
১. সংক্ষিপ্ত বিবরণ
এই কোডল্যাবে, আপনি Neo4j, Google Vertex AI, এবং Gemini-এর শক্তিকে একত্রিত করে একটি বুদ্ধিমান মুভি সুপারিশকারী চ্যাটবট তৈরি করবেন। এই সিস্টেমের কেন্দ্রবিন্দুতে রয়েছে একটি Neo4j নলেজ গ্রাফ, যা পরস্পর সংযুক্ত নোড এবং সম্পর্কের একটি সমৃদ্ধ নেটওয়ার্কের মাধ্যমে মুভি, অভিনেতা, পরিচালক, জনরা এবং আরও অনেক কিছুর মডেল তৈরি করে।
শব্দার্থগত বোধগম্যতার মাধ্যমে ব্যবহারকারীর অভিজ্ঞতা উন্নত করতে, আপনি ভার্টেক্স এআই-এর text-embedding-004 মডেল (বা নতুনতর) ব্যবহার করে সিনেমার কাহিনীর সারসংক্ষেপ থেকে ভেক্টর এম্বেডিং তৈরি করবেন। দ্রুত এবং সাদৃশ্য-ভিত্তিক পুনরুদ্ধারের জন্য এই এম্বেডিংগুলো নিও৪জে (Neo4j)-তে সূচিবদ্ধ করা হয়।
অবশেষে, আপনি জেমিনিকে একীভূত করে একটি কথোপকথনমূলক ইন্টারফেস তৈরি করবেন, যেখানে ব্যবহারকারীরা "ইন্টারস্টেলার আমার ভালো লাগলে কী দেখা উচিত?"-এর মতো স্বাভাবিক ভাষায় প্রশ্ন করতে পারবেন এবং শব্দার্থগত সাদৃশ্য ও গ্রাফ-ভিত্তিক প্রেক্ষাপটের ওপর ভিত্তি করে ব্যক্তিগতকৃত সিনেমার পরামর্শ পাবেন।
কোডল্যাবের মাধ্যমে, আপনি নিম্নলিখিত ধাপে ধাপে পদ্ধতিটি অনুসরণ করবেন:
- চলচ্চিত্র-সম্পর্কিত সত্তা এবং সম্পর্ক ব্যবহার করে একটি Neo4j নলেজ গ্রাফ তৈরি করুন।
- ভার্টেক্স এআই ব্যবহার করে সিনেমার সংক্ষিপ্ত বিবরণের জন্য টেক্সট এমবেডিং তৈরি/লোড করুন
- জেমিনি দ্বারা চালিত একটি গ্র্যাডিও চ্যাটবট ইন্টারফেস বাস্তবায়ন করুন যা ভেক্টর সার্চ এবং গ্রাফ-ভিত্তিক সাইফার এক্সিকিউশনকে একত্রিত করে।
- (ঐচ্ছিক) অ্যাপটিকে ক্লাউড রান-এ একটি স্বতন্ত্র ওয়েব অ্যাপ্লিকেশন হিসেবে স্থাপন করুন।
আপনি যা শিখবেন
- Cypher এবং Neo4j ব্যবহার করে কীভাবে একটি মুভি নলেজ গ্রাফ তৈরি এবং ডেটা দিয়ে পূর্ণ করা যায়
- সিমান্টিক টেক্সট এমবেডিং তৈরি ও তা নিয়ে কাজ করার জন্য কীভাবে ভার্টেক্স এআই ব্যবহার করবেন
- GraphRAG ব্যবহার করে বুদ্ধিদীপ্ত পুনরুদ্ধারের জন্য কীভাবে LLM এবং নলেজ গ্রাফ একত্রিত করা যায়
- Gradio ব্যবহার করে কীভাবে একটি ব্যবহারকারী-বান্ধব চ্যাট ইন্টারফেস তৈরি করবেন
- Google Cloud Run-এ কীভাবে ঐচ্ছিকভাবে স্থাপন করবেন
আপনার যা যা লাগবে
- ক্রোম ওয়েব ব্রাউজার
- একটি জিমেইল অ্যাকাউন্ট
- বিলিং সক্ষম একটি গুগল ক্লাউড প্রজেক্ট
- একটি বিনামূল্যের Neo4j Aura DB অ্যাকাউন্ট
- টার্মিনাল কমান্ড এবং পাইথন সম্পর্কে প্রাথমিক ধারণা (সহায়ক, তবে আবশ্যক নয়)
সকল স্তরের (শিক্ষানবিশ সহ) ডেভেলপারদের জন্য ডিজাইন করা এই কোডল্যাবটির নমুনা অ্যাপ্লিকেশনে পাইথন এবং নিও৪জে (Neo4j) ব্যবহার করা হয়েছে। যদিও পাইথন এবং গ্রাফ ডেটাবেস সম্পর্কে প্রাথমিক ধারণা থাকলে সহায়ক হতে পারে, তবে ধারণাগুলো বুঝতে বা অনুসরণ করতে কোনো পূর্ব অভিজ্ঞতার প্রয়োজন নেই।
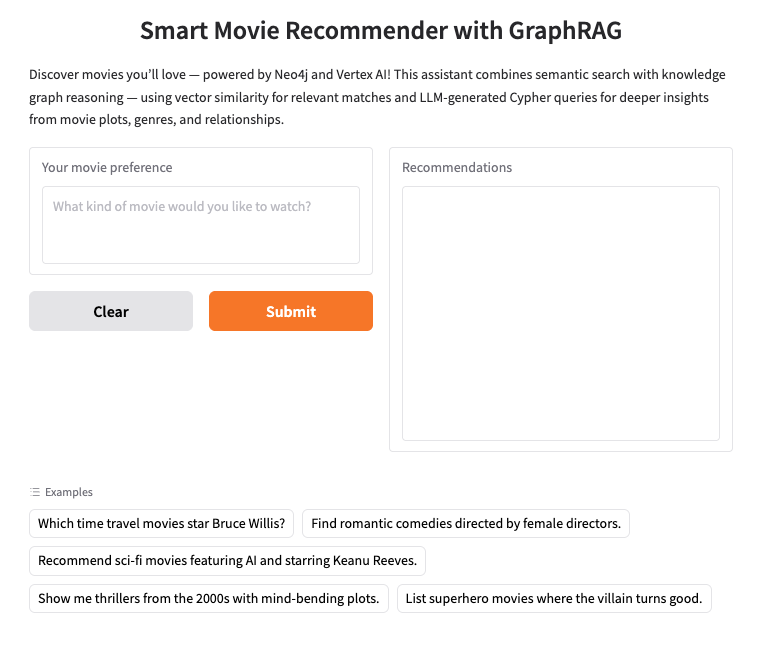
২. Neo4j AuraDB সেটআপ করুন
Neo4j হলো একটি অগ্রণী নেটিভ গ্রাফ ডেটাবেস যা ডেটাকে নোড (সত্তা) এবং সম্পর্ক (সত্তাগুলোর মধ্যে সংযোগ)-এর একটি নেটওয়ার্ক হিসেবে সংরক্ষণ করে। এটি এমন সব ব্যবহারের ক্ষেত্রে আদর্শ যেখানে সংযোগ বোঝাটা অত্যন্ত গুরুত্বপূর্ণ — যেমন সুপারিশ, জালিয়াতি শনাক্তকরণ, নলেজ গ্রাফ এবং আরও অনেক কিছু। রিলেশনাল বা ডকুমেন্ট-ভিত্তিক ডেটাবেসগুলো অনমনীয় টেবিল বা শ্রেণিবদ্ধ কাঠামোর উপর নির্ভর করলেও, Neo4j-এর নমনীয় গ্রাফ মডেল জটিল ও আন্তঃসংযুক্ত ডেটার স্বজ্ঞামূলক এবং কার্যকর উপস্থাপনার সুযোগ করে দেয়।
রিলেশনাল ডেটাবেসের মতো সারি এবং টেবিলে ডেটা সাজানোর পরিবর্তে, Neo4j একটি গ্রাফ মডেল ব্যবহার করে, যেখানে তথ্যকে নোড (সত্তা) এবং সম্পর্ক (সেই সত্তাগুলোর মধ্যে সংযোগ) হিসেবে উপস্থাপন করা হয়। এই মডেলটি সহজাতভাবে সংযুক্ত ডেটার সাথে কাজ করার জন্য এটিকে অত্যন্ত সহজবোধ্য করে তোলে — যেমন মানুষ, স্থান, পণ্য, অথবা আমাদের ক্ষেত্রে, চলচ্চিত্র, অভিনেতা এবং চলচ্চিত্রের ধরণ।
উদাহরণস্বরূপ, একটি মুভি ডেটাসেটে:
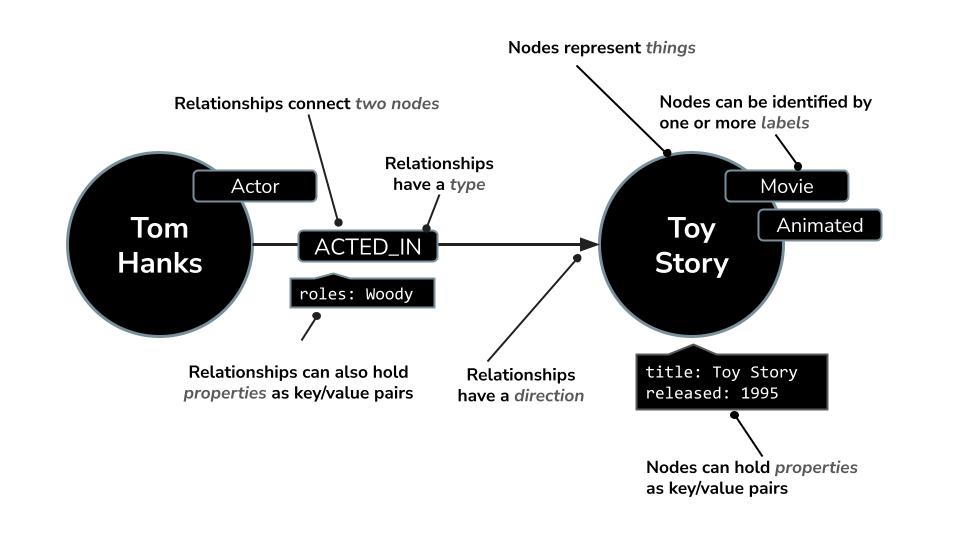
- একটি নোড একটি
Movie,ActorবাDirectorপ্রতিনিধিত্ব করতে পারে। - একটি সম্পর্ক
ACTED_INবাDIRECTEDহতে পারে।
এই কাঠামোটি আপনাকে সহজেই এই ধরনের প্রশ্ন জিজ্ঞাসা করতে সক্ষম করে:
- এই অভিনেতা কোন কোন চলচ্চিত্রে অভিনয় করেছেন?
- ক্রিস্টোফার নোলানের সাথে কারা কাজ করেছেন?
- একই অভিনেতা বা জনরার উপর ভিত্তি করে সাদৃশ্যপূর্ণ সিনেমাগুলো কী কী?
Neo4j-এর সাথে Cypher নামক একটি শক্তিশালী কোয়েরি ল্যাঙ্গুয়েজ রয়েছে, যা বিশেষভাবে গ্রাফ কোয়েরি করার জন্য ডিজাইন করা হয়েছে। Cypher আপনাকে জটিল প্যাটার্ন এবং সংযোগগুলোকে সংক্ষিপ্ত ও সহজে পাঠযোগ্য উপায়ে প্রকাশ করার সুযোগ দেয়। উদাহরণস্বরূপ: এই Cypher কোয়েরিটি MERGE ব্যবহার করে অভিনেতা, চলচ্চিত্র এবং ভূমিকার বিবরণের সাথে তাদের সম্পর্কের স্বতন্ত্র সৃষ্টি নিশ্চিত করে, এবং পুনরাবৃত্তি এড়িয়ে চলে।
MERGE (a:Actor {name: "Tom Hanks"})
MERGE (m:Movie {title: "Toy Story", released: 1995})
MERGE (a)-[:ACTED_IN {roles: ["Woody"]}]->(m);
আপনার প্রয়োজন অনুসারে Neo4j একাধিক ডেপ্লয়মেন্ট বিকল্প প্রদান করে:
- স্ব-পরিচালিত : Neo4j ডেস্কটপ ব্যবহার করে আপনার নিজস্ব পরিকাঠামোতে অথবা একটি ডকার ইমেজ হিসেবে (অন-প্রেম বা আপনার নিজস্ব ক্লাউডে) Neo4j চালান।
- ক্লাউড-পরিচালিত : মার্কেটপ্লেসের অফারগুলো ব্যবহার করে জনপ্রিয় ক্লাউড প্রোভাইডারদের উপর Neo4j স্থাপন করুন।
- সম্পূর্ণরূপে পরিচালিত : Neo4j AuraDB ব্যবহার করুন, যা Neo4j-এর সম্পূর্ণরূপে পরিচালিত ক্লাউড ডেটাবেস-অ্যাজ-এ-সার্ভিস এবং এটি আপনার জন্য প্রোভিশনিং, স্কেলিং, ব্যাকআপ ও নিরাপত্তার দায়িত্ব সামলায়।
এই কোডল্যাবে আমরা Neo4j AuraDB Free ব্যবহার করব, যা AuraDB-এর বিনামূল্যের সংস্করণ। এটি একটি সম্পূর্ণ পরিচালিত গ্রাফ ডেটাবেস ইনস্ট্যান্স প্রদান করে, যেখানে প্রোটোটাইপিং, শেখা এবং ছোট অ্যাপ্লিকেশন তৈরির জন্য পর্যাপ্ত স্টোরেজ ও ফিচার রয়েছে — যা আমাদের GenAI-চালিত মুভি সুপারিশকারী চ্যাটবট তৈরির লক্ষ্যের জন্য একেবারে উপযুক্ত।
এই ল্যাব জুড়ে আপনি একটি বিনামূল্যের AuraDB ইনস্ট্যান্স তৈরি করবেন, কানেকশন ক্রেডেনশিয়াল ব্যবহার করে সেটিকে আপনার অ্যাপ্লিকেশনের সাথে সংযুক্ত করবেন এবং আপনার মুভি নলেজ গ্রাফ সংরক্ষণ ও কোয়েরি করতে এটি ব্যবহার করবেন।
গ্রাফ কেন?
প্রচলিত রিলেশনাল ডেটাবেসে, "একই অভিনেতা বা জনরার ভিত্তিতে কোন সিনেমাগুলো ইনসেপশনের মতো?"- এর মতো প্রশ্নের উত্তর দিতে একাধিক টেবিলের মধ্যে জটিল JOIN অপারেশনের প্রয়োজন হয়। সম্পর্কের গভীরতা বাড়ার সাথে সাথে পারফরম্যান্স এবং পাঠযোগ্যতা হ্রাস পায়।
তবে, Neo4j-এর মতো গ্রাফ ডেটাবেসগুলো সম্পর্কগুলোকে দক্ষতার সাথে বিশ্লেষণ করার জন্য তৈরি করা হয়েছে, যা সেগুলোকে সুপারিশ ব্যবস্থা, শব্দার্থিক অনুসন্ধান এবং বুদ্ধিমান সহকারীদের জন্য স্বাভাবিকভাবেই উপযুক্ত করে তোলে। এগুলো বাস্তব জগতের প্রেক্ষাপট—যেমন সহযোগিতামূলক নেটওয়ার্ক, কাহিনি বা দর্শকের পছন্দ—তুলে ধরতে সাহায্য করে, যা প্রচলিত ডেটা মডেল ব্যবহার করে উপস্থাপন করা কঠিন হতে পারে।
এই সংযুক্ত ডেটাকে জেমিনির মতো এলএলএম এবং ভার্টেক্স এআই-এর ভেক্টর এমবেডিংয়ের সাথে একত্রিত করে, আমরা চ্যাটবটের অভিজ্ঞতাকে আরও শক্তিশালী করতে পারি — যা এটিকে আরও ব্যক্তিগতকৃত ও প্রাসঙ্গিক উপায়ে যুক্তি দিতে, তথ্য সংগ্রহ করতে এবং প্রতিক্রিয়া জানাতে সক্ষম করে।
Neo4j AuraDB বিনামূল্যে তৈরি
- https://console.neo4j.io দেখুন
- আপনার গুগল অ্যাকাউন্ট বা ইমেল দিয়ে লগ ইন করুন।
- "Create Free Instance"-এ ক্লিক করুন।
- ইনস্ট্যান্সটি প্রোভিশন করার সময়, একটি পপ-আপ উইন্ডো প্রদর্শিত হবে যেখানে আপনার ডাটাবেসের সংযোগের ক্রেডেনশিয়াল দেখানো হবে।
পপআপ থেকে নিম্নলিখিত বিবরণগুলি ডাউনলোড করে নিরাপদে সংরক্ষণ করুন — আপনার অ্যাপ্লিকেশনটিকে Neo4j-এর সাথে সংযোগ করার জন্য এগুলি অপরিহার্য:
NEO4J_URI=neo4j+s://<your-instance-id>.databases.neo4j.io
NEO4J_USERNAME=neo4j
NEO4J_PASSWORD=<your-generated-password>
AURA_INSTANCEID=<your-instance-id>
AURA_INSTANCENAME=<your-instance-name>
পরবর্তী ধাপে Neo4j-এর সাথে প্রমাণীকরণের জন্য আপনার প্রোজেক্টের .env ফাইলটি কনফিগার করতে আপনি এই মানগুলো ব্যবহার করবেন।

Neo4j AuraDB Free ডেভেলপমেন্ট, পরীক্ষা-নিরীক্ষা এবং এই কোডল্যাবের মতো ছোট আকারের অ্যাপ্লিকেশনের জন্য বেশ উপযুক্ত। এটি উদার ব্যবহারের সীমা প্রদান করে, যা ২,০০,০০০ নোড এবং ৪,০০,০০০ রিলেশনশিপ পর্যন্ত সমর্থন করে। যদিও এটি একটি নলেজ গ্রাফ তৈরি এবং কোয়েরি করার জন্য প্রয়োজনীয় সমস্ত অপরিহার্য বৈশিষ্ট্য সরবরাহ করে, তবে এটি কাস্টম প্লাগইন বা বর্ধিত স্টোরেজের মতো উন্নত কনফিগারেশন সমর্থন করে না। প্রোডাকশন ওয়ার্কলোড বা বৃহত্তর ডেটাসেটের জন্য, আপনি একটি উচ্চ-স্তরের AuraDB প্ল্যানে আপগ্রেড করতে পারেন যা আরও বেশি ধারণক্ষমতা, পারফরম্যান্স এবং এন্টারপ্রাইজ-গ্রেড বৈশিষ্ট্য সরবরাহ করে।
এর মাধ্যমে আপনার Neo4j AuraDB ব্যাকএন্ড সেট আপ করার পর্বটি শেষ হলো। পরবর্তী ধাপে, আমরা একটি গুগল ক্লাউড প্রজেক্ট তৈরি করব, রিপোজিটরি ক্লোন করব এবং আমাদের কোডল্যাব শুরু করার আগে ডেভেলপমেন্ট এনভায়রনমেন্ট প্রস্তুত করার জন্য প্রয়োজনীয় এনভায়রনমেন্ট ভেরিয়েবলগুলো কনফিগার করব।
৩. শুরু করার আগে
একটি প্রকল্প তৈরি করুন
- গুগল ক্লাউড কনসোলের প্রজেক্ট সিলেক্টর পেজে, একটি গুগল ক্লাউড প্রজেক্ট নির্বাচন করুন বা তৈরি করুন।
- আপনার ক্লাউড প্রোজেক্টের জন্য বিলিং চালু আছে কিনা তা নিশ্চিত করুন। কোনো প্রোজেক্টে বিলিং চালু আছে কিনা তা কীভাবে পরীক্ষা করবেন, তা জেনে নিন।
- আপনি ক্লাউড শেল ব্যবহার করবেন, যা গুগল ক্লাউডে চলমান একটি কমান্ড-লাইন পরিবেশ এবং এটি bq-এর সাথে আগে থেকেই লোড করা থাকে। গুগল ক্লাউড কনসোলের শীর্ষে থাকা ‘Activate Cloud Shell’-এ ক্লিক করুন।

- ক্লাউড শেলে সংযুক্ত হওয়ার পর, আপনি নিম্নলিখিত কমান্ডটি ব্যবহার করে যাচাই করে নিন যে আপনি ইতিমধ্যেই প্রমাণীকৃত এবং প্রজেক্টটি আপনার প্রজেক্ট আইডিতে সেট করা আছে:
gcloud auth list
- gcloud কমান্ডটি আপনার প্রজেক্ট সম্পর্কে অবগত আছে কিনা, তা নিশ্চিত করতে ক্লাউড শেলে নিম্নলিখিত কমান্ডটি চালান।
gcloud config list project
- আপনার প্রজেক্টটি সেট করা না থাকলে, এটি সেট করতে নিম্নলিখিত কমান্ডটি ব্যবহার করুন:
gcloud config set project <YOUR_PROJECT_ID>
- নিচে দেখানো কমান্ডের মাধ্যমে প্রয়োজনীয় API-গুলো সক্রিয় করুন। এতে কয়েক মিনিট সময় লাগতে পারে, তাই অনুগ্রহ করে ধৈর্য ধরুন।
gcloud services enable cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
cloudfunctions.googleapis.com \
aiplatform.googleapis.com
কমান্ডটি সফলভাবে কার্যকর হলে, আপনি এই বার্তাটি দেখতে পাবেন: " অপারেশন .... সফলভাবে সম্পন্ন হয়েছে"।
gcloud কমান্ডের বিকল্প হলো কনসোলের মাধ্যমে প্রতিটি পণ্য অনুসন্ধান করা অথবা এই লিঙ্কটি ব্যবহার করা।
যদি কোনো API বাদ পড়ে যায়, তাহলে আপনি বাস্তবায়ন চলাকালীন সময়েই তা সক্রিয় করে নিতে পারেন।
gcloud কমান্ড এবং এর ব্যবহার সম্পর্কে জানতে ডকুমেন্টেশন দেখুন।
রিপোজিটরি ক্লোন করুন এবং পরিবেশ সেটিংস সেটআপ করুন
পরবর্তী ধাপ হলো স্যাম্পল রিপোজিটরিটি ক্লোন করা, যা আমরা কোডল্যাবের বাকি অংশে রেফারেন্স হিসেবে ব্যবহার করব। ধরে নিন আপনি ক্লাউড শেলে আছেন, আপনার হোম ডিরেক্টরি থেকে নিম্নলিখিত কমান্ডটি দিন:
git clone https://github.com/sidagarwal04/neo4j-vertexai-codelab.git
এডিটর চালু করতে, ক্লাউড শেল উইন্ডোর টুলবারে থাকা ‘ওপেন এডিটর’-এ ক্লিক করুন। উপরের বাম কোণার মেনু বারে ক্লিক করুন এবং নিচে দেখানো অনুযায়ী ‘ফাইল → ওপেন ফোল্ডার’ নির্বাচন করুন:

neo4j-vertexai-codelab ফোল্ডারটি নির্বাচন করুন এবং আপনি দেখবেন যে ফোল্ডারটি নিচে দেখানো ছবির মতো কিছুটা একই কাঠামোসহ খুলে গেছে:

এরপরে, আমাদের এনভায়রনমেন্ট ভেরিয়েবলগুলো সেট করতে হবে যা পুরো কোডল্যাব জুড়ে ব্যবহৃত হবে। example.env ফাইলটিতে ক্লিক করুন এবং আপনি নীচে দেখানো বিষয়বস্তুর মতো দেখতে পাবেন:
NEO4J_URI=
NEO4J_USER=
NEO4J_PASSWORD=
NEO4J_DATABASE=
PROJECT_ID=
LOCATION=
এখন example.env ফাইলটি যে ফোল্ডারে আছে, সেই একই ফোল্ডারে .env নামে একটি নতুন ফাইল তৈরি করুন এবং বিদ্যমান example.env ফাইলের বিষয়বস্তু কপি করুন। এখন, নিম্নলিখিত ভেরিয়েবলগুলো আপডেট করুন:
-
NEO4J_URI,NEO4J_USER,NEO4J_PASSWORD, এবংNEO4J_DATABASE: - পূর্ববর্তী ধাপে Neo4j AuraDB Free ইনস্ট্যান্স তৈরির সময় প্রদত্ত ক্রেডেনশিয়াল ব্যবহার করে এই মানগুলি পূরণ করুন।
- AuraDB Free-এর জন্য
NEO4J_DATABASEসাধারণত neo4j-তে সেট করা থাকে। -
PROJECT_IDএবংLOCATION: - আপনি যদি গুগল ক্লাউড শেল থেকে কোডল্যাবটি চালান, তাহলে এই ফিল্ডগুলো খালি রাখতে পারেন, কারণ আপনার সক্রিয় প্রজেক্ট কনফিগারেশন থেকে এগুলো স্বয়ংক্রিয়ভাবে পূরণ হয়ে যাবে।
- আপনি যদি স্থানীয়ভাবে বা ক্লাউড শেল-এর বাইরে এটি চালান, তাহলে পূর্বে তৈরি করা গুগল ক্লাউড প্রজেক্টের আইডি দিয়ে
PROJECT_IDআপডেট করুন এবং সেই প্রজেক্টের জন্য আপনার নির্বাচিত অঞ্চলে (যেমন, us-central1)LOCATIONসেট করুন।
এই মানগুলি পূরণ করার পরে, .env ফাইলটি সংরক্ষণ করুন। এই কনফিগারেশনটি আপনার অ্যাপ্লিকেশনকে Neo4j এবং Vertex AI উভয় পরিষেবার সাথে সংযোগ করতে সক্ষম করবে।
আপনার ডেভেলপমেন্ট এনভায়রনমেন্ট সেট আপ করার চূড়ান্ত ধাপ হলো একটি পাইথন ভার্চুয়াল এনভায়রনমেন্ট তৈরি করা এবং requirements.txt ফাইলে তালিকাভুক্ত সমস্ত প্রয়োজনীয় ডিপেন্ডেন্সি ইনস্টল করা। এই ডিপেন্ডেন্সিগুলোর মধ্যে Neo4j, Vertex AI, Gradio এবং আরও অনেক কিছুর সাথে কাজ করার জন্য প্রয়োজনীয় লাইব্রেরি অন্তর্ভুক্ত রয়েছে।
প্রথমে, নিম্নলিখিত কমান্ডটি চালিয়ে .venv নামের একটি ভার্চুয়াল এনভায়রনমেন্ট তৈরি করুন:
python -m venv .venv
পরিবেশটি তৈরি হয়ে গেলে, নিম্নলিখিত কমান্ডের সাহায্যে সেটিকে সক্রিয় করতে হবে।
source .venv/bin/activate
এখন আপনি আপনার টার্মিনাল প্রম্পটের শুরুতে (.venv) দেখতে পাবেন, যা নির্দেশ করে যে এনভায়রনমেন্টটি সক্রিয় আছে। উদাহরণস্বরূপ: (.venv) yourusername@cloudshell:
এখন, নিম্নলিখিত কমান্ডটি চালিয়ে প্রয়োজনীয় ডিপেন্ডেন্সিগুলো ইনস্টল করুন:
pip install -r requirements.txt
ফাইলটিতে তালিকাভুক্ত মূল নির্ভরতাগুলোর একটি চিত্র নিচে দেওয়া হলো:
gradio>=4.0.0
neo4j>=5.0.0
numpy>=1.20.0
python-dotenv>=1.0.0
google-cloud-aiplatform>=1.30.0
vertexai>=0.0.1
সমস্ত ডিপেন্ডেন্সি সফলভাবে ইনস্টল হয়ে গেলে, এই কোডল্যাবের স্ক্রিপ্ট এবং চ্যাটবট চালানোর জন্য আপনার লোকাল পাইথন এনভায়রনমেন্ট সম্পূর্ণরূপে কনফিগার হয়ে যাবে।
চমৎকার! আমরা এখন পরবর্তী ধাপে যাওয়ার জন্য প্রস্তুত — ডেটাসেটটি বোঝা এবং গ্রাফ তৈরি ও শব্দার্থগত সমৃদ্ধির জন্য এটিকে প্রস্তুত করা।
৪. মুভি ডেটাসেট প্রস্তুত করুন
আমাদের প্রথম কাজ হলো মুভিজ ডেটাসেটটি প্রস্তুত করা, যা আমরা নলেজ গ্রাফ তৈরি করতে এবং আমাদের রিকমেন্ডেশন চ্যাটবটকে শক্তিশালী করতে ব্যবহার করব। একেবারে গোড়া থেকে শুরু করার পরিবর্তে, আমরা একটি বিদ্যমান ওপেন ডেটাসেট ব্যবহার করব এবং তার উপর ভিত্তি করে কাজটি করব।
আমরা রৌনক বণিকের তৈরি 'দ্য মুভিজ ডেটাসেট' ব্যবহার করছি, যা ক্যাগল-এ উপলব্ধ একটি সুপরিচিত পাবলিক ডেটাসেট। এতে TMDB থেকে নেওয়া ৪৫,০০০-এরও বেশি সিনেমার মেটাডেটা অন্তর্ভুক্ত রয়েছে, যার মধ্যে অভিনেতা-অভিনেত্রী, কলাকুশলী, কীওয়ার্ড, রেটিং এবং আরও অনেক কিছু আছে।

একটি নির্ভরযোগ্য এবং কার্যকর মুভি রিকমেন্ডেশন চ্যাটবট তৈরি করতে, পরিষ্কার, সামঞ্জস্যপূর্ণ এবং সুগঠিত ডেটা দিয়ে শুরু করা অপরিহার্য। যদিও ক্যাগল-এর 'দ্য মুভিজ ডেটাসেট' ৪৫,০০০-এরও বেশি মুভি রেকর্ড এবং বিস্তারিত মেটাডেটা—যার মধ্যে জনরা, কাস্ট, ক্রু এবং আরও অনেক কিছু অন্তর্ভুক্ত—সহ একটি সমৃদ্ধ উৎস, তবে এতে এমন নয়েজ, অসামঞ্জস্যতা এবং নেস্টেড ডেটা স্ট্রাকচারও রয়েছে যা গ্রাফ মডেলিং বা সিমান্টিক এমবেডিং-এর জন্য আদর্শ নয়।
এর সমাধান করতে, আমরা ডেটাসেটটিকে প্রিপ্রসেস ও নর্মালাইজ করেছি , যাতে এটি একটি Neo4j নলেজ গ্রাফ তৈরি এবং উচ্চ-মানের এমবেডিং তৈরির জন্য উপযুক্ত হয়। এই প্রক্রিয়ার মধ্যে অন্তর্ভুক্ত ছিল:
- নকল এবং অসম্পূর্ণ রেকর্ড অপসারণ করা
- গুরুত্বপূর্ণ ক্ষেত্রগুলির (যেমন, ধারার নাম, ব্যক্তির নাম) প্রমিতকরণ
- জটিল স্তরীভূত কাঠামোকে (যেমন, অভিনেতা ও কলাকুশলী) সুবিন্যস্ত CSV ফাইলে রূপান্তর করা
- Neo4j AuraDB Free-এর সীমা মেনে চলার জন্য প্রায় ১২,০০০ সিনেমার একটি প্রতিনিধিত্বমূলক উপসেট নির্বাচন করা হচ্ছে।
উচ্চ-মানের, স্বাভাবিকীকৃত ডেটা নিম্নলিখিত বিষয়গুলো নিশ্চিত করতে সাহায্য করে:
- ডেটার গুণমান : আরও নির্ভুল সুপারিশের জন্য ত্রুটি এবং অসঙ্গতি হ্রাস করে।
- কোয়েরি পারফরম্যান্স : সুবিন্যস্ত কাঠামো তথ্য পুনরুদ্ধারের গতি বাড়ায় এবং পুনরাবৃত্তি কমায়।
- এমবেডিং নির্ভুলতা : ত্রুটিমুক্ত ইনপুট আরও অর্থপূর্ণ এবং প্রাসঙ্গিক ভেক্টর এমবেডিং তৈরি করে।
আপনি এই গিটহাব রিপোজিটরির normalized_data/ ফোল্ডারে পরিমার্জিত এবং নর্মালাইজড ডেটাসেটটি অ্যাক্সেস করতে পারবেন। আসন্ন পাইথন স্ক্রিপ্টগুলিতে সহজে ব্যবহারের জন্য এই ডেটাসেটটি একটি গুগল ক্লাউড স্টোরেজ বাকেটেও মিরর করা আছে।
ডেটা পরিমার্জিত ও প্রস্তুত হয়ে গেলে, আমরা এখন এটি Neo4j-তে লোড করে আমাদের মুভি নলেজ গ্রাফ তৈরি করা শুরু করতে প্রস্তুত।
৫. চলচ্চিত্র জ্ঞান গ্রাফ তৈরি করুন
আমাদের GenAI-সক্ষম মুভি সুপারিশ চ্যাটবটকে কার্যকর করতে, আমাদের মুভি ডেটাসেটটিকে এমনভাবে সাজাতে হবে যা মুভি, অভিনেতা, পরিচালক, জনরা এবং অন্যান্য মেটাডেটার মধ্যেকার সমৃদ্ধ সংযোগ নেটওয়ার্ককে ধারণ করে। এই অংশে, আমরা আপনার পূর্বে প্রস্তুত করা পরিমার্জিত এবং নর্মালাইজড ডেটাসেটটি ব্যবহার করে Neo4j-তে একটি মুভিজ নলেজ গ্রাফ তৈরি করব।
আমরা একটি পাবলিক গুগল ক্লাউড স্টোরেজ (GCS) বাকেটে হোস্ট করা CSV ফাইলগুলো ইনজেস্ট করার জন্য Neo4j-এর LOAD CSV সক্ষমতা ব্যবহার করব। এই ফাইলগুলো মুভি ডেটাসেটের বিভিন্ন উপাদান, যেমন মুভি, জনরা, কাস্ট, ক্রু, প্রোডাকশন কোম্পানি এবং ইউজার রেটিং-এর প্রতিনিধিত্ব করে।
ধাপ ১: কনস্ট্রেইন্ট এবং ইনডেক্স তৈরি করুন
ডেটা ইম্পোর্ট করার আগে, ডেটার অখণ্ডতা নিশ্চিত করতে এবং কোয়েরির পারফরম্যান্স উন্নত করতে কনস্ট্রেইন্ট ও ইনডেক্স তৈরি করা একটি ভালো অভ্যাস।
CREATE CONSTRAINT unique_tmdb_id IF NOT EXISTS FOR (m:Movie) REQUIRE m.tmdbId IS UNIQUE;
CREATE CONSTRAINT unique_movie_id IF NOT EXISTS FOR (m:Movie) REQUIRE m.movieId IS UNIQUE;
CREATE CONSTRAINT unique_prod_id IF NOT EXISTS FOR (p:ProductionCompany) REQUIRE p.company_id IS UNIQUE;
CREATE CONSTRAINT unique_genre_id IF NOT EXISTS FOR (g:Genre) REQUIRE g.genre_id IS UNIQUE;
CREATE CONSTRAINT unique_lang_id IF NOT EXISTS FOR (l:SpokenLanguage) REQUIRE l.language_code IS UNIQUE;
CREATE CONSTRAINT unique_country_id IF NOT EXISTS FOR (c:Country) REQUIRE c.country_code IS UNIQUE;
CREATE INDEX actor_id IF NOT EXISTS FOR (p:Person) ON (p.actor_id);
CREATE INDEX crew_id IF NOT EXISTS FOR (p:Person) ON (p.crew_id);
CREATE INDEX movieId IF NOT EXISTS FOR (m:Movie) ON (m.movieId);
CREATE INDEX user_id IF NOT EXISTS FOR (p:Person) ON (p.user_id);
ধাপ ২: মুভির মেটাডেটা এবং সম্পর্কসমূহ ইম্পোর্ট করুন
চলুন দেখে নেওয়া যাক, আমরা কীভাবে LOAD CSV কমান্ড ব্যবহার করে মুভির মেটাডেটা ইম্পোর্ট করি। এই উদাহরণটি টাইটেল, ওভারভিউ, ল্যাঙ্গুয়েজ এবং রানটাইমের মতো কী অ্যাট্রিবিউটসহ মুভি নোড তৈরি করে:
LOAD CSV WITH HEADERS FROM "https://storage.googleapis.com/neo4j-vertexai-codelab/normalized_data/normalized_movies.csv" AS row
WITH row, toInteger(row.tmdbId) AS tmdbId
WHERE tmdbId IS NOT NULL
WITH row, tmdbId
LIMIT 12000
MERGE (m:Movie {tmdbId: tmdbId})
ON CREATE SET m.title = coalesce(row.title, "None"),
m.original_title = coalesce(row.original_title, "None"),
m.adult = CASE
WHEN toInteger(row.adult) = 1 THEN 'Yes'
ELSE 'No'
END,
m.budget = toInteger(coalesce(row.budget, 0)),
m.original_language = coalesce(row.original_language, "None"),
m.revenue = toInteger(coalesce(row.revenue, 0)),
m.tagline = coalesce(row.tagline, "None"),
m.overview = coalesce(row.overview, "None"),
m.release_date = coalesce(row.release_date, "None"),
m.runtime = toFloat(coalesce(row.runtime, 0)),
m.belongs_to_collection = coalesce(row.belongs_to_collection, "None");
একইভাবে, আপনি জেনার , প্রোডাকশন কোম্পানি , কথিত ভাষা , দেশ , কাস্ট , ক্রু এবং ব্যবহারকারীর রেটিং- এর মতো অন্যান্য উপাদানগুলোকে তাদের নিজ নিজ CSV এবং সাইফার কোয়েরি ব্যবহার করে ইম্পোর্ট ও লিঙ্ক করতে পারেন।
পাইথনের মাধ্যমে সম্পূর্ণ গ্রাফটি লোড করুন
ম্যানুয়ালি একাধিক সাইফার কোয়েরি চালানোর পরিবর্তে, আমরা এই কোডল্যাবে প্রদত্ত স্বয়ংক্রিয় পাইথন স্ক্রিপ্টটি ব্যবহার করার পরামর্শ দিই।
graph_build.py স্ক্রিপ্টটি আপনার .env ফাইলে থাকা ক্রেডেনশিয়াল ব্যবহার করে GCS থেকে সম্পূর্ণ ডেটাসেটটি আপনার Neo4j AuraDB ইনস্ট্যান্সে লোড করে।
python graph_build.py
স্ক্রিপ্টটি ক্রমানুসারে সমস্ত প্রয়োজনীয় CSV ফাইল লোড করবে, নোড ও সম্পর্ক তৈরি করবে এবং আপনার সম্পূর্ণ মুভি নলেজ গ্রাফের কাঠামো তৈরি করবে।
|
|

.png")
আপনার গ্রাফ যাচাই করুন
লোড করার পরে, নিম্নলিখিত স্ক্রিপ্টটি চালিয়ে আপনি আপনার গ্রাফটি যাচাই করতে পারেন:
python validate_graph.py
এটি আপনাকে আপনার গ্রাফে কী আছে তার একটি দ্রুত সারসংক্ষেপ দেবে: কতগুলি চলচ্চিত্র, অভিনেতা, ধরণ এবং ACTED_IN, DIRECTED ইত্যাদির মতো সম্পর্ক উপস্থিত রয়েছে—যা আপনার ইম্পোর্ট সফল হয়েছে কিনা তা নিশ্চিত করবে।
📦 Node Counts:
Movie: 11997 nodes
ProductionCompany: 7961 nodes
Genre: 20 nodes
SpokenLanguage: 100 nodes
Country: 113 nodes
Person: 92663 nodes
Actor: 81165 nodes
Director: 4846 nodes
Producer: 5981 nodes
User: 671 nodes
🔗 Relationship Counts:
HAS_GENRE: 28479 relationships
PRODUCED_BY: 22758 relationships
PRODUCED_IN: 14702 relationships
HAS_LANGUAGE: 16184 relationships
ACTED_IN: 191307 relationships
DIRECTED: 5047 relationships
PRODUCED: 6939 relationships
RATED: 90344 relationships
এখন আপনি আপনার গ্রাফটিতে সিনেমা, ব্যক্তি, জনরা এবং আরও অনেক কিছু দেখতে পাবেন — যা পরবর্তী ধাপে অর্থগতভাবে সমৃদ্ধ হওয়ার জন্য প্রস্তুত!
৬. ভেক্টর সাদৃশ্য অনুসন্ধান সম্পাদনের জন্য এমবেডিং তৈরি ও লোড করুন।
আমাদের চ্যাটবটে সিমান্টিক সার্চ চালু করতে, মুভি ওভারভিউগুলোর জন্য ভেক্টর এমবেডিং তৈরি করতে হবে। এই এমবেডিংগুলো টেক্সচুয়াল ডেটাকে নিউমেরিক্যাল ভেক্টরে রূপান্তরিত করে, যেগুলোর মধ্যে সাদৃশ্য তুলনা করা যায় — ফলে, কোয়েরিটি টাইটেল বা ডেসক্রিপশনের সাথে হুবহু না মিললেও চ্যাটবটটি প্রাসঙ্গিক মুভি খুঁজে বের করতে পারে।

বিকল্প ১: সাইফারের মাধ্যমে পূর্ব-গণনাকৃত এমবেডিং লোড করুন
Neo4j-তে সংশ্লিষ্ট Movie নোডগুলিতে এমবেডিংগুলি দ্রুত সংযুক্ত করতে, Neo4j ব্রাউজারে নিম্নলিখিত সাইফার কমান্ডটি চালান:
LOAD CSV WITH HEADERS FROM 'https://storage.googleapis.com/neo4j-vertexai-codelab/movie_embeddings.csv' AS row
WITH row
MATCH (m:Movie {tmdbId: toInteger(row.tmdbId)})
SET m.embedding = apoc.convert.fromJsonList(row.embedding)
এই কমান্ডটি CSV থেকে এমবেডিং ভেক্টরগুলো পড়ে এবং সেগুলোকে প্রতিটি Movie নোডে একটি প্রপার্টি ( m.embedding ) হিসেবে যুক্ত করে।
বিকল্প ২: পাইথন ব্যবহার করে এমবেডিং লোড করুন
আপনি প্রদত্ত পাইথন স্ক্রিপ্ট ব্যবহার করে প্রোগ্রাম্যাটিকভাবেও এমবেডিংগুলো লোড করতে পারেন। এই পদ্ধতিটি তখন উপযোগী যখন আপনি আপনার নিজের পরিবেশে কাজ করছেন অথবা প্রক্রিয়াটি স্বয়ংক্রিয় করতে চান:
python load_embeddings.py
এই স্ক্রিপ্টটি GCS থেকে একই CSV ফাইলটি পড়ে এবং পাইথন Neo4j ড্রাইভার ব্যবহার করে এমবেডিংগুলো Neo4j-তে লিখে দেয়।
[ঐচ্ছিক] অন্বেষণের জন্য নিজেই এমবেডিং তৈরি করুন
এমবেডিংগুলো কীভাবে তৈরি করা হয় তা বুঝতে যদি আপনি আগ্রহী হন, তবে আপনি generate_embeddings.py স্ক্রিপ্টটির ভেতরের কার্যপ্রণালী খতিয়ে দেখতে পারেন। এটি text-embedding-004 মডেল ব্যবহার করে প্রতিটি সিনেমার সংক্ষিপ্ত বিবরণের লেখা এমবেড করার জন্য Vertex AI ব্যবহার করে।
নিজে চেষ্টা করার জন্য, কোডের এমবেডিং জেনারেশন অংশটি খুলুন এবং চালান। আপনি যদি ক্লাউড শেলে এটি চালান, তাহলে নিম্নলিখিত লাইনটি কমেন্ট করে দিতে পারেন, কারণ ক্লাউড শেল আপনার সক্রিয় অ্যাকাউন্টের মাধ্যমে ইতিমধ্যেই প্রমাণীকৃত:
# os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = "./service-account.json"
একবার এমবেডিংগুলো Neo4j-তে লোড হয়ে গেলে, আপনার মুভি নলেজ গ্রাফটি সিম্যান্টিক-অ্যাওয়ার হয়ে ওঠে — যা ভেক্টর সিমিলারিটি ব্যবহার করে শক্তিশালী ন্যাচারাল ল্যাঙ্গুয়েজ সার্চ সমর্থন করার জন্য প্রস্তুত!
৭. মুভি সুপারিশকারী চ্যাটবট
আপনার নলেজ গ্রাফ এবং ভেক্টর এমবেডিং প্রস্তুত হয়ে গেলে, এখন সবকিছুকে একত্রিত করে একটি সম্পূর্ণ কার্যকরী কথোপকথনমূলক ইন্টারফেস তৈরি করার সময় এসেছে — আপনার GenAI-চালিত মুভি রিকমেন্ডেশন চ্যাটবট ।
এই চ্যাটবটটি পাইথনে গ্র্যাডিও (Gradio) ব্যবহার করে তৈরি করা হয়েছে, যা স্বজ্ঞাত ইউজার ইন্টারফেস তৈরির জন্য একটি হালকা ওয়েব ফ্রেমওয়ার্ক। এর মূল লজিকটি app.py ফাইলে রয়েছে, যা আপনার Neo4j AuraDB ইনস্ট্যান্সের সাথে সংযোগ স্থাপন করে এবং স্বাভাবিক ভাষার প্রশ্নগুলো প্রক্রিয়া ও উত্তর দেওয়ার জন্য গুগল ভার্টেক্স এআই (Google Vertex AI) ও জেমিনি (Gemini) ব্যবহার করে।
এটি কীভাবে কাজ করে
- ব্যবহারকারী স্বাভাবিক ভাষায় একটি প্রশ্ন টাইপ করেন, যেমন, "আমাকে ইন্টারস্টেলারের মতো সাই-ফাই থ্রিলারের সুপারিশ করুন"।
- Vertex AI-এর
text-embedding-004মডেল ব্যবহার করে কোয়েরিটির জন্য একটি ভেক্টর এমবেডিং তৈরি করুন। - শব্দার্থগতভাবে সাদৃশ্যপূর্ণ চলচ্চিত্রগুলো খুঁজে বের করার জন্য Neo4j-তে একটি ভেক্টর অনুসন্ধান চালান ।
- মিথুন রাশি ব্যবহার করুন :
- প্রসঙ্গের আলোকে প্রশ্নটি ব্যাখ্যা করুন।
- ভেক্টর অনুসন্ধানের ফলাফল এবং Neo4j স্কিমার উপর ভিত্তি করে একটি কাস্টম সাইফার কোয়েরি তৈরি করুন।
- সম্পর্কিত গ্রাফ ডেটা (যেমন, অভিনেতা, পরিচালক, ধরণ) বের করার জন্য কোয়েরিটি চালান।
- ব্যবহারকারীর জন্য কথোপকথনের ভঙ্গিতে ফলাফলগুলো সংক্ষিপ্ত করুন ।
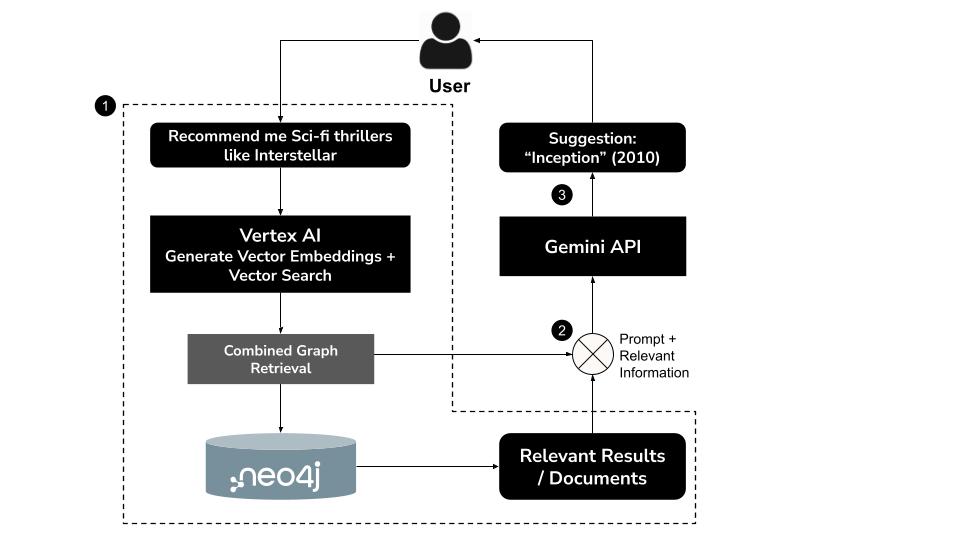
গ্রাফর্যাগ (গ্রাফ রিট্রিভাল-অগমেন্টেড জেনারেশন) নামে পরিচিত এই হাইব্রিড পদ্ধতিটি, আরও নির্ভুল, প্রাসঙ্গিক এবং ব্যাখ্যাযোগ্য সুপারিশ তৈরি করতে সিমান্টিক রিট্রিভাল এবং স্ট্রাকচার্ড রিজনিং-এর সমন্বয় ঘটায়।
চ্যাটবটটি স্থানীয়ভাবে চালান
আপনার ভার্চুয়াল পরিবেশ সক্রিয় করুন (যদি আগে থেকে সক্রিয় না থাকে), তারপর নিম্নলিখিত কমান্ড দিয়ে চ্যাটবটটি চালু করুন:
python app.py
আপনি নিম্নলিখিতের অনুরূপ একটি আউটপুট দেখতে পাবেন:
Vector index 'overview_embeddings' already exists. No need to create a new one.
* Running on local URL: http://0.0.0.0:8080
To create a public link, set `share=True` in `launch()`.
💡 চ্যাটবটটি বাইরে শেয়ার করতে, app.py ফাইলের launch() ফাংশনে share=True সেট করুন।
চ্যাটবটের সাথে যোগাযোগ করুন
চ্যাটবট ইন্টারফেসে প্রবেশ করতে আপনার টার্মিনালে প্রদর্শিত স্থানীয় ইউআরএলটি (সাধারণত 👉 http://0.0.0.0:8080 ) খুলুন।
এই ধরনের প্রশ্ন জিজ্ঞাসা করে দেখতে পারেন:
- ইন্টারস্টেলার আমার ভালো লাগলে কী দেখা উচিত?
- নোরা এফ্রন পরিচালিত একটি রোমান্টিক সিনেমার নাম বলুন।
- আমি টম হ্যাঙ্কসের সাথে একটি পারিবারিক সিনেমা দেখতে চাই।
- কৃত্রিম বুদ্ধিমত্তা সম্পর্কিত থ্রিলার সিনেমা খুঁজুন।
চ্যাটবটটি যা করবে:
✅ প্রশ্নটি বুঝুন
✅ এমবেডিং ব্যবহার করে অর্থগতভাবে সাদৃশ্যপূর্ণ সিনেমার কাহিনী খুঁজুন
✅ সম্পর্কিত গ্রাফ কনটেক্সট আনার জন্য একটি সাইফার কোয়েরি তৈরি ও রান করুন
✅ মাত্র কয়েক সেকেন্ডের মধ্যে একটি বন্ধুত্বপূর্ণ ও ব্যক্তিগতকৃত সুপারিশ পান
আপনার এখন যা আছে
আপনি এইমাত্র GraphRAG-চালিত একটি মুভি চ্যাটবট তৈরি করেছেন যা নিম্নলিখিত বিষয়গুলোকে একত্রিত করে:
- শব্দার্থগত প্রাসঙ্গিকতার জন্য ভেক্টর অনুসন্ধান
- Neo4j ব্যবহার করে নলেজ গ্রাফ রিজনিং
- জেমিনির মাধ্যমে এলএলএম সক্ষমতা
- Gradio-এর সাথে একটি সাবলীল চ্যাট ইন্টারফেস
এই স্থাপত্যটি এমন একটি ভিত্তি তৈরি করে, যাকে আপনি GenAI দ্বারা চালিত আরও উন্নত অনুসন্ধান, সুপারিশ, বা যুক্তি-ভিত্তিক সিস্টেমে প্রসারিত করতে পারেন।
৮. (ঐচ্ছিক) গুগল ক্লাউড রান-এ ডেপ্লয় করা
আপনি যদি আপনার মুভি রিকমেন্ডেশন চ্যাটবটটি সর্বসাধারণের জন্য উন্মুক্ত করতে চান, তবে আপনি এটিকে গুগল ক্লাউড রান-এ ডেপ্লয় করতে পারেন — এটি একটি সম্পূর্ণভাবে পরিচালিত, সার্ভারবিহীন প্ল্যাটফর্ম যা আপনার অ্যাপকে স্বয়ংক্রিয়ভাবে স্কেল করে এবং অবকাঠামোগত সমস্ত দুশ্চিন্তা দূর করে।
এই স্থাপনাটি ব্যবহার করে:
-
requirements.txt— পাইথন নির্ভরতাগুলো (Neo4j, Vertex AI, Gradio, ইত্যাদি) নির্ধারণ করার জন্য। -
Dockerfile— অ্যাপ্লিকেশনটি প্যাকেজ করার জন্য -
.env.yaml— রানটাইমে নিরাপদে এনভায়রনমেন্ট ভেরিয়েবল পাস করার জন্য
ধাপ ১: .env.yaml প্রস্তুত করুন।
আপনার রুট ডিরেক্টরিতে .env.yaml নামে একটি ফাইল তৈরি করুন এবং তাতে নিচের বিষয়বস্তুগুলো যোগ করুন:
NEO4J_URI: "neo4j+s://<your-aura-db-uri>"
NEO4J_USER: "neo4j"
NEO4J_PASSWORD: "<your-password>"
PROJECT_ID: "<your-gcp-project-id>"
LOCATION: "<your-gcp-region>" # e.g. us-central1
💡 এই ফরম্যাটটি --set-env-vars এর চেয়ে বেশি পছন্দনীয়, কারণ এটি আরও বেশি স্কেলেবল, ভার্সন-কন্ট্রোলযোগ্য এবং পাঠযোগ্য।
ধাপ ২: এনভায়রনমেন্ট ভেরিয়েবল সেট আপ করুন
আপনার টার্মিনালে নিম্নলিখিত এনভায়রনমেন্ট ভেরিয়েবলগুলো সেট করুন (প্লেসহোল্ডার মানগুলো আপনার প্রকৃত প্রোজেক্ট সেটিংস দিয়ে প্রতিস্থাপন করুন):
# Set your Google Cloud project ID
export GCP_PROJECT='your-project-id' # Change this
# Set your preferred deployment region
export GCP_REGION='us-central1'
ধাপ ২: আর্টিফ্যাক্ট রেজিস্ট্রি তৈরি করুন এবং কন্টেইনারটি বিল্ড করুন
# Artifact Registry repo and service name
export AR_REPO='your-repo-name' # Change this
export SERVICE_NAME='movies-chatbot' # Or any name you prefer
# Create the Artifact Registry repository
gcloud artifacts repositories create "$AR_REPO" \
--location="$GCP_REGION" \
--repository-format=Docker
# Authenticate Docker with Artifact Registry
gcloud auth configure-docker "$GCP_REGION-docker.pkg.dev"
# Build and submit the container image
gcloud builds submit \
--tag "$GCP_REGION-docker.pkg.dev/$GCP_PROJECT/$AR_REPO/$SERVICE_NAME"
এই কমান্ডটি Dockerfile ব্যবহার করে আপনার অ্যাপটিকে প্যাকেজ করে এবং কন্টেইনার ইমেজটি গুগল ক্লাউড আর্টিফ্যাক্ট রেজিস্ট্রি-তে আপলোড করে।
ধাপ ৩: ক্লাউড রান-এ ডেপ্লয় করুন
এখন রানটাইম কনফিগারেশনের জন্য .env.yaml ফাইলটি ব্যবহার করে আপনার অ্যাপটি ডেপ্লয় করুন:
gcloud run deploy "$SERVICE_NAME" \
--port=8080 \
--image="$GCP_REGION-docker.pkg.dev/$GCP_PROJECT/$AR_REPO/$SERVICE_NAME" \
--allow-unauthenticated \
--region=$GCP_REGION \
--platform=managed \
--project=$GCP_PROJECT \
--env-vars-file=.env.yaml
চ্যাটবট অ্যাক্সেস করুন
একবার স্থাপন করা হলে, ক্লাউড রান নিম্নলিখিতের মতো একটি পাবলিক URL প্রদান করবে:
https://movies-reco-[UNIQUE_ID].${GCP_REGION}.run.app
আপনার ব্রাউজারে এই URL-টি খুলুন আপনার ডেপ্লয় করা Gradio চ্যাটবট ইন্টারফেসটি অ্যাক্সেস করতে — যা GraphRAG, Gemini, এবং Neo4j ব্যবহার করে সিনেমার সুপারিশ পরিচালনা করার জন্য প্রস্তুত!
নোট ও টিপস
- নিশ্চিত করুন যে আপনার
Dockerfileবিল্ডের সময়pip install -r requirements.txtচালায়। - আপনি যদি ক্লাউড শেল ব্যবহার না করেন , তাহলে আপনাকে ভার্টেক্স এআই (Vertex AI) এবং আর্টিফ্যাক্ট রেজিস্ট্রি (Artifact Registry) অনুমতিসহ একটি সার্ভিস অ্যাকাউন্ট (Service Account) ব্যবহার করে আপনার এনভায়রনমেন্ট প্রমাণীকরণ করতে হবে।
- আপনি গুগল ক্লাউড কনসোল > ক্লাউড রান থেকে ডেপ্লয়মেন্ট লগ এবং মেট্রিক্স নিরীক্ষণ করতে পারেন।
আপনি গুগল ক্লাউড কনসোল থেকেও ক্লাউড রান-এ যেতে পারেন এবং সেখানে পরিষেবাগুলির তালিকা দেখতে পাবেন। movies-chatbot পরিষেবাটি সেখানে তালিকাভুক্ত পরিষেবাগুলির মধ্যে একটি হওয়া উচিত (যদি একমাত্রটি না হয়)।

নির্দিষ্ট সার্ভিসের নামে (আমাদের ক্ষেত্রে movies-chatbot ) ক্লিক করে আপনি সার্ভিসটির ইউআরএল, কনফিগারেশন, লগ এবং আরও অনেক কিছুর বিস্তারিত তথ্য দেখতে পারেন।
এর মাধ্যমে, আপনার মুভি রিকমেন্ডেশন চ্যাটবটটি এখন ডেপ্লয়েড, স্কেলেবল এবং শেয়ারযোগ্য । 🎉
৯. পরিষ্কার করুন
এই পোস্টে ব্যবহৃত রিসোর্সগুলোর জন্য আপনার গুগল ক্লাউড অ্যাকাউন্টে চার্জ হওয়া এড়াতে, এই ধাপগুলো অনুসরণ করুন:
- গুগল ক্লাউড কনসোলে, রিসোর্স পরিচালনা (Manage resources) পৃষ্ঠায় যান।
- প্রজেক্ট তালিকা থেকে, আপনি যে প্রজেক্টটি মুছতে চান সেটি নির্বাচন করুন এবং তারপর ডিলিট বোতামে ক্লিক করুন।
- ডায়ালগ বক্সে প্রজেক্ট আইডি টাইপ করুন এবং তারপর প্রজেক্টটি মুছে ফেলার জন্য 'শাট ডাউন'-এ ক্লিক করুন।
১০. অভিনন্দন
আপনি Neo4j , Vertex AI এবং Gemini ব্যবহার করে সফলভাবে একটি GraphRAG-চালিত ও GenAI-বর্ধিত মুভি সুপারিশকারী চ্যাটবট তৈরি এবং স্থাপন করেছেন। Neo4j-এর গ্রাফ-নেটিভ মডেলিং ক্ষমতার সাথে Vertex AI-এর মাধ্যমে সিমান্টিক সার্চ এবং Gemini-এর মাধ্যমে ন্যাচারাল ল্যাঙ্গুয়েজ রিজনিং-এর সমন্বয় ঘটিয়ে, আপনি এমন একটি বুদ্ধিমান সিস্টেম তৈরি করেছেন যা সাধারণ সার্চের ঊর্ধ্বে — এটি ব্যবহারকারীর উদ্দেশ্য বোঝে , সংযুক্ত ডেটার উপর ভিত্তি করে যুক্তি দেয় এবং কথোপকথনের ভঙ্গিতে উত্তর দেয় ।
এই কোডল্যাবে, আপনি নিম্নলিখিত কাজগুলো সম্পন্ন করেছেন:
✅ সিনেমা, অভিনেতা, সিনেমার ধরণ এবং সম্পর্ক মডেল করার জন্য Neo4j-তে একটি বাস্তব-জগতের মুভি নলেজ গ্রাফ তৈরি করা হয়েছে।
✅ ভার্টেক্স এআই-এর টেক্সট-এম্বেডিং মডেল ব্যবহার করে সিনেমার কাহিনী সংক্ষেপ-এর জন্য ভেক্টর এম্বেডিং তৈরি করা হয়েছে।
✅ আরও গভীর ও বহু-স্তরীয় যুক্তির জন্য ভেক্টর সার্চ এবং LLM-দ্বারা তৈরি সাইফার কোয়েরির সমন্বয়ে GraphRAG প্রয়োগ করা হয়েছে ।
✅ ব্যবহারকারীর প্রশ্ন ব্যাখ্যা করতে, সাইফার কোয়েরি তৈরি করতে এবং গ্রাফের ফলাফল স্বাভাবিক ভাষায় সংক্ষিপ্ত করতে জেমিনি (Gemini) সমন্বিত করা হয়েছে।
✅ Gradio ব্যবহার করে একটি সহজবোধ্য চ্যাট ইন্টারফেস তৈরি করা হয়েছে
✅ ঐচ্ছিকভাবে আপনার চ্যাটবটকে গুগল ক্লাউড রান-এ স্থাপন করুন, যা পরিমাপযোগ্য ও সার্ভারবিহীন হোস্টিংয়ের সুবিধা দেয়।
এরপর কী?
এই আর্কিটেকচারটি শুধু সিনেমার সুপারিশের মধ্যেই সীমাবদ্ধ নয় — এটিকে আরও প্রসারিত করা যেতে পারে:
- বই এবং সঙ্গীত আবিষ্কার প্ল্যাটফর্ম
- একাডেমিক গবেষণা সহকারী
- পণ্য সুপারিশ ইঞ্জিন
- স্বাস্থ্যসেবা, অর্থায়ন এবং আইনি জ্ঞান সহকারী
যেখানেই জটিল সম্পর্ক ও সমৃদ্ধ পাঠ্য ডেটা রয়েছে, সেখানেই নলেজ গ্রাফ, এলএলএম ও সিমান্টিক এমবেডিং- এর এই সংমিশ্রণ পরবর্তী প্রজন্মের বুদ্ধিমান অ্যাপ্লিকেশনগুলোকে চালিত করতে পারে।
জেমিনির মতো মাল্টিমোডাল জেনএআই মডেলগুলো বিকশিত হওয়ার সাথে সাথে, আপনি সত্যিকারের মানব-কেন্দ্রিক সিস্টেম তৈরি করার জন্য আরও সমৃদ্ধ প্রেক্ষাপট, ছবি, বক্তব্য এবং ব্যক্তিগতকরণের সুবিধা অন্তর্ভুক্ত করতে পারবেন।
অন্বেষণ করতে থাকুন, নির্মাণ করতে থাকুন — এবং আপনার ইন্টেলিজেন্ট অ্যাপ্লিকেশনগুলোকে পরবর্তী স্তরে নিয়ে যেতে Neo4j , Vertex AI , এবং Google Cloud- এর সর্বশেষ তথ্যের সাথে আপডেট থাকতে ভুলবেন না! Neo4j GraphAcademy- তে নলেজ গ্রাফের আরও হাতে-কলমে টিউটোরিয়াল দেখুন।