
1. 概要
この Codelab では、Google の Agent Development Kit(ADK)、Neo4j グラフ データベース、Model Context Protocol(MCP)ツールボックスの機能を組み合わせた、高度なマルチエージェント投資調査システムを構築します。このハンズオン チュートリアルでは、グラフ関係を通じてデータ コンテキストを理解し、非常に正確なクエリ レスポンスを提供するインテリジェント エージェントを作成する方法について説明します。
GraphRAG とマルチエージェント システムを使用する理由
GraphRAG(グラフベースの検索拡張生成)は、ナレッジグラフの豊富な関係構造を活用して、従来の RAG アプローチを強化します。GraphRAG エージェントは、類似ドキュメントを検索するだけでなく、次のこともできます。
- エンティティ間の複雑な関係をトラバースする
- グラフ構造を通じてコンテキストを理解する
- 接続されたデータに基づいて説明可能な結果を提供する
- ナレッジグラフ全体でマルチホップ推論を実行する
マルチエージェント システムでは次のことができます。
- 複雑な問題を専門的なサブタスクに分解する
- モジュール式で保守可能な AI アプリケーションを構築する
- 並列処理と効率的なリソース使用率を有効にする
- オーケストレーションを使用して階層型推論パターンを作成する
作成するアプリの概要
次のような機能を備えた完全な投資調査システムを作成します。
- グラフ データベース エージェント: Cypher クエリを実行し、Neo4j スキーマを理解します。
- 投資家調査エージェント: 投資家間の関係と投資ポートフォリオを検出します
- 投資調査エージェント: MCP ツールを使用して包括的なナレッジグラフにアクセスします
- ルート エージェント: すべてのサブエージェントをインテリジェントにオーケストレートします。
システムは、次のような複雑な質問に答えます。
- 「YouTube の主な競合他社はどこですか?」
- 「2023 年 1 月に肯定的な感情で言及された企業はどこですか?」
- 「ByteDance に投資した企業はどこですか?また、他に投資している企業はありますか?」
アーキテクチャの概要
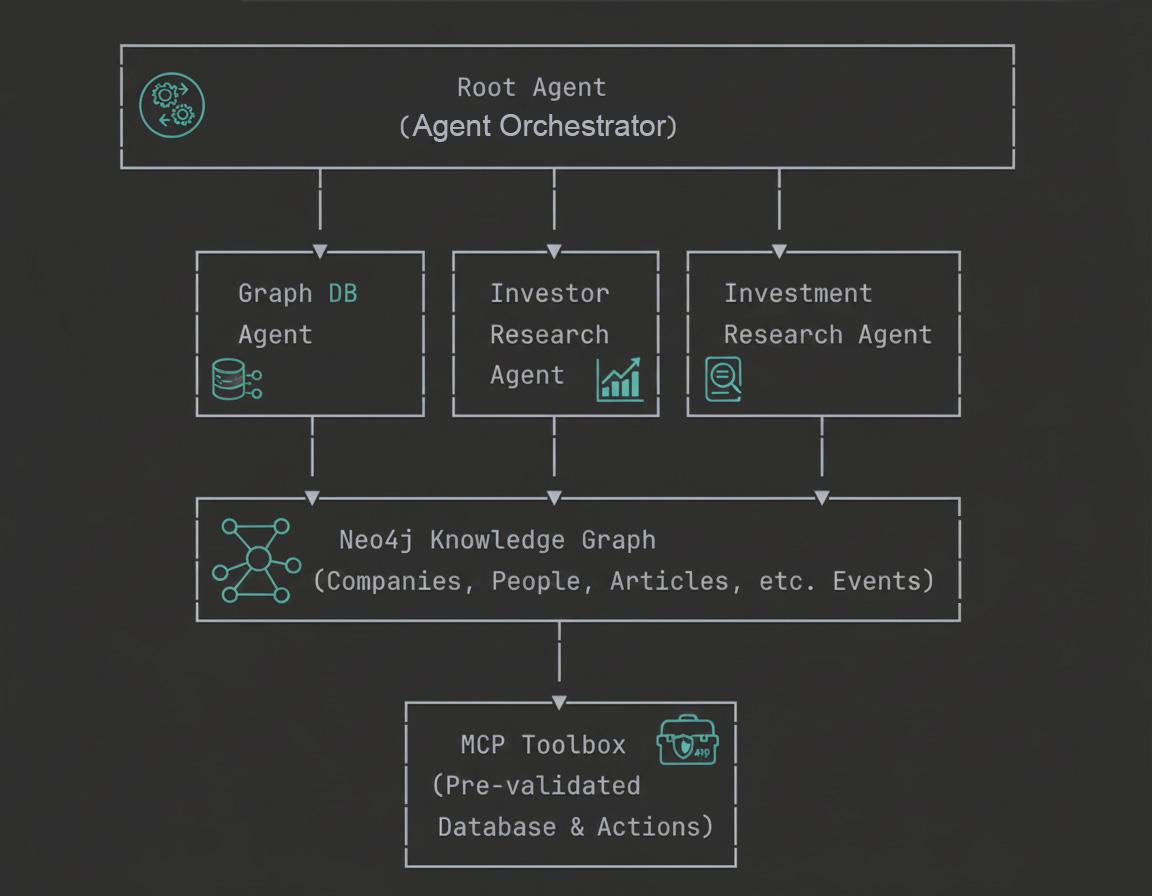
この Codelab では、エンタープライズ クラスの GraphRAG エージェントを構築するための概念的な基礎と実践的な実装の両方を学びます。
学習内容
- Google の Agent Development Kit(ADK)を使用してマルチエージェント システムを構築する方法
- GraphRAG アプリケーション用に Neo4j グラフ データベースを ADK と統合する方法
- 事前検証済みのデータベース クエリに Model Context Protocol(MCP)ツールボックスを実装する方法
- インテリジェント エージェント用のカスタムツールと関数を作成する方法
- エージェントの階層とオーケストレーション パターンを設計する方法
- 最適なパフォーマンスを実現するためのエージェント指示の構成方法
- マルチエージェントのインタラクションを効果的にデバッグする方法
必要なもの
- Chrome ウェブブラウザ
- Gmail アカウント
- 課金が有効になっている Google Cloud プロジェクト
- ターミナル コマンドと Python に関する基本的な知識(あると役立ちますが、必須ではありません)
この Codelab は、初心者を含むあらゆるレベルのデベロッパーを対象としており、サンプル アプリケーションで Python と Neo4j を使用します。Python とグラフ データベースの基本的な知識があると役立ちますが、コンセプトを理解したり、内容を把握したりするうえで、事前の経験は必要ありません。
2. GraphRAG とマルチエージェント システムについて
実装に入る前に、このシステムを支える重要なコンセプトを理解しましょう。
Neo4j は、データをノード(エンティティ)と関係(エンティティ間の接続)のネットワークとして保存する、代表的なネイティブ グラフ データベースです。そのため、レコメンデーション、不正行為の検出、ナレッジグラフなど、接続の理解が重要なユースケースに最適です。厳格なテーブルや階層構造に依存するリレーショナル データベースやドキュメント ベースのデータベースとは異なり、Neo4j の柔軟なグラフモデルでは、複雑で相互接続されたデータを直感的かつ効率的に表現できます。
Neo4j は、リレーショナル データベースのようにデータを行とテーブルに整理するのではなく、グラフモデルを使用します。このモデルでは、情報はノード(エンティティ)と関係(エンティティ間の接続)として表されます。このモデルは、人物、場所、商品、映画、俳優、ジャンルなど、本質的にリンクされているデータを扱う場合に非常に直感的です。
たとえば、映画のデータセットでは次のようになります。
- ノードは、
Movie、Actor、またはDirectorを表すことができます。 - 関係は
ACTED_INまたはDIRECTEDのいずれかになります
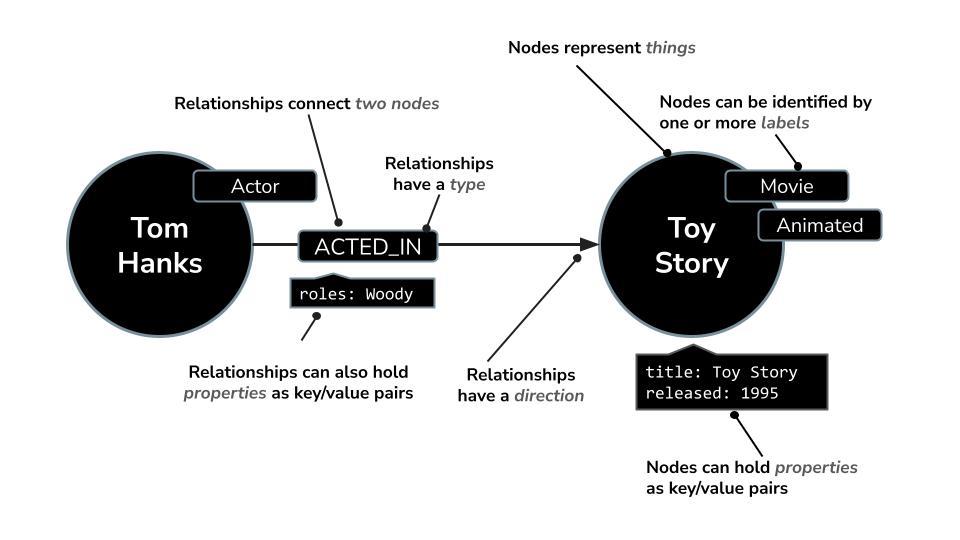
この構造により、次のような質問を簡単に実行できます。
- この俳優が出演した映画を教えて。
- クリストファー ノーランと仕事をしたことがあるのは誰ですか?
- 出演者やジャンルが共通する類似の映画は?
GraphRAG とは
検索拡張生成(RAG)は、外部ソースから関連情報を取得して LLM のレスポンスを強化します。従来の RAG は通常、次のようになります。
- ドキュメントをベクトルに埋め込む
- 類似ベクトルを検索する
- 取得したドキュメントを LLM に渡す
GraphRAG は、ナレッジグラフを使用してこれを拡張します。
- エンティティと関係を埋め込む
- グラフ接続を走査する
- マルチホップのコンテキスト情報を取得する
- 構造化された説明可能な結果を提供する
AI エージェントにグラフを使用する理由
「YouTube の競合他社はどこですか?また、YouTube とその競合他社の両方に資金を提供している投資家は誰ですか?」という質問を考えてみましょう。
従来の RAG アプローチでは次の処理が行われます。
- YouTube の競合他社に関するドキュメントを検索する
- 投資家情報を個別に検索する
- この 2 つの情報を結びつけることができない
- 暗黙的な関係が見つからない可能性がある
GraphRAG アプローチでは次の処理が行われます。
MATCH (org:Organization {name: "OpenAI"})-[:HAS_COMPETITOR]-(competitor:Organization)
MATCH (org)-[:HAS_INVESTOR]->(investor:Person)
MATCH (competitor)-[:HAS_INVESTOR]->(investor)
RETURN org, competitor, investor
グラフは関係を自然に表すため、マルチホップ クエリを簡単かつ効率的に実行できます。
ADK のマルチエージェント システム
Agent Development Kit(ADK)は、本番環境グレードの AI エージェントを構築してデプロイするための Google のオープンソース フレームワークです。マルチエージェント オーケストレーション、ツール統合、ワークフロー管理のための直感的なプリミティブが用意されているため、専門的なエージェントを高度なシステムに簡単に構成できます。ADK は Gemini とシームレスに連携し、Cloud Run、Kubernetes、任意のインフラストラクチャへのデプロイをサポートします。
Agent Development Kit(ADK)は、マルチエージェント システムを構築するためのプリミティブを提供します。
- エージェントの階層:
# Root agent coordinates specialized agents
root_agent = LlmAgent(
name="RootAgent",
sub_agents=[
graph_db_agent,
investor_agent,
investment_agent
]
)
- 専門エージェント: 各エージェントには
- 特定のツール: 呼び出すことができる関数
- 明確な指示: 役割と機能
- ドメインの専門知識: その分野の知識
- オーケストレーション パターン:
- Sequential: エージェントを順番に実行する
- 並列: 複数のエージェントを同時に実行する
- 条件付き: クエリタイプに基づいてルーティングする
データベース向け MCP ツールボックス
Model Context Protocol(MCP)は、AI システムを外部のデータソースやツールに接続するためのオープン標準です。データベース向け MCP ツールボックスは、宣言型データベース クエリ管理を可能にする Google の実装です。これにより、事前検証済みの専門家が作成したクエリを再利用可能なツールとして定義できます。MCP ツールボックスは、LLM に潜在的に安全でないクエリを生成させるのではなく、事前に承認されたクエリをパラメータ検証とともに提供し、AI エージェントの柔軟性を維持しながら、セキュリティ、パフォーマンス、信頼性を確保します。
従来のアプローチ:
# LLM generates query (may be incorrect/unsafe)
query = llm.generate("SELECT * FROM users WHERE...")
db.execute(query) # Risk of errors/SQL injection
MCP アプローチ:
# Pre-validated query definition
- name: get_industries
description: Fetch all industries from database
query: |
MATCH (i:Industry)
RETURN i.name, i.id
利点:
- 専門家による事前検証
- インジェクション攻撃から保護する
- パフォーマンス最適化
- 集中管理
- エージェント間で再利用可能
まとめ
GraphRAG、ADK のマルチエージェント フレームワーク、MCP を組み合わせることで、強力なシステムが実現します。
- ルートエージェントがユーザーのクエリを受信する
- クエリタイプに基づいて専門のエージェントに転送
- エージェントが MCP ツールを使用してデータを安全に取得する
- グラフ構造は豊富なコンテキストを提供します
- LLM がグラウンディングされた説明可能な回答を生成する
アーキテクチャを理解できたので、構築を始めましょう。
3. Google Cloud プロジェクトを設定する
プロジェクトを作成する
- Google Cloud コンソールのプロジェクト選択ページで、Google Cloud プロジェクトを選択または作成します。
- Cloud プロジェクトに対して課金が有効になっていることを確認します。詳しくは、プロジェクトで課金が有効になっているかどうかを確認する方法をご覧ください。
- Google Cloud 上で動作するコマンドライン環境の Cloud Shell を使用します。Google Cloud コンソールの上部にある [Cloud Shell をアクティブにする] をクリックします。Cloud Shell の対応するボタンをクリックすると、Cloud Shell ターミナル(クラウド コマンドの実行用)とエディタ(プロジェクトのビルド用)を切り替えることができます。
![[Cloud Shell をアクティブにする] ボタンの画像](https://codelabs.developers.google.com/static/neo4j-adk-graphrag-agents/img/91567e2f55467574.png?hl=ja)
- Cloud Shell に接続したら、次のコマンドを使用して、すでに認証済みであることと、プロジェクトがプロジェクト ID に設定されていることを確認します。
gcloud auth list
- Cloud Shell で次のコマンドを実行して、gcloud コマンドがプロジェクトを認識していることを確認します。
gcloud config list project
- プロジェクトが設定されていない場合は、次のコマンドを使用して設定します。
gcloud config set project <YOUR_PROJECT_ID>
gcloud コマンドとその使用方法については、ドキュメントをご覧ください。
これで準備が整いました。これで、次のステップであるデータセットの理解に進む準備ができました。
4. Companies データセットについて
この Codelab では、Diffbot のナレッジグラフから投資と企業データが事前入力された読み取り専用の Neo4j データベースを使用します。
このデータセットには次のものが含まれます。
- 237,358 個のノードは次のものを表しています。
- 組織(企業)
- 人(経営幹部、従業員)
- 記事(ニュースと言及)
- 業種
- テクノロジー
- 投資家
- 次のような関係:
HAS_INVESTOR- 投資接続HAS_COMPETITOR- 競合関係MENTIONS- 記事の参照HAS_CEO- 雇用関係HAS_CATEGORY- 業種分類
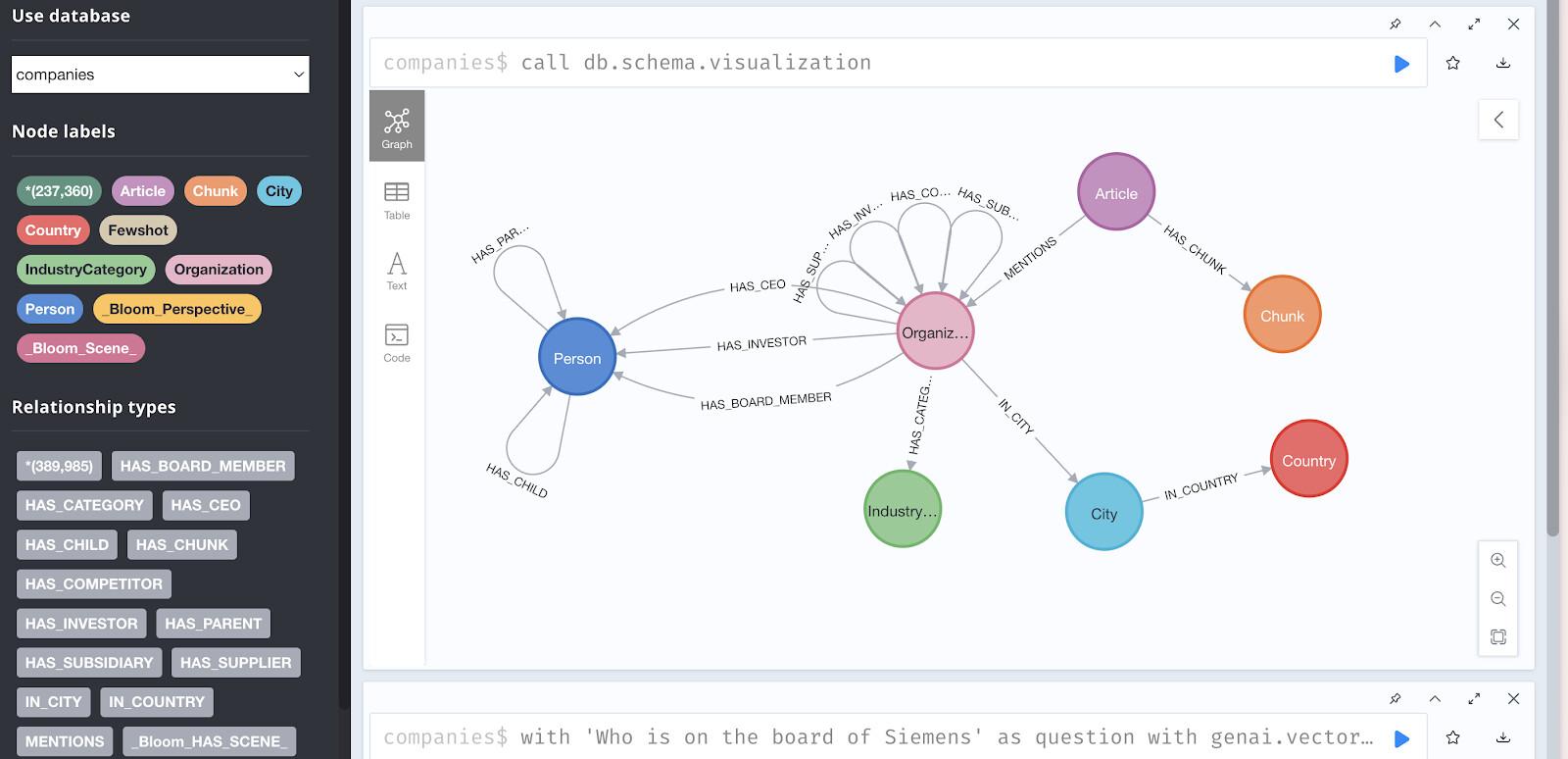
デモ データベースにアクセスする
この Codelab では、ホストされているデモ インスタンスを使用します。メモに以下の認証情報を追加します。
URI: neo4j+s://demo.neo4jlabs.com
Username: companies
Password: companies
Database: companies
ブラウザ アクセス:
https://demo.neo4jlabs.com:7473 でデータを視覚的に探索できます。
同じ認証情報でログインし、次のコマンドを実行してみてください。
// Sample query to explore the graph
MATCH (c:Organization)-[:HAS_COMPETITOR]-(competitor:Organization)
RETURN c.name, competitor.name
LIMIT 10
グラフ構造の可視化
Neo4j Browser で次のクエリを試して、リレーション パターンを確認します。
// Find investors and their portfolio companies
MATCH (company:Organization)-[:HAS_INVESTOR]->(investor:Person)
WITH investor, collect(company.name) as portfolio
RETURN investor.name, size(portfolio) as num_investments, portfolio
ORDER BY num_investments DESC
LIMIT 5
このクエリは、アクティブな投資家上位 5 人とそのポートフォリオを返します。
GraphRAG にこのデータベースを使用する理由
このデータセットは、次のような理由で GraphRAG のデモンストレーションに最適です。
- リッチな関係: エンティティ間の複雑な接続
- 実世界のデータ: 実際の企業、人物、ニュース記事
- マルチホップ クエリ: 複数の関係タイプをトラバースする必要があります
- 時系列データ: 時間ベースの分析用のタイムスタンプ付きの記事
- 感情分析: 記事の事前計算された感情スコア
データ構造を理解できたので、開発環境を設定しましょう。
5. リポジトリのクローンを作成して環境を構成する
リポジトリのクローンを作成する
Cloud Shell ターミナルで、次のコマンドを実行します。
# Clone the repository
git clone https://github.com/sidagarwal04/neo4j-adk-multiagents.git
# Navigate into the directory
cd neo4j-adk-multiagents
リポジトリ構造を確認する
プロジェクトのレイアウトを確認してください。
neo4j-adk-multiagents/
├── investment_agent/ # Main agent code
│ ├── agent.py # Agent definitions
│ ├── tools.py # Custom tool functions
│ └── .adk/ # ADK configuration
│ └── tools.yaml # MCP tool definitions
├── main.py # Application entry point
├── setup_tools_yaml.py # Configuration generator
├── requirements.txt # Python dependencies
├── example.env # Environment template
└── README.md # Project documentation
仮想環境を設定する
uv を使用して Python 仮想環境を作成してアクティブにします。
# Install uv if not already installed
pip install uv
# Create virtual environment
uv venv
# Activate the environment
source .venv/bin/activate # On macOS/Linux
# or
.venv\Scripts\activate # On Windows
ターミナル プロンプトの先頭に (.venv) が付加されます。
依存関係のインストール
必要なパッケージをすべてインストールします。
uv pip install -r requirements.txt
主な依存関係は次のとおりです。
txtgoogle-adk>=1.21.0 # Agent Development Kit
neo4j>=6.0.3 # Neo4j Python driver
python-dotenv>=1.0.0 # Environment variables
google-cloud-aiplatform>=1.30.0 # Vertex AI
環境変数を構成する
- **
.env** **ファイルを作成します。**
cp example.env .env
- **
.env** **ファイルを編集します。**
Cloud Shell を使用している場合は、ツールバーの [エディタを開く] をクリックし、.env に移動して更新します。
非表示の .env ファイルを表示するには:
Google Cloud Shell エディタで View > Toggle Hidden files をクリックします。
# Neo4j Configuration (Demo Database)
NEO4J_URI=neo4j+s://demo.neo4jlabs.com
NEO4J_USERNAME=companies
NEO4J_PASSWORD=companies
NEO4J_DATABASE=companies
# Google AI Configuration
# Choose ONE of the following options:
# Option 1: Google AI API (Recommended)
GOOGLE_GENAI_USE_VERTEXAI=0
GOOGLE_API_KEY=your_api_key_here # Get from https://aistudio.google.com/app/apikey
# Option 2: Vertex AI (If using GCP)
# GOOGLE_GENAI_USE_VERTEXAI=1
# GOOGLE_CLOUD_PROJECT=your-project-id
# GOOGLE_CLOUD_LOCATION=us-central1
# ADK Configuration
GOOGLE_ADK_MODEL=gemini-3.1-flash-lite-preview # or gemini-3-flash-preview
# MCP Toolbox Configuration
MCP_TOOLBOX_URL=https://toolbox-990868019953.us-central1.run.app/mcp/sse
- MCP ツールボックスの構成を生成します。
設定スクリプトを実行して、環境変数から tools.yaml ファイルを作成します。
python setup_tools_yaml.py
これにより、MCP ツール用に Neo4j 認証情報が正しく構成された investment_agent/.adk/tools.yaml が生成されます。
構成を確認する
すべてが正しく設定されていることを確認します。
# Verify .env file exists
ls -la .env
# Verify tools.yaml was generated
ls -la investment_agent/.adk/tools.yaml
# Test Python environment
python -c "import google.adk; print('ADK installed successfully')"
# Test Neo4j connection
python -c "from neo4j import GraphDatabase; print('Neo4j driver installed')"
これで開発環境の構成が完了しました。次に、マルチエージェント アーキテクチャについて詳しく説明します。
6. マルチエージェント アーキテクチャについて
The Four-Agent System
Google の投資調査システムは、階層型マルチエージェント アーキテクチャを使用しています。このアーキテクチャでは、4 つの特殊エージェントが連携して、企業、投資家、市場インテリジェンスに関する複雑なクエリに回答します。
┌──────────────┐
│ Root Agent │ ◄── User Query
└──────┬───────┘
│
┌────────────────┼────────────────┐
│ │ │
┌─────▼─────┐ ┌────▼─────┐ ┌────▼──────────┐
│ Graph DB │ │ Investor │ │ Investment │
│ Agent │ │ Research │ │ Research │
└───────────┘ │ Agent │ │ Agent │
└──────────┘ └───────────────┘
- ルート エージェント(オーケストレーター):
ルート エージェントは、システム全体のインテリジェントなコーディネーターとして機能します。ユーザークエリを受け取り、意図を分析して、リクエストを最適な専門エージェントに転送します。各タスクに最適なチームメンバーを把握しているプロジェクト マネージャーのようなものとお考えください。また、レスポンスの集計、リクエストに応じて結果をテーブルやグラフとしてフォーマット、複数のクエリにわたる会話コンテキストの維持も行います。ルート エージェントは常に一般的なデータベース エージェントよりも専門エージェントを優先するため、クエリは利用可能な最も専門的なコンポーネントによって処理されます。
- グラフ データベース エージェント:
グラフ データベース エージェントは、Neo4j の強力なグラフ機能に直接接続します。データベース スキーマを理解し、自然言語から Cypher クエリを生成して、複雑なグラフ トラバーサルを実行します。このエージェントは、ナレッジグラフ全体にわたる構造的な質問、集計、マルチホップ推論を専門としています。これは、事前定義されたツールでは処理できないカスタム ロジックがクエリに必要な場合の代替エキスパートです。システム設計で想定されていなかった探索的分析や複雑な分析クエリに不可欠です。
- 投資家調査エージェント:
投資調査エージェントは、投資関係とポートフォリオ分析のみに焦点を当てます。正確な名前の一致を使用して特定の企業に投資した人物を特定したり、すべての投資を示す投資家の完全なポートフォリオを取得したり、業界全体の投資パターンを分析したりできます。この特化により、「ByteDance に投資したのは誰か?」や「Sequoia Capital は他に何に投資したか?」といった質問に非常に効率的に答えることができます。エージェントは、投資家関連の関係について Neo4j データベースを直接クエリするカスタム Python 関数を使用します。
- 投資調査エージェント:
投資調査エージェントは、Model Context Protocol(MCP)ツールボックスを活用して、事前検証済みの専門家作成クエリにアクセスします。利用可能なすべての業界を取得したり、特定の業界内の企業を取得したり、感情分析を含む記事を見つけたり、ニュースで組織が言及されている箇所を見つけたり、企業で働く人々の情報を取得したりできます。クエリを動的に生成するグラフ データベース エージェントとは異なり、このエージェントは、一元管理および検証される安全で最適化された事前定義クエリを使用します。これにより、一般的な研究ワークフローで安全かつ高性能な環境が実現します。
7. マルチエージェント システムの実行とテスト
アプリケーションを起動する
アーキテクチャを理解したところで、システム全体を実行して操作してみましょう。
ADK ウェブ インターフェースを起動します。
# Make sure you're in the project directory with activated virtual environment
cd ~/neo4j-adk-multiagents
source .venv/bin/activate # If not already activated
# Launch the application
uv run adk web
次のような出力が表示されます。
INFO: Started server process [2542]
INFO: Waiting for application startup.
+----------------------------------------------------------------+
| ADK Web Server started |
| |
| For local testing, access at http://127.0.0.1:8000. |
+----------------------------------------------------------------+
INFO: Application startup complete.
INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
テストクエリと想定される動作
複雑なクエリを段階的に使用して、システムの機能を詳しく見ていきましょう。
基本的なクエリ(単一エージェント)
クエリ 1: 業界を検出する
What industries are available in the database?
期待される動作:
- ルート エージェントが投資調査エージェントに転送する
- MCP ツールを使用する:
get_industries() - すべての業種の形式設定済みリストを返します
観察すべきこと:
ADK UI で、実行の詳細を開いて次の情報を確認します。
- エージェント選択の決定
- ツール呼び出し:
get_industries() - Neo4j からの未加工の結果
- フォーマットされたレスポンス
クエリ 2: 投資家を見つける
Who invested in ByteDance?
期待される動作:
- ルート エージェントが投資家関連の問い合わせと判断
- 投資家調査エージェントへのルート
- 使用ツール:
find_investor_by_name("ByteDance") - 投資家とそのタイプ(個人/組織)を返します
想定される回答:
I found 2 investors in ByteDance:
1. Rong Yue (Person)
2. Wendi Murdoch (Person)
Would you like to know more about their investment portfolios?
クエリ 3: 業界別の企業数**
I found 2 investors in ByteDance:
1. Rong Yue (Person)
2. Wendi Murdoch (Person)
Would you like to know more about their investment portfolios?
"Show me companies in the Artificial Intelligence industry"
期待される動作:
- ルート エージェントが投資調査エージェントに転送する
- MCP ツールを使用する:
get_companies_in_industry("Artificial Intelligence") - ID と設立日を含む AI 企業のリストを返します
観察すべきこと:
- エージェントが業界名を正確に照合しているかどうかを確認する
- 結果は、出力が過剰にならないように制限されています
- データが読みやすいように明確にフォーマットされている
Intermediate Queries(1 人のエージェントによる複数ステップ)
クエリ 4: 感情分析
Find articles with positive sentiment from January 2023
期待される動作:
- 投資調査エージェントへのルート
- MCP ツールを使用する:
get_articles_with_sentiment(0.7, 2023, 1) - タイトル、感情スコア、公開日を含む記事を返します
デバッグのヒント:
ツール呼び出しパラメータを確認します。
min_sentiment: 0.7(エージェントは「ポジティブ」を 0.7 以上と解釈します)year: 2023month: 1
クエリ 5: 複雑なデータベース クエリ
How many companies are in the database?
期待される動作:
- ルート エージェントがグラフ データベース エージェントに転送する
- エージェントが最初に
get_neo4j_schema()を呼び出して構造を理解する - 生成される Cypher:
MATCH (c:Company) RETURN count(c) - クエリを実行してカウントを返します
想定される回答:
There are 8,064 companies in the database.
高度なクエリ(マルチエージェントの連携)
クエリ 6: ポートフォリオ分析
Who invested in ByteDance and what else have they invested in?
期待される動作:
これは、エージェントの調整が必要な 2 部構成のクエリです。
- ステップ 1: Root Agent → Investor Research Agent
find_investor_by_name("ByteDance")を呼び出します- 投資家リストを取得: [Rong Yue、Wendi Murdoch]
- ステップ 2: 各投資家 → Investor Research Agent
find_investor_by_id(investor_id)を呼び出します- ポートフォリオ全体を取得する
- ステップ 3: Root Agent が集計とフォーマットを行う
想定される回答:
I found 2 investors in ByteDance. Here are their portfolios:
1. Rong Yue (Person)
- ByteDance
- Inspur
2. Wendi Murdoch (Person)
- ByteDance
- (No other investments in database)
観察すべきこと:
- 複数のツール呼び出しが連続している
- ステップ間でコンテキストが維持される
- インテリジェントに集計された結果
クエリ 7: 複数ドメインの調査
What are 5 AI companies mentioned in positive articles, and who are their CEOs?
期待される動作:
この複雑なクエリには、複数のエージェントとツールが必要です。
- ステップ 1: Investment Research Agent
get_companies_in_industry("Artificial Intelligence")- AI 企業のリストを返します
- ステップ 2: Investment Research Agent
get_articles_with_sentiment(0.8)- 肯定的な記事を返す
- ステップ 3: Root Agent フィルタ
- 肯定的な記事に掲載されている AI 企業を特定する
- 上位 5 件を選択
- ステップ 4: 投資調査エージェント
get_people_in_organizations([company_names], "CEO")- CEO の情報を返します
- ステップ 5: Root エージェントが表形式でフォーマットする
想定される回答:
Here are 5 AI companies with positive news and their CEOs:
| Company | Industry | CEO | Avg Sentiment |
|---------|----------|-----|---------------|
| OpenAI | Artificial Intelligence | Sam Altman | 0.92 |
| Anthropic | Artificial Intelligence | Dario Amodei | 0.89 |
| ... | ... | ... | ... |
観察すべきこと:
- 異なるエージェント間の複数のツール呼び出し
- データのフィルタリングと組み合わせのロジック
- 表のプロフェッショナルな書式設定
クエリ 8: 競合分析
Who are YouTube's main competitors?
期待される動作:
- ルート エージェントがグラフ データベース エージェントにルーティング(関係クエリ)
- エージェントが GraphRAG 拡張 Cypher を生成する:
MATCH (c:Company {name: "YouTube"})-[:COMPETES_WITH]->(competitor)
RETURN competitor.name as competitor_name
- 競合他社のリストを返す
想定される回答:
YouTube's main competitors are:
- TikTok (ByteDance)
- Dailymotion
- Twitter
- BuzzFeed
- Mixer
- OpenAI (for video content)
コンテキストアウェアのフォローアップ クエリ
クエリ 9: フォローアップの質問(クエリ 8 の後)
Which investors funded both YouTube and its competitors?
期待される動作:
- ルート エージェントが以前のコンテキスト(YouTube と競合他社)を記憶する
- 投資家調査エージェントへのルート
- YouTube と各競合他社の投資家を特定する
- 複数の企業に登場する投資家を特定する
想定される回答:
Based on our previous analysis of YouTube's competitors, I found these
investors who funded multiple companies in this competitive landscape:
Sequoia Capital invested in:
- YouTube
- TikTok (ByteDance)
- Twitter
Accel Partners invested in:
- YouTube
- BuzzFeed
This suggests these investors have strategic positions across the video content platform ecosystem.
クエリ 10: 調査の概要
Summarize our research findings so far
期待される動作:
- Root Agent が会話履歴を確認する
- 以前のクエリから得られた重要な知見を統合する
- 一貫性のある要約を提供する
想定される回答:
Here's a summary of our investment research session:
1. Industry Overview: We explored the Artificial Intelligence industry
with 150+ companies in the database.
2. ByteDance Analysis:
- Investors: Rong Yue, Wendi Murdoch
- Rong Yue also invested in Inspur
3. Market Sentiment: We analyzed articles from January 2023, finding
strong positive sentiment (avg 0.85) for tech companies.
4. Competitive Landscape: YouTube faces competition from TikTok,
Dailymotion, and others, with some investors (Sequoia, Accel) holding
positions across competing platforms.
5. Key Players: Identified CEOs of major AI companies with positive media coverage.
デバッグビューでのエージェントのインタラクションについて
ADK ウェブ インターフェースでは、実行の詳細な可視性が提供されます。次の点を確認してください。
- イベント タイムライン
時系列フローを表示します。
[USER] Query received
[ROOT_AGENT] Analyzing query intent
[ROOT_AGENT] Routing to investment_research_agent
[INVESTMENT_RESEARCH_AGENT] Tool call: get_companies_in_industry
[TOOL] Executing with params: {"industry_name": "Artificial Intelligence"}
[TOOL] Returned 47 results
[INVESTMENT_RESEARCH_AGENT] Formatting response
[ROOT_AGENT] Presenting to user
- ツールの呼び出しの詳細
ツール呼び出しをクリックすると、次の内容が表示されます。
- 関数名
- 入力パラメータ
- 戻り値
- 実行時間
- エラー
- エージェントの意思決定
LLM の推論を確認します。
- 特定のエージェントが選択された理由
- クエリの解釈方法
- 検討したツール
- 結果が特定の形式で表示された理由
一般的な観察結果と分析情報
- クエリのルーティング パターン:
- 「投資家」、「投資」などのキーワード → 投資家調査エージェント
- 「業界」、「企業」、「記事」などのキーワード → 投資調査エージェント
- 集計、カウント、複雑なロジック → グラフ データベース エージェント
- パフォーマンスに関する注意事項:
- MCP ツールは通常、高速です(事前最適化されたクエリ)。
- 複雑な Cypher の生成に時間がかかる(LLM の思考時間)
- 複数のツール呼び出しはレイテンシを追加しますが、より豊富な結果を提供します
- エラー処理:
- クエリが失敗した場合:
- エージェントが問題点を説明する
- 修正候補を提案する(例: 「会社名が見つかりません。スペルを確認してください」)
- 別のアプローチを試す場合がある
効果的なテストのヒント
- シンプルなテストから始める: 複雑なクエリの前に、各エージェントのコア機能をテストする
- フォローアップを使用する: フォローアップの質問でコンテキストの保持をテストする
- Observe Routing: 各クエリを処理するエージェントを監視して、ロジックを理解する
- ツール呼び出しを確認する: 自然言語からパラメータが正しく抽出されていることを確認する
- エッジケースをテストする: 曖昧なクエリ、スペルミス、異常なリクエストを試す
これで、完全に機能するマルチエージェント GraphRAG システムが完成しました。独自の質問を試して、その機能を試してみましょう。
8. クリーンアップ
この投稿で使用したリソースについて、Google Cloud アカウントに課金されないようにするには、次の操作を行います。
- Google Cloud コンソールで、[リソースの管理] ページに移動します。
- プロジェクト リストで、削除するプロジェクトを選択し、[削除] をクリックします。
- ダイアログでプロジェクト ID を入力し、[シャットダウン] をクリックしてプロジェクトを削除します。
9. 完了
お疲れさまでしたGoogle の Agent Development Kit、Neo4j、MCP ツールボックスを使用して、本番環境品質のマルチエージェント GraphRAG システムを正常に構築しました。
ADK のインテリジェントなオーケストレーション機能と、Neo4j の関係性の豊富なデータモデル、事前検証済みの MCP クエリの安全性を組み合わせることで、単純なデータベース クエリを超えた高度なシステムが作成されました。このシステムは、コンテキストを理解し、複雑な関係性を理由付けし、専門のエージェントを調整して、包括的で正確な分析情報を提供します。
この Codelab では、次のことを行いました。
✅ 階層オーケストレーションで Google の Agent Development Kit(ADK)を使用してマルチエージェント システムを構築した
✅ 関係認識クエリとマルチホップ推論を活用するための Neo4j グラフ データベースの統合
✅ 再利用可能なツールとして、安全で事前検証済みのデータベース クエリ用に MCP ツールボックスを実装
✅ 投資家調査、投資分析、グラフ データベース オペレーション用の専門エージェントを作成しました
✅ インテリジェント ルーティングを設計し、クエリを最適な専門エージェントに自動的に委任
✅ シームレスな Python 統合のために適切な Neo4j 型シリアル化を使用して複雑なデータ型を処理
✅ エージェントの設計、エラー処理、システム デバッグに本番環境のベスト プラクティスを適用する
次のステップ
このマルチエージェント GraphRAG アーキテクチャは投資調査に限定されず、次のように拡張できます。
- 金融サービス: ポートフォリオの最適化、リスク評価、不正行為の検出
- 医療: 患者ケアの調整、薬物相互作用の分析、臨床研究
- e コマース: パーソナライズされたおすすめ、サプライ チェーンの最適化、顧客分析情報
- 法務とコンプライアンス: 契約分析、規制のモニタリング、判例調査
- 学術研究: 文献調査、共同研究の発見、引用分析
- エンタープライズ インテリジェンス: 競合分析、市場調査、組織のナレッジグラフ
複雑に相互接続されたデータ、ドメインの専門知識、自然言語インターフェースがある場所であれば、ADK マルチエージェント システム、Neo4j ナレッジグラフ、MCP 検証済みクエリの組み合わせにより、次世代のインテリジェント エンタープライズ アプリケーションを強化できます。
Google の Agent Development Kit と Gemini モデルは進化を続けており、より高度な推論パターン、リアルタイムのデータ統合、マルチモーダル機能を組み込んで、真にインテリジェントでコンテキスト認識型のシステムを構築できるようになります。
探索と構築を続け、インテリジェント エージェント アプリケーションを次のレベルに引き上げましょう。
Neo4j GraphAcademy で、ナレッジグラフに関するその他の実践的なチュートリアルを確認し、ADK サンプル リポジトリで、その他のエージェント パターンを確認する。
🚀 次世代のインテリジェント エージェント システムを構築する準備はできていますか?