
1. Przegląd
W tym ćwiczeniu utworzysz zaawansowany system badań inwestycyjnych oparty na wielu agentach, który łączy w sobie możliwości pakietu Agent Development Kit (ADK) od Google, bazy danych grafów Neo4j i zestawu narzędzi Model Context Protocol (MCP). Ten praktyczny samouczek pokazuje, jak tworzyć inteligentne agenty, które rozumieją kontekst danych dzięki relacjom w grafie i udzielają bardzo dokładnych odpowiedzi na zapytania.
Dlaczego warto używać GraphRAG i systemów wieloagentowych?
GraphRAG (Graph-based Retrieval-Augmented Generation) ulepsza tradycyjne podejścia RAG, wykorzystując bogatą strukturę relacji grafów wiedzy. Zamiast tylko wyszukiwać podobne dokumenty, agenci GraphRAG mogą:
- przechodzić złożone relacje między encjami,
- Poznawanie kontekstu za pomocą struktury wykresu
- wyświetlać wyniki, które można wyjaśnić na podstawie połączonych danych.
- Przeprowadzanie rozumowania wieloetapowego w grafie wiedzy
Systemy z wieloma agentami umożliwiają:
- Dzielenie złożonych problemów na wyspecjalizowane podzadania
- Tworzenie modułowych aplikacji AI, które można łatwo utrzymywać
- Włączanie przetwarzania równoległego i efektywnego wykorzystania zasobów
- Tworzenie hierarchicznych wzorców rozumowania za pomocą aranżacji
Co utworzysz
Utworzysz kompletny system badań inwestycyjnych, który będzie obejmować:
- Agent bazy danych wykresu: wykonuje zapytania Cypher i rozumie schemat Neo4j.
- Investor Research Agent: wykrywa relacje inwestorskie i portfele inwestycyjne.
- Agent ds. badań inwestycyjnych: uzyskuje dostęp do kompleksowych grafów wiedzy za pomocą narzędzi MCP.
- Agent główny: inteligentnie zarządza wszystkimi agentami podrzędnymi.
System odpowie na złożone pytania, takie jak:
- „Kim są główni konkurenci YouTube?”
- „Jakie firmy są wymieniane w pozytywnym kontekście w styczniu 2023 r.?”
- „Kto zainwestował w ByteDance i w jakie inne firmy zainwestował?”
Omówienie architektury
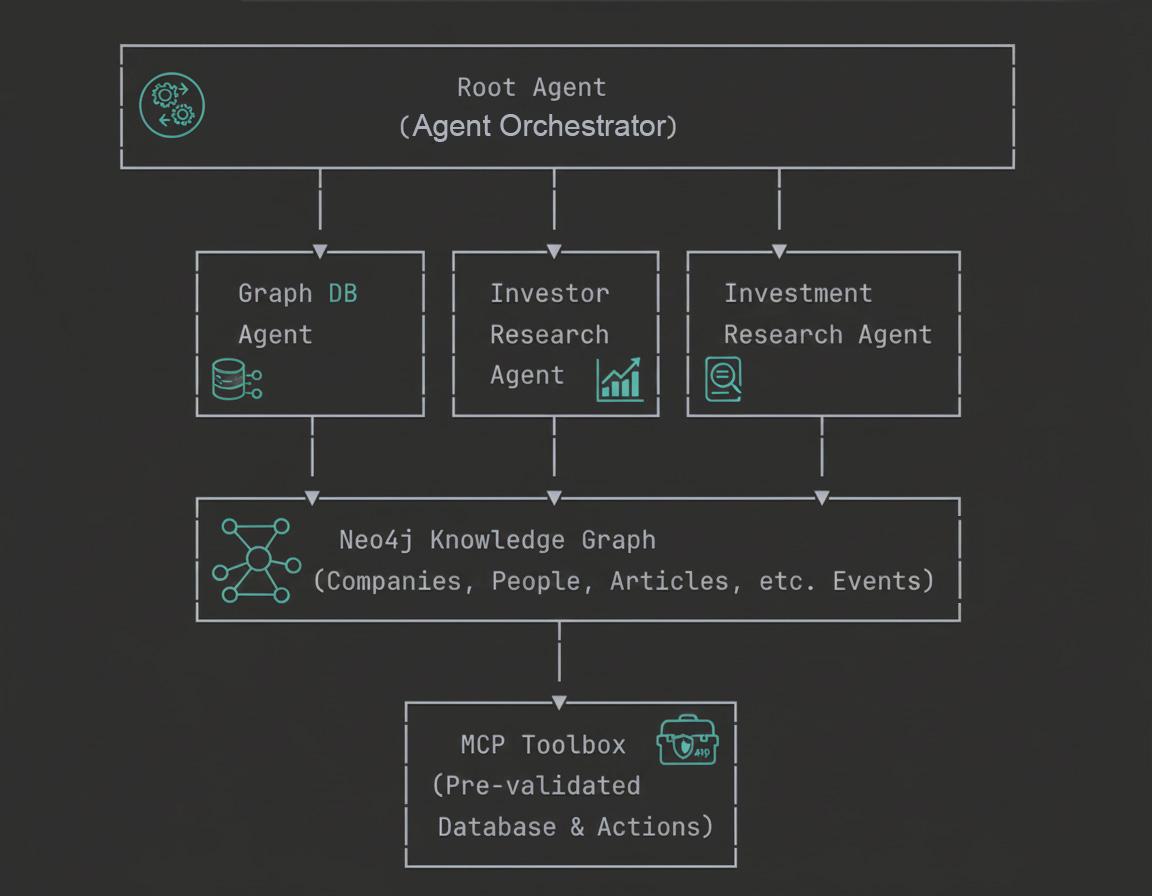
Z tego ćwiczenia dowiesz się, jak tworzyć agentów GraphRAG klasy korporacyjnej – zarówno od strony teoretycznej, jak i praktycznej.
Czego się nauczysz
- Jak tworzyć systemy wieloagentowe za pomocą pakietu Agent Development Kit (ADK) od Google
- Jak zintegrować bazę danych wykresu Neo4j z pakietem ADK na potrzeby aplikacji GraphRAG
- Jak wdrożyć zestaw narzędzi Model Context Protocol (MCP) do wstępnie zweryfikowanych zapytań do bazy danych
- Jak tworzyć niestandardowe narzędzia i funkcje dla inteligentnych agentów
- Projektowanie hierarchii agentów i wzorców orkiestracji
- Jak tworzyć instrukcje dla agenta, aby uzyskać optymalną skuteczność
- Jak skutecznie debugować interakcje między wieloma agentami
Czego potrzebujesz
- przeglądarki Chrome,
- konto Gmail,
- Projekt Google Cloud z włączonymi płatnościami
- Podstawowa znajomość poleceń terminala i języka Python (pomocna, ale nie wymagana)
To ćwiczenie, przeznaczone dla deweloperów na wszystkich poziomach zaawansowania (w tym dla początkujących), wykorzystuje w przykładowej aplikacji język Python i bazę danych Neo4j. Podstawowa znajomość języka Python i baz danych grafów może być przydatna, ale nie jest wymagana do zrozumienia koncepcji ani do śledzenia treści.
2. Informacje o GraphRAG i systemach wieloagentowych
Zanim przejdziemy do wdrożenia, poznajmy najważniejsze pojęcia, na których opiera się ten system.
Neo4j to wiodąca natywna grafowa baza danych, która przechowuje dane jako sieć węzłów (encji) i relacji (połączeń między encjami). Dzięki temu idealnie nadaje się do zastosowań, w których kluczowe jest zrozumienie połączeń, takich jak rekomendacje, wykrywanie oszustw, grafy wiedzy i inne. W przeciwieństwie do relacyjnych baz danych lub baz danych opartych na dokumentach, które opierają się na sztywnych tabelach lub strukturach hierarchicznych, elastyczny model grafu Neo4j umożliwia intuicyjne i wydajne przedstawianie złożonych, połączonych danych.
Zamiast porządkować dane w wierszach i tabelach, jak w relacyjnych bazach danych, Neo4j używa modelu grafu, w którym informacje są reprezentowane jako węzły (obiekty) i relacje (połączenia między tymi obiektami). Dzięki temu modelowi praca z danymi, które są ze sobą powiązane, jest wyjątkowo intuicyjna. Dotyczy to np. osób, miejsc, produktów, a w naszym przypadku – filmów, aktorów i gatunków.
Na przykład w zbiorze danych o filmach:
- Węzeł może reprezentować
Movie,ActorlubDirector. - Relacja może być
ACTED_INlubDIRECTED
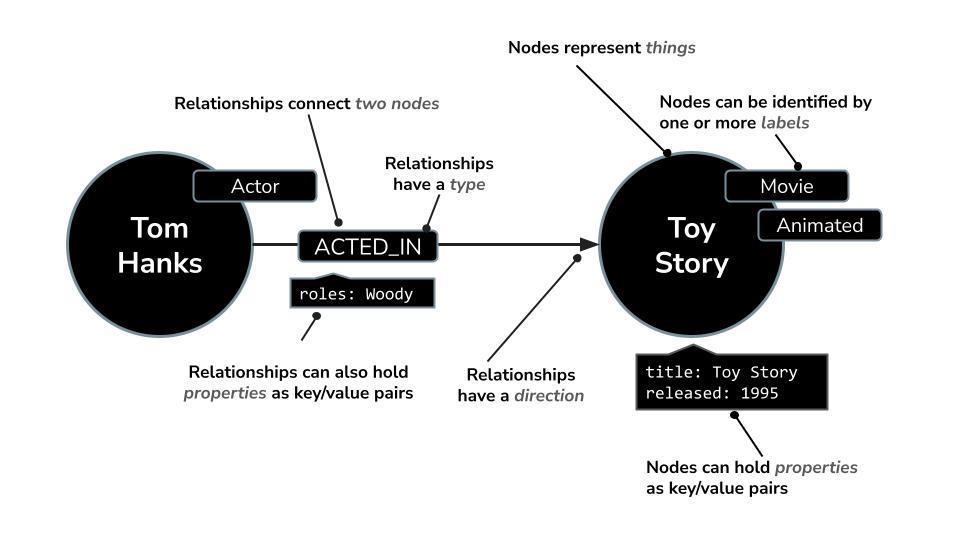
Ta struktura umożliwia łatwe zadawanie pytań takich jak:
- W jakich filmach wystąpił ten aktor?
- Z kim współpracował Christopher Nolan?
- Jakie są podobne filmy na podstawie wspólnych aktorów lub gatunków?
Co to jest GraphRAG?
Generowanie wspomagane wyszukiwaniem (RAG) ulepsza odpowiedzi LLM, pobierając odpowiednie informacje ze źródeł zewnętrznych. Tradycyjny RAG zwykle:
- osadza dokumenty w wektorach,
- Wyszukiwanie podobnych wektorów
- przekazuje pobrane dokumenty do modelu LLM,
GraphRAG rozszerza tę metodę, wykorzystując grafy wiedzy:
- Osadzanie encji i relacji
- Przechodzi połączenia na wykresie
- Pobieranie informacji kontekstowych z wielu przeskoków
- Udostępnia uporządkowane i wyjaśnialne wyniki
Dlaczego wykresy są przydatne w przypadku agentów AI?
Zastanów się nad tym pytaniem: „Kim są konkurenci YouTube i którzy inwestorzy finansowali zarówno YouTube, jak i jego konkurentów?”.
Co się dzieje w przypadku tradycyjnego podejścia RAG:
- wyszukiwanie dokumentów dotyczących konkurencji YouTube;
- Wyszukiwanie informacji o inwestorach
- trudności z powiązaniem tych dwóch informacji,
- Może pomijać relacje domyślne
Co się dzieje w przypadku podejścia GraphRAG:
MATCH (org:Organization {name: "OpenAI"})-[:HAS_COMPETITOR]-(competitor:Organization)
MATCH (org)-[:HAS_INVESTOR]->(investor:Person)
MATCH (competitor)-[:HAS_INVESTOR]->(investor)
RETURN org, competitor, investor
Graf naturalnie odzwierciedla relacje, dzięki czemu zapytania wieloetapowe są proste i wydajne.
Systemy wieloagentowe w pakiecie ADK
Pakiet Agent Development Kit (ADK) to platforma open source od Google do tworzenia i wdrażania agentów AI, których można wykorzystać w środowisku produkcyjnym. Zapewnia intuicyjne elementy do zarządzania wieloma agentami, integracji narzędzi i zarządzania przepływami pracy, co ułatwia tworzenie zaawansowanych systemów z wyspecjalizowanych agentów. ADK bezproblemowo współpracuje z Gemini i obsługuje wdrażanie w Cloud Run, Kubernetes lub dowolnej infrastrukturze.
Pakiet Agent Development Kit (ADK) udostępnia elementy do tworzenia systemów wieloagentowych:
- Hierarchia agentów:
# Root agent coordinates specialized agents
root_agent = LlmAgent(
name="RootAgent",
sub_agents=[
graph_db_agent,
investor_agent,
investment_agent
]
)
- Wyspecjalizowani pracownicy obsługi klienta: każdy pracownik obsługi klienta ma
- Konkretne narzędzia: funkcje, które może wywoływać
- Jasne instrukcje: rola i możliwości
- Wiedza specjalistyczna: znajomość danego obszaru
- Wzorce administracji:
- Sekwencyjne: wykonywanie agentów w określonej kolejności
- Równolegle: uruchamiaj wielu agentów jednocześnie
- Warunkowe: kierowanie na podstawie typu zapytania
Narzędzia MCP dla baz danych
Model Context Protocol (MCP) to otwarty standard służący do łączenia systemów AI z zewnętrznymi źródłami danych i narzędziami. MCP Toolbox for Databases to implementacja Google, która umożliwia deklaratywne zarządzanie zapytaniami do bazy danych. Pozwala definiować wstępnie zweryfikowane zapytania opracowane przez ekspertów jako narzędzia wielokrotnego użytku. Zamiast pozwalać dużym modelom językowym generować potencjalnie niebezpieczne zapytania, MCP Toolbox udostępnia wstępnie zatwierdzone zapytania z weryfikacją parametrów, co zapewnia bezpieczeństwo, wydajność i niezawodność przy jednoczesnym zachowaniu elastyczności dla agentów AI.
Podejście tradycyjne:
# LLM generates query (may be incorrect/unsafe)
query = llm.generate("SELECT * FROM users WHERE...")
db.execute(query) # Risk of errors/SQL injection
Podejście MCP:
# Pre-validated query definition
- name: get_industries
description: Fetch all industries from database
query: |
MATCH (i:Industry)
RETURN i.name, i.id
Zalety:
- Wstępnie zweryfikowane przez ekspertów
- Ochrona przed atakami typu „wstrzykiwanie kodu”
- Optymalizacja pod kątem skuteczności
- Zarządzane centralnie
- Można używać w przypadku różnych agentów
Złożenie wszystkiego w całość
Połączenie GraphRAG, platformy wieloagentowej ADK i protokołu MCP tworzy zaawansowany system:
- Agent główny otrzymuje zapytanie użytkownika.
- Kierowanie do specjalisty na podstawie typu zapytania
- Agent używa narzędzi MCP do bezpiecznego pobierania danych
- Struktura wykresu zapewnia bogaty kontekst
- LLM generuje odpowiedź opartą na faktach i wyjaśniającą
Znasz już architekturę, więc zacznijmy tworzyć!
3. Konfigurowanie projektu Google Cloud
Utwórz projekt
- W konsoli Google Cloud na stronie selektora projektów wybierz lub utwórz projekt Google Cloud.
- Sprawdź, czy w projekcie Cloud włączone są płatności. Dowiedz się, jak sprawdzić, czy w projekcie są włączone płatności .
- Będziesz używać Cloud Shell, czyli środowiska wiersza poleceń działającego w Google Cloud. U góry konsoli Google Cloud kliknij Aktywuj Cloud Shell. Możesz przełączać się między terminalem Cloud Shell (do uruchamiania poleceń w chmurze) a edytorem (do tworzenia projektów), klikając odpowiedni przycisk w Cloud Shell.

- Po połączeniu z Cloud Shell sprawdź, czy uwierzytelnianie zostało już przeprowadzone, a projekt jest już ustawiony na Twój identyfikator projektu, używając tego polecenia:
gcloud auth list
- Aby potwierdzić, że polecenie gcloud zna Twój projekt, uruchom w Cloud Shell to polecenie:
gcloud config list project
- Jeśli projekt nie jest ustawiony, użyj tego polecenia, aby go ustawić:
gcloud config set project <YOUR_PROJECT_ID>
Informacje o poleceniach gcloud i ich użyciu znajdziesz w dokumentacji.
Świetnie! Możemy teraz przejść do następnego kroku, czyli zrozumienia zbioru danych.
4. Informacje o zbiorze danych Firmy
W tym samouczku używamy bazy danych Neo4j tylko do odczytu, która jest wstępnie wypełniona danymi o inwestycjach i firmach z grafu wiedzy Diffbot.
Zbiór danych zawiera:
- 237 358 węzłów reprezentujących:
- Organizacje (firmy)
- osoby (kierownictwo, pracownicy),
- Artykuły (wiadomości i wzmianki)
- Branże
- Technologie
- Inwestorzy
- Relacje, w tym:
HAS_INVESTOR– połączenia inwestycyjne,HAS_COMPETITOR– relacje z konkurencjąMENTIONS– odniesienia do artykułówHAS_CEO– stosunki pracy;HAS_CATEGORY– klasyfikacje branżowe,
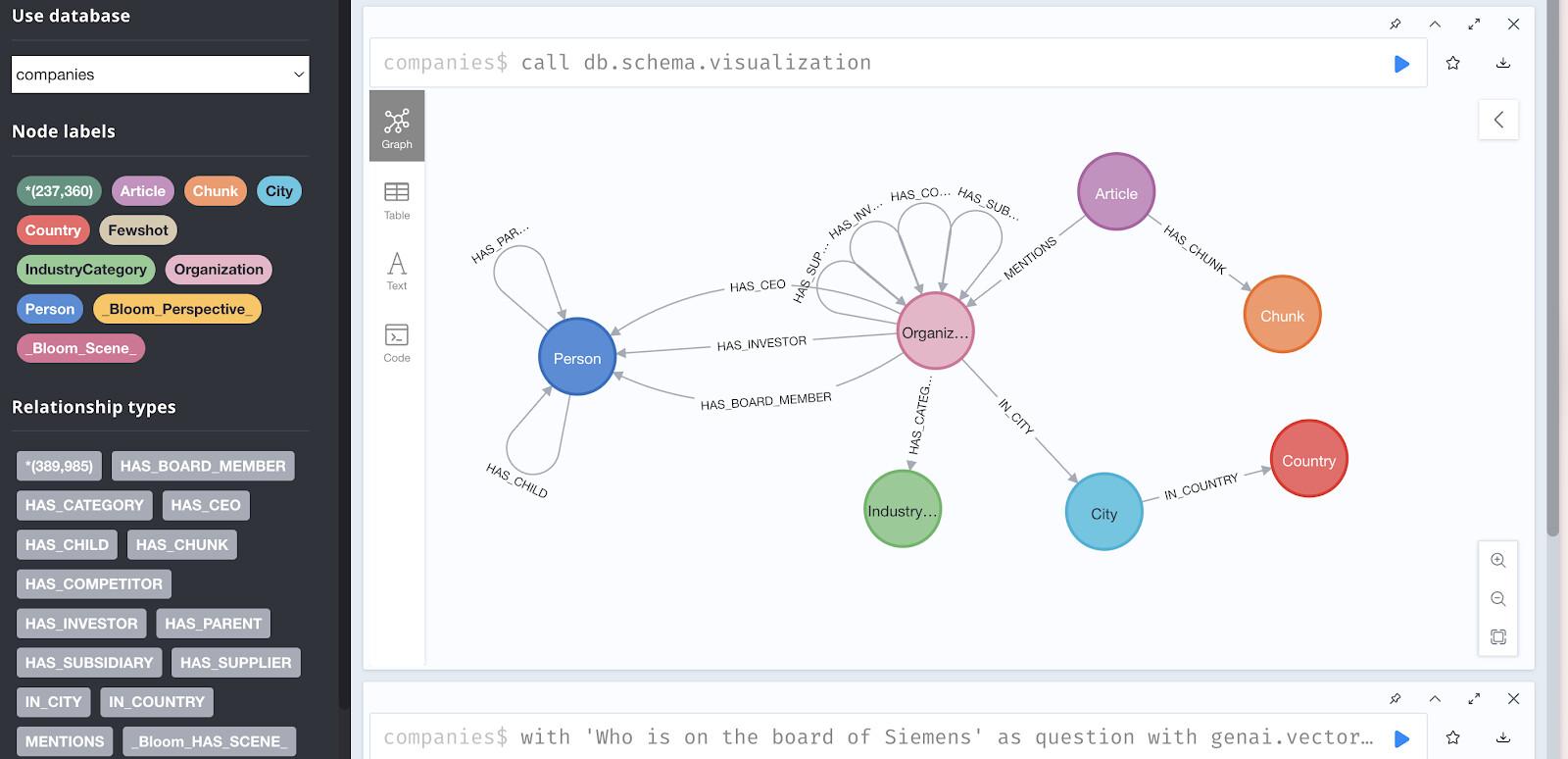
Dostęp do bazy danych demonstracyjnych
W tym samouczku użyjemy hostowanej instancji demonstracyjnej. Dodaj do notatek te dane logowania:
URI: neo4j+s://demo.neo4jlabs.com
Username: companies
Password: companies
Database: companies
Dostęp w przeglądarce:
Dane możesz przeglądać wizualnie na stronie https://demo.neo4jlabs.com:7473
Zaloguj się za pomocą tych samych danych logowania i spróbuj uruchomić to polecenie:
// Sample query to explore the graph
MATCH (c:Organization)-[:HAS_COMPETITOR]-(competitor:Organization)
RETURN c.name, competitor.name
LIMIT 10
Wizualizacja struktury wykresu
Aby zobaczyć wzorce relacji, wypróbuj to zapytanie w przeglądarce Neo4j:
// Find investors and their portfolio companies
MATCH (company:Organization)-[:HAS_INVESTOR]->(investor:Person)
WITH investor, collect(company.name) as portfolio
RETURN investor.name, size(portfolio) as num_investments, portfolio
ORDER BY num_investments DESC
LIMIT 5
To zapytanie zwraca 5 najbardziej aktywnych inwestorów i ich portfele.
Dlaczego ta baza danych jest odpowiednia dla GraphRAG?
Ten zbiór danych idealnie nadaje się do zademonstrowania GraphRAG, ponieważ:
- Rich Relationships: złożone powiązania między elementami.
- Dane z rzeczywistego świata: prawdziwe firmy, osoby i artykuły prasowe.
- Zapytania wieloetapowe: wymagają przechodzenia przez wiele typów relacji.
- Dane czasowe: artykuły z sygnaturami czasowymi do analizy opartej na czasie.
- Analiza nastawienia: wstępnie obliczone wyniki nastawienia dla artykułów.
Teraz, gdy znasz już strukturę danych, skonfigurujmy środowisko programistyczne.
5. Klonowanie repozytorium i konfigurowanie środowiska
Klonowanie repozytorium
W terminalu Cloud Shell uruchom to polecenie:
# Clone the repository
git clone https://github.com/sidagarwal04/neo4j-adk-multiagents.git
# Navigate into the directory
cd neo4j-adk-multiagents
Poznaj strukturę repozytorium
Poświęć chwilę na zapoznanie się z układem projektu:
neo4j-adk-multiagents/
├── investment_agent/ # Main agent code
│ ├── agent.py # Agent definitions
│ ├── tools.py # Custom tool functions
│ └── .adk/ # ADK configuration
│ └── tools.yaml # MCP tool definitions
├── main.py # Application entry point
├── setup_tools_yaml.py # Configuration generator
├── requirements.txt # Python dependencies
├── example.env # Environment template
└── README.md # Project documentation
Konfigurowanie środowiska wirtualnego
Utwórz i aktywuj wirtualne środowisko Pythona za pomocą narzędzia uv:
# Install uv if not already installed
pip install uv
# Create virtual environment
uv venv
# Activate the environment
source .venv/bin/activate # On macOS/Linux
# or
.venv\Scripts\activate # On Windows
Przed promptem terminala powinien pojawić się tekst (.venv).
Instalowanie zależności
Zainstaluj wszystkie wymagane pakiety:
uv pip install -r requirements.txt
Kluczowe zależności:
txtgoogle-adk>=1.21.0 # Agent Development Kit
neo4j>=6.0.3 # Neo4j Python driver
python-dotenv>=1.0.0 # Environment variables
google-cloud-aiplatform>=1.30.0 # Vertex AI
Konfigurowanie zmiennych środowiskowych
- Utwórz**
.env** **plik:**
cp example.env .env
- Edytuj **
.env** **plik:**
Jeśli używasz Cloud Shell, na pasku narzędzi kliknij Otwórz edytor, a następnie przejdź do .env i zaktualizuj:
Aby wyświetlić ukryty plik .env:
W edytorze Google Cloud Shell kliknij View > Toggle Hidden files.
# Neo4j Configuration (Demo Database)
NEO4J_URI=neo4j+s://demo.neo4jlabs.com
NEO4J_USERNAME=companies
NEO4J_PASSWORD=companies
NEO4J_DATABASE=companies
# Google AI Configuration
# Choose ONE of the following options:
# Option 1: Google AI API (Recommended)
GOOGLE_GENAI_USE_VERTEXAI=0
GOOGLE_API_KEY=your_api_key_here # Get from https://aistudio.google.com/app/apikey
# Option 2: Vertex AI (If using GCP)
# GOOGLE_GENAI_USE_VERTEXAI=1
# GOOGLE_CLOUD_PROJECT=your-project-id
# GOOGLE_CLOUD_LOCATION=us-central1
# ADK Configuration
GOOGLE_ADK_MODEL=gemini-3.1-flash-lite-preview # or gemini-3-flash-preview
# MCP Toolbox Configuration
MCP_TOOLBOX_URL=https://toolbox-990868019953.us-central1.run.app/mcp/sse
- Wygeneruj konfigurację zestawu narzędzi MCP:
Uruchom skrypt konfiguracji, aby utworzyć plik tools.yaml ze zmiennych środowiskowych:
python setup_tools_yaml.py
Spowoduje to wygenerowanie pliku investment_agent/.adk/tools.yaml z prawidłowo skonfigurowanymi danymi logowania do Neo4j dla narzędzi MCP.
Weryfikacja konfiguracji
Sprawdź, czy wszystko jest prawidłowo skonfigurowane:
# Verify .env file exists
ls -la .env
# Verify tools.yaml was generated
ls -la investment_agent/.adk/tools.yaml
# Test Python environment
python -c "import google.adk; print('ADK installed successfully')"
# Test Neo4j connection
python -c "from neo4j import GraphDatabase; print('Neo4j driver installed')"
Środowisko programistyczne jest już w pełni skonfigurowane. Następnie przyjrzymy się architekturze z wieloma agentami.
6. Omówienie architektury systemu wieloagentowego
System czterech agentów
Nasz system badań inwestycyjnych korzysta z hierarchicznej architektury wieloagentowej z 4 wyspecjalizowanymi agentami, którzy współpracują ze sobą, aby odpowiadać na złożone zapytania dotyczące firm, inwestorów i informacji rynkowych.
┌──────────────┐
│ Root Agent │ ◄── User Query
└──────┬───────┘
│
┌────────────────┼────────────────┐
│ │ │
┌─────▼─────┐ ┌────▼─────┐ ┌────▼──────────┐
│ Graph DB │ │ Investor │ │ Investment │
│ Agent │ │ Research │ │ Research │
└───────────┘ │ Agent │ │ Agent │
└──────────┘ └───────────────┘
- Główny agent (orkiestrator):
Agent główny pełni funkcję inteligentnego koordynatora całego systemu. Otrzymuje zapytania użytkowników, analizuje ich intencje i kieruje żądania do najbardziej odpowiedniego wyspecjalizowanego agenta. Można go traktować jako menedżera projektu, który wie, który członek zespołu najlepiej nadaje się do danego zadania. Zajmuje się też agregowaniem odpowiedzi, formatowaniem wyników w postaci tabel lub wykresów na żądanie oraz utrzymywaniem kontekstu rozmowy w wielu zapytaniach. Agent główny zawsze preferuje wyspecjalizowanych agentów od ogólnego agenta bazy danych, dzięki czemu zapytania są obsługiwane przez najbardziej kompetentny dostępny komponent.
- Agent bazy danych grafów:
Agent bazy danych wykresu to bezpośrednie połączenie z zaawansowanymi funkcjami wykresów Neo4j. Rozumie schemat bazy danych, generuje zapytania Cypher w języku naturalnym i wykonuje złożone przejścia po grafie. Ten agent specjalizuje się w pytaniach strukturalnych, agregacjach i wielokrotnych wnioskowaniach w grafie wiedzy. Jest to ekspert rezerwowy, gdy zapytania wymagają niestandardowej logiki, której nie mogą obsłużyć predefiniowane narzędzia. Dzięki temu jest niezbędny w przypadku analizy eksploracyjnej i złożonych zapytań analitycznych, których nie przewidziano w projekcie systemu.
- Pracownik obsługi klienta ds. badań inwestorskich:
Agent ds. badań inwestycyjnych koncentruje się wyłącznie na relacjach inwestycyjnych i analizie portfela. Może ona wykrywać, kto zainwestował w konkretne firmy, korzystając z dokładnego dopasowania nazw, pobierać pełne portfele inwestorów, pokazujące wszystkie ich inwestycje, oraz analizować wzorce inwestycyjne w różnych branżach. Dzięki tej specjalizacji jest niezwykle skuteczny w odpowiadaniu na pytania takie jak „Kto zainwestował w ByteDance?” lub „W co jeszcze zainwestował Sequoia Capital?”. Agent używa niestandardowych funkcji Pythona, które bezpośrednio wysyłają do bazy danych Neo4j zapytania o relacje związane z inwestorami.
- Pracownik obsługi klienta ds. badań inwestycyjnych:
Agent do badań inwestycyjnych korzysta z zestawu narzędzi Model Context Protocol (MCP) Toolbox, aby uzyskiwać dostęp do wstępnie zweryfikowanych zapytań napisanych przez ekspertów. Może pobierać wszystkie dostępne branże, wyszukiwać firmy w określonych branżach, znajdować artykuły z analizą nastawienia, wykrywać wzmianki o organizacjach w wiadomościach i uzyskiwać informacje o osobach pracujących w firmach. W przeciwieństwie do agenta bazy danych grafów, który dynamicznie generuje zapytania, ten agent używa bezpiecznych, zoptymalizowanych, wstępnie zdefiniowanych zapytań, które są zarządzane i weryfikowane centralnie. Dzięki temu jest bezpieczna i wydajna w przypadku typowych przepływów pracy związanych z badaniami.
7. Uruchamianie i testowanie systemu wieloagentowego
Uruchamianie aplikacji
Teraz, gdy znasz już architekturę, uruchommy cały system i zacznijmy z nim wchodzić w interakcje.
Uruchom interfejs internetowy ADK:
# Make sure you're in the project directory with activated virtual environment
cd ~/neo4j-adk-multiagents
source .venv/bin/activate # If not already activated
# Launch the application
uv run adk web
Dane wyjściowe powinny być podobne do tych:
INFO: Started server process [2542]
INFO: Waiting for application startup.
+----------------------------------------------------------------+
| ADK Web Server started |
| |
| For local testing, access at http://127.0.0.1:8000. |
+----------------------------------------------------------------+
INFO: Application startup complete.
INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
Zapytania testowe i oczekiwane działanie
Przyjrzyjmy się możliwościom systemu na przykładzie coraz bardziej złożonych zapytań:
Zapytania podstawowe (jeden agent)
Zapytanie 1. Odkrywanie branż
What industries are available in the database?
Oczekiwane działanie:
- Agent główny kieruje do agenta ds. badań inwestycyjnych
- Korzysta z narzędzia MCP:
get_industries() - Zwraca sformatowaną listę wszystkich branż.
Co obserwować:
W interfejsie ADK rozwiń szczegóły wykonania, aby zobaczyć:
- Decyzja dotycząca wyboru agenta
- Wywołanie narzędzia:
get_industries() - Nieprzetworzone wyniki z Neo4j
- Sformatowana odpowiedź
Zapytanie 2. Znajdź inwestorów
Who invested in ByteDance?
Oczekiwane działanie:
- Root Agent identyfikuje to jako zapytanie związane z inwestorami
- Trasy do agenta ds. badań inwestorskich
- Używa narzędzia:
find_investor_by_name("ByteDance") - Zwraca inwestorów wraz z ich typami (osoba lub organizacja).
Oczekiwana odpowiedź:
I found 2 investors in ByteDance:
1. Rong Yue (Person)
2. Wendi Murdoch (Person)
Would you like to know more about their investment portfolios?
Zapytanie 3. Firmy według branży**
I found 2 investors in ByteDance:
1. Rong Yue (Person)
2. Wendi Murdoch (Person)
Would you like to know more about their investment portfolios?
"Show me companies in the Artificial Intelligence industry"
Oczekiwane działanie:
- Agent główny kieruje do agenta ds. badań inwestycyjnych
- Korzysta z narzędzia MCP:
get_companies_in_industry("Artificial Intelligence") - Zwraca listę firm zajmujących się AI wraz z identyfikatorami i datami założenia.
Co obserwować:
- Zwróć uwagę, jak agent używa dokładnego dopasowania nazwy branży.
- Wyniki są ograniczone, aby zapobiec przeładowaniu danych wyjściowych.
- Dane są sformatowane w czytelny sposób.
Zapytania średnio zaawansowane (wielokrokowe w ramach jednego agenta)
Zapytanie 4. Analiza nastawienia
Find articles with positive sentiment from January 2023
Oczekiwane działanie:
- Trasy do agenta ds. badań inwestycyjnych
- Korzysta z narzędzia MCP:
get_articles_with_sentiment(0.7, 2023, 1) - Zwraca artykuły z tytułami, wynikami analizy sentymentu i datami publikacji.
Wskazówka dotycząca debugowania:
Sprawdź parametry wywołania narzędzia:
min_sentiment: 0,7 (pracownik obsługi klienta interpretuje „pozytywny” jako >= 0,7)year: 2023month: 1
Zapytanie 5. Złożone zapytanie do bazy danych
How many companies are in the database?
Oczekiwane działanie:
- Agent główny kieruje do agenta bazy danych grafów
- Przedstawiciel dzwoni
get_neo4j_schema()w pierwszej kolejności, aby poznać strukturę - Generuje Cypher:
MATCH (c:Company) RETURN count(c) - Wykonuje zapytanie i zwraca liczbę.
Oczekiwana odpowiedź:
There are 8,064 companies in the database.
Zapytania zaawansowane (koordynacja wielu agentów)
Zapytanie 6. Analiza portfolio
Who invested in ByteDance and what else have they invested in?
Oczekiwane działanie:
Jest to zapytanie dwuczęściowe, które wymaga koordynacji agenta:
- Krok 1. Agent główny → Agent ds. badań inwestorskich
- Połączenia
find_investor_by_name("ByteDance") - Pobieranie listy inwestorów: [Rong Yue, Wendi Murdoch]
- Krok 2: dla każdego inwestora → agent ds. analizy inwestorów
- Połączenia
find_investor_by_id(investor_id) - Pobiera pełne portfolio
- Krok 3. Agent główny agreguje i formatuje
Oczekiwana odpowiedź:
I found 2 investors in ByteDance. Here are their portfolios:
1. Rong Yue (Person)
- ByteDance
- Inspur
2. Wendi Murdoch (Person)
- ByteDance
- (No other investments in database)
Co obserwować:
- Wiele wywołań narzędzi w sekwencji
- Kontekst zachowywany między krokami
- Inteligentne agregowanie wyników
Zapytanie 7. Badanie wielu domen
What are 5 AI companies mentioned in positive articles, and who are their CEOs?
Oczekiwane działanie:
To złożone zapytanie wymaga użycia wielu agentów i narzędzi:
- Krok 1. Agent ds. badań inwestycyjnych
get_companies_in_industry("Artificial Intelligence")- Zwraca listę firm zajmujących się AI
- Krok 2. Agent ds. analizy inwestycyjnej
get_articles_with_sentiment(0.8)- zwraca pozytywne artykuły,
- Krok 3. Filtry agenta głównego
- Określa, które firmy zajmujące się AI pojawiają się w pozytywnych artykułach
- Wybiera 5 najważniejszych
- Krok 4. Agent ds. analizy inwestycyjnej
get_people_in_organizations([company_names], "CEO")- Zwraca informacje o prezesie
- Krok 5. Formatowanie agenta głównego w postaci tabeli
Oczekiwana odpowiedź:
Here are 5 AI companies with positive news and their CEOs:
| Company | Industry | CEO | Avg Sentiment |
|---------|----------|-----|---------------|
| OpenAI | Artificial Intelligence | Sam Altman | 0.92 |
| Anthropic | Artificial Intelligence | Dario Amodei | 0.89 |
| ... | ... | ... | ... |
Co obserwować:
- Wiele wywołań narzędzi na różnych agentach
- Logika filtrowania i łączenia danych
- Profesjonalne formatowanie tabeli
Zapytanie 8. Analiza konkurencji
Who are YouTube's main competitors?
Oczekiwane działanie:
- Agent główny kieruje do agenta bazy danych grafów (zapytanie o relację)
- Agent generuje język Cypher ulepszony przez GraphRAG:
MATCH (c:Company {name: "YouTube"})-[:COMPETES_WITH]->(competitor)
RETURN competitor.name as competitor_name
- Zwraca listę konkurencyjnych firm
Oczekiwana odpowiedź:
YouTube's main competitors are:
- TikTok (ByteDance)
- Dailymotion
- Twitter
- BuzzFeed
- Mixer
- OpenAI (for video content)
Zapytania uzupełniające zależne od kontekstu
Zapytanie 9. Pytanie uzupełniające (po zapytaniu 8)
Which investors funded both YouTube and its competitors?
Oczekiwane działanie:
- Root Agent pamięta poprzedni kontekst (YouTube i jego konkurenci).
- Trasy do agenta ds. badań inwestorskich
- Dla YouTube i każdego konkurenta znajduje inwestorów
- Identyfikowanie inwestorów pojawiających się w wielu firmach
Oczekiwana odpowiedź:
Based on our previous analysis of YouTube's competitors, I found these
investors who funded multiple companies in this competitive landscape:
Sequoia Capital invested in:
- YouTube
- TikTok (ByteDance)
- Twitter
Accel Partners invested in:
- YouTube
- BuzzFeed
This suggests these investors have strategic positions across the video content platform ecosystem.
Zapytanie 10. Podsumowanie badań
Summarize our research findings so far
Oczekiwane działanie:
- Root Agent sprawdza historię rozmów
- syntetyzuje najważniejsze wnioski z poprzednich zapytań;
- zapewnia spójne podsumowanie,
Oczekiwana odpowiedź:
Here's a summary of our investment research session:
1. Industry Overview: We explored the Artificial Intelligence industry
with 150+ companies in the database.
2. ByteDance Analysis:
- Investors: Rong Yue, Wendi Murdoch
- Rong Yue also invested in Inspur
3. Market Sentiment: We analyzed articles from January 2023, finding
strong positive sentiment (avg 0.85) for tech companies.
4. Competitive Landscape: YouTube faces competition from TikTok,
Dailymotion, and others, with some investors (Sequoia, Accel) holding
positions across competing platforms.
5. Key Players: Identified CEOs of major AI companies with positive media coverage.
Omówienie interakcji agenta w widoku debugowania
Interfejs internetowy pakietu ADK zapewnia szczegółowy wgląd w wykonanie. Oto na co należy zwrócić uwagę:
- Oś czasu zdarzeń
Wyświetla przepływ chronologiczny:
[USER] Query received
[ROOT_AGENT] Analyzing query intent
[ROOT_AGENT] Routing to investment_research_agent
[INVESTMENT_RESEARCH_AGENT] Tool call: get_companies_in_industry
[TOOL] Executing with params: {"industry_name": "Artificial Intelligence"}
[TOOL] Returned 47 results
[INVESTMENT_RESEARCH_AGENT] Formatting response
[ROOT_AGENT] Presenting to user
- Szczegóły wywołania narzędzia
Kliknij dowolne wywołanie narzędzia, aby zobaczyć:
- Nazwa funkcji
- Parametry wejściowe
- Zwracana wartość
- Czas wykonywania
- Wszystkie błędy
- Podejmowanie decyzji przez agenta
Obserwuj rozumowanie LLM:
- powód wyboru konkretnego agenta.
- Jak zinterpretowano zapytanie
- Jakie narzędzia były brane pod uwagę
- dlaczego wyniki zostały sformatowane w określony sposób,
Najczęstsze obserwacje i statystyki
- Wzorce kierowania zapytań:
- Słowa kluczowe takie jak „inwestor”, „inwestycja” → Agent ds. badań inwestorskich
- Słowa kluczowe takie jak „branża”, „firmy”, „artykuły” → agent ds. badań inwestycyjnych
- Agregacje, zliczanie, złożona logika → agent bazy danych grafów
- Uwagi dotyczące skuteczności:
- Narzędzia MCP są zwykle szybsze (wstępnie zoptymalizowane zapytania).
- Generowanie złożonych zapytań w języku Cypher trwa dłużej (czas myślenia LLM).
- Wiele wywołań narzędzi zwiększa opóźnienie, ale zapewnia bogatsze wyniki
- Obsługa błędów:
- Jeśli zapytanie się nie powiedzie:
- Agent wyjaśnia, co poszło nie tak
- sugeruje poprawki (np. „Nie znaleziono nazwy firmy, sprawdź pisownię”);
- Może wypróbować alternatywne podejścia
Wskazówki dotyczące skutecznego testowania
- Zacznij od prostych zapytań: przed zadaniem złożonych zapytań przetestuj główną funkcjonalność każdego agenta.
- Używaj dodatkowych promptów: sprawdzaj zachowywanie kontekstu za pomocą dodatkowych pytań.
- Obserwowanie routingu: sprawdzaj, który agent obsługuje poszczególne zapytania, aby zrozumieć logikę.
- Sprawdzanie wywołań narzędzi: weryfikowanie, czy parametry są prawidłowo wyodrębniane z języka naturalnego.
- Testowanie przypadków skrajnych: wypróbuj niejednoznaczne zapytania, błędy pisowni lub nietypowe żądania.
Masz teraz w pełni funkcjonalny system GraphRAG z wieloma agentami. Eksperymentuj z własnymi pytaniami, aby poznać jego możliwości.
8. Czyszczenie danych
Aby uniknąć obciążenia konta Google Cloud opłatami za zasoby użyte w tym poście, wykonaj te czynności:
- W konsoli Google Cloud otwórz stronę Zarządzanie zasobami.
- Z listy projektów wybierz projekt do usunięcia, a potem kliknij Usuń.
- W oknie wpisz identyfikator projektu i kliknij Wyłącz, aby usunąć projekt.
9. Gratulacje
🎉 Gratulacje! Udało Ci się utworzyć system GraphRAG o jakości produkcyjnej oparty na wielu agentach przy użyciu pakietu Agent Development Kit od Google, Neo4j i zestawu narzędzi MCP Toolbox.
Łącząc inteligentne możliwości orkiestracji ADK z bogatym w relacje modelem danych Neo4j i bezpieczeństwem wstępnie zweryfikowanych zapytań MCP, stworzyliśmy zaawansowany system, który wykracza poza proste zapytania do bazy danych – rozumie kontekst, analizuje złożone relacje i koordynuje pracę wyspecjalizowanych agentów, aby dostarczać kompleksowe i dokładne informacje.
W tym ćwiczeniu wykonaliśmy te czynności:
✅ Utworzono system wieloagentowy za pomocą pakietu Agent Development Kit (ADK) od Google z hierarchicznym zarządzaniem.
✅ Zintegrowana grafowa baza danych Neo4j, która umożliwia korzystanie z zapytań uwzględniających relacje i wielokrokowe rozumowanie.
✅ Wdrożono zestaw narzędzi MCP do bezpiecznych, wstępnie zweryfikowanych zapytań do bazy danych jako narzędzi wielokrotnego użytku.
✅ Utworzono wyspecjalizowane agenty do badań inwestycyjnych, analiz inwestycyjnych i operacji na grafowych bazach danych.
✅ Zaprojektowano inteligentne przekierowywanie, które automatycznie przekazuje zapytania do najbardziej odpowiedniego agenta.
✅ Obsługa złożonych typów danych z odpowiednią serializacją typów Neo4j w celu zapewnienia płynnej integracji z Pythonem.
✅ Zastosowanie sprawdzonych metod produkcyjnych w zakresie projektowania agenta, obsługi błędów i debugowania systemu.
Co dalej?
Ta architektura GraphRAG z wieloma agentami nie ogranicza się do badań inwestycyjnych – można ją rozszerzyć na:
- Usługi finansowe: optymalizacja portfolio, ocena ryzyka, wykrywanie oszustw
- Opieka zdrowotna: koordynacja opieki nad pacjentem, analiza interakcji leków, badania kliniczne
- E-commerce: spersonalizowane rekomendacje, optymalizacja łańcucha dostaw, statystyki dotyczące klientów
- Kwestie prawne i zgodność z przepisami: analiza umów, monitorowanie przepisów, badania orzecznictwa
- Badania naukowe: przegląd literatury, odkrywanie współpracy, analiza cytowań
- Informacje o przedsiębiorstwie: analiza konkurencji, badania rynku, wykresy wiedzy organizacji
Wszędzie tam, gdzie masz złożone, powiązane ze sobą dane + wiedzę specjalistyczną + interfejsy w języku naturalnym, ta kombinacja systemów wieloagentowych ADK + grafów wiedzy Neo4j + zapytań zweryfikowanych przez MCP może stanowić podstawę nowej generacji inteligentnych aplikacji dla przedsiębiorstw.
Wraz z rozwojem pakietu Agent Development Kit Google i modeli Gemini będziesz mieć możliwość włączania jeszcze bardziej zaawansowanych wzorców rozumowania, integracji danych w czasie rzeczywistym i funkcji wielomodowych, aby tworzyć prawdziwie inteligentne systemy uwzględniające kontekst.
Nie przestawaj odkrywać i tworzyć, aby przenieść swoje aplikacje z inteligentnymi agentami na wyższy poziom.
Więcej praktycznych samouczków dotyczących grafów wiedzy znajdziesz na stronie Neo4j GraphAcademy, a dodatkowe wzorce agentów – w repozytorium z przykładami pakietu ADK.
🚀 Chcesz stworzyć kolejny inteligentny system agentów?