
1. ภาพรวม
ใน Codelab นี้ คุณจะได้สร้างระบบการวิจัยการลงทุนแบบหลาย Agent ที่ซับซ้อนซึ่งผสานรวมศักยภาพของ Agent Development Kit (ADK) ของ Google, ฐานข้อมูลกราฟ Neo4j และ Model Context Protocol (MCP) Toolbox บทแนะนำแบบลงมือปฏิบัติจริงนี้แสดงวิธีสร้างเอเจนต์อัจฉริยะที่เข้าใจบริบทของข้อมูลผ่านความสัมพันธ์ของกราฟ และให้คำตอบของคำค้นหาที่มีความแม่นยำสูง
ทำไมต้องใช้ GraphRAG + ระบบ Multi-Agent
GraphRAG (การดึงข้อมูลมาเสริม (Retrieval-Augmented Generation) ที่อิงตามกราฟ) ช่วยปรับปรุงแนวทาง RAG แบบดั้งเดิมด้วยการใช้ประโยชน์จากโครงสร้างความสัมพันธ์ที่หลากหลายของกราฟความรู้ แทนที่จะค้นหาเฉพาะเอกสารที่คล้ายกัน GraphRAG Agent สามารถทำสิ่งต่อไปนี้ได้
- สำรวจความสัมพันธ์ที่ซับซ้อนระหว่างเอนทิตี
- ทําความเข้าใจบริบทผ่านโครงสร้างกราฟ
- แสดงผลลัพธ์ที่อธิบายได้โดยอิงตามข้อมูลที่เชื่อมต่อ
- ดำเนินการให้เหตุผลแบบหลายขั้นตอนในกราฟความรู้
ระบบแบบหลายเอเจนต์ช่วยให้คุณทำสิ่งต่อไปนี้ได้
- แยกปัญหาที่ซับซ้อนออกเป็นงานย่อยเฉพาะทาง
- สร้างแอปพลิเคชัน AI ที่เป็นโมดูลและบำรุงรักษาได้
- เปิดใช้การประมวลผลแบบคู่ขนานและการใช้ทรัพยากรอย่างมีประสิทธิภาพ
- สร้างรูปแบบการให้เหตุผลแบบลำดับชั้นด้วยการประสานงาน
สิ่งที่คุณจะสร้าง
คุณจะได้สร้างระบบการวิจัยการลงทุนที่สมบูรณ์แบบซึ่งมีฟีเจอร์ต่อไปนี้
- Graph Database Agent: เรียกใช้การค้นหา Cypher และทำความเข้าใจสคีมา Neo4j
- ตัวแทนวิจัยนักลงทุน: ค้นพบความสัมพันธ์ของนักลงทุนและพอร์ตการลงทุน
- เอเจนต์วิจัยการลงทุน: เข้าถึงกราฟความรู้ที่ครอบคลุมผ่านเครื่องมือ MCP
- Root Agent: จัดการ Sub-Agent ทั้งหมดอย่างชาญฉลาด
ระบบจะตอบคำถามที่ซับซ้อน เช่น
- "คู่แข่งหลักของ YouTube คือใคร"
- บริษัทใดบ้างที่ได้รับการกล่าวถึงในเชิงบวกในเดือนมกราคม 2023
- "ใครลงทุนใน ByteDance และพวกเขาลงทุนในบริษัทอื่นใดอีก"
ภาพรวมสถาปัตยกรรม
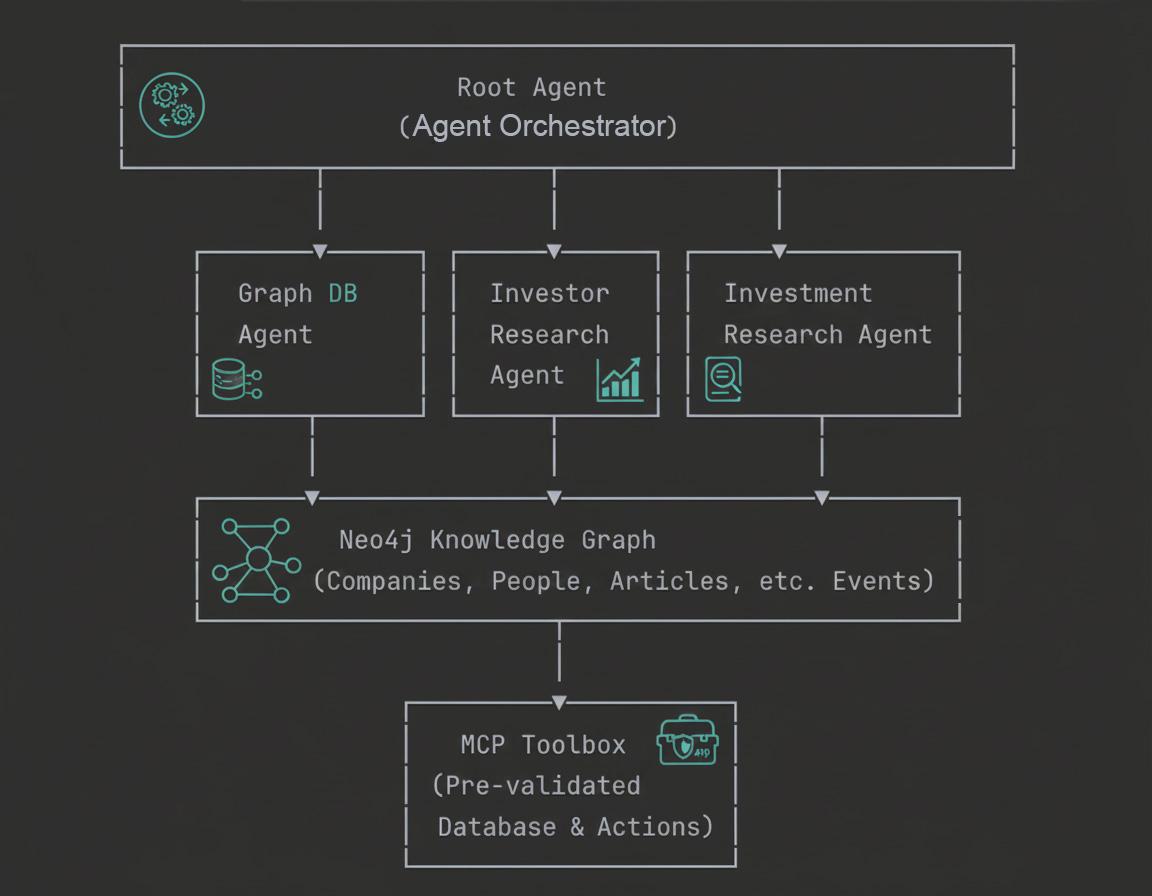
Codelab นี้จะช่วยให้คุณได้เรียนรู้ทั้งพื้นฐานเชิงแนวคิดและการใช้งานจริงในการสร้างเอเจนต์ GraphRAG ระดับองค์กร
สิ่งที่คุณจะได้เรียนรู้
- วิธีสร้างระบบ Multi-Agent โดยใช้ Agent Development Kit (ADK) ของ Google
- วิธีผสานรวมฐานข้อมูลกราฟ Neo4j กับ ADK สำหรับแอปพลิเคชัน GraphRAG
- วิธีติดตั้งใช้งาน Model Context Protocol (MCP) Toolbox สำหรับการค้นหาฐานข้อมูลที่ตรวจสอบแล้วล่วงหน้า
- วิธีสร้างเครื่องมือและฟังก์ชันที่กำหนดเองสำหรับเอเจนต์อัจฉริยะ
- วิธีออกแบบลำดับชั้นของตัวแทนและรูปแบบการประสานงาน
- วิธีจัดโครงสร้างคำสั่งของเอเจนต์เพื่อให้ได้ประสิทธิภาพสูงสุด
- วิธีแก้ไขข้อบกพร่องของการโต้ตอบแบบหลายเอเจนต์อย่างมีประสิทธิภาพ
สิ่งที่คุณต้องมี
- เว็บเบราว์เซอร์ Chrome
- บัญชี Gmail
- โปรเจ็กต์ Google Cloud ที่เปิดใช้การเรียกเก็บเงิน
- คุ้นเคยกับคำสั่งเทอร์มินัลและ Python ในระดับพื้นฐาน (มีประโยชน์แต่ไม่จำเป็น)
Codelab นี้ออกแบบมาสำหรับนักพัฒนาซอฟต์แวร์ทุกระดับ (รวมถึงผู้เริ่มต้น) โดยใช้ Python และ Neo4j ในแอปพลิเคชันตัวอย่าง แม้ว่าความคุ้นเคยพื้นฐานกับ Python และฐานข้อมูลกราฟอาจมีประโยชน์ แต่คุณไม่จำเป็นต้องมีประสบการณ์มาก่อนเพื่อทำความเข้าใจแนวคิดหรือทำตาม
2. ทำความเข้าใจ GraphRAG และระบบ Multi-Agent
ก่อนที่จะลงมือติดตั้งใช้งาน มาทำความเข้าใจแนวคิดหลักที่ขับเคลื่อนระบบนี้กันก่อน
Neo4j เป็นฐานข้อมูลกราฟดั้งเดิมชั้นนำที่จัดเก็บข้อมูลเป็นเครือข่ายของโหนด (เอนทิตี) และความสัมพันธ์ (การเชื่อมต่อระหว่างเอนทิตี) จึงเหมาะสำหรับกรณีการใช้งานที่การทำความเข้าใจการเชื่อมต่อเป็นสิ่งสำคัญ เช่น คำแนะนำ การตรวจหาการฉ้อโกง กราฟความรู้ และอื่นๆ โมเดลกราฟที่ยืดหยุ่นของ Neo4j ช่วยให้แสดงข้อมูลที่ซับซ้อนและเชื่อมต่อกันได้อย่างมีประสิทธิภาพและเป็นธรรมชาติ ซึ่งแตกต่างจากฐานข้อมูลเชิงสัมพันธ์หรือฐานข้อมูลที่อิงตามเอกสารซึ่งอาศัยตารางที่เข้มงวดหรือโครงสร้างแบบลำดับชั้น
Neo4j ใช้โมเดลกราฟแทนการจัดระเบียบข้อมูลในแถวและตารางเหมือนกับฐานข้อมูลเชิงสัมพันธ์ โดยจะแสดงข้อมูลเป็นโหนด (เอนทิตี) และความสัมพันธ์ (การเชื่อมต่อระหว่างเอนทิตีเหล่านั้น) โมเดลนี้ช่วยให้การทำงานกับข้อมูลที่เชื่อมโยงกันโดยธรรมชาติเป็นไปอย่างง่ายดาย เช่น บุคคล สถานที่ ผลิตภัณฑ์ หรือในกรณีของเราคือภาพยนตร์ นักแสดง และประเภท
เช่น ในชุดข้อมูลภาพยนตร์
- โหนดอาจแสดงถึง
Movie,ActorหรือDirector - ความสัมพันธ์อาจเป็น
ACTED_INหรือDIRECTED
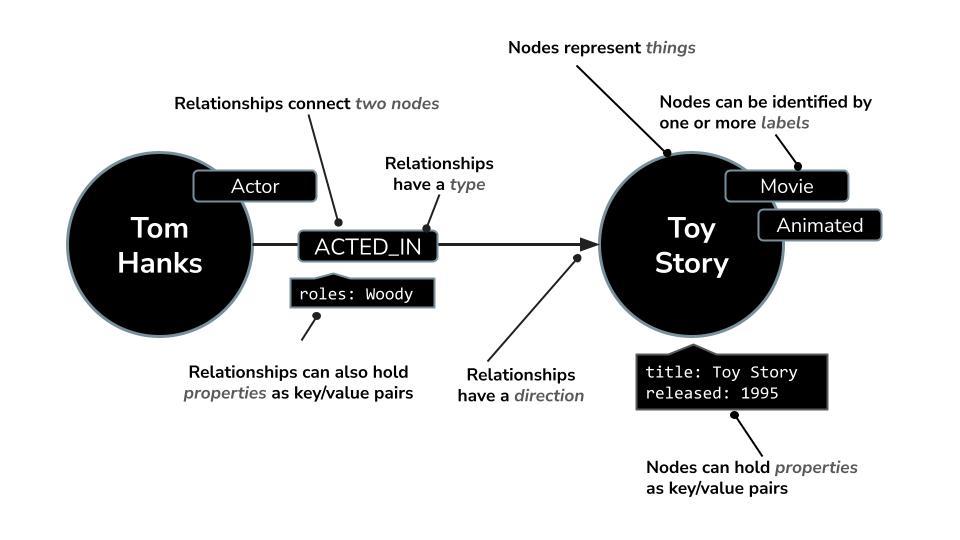
โครงสร้างนี้ช่วยให้คุณถามคำถามต่างๆ ได้อย่างง่ายดาย เช่น
- นักแสดงคนนี้เคยแสดงในภาพยนตร์เรื่องใดบ้าง
- ใครเคยร่วมงานกับคริสโตเฟอร์ โนแลนบ้าง
- มีภาพยนตร์ที่คล้ายกันซึ่งอิงตามนักแสดงหรือประเภทที่แชร์กันไหม
GraphRAG คืออะไร
Retrieval-Augmented Generation (RAG) ช่วยปรับปรุงคำตอบของ LLM โดยการดึงข้อมูลที่เกี่ยวข้องจากแหล่งข้อมูลภายนอก โดยทั่วไปแล้ว RAG แบบดั้งเดิมจะทำสิ่งต่อไปนี้
- ฝังเอกสารลงในเวกเตอร์
- ค้นหาเวกเตอร์ที่คล้ายกัน
- ส่งเอกสารที่ดึงข้อมูลมาให้ LLM
GraphRAG ขยายความสามารถนี้โดยใช้กราฟความรู้
- ฝังเอนทิตีและความสัมพันธ์
- สำรวจการเชื่อมต่อกราฟ
- เรียกข้อมูลตามบริบทแบบหลายฮอป
- ให้ผลลัพธ์ที่มีโครงสร้างและอธิบายได้
เหตุใดจึงต้องใช้กราฟสำหรับเอเจนต์ AI
ลองพิจารณาคำถามที่ว่า "คู่แข่งของ YouTube คือใคร และนักลงทุนรายใดที่ลงทุนทั้งใน YouTube และคู่แข่ง"
สิ่งที่เกิดขึ้นในแนวทาง RAG แบบเดิม
- การค้นหาเอกสารเกี่ยวกับคู่แข่งของ YouTube
- ค้นหาข้อมูลนักลงทุนแยกกัน
- การเชื่อมโยงข้อมูล 2 ส่วนนี้
- อาจพลาดความสัมพันธ์โดยนัย
สิ่งที่เกิดขึ้นในแนวทาง GraphRAG
MATCH (org:Organization {name: "OpenAI"})-[:HAS_COMPETITOR]-(competitor:Organization)
MATCH (org)-[:HAS_INVESTOR]->(investor:Person)
MATCH (competitor)-[:HAS_INVESTOR]->(investor)
RETURN org, competitor, investor
กราฟแสดงความสัมพันธ์ได้อย่างเป็นธรรมชาติ ทำให้การค้นหาแบบหลายขั้นตอนเป็นเรื่องง่ายและมีประสิทธิภาพ
ระบบ Multi-Agent ใน ADK
Agent Development Kit (ADK) คือเฟรมเวิร์กโอเพนซอร์สของ Google สำหรับการสร้างและติดตั้งใช้งาน AI Agent ระดับเวอร์ชันที่ใช้งานจริง โดยมีองค์ประกอบพื้นฐานที่ใช้งานง่ายสำหรับการจัดการเป็นกลุ่มแบบหลาย Agent, การผสานรวมเครื่องมือ และการจัดการเวิร์กโฟลว์ ซึ่งช่วยให้สร้าง Agent เฉพาะทางเป็นระบบที่ซับซ้อนได้อย่างง่ายดาย ADK ทำงานร่วมกับ Gemini ได้อย่างราบรื่นและรองรับการติดตั้งใช้งานใน Cloud Run, Kubernetes หรือโครงสร้างพื้นฐานใดก็ได้
Agent Development Kit (ADK) มีองค์ประกอบพื้นฐานสำหรับการสร้างระบบแบบหลาย Agent ดังนี้
- ลำดับชั้นของตัวแทน
# Root agent coordinates specialized agents
root_agent = LlmAgent(
name="RootAgent",
sub_agents=[
graph_db_agent,
investor_agent,
investment_agent
]
)
- ตัวแทนเฉพาะทาง: ตัวแทนแต่ละรายมี
- เครื่องมือที่เฉพาะเจาะจง: ฟังก์ชันที่เรียกใช้ได้
- คำสั่งที่ชัดเจน: บทบาทและความสามารถ
- ความเชี่ยวชาญเฉพาะด้าน: ความรู้ในสาขาของตน
- รูปแบบการจัดการเป็นกลุ่ม:
- ตามลำดับ: เรียกใช้ Agent ตามลำดับ
- ขนานกัน: เรียกใช้เอเจนต์หลายตัวพร้อมกัน
- มีเงื่อนไข: กำหนดเส้นทางตามประเภทการค้นหา
MCP Toolbox สำหรับฐานข้อมูล
Model Context Protocol (MCP) เป็นมาตรฐานแบบเปิดสำหรับการเชื่อมต่อระบบ AI กับแหล่งข้อมูลและเครื่องมือภายนอก MCP Toolbox สำหรับฐานข้อมูลคือการติดตั้งใช้งานของ Google ที่ช่วยให้จัดการการค้นหาฐานข้อมูลแบบประกาศได้ ซึ่งช่วยให้คุณกำหนดการค้นหาที่ผ่านการตรวจสอบล่วงหน้าและเขียนโดยผู้เชี่ยวชาญเป็นเครื่องมือที่นำกลับมาใช้ใหม่ได้ MCP Toolbox จะแสดงคำค้นหาที่ได้รับอนุมัติล่วงหน้าพร้อมการตรวจสอบพารามิเตอร์แทนที่จะปล่อยให้ LLM สร้างคำค้นหาที่อาจไม่ปลอดภัย ซึ่งจะช่วยให้มั่นใจได้ถึงความปลอดภัย ประสิทธิภาพ และความน่าเชื่อถือ พร้อมทั้งรักษาความยืดหยุ่นสำหรับเอเจนต์ AI
แนวทางแบบดั้งเดิม
# LLM generates query (may be incorrect/unsafe)
query = llm.generate("SELECT * FROM users WHERE...")
db.execute(query) # Risk of errors/SQL injection
แนวทาง MCP
# Pre-validated query definition
- name: get_industries
description: Fetch all industries from database
query: |
MATCH (i:Industry)
RETURN i.name, i.id
ข้อดี
- ผ่านการตรวจสอบล่วงหน้าโดยผู้เชี่ยวชาญ
- ปลอดภัยจากการโจมตีแบบแทรกโค้ด
- เพิ่มประสิทธิภาพแล้ว
- จัดการจากส่วนกลาง
- นำไปใช้ซ้ำใน Agent ต่างๆ ได้
การรวมทั้งหมดเข้าด้วยกัน
การผสมผสานระหว่าง GraphRAG + กรอบงาน Multi-Agent โดย ADK + MCP จะสร้างระบบที่มีประสิทธิภาพ
- Root Agent ได้รับคำค้นหาจากผู้ใช้
- กำหนดเส้นทางไปยังตัวแทนผู้เชี่ยวชาญตามประเภทคำค้นหา
- เอเจนต์ใช้เครื่องมือ MCP เพื่อดึงข้อมูลอย่างปลอดภัย
- โครงสร้างกราฟให้บริบทที่สมบูรณ์
- LLM สร้างคำตอบที่อิงตามข้อมูลและอธิบายได้
เมื่อเข้าใจสถาปัตยกรรมแล้ว เรามาเริ่มสร้างกันเลย
3. ตั้งค่าโปรเจ็กต์ Google Cloud
สร้างโปรเจ็กต์
- ในคอนโซล Google Cloud ให้เลือกหรือสร้างโปรเจ็กต์ Google Cloud ในหน้าตัวเลือกโปรเจ็กต์
- ตรวจสอบว่าได้เปิดใช้การเรียกเก็บเงินสำหรับโปรเจ็กต์ที่อยู่ในระบบคลาวด์แล้ว ดูวิธีตรวจสอบว่าได้เปิดใช้การเรียกเก็บเงินในโปรเจ็กต์แล้วหรือไม่
- คุณจะใช้ Cloud Shell ซึ่งเป็นสภาพแวดล้อมบรรทัดคำสั่งที่ทำงานใน Google Cloud คลิกเปิดใช้งาน Cloud Shell ที่ด้านบนของคอนโซล Google Cloud คุณสลับระหว่างเทอร์มินัล Cloud Shell (สําหรับเรียกใช้คําสั่งคลาวด์) กับ Editor (สําหรับสร้างโปรเจ็กต์) ได้โดยคลิกปุ่มที่เกี่ยวข้องจาก Cloud Shell

- เมื่อเชื่อมต่อกับ Cloud Shell แล้ว ให้ตรวจสอบว่าคุณได้รับการตรวจสอบสิทธิ์แล้วและตั้งค่าโปรเจ็กต์เป็นรหัสโปรเจ็กต์โดยใช้คำสั่งต่อไปนี้
gcloud auth list
- เรียกใช้คำสั่งต่อไปนี้ใน Cloud Shell เพื่อยืนยันว่าคำสั่ง gcloud รู้จักโปรเจ็กต์ของคุณ
gcloud config list project
- หากไม่ได้ตั้งค่าโปรเจ็กต์ ให้ใช้คำสั่งต่อไปนี้เพื่อตั้งค่า
gcloud config set project <YOUR_PROJECT_ID>
โปรดดูคำสั่งและการใช้งาน gcloud ในเอกสารประกอบ
เยี่ยม ตอนนี้เราพร้อมที่จะไปยังขั้นตอนถัดไปแล้ว นั่นคือการทำความเข้าใจชุดข้อมูล
4. ทำความเข้าใจชุดข้อมูลบริษัท
สำหรับ Codelab นี้ เราจะใช้ฐานข้อมูล Neo4j แบบอ่านอย่างเดียวที่ป้อนข้อมูลการลงทุนและบริษัทจากกราฟความรู้ของ Diffbot ไว้ล่วงหน้า
ชุดข้อมูลประกอบด้วย
- โหนด 237,358 รายการที่แสดงถึง
- องค์กร (บริษัท)
- บุคคล (ผู้บริหาร พนักงาน)
- บทความ (ข่าวและการกล่าวถึง)
- อุตสาหกรรม
- เทคโนโลยี
- นักลงทุน
- ความสัมพันธ์ซึ่งรวมถึง
HAS_INVESTOR- การเชื่อมต่อการลงทุนHAS_COMPETITOR- ความสัมพันธ์เชิงแข่งขันMENTIONS- การอ้างอิงบทความHAS_CEO- ความสัมพันธ์ในการจ้างงานHAS_CATEGORY- การจัดประเภทอุตสาหกรรม
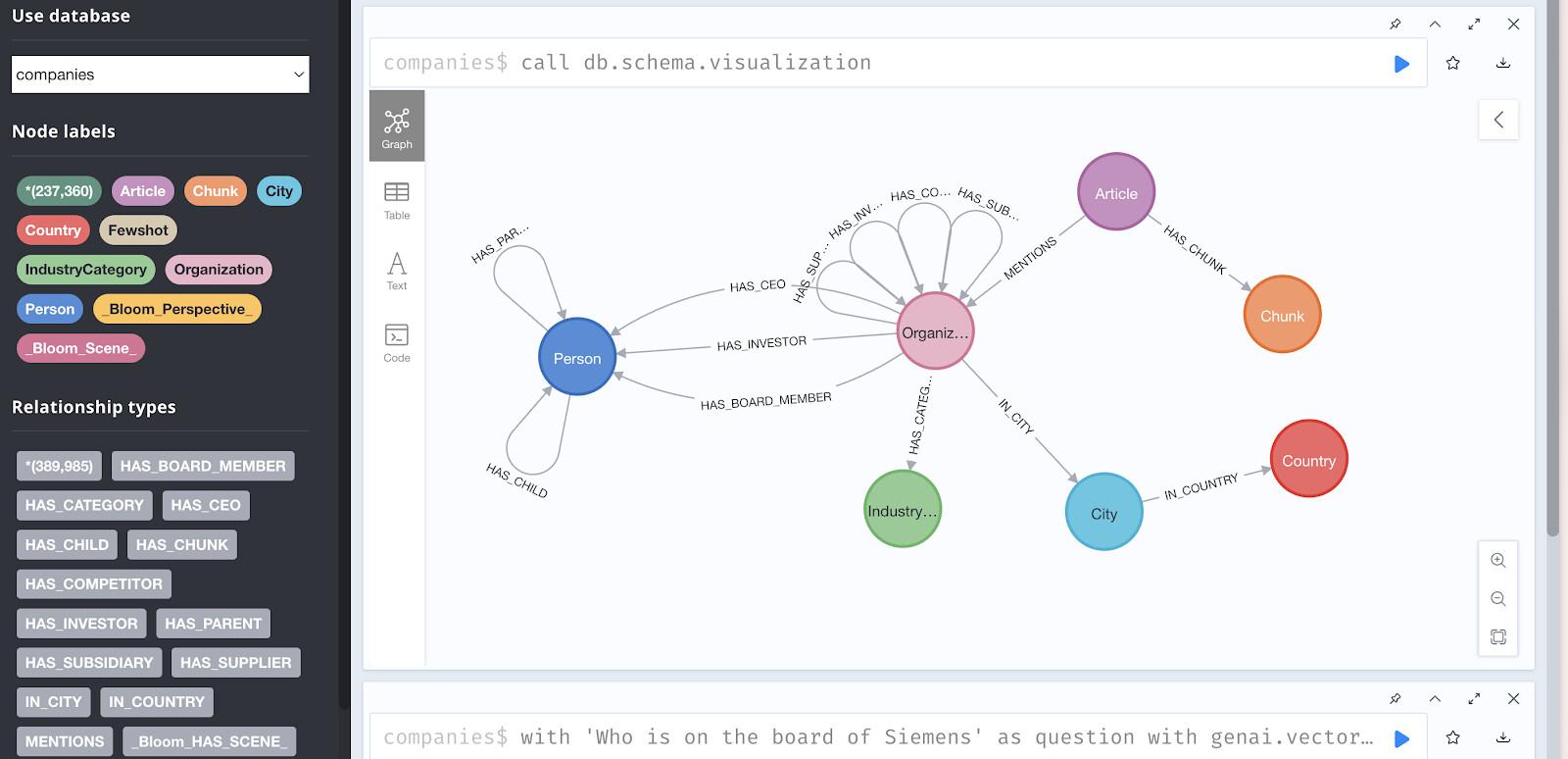
เข้าถึงฐานข้อมูลสาธิต
สำหรับ Codelab นี้ เราจะใช้อินสแตนซ์สาธิตที่โฮสต์ เพิ่มข้อมูลเข้าสู่ระบบต่อไปนี้ลงในโน้ต
URI: neo4j+s://demo.neo4jlabs.com
Username: companies
Password: companies
Database: companies
การเข้าถึงเบราว์เซอร์:
คุณสามารถสำรวจข้อมูลแบบภาพได้ที่ https://demo.neo4jlabs.com:7473
เข้าสู่ระบบด้วยข้อมูลเข้าสู่ระบบเดียวกัน แล้วลองเรียกใช้คำสั่งต่อไปนี้
// Sample query to explore the graph
MATCH (c:Organization)-[:HAS_COMPETITOR]-(competitor:Organization)
RETURN c.name, competitor.name
LIMIT 10
การแสดงโครงสร้างกราฟเป็นภาพ
ลองใช้การค้นหานี้ใน Neo4j Browser เพื่อดูรูปแบบความสัมพันธ์
// Find investors and their portfolio companies
MATCH (company:Organization)-[:HAS_INVESTOR]->(investor:Person)
WITH investor, collect(company.name) as portfolio
RETURN investor.name, size(portfolio) as num_investments, portfolio
ORDER BY num_investments DESC
LIMIT 5
คําค้นหานี้จะแสดงนักลงทุนที่ใช้งานมากที่สุด 5 อันดับแรกและพอร์ตโฟลิโอของนักลงทุนเหล่านั้น
เหตุใดจึงควรใช้ฐานข้อมูลนี้สำหรับ GraphRAG
ชุดข้อมูลนี้เหมาะอย่างยิ่งสำหรับการสาธิต GraphRAG เนื่องจาก
- ความสัมพันธ์ที่ซับซ้อน: ความเชื่อมโยงที่ซับซ้อนระหว่างเอนทิตี
- ข้อมูลในโลกแห่งความเป็นจริง: บริษัท บุคคล และบทความข่าวจริง
- การค้นหาแบบหลายขั้นตอน: ต้องมีการข้ามประเภทความสัมพันธ์หลายประเภท
- ข้อมูลตามเวลา: บทความที่มีการประทับเวลาสำหรับการวิเคราะห์ตามเวลา
- การวิเคราะห์ความเห็น: คะแนนความเห็นที่คำนวณไว้ล่วงหน้าสำหรับบทความ
เมื่อคุณเข้าใจโครงสร้างข้อมูลแล้ว มาตั้งค่าสภาพแวดล้อมในการพัฒนาซอฟต์แวร์กันเลย
5. โคลนที่เก็บและกำหนดค่าสภาพแวดล้อม
โคลนที่เก็บ
ในเทอร์มินัล Cloud Shell ให้เรียกใช้คำสั่งต่อไปนี้
# Clone the repository
git clone https://github.com/sidagarwal04/neo4j-adk-multiagents.git
# Navigate into the directory
cd neo4j-adk-multiagents
สำรวจโครงสร้างที่เก็บ
โปรดสละเวลาสักครู่เพื่อทำความเข้าใจเลย์เอาต์ของโปรเจ็กต์
neo4j-adk-multiagents/
├── investment_agent/ # Main agent code
│ ├── agent.py # Agent definitions
│ ├── tools.py # Custom tool functions
│ └── .adk/ # ADK configuration
│ └── tools.yaml # MCP tool definitions
├── main.py # Application entry point
├── setup_tools_yaml.py # Configuration generator
├── requirements.txt # Python dependencies
├── example.env # Environment template
└── README.md # Project documentation
ตั้งค่าสภาพแวดล้อมเสมือน
สร้างและเปิดใช้งานสภาพแวดล้อมเสมือนของ Python โดยใช้ uv
# Install uv if not already installed
pip install uv
# Create virtual environment
uv venv
# Activate the environment
source .venv/bin/activate # On macOS/Linux
# or
.venv\Scripts\activate # On Windows
คุณควรเห็น (.venv) นำหน้าพรอมต์ของเทอร์มินัล
ติดตั้งการอ้างอิง
ติดตั้งแพ็กเกจที่จำเป็นทั้งหมด
uv pip install -r requirements.txt
การขึ้นต่อกันที่สำคัญมีดังนี้
txtgoogle-adk>=1.21.0 # Agent Development Kit
neo4j>=6.0.3 # Neo4j Python driver
python-dotenv>=1.0.0 # Environment variables
google-cloud-aiplatform>=1.30.0 # Vertex AI
กำหนดค่าตัวแปรสภาพแวดล้อม
- สร้าง**
.env** **ไฟล์**
cp example.env .env
- แก้ไขไฟล์ **
.env** ดังนี้
หากใช้ Cloud Shell ให้คลิก "เปิดตัวแก้ไข" ในแถบเครื่องมือ แล้วไปที่ .env และอัปเดตดังนี้
วิธีแสดงไฟล์ .env ที่ซ่อนไว้
คลิก View > Toggle Hidden files ใน Google Cloud Shell Editor
# Neo4j Configuration (Demo Database)
NEO4J_URI=neo4j+s://demo.neo4jlabs.com
NEO4J_USERNAME=companies
NEO4J_PASSWORD=companies
NEO4J_DATABASE=companies
# Google AI Configuration
# Choose ONE of the following options:
# Option 1: Google AI API (Recommended)
GOOGLE_GENAI_USE_VERTEXAI=0
GOOGLE_API_KEY=your_api_key_here # Get from https://aistudio.google.com/app/apikey
# Option 2: Vertex AI (If using GCP)
# GOOGLE_GENAI_USE_VERTEXAI=1
# GOOGLE_CLOUD_PROJECT=your-project-id
# GOOGLE_CLOUD_LOCATION=us-central1
# ADK Configuration
GOOGLE_ADK_MODEL=gemini-3.1-flash-lite-preview # or gemini-3-flash-preview
# MCP Toolbox Configuration
MCP_TOOLBOX_URL=https://toolbox-990868019953.us-central1.run.app/mcp/sse
- สร้างการกำหนดค่า MCP Toolbox
เรียกใช้สคริปต์การตั้งค่าเพื่อสร้างไฟล์ tools.yaml จากตัวแปรสภาพแวดล้อม
python setup_tools_yaml.py
ซึ่งจะสร้าง investment_agent/.adk/tools.yaml โดยกำหนดค่าข้อมูลเข้าสู่ระบบ Neo4j อย่างถูกต้องสำหรับเครื่องมือ MCP
ยืนยันการกำหนดค่า
ตรวจสอบว่าได้ตั้งค่าทุกอย่างอย่างถูกต้องแล้ว
# Verify .env file exists
ls -la .env
# Verify tools.yaml was generated
ls -la investment_agent/.adk/tools.yaml
# Test Python environment
python -c "import google.adk; print('ADK installed successfully')"
# Test Neo4j connection
python -c "from neo4j import GraphDatabase; print('Neo4j driver installed')"
ตอนนี้สภาพแวดล้อมในการพัฒนาซอฟต์แวร์ได้รับการกำหนดค่าอย่างสมบูรณ์แล้ว จากนั้นเราจะเจาะลึกสถาปัตยกรรมแบบหลายเอเจนต์
6. ทำความเข้าใจสถาปัตยกรรมแบบหลาย Agent
ระบบตัวแทน 4 ราย
ระบบการวิจัยการลงทุนของเราใช้สถาปัตยกรรมแบบหลายเอเจนต์แบบลำดับชั้น โดยมีเอเจนต์เฉพาะทาง 4 รายทำงานร่วมกันเพื่อตอบคำค้นหาที่ซับซ้อนเกี่ยวกับบริษัท นักลงทุน และข้อมูลเชิงลึกของตลาด
┌──────────────┐
│ Root Agent │ ◄── User Query
└──────┬───────┘
│
┌────────────────┼────────────────┐
│ │ │
┌─────▼─────┐ ┌────▼─────┐ ┌────▼──────────┐
│ Graph DB │ │ Investor │ │ Investment │
│ Agent │ │ Research │ │ Research │
└───────────┘ │ Agent │ │ Agent │
└──────────┘ └───────────────┘
- Root Agent (Orchestrator):
Root Agent ทำหน้าที่เป็นผู้ประสานงานอัจฉริยะของทั้งระบบ โดยจะรับคำค้นหาของผู้ใช้ วิเคราะห์ความตั้งใจ และกำหนดเส้นทางคำขอไปยังเอเจนต์ผู้เชี่ยวชาญที่เหมาะสมที่สุด โดยคุณสามารถคิดว่าเครื่องมือนี้เป็นเหมือนผู้จัดการโปรเจ็กต์ที่เข้าใจว่าสมาชิกในทีมคนใดเหมาะกับงานแต่ละอย่างมากที่สุด นอกจากนี้ยังจัดการการรวบรวมคำตอบ จัดรูปแบบผลลัพธ์เป็นตารางหรือแผนภูมิเมื่อมีการขอ และรักษาบริบทการสนทนาในการค้นหาหลายครั้ง Root Agent จะเลือกใช้ Agent เฉพาะทางมากกว่า Agent ฐานข้อมูลทั่วไปเสมอ เพื่อให้มั่นใจว่าคำค้นหาจะได้รับการจัดการโดยคอมโพเนนต์ที่มีความเชี่ยวชาญมากที่สุด
- Graph Database Agent:
Graph Database Agent คือการเชื่อมต่อโดยตรงกับความสามารถของกราฟที่มีประสิทธิภาพของ Neo4j โดยจะเข้าใจสคีมาของฐานข้อมูล สร้างการค้นหา Cypher จากภาษาธรรมชาติ และดำเนินการกราฟที่ซับซ้อน เอเจนต์นี้เชี่ยวชาญด้านคำถามเชิงโครงสร้าง การรวบรวม และการให้เหตุผลแบบหลายขั้นตอนในกราฟความรู้ ซึ่งเป็นผู้เชี่ยวชาญสำรองเมื่อการค้นหาต้องใช้ตรรกะที่กำหนดเองซึ่งเครื่องมือที่กำหนดไว้ล่วงหน้าจัดการไม่ได้ จึงเป็นสิ่งจำเป็นสำหรับการวิเคราะห์เชิงสำรวจและการค้นหาเชิงวิเคราะห์ที่ซับซ้อนซึ่งไม่ได้คาดการณ์ไว้ในการออกแบบระบบ
- ตัวแทนวิจัยนักลงทุน:
เอเจนต์การวิจัยนักลงทุนมุ่งเน้นเฉพาะความสัมพันธ์ด้านการลงทุนและการวิเคราะห์พอร์ตโฟลิโอ โดยสามารถค้นหาผู้ที่ลงทุนในบริษัทที่เฉพาะเจาะจงโดยใช้การจับคู่ชื่อที่ตรงกันทุกประการ ดึงข้อมูลพอร์ตโฟลิโอการลงทุนที่สมบูรณ์ซึ่งแสดงการลงทุนทั้งหมด และวิเคราะห์รูปแบบการลงทุนในอุตสาหกรรมต่างๆ ความเชี่ยวชาญนี้ทำให้โมเดลมีประสิทธิภาพอย่างยิ่งในการตอบคำถาม เช่น "ใครลงทุนใน ByteDance" หรือ "Sequoia Capital ลงทุนในอะไรอีก" Agent ใช้ฟังก์ชัน Python ที่กำหนดเองซึ่งค้นหาฐานข้อมูล Neo4j โดยตรงเพื่อหาความสัมพันธ์ที่เกี่ยวข้องกับนักลงทุน
- ตัวแทนวิจัยการลงทุน:
Investment Research Agent ใช้ประโยชน์จาก Model Context Protocol (MCP) Toolbox เพื่อเข้าถึงคำค้นหาที่ผ่านการตรวจสอบล่วงหน้าและเขียนโดยผู้เชี่ยวชาญ โดยสามารถดึงข้อมูลอุตสาหกรรมทั้งหมดที่มี เรียกข้อมูลบริษัทภายในอุตสาหกรรมที่เฉพาะเจาะจง ค้นหาบทความที่มีการวิเคราะห์ความเห็น ค้นพบการกล่าวถึงองค์กรในข่าว และรับข้อมูลเกี่ยวกับผู้ที่ทำงานในบริษัท ต่างจาก Graph Database Agent ที่สร้างการค้นหาแบบไดนามิก เอเจนต์นี้ใช้การค้นหาที่ปลอดภัย มีการเพิ่มประสิทธิภาพ กำหนดไว้ล่วงหน้า ซึ่งได้รับการจัดการและตรวจสอบจากส่วนกลาง ซึ่งทำให้ทั้งปลอดภัยและมีประสิทธิภาพสำหรับเวิร์กโฟลว์การวิจัยทั่วไป
7. การเรียกใช้และการทดสอบระบบหลายเอเจนต์
เปิดแอปพลิเคชัน
เมื่อคุณเข้าใจสถาปัตยกรรมแล้ว เรามาเรียกใช้ระบบทั้งหมดและโต้ตอบกับระบบกัน
เปิดอินเทอร์เฟซเว็บของ ADK
# Make sure you're in the project directory with activated virtual environment
cd ~/neo4j-adk-multiagents
source .venv/bin/activate # If not already activated
# Launch the application
uv run adk web
คุณควรเห็นเอาต์พุตที่คล้ายกับตัวอย่างต่อไปนี้
INFO: Started server process [2542]
INFO: Waiting for application startup.
+----------------------------------------------------------------+
| ADK Web Server started |
| |
| For local testing, access at http://127.0.0.1:8000. |
+----------------------------------------------------------------+
INFO: Application startup complete.
INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
คำค้นหาทดสอบและลักษณะการทำงานที่คาดไว้
มาดูความสามารถของระบบด้วยการค้นหาที่ซับซ้อนขึ้นเรื่อยๆ กัน
การค้นหาพื้นฐาน (ตัวแทนรายเดียว)
คำค้นหา 1: ค้นพบอุตสาหกรรม
What industries are available in the database?
ลักษณะการทำงานที่คาดไว้
- Root Agent จะกำหนดเส้นทางไปยัง Investment Research Agent
- ใช้เครื่องมือ MCP:
get_industries() - แสดงผลรายการอุตสาหกรรมทั้งหมดในรูปแบบ
สิ่งที่ควรสังเกต
ใน UI ของ ADK ให้ขยายรายละเอียดการดำเนินการเพื่อดูข้อมูลต่อไปนี้
- การตัดสินใจเลือกตัวแทน
- การเรียกใช้เครื่องมือ:
get_industries() - ผลลัพธ์ดิบจาก Neo4j
- คำตอบที่จัดรูปแบบ
คำค้นหา 2: ค้นหานักลงทุน
Who invested in ByteDance?
ลักษณะการทำงานที่คาดไว้
- ตัวแทนรูทระบุว่านี่คือคำถามที่เกี่ยวข้องกับนักลงทุน
- เส้นทางไปยังตัวแทนวิจัยด้านการลงทุน
- ใช้เครื่องมือ:
find_investor_by_name("ByteDance") - แสดงผู้ลงทุนพร้อมประเภท (บุคคล/องค์กร)
การตอบกลับที่คาดไว้:
I found 2 investors in ByteDance:
1. Rong Yue (Person)
2. Wendi Murdoch (Person)
Would you like to know more about their investment portfolios?
คำค้นหาที่ 3: บริษัทตามอุตสาหกรรม**
I found 2 investors in ByteDance:
1. Rong Yue (Person)
2. Wendi Murdoch (Person)
Would you like to know more about their investment portfolios?
"Show me companies in the Artificial Intelligence industry"
ลักษณะการทำงานที่คาดไว้
- Root Agent จะกำหนดเส้นทางไปยัง Investment Research Agent
- ใช้เครื่องมือ MCP:
get_companies_in_industry("Artificial Intelligence") - แสดงรายการบริษัท AI พร้อมรหัสและวันที่ก่อตั้ง
สิ่งที่ควรสังเกต
- สังเกตวิธีที่ Agent ใช้การจับคู่ชื่ออุตสาหกรรมที่ตรงกันทุกประการ
- ระบบจะจำกัดผลลัพธ์เพื่อป้องกันไม่ให้มีเอาต์พุตมากเกินไป
- จัดรูปแบบข้อมูลอย่างชัดเจนเพื่อให้สามารถอ่านได้
คำถามระดับกลาง (หลายขั้นตอนภายในเอเจนต์เดียว)
คำค้นหาที่ 4: การวิเคราะห์ความรู้สึก
Find articles with positive sentiment from January 2023
ลักษณะการทำงานที่คาดไว้
- เส้นทางไปยัง Investment Research Agent
- ใช้เครื่องมือ MCP:
get_articles_with_sentiment(0.7, 2023, 1) - แสดงบทความที่มีชื่อ คะแนนความรู้สึก และวันที่ตีพิมพ์
เคล็ดลับการแก้ไขข้อบกพร่อง:
ดูพารามิเตอร์การเรียกใช้เครื่องมือ
min_sentiment: 0.7 (เอเจนต์ตีความ "เป็นบวก" เป็น >= 0.7)year: 2023month: 1
คำค้นหา 5: การค้นหาฐานข้อมูลที่ซับซ้อน
How many companies are in the database?
ลักษณะการทำงานที่คาดไว้
- Root Agent จะกำหนดเส้นทางไปยัง Graph Database Agent
- ตัวแทนโทรหา
get_neo4j_schema()ก่อนเพื่อทำความเข้าใจโครงสร้าง - สร้าง Cypher:
MATCH (c:Company) RETURN count(c) - เรียกใช้การค้นหาและแสดงผลจำนวน
การตอบกลับที่คาดไว้:
There are 8,064 companies in the database.
การสืบค้นขั้นสูง (การประสานงานแบบหลายเอเจนต์)
คำค้นหาที่ 6: การวิเคราะห์พอร์ตโฟลิโอ
Who invested in ByteDance and what else have they invested in?
ลักษณะการทำงานที่คาดไว้
นี่คือคำค้นหา 2 ส่วนที่ต้องมีการประสานงานกับตัวแทน
- ขั้นตอนที่ 1: Root Agent → Investor Research Agent
- การโทร
find_investor_by_name("ByteDance") - รับรายชื่อนักลงทุน: [Rong Yue, Wendi Murdoch]
- ขั้นตอนที่ 2: สำหรับนักลงทุนแต่ละราย → ตัวแทนวิจัยนักลงทุน
- การโทร
find_investor_by_id(investor_id) - ดึงข้อมูลพอร์ตโฟลิโอทั้งหมด
- ขั้นตอนที่ 3: Root Agent รวบรวมและจัดรูปแบบ
การตอบกลับที่คาดไว้:
I found 2 investors in ByteDance. Here are their portfolios:
1. Rong Yue (Person)
- ByteDance
- Inspur
2. Wendi Murdoch (Person)
- ByteDance
- (No other investments in database)
สิ่งที่ควรสังเกต
- การเรียกใช้เครื่องมือหลายรายการตามลำดับ
- คงบริบทไว้ระหว่างขั้นตอน
- ผลลัพธ์ที่รวบรวมอย่างชาญฉลาด
คำค้นหา 7: การวิจัยแบบหลายโดเมน
What are 5 AI companies mentioned in positive articles, and who are their CEOs?
ลักษณะการทำงานที่คาดไว้
การค้นหาที่ซับซ้อนนี้ต้องใช้ตัวแทนและเครื่องมือหลายอย่าง
- ขั้นตอนที่ 1: ตัวแทนวิจัยการลงทุน
get_companies_in_industry("Artificial Intelligence")- แสดงรายการบริษัท AI
- ขั้นตอนที่ 2: ตัวแทนวิจัยการลงทุน
get_articles_with_sentiment(0.8)- แสดงบทความเชิงบวก
- ขั้นตอนที่ 3: ตัวกรองของเอเจนต์รูท
- ระบุบริษัท AI ที่ปรากฏในบทความเชิงบวก
- เลือก 5 อันดับแรก
- ขั้นตอนที่ 4: ตัวแทนวิจัยการลงทุน
get_people_in_organizations([company_names], "CEO")- แสดงข้อมูล CEO
- ขั้นตอนที่ 5: จัดรูปแบบ Agent รูทเป็นตาราง
การตอบกลับที่คาดไว้:
Here are 5 AI companies with positive news and their CEOs:
| Company | Industry | CEO | Avg Sentiment |
|---------|----------|-----|---------------|
| OpenAI | Artificial Intelligence | Sam Altman | 0.92 |
| Anthropic | Artificial Intelligence | Dario Amodei | 0.89 |
| ... | ... | ... | ... |
สิ่งที่ควรสังเกต
- การเรียกใช้เครื่องมือหลายรายการในเอเจนต์ต่างๆ
- ตรรกะการกรองและการรวมข้อมูล
- การจัดรูปแบบตารางอย่างมืออาชีพ
คำค้นหาที่ 8: การวิเคราะห์คู่แข่ง
Who are YouTube's main competitors?
ลักษณะการทำงานที่คาดไว้
- Root Agent จะกำหนดเส้นทางไปยัง Graph Database Agent (การค้นหาความสัมพันธ์)
- Agent สร้าง Cypher ที่ปรับปรุงด้วย GraphRAG ดังนี้
MATCH (c:Company {name: "YouTube"})-[:COMPETES_WITH]->(competitor)
RETURN competitor.name as competitor_name
- แสดงรายการบริษัทคู่แข่ง
การตอบกลับที่คาดไว้:
YouTube's main competitors are:
- TikTok (ByteDance)
- Dailymotion
- Twitter
- BuzzFeed
- Mixer
- OpenAI (for video content)
คำค้นหาติดตามผลแบบ Context-Aware
คำค้นหา 9: คำถามติดตามผล (หลังจากคำค้นหา 8)
Which investors funded both YouTube and its competitors?
ลักษณะการทำงานที่คาดไว้
- Root Agent จะจดจำบริบทก่อนหน้า (YouTube และคู่แข่ง)
- เส้นทางไปยังตัวแทนวิจัยด้านการลงทุน
- สำหรับ YouTube และคู่แข่งแต่ละราย ให้ค้นหานักลงทุน
- ระบุนักลงทุนที่ปรากฏในหลายบริษัท
การตอบกลับที่คาดไว้:
Based on our previous analysis of YouTube's competitors, I found these
investors who funded multiple companies in this competitive landscape:
Sequoia Capital invested in:
- YouTube
- TikTok (ByteDance)
- Twitter
Accel Partners invested in:
- YouTube
- BuzzFeed
This suggests these investors have strategic positions across the video content platform ecosystem.
คำค้นหา 10: สรุปการวิจัย
Summarize our research findings so far
ลักษณะการทำงานที่คาดไว้
- Root Agent ตรวจสอบประวัติการสนทนา
- สังเคราะห์ผลลัพธ์ที่สำคัญจากคำค้นหาก่อนหน้า
- ให้ข้อมูลสรุปที่สอดคล้องกัน
การตอบกลับที่คาดไว้:
Here's a summary of our investment research session:
1. Industry Overview: We explored the Artificial Intelligence industry
with 150+ companies in the database.
2. ByteDance Analysis:
- Investors: Rong Yue, Wendi Murdoch
- Rong Yue also invested in Inspur
3. Market Sentiment: We analyzed articles from January 2023, finding
strong positive sentiment (avg 0.85) for tech companies.
4. Competitive Landscape: YouTube faces competition from TikTok,
Dailymotion, and others, with some investors (Sequoia, Accel) holding
positions across competing platforms.
5. Key Players: Identified CEOs of major AI companies with positive media coverage.
ทำความเข้าใจการโต้ตอบของเอเจนต์ในมุมมองการแก้ไขข้อบกพร่อง
อินเทอร์เฟซเว็บของ ADK จะให้การมองเห็นการดำเนินการโดยละเอียด สิ่งที่คุณควรตรวจสอบมีดังนี้
- ลำดับเวลาของเหตุการณ์
แสดงลำดับเวลา
[USER] Query received
[ROOT_AGENT] Analyzing query intent
[ROOT_AGENT] Routing to investment_research_agent
[INVESTMENT_RESEARCH_AGENT] Tool call: get_companies_in_industry
[TOOL] Executing with params: {"industry_name": "Artificial Intelligence"}
[TOOL] Returned 47 results
[INVESTMENT_RESEARCH_AGENT] Formatting response
[ROOT_AGENT] Presenting to user
- รายละเอียดการเรียกใช้เครื่องมือ
คลิกการเรียกใช้เครื่องมือเพื่อดูข้อมูลต่อไปนี้
- ชื่อฟังก์ชัน
- พารามิเตอร์อินพุต
- ค่าที่แสดงผล
- เวลาดำเนินการ
- ข้อผิดพลาด
- การตัดสินใจของเอเจนต์
สังเกตการให้เหตุผลของ LLM
- เหตุผลที่เลือกเอเจนต์รายใดรายหนึ่ง
- วิธีที่ระบบตีความคำค้นหา
- เครื่องมือที่พิจารณา
- เหตุผลที่จัดรูปแบบผลลัพธ์ในลักษณะหนึ่งๆ
การสังเกตการณ์และข้อมูลเชิงลึกที่พบบ่อย
- รูปแบบการกำหนดเส้นทางการค้นหา:
- คีย์เวิร์ด เช่น "นักลงทุน" "ลงทุน" → ตัวแทนการวิจัยนักลงทุน
- คีย์เวิร์ด เช่น "อุตสาหกรรม" "บริษัท" "บทความ" → ตัวแทนการวิจัยการลงทุน
- การรวม การนับ ตรรกะที่ซับซ้อน → Graph Database Agent
- หมายเหตุเกี่ยวกับประสิทธิภาพ:
- โดยปกติแล้วเครื่องมือ MCP จะเร็วกว่า (การค้นหาที่เพิ่มประสิทธิภาพไว้ล่วงหน้า)
- การสร้าง Cypher ที่ซับซ้อนจะใช้เวลานานกว่า (เวลาที่ LLM ใช้ในการคิด)
- การเรียกใช้เครื่องมือหลายรายการจะเพิ่มเวลาในการตอบสนอง แต่ให้ผลลัพธ์ที่สมบูรณ์ยิ่งขึ้น
- การจัดการข้อผิดพลาด:
- หากการค้นหาล้มเหลว ให้ทำดังนี้
- ตัวแทนอธิบายสิ่งที่ผิดพลาด
- แนะนำการแก้ไข (เช่น "ไม่พบชื่อบริษัท โปรดตรวจสอบตัวสะกด")
- อาจลองใช้วิธีอื่น
เคล็ดลับในการทดสอบที่มีประสิทธิภาพ
- เริ่มจากง่ายๆ: ทดสอบฟังก์ชันหลักของเอเจนต์แต่ละรายก่อนที่จะทดสอบคำค้นหาที่ซับซ้อน
- ใช้คำถามติดตามผล: ทดสอบการจดจำบริบทด้วยคำถามติดตามผล
- สังเกตการกำหนดเส้นทาง: ดูว่าตัวแทนคนใดจัดการคำค้นหาแต่ละรายการเพื่อทำความเข้าใจตรรกะ
- ตรวจสอบการเรียกใช้เครื่องมือ: ตรวจสอบว่าระบบดึงพารามิเตอร์จากภาษาธรรมชาติได้อย่างถูกต้อง
- ทดสอบกรณีสุดโต่ง: ลองใช้คำค้นหาที่คลุมเครือ คำที่สะกดผิด หรือคำขอที่ผิดปกติ
ตอนนี้คุณมีระบบ GraphRAG แบบหลายเอเจนต์ที่ทำงานได้อย่างเต็มรูปแบบแล้ว ทดลองใช้คำถามของคุณเองเพื่อสำรวจความสามารถของโมเดล
8. ล้างข้อมูล
โปรดทำตามขั้นตอนต่อไปนี้เพื่อเลี่ยงไม่ให้เกิดการเรียกเก็บเงินกับบัญชี Google Cloud สำหรับทรัพยากรที่ใช้ในโพสต์นี้
- ในคอนโซล Google Cloud ให้ไปที่หน้าจัดการทรัพยากร
- ในรายการโปรเจ็กต์ ให้เลือกโปรเจ็กต์ที่ต้องการลบ แล้วคลิกลบ
- ในกล่องโต้ตอบ ให้พิมพ์รหัสโปรเจ็กต์ แล้วคลิกปิดเพื่อลบโปรเจ็กต์
9. ขอแสดงความยินดี
🎉 ยินดีด้วย คุณสร้างระบบ GraphRAG แบบหลาย Agent ที่มีคุณภาพระดับโปรดักชันได้สำเร็จแล้วโดยใช้ Agent Development Kit, Neo4j และ MCP Toolbox ของ Google
การรวมความสามารถในการจัดระเบียบอัจฉริยะของ ADK เข้ากับโมเดลข้อมูลที่อิงตามความสัมพันธ์ของ Neo4j และความปลอดภัยของคำค้นหา MCP ที่ตรวจสอบล่วงหน้าแล้ว ทำให้คุณได้สร้างระบบที่ซับซ้อนซึ่งทำงานได้มากกว่าการค้นหาฐานข้อมูลแบบง่ายๆ โดยระบบจะทำความเข้าใจบริบท การให้เหตุผลในความสัมพันธ์ที่ซับซ้อน และประสานงานกับ Agent เฉพาะทางเพื่อมอบข้อมูลเชิงลึกที่ครอบคลุมและแม่นยำ
ใน Codelab นี้ คุณได้ทำสิ่งต่อไปนี้
✅ สร้างระบบ Multi-Agent โดยใช้ Agent Development Kit (ADK) ของ Google พร้อมการจัดระเบียบแบบลำดับชั้น
✅ ฐานข้อมูลกราฟ Neo4j ที่ผสานรวมเพื่อใช้ประโยชน์จากคำค้นหาที่รับรู้ความสัมพันธ์และการให้เหตุผลแบบหลายขั้นตอน
✅ ใช้ MCP Toolbox สำหรับการค้นหาฐานข้อมูลที่ปลอดภัยและตรวจสอบล่วงหน้าเป็นเครื่องมือที่นำกลับมาใช้ใหม่ได้
✅ สร้างเอเจนต์เฉพาะทางสำหรับการวิจัยนักลงทุน การวิเคราะห์การลงทุน และการดำเนินการฐานข้อมูลกราฟ
✅ ออกแบบการกำหนดเส้นทางอัจฉริยะที่มอบหมายคำถามไปยังตัวแทนผู้เชี่ยวชาญที่เหมาะสมที่สุดโดยอัตโนมัติ
✅ จัดการประเภทข้อมูลที่ซับซ้อนด้วยการซีเรียลไลซ์ประเภท Neo4j ที่เหมาะสมเพื่อการผสานรวม Python ที่ราบรื่น
✅ ใช้แนวทางปฏิบัติแนะนำในการผลิตสำหรับการออกแบบเอเจนต์ การจัดการข้อผิดพลาด และการแก้ไขข้อบกพร่องของระบบ
ขั้นตอนต่อไปคือ
สถาปัตยกรรม GraphRAG แบบหลายเอเจนต์นี้ไม่ได้จำกัดอยู่แค่การวิจัยด้านการลงทุน แต่ยังขยายไปถึงสิ่งต่อไปนี้ได้ด้วย
- บริการทางการเงิน: การเพิ่มประสิทธิภาพพอร์ตโฟลิโอ การประเมินความเสี่ยง การตรวจหาการประพฤติมิชอบ
- การดูแลสุขภาพ: การประสานงานการดูแลผู้ป่วย การวิเคราะห์ปฏิกิริยาระหว่างยา การวิจัยทางคลินิก
- อีคอมเมิร์ซ: คำแนะนำที่ปรับเปลี่ยนในแบบของคุณ การเพิ่มประสิทธิภาพซัพพลายเชน ข้อมูลเชิงลึกเกี่ยวกับลูกค้า
- กฎหมายและการปฏิบัติตามข้อกำหนด: การวิเคราะห์สัญญา การตรวจสอบกฎระเบียบ การค้นคว้ากฎหมาย
- การวิจัยเชิงวิชาการ: การทบทวนวรรณกรรม การค้นพบการทำงานร่วมกัน การวิเคราะห์การอ้างอิง
- ข้อมูลอัจฉริยะขององค์กร: การวิเคราะห์การแข่งขัน การวิจัยตลาด กราฟความรู้ขององค์กร
ไม่ว่าคุณจะมีข้อมูลที่ซับซ้อนและเชื่อมต่อกัน + ความเชี่ยวชาญเฉพาะด้าน + อินเทอร์เฟซภาษาธรรมชาติ ที่ใดก็ตาม การผสมผสานระบบหลาย Agent ของ ADK + กราฟความรู้ของ Neo4j + คำค้นหาที่ผ่านการตรวจสอบ MCP จะช่วยขับเคลื่อนแอปพลิเคชันอัจฉริยะสำหรับองค์กรในยุคถัดไป
เมื่อชุดพัฒนา Agent ของ Google และโมเดล Gemini พัฒนาต่อไป คุณจะสามารถรวมรูปแบบการให้เหตุผลที่ซับซ้อนยิ่งขึ้น การผสานรวมข้อมูลแบบเรียลไทม์ และความสามารถแบบมัลติโมดัลเพื่อสร้างระบบที่ชาญฉลาดอย่างแท้จริงและรับรู้บริบทได้
สำรวจและสร้างสรรค์ต่อไป แล้วยกระดับแอปพลิเคชันเอเจนต์อัจฉริยะของคุณไปอีกขั้น
สำรวจบทแนะนำเกี่ยวกับกราฟความรู้ภาคปฏิบัติเพิ่มเติมได้ที่ Neo4j GraphAcademy และค้นพบรูปแบบเอเจนต์เพิ่มเติมในที่เก็บตัวอย่าง ADK
🚀 พร้อมที่จะสร้างระบบเอเจนต์อัจฉริยะตัวถัดไปแล้วหรือยัง