
1. Ringkasan
Dalam codelab ini, Anda akan membangun chatbot rekomendasi film cerdas dengan menggabungkan kecanggihan Neo4j, Google Vertex AI, dan Gemini. Inti dari sistem ini adalah Grafik Pengetahuan Neo4j yang memodelkan film, aktor, sutradara, genre, dan lainnya melalui jaringan kaya akan node dan hubungan yang saling terhubung.
Untuk meningkatkan pengalaman pengguna dengan pemahaman semantik, Anda akan membuat embedding vektor dari ringkasan plot film menggunakan model text-embedding-004 Vertex AI (atau yang lebih baru). Embedding ini diindeks di Neo4j untuk pengambilan cepat berbasis kemiripan.
Terakhir, Anda akan mengintegrasikan Gemini untuk mendukung antarmuka percakapan tempat pengguna dapat mengajukan pertanyaan dalam bahasa alami seperti "Apa yang harus saya tonton jika saya menyukai Interstellar?" dan menerima saran film yang dipersonalisasi berdasarkan kesamaan semantik dan konteks berbasis grafik.
Selama mengikuti codelab, Anda akan menggunakan pendekatan langkah demi langkah sebagai berikut:
- Membangun Grafik Pengetahuan Neo4j dengan entity dan hubungan terkait film
- Membuat/Memuat embedding teks untuk ringkasan film menggunakan Vertex AI
- Menerapkan antarmuka chatbot Gradio yang didukung oleh Gemini yang menggabungkan penelusuran vektor dengan eksekusi Cypher berbasis grafik
- (Opsional) Deploy aplikasi ke Cloud Run sebagai aplikasi web mandiri
Yang akan Anda pelajari
- Cara membuat dan mengisi grafik pengetahuan film menggunakan Cypher dan Neo4j
- Cara menggunakan Vertex AI untuk membuat dan menggunakan embedding teks semantik
- Cara menggabungkan LLM dan Pustaka Pengetahuan untuk pengambilan cerdas menggunakan GraphRAG
- Cara membuat antarmuka chat yang mudah digunakan dengan Gradio
- Cara men-deploy secara opsional di Google Cloud Run
Yang Anda butuhkan
- Browser web Chrome
- Akun Gmail
- Project Google Cloud dengan penagihan diaktifkan
- Akun DB Neo4j Aura gratis
- Pemahaman dasar tentang perintah terminal dan Python (akan membantu, tetapi tidak wajib)
Codelab ini, yang dirancang untuk developer dari semua tingkat keahlian (termasuk pemula), menggunakan Python dan Neo4j dalam aplikasi contohnya. Meskipun pemahaman dasar tentang Python dan database grafik dapat membantu, Anda tidak memerlukan pengalaman sebelumnya untuk memahami konsep atau mengikuti langkah-langkahnya.
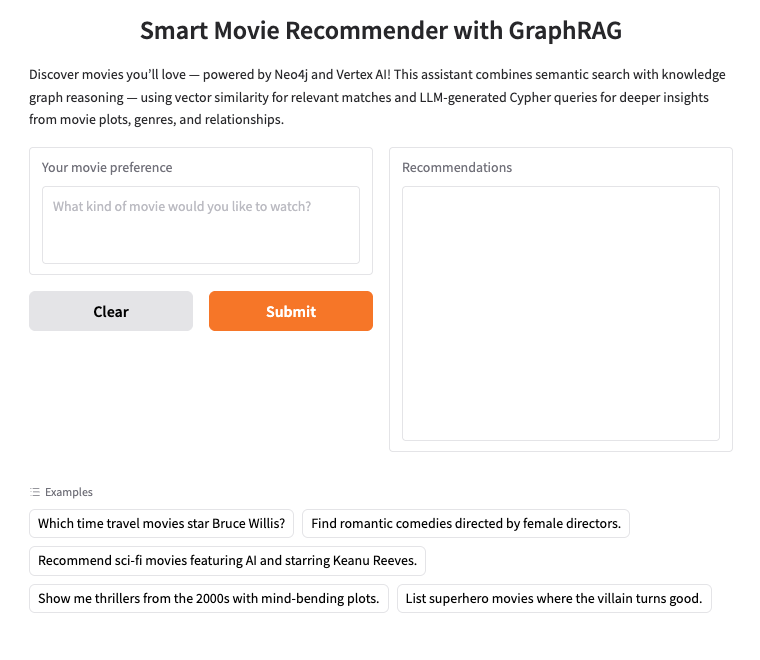
2. Siapkan Neo4j AuraDB
Neo4j adalah database grafik native terkemuka yang menyimpan data sebagai jaringan node (entitas) dan hubungan (koneksi antar-entitas), sehingga ideal untuk kasus penggunaan yang memerlukan pemahaman koneksi — seperti rekomendasi, deteksi penipuan, pustaka pengetahuan, dan lainnya. Tidak seperti database relasional atau berbasis dokumen yang mengandalkan tabel yang kaku atau struktur hierarkis, model grafik fleksibel Neo4j memungkinkan representasi data yang kompleks dan saling terhubung secara intuitif dan efisien.
Daripada mengatur data dalam baris dan tabel seperti database relasional, Neo4j menggunakan model grafik, tempat informasi direpresentasikan sebagai node (entitas) dan hubungan (koneksi antara entitas tersebut). Model ini membuatnya sangat intuitif untuk bekerja dengan data yang secara inheren terkait — seperti orang, tempat, produk, atau, dalam kasus kami, film, aktor, dan genre.
Misalnya, dalam set data film:
- Node dapat merepresentasikan
Movie,Actor, atauDirector - Hubungan dapat berupa
ACTED_INatauDIRECTED
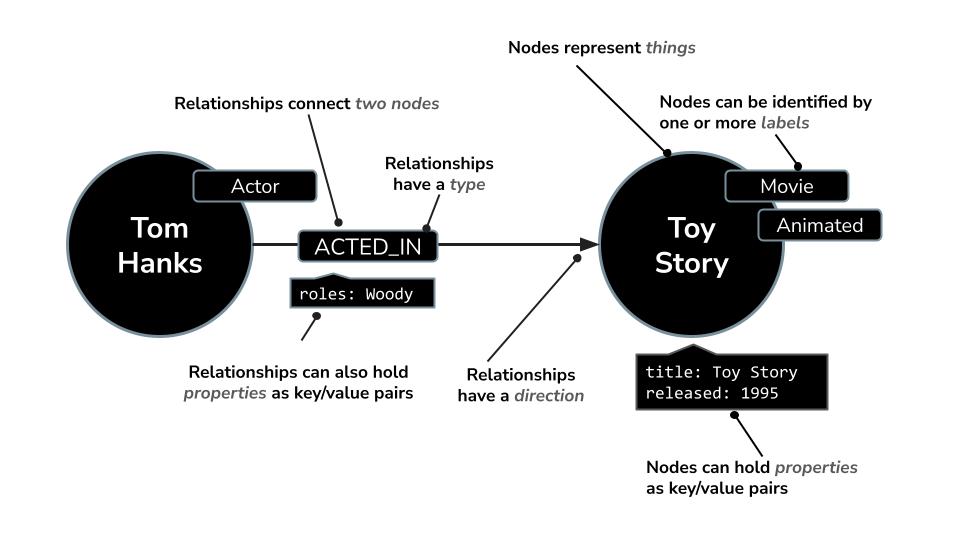
Struktur ini memungkinkan Anda mengajukan pertanyaan dengan mudah seperti:
- Film apa saja yang dibintangi aktor ini?
- Siapa yang pernah bekerja sama dengan Christopher Nolan?
- Apa saja film serupa berdasarkan aktor atau genre yang sama?
Neo4j dilengkapi dengan bahasa kueri canggih yang disebut Cypher, yang dirancang khusus untuk membuat kueri grafik. Cypher memungkinkan Anda mengekspresikan pola dan koneksi yang kompleks dengan cara yang ringkas dan mudah dibaca. Misalnya: kueri Cypher ini menggunakan MERGE untuk memastikan pembuatan aktor, film, dan hubungannya dengan detail peran yang unik, sehingga menghindari duplikat.
MERGE (a:Actor {name: "Tom Hanks"})
MERGE (m:Movie {title: "Toy Story", released: 1995})
MERGE (a)-[:ACTED_IN {roles: ["Woody"]}]->(m);
Neo4j menawarkan beberapa opsi deployment, bergantung pada kebutuhan Anda:
- Dikelola sendiri: Jalankan Neo4j di infrastruktur Anda sendiri menggunakan Neo4j Desktop atau sebagai image Docker (di lokasi atau di cloud Anda sendiri).
- Dikelola cloud: Deploy Neo4j di penyedia cloud populer menggunakan penawaran marketplace.
- Dikelola sepenuhnya: Gunakan Neo4j AuraDB, layanan database-as-a-service berbasis cloud terkelola sepenuhnya dari Neo4j, yang menangani penyediaan, penskalaan, pencadangan, dan keamanan untuk Anda.
Dalam codelab ini, kita akan menggunakan Neo4j AuraDB Free, paket AuraDB tanpa biaya. Layanan ini menyediakan instance database grafik yang terkelola sepenuhnya dengan penyimpanan dan fitur yang cukup untuk pembuatan prototipe, pembelajaran, dan pembuatan aplikasi kecil — sangat cocok untuk tujuan kita dalam membangun chatbot rekomendasi film yang didukung GenAI.
Anda akan membuat instance AuraDB gratis, menghubungkannya ke aplikasi menggunakan kredensial koneksi, dan menggunakannya untuk menyimpan serta mengkueri grafik pengetahuan film Anda di seluruh lab ini.
Mengapa Grafik?
Dalam database relasional tradisional, menjawab pertanyaan seperti "Film mana yang mirip dengan Inception berdasarkan pemeran atau genre yang sama?" akan melibatkan operasi JOIN yang kompleks di beberapa tabel. Seiring bertambahnya kedalaman hubungan, performa dan keterbacaan akan menurun.
Namun, database grafik seperti Neo4j dibuat untuk menelusuri hubungan secara efisien, sehingga sangat cocok untuk sistem rekomendasi, penelusuran semantik, dan asisten cerdas. Grafik ini membantu menangkap konteks dunia nyata — seperti jaringan kolaborasi, alur cerita, atau preferensi penonton — yang sulit direpresentasikan menggunakan model data tradisional.
Dengan menggabungkan data yang terhubung ini dengan LLM seperti Gemini dan embedding vektor dari Vertex AI, kita dapat mengoptimalkan pengalaman chatbot — sehingga chatbot dapat melakukan penalaran, mengambil, dan merespons dengan cara yang lebih dipersonalisasi dan relevan.
Pembuatan Neo4j AuraDB Gratis
- Buka https://console.neo4j.io
- Login dengan email atau Akun Google Anda.
- Klik "Create Free Instance".
- Saat instance sedang disediakan, jendela pop-up akan muncul yang menampilkan kredensial koneksi untuk database Anda.
Pastikan untuk mendownload dan menyimpan detail berikut dari pop-up dengan aman. Detail ini penting untuk menghubungkan aplikasi Anda ke Neo4j:
NEO4J_URI=neo4j+s://<your-instance-id>.databases.neo4j.io
NEO4J_USERNAME=neo4j
NEO4J_PASSWORD=<your-generated-password>
AURA_INSTANCEID=<your-instance-id>
AURA_INSTANCENAME=<your-instance-name>
Anda akan menggunakan nilai ini untuk mengonfigurasi file .env di project Anda untuk melakukan autentikasi dengan Neo4j pada langkah berikutnya.

Neo4j AuraDB Free sangat cocok untuk pengembangan, eksperimen, dan aplikasi skala kecil seperti codelab ini. Layanan ini menawarkan batas penggunaan yang besar, mendukung hingga 200.000 node dan 400.000 hubungan. Meskipun menyediakan semua fitur penting yang diperlukan untuk membuat dan mengkueri grafik pengetahuan, alat ini tidak mendukung konfigurasi lanjutan seperti plugin kustom atau peningkatan penyimpanan. Untuk workload produksi atau set data yang lebih besar, Anda dapat mengupgrade ke paket AuraDB tingkat yang lebih tinggi yang menawarkan kapasitas, performa, dan fitur tingkat perusahaan yang lebih besar.
Tindakan ini akan menyelesaikan bagian untuk menyiapkan backend Neo4j AuraDB Anda. Pada langkah berikutnya, kita akan membuat project Google Cloud, meng-clone repositori, dan mengonfigurasi variabel lingkungan yang diperlukan untuk menyiapkan lingkungan pengembangan Anda sebelum memulai codelab.
3. Sebelum memulai
Membuat project
- Di Konsol Google Cloud, di halaman pemilih project, pilih atau buat project Google Cloud.
- Pastikan penagihan diaktifkan untuk project Cloud Anda. Pelajari cara memeriksa apakah penagihan telah diaktifkan pada suatu project .
- Anda akan menggunakan Cloud Shell, lingkungan command line yang berjalan di Google Cloud yang telah dilengkapi dengan bq. Klik Activate Cloud Shell di bagian atas konsol Google Cloud.

- Setelah terhubung ke Cloud Shell, Anda dapat memeriksa bahwa Anda sudah diautentikasi dan project sudah ditetapkan ke project ID Anda menggunakan perintah berikut:
gcloud auth list
- Jalankan perintah berikut di Cloud Shell untuk mengonfirmasi bahwa perintah gcloud mengetahui project Anda.
gcloud config list project
- Jika project Anda belum ditetapkan, gunakan perintah berikut untuk menetapkannya:
gcloud config set project <YOUR_PROJECT_ID>
- Aktifkan API yang diperlukan melalui perintah yang ditampilkan di bawah. Proses ini mungkin memerlukan waktu beberapa menit, jadi bersabarlah.
gcloud services enable cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
cloudfunctions.googleapis.com \
aiplatform.googleapis.com
Setelah perintah berhasil dieksekusi, Anda akan melihat pesan: "Operation .... finished successfully".
Alternatif untuk perintah gcloud adalah melalui konsol dengan menelusuri setiap produk atau menggunakan link ini.
Jika ada API yang terlewat, Anda dapat mengaktifkannya selama proses penerapan.
Baca dokumentasi untuk mempelajari perintah gcloud dan penggunaannya.
Meng-clone repositori dan menyiapkan setelan lingkungan
Langkah berikutnya adalah meng-clone repositori contoh yang akan kita rujuk di bagian codelab lainnya. Dengan asumsi Anda berada di Cloud Shell, berikan perintah berikut dari direktori utama Anda:
git clone https://github.com/sidagarwal04/neo4j-vertexai-codelab.git
Untuk meluncurkan editor, klik Open Editor di toolbar jendela Cloud Shell. Klik panel menu di pojok kiri atas, lalu pilih File → Open Folder seperti yang ditunjukkan di bawah:

Pilih folder neo4j-vertexai-codelab dan Anda akan melihat folder terbuka dengan struktur yang agak mirip seperti yang ditunjukkan di bawah ini:

Selanjutnya, kita perlu menyiapkan variabel lingkungan yang akan digunakan di seluruh codelab. Klik file example.env dan Anda akan melihat isinya seperti yang ditunjukkan di bawah:
NEO4J_URI=
NEO4J_USER=
NEO4J_PASSWORD=
NEO4J_DATABASE=
PROJECT_ID=
LOCATION=
Sekarang buat file baru bernama .env di folder yang sama dengan file example.env, lalu salin konten file example.env yang ada. Sekarang, perbarui variabel berikut:
NEO4J_URI,NEO4J_USER,NEO4J_PASSWORD, danNEO4J_DATABASE:- Isi nilai ini menggunakan kredensial yang diberikan selama pembuatan instance Neo4j AuraDB Free pada langkah sebelumnya.
NEO4J_DATABASEbiasanya disetel ke neo4j untuk AuraDB Free.PROJECT_IDdanLOCATION:- Jika menjalankan codelab dari Google Cloud Shell, Anda dapat mengosongkan kolom ini karena akan disimpulkan secara otomatis dari konfigurasi project aktif Anda.
- Jika Anda menjalankan secara lokal atau di luar Cloud Shell, perbarui
PROJECT_IDdengan ID project Google Cloud yang Anda buat sebelumnya, dan tetapkanLOCATIONke region yang Anda pilih untuk project tersebut (misalnya, us-central1).
Setelah Anda mengisi nilai ini, simpan file .env. Konfigurasi ini akan memungkinkan aplikasi Anda terhubung ke layanan Neo4j dan Vertex AI.
Langkah terakhir dalam menyiapkan lingkungan pengembangan adalah membuat lingkungan virtual Python dan menginstal semua dependensi yang diperlukan yang tercantum dalam file requirements.txt. Dependensi ini mencakup library yang diperlukan untuk bekerja dengan Neo4j, Vertex AI, Gradio, dan lainnya.
Pertama, buat lingkungan virtual bernama .venv dengan menjalankan perintah berikut:
python -m venv .venv
Setelah lingkungan dibuat, kita perlu mengaktifkan lingkungan yang dibuat dengan perintah berikut
source .venv/bin/activate
Sekarang Anda akan melihat (.venv) di awal prompt terminal, yang menunjukkan bahwa lingkungan sudah aktif. Contoh: (.venv) yourusername@cloudshell:
Sekarang, instal dependensi yang diperlukan dengan menjalankan:
pip install -r requirements.txt
Berikut adalah cuplikan dependensi utama yang tercantum dalam file:
gradio>=4.0.0
neo4j>=5.0.0
numpy>=1.20.0
python-dotenv>=1.0.0
google-cloud-aiplatform>=1.30.0
vertexai>=0.0.1
Setelah semua dependensi berhasil diinstal, lingkungan Python lokal Anda akan sepenuhnya dikonfigurasi untuk menjalankan skrip dan chatbot dalam codelab ini.
Bagus! Sekarang kita siap melanjutkan ke langkah berikutnya — memahami set data dan menyiapkannya untuk pembuatan grafik dan pengayaan semantik.
4. Menyiapkan set data Film
Tugas pertama kita adalah menyiapkan set data Film yang akan kita gunakan untuk membangun grafik pengetahuan dan mendukung chatbot rekomendasi kita. Daripada memulai dari awal, kita akan menggunakan set data terbuka yang sudah ada dan mengembangkannya.
Kita akan menggunakan The Movies Dataset oleh Rounak Banik, sebuah set data publik terkenal yang tersedia di Kaggle. Set data ini mencakup metadata untuk lebih dari 45.000 film dari TMDB, termasuk pemeran, kru, kata kunci, rating, dan lainnya.

Untuk membuat Chatbot Rekomendasi Film yang andal dan efektif, Anda harus memulai dengan data yang bersih, konsisten, dan terstruktur. Meskipun The Movies Dataset dari Kaggle adalah sumber daya yang kaya dengan lebih dari 45.000 data film dan metadata mendetail—termasuk genre, pemeran, kru, dan lainnya—dataset ini juga berisi derau, inkonsistensi, dan struktur data bertingkat yang tidak ideal untuk pemodelan grafik atau penyematan semantik.
Untuk mengatasi hal ini, kami telah memproses dan menormalisasi set data untuk memastikan set data tersebut cocok untuk membangun grafik pengetahuan Neo4j dan menghasilkan sematan berkualitas tinggi. Proses ini melibatkan:
- Menghapus duplikat dan data yang tidak lengkap
- Menstandardisasi kolom utama (misalnya, nama genre, nama orang)
- Meratakan struktur bertingkat yang kompleks (misalnya, pemeran dan kru) ke dalam CSV terstruktur
- Memilih subset representatif dari ~12.000 film agar tetap berada dalam batas Neo4j AuraDB Free
Data yang dinormalisasi dan berkualitas tinggi membantu memastikan:
- Kualitas data: Meminimalkan error dan inkonsistensi untuk rekomendasi yang lebih akurat
- Performa kueri: Struktur yang disederhanakan meningkatkan kecepatan pengambilan dan mengurangi redundansi
- Akurasi embedding: Input yang bersih menghasilkan embedding vektor yang lebih bermakna dan kontekstual
Anda dapat mengakses set data yang telah dibersihkan dan dinormalisasi di folder normalized_data/ dari repositori GitHub ini. Set data ini juga dicerminkan di bucket Google Cloud Storage untuk memudahkan akses dalam skrip Python mendatang.
Setelah data dibersihkan dan siap, kita sekarang siap memuatnya ke Neo4j dan mulai membuat grafik pengetahuan film.
5. Membangun Pustaka Pengetahuan Film
Untuk mendukung chatbot rekomendasi film yang didukung GenAI, kita perlu menyusun set data film dengan cara yang mencakup jaringan koneksi yang kaya antara film, aktor, sutradara, genre, dan metadata lainnya. Di bagian ini, kita akan membangun Grafik Pengetahuan Film di Neo4j menggunakan set data yang telah dibersihkan dan dinormalisasi yang Anda siapkan sebelumnya.
Kita akan menggunakan kemampuan LOAD CSV Neo4j untuk memproses file CSV yang dihosting di bucket Google Cloud Storage (GCS) publik. File ini mewakili berbagai komponen set data film, seperti film, genre, pemeran, kru, perusahaan produksi, dan rating pengguna.
Langkah 1: Buat Batasan dan Indeks
Sebelum mengimpor data, sebaiknya buat batasan dan indeks untuk menerapkan integritas data dan mengoptimalkan performa kueri.
CREATE CONSTRAINT unique_tmdb_id IF NOT EXISTS FOR (m:Movie) REQUIRE m.tmdbId IS UNIQUE;
CREATE CONSTRAINT unique_movie_id IF NOT EXISTS FOR (m:Movie) REQUIRE m.movieId IS UNIQUE;
CREATE CONSTRAINT unique_prod_id IF NOT EXISTS FOR (p:ProductionCompany) REQUIRE p.company_id IS UNIQUE;
CREATE CONSTRAINT unique_genre_id IF NOT EXISTS FOR (g:Genre) REQUIRE g.genre_id IS UNIQUE;
CREATE CONSTRAINT unique_lang_id IF NOT EXISTS FOR (l:SpokenLanguage) REQUIRE l.language_code IS UNIQUE;
CREATE CONSTRAINT unique_country_id IF NOT EXISTS FOR (c:Country) REQUIRE c.country_code IS UNIQUE;
CREATE INDEX actor_id IF NOT EXISTS FOR (p:Person) ON (p.actor_id);
CREATE INDEX crew_id IF NOT EXISTS FOR (p:Person) ON (p.crew_id);
CREATE INDEX movieId IF NOT EXISTS FOR (m:Movie) ON (m.movieId);
CREATE INDEX user_id IF NOT EXISTS FOR (p:Person) ON (p.user_id);
Langkah 2: Impor Metadata dan Hubungan Film
Mari kita lihat cara mengimpor metadata film menggunakan perintah LOAD CSV. Contoh ini membuat node Film dengan atribut utama seperti judul, ringkasan, bahasa, dan durasi:
LOAD CSV WITH HEADERS FROM "https://storage.googleapis.com/neo4j-vertexai-codelab/normalized_data/normalized_movies.csv" AS row
WITH row, toInteger(row.tmdbId) AS tmdbId
WHERE tmdbId IS NOT NULL
WITH row, tmdbId
LIMIT 12000
MERGE (m:Movie {tmdbId: tmdbId})
ON CREATE SET m.title = coalesce(row.title, "None"),
m.original_title = coalesce(row.original_title, "None"),
m.adult = CASE
WHEN toInteger(row.adult) = 1 THEN 'Yes'
ELSE 'No'
END,
m.budget = toInteger(coalesce(row.budget, 0)),
m.original_language = coalesce(row.original_language, "None"),
m.revenue = toInteger(coalesce(row.revenue, 0)),
m.tagline = coalesce(row.tagline, "None"),
m.overview = coalesce(row.overview, "None"),
m.release_date = coalesce(row.release_date, "None"),
m.runtime = toFloat(coalesce(row.runtime, 0)),
m.belongs_to_collection = coalesce(row.belongs_to_collection, "None");
Demikian pula, Anda dapat mengimpor dan menautkan entity lain seperti Genre, Perusahaan Produksi, Bahasa Lisan, Negara, Pemeran, Kru, dan Rating Pengguna menggunakan CSV dan kueri Cypher masing-masing.
Memuat Grafik Lengkap melalui Python
Daripada menjalankan beberapa kueri Cypher secara manual, sebaiknya gunakan skrip Python otomatis yang disediakan dalam codelab ini.
Skrip graph_build.py memuat seluruh set data dari GCS ke instance Neo4j AuraDB Anda menggunakan kredensial dalam file .env Anda.
python graph_build.py
Skrip akan memuat semua CSV yang diperlukan secara berurutan, membuat node dan hubungan, serta menyusun grafik pengetahuan film lengkap Anda.
|
|

.png")
Memvalidasi Grafik Anda
Setelah memuat, Anda dapat memvalidasi grafik dengan menjalankan skrip berikut:
python validate_graph.py
Hal ini akan memberi Anda ringkasan cepat tentang isi grafik Anda: berapa banyak film, aktor, genre, dan hubungan seperti ACTED_IN, DIRECTED, dll., yang ada—untuk memastikan impor Anda berhasil.
📦 Node Counts:
Movie: 11997 nodes
ProductionCompany: 7961 nodes
Genre: 20 nodes
SpokenLanguage: 100 nodes
Country: 113 nodes
Person: 92663 nodes
Actor: 81165 nodes
Director: 4846 nodes
Producer: 5981 nodes
User: 671 nodes
🔗 Relationship Counts:
HAS_GENRE: 28479 relationships
PRODUCED_BY: 22758 relationships
PRODUCED_IN: 14702 relationships
HAS_LANGUAGE: 16184 relationships
ACTED_IN: 191307 relationships
DIRECTED: 5047 relationships
PRODUCED: 6939 relationships
RATED: 90344 relationships
Sekarang Anda akan melihat grafik yang diisi dengan film, orang, genre, dan lainnya — siap untuk diperkaya secara semantik pada langkah berikutnya.
6. Membuat dan Memuat Embedding untuk melakukan Penelusuran Kemiripan Vektor
Untuk mengaktifkan penelusuran semantik di chatbot, kita perlu membuat embedding vektor untuk ringkasan film. Embedding ini mengubah data tekstual menjadi vektor numerik yang dapat dibandingkan kesamaannya — sehingga chatbot dapat mengambil film yang relevan meskipun kueri tidak sama persis dengan judul atau deskripsi.

Opsi 1: Memuat Sematan yang Sudah Dihitung Sebelumnya melalui Cypher
Untuk melampirkan sematan dengan cepat ke node Movie yang sesuai di Neo4j, jalankan perintah Cypher berikut di Neo4j Browser:
LOAD CSV WITH HEADERS FROM 'https://storage.googleapis.com/neo4j-vertexai-codelab/movie_embeddings.csv' AS row
WITH row
MATCH (m:Movie {tmdbId: toInteger(row.tmdbId)})
SET m.embedding = apoc.convert.fromJsonList(row.embedding)
Perintah ini membaca vektor sematan dari CSV dan melampirkannya sebagai properti (m.embedding) di setiap node Movie.
Opsi 2: Memuat Sematan Menggunakan Python
Anda juga dapat memuat embedding secara terprogram menggunakan skrip Python yang disediakan. Pendekatan ini berguna jika Anda bekerja di lingkungan Anda sendiri atau ingin mengotomatiskan proses:
python load_embeddings.py
Skrip ini membaca CSV yang sama dari GCS dan menuliskan penyematan ke Neo4j menggunakan driver Neo4j Python.
[Opsional] Membuat Embedding Sendiri (untuk Eksplorasi)
Jika Anda ingin memahami cara pembuatan embedding, Anda dapat mempelajari logika dalam skrip generate_embeddings.py itu sendiri. Model ini menggunakan Vertex AI untuk menyematkan setiap teks ringkasan film menggunakan model text-embedding-004.
Untuk mencobanya sendiri, buka dan jalankan bagian pembuatan sematan kode. Jika Anda menjalankan di Cloud Shell, Anda dapat mengomentari baris berikut, karena Cloud Shell sudah diautentikasi melalui akun aktif Anda:
# os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = "./service-account.json"
Setelah embedding dimuat ke Neo4j, grafik pengetahuan film Anda menjadi sadar semantik — siap mendukung penelusuran bahasa alami yang efektif menggunakan kemiripan vektor.
7. Chatbot Rekomendasi Film
Setelah pustaka pengetahuan dan penyematan vektor Anda siap, sekarang saatnya menggabungkan semuanya ke dalam antarmuka percakapan yang berfungsi penuh — Chatbot Rekomendasi Film yang Didukung GenAI.
Chatbot ini diimplementasikan di Python menggunakan Gradio, framework web ringan untuk membangun antarmuka pengguna yang intuitif. Logika inti berada di app.py, yang terhubung ke instance Neo4j AuraDB Anda dan menggunakan Google Vertex AI dan Gemini untuk memproses dan merespons kueri bahasa alami.
Cara Kerjanya
- Pengguna mengetik kueri bahasa alamimisalnya, "Recommend me sci-fi thrillers like Interstellar" (Rekomendasikan film thriller fiksi ilmiah seperti Interstellar)
- Buat embedding vektor untuk kueri menggunakan model
text-embedding-004Vertex AI - Lakukan penelusuran vektor di Neo4j untuk mengambil film yang secara semantik serupa
- Gunakan Gemini untuk:
- Menafsirkan kueri dalam konteks
- Membuat kueri Cypher kustom berdasarkan hasil penelusuran vektor dan skema Neo4j
- Jalankan kueri untuk mengekstrak data grafik terkait (misalnya, aktor, sutradara, genre)
- Meringkas hasil secara percakapan untuk pengguna
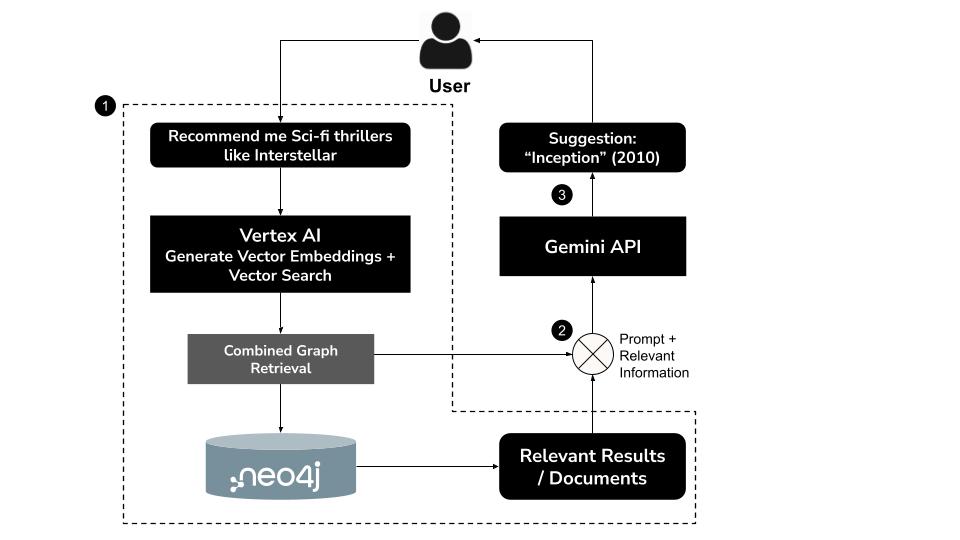
Pendekatan hybrid ini, yang dikenal sebagai GraphRAG (Graph Retrieval-Augmented Generation), menggabungkan pengambilan semantik dan penalaran terstruktur untuk menghasilkan rekomendasi yang lebih akurat, kontekstual, dan dapat dijelaskan.
Menjalankan Chatbot secara lokal
Aktifkan lingkungan virtual Anda (jika belum aktif), lalu luncurkan chatbot dengan:
python app.py
Anda akan melihat output yang mirip dengan berikut ini:
Vector index 'overview_embeddings' already exists. No need to create a new one.
* Running on local URL: http://0.0.0.0:8080
To create a public link, set `share=True` in `launch()`.
💡 Untuk membagikan chatbot secara eksternal, tetapkan share=True dalam fungsi launch() di app.py.
Berinteraksi dengan Chatbot
Buka URL lokal yang ditampilkan di terminal Anda (biasanya 👉 http://0.0.0.0:8080) untuk mengakses antarmuka chatbot.
Coba ajukan pertanyaan seperti:
- "Apa yang harus saya tonton jika saya menyukai Interstellar?"
- "Sarankan film romantis yang disutradarai oleh Nora Ephron"
- "Saya ingin menonton film keluarga bersama Tom Hanks"
- "Find thriller movies involving artificial intelligence" (Cari film thriller yang melibatkan kecerdasan buatan)
Chatbot akan:
✅ Memahami kueri
✅ Menemukan plot film yang serupa secara semantik menggunakan embedding
✅ Buat dan jalankan kueri Cypher untuk mengambil konteks grafik terkait
✅ Memberikan rekomendasi yang ramah dan dipersonalisasi — semuanya dalam hitungan detik
Yang Anda Miliki Sekarang
Anda baru saja membuat chatbot film yang didukung GraphRAG yang menggabungkan:
- Penelusuran vektor untuk relevansi semantik
- Penalaran grafik pengetahuan dengan Neo4j
- Kemampuan LLM melalui Gemini
- Antarmuka chat yang lancar dengan Gradio
Arsitektur ini membentuk fondasi yang dapat Anda perluas ke sistem penelusuran, rekomendasi, atau penalaran yang lebih canggih yang didukung oleh AI generatif.
8. (Opsional) Men-deploy ke Google Cloud Run
Jika ingin membuat Chatbot Rekomendasi Film Anda dapat diakses secara publik, Anda dapat men-deploy-nya ke Google Cloud Run — platform serverless terkelola sepenuhnya yang menskalakan aplikasi Anda secara otomatis dan menyederhanakan semua masalah infrastruktur.
Deployment ini menggunakan:
requirements.txt— untuk menentukan dependensi Python (Neo4j, Vertex AI, Gradio, dll.)Dockerfile— untuk memaketkan aplikasi.env.yaml— untuk meneruskan variabel lingkungan secara aman saat runtime
Langkah 1: Siapkan .env.yaml
Buat file bernama .env.yaml di direktori root Anda dengan konten seperti:
NEO4J_URI: "neo4j+s://<your-aura-db-uri>"
NEO4J_USER: "neo4j"
NEO4J_PASSWORD: "<your-password>"
PROJECT_ID: "<your-gcp-project-id>"
LOCATION: "<your-gcp-region>" # e.g. us-central1
💡 Format ini lebih disukai daripada --set-env-vars karena lebih skalabel, dapat dikontrol versinya, dan mudah dibaca.
Langkah 2: Siapkan Variabel Lingkungan
Di terminal, tetapkan variabel lingkungan berikut (ganti nilai placeholder dengan setelan project Anda yang sebenarnya):
# Set your Google Cloud project ID
export GCP_PROJECT='your-project-id' # Change this
# Set your preferred deployment region
export GCP_REGION='us-central1'
Langkah 2: Buat Artifact Registry dan Bangun Container
# Artifact Registry repo and service name
export AR_REPO='your-repo-name' # Change this
export SERVICE_NAME='movies-chatbot' # Or any name you prefer
# Create the Artifact Registry repository
gcloud artifacts repositories create "$AR_REPO" \
--location="$GCP_REGION" \
--repository-format=Docker
# Authenticate Docker with Artifact Registry
gcloud auth configure-docker "$GCP_REGION-docker.pkg.dev"
# Build and submit the container image
gcloud builds submit \
--tag "$GCP_REGION-docker.pkg.dev/$GCP_PROJECT/$AR_REPO/$SERVICE_NAME"
Perintah ini memaketkan aplikasi Anda menggunakan Dockerfile dan mengupload image container ke Google Cloud Artifact Registry.
Langkah 3: Deploy ke Cloud Run
Sekarang deploy aplikasi Anda menggunakan file .env.yaml untuk konfigurasi runtime:
gcloud run deploy "$SERVICE_NAME" \
--port=8080 \
--image="$GCP_REGION-docker.pkg.dev/$GCP_PROJECT/$AR_REPO/$SERVICE_NAME" \
--allow-unauthenticated \
--region=$GCP_REGION \
--platform=managed \
--project=$GCP_PROJECT \
--env-vars-file=.env.yaml
Mengakses Chatbot
Setelah di-deploy, Cloud Run akan memberikan URL publik seperti:
https://movies-reco-[UNIQUE_ID].${GCP_REGION}.run.app
Buka URL ini di browser Anda untuk mengakses antarmuka chatbot Gradio yang di-deploy — siap menangani rekomendasi film menggunakan GraphRAG, Gemini, dan Neo4j.
Catatan & Tips
- Pastikan
DockerfileAnda menjalankanpip install -r requirements.txtselama build. - Jika tidak menggunakan Cloud Shell, Anda harus melakukan autentikasi lingkungan menggunakan Akun Layanan dengan izin Vertex AI dan Artifact Registry.
- Anda dapat memantau log dan metrik deployment dari Google Cloud Console > Cloud Run.
Anda juga dapat membuka Cloud Run dari konsol Google Cloud dan Anda akan melihat daftar layanan di Cloud Run. Layanan movies-chatbot harus menjadi salah satu layanan (jika bukan satu-satunya) yang tercantum di sana.

Anda dapat melihat detail layanan seperti URL, konfigurasi, log, dan lainnya dengan mengklik nama layanan tertentu (movies-chatbot dalam kasus ini).

Dengan demikian, Chatbot Rekomendasi Film Anda kini di-deploy, dapat diskalakan, dan dapat dibagikan. 🎉
9. Pembersihan
Agar tidak menimbulkan biaya pada akun Google Cloud Anda untuk resource yang digunakan dalam posting ini, ikuti langkah-langkah berikut:
- Di konsol Google Cloud, buka halaman Manage resources.
- Dalam daftar project, pilih project yang ingin Anda hapus, lalu klik Delete.
- Pada dialog, ketik project ID, lalu klik Shut down untuk menghapus project.
10. Selamat
Anda telah berhasil membangun dan men-deploy chatbot rekomendasi film yang ditingkatkan dengan GenAI dan didukung GraphRAG menggunakan Neo4j, Vertex AI, dan Gemini. Dengan menggabungkan kemampuan pemodelan native grafik Neo4j dengan penelusuran semantik melalui Vertex AI dan penalaran bahasa alami melalui Gemini, Anda telah membuat sistem cerdas yang melampaui penelusuran dasar — sistem ini memahami maksud pengguna, melakukan penalaran atas data yang terhubung, dan merespons secara percakapan.
Dalam codelab ini, Anda telah menyelesaikan hal berikut:
✅ Membangun Grafik Pengetahuan film dunia nyata di Neo4j untuk memodelkan film, aktor, genre, dan hubungan
✅ Embedding vektor yang dihasilkan untuk ringkasan plot film menggunakan model penyematan teks Vertex AI
✅ Menerapkan GraphRAG, yang menggabungkan penelusuran vektor dan kueri Cypher yang dihasilkan LLM untuk penalaran multi-hop yang lebih mendalam
✅ Mengintegrasikan Gemini untuk menginterpretasikan pertanyaan pengguna, membuat kueri Cypher, dan meringkas hasil grafik dalam bahasa alami
✅ Membuat antarmuka chat yang intuitif menggunakan Gradio
✅ Secara opsional men-deploy chatbot Anda ke Google Cloud Run untuk hosting serverless yang skalabel
Apa Langkah Selanjutnya?
Arsitektur ini tidak terbatas pada rekomendasi film — arsitektur ini dapat diperluas ke:
- Platform penemuan buku dan musik
- Asisten penelitian akademis
- Mesin pemberi rekomendasi produk
- Asisten pengetahuan hukum, keuangan, dan kesehatan
Di mana pun Anda memiliki hubungan yang kompleks + data tekstual yang kaya, kombinasi Grafik Pengetahuan + LLM + sematan semantik ini dapat mendukung aplikasi cerdas generasi berikutnya.
Seiring berkembangnya model GenAI multimodal seperti Gemini, Anda akan dapat menyertakan konteks, gambar, ucapan, dan personalisasi yang lebih kaya untuk membangun sistem yang benar-benar berfokus pada manusia.
Teruslah menjelajahi, teruslah membangun — dan jangan lupa untuk terus mendapatkan info terbaru dari Neo4j, Vertex AI, dan Google Cloud untuk meningkatkan kualitas aplikasi cerdas Anda. Jelajahi tutorial grafik pengetahuan yang lebih praktis di Neo4j GraphAcademy.