
1. 概览
在此 Codelab 中,您将构建一个复杂的多智能体投资研究系统,该系统将 Google 的智能体开发套件 (ADK)、Neo4j 图数据库和 Model Context Protocol (MCP) Toolbox 的强大功能融为一体。本实践教程演示了如何创建可通过图关系了解数据上下文并提供高度准确的查询回答的智能代理。
为什么选择 GraphRAG + 多智能体系统?
GraphRAG(基于图的检索增强生成)利用知识图谱丰富的关系结构来增强传统的 RAG 方法。GraphRAG 代理不仅可以搜索相似文档,还可以:
- 遍历实体之间的复杂关系
- 通过图结构了解上下文
- 根据关联的数据提供可解释的结果
- 在知识图谱中执行多跳推理
借助多智能体系统,您可以:
- 将复杂问题分解为专门的子任务
- 构建模块化、可维护的 AI 应用
- 实现并行处理和高效资源利用
- 通过编排创建分层推理模式
构建内容
您将创建一个完整的投资研究系统,其中包含:
- 图数据库代理:执行 Cypher 查询并了解 Neo4j 架构
- 投资者研究代理:发现投资者关系和投资组合
- 投资研究代理:通过 MCP 工具访问全面的知识图谱
- 根代理:智能编排所有子代理
系统将回答复杂的问题,例如:
- “YouTube 的主要竞争对手有哪些?”
- 2023 年 1 月,哪些公司被正面提及?
- “谁投资了字节跳动,他们还投资了哪些公司?”
架构概览
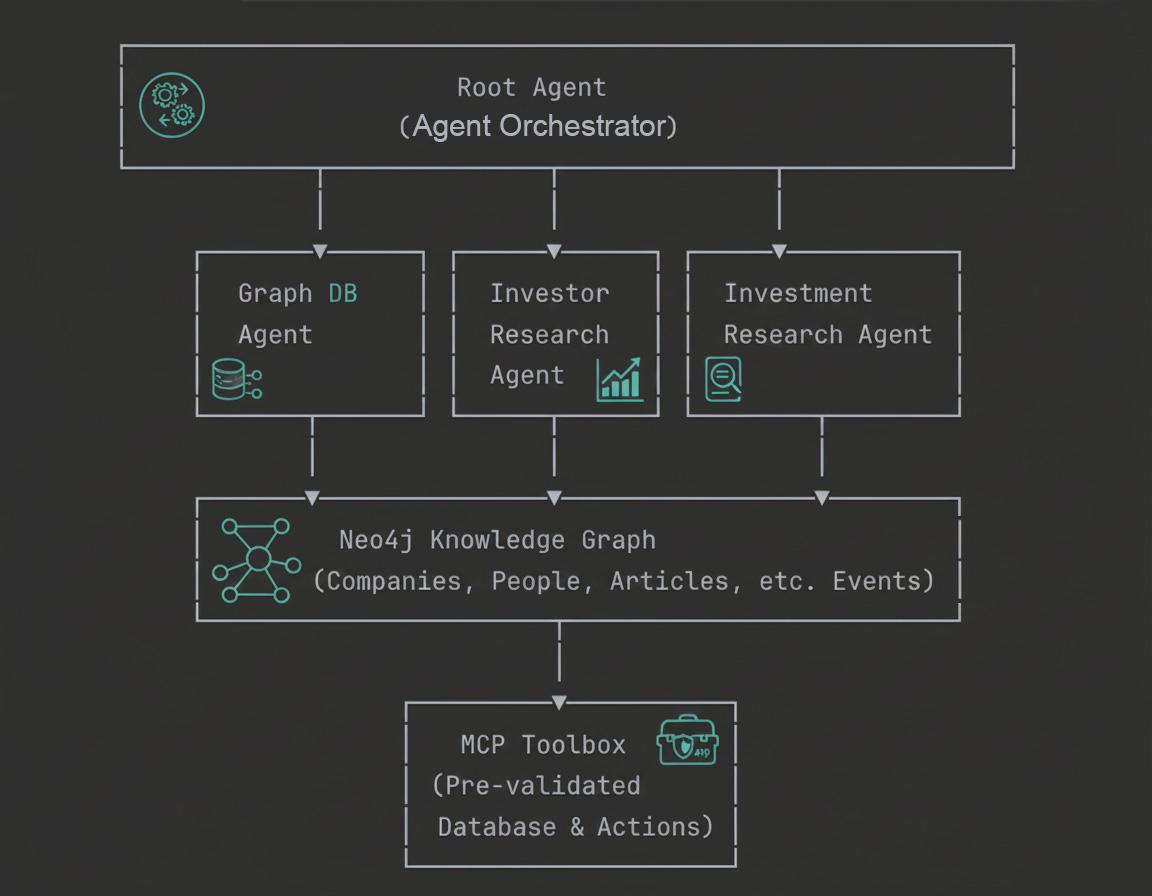
在此 Codelab 中,您将学习构建企业级 GraphRAG 代理的概念基础和实际实现。
学习内容
- 如何使用 Google 的智能体开发套件 (ADK) 构建多智能体系统
- 如何将 Neo4j 图数据库与 ADK 集成,以用于 GraphRAG 应用
- 如何为预验证的数据库查询实现 Model Context Protocol (MCP) 工具箱
- 如何为智能代理创建自定义工具和函数
- 如何设计智能体层次结构和编排模式
- 如何合理规划代理指令,以获得最佳效果
- 如何有效地调试多智能体互动
所需条件
- Chrome 网络浏览器
- Gmail 账号
- 启用了结算功能的 Google Cloud 项目
- 基本熟悉终端命令和 Python(有帮助,但不是必需的)
此 Codelab 专为各种水平的开发者(包括新手)设计,并在其示例应用中使用 Python 和 Neo4j。虽然对 Python 和图数据库有基本的了解会有所帮助,但无需任何先验知识即可理解相关概念或继续学习。
2. 了解 GraphRAG 和多智能体系统
在深入了解实现之前,我们先来了解一下支持此系统的关键概念。
Neo4j 是一款领先的原生图数据库,可将数据存储为节点(实体)和关系(实体之间的连接)的网络,非常适合需要了解连接的应用场景,例如推荐、欺诈检测、知识图谱等。与依赖于刚性表格或分层结构的关系型数据库或基于文档的数据库不同,Neo4j 的灵活图模型可以直观高效地表示复杂且相互关联的数据。
与关系型数据库以行和表的形式组织数据不同,Neo4j 使用图模型,其中信息表示为节点(实体)和关系(这些实体之间的连接)。此模型可让您非常直观地处理本身就存在关联的数据,例如人物、地点、商品,或者在本例中,电影、演员和电影类型。
例如,在电影数据集中:
- 节点可以表示
Movie、Actor或Director - 关系可以是
ACTED_IN或DIRECTED
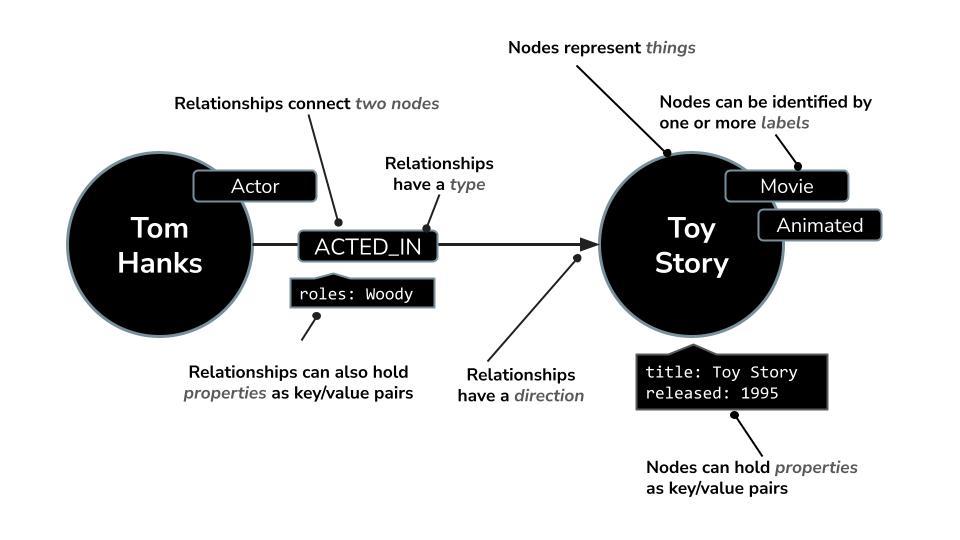
借助此结构,您可以轻松提出以下问题:
- 这位演员出演过哪些电影?
- 谁曾与克里斯托弗·诺兰合作过?
- 哪些电影因演员或类型相同而相似?
什么是 GraphRAG?
检索增强生成 (RAG) 通过从外部来源检索相关信息来增强 LLM 的回答。传统 RAG 通常会:
- 将文档嵌入到向量中
- 搜索相似向量
- 将检索到的文档传递给 LLM
GraphRAG 通过使用知识图谱来扩展此功能:
- 嵌入实体和关系
- 遍历图连接
- 检索多跳上下文信息
- 提供结构化且可解释的结果
为什么 AI 智能体需要图?
请考虑以下问题:“YouTube 的竞争对手有哪些?哪些投资者同时为 YouTube 及其竞争对手提供了资金?”
传统 RAG 方法中会发生什么:
- 搜索有关 YouTube 竞争对手的文档
- 单独搜索投资者信息
- 难以将这两部分信息联系起来
- 可能缺少隐式关系
GraphRAG 方法的运作方式:
MATCH (org:Organization {name: "OpenAI"})-[:HAS_COMPETITOR]-(competitor:Organization)
MATCH (org)-[:HAS_INVESTOR]->(investor:Person)
MATCH (competitor)-[:HAS_INVESTOR]->(investor)
RETURN org, competitor, investor
图表自然地表示关系,使多跳查询变得简单高效。
ADK 中的多智能体系统
智能体开发套件 (ADK) 是 Google 的开源框架,用于构建和部署可用于生产环境的 AI 智能体。它为多智能体编排、工具集成和工作流管理提供了直观的原语,可轻松将专业智能体组合成复杂的系统。ADK 可与 Gemini 无缝协作,并支持部署到 Cloud Run、Kubernetes 或任何基础架构。
智能体开发套件 (ADK) 提供用于构建多智能体系统的原语:
- 代理层次结构:
# Root agent coordinates specialized agents
root_agent = LlmAgent(
name="RootAgent",
sub_agents=[
graph_db_agent,
investor_agent,
investment_agent
]
)
- 专业化智能体:每个智能体都有
- 特定工具:可调用的函数
- 清晰的指令:其作用和功能
- 领域专业知识:了解其领域
- 编排模式:
- 顺序:按顺序执行智能体
- 并行:同时运行多个代理
- 有条件:根据查询类型进行路由
MCP Toolbox for Databases
Model Context Protocol (MCP) 是一种开放标准,用于将 AI 系统连接到外部数据源和工具。MCP Toolbox for Databases 是 Google 的一项实现,可实现声明式数据库查询管理,让您能够将预先验证的专家撰写的查询定义为可重用的工具。MCP Toolbox 不会让 LLM 生成可能不安全的查询,而是提供经过预先批准的查询并进行参数验证,从而在确保安全性、性能和可靠性的同时,为 AI 智能体保持灵活性。
传统方法:
# LLM generates query (may be incorrect/unsafe)
query = llm.generate("SELECT * FROM users WHERE...")
db.execute(query) # Risk of errors/SQL injection
MCP 方法:
# Pre-validated query definition
- name: get_industries
description: Fetch all industries from database
query: |
MATCH (i:Industry)
RETURN i.name, i.id
优点:
- 经过专家预先验证
- 免受注入攻击
- 优化性能
- 集中管理
- 可在多个代理中重复使用
重点内容一览
ADK 的 GraphRAG + 多智能体框架 + MCP 组合可打造强大的系统:
- 根代理接收用户查询
- 根据查询类型转接到专业客服人员
- 智能体使用 MCP 工具安全地提取数据
- 图结构提供丰富的上下文
- LLM 生成有事实依据且可解释的回答
现在我们已经了解了架构,接下来开始构建吧!
3. 设置 Google Cloud 项目
创建项目
- 在 Google Cloud Console 的项目选择器页面上,选择或创建一个 Google Cloud 项目。
- 确保您的 Cloud 项目已启用结算功能。了解如何检查项目是否已启用结算功能。
- 您将使用 Cloud Shell,它是在 Google Cloud 中运行的命令行环境。点击 Google Cloud 控制台顶部的“激活 Cloud Shell”。您可以在 Cloud Shell 中点击相应按钮,在 Cloud Shell 终端(用于运行云命令)和编辑器(用于构建项目)之间切换。

- 连接到 Cloud Shell 后,您可以使用以下命令检查自己是否已通过身份验证,以及项目是否已设置为您的项目 ID:
gcloud auth list
- 在 Cloud Shell 中运行以下命令,以确认 gcloud 命令了解您的项目。
gcloud config list project
- 如果项目未设置,请使用以下命令进行设置:
gcloud config set project <YOUR_PROJECT_ID>
如需了解 gcloud 命令和用法,请参阅文档。
太棒了!现在,我们可以继续执行下一步了,即了解数据集。
4. 了解 Companies 数据集
在此 Codelab 中,我们将使用一个只读 Neo4j 数据库,该数据库已预先填充了来自 Diffbot 的知识图谱的投资和公司数据。
该数据集包含:
- 237,358 个节点,表示:
- 组织(公司)
- 人员(高管、员工)
- 文章(新闻和提及)
- 行业
- 技术
- 投资方
- 关系包括:
HAS_INVESTOR- 投资关系HAS_COMPETITOR- 竞争关系MENTIONS- 文章参考HAS_CEO- 雇佣关系HAS_CATEGORY- 行业分类
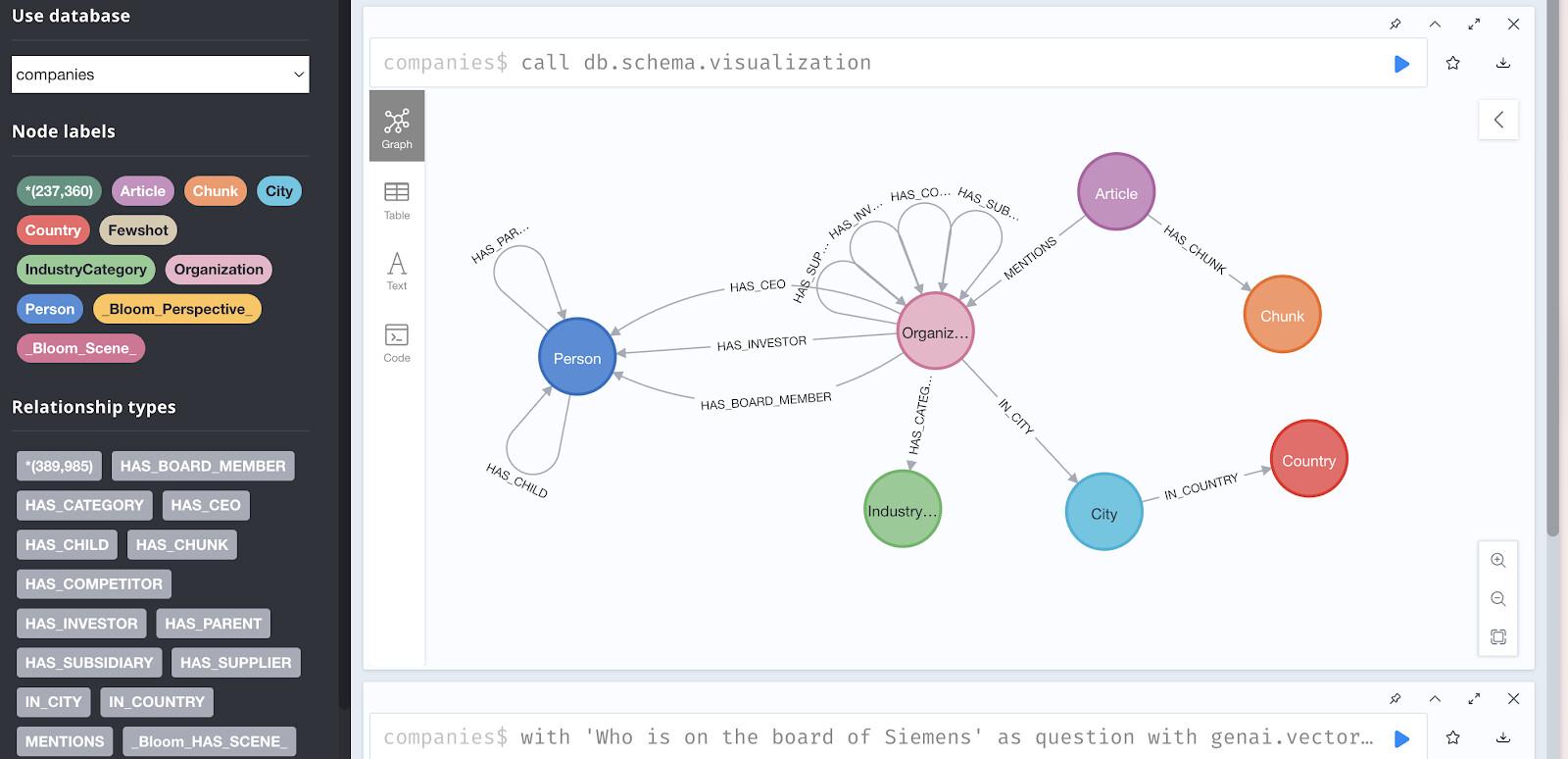
访问演示数据库
在此 Codelab 中,我们将使用托管的演示实例。将这些凭据添加到您的笔记中:
URI: neo4j+s://demo.neo4jlabs.com
Username: companies
Password: companies
Database: companies
浏览器访问权限:
您可以通过以下网址直观地探索数据:https://demo.neo4jlabs.com:7473
使用相同的凭据登录,然后尝试运行:
// Sample query to explore the graph
MATCH (c:Organization)-[:HAS_COMPETITOR]-(competitor:Organization)
RETURN c.name, competitor.name
LIMIT 10
直观呈现图结构
在 Neo4j 浏览器中尝试以下查询,以查看关系模式:
// Find investors and their portfolio companies
MATCH (company:Organization)-[:HAS_INVESTOR]->(investor:Person)
WITH investor, collect(company.name) as portfolio
RETURN investor.name, size(portfolio) as num_investments, portfolio
ORDER BY num_investments DESC
LIMIT 5
此查询会返回前 5 名最活跃的投资者及其投资组合。
为何选择此数据库用于 GraphRAG?
此数据集非常适合用于演示 GraphRAG,原因如下:
- 丰富的关系:实体之间复杂的连接
- 真实世界的数据:真实的公司、人物和新闻报道
- 多跳查询:需要遍历多种关系类型
- 时间序列数据:包含时间戳的文章,可用于基于时间的分析
- 情感分析:文章的预计算情感得分
现在您已了解数据结构,接下来让我们设置开发环境!
5. 克隆代码库并配置环境
克隆代码库
在 Cloud Shell 终端中,运行以下命令:
# Clone the repository
git clone https://github.com/sidagarwal04/neo4j-adk-multiagents.git
# Navigate into the directory
cd neo4j-adk-multiagents
探索代码库结构
花点时间了解项目布局:
neo4j-adk-multiagents/
├── investment_agent/ # Main agent code
│ ├── agent.py # Agent definitions
│ ├── tools.py # Custom tool functions
│ └── .adk/ # ADK configuration
│ └── tools.yaml # MCP tool definitions
├── main.py # Application entry point
├── setup_tools_yaml.py # Configuration generator
├── requirements.txt # Python dependencies
├── example.env # Environment template
└── README.md # Project documentation
设置虚拟环境
使用 uv 创建并激活 Python 虚拟环境:
# Install uv if not already installed
pip install uv
# Create virtual environment
uv venv
# Activate the environment
source .venv/bin/activate # On macOS/Linux
# or
.venv\Scripts\activate # On Windows
您应该会在终端提示符前看到 (.venv)。
安装依赖项
安装所有必需的软件包:
uv pip install -r requirements.txt
主要依赖项包括:
txtgoogle-adk>=1.21.0 # Agent Development Kit
neo4j>=6.0.3 # Neo4j Python driver
python-dotenv>=1.0.0 # Environment variables
google-cloud-aiplatform>=1.30.0 # Vertex AI
配置环境变量
- 创建**
.env** **文件:**
cp example.env .env
- 修改**
.env** **文件:**
如果使用 Cloud Shell,请点击工具栏中的“打开编辑器”,然后前往 .env 并更新:
如需显示隐藏的 .env 文件,请执行以下操作:
在 Google Cloud Shell 编辑器中,点击 View > Toggle Hidden files。
# Neo4j Configuration (Demo Database)
NEO4J_URI=neo4j+s://demo.neo4jlabs.com
NEO4J_USERNAME=companies
NEO4J_PASSWORD=companies
NEO4J_DATABASE=companies
# Google AI Configuration
# Choose ONE of the following options:
# Option 1: Google AI API (Recommended)
GOOGLE_GENAI_USE_VERTEXAI=0
GOOGLE_API_KEY=your_api_key_here # Get from https://aistudio.google.com/app/apikey
# Option 2: Vertex AI (If using GCP)
# GOOGLE_GENAI_USE_VERTEXAI=1
# GOOGLE_CLOUD_PROJECT=your-project-id
# GOOGLE_CLOUD_LOCATION=us-central1
# ADK Configuration
GOOGLE_ADK_MODEL=gemini-3.1-flash-lite-preview # or gemini-3-flash-preview
# MCP Toolbox Configuration
MCP_TOOLBOX_URL=https://toolbox-990868019953.us-central1.run.app/mcp/sse
- 生成 MCP Toolbox 配置:
运行设置脚本以根据您的环境变量创建 tools.yaml 文件:
python setup_tools_yaml.py
这会生成 investment_agent/.adk/tools.yaml,其中包含为 MCP 工具正确配置的 Neo4j 凭据。
验证配置
检查所有设置是否正确无误:
# Verify .env file exists
ls -la .env
# Verify tools.yaml was generated
ls -la investment_agent/.adk/tools.yaml
# Test Python environment
python -c "import google.adk; print('ADK installed successfully')"
# Test Neo4j connection
python -c "from neo4j import GraphDatabase; print('Neo4j driver installed')"
您的开发环境现已完全配置完毕!接下来,我们将深入探讨多智能体架构。
6. 了解多智能体架构
四智能体系统
我们的投资研究系统采用分层多代理架构,其中包含四个专业代理,它们协同工作,可回答有关公司、投资者和市场情报的复杂查询。
┌──────────────┐
│ Root Agent │ ◄── User Query
└──────┬───────┘
│
┌────────────────┼────────────────┐
│ │ │
┌─────▼─────┐ ┌────▼─────┐ ┌────▼──────────┐
│ Graph DB │ │ Investor │ │ Investment │
│ Agent │ │ Research │ │ Research │
└───────────┘ │ Agent │ │ Agent │
└──────────┘ └───────────────┘
- 根代理(编排器):
根代理充当整个系统的智能协调器。它接收用户查询、分析意图,并将请求路由到最合适的专业代理。您可以将其视为项目经理,它了解哪位团队成员最适合执行哪项任务。它还负责处理响应聚合、根据要求将结果格式化为表格或图表,以及在多个查询中保持对话上下文。根代理始终优先选择专业代理,而不是通用数据库代理,从而确保查询由最专业的组件处理。
- 图数据库代理:
图数据库代理可让您直接使用 Neo4j 强大的图功能。它能理解数据库架构,根据自然语言生成 Cypher 查询,并执行复杂的图遍历。此代理擅长处理结构化问题、聚合和知识图谱中的多跳推理。当查询需要预定义工具无法处理的自定义逻辑时,它是后备专家,因此对于探索性分析和系统设计中未预料到的复杂分析查询至关重要。
- 投资者研究代理:
投资者研究代理专注于投资关系和投资组合分析。它可以发现哪些人投资了特定公司(使用确切的名称匹配),检索显示所有投资的完整投资者投资组合,并分析各行业的投资模式。这种专业化使其能够非常高效地回答“谁投资了字节跳动?”或“红杉资本还投资了什么?”之类的问题。该代理使用自定义 Python 函数直接查询 Neo4j 数据库中与投资者相关的关系。
- 投资研究代理:
投资研究代理利用 Model Context Protocol (MCP) 工具箱访问预先验证的专家撰写查询。它可以获取所有可用的行业、检索特定行业内的公司、查找包含情感分析的文章、发现新闻中提及的组织,以及获取有关公司员工的信息。与动态生成查询的图数据库代理不同,此代理使用经过集中管理和验证的安全、优化的预定义查询。这使得该笔记本电脑在常见的研究工作流中既安全又高效。
7. 运行和测试多智能体系统
启动应用
现在您已了解该架构,接下来我们运行整个系统并与之互动。
启动 ADK 网页界面:
# Make sure you're in the project directory with activated virtual environment
cd ~/neo4j-adk-multiagents
source .venv/bin/activate # If not already activated
# Launch the application
uv run adk web
您看到的输出结果应该类似于以下内容:
INFO: Started server process [2542]
INFO: Waiting for application startup.
+----------------------------------------------------------------+
| ADK Web Server started |
| |
| For local testing, access at http://127.0.0.1:8000. |
+----------------------------------------------------------------+
INFO: Application startup complete.
INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
测试查询和预期行为
下面,我们通过逐步复杂的查询来探索系统的功能:
基本查询(单个代理)
查询 1:发现行业
What industries are available in the database?
预期行为:
- 根代理路由到投资研究代理
- 使用 MCP 工具:
get_industries() - 返回所有行业的格式化列表
需要观察的内容:
在 ADK 界面中,展开执行详情以查看:
- 代理选择决策
- 工具调用:
get_industries() - 来自 Neo4j 的原始结果
- 格式化回答
查询 2:寻找投资者
Who invested in ByteDance?
预期行为:
- 根代理将此查询识别为与投资者相关的查询
- 投资者研究代理的路线
- 使用工具:
find_investor_by_name("ByteDance") - 返回投资者及其类型(个人/组织)
预期回答:
I found 2 investors in ByteDance:
1. Rong Yue (Person)
2. Wendi Murdoch (Person)
Would you like to know more about their investment portfolios?
查询 3:按行业划分的公司**
I found 2 investors in ByteDance:
1. Rong Yue (Person)
2. Wendi Murdoch (Person)
Would you like to know more about their investment portfolios?
"Show me companies in the Artificial Intelligence industry"
预期行为:
- 根代理路由到投资研究代理
- 使用 MCP 工具:
get_companies_in_industry("Artificial Intelligence") - 返回包含 ID 和成立日期的 AI 公司列表
需要观察的内容:
- 请注意智能体如何使用确切的行业名称匹配
- 结果数量有限,以免输出内容过多
- 数据格式清晰,便于阅读
中间查询(单个代理中的多步查询)
查询 4:情感分析
Find articles with positive sentiment from January 2023
预期行为:
- 投资研究代理的路由
- 使用 MCP 工具:
get_articles_with_sentiment(0.7, 2023, 1) - 返回包含标题、情感得分和发布日期的文章
调试提示:
查看工具调用参数:
min_sentiment:0.7(代理将“正”解释为 >= 0.7)year:2023 年month: 1
查询 5:复杂的数据库查询
How many companies are in the database?
预期行为:
- 根代理路由到图数据库代理
- 代理会先调用
get_neo4j_schema()来了解结构 - 生成 Cypher:
MATCH (c:Company) RETURN count(c) - 执行查询并返回数量
预期回答:
There are 8,064 companies in the database.
高级查询(多代理协调)
问题 6:投资组合分析
Who invested in ByteDance and what else have they invested in?
预期行为:
这是一个需要客服人员协调的两部分查询:
- 第 1 步:根代理 → 投资者研究代理
- 调用
find_investor_by_name("ByteDance") - 获取投资方列表:[Rong Yue, Wendi Murdoch]
- 第 2 步:针对每位投资者 → 投资者研究代理
- 调用
find_investor_by_id(investor_id) - 检索完整投资组合
- 第 3 步:根代理汇总并设置格式
预期回答:
I found 2 investors in ByteDance. Here are their portfolios:
1. Rong Yue (Person)
- ByteDance
- Inspur
2. Wendi Murdoch (Person)
- ByteDance
- (No other investments in database)
需要观察的内容:
- 按顺序多次调用工具
- 在各步骤之间保持上下文
- 智能汇总的结果
查询 7:多领域研究
What are 5 AI companies mentioned in positive articles, and who are their CEOs?
预期行为:
这个复杂的查询需要多个代理和工具:
- 第 1 步:投资研究代理
get_companies_in_industry("Artificial Intelligence")- 返回 AI 公司列表
- 第 2 步:投资研究代理
get_articles_with_sentiment(0.8)- 返回正面文章
- 第 3 步:根代理过滤条件
- 确定哪些 AI 公司出现在正面文章中
- 选择前 5 大
- 第 4 步:投资研究代理
get_people_in_organizations([company_names], "CEO")- 返回首席执行官信息
- 第 5 步:以表格形式显示根代理
预期回答:
Here are 5 AI companies with positive news and their CEOs:
| Company | Industry | CEO | Avg Sentiment |
|---------|----------|-----|---------------|
| OpenAI | Artificial Intelligence | Sam Altman | 0.92 |
| Anthropic | Artificial Intelligence | Dario Amodei | 0.89 |
| ... | ... | ... | ... |
需要观察的内容:
- 不同代理之间的多次工具调用
- 数据过滤和组合逻辑
- 专业表格格式
查询 8:竞争分析
Who are YouTube's main competitors?
预期行为:
- 根代理路由到图数据库代理(关系查询)
- 智能体生成经过 GraphRAG 增强的 Cypher:
MATCH (c:Company {name: "YouTube"})-[:COMPETES_WITH]->(competitor)
RETURN competitor.name as competitor_name
- 返回竞争公司列表
预期回答:
YouTube's main competitors are:
- TikTok (ByteDance)
- Dailymotion
- Twitter
- BuzzFeed
- Mixer
- OpenAI (for video content)
情境感知后续查询
查询 9:后续问题(在查询 8 之后)
Which investors funded both YouTube and its competitors?
预期行为:
- 根代理记得之前的上下文(YouTube 及其竞争对手)
- 投资者研究代理的路线
- 对于 YouTube 和每个竞争对手,查找投资者
- 识别出现在多家公司中的投资者
预期回答:
Based on our previous analysis of YouTube's competitors, I found these
investors who funded multiple companies in this competitive landscape:
Sequoia Capital invested in:
- YouTube
- TikTok (ByteDance)
- Twitter
Accel Partners invested in:
- YouTube
- BuzzFeed
This suggests these investors have strategic positions across the video content platform ecosystem.
问题 10:研究总结
Summarize our research findings so far
预期行为:
- 根代理会查看对话历史记录
- 综合之前查询的关键发现
- 提供连贯的摘要
预期回答:
Here's a summary of our investment research session:
1. Industry Overview: We explored the Artificial Intelligence industry
with 150+ companies in the database.
2. ByteDance Analysis:
- Investors: Rong Yue, Wendi Murdoch
- Rong Yue also invested in Inspur
3. Market Sentiment: We analyzed articles from January 2023, finding
strong positive sentiment (avg 0.85) for tech companies.
4. Competitive Landscape: YouTube faces competition from TikTok,
Dailymotion, and others, with some investors (Sequoia, Accel) holding
positions across competing platforms.
5. Key Players: Identified CEOs of major AI companies with positive media coverage.
了解调试视图中的智能体互动
ADK 网络界面可提供详细的执行情况。以下是需要注意的事项:
- 活动时间安排
显示时间顺序流程:
[USER] Query received
[ROOT_AGENT] Analyzing query intent
[ROOT_AGENT] Routing to investment_research_agent
[INVESTMENT_RESEARCH_AGENT] Tool call: get_companies_in_industry
[TOOL] Executing with params: {"industry_name": "Artificial Intelligence"}
[TOOL] Returned 47 results
[INVESTMENT_RESEARCH_AGENT] Formatting response
[ROOT_AGENT] Presenting to user
- 工具调用详情
点击任意工具调用即可查看:
- 函数名称
- 输入参数
- 返回值
- 执行时间
- 任何错误
- 代理决策
观察 LLM 的推理过程:
- 选择特定代理的原因
- 它如何解读查询
- 它考虑了哪些工具
- 为什么以特定方式设置结果格式
常见观测结果和数据分析
- 查询路由模式:
- “投资者”“投资”等关键字 → 投资者研究代理
- “行业”“公司”“文章”等关键字 → 投资研究代理
- 汇总、计数、复杂逻辑 → 图数据库代理
- 性能说明:
- MCP 工具通常速度更快(预优化查询)
- 复杂的 Cypher 生成需要更长时间(LLM 思考时间)
- 多次工具调用会增加延迟时间,但可提供更丰富的结果
- 错误处理:
- 如果查询失败:
- 智能体说明问题所在
- 建议更正(例如,“未找到公司名称,请检查拼写”)
- 可能会尝试其他方法
有效测试的技巧
- 从简单开始:在提出复杂的查询之前,先测试每个代理的核心功能
- 使用后续问题:通过后续问题测试上下文保留情况
- 观察路由:观察哪个代理处理了每项查询,以了解路由逻辑
- 检查工具调用:验证参数是否已从自然语言中正确提取
- 测试边缘情况:尝试模糊的查询、拼写错误的查询或不寻常的请求
现在,您已拥有功能齐全的多智能体 GraphRAG 系统!尝试提出自己的问题,探索其功能。
8. 清理
为避免系统因本博文中使用的资源向您的 Google Cloud 账号收取费用,请按照以下步骤操作:
- 在 Google Cloud 控制台中,前往管理资源页面。
- 在项目列表中,选择要删除的项目,然后点击删除。
- 在对话框中输入项目 ID,然后点击关停以删除项目。
9. 恭喜
🎉 恭喜!您已成功使用 Google 的智能体开发套件、Neo4j 和 MCP Toolbox 构建了生产质量的多智能体 GraphRAG 系统!
通过将 ADK 的智能编排功能与 Neo4j 的关系丰富的数据模型以及预验证的 MCP 查询的安全性相结合,您创建了一个超越简单数据库查询的复杂系统。该系统可以理解上下文、在复杂关系中进行推理,并协调专业代理来提供全面而准确的数据洞见。
在此 Codelab 中,您完成了以下任务:
✅ 使用 Google 的智能体开发套件 (ADK) 通过分层编排构建了多智能体系统
✅ 集成 Neo4j 图数据库,以利用关系感知查询和多跳推理
✅ 实现了 MCP Toolbox,可将安全且预先验证的数据库查询作为可重复使用的工具
✅ 创建了专门的智能体,用于投资者研究、投资分析和图数据库操作
✅ 设计了智能路由,可自动将查询委托给最合适的专家代理
✅ 处理了复杂数据类型,并使用适当的 Neo4j 类型序列化来实现无缝的 Python 集成
✅ 应用了生产方面的最佳实践,用于代理设计、错误处理和系统调试
后续步骤
这种多智能体 GraphRAG 架构不仅限于投资研究,还可以扩展到以下领域:
- 金融服务:投资组合优化、风险评估、欺诈检测
- 医疗保健:患者护理协调、药品相互作用分析、临床研究
- 电子商务:个性化推荐、供应链优化、客户数据分析
- 法律和法规遵从:合同分析、法规监控、判例法研究
- 学术研究:文献综述、合作发现、引用分析
- 企业情报:竞争分析、市场研究、组织知识图谱
在任何需要复杂关联数据、领域专业知识和自然语言界面的场景中,ADK 多智能体系统、Neo4j 知识图谱和 MCP 验证查询的组合都可以为下一代智能企业应用提供支持。
随着 Google 的智能体开发套件和 Gemini 模型不断发展,您将能够纳入更复杂的推理模式、实时数据集成和多模态能力,从而构建真正智能且能感知上下文的系统。
继续探索,继续构建,让您的智能代理应用更上一层楼!
如需探索更多知识图谱实践教程,请访问 Neo4j GraphAcademy;如需发现更多智能体模式,请访问 ADK 示例代码库。
🚀 准备好构建下一个智能代理系统了吗?
参考文档
- Google ADK:
- 官方 GitHub 代码库
- 全面的文档
- 示例代码库
- 发布博客
- Neo4j:
- Neo4j GenAI Hub
- Neo4j 开发者
- GraphRAG
- Neo4j GenAI 生态系统
- 使用 Neo4j 和 MCP Toolbox 的 AI 智能体