
1. Przegląd
W tym ćwiczeniu utworzysz inteligentnego czatbota do rekomendacji filmów, łącząc możliwości Neo4j, Google Vertex AI i Gemini. Podstawą tego systemu jest graf wiedzy Neo4j, który modeluje filmy, aktorów, reżyserów, gatunki i inne elementy za pomocą rozbudowanej sieci połączonych węzłów i relacji.
Aby poprawić komfort użytkowników dzięki zrozumieniu semantycznemu, wygenerujesz wektory dystrybucyjne z opisów fabuły filmów za pomocą modelu text-embedding-004 Vertex AI (lub nowszego). Te wektory są indeksowane w Neo4j, co umożliwia szybkie wyszukiwanie na podstawie podobieństwa.
Na koniec zintegrujesz Gemini, aby stworzyć interfejs konwersacyjny, w którym użytkownicy będą mogli zadawać pytania w języku naturalnym, np. „Co obejrzeć, jeśli podobał mi się film Interstellar?”, i otrzymywać spersonalizowane sugestie filmów na podstawie podobieństwa semantycznego i kontekstu opartego na grafach.
W ramach ćwiczeń z programowania będziesz wykonywać kolejne czynności:
- Tworzenie grafu wiedzy Neo4j z encjami i relacjami związanymi z filmami
- Generowanie i wczytywanie wektorów dystrybucyjnych tekstu dla opisów filmów za pomocą Vertex AI
- Wdrożenie interfejsu czatbota Gradio opartego na Gemini, który łączy wyszukiwanie wektorowe z wykonywaniem zapytań w języku Cypher na podstawie grafu
- (Opcjonalnie) Wdrażanie aplikacji w Cloud Run jako samodzielnej aplikacji internetowej
Czego się nauczysz
- Jak utworzyć i wypełnić graf wiedzy o filmach za pomocą Cypher i Neo4j
- Jak używać Vertex AI do generowania i pracy z semantycznymi wektorami dystrybucyjnymi tekstu
- Jak łączyć LLM-y i grafy wiedzy w celu inteligentnego wyszukiwania za pomocą GraphRAG
- Jak utworzyć przyjazny dla użytkownika interfejs czatu za pomocą Gradio
- Jak opcjonalnie wdrożyć w Google Cloud Run
Czego potrzebujesz
- przeglądarki Chrome,
- konto Gmail,
- Projekt Google Cloud z włączonymi płatnościami
- bezpłatne konto bazy danych Neo4j Aura,
- Podstawowa znajomość poleceń terminala i języka Python (pomocna, ale nie wymagana)
To ćwiczenie, przeznaczone dla deweloperów na wszystkich poziomach zaawansowania (w tym dla początkujących), wykorzystuje w przykładowej aplikacji język Python i bazę danych Neo4j. Podstawowa znajomość języka Python i baz danych grafów może być przydatna, ale nie jest wymagana do zrozumienia koncepcji ani do śledzenia treści.
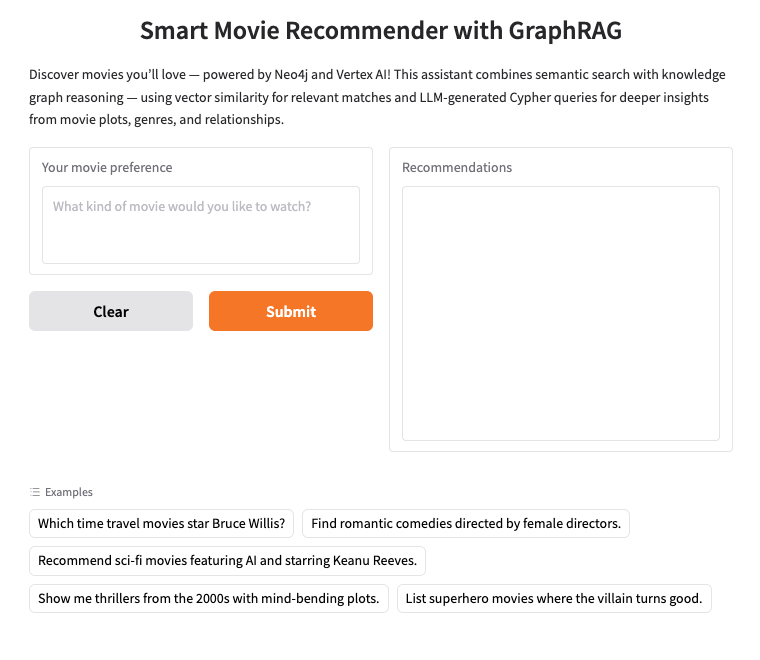
2. Konfigurowanie Neo4j AuraDB
Neo4j to wiodąca natywna grafowa baza danych, która przechowuje dane jako sieć węzłów (encji) i relacji (połączeń między encjami). Dzięki temu idealnie nadaje się do zastosowań, w których kluczowe jest zrozumienie połączeń, takich jak rekomendacje, wykrywanie oszustw, grafy wiedzy i inne. W przeciwieństwie do relacyjnych baz danych lub baz danych opartych na dokumentach, które opierają się na sztywnych tabelach lub strukturach hierarchicznych, elastyczny model grafu Neo4j umożliwia intuicyjne i wydajne przedstawianie złożonych, połączonych danych.
Zamiast porządkować dane w wierszach i tabelach, jak w relacyjnych bazach danych, Neo4j używa modelu grafu, w którym informacje są reprezentowane jako węzły (obiekty) i relacje (połączenia między tymi obiektami). Dzięki temu modelowi praca z danymi, które są ze sobą powiązane, jest wyjątkowo intuicyjna. Dotyczy to np. osób, miejsc, produktów czy, w naszym przypadku, filmów, aktorów i gatunków.
Na przykład w zbiorze danych o filmach:
- Węzeł może reprezentować
Movie,ActorlubDirector. - Relacja może być
ACTED_INlubDIRECTED
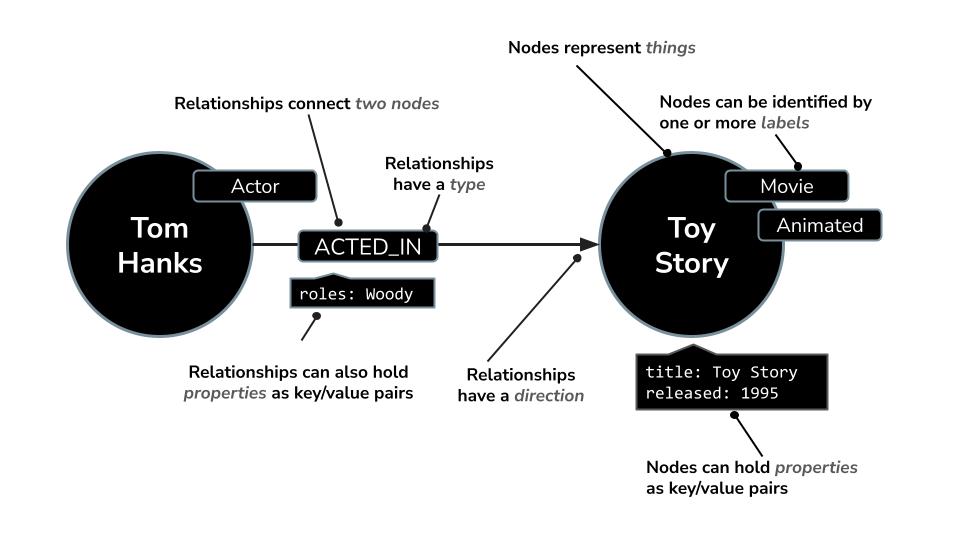
Ta struktura umożliwia łatwe zadawanie pytań takich jak:
- W jakich filmach wystąpił ten aktor?
- Z kim współpracował Christopher Nolan?
- Jakie są podobne filmy na podstawie wspólnych aktorów lub gatunków?
Neo4j ma zaawansowany język zapytań o nazwie Cypher, który został zaprojektowany specjalnie do wykonywania zapytań dotyczących grafów. Cypher umożliwia wyrażanie złożonych wzorców i połączeń w zwięzły i czytelny sposób. Na przykład to zapytanie w języku Cypher używa MERGE, aby zapewnić unikalne utworzenie aktora, filmu i ich relacji ze szczegółami roli, unikając duplikatów.
MERGE (a:Actor {name: "Tom Hanks"})
MERGE (m:Movie {title: "Toy Story", released: 1995})
MERGE (a)-[:ACTED_IN {roles: ["Woody"]}]->(m);
Neo4j oferuje wiele opcji wdrożenia w zależności od potrzeb:
- Zarządzanie samodzielne: uruchom Neo4j we własnej infrastrukturze za pomocą Neo4j Desktop lub jako obraz Dockera (lokalnie lub we własnej chmurze).
- Zarządzanie w chmurze: wdróż Neo4j u popularnych dostawców usług w chmurze, korzystając z ofert na platformach handlowych.
- W pełni zarządzana: używaj Neo4j AuraDB, w pełni zarządzanej usługi bazy danych w chmurze Neo4j, która zajmuje się aprowizacją, skalowaniem, tworzeniem kopii zapasowych i bezpieczeństwem.
W tym ćwiczeniu w Codelabs będziemy korzystać z Neo4j AuraDB Free, czyli bezpłatnej wersji AuraDB. Zapewnia usługę w pełni zarządzanej instancji bazy danych grafów z wystarczającą ilością miejsca na dane i funkcjami do prototypowania, uczenia się i tworzenia małych aplikacji – idealną do naszego celu, jakim jest stworzenie czatbota do rekomendowania filmów opartego na generatywnej AI.
Utworzysz bezpłatną instancję AuraDB, połączysz ją z aplikacją za pomocą danych logowania i będziesz jej używać do przechowywania grafu wiedzy o filmach i wysyłania do niego zapytań w tym laboratorium.
Dlaczego wykresy?
W tradycyjnych relacyjnych bazach danych odpowiedź na pytania takie jak „Które filmy są podobne do Incepcji ze względu na wspólną obsadę lub gatunek?” wymagałaby złożonych operacji JOIN w wielu tabelach. Wraz ze wzrostem głębokości relacji wydajność i czytelność maleją.
Grafowe bazy danych, takie jak Neo4j, są jednak stworzone do wydajnego przemierzania relacji, co sprawia, że idealnie nadają się do systemów rekomendacji, wyszukiwania semantycznego i inteligentnych asystentów. Pomagają one uchwycić kontekst świata rzeczywistego, taki jak sieci współpracy, fabuły czy preferencje widzów, który może być trudny do przedstawienia za pomocą tradycyjnych modeli danych.
Łącząc te dane z modelami LLM, takimi jak Gemini, i wektorami dystrybucyjnymi z Vertex AI, możemy znacznie ulepszyć działanie chatbota, umożliwiając mu rozumowanie, wyszukiwanie i odpowiadanie w bardziej spersonalizowany i trafny sposób.
Tworzenie bezpłatnej bazy danych Neo4j AuraDB
- Otwórz stronę https://console.neo4j.io.
- Zaloguj się za pomocą konta Google lub adresu e-mail.
- Kliknij „Utwórz bezpłatną instancję”.
- Podczas udostępniania instancji pojawi się wyskakujące okienko z danymi logowania do bazy danych.
Pamiętaj, aby pobrać i bezpiecznie zapisać te informacje z wyskakującego okienka – są one niezbędne do połączenia aplikacji z Neo4j:
NEO4J_URI=neo4j+s://<your-instance-id>.databases.neo4j.io
NEO4J_USERNAME=neo4j
NEO4J_PASSWORD=<your-generated-password>
AURA_INSTANCEID=<your-instance-id>
AURA_INSTANCENAME=<your-instance-name>
Tych wartości użyjesz w następnym kroku do skonfigurowania pliku .env w projekcie na potrzeby uwierzytelniania w Neo4j.

Neo4j AuraDB Free doskonale nadaje się do tworzenia, eksperymentowania i aplikacji na małą skalę, takich jak to ćwiczenie. Oferuje ona wysokie limity wykorzystania, obsługując do 200 tys. węzłów i 400 tys. relacji. Zapewnia wszystkie podstawowe funkcje potrzebne do tworzenia grafu wiedzy i wysyłania do niego zapytań, ale nie obsługuje zaawansowanych konfiguracji, takich jak niestandardowe wtyczki czy zwiększona ilość miejsca na dane. W przypadku zadań produkcyjnych lub większych zbiorów danych możesz przejść na wyższy poziom subskrypcji AuraDB, który oferuje większą pojemność, wydajność i funkcje klasy korporacyjnej.
W tym momencie kończy się sekcja dotycząca konfigurowania backendu Neo4j AuraDB. W następnym kroku utworzymy projekt Google Cloud, sklonujemy repozytorium i skonfigurujemy niezbędne zmienne środowiskowe, aby przygotować środowisko programistyczne przed rozpoczęciem ćwiczeń w Codelabs.
3. Zanim zaczniesz
Utwórz projekt
- W konsoli Google Cloud na stronie selektora projektów wybierz lub utwórz projekt Google Cloud.
- Sprawdź, czy w projekcie Cloud włączone są płatności. Dowiedz się, jak sprawdzić, czy w projekcie są włączone płatności .
- Będziesz używać Cloud Shell, czyli środowiska wiersza poleceń działającego w Google Cloud, które jest wstępnie załadowane narzędziem bq. U góry konsoli Google Cloud kliknij Aktywuj Cloud Shell.

- Po połączeniu z Cloud Shell sprawdź, czy uwierzytelnianie zostało już przeprowadzone, a projekt jest już ustawiony na Twój identyfikator projektu, używając tego polecenia:
gcloud auth list
- Aby potwierdzić, że polecenie gcloud zna Twój projekt, uruchom w Cloud Shell to polecenie:
gcloud config list project
- Jeśli projekt nie jest ustawiony, użyj tego polecenia, aby go ustawić:
gcloud config set project <YOUR_PROJECT_ID>
- Włącz wymagane interfejsy API za pomocą polecenia pokazanego poniżej. Może to potrwać kilka minut, więc zachowaj cierpliwość.
gcloud services enable cloudresourcemanager.googleapis.com \
servicenetworking.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
cloudfunctions.googleapis.com \
aiplatform.googleapis.com
Po pomyślnym wykonaniu polecenia powinien wyświetlić się komunikat: „Operation .... finished successfully” (Operacja ... została zakończona).
Alternatywą dla polecenia gcloud jest wyszukanie poszczególnych usług w konsoli lub skorzystanie z tego linku.
Jeśli pominiesz jakiś interfejs API, możesz go włączyć w trakcie wdrażania.
Informacje o poleceniach gcloud i ich użyciu znajdziesz w dokumentacji.
Klonowanie repozytorium i konfigurowanie ustawień środowiska
Następnym krokiem jest sklonowanie przykładowego repozytorium, do którego będziemy się odwoływać w dalszej części tego ćwiczenia. Zakładając, że jesteś w Cloud Shell, wpisz to polecenie w katalogu głównym:
git clone https://github.com/sidagarwal04/neo4j-vertexai-codelab.git
Aby uruchomić edytor, na pasku narzędzi w oknie Cloud Shell kliknij Otwórz edytor. Kliknij pasek menu w lewym górnym rogu i wybierz Plik → Otwórz folder, jak pokazano poniżej:

Wybierz folder neo4j-vertexai-codelab. Powinien się otworzyć z podobną strukturą jak poniżej:

Następnie musimy skonfigurować zmienne środowiskowe, których będziemy używać podczas naszych ćwiczeń z programowania. Kliknij plik example.env. Powinna wyświetlić się jego zawartość, jak pokazano poniżej:
NEO4J_URI=
NEO4J_USER=
NEO4J_PASSWORD=
NEO4J_DATABASE=
PROJECT_ID=
LOCATION=
Teraz utwórz nowy plik o nazwie .env w tym samym folderze co plik example.env i skopiuj zawartość istniejącego pliku example.env. Teraz zaktualizuj te zmienne:
NEO4J_URI,NEO4J_USER,NEO4J_PASSWORDiNEO4J_DATABASE- Wpisz te wartości, używając danych logowania podanych podczas tworzenia instancji Neo4j AuraDB Free w poprzednim kroku.
NEO4J_DATABASEjest zwykle ustawiona na neo4j w przypadku AuraDB Free.PROJECT_IDiLOCATION:- Jeśli korzystasz z codelabu w Google Cloud Shell, możesz pozostawić te pola puste, ponieważ zostaną one automatycznie wywnioskowane z aktywnej konfiguracji projektu.
- Jeśli uruchamiasz skrypt lokalnie lub poza Cloud Shell, zastąp
PROJECT_IDidentyfikatorem utworzonego wcześniej projektu w chmurze Google, aLOCATION– wybranym regionem tego projektu (np. us-central1).
Po wypełnieniu tych wartości zapisz plik .env. Ta konfiguracja umożliwi aplikacji łączenie się zarówno z usługami Neo4j, jak i Vertex AI.
Ostatnim krokiem w konfigurowaniu środowiska programistycznego jest utworzenie środowiska wirtualnego Pythona i zainstalowanie wszystkich wymaganych zależności wymienionych w pliku requirements.txt. Te zależności obejmują biblioteki potrzebne do pracy z Neo4j, Vertex AI, Gradio i innymi usługami.
Najpierw utwórz środowisko wirtualne o nazwie .venv, uruchamiając to polecenie:
python -m venv .venv
Po utworzeniu środowiska musimy je aktywować za pomocą tego polecenia:
source .venv/bin/activate
Na początku wiersza poleceń terminala powinien pojawić się tekst (.venv), co oznacza, że środowisko jest aktywne. Na przykład: (.venv) yourusername@cloudshell:
Teraz zainstaluj wymagane zależności, uruchamiając to polecenie:
pip install -r requirements.txt
Oto zrzut ekranu z najważniejszymi zależnościami wymienionymi w pliku:
gradio>=4.0.0
neo4j>=5.0.0
numpy>=1.20.0
python-dotenv>=1.0.0
google-cloud-aiplatform>=1.30.0
vertexai>=0.0.1
Po zainstalowaniu wszystkich zależności lokalne środowisko Pythona zostanie w pełni skonfigurowane do uruchamiania skryptów i chatbota w tym ćwiczeniu w Codelabs.
Świetnie! Możemy teraz przejść do następnego kroku – zrozumienia zbioru danych i przygotowania go do utworzenia wykresu oraz wzbogacenia semantycznego.
4. Przygotowywanie zbioru danych Movies
Naszym pierwszym zadaniem jest przygotowanie zbioru danych Movies, którego użyjemy do zbudowania wykresu wiedzy i zasilenia naszego chatbota z rekomendacjami. Zamiast zaczynać od zera, użyjemy istniejącego otwartego zbioru danych i go rozbudujemy.
Używamy zbioru danych The Movies Dataset autorstwa Rounaka Banika, znanego publicznego zbioru danych dostępnego w Kaggle. Zawiera metadane ponad 45 tys. filmów z TMDB, w tym obsadę, ekipę, słowa kluczowe, oceny i inne informacje.
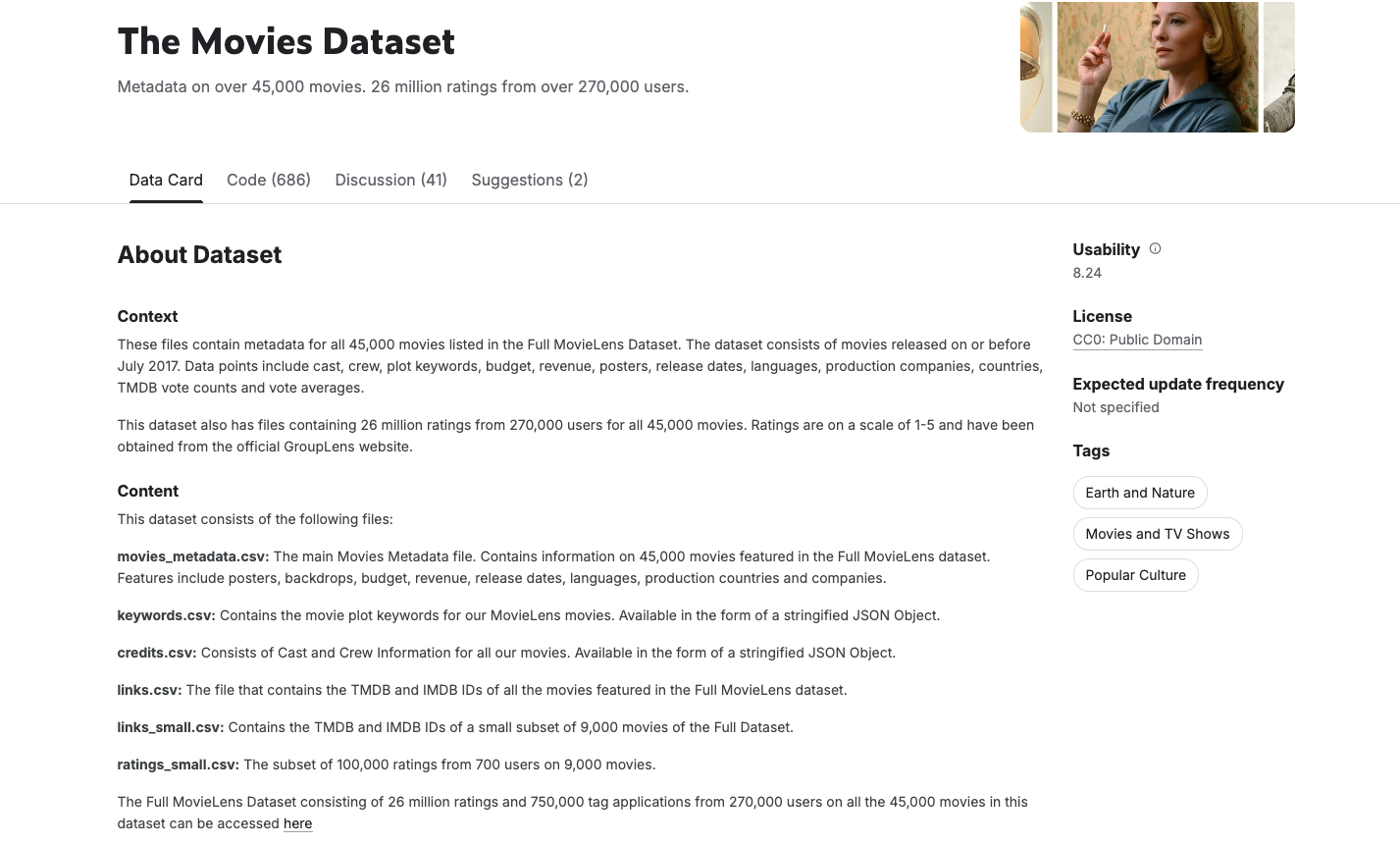
Aby stworzyć niezawodnego i skutecznego czatbota do rekomendacji filmów, musisz zacząć od czystych, spójnych i uporządkowanych danych. Zbiór danych o filmach z Kaggle to bogate źródło informacji,które zawiera ponad 45 tys. rekordów filmów i szczegółowe metadane, w tym gatunki, obsadę, ekipę i inne informacje. Zawiera on jednak również szum, niespójności i zagnieżdżone struktury danych, które nie są idealne do modelowania grafów ani osadzania semantycznego.
Aby temu zapobiec, wstępnie przetworzyliśmy i znormalizowaliśmy zbiór danych, aby był odpowiedni do tworzenia wykresu wiedzy Neo4j i generowania wysokiej jakości osadzeń. Proces ten obejmował:
- Usuwanie duplikatów i niekompletnych rekordów
- standaryzacja kluczowych pól (np. nazwy gatunków, nazwiska osób);
- spłaszczanie złożonych struktur zagnieżdżonych (np. obsady) do uporządkowanych plików CSV;
- Wybranie reprezentatywnej podgrupy około 12 tys. filmów,aby zmieścić się w limitach Neo4j AuraDB Free.
Wysokiej jakości znormalizowane dane pomagają zapewnić:
- Jakość danych: minimalizuje błędy i niezgodności, aby zapewnić dokładniejsze rekomendacje.
- Wydajność zapytań: uproszczona struktura zwiększa szybkość pobierania i zmniejsza redundancję.
- Dokładność wektorów dystrybucyjnych: czyste dane wejściowe prowadzą do bardziej miarodajnych i kontekstowych wektorów dystrybucyjnych.
Oczyszczony i znormalizowany zbiór danych znajdziesz w folderze normalized_data/ w tym repozytorium GitHub. Ten zbiór danych jest też powielony w zasobniku Cloud Storage, aby można było łatwo uzyskać do niego dostęp w przyszłych skryptach w Pythonie.
Po oczyszczeniu i przygotowaniu danych możemy je wczytać do Neo4j i zacząć tworzyć graf wiedzy o filmach.
5. Tworzenie grafu wiedzy o filmach
Aby zasilać naszego chatbota do rekomendacji filmów opartego na generatywnej AI, musimy uporządkować nasz zbiór danych o filmach w taki sposób, aby uchwycić bogatą sieć powiązań między filmami, aktorami, reżyserami, gatunkami i innymi metadanymi. W tej sekcji utworzymy w Neo4j graf wiedzy o filmach, korzystając z oczyszczonego i znormalizowanego zbioru danych przygotowanego wcześniej.
Użyjemy funkcji LOAD CSV Neo4j, aby pozyskać pliki CSV przechowywane w publicznym zasobniku Google Cloud Storage (GCS). Te pliki reprezentują różne komponenty zbioru danych o filmach, takie jak filmy, gatunki, obsada, ekipa, wytwórnie i oceny użytkowników.
Krok 1. Tworzenie ograniczeń i indeksów
Przed zaimportowaniem danych warto utworzyć ograniczenia i indeksy, aby wymusić integralność danych i zoptymalizować wydajność zapytań.
CREATE CONSTRAINT unique_tmdb_id IF NOT EXISTS FOR (m:Movie) REQUIRE m.tmdbId IS UNIQUE;
CREATE CONSTRAINT unique_movie_id IF NOT EXISTS FOR (m:Movie) REQUIRE m.movieId IS UNIQUE;
CREATE CONSTRAINT unique_prod_id IF NOT EXISTS FOR (p:ProductionCompany) REQUIRE p.company_id IS UNIQUE;
CREATE CONSTRAINT unique_genre_id IF NOT EXISTS FOR (g:Genre) REQUIRE g.genre_id IS UNIQUE;
CREATE CONSTRAINT unique_lang_id IF NOT EXISTS FOR (l:SpokenLanguage) REQUIRE l.language_code IS UNIQUE;
CREATE CONSTRAINT unique_country_id IF NOT EXISTS FOR (c:Country) REQUIRE c.country_code IS UNIQUE;
CREATE INDEX actor_id IF NOT EXISTS FOR (p:Person) ON (p.actor_id);
CREATE INDEX crew_id IF NOT EXISTS FOR (p:Person) ON (p.crew_id);
CREATE INDEX movieId IF NOT EXISTS FOR (m:Movie) ON (m.movieId);
CREATE INDEX user_id IF NOT EXISTS FOR (p:Person) ON (p.user_id);
Krok 2. Zaimportuj metadane filmu i powiązania
Zobaczmy, jak importować metadane filmów za pomocą polecenia LOAD CSV. W tym przykładzie tworzone są węzły Movie z kluczowymi atrybutami, takimi jak tytuł, opis, język i czas trwania:
LOAD CSV WITH HEADERS FROM "https://storage.googleapis.com/neo4j-vertexai-codelab/normalized_data/normalized_movies.csv" AS row
WITH row, toInteger(row.tmdbId) AS tmdbId
WHERE tmdbId IS NOT NULL
WITH row, tmdbId
LIMIT 12000
MERGE (m:Movie {tmdbId: tmdbId})
ON CREATE SET m.title = coalesce(row.title, "None"),
m.original_title = coalesce(row.original_title, "None"),
m.adult = CASE
WHEN toInteger(row.adult) = 1 THEN 'Yes'
ELSE 'No'
END,
m.budget = toInteger(coalesce(row.budget, 0)),
m.original_language = coalesce(row.original_language, "None"),
m.revenue = toInteger(coalesce(row.revenue, 0)),
m.tagline = coalesce(row.tagline, "None"),
m.overview = coalesce(row.overview, "None"),
m.release_date = coalesce(row.release_date, "None"),
m.runtime = toFloat(coalesce(row.runtime, 0)),
m.belongs_to_collection = coalesce(row.belongs_to_collection, "None");
Podobnie możesz importować i łączyć inne elementy, takie jak gatunki, firmy produkcyjne, języki, kraje, obsada, ekipa i oceny użytkowników, za pomocą odpowiednich plików CSV i zapytań w języku Cypher.
Wczytywanie pełnego wykresu za pomocą Pythona
Zamiast ręcznie uruchamiać wiele zapytań Cypher, zalecamy użycie zautomatyzowanego skryptu w języku Python podanego w tym ćwiczeniu.
Skrypt graph_build.py wczytuje cały zbiór danych z GCS do instancji Neo4j AuraDB, używając danych logowania z pliku .env.
python graph_build.py
Skrypt kolejno wczyta wszystkie niezbędne pliki CSV, utworzy węzły i relacje oraz ustrukturyzuje kompletny graf wiedzy o filmach.
|
|

.png")
Weryfikowanie wykresu
Po wczytaniu możesz sprawdzić wykres, uruchamiając ten skrypt:
python validate_graph.py
Dzięki temu uzyskasz szybkie podsumowanie zawartości wykresu: liczbę filmów, aktorów, gatunków i relacji, takich jak ACTED_IN, DIRECTED itp. Pozwoli Ci to sprawdzić, czy importowanie się powiodło.
📦 Node Counts:
Movie: 11997 nodes
ProductionCompany: 7961 nodes
Genre: 20 nodes
SpokenLanguage: 100 nodes
Country: 113 nodes
Person: 92663 nodes
Actor: 81165 nodes
Director: 4846 nodes
Producer: 5981 nodes
User: 671 nodes
🔗 Relationship Counts:
HAS_GENRE: 28479 relationships
PRODUCED_BY: 22758 relationships
PRODUCED_IN: 14702 relationships
HAS_LANGUAGE: 16184 relationships
ACTED_IN: 191307 relationships
DIRECTED: 5047 relationships
PRODUCED: 6939 relationships
RATED: 90344 relationships
W grafie powinny się teraz pojawić filmy, osoby, gatunki i inne elementy – w następnym kroku możesz je wzbogacić semantycznie.
6. Generowanie i wczytywanie wektorów dystrybucyjnych w celu wyszukiwania podobieństwa wektorów
Aby włączyć wyszukiwanie semantyczne w naszym chatbotcie, musimy wygenerować wektory dystrybucyjne dla streszczeń filmów. Te osadzenia przekształcają dane tekstowe w wektory liczbowe, które można porównywać pod kątem podobieństwa. Dzięki temu chatbot może wyszukiwać odpowiednie filmy, nawet jeśli zapytanie nie pasuje dokładnie do tytułu lub opisu.

Opcja 1. Wczytywanie wstępnie obliczonych osadzeń za pomocą języka Cypher
Aby szybko dołączyć wektory do odpowiednich węzłów Movie w Neo4j, uruchom w przeglądarce Neo4j to polecenie Cypher:
LOAD CSV WITH HEADERS FROM 'https://storage.googleapis.com/neo4j-vertexai-codelab/movie_embeddings.csv' AS row
WITH row
MATCH (m:Movie {tmdbId: toInteger(row.tmdbId)})
SET m.embedding = apoc.convert.fromJsonList(row.embedding)
To polecenie odczytuje wektory osadzania z pliku CSV i dołącza je jako właściwość (m.embedding) do każdego węzła Movie.
Opcja 2. Wczytywanie wektorów za pomocą Pythona
Możesz też wczytać wektory osadzeń programowo za pomocą udostępnionego skryptu w Pythonie. To podejście jest przydatne, jeśli pracujesz we własnym środowisku lub chcesz zautomatyzować proces:
python load_embeddings.py
Ten skrypt odczytuje ten sam plik CSV z GCS i zapisuje osadzanie w Neo4j za pomocą sterownika Python Neo4j.
[Opcjonalnie] Samodzielne generowanie wektorów (na potrzeby eksploracji)
Jeśli chcesz dowiedzieć się, jak są generowane wektory, możesz zapoznać się z logiką w generate_embeddings.pyskrypcie. Wykorzystuje Vertex AI do osadzania tekstu każdego opisu filmu za pomocą modelu text-embedding-004.
Aby wypróbować tę funkcję, otwórz i uruchom sekcję generowania osadzania w kodzie. Jeśli korzystasz z Cloud Shell, możesz dodać komentarz do tego wiersza, ponieważ Cloud Shell jest już uwierzytelniony za pomocą Twojego aktywnego konta:
# os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = "./service-account.json"
Gdy osadzenia zostaną wczytane do Neo4j, Twój graf wiedzy o filmach stanie się świadomy semantyki – będzie gotowy do obsługi zaawansowanego wyszukiwania w języku naturalnym za pomocą podobieństwa wektorowego.
7. Czatbot do rekomendacji filmów
Gdy masz już graf wiedzy i osadzenia wektorowe, możesz połączyć je w pełni funkcjonalny interfejs konwersacyjny – czatbota do rekomendacji filmów opartego na generatywnej AI.
Ten chatbot jest zaimplementowany w Pythonie przy użyciu Gradio, lekkiej platformy internetowej do tworzenia intuicyjnych interfejsów użytkownika. Główna logika znajduje się w app.py, która łączy się z instancją Neo4j AuraDB i używa Google Vertex AI oraz Gemini do przetwarzania zapytań w języku naturalnym i odpowiadania na nie.
Jak to działa
- Użytkownik wpisuje zapytanie w języku naturalnymnp. „Poleć mi thrillery science fiction podobne do Interstellar”
- Wygeneruj wektor dystrybucyjny zapytania za pomocą modelu
text-embedding-004w Vertex AI. - Wykonywanie wyszukiwania wektorowego w Neo4j w celu pobrania podobnych semantycznie filmów
- Używaj Gemini, aby:
- Interpretowanie zapytania w kontekście
- Generowanie niestandardowego zapytania Cypher na podstawie wyników wyszukiwania wektorowego i schematu Neo4j.
- Wykonaj zapytanie, aby wyodrębnić powiązane dane wykresu (np.aktorów, reżyserów, gatunki).
- Podsumuj wyniki w formie rozmowy z użytkownikiem.
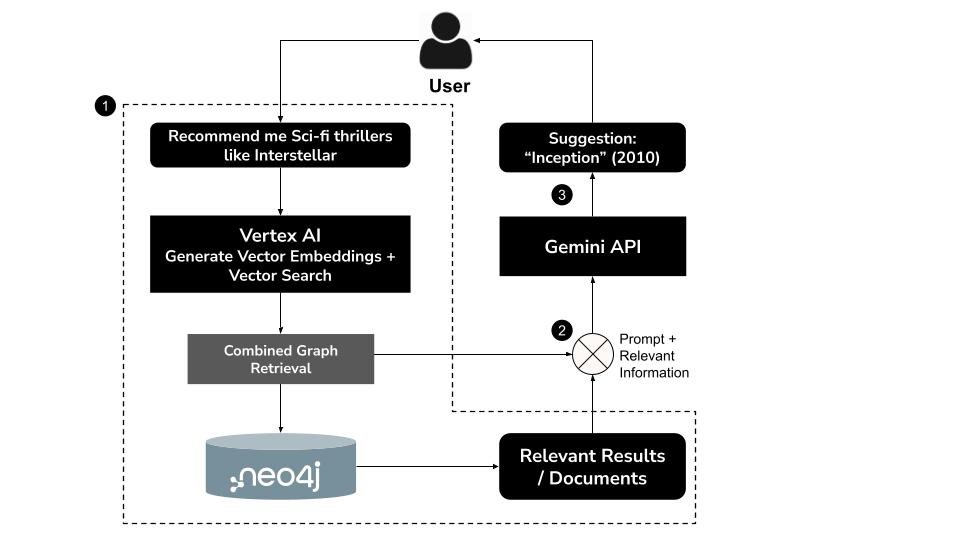
To hybrydowe podejście, znane jako GraphRAG (Graph Retrieval-Augmented Generation), łączy wyszukiwanie semantyczne i strukturalne rozumowanie, aby generować dokładniejsze, oparte na kontekście i łatwiejsze do wyjaśnienia rekomendacje.
Lokalne uruchamianie czatbota
Aktywuj środowisko wirtualne (jeśli nie jest jeszcze aktywne), a następnie uruchom chatbota za pomocą tego polecenia:
python app.py
Powinny się wyświetlić dane wyjściowe podobne do tych:
Vector index 'overview_embeddings' already exists. No need to create a new one.
* Running on local URL: http://0.0.0.0:8080
To create a public link, set `share=True` in `launch()`.
💡 Aby udostępnić chatbota zewnętrznie, ustaw share=True w funkcji launch() w app.py.
Interakcja z czatbotem
Otwórz lokalny adres URL wyświetlany w terminalu (zwykle 👉 http://0.0.0.0:8080), aby uzyskać dostęp do interfejsu czatbota.
Spróbuj zadać pytania takie jak:
- „Co obejrzeć, jeśli podobał mi się film Interstellar?”
- „Zaproponuj film romantyczny wyreżyserowany przez Norę Ephron”
- „Chcę obejrzeć film familijny z Tomem Hanksem”
- „Znajdź thrillery z udziałem sztucznej inteligencji”
Czatbot:
✅ Zrozumienie zapytania
✅ Znajdowanie podobnych semantycznie fabuł filmów za pomocą wektorów dystrybucyjnych
✅ Generowanie i uruchamianie zapytania w języku Cypher w celu pobrania powiązanego kontekstu wykresu
✅ W ciągu kilku sekund otrzymasz przyjazną, spersonalizowaną rekomendację.
Co masz teraz
Właśnie udało Ci się utworzyć czatbota do filmów opartego na GraphRAG, który łączy:
- Wyszukiwanie wektorowe pod kątem trafności semantycznej
- Wnioskowanie na podstawie grafu wiedzy za pomocą Neo4j
- Funkcje LLM w Gemini
- Płynny interfejs czatu z Gradio
Ta architektura stanowi podstawę, którą możesz rozbudować o bardziej zaawansowane systemy szukania zaawansowanego, rekomendacji lub rozumowania oparte na generatywnej AI.
8. (Opcjonalnie) Wdrażanie w Google Cloud Run
Jeśli chcesz udostępnić publicznie swojego chatbota do rekomendowania filmów, możesz wdrożyć go w Google Cloud Run – w pełni zarządzanej platformie bezserwerowej, która automatycznie skaluje aplikację i zapewnia kompletną obsługę infrastruktury.
To wdrożenie korzysta z:
requirements.txt– do definiowania zależności Pythona (Neo4j, Vertex AI, Gradio itp.)Dockerfile– aby spakować aplikację..env.yaml– aby bezpiecznie przekazywać zmienne środowiskowe w czasie działania
Krok 1. Przygotuj .env.yaml
W katalogu głównym utwórz plik o nazwie .env.yaml z taką treścią:
NEO4J_URI: "neo4j+s://<your-aura-db-uri>"
NEO4J_USER: "neo4j"
NEO4J_PASSWORD: "<your-password>"
PROJECT_ID: "<your-gcp-project-id>"
LOCATION: "<your-gcp-region>" # e.g. us-central1
💡 Ten format jest preferowany w stosunku do formatu --set-env-vars, ponieważ jest bardziej skalowalny, łatwiejszy do kontrolowania pod względem wersji i czytelniejszy.
Krok 2. Skonfiguruj zmienne środowiskowe
W terminalu ustaw te zmienne środowiskowe (zastąp wartości zmiennych rzeczywistymi ustawieniami projektu):
# Set your Google Cloud project ID
export GCP_PROJECT='your-project-id' # Change this
# Set your preferred deployment region
export GCP_REGION='us-central1'
Krok 2. Utwórz Artifact Registry i skompiluj kontener
# Artifact Registry repo and service name
export AR_REPO='your-repo-name' # Change this
export SERVICE_NAME='movies-chatbot' # Or any name you prefer
# Create the Artifact Registry repository
gcloud artifacts repositories create "$AR_REPO" \
--location="$GCP_REGION" \
--repository-format=Docker
# Authenticate Docker with Artifact Registry
gcloud auth configure-docker "$GCP_REGION-docker.pkg.dev"
# Build and submit the container image
gcloud builds submit \
--tag "$GCP_REGION-docker.pkg.dev/$GCP_PROJECT/$AR_REPO/$SERVICE_NAME"
To polecenie pakuje aplikację za pomocą Dockerfile i przesyła obraz kontenera do Google Cloud Artifact Registry.
Krok 3. Wdróż w Cloud Run
Teraz wdróż aplikację, używając pliku .env.yaml do konfiguracji środowiska wykonawczego:
gcloud run deploy "$SERVICE_NAME" \
--port=8080 \
--image="$GCP_REGION-docker.pkg.dev/$GCP_PROJECT/$AR_REPO/$SERVICE_NAME" \
--allow-unauthenticated \
--region=$GCP_REGION \
--platform=managed \
--project=$GCP_PROJECT \
--env-vars-file=.env.yaml
Dostęp do czatbota
Po wdrożeniu Cloud Run udostępni publiczny adres URL, np.:
https://movies-reco-[UNIQUE_ID].${GCP_REGION}.run.app
Otwórz ten adres URL w przeglądarce, aby uzyskać dostęp do wdrożonego interfejsu czatbota Gradio, który jest gotowy do obsługi rekomendacji filmów z użyciem GraphRAG, Gemini i Neo4j.
Notatki i wskazówki
- Upewnij się, że urządzenie
Dockerfiledziałapip install -r requirements.txtpodczas kompilacji. - Jeśli nie używasz Cloud Shell, musisz uwierzytelnić środowisko za pomocą konta usługi z uprawnieniami do Vertex AI i Artifact Registry.
- Dzienniki i dane wdrożenia możesz monitorować w konsoli Google Cloud > Cloud Run.
Możesz też otworzyć Cloud Run w konsoli Google Cloud i wyświetlić listę usług w Cloud Run. Usługa movies-chatbot powinna być jedną z usług (jeśli nie jedyną) wymienionych w tym miejscu.

Aby wyświetlić szczegóły usługi, takie jak adres URL, konfiguracje, logi i inne, kliknij nazwę konkretnej usługi (w naszym przypadku movies-chatbot).
Dzięki temu Twój czatbot rekomendujący filmy jest teraz wdrożony, skalowalny i można go udostępniać. 🎉
9. Czyszczenie danych
Aby uniknąć obciążenia konta Google Cloud opłatami za zasoby użyte w tym poście, wykonaj te czynności:
- W konsoli Google Cloud otwórz stronę Zarządzanie zasobami.
- Z listy projektów wybierz projekt do usunięcia, a potem kliknij Usuń.
- W oknie wpisz identyfikator projektu i kliknij Wyłącz, aby usunąć projekt.
10. Gratulacje
Udało Ci się utworzyć i wdrożyć czatbota do rekomendacji filmów opartego na GraphRAG i ulepszonego przez generatywną AI z użyciem Neo4j, Vertex AI i Gemini. Łącząc możliwości modelowania natywnego dla grafów Neo4j z wyszukiwaniem semantycznym za pomocą Vertex AI i rozumowaniem w języku naturalnym za pomocą Gemini, stworzyliśmy inteligentny system, który wykracza poza podstawowe wyszukiwanie – rozumie intencje użytkownika, analizuje połączone dane i odpowiada w formie konwersacji.
W tym ćwiczeniu wykonaliśmy te czynności:
✅ Utworzenie w Neo4j grafu wiedzy o filmach, który modeluje filmy, aktorów, gatunki i relacje.
✅ Wygenerowane wektory dystrybucyjne dla streszczeń fabuły filmu przy użyciu modeli wektorów dystrybucyjnych tekstu w Vertex AI
✅ Wdrożono GraphRAG, czyli połączenie wyszukiwania wektorowego i zapytań Cypher generowanych przez LLM, co umożliwia bardziej szczegółowe wnioskowanie wieloetapowe.
✅ Zintegrowana usługa Gemini, która interpretuje pytania użytkowników, generuje zapytania w języku Cypher i podsumowuje wyniki wykresów w języku naturalnym.
✅ Utworzono intuicyjny interfejs czatu za pomocą Gradio.
✅ Opcjonalnie wdrożono chatbota w Google Cloud Run, aby zapewnić skalowalne, bezserwerowe hostowanie.
Co dalej?
Ta architektura nie ogranicza się do rekomendacji filmów – można ją rozszerzyć na:
- Platformy do odkrywania książek i muzyki
- Asystenci naukowi
- Systemy rekomendacji produktów
- Asystenci wiedzy z zakresu opieki zdrowotnej, finansów i prawa
Wszędzie tam, gdzie masz złożone relacje i bogate dane tekstowe, ta kombinacja grafów wiedzy, dużych modeli językowych i osadzania semantycznego może stanowić podstawę nowej generacji inteligentnych aplikacji.
Wraz z rozwojem multimodalnych modeli generatywnej AI, takich jak Gemini, będziesz mieć możliwość uwzględniania jeszcze bogatszego kontekstu, obrazów, mowy i personalizacji, aby tworzyć systemy prawdziwie zorientowane na człowieka.
Eksperymentuj i twórz nowe rozwiązania. Nie zapomnij też śledzić najnowszych informacji o Neo4j, Vertex AI i Google Cloud, aby przenieść swoje inteligentne aplikacje na wyższy poziom. Więcej praktycznych samouczków dotyczących grafów wiedzy znajdziesz na stronie Neo4j GraphAcademy.