
1. Übersicht
In diesem Codelab erstellen Sie einen intelligenten Chatbot für Filmempfehlungen, indem Sie die Leistungsfähigkeit von Neo4j, Google Vertex AI und Gemini kombinieren. Das Herzstück dieses Systems ist ein Neo4j-Knowledge Graph, in dem Filme, Schauspieler, Regisseure, Genres und mehr durch ein umfangreiches Netzwerk aus miteinander verbundenen Knoten und Beziehungen modelliert werden.
Um die Nutzerfreundlichkeit durch semantisches Verständnis zu verbessern, generieren Sie mit dem Modell text-embedding-004 (oder neuer) von Vertex AI Vektoreinbettungen aus Filmzusammenfassungen. Diese Einbettungen werden in Neo4j indexiert, um sie schnell und basierend auf Ähnlichkeit abrufen zu können.
Schließlich integrieren Sie Gemini, um eine Konversationsoberfläche zu erstellen, über die Nutzer Fragen in natürlicher Sprache stellen können, z. B. „Was soll ich mir ansehen, wenn mir ‚Interstellar‘ gefallen hat?“, und personalisierte Filmvorschläge basierend auf semantischer Ähnlichkeit und grafischem Kontext erhalten.
In diesem Codelab gehen Sie schrittweise so vor:
- Neo4j-Knowledge Graph mit filmbezogenen Entitäten und Beziehungen erstellen
- Texteinbettungen für Filzübersichten mit Vertex AI generieren/laden
- Eine Gradio-Chatbot-Oberfläche implementieren, die auf Gemini basiert und die Vektorsuche mit der graphbasierten Cypher-Ausführung kombiniert
- Optional: Anwendung als eigenständige Webanwendung in Cloud Run bereitstellen
Lerninhalte
- Knowledge Graph für Filme mit Cypher und Neo4j erstellen und mit Daten füllen
- Semantische Texteinbettungen mit Vertex AI generieren und verwenden
- LLMs und Knowledge Graphs für intelligenten Abruf mit GraphRAG kombinieren
- Nutzerfreundliche Chat-Oberfläche mit Gradio erstellen
- Optionale Bereitstellung in Google Cloud Run
Voraussetzungen
- Chrome-Webbrowser
- Ein Gmail-Konto
- Ein Google Cloud-Projekt mit aktivierter Abrechnung
- Ein kostenloses Neo4j Aura DB-Konto
- Grundkenntnisse in Terminalbefehlen und Python (sind hilfreich, aber nicht erforderlich)
In diesem Codelab, das sich an Entwickler aller Erfahrungsstufen (auch Anfänger) richtet, werden Python und Neo4j in der Beispielanwendung verwendet. Grundkenntnisse in Python und Graphdatenbanken können hilfreich sein, sind aber nicht erforderlich, um die Konzepte zu verstehen oder dem Kurs zu folgen.
2. Neo4j AuraDB einrichten
Neo4j ist eine führende native Graphendatenbank, in der Daten als Netzwerk von Knoten (Entitäten) und Beziehungen (Verbindungen zwischen Entitäten) gespeichert werden. Sie eignet sich daher ideal für Anwendungsfälle, in denen es wichtig ist, Verbindungen zu verstehen, z. B. Empfehlungen, Betrugserkennung und Knowledge Graphs. Im Gegensatz zu relationalen oder dokumentbasierten Datenbanken, die auf starren Tabellen oder hierarchischen Strukturen basieren, ermöglicht das flexible Graphmodell von Neo4j eine intuitive und effiziente Darstellung komplexer, miteinander verbundener Daten.
Anstatt Daten wie in relationalen Datenbanken in Zeilen und Tabellen zu organisieren, verwendet Neo4j ein Graphenmodell, in dem Informationen als Knoten (Entitäten) und Beziehungen (Verbindungen zwischen diesen Entitäten) dargestellt werden. Dieses Modell ist besonders intuitiv für die Arbeit mit Daten, die von Natur aus miteinander verknüpft sind, z. B. Personen, Orte, Produkte oder in unserem Fall Filme, Schauspieler und Genres.
Beispiel: In einem Filmdataset:
- Ein Knoten kann eine
Movie,ActoroderDirectordarstellen. - Eine Beziehung kann
ACTED_INoderDIRECTEDsein.
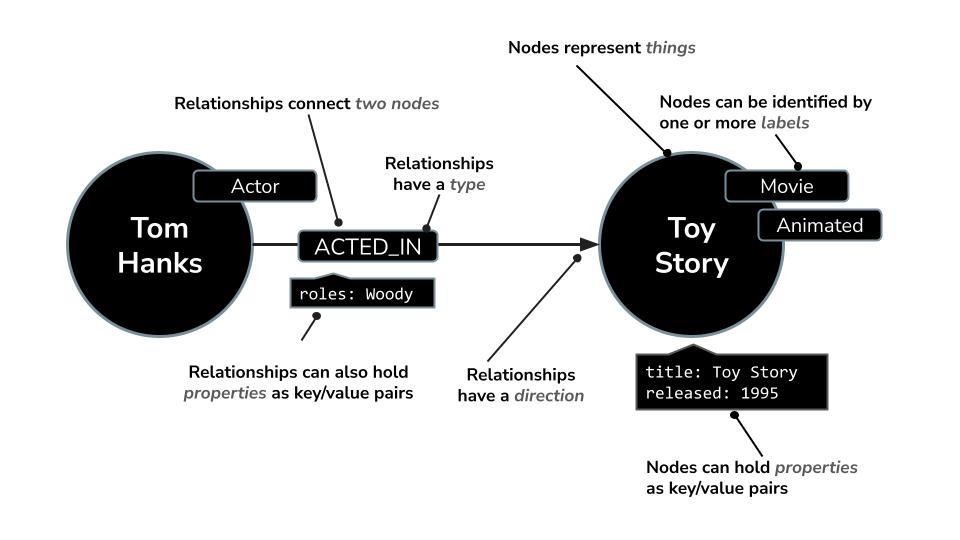
So können Sie ganz einfach Fragen stellen wie:
- In welchen Filmen hat dieser Schauspieler mitgespielt?
- Wer hat mit Christopher Nolan zusammengearbeitet?
- Was sind ähnliche Filme basierend auf gemeinsamen Schauspielern oder Genres?
Neo4j bietet eine leistungsstarke Abfragesprache namens Cypher, die speziell für das Abfragen von Grafiken entwickelt wurde. Mit Cypher können Sie komplexe Muster und Verbindungen prägnant und lesbar ausdrücken. Beispiel: In dieser Cypher-Abfrage wird MERGE verwendet, um sicherzustellen, dass Schauspieler, Filme und ihre Beziehung mit Rollendetails eindeutig erstellt werden und Duplikate vermieden werden.
MERGE (a:Actor {name: "Tom Hanks"})
MERGE (m:Movie {title: "Toy Story", released: 1995})
MERGE (a)-[:ACTED_IN {roles: ["Woody"]}]->(m);
Neo4j bietet je nach Bedarf mehrere Bereitstellungsoptionen:
- Selbstverwaltet: Führen Sie Neo4j auf Ihrer eigenen Infrastruktur mit Neo4j Desktop oder als Docker-Image (lokal oder in Ihrer eigenen Cloud) aus.
- Cloud-verwaltet: Stellen Sie Neo4j bei beliebten Cloud-Anbietern mit Marketplace-Angeboten bereit.
- Vollständig verwaltet: Verwenden Sie Neo4j AuraDB, die vollständig verwaltete Cloud-Datenbank-as-a-Service von Neo4j, die sich um Bereitstellung, Skalierung, Sicherungen und Sicherheit kümmert.
In diesem Codelab verwenden wir Neo4j AuraDB Free, die kostenlose Stufe von AuraDB. Sie bietet eine vollständig verwaltete Graphdatenbankinstanz mit ausreichend Speicherplatz und Funktionen für Prototyping, Lernen und die Entwicklung kleiner Anwendungen – perfekt für unser Ziel, einen auf generativer KI basierenden Filmempfehlungs-Chatbot zu entwickeln.
In diesem Lab erstellen Sie eine kostenlose AuraDB-Instanz, verbinden sie mit Ihrer Anwendung und verwenden sie zum Speichern und Abfragen Ihres Film-Knowledge-Graph.
Warum Grafiken?
In herkömmlichen relationalen Datenbanken wären für die Beantwortung von Fragen wie „Welche Filme ähneln Inception in Bezug auf Besetzung oder Genre?“ komplexe JOIN-Vorgänge über mehrere Tabellen hinweg erforderlich. Je komplexer die Beziehungen werden, desto schlechter werden Leistung und Lesbarkeit.
Grafikdatenbanken wie Neo4j sind jedoch darauf ausgelegt, Beziehungen effizient zu durchlaufen. Daher eignen sie sich besonders für Empfehlungssysteme, semantische Suche und intelligente Assistenten. Sie helfen dabei, den Kontext der realen Welt zu erfassen, z. B. Kollaborationsnetzwerke, Handlungsstränge oder Zuschauerpräferenzen, die mit herkömmlichen Datenmodellen nur schwer darzustellen sind.
Durch die Kombination dieser verbundenen Daten mit LLMs wie Gemini und Vektoreinbettungen aus Vertex AI können wir die Chatbot-Erfahrung optimieren und ihm ermöglichen, auf personalisierte und relevante Weise zu argumentieren, abzurufen und zu antworten.
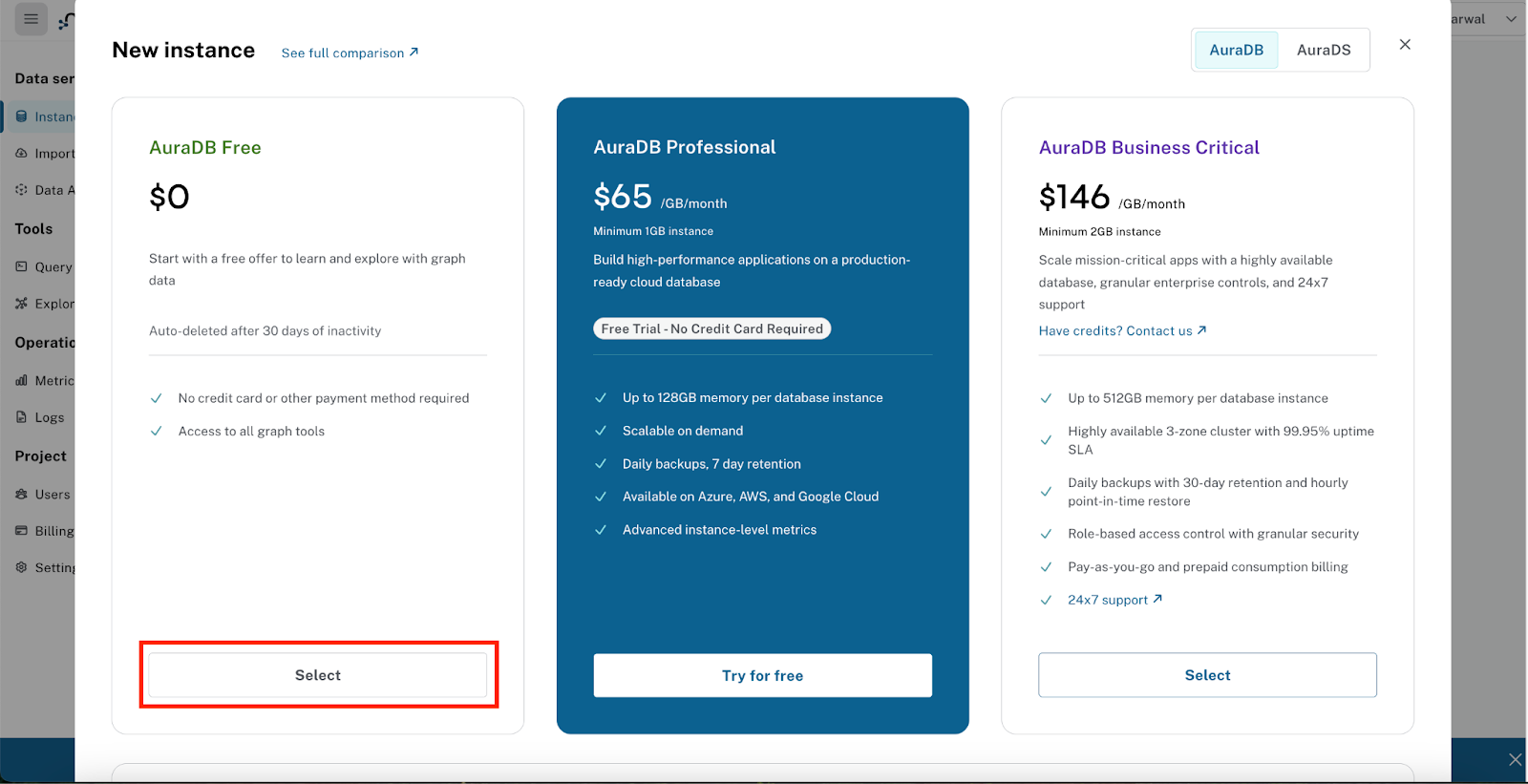
Neo4j AuraDB Free-Instanz erstellen
- Rufen Sie https://console.neo4j.io auf.
- Melden Sie sich mit Ihrem Google-Konto oder Ihrer E‑Mail-Adresse an.
- Klicken Sie auf „Create Free Instance“ (Kostenlose Instanz erstellen).
- Während die Instanz bereitgestellt wird, wird ein Pop-up-Fenster mit den Anmeldedaten für die Verbindung zu Ihrer Datenbank angezeigt.
Laden Sie die folgenden Details aus dem Pop-up herunter und speichern Sie sie sicher. Sie sind für die Verbindung Ihrer Anwendung mit Neo4j erforderlich:
NEO4J_URI=neo4j+s://<your-instance-id>.databases.neo4j.io
NEO4J_USERNAME=neo4j
NEO4J_PASSWORD=<your-generated-password>
AURA_INSTANCEID=<your-instance-id>
AURA_INSTANCENAME=<your-instance-name>
Mit diesen Werten konfigurieren Sie im nächsten Schritt die .env-Datei in Ihrem Projekt für die Authentifizierung bei Neo4j.
Neo4j AuraDB Free eignet sich gut für die Entwicklung, das Experimentieren und kleine Anwendungen wie dieses Codelab. Es bietet großzügige Nutzungslimits und unterstützt bis zu 200.000 Knoten und 400.000 Beziehungen. Es bietet alle wichtigen Funktionen, die zum Erstellen und Abfragen eines Wissensgraphen erforderlich sind, unterstützt jedoch keine erweiterten Konfigurationen wie benutzerdefinierte Plug-ins oder mehr Speicherplatz. Für Produktionsarbeitslasten oder größere Datasets können Sie auf ein AuraDB-Abo der höheren Stufe upgraden, das mehr Kapazität, Leistung und Funktionen auf Unternehmensniveau bietet.
Damit haben Sie den Abschnitt zum Einrichten Ihres Neo4j AuraDB-Backends abgeschlossen. Im nächsten Schritt erstellen wir ein Google Cloud-Projekt, klonen das Repository und konfigurieren die erforderlichen Umgebungsvariablen, um Ihre Entwicklungsumgebung vorzubereiten, bevor wir mit dem Codelab beginnen.
3. Hinweis
Projekt erstellen
- Wählen Sie in der Google Cloud Console auf der Seite zur Projektauswahl ein Google Cloud-Projekt aus oder erstellen Sie eines.
- Die Abrechnung für das Cloud-Projekt muss aktiviert sein. So prüfen Sie, ob die Abrechnung für ein Projekt aktiviert ist .
- Sie verwenden Cloud Shell, eine Befehlszeilenumgebung, die in Google Cloud ausgeführt wird und in der bq vorinstalliert ist. Klicken Sie oben in der Google Cloud Console auf „Cloud Shell aktivieren“.

- Sobald die Verbindung mit der Cloud Shell hergestellt ist, prüfen Sie mit dem folgenden Befehl, ob Sie bereits authentifiziert sind und für das Projekt schon Ihre Projekt-ID eingestellt ist:
gcloud auth list
- Führen Sie den folgenden Befehl in Cloud Shell aus, um zu bestätigen, dass der gcloud-Befehl Ihr Projekt kennt.
gcloud config list project
- Wenn Ihr Projekt nicht festgelegt ist, verwenden Sie den folgenden Befehl, um es festzulegen:
gcloud config set project <YOUR_PROJECT_ID>
- Aktivieren Sie die erforderlichen APIs mit dem unten gezeigten Befehl. Dies kann einige Minuten dauern.
gcloud services enable cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
cloudfunctions.googleapis.com \
aiplatform.googleapis.com
Bei erfolgreicher Ausführung des Befehls sollte die Meldung Vorgang … wurde abgeschlossen angezeigt werden.
Alternativ zum gcloud-Befehl können Sie in der Konsole nach den einzelnen Produkten suchen oder diesen Link verwenden.
Wenn eine API fehlt, können Sie sie jederzeit während der Implementierung aktivieren.
Informationen zu gcloud-Befehlen und deren Verwendung finden Sie in der Dokumentation.
Repository klonen und Umgebungseinstellungen einrichten
Als Nächstes klonen Sie das Beispiel-Repository, auf das wir im Rest des Codelabs verweisen. Wenn Sie sich in Cloud Shell befinden, geben Sie den folgenden Befehl in Ihrem Basisverzeichnis ein:
git clone https://github.com/sidagarwal04/neo4j-vertexai-codelab.git
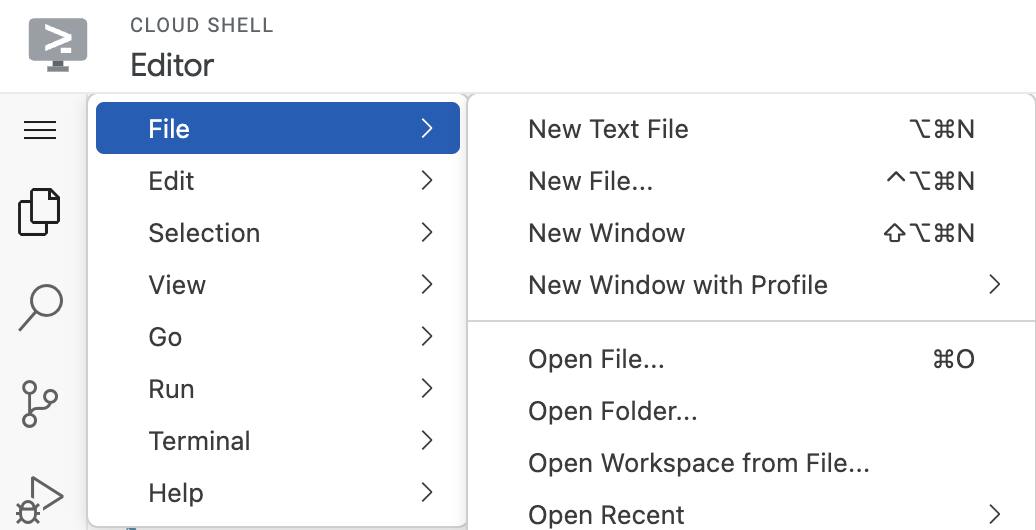
Klicken Sie zum Starten des Editors in der Symbolleiste des Cloud Shell-Fensters auf Editor öffnen. Klicken Sie links oben auf die Menüleiste und wählen Sie „Datei“ → „Ordner öffnen“ aus, wie unten dargestellt:
Wählen Sie den Ordner neo4j-vertexai-codelab aus. Er sollte sich mit einer ähnlichen Struktur wie unten gezeigt öffnen:
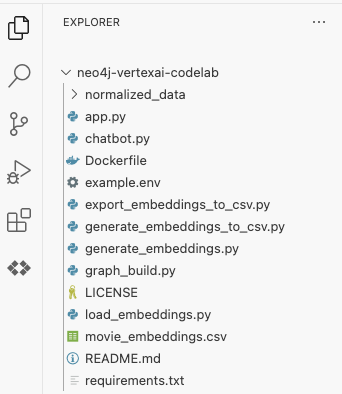
Als Nächstes müssen wir die Umgebungsvariablen einrichten, die im gesamten Codelab verwendet werden. Klicken Sie auf die Datei example.env. Der Inhalt sollte so aussehen:
NEO4J_URI=
NEO4J_USER=
NEO4J_PASSWORD=
NEO4J_DATABASE=
PROJECT_ID=
LOCATION=
Erstellen Sie nun im selben Ordner wie die Datei example.env eine neue Datei mit dem Namen .env und kopieren Sie den Inhalt der vorhandenen Datei „example.env“. Aktualisieren Sie nun die folgenden Variablen:
NEO4J_URI,NEO4J_USER,NEO4J_PASSWORDundNEO4J_DATABASE:- Geben Sie diese Werte mit den Anmeldedaten ein, die Sie im vorherigen Schritt beim Erstellen der Neo4j AuraDB Free-Instanz erhalten haben.
NEO4J_DATABASEist für AuraDB Free in der Regel auf „neo4j“ festgelegt.PROJECT_IDundLOCATION:- Wenn Sie das Codelab in Google Cloud Shell ausführen, können Sie diese Felder leer lassen, da sie automatisch aus Ihrer aktiven Projektkonfiguration abgeleitet werden.
- Wenn Sie die Anwendung lokal oder außerhalb von Cloud Shell ausführen, ersetzen Sie
PROJECT_IDdurch die ID des Google Cloud-Projekts, das Sie zuvor erstellt haben, und legen SieLOCATIONauf die Region fest, die Sie für dieses Projekt ausgewählt haben (z.B. „us-central1“).
Speichern Sie die Datei .env, nachdem Sie diese Werte eingegeben haben. Mit dieser Konfiguration kann Ihre Anwendung sowohl eine Verbindung zu Neo4j- als auch zu Vertex AI-Diensten herstellen.
Der letzte Schritt beim Einrichten Ihrer Entwicklungsumgebung besteht darin, eine virtuelle Python-Umgebung zu erstellen und alle erforderlichen Abhängigkeiten zu installieren, die in der Datei requirements.txt aufgeführt sind. Diese Abhängigkeiten umfassen Bibliotheken, die für die Arbeit mit Neo4j, Vertex AI, Gradio und anderen Tools erforderlich sind.
Erstellen Sie zuerst eine virtuelle Umgebung mit dem Namen „.venv“, indem Sie den folgenden Befehl ausführen:
python -m venv .venv
Nachdem die Umgebung erstellt wurde, müssen wir sie mit dem folgenden Befehl aktivieren.
source .venv/bin/activate
Sie sollten jetzt (.venv) am Anfang der Eingabeaufforderung Ihres Terminals sehen. Das bedeutet, dass die Umgebung aktiv ist. Beispiel: (.venv) yourusername@cloudshell:
Installieren Sie nun die erforderlichen Abhängigkeiten mit dem folgenden Befehl:
pip install -r requirements.txt
Hier sehen Sie einen Ausschnitt der wichtigsten Abhängigkeiten, die in der Datei aufgeführt sind:
gradio>=4.0.0
neo4j>=5.0.0
numpy>=1.20.0
python-dotenv>=1.0.0
google-cloud-aiplatform>=1.30.0
vertexai>=0.0.1
Sobald alle Abhängigkeiten installiert sind, ist Ihre lokale Python-Umgebung vollständig für die Ausführung der Skripts und des Chatbots in diesem Codelab konfiguriert.
Super! Wir können nun mit dem nächsten Schritt fortfahren: das Dataset analysieren und für die Erstellung von Diagrammen und die semantische Anreicherung vorbereiten.
4. Filmdataset vorbereiten
Als Erstes bereiten wir das Movies-Dataset vor, das wir zum Erstellen des Wissensgraphen und für unseren Empfehlungs-Chatbot verwenden. Statt von Grund auf neu zu beginnen, verwenden wir ein vorhandenes offenes Dataset und bauen darauf auf.
Wir verwenden das Film-Dataset von Rounak Banik, ein bekanntes öffentliches Dataset, das auf Kaggle verfügbar ist. Es enthält Metadaten zu über 45.000 Filmen aus TMDB, darunter Cast, Crew, Schlüsselwörter und Bewertungen.
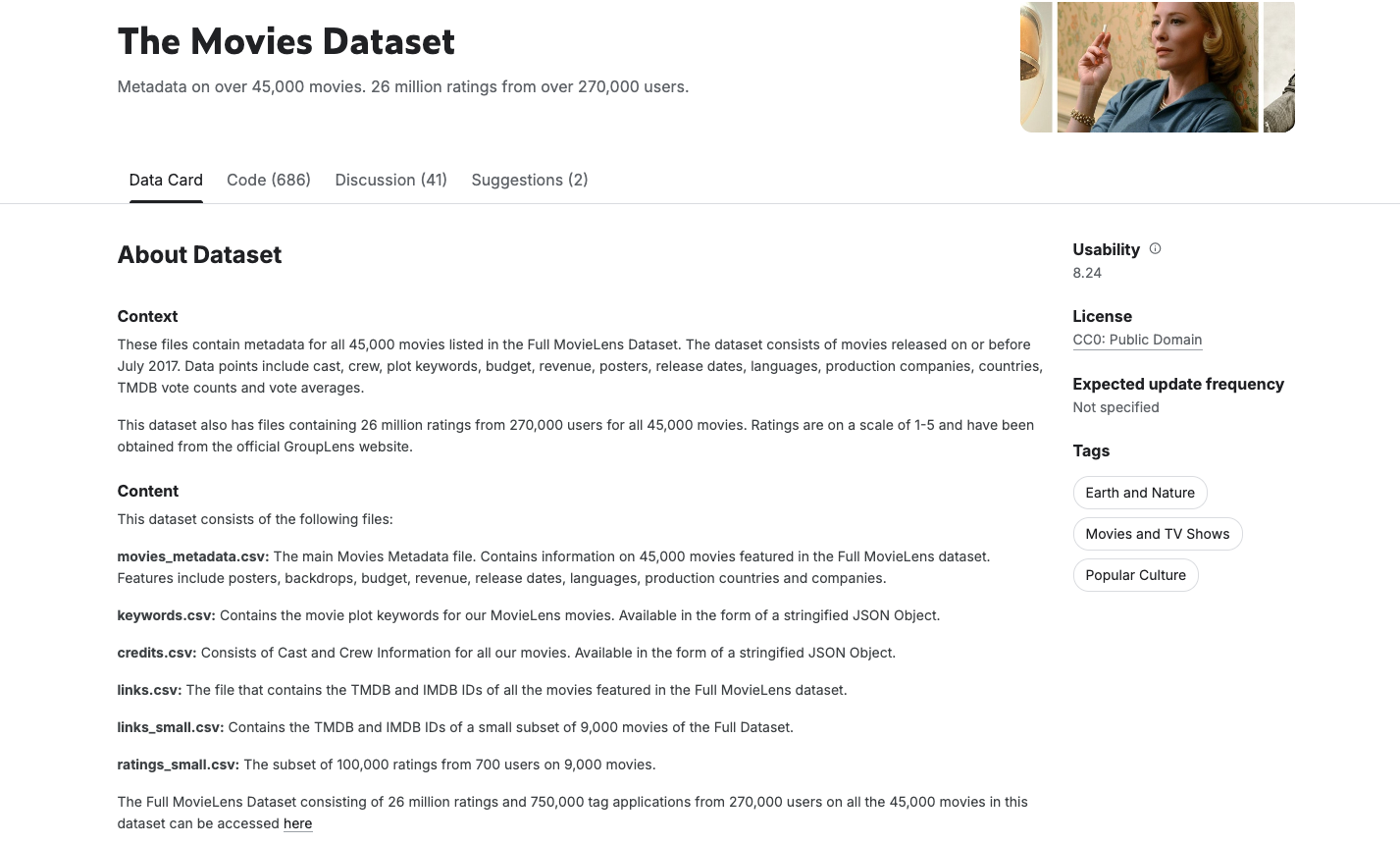
Um einen zuverlässigen und effektiven Chatbot für Filmpfehlungen zu erstellen, ist es wichtig, mit sauberen, konsistenten und strukturierten Daten zu beginnen. The Movies Dataset von Kaggle ist zwar eine umfangreiche Ressource mit über 45.000 Filmdatensätzen und detaillierten Metadaten wie Genres, Besetzung und Crew, enthält aber auch Rauschen, Inkonsistenzen und verschachtelte Datenstrukturen, die nicht ideal für die Graphmodellierung oder semantische Einbettung sind.
Um dieses Problem zu beheben, haben wir den Datensatz vorverarbeitet und normalisiert, damit er sich gut für die Erstellung eines Neo4j-Knowledge-Graph und die Generierung hochwertiger Einbettungen eignet. Dazu waren folgende Schritte erforderlich:
- Duplikate und unvollständige Datensätze entfernen
- Schlüsselfelder standardisieren (z.B. Genrenamen, Personennamen)
- Komplexe verschachtelte Strukturen (z.B. Besetzung und Crew) in strukturierte CSV-Dateien umwandeln
- Auswahl einer repräsentativen Teilmenge von etwa 12.000 Filmen,um die Grenzwerte von Neo4j AuraDB Free einzuhalten
Hochwertige, normalisierte Daten tragen zu Folgendem bei:
- Datenqualität: Fehler und Inkonsistenzen werden minimiert, um genauere Empfehlungen zu erhalten.
- Abfrageleistung: Durch die optimierte Struktur wird die Abrufgeschwindigkeit verbessert und die Redundanz verringert.
- Genauigkeit von Einbettungen: Bereinigte Eingaben führen zu aussagekräftigeren und kontextbezogenen Vektoreinbettungen.
Sie können auf das bereinigte und normalisierte Dataset im Ordner normalized_data/ dieses GitHub-Repositorys zugreifen. Dieses Dataset wird auch in einem Google Cloud Storage-Bucket gespiegelt, um den Zugriff in den kommenden Python-Skripts zu erleichtern.
Nachdem die Daten bereinigt und vorbereitet wurden, können wir sie jetzt in Neo4j laden und mit der Erstellung unseres Film-Knowledge-Graph beginnen.
5. Knowledge Graph für Filme erstellen
Damit unser auf generativer KI basierender Filmempfehlungs-Chatbot funktioniert, müssen wir unser Film-Dataset so strukturieren, dass das komplexe Netzwerk von Verbindungen zwischen Filmen, Schauspielern, Regisseuren, Genres und anderen Metadaten erfasst wird. In diesem Abschnitt erstellen wir in Neo4j einen Filmwissensgraph mit dem bereinigten und normalisierten Dataset, das Sie zuvor vorbereitet haben.
Wir verwenden die LOAD CSV-Funktion von Neo4j, um CSV-Dateien aufzunehmen, die in einem öffentlichen Google Cloud Storage-Bucket (GCS) gehostet werden. Diese Dateien stellen verschiedene Komponenten des Filmdatasets dar, z. B. Filme, Genres, Besetzung, Crew, Produktionsfirmen und Nutzerbewertungen.
Schritt 1: Einschränkungen und Indexe erstellen
Vor dem Importieren von Daten empfiehlt es sich, Einschränkungen und Indexe zu erstellen, um die Datenintegrität zu erzwingen und die Abfrageleistung zu optimieren.
CREATE CONSTRAINT unique_tmdb_id IF NOT EXISTS FOR (m:Movie) REQUIRE m.tmdbId IS UNIQUE;
CREATE CONSTRAINT unique_movie_id IF NOT EXISTS FOR (m:Movie) REQUIRE m.movieId IS UNIQUE;
CREATE CONSTRAINT unique_prod_id IF NOT EXISTS FOR (p:ProductionCompany) REQUIRE p.company_id IS UNIQUE;
CREATE CONSTRAINT unique_genre_id IF NOT EXISTS FOR (g:Genre) REQUIRE g.genre_id IS UNIQUE;
CREATE CONSTRAINT unique_lang_id IF NOT EXISTS FOR (l:SpokenLanguage) REQUIRE l.language_code IS UNIQUE;
CREATE CONSTRAINT unique_country_id IF NOT EXISTS FOR (c:Country) REQUIRE c.country_code IS UNIQUE;
CREATE INDEX actor_id IF NOT EXISTS FOR (p:Person) ON (p.actor_id);
CREATE INDEX crew_id IF NOT EXISTS FOR (p:Person) ON (p.crew_id);
CREATE INDEX movieId IF NOT EXISTS FOR (m:Movie) ON (m.movieId);
CREATE INDEX user_id IF NOT EXISTS FOR (p:Person) ON (p.user_id);
Schritt 2: Filmdaten und ‑Beziehungen importieren
Sehen wir uns an, wie wir Filmdaten mit dem Befehl LOAD CSV importieren. In diesem Beispiel werden Movie-Knoten mit Schlüsselattributen wie „title“, „overview“, „language“ und „runtime“ erstellt:
LOAD CSV WITH HEADERS FROM "https://storage.googleapis.com/neo4j-vertexai-codelab/normalized_data/normalized_movies.csv" AS row
WITH row, toInteger(row.tmdbId) AS tmdbId
WHERE tmdbId IS NOT NULL
WITH row, tmdbId
LIMIT 12000
MERGE (m:Movie {tmdbId: tmdbId})
ON CREATE SET m.title = coalesce(row.title, "None"),
m.original_title = coalesce(row.original_title, "None"),
m.adult = CASE
WHEN toInteger(row.adult) = 1 THEN 'Yes'
ELSE 'No'
END,
m.budget = toInteger(coalesce(row.budget, 0)),
m.original_language = coalesce(row.original_language, "None"),
m.revenue = toInteger(coalesce(row.revenue, 0)),
m.tagline = coalesce(row.tagline, "None"),
m.overview = coalesce(row.overview, "None"),
m.release_date = coalesce(row.release_date, "None"),
m.runtime = toFloat(coalesce(row.runtime, 0)),
m.belongs_to_collection = coalesce(row.belongs_to_collection, "None");
Ebenso können Sie andere Entitäten wie Genres, Produktionsfirmen, Gesprochene Sprachen, Länder, Besetzung, Crew und Nutzerbewertungen mit den entsprechenden CSV-Dateien und Cypher-Abfragen importieren und verknüpfen.
Vollständigen Graphen über Python laden
Anstatt mehrere Cypher-Abfragen manuell auszuführen, empfehlen wir, das automatisierte Python-Skript zu verwenden, das in diesem Codelab bereitgestellt wird.
Das Script graph_build.py lädt das gesamte Dataset aus GCS in Ihre Neo4j AuraDB-Instanz. Dabei werden die Anmeldedaten aus der Datei .env verwendet.
python graph_build.py
Das Skript lädt nacheinander alle erforderlichen CSV-Dateien, erstellt Knoten und Beziehungen und strukturiert Ihren vollständigen Film-Wissensgraphen.
|
|

.png")
Diagramm validieren
Nach dem Laden können Sie das Diagramm mit dem folgenden Skript validieren:
python validate_graph.py
So erhalten Sie eine kurze Zusammenfassung der Inhalte Ihres Diagramms: wie viele Filme, Schauspieler, Genres und Beziehungen wie ACTED_IN, DIRECTED usw. vorhanden sind. So können Sie prüfen, ob der Import erfolgreich war.
📦 Node Counts:
Movie: 11997 nodes
ProductionCompany: 7961 nodes
Genre: 20 nodes
SpokenLanguage: 100 nodes
Country: 113 nodes
Person: 92663 nodes
Actor: 81165 nodes
Director: 4846 nodes
Producer: 5981 nodes
User: 671 nodes
🔗 Relationship Counts:
HAS_GENRE: 28479 relationships
PRODUCED_BY: 22758 relationships
PRODUCED_IN: 14702 relationships
HAS_LANGUAGE: 16184 relationships
ACTED_IN: 191307 relationships
DIRECTED: 5047 relationships
PRODUCED: 6939 relationships
RATED: 90344 relationships
Ihr Diagramm sollte jetzt mit Filmen, Personen, Genres usw. gefüllt sein. Im nächsten Schritt wird es semantisch angereichert.
6. Einbettungen generieren und laden, um die Vektorähnlichkeitssuche durchzuführen
Damit wir die semantische Suche in unserem Chatbot aktivieren können, müssen wir Vektoreinbettungen für Filzübersichten generieren. Durch diese Einbettungen werden Textdaten in numerische Vektoren umgewandelt, die auf Ähnlichkeit verglichen werden können. So kann der Chatbot relevante Filme abrufen, auch wenn die Anfrage nicht genau mit dem Titel oder der Beschreibung übereinstimmt.

Option 1: Vorab berechnete Einbettungen über Cypher laden
Führen Sie den folgenden Cypher-Befehl im Neo4j-Browser aus, um die Einbettungen schnell den entsprechenden Movie-Knoten in Neo4j zuzuweisen:
LOAD CSV WITH HEADERS FROM 'https://storage.googleapis.com/neo4j-vertexai-codelab/movie_embeddings.csv' AS row
WITH row
MATCH (m:Movie {tmdbId: toInteger(row.tmdbId)})
SET m.embedding = apoc.convert.fromJsonList(row.embedding)
Mit diesem Befehl werden die Einbettungsvektoren aus der CSV-Datei gelesen und als Attribut (m.embedding) an jeden Movie-Knoten angehängt.
Option 2: Embeddings mit Python laden
Sie können die Einbettungen auch programmatisch mit dem bereitgestellten Python-Skript laden. Dieser Ansatz ist nützlich, wenn Sie in Ihrer eigenen Umgebung arbeiten oder den Prozess automatisieren möchten:
python load_embeddings.py
Dieses Script liest dieselbe CSV-Datei aus GCS und schreibt die Einbettungen mit dem Python-Neo4j-Treiber in Neo4j.
[Optional] Embeddings selbst generieren (für die Analyse)
Wenn Sie wissen möchten, wie die Einbettungen generiert werden, können Sie sich die Logik im generate_embeddings.py-Script ansehen. Dazu wird Vertex AI verwendet, um jeden Filmoversichtstext mit dem Modell text-embedding-004 einzubetten.
Wenn Sie es selbst ausprobieren möchten, öffnen Sie den Abschnitt zur Einbettungsgenerierung im Code und führen Sie ihn aus. Wenn Sie Cloud Shell verwenden, können Sie die folgende Zeile auskommentieren, da Cloud Shell bereits über Ihr aktives Konto authentifiziert ist:
# os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = "./service-account.json"
Sobald die Einbettungen in Neo4j geladen sind, ist Ihr Film-Wissensgraph semantisch bewusst und kann leistungsstarke Suchanfragen in natürlicher Sprache mithilfe von Vektorähnlichkeit unterstützen.
7. Der Filmempfehlungs-Chatbot
Nachdem Sie Ihren Knowledge Graph und Ihre Vektoreinbettungen erstellt haben, ist es an der Zeit, alles in einer voll funktionsfähigen konversationellen Benutzeroberfläche zusammenzuführen – Ihrem auf generativer KI basierenden Chatbot für Filmempfehlungen.
Dieser Chatbot wird in Python mit Gradio implementiert, einem einfachen Web-Framework zum Erstellen intuitiver Benutzeroberflächen. Die Kernlogik befindet sich in app.py, das eine Verbindung zu Ihrer Neo4j AuraDB-Instanz herstellt und Google Vertex AI und Gemini verwendet, um Anfragen in natürlicher Sprache zu verarbeiten und darauf zu reagieren.
Funktionsweise
- Nutzer gibt eine Anfrage in natürlicher Sprache einz.B. „Recommend me sci-fi thrillers like Interstellar“ (Empfiehl mir Science-Fiction-Thriller wie „Interstellar“)
- Vektoreinbettung für die Anfrage mit dem
text-embedding-004-Modell von Vertex AI generieren - Vektorsuche in Neo4j durchführen, um semantisch ähnliche Filme abzurufen
- Mit Gemini können Sie:
- Abfrage im Kontext interpretieren
- Eine benutzerdefinierte Cypher-Abfrage basierend auf den Vektorsuchergebnissen und dem Neo4j-Schema generieren
- Führen Sie die Abfrage aus, um zugehörige Diagrammdaten (z. B. Schauspieler, Regisseure, Genres) zu extrahieren.
- Ergebnisse in einem Gesprächston für den Nutzer zusammenfassen
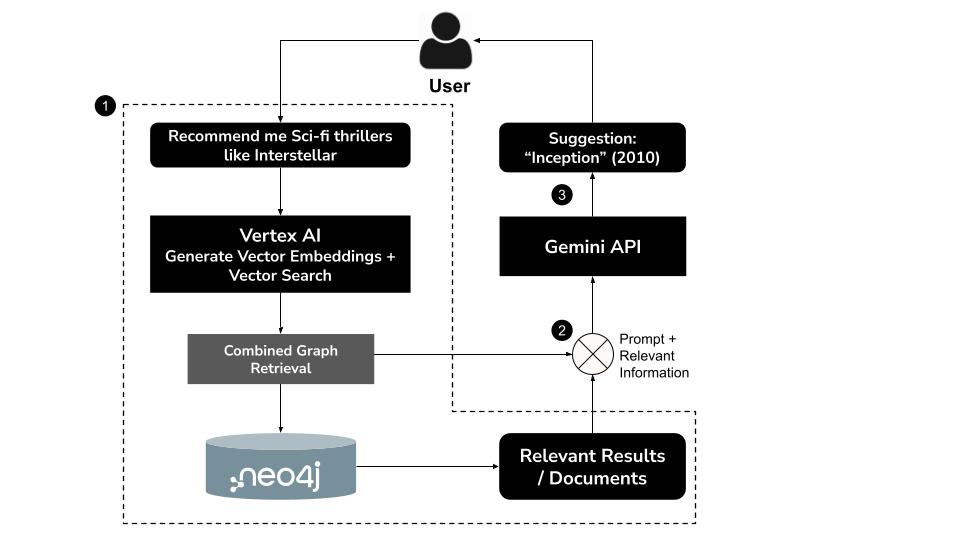
Dieser hybride Ansatz, der als GraphRAG (Graph Retrieval-Augmented Generation) bezeichnet wird, kombiniert semantisches Abrufen und strukturiertes Reasoning, um genauere, kontextbezogene und nachvollziehbare Empfehlungen zu generieren.
Chatbot lokal ausführen
Aktivieren Sie Ihre virtuelle Umgebung (falls noch nicht geschehen) und starten Sie den Chatbot dann mit:
python app.py
Die Ausgabe sollte in etwa so aussehen:
Vector index 'overview_embeddings' already exists. No need to create a new one.
* Running on local URL: http://0.0.0.0:8080
To create a public link, set `share=True` in `launch()`.
💡 Wenn Sie den Chatbot extern freigeben möchten, legen Sie share=True in der Funktion launch() in app.py fest.
Mit dem Chatbot interagieren
Öffnen Sie die lokale URL, die in Ihrem Terminal angezeigt wird (in der Regel 👉 http://0.0.0.0:8080), um auf die Chatbot-Oberfläche zuzugreifen.
Stellen Sie Fragen wie:
- „Was soll ich mir ansehen, wenn mir ‚Interstellar‘ gefallen hat?“
- „Schlage einen romantischen Film unter der Regie von Nora Ephron vor.“
- „Ich möchte einen Familienfilm mit Tom Hanks ansehen.“
- „Finde Thriller, in denen es um künstliche Intelligenz geht“
Der Chatbot:
✅ Die Anfrage verstehen
✅ Semantisch ähnliche Filminhalte mithilfe von Einbettungen finden
✅ Eine Cypher-Abfrage generieren und ausführen, um den zugehörigen Graphkontext abzurufen
✅ Freundliche, personalisierte Empfehlungen innerhalb von Sekunden
Ihre aktuellen Funktionen
Sie haben gerade einen auf GraphRAG basierenden Film-Chatbot erstellt, der Folgendes kombiniert:
- Vektorsuche nach semantischer Relevanz
- Knowledge Graph-Schlussfolgerungen mit Neo4j
- LLM-Funktionen über Gemini
- Eine reibungslose Chat-Oberfläche mit Gradio
Diese Architektur bildet eine Grundlage, die Sie in erweiterte Such-, Empfehlungs- oder Reasoning-Systeme auf Basis von generativer KI einbinden können.
8. (Optional) In Google Cloud Run bereitstellen
Wenn Sie Ihren Filmempfehlungs-Chatbot öffentlich zugänglich machen möchten, können Sie ihn in Google Cloud Run bereitstellen. Cloud Run ist eine vollständig verwaltete, serverlose Plattform, die Ihre App automatisch skaliert und alle Infrastrukturprobleme abstrahiert.
Für diese Bereitstellung wird Folgendes verwendet:
requirements.txt– zum Definieren von Python-Abhängigkeiten (Neo4j, Vertex AI, Gradio usw.)Dockerfile– zum Verpacken der Anwendung.env.yaml– zum sicheren Übergeben von Umgebungsvariablen zur Laufzeit
Schritt 1: .env.yaml vorbereiten
Erstellen Sie im Stammverzeichnis eine Datei mit dem Namen .env.yaml mit folgendem Inhalt:
NEO4J_URI: "neo4j+s://<your-aura-db-uri>"
NEO4J_USER: "neo4j"
NEO4J_PASSWORD: "<your-password>"
PROJECT_ID: "<your-gcp-project-id>"
LOCATION: "<your-gcp-region>" # e.g. us-central1
💡 Dieses Format wird gegenüber --set-env-vars bevorzugt, da es besser skalierbar, versionskontrollierbar und lesbar ist.
Schritt 2: Umgebungsvariablen einrichten
Legen Sie in Ihrem Terminal die folgenden Umgebungsvariablen fest und ersetzen Sie die Platzhalterwerte durch Ihre tatsächlichen Projekteinstellungen:
# Set your Google Cloud project ID
export GCP_PROJECT='your-project-id' # Change this
# Set your preferred deployment region
export GCP_REGION='us-central1'
Schritt 2: Artifact Registry erstellen und Container erstellen
# Artifact Registry repo and service name
export AR_REPO='your-repo-name' # Change this
export SERVICE_NAME='movies-chatbot' # Or any name you prefer
# Create the Artifact Registry repository
gcloud artifacts repositories create "$AR_REPO" \
--location="$GCP_REGION" \
--repository-format=Docker
# Authenticate Docker with Artifact Registry
gcloud auth configure-docker "$GCP_REGION-docker.pkg.dev"
# Build and submit the container image
gcloud builds submit \
--tag "$GCP_REGION-docker.pkg.dev/$GCP_PROJECT/$AR_REPO/$SERVICE_NAME"
Mit diesem Befehl wird Ihre App mit Dockerfile verpackt und das Container-Image in Google Cloud Artifact Registry hochgeladen.
Schritt 3: In Cloud Run bereitstellen
Stellen Sie die App jetzt mit der Datei .env.yaml für die Laufzeitkonfiguration bereit:
gcloud run deploy "$SERVICE_NAME" \
--port=8080 \
--image="$GCP_REGION-docker.pkg.dev/$GCP_PROJECT/$AR_REPO/$SERVICE_NAME" \
--allow-unauthenticated \
--region=$GCP_REGION \
--platform=managed \
--project=$GCP_PROJECT \
--env-vars-file=.env.yaml
Auf den Chatbot zugreifen
Nach der Bereitstellung stellt Cloud Run eine öffentliche URL wie die folgende bereit:
https://movies-reco-[UNIQUE_ID].${GCP_REGION}.run.app
Öffnen Sie diese URL in Ihrem Browser, um auf die bereitgestellte Gradio-Chatbot-Oberfläche zuzugreifen. Sie ist bereit, Filmempfehlungen mit GraphRAG, Gemini und Neo4j zu verarbeiten.
Hinweise und Tipps
- Achten Sie darauf, dass
Dockerfilewährend des Buildspip install -r requirements.txtausführt. - Wenn Sie Cloud Shell nicht verwenden, müssen Sie Ihre Umgebung mit einem Dienstkonto mit Vertex AI- und Artifact Registry-Berechtigungen authentifizieren.
- Sie können Bereitstellungslogs und ‑messwerte über die Google Cloud Console > Cloud Run aufrufen.
Sie können auch in der Google Cloud Console Cloud Run aufrufen. Dort wird die Liste der Dienste in Cloud Run angezeigt. Der Dienst movies-chatbot sollte einer der (oder der einzige) dort aufgeführten Dienste sein.
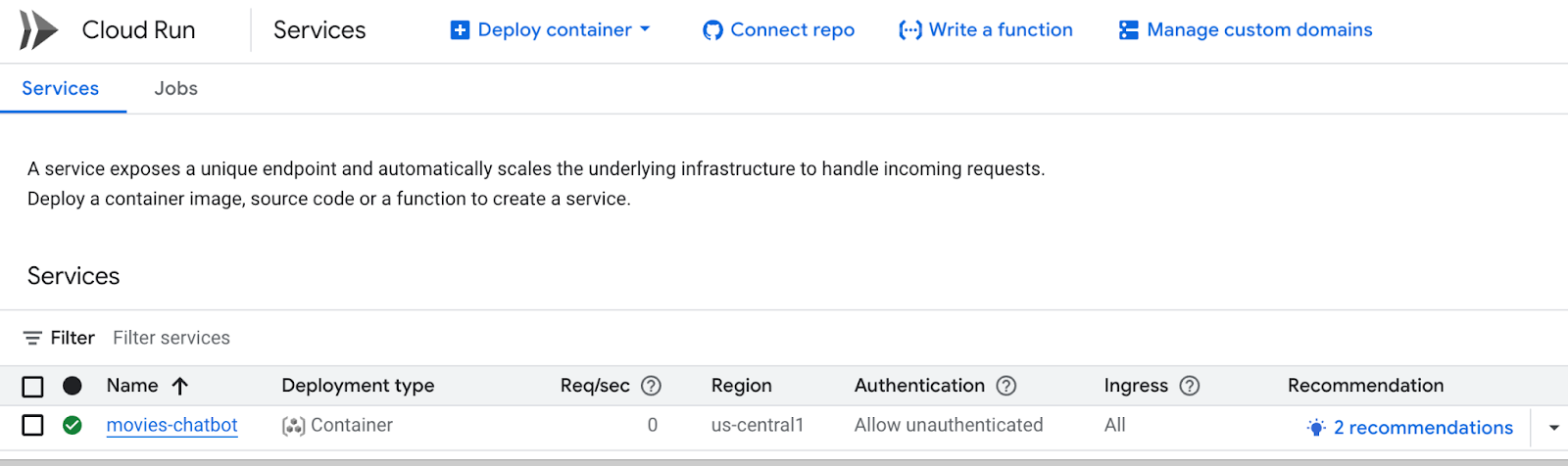
Sie können die Details des Dienstes wie URL, Konfigurationen und Logs aufrufen, indem Sie auf den jeweiligen Dienstnamen klicken (in unserem Fall movies-chatbot).
Damit ist Ihr Chatbot für Filmpfehlungen jetzt bereitgestellt, skalierbar und teilbar. 🎉
9. Bereinigen
So vermeiden Sie, dass Ihrem Google Cloud-Konto die in diesem Beitrag verwendeten Ressourcen in Rechnung gestellt werden:
- Wechseln Sie in der Google Cloud Console zur Seite Ressourcen verwalten.
- Wählen Sie in der Projektliste das Projekt aus, das Sie löschen möchten, und klicken Sie auf Löschen.
- Geben Sie im Dialogfeld die Projekt-ID ein und klicken Sie auf Beenden, um das Projekt zu löschen.
10. Glückwunsch
Sie haben erfolgreich einen GraphRAG-basierten, GenAI-optimierten Chatbot für Filmempfehlungen mit Neo4j, Vertex AI und Gemini erstellt und bereitgestellt. Durch die Kombination der graphnativen Modellierungsfunktionen von Neo4j mit der semantischen Suche über Vertex AI und der Verarbeitung natürlicher Sprache über Gemini haben Sie ein intelligentes System geschaffen, das über die einfache Suche hinausgeht. Es versteht die Nutzerabsicht, analysiert verbundene Daten und antwortet in Konversationsform.
In diesem Codelab haben Sie Folgendes erreicht:
✅ Einen realen Knowledge Graph für Filme in Neo4j erstellt, um Filme, Schauspieler, Genres und Beziehungen zu modellieren
✅ Generierte Vektoreinbettungen für Filmzusammenfassungen mit den Modelle zur Texteinbettung von Vertex AI
✅ GraphRAG implementiert, das Vektorsuche und von LLMs generierte Cypher-Abfragen für eine tiefere, mehrstufige Argumentation kombiniert
✅ Integrierte Gemini-Funktionen zum Interpretieren von Nutzerfragen, Generieren von Cypher-Abfragen und Zusammenfassen von Grafikergebnissen in natürlicher Sprache
✅ Intuitive Chat-Oberfläche mit Gradio erstellt
✅ Chatbot optional in Google Cloud Run bereitgestellt für skalierbares, serverloses Hosting
Wie geht es weiter?
Diese Architektur ist nicht auf Filmempfehlungen beschränkt, sondern kann auf Folgendes ausgeweitet werden:
- Plattformen zum Entdecken von Büchern und Musik
- Wissenschaftliche Mitarbeiter
- Empfehlungssysteme für Produkte
- Wissensassistenten für das Gesundheitswesen, Finanzwesen und Recht
Überall dort, wo Sie komplexe Beziehungen + umfangreiche Textdaten haben, kann diese Kombination aus Wissensgraphen + LLMs + semantischen Einbettungen die nächste Generation intelligenter Anwendungen unterstützen.
Mit der Weiterentwicklung von multimodalen GenAI-Modellen wie Gemini können Sie noch mehr Kontext, Bilder, Sprache und Personalisierung einbeziehen, um wirklich nutzerorientierte Systeme zu entwickeln.
Entwickeln Sie weiter und vergessen Sie nicht, sich über die neuesten Entwicklungen bei Neo4j, Vertex AI und Google Cloud auf dem Laufenden zu halten, um Ihre intelligenten Anwendungen auf die nächste Stufe zu heben. Weitere praktische Tutorials zu Knowledge Graphs finden Sie in der Neo4j GraphAcademy.