
कोडलैब - Neo4j और Vertex AI का इस्तेमाल करके, मूवी के सुझाव देने वाला चैटबॉट बनाना
इस कोडलैब (कोड बनाना सीखने के लिए ट्यूटोरियल) के बारे में जानकारी
1. खास जानकारी
इस कोडलैब में, Neo4j, Google Vertex AI, और Gemini की मदद से, फ़िल्म के सुझाव देने वाला चैटबॉट बनाया जाएगा. इस सिस्टम के मुख्य हिस्से में Neo4j नॉलेज ग्राफ़ होता है. यह फ़िल्मों, कलाकारों, निर्देशकों, शैलियों वगैरह का मॉडल बनाता है. इसके लिए, यह इंटरकनेक्ट किए गए नोड और रिश्तों के बेहतर नेटवर्क का इस्तेमाल करता है.
सेमेटिक समझ की मदद से उपयोगकर्ता अनुभव को बेहतर बनाने के लिए, आपको Vertex AI के text-embedding-004 मॉडल (या नए मॉडल) का इस्तेमाल करके, मूवी प्लॉट की खास जानकारी से वेक्टर एम्बेड जनरेट करने होंगे. इन एम्बेड को Neo4j में इंडेक्स किया जाता है, ताकि मिलते-जुलते कॉन्टेंट को तुरंत खोजा जा सके.
आखिर में, आपको Gemini को बातचीत वाले इंटरफ़ेस के साथ इंटिग्रेट करना होगा. यहां उपयोगकर्ता, "अगर मुझे Interstellar पसंद आया, तो मुझे क्या देखना चाहिए?" जैसे नैचुरल भाषा वाले सवाल पूछ सकते हैं. साथ ही, उन्हें सेमेटिक मिलते-जुलते शब्दों और ग्राफ़ पर आधारित कॉन्टेक्स्ट के हिसाब से, उनकी पसंद के मुताबिक फ़िल्म के सुझाव मिलेंगे.
कोडलैब में, आपको सिलसिलेवार तरीके से यह तरीका अपनाना होगा:
- फ़िल्म से जुड़ी इकाइयों और रिश्तों के साथ Neo4j नॉलेज ग्राफ़ बनाना
- Vertex AI का इस्तेमाल करके, मूवी की खास जानकारी के लिए टेक्स्ट एम्बेड जनरेट करना या लोड करना
- Gemini की मदद से Gradio चैटबॉट इंटरफ़ेस लागू करना, जो वेक्टर सर्च को ग्राफ़ पर आधारित Cypher एक्सीक्यूशन के साथ जोड़ता है
- (ज़रूरी नहीं) ऐप्लिकेशन को स्टैंडअलोन वेब ऐप्लिकेशन के तौर पर Cloud Run में डिप्लॉय करना
आपको क्या सीखने को मिलेगा
- Cypher और Neo4j का इस्तेमाल करके, मूवी के बारे में जानकारी देने वाला ग्राफ़ बनाने और उसमें जानकारी भरने का तरीका
- सिमेंटिक टेक्स्ट एम्बेड जनरेट करने और उनका इस्तेमाल करने के लिए, Vertex AI का इस्तेमाल करने का तरीका
- GraphRAG का इस्तेमाल करके, बेहतर तरीके से जानकारी पाने के लिए एलएलएम और नॉलेज ग्राफ़ को जोड़ने का तरीका
- Gradio का इस्तेमाल करके, उपयोगकर्ता के हिसाब से चैट इंटरफ़ेस बनाने का तरीका
- Google Cloud Run पर डिप्लॉय करने का वैकल्पिक तरीका
आपको इन चीज़ों की ज़रूरत होगी
- Chrome वेब ब्राउज़र
- Gmail खाता
- बिलिंग की सुविधा वाला Google Cloud प्रोजेक्ट
- Neo4j Aura DB का मुफ़्त खाता
- टर्मिनल निर्देशों और Python के बारे में बुनियादी जानकारी (यह मददगार है, लेकिन ज़रूरी नहीं है)
यह कोडलैब, सभी लेवल के डेवलपर (शुरुआती डेवलपर भी) के लिए डिज़ाइन किया गया है. इसमें सैंपल ऐप्लिकेशन के लिए, Python और Neo4j का इस्तेमाल किया गया है. Python और ग्राफ़ डेटाबेस के बारे में बुनियादी जानकारी होना मददगार हो सकता है. हालांकि, कॉन्सेप्ट को समझने या उन्हें फ़ॉलो करने के लिए, पहले से कोई अनुभव होना ज़रूरी नहीं है.
2. Neo4j AuraDB सेटअप करना
Neo4j एक लोकप्रिय नेटिव ग्राफ़ डेटाबेस है. यह डेटा को नोड (इकाइयों) और रिलेशनशिप (इकाइयों के बीच के कनेक्शन) के नेटवर्क के तौर पर सेव करता है. इस वजह से, यह उन कामों के लिए आदर्श है जहां कनेक्शन को समझना ज़रूरी है. जैसे, सुझाव, धोखाधड़ी का पता लगाना, नॉलेज ग्राफ़ वगैरह. रिलेशनल या दस्तावेज़ पर आधारित डेटाबेस, तय टेबल या हैरारकी वाले स्ट्रक्चर पर निर्भर होते हैं. वहीं, Neo4j का फ़्लेक्सिबल ग्राफ़ मॉडल, जटिल और आपस में जुड़े डेटा को आसानी से और बेहतर तरीके से दिखाता है.
रिलेशनल डेटाबेस की तरह, डेटा को पंक्तियों और टेबल में व्यवस्थित करने के बजाय, Neo4j ग्राफ़ मॉडल का इस्तेमाल करता है. इसमें जानकारी को नोड (इकाइयां) और रिश्तों (उन इकाइयों के बीच के कनेक्शन) के तौर पर दिखाया जाता है. इस मॉडल की मदद से, ऐसे डेटा के साथ काम करना बेहद आसान हो जाता है जो पहले से ही आपस में जुड़ा होता है. जैसे, लोग, जगहें, प्रॉडक्ट या हमारे मामले में, फ़िल्में, कलाकार, और शैलियां.
उदाहरण के लिए, किसी फ़िल्म के डेटासेट में:
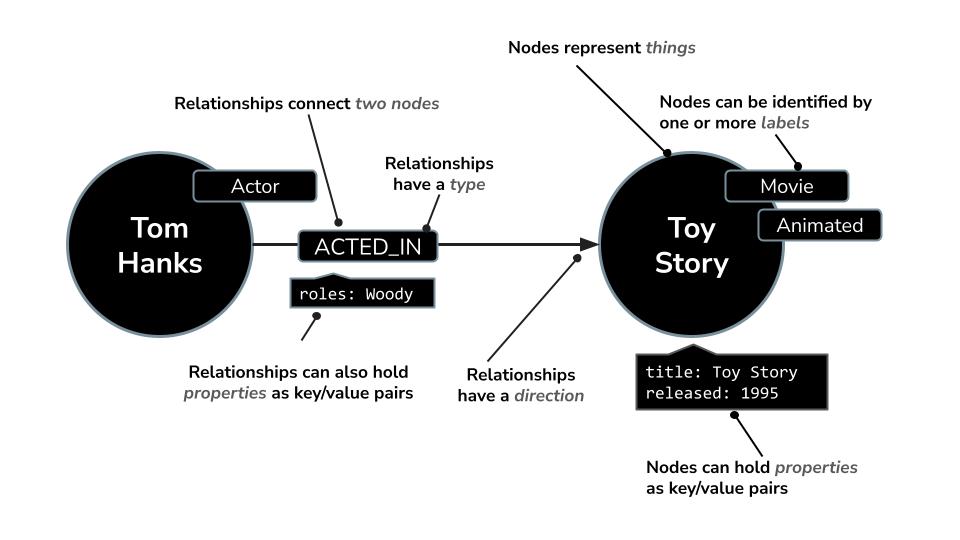
- कोई नोड,
Movie,ActorयाDirectorको दिखा सकता है - संबंध
ACTED_INयाDIRECTEDहो सकता है
इस स्ट्रक्चर की मदद से, आसानी से ये सवाल पूछे जा सकते हैं:
- यह अभिनेता किन फ़िल्मों में दिख चुका है?
- क्रिस्टोफ़र नोलन के साथ किन लोगों ने काम किया है?
- एक जैसे कलाकारों या शैलियों वाली मिलती-जुलती फ़िल्में कौनसी हैं?
Neo4j में Cypher नाम की एक बेहतरीन क्वेरी भाषा होती है. इसे खास तौर पर ग्राफ़ से जुड़ी क्वेरी के लिए डिज़ाइन किया गया है. साइफ़र की मदद से, जटिल पैटर्न और कनेक्शन को कम शब्दों में और आसानी से पढ़े जा सकने वाले तरीके से दिखाया जा सकता है. उदाहरण के लिए: यह Cypher क्वेरी MERGE का इस्तेमाल करती है, ताकि यह पक्का किया जा सके कि कलाकार, फ़िल्म, और उनकी भूमिका की जानकारी के साथ उनके संबंध को डुप्लीकेट से बचाकर, यूनीक बनाया जा सके.
MERGE (a:Actor {name: "Tom Hanks"})
MERGE (m:Movie {title: "Toy Story", released: 1995})
MERGE (a)-[:ACTED_IN {roles: ["Woody"]}]->(m);
Neo4j, आपकी ज़रूरतों के हिसाब से डिप्लॉयमेंट के कई विकल्प उपलब्ध कराता है:
- खुद मैनेज करना: Neo4j डेस्कटॉप का इस्तेमाल करके या Docker इमेज के तौर पर (ऑन-प्रीमिस या अपने क्लाउड में) अपने इंफ़्रास्ट्रक्चर पर Neo4j चलाएं.
- क्लाउड से मैनेज किया जाने वाला वर्शन: मार्केटप्लेस पर उपलब्ध ऑफ़र का इस्तेमाल करके, लोकप्रिय क्लाउड सेवा देने वाली कंपनियों के प्लैटफ़ॉर्म पर Neo4j को डिप्लॉय करें.
- पूरी तरह से मैनेज किया गया: Neo4j AuraDB का इस्तेमाल करें. यह Neo4j का पूरी तरह से मैनेज किया जाने वाला क्लाउड डेटाबेस-ऐज़-अ-सर्विस है. यह आपके लिए प्रोविज़निंग, स्केलिंग, बैकअप, और सुरक्षा को मैनेज करता है.
इस कोडलैब में, हम Neo4j AuraDB Free का इस्तेमाल करेंगे. यह AuraDB का बिना किसी शुल्क वाला टीयर है. यह पूरी तरह से मैनेज किया जाने वाला ग्राफ़ डेटाबेस इंस्टेंस उपलब्ध कराता है. इसमें प्रोटोटाइप बनाने, लर्निंग, और छोटे ऐप्लिकेशन बनाने के लिए ज़रूरत के मुताबिक स्टोरेज और सुविधाएं मिलती हैं. यह जनरेटिव एआई की मदद से, मूवी के सुझाव देने वाला चैटबॉट बनाने के हमारे लक्ष्य के लिए एकदम सही है.
आपको एक मुफ़्त AuraDB इंस्टेंस बनाना होगा. इसके बाद, कनेक्शन क्रेडेंशियल का इस्तेमाल करके, उसे अपने ऐप्लिकेशन से कनेक्ट करना होगा. साथ ही, इस पूरे लैब में, मूवी के नॉलेज ग्राफ़ को सेव करने और उससे जुड़ी क्वेरी करने के लिए, इसका इस्तेमाल करना होगा.
ग्राफ़ क्यों इस्तेमाल करें?
पारंपरिक रिलेशनल डेटाबेस में, "शेयर की गई कास्ट या शैली के आधार पर, Inception जैसी कौनसी फ़िल्में हैं?" जैसे सवालों के जवाब देने के लिए, एक से ज़्यादा टेबल में जॉइन ऑपरेशन की ज़रूरत होती है. ज़्यादा डेटा जुड़ने पर, परफ़ॉर्मेंस और कॉन्टेंट को पढ़ने में मुश्किल आती है.
हालांकि, Neo4j जैसे ग्राफ़ डेटाबेस, रिश्तों को असरदार तरीके से ट्रैवर्स करने के लिए बनाए गए हैं. इस वजह से, ये सुझाव देने वाले सिस्टम, सेमैनटिक सर्च, और बेहतर सहायकों के लिए सबसे सही हैं. इनसे असल दुनिया के कॉन्टेक्स्ट को कैप्चर करने में मदद मिलती है. जैसे, सहयोग करने वाले नेटवर्क, स्टोरीलाइन या दर्शकों की प्राथमिकताएं. इन्हें पारंपरिक डेटा मॉडल का इस्तेमाल करके दिखाना मुश्किल हो सकता है.
कनेक्ट किए गए इस डेटा को Gemini जैसे एलएलएम और Vertex AI के वेक्टर एम्बेड के साथ जोड़कर, चैटबॉट के अनुभव को बेहतर बनाया जा सकता है. इससे, चैटबॉट आपके हिसाब से काम का डेटा इकट्ठा कर पाएगा, उसे वापस ला पाएगा, और ज़्यादा काम के जवाब दे पाएगा.
Neo4j AuraDB को बिना किसी शुल्क के बनाना
- https://console.neo4j.io पर जाएं
- अपने Google खाते या ईमेल से लॉग इन करें.
- "बिना शुल्क वाला इंस्टेंस बनाएं" पर क्लिक करें.
- इंस्टेंस को प्रोविज़न करते समय, आपको एक पॉप-अप विंडो दिखेगी. इसमें आपके डेटाबेस के कनेक्शन क्रेडेंशियल दिखेंगे.
पॉप-अप से यह जानकारी डाउनलोड करके सुरक्षित तरीके से सेव करना न भूलें — ये आपके ऐप्लिकेशन को Neo4j से कनेक्ट करने के लिए ज़रूरी हैं:
NEO4J_URI=neo4j+s://<your-instance-id>.databases.neo4j.io
NEO4J_USERNAME=neo4j
NEO4J_PASSWORD=<your-generated-password>
AURA_INSTANCEID=<your-instance-id>
AURA_INSTANCENAME=<your-instance-name>
अगले चरण में Neo4j के साथ पुष्टि करने के लिए, अपने प्रोजेक्ट में .env फ़ाइल को कॉन्फ़िगर करने के लिए इन वैल्यू का इस्तेमाल किया जाएगा.

Neo4j AuraDB Free, डेवलपमेंट, प्रयोग, और इस कोडलैब जैसे छोटे ऐप्लिकेशन के लिए बेहतरीन है. इसमें इस्तेमाल की ज़्यादा सीमाएं होती हैं. इसमें 2,00,000 नोड और 4,00,000 रिलेशनशिप तक काम किए जा सकते हैं. इसमें नॉलेज ग्राफ़ बनाने और उससे जुड़ी क्वेरी करने के लिए ज़रूरी सभी सुविधाएं मौजूद हैं. हालांकि, इसमें कस्टम प्लग इन या ज़्यादा स्टोरेज जैसे बेहतर कॉन्फ़िगरेशन काम नहीं करते. प्रोडक्शन वर्कलोड या बड़े डेटासेट के लिए, AuraDB के किसी बेहतर टीयर वाले प्लान पर अपग्रेड किया जा सकता है. इस प्लान में ज़्यादा क्षमता, परफ़ॉर्मेंस, और एंटरप्राइज़-ग्रेड की सुविधाएं मिलती हैं.
इससे, Neo4j AuraDB बैकएंड को सेट अप करने का सेक्शन पूरा हो जाता है. अगले चरण में, हम Google Cloud प्रोजेक्ट बनाएंगे, रिपॉज़िटरी को क्लोन करेंगे, और ज़रूरी एनवायरमेंट वैरिएबल कॉन्फ़िगर करेंगे. इससे, कोडलैब शुरू करने से पहले आपका डेवलपमेंट एनवायरमेंट तैयार हो जाएगा.
3. शुरू करने से पहले
प्रोजेक्ट बनाना
- Google Cloud Console में, प्रोजेक्ट चुनने वाले पेज पर, Google Cloud प्रोजेक्ट चुनें या बनाएं.
- पक्का करें कि आपके Cloud प्रोजेक्ट के लिए बिलिंग की सुविधा चालू हो. किसी प्रोजेक्ट के लिए बिलिंग की सुविधा चालू है या नहीं, यह देखने का तरीका जानें .
- इसके लिए, आपको Cloud Shell का इस्तेमाल करना होगा. यह Google Cloud में चलने वाला कमांड-लाइन एनवायरमेंट है, जिसमें bq पहले से लोड होता है. Google Cloud कंसोल में सबसे ऊपर, 'Cloud Shell चालू करें' पर क्लिक करें.

- Cloud Shell से कनेक्ट होने के बाद, यह जांच करें कि आपकी पुष्टि पहले ही हो चुकी है या नहीं. साथ ही, यह भी देखें कि प्रोजेक्ट आपके प्रोजेक्ट आईडी पर सेट है या नहीं. इसके लिए, यह कमांड इस्तेमाल करें:
gcloud auth list
- Cloud Shell में यह कमांड चलाकर पुष्टि करें कि gcloud कमांड को आपके प्रोजेक्ट के बारे में पता है.
gcloud config list project
- अगर आपका प्रोजेक्ट सेट नहीं है, तो इसे सेट करने के लिए इस निर्देश का इस्तेमाल करें:
gcloud config set project <YOUR_PROJECT_ID>
- नीचे दिए गए निर्देश का इस्तेमाल करके, ज़रूरी एपीआई चालू करें. इसमें कुछ मिनट लग सकते हैं. इसलिए, कृपया इंतज़ार करें.
gcloud services enable cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
cloudfunctions.googleapis.com \
aiplatform.googleapis.com
निर्देश पूरा होने पर, आपको यह मैसेज दिखेगा: "कार्रवाई .... पूरी हो गई".
gcloud कमांड के बजाय, कंसोल में जाकर हर प्रॉडक्ट को खोजें या इस लिंक का इस्तेमाल करें.
अगर कोई एपीआई छूट जाता है, तो उसे लागू करने के दौरान कभी भी चालू किया जा सकता है.
gcloud के निर्देशों और इस्तेमाल के बारे में जानने के लिए, दस्तावेज़ देखें.
रिपॉज़िटरी को क्लोन करना और एनवायरमेंट सेटिंग सेट अप करना
अगला चरण, सैंपल रिपॉज़िटरी को क्लोन करना है. इसका इस्तेमाल, हम कोडलैब के बाकी हिस्से में करेंगे. मान लें कि आप Cloud Shell में हैं, तो अपनी होम डायरेक्ट्री से यह कमांड दें:
git clone https://github.com/sidagarwal04/neo4j-vertexai-codelab.git
एडिटर लॉन्च करने के लिए, Cloud Shell विंडो के टूलबार में एडिटर खोलें पर क्लिक करें. सबसे ऊपर बाएं कोने में मौजूद मेन्यू बार पर क्लिक करें. इसके बाद, फ़ाइल → फ़ोल्डर खोलें को चुनें, जैसा कि यहां दिखाया गया है:

neo4j-vertexai-codelab फ़ोल्डर चुनें. इसके बाद, आपको नीचे दिखाए गए फ़ोल्डर से मिलते-जुलते स्ट्रक्चर वाला फ़ोल्डर दिखेगा:

इसके बाद, हमें ऐसे एनवायरमेंट वैरिएबल सेट अप करने होंगे जिनका इस्तेमाल पूरे कोडलैब में किया जाएगा. example.env फ़ाइल पर क्लिक करें. इसके बाद, आपको नीचे दिखाया गया कॉन्टेंट दिखेगा:
NEO4J_URI=
NEO4J_USER=
NEO4J_PASSWORD=
NEO4J_DATABASE=
PROJECT_ID=
LOCATION=
अब example.env फ़ाइल वाले फ़ोल्डर में, .env नाम की एक नई फ़ाइल बनाएं और मौजूदा example.env फ़ाइल का कॉन्टेंट कॉपी करें. अब, इन वैरिएबल को अपडेट करें:
NEO4J_URI,NEO4J_USER,NEO4J_PASSWORD, औरNEO4J_DATABASE:- पिछले चरण में Neo4j AuraDB का मुफ़्त इंस्टेंस बनाते समय दिए गए क्रेडेंशियल का इस्तेमाल करके, ये वैल्यू भरें.
- आम तौर पर, AuraDB Free के लिए
NEO4J_DATABASEको neo4j पर सेट किया जाता है. PROJECT_IDऔरLOCATION:- अगर Google Cloud Shell से कोडलैब चलाया जा रहा है, तो इन फ़ील्ड को खाली छोड़ा जा सकता है. ऐसा इसलिए, क्योंकि ये आपके चालू प्रोजेक्ट कॉन्फ़िगरेशन से अपने-आप पता चल जाएंगे.
- अगर इसे स्थानीय तौर पर या Cloud Shell के बाहर चलाया जा रहा है, तो
PROJECT_IDको उस Google Cloud प्रोजेक्ट के आईडी से अपडेट करें जिसे आपने पहले बनाया था. साथ ही,LOCATIONको उस प्रोजेक्ट के लिए चुने गए इलाके (उदाहरण के लिए, us-central1) पर सेट करें.
इन वैल्यू को भरने के बाद, .env फ़ाइल को सेव करें. इस कॉन्फ़िगरेशन की मदद से, आपका ऐप्लिकेशन Neo4j और Vertex AI, दोनों सेवाओं से कनेक्ट हो पाएगा.
डेवलपमेंट एनवायरमेंट सेट अप करने का आखिरी चरण, Python वर्चुअल एनवायरमेंट बनाना और requirements.txt फ़ाइल में दी गई सभी ज़रूरी डिपेंडेंसी इंस्टॉल करना है. इन डिपेंडेंसी में, Neo4j, Vertex AI, Gradio वगैरह के साथ काम करने के लिए ज़रूरी लाइब्रेरी शामिल हैं.
सबसे पहले, यह कमांड चलाकर .venv नाम का वर्चुअल एनवायरमेंट बनाएं:
python -m venv .venv
एनवायरमेंट बन जाने के बाद, हमें इस कमांड की मदद से बनाए गए एनवायरमेंट को चालू करना होगा
source .venv/bin/activate
अब आपको अपने टर्मिनल प्रॉम्प्ट की शुरुआत में (.venv) दिखेगा. इससे पता चलता है कि एनवायरमेंट चालू है. उदाहरण के लिए: (.venv) yourusername@cloudshell:
अब, ज़रूरी डिपेंडेंसी इंस्टॉल करने के लिए, यह तरीका अपनाएं:
pip install -r requirements.txt
यहां फ़ाइल में दी गई मुख्य डिपेंडेंसी का स्नैपशॉट दिया गया है:
gradio>=4.0.0
neo4j>=5.0.0
numpy>=1.20.0
python-dotenv>=1.0.0
google-cloud-aiplatform>=1.30.0
vertexai>=0.0.1
सभी डिपेंडेंसी इंस्टॉल हो जाने के बाद, इस कोडलैब में स्क्रिप्ट और चैटबॉट चलाने के लिए, आपका स्थानीय Python एनवायरमेंट पूरी तरह से कॉन्फ़िगर हो जाएगा.
बढ़िया ! अब हम अगले चरण पर जाने के लिए तैयार हैं — डेटासेट को समझना और उसे ग्राफ़ बनाने और सेमैनटिक एनरिचमेंट के लिए तैयार करना.
4. फ़िल्मों का डेटासेट तैयार करना
हमारा पहला काम, मूवी का डेटासेट तैयार करना है. इसका इस्तेमाल, नॉलेज ग्राफ़ बनाने और सुझाव देने वाले चैटबॉट को बेहतर बनाने के लिए किया जाएगा. हम शुरू से नया डेटासेट बनाने के बजाय, किसी मौजूदा ओपन डेटासेट का इस्तेमाल करेंगे और उस पर काम करेंगे.
हम Rounak Banik के The Movies Dataset का इस्तेमाल कर रहे हैं. यह Kaggle पर उपलब्ध एक लोकप्रिय सार्वजनिक डेटासेट है. इसमें TMDB की 45,000 से ज़्यादा फ़िल्मों का मेटाडेटा शामिल है. इसमें कलाकार, क्रू, कीवर्ड, रेटिंग वगैरह की जानकारी शामिल है.
मूवी के सुझाव देने वाला भरोसेमंद और असरदार चैटबॉट बनाने के लिए, साफ़, एक जैसा, और स्ट्रक्चर्ड डेटा से शुरुआत करना ज़रूरी है. Kaggle का फ़िल्मों का डेटासेट एक बेहतरीन संसाधन है. इसमें 45,000 से ज़्यादा फ़िल्मों के रिकॉर्ड और ज़्यादा जानकारी वाला मेटाडेटा शामिल है. इसमें शैलियां, कास्ट, क्रू वगैरह शामिल हैं. हालांकि, इसमें ग़ैर-ज़रूरी जानकारी, गड़बड़ियां, और नेस्ट किए गए डेटा स्ट्रक्चर भी शामिल हैं. ये डेटा स्ट्रक्चर, ग्राफ़ मॉडलिंग या सेमैंटिक एम्बेडिंग के लिए सही नहीं हैं.
इस समस्या को हल करने के लिए, हमने डेटासेट को प्रीप्रोसेस और नॉर्मलाइज़ किया है, ताकि यह Neo4j नॉलेज ग्राफ़ बनाने और अच्छी क्वालिटी के एम्बेड जनरेट करने के लिए सही हो. इस प्रोसेस में ये काम शामिल थे:
- डुप्लीकेट और अधूरे रिकॉर्ड हटाना
- मुख्य फ़ील्ड को स्टैंडर्ड बनाना. जैसे, शैली के नाम, व्यक्ति के नाम
- नेस्ट किए गए जटिल स्ट्रक्चर (जैसे, कास्ट और क्रू) को स्ट्रक्चर्ड CSV में फ़्लैट करना
- Neo4j AuraDB के मुफ़्त वर्शन की सीमाओं के अंदर रहने के लिए, ~12,000 फ़िल्मों का एक प्रतिनिधि सबसेट चुनना
अच्छी क्वालिटी और सामान्य किए गए डेटा से यह पक्का करने में मदद मिलती है कि:
- डेटा क्वालिटी: इससे ज़्यादा सटीक सुझाव पाने के लिए, गड़बड़ियों और अंतर को कम किया जाता है
- क्वेरी की परफ़ॉर्मेंस: बेहतर स्ट्रक्चर की मदद से, डेटा को वापस पाने की स्पीड बढ़ती है और डेटा का दोहराव कम होता है
- सटीक तरीके से एंबेड करना: साफ़ इनपुट से, ज़्यादा काम के और संदर्भ के हिसाब से वेक्टर एंबेड मिलते हैं
इस GitHub रिपॉज़िटरी के normalized_data/ फ़ोल्डर में, साफ़ और नॉर्मलाइज़ किया गया डेटासेट ऐक्सेस किया जा सकता है. आने वाली Python स्क्रिप्ट में आसानी से ऐक्सेस करने के लिए, इस डेटासेट को Google Cloud Storage बकेट में भी मिरर किया जाता है.
डेटा को साफ़ और तैयार करने के बाद, अब हम इसे Neo4j में लोड करने और मूवी के नॉलेज ग्राफ़ को बनाने के लिए तैयार हैं.
5. फ़िल्मों का नॉलेज ग्राफ़ बनाना
जनरेटिव एआई (जीएआई) की मदद से फ़िल्मों के सुझाव देने वाले चैटबॉट को बेहतर बनाने के लिए, हमें फ़िल्मों के डेटासेट को इस तरह से स्ट्रक्चर करना होगा कि फ़िल्मों, कलाकारों, निर्देशकों, शैलियों, और अन्य मेटाडेटा के बीच के कनेक्शन का बेहतर नेटवर्क कैप्चर किया जा सके. इस सेक्शन में, हम Neo4j में मूवी के बारे में जानकारी देने वाला नेटवर्क बनाएंगे. इसके लिए, हम उस डेटासेट का इस्तेमाल करेंगे जिसे आपने पहले तैयार किया था और जो साफ़ और सामान्य किया गया है.
हम सार्वजनिक Google Cloud Storage (जीसीएस) बकेट में होस्ट की गई CSV फ़ाइलों को डालने के लिए, Neo4j की LOAD CSV सुविधा का इस्तेमाल करेंगे. ये फ़ाइलें, फ़िल्म के डेटासेट के अलग-अलग कॉम्पोनेंट दिखाती हैं. जैसे, फ़िल्में, शैलियां, कलाकार, क्रू, प्रोडक्शन कंपनियां, और उपयोगकर्ता रेटिंग.
पहला चरण: पाबंदियां और इंडेक्स बनाना
डेटा इंपोर्ट करने से पहले, कंस्ट्रेंट और इंडेक्स बनाना अच्छा होता है. इससे डेटा की सुरक्षा को बेहतर बनाया जा सकता है और क्वेरी की परफ़ॉर्मेंस को ऑप्टिमाइज़ किया जा सकता है.
CREATE CONSTRAINT unique_tmdb_id IF NOT EXISTS FOR (m:Movie) REQUIRE m.tmdbId IS UNIQUE;
CREATE CONSTRAINT unique_movie_id IF NOT EXISTS FOR (m:Movie) REQUIRE m.movieId IS UNIQUE;
CREATE CONSTRAINT unique_prod_id IF NOT EXISTS FOR (p:ProductionCompany) REQUIRE p.company_id IS UNIQUE;
CREATE CONSTRAINT unique_genre_id IF NOT EXISTS FOR (g:Genre) REQUIRE g.genre_id IS UNIQUE;
CREATE CONSTRAINT unique_lang_id IF NOT EXISTS FOR (l:SpokenLanguage) REQUIRE l.language_code IS UNIQUE;
CREATE CONSTRAINT unique_country_id IF NOT EXISTS FOR (c:Country) REQUIRE c.country_code IS UNIQUE;
CREATE INDEX actor_id IF NOT EXISTS FOR (p:Person) ON (p.actor_id);
CREATE INDEX crew_id IF NOT EXISTS FOR (p:Person) ON (p.crew_id);
CREATE INDEX movieId IF NOT EXISTS FOR (m:Movie) ON (m.movieId);
CREATE INDEX user_id IF NOT EXISTS FOR (p:Person) ON (p.user_id);
दूसरा चरण: फ़िल्म का मेटाडेटा और रिलेशनशिप इंपोर्ट करना
आइए, LOAD CSV कमांड का इस्तेमाल करके फ़िल्म का मेटाडेटा इंपोर्ट करने का तरीका देखें. इस उदाहरण में, टाइटल, खास जानकारी, भाषा, और रनटाइम जैसे मुख्य एट्रिब्यूट के साथ मूवी नोड बनाए गए हैं:
LOAD CSV WITH HEADERS FROM "https://storage.googleapis.com/neo4j-vertexai-codelab/normalized_data/normalized_movies.csv" AS row
WITH row, toInteger(row.tmdbId) AS tmdbId
WHERE tmdbId IS NOT NULL
WITH row, tmdbId
LIMIT 12000
MERGE (m:Movie {tmdbId: tmdbId})
ON CREATE SET m.title = coalesce(row.title, "None"),
m.original_title = coalesce(row.original_title, "None"),
m.adult = CASE
WHEN toInteger(row.adult) = 1 THEN 'Yes'
ELSE 'No'
END,
m.budget = toInteger(coalesce(row.budget, 0)),
m.original_language = coalesce(row.original_language, "None"),
m.revenue = toInteger(coalesce(row.revenue, 0)),
m.tagline = coalesce(row.tagline, "None"),
m.overview = coalesce(row.overview, "None"),
m.release_date = coalesce(row.release_date, "None"),
m.runtime = toFloat(coalesce(row.runtime, 0)),
m.belongs_to_collection = coalesce(row.belongs_to_collection, "None");
इसी तरह, शैलियां, प्रोडक्शन कंपनियां, बोली जाने वाली भाषाएं, देश, कलाकार, क्रू, और उपयोगकर्ता रेटिंग जैसी अन्य इकाइयों को इंपोर्ट और लिंक किया जा सकता है. इसके लिए, आपको उनकी CSV फ़ाइलों और Cypher क्वेरी का इस्तेमाल करना होगा.
Python की मदद से पूरा ग्राफ़ लोड करना
हमारा सुझाव है कि आप एक से ज़्यादा Cypher क्वेरी को मैन्युअल तरीके से चलाने के बजाय, इस कोडलैब में दी गई ऑटोमेटेड Python स्क्रिप्ट का इस्तेमाल करें.
स्क्रिप्ट graph_build.py, .env फ़ाइल में मौजूद क्रेडेंशियल का इस्तेमाल करके, GCS से पूरे डेटासेट को आपके Neo4j AuraDB इंस्टेंस में लोड करती है.
python graph_build.py
स्क्रिप्ट, सभी ज़रूरी CSV फ़ाइलों को क्रम से लोड करेगी, नोड और संबंध बनाएगी, और मूवी के नॉलेज ग्राफ़ को पूरी तरह से तैयार करेगी.
|
|


अपने ग्राफ़ की पुष्टि करना
लोड होने के बाद, इस स्क्रिप्ट को चलाकर अपने ग्राफ़ की पुष्टि की जा सकती है:
python validate_graph.py
इससे आपको यह जानकारी तुरंत मिल जाएगी कि आपके ग्राफ़ में क्या है: कितनी फ़िल्में, कलाकार, शैलियां, और ACTED_IN, DIRECTED वगैरह जैसे रिलेशनशिप मौजूद हैं. इससे यह पक्का किया जा सकेगा कि इंपोर्ट पूरा हो गया है.
📦 Node Counts:
Movie: 11997 nodes
ProductionCompany: 7961 nodes
Genre: 20 nodes
SpokenLanguage: 100 nodes
Country: 113 nodes
Person: 92663 nodes
Actor: 81165 nodes
Director: 4846 nodes
Producer: 5981 nodes
User: 671 nodes
🔗 Relationship Counts:
HAS_GENRE: 28479 relationships
PRODUCED_BY: 22758 relationships
PRODUCED_IN: 14702 relationships
HAS_LANGUAGE: 16184 relationships
ACTED_IN: 191307 relationships
DIRECTED: 5047 relationships
PRODUCED: 6939 relationships
RATED: 90344 relationships
अब आपको अपना ग्राफ़, फ़िल्मों, लोगों, शैलियों वगैरह से भरा हुआ दिखेगा. यह अगले चरण में, सेमेटिक तरीके से बेहतर बनाने के लिए तैयार है!
6. वेक्टर मिलती-जुलती खोज करने के लिए, एम्बेड जनरेट और लोड करना
अपने चैटबॉट में सेमैनटिक सर्च की सुविधा चालू करने के लिए, हमें फ़िल्म की खास जानकारी के लिए वेक्टर एम्बेड जनरेट करने होंगे. ये एम्बेड, टेक्स्ट डेटा को संख्या वाले वैक्टर में बदल देते हैं. इनकी तुलना करके, यह पता लगाया जा सकता है कि वे कितने मिलते-जुलते हैं. इससे चैटबॉट, काम की फ़िल्में खोज सकता है, भले ही क्वेरी, टाइटल या ब्यौरे से पूरी तरह मेल न खाती हो.

पहला विकल्प: Cypher की मदद से, पहले से कैलकुलेट किए गए एम्बेड लोड करना
Neo4j में, एम्बेड किए गए डेटा को संबंधित Movie नोड से तुरंत अटैच करने के लिए, Neo4j ब्राउज़र में यह Cypher कमांड चलाएं:
LOAD CSV WITH HEADERS FROM 'https://storage.googleapis.com/neo4j-vertexai-codelab/movie_embeddings.csv' AS row
WITH row
MATCH (m:Movie {tmdbId: toInteger(row.tmdbId)})
SET m.embedding = apoc.convert.fromJsonList(row.embedding)
यह कमांड, CSV से एम्बेड किए गए वेक्टर को पढ़ता है और उन्हें हर Movie नोड पर प्रॉपर्टी (m.embedding) के तौर पर अटैच करता है.
दूसरा विकल्प: Python का इस्तेमाल करके एम्बेड लोड करना
दी गई Python स्क्रिप्ट का इस्तेमाल करके, प्रोग्राम के हिसाब से भी एम्बेड लोड किए जा सकते हैं. यह तरीका तब फ़ायदेमंद होता है, जब आप अपने काम के माहौल में काम कर रहे हों या आपको प्रोसेस को ऑटोमेट करना हो:
python load_embeddings.py
यह स्क्रिप्ट, GCS से उसी CSV को पढ़ती है और Python Neo4j ड्राइवर का इस्तेमाल करके, Neo4j में एम्बेडिंग लिखती है.
[ज़रूरी नहीं] एक्सप्लोरेशन के लिए, खुद एम्बेड जनरेट करना
अगर आपको यह जानना है कि एम्बेड कैसे जनरेट होते हैं, तो generate_embeddings.py स्क्रिप्ट में लॉजिक को एक्सप्लोर करें. यह text-embedding-004 मॉडल का इस्तेमाल करके, हर फ़िल्म की खास जानकारी वाले टेक्स्ट को एम्बेड करने के लिए, Vertex AI का इस्तेमाल करता है.
इसे खुद आज़माने के लिए, कोड के एम्बेड जनरेशन सेक्शन को खोलें और चलाएं. अगर Cloud Shell में चल रहा है, तो नीचे दी गई लाइन पर टिप्पणी की जा सकती है, क्योंकि Cloud Shell की पुष्टि आपके ऐक्टिव खाते से पहले ही हो चुकी है:
# os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = "./service-account.json"
Neo4j में एम्बेड लोड होने के बाद, फ़िल्म का नॉलेज ग्राफ़ सेमांटिक-अवेयर हो जाता है. साथ ही, वेक्टर मिलते-जुलते होने की सुविधा का इस्तेमाल करके, सामान्य भाषा में की जाने वाली खोज के लिए तैयार हो जाता है!
7. मूवी का सुझाव देने वाला चैटबॉट
नॉलेज ग्राफ़ और वेक्टर एम्बेडिंग की सुविधा सेट अप हो जाने के बाद, अब इन सभी चीज़ों को एक साथ जोड़कर, बातचीत वाले इंटरफ़ेस में बदलने का समय आ गया है. यह आपका GenAI से चलने वाला, फ़िल्म के सुझाव देने वाला चैटबॉट होगा.
इस चैटबॉट को Python में लागू किया गया है. इसके लिए, Gradio का इस्तेमाल किया गया है. यह एक हल्का वेब फ़्रेमवर्क है, जिसका इस्तेमाल आसान यूज़र इंटरफ़ेस बनाने के लिए किया जाता है. मुख्य लॉजिक app.py में मौजूद होता है. यह आपके Neo4j AuraDB इंस्टेंस से कनेक्ट होता है. साथ ही, नैचुरल लैंग्वेज क्वेरी को प्रोसेस करने और उनका जवाब देने के लिए, Google Vertex AI और Gemini का इस्तेमाल करता है.
यह कैसे काम करता है
- उपयोगकर्ता, सामान्य भाषा में क्वेरी टाइप करता हैउदाहरण के लिए, "मुझे इंटरस्टेलर जैसी साइंस-फ़िक्शन थ्रिलर का सुझाव दो"
- Vertex AI के
text-embedding-004मॉडल का इस्तेमाल करके, क्वेरी के लिए वेक्टर एम्बेडिंग जनरेट करना - मिलती-जुलती फ़िल्में खोजने के लिए, Neo4j में वेक्टर सर्च की सुविधा का इस्तेमाल करना
- Gemini का इस्तेमाल करके:
- क्वेरी को कॉन्टेक्स्ट के हिसाब से समझना
- वेक्टर खोज के नतीजों और Neo4j स्कीमा के आधार पर, पसंद के मुताबिक Cypher क्वेरी जनरेट करना
- क्वेरी को चलाकर, उससे जुड़ा ग्राफ़ डेटा निकालें. जैसे, कलाकार, डायरेक्टर, और शैलियां
- उपयोगकर्ता के लिए, बातचीत के तौर पर नतीजों की खास जानकारी देना
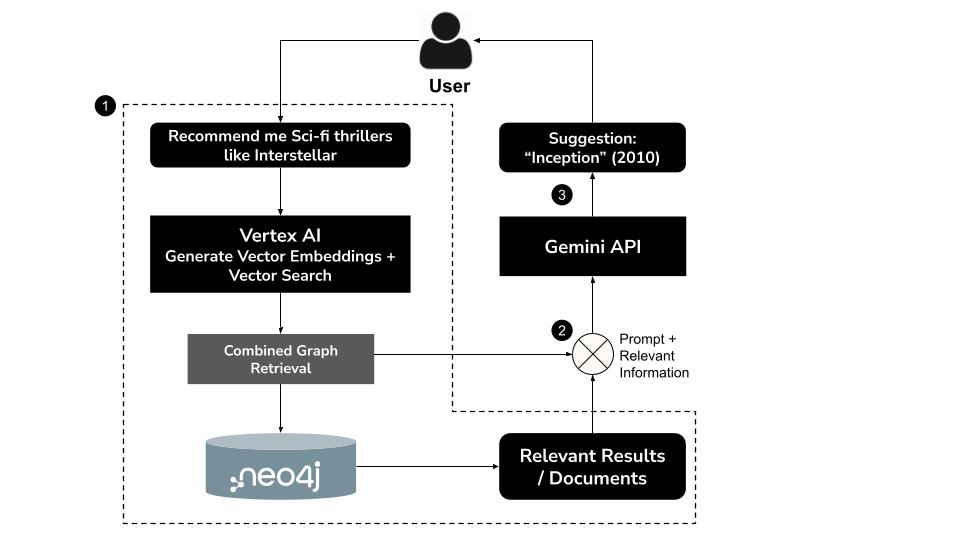
इस हाइब्रिड तरीके को GraphRAG (Graph Retrieval-Augmented Generation) कहा जाता है. इसमें, सेमैनटिक रीट्रिवल और स्ट्रक्चर्ड रीज़निंग को जोड़ा जाता है, ताकि ज़्यादा सटीक, काम के, और समझने लायक सुझाव दिए जा सकें.
चैटबॉट को स्थानीय तौर पर चलाना
अगर वर्चुअल एनवायरमेंट पहले से चालू नहीं है, तो उसे चालू करें. इसके बाद, चैटबॉट को इनमें से किसी एक तरीके से लॉन्च करें:
python app.py
आपको इससे मिलता-जुलता आउटपुट दिखेगा:
Vector index 'overview_embeddings' already exists. No need to create a new one.
* Running on local URL: http://0.0.0.0:8080
To create a public link, set `share=True` in `launch()`.
💡 चैटबॉट को संगठन से बाहर शेयर करने के लिए, app.py में launch() फ़ंक्शन में share=True सेट करें.
चैटबॉट से इंटरैक्ट करना
चैटबॉट इंटरफ़ेस को ऐक्सेस करने के लिए, अपने टर्मिनल में दिखने वाला लोकल यूआरएल खोलें. आम तौर पर, यह यूआरएल 👉 http://0.0.0.0:8080 होता है.
इस तरह के सवाल पूछें:
- "अगर मुझे Interstellar पसंद आई है, तो मुझे क्या देखना चाहिए?"
- "नोरा एफ़्रोन के निर्देशन में बनी कोई रोमैंटिक फ़िल्म सुझाओ"
- "मुझे टॉम हैंक्स की कोई फ़ैमिली मूवी देखनी है"
- "ऐसी थ्रिलर फ़िल्में खोजें जिनमें आर्टिफ़िशियल इंटेलिजेंस का इस्तेमाल किया गया हो"
चैटबॉट:
✅ क्वेरी को समझना
✅ एम्बेडमेंट का इस्तेमाल करके, मिलते-जुलते शब्दों वाले फ़िल्म के प्लॉट ढूंढना
✅ मिलते-जुलते ग्राफ़ कॉन्टेक्स्ट को फ़ेच करने के लिए, Cypher क्वेरी जनरेट करना और उसे चलाना
✅ कुछ ही सेकंड में, उपयोगकर्ता के हिसाब से सुझाव देना
आपके पास फ़िलहाल क्या है
आपने अभी-अभी GraphRAG की मदद से मूवी चैटबॉट बनाया है. इसमें ये चीज़ें शामिल हैं:
- काम के नतीजे दिखाने के लिए वेक्टर सर्च
- Neo4j की मदद से नॉलेज ग्राफ़ से जुड़ी रीज़निंग
- Gemini की मदद से LLM की सुविधाएं
- Gradio की मदद से, आसानी से इस्तेमाल किया जा सकने वाला चैट इंटरफ़ेस
यह आर्किटेक्चर, एक ऐसा फ़ाउंडेशन बनाता है जिसे GenAI की मदद से, खोज, सुझाव या तर्क करने वाले ज़्यादा बेहतर सिस्टम में बदला जा सकता है.
8. (ज़रूरी नहीं) Google Cloud Run में डिप्लॉय करना
अगर आपको अपने मूवी सुझाव देने वाले चैटबॉट को सार्वजनिक तौर पर ऐक्सेस करने की सुविधा देनी है, तो उसे Google Cloud Run पर डिप्लॉय करें. यह पूरी तरह से मैनेज किया जाने वाला, सर्वरलेस प्लैटफ़ॉर्म है. यह आपके ऐप्लिकेशन को अपने-आप स्केल करता है और इन्फ़्रास्ट्रक्चर से जुड़ी सभी समस्याओं को हल करता है.
इस डिप्लॉयमेंट में इनका इस्तेमाल किया जाता है:
requirements.txt— Python डिपेंडेंसी (Neo4j, Vertex AI, Gradio वगैरह) तय करने के लिएDockerfile— ऐप्लिकेशन को पैकेज करने के लिए.env.yaml— रनटाइम के दौरान, एनवायरमेंट वैरिएबल को सुरक्षित तरीके से पास करने के लिए
पहला चरण: .env.yaml तैयार करना
अपनी रूट डायरेक्ट्री में .env.yaml नाम की फ़ाइल बनाएं. इसमें यह कॉन्टेंट शामिल करें:
NEO4J_URI: "neo4j+s://<your-aura-db-uri>"
NEO4J_USER: "neo4j"
NEO4J_PASSWORD: "<your-password>"
PROJECT_ID: "<your-gcp-project-id>"
LOCATION: "<your-gcp-region>" # e.g. us-central1
💡 --set-env-vars के मुकाबले, इस फ़ॉर्मैट को प्राथमिकता दी जाती है, क्योंकि इसे आसानी से स्केल किया जा सकता है, इसके वर्शन को कंट्रोल किया जा सकता है, और इसे आसानी से पढ़ा जा सकता है.
दूसरा चरण: एनवायरमेंट वैरिएबल सेट अप करना
अपने टर्मिनल में, ये एनवायरमेंट वैरिएबल सेट करें. प्लेसहोल्डर की वैल्यू को अपनी प्रोजेक्ट सेटिंग से बदलें:
# Set your Google Cloud project ID
export GCP_PROJECT='your-project-id' # Change this
# Set your preferred deployment region
export GCP_REGION='us-central1'
दूसरा चरण: आर्टफ़ैक्ट रजिस्ट्री बनाना और कंटेनर बनाना
# Artifact Registry repo and service name
export AR_REPO='your-repo-name' # Change this
export SERVICE_NAME='movies-chatbot' # Or any name you prefer
# Create the Artifact Registry repository
gcloud artifacts repositories create "$AR_REPO" \
--location="$GCP_REGION" \
--repository-format=Docker
# Authenticate Docker with Artifact Registry
gcloud auth configure-docker "$GCP_REGION-docker.pkg.dev"
# Build and submit the container image
gcloud builds submit \
--tag "$GCP_REGION-docker.pkg.dev/$GCP_PROJECT/$AR_REPO/$SERVICE_NAME"
यह कमांड, Dockerfile का इस्तेमाल करके आपके ऐप्लिकेशन को पैकेज करता है और कंटेनर इमेज को Google Cloud Artifact Registry पर अपलोड करता है.
तीसरा चरण: Cloud Run पर डिप्लॉय करना
अब रनटाइम कॉन्फ़िगरेशन के लिए, .env.yaml फ़ाइल का इस्तेमाल करके अपना ऐप्लिकेशन डिप्लॉय करें:
gcloud run deploy "$SERVICE_NAME" \
--port=8080 \
--image="$GCP_REGION-docker.pkg.dev/$GCP_PROJECT/$AR_REPO/$SERVICE_NAME" \
--allow-unauthenticated \
--region=$GCP_REGION \
--platform=managed \
--project=$GCP_PROJECT \
--env-vars-file=.env.yaml
चैटबॉट को ऐक्सेस करना
डिप्लॉय होने के बाद, Cloud Run एक सार्वजनिक यूआरएल देगा, जैसे:
https://movies-reco-[UNIQUE_ID].${GCP_REGION}.run.app
डिप्लॉय किए गए Gradio चैटबॉट इंटरफ़ेस को ऐक्सेस करने के लिए, अपने ब्राउज़र में यह यूआरएल खोलें. यह इंटरफ़ेस, GraphRAG, Gemini, और Neo4j का इस्तेमाल करके, फ़िल्म के सुझाव देने के लिए तैयार है!
ध्यान देने वाली बातें और सलाह
- पक्का करें कि बिल्ड के दौरान,
Dockerfilepip install -r requirements.txtचलाता हो. - अगर Cloud Shell का इस्तेमाल नहीं किया जा रहा है, तो आपको Vertex AI और Artifact Registry की अनुमतियों वाले सेवा खाते का इस्तेमाल करके, अपने एनवायरमेंट की पुष्टि करनी होगी.
- Google Cloud Console > Cloud Run से, डिप्लॉयमेंट लॉग और मेट्रिक को मॉनिटर किया जा सकता है.
Google Cloud Console से Cloud Run पर भी जाया जा सकता है. यहां आपको Cloud Run में मौजूद सेवाओं की सूची दिखेगी. movies-chatbot सेवा, सूची में दी गई सेवाओं में से एक होनी चाहिए.

सेवा के नाम (हमारे मामले में movies-chatbot) पर क्लिक करके, सेवा की जानकारी देखी जा सकती है. जैसे, यूआरएल, कॉन्फ़िगरेशन, लॉग वगैरह.

इसकी मदद से, फ़िल्म के सुझाव देने वाला चैटबॉट अब डिप्लॉय किया जा सकता है, स्केल किया जा सकता है, और शेयर किया जा सकता है. 🎉
9. व्यवस्थित करें
इस पोस्ट में इस्तेमाल किए गए संसाधनों के लिए, अपने Google Cloud खाते से शुल्क न लिए जाएं, इसके लिए यह तरीका अपनाएं:
- Google Cloud Console में, संसाधन मैनेज करें पेज पर जाएं.
- प्रोजेक्ट की सूची में, वह प्रोजेक्ट चुनें जिसे मिटाना है. इसके बाद, मिटाएं पर क्लिक करें.
- डायलॉग बॉक्स में, प्रोजेक्ट आईडी टाइप करें. इसके बाद, प्रोजेक्ट मिटाने के लिए बंद करें पर क्लिक करें.
10. बधाई हो
आपने Neo4j, Vertex AI, और Gemini का इस्तेमाल करके, GraphRAG की मदद से काम करने वाला, जनरेटिव एआई की मदद से बेहतर बनाया गया, मूवी के सुझाव देने वाला चैटबॉट बनाया और डिप्लॉय किया है. Neo4j के ग्राफ़-नेटिव मॉडलिंग की सुविधाओं को Vertex AI की मदद से सेमैनटिक सर्च और Gemini की मदद से नैचुरल लैंग्वेज रिज़निंग के साथ जोड़कर, आपने एक ऐसा बेहतर सिस्टम बनाया है जो बुनियादी खोज से परे है. यह उपयोगकर्ता के इंटेंट को समझता है, कनेक्ट किए गए डेटा के बारे में बताता है, और बातचीत के तौर पर जवाब देता है.
इस कोडलैब में, आपने ये काम किए हैं:
✅ Neo4j में असल दुनिया की फ़िल्मों का नॉलेज ग्राफ़ बनाया, ताकि फ़िल्मों, कलाकारों, शैलियों, और रिलेशनशिप को मॉडल किया जा सके
✅ Vertex AI के टेक्स्ट-एम्बेडिंग मॉडल का इस्तेमाल करके, मूवी के प्लॉट की खास जानकारी के लिए जनरेट किए गए वेक्टर एम्बेड
✅ GraphRAG लागू किया गया. इसमें वेक्टर सर्च और एलएलएम से जनरेट की गई साइफर क्वेरी को जोड़ा गया है, ताकि बेहतर और मल्टी-हॉप रीज़निंग की जा सके
✅ उपयोगकर्ता के सवालों को समझने, Cypher क्वेरी जनरेट करने, और ग्राफ़ के नतीजों को सामान्य भाषा में बताने के लिए, Gemini को इंटिग्रेट किया गया
✅ Gradio का इस्तेमाल करके, आसान चैट इंटरफ़ेस बनाया
✅ ज़्यादा उपयोगकर्ताओं को हैंडल करने वाले, बिना किसी रुकावट के होस्ट किए जा सकने वाले, और बिना सर्वर के काम करने वाले चैटबॉट को होस्ट करने के लिए, अपने चैटबॉट को Google Cloud Run पर डिप्लॉय किया
अगला चरण?
यह आर्किटेक्चर, सिर्फ़ मूवी के सुझावों तक सीमित नहीं है — इसे इनके लिए भी इस्तेमाल किया जा सकता है:
- किताब और संगीत खोजने की सुविधा देने वाले प्लैटफ़ॉर्म
- अकैडमिक रिसर्च असिस्टेंट
- प्रॉडक्ट के सुझाव देने वाले इंजन
- स्वास्थ्य सेवा, वित्त, और कानूनी जानकारी देने वाली सहायक
जहां भी जटिल संबंध + रिच टेक्स्ट डेटा मौजूद है वहां नॉलेज ग्राफ़ + एलएलएम + सेमैटिक एम्बेडिंग का यह कॉम्बिनेशन, अगली पीढ़ी के बेहतर ऐप्लिकेशन को बेहतर बना सकता है.
Gemini जैसे मल्टीमोडल जनरेटिव एआई मॉडल के बेहतर होने के साथ-साथ, आपको ज़्यादा बेहतर कॉन्टेक्स्ट, इमेज, बोली, और उपयोगकर्ता के हिसाब से जानकारी देने की सुविधा मिल पाएगी. इससे, असल तौर पर लोगों के हिसाब से सिस्टम बनाए जा सकेंगे.
एक्सप्लोर करते रहें, बनाते रहें — और अपने बेहतर ऐप्लिकेशन को अगले लेवल पर ले जाने के लिए, Neo4j, Vertex AI, और Google Cloud से जुड़ी नई जानकारी से अपडेट रहते रहें! Neo4j GraphAcademy पर, नॉलेज ग्राफ़ के बारे में ज़्यादा ट्यूटोरियल देखें.