
Codelab - Neo4j ve Vertex AI'ı kullanarak film önerisi sohbet robotu oluşturma
Bu codelab hakkında
1. Genel Bakış
Bu codelab'de, Neo4j, Google Vertex AI ve Gemini'nin gücünü birleştirerek akıllı bir film önerisi sohbet robotu oluşturacaksınız. Bu sistemin merkezinde, filmleri, aktörleri, yönetmenleri, türleri ve daha fazlasını birbirine bağlı düğümler ve ilişkilerden oluşan zengin bir ağ üzerinden modelleyen bir Neo4j Bilgi Grafiği yer alır.
Anlamsal anlama ile kullanıcı deneyimini iyileştirmek için Vertex AI'ın text-embedding-004 modelini (veya daha yeni bir modeli) kullanarak filmin konusuna genel bakışlardan vektör gömmeleri oluşturursunuz. Bu yerleştirmeler, benzerlik temelli hızlı arama için Neo4j'da dizine eklenir.
Son olarak, kullanıcıların "Yıldızlararası filmini beğendiysem ne izlemeliyim?" gibi doğal dil sorularını sorabileceği ve anlamsal benzerliğe ve grafik tabanlı bağlama dayalı kişiselleştirilmiş film önerileri alabileceği bir sohbet arayüzü oluşturmak için Gemini'yi entegre edersiniz.
Codelab'de aşağıdaki gibi adım adım bir yaklaşım uygulayacaksınız:
- Filmlerle ilgili öğeler ve ilişkiler içeren bir Neo4j Bilgi Grafiği oluşturma
- Vertex AI'ı kullanarak film özetlerine yönelik metin gömmeleri oluşturma/yükleme
- Gemini tarafından desteklenen ve vektör aramayı grafik tabanlı Cypher yürütmeyle birleştiren bir Gradio chatbot arayüzü uygulama
- (İsteğe bağlı) Uygulamayı bağımsız bir web uygulaması olarak Cloud Run'a dağıtma
Neler öğreneceksiniz?
- Cypher ve Neo4j kullanarak film bilgi grafiği oluşturma ve doldurma
- Semantik metin yerleştirilmiş öğeleri oluşturmak ve bunlarla çalışmak için Vertex AI'ı kullanma
- GraphRAG'ı kullanarak akıllı arama için LLM'leri ve Bilgi Grafikleri'ni birleştirme
- Gradio'yu kullanarak kullanıcı dostu bir sohbet arayüzü oluşturma
- İsteğe bağlı olarak Google Cloud Run'a dağıtma
Gerekenler
- Chrome web tarayıcısı
- Gmail hesabı
- Faturalandırmanın etkin olduğu bir Google Cloud projesi
- Ücretsiz Neo4j Aura DB hesabı
- Terminal komutları ve Python hakkında temel düzeyde bilgi sahibi olmanız (yararlı ancak zorunlu değildir)
Her seviyedeki geliştiriciler (yeni başlayanlar dahil) için tasarlanan bu codelab'de, örnek uygulamada Python ve Neo4j kullanılmaktadır. Python ve grafik veritabanlarıyla ilgili temel düzeyde bilgi sahibi olmak faydalı olabilir ancak kavramları anlamak veya takip etmek için herhangi bir deneyime sahip olmanız gerekmez.
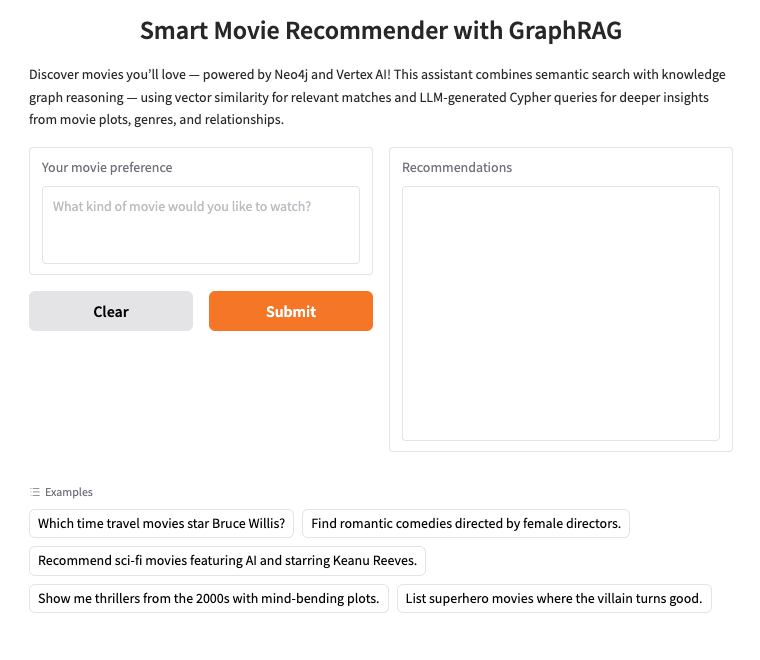
2. Neo4j AuraDB'yi kurma
Neo4j, verileri bir düğüm (nesne) ve ilişki (nesneler arasındaki bağlantılar) ağı olarak depolayan lider bir yerel grafik veritabanı olduğundan, bağlantıları anlamanın önemli olduğu kullanım alanları (ör. öneriler, sahtekarlık algılama, bilgi grafikleri) için idealdir. Katı tablolara veya hiyerarşik yapılara dayanan ilişkisel ya da belge tabanlı veritabanlarının aksine Neo4j'ın esnek grafik modeli, karmaşık ve birbirine bağlı verilerin sezgisel ve verimli bir şekilde temsil edilmesine olanak tanır.
Neo4j, verileri ilişkisel veritabanları gibi satır ve tablolarda düzenlemek yerine, bilgilerin düğümler (varlıklar) ve ilişkiler (bu varlıklar arasındaki bağlantılar) olarak gösterildiği bir grafik modeli kullanır. Bu model, kişiler, yerler, ürünler veya bizim durumumuzda filmler, aktörler ve türler gibi doğal olarak bağlantılı verilerle çalışmayı son derece sezgisel hale getirir.
Örneğin, bir film veri kümesindeki:
- Düğümler
Movie,ActorveyaDirectoröğelerini temsil edebilir. - İlişki
ACTED_INveyaDIRECTEDolabilir
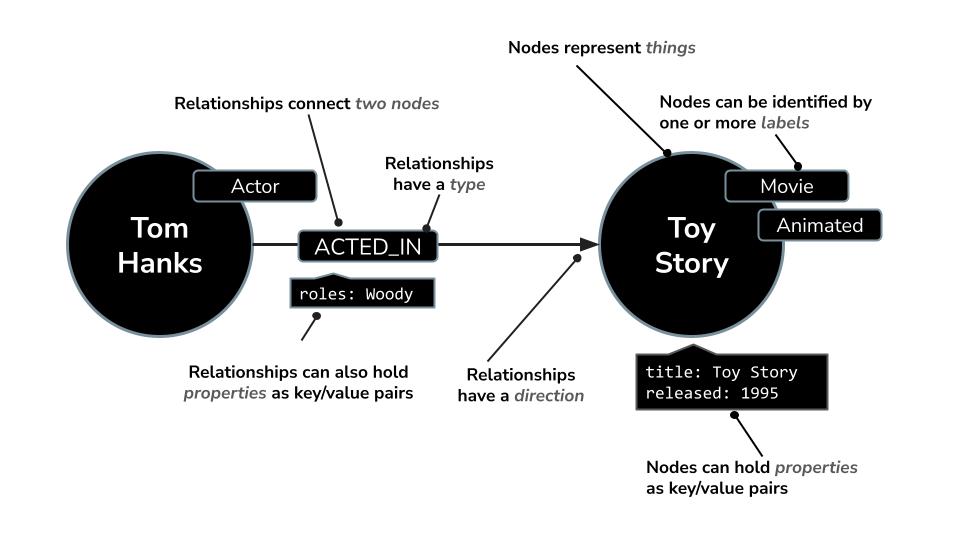
Bu yapı, aşağıdaki gibi soruları kolayca sormanıza olanak tanır:
- Bu oyuncu hangi filmlerde oynadı?
- Christopher Nolan ile kimler çalıştı?
- Ortak oyunculara veya türlere göre benzer filmler hangileridir?
Neo4j, grafikleri sorgulamak için özel olarak tasarlanmış Cypher adlı güçlü bir sorgu dili ile birlikte gelir. Cypher, karmaşık kalıpları ve bağlantıları kısa ve okunaklı bir şekilde ifade etmenize olanak tanır. Örneğin: Bu Cypher sorgusunda, MERGE kullanılarak aktör, film ve bunların rol ayrıntılarıyla ilişkisi benzersiz bir şekilde oluşturulur ve yinelenen öğeler önlenir.
MERGE (a:Actor {name: "Tom Hanks"})
MERGE (m:Movie {title: "Toy Story", released: 1995})
MERGE (a)-[:ACTED_IN {roles: ["Woody"]}]->(m);
Neo4j, ihtiyaçlarınıza bağlı olarak birden fazla dağıtım seçeneği sunar:
- Kendi kendine yönetilen: Neo4j'ı Neo4j Desktop'u kullanarak kendi altyapınızda veya Docker görüntüsü olarak (şirket içinde ya da kendi bulutunuzda) çalıştırın.
- Bulut tarafından yönetilen: Marketplace tekliflerini kullanarak Neo4j'ı popüler bulut sağlayıcılara dağıtın.
- Tümüyle yönetilen: Neo4j'ın tümüyle yönetilen bulut veritabanı hizmeti olan Neo4j AuraDB'yi kullanın. Bu hizmet, temel hazırlığı, ölçeklemeyi, yedeklemeleri ve güvenliği sizin yerinize yönetir.
Bu codelab'de, AuraDB'nin ücretsiz katmanı olan Neo4j AuraDB Free'i kullanacağız. Prototip oluşturma, öğrenme ve küçük uygulamalar geliştirme için yeterli depolama alanı ve özelliklere sahip, tümüyle yönetilen bir grafik veritabanı örneği sağlar. Bu, üretken yapay zeka destekli bir film önerisi sohbet robotu oluşturma hedefimiz için mükemmel bir seçimdir.
Ücretsiz bir AuraDB örneği oluşturacak, bağlantı kimlik bilgilerini kullanarak uygulamanıza bağlayacak ve bu laboratuvar boyunca film bilgi grafiğinizi depolamak ve sorgulamak için kullanacaksınız.
Neden grafikler?
Geleneksel ilişkisel veritabanlarında, "Ortak oyuncu veya türe göre Inception'a benzer hangi filmler var?" gibi soruları yanıtlamak birden fazla tabloda karmaşık JOIN işlemleri gerektirir. İlişkilerin derinliği arttıkça performans ve okunabilirlik azalır.
Ancak Neo4j gibi grafik veritabanları, ilişkileri verimli bir şekilde tarayacak şekilde tasarlandığından öneri sistemleri, semantik arama ve akıllı asistanlar için idealdir. Geleneksel veri modelleri kullanılarak temsil edilmesi zor olabilecek gerçek dünya bağlamını (ör. ortak çalışma ağları, hikaye hatları veya izleyici tercihleri) yakalamanıza yardımcı olurlar.
Bu bağlı verileri Gemini gibi büyük dil modelleriyle ve Vertex AI'daki vektör yerleştirmeleriyle birleştirerek chatbot deneyimini güçlendirebiliriz. Böylece chatbot'un daha kişiselleştirilmiş ve alakalı bir şekilde akıl yürütmesine, bilgi almasına ve yanıt vermesine olanak tanıyabiliriz.
Neo4j AuraDB Ücretsiz Oluşturma
- https://console.neo4j.io adresine gidin.
- Google Hesabınız veya e-posta adresinizle giriş yapın.
- "Ücretsiz Örnek Oluştur"u tıklayın.
- Örnek hazırlanırken veritabanınızın bağlantı kimlik bilgilerini gösteren bir pop-up pencere açılır.
Uygulamanızı Neo4j'a bağlamak için gerekli olan aşağıdaki bilgileri pop-up'tan indirip güvenli bir şekilde kaydettiğinizden emin olun:
NEO4J_URI=neo4j+s://<your-instance-id>.databases.neo4j.io
NEO4J_USERNAME=neo4j
NEO4J_PASSWORD=<your-generated-password>
AURA_INSTANCEID=<your-instance-id>
AURA_INSTANCENAME=<your-instance-name>
Bu değerleri, sonraki adımda Neo4j ile kimlik doğrulama yapmak için projenizdeki .env dosyasını yapılandırmak üzere kullanacaksınız.
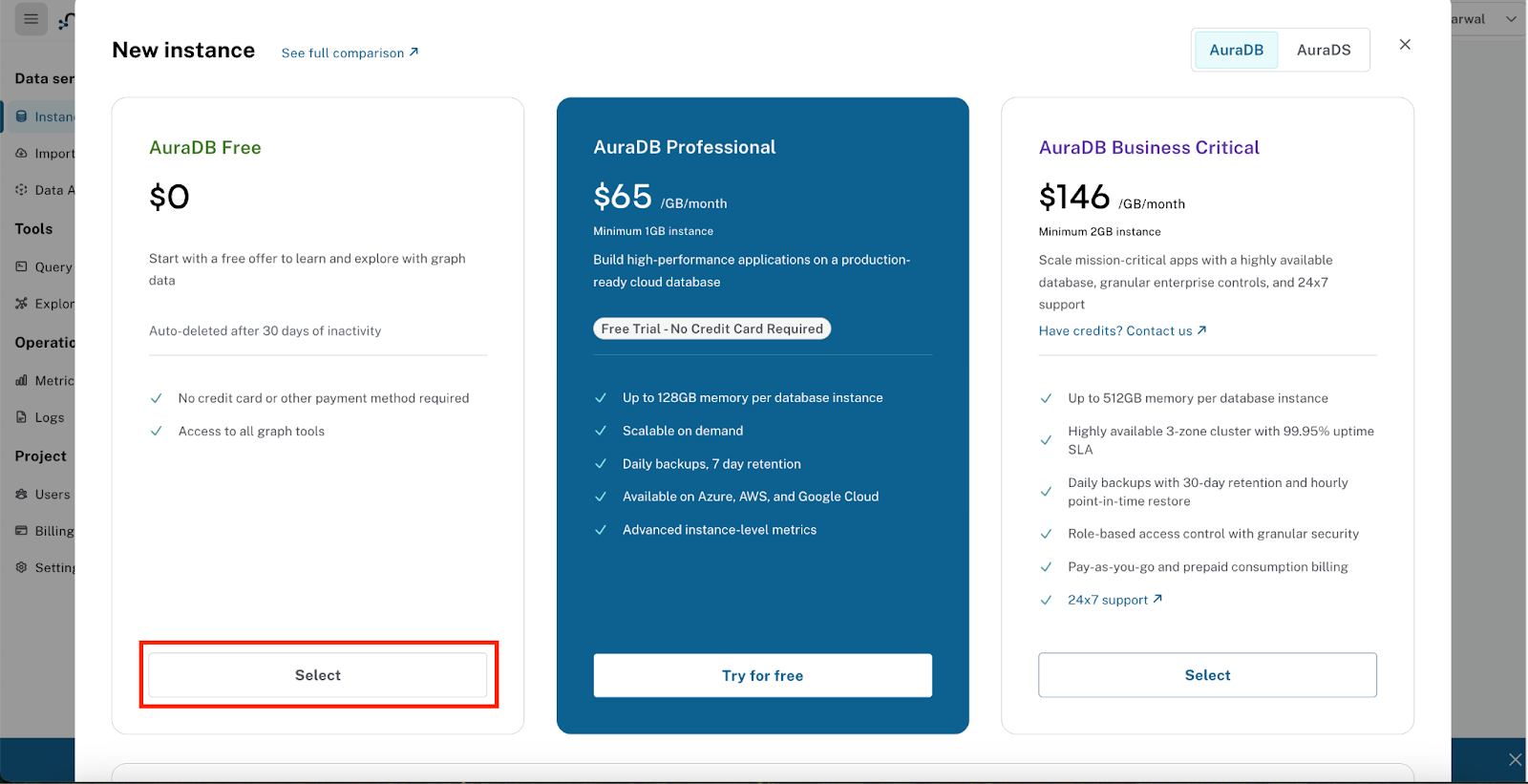
Neo4j AuraDB Free, geliştirme, deneme ve bu codelab gibi küçük ölçekli uygulamalar için idealdir. 200.000 düğüm ve 400.000 ilişki destekleyen geniş kullanım sınırları sunar. Bilgi grafiği oluşturmak ve sorgulamak için gereken tüm temel özellikleri sunsa da özel eklentiler veya daha fazla depolama alanı gibi gelişmiş yapılandırmaları desteklemez. Üretim iş yükleri veya daha büyük veri kümeleri için daha fazla kapasite, performans ve kurumsal düzeyde özellikler sunan daha üst düzey bir AuraDB planına geçebilirsiniz.
Neo4j AuraDB arka ucunuzu ayarlama bölümü tamamlandı. Bir sonraki adımda, kod laboratuvarımıza başlamadan önce bir Google Cloud projesi oluşturacağız, deposu klonlayacağız ve geliştirme ortamınızı hazırlamak için gerekli ortam değişkenlerini yapılandıracağız.
3. Başlamadan önce
Proje oluşturma
- Google Cloud Console'daki proje seçici sayfasında bir Google Cloud projesi seçin veya oluşturun.
- Cloud projeniz için faturalandırmanın etkinleştirildiğinden emin olun. Projede faturalandırmanın etkin olup olmadığını nasıl kontrol edeceğinizi öğrenin .
- Google Cloud'da çalışan ve bq ile önceden yüklenmiş bir komut satırı ortamı olan Cloud Shell'i kullanacaksınız. Google Cloud Console'un üst kısmından Cloud Shell'i etkinleştir'i tıklayın.

- Cloud Shell'e bağlandıktan sonra aşağıdaki komutu kullanarak kimliğinizin doğrulanıp doğrulanmadığını ve projenin proje kimliğinize ayarlanıp ayarlanmadığını kontrol edin:
gcloud auth list
- gcloud komutunun projeniz hakkında bilgi sahibi olduğunu onaylamak için Cloud Shell'de aşağıdaki komutu çalıştırın.
gcloud config list project
- Projeniz ayarlanmadıysa ayarlamak için aşağıdaki komutu kullanın:
gcloud config set project <YOUR_PROJECT_ID>
- Aşağıda gösterilen komutu kullanarak gerekli API'leri etkinleştirin. Bu işlem birkaç dakika sürebilir. Lütfen bekleyin.
gcloud services enable cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
cloudfunctions.googleapis.com \
aiplatform.googleapis.com
Komut başarıyla yürütüldüğünde şu mesajı görürsünüz: "İşlem .... başarıyla tamamlandı".
gcloud komutunun alternatifi, her ürünü arayarak veya bu bağlantıyı kullanarak konsoldan geçmektir.
Atlanan bir API varsa uygulama sırasında istediğiniz zaman etkinleştirebilirsiniz.
gcloud komutları ve kullanımı için belgelere bakın.
Depoyu klonlama ve ortam ayarlarını yapma
Sonraki adım, codelab'in geri kalanında referans vereceğimiz örnek deposunu klonlamaktır. Cloud Shell'de olduğunuzu varsayarak ana dizininizden aşağıdaki komutu verin:
git clone https://github.com/sidagarwal04/neo4j-vertexai-codelab.git
Düzenleyiciyi başlatmak için Cloud Shell penceresinin araç çubuğunda Düzenleyiciyi aç'ı tıklayın. Sol üst köşedeki menü çubuğunu tıklayın ve aşağıda gösterildiği gibi Dosya → Klasör Aç'ı seçin:
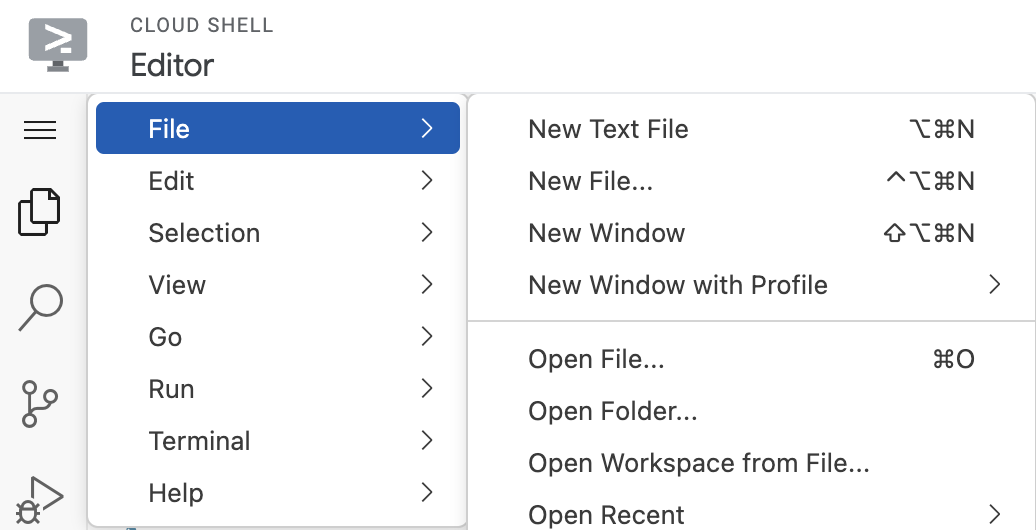
neo4j-vertexai-codelab klasörünü seçin. Klasör, aşağıda gösterilen yapıya benzer bir şekilde açılır:
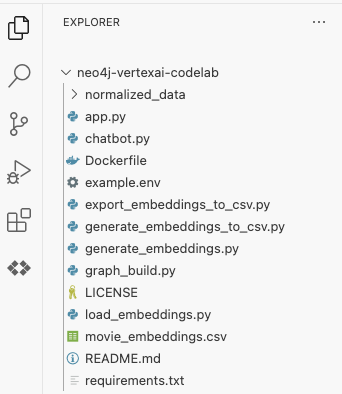
Ardından, codelab boyunca kullanılacak ortam değişkenlerini ayarlamamız gerekir. example.env dosyasını tıkladığınızda, içeriği aşağıdaki gibi görürsünüz:
NEO4J_URI=
NEO4J_USER=
NEO4J_PASSWORD=
NEO4J_DATABASE=
PROJECT_ID=
LOCATION=
Şimdi example.env dosyasıyla aynı klasörde .env adlı yeni bir dosya oluşturun ve mevcut example.env dosyasının içeriğini kopyalayın. Ardından aşağıdaki değişkenleri güncelleyin:
NEO4J_URI,NEO4J_USER,NEO4J_PASSWORDveNEO4J_DATABASE:- Önceki adımda Neo4j AuraDB Free örneği oluşturulurken sağlanan kimlik bilgilerini kullanarak bu değerleri doldurun.
NEO4J_DATABASE, AuraDB Free için genellikle neo4j olarak ayarlanır.PROJECT_IDveLOCATION:- Codelab'i Google Cloud Shell'dan çalıştırıyorsanız etkin proje yapılandırmanızdan otomatik olarak anlaşılacağı için bu alanları boş bırakabilirsiniz.
- Yerel olarak veya Cloud Shell dışında çalıştırıyorsanız
PROJECT_IDdeğerini daha önce oluşturduğunuz Google Cloud projesinin kimliğiyle güncelleyin veLOCATIONdeğerini bu proje için seçtiğiniz bölgeye (ör. us-central1) ayarlayın.
Bu değerleri doldurduktan sonra .env dosyasını kaydedin. Bu yapılandırma, uygulamanızın hem Neo4j hem de Vertex AI hizmetlerine bağlanmasına olanak tanır.
Geliştirme ortamınızı oluşturmanın son adımı, bir Python sanal ortamı oluşturmak ve requirements.txt dosyasında listelenen tüm gerekli bağımlılıkları yüklemektir. Bu bağımlılıklar arasında Neo4j, Vertex AI, Gradio ve daha fazlasıyla çalışmak için gereken kitaplıklar bulunur.
Öncelikle aşağıdaki komutu çalıştırarak .venv adlı bir sanal ortam oluşturun:
python -m venv .venv
Ortam oluşturulduktan sonra, oluşturulan ortamı aşağıdaki komutla etkinleştirmemiz gerekir.
source .venv/bin/activate
Artık terminal isteminizin başında, ortamın etkin olduğunu belirten (.venv) ifadesini göreceksiniz. Örneğin: (.venv) yourusername@cloudshell:
Ardından, aşağıdaki komutu çalıştırarak gerekli bağımlılıkları yükleyin:
pip install -r requirements.txt
Dosyada listelenen temel bağımlılıkların anlık görüntüsünü aşağıda bulabilirsiniz:
gradio>=4.0.0
neo4j>=5.0.0
numpy>=1.20.0
python-dotenv>=1.0.0
google-cloud-aiplatform>=1.30.0
vertexai>=0.0.1
Tüm bağımlılıklar başarıyla yüklendikten sonra yerel Python ortamınız, bu kod laboratuvarındaki komut dosyalarını ve chatbot'u çalıştıracak şekilde tamamen yapılandırılır.
Mükemmel. Artık bir sonraki adıma geçmeye hazırız. Veri kümesini anlamak ve grafik oluşturma ve semantik zenginleştirme için hazırlamak istiyoruz.
4. Filmler veri kümesini hazırlama
İlk işimiz, bilgi grafiğini oluşturmak ve öneri chatbot'umuzu desteklemek için kullanacağımız Filmler veri kümesini hazırlamaktır. Sıfırdan başlamak yerine, mevcut bir açık veri kümesini kullanıp bu veri kümesini temel alacağız.
Kaggle'da herkese açık olarak bulunan ve iyi bilinen bir veri kümesi olan Rounak Banik'in Filmler Veri Kümesi'ni kullanıyoruz. Bu API, oyuncu kadrosu, ekip, anahtar kelimeler, derecelendirmeler ve daha fazlası dahil olmak üzere TMDB'deki 45.000'den fazla filmin meta verilerini içerir.
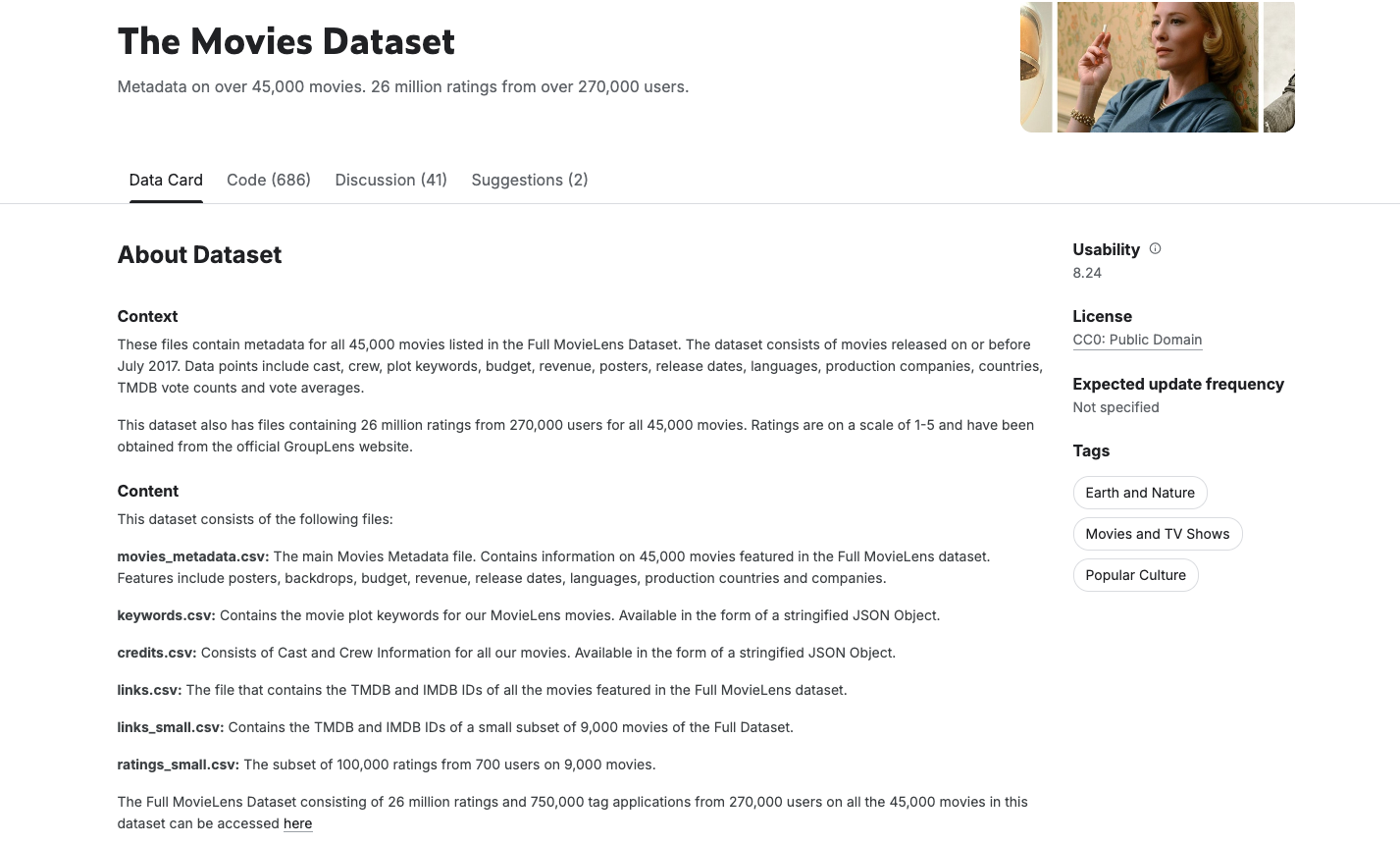
Güvenilir ve etkili bir film önerisi sohbet botu oluşturmak için temiz, tutarlı ve yapılandırılmış verilerle başlamak önemlidir. Kaggle'daki Filmler Veri Kümesi, 45.000'den fazla film kaydı ve tür, oyuncu kadrosu, ekip vb. dahil olmak üzere ayrıntılı meta veriler içeren zengin bir kaynak olsa da grafik modelleme veya semantik yerleştirme için ideal olmayan gürültü, tutarsızlık ve iç içe yerleştirilmiş veri yapıları da içerir.
Bu sorunu gidermek için Neo4j bilgi grafiği oluşturmaya ve yüksek kaliteli yerleştirmeler oluşturmaya uygun olmasını sağlamak amacıyla veri kümesini önceden işleyip normalleştirdik. Bu süreç aşağıdakileri içeriyordu:
- Yinelenen ve eksik kayıtları kaldırma
- Anahtar alanları (ör. tür adları, kişi adları) standartlaştırma
- Karmaşık iç içe yerleştirilmiş yapıları (ör. oyuncu kadrosu ve ekip) yapılandırılmış CSV'lere düzleştirme
- Neo4j AuraDB Free sınırlarını aşmamak için yaklaşık 12.000 filmden oluşan temsili bir alt küme seçme
Yüksek kaliteli ve normalleştirilmiş veriler aşağıdakileri sağlamaya yardımcı olur:
- Veri kalitesi: Daha doğru öneriler sunmak için hataları ve tutarsızlıkları en aza indirir.
- Sorgu performansı: Basitleştirilmiş yapı, getirme hızını artırır ve fazlalığı azaltır
- Yerleştirme doğruluğu: Net girişler, daha anlamlı ve bağlama dayalı vektör yerleştirmelerine yol açar.
Temizlenmiş ve normalleştirilmiş veri kümesine bu GitHub deposunun normalized_data/ klasöründen erişebilirsiniz. Bu veri kümesi, gelecekteki Python komut dosyalarında kolayca erişilebilmesi için bir Google Cloud Storage paketine de yansıtılır.
Veriler temizlenip hazır olduğunda Neo4j'a yükleyip film bilgi grafiğimizi oluşturmaya başlayabiliriz.
5. Filmler Bilgi Grafiği'ni oluşturma
Yapay zeka destekli film önerisi sohbet robotumuzu desteklemek için film veri kümemizi filmler, oyuncular, yönetmenler, türler ve diğer meta veriler arasındaki zengin bağlantı ağını yakalayacak şekilde yapılandırmamız gerekir. Bu bölümde, daha önce hazırladığınız temizlenmiş ve normalleştirilmiş veri kümesini kullanarak Neo4j'da bir Film Bilgi Grafiği oluşturacağız.
Herkese açık bir Google Cloud Storage (GCS) paketinde barındırılan CSV dosyalarını beslemek için Neo4j'ın LOAD CSV özelliğini kullanacağız. Bu dosyalar; film veri kümesinin filmler, türler, oyuncu kadrosu, ekip, yapım şirketleri ve kullanıcı puanları gibi farklı bileşenlerini temsil eder.
1. Adım: Kısıtlar ve dizine eklemeler oluşturun
Verileri içe aktarmadan önce, veri bütünlüğünü zorunlu kılmak ve sorgu performansını optimize etmek için kısıtlar ve dizinler oluşturmak iyi bir uygulamadır.
CREATE CONSTRAINT unique_tmdb_id IF NOT EXISTS FOR (m:Movie) REQUIRE m.tmdbId IS UNIQUE;
CREATE CONSTRAINT unique_movie_id IF NOT EXISTS FOR (m:Movie) REQUIRE m.movieId IS UNIQUE;
CREATE CONSTRAINT unique_prod_id IF NOT EXISTS FOR (p:ProductionCompany) REQUIRE p.company_id IS UNIQUE;
CREATE CONSTRAINT unique_genre_id IF NOT EXISTS FOR (g:Genre) REQUIRE g.genre_id IS UNIQUE;
CREATE CONSTRAINT unique_lang_id IF NOT EXISTS FOR (l:SpokenLanguage) REQUIRE l.language_code IS UNIQUE;
CREATE CONSTRAINT unique_country_id IF NOT EXISTS FOR (c:Country) REQUIRE c.country_code IS UNIQUE;
CREATE INDEX actor_id IF NOT EXISTS FOR (p:Person) ON (p.actor_id);
CREATE INDEX crew_id IF NOT EXISTS FOR (p:Person) ON (p.crew_id);
CREATE INDEX movieId IF NOT EXISTS FOR (m:Movie) ON (m.movieId);
CREATE INDEX user_id IF NOT EXISTS FOR (p:Person) ON (p.user_id);
2. Adım: Film Meta Verilerini ve İlişkilerini İçe Aktarma
LOAD CSV komutunu kullanarak film meta verilerini nasıl içe aktardığımıza göz atalım. Bu örnekte, başlık, genel bakış, dil ve süre gibi temel özelliklere sahip Film düğümleri oluşturulur:
LOAD CSV WITH HEADERS FROM "https://storage.googleapis.com/neo4j-vertexai-codelab/normalized_data/normalized_movies.csv" AS row
WITH row, toInteger(row.tmdbId) AS tmdbId
WHERE tmdbId IS NOT NULL
WITH row, tmdbId
LIMIT 12000
MERGE (m:Movie {tmdbId: tmdbId})
ON CREATE SET m.title = coalesce(row.title, "None"),
m.original_title = coalesce(row.original_title, "None"),
m.adult = CASE
WHEN toInteger(row.adult) = 1 THEN 'Yes'
ELSE 'No'
END,
m.budget = toInteger(coalesce(row.budget, 0)),
m.original_language = coalesce(row.original_language, "None"),
m.revenue = toInteger(coalesce(row.revenue, 0)),
m.tagline = coalesce(row.tagline, "None"),
m.overview = coalesce(row.overview, "None"),
m.release_date = coalesce(row.release_date, "None"),
m.runtime = toFloat(coalesce(row.runtime, 0)),
m.belongs_to_collection = coalesce(row.belongs_to_collection, "None");
Benzer şekilde, ilgili CSV'lerini ve Cypher sorgularını kullanarak Türler, Yapım Şirketleri, Konuşulan Diller, Ülkeler, Oyuncular, Ekip ve Kullanıcı Puanları gibi diğer öğeleri de içe aktarıp bağlayabilirsiniz.
Python üzerinden tam grafiği yükleme
Birden fazla Cypher sorgusunu manuel olarak çalıştırmak yerine bu kod laboratuvarının sağladığı otomatik Python komut dosyasını kullanmanızı öneririz.
graph_build.py komut dosyası, .env dosyanızdaki kimlik bilgilerini kullanarak GCS'deki veri kümesinin tamamını Neo4j AuraDB örneğinize yükler.
python graph_build.py
Komut dosyası, gerekli tüm CSV dosyalarını sırayla yükler, düğümler ve ilişkiler oluşturur ve film bilgi grafiğinizi tamamen yapılandırır.
|
|

.png")
Grafiğinizi doğrulama
Yükledikten sonra aşağıdaki komut dosyasını çalıştırarak grafiğinizi doğrulayabilirsiniz:
python validate_graph.py
Bu işlem, grafiğinizde nelerin bulunduğuna dair kısa bir özet sunar: kaç film, aktör, tür ve ACTED_IN, DIRECTED gibi ilişkiler mevcuttur. Böylece içe aktarma işleminizin başarılı olup olmadığını anlayabilirsiniz.
📦 Node Counts:
Movie: 11997 nodes
ProductionCompany: 7961 nodes
Genre: 20 nodes
SpokenLanguage: 100 nodes
Country: 113 nodes
Person: 92663 nodes
Actor: 81165 nodes
Director: 4846 nodes
Producer: 5981 nodes
User: 671 nodes
🔗 Relationship Counts:
HAS_GENRE: 28479 relationships
PRODUCED_BY: 22758 relationships
PRODUCED_IN: 14702 relationships
HAS_LANGUAGE: 16184 relationships
ACTED_IN: 191307 relationships
DIRECTED: 5047 relationships
PRODUCED: 6939 relationships
RATED: 90344 relationships
Artık grafiğinizin filmler, kişiler, türler ve daha fazlasıyla doldurulduğunu ve sonraki adımda anlamsal olarak zenginleştirilmeye hazır olduğunu göreceksiniz.
6. Vektör Benzerliği Araması yapmak için yerleştirilmiş öğeler oluşturma ve yükleme
Sohbet robotumuzda anlamsal aramayı etkinleştirmek için film özetlerine yönelik vektör gömmelerini oluşturmamız gerekir. Bu yerleştirmeler, metin verilerini benzerlik açısından karşılaştırılabilen sayısal vektörlere dönüştürür. Böylece sorgu başlık veya açıklamayla tam olarak eşleşmese bile sohbet botunun alakalı filmleri alabilmesi sağlanır.

1. seçenek: Önceden hesaplanmış yerleştirmeleri Cypher aracılığıyla yükleme
Neo4j'daki ilgili Movie düğümlerine yerleştirmeleri hızlıca eklemek için Neo4j Tarayıcı'da aşağıdaki Cypher komutunu çalıştırın:
LOAD CSV WITH HEADERS FROM 'https://storage.googleapis.com/neo4j-vertexai-codelab/movie_embeddings.csv' AS row
WITH row
MATCH (m:Movie {tmdbId: toInteger(row.tmdbId)})
SET m.embedding = apoc.convert.fromJsonList(row.embedding)
Bu komut, CSV'deki yerleştirme vektörlerini okur ve her Movie düğümüne özellik (m.embedding) olarak ekler.
2. Seçenek: Python'u kullanarak yerleşik öğeleri yükleme
Sağlanan Python komut dosyasını kullanarak embeddings'i programatik olarak da yükleyebilirsiniz. Bu yaklaşım, kendi ortamınızda çalışıyorsanız veya süreci otomatikleştirmek istiyorsanız yararlıdır:
python load_embeddings.py
Bu komut dosyası, GCS'den aynı CSV dosyasını okur ve Python Neo4j sürücüsünü kullanarak yerleştirmeleri Neo4j'a yazar.
[İsteğe bağlı] Yerleşimlerinizi kendiniz oluşturun (Keşif için)
Yerleşimlerin nasıl oluşturulduğunu öğrenmek istiyorsanız generate_embeddings.py komut dosyasının mantığını keşfedebilirsiniz. text-embedding-004 modelini kullanarak her filme genel bakış metnini yerleştirmek için Vertex AI'ı kullanır.
Bunu kendiniz denemek için kodun yerleşik oluşturma bölümünü açıp çalıştırın. Cloud Shell'de çalıştırıyorsanız Cloud Shell zaten etkin hesabınız üzerinden kimliğinizi doğruladığından aşağıdaki satırı yorumlayabilirsiniz:
# os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = "./service-account.json"
Yerleşimler Neo4j'a yüklendikten sonra film bilgi grafiğiniz semantik farkında hale gelir ve vektör benzerliğini kullanarak güçlü doğal dil aramayı desteklemeye hazır olur.
7. Film Önerisi Chatbot'u
Bilgi grafiğiniz ve vektör yerleştirmeleriniz hazır olduğunda, tüm bunları GenAI destekli Film Önerisi Sohbet Bot'unuz olan tam işlevli bir sohbet arayüzünde bir araya getirmenin zamanı gelmiştir.
Bu chatbot, sezgisel kullanıcı arayüzleri oluşturmak için kullanılan hafif bir web çerçevesi olan Gradio kullanılarak Python'da uygulanmıştır. Temel mantık, Neo4j AuraDB örneğinize bağlanan ve doğal dil sorgularını işlemek ve yanıtlamak için Google Vertex AI ile Gemini'yi kullanan app.py'te bulunur.
Nasıl Çalışır?
- Kullanıcı doğal dil sorgusu yazarör. "Bana Interstellar gibi bilim kurgu gerilim filmleri öner"
- Vertex AI'ın
text-embedding-004modelini kullanarak sorgu için vektör gömme oluşturma - Semantik olarak benzer filmleri almak için Neo4j'da vektör araması yapın.
- Gemini'yi kullanarak:
- Sorguyu bağlam içinde yorumlama
- Vektör arama sonuçlarını ve Neo4j şemasını temel alan özel bir Cypher sorgusu oluşturma
- İlgili grafik verilerini (ör.aktörler, yönetmenler, türler) ayıklamak için sorguyu yürütün.
- Kullanıcı için sonuçları sohbet dilinde özetleyin.
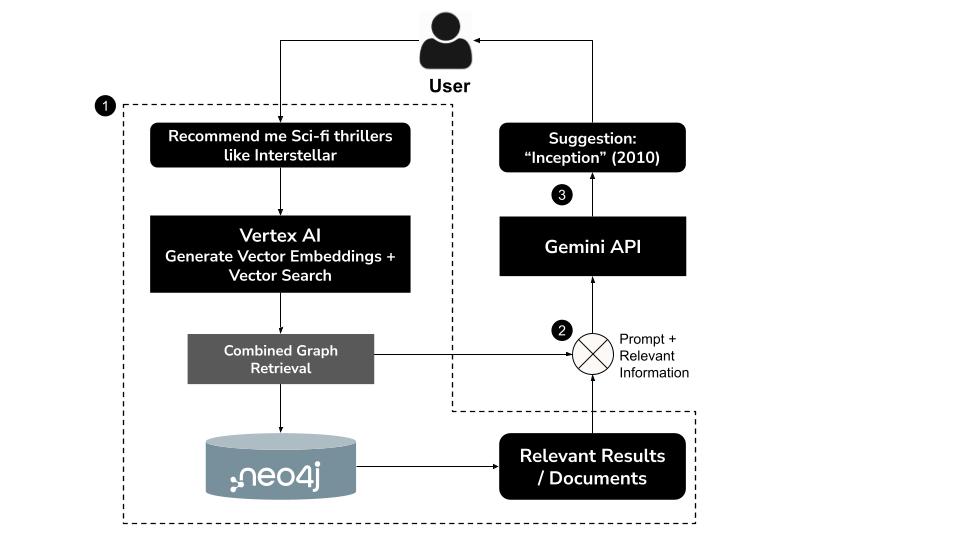
GraphRAG (Graph Retrieval-Augmented Generation) olarak bilinen bu karma yaklaşım, daha doğru, bağlamsal ve açıklanabilir öneriler sunmak için anlamsal alma ve yapılandırılmış akıl yürütmeyi birleştirir.
Chatbot'u yerel olarak çalıştırma
Sanal ortamınızı etkinleştirin (henüz etkin değilse) ve ardından chatbot'u şu şekilde başlatın:
python app.py
Aşağıdakine benzer bir çıkış görürsünüz:
Vector index 'overview_embeddings' already exists. No need to create a new one.
* Running on local URL: http://0.0.0.0:8080
To create a public link, set `share=True` in `launch()`.
💡 Chatbot'u harici olarak paylaşmak için app.py içindeki launch() işlevinde share=True değerini ayarlayın.
Chatbot ile etkileşime geçme
Chatbot arayüzüne erişmek için terminalinizde görüntülenen yerel URL'yi (genellikle 👉 http://0.0.0.0:8080) açın.
Şunlara benzer sorular sormayı deneyin:
- "Yıldızlararası filmini beğendiysem ne izlemeliyim?"
- "Nora Ephron tarafından yönetilen romantik bir film öner"
- "Tom Hanks'in oynadığı bir aile filmi izlemek istiyorum"
- "Yapay zeka içeren gerilim filmleri bul"
Chatbot:
✅ Sorguyu anlama
✅ Yerleşimleri kullanarak anlamsal olarak benzer film olay örgülerini bulma
✅ İlgili grafik bağlamını almak için bir Cypher sorgusu oluşturup çalıştırma
✅ Saniyeler içinde samimi ve kişiselleştirilmiş bir öneride bulunun
Mevcut işlevleriniz
Aşağıdakileri birleştiren bir GraphRAG destekli film chatbot'u oluşturdunuz:
- Semantik alaka düzeyi için vektör araması
- Neo4j ile Bilgi Grafiği akıl yürütme
- Gemini aracılığıyla LLM özellikleri
- Gradio ile sorunsuz bir sohbet arayüzü
Bu mimari, GenAI tarafından desteklenen daha gelişmiş arama, öneri veya akıl yürütme sistemlerine genişletebileceğiniz bir temel oluşturur.
8. (İsteğe bağlı) Google Cloud Run'a dağıtma
Film Önerisi Sohbet Bot'unuzu herkese açık hale getirmek istiyorsanız Google Cloud Run'a dağıtabilirsiniz. Google Cloud Run, uygulamanızı otomatik olarak ölçeklendiren ve tüm altyapı sorunlarını ortadan kaldıran, tümüyle yönetilen ve sunucusuz bir platformdur.
Bu dağıtım şunu kullanır:
requirements.txt: Python bağımlılıklarını (Neo4j, Vertex AI, Gradio vb.) tanımlamak içinDockerfile: Uygulamayı paketlemek için.env.yaml: Ortam değişkenlerini çalışma zamanında güvenli bir şekilde iletmek için
1. adım: .env.yaml dosyasını hazırlayın
Kök dizininizde .env.yaml adlı bir dosya oluşturun ve aşağıdaki gibi içerikler ekleyin:
NEO4J_URI: "neo4j+s://<your-aura-db-uri>"
NEO4J_USER: "neo4j"
NEO4J_PASSWORD: "<your-password>"
PROJECT_ID: "<your-gcp-project-id>"
LOCATION: "<your-gcp-region>" # e.g. us-central1
💡 Daha ölçeklenebilir, sürüm kontrol edilebilir ve okunaklı olduğu için bu biçim --set-env-vars yerine tercih edilir.
2. Adım: Ortam Değişkenlerini Ayarlama
Terminalinizde aşağıdaki ortam değişkenlerini ayarlayın (yer tutucu değerlerini gerçek proje ayarlarınızla değiştirin):
# Set your Google Cloud project ID
export GCP_PROJECT='your-project-id' # Change this
# Set your preferred deployment region
export GCP_REGION='us-central1'
2. Adım: Artifact Registry'yi oluşturun ve kapsayıcıyı derleyin
# Artifact Registry repo and service name
export AR_REPO='your-repo-name' # Change this
export SERVICE_NAME='movies-chatbot' # Or any name you prefer
# Create the Artifact Registry repository
gcloud artifacts repositories create "$AR_REPO" \
--location="$GCP_REGION" \
--repository-format=Docker
# Authenticate Docker with Artifact Registry
gcloud auth configure-docker "$GCP_REGION-docker.pkg.dev"
# Build and submit the container image
gcloud builds submit \
--tag "$GCP_REGION-docker.pkg.dev/$GCP_PROJECT/$AR_REPO/$SERVICE_NAME"
Bu komut, uygulamanızı Dockerfile kullanarak paketler ve container görüntüsünü Google Cloud Artifact Registry'ye yükler.
3. Adım: Cloud Run'a dağıtma
Artık çalışma zamanı yapılandırması için .env.yaml dosyasını kullanarak uygulamanızı dağıtın:
gcloud run deploy "$SERVICE_NAME" \
--port=8080 \
--image="$GCP_REGION-docker.pkg.dev/$GCP_PROJECT/$AR_REPO/$SERVICE_NAME" \
--allow-unauthenticated \
--region=$GCP_REGION \
--platform=managed \
--project=$GCP_PROJECT \
--env-vars-file=.env.yaml
Chatbot'a erişme
Dağıtıldıktan sonra Cloud Run, aşağıdaki gibi herkese açık bir URL sağlar:
https://movies-reco-[UNIQUE_ID].${GCP_REGION}.run.app
Dağıtılan Gradio chatbot arayüzünüze erişmek için tarayıcınızda bu URL'yi açın. GraphRAG, Gemini ve Neo4j'ı kullanarak film önerilerini işlemeye hazırsınız.
Notlar ve İpuçları
- Derleme sırasında
Dockerfile'ünpip install -r requirements.txtçalıştırıldığından emin olun. - Cloud Shell'i kullanmıyorsanız Vertex AI ve Artifact Registry izinlerine sahip bir hizmet hesabı kullanarak ortamınızın kimliğini doğrulamanız gerekir.
- Dağıtım günlüklerini ve metriklerini Google Cloud Console > Cloud Run'dan izleyebilirsiniz.
Google Cloud Console'dan Cloud Run'u da ziyaret edebilirsiniz. Burada Cloud Run'daki hizmetlerin listesini görebilirsiniz. movies-chatbot hizmeti, burada listelenen hizmetlerden biri (tek hizmet değilse) olmalıdır.
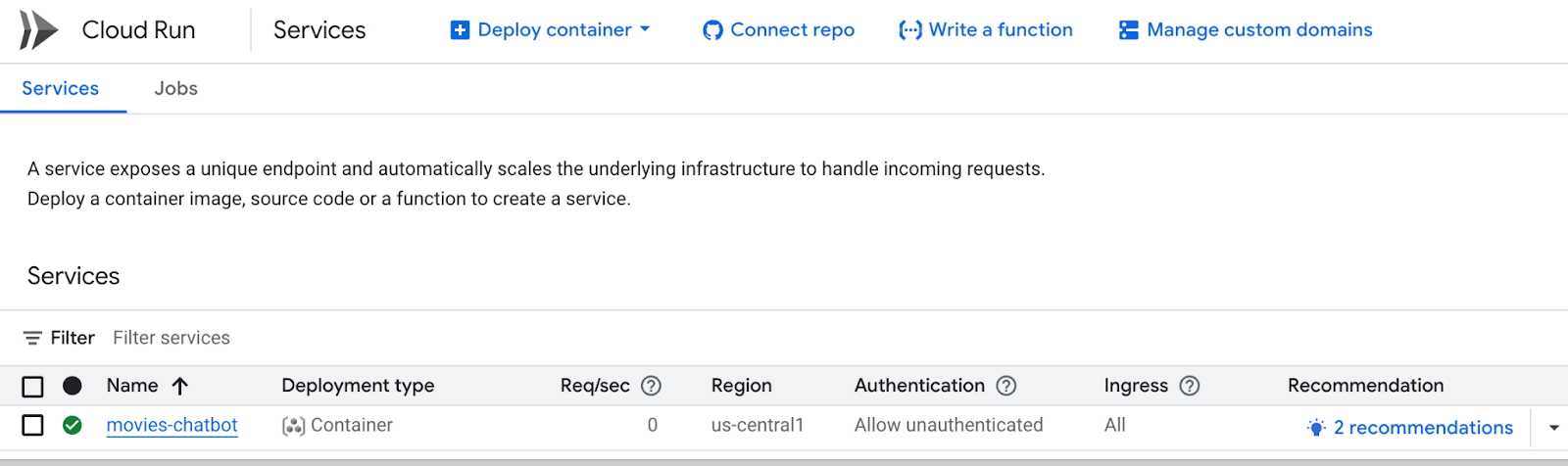
Belirli bir hizmet adını (bizim durumumuzda movies-chatbot) tıklayarak hizmetin URL'si, yapılandırmaları, günlükleri ve diğer ayrıntılarını görüntüleyebilirsiniz.
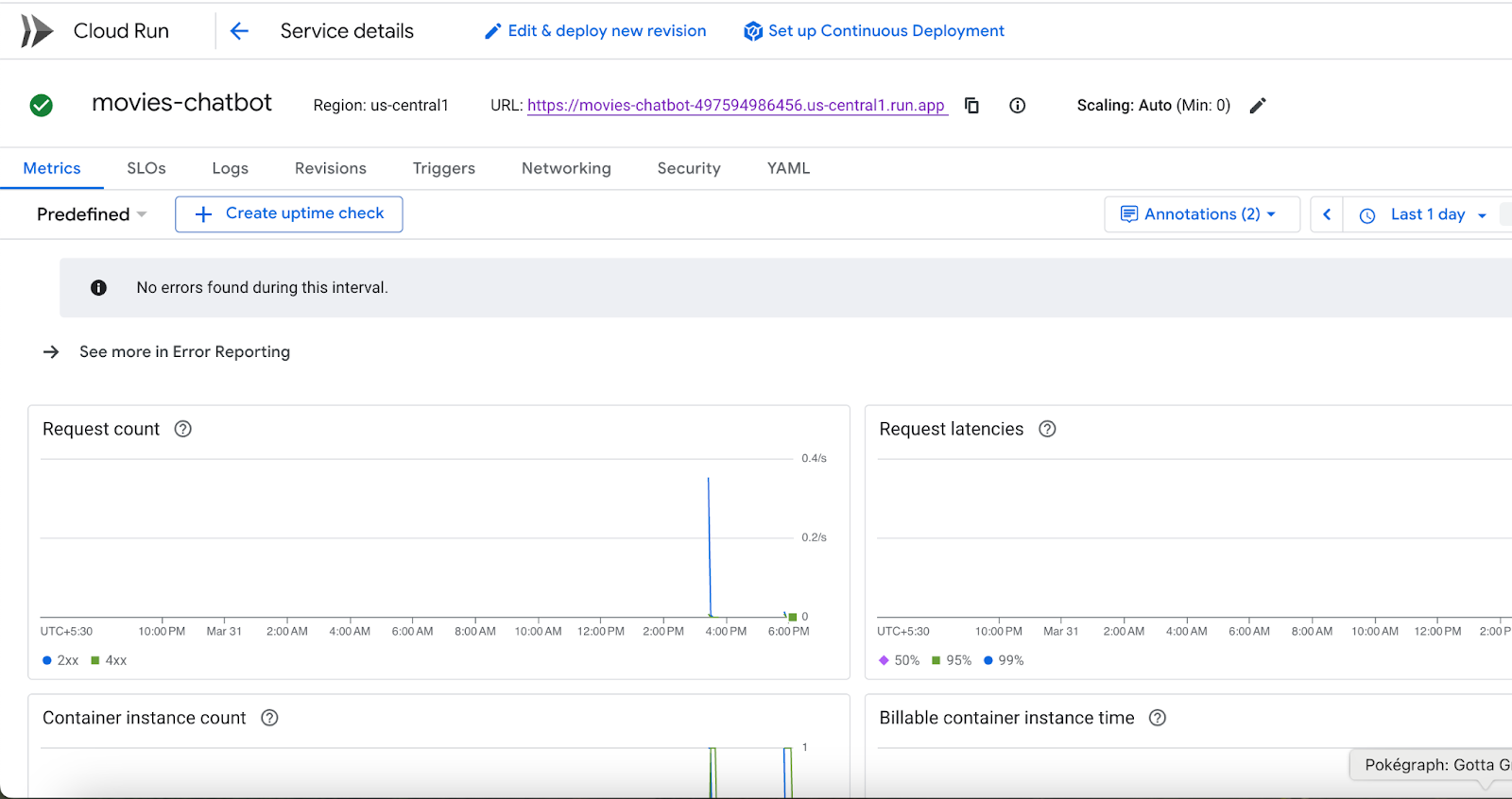
Bu işlemle, Film Önerisi Sohbet Bot'unuz artık yayılmış, ölçeklenebilir ve paylaşılabilir durumdadır. 🎉
9. Temizleme
Bu yayında kullanılan kaynaklar için Google Cloud hesabınızın ücretlendirilmesini istemiyorsanız şu adımları uygulayın:
- Google Cloud Console'da Kaynakları yönetin sayfasına gidin.
- Proje listesinde, silmek istediğiniz projeyi seçin ve ardından Sil'i tıklayın.
- İletişim kutusuna proje kimliğini yazın ve projeyi silmek için Kapat'ı tıklayın.
10. Tebrikler
Neo4j, Vertex AI ve Gemini'yi kullanarak GraphRAG destekli, üretken yapay zeka ile geliştirilmiş bir film önerisi sohbet robotu başarıyla oluşturdunuz ve dağıttınız. Neo4j'ın grafik tabanlı modelleme özelliklerini Vertex AI aracılığıyla semantik arama ve Gemini aracılığıyla doğal dil akıl yürütme ile birleştirerek temel aramanın ötesine geçen akıllı bir sistem oluşturdunuz. Bu sistem kullanıcı amacını anlar, bağlı veriler üzerinde akıl yürütür ve sohbet şeklinde yanıt verir.
Bu codelab'de şunları yaptınız:
✅ Filmleri, aktörleri, türleri ve ilişkileri modellemek için Neo4j'da gerçek bir film bilgi grafiği oluşturdu
✅ Vertex AI'ın metin gömme modellerini kullanarak filmin konusuna genel bakış için oluşturulan vektör gömmeleri
✅ Daha derin ve çok adımlı akıl yürütme için vektör aramasını ve LLM tarafından oluşturulan Cypher sorgularını birleştiren GraphRAG'yi uyguladı
✅ Kullanıcı sorularını yorumlamak, Cypher sorguları oluşturmak ve grafik sonuçlarını doğal dilde özetlemek için entegre Gemini
✅ Gradio'yu kullanarak sezgisel bir sohbet arayüzü oluşturdu
✅ Ölçeklenebilir, sunucusuz barındırma için isteğe bağlı olarak sohbet botunuzu Google Cloud Run'a dağıttınız
Sırada ne var?
Bu mimari, film önerileriyle sınırlı değildir. Aşağıdakiler için de kullanılabilir:
- Kitap ve müzik keşif platformları
- Akademik araştırma asistanları
- Ürün öneri motorları
- Sağlık, finans ve hukuk alanındaki bilgi asistanları
Karmaşık ilişkiler ve zengin metin verilerinin bulunduğu her yerde Bilgi Grafiği + LLM + semantik yerleştirmeler kombinasyonu, yeni nesil akıllı uygulamaları destekleyebilir.
Gemini gibi çok formatlı genel yapay zeka modelleri geliştikçe, gerçekten insan odaklı sistemler oluşturmak için daha da zengin bağlam, resim, konuşma ve kişiselleştirme özelliklerini kullanabileceksiniz.
Keşfetmeye ve uygulama geliştirmeye devam edin. Akıllı uygulamalarınızı bir üst seviyeye çıkarmak için Neo4j, Vertex AI ve Google Cloud'daki en son gelişmelerden haberdar olmayı unutmayın. Neo4j GraphAcademy'de daha fazla uygulamalı Bilgi Grafiği eğitimi keşfedin.