
1. 개요
이 Codelab에서는 Google의 에이전트 개발 키트 (ADK), Neo4j 그래프 데이터베이스, 모델 컨텍스트 프로토콜 (MCP) Toolbox의 기능을 결합한 정교한 멀티 에이전트 투자 조사 시스템을 빌드합니다. 이 실습 튜토리얼에서는 그래프 관계를 통해 데이터 컨텍스트를 이해하고 매우 정확한 쿼리 응답을 제공하는 지능형 에이전트를 만드는 방법을 보여줍니다.
GraphRAG + 멀티 에이전트 시스템을 사용하는 이유
GraphRAG (그래프 기반 검색 증강 생성)는 지식 그래프의 풍부한 관계 구조를 활용하여 기존 RAG 접근 방식을 개선합니다. 유사한 문서를 검색하는 대신 GraphRAG 에이전트는 다음 작업을 할 수 있습니다.
- 항목 간의 복잡한 관계 탐색
- 그래프 구조를 통해 맥락 이해하기
- 연결된 데이터를 기반으로 설명 가능한 결과 제공
- 지식 그래프에서 멀티홉 추론 실행
멀티 에이전트 시스템을 사용하면 다음 작업을 할 수 있습니다.
- 복잡한 문제를 전문적인 하위 작업으로 분해
- 유지관리 가능한 모듈식 AI 애플리케이션 빌드
- 병렬 처리 및 효율적인 리소스 사용 설정
- 조정으로 계층적 추론 패턴 만들기
빌드할 항목
다음과 같은 기능을 갖춘 완전한 투자 조사 시스템을 만듭니다.
- 그래프 데이터베이스 에이전트: Cypher 쿼리를 실행하고 Neo4j 스키마를 이해합니다.
- 투자자 조사 에이전트: 투자자 관계 및 투자 포트폴리오를 파악합니다.
- 투자 조사 에이전트: MCP 도구를 통해 포괄적인 지식 그래프에 액세스
- 루트 에이전트: 모든 하위 에이전트를 지능적으로 조정합니다.
시스템은 다음과 같은 복잡한 질문에 답변합니다.
- 'YouTube의 주요 경쟁업체는 어디인가요?'
- 2023년 1월에 긍정적인 감정으로 언급된 회사는 뭐야?
- 'ByteDance에 투자한 사람은 누구이고, 어디에 투자했어?'
아키텍처 개요
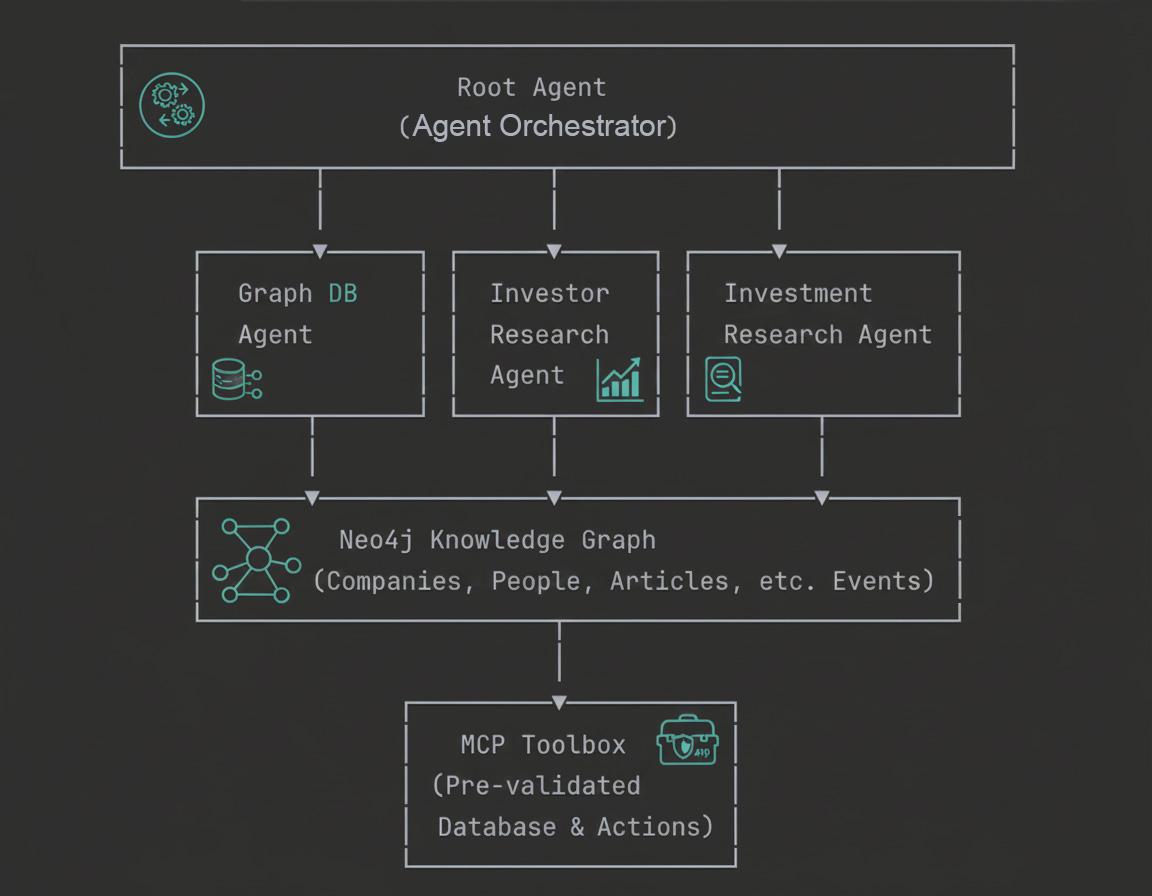
이 Codelab을 통해 엔터프라이즈급 GraphRAG 에이전트를 빌드하는 개념적 기반과 실제 구현을 모두 알아봅니다.
학습할 내용
- Google의 에이전트 개발 키트 (ADK)를 사용하여 멀티 에이전트 시스템을 빌드하는 방법
- GraphRAG 애플리케이션을 위해 Neo4j 그래프 데이터베이스를 ADK와 통합하는 방법
- 사전 검증된 데이터베이스 쿼리를 위해 모델 컨텍스트 프로토콜 (MCP) Toolbox를 구현하는 방법
- 지능형 에이전트를 위한 맞춤 도구 및 함수를 만드는 방법
- 에이전트 계층 구조 및 오케스트레이션 패턴을 설계하는 방법
- 최적의 성능을 위해 에이전트 요청을 구성하는 방법
- 멀티 에이전트 상호작용을 효과적으로 디버그하는 방법
필요한 항목
- Chrome 웹브라우저
- Gmail 계정
- 결제가 사용 설정된 Google Cloud 프로젝트
- 터미널 명령어 및 Python에 대한 기본적인 지식 (있으면 좋지만 필수는 아님)
이 Codelab은 초보자를 포함한 모든 수준의 개발자를 대상으로 하며 샘플 애플리케이션에서 Python과 Neo4j를 사용합니다. Python 및 그래프 데이터베이스에 대한 기본적인 지식이 있으면 도움이 되지만 개념을 이해하거나 따라가는 데 사전 경험은 필요하지 않습니다.
2. GraphRAG 및 멀티 에이전트 시스템 이해하기
구현에 들어가기 전에 이 시스템을 지원하는 주요 개념을 이해해 보겠습니다.
Neo4j는 데이터를 노드 (엔티티)와 관계 (엔티티 간 연결)의 네트워크로 저장하는 선도적인 기본 그래프 데이터베이스로, 추천, 사기 감지, 지식 그래프 등 연결을 이해하는 것이 중요한 사용 사례에 적합합니다. 엄격한 테이블이나 계층 구조에 의존하는 관계형 또는 문서 기반 데이터베이스와 달리 Neo4j의 유연한 그래프 모델을 사용하면 복잡하게 상호 연결된 데이터를 직관적이고 효율적으로 표현할 수 있습니다.
Neo4j는 관계형 데이터베이스처럼 행과 테이블로 데이터를 구성하는 대신 정보가 노드 (항목)와 관계 (항목 간 연결)로 표현되는 그래프 모델을 사용합니다. 이 모델은 사람, 장소, 제품 또는 Google의 경우 영화, 배우, 장르와 같이 본질적으로 연결된 데이터를 사용하는 데 매우 직관적입니다.
예를 들어 영화 데이터 세트에서
- 노드는
Movie,Actor또는Director를 나타낼 수 있습니다. - 관계는
ACTED_IN또는DIRECTED일 수 있습니다.
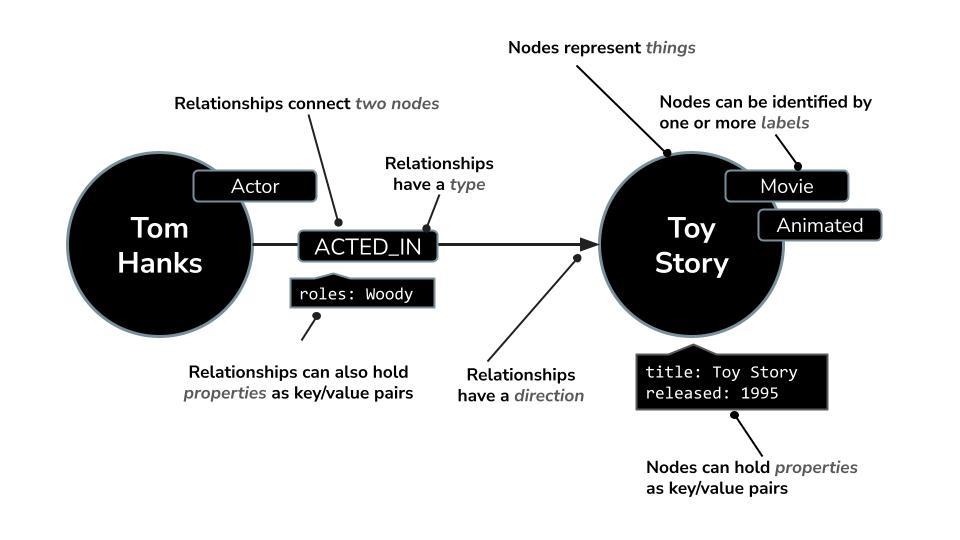
이 구조를 사용하면 다음과 같은 질문을 쉽게 할 수 있습니다.
- 이 배우가 출연한 영화는 뭐야?
- 크리스토퍼 놀런과 함께 작업한 사람은 누구인가요?
- 공통된 배우나 장르를 기반으로 한 유사한 영화는 무엇인가요?
GraphRAG란 무엇인가요?
검색 증강 생성 (RAG)은 외부 소스에서 관련 정보를 검색하여 LLM 응답을 개선합니다. 기존 RAG는 일반적으로 다음과 같습니다.
- 문서를 벡터로 삽입합니다.
- 유사한 벡터를 검색합니다.
- 검색된 문서를 LLM에 전달
GraphRAG는 지식 그래프를 사용하여 이를 확장합니다.
- 항목 및 관계를 삽입합니다.
- 그래프 연결을 순회합니다.
- 멀티 홉 컨텍스트 정보를 가져옵니다.
- 구조화되고 설명 가능한 결과 제공
AI 에이전트에 그래프가 필요한 이유
'YouTube의 경쟁업체는 어디이며, YouTube와 경쟁업체 모두에 투자한 투자자는 누구인가?'라는 질문을 생각해 보세요.
기존 RAG 접근 방식에서 발생하는 일:
- YouTube 경쟁업체에 관한 문서를 검색합니다.
- 투자자 정보를 별도로 검색합니다.
- 이 두 정보를 연결하는 데 어려움을 겪음
- 암시적 관계가 누락될 수 있음
GraphRAG 접근 방식에서 발생하는 일:
MATCH (org:Organization {name: "OpenAI"})-[:HAS_COMPETITOR]-(competitor:Organization)
MATCH (org)-[:HAS_INVESTOR]->(investor:Person)
MATCH (competitor)-[:HAS_INVESTOR]->(investor)
RETURN org, competitor, investor
그래프는 관계를 자연스럽게 나타내므로 멀티 홉 쿼리가 간단하고 효율적입니다.
ADK의 멀티 에이전트 시스템
에이전트 개발 키트 (ADK)는 프로덕션 등급 AI 에이전트를 빌드하고 배포하기 위한 Google의 오픈소스 프레임워크입니다. 멀티 에이전트 오케스트레이션, 도구 통합, 워크플로 관리를 위한 직관적인 기본 요소를 제공하므로 전문 에이전트를 정교한 시스템으로 쉽게 구성할 수 있습니다. ADK는 Gemini와 원활하게 작동하며 Cloud Run, Kubernetes 또는 모든 인프라에 대한 배포를 지원합니다.
에이전트 개발 키트 (ADK)는 멀티 에이전트 시스템을 빌드하기 위한 기본 요소를 제공합니다.
- 상담사 계층 구조:
# Root agent coordinates specialized agents
root_agent = LlmAgent(
name="RootAgent",
sub_agents=[
graph_db_agent,
investor_agent,
investment_agent
]
)
- 전문 에이전트: 각 에이전트에는
- 특정 도구: 호출할 수 있는 함수
- 명확한 요청 사항: 역할 및 기능
- 도메인 전문성: 해당 분야에 대한 지식
- 오케스트레이션 패턴:
- 순차: 에이전트를 순서대로 실행
- 병렬: 여러 에이전트를 동시에 실행
- 조건부: 질문 유형에 따라 라우팅
데이터베이스용 MCP 도구 상자
모델 컨텍스트 프로토콜 (MCP)은 AI 시스템을 외부 데이터 소스 및 도구에 연결하기 위한 개방형 표준입니다. 데이터베이스용 MCP 도구 상자는 선언적 데이터베이스 쿼리 관리를 지원하는 Google의 구현으로, 사전 검증된 전문가 작성 쿼리를 재사용 가능한 도구로 정의할 수 있습니다. MCP Toolbox는 LLM이 잠재적으로 안전하지 않은 쿼리를 생성하도록 허용하는 대신 매개변수 검증을 통해 사전 승인된 쿼리를 제공하여 AI 에이전트의 유연성을 유지하면서 보안, 성능, 안정성을 보장합니다.
기존 접근 방식:
# LLM generates query (may be incorrect/unsafe)
query = llm.generate("SELECT * FROM users WHERE...")
db.execute(query) # Risk of errors/SQL injection
MCP 접근 방식:
# Pre-validated query definition
- name: get_industries
description: Fetch all industries from database
query: |
MATCH (i:Industry)
RETURN i.name, i.id
장점:
- 전문가의 사전 검증
- 삽입 공격으로부터 안전함
- 성능에 최적화됨
- 중앙에서 관리
- 여러 에이전트에서 재사용 가능
정리
ADK + MCP의 GraphRAG + 멀티 에이전트 프레임워크를 결합하면 강력한 시스템이 만들어집니다.
- 루트 에이전트가 사용자 질문을 수신합니다.
- 질문 유형에 따라 전문 상담사로 라우팅
- 에이전트가 MCP 도구를 사용하여 데이터를 안전하게 가져옴
- 그래프 구조는 풍부한 컨텍스트를 제공합니다.
- LLM이 그라운딩되고 설명 가능한 대답을 생성합니다.
이제 아키텍처를 이해했으니 빌드를 시작해 보겠습니다.
3. Google Cloud 프로젝트 설정
프로젝트 만들기
- Google Cloud 콘솔의 프로젝트 선택기 페이지에서 Google Cloud 프로젝트를 선택하거나 만듭니다.
- Cloud 프로젝트에 결제가 사용 설정되어 있는지 확인합니다. 프로젝트에 결제가 사용 설정되어 있는지 확인하는 방법을 알아보세요 .
- Google Cloud에서 실행되는 명령줄 환경인 Cloud Shell을 사용합니다. Google Cloud 콘솔 상단에서 Cloud Shell 활성화를 클릭합니다. Cloud Shell에서 해당 버튼을 클릭하여 Cloud Shell 터미널 (클라우드 명령어 실행)과 편집기 (프로젝트 빌드) 간에 전환할 수 있습니다.

- Cloud Shell에 연결되면 다음 명령어를 사용하여 이미 인증되었는지, 프로젝트가 프로젝트 ID로 설정되었는지 확인합니다.
gcloud auth list
- Cloud Shell에서 다음 명령어를 실행하여 gcloud 명령어가 프로젝트를 알고 있는지 확인합니다.
gcloud config list project
- 프로젝트가 설정되지 않은 경우 다음 명령어를 사용하여 설정합니다.
gcloud config set project <YOUR_PROJECT_ID>
gcloud 명령어 및 사용법은 문서를 참조하세요.
좋습니다. 이제 다음 단계인 데이터 세트 이해로 넘어갈 준비가 되었습니다.
4. 회사 데이터 세트 이해하기
이 Codelab에서는 Diffbot의 지식 그래프에서 투자 및 회사 데이터가 미리 채워진 읽기 전용 Neo4j 데이터베이스를 사용합니다.
데이터 세트에는 다음이 포함됩니다.
- 다음 항목을 나타내는 237,358개의 노드
- 조직 (회사)
- 사람 (임원, 직원)
- 기사 (뉴스 및 멘션)
- 산업
- 기술
- 투자자
- 다음과 같은 관계
HAS_INVESTOR- 투자 연결HAS_COMPETITOR- 경쟁 관계MENTIONS- 문서 참조HAS_CEO- 고용 관계HAS_CATEGORY- 업종 분류
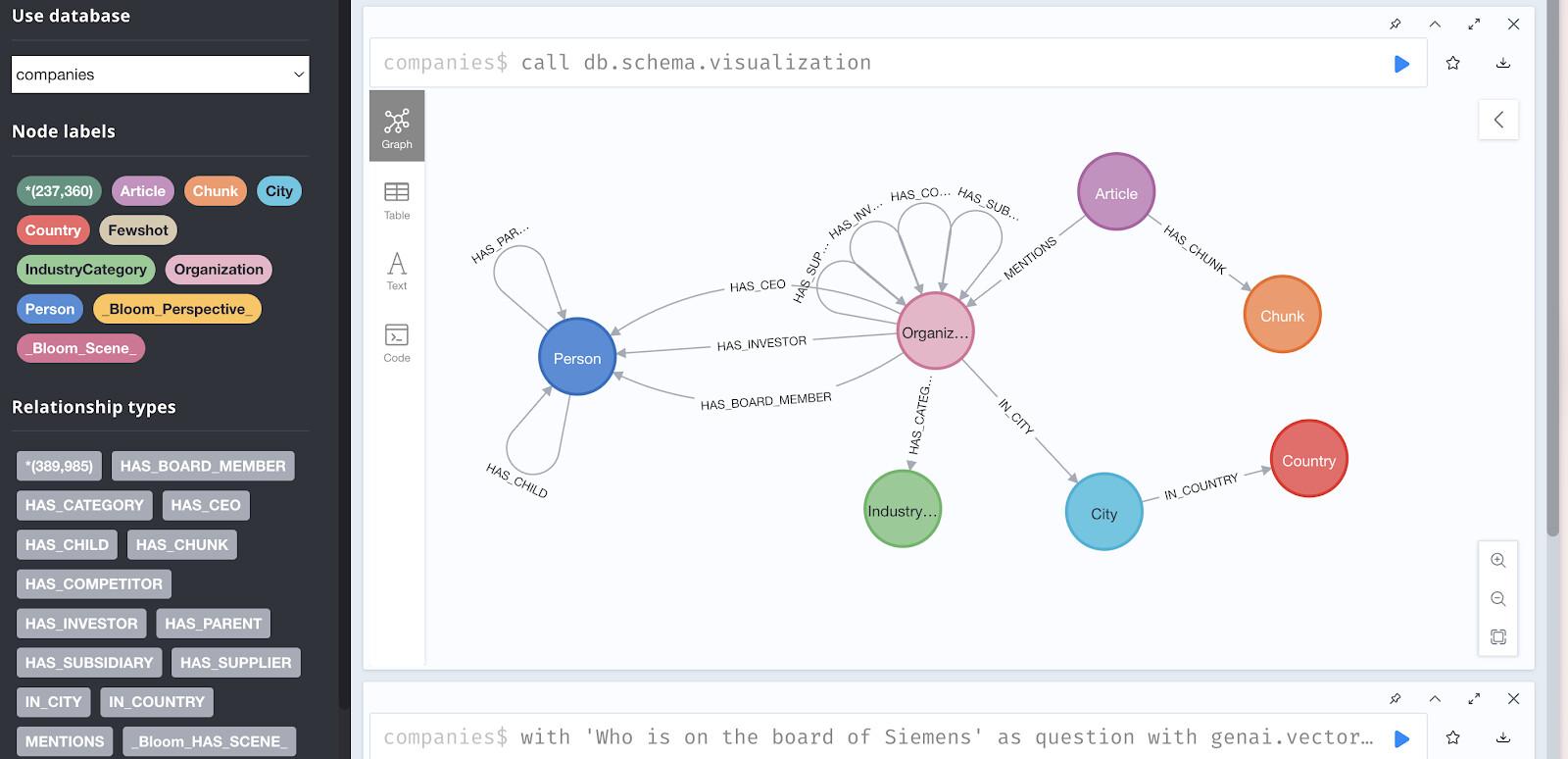
데모 데이터베이스 액세스
이 Codelab에서는 호스팅된 데모 인스턴스를 사용합니다. 다음 사용자 인증 정보를 메모에 추가합니다.
URI: neo4j+s://demo.neo4jlabs.com
Username: companies
Password: companies
Database: companies
브라우저 액세스:
https://demo.neo4jlabs.com:7473에서 데이터를 시각적으로 탐색할 수 있습니다.
동일한 사용자 인증 정보로 로그인하고 다음을 실행해 보세요.
// Sample query to explore the graph
MATCH (c:Organization)-[:HAS_COMPETITOR]-(competitor:Organization)
RETURN c.name, competitor.name
LIMIT 10
그래프 구조 시각화
Neo4j 브라우저에서 다음 쿼리를 실행하여 관계 패턴을 확인하세요.
// Find investors and their portfolio companies
MATCH (company:Organization)-[:HAS_INVESTOR]->(investor:Person)
WITH investor, collect(company.name) as portfolio
RETURN investor.name, size(portfolio) as num_investments, portfolio
ORDER BY num_investments DESC
LIMIT 5
이 쿼리는 가장 활발한 투자자 상위 5명과 그들의 포트폴리오를 반환합니다.
GraphRAG에 이 데이터베이스를 사용하는 이유
이 데이터 세트는 다음과 같은 이유로 GraphRAG를 시연하는 데 적합합니다.
- 리치 관계: 항목 간의 복잡한 연결
- 실제 데이터: 실제 회사, 사람, 뉴스 기사
- 멀티 홉 쿼리: 여러 관계 유형을 탐색해야 합니다.
- 시간 데이터: 시간 기반 분석을 위한 타임스탬프가 있는 문서
- 감정 분석: 기사의 사전 계산된 감정 점수
데이터 구조를 이해했으니 이제 개발 환경을 설정해 보겠습니다.
5. 저장소 클론 및 환경 구성
저장소 클론
Cloud Shell 터미널에서 다음을 실행합니다.
# Clone the repository
git clone https://github.com/sidagarwal04/neo4j-adk-multiagents.git
# Navigate into the directory
cd neo4j-adk-multiagents
저장소 구조 살펴보기
잠시 시간을 내어 프로젝트 레이아웃을 이해하세요.
neo4j-adk-multiagents/
├── investment_agent/ # Main agent code
│ ├── agent.py # Agent definitions
│ ├── tools.py # Custom tool functions
│ └── .adk/ # ADK configuration
│ └── tools.yaml # MCP tool definitions
├── main.py # Application entry point
├── setup_tools_yaml.py # Configuration generator
├── requirements.txt # Python dependencies
├── example.env # Environment template
└── README.md # Project documentation
가상 환경 설정
uv를 사용하여 Python 가상 환경을 만들고 활성화합니다.
# Install uv if not already installed
pip install uv
# Create virtual environment
uv venv
# Activate the environment
source .venv/bin/activate # On macOS/Linux
# or
.venv\Scripts\activate # On Windows
터미널 프롬프트 앞에 (.venv)가 표시됩니다.
종속 항목 설치
필수 패키지를 모두 설치합니다.
uv pip install -r requirements.txt
주요 종속 항목은 다음과 같습니다.
txtgoogle-adk>=1.21.0 # Agent Development Kit
neo4j>=6.0.3 # Neo4j Python driver
python-dotenv>=1.0.0 # Environment variables
google-cloud-aiplatform>=1.30.0 # Vertex AI
환경 변수 구성
.env**파일을** **만듭니다.**
cp example.env .env
- **
.env** **파일을 수정합니다.**
Cloud Shell을 사용하는 경우 툴바에서 편집기 열기를 클릭한 다음 .env로 이동하여 다음을 업데이트합니다.
숨겨진 .env 파일을 표시하려면 다음 단계를 따르세요.
Google Cloud Shell 편집기에서 View > Toggle Hidden files를 클릭합니다.
# Neo4j Configuration (Demo Database)
NEO4J_URI=neo4j+s://demo.neo4jlabs.com
NEO4J_USERNAME=companies
NEO4J_PASSWORD=companies
NEO4J_DATABASE=companies
# Google AI Configuration
# Choose ONE of the following options:
# Option 1: Google AI API (Recommended)
GOOGLE_GENAI_USE_VERTEXAI=0
GOOGLE_API_KEY=your_api_key_here # Get from https://aistudio.google.com/app/apikey
# Option 2: Vertex AI (If using GCP)
# GOOGLE_GENAI_USE_VERTEXAI=1
# GOOGLE_CLOUD_PROJECT=your-project-id
# GOOGLE_CLOUD_LOCATION=us-central1
# ADK Configuration
GOOGLE_ADK_MODEL=gemini-3.1-flash-lite-preview # or gemini-3-flash-preview
# MCP Toolbox Configuration
MCP_TOOLBOX_URL=https://toolbox-990868019953.us-central1.run.app/mcp/sse
- MCP 도구 상자 구성 생성:
설정 스크립트를 실행하여 환경 변수에서 tools.yaml 파일을 만듭니다.
python setup_tools_yaml.py
이렇게 하면 MCP 도구에 맞게 Neo4j 사용자 인증 정보가 올바르게 구성된 investment_agent/.adk/tools.yaml가 생성됩니다.
구성 확인
모든 항목이 올바르게 설정되었는지 확인합니다.
# Verify .env file exists
ls -la .env
# Verify tools.yaml was generated
ls -la investment_agent/.adk/tools.yaml
# Test Python environment
python -c "import google.adk; print('ADK installed successfully')"
# Test Neo4j connection
python -c "from neo4j import GraphDatabase; print('Neo4j driver installed')"
이제 개발 환경이 완전히 구성되었습니다. 다음으로 멀티 에이전트 아키텍처를 살펴보겠습니다.
6. 멀티 에이전트 아키텍처 이해
4개의 에이전트 시스템
Google의 투자 조사 시스템은 회사, 투자자, 시장 인텔리전스에 관한 복잡한 질문에 답변하기 위해 함께 작동하는 4개의 전문 에이전트가 있는 계층적 멀티 에이전트 아키텍처를 사용합니다.
┌──────────────┐
│ Root Agent │ ◄── User Query
└──────┬───────┘
│
┌────────────────┼────────────────┐
│ │ │
┌─────▼─────┐ ┌────▼─────┐ ┌────▼──────────┐
│ Graph DB │ │ Investor │ │ Investment │
│ Agent │ │ Research │ │ Research │
└───────────┘ │ Agent │ │ Agent │
└──────────┘ └───────────────┘
- 루트 에이전트 (오케스트레이터):
루트 에이전트는 전체 시스템의 지능형 코디네이터 역할을 합니다. 사용자 쿼리를 수신하고, 인텐트를 분석하고, 요청을 가장 적절한 전문 에이전트로 라우팅합니다. 각 작업에 가장 적합한 팀 구성원을 파악하는 프로젝트 관리자라고 생각하면 됩니다. 또한 요청 시 응답 집계, 결과를 표 또는 차트로 포맷팅, 여러 쿼리에 걸쳐 대화 컨텍스트 유지 등의 작업을 처리합니다. 루트 에이전트는 항상 일반 데이터베이스 에이전트보다 전문 에이전트를 선호하므로 쿼리가 사용 가능한 가장 전문적인 구성요소에 의해 처리됩니다.
- 그래프 데이터베이스 에이전트:
그래프 데이터베이스 에이전트는 Neo4j의 강력한 그래프 기능에 직접 연결됩니다. 데이터베이스 스키마를 이해하고, 자연어에서 Cypher 쿼리를 생성하고, 복잡한 그래프 순회를 실행합니다. 이 에이전트는 지식 그래프 전반의 구조적 질문, 집계, 멀티홉 추론을 전문으로 합니다. 사전 정의된 도구로 처리할 수 없는 맞춤 로직이 필요한 쿼리의 경우 대체 전문가이므로 시스템 설계에서 예상하지 못한 탐색 분석 및 복잡한 분석 쿼리에 필수적입니다.
- 투자자 조사 에이전트:
투자 조사 에이전트는 투자 관계 및 포트폴리오 분석에만 집중합니다. 정확한 이름 일치를 사용하여 특정 회사에 투자한 사람을 파악하고, 모든 투자를 보여주는 완전한 투자자 포트폴리오를 검색하고, 업계 전반의 투자 패턴을 분석할 수 있습니다. 이 전문화 덕분에 'ByteDance에 투자한 사람은 누구인가?' 또는 'Sequoia Capital은 어디에 투자했는가?'와 같은 질문에 매우 효율적으로 답변할 수 있습니다. 에이전트는 투자자 관련 관계를 위해 Neo4j 데이터베이스를 직접 쿼리하는 맞춤 Python 함수를 사용합니다.
- 투자 조사 에이전트:
투자 조사 에이전트는 모델 컨텍스트 프로토콜 (MCP) Toolbox를 활용하여 사전 검증된 전문가 작성 질문에 액세스합니다. 사용 가능한 모든 업종을 가져오고, 특정 업종 내의 회사를 검색하고, 감정 분석이 포함된 기사를 찾고, 뉴스에서 조직 언급을 발견하고, 회사에서 근무하는 사람에 관한 정보를 가져올 수 있습니다. 쿼리를 동적으로 생성하는 그래프 데이터베이스 에이전트와 달리 이 에이전트는 중앙에서 관리되고 검증된 안전하고 최적화된 사전 정의된 쿼리를 사용합니다. 따라서 일반적인 연구 워크플로에 안전하고 성능이 좋습니다.
7. 멀티 에이전트 시스템 실행 및 테스트
애플리케이션 실행
이제 아키텍처를 이해했으므로 전체 시스템을 실행하고 상호작용해 보겠습니다.
ADK 웹 인터페이스를 시작합니다.
# Make sure you're in the project directory with activated virtual environment
cd ~/neo4j-adk-multiagents
source .venv/bin/activate # If not already activated
# Launch the application
uv run adk web
다음과 비슷한 출력이 표시됩니다.
INFO: Started server process [2542]
INFO: Waiting for application startup.
+----------------------------------------------------------------+
| ADK Web Server started |
| |
| For local testing, access at http://127.0.0.1:8000. |
+----------------------------------------------------------------+
INFO: Application startup complete.
INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
테스트 쿼리 및 예상 동작
점점 더 복잡한 질문을 통해 시스템의 기능을 살펴보겠습니다.
기본 질문 (단일 상담사)
질문 1: 업종 검색
What industries are available in the database?
예상 동작:
- 루트 에이전트가 투자 조사 에이전트로 라우팅
- MCP 도구 사용:
get_industries() - 모든 업계의 형식이 지정된 목록을 반환합니다.
관찰할 내용:
ADK UI에서 실행 세부정보를 펼쳐 다음을 확인합니다.
- 상담사 선택 결정
- 도구 호출:
get_industries() - Neo4j의 원시 결과
- 형식이 지정된 대답
질문 2: 투자자 찾기
Who invested in ByteDance?
예상 동작:
- Root Agent가 투자자 관련 질문으로 식별
- 투자자 조사 에이전트로 라우팅
- 도구 사용:
find_investor_by_name("ByteDance") - 유형 (개인/조직)이 있는 투자자를 반환합니다.
예상 응답:
I found 2 investors in ByteDance:
1. Rong Yue (Person)
2. Wendi Murdoch (Person)
Would you like to know more about their investment portfolios?
질문 3: 업종별 회사**
I found 2 investors in ByteDance:
1. Rong Yue (Person)
2. Wendi Murdoch (Person)
Would you like to know more about their investment portfolios?
"Show me companies in the Artificial Intelligence industry"
예상 동작:
- 루트 에이전트가 투자 조사 에이전트로 라우팅
- MCP 도구 사용:
get_companies_in_industry("Artificial Intelligence") - ID와 설립일이 포함된 AI 회사 목록을 반환합니다.
관찰할 내용:
- 에이전트가 정확한 업계 이름 일치를 사용하는 방식에 주목하세요.
- 출력이 너무 많아지지 않도록 결과가 제한됩니다.
- 데이터가 가독성을 위해 명확하게 서식이 지정됨
중간 질문 (하나의 상담사 내에서 여러 단계)
질문 4: 감정 분석
Find articles with positive sentiment from January 2023
예상 동작:
- 투자 조사 에이전트로 연결되는 경로
- MCP 도구 사용:
get_articles_with_sentiment(0.7, 2023, 1) - 제목, 감정 점수, 게시일이 포함된 기사를 반환합니다.
디버깅 팁:
도구 호출 매개변수를 확인합니다.
min_sentiment: 0.7 (상담사가 '긍정'을 0.7 이상으로 해석함)year: 2023month: 1
질문 5: 복잡한 데이터베이스 쿼리
How many companies are in the database?
예상 동작:
- 루트 에이전트가 그래프 데이터베이스 에이전트로 라우팅
- 에이전트가 먼저
get_neo4j_schema()를 호출하여 구조를 파악합니다. - 생성된 암호:
MATCH (c:Company) RETURN count(c) - 쿼리를 실행하고 개수를 반환합니다.
예상 응답:
There are 8,064 companies in the database.
고급 쿼리 (다중 에이전트 조정)
질문 6: 포트폴리오 분석
Who invested in ByteDance and what else have they invested in?
예상 동작:
다음은 상담사의 조율이 필요한 두 부분으로 구성된 질문입니다.
- 1단계: Root Agent → Investor Research Agent
find_investor_by_name("ByteDance")호출- 투자자 목록 가져오기: [Rong Yue, Wendi Murdoch]
- 2단계: 각 투자자 → 투자자 조사 상담사
find_investor_by_id(investor_id)호출- 전체 포트폴리오를 가져옵니다.
- 3단계: 루트 에이전트가 집계하고 형식을 지정함
예상 응답:
I found 2 investors in ByteDance. Here are their portfolios:
1. Rong Yue (Person)
- ByteDance
- Inspur
2. Wendi Murdoch (Person)
- ByteDance
- (No other investments in database)
관찰할 내용:
- 여러 도구 호출이 순서대로 실행됨
- 단계 간 컨텍스트 유지
- 지능적으로 집계된 결과
질문 7: 다중 도메인 연구
What are 5 AI companies mentioned in positive articles, and who are their CEOs?
예상 동작:
이 복잡한 질문에는 여러 상담사와 도구가 필요합니다.
- 1단계: 투자 조사 에이전트
get_companies_in_industry("Artificial Intelligence")- AI 회사 목록을 반환합니다.
- 2단계: 투자 조사 상담사
get_articles_with_sentiment(0.8)- 긍정적인 기사를 반환합니다.
- 3단계: 루트 에이전트 필터
- 긍정적인 기사에 등장하는 AI 회사를 식별합니다.
- 상위 5개 선택
- 4단계: 투자 조사 에이전트
get_people_in_organizations([company_names], "CEO")- CEO 정보를 반환합니다.
- 5단계: Root Agent가 표로 서식을 지정함
예상 응답:
Here are 5 AI companies with positive news and their CEOs:
| Company | Industry | CEO | Avg Sentiment |
|---------|----------|-----|---------------|
| OpenAI | Artificial Intelligence | Sam Altman | 0.92 |
| Anthropic | Artificial Intelligence | Dario Amodei | 0.89 |
| ... | ... | ... | ... |
관찰할 내용:
- 여러 에이전트의 여러 도구 호출
- 데이터 필터링 및 결합 로직
- 전문적인 표 서식 지정
질문 8: 경쟁사 분석
Who are YouTube's main competitors?
예상 동작:
- 루트 에이전트가 그래프 데이터베이스 에이전트 (관계 쿼리)로 라우팅됨
- 에이전트가 GraphRAG로 개선된 사이퍼를 생성합니다.
MATCH (c:Company {name: "YouTube"})-[:COMPETES_WITH]->(competitor)
RETURN competitor.name as competitor_name
- 경쟁업체 목록을 반환합니다.
예상 응답:
YouTube's main competitors are:
- TikTok (ByteDance)
- Dailymotion
- Twitter
- BuzzFeed
- Mixer
- OpenAI (for video content)
컨텍스트 인식 후속 질문
질문 9: 후속 질문 (질문 8 이후)
Which investors funded both YouTube and its competitors?
예상 동작:
- 루트 에이전트가 이전 컨텍스트를 기억합니다 (YouTube 및 경쟁업체).
- 투자자 조사 에이전트로 라우팅
- YouTube 및 각 경쟁업체의 투자자를 찾습니다.
- 여러 회사에 등장하는 투자자를 식별합니다.
예상 응답:
Based on our previous analysis of YouTube's competitors, I found these
investors who funded multiple companies in this competitive landscape:
Sequoia Capital invested in:
- YouTube
- TikTok (ByteDance)
- Twitter
Accel Partners invested in:
- YouTube
- BuzzFeed
This suggests these investors have strategic positions across the video content platform ecosystem.
질문 10: 연구 요약
Summarize our research findings so far
예상 동작:
- 루트 에이전트가 대화 기록을 검토합니다.
- 이전 질문의 주요 내용을 종합합니다.
- 일관된 요약 제공
예상 응답:
Here's a summary of our investment research session:
1. Industry Overview: We explored the Artificial Intelligence industry
with 150+ companies in the database.
2. ByteDance Analysis:
- Investors: Rong Yue, Wendi Murdoch
- Rong Yue also invested in Inspur
3. Market Sentiment: We analyzed articles from January 2023, finding
strong positive sentiment (avg 0.85) for tech companies.
4. Competitive Landscape: YouTube faces competition from TikTok,
Dailymotion, and others, with some investors (Sequoia, Accel) holding
positions across competing platforms.
5. Key Players: Identified CEOs of major AI companies with positive media coverage.
디버그 뷰에서 에이전트 상호작용 이해하기
ADK 웹 인터페이스는 자세한 실행 가시성을 제공합니다. 다음 사항을 확인하세요.
- 이벤트 타임라인
시간순 흐름을 보여줍니다.
[USER] Query received
[ROOT_AGENT] Analyzing query intent
[ROOT_AGENT] Routing to investment_research_agent
[INVESTMENT_RESEARCH_AGENT] Tool call: get_companies_in_industry
[TOOL] Executing with params: {"industry_name": "Artificial Intelligence"}
[TOOL] Returned 47 results
[INVESTMENT_RESEARCH_AGENT] Formatting response
[ROOT_AGENT] Presenting to user
- 도구 호출 세부정보
도구 호출을 클릭하면 다음이 표시됩니다.
- 함수 이름
- 입력 매개변수
- 반환 값
- 실행 시간
- 오류가 있음
- 상담사 의사 결정
LLM의 추론을 확인합니다.
- 특정 에이전트를 선택한 이유
- 질문을 해석한 방식
- 고려한 도구
- 결과가 특정 방식으로 형식이 지정된 이유
일반적인 관찰 및 통계
- 쿼리 라우팅 패턴:
- '투자자', '투자'와 같은 키워드 → 투자자 조사 에이전트
- '업계', '회사', '기사'와 같은 키워드 → 투자 조사 에이전트
- 집계, 개수, 복잡한 로직 → 그래프 데이터베이스 에이전트
- 성능 참고사항:
- MCP 도구는 일반적으로 더 빠릅니다 (사전 최적화된 쿼리).
- 복잡한 사이퍼 생성에 시간이 더 오래 걸림 (LLM 사고 시간)
- 도구를 여러 번 호출하면 지연 시간이 추가되지만 더 풍부한 결과를 제공합니다.
- 오류 처리:
- 쿼리가 실패하는 경우:
- 상담사가 문제 설명
- 수정사항을 제안합니다 (예: '회사 이름을 찾을 수 없습니다.철자를 확인하세요').
- 대체 방법을 시도할 수 있음
효과적인 테스트를 위한 팁
- 간단하게 시작하기: 복잡한 질문 전에 각 에이전트의 핵심 기능을 테스트합니다.
- 후속 질문 사용: 후속 질문으로 컨텍스트 유지 테스트
- 관찰 라우팅: 각 질문을 처리하는 상담사를 확인하여 로직을 파악합니다.
- 도구 호출 확인: 자연어에서 파라미터가 올바르게 추출되었는지 확인합니다.
- 특이 사례 테스트: 모호한 질문, 맞춤법 오류, 특이한 요청을 시도해 보세요.
이제 완전히 작동하는 멀티 에이전트 GraphRAG 시스템이 완성되었습니다. 직접 질문을 실험하여 기능을 살펴보세요.
8. 삭제
이 게시물에서 사용한 리소스의 비용이 Google Cloud 계정에 청구되지 않도록 하려면 다음 단계를 따르세요.
- Google Cloud 콘솔에서 리소스 관리 페이지로 이동합니다.
- 프로젝트 목록에서 삭제할 프로젝트를 선택하고 삭제를 클릭합니다.
- 대화상자에서 프로젝트 ID를 입력하고 종료를 클릭하여 프로젝트를 삭제합니다.
9. 축하합니다
🎉 수고하셨습니다. Google의 에이전트 개발 키트, Neo4j, MCP 도구 상자를 사용하여 프로덕션 품질의 멀티 에이전트 GraphRAG 시스템을 성공적으로 빌드했습니다.
ADK의 지능형 오케스트레이션 기능과 Neo4j의 관계가 풍부한 데이터 모델, 사전 검증된 MCP 쿼리의 안전성을 결합하여 단순한 데이터베이스 쿼리를 넘어 맥락을 이해하고, 복잡한 관계 전반의 이유를 파악하며, 전문 에이전트를 조정하여 포괄적이고 정확한 유용한 정보를 제공하는 정교한 시스템을 만들었습니다.
이 Codelab에서는 다음 작업을 완료했습니다.
✅ 계층적 조정을 사용하여 Google의 에이전트 개발 키트 (ADK)를 사용하여 멀티 에이전트 시스템을 빌드했습니다.
✅ 통합 Neo4j 그래프 데이터베이스를 사용하여 관계 인식 쿼리 및 멀티홉 추론 활용
✅ 재사용 가능한 도구로 안전하고 사전 검증된 데이터베이스 쿼리를 위해 MCP 도구 상자 구현
✅ 투자자 조사, 투자 분석, 그래프 데이터베이스 작업을 위한 전문 에이전트 생성
✅ 지능형 라우팅 설계: 쿼리를 가장 적합한 전문가 에이전트에게 자동으로 위임
✅ 원활한 Python 통합을 위해 적절한 Neo4j 유형 직렬화를 사용하여 복잡한 데이터 유형을 처리했습니다.
✅ 에이전트 설계, 오류 처리, 시스템 디버깅을 위한 프로덕션 권장사항 적용
다음 단계
이 다중 에이전트 GraphRAG 아키텍처는 투자 조사에만 국한되지 않으며 다음과 같이 확장할 수 있습니다.
- 금융 서비스: 포트폴리오 최적화, 위험 평가, 사기 감지
- 의료: 환자 관리 조정, 의약품 상호작용 분석, 임상 연구
- 전자상거래: 맞춤 추천, 공급망 최적화, 고객 인사이트
- 법률 및 규정 준수: 계약 분석, 규제 모니터링, 판례 조사
- 학술 연구: 문헌 검토, 공동작업 검색, 인용 분석
- 엔터프라이즈 인텔리전스: 경쟁 분석, 시장 조사, 조직 지식 그래프
복잡하게 상호 연결된 데이터 + 도메인 전문성 + 자연어 인터페이스가 있는 모든 곳에서 ADK 멀티 에이전트 시스템 + Neo4j 지식 그래프 + MCP 검증 쿼리의 조합은 차세대 지능형 엔터프라이즈 애플리케이션을 지원할 수 있습니다.
Google의 에이전트 개발 키트와 Gemini 모델이 계속 발전함에 따라 더욱 정교한 추론 패턴, 실시간 데이터 통합, 멀티모달 기능을 통합하여 진정으로 지능적이고 상황 인식 시스템을 구축할 수 있습니다.
계속 탐색하고 계속 빌드하여 지능형 에이전트 애플리케이션을 한 단계 업그레이드하세요.
Neo4j GraphAcademy에서 실습 지식 그래프 튜토리얼을 더 둘러보고 ADK 샘플 저장소에서 추가 에이전트 패턴을 알아보세요.
🚀 다음 지능형 에이전트 시스템을 빌드할 준비가 되셨나요?