtgoogle-adk>=1.21.0 # Agent Development Kit
neo4j>=6.0.3 # Neo4j Python driver
python-dotenv>=1.0.0 # Environment variables
google-cloud-aiplatform>=1.30.0 # Vertex AI
Configura le variabili di ambiente
- Crea il tuo **
.env** **file:**
cp example.env .env
- Modifica il **file** **
.env**:
Se utilizzi Cloud Shell, fai clic su Apri editor nella barra degli strumenti, quindi vai a .env e aggiorna:
Per visualizzare il file .env nascosto:
Fai clic su View > Toggle Hidden files nell'editor di Google Cloud Shell.
# Neo4j Configuration (Demo Database)
NEO4J_URI=neo4j+s://demo.neo4jlabs.com
NEO4J_USERNAME=companies
NEO4J_PASSWORD=companies
NEO4J_DATABASE=companies
# Google AI Configuration
# Choose ONE of the following options:
# Option 1: Google AI API (Recommended)
GOOGLE_GENAI_USE_VERTEXAI=0
GOOGLE_API_KEY=your_api_key_here # Get from https://aistudio.google.com/app/apikey
# Option 2: Vertex AI (If using GCP)
# GOOGLE_GENAI_USE_VERTEXAI=1
# GOOGLE_CLOUD_PROJECT=your-project-id
# GOOGLE_CLOUD_LOCATION=us-central1
# ADK Configuration
GOOGLE_ADK_MODEL=gemini-3.1-flash-lite-preview # or gemini-3-flash-preview
# MCP Toolbox Configuration
MCP_TOOLBOX_URL=https://toolbox-990868019953.us-central1.run.app/mcp/sse
- Genera la configurazione di MCP Toolbox:
Esegui lo script di configurazione per creare il file tools.yaml dalle variabili di ambiente:
python setup_tools_yaml.py
In questo modo viene generato investment_agent/.adk/tools.yaml con le tue credenziali Neo4j configurate correttamente per gli strumenti MCP.
Verifica la configurazione
Verifica che tutto sia configurato correttamente:
# Verify .env file exists
ls -la .env
# Verify tools.yaml was generated
ls -la investment_agent/.adk/tools.yaml
# Test Python environment
python -c "import google.adk; print('ADK installed successfully')"
# Test Neo4j connection
python -c "from neo4j import GraphDatabase; print('Neo4j driver installed')"
Il tuo ambiente di sviluppo è ora completamente configurato. Successivamente, esamineremo l'architettura multi-agente.
6. Informazioni sull'architettura multi-agente
Il sistema a quattro agenti
Il nostro sistema di ricerca sugli investimenti utilizza un'architettura multi-agente gerarchica con quattro agenti specializzati che lavorano insieme per rispondere a query complesse su aziende, investitori e market intelligence.
┌──────────────┐
│ Root Agent │ ◄── User Query
└──────┬───────┘
│
┌────────────────┼────────────────┐
│ │ │
┌─────▼─────┐ ┌────▼─────┐ ┌────▼──────────┐
│ Graph DB │ │ Investor │ │ Investment │
│ Agent │ │ Research │ │ Research │
└───────────┘ │ Agent │ │ Agent │
└──────────┘ └───────────────┘
- Agente root (orchestratore):
L'agente root funge da coordinatore intelligente dell'intero sistema. Riceve le query degli utenti, analizza l'intento e indirizza le richieste all'agente specializzato più appropriato. Consideralo un project manager che sa quale membro del team è più adatto a ogni attività. Gestisce anche l'aggregazione delle risposte, la formattazione dei risultati come tabelle o grafici quando richiesto e il mantenimento del contesto conversazionale in più query. L'agente principale preferisce sempre gli agenti specializzati all'agente di database generale, garantendo che le query vengano gestite dal componente più esperto disponibile.
- Agente del database a grafo:
L'agente del database grafico è la tua connessione diretta alle potenti funzionalità grafiche di Neo4j. Comprende lo schema del database, genera query Cypher dal linguaggio naturale ed esegue attraversamenti complessi del grafico. Questo agente è specializzato in domande strutturali, aggregazioni e ragionamenti multi-hop nel knowledge graph. È l'esperto di fallback quando le query richiedono una logica personalizzata che gli strumenti predefiniti non sono in grado di gestire, il che lo rende essenziale per l'analisi esplorativa e le query analitiche complesse che non erano previste nella progettazione del sistema.
- Agente di ricerca per gli investitori:
L'agente di ricerca sugli investitori si concentra esclusivamente sulle relazioni di investimento e sull'analisi del portafoglio. Può scoprire chi ha investito in società specifiche utilizzando la corrispondenza esatta del nome, recuperare portafogli di investitori completi che mostrano tutti i loro investimenti e analizzare i modelli di investimento nei vari settori. Questa specializzazione lo rende estremamente efficiente nel rispondere a domande come "Chi ha investito in ByteDance?" o "In che altro ha investito Sequoia Capital?" L'agente utilizza funzioni Python personalizzate che eseguono query direttamente nel database Neo4j per le relazioni correlate agli investitori.
- Investment Research Agent:
L'agente di ricerca sugli investimenti utilizza Model Context Protocol (MCP) Toolbox per accedere a query prevalidate e create da esperti. Può recuperare tutti i settori disponibili, recuperare le aziende all'interno di settori specifici, trovare articoli con analisi del sentiment, scoprire le menzioni di organizzazioni nelle notizie e ottenere informazioni sulle persone che lavorano nelle aziende. A differenza dell'agente del database a grafo che genera query in modo dinamico, questo agente utilizza query sicure, ottimizzate e predefinite che vengono gestite e convalidate centralmente. Ciò lo rende sicuro e performante per i flussi di lavoro di ricerca comuni.
7. Esecuzione e test del sistema multi-agente
Avviare l'applicazione
Ora che hai compreso l'architettura, eseguiamo il sistema completo e interagiamo con esso.
Avvia l'interfaccia web di ADK:
# Make sure you're in the project directory with activated virtual environment
cd ~/neo4j-adk-multiagents
source .venv/bin/activate # If not already activated
# Launch the application
uv run adk web
Dovresti visualizzare un output simile al seguente:
INFO: Started server process [2542]
INFO: Waiting for application startup.
+----------------------------------------------------------------+
| ADK Web Server started |
| |
| For local testing, access at http://127.0.0.1:8000. |
+----------------------------------------------------------------+
INFO: Application startup complete.
INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
Query di test e comportamento previsto
Esploriamo le funzionalità del sistema con query progressivamente più complesse:
Query di base (un solo agente)
Query 1: Discover Industries
What industries are available in the database?
Comportamento previsto:
- L'agente principale indirizza all'agente di ricerca sugli investimenti
- Utilizza lo strumento MCP:
get_industries() - Restituisce un elenco formattato di tutti i settori
Cosa osservare:
Nell'interfaccia utente dell'ADK, espandi i dettagli dell'esecuzione per visualizzare:
- Decisione sulla selezione dell'agente
- Chiamata allo strumento:
get_industries() - Risultati non elaborati di Neo4j
- Risposta formattata
Query 2: Find Investors
Who invested in ByteDance?
Comportamento previsto:
- L'agente principale identifica questa query come correlata agli investitori
- Percorsi per l'agente di ricerca degli investitori
- Utilizza lo strumento:
find_investor_by_name("ByteDance") - Restituisce gli investitori con i relativi tipi (persona/organizzazione)
Risposta prevista:
I found 2 investors in ByteDance:
1. Rong Yue (Person)
2. Wendi Murdoch (Person)
Would you like to know more about their investment portfolios?
Query 3: Aziende per settore**
I found 2 investors in ByteDance:
1. Rong Yue (Person)
2. Wendi Murdoch (Person)
Would you like to know more about their investment portfolios?
"Show me companies in the Artificial Intelligence industry"
Comportamento previsto:
- L'agente principale indirizza all'agente di ricerca sugli investimenti
- Utilizza lo strumento MCP:
get_companies_in_industry("Artificial Intelligence") - Restituisce l'elenco delle società di AI con ID e date di fondazione
Cosa osservare:
- Nota come l'agente utilizza la corrispondenza esatta del nome del settore
- I risultati sono limitati per evitare un output eccessivo
- I dati sono formattati in modo chiaro per una facile lettura
Query intermedie (più passaggi all'interno di un agente)
Query 4: analisi del sentiment
Find articles with positive sentiment from January 2023
Comportamento previsto:
- Percorsi per l'agente di ricerca sugli investimenti
- Utilizza lo strumento MCP:
get_articles_with_sentiment(0.7, 2023, 1) - Restituisce articoli con titoli, punteggi del sentiment e date di pubblicazione
Suggerimento per il debug:
Esamina i parametri di chiamata dello strumento:
min_sentiment: 0,7 (l'agente interpreta "positivo" come >= 0,7)year: 2023month: 1
Query 5: query complessa del database
How many companies are in the database?
Comportamento previsto:
- L'agente principale esegue il routing all'agente del database a grafo
- L'agente chiama
get_neo4j_schema()per primo per comprendere la struttura - Genera Cypher:
MATCH (c:Company) RETURN count(c) - Esegue la query e restituisce il conteggio.
Risposta prevista:
There are 8,064 companies in the database.
Query avanzate (coordinamento multi-agente)
Query 6: analisi del portafoglio
Who invested in ByteDance and what else have they invested in?
Comportamento previsto:
Questa è una query in due parti che richiede il coordinamento dell'agente:
- Passaggio 1: Root Agent → Investor Research Agent
- Chiamate
find_investor_by_name("ByteDance") - Ottiene l'elenco degli investitori: [Rong Yue, Wendi Murdoch]
- Passaggio 2: per ogni investitore → Agente di ricerca degli investitori
- Chiamate
find_investor_by_id(investor_id) - Recupera il portafoglio completo
- Passaggio 3: l'agente root aggrega e formatta
Risposta prevista:
I found 2 investors in ByteDance. Here are their portfolios:
1. Rong Yue (Person)
- ByteDance
- Inspur
2. Wendi Murdoch (Person)
- ByteDance
- (No other investments in database)
Cosa osservare:
- Più chiamate di strumenti in sequenza
- Contesto mantenuto tra i passaggi
- Risultati aggregati in modo intelligente
Query 7: ricerca su più domini
What are 5 AI companies mentioned in positive articles, and who are their CEOs?
Comportamento previsto:
Questa query complessa richiede più agenti e strumenti:
- Passaggio 1: Investment Research Agent
get_companies_in_industry("Artificial Intelligence")- Restituisce l'elenco delle società di AI
- Passaggio 2: Investment Research Agent
get_articles_with_sentiment(0.8)- Restituisce articoli positivi
- Passaggio 3: filtri agente root
- Identifica le aziende di AI che compaiono negli articoli positivi
- Seleziona le prime 5
- Passaggio 4: Investment Research Agent
get_people_in_organizations([company_names], "CEO")- Restituisce i dati del CEO
- Passaggio 5: formati dell'agente principale come tabella
Risposta prevista:
Here are 5 AI companies with positive news and their CEOs:
| Company | Industry | CEO | Avg Sentiment |
|---------|----------|-----|---------------|
| OpenAI | Artificial Intelligence | Sam Altman | 0.92 |
| Anthropic | Artificial Intelligence | Dario Amodei | 0.89 |
| ... | ... | ... | ... |
Cosa osservare:
- Più chiamate di strumenti in agenti diversi
- Logica di combinazione e filtraggio dei dati
- Formattazione professionale delle tabelle
Query 8: analisi della concorrenza
Who are YouTube's main competitors?
Comportamento previsto:
- L'agente principale esegue il routing all'agente del database a grafo (query sulle relazioni)
- L'agente genera Cypher migliorato con GraphRAG:
MATCH (c:Company {name: "YouTube"})-[:COMPETES_WITH]->(competitor)
RETURN competitor.name as competitor_name
- Restituisce l'elenco delle società concorrenti
Risposta prevista:
YouTube's main competitors are:
- TikTok (ByteDance)
- Dailymotion
- Twitter
- BuzzFeed
- Mixer
- OpenAI (for video content)
Query di follow-up sensibili al contesto
Query 9: domanda di follow-up (dopo la query 8)
Which investors funded both YouTube and its competitors?
Comportamento previsto:
- L'agente principale ricorda il contesto precedente (YouTube e i suoi concorrenti)
- Percorsi per l'agente di ricerca degli investitori
- Per YouTube e ogni concorrente, trova gli investitori
- Identifica gli investitori che compaiono in più società
Risposta prevista:
Based on our previous analysis of YouTube's competitors, I found these
investors who funded multiple companies in this competitive landscape:
Sequoia Capital invested in:
- YouTube
- TikTok (ByteDance)
- Twitter
Accel Partners invested in:
- YouTube
- BuzzFeed
This suggests these investors have strategic positions across the video content platform ecosystem.
Query 10: Riepilogo della ricerca
Summarize our research findings so far
Comportamento previsto:
- L'agente principale esamina la cronologia delle conversazioni
- Sintetizza i risultati chiave delle query precedenti
- Fornisce un riepilogo coerente
Risposta prevista:
Here's a summary of our investment research session:
1. Industry Overview: We explored the Artificial Intelligence industry
with 150+ companies in the database.
2. ByteDance Analysis:
- Investors: Rong Yue, Wendi Murdoch
- Rong Yue also invested in Inspur
3. Market Sentiment: We analyzed articles from January 2023, finding
strong positive sentiment (avg 0.85) for tech companies.
4. Competitive Landscape: YouTube faces competition from TikTok,
Dailymotion, and others, with some investors (Sequoia, Accel) holding
positions across competing platforms.
5. Key Players: Identified CEOs of major AI companies with positive media coverage.
Informazioni sulle interazioni dell'agente nella visualizzazione di debug
L'interfaccia web dell'ADK fornisce una visibilità dettagliata dell'esecuzione. Ecco cosa cercare:
- Cronologia degli eventi
Mostra il flusso cronologico:
[USER] Query received
[ROOT_AGENT] Analyzing query intent
[ROOT_AGENT] Routing to investment_research_agent
[INVESTMENT_RESEARCH_AGENT] Tool call: get_companies_in_industry
[TOOL] Executing with params: {"industry_name": "Artificial Intelligence"}
[TOOL] Returned 47 results
[INVESTMENT_RESEARCH_AGENT] Formatting response
[ROOT_AGENT] Presenting to user
- Dettagli chiamata dello strumento
Fai clic su una chiamata allo strumento per visualizzare:
- Nome funzione
- Parametri di input
- Valore restituito
- Tempo di esecuzione
- Eventuali errori
- Agent Decision Making
Osserva il ragionamento del modello LLM:
- Perché ha scelto un agente specifico
- Come ha interpretato la query
- Quali strumenti ha preso in considerazione
- Perché ha formattato i risultati in un determinato modo
Osservazioni e approfondimenti comuni
- Pattern di routing delle query:
- Parole chiave come "investitore", "investito" → Agente di ricerca sugli investitori
- Parole chiave come "settore", "aziende", "articoli" → Agente di ricerca sugli investimenti
- Aggregazioni, conteggi, logica complessa → Graph Database Agent
- Note sul rendimento:
- Gli strumenti MCP sono in genere più veloci (query pre-ottimizzate)
- La generazione di Cypher complessi richiede più tempo (tempo di elaborazione dell'LLM)
- Più chiamate di strumenti aggiungono latenza, ma forniscono risultati più ricchi
- Gestione degli errori:
- Se una query non riesce:
- L'agente spiega cosa non ha funzionato
- Suggerisce correzioni (ad es. "Nome dell'azienda non trovato, controlla l'ortografia")
- Potrebbe provare approcci alternativi
Suggerimenti per test efficaci
- Inizia in modo semplice: testa la funzionalità di base di ogni agente prima di passare a query complesse
- Utilizza i follow-up: verifica la conservazione del contesto con domande aggiuntive
- Osserva il routing: guarda quale agente gestisce ogni query per comprendere la logica
- Controlla le chiamate agli strumenti: verifica che i parametri vengano estratti correttamente dal linguaggio naturale
- Testa i casi limite: prova query ambigue, errori ortografici o richieste insolite.
Ora hai un sistema GraphRAG multiagente completamente funzionante. Sperimenta con le tue domande per esplorarne le funzionalità.
8. Esegui la pulizia
Per evitare che al tuo account Google Cloud vengano addebitati costi relativi alle risorse utilizzate in questo post, segui questi passaggi:
- Nella console Google Cloud, vai alla pagina Gestisci risorse.
- Nell'elenco dei progetti, seleziona il progetto che vuoi eliminare, quindi fai clic su Elimina.
- Nella finestra di dialogo, digita l'ID progetto, quindi fai clic su Chiudi per eliminare il progetto.
9. Complimenti
🎉 Complimenti! Hai creato correttamente un sistema GraphRAG multi-agente di qualità di produzione utilizzando l'Agent Development Kit, Neo4j e MCP Toolbox di Google.
Combinando le funzionalità di orchestrazione intelligente di ADK con il modello di dati ricco di relazioni di Neo4j e la sicurezza delle query MCP pre-convalidate, hai creato un sistema sofisticato che va oltre le semplici query di database: comprende il contesto, i motivi delle relazioni complesse e coordina agenti specializzati per fornire informazioni complete e accurate.
In questo codelab hai imparato a:
✅ Creazione di un sistema multi-agente utilizzando l'Agent Development Kit (ADK) di Google con orchestrazione gerarchica
✅ Database di grafici Neo4j integrato per sfruttare le query sensibili alle relazioni e il ragionamento multihop
✅ Implementazione di MCP Toolbox per query di database sicure e pre-validate come strumenti riutilizzabili
✅ Creati agenti specializzati per la ricerca di investitori, l'analisi degli investimenti e le operazioni sui database grafici
✅ Progettazione di un routing intelligente che delega automaticamente le query all'agente esperto più appropriato
✅ Gestione di tipi di dati complessi con la corretta serializzazione dei tipi Neo4j per un'integrazione perfetta di Python
✅ Best practice di produzione applicate per la progettazione di agenti, la gestione degli errori e il debug del sistema
Passaggi successivi
Questa architettura GraphRAG multi-agente non è limitata alla ricerca sugli investimenti, ma può essere estesa a:
- Servizi finanziari: ottimizzazione del portafoglio, valutazione dei rischi, rilevamento di frodi
- Sanità: coordinamento dell'assistenza ai pazienti, analisi delle interazioni farmacologiche, ricerca clinica
- E-commerce: consigli personalizzati, ottimizzazione della catena di fornitura, approfondimenti sui clienti
- Aspetti legali e conformità: analisi dei contratti, monitoraggio delle normative, ricerca di giurisprudenza
- Ricerca accademica: analisi dei documenti, scoperta della collaborazione, analisi delle citazioni
- Enterprise Intelligence: analisi della concorrenza, ricerche di mercato, knowledge graph organizzativi
Ovunque tu abbia dati complessi interconnessi + esperienza nel dominio + interfacce in linguaggio naturale, questa combinazione di sistemi multi-agente ADK + grafici della conoscenza Neo4j + query convalidate da MCP può alimentare la prossima generazione di applicazioni aziendali intelligenti.
Man mano che l'Agent Development Kit e i modelli Gemini di Google continuano a evolversi, potrai incorporare pattern di ragionamento ancora più sofisticati, integrazione di dati in tempo reale e funzionalità multimodali per creare sistemi veramente intelligenti e sensibili al contesto.
Continua a esplorare e a creare e porta le tue applicazioni di agenti intelligenti a un livello superiore.
Esplora altri tutorial pratici sui grafici della conoscenza su Neo4j GraphAcademy e scopri altri pattern di agenti nel repository di esempi di ADK.
🚀 Vuoi creare il tuo prossimo sistema di agenti intelligenti?